
Abstract
The Explicit and Implicit Sexual Interest Profile (EISIP) is a multimethod measure of sexual interest in children and adults. It combines indirect latency-based measures such as the Implicit Association Test (IAT), Viewing Time (VT), and explicit self-report measures. This study examined test–retest reliability and absolute temporal agreement of the EISIP over a 2-week interval in persons who were convicted of sexual offenses against children (n = 33) and nonoffending controls (n = 48). Test–retest reliability of the aggregated EISIP measures was high across the whole sample (rtt = .90, intraclass correlation coefficient [ICC] = .90) with the IAT yielding the lowest retest correlations (rtt = .66, ICC = .66). However, these indicators of relative reliability only quantify the temporal stability of individual differences within the group, not the detectability of individual change. Absolute temporal agreement as assessed via Bland–Altman plots ranged from one fourth to three thirds of a standardized unit in the sexual preference scores. This implies that individual change has to exceed medium to large standardized effect sizes to be distinguishable from spontaneous temporal variation in the EISIP measures. Overall, scores of combined measures were largely superior to single measures in terms of both absolute and relative reliability.
Introduction
The assessment of nonnormative sexual interest has a long history within sex research. Commonly, sexual inclinations toward different types of normative and atypical sexual stimuli are assessed using self-report scales or clinical interviews (Kalmus & Beech, 2005). However, both standard measurement approaches are limited due to social desirability or impression management, because particularly nonnormative sexual behaviors and fantasies are sensitive personal issues that many individuals feel uncomfortable reporting about. This is likely even more pronounced in forensic contexts where particularly paraphilic sexual interests are a focal assessment concern. For individuals convicted of sexual offenses, the disclosure of paraphilic sexual preferences (e.g., pedophilic interest) will likely have severe legal repercussions as far as risk assessment and risk management are concerned, due to the fact that sexual interest in children is a core risk factor for sexual recidivism (Mann et al., 2010). The desire to prevent such negative legal ramifications likely contributes to the unacceptably low levels of observer agreement, particularly for categorical pedophilic disorder diagnoses (Mokros et al., 2018). Therefore, researchers have aimed to develop alternative assessment approaches that unobtrusively measure sexual interests based on victim characteristics and offending behavior (Lehmann et al., 2018), physiological (e.g., McPhail et al., 2019) or other—most often latency-based—indirect measures (e.g., Banse et al., 2010; Larue et al., 2014) which are hypothesized to be less susceptible to deliberate faking or social desirable responding.
Indirect Latency-Based Measures of Sexual Interest in Forensic Contexts
To date, the most prominently researched indirect measurement approaches in forensic contexts (for current overviews, see Bartels et al., 2016; Schmidt et al., 2015) are the Implicit Association Test (IAT; Babchishin et al., 2013) and Viewing Time tasks (VT; Schmidt et al., 2017). The IAT, originally developed by Greenwald et al. (1998) to measure racial prejudice, has been adapted to a range of different research fields (for a review, see Schnabel et al., 2008). The IAT is a latency-based measure that serves as an indicator of the strengths of implicit associations between attributes (e.g., sexual arousing and non-arousing words) and categories of stimuli (e.g., pictures of children or adults) both arranged on bipolar dimensions. Respondents classify word or picture stimuli that represent these four categories (e.g., images of men vs. women as target categories and words representing sexual excitement vs. no excitement attribute categories, respectively) using two response keys, each assigned to the crosswise combined target and attribute categories. In such a double discrimination task, classifications are accelerated if two closely associated target and attribute concepts share the same response key (compared with trials in which they are assigned to different response keys). The underlying process is most likely an effect of response interference if two nonassociated concepts share the same response key (Gawronski et al., 2011). However, which psychological processes exactly drive IAT-effects is still unclear.
The VT task is based on a measure first introduced by Rosenzweig (1942). In the context of sex research, it demands respondents to subjectively rate stimuli in terms of how sexually arousing or attractive they are perceived. During the rating of each stimulus, the time spent for reaching the decision is recorded unobtrusively. Thereby, longer VTs are deemed to indicate increased sexual interest (e.g., Harris et al., 1996). In a series of experiments, stimulus-driven causal explanations for VT effects such as attentional capture or deliberate delay to spend more time looking at sexually appealing pictures have been ruled out (Imhoff et al., 2010). Instead, a task-driven feature-checking process may cause prolonged decision latencies. This means that depending on the task (i.e., to judge sexual attractiveness) a set of idiosyncratic features need to be checked and affirmed. Once crucial features can be denied (e.g., too young, wrong sex), the judgment is easier (i.e., faster) than in case of a sexually attractive target where more fine-grained decisions are necessary (i.e., further features need to be checked) to gauge the subjective degree of sexual appeal. This implies that VT effects are to a larger degree a function of the underlying task than of the actual stimulus qualities (Imhoff et al., 2012; Pohl et al., 2016).
Combining a self-report questionnaire with IAT and VT tasks, Banse et al. (2010) developed a multimethodal assessment battery—the Explicit and Implicit Sexual Interest Profile (EISIP)— to profit from the psychometric advantages of tying together conceptually different assessment approaches. Adding to prior forensic validation studies (Babchishin et al., 2013; Banse et al., 2010; Schmidt et al., 2013, 2014, 2017), the present study for the first time seeks to examine relative and absolute test–retest reliability indicators (Aldridge et al., 2017) of the distinct EISIP measures.
Psychometric Properties of Indirect Latency-Based Measures in Forensic Contexts
Indirect latency-based measurement approaches, such as the IAT and VT, describe test procedures where the measured variable is (indirectly) inferred from individual differences in response latencies during decision or classification tasks. Although these measures share with self-report measures the fact that it is relatively easy for the respondent to guess the construct of interest, latency-based measures are much less transparent in terms of how the underlying measurement rationale relates to the assessed sexual interest categories. Thus, the respondent is able to guess what particular construct is measured but it may be hard to guess how the construct is measured. Accordingly, indirect latency-based measures should be less susceptible to faking than self-reports (Schmidt et al., 2015). Setting high psychometric standards concerning reliability (i.e., internal consistency, test–retest reliability, and interrater reliability) as well as on validity is particularly important in applied forensic assessment contexts, as decisions informed by outcomes of such indirect measures could have far-reaching legal and personal consequences on individual and societal levels (Dror & Murrie, 2018). To this end, construct validity can be considered quite well researched: For example, recent meta-analyses for IAT and VT measures of sexual interest in children (Babchishin et al., 2013; Schmidt et al., 2017) and comprehensive validation studies (Ó Ciardha et al., 2018) have demonstrated meaningful differences between varying criterion groups, as well as convergent validity with conceptually different measures of pedophilic sexual interest such as self-reports, various indirect latency-based measures, penile plethysmography, offense behavioral measures, and oculometric assessments.
Available reliability data typically show a wide range in internal consistency coefficients for VT (e.g., Abel et al., 1998; Mokros et al., 2013) and IAT (e.g., Gray et al., 2005) measures in forensic contexts (for an overview, see Schmidt et al., 2015), within the distinct EISIP measures (with Cronbach’s α ranging from .77 to .95 for VT measures and from .61 to .82 for the different IATs; Banse et al., 2010; Schmidt et al., 2014). Although internal consistency within measurements has been explored in a smaller set of studies and for different indirect latency-based paradigms, very little is known about the temporal stability of latency-based assessment approaches.
Relative and absolute test–retest reliability
Traditionally, test–retest reliability estimates in psychology are based on the correlations between measurements across two time points. These are calculated as either standard Pearson (rtt) or intraclass correlation coefficients (ICC that control for intra- and intermeasurement variability; Aldridge et al., 2017). This statistical approach investigates relative test–retest reliability. It quantifies the stability of ranks within groups and whether distance of measurements within the groups varies between test and retest (Berchtold, 2016). Consider the case in which Participant A scores 90%, Participant B scores 70%, and Participant C scores only 50% on the initial test, in the retest these three participants score 40%, 20%, and 0%, respectively. Although all participants score 50% worse when comparing test and retest, relative stability is perfect in this case with r = 1. Hence, it is possible to reach near perfect test–retest correlations although the measurements show considerable dissimilarity in terms of absolute agreement over time (for additional examples, see Berchtold, 2016).
Other more appropriate absolute measures of reliability across time take into account the level of actual concordance between measurement times (i.e., the possible change of mean scores or bias; Bland & Altman, 1986, 1999). Specifically, absolute test–retest reliability seeks “to systematically evaluate the consistency, reproducibility, and agreement among two or more measurements of the same tool under unchanged conditions” (Aldridge et al., 2017, p. 208). This level of control can rule out individual change on the given construct, to assure that observed changes in later measurement applications can be attributed to change in individuals rather than to transient measurement error (e.g., Aldridge et al., 2017; Berchtold, 2016). In contrast, relative test–retest reliability measures based solely on correlation coefficients between measurement times fall short of this aim as it is possible that a measure reproduces the same rank-order and differences between participants although systematic mean changes can be observed (e.g., due to learning effects from repeated test taking). Furthermore, measures of relative reliability are susceptible to restrictions of variability (Bland & Altman, 1986; Goodwin & Leech, 2006).
In contrast to the relative consistency approach, the absolute test–retest reliability approach aims to quantify the magnitude of random change when reassessing unchanged individuals. To this end, a simple graphical and statistical method is based on plotting the differences on a measure over two measurement times against the means of these measurements for the same individuals (Bland & Altman, 1986, 1999). This plot can be used to examine the data distribution, systematic bias, and to screen for outliers or heteroscedasticity (i.e., the level of agreement between measurements depends on, or is proportionate to the size of the measurement). Aldridge and colleagues (2017) as well as Berchtold (2016) give a nontechnical overview of the Bland–Altman method and Welsch et al. (2019) provide an example for the applicability of the Bland–Altman plot for measuring absolute reliability in experimental research.
Relative test–retest reliability of indirect latency-based measures
In a nonforensic context, Egloff et al. (2005) systemically investigated the relative test–retest reliability of the latent construct measured by an Anxiety-IAT. Moderate relative test–retest reliability was found on the individual D-scores, which is an effect size similar to Cohen’s d (Cohen, 1992) estimated by calculating the mean difference in the diagnostic IAT-blocks and standardizing on the variation within trials (Greenwald et al., 2003). This was the case across three studies with varying retest intervals (1 week, rtt =.58; 1 month, rtt= .62; and 1 year, rtt = .47). Interestingly, for an IAT measuring attitudes toward homosexuality, a relatively low test–retest reliability of rtt = .38 was reported by Banse et al. (2001). Based on a large-scale comparison of several indirect attitude measures, Bar-Anan and Nosek (2014) reported an average test–retest reliability of rtt = .45 for three different implicit attitude IATs within 60-min retest intervals.
More relevant to the current study, first evidence has been reported for a pedophilic sexual interest IAT in forensic samples that was administered twice within a 1-hr interval (rtt = .63; Brown et al., 2009). For VT measures of sexual interest in adults, findings are even sparser. Imhoff et al. (2010) found quite high relative test–retest reliability of non-gender-specific difference scores in a nonforensic sample when the retest was administered within the same test session (10-minute interval; rtt = .86). Dombert and colleagues (2017) reported split-half reliabilities for a choice-reaction time measure of sexual interest in children and adults in a forensic sample of rtt = .70 and rtt = .53 within the same test run.
These preliminary data from nonforensic and forensic samples corroborate that indirect latency-based measures of sexual interest are capable to reach at least moderate test–retest correlations for rather short time intervals. The cited studies also suggested that VT measures are slightly more stable than IATs as indicated by the correlation of test and retest scores.
Current Study
When evaluating individuals in terms of individual change (e.g., due to some form of intervention) one has to qualify not relative but absolute differences in measurements. A necessary prerequisite for this diagnostic task is that we investigate the extent to which the assessed change is attributable to measurement error, that is, unreliability of the measure. This can be accomplished by assessing absolute test–retest reliability, which so far has not been tested for any indirect latency-based measure in general nor specifically in the context of sexual or forensic assessment.
To this end, the aim of the present study was to explore indicators of temporal rank-order stability (i.e., relative test–retest reliability) and temporal agreement (i.e., absolute reliability) of the EISIP within a 2-week retest interval. We sought to elucidate the psychometric properties of its underlying measures for research and clinical single-case purposes alike. The 2-week interval was chosen as spontaneous or therapeutically induced changes in sexual preferences for children over adults are unlikely over this period of time (e.g., Imhoff et al., 2017; Seto, 2012). We also reported how we have determined our sample size, all data exclusions, all manipulations, and all measures in the study.
Method
Participants
As part of a larger study, we tested 55 men who never had been convicted for any offenses serving as control group (MNOC) and 51 men who had been convicted for sexual offenses against children (MSOC). Due to software errors and visitation restrictions concerning prisons and forensic psychiatric facilities, the retest data of 7 MNOC and 14 MSOC could not be collected or analyzed. Furthermore, four MSOC were excluded due to excessive error rates and prolonged latencies in the IATs of the first or second test session after inspecting the data (percent incorrect > 16.7% according to the Tukey criterion that equals to 1.5 times the interquartile range plus the 75% quantile of the error distribution across participants). Thus, our effective sample that had both completed the first and the second test session of the EISIP consisted of 48 MNOC and 33 MSOC. The MNOC were recruited at the Johannes Gutenberg-University of Mainz and through online advertisement. They either received 20€ in cash or course credit for participation. Mean age of MNOC was M = 24.91 years (SD = 5.32). In this exploratory study, sample size was not determined by means of study-relevant variables as the measurements were part of a larger test battery. Still, test–retest correlations typically range within medium to large effects sizes and thus even our smallest subsample with n = 33 was sufficiently large to reliably detect effects distinguishable from zero (lower critical rtt = .34).
The MSOC were recruited through advertisements and through personal contacts in forensic psychiatric clinics and prisons in Rhineland-Palatine, Germany. For taking part in a larger test battery, they received 20€ in cash or as a telephone credit voucher. All MSOC have received or were currently undergoing psychotherapeutic treatment within sexual offender specific treatment programs at the moment of testing. Mean age of the MSOC was M = 42.56 years (SD = 12.29), differing significantly from MNOC, t(80) = 8.86; p < .001; d = 1.96. Eighteen (54.5%) MSOC had girl victims only, five (15.2%) had sexually victimized both girls and boys, six (18.2%) offenders had boy victims only, and in four offenders (12.1%) victim type could not be determined. The average score on the Screening Scale for Pedophilic Interests (SSPI; Seto & Lalumiére, 2001; German version, Eher et al., 2015; possible range 0-5)—a phallometrically validated measure of pedophilic sexual interest based on information from the individual offense history—was M = 2.90 (SD = 1.21) and did not differ from the original validation sample (Seto & Lalumiére, 2001; N = 1,113 MSOC), t < 1, p = .678, d = 0.07. Thirteen participants (39.4%) in the MSOC subsample fulfilled the ICD-10 criteria for pedophilia (F65.4) as indicated by official diagnoses in their prison or forensic psychiatric files. The mean recidivism Static-99 score (Hanson & Thornton, 2000; German version Rettenberger et al., 2013; possible range 0–12) was 2.97 (SD = 2.06) and also did not differ from the original German validation sample (Rettenberger et al., 2013; N = 1,077 adult sexual offenders), 1 t < 1, p = .752, d = 0.12.
Explicit and Implicit Sexual Interest Profile (EISIP)
The EISIP (Banse et al., 2010) is a multimethod testing battery of pedohebephilic sexual interests. Prior forensic validation studies (Banse et al., 2010; Schmidt et al., 2013, 2014) have shown that it distinguishes between MSOC and various control groups of individuals who have been convicted of violent and sexual offenses against children and adults as well as nonoffending groups. It is also associated with recidivism risk-relevant indicators and offense-related indicators of pedophilic interest. Furthermore, the underlying indirect latency-based measures have been meta-analytically supported (Babchishin et al., 2013; Schmidt et al., 2017).
The EISIP consists of three different measurement tasks. First, participants had to perform a VT-task that demanded the participant to rate 80 (+4 practice) pictures of people wearing bathing suits of different sexual maturity and gender on a scale from 1 (sexually unexciting) to 5 (sexually exciting). Alongside, the time participants took to rate each stimulus was recorded unobtrusively. Reaction time was averaged as a function of Gender × Sexual Maturity target category for each participant for test and retest. Longer reaction times in one of these categories as compared with another category indicate a relatively stronger sexual interest.
Afterward, participants completed the three IAT tasks of the EISIP. First, the participants had to categorize five sexually arousing and nonarousing attribute words into corresponding two attribute categories (40 trials). Then target pictures of men and women were presented (40 trials) and had to be categorized by gender (or in subsequent IATs by age). Subsequently, attributes (sexually arousing, sexually nonarousing) and target categories (men, women) were crosswise combined (80 + 4 practice trials each) with a block of 40 trials with practice trials in between the reversed men/women categories. The differences in reaction times between those critical trials are an estimate for the association of target and attribute (Roefs et al., 2011). This five-block structure was repeated for the subsequent combinations with girl–women and boy–men IATs (Banse et al., 2010). Higher IAT scores indicate more sexual interest in men versus women or children versus adults, depending on the respective target combination.
Finally, explicit sexual interest was measured with 40 self-report questions related to two different subscales: sexual behavior (e.g., “I have enjoyed getting my private parts touched by a woman/man/young girl/young boy”) and sexual fantasy (e.g., “I had daydreams about having sex with a woman/man/young girl/young boy”) of the Explicit Sexual Interest Questionnaire (ESIQ; Banse et al., 2010). Both scales had five items combined with the four stimulus categories (men, women, prepubescent boys and girls). Cronbach’s α was high for the behavior subscale (men = .91, women = .91, prepubescent boys = .91 and girls = .93) as well as for the fantasy subscale (men = .91, women = .79, prepubescent boys = .75 and girls = .85). Every item was answered on a dichotomous answering scale referring to sexual experiences after respondents were 18 years of age (i.e., adult lifetime prevalence). Higher frequency of agreed items in one category indicated more sexual behavior and sexual fantasizing.
Trials in each task were presented in a fixed order to maximize individual differences across participants. Completing the EISIP took the participants about 25 min. The sexual stimuli used within the EISIP consisted of computer-generated composite pictures of male and female children and adults wearing bathing attire from the Not Real People Set (NRP; Pacific Psychological Assessment Cooperation, 2004) assigned to the five different stages of sexual maturity (Tanner, 1973; eight stimuli per category, 80 stimuli in total). Tanner Stage 1 represents prepubescent stimuli, Tanner Stages 2 and 3 peripubescent stimuli, and Stages 4 and 5 postpubescent stimuli.
Procedure
All participants took part in a larger test battery including the EISIP (Banse et al., 2010). Other parts of the project consisted of tasks such as an adapted Go/No-GO Task, the Iowa Gambling Task, or the Game of Dice Task; for a more detailed description of these tasks, see Turner et al. (2018). The study protocol was approved by the Ethical Committee of the Chamber of Psychotherapists in Hamburg, Germany. On two separate dates, participants first performed the EISIP followed by the different behavioral paradigms on a computer and afterward paper–pencil tests were filled out. The duration of each test session ranged between 75 and 115 min. The retest interval in days for MNOC (M = 16.31, SD = 3.71) did not differ from MSOC’s retest interval (M = 15.15 SD = 2.85), t(79) = 0.62, p = .243, d = 0.26. All participants completed computer procedures on notebooks in a quiet room alone (i.e., without other participants; the test advisor was present but was not able to look at the screen).
Scoring
Reaction times under 300 ms and above 10,000 ms were discarded (for a discussion, see Greenwald et al., 2003) in the IAT (3,334 of 78,720; 4.2%) and latencies longer than 10,000 ms were truncated to 10,000 ms (Banse et al., 2010) in the VT task (184 of 14,105; 1.3%). Then, we log10-transformed all reaction times, in order to correct the skew in the distribution of reaction times. Subsequently, we calculated relative pedohebephilic sexual preference indices that quantify how much participants are sexually interested in postpubescent adults relative to pre- or peripubescent children. 2 For VT measures and the ESIQ, maximized and standardized gender-neutral mean differences between sexually mature and immature (i.e., pre- or peripubescent) stimuli were calculated. The highest mean response latency/mean item score for any child category (Tanner 1/2/3 or child category for the ESIQ) was subtracted from the highest mean response latency/mean item score for any adult category (Tanner 4/5 for the VT or adult items for the ESIQ), respectively. This score has the advantage that it is independent of idiosyncratic sexual gender preferences, which are usually diverse among MSOC samples. It also has been shown to maximize indicators of validity for VT measures (Schmidt et al., 2017). Finally, these difference scores were standardized by dividing through the standard deviation of the relevant trials, in order to yield a comparable metric across all EISIP measures.
For the IATs, the D-score was calculated as the mean difference between diagnostic blocks divided through the individual standard deviation across both diagnostic blocks (Greenwald et al., 2003). Only trials with a correct answer were used; error trials were discarded. To have comparable maximized pedohebephilic preference scores for the IAT, we selected the minimum score (i.e., reflecting the strongest pedophilic preference) of the men–boys or women–girls IATs for our analyses.
Finally, we aggregated the three different maximized and standardized sexual preference scores for adults over children into a total EISIP sexual preference score by averaging across standardized ESIQ, VT, and IAT sexual preference scores. All subsequent analyses were based on these adult sexual preference indices. 3
Statistical Analyses
To investigate absolute retest reliability of the EISIP, we applied the Bland and Altman (1986, 1999) method to the data. Bland–Altman plots depict the mean difference between test and retest as a function of the mean of both test sessions for every participant (see Figure 2). Gray lines in the plots denote the limits of agreement. The limits of agreement represent a 95% confidence interval around the mean difference of the test session. 4 Thus, they show the range in which 95% of the values are to be expected. The upper and lower bound of the limits of agreement both are parameters estimated with sample-dependent uncertainty. This uncertainty is again qualified by a 95% confidence interval 5 (for details regarding the approximation and how to calculate the respective parameters, see Bland & Altman, 1999).
In addition, the repeatability coefficient was calculated by multiplying 1.96 times the respective standard deviations of the differences between test and retest which equals to half of the difference between the upper and lower bound of the limits of agreement. The repeatability coefficient can be interpreted as the largest absolute difference likely to occur due to unreliability of the measurement (i.e., the minimum difference needed to ascertain that change between measurement times exceed mere measurement error). The larger the limits of agreement and, thus, the repeatability coefficient, the worse is the absolute reproducibility of the measure (i.e., the absolute agreement between measurement times). Both repeatability coefficient and limits of agreement are expressed in the standardized units of the EISIP sexual preference scores and rely on the assumption that the mean differences between test and retest follow a Gaussian distribution. The alpha level for all analysis was set at .05.
Results
Control Analyses
Table 1 shows all EISIP sexual preference score means as a function of group and measurement times. Descriptively, there were large differences across groups and MSOC showed relatively more pedohebephilic sexual preference on all measures. This was the case across both measurements; however, there were some changes in the D-scores for VT in MSOC. Control analyses utilizing three 2 (Group; MSOC vs. MNOC; between-subjects) × 2 (Time; test vs. retest; within-subjects) mixed model ANOVAs with VT, IAT, and ESIQ sexual preference scores as dependent variables yielded for all dependent variables theoretically meaningful main effects of Group (ps ≤ .001, ηp²s ≥ .13). Specifically, showing that MSOC had on average lower sexual preferences for adults over children than MNOC. No main effects of Time were revealed, ps ≥ .428, ηp²s < .01, see also t tests in Table 1. However, for the VT task, Time yielded a nonsignificant interaction effect with Group, F(1,79) = 3.52, p = .064, ηp² = .04, indicating descriptively increased sexual preferences for adults over children at the second measurement (Table 1). No interaction effects emerged for the ESIQ or the IAT (ps ≥ .37, ηp²s < .01). Notably, none of the dependent variables significantly correlated with participant age within groups and test sessions (rs ≤ .26, ps ≥ .078). Thus, sexual preference scores were not confounded with participant age.
Overview of Measurement Times and Test–Retest Reliability Estimates as a Function of Groups for EISIP Pedohebephilic Sexual Interest Difference Indices.
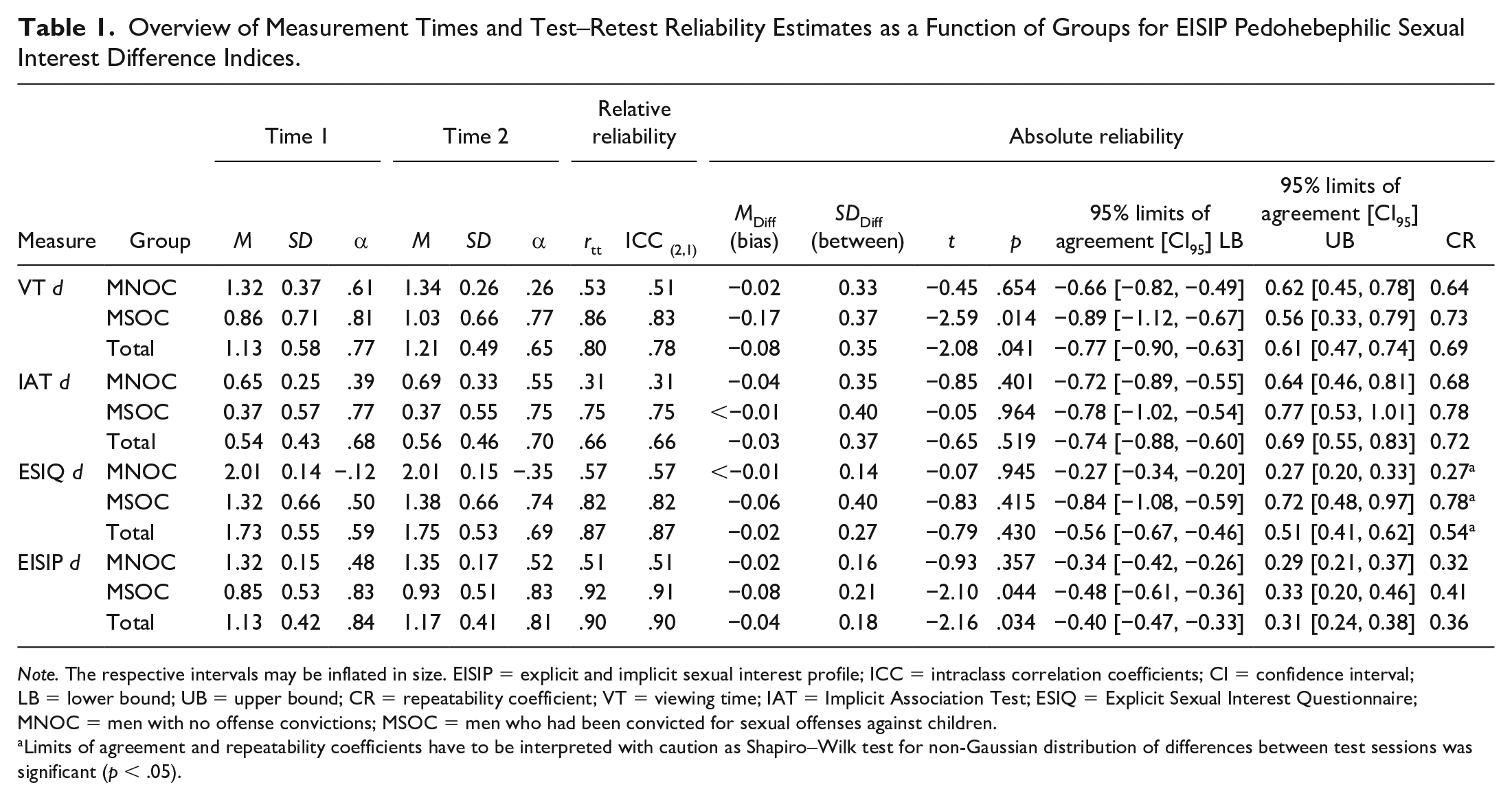
Note. The respective intervals may be inflated in size. EISIP = explicit and implicit sexual interest profile; ICC = intraclass correlation coefficients; CI = confidence interval; LB = lower bound; UB = upper bound; CR = repeatability coefficient; VT = viewing time; IAT = Implicit Association Test; ESIQ = Explicit Sexual Interest Questionnaire; MNOC = men with no offense convictions; MSOC = men who had been convicted for sexual offenses against children.
Limits of agreement and repeatability coefficients have to be interpreted with caution as Shapiro–Wilk test for non-Gaussian distribution of differences between test sessions was significant (p < .05).
Although the change in mean VT across measurements was not significant, it could still be potentially relevant in terms of absolute reliability. Thus, we plotted reaction time as a function of Stimulus Gender, Stimulus Age, and Group in Figure 1. The pattern of results for MSOC was descriptively similar across measurements; however, in the second test session MSOC responded marginally faster and in turn produced a smaller amount of variation in the data. We further decomposed this with another 2 (Time; test vs. retest) × 2 (Stimulus Gender; male vs. female) × 2 (Stimulus Age; child vs. adult) × 2 (Group; MSOC vs. MNOC; between-subjects) mixed-model ANOVA on log-transformed category reaction times in the VT-task. The analysis revealed theoretically meaningful main effects of Stimulus Gender (female > male stimuli), F(1,79) = 118.67, p < .001, ηp² = .60, and Stimulus Age (adult stimuli > child stimuli), F(1,79) = 299.27, p < .001, ηp² = .79, as well as their interaction (female adults produced the longest reaction times), F(1,79) = 97.50, p < .001, ηp² = .55. The analysis revealed an interaction of the factors Stimulus Age and Group, F(1,79) = 28.51, p < .001, ηp² = .27, with MSOC showing relatively increased sexual interest in children compared with MNOC. Furthermore, MNOC produced overall longer reaction times than MSOC, F(1,79) = 5.43, p =.022, ηp² = .06.
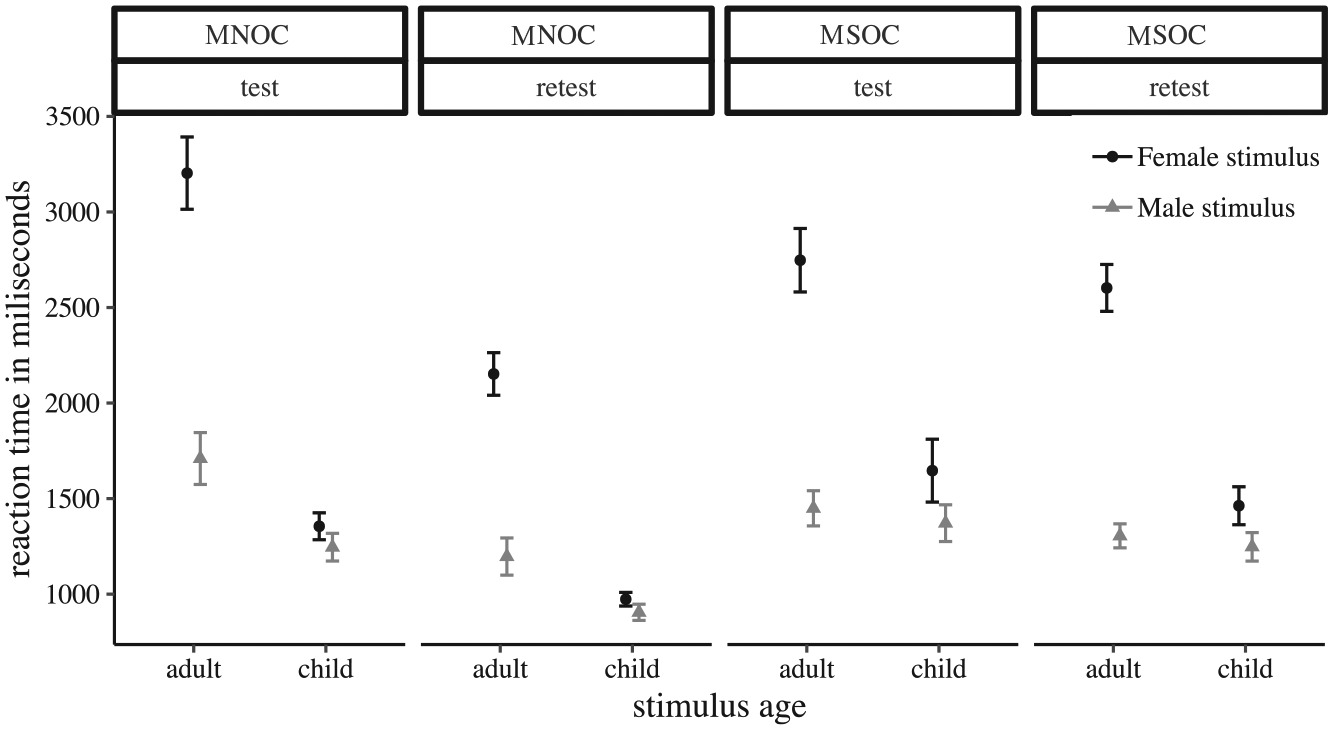
Mean Viewing Time as a function of gender and age of stimulus for every test session and group.
Notably, a main effect of Time appeared: Participants were generally faster in the second test session as compared with the first session, F(1,79) = 94.61, p < .001, ηp² = .55. This was particularly pronounced in MSOC, as indicated by a Group × Time interaction, F(1,79) = 31.96, p < .001, ηp² = .28. No further interaction effects with Time or Group emerged, (ps ≥ .056, ηp²s < .01). Based on these findings, we conclude that the relative reduction of pedohebephilic preferences in the EISIP-VT sexual preference index in MSOC is simply a consequence of generally faster responding to any stimulus category rather than a systematically increased or decreased response to adult or child stimuli, respectively.
Relative Test–Retest Reliability
All EISIP sexual preference scores yielded at least good levels of association over two weeks for the whole sample (see Table 1) with particularly high rank-order consistency and equidistance for the VT (ICC = .78) and self-report measures (ICC = .87). Furthermore, for all subgroups, the IAT showed the lowest relative test–retest reliability estimates. The aggregated EISIP sexual preference score revealed good to excellent associations between test and retest for the whole sample and the MSOC. Notably, relative reliability estimates for MNOC were attenuated compared with the MSOC.
Mean Bias and Absolute Test–Retest Reliability
Using the Bland–Altman method (Bland & Altman, 1986, 1999), we plotted the mean score of the respective measures averaged over both test sessions as a function of the difference between the scores of both test sessions for every measure and the corresponding limits of agreement (see Figure 2). The differences of EISIP scores were approximately normally distributed (except for the self-report data) as indicated by Shapiro–Wilks tests (see Table 1). Graphical inspection revealed that there was no skew in the plots illustrating the psychometrically desirable lack of a systematic association between the differences of both test sessions and the overall means. Hence, measurement error across time varied independently from the mean score. Bland–Altman plots also showed no systematic biases over time for all distinct EISIP measures in MNOC as well as the IAT and the self-report data in both groups. However, for MSOC and the total sample, the VT and total EISIP scores showed slight but statistically significant biases indicating an unexpected decrease of relative pedohebephilic preference levels (see Table 1) as had already been indicated by the control analyses described above.
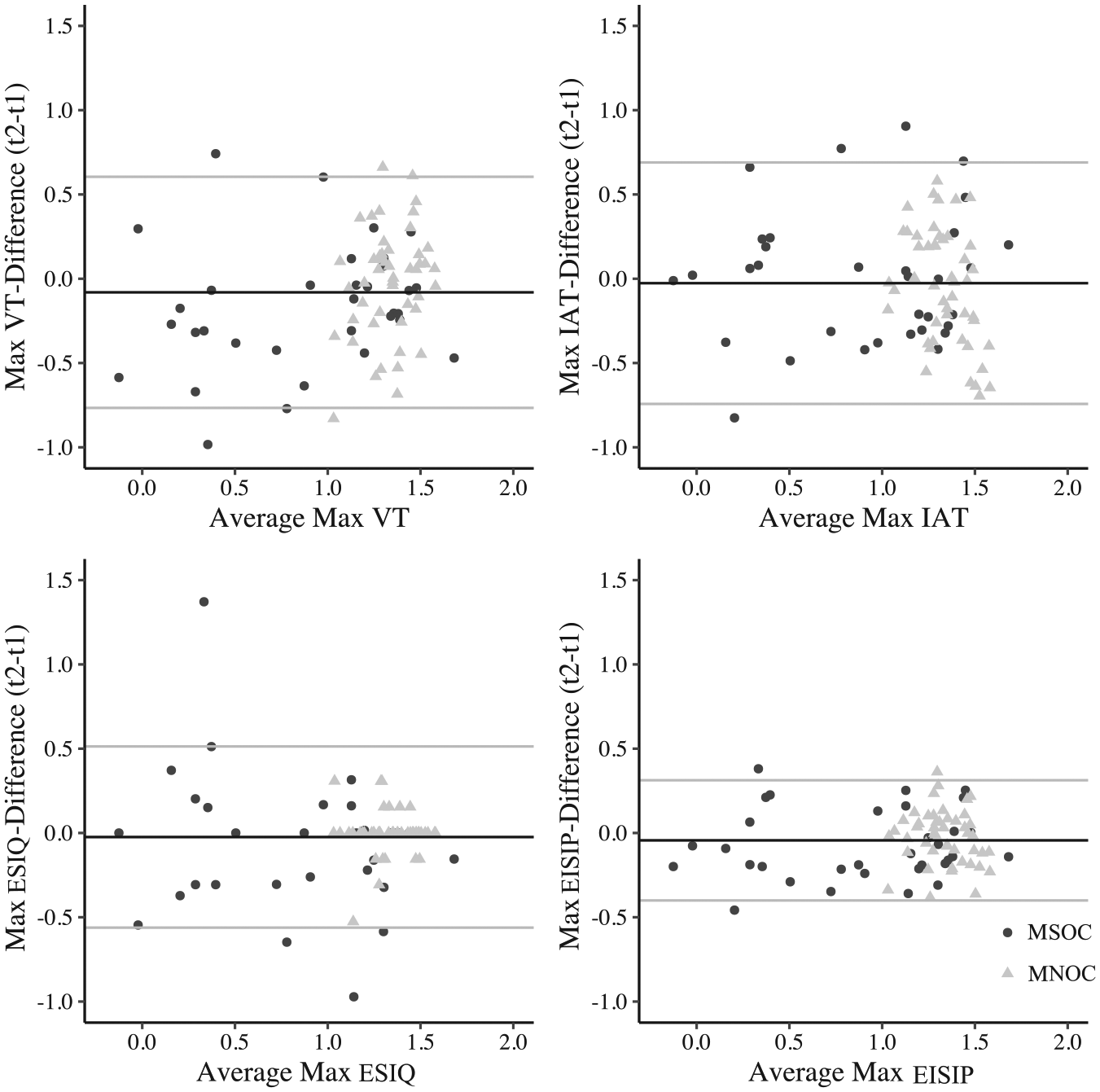
Difference of maximized and standardized adult sexual preference scores from both test sessions(t2-t1) as a function of averaged score of both test sessions for every participant separated for MSOC and MNOC (Panel A: VT; Panel B: IAT; Panel C: ESIQ; Panel D: EISIP total score) with mean bias (black line) and 95% limits of agreement (gray lines).
In addition, as tested in the control analyses, MSOC and MNOC clearly differed in their mean sexual interest in children and the variation of mean differences seemed to be stronger in MSOC (see Table 1). Also, the limits of agreement appeared to differ across measures and groups. To quantify this, we calculated the repeatability coefficients, which are also shown in Table 1. Note that the ESIQ differences between measurement times did not follow a Gaussian distribution, as indicated by significant Shapiro–Wilk tests, which could have unduly inflated the limits of agreement and consequently the repeatability coefficient. The repeatability coefficient across groups and EISIP measures ranged from 27% to 78% of a standardized measurement unit indicating that in order to be attributable to genuine individual change instead of transient measurement error, change needed to exceed conventionally small to large effect sizes. Across all measures of sexual interest, the repeatability coefficient is descriptively larger in MSOC than in MNOC. This was particularly pronounced in the ESIQ for MNOC where participants almost always responded in the same manner across both test sessions whereas MSOC produced considerable variation as well as two significant outliers indicating highly unrealistic sexual interest changes equal or greater than one standard unit of measurement over the 2-week interval.
Finally, for the latency-based measures the total repeatability coefficient was larger than the mean difference between groups. Thus, variability across test sessions encompassed the systematic difference between both groups. However, as expected from the psychodiagnostic convergence principle (i.e., aggregation over conceptually different measures enhances reliability), this was not the case for the EISIP aggregate.
Discussion
The primary aim of this study was to examine the relative and absolute test–retest reliability of the EISIP in a forensic sample of MSOC and MNOC over a 2-week interval. We will discuss these aspects separately as they have distinct implications for the unique research questions concerning repeated measurements (i.e., assessing stability of individual differences versus measuring individual change).
Relative Test–Retest Reliability
Concerning relative test–retest reliability for all measures ICCs revealed high degrees of stability, although—in line with the literature—the IAT revealed lower test–retest reliability for the whole and MSOC sample. Compared with generally reported test–retest correlations for these measures (Bar-Anan & Nosek, 2014), the EISIP measures perform similarly or better, particularly taking into account that these indirect measures depend on latency assessments that are notorious for being sensitive to measurement error. In case of the MNOC subsample, test–retest correlations were considerably lower. Here, it has to be considered that in this teleiophilic subgroup the measurement variance was much more restricted than in the MSOC sample consisting of pedohebephilic as well as teleiophilic individuals. As correlation coefficients rely on shared variance, this is to be expected and highlights one of the drawbacks of classic correlation analyses of test–retest reliability (Aldridge et al., 2017; Berchtold, 2016). Hence, test–retest reliability coefficients in the total sample have to be regarded as the more robust relative test–retest reliability estimates.
If the assessment of individual rank-order differences over time is the primary research question, the EISIP is situated among the best measures in the—admittedly scarcely researched—literature on test–retest reliability in either specifically the forensic assessment of sexual interest in children and adults or the field of indirect (latency-based) measures in general. However, stopping the analysis here would paint an overly optimistic picture of the temporal stability of the EISIP, particularly if it comes to research questions that rely on absolute agreement of measurements such as the assessment of individual change over time (e.g., therapeutically induced change as outcome measure). The accuracy of the EISIP for such questions can be meaningfully addressed only within analyses of absolute test–retest reliability (Bland & Altman, 1986, 1999).
Systematic Retest Bias
Although the desired negligible unsystematic bias over time emerged for most EISIP measures, MSOC revealed a slight (statistically non-significant) decrease of pedohebephilic sexual preferences over time on the VT measure (and, consequentially, the EISIP total score). Considering that systematic change of sexual interests is unlikely during a 2-week interval, other explanations are needed. Specifically, the initial control analyses corroborated that the faster responses across all stimulus categories for MSOC as compared with MNOC in the second test session restricted the variance in the D-score denominator, thereby for purely mathematical reasons, increasing the adult sexual preference index. One might speculate whether this is at least partially attributable to the short retest interval. It is an open empirical question whether these systematic bias effects hold for much longer time frames for change assessments such as, for example, a 1-year follow-up. But still, it remains open why this only happened in the MSOC but not in the MNOC group. Apparently, MSOC showed comparatively stronger learning, habituation, or motivational effects that led to faster (and less variable) responses in general which might have been a function of the fact that MSOC were older and less practiced in computer assessments than MNOC. Thus, it may be argued here that the learning curve for MSOC could have been steeper, which contributed to the differential bias effects.
Absolute Test–Retest Reliability
To arrive at more nuanced conclusions, we visualized the variation of the differences between measurements as this is the crucial aspect for the absolute agreement between measurements regardless of whether systematic bias can be ascertained or not (i.e., more exact measures produce less random noise instead of systematic variation; Bland & Altman, 1986, 1999). Absolute test–retest reliability across the EISIP submeasures was much lower than relative reliability with the repeatability coefficient in the total sample ranging from roughly a fourth (for the EISIP aggregate score) to roughly three thirds (for the VT measure) of a standardized measurement unit of the adult sexual preference score. This means that small to large standardized effect size differences in terms of Cohen’s (1992) conventions need to be exceeded before genuine individual change can be supposed for the respective EISIP scores.
However, is this necessarily problematic for measuring change over time due to, for example, therapeutic intervention? Given the fact that pedophilic sexual interest is among the strongest risk factors for sexual reoffending (Mann et al., 2010) and that it shows links to sexual offending in community men (Dombert et al., 2016), from a clinical perspective one probably would even regard only larger changes of sexual preferences to be clinically meaningful. Specifically, the effect sizes for differences between pedohebephilic versus nonpedohebephilic taxa reported by Schmidt et al. (2013) exceeded ds > 1.10 (>1.40 if taxa were based on latency-based measures exclusively) for every EISIP measure across several taxometric methods (see McPhail et al., 2018, for similarly large effects with penile plethysmographic measures). This implies that the small to large effect sizes needed for attesting an individual decrease of pedophilic preferences produced by any treatment or natural development over time revealed in this study might not exceed the threshold for clinically relevant change. According to Jacobson and Truax (1991) for clinically significant change clinical symptoms need to (a) reliably decrease (i.e., symptom change exceeds measurement error as a property of the measure) and (b) sink from an initially clinical margin to a normatively healthy level (e.g., falling more than two standard deviations below the mean of the dysfunctional comparison group as a property of the individual development). Given that the taxometric gap between sexual preference indexes of pedohebephilic and nondeviant males as assessed with the EISIP (Schmidt et al., 2013) is considerably larger than the repeatability coefficients reported here only change levels exceeding this empirical difference might be considered a threshold for diagnosing genuinely changed sexual preferences. Whether such an amount of change for pedohebephilic preferences is clinically achievable at all remains at present as much an open empirical question as how much change of pedohebephilic preferences is necessary to reduce recidivism risk in the subgroup of MSOC who exhibit pedohebephilic preferences (Seto, 2019). Therefore, future research should focus on how well pedohebephilic sexual preferences are amenable to treatment-induced change and how achievable sexual preference changes empirically relate to recidivism risk reduction in pedohebephilic MSOC.
In summary, mirroring the results of relative test–retest reliability, we suggest that when change in sexual interest in children and adults across time is of interest, the total EISIP score is the best option to choose in absence of similar analyses for any utilized forensically relevant measure of sexual interest, although particularly the indirect latency-based measures showed relatively large repeatability coefficients in terms of conventional effect size magnitudes. The current study also provides further evidence that more reliable assessments are provided by the combination of multiple measures rather than single measures.
Limitations and Outlook
The small sample sizes of the MSOC and MNOC subgroups restrict the generalizability of our findings. Thus, particularly the findings from the subgroup analyses have to be regarded as preliminary and need to be replicated within larger samples. In consequence, the more robust full sample results that seem rather promising at least for relative test–retest reliability estimates should be focused on. In addition, the four participants who were excluded from the analyses because they did not comply with task instructions and produced high error rates in the IATs attest to the fact that the EISIP may not be accessible for all participants. Furthermore, although the 14-day test–retest interval used here has its strengths in terms of ruling out short-term individual change in sexual interests, it also has its drawbacks in terms of the immediate repetition of the EISIP test battery. This might facilitate carry-over effects from the first measurement application as items and respective responses particularly in the VT and the ESIQ might be remembered and thus affect general response speed. Of note, as other research on applied diagnostic questions usually examines much longer follow-up intervals the short retest interval applied in this study limits generalizability.
Nevertheless, it has to be pointed out that in case of MSOC—for whom the EISIP has been originally designed—and particularly for the total sample, test–retest reliability for maximized preference scores can be regarded as substantially higher than what has been established for penile plethysmographic measures that are commonly regarded as the gold standard for objective measures of pedohebephilic sexual interest (McPhail et al., 2019; Seto, 2018). Specifically, test–retest reliability for penile plethysmographic measures of sexual interest in children has rarely been tested (see Mokros & Habermeyer, 2016; Wormith, 1986, for at best moderate relative test–retest reliability correlations).
Therefore, at the present stage of research on the temporal stability of indirect (latency-based) measures of sexual interest in children and adults, the EISIP can be considered as a comparably stable assessment instrument. Admittedly, based on the present data assessing meaningful change in pedohebephilic sexual preferences requires treatments and time frames that render at least moderate to large effect sizes plausible. This limitation in terms of absolute agreement needs to be taken into account for repeated EISIP measurements. On the other hand, if the emphasis lies on rank-order stability of differences over time, the EISIP total score shows excellent relative test–retest reliability (rtt = .90; ICC = .90). This is a threshold that most existing forensic assessments in the published literature fail to reach. In lack of psychometrically more favorable alternatives to ascertain sexual interest in children in clinical/forensic contexts (i.e., easy to manipulate self-reports, unclear reliability of most indirect latency-based measures, less reliable penile plethysmographic assessments) and carefully taking into account the present findings, the EISIP may be regarded as an useful adjunct to existing diagnostic practices.
In summary, based on the present results, the EISIP may set the stage for future empirical research on the temporal stability of pedohebephilic sexual interests. Although clinicians are skeptical whether meaningful (i.e., clinically relevant) change in such sexual preferences can be accomplished at all, this remains an open empirical question that so far suffers from the unacceptably low test–retest reliability of the sexual interest measures that have been used to shed light on this issue (cf. the debate by Mokros & Habermeyer, 2016; Müller et al., 2014). Last but not least, we hope that introducing the Bland–Altman approach (Bland & Altman, 1986, 1999) to test absolute agreement between measurements over time to forensic researchers might encourage our colleagues to use this method to elucidate this highly relevant psychometric property for forensic assessment settings.
Footnotes
Authors’ Note
The authors take responsibility for the integrity of the data, the accuracy of the data analyses, and have made every effort to avoid inflating statistically significant results.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.