
Abstract
In the era of the digital economy, the exploration of useful knowledge from data streams has garnered significant attention due to its wide-ranging applications. However, the rapid and infinite nature of data streams poses challenges for efficiently mining high utility sequential patterns, including strong spatio-temporal constraints and the combinatorial explosion of sequence data search spaces. To address this and adapt to a variety of application scenarios, this paper delves into the investigation and design of an efficient algorithm for high utility sequential pattern mining over data streams based on the sliding window model (HUSP_DS). This algorithm utilizes a projection mechanism within a sliding window to recursively search for all interesting patterns. Additionally, it introduces a novel structure called the dynamic utility index table, which stores information such as the utility and index positions of data stream sequences. Notably, this structure proves highly effective in recursive search processes and utility updates. Comprehensive experimentation, conducted on both real-world and synthetic datasets, have shown that the superior performance of the HUSP_DS algorithm compared to state-of-the-art algorithms. This superiority is particularly evident in terms of temporal and spatial efficiency. Furthermore, the algorithm demonstrates suitability for mining sliding windows of arbitrary sizes, showcasing stable scalability.
Introduction
High utility sequential pattern mining (HUSPM) 1 has emerged as a research hotspot in the field of data mining in recent years. Its primary goal is to discover valuable and interesting patterns from sequence data, which greatly aids business decision-makers in understanding and responding to customer behavior. HUSPM considers both the utility factor and the relative order of each sequence, making it more valuable for decision-making compared to traditional sequential pattern mining (SPM).2,3 Furthermore, extracting implicit information from dynamically changing data streams has become increasingly important, as real-world data is often generated in continuous, infinite sequences in real time. Examples of such data include sensor networks, web clickstreams, satellite signals, and stock transactions, all of which are presented as data streams. The technology of mining high utility sequential patterns (HUSPs) from data streams has thus become an important technique in the field of pattern mining. Traditional high utility sequential pattern mining algorithms are mostly designed for static data and cannot handle real-time data streams. Additionally, the massive and rapidly arriving nature of data streams presents significant challenges for mining high utility sequential patterns within limited time and memory resources. Currently, data stream processing typically employs window models to continuously process segments of the data stream. Windows address the infinity of data streams by limiting the algorithm's operations to the window's scope, mainly targeting recent sequence data. 4 Depending on the processing method, window models are classified into landmark windows, damped windows, and sliding windows. 5 Sliding windows and landmark windows process only a certain amount of recent data, treating all data within the window equally. However, compared to sliding windows, landmark windows may lose data at the window boundaries, leading to information bias. 6 Damped windows assign different importance to data based on insertion time, but they require processing all data, resulting in significant computational overhead. 7
Several high utility sequential pattern mining algorithms for data streams have been proposed to handle sequential data streams. These algorithms use different window models and data structures to mine high utility sequential patterns from data streams. MAHUSP 5 algorithm uses a landmark window to mine high utility sequential patterns from data streams. It employs memory-adaptive mechanisms of SBMA and LBMA to find result sets within limited memory resources. However, it is disadvantageous for time-sensitive data, as important events occurring at window boundaries may be overlooked, and its ability to detect burst or irregular events is poor. Additionally, the SBMA mechanism's long runtime for dense datasets results in low algorithm efficiency. HUSP-Stream 8 algorithm uses a sliding window model to process data streams. The HUSP-Tree structure used in this algorithm is not suitable for long-term information storage because its main idea is to facilitate the update process when new transactions enter or leave the window. This data structure is ineffective for mining HUSPs over the entire data stream, as it consumes more memory. Sliding windows are widely used due to their emphasis on recent data and limited memory usage,9,10,11 HUSP-UT 12 algorithm uses a sliding window model to mine high utility sequential patterns from data streams. It employs the UT-Tree (Utility on Tail Tree) structure to update and maintain the utility information of data stream sequences. Using a pattern growth approach, it can mine high utility sequences by scanning the dataset only once. However, when dealing with large, dense data streams, the UT-Tree requires frequent updates to its leaf nodes, necessitating multiple traversals from the root node, leading to significant time and memory overhead. RStreamHusp 13 algorithm is a concise pattern mining algorithm for data streams that uses a sliding window model to mine regularly occurring patterns in data streams. The DSRHUS-Trie structure is used to store utility information of sequences within the window. To determine whether a pattern is a high utility sequential pattern, it requires traversing each node from the root and calculating the sum of utility values in the utility array, resulting in significant time overhead.
Dynamic data structure. To record utility information of sequences in real-time changing data streams, we designed a compact and dynamic utility index table (DUI-table). This data structure is dedicated to storing and maintaining the utility information of sequences within the sliding window. Efficient algorithm. An efficient algorithm for high utility sequential pattern mining over data streams (HUSP_DS) is proposed, leveraging the DUI-table. The algorithm employs a projection mechanism within a sliding window to rapidly mine high utility sequential patterns in a data stream environment. The projection mechanism within the window uses a pattern growth approach, which effectively reduces the number of candidate items generated. Sufficient experimentation. Extensive experiments, conducted on both real and synthetic datasets, affirm the high spatio-temporal efficiency and stable scalability of the proposed algorithm. The results demonstrate the algorithm's effectiveness in mining high utility sequential patterns within a data streams environment.
The following sections of this paper are structured as follows: Section 2 provides an in-depth review of existing high utility sequential pattern mining algorithms, with a specific focus on those tailored for data streams. Section 3 introduces and elucidates the essential definitions related to HUSPM. Section 4 introduces the algorithm proposed in this article. Section 5 conducts a rigorous evaluation of the proposed algorithm through extensive experiments on real and synthetic datasets. Section 6 summarizes the key findings and insights from the entire paper and initiates a discussion on potential avenues for further research.
High utility sequential pattern mining
High utility sequential pattern mining involves extracting valuable information from data by considering both the order and utility factors of sequences. In 2010, Ahmed et al. 14 introduced two novel data structures, UWAS-tree and IUWAS-tree, tailored for mining web log sequences in static and incremental databases. While this algorithm eliminates the need for multiple database scans, it falls short in supporting sequence elements with multiple items, limiting its applicability to relatively simple scenarios. Following this, Ahmed et al. 15 proposed two additional algorithms: the UL (Utility Level) algorithm, employing a layer-by-layer search, and the US (Utility Span) algorithm, relying on pattern expansion. The UL algorithm, however, generates a large number of candidate sequences through layer-by-layer candidate sequence generation and testing, with the number of database scans contingent on the maximum length of the candidate sequences. The US algorithm, on the other hand, is time-consuming due to its requirement for multiple database scans. In 2011, Shie et al. 16 presented the UMSP algorithm based on MTS-tree for mining mobile sequence data. This algorithm utilizes depth-first search and breadth-first search methods to extract mobile sequence patterns with high utility values. However, these algorithms are limited to mining simple sequence data and struggle with handling complex time series data. Additionally, the utility values defined by these algorithms are uncertain and not well-suited for general mining frameworks. To address these limitations, Yin et al. 1 formally defined the general model of HUSPM for the first time. They proposed the USpan algorithm based on a utility matrix, employing a depth-first approach based on a lexicographic q-sequence tree to mine all high utility sequential patterns. However, the algorithm's spatio-temporal efficiency is hindered by the insufficient compactness of the upper bound SWU used in the algorithm.
Aiming at the difficulty of setting the minimum utility threshold, Yin 17 et al. proposed a high utility sequential pattern mining algorithm TUS for mining the top-k items, using two threshold raising strategies and a pruning strategy to prune unpromising items, effectively improving the mining efficiency of the algorithm. In 2015, Alkan 18 et al. proposed a data matrix structure and pruning strategy based on the cumulated rest of match (CRoM) upper bound. However, this algorithm requires a large amount of memory to store sequences and is not suitable for processing large data. In 2016, Wang 19 et al. proposed a more efficient high utility sequential pattern mining algorithm, HUS-Span, which uses more compact upper bounds PEU and RSU to reduce the search space, and uses a utility linked list structure to store sequence utility information, although it reduces the algorithm running time, it also increases memory consumption. In 2020, Gan 20 et al. proposed the projection-based high utility sequential pattern mining algorithm ProUM. This algorithm designed a new utility upper bound SEU and used a more compact utility array to store sequence information. And it adopts depth-first search manner recursively mines high utility sequential patterns. Therefore, this algorithm performance is significantly better than USpan and HUS-Span. In order to further improve the mining efficiency, Gan 21 et al. proposed the HUSP-ULL algorithm, which uses the lexicographic q-sequence tree and the utility linked list (UL-list) structure to store the utility information of each sequence. HUSP-ULL has good performance in mining large sequence data, especially datasets with a large average number of elements per sequence or a large average number of items per element. In 2020, Zhang 22 et al. standardized the top-k high utility sequential pattern mining problem. The TKUS algorithm uses a projection mechanism and a local search mechanism to effectively reduce the search space. In 2021, Zhang 23 et al. designed on-shelf sequential pattern mining algorithms OSUMS and OSUMS+, using TPEU and TRSU to efficiently prune unpromising sequences. However, the memory consumption of the algorithm is large. In 2023, Zhang 24 et al. proposed a more efficient mining algorithm HUSP-SP. This algorithm designed a seqPro structure and used a more compact upper bound (TRSU). The algorithm based on the TRSU upper bound value and two pruning strategies (IIP and EP) are proposed to effectively reduce the search space. In addition, Zhang 25 et al. conducted a systematic and detailed survey and overview of existing high utility sequential pattern mining algorithms, including the advantages and disadvantages of the HUSPM algorithm and future research directions.
High utility sequential pattern mining over data streams
Data streams are an ordered, continuous, and unbounded sequence of data records that usually arrives in a rapid manner. Data streams are not suitable for batch calculations because data streams come from many sources and have complex formats. At present, high utility sequential pattern mining in data streams widely uses window technology to continuously process data. The main window models used are sliding window and landmark window. The sliding window uses the first-in-first-out (FIFO) method to discard oldest batches and add the latest batch in the data streams. That is, the window mainly focuses on the recent sequence between Snew−w + 1 and Snew, where w is the window size. The sequences in the window have of equal importance. Landmark windows split the data stream into discrete chunks based on events. The data from the starting time 1 to the current time t is recorded as W [1, t], that is, all data points after the arrival of the landmark are equally important, and there is no difference between the past and the present. Whenever a new landmark appears, all data in the window is deleted and new data is captured.
In 2017, Zihayat et al. 5 introduced the MAHUSP algorithm, aiming to discover high utility sequential patterns (HUSPs) in data streams. The algorithm utilizes a tree structure known as MAS-Tree to efficiently store potential HUSPs within the data streams. This tree is adeptly updated upon the discovery of new potential HUSPs. Subsequently, Zihayat et al. 8 incorporated a sliding window model into their approach. The HUSP-Stream algorithm employs two data structures, namely ItemUtilList and HUSP-Tree, to store fundamental information about generated patterns, both in static and data stream scenarios. However, the HUSP-Tree is less suitable for long-term storage as it is primarily designed to facilitate updates when new transactions arrive or depart from the window. While effective for mining HUSPs across entire data streams, it proves inefficient due to increased memory consumption. In 2019, Tang et al. 12 presented the HUSP-UT algorithm for mining HUSPs in data streams. The algorithm utilizes a data structure called UT-tree (utility on Tail Tree) to manage outdated data removal and new data addition. In 2022, Ishita et al. 13 introduced the concept of regular high utility sequential patterns and developed the RHusp algorithm for mining such patterns from static databases. Building upon RHusp, the authors extended the algorithm from static databases to mine regular high utility sequential patterns from incremental databases and sliding window-based data streams. In the realm of data streaming, the algorithm is further extended to RStreamHusp, specifically designed to mine regular high utility sequential patterns from dynamically changing data streams.
Preliminaries
A sequence data stream is a collection of infinite sequence records, where each sequence is composed of some items and itemsets. Let X = [i1,i2, …, ik] be a finite set containing all non-repeating items, where each item i is associated with a positive number p(i), referred to as external utility. An itemset I = [i1,i2, …, in] is an unordered set consisting of n (1 ≤ n ≤ k) distinct data items in X, meaning I is a subset of X (
The sliding window (SW) is a window model defined on data streams, maintaining a fixed batch size. It represents a window of certain length that slides as data streams continue to arrive. The batch size pertains to the data encompassed in the mined data object. This window model consists of a fixed number of recent sequences in the data streams, with the window size defined by the number of batches it contains. The sliding window employs the first-in-first-out (FIFO) method to discard the oldest batches and accommodate the latest batch in the data streams. In essence, the window primarily focuses on the recent sequence between Snew−w + 1 and Snew. All sequences within the window are considered of equal importance.
Figure 1 is an example data stream (A) and external utility table (B). Each row in Figure 1(A) represents a sequence, which consists of a sequence identifier SID and a quantized sequence. The example data stream contains a total of six sequences Si = {S1, S2, S3, S4, S5, S6}, where every two sequences form a batch, resulting in a total of three batches Bj = {B1, B2, B3}. Furthermore, every two batches form a sliding window, leading to a total of two sliding windows Ws = {W1, W2}.

Example data streams and external utility table.
The utility of item/itemset.
19
The utility value of item i in the jth itemset in sequence S is defined as
For example, considering the example data streams, the utility value of item a in the first itemset of sequence S1 is denoted as u(a,1,S1) = 6 × 1 = 6. The utility value of the first itemset [a, f] in sequence S1 is calculated as u([a, f], S1) = 6 × 1 + 1 × 1 = 7.
q-sequence utility.
19
The utility value of q-sequence Si is defined as
For example, in the example data streams, the q-sequence utility value of sequence S1 is calculated as SU(S1) = u([a,f],S1) + u([a],S1) + u([d],S1) = 6 × 1 + 1 × 1 + 3 × 1 + 1 × 1 = 11.
The maximum utility of sequence t.
19
Given that the non-quantized sequence t may match multiple quantized sequences S, the HUSPM problem defines the utility of t in S as the maximum matching utility of t across all S. Assume that the extended position set of all non-quantized sequences t is P = (p1, p2, …, px), then the maximum utility value of the sequence t is defined as
For example, in the example data streams, the non-quantized sequence t = <[a][e]> has two matches in sequence S3, then u(<[a][e], S3>) = max{u(< [(a,6)][(e,1)]>), u(<[(a,3)][(e,1)]>)} = max{9,6} = 9.
Remaining utility.
19
The remaining utility of sequence t at position p in Si is defined as
For example, in the example data streams, the remaining utility of sequence t = <[a]> at the first matching position in sequence S1 is calculated as ru(t, 0, S1) = u(<[(f,1)][(a, 3)][d,1]>,S1) = 1 + 3 + 1 = 5.
The total utility of a batch. The total utility of a batch in the sliding window SWk is
For example, in the example data streams, the total utility of batch B1 is calculated as BU(B1) = SU(S1) +SU(S2) = 11 + 18 = 29.
Total utility of a window. The total utility of a sliding window SWk is expressed as
For example, in the example data streams, the total utility of window SW1 is calculated as WU(W1) = BU(B1) +BU(B2) = 29 + 27 = 56.
Batch weighted utility of sequence t. The utility value of sequence t in batch Bi is the sum of the maximum utility values of sequence t in all Sj, defined as
For example, in the example data streams, the utility of sequence t = <[a]> in batch B1 is BWU (t, B1) = u (t, S1) + u (t, S2) = 6 + 0 = 6.
Window weighted utility of sequence t. The utility value of sequence t in window Ws is the sum of the weighted utility values of sequence t within the batch, defined as
For example, in the example data streams, the weighted utility of sequence t =<[a]> in window W1 is WWU (t, W1) = BWU (t, B1) + BWU (t, B2) = 6 + 16 = 22.
Data streams. Data streams DS = {S1, S2, …, St, …} is an ordered and infinite sequence composed of quantized sequences, where St (t = 1, 2, …) is generated by the t-th sequences, each containing a unique sequence identifier SID.
High utility sequential patterns. If the utility value of sequence t in the sliding window SWk is not less than the minimum utility threshold (minutil), then sequence t is called high utility sequential patterns, which is defined as follows:
For example, the utility of sequence t = <[a]> in window SW1 is WWU (t, W1) = 22. If minutil = 20, sequence t is called a high utility sequential pattern in SW1.
This section initiates with an introduction to the algorithm's search space and the employed pruning strategy. Subsequently, it delineates the designed data structure and outlines the steps in algorithm design. Finally, a comprehensive complexity analysis of the algorithm is provided.
Search space and pruning strategy
Search space
The Lexicographic Q-sequence tree (LQS-tree) structure serves as an extension of the lexicographic sequence tree, 26 a commonly utilized framework in HUSPM for representing the search space.1,19 Figure 2 illustrates the structure of the LQS-tree built based on sample data streams. The root node of the LQS-tree is an empty node, and subsequent child nodes extend from their parent node. Each node within the tree signifies a candidate sequence, with all nodes organized in ascending alphabetical order within the dictionary. The adoption of the LQS tree is motivated by its effective approach to pattern growth and the recursive projection. The algorithm employs a depth-first search to recursively generate sub-sequences based on prefix sequences. Utilizing the LQS-tree helps prevent the generation of patterns not present in the window or redundant testing of the same patterns. This ensures efficiency in pattern generation and testing within the algorithm.
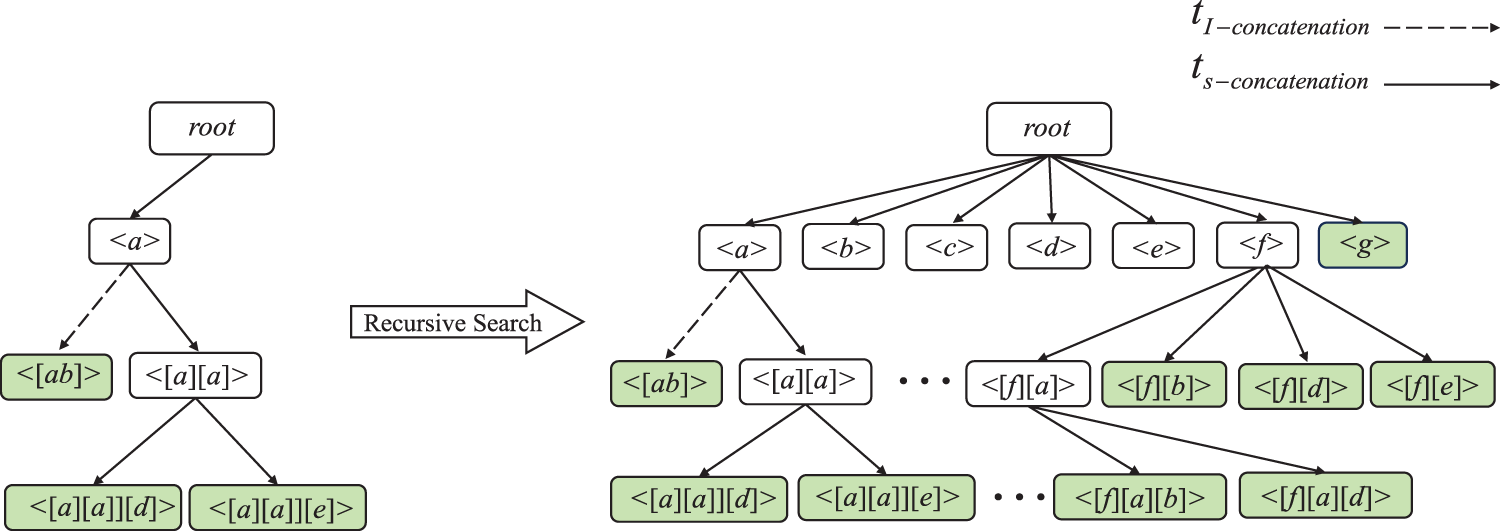
Lexicographic Q-sequence tree.
Concatenation operation.
1
Given a sequence t = <I1,I2, …, In> and an item to be expanded ik, the I-Concatenation operation refers to adding the item ik to be expanded to the sequence t in the last itemset In, it is recorded as
For example, in the example data streams, let's consider the sequence t = <[b]> and the item e to be expanded in S2. The subsequence obtained after operating
Sequence weighted utilization (SWU).
1
Given a sequence t, its sequence weighted utility in the current window Ws refers to the sum of the utility of all q-sequences containing t in the window. The specific definition is as follows formula (1) shows:

For example, SWU (<a>) of sequence t =<[a]> in window W1 = SU(S1) + SU(S3) + SU(S4) = 11 + 15 + 27 = 53.
Given a quantified sequence window W and two sequences t and t’, if t’ is a superset of t, then the following relationship exists:
Because t’ is a superset of t, then the number of q-sequences containing t is greater than or equal to the number of q-sequences containing t’, so
Prefix extension utility (PEU).
19
Given a sequence t, its prefix extension utility at position p is defined as follows:
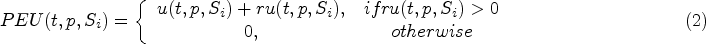
Among them, u(t,p,Si) refers to the utility of sequence t at position p, and ru(t,p,Si) refers to the remaining utility of sequence t at position p (excluding the element at position p).
The PEU of sequence t in q-sequence Si is defined as:
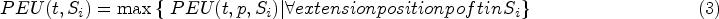

Given a quantized sequence window W and two sequences t and t’, if t’ is a superset of t, then the following relationship exists:
First prove the first half of the equation, because
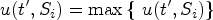
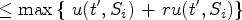
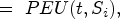
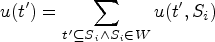
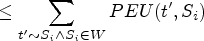
Let's prove the second half of the equation. Because t’ is a superset of t, so
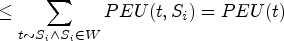
Compact Sequence Utility (CSU) Assume that sequence t has i matches in the quantized sequence S of window W, and their matching positions are δ1, δ2, …, δi, where δ1<δ2< … <δi, given by t the subsequence generated by performing I-Concatenation or S-Concatenation operation on item k is t’, and the minimum position of item k to be expanded in S (i.e., the first matching position) is p1 (δi < p1), then CSU is defined as in formula (5), where u(t,δ,s) = max{u(t,δi,s)} refers to the maximum utility value of prefix t in S.
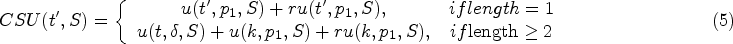
Note that the CSU of sequence t’ in window W is defined as:
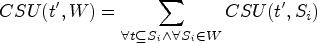
Given a quantified sequence window W and two sequences t and t’, if t’ is a superset of t, then the following relationship exists:
First, prove that when the length of is 1. All sequences are single-item sequences. u(t’,S) is the maximum value at each extended position pj in the q-sequence S. When u(t’,S) = u(t’,p1,S), u(t’,S)
For example, in S2 of the example data stream, the item to be expanded for the sequence t = <[b]> is e, and the subsequence formed by S-Concatenation of the sequence t is t’ = <[b][e]>. Among them, the first position of the item e to be expanded is 3. When δ < 6, the maximum utility value of the prefix [b] is u(<[(b,1)]>) = 1. Because the length of the sequence t’ is greater than or equal to 2, then CSU(<[b][e]>, S2) = u(<[(b,1)]>) + u(e,S2) + ru(e,S2) = 1 + 3 + 4 = 8, guaranteeing the most compact upper bound.
The paper introduces a data structure called the dynamic utility index table (DUI-table). This structure is constructed or updated after scanning the current window and encompasses all batches within the window. As the window slides, the oldest batches are removed, and new batches are added. Figure 3 illustrates the information of the two batches contained in the initial window.
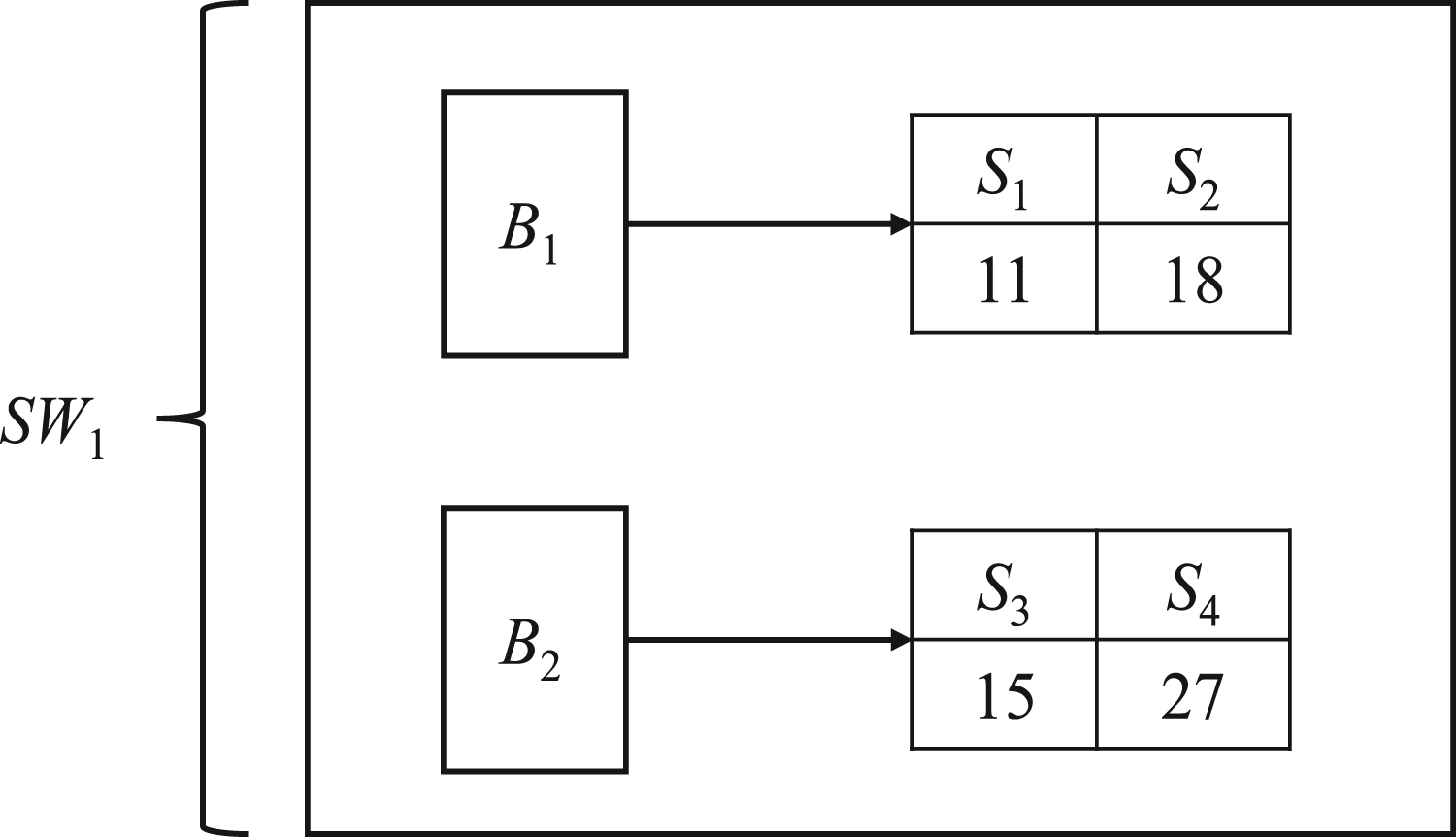
DUI-table structure within the first window.
The DUI-table structure is utilized for storing information about sequences within the sliding window Ws, including the batch they belong to, index positions, and utility information. Each DUI-table structure consists of two parts: the header table and data items. The header table stores the current batch number Bi, non-repeated items contained in the batch, and their respective positions in the sequences. The data items are used to store information about the current sequence, sequence identifier (SID), utility u, remaining utility ru, and the starting position in the itemset (same position indicates within the same itemset). The structure of the dynamic utility index table for the first batch in the initial window is depicted in Figure 4.
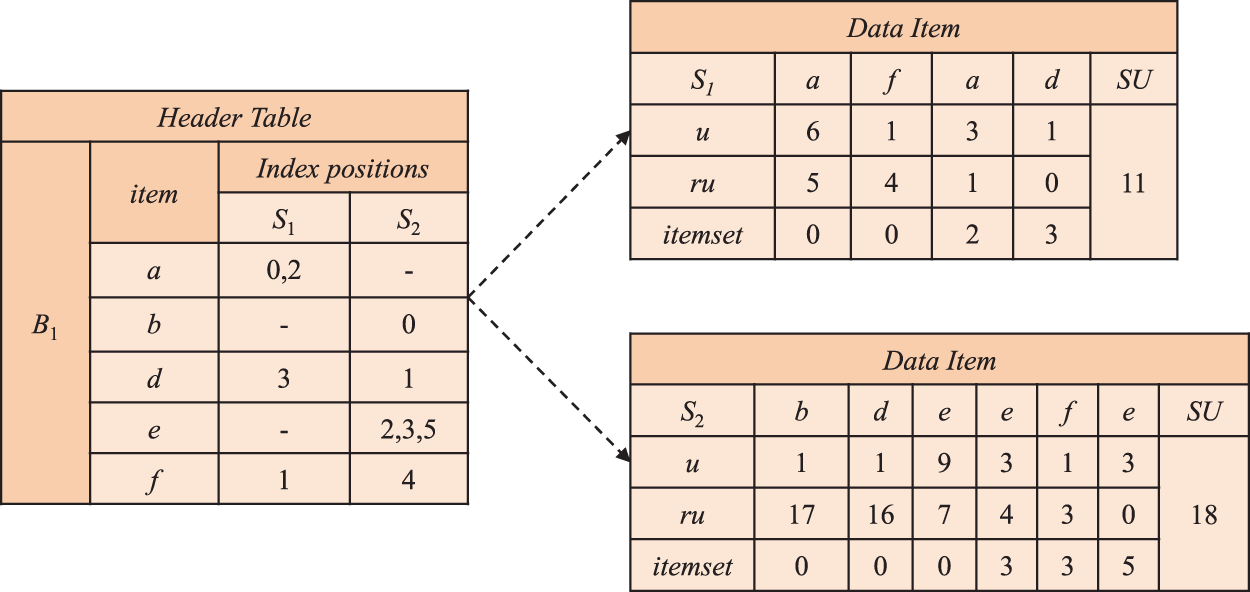
Dynamic utility index table structure for B1.
The DUI-table structure provides an equivalent projection window to the original window with significantly reduced space requirements. By scanning the initial DUI-table structure and constructing new sequence DUI-table structures based on the currently obtained prefix sequences, it only retains the corresponding suffix sets. Therefore, the total number of sequences in the DUI-table is always less than or equal to the size of the original window data. Figure 5 illustrates the projection DUI-table based on the prefix <[a]> for the first batch. The suffix set in S1, based on <[a]>, includes elements <[f],[a],[d]>. The DUI-table retains information only for the corresponding suffix set, while S2 does not contain the element <[a]>, resulting in an empty storage for S2. The DUI-table, following a pattern-growth approach, constructs a projection window for each sequence that appears in the data streams. It does not construct sequences outside the window. In other words, during each projection operation, the DUI-table is first constructed, then scanned, and subsequently used to build the next DUI-table structure based on its prefix. As the sequence pattern grows, and Si containing the sequence becomes less frequent, the size of the projected DUI-table gradually decreases. This results in a reduction in the generated new sequences, leading to an acceleration in the search speed of the algorithm.
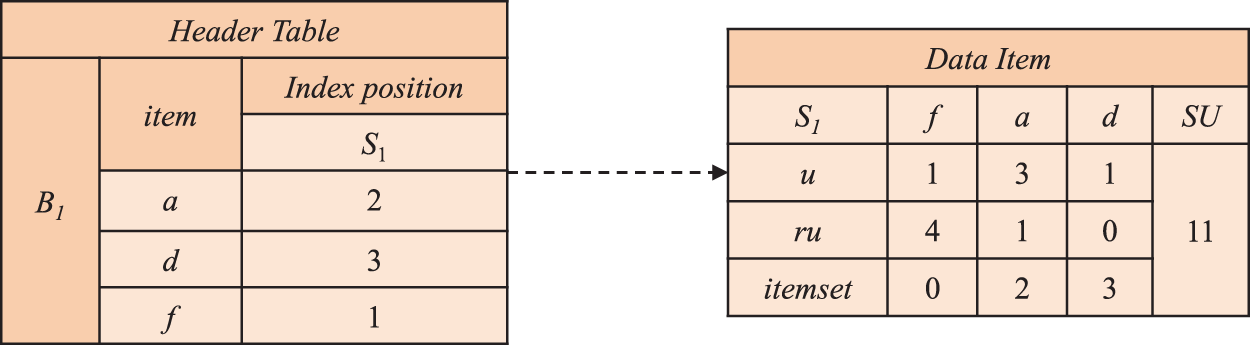
Projected DUI-table based on prefix <[a]> within batch B1.
Based on the designed DUI-table structure in this paper, the dynamic utility index table possesses the following characteristics: (1) Projection mechanism. DUI-table is based on a projection mechanism using prefixes. It recursively partitions the DUI-table structure without the need to construct a projected sub-window. This approach forms a divide-and-conquer mining framework. The information about sequences obtained through the prefix projection mechanism is accurate and does not generate sequences outside the window. (2) Compact structure. The DUI-table structure comprises a header table and data items. The header table stores non-repeating items in the sequence along with their index positions, while data items store the items, utility values, remaining utility, itemset positions, and q-sequence utility (SU) in the sequence. It requires only a negligible amount of memory to construct, enabling the handling of a substantial number of sequences within limited memory resources. (3) Efficiency. The DUI-table structure accelerates sequence generation, enhances the computation speed of subsequence utility values and upper bounds. Furthermore, it records the position information of extension items, eliminating the need to traverse the entire sequence to find all extension points. This capability facilitates the identification of candidate sequences, enabling the recognition of all high utility sequential patterns within a finite time frame.
Based on the DUI-table structure and the pruning strategies mentioned above, this paper proposes an algorithm, named HUSP_DS, for mining high utility sequential patterns over data streams based on the sliding window model. The overall mining process of the algorithm is illustrated in Figure 6.
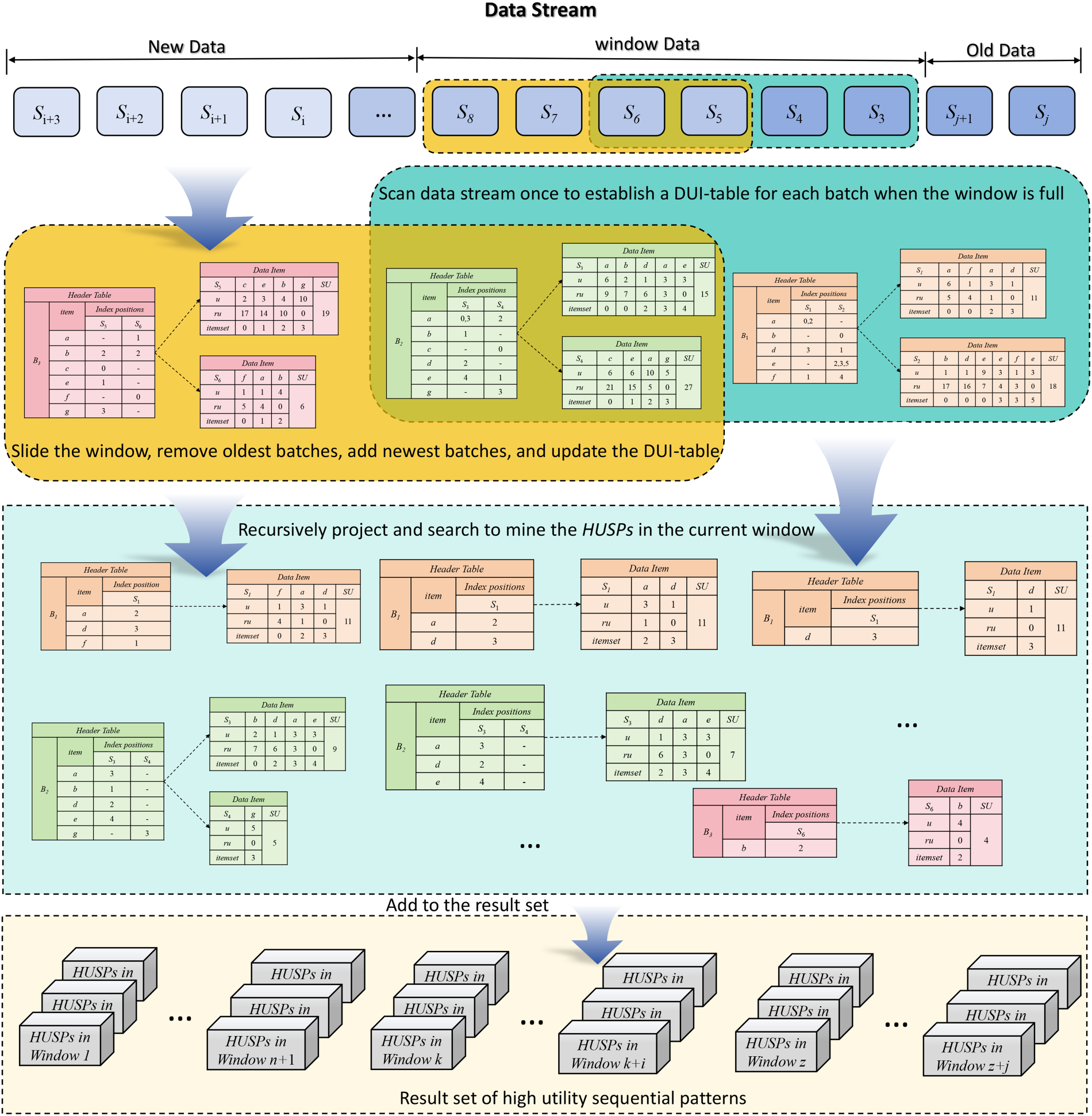
General framework of the algorithm.
The algorithm can be divided into three modules: initialization, mining, and search. Algorithm 1 represents the main program of the proposed algorithm. The algorithm utilizes a sliding window model to process data streams, where the data from the first window are added all at once upon arrival, while subsequent windows require the removal of old batches and addition of new batches. Therefore, different processing methods are employed for the first window. Firstly, the algorithm scans the data stream to determine if it is the first window. If it is, the newly arrived sequences from the data stream are added to the current batch (lines 1–5). Subsequently, the algorithm checks if the batch limit in the current window is reached. If the number of batches in the window equals the user-defined batch size, the new batch is added to the window (lines 6–8). When the window is full, the mining algorithm is invoked to process the first window (lines 9–12).

Secondly, if the current window is not the first one, the algorithm adds new batches until the window size meets the specified size. Then, it slides the window, simultaneously processing the old and new batches (lines 13–26).
Algorithm 2 initializes and updates the DUI-table, mines all high-utility 1-sequence sets, and calls Algorithm 3 for search and mining when the window is full or the data stream stops. Algorithm 2 scans the sequence set SeqSet within the window and evaluates each sequence in the batch, calculating the sequence weighted utility for all 1-sequences. If the sequence weighted utility is not less than the minimum utility threshold and the sequence's DUI-table is empty, a DUI-table is created for that sequence; otherwise, the sequence's DUI-table is updated (lines 1–7). Then, the actual utility values for all 1-sequences are calculated, and sequences with utility values greater than or equal to the predefined threshold are added to the pattern result set HUSPs according to definition 10 (lines 8–10). Each sequence's DUI-table is added to the DUI-table set after creation or updating, and a depth-first search is performed by calling the recursive search Algorithm 3 based on the prefix sequences (lines 11–15).

To determine whether the newly generated sequence is a candidate sequence and a high utility sequential pattern, Algorithm 3 scans the DUI-table to obtain information about the new sequence. As the search space of the algorithm is arranged in lexicographic order based on the alphabetical sequence of the lexicographic q-sequence tree, the algorithm conducts a depth-first search, recursively moving downward based on prefix sequences until all high utility sequences are identified. Firstly, the algorithm scans the DUI-table and adds candidate sequences from

To better understand the algorithm proposed in this paper, this section uses an example to describe the working principles of the algorithm. Consider the example data stream shown in Figure 1, where the window size is 2B (i.e., each window contains two batches), the batch size is 2 (i.e., each batch contains two sequences), and the minimum utility threshold is set to 20. Figure 7 illustrates the DUI-table structure of the example data streams, including two windows and three batches.
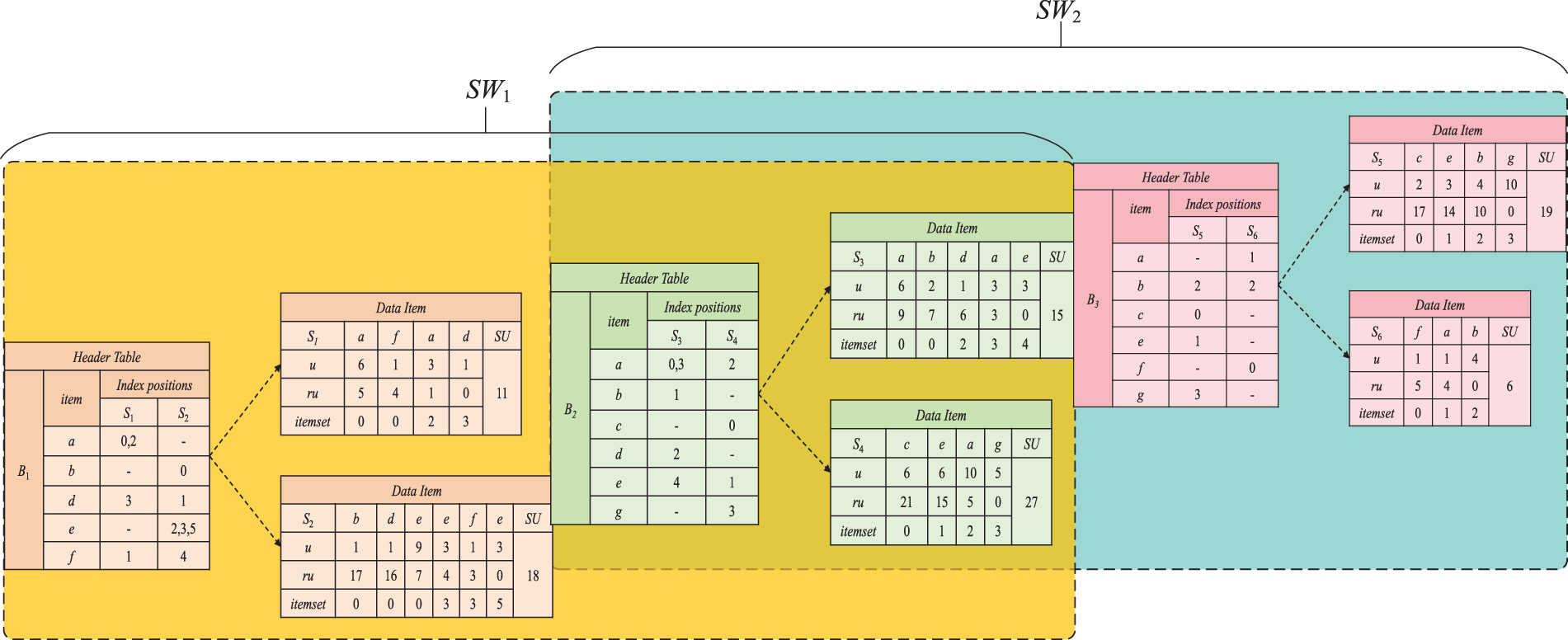
DUI-table structure in the example data streams.
For example, in Figure 1, batch B1 contains two sequences S1 and S2, in which all non-repeating items include a, b, d, e, and f. Therefore, the header table of DUI-table stores a, b, d, e, and f as well as their index positions in sequences S1 and S2, and the data items store sequence elements, utility, remaining utility, and the starting position of the itemset, as shown in Algorithm 2. After calculation, according to definition 10, the utility value of the single-item sequence <[a]> in W1 can be calculated to be 22, and its utility is greater than the minimum utility threshold of 20. Therefore, <[a]> is a high utility sequence.
Resultsets in W1.

The time consumption of the HUSP_DS algorithm mainly includes: ① establishment and update of DUI-table; ② recursive expansion search process. First, assume that the number of sequences contained in the current window is nw, the average length of the sequence is Savg, and the number of sequences in the new batch contained in the current window is nb. For the first window, the algorithm needs to traverse all batches and sequences and create a DUI-table for each sequence, so the time required for the first window is O(nw × Savg). For other windows, the algorithm only needs to establish a DUI-table for the sequences in the new batch, and the time complexity required for the other windows is O(nb × Savg). Therefore, the time complexity required by the algorithm in the DUI-table establishment and maintenance phase is O((nw + nb)×Savg). Secondly, when the window is full, the algorithm recursively calls the Search() operation to perform depth-first search. The number of calls to the Search() operation is proportional to the number of prefixes t. In the worst case, if none of the prefixes are pruned, then the algorithm the time required is O(2m − 1).
The space consumption of the algorithm is mainly the establishment and maintenance of DUI-table. Assume that the header table of each batch contains nt different items, each batch contains nb sequences, and the average length of each sequence is Savg. The space complexity required to create the DUI-table header table is O(nt + Savg), and the space complexity required to create the data items is O(nb × Savg). Then the total space complexity of the algorithm is O(nt + Savg + nb × Savg).
In short, in the worst case, the total time complexity of the algorithm is O((nw + nb)×Savg + 2m − 1), and the total space complexity of the algorithm is O(nt + Savg + nb × Savg). It is worth noting that as the sequence length increases, the number of sequences contained in the database decreases, the projected dynamic utility index table decreases, the number of candidate sequences and the number of items to be expanded also decreases accordingly, and the running time of the algorithm will also be accelerated. Therefore, the actual running time and memory consumption required by the algorithm may be less.
Experiments
To assess the effectiveness of the HUSP_DS algorithm, this section conducts a comprehensive set of experiments to evaluate the algorithm's efficiency. The experiments encompass its performance in three scenarios: 1) the impact of threshold size on algorithm performance; 2) the influence of window size and batch size on algorithm performance; 3) the effect of dataset size on algorithm performance (scalability testing).
Experimental environment and datasets
The experiments involve comparing the HUSP_DS algorithm with state-of-the-art algorithms. Since ProUM is designed for static data, it is modified to ProUM_DS to handle data streams. To test the effectiveness of pruning strategies, a comparison is made between HUSP_DS, utilizing the CSU-based pruning strategy, and HUSP_DS*, which does not use the CSU-based pruning strategy. All algorithms are implemented in Java, with the JDK version being 1.8.0_40. The experimental environment consists of an Intel(R) Xeon(R) Gold 6154 CPU running at 3.00 GHz, with 256GB of RAM, and the operating system is Ubuntu 16.04.6 LTS x86_64. Table 2 presents the datasets used in the experiments, where |D| indicates the total number of sequences in the database, Items represents the number of distinct items in the database, Lavg denotes the average length of sequences in the database, and Element indicates the average number of items in each itemset.
Basic characteristics of the experimental dataset.

Basic characteristics of the experimental dataset.
Additionally, to assess the algorithm's performance on datasets of varying sizes, a synthetic large dataset S10I5E2DD|x|K is generated using the IBM synthetic data set generator (http://www.Almaden.ibm.com/cs/quest/syndata.html). The parameter x denotes the number of sequences in the database, ranging from 100 K to 500 K.
The setting of the minimum utility threshold has a significant impact on algorithm performance. In this section, the influence of different minimum utility threshold sizes on algorithm runtime, memory consumption, and the number of generated candidate sequences is observed. Runtime is defined as the total time, including CPU runtime and disk I/O time, spent on reading input data, discovering high utility sequential patterns, and writing the results to the output file. Memory consumption is defined as the peak memory consumption throughout the entire mining process. The number of candidate sequences is defined as all sequence patterns processed during the algorithm's mining process.
Firstly, the impact of different threshold sizes on algorithm runtime is analyzed. In Figure 8, the runtime of all algorithms is inversely proportional to the threshold size. As the threshold increases, pruning strategies remove a significant number of candidate sequences, resulting in less runtime. The rate of runtime decrease varies depending on the search and pruning strategies employed by each algorithm. On the BIKE dataset, with a fixed window size of 2B and batch size of 10 K, it is evident that the proposed algorithms, with or without the CSU-based pruning strategy, are 3 to 4 orders of magnitude faster than the ProUM_DS algorithm. The ProUM algorithm requires recursive partitioning of utility arrays, and with lower thresholds, it needs to construct a massive number of projected utility arrays, leading to a rapid increase in runtime. Additionally, it is noteworthy that there is little difference in runtime between HUSP_DS and HUSP_DS*, as the BIKE dataset contains a large number of sequences, a small number of different items, and many short sequences. This makes short sequences more likely to become high utility sequential patterns, resulting in a small difference in runtime when using or not using the CSU-based pruning strategy. For the Leviathan dataset, with a window size of 2B and a batch size of 1 K, when the threshold is set low, the runtime of all three algorithms increases linearly. When the threshold is set high, the runtime of HUSP_DS and HUSP_DS* tends to stabilize with a small variation, while the ProUM_DS algorithm still exhibits a significant variation. When the minimum utility threshold changes from 4000 to 5000, the ProUM_DS runtime decreases by 36%, while the HUSP_DS runtime only decreases by 25%. This indicates that the ProUM_DS algorithm is highly sensitive to the threshold setting, as can also be observed from the MSNBC dataset. When the window size for MSNBC is set to 4B, the batch size is set to 4 K, and the threshold increases from 200 K to 240 K, HUSP_DS and HUSP_DS* algorithms show a stable trend, with the runtime difference between the minimum and maximum thresholds not exceeding 25%.
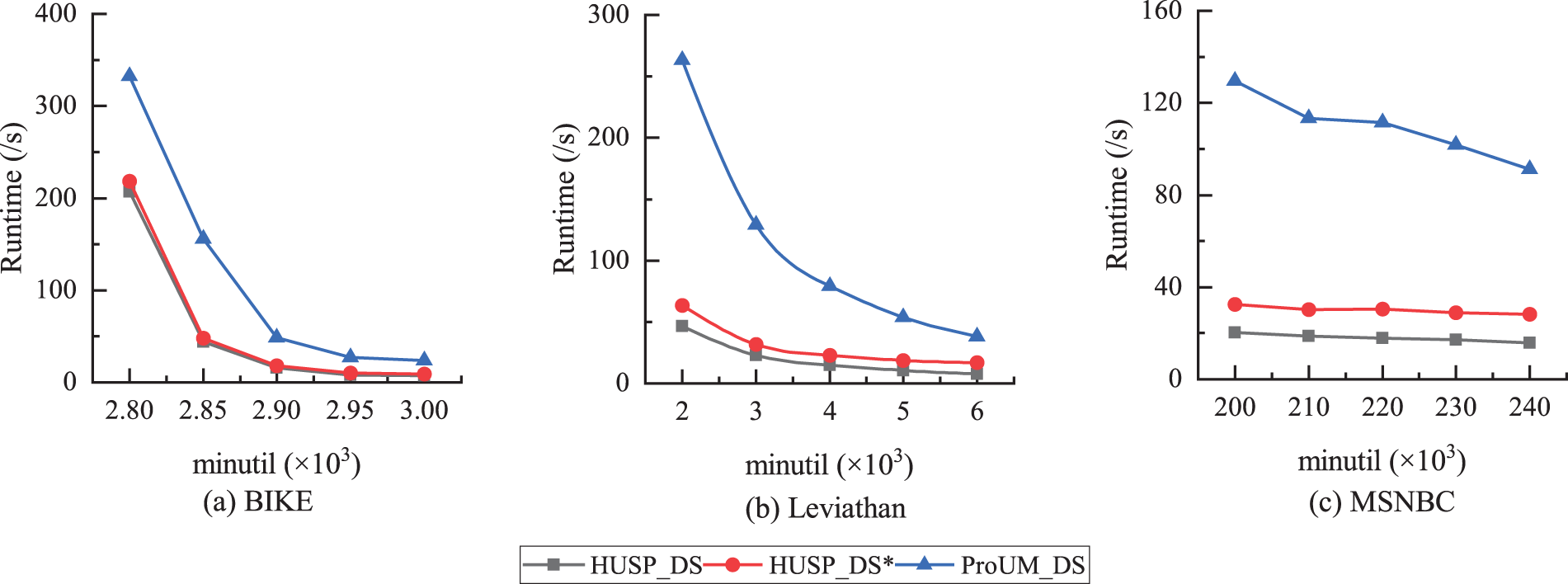
Comparison of runtime at different thresholds.
Next, the memory consumption of the algorithms is compared under different threshold values. As shown in Figure 9, in terms of memory consumption, the increase in the threshold leads to a reduction in the number of sequences in the result set, resulting in a continuous decrease in algorithm memory consumption. On the BIKE dataset, when the threshold is set to 2900, the memory consumption of HUSP_DS, HUSP_DS*, and ProUM_DS is 2294.26MB, 3113.49MB, and 2859.68MB, respectively. When the threshold is set to 2950, the average memory consumption of HUSP_DS, HUSP_DS*, and ProUM_DS decreases by about 32%, 34%, and 12%, respectively. Among them, the memory occupancy of ProUM_DS decreases most slowly, while HUSP_DS* decreases most rapidly. This is because HUSP_DS* does not use the CSU-based pruning strategy and generates more candidate sequences. On the Leviathan and MSNBC datasets, the memory consumption of the ProUM_DS algorithm is much higher than that of the HUSP_DS algorithm. As the threshold decreases, the memory consumption of the HUSP_DS algorithm remains relatively stable, while the memory consumption of the ProUM_DS algorithm increases significantly. Overall, these results fully demonstrate that the proposed algorithm outperforms state-of-the-art algorithms in terms of runtime and memory consumption, with a general improvement of 3 to 4 times in runtime and 1.4 times increase in memory consumption.
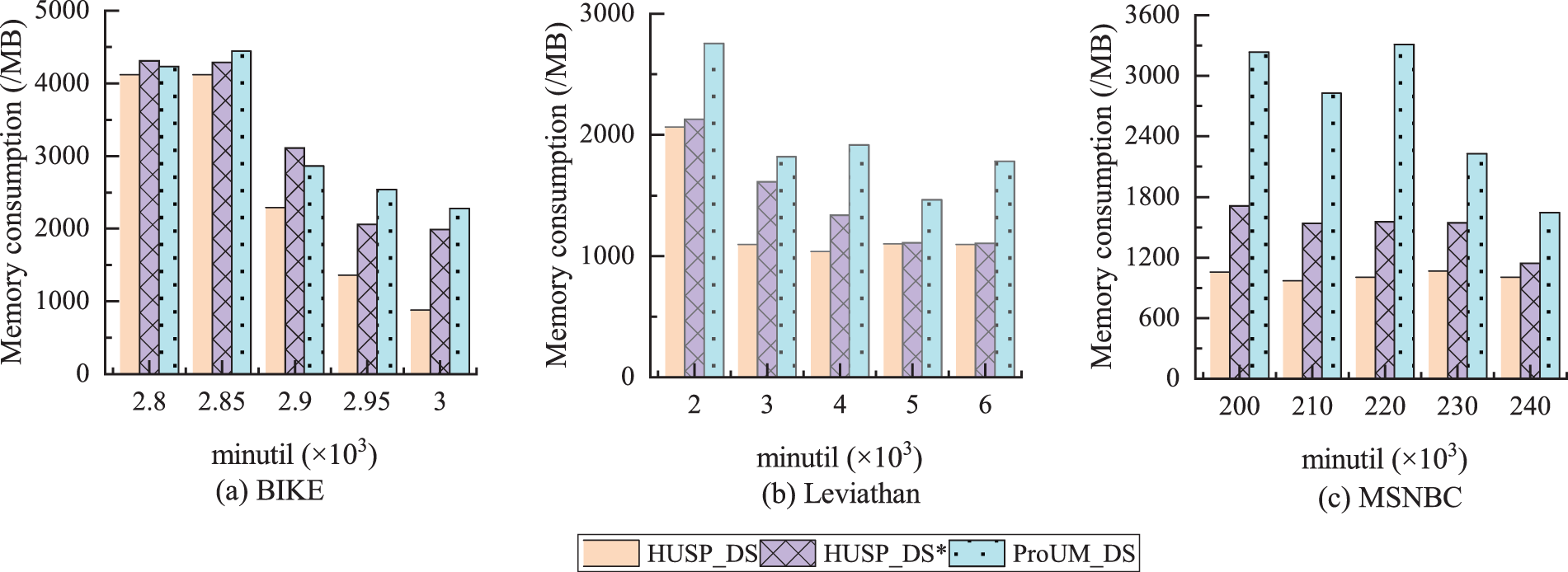
Comparison of memory consumption at different thresholds.
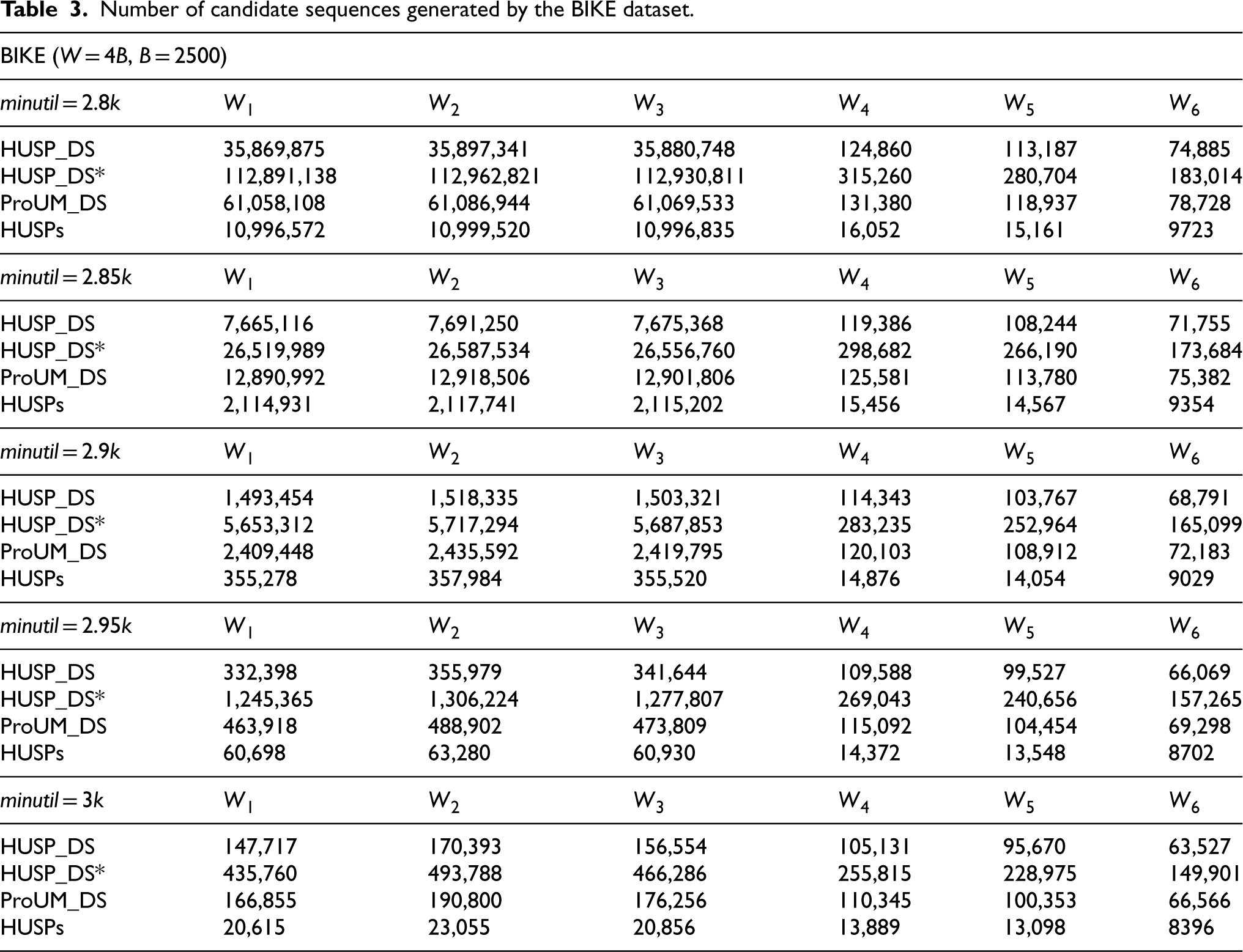
Table 3 shows the number of candidate sequences generated by each window sliding during the mining process of the BIKE dataset. The number of candidate sequences is closely related to the performance of the algorithm because once identified as candidate sequences, their actual utility values need to be calculated to determine if they are high utility sequential patterns. It should be noted that the number of patterns mined by the three algorithms is consistent. On this dataset, the window size is fixed at 4B, batch size at 2500, and the threshold is dynamically adjusted from 2.8k to 3k. Overall, the number of candidate sequences generated by the three algorithms increases with the threshold. When minutil = 2800, HUSP_DS* generates the most candidate sequences, with 2–3 times more than the ProUM_DS algorithm and 3–4 times more than the HUSP_DS algorithm. From the graph, it can be seen that when minutil = 3000, the HUSP_DS algorithm generates the fewest candidate sequences in the first window, while the HUSP_DS* algorithm generates the most, with 2.4 times more than the former. The experimental data in Table 3 shows that the HUSP_DS algorithm generates the fewest candidate sequences during the mining process.
Number of candidate sequences generated by the BIKE dataset.
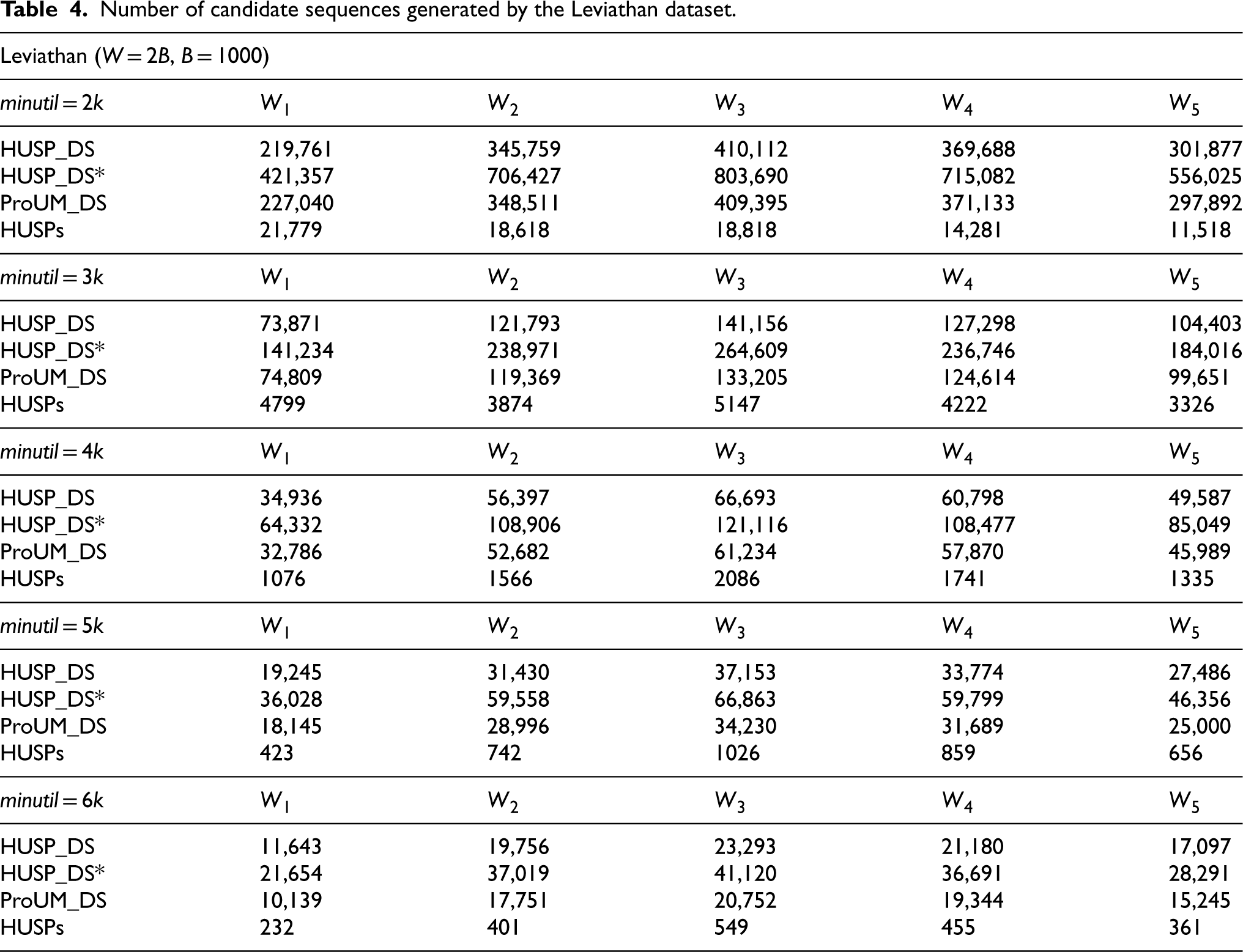
The number of candidate sequences generated by the algorithm on the Leviathan dataset is shown in Table 4, where the window size is set to 2B, batch size to 1000, and minutil ranges from 2000 to 6000 to observe the experimental results under different thresholds. It is worth noting that the sets of pattern results mined by the three algorithms are consistent. From Table 4, it can be seen that the HUSP_DS* algorithm generates the most candidate sequences, approximately doubling compared to HUSP_DS and ProUM_DS. When the minimum utility threshold is 2000, the HUSP_DS algorithm generates 219761 candidate sequences in the first window, while ProUM_DS shows a 3% increase in the number of sequences generated. With a threshold of 6000, ProUM_DS generates 10139 candidate sequences in the first window, representing a 15% increase in the number of sequences generated by the HUSP_DS algorithm. However, in most cases, there is little difference in the number of candidate sequences generated by the HUSP_DS and ProUM_DS algorithms. This is because the Leviathan dataset contains a large number of unique items and has a relatively small overall database size, causing high utility sequential patterns to be less affected by each sequence record in the database. Therefore, the pruning strategies used by both the ProUM_DS and HUSP_DS algorithms do not show significant differences.
Number of candidate sequences generated by the Leviathan dataset.
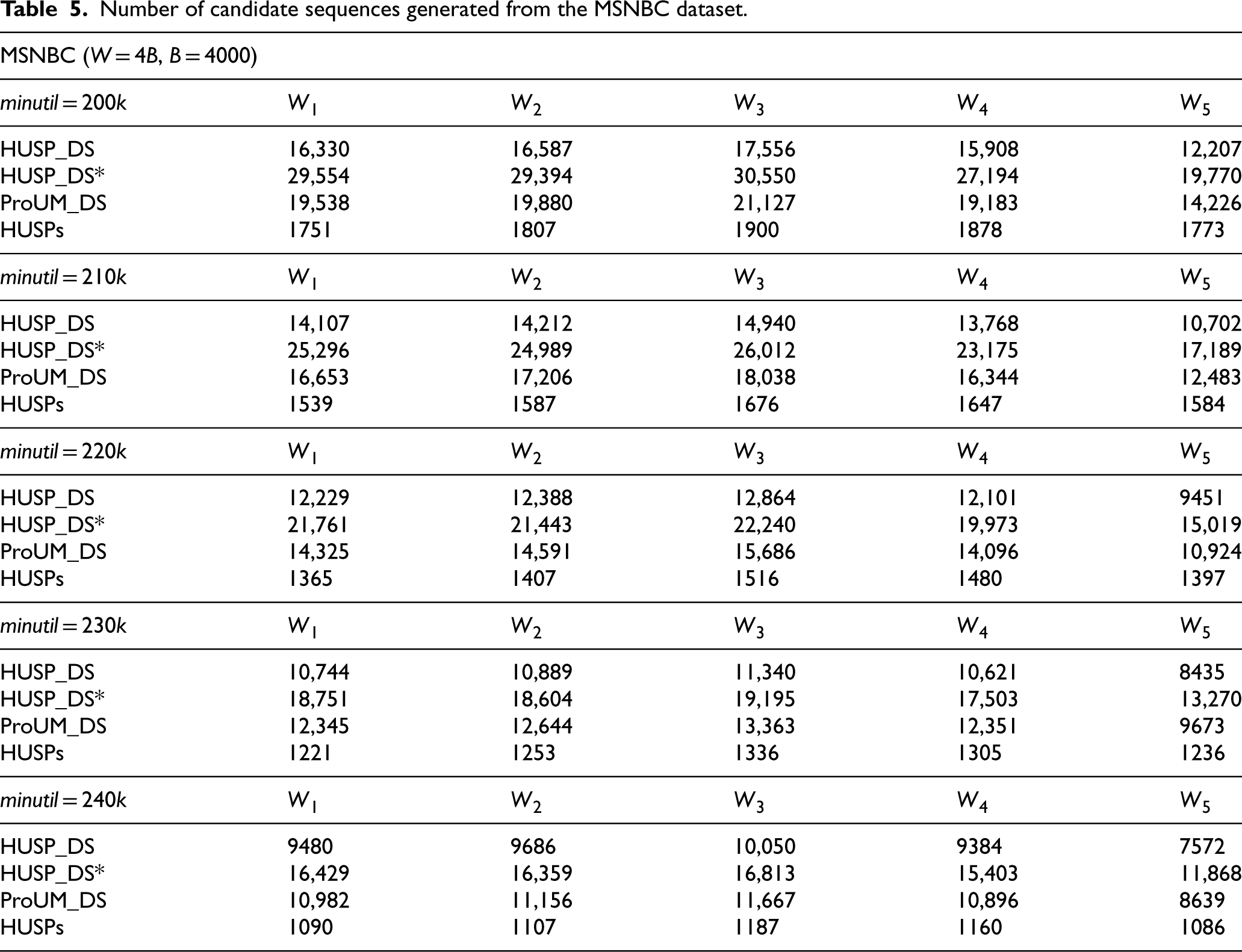
The number of candidate sequences generated by the three algorithms on the MSNBC dataset is shown in Table 5, the pattern result sets they mine is consistent, where the window size is set to 4B, batch size to 4000, and minutil ranges from 200k to 240k to observe the experimental results under different thresholds. On the MSNBC dataset, the HUSP_DS algorithm generates the fewest candidate sequences. When the threshold is 200k, the number of candidate patterns generated by HUSP_DS is approximately 20% fewer than ProUM_DS and 80% fewer than HUSP_DS*. When the threshold is 240k, HUSP_DS still generates the fewest candidate sequences, with approximately 15% fewer than ProUM_DS and 35% fewer than HUSP_DS* algorithm. From these results, it can be concluded that compared to similar algorithms, the proposed algorithm in this paper generates relatively fewer candidate sequences during the mining process.
Number of candidate sequences generated from the MSNBC dataset.
From the above experiments, it can be observed that the choice of different threshold values significantly affects the algorithm's time and space efficiency. The HUSP_DS algorithm consistently outperforms other algorithms in terms of efficiency across various threshold settings. Therefore, the HUSP_DS algorithm is well-suited for mining high utility sequential patterns in data streams.
The window size and batch size are two crucial parameters in the sliding window model. The experiment involves fixing the minimum utility threshold (minutil) and varying the window size (WinSize) and batch size (BatchSize) to compare the algorithm's runtime and memory consumption.
Firstly, the impact of different window sizes on algorithm performance is analyzed. The window size represents the number of batches contained in the window, while the batch size indicates the number of sequences in each batch. The experiment maintains a fixed minimum utility threshold and batch size, examining the algorithm's spatiotemporal efficiency under different window sizes. For the BIKE dataset, with minutil = 2800 and BatchSize = 5000, WinSize ∈[1,5]. Similarly, for the Leviathan dataset, minutil = 3000, BatchSize = 1000, and WinSize ∈ [1,5]. For the MSNBC dataset, minutil =100000, BatchSize = 5000, and WinSize ∈ [1,5]. As shown in Figure 10, HUSP_DS proves to be the fastest algorithm across all datasets. Particularly noteworthy is the comparison on the BIKE dataset, where ProUM_DS consumes 2–4 times more runtime than HUSP_DS and 2–3 times more than HUSP_DS when the window size is 5B. The significant reduction in runtime for all algorithms when the window size is 5B is attributed to the window encompassing all sequences in the dataset. The algorithms adopt a single-window approach for mining, eliminating the need for batch insertions and deletions, thereby reducing runtime. On the Leviathan dataset, the runtime increases proportionally with the window size. HUSP_DS consistently exhibits the minimum average runtime, demonstrating approximately 11% and 79% lower consumption compared to HUSP_DS* and ProUM_DS, respectively. For the MSNBC dataset, when the window size increases from 2B to 3B, ProUM_DS experiences a runtime increase of 398.3%, while HUSP_DS* and HUSP_DS increase by 276.5% and 229.8%, respectively. Additionally, when the window size exceeds 5B, ProUM_DS fails to mine patterns within a limited time.
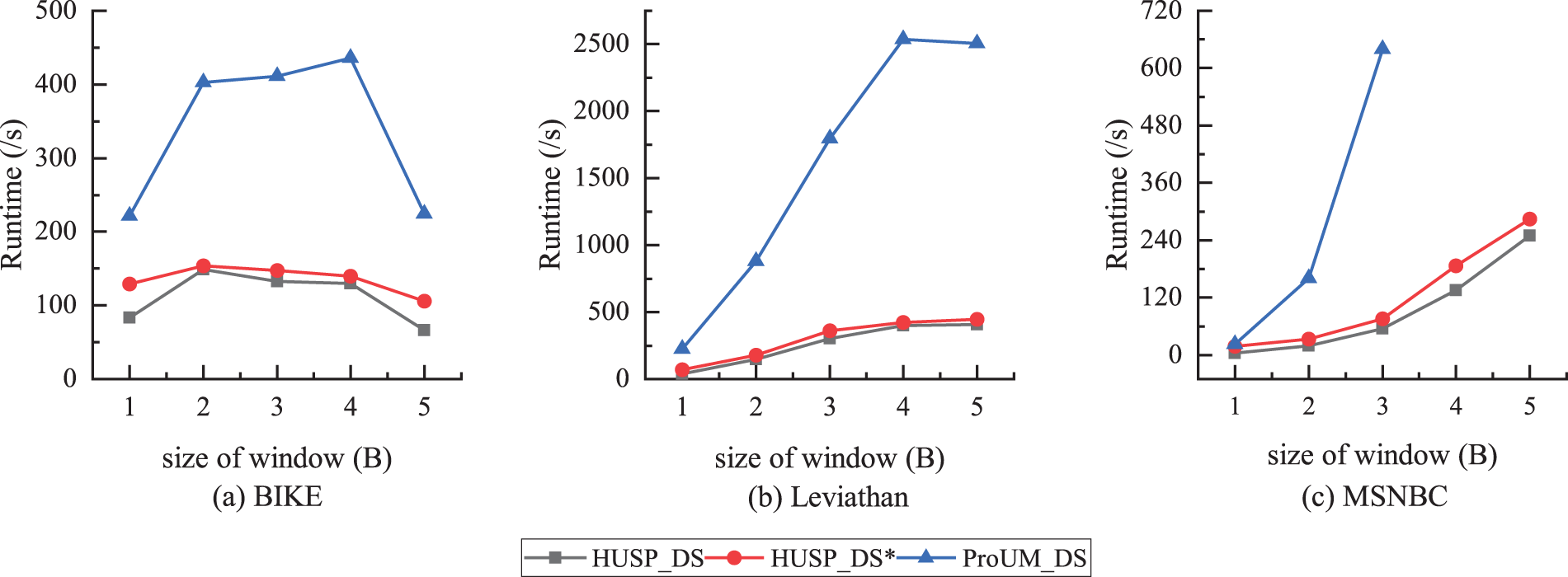
Comparison of running time under different window sizes.
Figure 11 illustrates the maximum memory consumption for the three algorithms under different window sizes. HUSP_DS consistently exhibits the lowest memory consumption, with an average of approximately 4554.18MB on the BIKE dataset. In contrast, HUSP_DS* and ProUM_DS experience an average memory consumption increase of 10% and 16%, respectively. The observed increase in memory usage with larger window sizes is attributed to a decrease in the number of generated windows, leading to a reduction in the frequency of mining operations. However, the increased number of sequences within each window necessitates the construction of additional data structures, consequently increasing memory usage. Overall, these results strongly support the suitability of the proposed algorithm for mining high utility sequential patterns within sliding windows of any size.
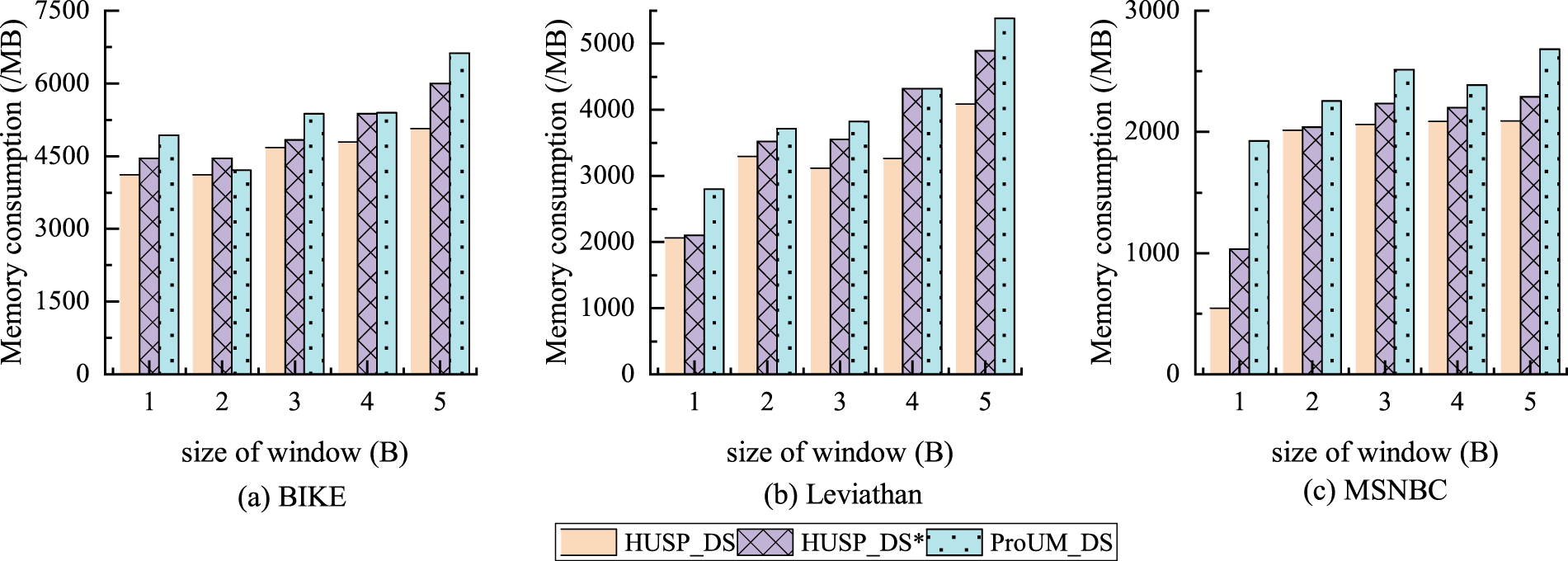
Comparison of memory consumption under different window sizes.
The number of efficient sequence patterns mined by the three algorithms is shown in Figure 12. It can be seen that the number of patterns mined on BIKE, Leviathan, and MSNBC is consistent.
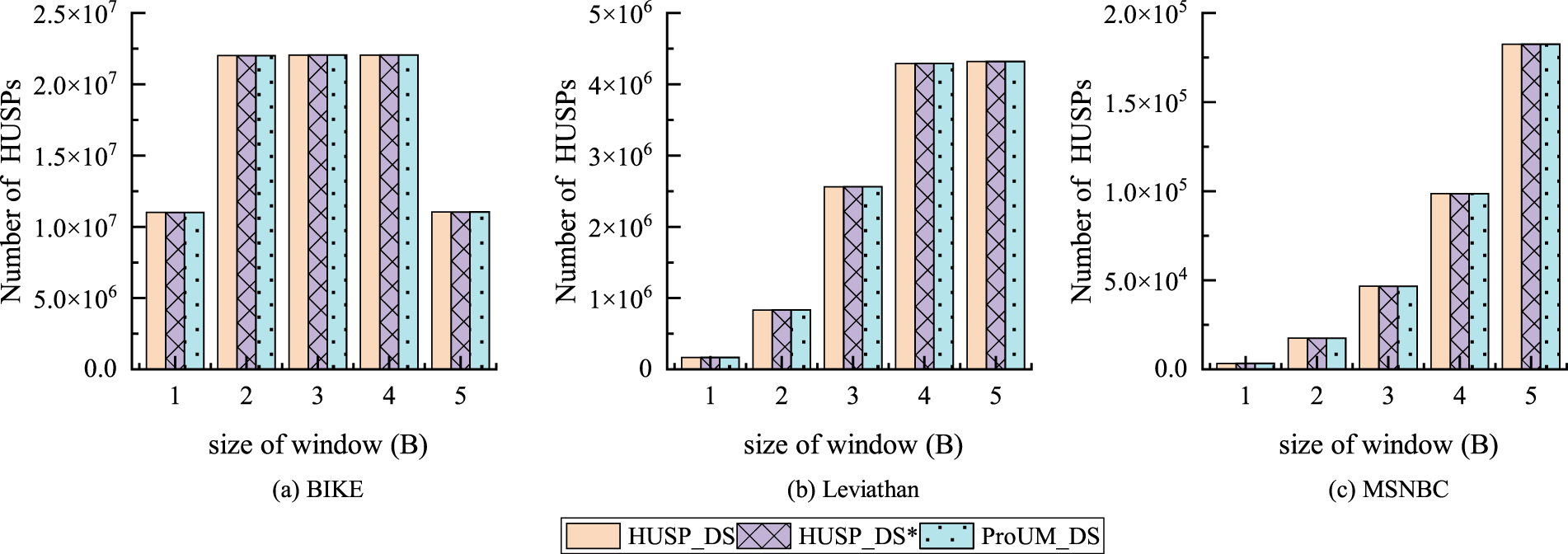
Number of patterns under different window sizes.
Next, the impact of different batch sizes on algorithm performance is analyzed. Considering the BIKE dataset, with minutil = 2800, WinSize = 2, and BatchSize
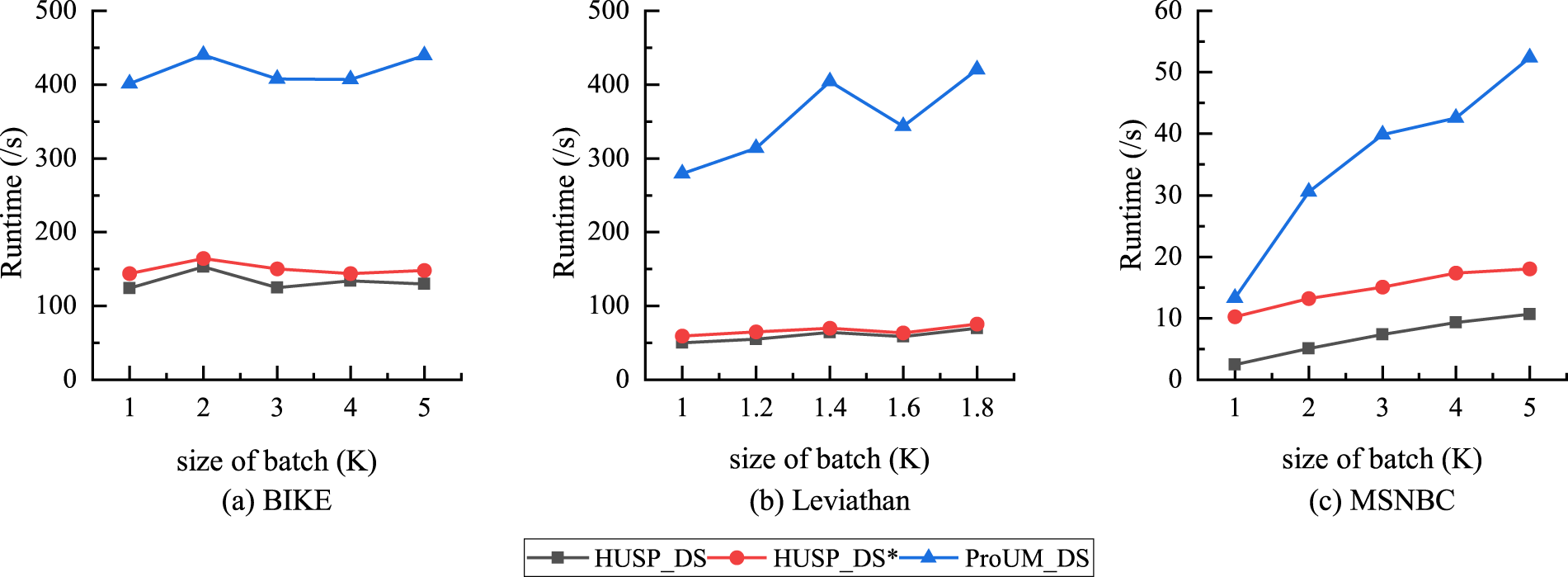
Comparison of runtime with different batch sizes.
The experimental results for memory consumption of the three algorithms are illustrated in Figure 14. On BIKE and Leviathan datasets, the memory consumption for all algorithms shows a relatively small increase, tending towards a stable state. On the MSNBC dataset, HUSP_DS exhibits 65% less memory consumption than ProUM_DS. Therefore, the proposed algorithm in this paper demonstrates the ability to mine high utility sequential patterns under varying batch sizes.
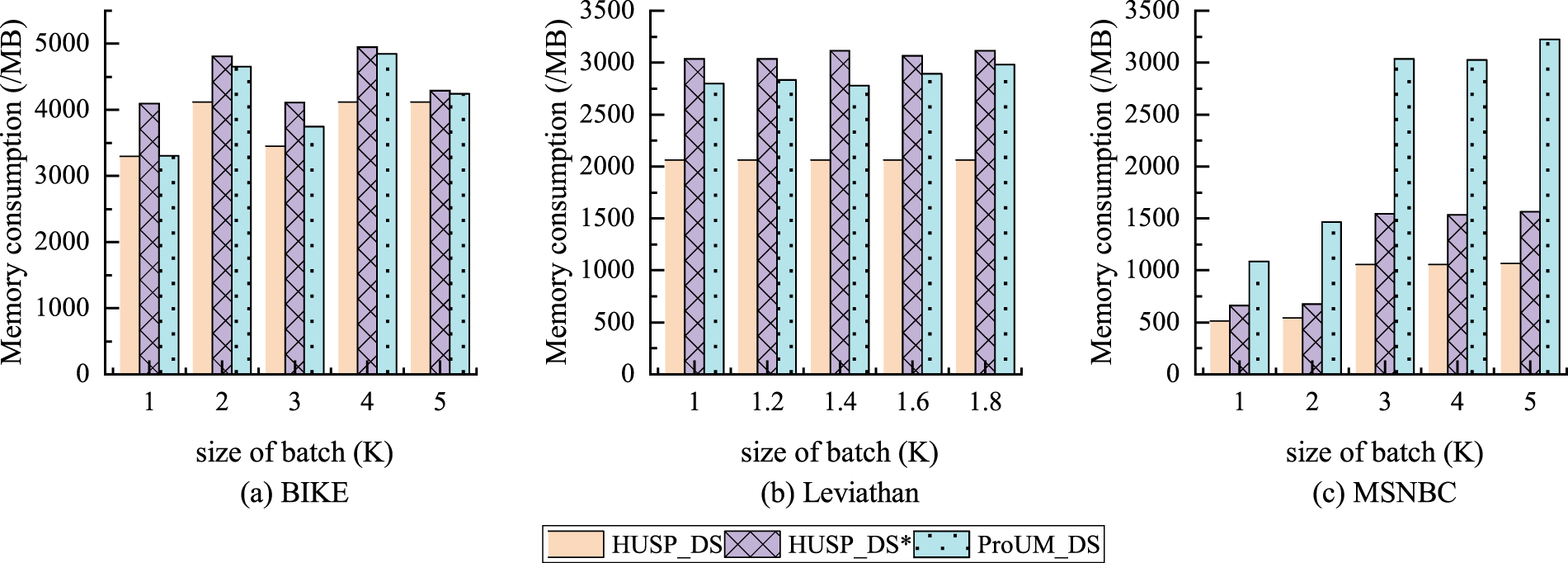
Comparison of memory consumption with different batch sizes.
The number of high utility sequential patterns mined by the three algorithms is shown in Figure 15. It can be observed that, on the BIKE, Leviathan, and MSNBC datasets, the number of patterns mined is consistent across different batch sizes.
Number of patterns with different batch sizes.
In conclusion, the comprehensive analysis of the experiments reveals that the HUSP_DS algorithm performs well in terms of runtime and memory consumption under different window and batch sizes. It is suitable for mining high utility sequential patterns within windows of arbitrary sizes.
This section conducts scalability tests on the synthetic dataset S10I5E2D|x|K, as presented in Table 2. The experimental results are illustrated in Figure 16 and Table 6. The experiments were conducted with a minimum utility threshold of 20,000, window size of 3B, and batch size of 20,000 on dataset S10I5E2D|x|K, varying the value of x from 100 to 500.
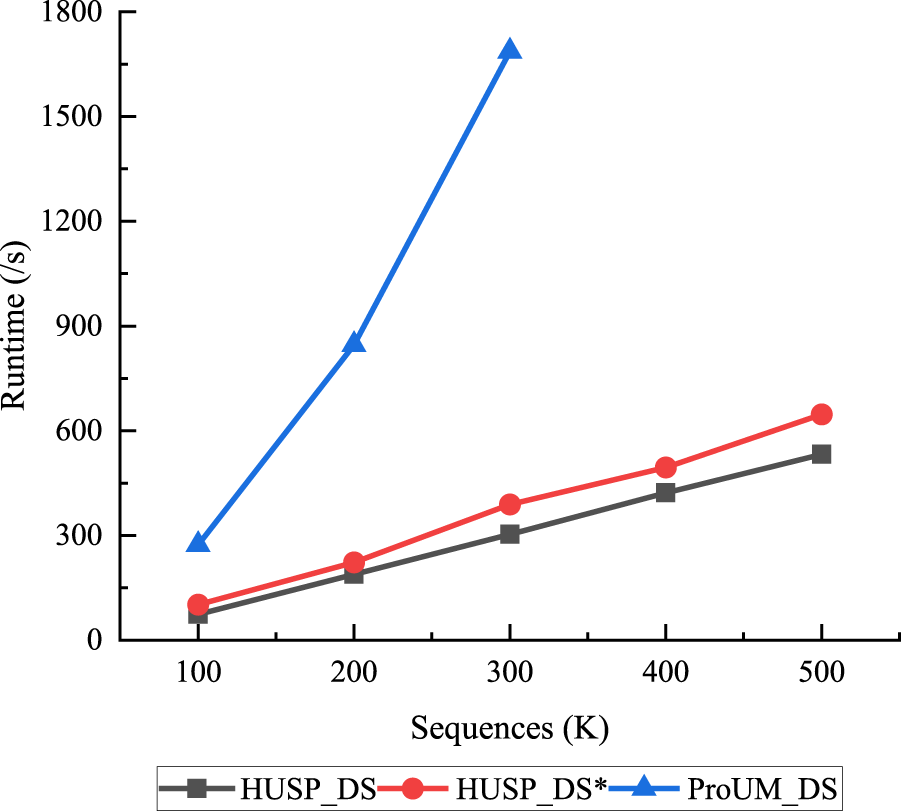
Time scalability test.
Memory scalability test (MB).

The analysis of the experimental results indicates a linear increase in both time and space efficiency as the data stream size grows. The HUSP_DS algorithm, leveraging a sliding window model and focusing solely on the current window's sequences, efficiently updates transactions in real-time, swiftly discovering high utility sequential patterns. This advantageous approach results in superior runtime and memory consumption. The outcomes demonstrate that the HUSP_DS algorithm exhibits excellent performance on large datasets, showcasing strong scalability and suitability for handling big data.
To test the performance comparison between the proposed algorithm and state-of-the-art static algorithms, this study compares the proposed algorithm with HUSP-SP 24 and HUS-Span, 19 with a threshold set at minutil = 0.03%. The proposed algorithm and the ProUM_DS algorithm are both operated in a single-window manner (with window size set to 1 and batch size set to the dataset size). The experimental results are shown in Figure 17 and Table 7. Among all the test results, the HUSP_DS algorithm shows the lowest runtime and memory consumption, demonstrating the best scalability among all compared algorithms. From Figure 17, it is observed that the runtime of the HUSP_DS algorithm linearly increases with the number of sequences in the data stream. The table indicates that the memory consumption of the HUSP_DS algorithm remains relatively stable. These results indicate that compared to existing static algorithms, the scalability of the HUSP_DS algorithm is optimal for large-scale datasets, making it suitable for handling big data.
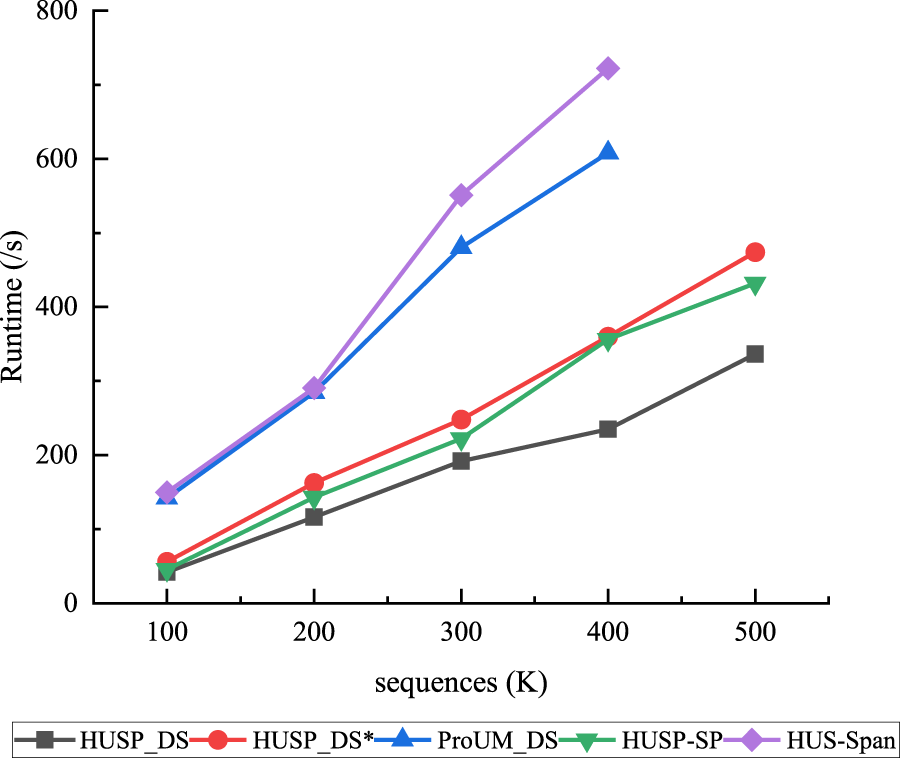
Time scalability test with static data.
Memory scalability test with static data (MB).

To tackle the challenge of efficiently extracting high utility sequential patterns from dynamically changing data streams, this study introduces a novel algorithm. Firstly, addressing the inefficiencies in existing algorithms for mining high utility sequential patterns in data streams, this paper presents a new structure called DUI-table, serving as a dynamic utility index table. This structure optimally reduces the search space using a prefix recursive projection mechanism, allowing for swift and accurate construction and updating of abundant information in the sequential data of the data stream. The DUI-table proves to be well-suited for mining high utility sequential patterns in data streams. Secondly, based on the DUI-table structure, a data stream high utility sequential pattern mining algorithm is devised. This algorithm employs a sliding window model for real-time discovery of valuable patterns. Finally, to evaluate the effectiveness of the proposed algorithm, extensive experiments are conducted on both real and synthetic datasets. The results demonstrate that the HUSP_DS algorithm can efficiently mine high utility sequential patterns in data streams with arbitrary window and batch sizes, showcasing strong scalability. In summary, HUSP_DS provides a feasible and effective solution for mining high utility sequential patterns in complex and dynamic data stream environments.
In addition, this algorithm faces two key issues: the difficulty in setting the minimum utility threshold and handling the oldest batch within a window and the common batch between two adjacent windows. First, in the process of mining high utility sequential patterns in data streams, multiple experiments are required to validate the threshold's effectiveness, or the threshold is set based on expert experience. However, users lack sufficient prior knowledge, resulting in difficulty in setting the threshold. Second, the sliding window used by this algorithm focuses on the value generated by recent data, neglecting the value generated by historical data. Additionally, the common batches between two sliding windows need to be re-mined, which increases spatiotemporal consumption. Therefore, considering the value generated by historical data and reducing the number of re-mining of common batches based on the result set of the previous window are issues that need further resolution by this algorithm. For the first issue, an effective solution is to not set a minimum utility threshold but directly mine the top k patterns with the highest utility values. Therefore, future research can focus on introducing a self-adaptive selection mechanism for the minimum utility threshold to improve the algorithm's robustness and application scope. For the second issue, overlapping windows can capture more events, reducing the possibility of missed events. They can also flexibly adjust the sliding step to meet various data processing needs. However, this also brings the drawback of repeated mining in overlapping windows and neglecting the value generated by historical data. Therefore, future work can focus on combining the advantages of both landmark windows and sliding windows to mine high utility sequential patterns in data streams.
Footnotes
Acknowledgements
This research was supported by the National Natural Science Foundation of China (62062004), the Natural Science Foundation of Ningxia (2023AAC03315), the Central Universities Foundation of North Minzu University (2021KJCX10), and the Graduate Innovation Project of North Minzu University (YCX24120).
Credit authorship contribution statement
Meng Han: Supervision, Writing, Reviewing. Ruihua Zhang: Conceptualization, Methodology, Writing-original draft. Feifei He: Data curation, Writing-original draft. Fanxing Meng and Chunpeng Li: Co-supervision, Writing, Editing.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China (62062004), the Natural Science Foundation of Ningxia (2023AAC03315), the Central Universities Foundation of North Minzu University (2021KJCX10), and the Graduate Innovation Project of North Minzu University (YCX24120).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.