
Abstract
The refining of information from the immense amount of unstructured data on the internet can be a critical issue in identifying public opinion. It is difficult to extract relevant concepts from huge amounts of data. Concept level semantic parsing is improved over word-based investigation as it conserves the semantical data relevant to many-word articulations. The semantic proposals offer a superior comprehension of textual data and serve to altogether precision the exactness of numerous mining operations in text assignments. The extraction of concepts from textual data is a significant step forward in content analysis at the concept stage. We present a CLSA-CapsNet method that extracts concepts from natural language text. Then the extracted concepts are applied in Capsule networks (CapsNet). Moreover, the integration of Concept Level Sentiment Analysis (CLSA) and Capsule Networks (CapsNet) has not yet been implemented on the hotel review dataset. This is the first attempt, which we researched and embraced by the capsule network, to develop classification models for hotel reviews. The developed results demonstrated excellent performance with a prediction accuracy of 86.6% for CLSA-CapsNet models, respectively. Various similarities have also been made across our techniques and they are implemented by some other deep learning algorithms, such as rnn-lstm. Overall, the outstanding success obtained by CLSA-CapsNet in this investigation highlights its ability in the hotel review dataset. We likewise show exploratory outcomes, in which the proposed system outpaced the state-of-the-art CLSA-CapsNet model.
Introduction
Facts and opinion statements are the two kinds of textual data available on the Web. The entities are described in objective sentences and they do not show any sentiment in the facts. whereas, opinions describe people’s feelings toward entities and are descriptive in nature. Owing to an extensive range of business and applications like securing multimedia data [6], e-health and e-learning [4, 5] in human-centric environments [3], air quality modelling [7], increasing sentiment analysis research. It includes both multimodal [1, 2] and text-based. Comprehending what others think has consistently been viewed as a significant key for decision-making. People tend to ask for suggestions from friends when buying a new gadget. But nowadays, due to the advancement in the trends in the Web, people tend to share their experiences, reviews of products, and feelings on social networks, blogs, forums, etc.
The importance of understanding and analysing these reviews and online user-generated data has increased gradually. The purchase decisions [8] can be made by the qualities and the demerits of an invention on the basis of the knowledge provided by the existing users. The current trends were adopted by e-commerce companies, and they analysed the reviews of users to improve their products and services. Identifying the feedback from online movie reviews, finding the best gadgets, and listening to music that most users like are a few examples of sentiment analysis applications. In the product review, polarity categories such as positive, neutral or negative created on its descriptive information are assigned to a document in the sentiment classification. Even sentiment analysis is representing in different modality. recent research in various multi-modality analysis employing deep learning methodology is gaining popularity. Every day, massive amounts of data are available through public media platforms such as, WhatsApp, microblogs, YouTube, Facebook and Twitter [47]. Moreover, machine learning techniques are used in medical field. With the development of machine learning techniques, for example, it is now possible to identify insulin resistance without using clinical procedures. Insulin resistance is discovered in this work using non-invasive procedures and machine learning methodologies for individuals with high triglycerides and a low HDL-c ratio [9]. Chakradar et al. [10] defined the ontological prototype of a diverse learning system for children with distinct learning challenges in the modelling process of an educational activity. In a preference-based learning environment, it serves the needs of the students who demand differentiated instruction. This strategy can help students figure out which learning domains and multiple-criteria are most important to them. The learning resources and questionnaires for diagnosing problems are structured and combined with multiple learning methodologies to provide a variety of learning settings, including case-based, game-based, practice-based, and visual-based learning environments [10].
The fundamental understanding that people acquire through experience [11] is referred to as common-sense knowledge. The reasoning algorithms like machine learning and predicate logic are used to perform common-sense ontologies in automatic common-sense reasoning. In particular, common sense is required to appropriately classify sentiments in natural language textual data. The best example of common sense is that a small queue in a billing place in a department store is considered positive, whereas a small legroom in a flight is considered negative. Even the machine learning is used everywhere. For example, Kumar, Manoj, et al [12] used Deep Neural Networks (DNNs) to completely automate the cerebrum tumour division process in this work. Authors looked at a lot of different designs that used K-Nearest Neighbors (KNN), like DNNs that were made to look at images. In contrast to those utilised in computer vision, an innovative KNN is implemented. At the same time, the suggested KNN handles both neighbourhoods and increasingly universally applicable traits. In addition, a way for dealing with the issues associated with the unevenness of tumour kinds is offered. The approach’s efficiency is demonstrated by the results, which were calculated using the 2017 BRATS test dataset. And images are not only used in sentiment analysis. it is used in forensic analysis also. The process of recognizing, analysing, and authenticating the source, and repercussions of a safety incident and organisation laws is referred to as forensic analysis. Manipulation of digital media has become popular in recent years. As one of the key vehicles of communication, digital media, particularly photographs, can be easily altered. The current research trends in digital picture forensics are centred on validating the image’s validity. Kumar et al. [13] demonstrated a digital picture forensic technique based on determining the image’s light source(s).
If the performance of classification degrades in machine learning, after eliminating a particular feature, then that feature is relevant for classification. The classification does not include irrelevant features [15, 16]. The performance of the classification is degraded by such redundant features. The relationship between the features [17] is measured and they are used to detect the redundancy of features. The unwanted features can reduce the efficiency of machine learning methods. Thus, the overall way classification is done can be better if these extra and unnecessary features are removed. And also the performance analysis is represented based on the artificial intelligence algorithms for big data analysis [18]. The new class of a sample [20] should be foreseen with the information present on this feature which is discriminated against by the classifier. It is treated as one of the key points of a characteristic of a salient feature. The Irrelevant features and noises are eliminated by the selection of feature methods, resulting in the selection of features that are necessary for the classification. The selection of feature techniques enables the representation of a minimal number of salient features for a class attribute. The two main benefits of feature selection are (1) a clear perspective of [14] of arguments in the sentiment and clear understanding of salient class features by the improved classification accuracy. These are the two main benefits of Feature selection. The efficiency of methods of machine learning [15, 20], in which computation speed is increased through prominent features of the reduced feature vector. The data can be represented in lower-dimensional feature space more efficiently by the feature selection. Generally, cloud computing provides compute, storage, and application capabilities. It provides a platform for users to study computational assets and use them on a “pay per use” basis. The author [21] proposed protocol employs inter-cloud resource management, in which a cloud leader is chosen to interface with other clouds and make decisions on virtual machine (VM) migration.
Aspect-based sentiment analysis (ABSA) is made up of three main parts: extracting aspect terms, extracting opinion terms, and classifying aspects. These three parts are usually done separately or together. However, previous approaches don’t take advantage of how the three subtasks work together and don’t take advantage of the simply accessible sentiment data, which limits their performance. To solve these problems, Yunlong, et al. [48], came up with a new methodology named Iterative Multi-Knowledge Transfer Network (IMKTN) for entire aspect based sentiment analysis. The selection techniques, like mutual information (MI) and information gain (IG), do not tend to remove the redundant features. But, the Maximum Relevance (mRMR) and Minimum Redundancy techniques select only appropriate features, which serves as an advantage to the feature selection technique. The other selection techniques focus mainly on the appropriate features rather than considering redundant information. Using an EM routing method, Chunning et al. [49] presented a capsule network to construct word vectors of features and cluster features. In addition, to simulate the possible relationships between aspect keywords and the context, an active attention model is incorporated to the capsule routing method. You can also encapsulate a statement from a global perspective using iterative routing.
We propose a new concept termed the CLSA-CapsNet technique. It is based on a semantic parser that extracts concepts based on dependency relations between clauses from natural language text. The machine learning model is trained with the components extracted from the two proposed algorithms. The favourable and the unfavourable categories of documents are classified by the pattern of the concept. This paper proposes a capsule network-based concept level sentiment analysis model to address the shortcomings of existing approaches, which shows excellent performance on two datasets. The suggested method is based on CapsNet concept level sentiment analysis and uses senticnet to identify the sentiment values. Senticnet and combining part-of-speech, syntactic dependency, and concept extraction algorithms are fed into the CapsNet Concept Level Sentiment Analysis model, which could mix features from various standpoints and acquire the inner association of sentences much better. The CapsNet-CLSA model will increase its ability to solve semantically complex sentences with the help of effective features. As a result, the CapsNet-CLSA model will perform much better. The core contributions of this effort are categorized as: We propose the part-of-speech-based bigram algorithm and the event concept extraction algorithm that extract concepts based on dependency relations between clauses from natural language text. We designed an attention mechanism. One of the accomplishments of senticnet is polarity detection and part-of-speech-based bigram algorithms and event concept extraction algorithms are fed into the attention mechanism collected to ensure that the calculated word representation is only associated with the target aspect. We integrated the proposed algorithms and the capsule network has not yet been implemented into the hotel review dataset. We demonstrate the feasibility of the proposed CapsNet-CLSA by conducting experiments on two real-world review data sets.
Related work
There are four main categories of recent approaches to measuring sentiment: statistical approaches, catch of keywords, lexical affinity, and concept level methodologies. The spotting of keywords is the maximum ingenuous and common approach due to the usability and budget. Textual data is grouped into categories that move determined by the presence of terms that have a reasonably unambiguous effect, like happy, sad, bored, and scared. The shortcomings of this method are focused on two areas: one is an inadequate understanding of the effect when negation is alleviated and the other is based on surface characteristics. In connection with its primary weakness, whereas the method be able to define the statement “Yesterday was a wonderful day for me “in the sense of happiness.”, and a sentence will most likely fail such as “Yesterday was not at all a happy day for me”. Regarding the approaches to the of second weakness, it depends on the existence of obvious terms that are just surface characteristics of the text. In practical terms, many phrases express results through the underlying context rather than the effect of the adjective concepts. For instance, “my husband just submitted for divorce, and he is trying to take away custody of my kids.” Strong emotions can be seen, but no affect keywords are used, so it can’t be classified by keyword approaches.
Lexical sensitivity is much more advanced than simple keyword spotting. instead of just spotting obvious affect word sequence, it allocates a probabilistic ‘affinity’ to the arbitrary phrases for a specific sentiment. For instance, an accident may be given a probability of 75% showing a negative effect, such as a car accident or being offended by an accident. Typically, such predictions are learned using linguistic language. Despite the fact that pure keyword detection consistently outperforms, the method has two major flaws. First, lexical affinity can easily be influenced by working only at the word level via sentences such as “I prevented an accident” and “I met my girlfriend by accident.” The probabilities of lexical affinity are always skewed towards the text of a specific genre, as determined by the linguistic corpora’s source.
The relationship between words and their subsequences was used for sentiment classification by Matsumoto et al. [23]. Text mining techniques were applied to extract such relationships. In a movie review dataset, Pang et al. [22] generated features by using bigrams and unigrams. One such feature of the classification of sentiment includes dependency tree subgraphs that were extracted from a parsed sentence by Pak and Paroubek [24]. Mongia, Shweta, et al. [25] used supervised learning technique to predict the amount of confirmed covid cases, recovered cases and death cases of COVID-19 cases in India. The necessity of the hour is for governments to be equipped with tools for early identification, prevention, and mitigation of infectious diseases. Death and recovery rates have also been anticipated by the authors. The authors empowered the relevant authorities in implementing effective preventive measures during the decision-making process. The SVM classifier with extracted subgraphs dominated the n-gram features and bag-of-words in a movie review dataset. The bag-of-word features were beaten by the linguistic dependency trees, which were used by Nakagawa et al. [26] for analysis of sentiment. Xia et al. [27] investigated aspects of word relationships that included practical aspects of conditioning. URoffoff et al. [28] used the entry-level to officially define different kinds of lexical symptoms. Rose et al. [29] looked at syntactic features of sensory differentiation and came up with common dependence factors that made mining more effective.
The Adjectives, pronouns, and nouns were also considered in the classification of sentiments against the independent features in machine learning methods. The efficiency of the POS tag was experimented with by Mejova and Srinivasan [30]. They verified that adjectives, nouns, etc., overlapped other features of individual POS-tags. Based on the theory of the orientation method using semantics by Turney’s [33] and Osgood’s [32], a new method was proposed by Mullen and Collier [31] to expand the set of features. The efficiency of sentiment classification was improved by the combination of the linguistic-based method of orientation and machine learning by the lexicon proposed by Dang et al. [34]. The sentiment classification was improved by the newly proposed feature based on the lexicon. Other mining-related activities focus on conceptualization. Gelfand et al. [35] established a type of graph semantic relationship method to retrieve concepts throughout the document. They use associations among the words, drawn from lexical knowledge, to create concepts.
Concept based sentiment analysis using senticnet and capsule networks
Sensitivity computing refers to a variety of disciplinary methods of opinion mining that straddle the line between common sense computing and affective computing [14], utilising both social media and personal computers to improve their opinions, feelings, and perceptions over the internet. Sentic computing is a tool related to common sense reasoning and affective ontologies that enables text to be analysed not only at the paragraph, page, document, sentence, clause, or concept level, but also at the document, paragraph, page, sentence or concept based [37]. Sentic Album is a new, information-based, and concept-managed online personal photo system that intelligently annotates, organizes, and retrieves online personal photos using data and metadata [19].
Specifically, sentic registering includes disciplinary utilisation of counterfeit insight and Semantic Web methods for information portrayal and deduction; arithmetic, for completing assignments such as chart mining and many-dimensionality decrease; phonetics, for talk examination and pragmatics; brain science, for psychological also, full of feeling demonstrating; humanism, for getting social media elements and public impact; and lastly, morals, for thoughtful allied problems around the idea of the brain and the making of enthusiastic technologies.
The part of the speech-based bigram pseudo-code identifies concepts such as fruits, bazaar, some vegetables, and fruits. To detect event-based concepts, that tie between the normalised web chunks and object concepts. This work is completed by exploiting a parsing graph that plots many numbers of word expressions that exist in the knowledge bases. That is, to easily define complex concepts, an unweighted directed graph is used. Algorithm 2 is used to fetch the event concepts like “buy fruits,” “goto the bazaar,” “buy vegetables,” “buy some vegetables” on behalf of an algorithm for extra processing. We also used a sentic computing system in this work, using the semantic parser to decompose text content into natural language concepts, which are then interpreted and analysed using the capsule network technique.
Feature extraction
The machine learning model is built by constructing various sets of features for sentiment analysis. These features are explained clearly in the below section.
Unigrams
The spaces, along with noise characters, are separated from the bag of words that are extracted to form the Unigram. For example, ‘The Taj Mahal is beautiful.” The words “the,” “Taj,” ‘Mahal,” “is,” ‘beautiful’ are all unique unigrams.
Bigrams
The two successive words in a sentence are known as “bigrams.” For example, in the sentence ‘BMW is an expensive car,” “is an expensive car,” “expensive car,” ‘expensive car’ are features of Bigram. It has the ability to combine some contextual data.
Bi-tagged
The fixed patterns extracted from a part-of-speech (POS) are called “Bi-tagged.” The adjectives in most of the Bigrams are thought to be more likely to have a strong emotional impact and adverbs tend to be descriptive [33, 36]. Hence, we use sentiment-rich features extracted from the POS-based information. These features that are extracted from two-words are proposed by Turney [33], of which one word is either an adverb or adjective. We accepted the part-of-speech based patterns from Turney’s study. From our observation, we found that verbs also contained information about sentiments resulting in more extraction of sentiment-bearing features. A few details of the guidelines are represented in Table 1 and Table 2 to extract Turney’s feature.
Rules to get Turney’s data
Rules to get Turney’s data
Guidelines to fetch verb-based features
The sentiment analysis model is used to form a semantic relationship between the words in a sentence. Semantic patterns are very useful in subjective detection [24–26]. The dependency parser tree captures the information available in the interminability of a sentence.
Syntactic N-grams (sn-grams)
The sentiment classification [37] used patterns from the text obtained from machine learning algorithms. This feature is called Syntactic N-grams (sn-grams). The nodes [38] contained in the subtree of a sentence are understood by the sn-gram. Vectors are used to represent the dependency tree in the sn-gram. They are less noisy and more explanatory as they are represented by semantic entities when compared to the traditional n-grams. These sn-grams go an elongated way towards semantically essential representations in a sentence, and they convey the relationship between words in a sentence. All the possible words are formed from their leaf nodes. For example, “the food is delicious.” in this sentence, the features are extracted as follows: delicious food, food is delicious, food, the delicious. The semantic message from the machine learning model is conveyed by the syntactic n-grams.
Main algorithm (Proposed Approach)
Our processing system is shown belowrepresented in Figs. 1 and 2. The following is our processing system. First, we extract relationships of dependency among the sentence’s terms. Then we use these relationships of dependence to develop difficult level relationships and concepts that involve semantics. Observing these principles, we were extracted, and we acquired common sense related understanding from capsule networks. Furthermore, only main concepts are chosen. To build relations of dependency between the words, the dependency parser from Stanford was utilised [39]. Figure 3 signifies the proposed capsule network architecture for concept level sentiment classification and Fig. 4 indicates flow diagram of our technique to predict polarity detection.

Algorithm 1- Part-of-speech-based bigram algorithm.

Algorithm 2- Algorithm for extracting event concepts.
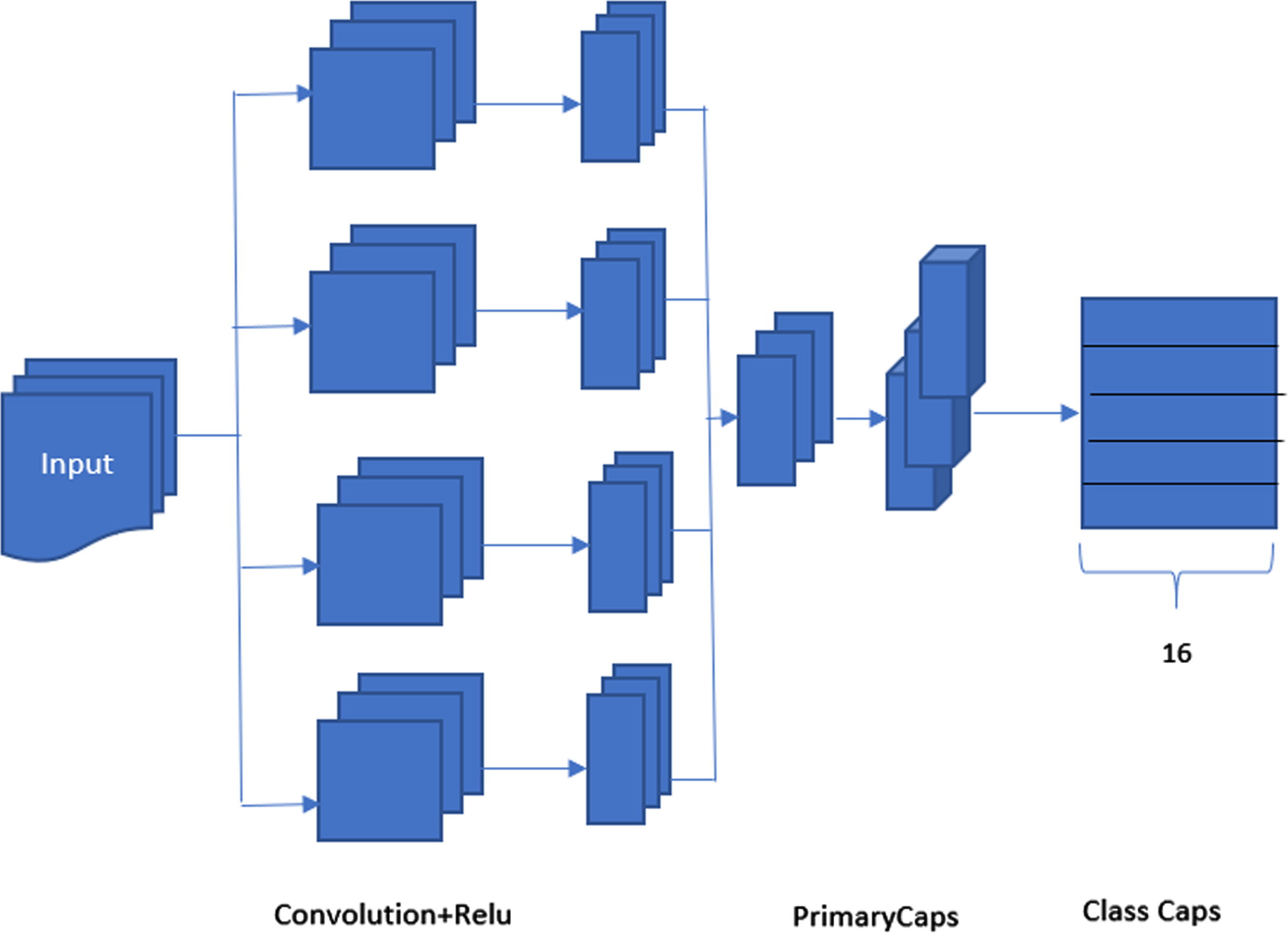
Proposed capsule network architecture for concept level sentiment classification.

Flow diagram depicting our method to sentiment analysis at the concept level.
The sematic parser’s aim is to decompose content into clauses and then back into concepts. knowledge of text semantics, as well as some additional data (influence) relevant to such semantics, is frequently sufficient to perform emotion recognition and polarity detection quickly.
One of the well-known algorithms used to perform textual sentiment analysis is semantic parsing POS-based bigram algorithm [1]. Figure 1 briefly represents the semantic parsing Part-of-speech based bigram algorithm.
To build relations of the dependency between the words, we used the Standford dependency parser. Below is the example for representing the part of speech from Sandford dependency parser.
Part-of-speech
Bracked parse tree
Figure 5 is an example of a part of speech from a sentence. Figure 6 represents an example of a bracketed parse tree. The “bracketed parse (tree)” is the name of the Stanford Parser’s output format. It’s meant to be seen as a graph, with words, phrases, and edges represented as nodes, labels, and linked hierarchy. The root node is usually a delirious root.

An example of part-of-speech for a sentence.

An example of bracketed parse tree.
It is considered that the technique based on sentic computing is more powerful than word-based technique which is restricted by the way it doesn’t consider into account structure. The bag-of-concepts outperforms the bag-of-words, and that a can signify the semantics related to a normal linguistic sentence. The bag of words technique breaks down concepts like grid computing formed in two distinct word which represents the semantic inputs. Though the bag of model technique cannot correctly extract the polarisation of a sentence, such as “the house is tidy but the yard is a mess,” it can extract the concepts “house,” “tidy,” “yard,” and “mess.” The sentence polarity is negative.
To this purpose, we continue to develop and utilise structured linguistic patterns. We create a methodology for fetching concepts from the syntactic erections of sentences. The relation form, the head word, and the dependent word are the three types of elements that make up a dependence relation. The syntactic relationship between the two terms in the sentence is determined by the form of the relation. The head passes down the pair’s important syntactic and semantic features. The factor that is based on the head word is referred to as the relationship dependent word [40, 41].
Universal Rules
Law of Subject Noun
When the multi-word definition (s-t) is found in the sentence.
In the above example, ‘cartoon’ is the relation between subject and ‘tedious’. As a result, the concept (tedious cartoon) is mined.
Conjunctions
Law of combined subject noun and adjective complement rule
In the above example, “car” is linked to ‘looks’ and ‘looks’ is a relationship between the adjective complement and “beautiful”. So, the concept (beautiful car) is extracted.
Direct token items
In the above example, the method extracts the concept (play game).
Law of negation
Trigger: Negation is a key element of natural language content, which generally spins the text’s meaning. It is used in the text to extract whether a word is negated.
When the multi-word definition (s-t) is discovered in the sentence, it is utilised to measure the polarity of the relationship.
Adjectival complement
Adverbial, adjectival clause modifier
In the above example, the concept “good boy” is extracted.
Relative pronoun in the adjectival clause with subordinating conjunctions
Noun compound modifier
Single word concepts
Generally, a sentence is a collection of words that represent a part of speech, such as a verb, noun, adverb and Adjective. These words are used to extract the relevant information from the context.
Adverbial clause convertor
Complete clauses that act as convertors of a verb are vulnerable in this way. Standard examples contain conditional structures and temporal clauses.
An appositive phrase
The appositive and its modifiers make up an appositive expression. Appositives may be either mandatory or optional. The required appositive provides data for retrieving the pronoun or noun in order to proceed to the next process. The sentence would be meaningless without the required appositive. An optional appositive delivers some more data about a pronoun or noun in a sentence. It provides the reader with an additional but unimportant detail. Commas can be used to separate non-essential appositives.
Senticnet.net/demos/
frankie_dog
dog
go_for_walk
walk
walk_in_park
park
The SenticNet
The system of emotion classification is built to obtain as input a concept of natural language expressed by a dimension of space and the related sentic levels (Figure 7) to identify the four affective dimensions involved. such as sensitivity, pleasantness, aptitude, and attention. The dimensionality M of the space of inputs stems from Affective Space’s unique architecture. As for the results, each affective dimension can be defined in general by an affective dimension along with a range value [1, –1], that reflects the strength of the feelings felt.
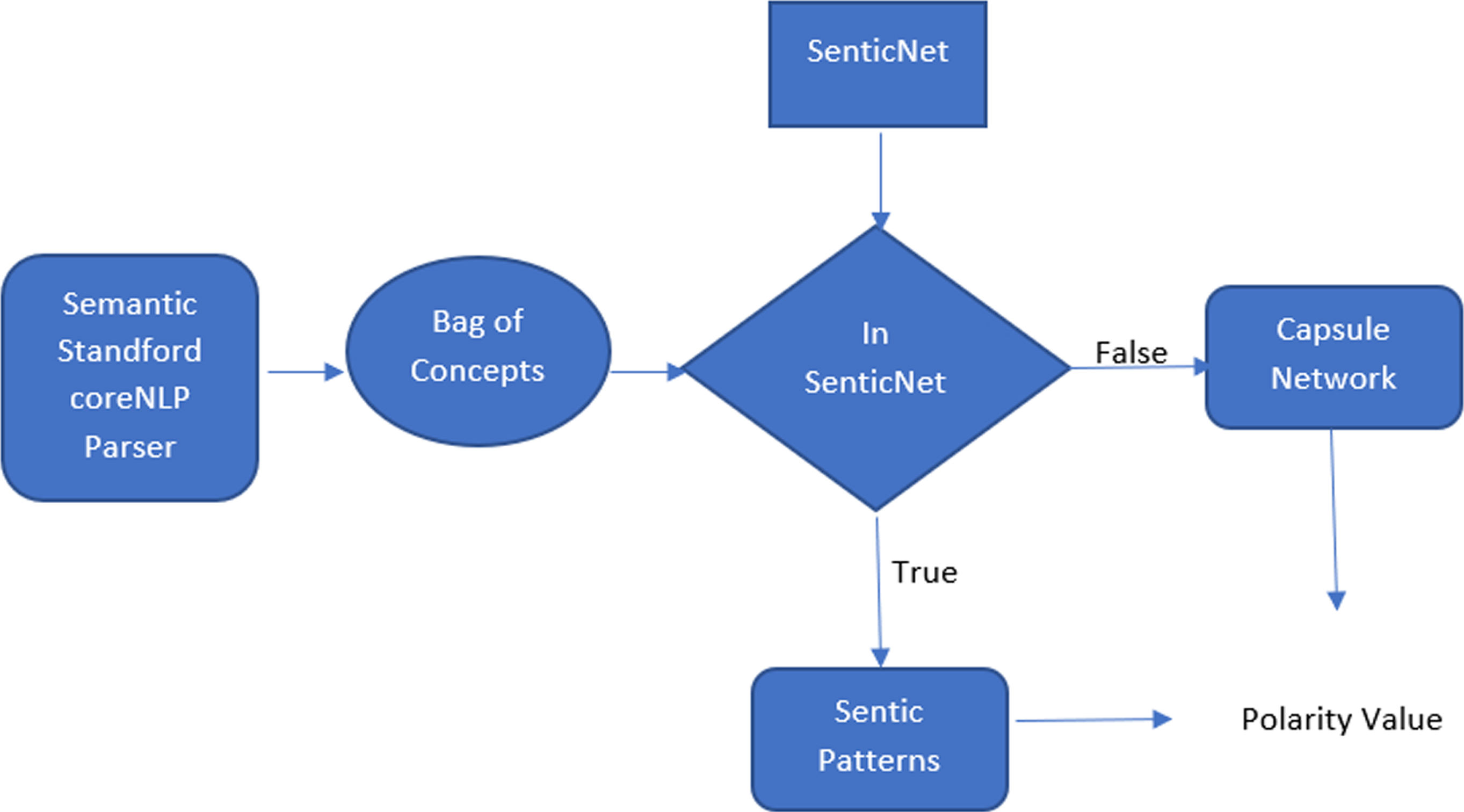
Flowchart represents the polarity detection of sentence level method. The text in natural language is first broken down into concepts by Standford CoreNLP parser. Sentic patterns are implemented if these are contained in SenticNet. The capsule network classifier is used if none of the definitions are accessible in SenticNet.
Capsule Networks (Figure 8 & 9) are a type of deep neural network design that is relatively new. Hinton et al. recently proposed, they have shown great progress in many fields, particularly in the areas of computer vision and natural language processing. A capsule is a collection of neurons that trigger individually, such as location, size, and hue, for different properties of an object type. A capsule is a collection of neurons that work together to form an activity vector with one element for each neuron, each of which contains the value of that neuron.

Architecture of capsule networks (CapsNet).
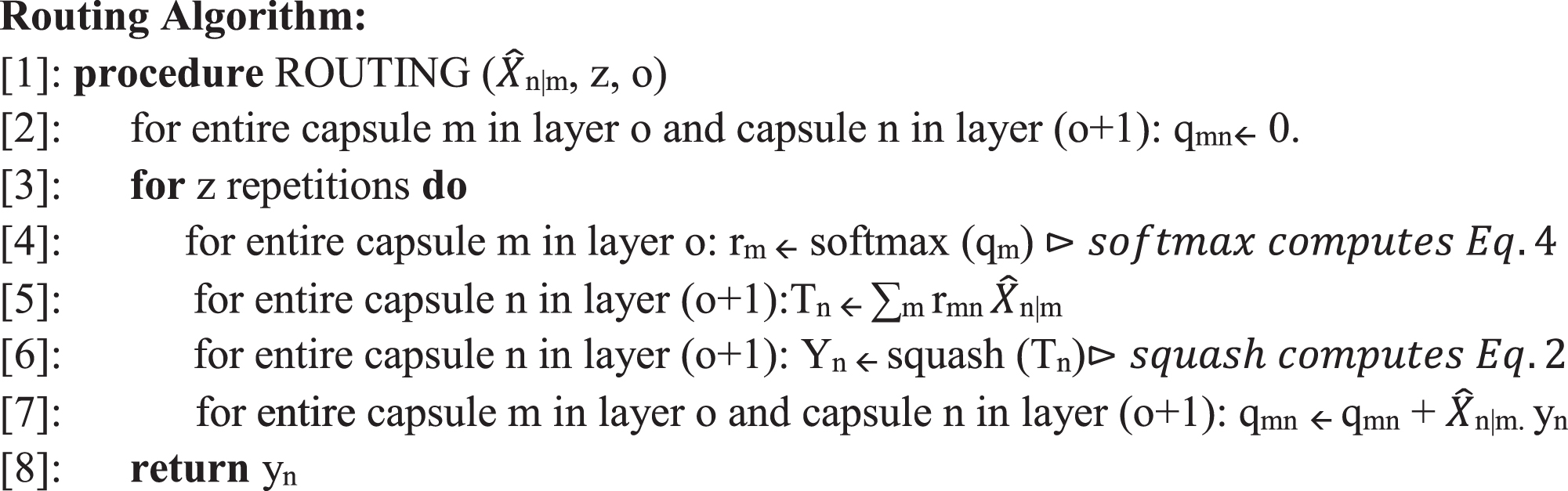
Routing algorithm [41].
A CapsNet (Capsule Neural Network) is a machine learning framework that can be used for better modelling hierarchical relationships. The method aims to be as close to biological neural organisation as possible [41]. A capsule is a collection of neurons that each respond to particular features of an item, such as size, colour, and location. A capsule is a collection of neurons which produce an activity vector along with one item for each neuron, which contains the neuron’s instantiation value. Capsnets substitute vector-output capsules for scalar-output function detectors, and allow max-pooling for routing-by-agreement. According to the documentation, Conv-CapsNet has four layers: a secret function layer, a convolutional layer, a PrimaryCaps layer, and a DigitCaps layer. The PrimaryCaps layer consists of eight capsules (um), each of which contains eight-dimensional features. We have used Eq. to calculate the contribution (unnm) of each capsule (um) in PrimaryCaps to the contribution (vn) in DigitCaps. Using Eq. 1 as a starting point Because capsules are self-contained, when a lot of them agree, the chances of getting an accurate reading go up a lot.
A Capsule Neural Network (CapsNet) is a machine learning system for more effectively modelling hierarchical relationships. The technique is an experiment to more accurately represent biological neural organisation [41].
We need the length of a capsule’s result vector to reflect the likelihood that the object it represents an existent in the current input. We apply a non-linear “squashing” feature to assure that short vectors are reduced to practically zero length while long vectors are compressed to a length slightly less than zero. We believe discriminative learning is the best way to take advantage of this non-linearity.
Here, the vector output of the capsule n is denoted by vn and the total input is denoted by sn.
The capsule input sj is a weighted amount of all “prediction vectors” unm, except for the first layer of capsules, and it is determined by increasing the output um of a layer in a capsule below by a weight matrix Wmn.
The iterative dynamic routing method specifies the cmn, which are coupling coefficients. All the capsules in the layer represents the coupling coefficients add up to one and are determined using a “routing softmax” with initial logits bmn equal to the log earlier probabilities that capsule I should be joined to capsule n.
The log priors can be discriminatively taught at the same time as the other weights. They are influenced by the position and shape of the two capsules, but not by the current input image2. The initial coupling coefficients are then improved iteratively by comparing each capsule’s current output Yn in the layer above with capsule m’s prediction Xnnm. The agreement is the scalar product pmn = Yn: Xnnm. This agreement is treated as if it were a log probability and applied to the starting logit, qmn, until the new values for all the coupling coefficients linking capsule I to higher level capsules are computed. Each capsule in a convolutional capsule layer generates a vector for each capsule type in the layer above, with different revolution matrices for each grid member and capsule type.
Despite being more effective than the bag-of-words technique, the proposed model is still less research work in nlp and the collection of dependency rules. Natural Language Processing implementations use sentiment analysis to extract emotions that are associated with few raw texts. Sentiment analysis is the analysis of tweets, Facebook posts over some time to fetch the sentiment of a few audiences. Further, we extract concepts to create a better understanding, and even if sentic pattern is not matched, we choose an alternative to capsule networks for representing the sentiment analysis. We used two familiar datasets of sentiment analysis and the Capsule Network further gives the sentiment either positive or negative from the text.
Dataset used
Movie review dataset
We have used a movie review dataset from the corpus implemented by Pang and Lee [42]. This dataset contains 1000 negative and 1000 positive reviews based on movies inspected by professional movie reviewers. This dataset is gathered from rottentomatos.com where all the contextual data is converted to lemmatized, lowercase, and HTML elements are removed. Every movie review is manually labelled by Pang and Lee. After that, Socher et al. [43] annotated this movie dataset at the sentence level. [43] extracted 11855 sentences from the movie reviews and marked them, utilising a fine-grained inventory of five sentiment labels as positive, negative, neutral, strongly positive, and strongly negative. Then, in this implementation work, we focused on binary classification.
Trip advisor hotel review dataset
We also conducted additional experiments using 8000 TripAdvisor hotel review datasets for the evaluation and performance of sentiment analysis. This trip advisor dataset [45], provided by [44], constructed a vocabulary list of nearly 4750 words. We have done preprocessing stages such as removing stop words and punctuation to reduce the complexity of the original content.
Representation of the feature set
Features of common-sense knowledge
Common-sense awareness entails concepts represented via AffectiveSpace. The semantic parser encodes concepts derived from text, particularly 300-dimensional concepts. Vectors that have been real-valued and then aggregated into a single vector via coordinate-wise summing and describing the sentence:
Where, N signifies the amount of concepts extracted form a sentence and xi is the vector of the ith organize of the sentence feature when i = 1 to 100. xij is the ith coordinate of its vector of jth concepts [46].
Features of part of speech
The amount of speech feature is obtained by the amount of nouns, adverbs, conjunctions, interjections, and adjectives.
Features of senticnet
Each notion’s polarity scores were extracted from the sentence, and they were obtained from SenticNet to create a single scalar feature.
Feature of modification
We also conducted additional experiments using 800This is a single function feature of binary. we obtained, the sentences from the dependency parser. From the dependency parser, we obtained the sentences of the dependency tree. We have considered this tree to decide whether any words are modified by an adjective, noun, conjunction, interjection, or adverb. The purpose of the adjustment was set to 1 if we establish any alteration association in the sentence; otherwise, it was set to 0.0. trip advisor hotel review datasets for the evaluation and performance of sentiment analysis. This trip advisor dataset [45], provided by [44], constructed a vocabulary list of nearly 4750 words. We have done preprocessing stages such as removing stop words and punctuation to reduce the complexity of the original content.
Features of negation
Likewise, the feature of negation was a single binary element and it is determined by if in the sentence with any negation. It is important since negation will reverse the polarity of that phrase.
Classification methods
Over the training phase of the movie review dataset, lstm-rnn and Capsule Network classifier was trained. In the training part, lstm-rnn and capsule network classifiers are trained using the sentence feature set of the movie analysis dataset. We discovered that the capsule network outperformed the lstm-rnn in terms of both accuracy and processing time. In specific, on the testing portion of the research, we achieved 88.5% accuracy from the movie analysis dataset and 79.4% with the lstm-rnn classifier. Similarly, the same method that was tested on the TripAdvisor hotel review dataset sentence and achieved 86.6% accuracy level with Capsule Network and achieved an 81.7% accuracy level with lstm-rnn. Then, If SenticNet is unable to interpret a sentence, the learned capsule network classifier is used to create a better guess at the phrase’s polarity based on the existing feature.
Experimental results and discussion
The proposed approach was checked on two datasets, such as the movie review dataset described in section 5.1.1 and the trip advisor dataset described in 5.1.2. As exposed by result lower, the best the results in accuracy are accomplished by implementing a capsule network and deep learning technique. After the preprocessing and semantic extension, the text of the comment was usually under 300 characters long. The length of the comment text after preprocessing and semantic extension was typically less than 300 characters. As a result, Google news-vectors-negative300.bin [41], the Google Pre-Trained Corporate News word vector library, was chosen to generate a text vector for the feedback.
Results
The two datasets (movie review data and hotel review data) were applied to the proposed CLSA-CapsNet model, the capsule network model and traditional deep learning models. Table 3 displays the results of binary classification experiments, where each cell’s two values correspond to the “positive” and “negative” groups, respectively. Accuracy, precision, recall, and F1 score are all described in these tables.
Results of all the model
Results of all the model
It can be challenging to find a model in Machine Learning and Deep Learning is co-adapt. This means that each neuron is very important to the other ones. They have a big impact on each other and aren’t as independent as they should be when it comes to what they say. It’s also common to find cases where some neurons have a predictive power that is more important than those of other neurons.
These effects must be avoided, and the weight must be spread out to avoid overfitting. Regulating the co-adaptation and high predictive power of some neurons can be done in different ways. One of the familiar is the Dropout. We tested our approach to the hotel review dataset and the movie analysis dataset without SenticNet and obtained an accuracy of 84.6 percent and 86.4 percent. Then we tested our approach to the hotel review dataset and the movie analysis dataset with SenticNet along with dropout layer and obtained an accuracy of 86.6 percent and 88.5 percent.
Tables 4 5 had the highest F1 scores, while deep learning algorithms had similar outcomes for the two datasets. Our first CLSA+SenticNet+Capsule network was the best among all models.
Results of movie review dataset
Results of hotel review dataset
There were just a few thousand exabytes of knowledge on the Web between the beginning of humanity in 2003 and the present. Today, a huge amount of data is generated each week. The Social media has given public new applications for making and sharing their content, thoughts, and views with virtually millions of people linked to the Internet in a timely and cost-effective manner. This vast amount of useful data, on the other hand, is largely unstructured, having been created primarily for human use, and therefore is not explicitly machine-processable. Concept-level sentiment analysis, unlike previous word-based methodologies, uses web ontologies or semantic networks to perform a semantic analysis of text, allowing for the accumulation of concepts and affective knowledge connected with natural language opinions. Concept-level sentiment analysis is limited by the richness of the knowledge base and the fact that the bag-of-concepts model, while more evolved than to the bag-of-words model, misses out on essential discourse structure data that is necessary for correctly detecting the polarity expressed by natural language opinions. In this paper, we introduced a innovative paradigm to CLSA that combines semantics, common sense computing, and capsule networks to increase the accuracy of polarity detection. We demonstrated that CLSA+SenticNet+Capsnet improved performance on relatively long text. The proposed CLSA+ SenticNet +Capsnet models achieved 88.5 percent and 86.6 percent accuracy in binary classification, respectively. Accuracy, Precision, recall and F1 Score of classification models are representd in Figure 10, 11, 12, 13.
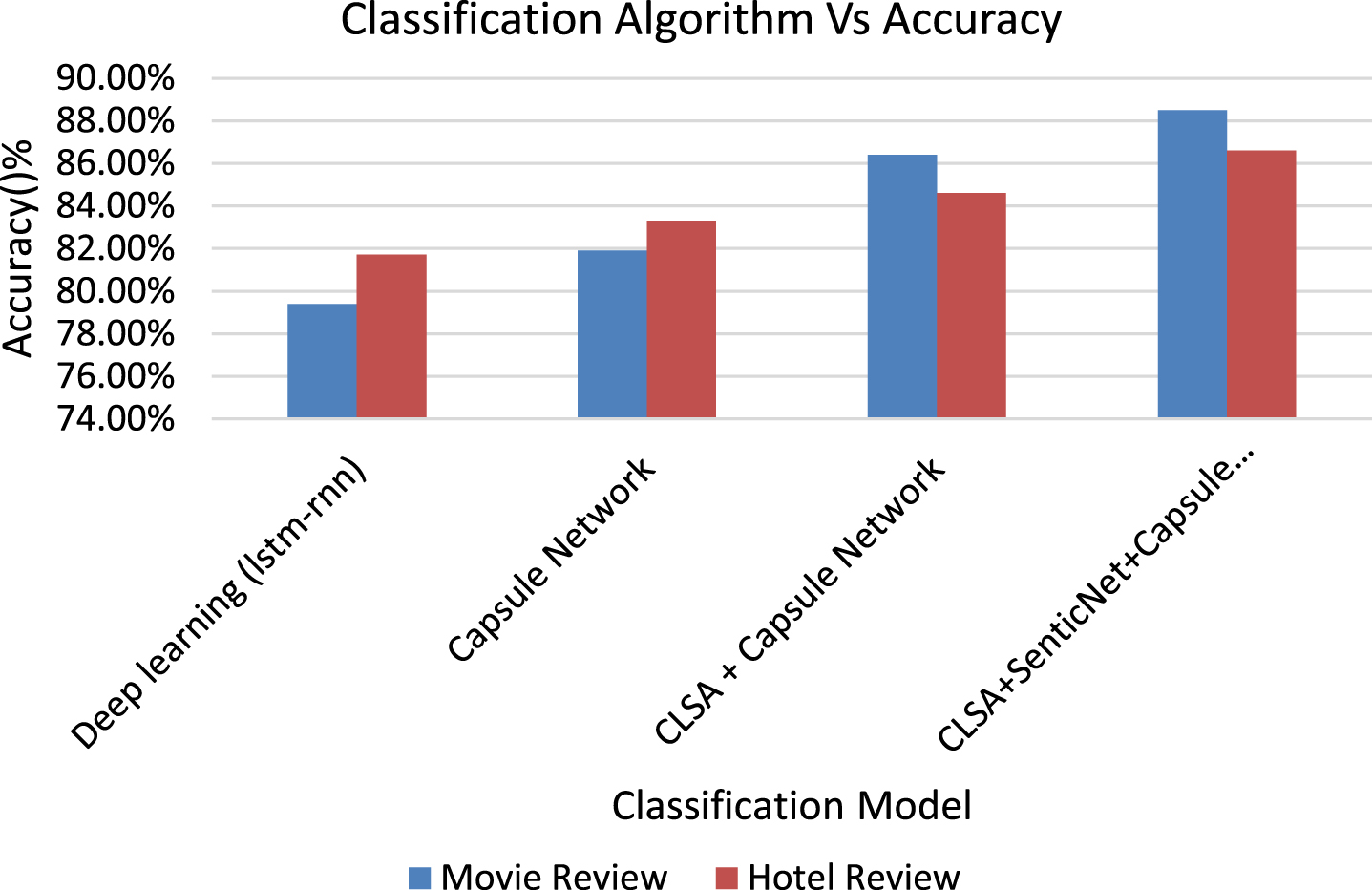
Accuracy of classification models.

Precision of classification models.
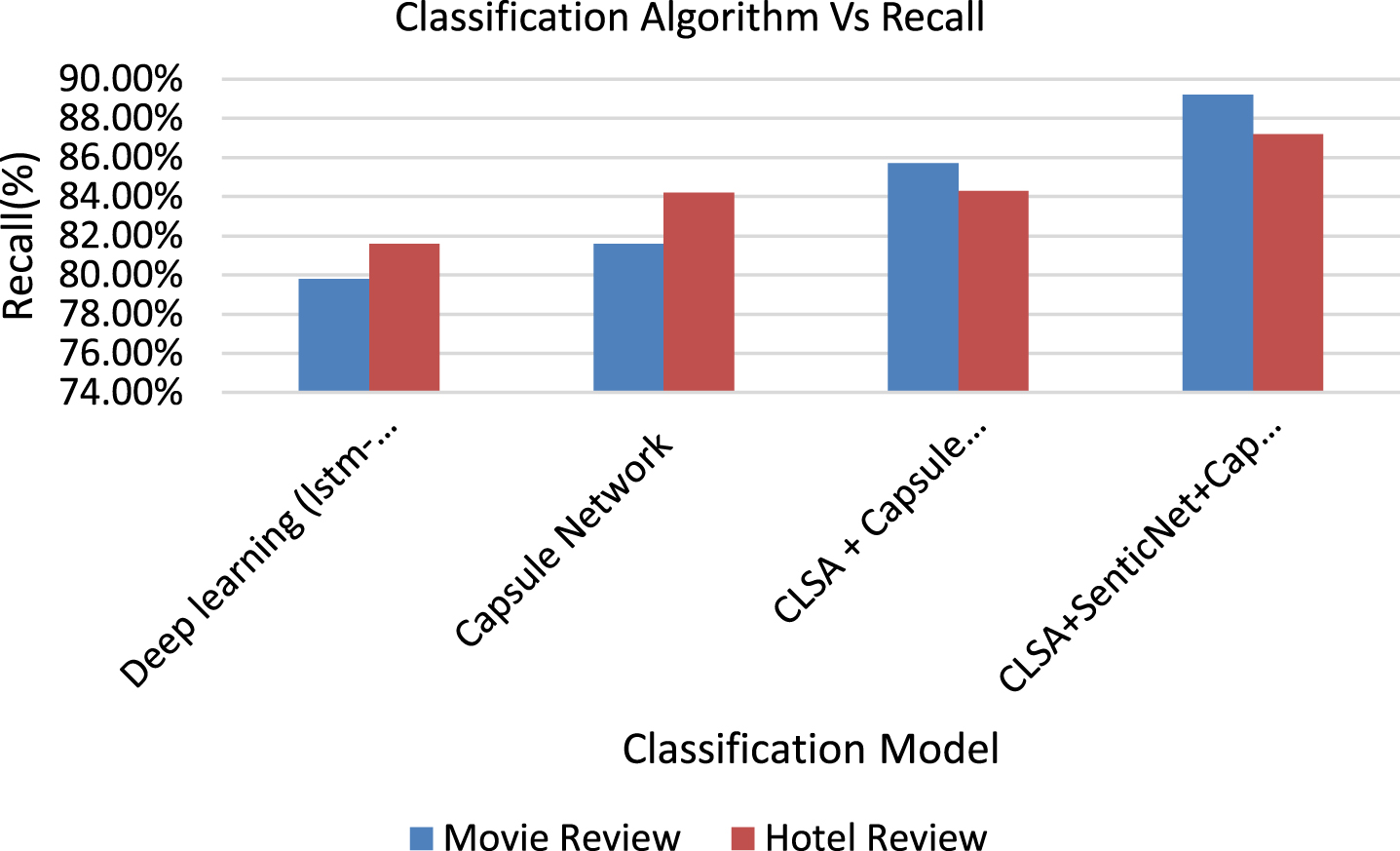
Recall of classification models.

F1 Score of classification models.