
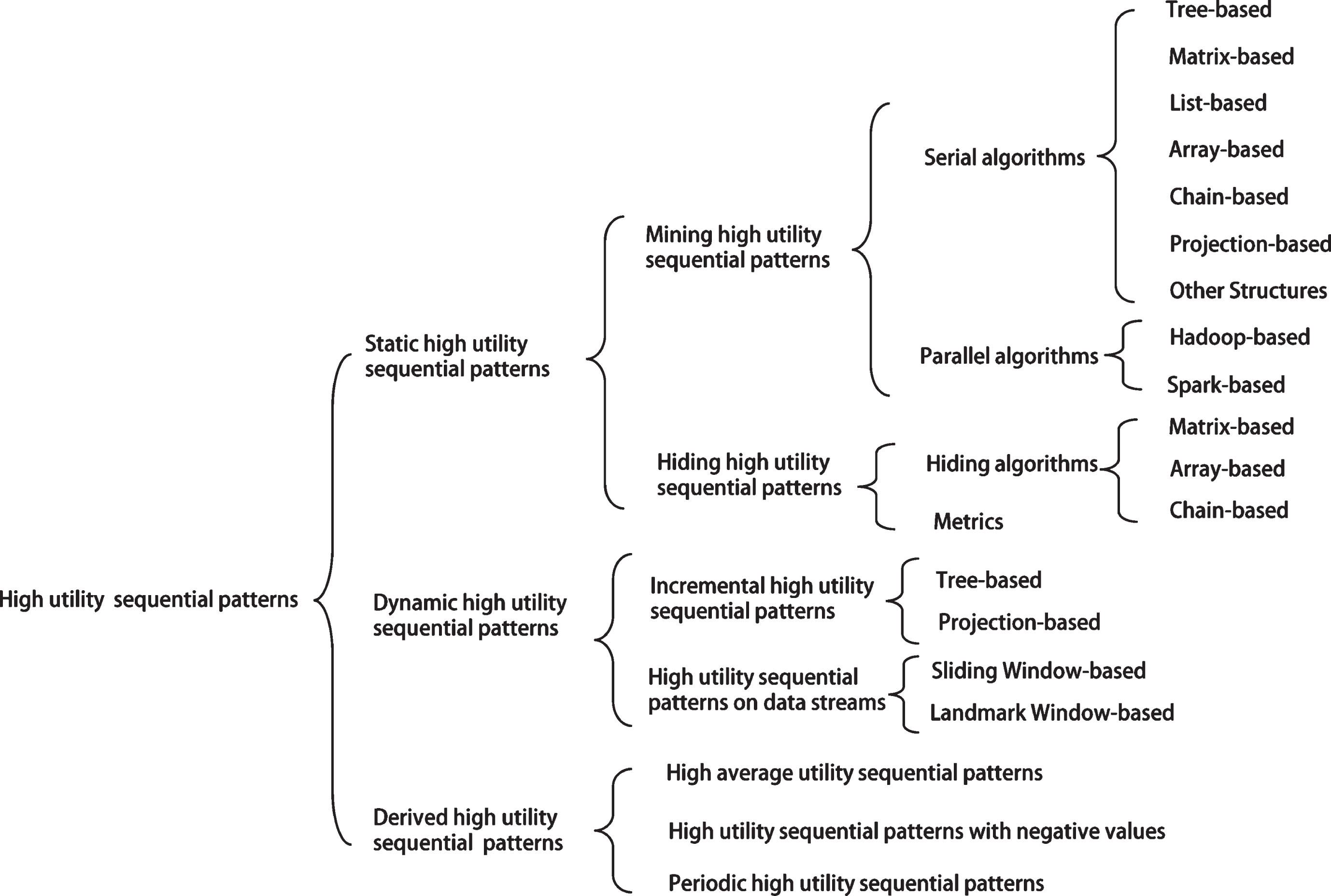
Abstract
In recent years, there has been an increasing demand for high utility sequential pattern (HUSP) mining. Different from high utility itemset mining, the “combinatorial explosion” problem of sequence data makes it more challenging. This survey aims to provide a general, comprehensive, and structured overview of the state-of-the-art methods of HUSP from a novel perspective. Firstly, from the perspective of serial and parallel, the data structure used by the mining methods are illustrated and the pros and cons of the algorithms are summarized. In order to protect data privacy, many HUSP hiding algorithms have been proposed, which are classified into array-based, chain-based and matrix-based algorithms according to the key technologies. The hidden strategies and evaluation metrics adopted by the algorithms are summarized. Next, a taxonomy of the most common and the state-of-the-art approaches for incremental mining algorithms is presented, including tree-based and projection-based. In order to deal with the latest sequence in the data stream, the existing algorithms often use the window model to update dynamically, and the algorithms are divided into methods based on sliding windows and landmark windows for analysis. Afterwards, a summary of derived high utility sequential pattern is presented. Finally, aiming at the deficiencies of the existing HUSP research, the next work that the author plans to do is given.
Introduction
High Utility Itemsets Mining (HUIM) [1] is an important topic in the field of data mining, and its main purpose is to extract interesting patterns from transactional databases. HUIM breaks through the limitations of the traditional Frequent Pattern Mining (FPM) [2] (assuming that all itemsets in the database have the same weight), HUIM considers the number and relative weight of each itemset in the transaction database to mining itemsets with high utility (such as profit per unit), it is more general than FPM. However, there is a flaw in HUIM, which ignores the sequence of itemsets and can only mine itemsets that have no temporal relationship, so it is not suitable for dealing with time series or sequential data in real life, such as stock data in the financial field or biomedical fields DNA sequence data. In addition, in the fields of shopping basket analysis, web page click stream, mobile computing, bioinformatics, failure risk prediction and medical diagnosis [3, 4], there are a large amount of time series data, which has rich characteristics: time-varying, multidimensionality, uncertainty and noise interference, etc. [21]. Traditional high utility pattern mining cannot effectively analyze these data.
In order to deal with the reality related to sequence sorting, in 1995 Agrawal [5] et al. first proposed the concept of Sequential Pattern Mining (SPM), and designed AprioriSome, AprioriAll and DynamicSome algorithms for sequential pattern mining. Subsequently, in order to improve the efficiency of the AprioriAll algorithm, Srikant [6] et al. proposed a GSP algorithm, which uses a hash tree to save the candidate set and speed up the mining efficiency. All of the above algorithms are based on Apriori’s algorithm, and a large number of candidate sets will be generated during operation, and the database needs to be scanned multiple times. Zaki [7] and others proposed the SPADE algorithm based on the vertical database, which uses equivalence classes to find frequent sequence patterns, and only needs to scan the database three times. The FreeSpan [8] algorithm and PrefixSpan [9] algorithm based on pattern growth adopt the idea of divide and conquer to search the local projection database, and then find all frequent sequences. However, SPM only uses the support of the sequence as the measurement standard, and cannot find high utility information in the database, which limits the application field of the algorithm. The main goal of SPM is to discover itemsets of frequent sequences measured by a user-specified minimum support threshold. However, this process may not be very informative for decision makers because they cannot discover patterns of high value or high impact. Therefore, merely mining sequence itemsets cannot provide efficient assistance to decision makers.
High Utility Sequential Pattern Mining (HUSPM) aims to find sequences whose utility is not less than the minimum utility threshold specified by the user in the sequence database. HUSPM was first used to mine web logs. Ahmed [10] et al. proposed two new tree structures called UWAS-tree and IUWAS-tree. It is suitable for processing web log sequence data in static and dynamic databases. However, the algorithm does not support sequence elements with multiple items, and the considered scenario is rather simple, which is not suitable for processing complex sequences. In order to help business decision-makers make better strategies, Ahmed [11] et al. considered the utility factor and the itemset order at the same time, and proposed a new method to mine high utility sequences in sequence databases, that is, the layer-by-layer search UL algorithm and the US algorithm based on pattern extensions. However, this literature does not give a formal definition of the HUSPM problem. Later, Yin [28] et al. incorporated utility into sequential pattern mining, and defined a general framework for high utility sequence mining, which played a key role in promoting the development of HUSPM. Wang [12] proposed a high utility sequential pattern mining algorithm for mining top-k items, which can efficiently mine top-k high utility sequences. In addition, Tang [13] proposed a tree-based pattern growth algorithm for mining high utility sequences. Most of the algorithms proposed before are serial algorithms, which do not take advantage of parallel computing by multiple machines. With the development of the big data era, research on distributed mining algorithms is becoming more and more extensive. Researchers have proposed many parallel distributed algorithms based on the MapReduce framework, such as BigHUSP [14], DHUTISP [15], ML-HUSPM [16], most of which use the big data processing platform Hadoop or Spark to process and analyze massive data.
At present, Truong-Chi [17] et al. introduced the problems of high utility sequence mining, the status quo of algorithms and their applications in chronological order. Li [18] et al. described the high utility pattern mining algorithm from the perspective of high utility fusion and derived patterns. Gan et al. [4]present a comprehensive survey of utility-oriented pattern mining, reviewing the advanced topics of existing high utility pattern mining techniques, and discussing their advantages and disadvantages. Gan [19] et al. reviewed privacy-preserving utility mining. The article introduced the background of hiding high utility sequences, the advantages and disadvantages of the algorithm, and so on. There is no comprehensive review of high utility sequential pattern mining algorithms and hidden algorithms from the perspective of dynamic and static in the existing related reviews. Therefore, this paper provides a review of high utility sequence pattern mining algorithms from a novel perspective of dynamic and static.
The major contributions of this paper are listed as follows: The first comprehensive analysis and summary of the dynamic high utility sequential patterns, including pruning strategies, algorithm pros and cons and HUSPM algorithms under different techniques (incremental database) and different windows (data stream). A taxonomy of the most common and the state-of-the-art approaches for high utility sequential pattern mining algorithms is presented, including serial centralized algorithms and parallel distributed algorithms, and make a detailed and comprehensive analyze of them. The high utility sequential pattern hiding algorithms are classified into array-based, chain-based and matrix-based algorithms, and the hiding strategies and evaluation metrics adopted by the algorithms are summarized. According to the latest research progress, plan the next research works, including high utility sequential pattern mining with positive and negative values on data streams, high utility sequential pattern mining and hiding in incremental databases, high utility sequential pattern mining algorithms on uncertain data streams, and high utility sequential pattern mining and hiding methods based on heuristics algorithms.
The overall framework of this paper is shown in Fig. 1.
Overall framework of the article.
Unlike transactional data that ignores temporal relationships, sequential data usually contains rich semantic information, and temporal data that contains temporal relationships is a common and important type of data in data mining. Generally speaking, time series data can be divided into the following types: Time Sequence, Transactional Sequence and Event Sequence. In this chapter, the measurement is mainly transaction-based time series data, hereinafter referred to as sequential data.
Assuming that I = {i1, i2, …, in} is a finite set of n different items, the item set w is a subset of I, expressed as w = [i1, i2, …, ic], that is, the quantization Itemset means that the itemset is given a quantitative index, and each quantified itemset has a quantity (internal utility) associated with it, and its form can be expressed as v = [(i1,q1),(i2,q2), …, (ic,qc)] [21]. A quantization sequence is an ordered arrangement of multiple quantization itemsets, denoted as s =< w1, w2, …, w d > [21].
The q-item (quantitative-item) means that the quantity of the item is q, which is generally expressed as (i, q), and q is usually a positive integer, also known as internal utility. A q-itemset (quantitative-itemset) is a collection of multiple q-items, generally expressed as {(i1, q1) , (i2, q2) , …, (i c , q c )}. A q-sequence (quantative-sequence) is an ordered arrangement of q-itemsets. For example, (a,1) is a q-item, [(a,1), (b,2)] is a q-itemset, < [(a, 1) , (b, 2)] , [(a, 1) , (c, 3)] , [(b, 1) , (d, 4) , (e, 5)]> is a q-sequence.
The transaction database D = {T1, T2, …, T n } consists of a set of quantized sequences containing n transactions, each of which has a unique identifier SID. Table 1 is a quantitative sequence database. In the sample database, each transaction contains items and their quantities (also known as internal utility), and Table 2 is the external utility table corresponding to Table 1. The utility of an item is the product of quantity and value, that is, the product of internal utility and external utility.
Quantitative sequence database (QSDB)
Quantitative sequence database (QSDB)
External utility table
For example, in the sample database, the utility of item a in q-itemset [(a,1) (b,1)] is: 1×3 = 3; item c in q-itemset [(b,1) (c,2)] the utility is: 2×2 = 4.
For example, the utility value of the q-itemset [(a,3)(c,2)] is: 3×3 + 2×2 = 13.
For example, u (S1) = u ([(a, 2) (f, 2)]) + u ([(a, 1) (b, 1)]) + u ([(c, 2) (d, 4)]) + u ([(e, 4) (f, 1) (g, 1)]) =18 + 12 + 8 +20 = 58.
For example, the utility of sequence database D is u (D) = u (S1) + u (S2) + u (S3) + u (S4) + u (S5) =58 + 15 + 37 + 26 + 45 = 181.
For example, given sequence t =< [f] , [ad] > and quantized sequence s =< [(f, 2)] , [(a, 5) (d, 2)] , [(d, 2)] , [(b, 4)] , [(a, 4) (d, 1)] >, the sequence t has two quantized sequence values in the quantized sequence s, so u (t → s) = max {u < [(f, 2)] , [(a, 5) (d, 2)] > , u < [(f, 2)] , [(a, 4) (d, 1)] >} = max {29, 13} =29. In addition, note that the sequence < [a] , [b]> is different from the sequence < [b] , [a]>, because the complex temporal relationship in the sequence is fully considered in the high utility sequence pattern mining.
For example, in the example database, the sequence weighted utility for the sequence < [af]> is: SWU (< [af] >) = u (S1) + u (S5) =58 + 45 = 103.
For example, append s1 =< f, b, [d, e] , c > to s2 =< e, c >, then s2 is updated to
For example, s =< [(e, 5)] [(c, 2)] > is the sequence in the original database, when a new itemset k = [(c,2)(d,6)] is added to s, then define k as the incremental part of the sequence s, expressed as Δdb=k. Figure 2 shows the incremental part of the original database.

incremental part.
For example, Fig. 3 shows a data stream DS =< S11, S14, S17, S22, S23, S25, S36 > with 7 transactions, each of which belongs to one of three sequences: S1, S2, and S3.

Sequence data stream.
For example, in the example database, the minimum utility threshold is set to be 25%, then δ×u(D)=25% ×181 = 45.25. Therefore, the sequence < [(a, 1) (b, 1)] , [(c, 1) (d, 1)]> is not a high utility sequence, because u (< [(a, 1) (b, 1)] , [(c, 1) (d, 1)] >) =15 ≤ 45.25.
HUSPM aims to find out all sequences that are complete and not lower than the user-defined threshold. It is a research hotspot in recent years and has a wide range of applications in real life. Compared with high utility itemset mining, HUSPM considers the utility and order of itemsets at the same time, so it is more widely used but also more complex than traditional high utility itemset mining. High Utility Sequential Pattern Hiding (HUSPH) aims to find a way to hide all sensitive high utility sequential patterns so that adversaries cannot mine them from sanitized databases. Hiding high utility sequential patterns helps protect user privacy, improve information security. This chapter classifies and summarizes high utility sequential pattern mining and hiding algorithms.
Mining high utility sequential pattens
Nowadays, there are many high utility sequential pattern mining algorithms, which can be classified into serial algorithms and parallel algorithms according to the calculation type. Typically, serial algorithms are used to process small or medium-sized data, and parallel algorithms are used to process massive amounts of big data. This section summarizes the HUSPM related algorithms in the order of serial and parallel.
Serial algorithms
Serial algorithms can be divided into tree-based, matrix-based, list-based, array-based, chain-based, projection-based and other structure-based algorithms according to the data representation. This section summarizes the algorithms of different representation forms respectively.
(1) The tree-based algorithm scans the database once to establish a tree structure, and then finds high utility sequences based on the tree structure. Compared with the two-phase algorithm, the space-time efficiency is better improved [24]. Shie [25] proposed two tree-based methods, UMSPDFG and UMSPBFG, in order to mine high utility mobile sequence patterns in the mobile commerce environment. The main difference between the two algorithms is the different methods used to generate patterns of length 2 during the mining process and UMSPDFG uses a depth-first approach to generate candidate sequences, while UMSPBFG uses a breadth-first generation strategy to generate candidate sequences. The same point of the two algorithms is that they scan the database once to generate a mapping table and build a tree structure MTS-tree (Mobile Transaction Sequence Tree) to summarize information such as location, item, path and utility in the mobile transaction database. Zihayat [23] proposed an efficient algorithm HUSP-Miner, and used a utility model called Sequence Suffix utility to effectively prune the search space in HUSP mining. It reduces the number of candidate items in the mining process through the tree chain mode, and the algorithm has a great improvement in time and space efficiency. In 2021, Huynh [26] et al. proposed a new utility function to calculate the utility of sequences. FHNewUSM uses three pruning strategies to prune the search space, namely: width pruning based on SWU, compact pruning based on UBs, depth pruning based on AMF_SUB. However, the new utility function is time-consuming to calculate the utility. The high utility sequence based on time intervals reflects the scene of events with unequal time intervals. Mirbagheri [27] et al. designed an algorithm HUIPMiner based on time interval sequences. This algorithm introduces two new pruning strategies DUC and ICE into two phase to mine high utility sequential patterns based on intervals. In two-phase, each iteration generates a specific type of candidate of a certain length. However, the algorithm produces too many candidates’ sequence itemsets, which has a great impact on the space-time efficiency of the algorithm. In order to solve the problem of high computational complexity of the HUSPM algorithm, Tang [13] et al. proposed a new algorithm for mining sequential patterns with high utility named HUSP-FP. The algorithm adopts the method of pattern growth to mine high utility sequence patterns, and all high utility sequence itemsets can be obtained from the tree without scanning the original data set. The algorithm establishes a global tree to store the sequence, the leaf node stores the utility value of the sequence, and mines all high utility sequences at one time based on the pattern growth method, without generating candidates. Figure 4 shows the tree structure corresponding to S2 in Table 1 established by the HUSP-FP algorithm. Taking the sample database as an example, set the minimum utility threshold to 100, and the process of building a global tree is as follows: the first step is scanning the data set once, counting the utility value and sequence weighted utility value (SWU) of each item, and establishing the header table structure, as shown in Fig. 4 shown in the table. The second step is to delete items in the header table that are less than the minimum utility threshold (the SWU of e is less than 100, so delete them), and update the header table structure. The third step is to scan the original data set again, and build a tree structure according to the order in which the original items appear. In Table 1, S1 is < [(a, 2) (f, 2)] , [(a, 1) (b, 1)] , [(c, 2) (d, 4)] , [(e, 4) (f, 1) (g, 1)]>, added to the tree structure as shown in Fig. 4, the left branch of the tree is S1, the right branch is S2, and the right leaf node stores the utility values of all items in S1, List ={a = 9, f = 18, b = 9, c = 4, d = 4, g = 10}.

Transaction tree corresponding to S2 in Table 1.
(2) Since high utility sequential pattern mining considers the order and utility of the sequence at the same time, an item may appear multiple times in the sequence, so there will be a combinatorial explosion problem. Therefore, a new and more compact data structure called the utility matrix structure is proposed to store the utility information of sequence data, including sequence position, utility value, remaining utility, time order, etc. The utility matrix consists of items and q-itemsets, each element consists of a tuple, the first value represents the utility of the quantized item, and the second value represents the remaining utility of the quantized item. Table 3 shows the utility matrix information of S4 in Table 1.
Utility matrix of quantization sequence S4 in Table 1
The USpan [28] algorithm uses a Lexicographic Q-sequence tree (LQS-tree) and a utility matrix. The LQS-tree structure is shown in Fig. 5. The LQS-tree expands the sequence through I-concatenation and S-concatenation. The authors construct sequence utility by considering the value and quantity associated with each item, and define the problem of mining high utility sequence patterns; USpan uses a full lexicographically quantified sequence tree to construct a sequence based on utility, LQS-tree Each node in is associated with the q-sequence and the utility value of the sequence, and its root node is empty, except for the root node of the LQS-tree, all nodes are prefix-based extensions of their parent nodes and all children of any node in the tree are listed in increasing order. Two cascading mechanisms, I-concatena-tion and S-concatenation, are used to generate new concatenated sequences. In addition, two pruning methods (width pruning and depth pruning) are defined, which greatly reduce the search space in the LQS-tree. However, it needs to compress the dataset into an LQS-tree, which requires high memory consumption for large-scale datasets.
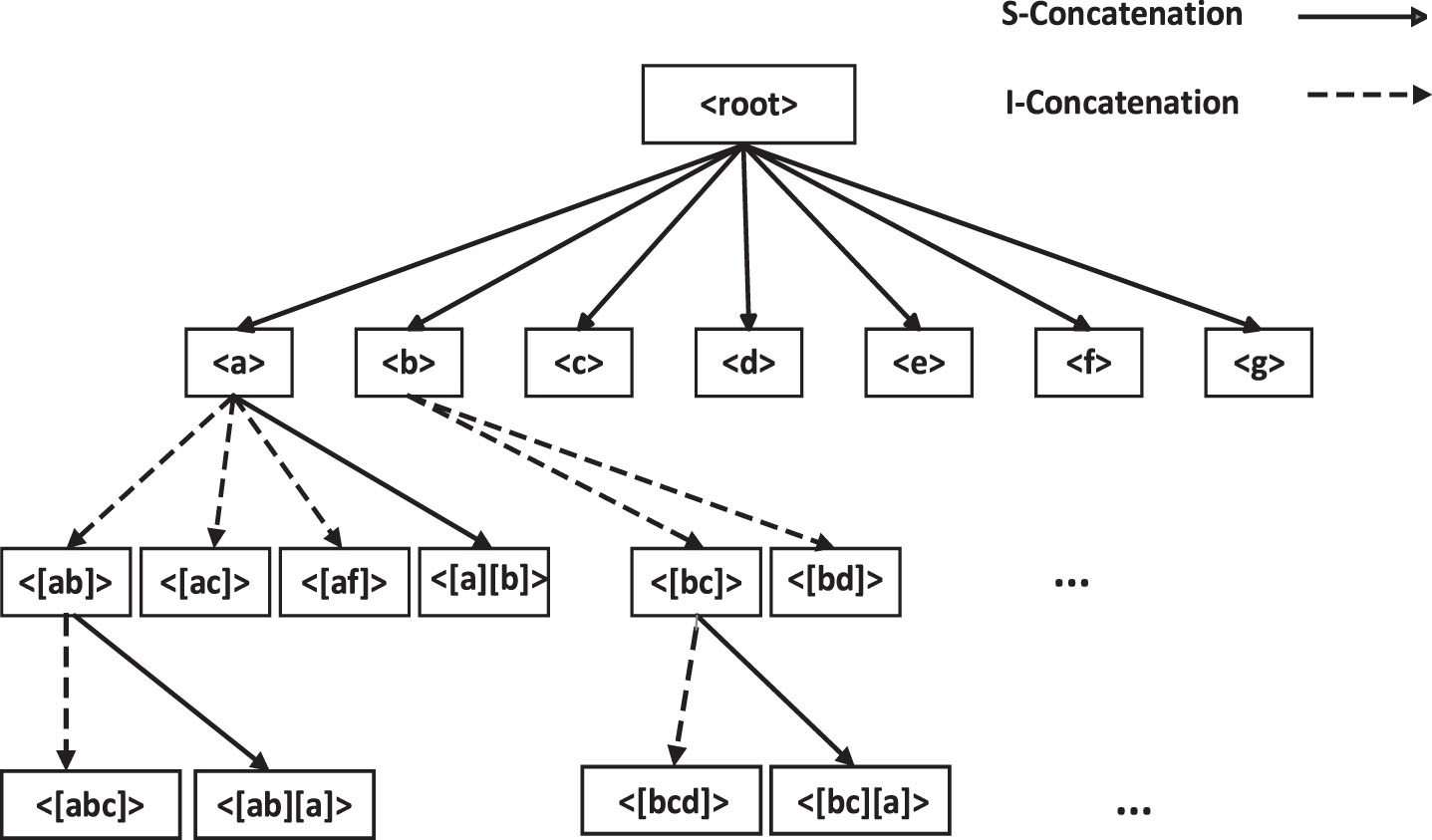
Lexicographic Q-sequence Tree.
In 2014, Wang [12] et al. proposed an algorithm HUS-Span for efficiently mining high utility sequential patterns, which traverses in a depth-first manner based on LQS-tree. In order to solve the problem that SWU is too loose, two new quantitative indicators, namely Reduced Sequence Utility (RSU) and Projected-Database Utility (PDU), are proposed to prune low-utility sequences. However, since the utility matrix is used to store the utility values, when the data is sparse, the utility matrix will waste more storage space, so the algorithm is not efficient enough when dealing with sparse data. Alkan [29] et al. propose efficient data structures and pruning techniques based on Cumulated Rest of Match (CRoM). CRoM allows stricter pruning before generating candidate patterns by defining a stricter upper bound on candidate utility. Furthermore, they developed an efficient algorithm called HuspExt, which is based on Lexicographic pattern tree, and it computes the utility of child pattern based on the utility of parent pattern. For each sequence in the database, a new structure called data matrix is used for storage. However, this algorithm requires a large amount of memory to store sequences, and is not suitable for processing large data. Furthermore, the set of sequences generated based on the upper bound of CRoM is not a complete set of HUSPs. In order to solve the problem of the irrationality of a single threshold, in 2018, Xu [30] proposed a multi-threshold high utility sequential pattern mining method HUSpan-MMU, which traverses the LQS-tree in a depth-first manner and uses two the pruning strategies SPU (Sequence-projected utility) and SWU prune the LQS-tree to output the entire high utility sequence. This algorithm solves the problem of how to establish multiple minimum utilities of sequences. Literature [31] proposed a new high utility sequential pattern mining algorithm based on maximum remaining utility (HUSP-MRU). In HUSP-MRU, the Maximum Remaining Utility (MRU) is defined as a candidate more compact upper bound. The search space is built with a Lexicographic sequence pattern tree, and the Lexicographic pattern tree is traversed in a depth-first manner. The utility matrix structure is used for MRU storage, and pruning is performed based on MRU to improve mining efficiency.
(3) The utility list structure stores the original database information and some basic information that needs to be calculated. It consists of UP Information (storage of item name, utility value, remaining utility value and the next occurrence position) and Header Table (storage of quantization sequence and the first occurrence position). The utility list is a data structure designed based on the idea of “space for time”. It is formed by the transformation and expansion of transactions in the original database. Table 4 shows the utility list structure of S1 in Table 1.
Utility list structure of S1 in Table 1
Yin [32] et al. proposed TUS, an efficient algorithm for mining top-k high utility sequence patterns, and developed a new sequence boundary and corresponding pruning strategy to effectively filter out unpromising candidates. In addition, pre-insertion and sorting strategies are also introduced to improve the minimum utility threshold, and the proposed strategy effectively reduces the search space and the number of candidates, so the mining performance is significantly improved. In 2017, Lin [33] et al. introduced the concept of multi-threshold high utility sequential pattern mining algorithm. The article designed a high utility sequential pattern algorithm with multiple minimum utility thresholds, LS-tree and UL-list structures. The algorithm first searches the entire LS-tree in a depth-first manner, and then uses the UL-list structure to store the utility value of the sequence. A large number of experiments on real data sets show that the algorithm proposed by the author can effectively mine complete HUSP collections with multiple minimum utility thresholds. The HUSP-Miner [20] algorithm searches in a depth-first manner, and generates and searches new sequences in a pattern-growing manner. The role of UL-list is to speed up the generation of new sequences, improve the calculation speed of sequence utility upper bounds and utility values, and avoid multiple scans of the original database. Compared with the HUS-SPan and HuspExt algorithms, the HUSP-Miner algorithm has obvious advantages in the running time, the number of candidate sequences and the scalability of the algorithm. Buffett [34] proposed a new method to solve the problem of establishing a more compact upper bound on the candidate pattern set to reduce the search space required to identify the complete pattern set, which maintains a list of possible candidate connection items, this list specifies the only candidates that need to be considered possible for concatenating with the sequential pattern being considered or any future sequential patterns that occur as descendants in the search tree. The article uses two list structures RUL (removed-utilities list) and RUPL (removed-utility-positions list) storage utility, compared with the SWU used by Uspan and the RSU used by HUS-Span, the two new upper-bound MCU and RCU are more compact and have smaller search spaces. Reference [35] proposes an efficient algorithm for the HUSP mining task, called HUSP-ULL. It utilizes a LQS-tree and a utility linked list (UL-list) structure to store the utility information of each sequence. HUSP-ULL has a good performance on large sequence data mining, especially datasets with large average number of elements per sequence or large average number of items per element. However, the UL-list structure proposed in the literature is a complex structure that is not easy to implement.
(4) Compared with the matrix structure, the array structure consumes less memory and can effectively improve the mining efficiency. In the array structure, each column stores the itemset ID, item, actual utility, remaining utility, and item in the sequence s respectively. The next position and the position of the first element in the next item set, Table 5 shows the utility array structure of S3 in Table 1.
Utility array structure of S3 in Table 1
PAS (Pure Array Structure) is a compact structure that maintains the full utility information of the sequence in a one-dimensional array structure. Therefore, it is purer and simpler than the two-dimensional array structure used in the utility matrix. In 2018, Le [36] introduced a pure array structure to solve the problem that the utility matrix consumes a large amount of main memory, and proposed a new algorithm AHUS-P based on the pure array structure to effectively solve the HUSPM problem. The AHUS-P algorithm uses breadth-first search (BFS) to traverse the LQS-tree. The article argues that when AHUS-P evaluates nodes in an LQS-tree, the mining order on each node does not depend on its sibling nodes. Therefore, all child nodes of any node in the LQS-tree can be processed simultaneously without affecting the mining results. Compared with the HUS-Span algorithm, this algorithm has a good performance in terms of running time, memory and scalability. In 2019, Gan [37] et al. proposed an efficient projection-based utility mining method, called ProUM, to discover high utility sequences by using upper bounds (Sequence Extended Utility (SEU) and utility array structures). Based on the projection mechanism, this algorithm proposes a new structure for processing time series data called Utility-Array. The utility array can calculate the utility and remaining utility of the sequence without scanning the database, and can filter out hopeless candidates as early as possible, it greatly saves search time.
(5) The chain structure scans the database once to establish a utility chain. The chain structure consists of SID, TID, sequence utility, remaining utility and the next position of the sequence. Its structure is shown in the Fig. 6.

Utility chain of sequence <a> in Table 1.
In 2016, HUSP-Span [38] proposed by Wang traversed the LQS-tree in a depth-first manner and used two more compact upper bounds PEU (prefix extension utility) and RSU (reduced sequence utility) to prune the search space, using the utility chain structure speeds up the calculation of upper bounds and sequence utility values. Although HUSP-Span can effectively mine high utility sequential patterns, it is usually difficult for users who do not have sufficient knowledge of QSDB to set an appropriate utility threshold. In view of this, the author proposes the TKHUSP-Span algorithm to mine former k-item high utility sequence. The TKHUSP-Span algorithm uses three search strategies: guided depth-first search (GDFS), best-first search (BFS), and a hybrid search of BFS and GDFS. Experimental results show that TKUSP-Span Hybrid is superior to TUS algorithm both in terms of time and memory. Mining high utility sequential patterns in uncertain data has always been a relatively complicated problem. HEUSPs [39] algorithm was proposed to mine uncertain data sets. HEUSPs is based on the PUL-chain (probability utility list-Chain) of each item. The structure searches the database once to calculate the upper bound value of PSWU and calculates the total estimated utility of expected utility eu(D). During the mining process, the algorithm traverses the entire search space in a depth-first manner, and prunes unpromising sequences according to the pruning strategy PPEU. Compared with the general HUS-Span model, the constructed algorithm can effectively deal with uncertain datasets to mine the desired HEUSP (high-expected utility sequential patterns) and extract them efficiently. In 2020, Lin [40] et al. designed a new efficient data structure SU-chain to store utility information. Several pruning strategies are used in the SU-chain structure to identify information that is irrelevant to the early pruning process, so it can be obtained from the projection database, and also reduce the search space. Traditional high utility sequential pattern mining aims to discover the complete set of patterns that satisfy a user-defined minimum utility threshold in the database; However, they do not allow the user to execute the target query. In order to meet the needs of users, a series of frequency-based methods for searching specific target items are proposed. So far, the goal-oriented frequent itemset query, association rule query, and sequential pattern query (SPQ) have played an important role in the query in the database, and these three goal-oriented techniques can effectively mine patterns and rules, and have shown great potential in some real-life applications [41]. Based on this, TUSQ [42] was designed for high utility sequence mode query. The algorithm is based on two new upper bounds, suffix remaining utility and terminated descendants’ utility, and a vertical Last Instance Table structure. To further improve efficiency, TUSQ relies on a projection technique that relies on a compact data structure called a targeted chain.
(6) Some known algorithms have problems such as multi-pass data set scanning, generation of a large number of candidate item sets, and low timeliness. The algorithm based on the projection mechanism does not need to scan the database multiple times, which can greatly improve the efficiency of the algorithm. The general idea of projection-based methods is to recursively project the processed database into some smaller projected sub databases, and then grow itemsets or subsequence fragments in each projected subdatabase [43]. In order to effectively deal with the problem of high utility sequential pattern mining, Lan [44] et al. proposed a high-efficiency projection-based algorithm (PHUS) to achieve this goal, which uses a maximum utility measure and sequence utility upper bound (SUUB). Especially, in mining, an effective projection-based pruning strategy is used to further obtain a more precise utility upper bound of subsequences, and then a large number of unpromising candidate subsequences can be avoided. Furthermore, an efficient index structure is designed to quickly find the relevant quantization sequences of prefixes to be processed in the recursive process. Two baseline algorithms, U-HUSPM and P-HUSPM [45], are used to efficiently mine High Utility Probabilistic Sequential Patterns (HUPSP) in uncertain databases. Both algorithms first perform a breadth-first search to prune all patterns with SWU values smaller than the minimum utility threshold or probability values smaller than the minimum expected support. In the second stage, they identify actual HUPSPs from the candidates obtained in the first stage. The U-HUSPM algorithm mines HUPSPs using a hierarchical approach and applies three pruning strategies to reduce the number of unpromising candidates in the search space. The P-HUSPM algorithm uses a projection mechanism to create a small projection database for each processed sequence, which speeds up the mining process. In order to effectively mine the top-k high utility sequences, the TKUS [46] algorithm adopts projection and local search mechanisms, and follows a variety of strategies, including SUR (Sequence Utility Raising strategy), TDE (Terminate Descendants Early strategy) and EUI (Eliminate Unpromising Items strategy), these strategies can greatly reduce the search space and speed up the mining process. The TKUS algorithm traverses the entire LQS-tree in a depth-first manner, which can quickly increase the minimum utility threshold and effectively extract the first k HUSPs.
(7) In addition to the algorithms based on the above structures, there are several other new data structure algorithms. The UTMing [47] algorithm is the first algorithm used to process time-interval sequence data. It uses the minutil for Unit pruning strategy to cut off all unpromising items, and uses the time-interval tables structure to store the utility information of the sequence during the search process. In the real-world, some goods are only placed on the shelf for a specific short period of time; traditional utility mining methods are biased towards items with a longer shelf life because they have a higher probability of generating high utility. In order to eliminate this bias, Zhang [48] proposed the problem of on-shelf utility mining (OSUM). The algorithm uses a PLS-Forest structure to store utility, in which the database is divided into multiple partitions according to the time period, and each item is associated with multiple partitions. associated with a shelf time period. Incorporating the information on the shelf (utility) into raw measures is crucial to discover interesting and informative time-dependent patterns. Gupta [49] et al. proposed a hybrid pattern growth algorithm HUFTI-SPM based on the three constraints of frequency, time interval and utility. This algorithm uses two data structures: the modified time series table and the supporting utility table, and the time series table stores support and utility information about subsequences, and the support utility table is used to capture support and utility corresponding to different time intervals.
Parallel algorithms can be divided into Hadoop-based and Spark-based algorithms according to the different big data processing platforms used. This section summarizes the algorithms and their advantages and disadvantages of the two different platform technologies.
(1) Hadoop is composed of distributed file system HDFS and MapReduce. HDFS can store data in a distributed manner and replicate data with high reliability in multiple nodes [50]. The MapReduce framework is designed to execute tasks across multiple nodes with key-value pairs as input and output. MapReduce highly abstracts the complex parallel computing process running on large-scale clusters into two functions——Map function and Reduce function. Through the Map function, the data is mapped to different blocks and then distributed to computer clusters for distributed processing. For calculation, reduce uses the output of Map as input, gathers the same key into the same Reduce, and obtains the final result through processing. This method well embodies the “divide and conquer” strategy [51]. The operating principle of MapReduce is shown in the Fig. 7. Hadoop uses the MRv1 version of the MapReduce programming model, which is a disk-based architecture, in which MapReduce needs to be stored on the disk.
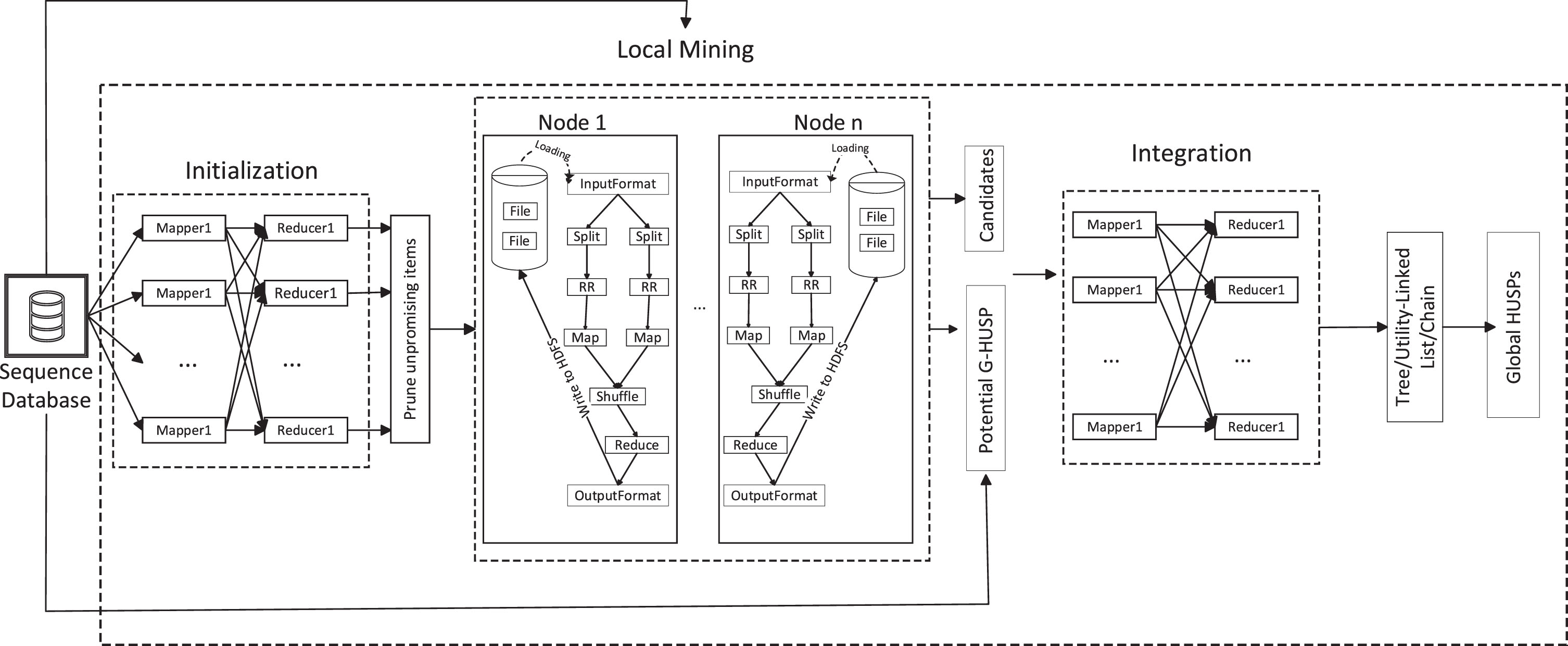
Working principle of MapReduce.
In 2022, Saleti [52] et al. used a MapReduce-based approach to mine high utility time-interval sequences. A multi-threshold algorithm called MRHUTSP-MMU is proposed in the literature, which is based on the Hadoop platform for mining in three stages. The algorithm uses MMU to store utility values, which greatly improves mining efficiency.
In 2022, Wu [53] and others proposed an algorithm MR-HUPSP for mining high utility sequences in large-scale uncertain data. This algorithm is an extension of the U-HUSPM [40] algorithm, based on the MapReduce framework in the Hadoop platform. The raw database is scanned by MR-HUPSP created by running multiple MapReduce jobs. The developed MR-HUPSP is able to segment the database and transfer these segments to multiple nodes for parallel processing, which can collect all the required information in one scan, which greatly reduces the running time of the database.
(2) Unlike the Hadoop framework, Spark has improved the MRv1 version of MapReduce. It is a memory architecture that stores the results in the main memory and can greatly reduce I/O operations. For the Spark framework, it is called Resilient Distributed Dataset (RDD) structure can manage memory data distributed in the cluster through fault recovery to maintain high scalability.
In 2015, Cheng [54] et al. proposed a high utility sequential pattern mining algorithm HusMaR based on the MapReduce framework. This algorithm uses a utility matrix to filter useless single-item sequences, generates sequence candidates, and uses a random mapping strategy to balance the amount of computation. This algorithm was used by Zhao et al. [56] to deal with catenary fault sequence database. In the literature, for the slotted busbar components used in the catenary rigid-flexible transition, CAD is used to analyze the moment of inertia of each slot, and compared with the moment of inertia of a single contact wire and a single contact wire with a positioning wire clamp, the obtained the position of the flexible anchor point is obtained, and the specific height of the flexible anchor point is obtained through the analysis and calculation of the contact line uplift. This scheme has been applied in the rigid-flexible transition of the depot of Metro Line 2 in Guiyang City, China, and achieved good results.
The BigHUSP [14] algorithm defines a parallel distributed computing framework based on Apache Spark. The algorithm implements distributed parallel computing tasks based on MapReduce, which is divided into initialization phase and mining phase. In the initialization phase, the MapReduce step is first performed to calculate the Global Sequence-Weighted Utility (GSWU) of each item, and items whose GSWU is less than the minimum utility threshold are pruned to reduce the search space. In the mining phase, BigHUSP uses existing HUSP mining algorithms (such as the USpan algorithm) on each partition to mine local HUSP. After that, G-HUSP (Global High Utility Sequential Pattern) can be found by calculating the utility of L-HUSP (Local High Utility Sequential Pattern) on all partitions.
In order to solve the shortcoming of low efficiency of the serial algorithm, Zhang [56] et al. proposed an efficient HUSPM distributed algorithm PHUSP. The algorithm makes full use of the advantages of multi-machines and multi-core processors, and can quickly complete mining tasks. The algorithm first forms n partitions (D1-Dn) through the partition strategy SLST (similar length, similar time) and transfers them to related machines, and then each machine executes a multi-threaded algorithm based on HUS-Span to obtain from the corresponding Di find all local HUSPs in. All local HUSPs will be merged into global candidates for D. Afterwards, to discover the global HUSP of D, it sends the global candidates to each computer to compute the utility, and filters the HUSP according to the returned results.
HUSP-Spark [50] is a HUSPM algorithm based on the iterative four-stage MapReduce framework of the Apache Spark platform. It consists of four phases that execute the MapReduce framework. These phases can be summarized as: initialization process, mining process, update process, and generation process. The initialization process screens out all 1-sequences for subsequent use; the mining process constructs SU-Chain to mine k-HUSP and all potential candidate sequences; the update process prunes through the constraint PEU [34] to reduce the search space; A fourth MapReduce framework performs partitioning of the database during generation to find potential (k + 1)-HUSPs.
In 2020, Sumalatha [15] et al. proposed a distributed mining algorithm based on DHUTISP of three-stage MapReduce to discover high utility time-interval sequential patterns (HUTISP). The algorithm considers the time interval between consecutive sequences, so it is more complex than general high utility sequence mining algorithms.
In the same year, Zeng [57] et al. proposed a distributed high utility sequential pattern mining algorithm based on multiple utility thresholds, called SHEMA, to solve the problems of large search space and high computational complexity in the process of mining high utility patterns of sequential patterns algorithm. The algorithm uses a pure array structure to maintain utility information and a prefix tree trie-tree to maintain sequence patterns. These two data structures can effectively improve the time-space efficiency of the mining process. In the process of evaluating the prefix tree nodes, the mining order of each node is independent of other peer nodes, so all child nodes in the prefix tree can be processed in parallel without affecting the results. Based on this, the distributed implementation scheme of this algorithm is given, which can realize parallel computing on platforms such as cloud computing, GPU (graphics processing unit), multi-core processors, etc., so as to realize fast mining processing.
Algorithm DHUTISP-MMU [59] is used to mine high utility sequential patterns with time intervals in big data environments. A new data structure TIUL (Time Interval Utility Linked List) is used to store sequence utility information. MMU-table (minimum utility threshold table) structure to store multiple threshold information.
Srivastava [58] proposed a four-stage MapReduce algorithm HUSP-Spark based on the Spark platform. The processing of large data sets is divided into four stages: initialization, mining, updating and generation. Experiments show that the designed model can handle very large dataset, while state-of-the-art algorithms can only achieve good performance on small datasets.
ML-HUSPM [16] is a scalable mining algorithm for high utility sequential patterns based on a three-layer MapReduce model. Two new data structures are used in the literature, called sidset and Utility-Linked List respectively, and these two data structures are used to store the necessary information that needs to be stored in the mining process. Sidset is used to reduce the utility computation of the patterns computed in each node mining during the second phase. At the same time, the Utility-Linked List is converted and expanded by the sequences in the original database, and records information about the original database and the required utility information.
This section describes the high utility sequential pattern mining algorithms in static databases from the serial and parallel perspectives. Figure 8 summarizes the proposed algorithms in terms of comparison algorithms, key technologies, pruning strategies, and advantages and disadvantages of the algorithms.

High utility sequential pattern mining algorithms.
Among serial algorithms, there are many algorithms using tree structure, list structure and matrix structure. The algorithm based on the tree structure only needs to scan the database once to establish the tree structure, and then find out the high utility sequence according to the tree structure. However, the establishment and maintenance of the tree structure is time-consuming. For example, the HUSP-Miner [23] algorithm based on the tree structure uses the depth-first method to search the tree, and its time complexity is O (M × Lavg + NumPot × NumOcavg), where M is the size of the data set, and Lavg is the average of these transactions’ length, NumPot is the number of potentially high utility patterns, and NumOcavg is the average number of occurrences of potentially high utility sequential patterns. The list structure is a data structure designed based on the idea of “space for time”, which is relatively easy to implement, but the list itself requires additional storage space, and its connection operation will take a lot of time, resulting in a decrease in the space-time efficiency of the algorithm. For example, based on the list structure The HUSP-ULL [35] algorithm needs O (M × L)time to scan the database, and O (2M)time to calculate the utility and remaining utility of the sequence in the data set, where M is the number of sequences in the database, and L is the average length of the sequence. The algorithm based on the matrix structure uses the utility matrix to store the utility information of the sequence data, including the sequence position, utility value, remaining utility, time order, etc. However, when the data is sparse, the matrix will waste more storage space, therefore, the matrix structure not suitable for storing sparse datasets. For example, the HuspExt [29] algorithm only needs the time complexity of O (1)to access the data matrix, but the space complexity in the worst case is O (n × k !), where n is the number of sequences and k is each the largest set of k items contained in a sequence. Most of the existing high utility sequential pattern mining algorithms focus on how to improve the mining efficiency of HUSPM, such as USpan algorithm, HuspExt algorithm, PHUS algorithm, and HUS-Span algorithm. Among them, the USpan algorithm, HuspExt algorithm, and HUS-Span algorithm are all based on the LQS-tree using two node expansion mechanisms, and different sequence utility upper bounds.
Parallel algorithms are mainly used to process massive data. Faced with the problem of huge data sets and the “combination explosion” of sequence data, a single machine cannot handle very large data sets, and parallel distributed processing of data is particularly important. The BigHUSP [14] algorithm first defines a parallel distributed computing framework on large datasets based on Apache Spark, and lays the foundation for parallel distributed mining of high utility sequential patterns. The HUSP-Spark algorithm proposed by Lin takes 2759 seconds to mine high utility sequences on one machine, but only 777 seconds to mine high utility sequences on five machines, and the performance of the algorithm is better as the number of machines increases. Therefore, HUSP-Spark [50] is well suited for distributed mining of large datasets. The HUSP-Spark algorithm proposed by Srivastava [58] shows that when the size of the dataset is very small, traditional algorithms such as USpan, HUS-Span and HUSP-ULL outperform the designed HUSP-Spark in all datasets. In the experiment, the running time of USpan, HUS-Span and HUSP-ULL are 117.9 seconds, 43.7 seconds and 14.56 seconds respectively, while HUSP-Spark needs 2262.16 seconds. This is reasonable because initializing the MapReduce framework requires a higher computational cost compared to traditional algorithms. However, when the size of the database increases, these traditional algorithms cannot produce results due to the out-of-memory problem, while the HUSP-Spark algorithm can perform mining well.
In general, there are still some serious challenges in HUSPM mining, which are as follows: First, in pattern mining, the utility-based computation mechanism is different from the frequency-based computation mechanism. The former is more complicated, and the utility value of the sequence does not have the property of downward closure. This means that support-based pattern mining techniques and models cannot be directly applied to mine interesting patterns driven by utility. In addition, pruning the search space of HUSPM is more difficult. Second, the HUSPM problem is inherently more complex than HUIM and FPM. Due to the inherent temporal order implied in sequence data, HUSPM may easily face the problem of combinatorial explosion of the search space if it lacks a pruning strategy based on a compact upper bound on utility overestimation. Third, a common approach to identify high utility sequential patterns is to recursively generate projection-based sub-databases, and then scan these sub-databases to calculate specific utility values for each sequential pattern. However, when the number of sequences in the processed database is very large, these operations can lead to excessively long running times and prohibitively high memory consumption costs. Therefore, how to effectively reduce the size of the database that needs to be projected and scanned is crucial for efficiently mining high utility sequential patterns. Fourth, most of the current algorithms only focus on improving the efficiency of the algorithm, while ignoring the object-oriented effectiveness issues, for example, only mining the top-k items that users are interested in, mining high utility sequences in uncertain or multi-source heterogeneous data Various situations will be encountered in real life, such as mining highly correlated high utility sequences. Therefore, how to solve the problem of algorithm effectiveness so that it can be used in more application scenarios is an urgent problem to be solved. Finally, in HUSPM, how to speed up the running time and reduce memory consumption while ensuring that HUSP is not missed is crucial. How to improve the efficiency of utility mining for sequence data is still an open key issue.
Nowadays, privacy-preserving data mining is more and more important in practical applications, and hiding high utility sequential patterns is very necessary in business, health and safety applications, etc. Privacy-preserving utility mining (PPUM) has become an important research topic in recent years. For privacy-preserving utility mining [19, 60, 70], the quantity and value of each object (e.g., item, sequence, event) are considered during the sanitization process. The overall utility of a particular schema in the database is defined as the sum of quantities multiplied by its unit value. In general, there are two hidden strategies to reduce the utility value of a pattern: 1) directly reduce the amount of a particular pattern, 2) change the unit value to reduce the value of that pattern. In real life, the value doesn’t change visibly. Therefore, it is more reasonable and acceptable to reduce the number of occurrences of objects. The mining-hiding module is the core part of high utility sequence pattern hiding. There are two basic strategies for mining and hiding: one is to find all high utility sequences first, and then for each high utility sequence, modify the database to reduce the utility value, called the model is generated for HUSPH, and its mining hidden structure is shown in the Fig. 9; the other is dynamic modification at runtime, that is, every time a high utility sequence is mined, the hidden algorithm is called to modify the database to update the current and the obtained sequence is hidden, which is called the HUSPH integrated model, and its structure is shown in the Fig. 10. This section summarizes high utility sequential pattern hiding algorithms and evaluation metrics.
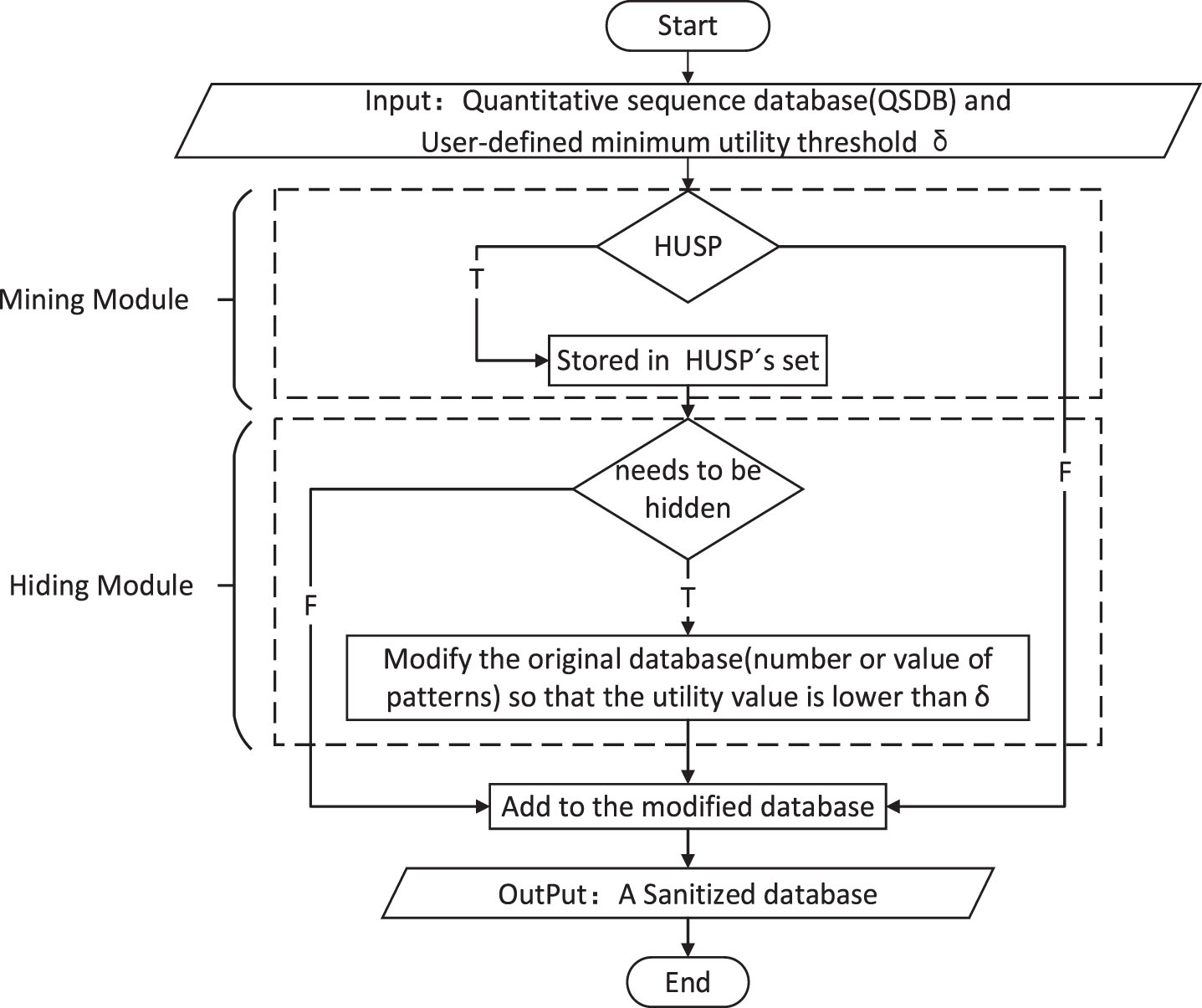
HUSPH generation model.
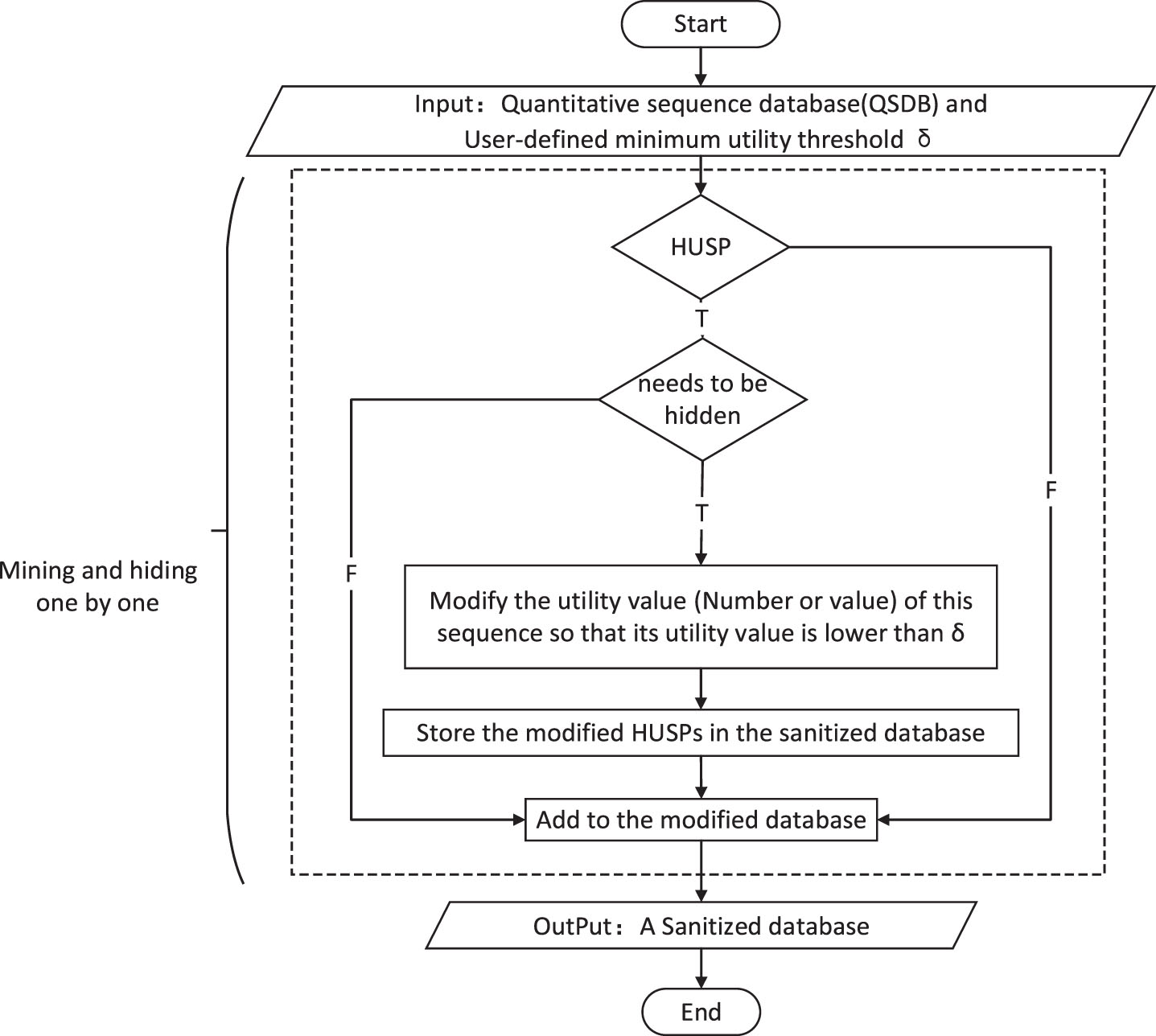
HUSPH integration model.
The purpose of hiding is to find a way to hide all high utility sequential patterns so that adversaries cannot mine them from sanitized databases. High utility sequence hiding algorithms can be classified into array-based, chain-based and matrix-based algorithms according to key technologies. This subsection summarizes algorithms for hiding high utility sequential patterns.
(1) Algorithm based on matrix structure
The matrix structure is widely used to store the utility and remaining utility of the sequence. Dinh [61] et al. extended the USpan algorithm to mine all high utility sequence patterns, and then proposed two hidden algorithms (Hiding High Utility Sequential Pattern) HHUSP and (Maximum Sequential Patterns Conflict First) MSPCF, the algorithm achieves the purpose of “hiding” by reducing the utility value of some high utility sequences to be hidden. The HHUSP algorithm first mining the high utility sequence patterns, then screens out the high utility sequences that need to be hidden, and finally outputs the sanitized database. The MSPCF algorithm is the same as the HHUSP algorithm, first scans the original database and extends the USpan algorithm to mine all high utility sequences. Unlike the HHUSP algorithm, the main purpose of the MSPCF algorithm is to find the item with the highest number of occurrences, or another way to find the item with the largest number of conflicts between items in the high utility sequence pattern set, and then preferentially hide the item containing the high utility sequence pattern. The advantage of Dinh’s method is that the database is only scanned during the mining step, avoiding multiple scans, and thus, it will be very efficient when performed on large databases. However, the computation time and memory usage of these two algorithms are similar to those of USpan [28], which is easily plagued by computational problems. Also, they did not consider the difference between the original database and the sanitized database after the hidden stage. HUSP-D [62] and HUSP-A [62] algorithms, hide high utility sequential patterns by descending and ascending order of utility to reduce variance and reduce execution time. The general process of this algorithm to hide HUSPs includes three steps: 1) mining step: use the HUSPM algorithm to mine all HUSPs from the original sequence database; 2) sorting step: sort the HUSP set using a specific order; 3) hiding step: modify the original sequence database, and returns the final sanitized database. These two algorithms are the HHUSP [61] algorithm with an additional step added to rearrange the hidden order of HUSP. Experimental results show that the proposed improvements lead to better performance of the HHUSP-D algorithm in terms of running time, memory usage, and loss cost compared to the HHUSP algorithm. The previous algorithm is to mining all high utility sequences first and then hide them. A new mining and hiding method are to hide while mining. Quang [63] et al. integrate the ideas of HHUSP [61] into USpan [28] to form MHHUSP algorithm, which is an integrated method combining mining and hiding. Actually, the key idea of MHHUSP is to first find the high utility mode, and then modify its utility to be lower than minutil. Every time MHHUSP algorithm finds a HUSP, it immediately invokes the hidden algorithm to reduce the utility value of the sequence. It is not necessary to modify the database after finding all high utility sequences. This algorithm can greatly reduce the number of candidate sequences. Therefore, it can run faster and more efficiently than other systems.
(2) Algorithm based on chain structure
The chain structure is flexible and efficient. In 2018, Le [64] et al. proposed an efficient and high utility sequence hiding algorithm HUS-Hiding. HUS-Hiding relies on a new structure called UCH (Utility-chain for Hiding) to facilitate the hiding process. The UCH structure adopts the idea of exchanging space for time, and records the previously appeared location information in the table in advance to avoid repeated lookups. HUS-Hiding uses an existing mining algorithm to find HUSPs, and for each HUSP found, the database is immediately modified (making its utility value less than minutil) to achieve the purpose of hiding. Repeating the process until no HUSP is found, the algorithm then returns the sanitized database.
(3) Algorithms based on array structure
The compact structure of the array structure can greatly improve memory utilization. In 2019, Zhang [65] et al. proposed an efficient algorithm FH-HUSP for HUSPH. The algorithm uses a new structure IUA (index-based utility array) to store all the utility information in the extraction process, which speeds up the utility calculation speed, adopts the separation and integration strategy to reduce the search space, and uses the dynamic programming method to find q item to be modified, so all high utility sequential patterns can be quickly hidden at a certain minimum utility with relatively fast speed. In 2022, Huynh et al. [66] introduced a multi-core parallel method for hiding all high utility sequential patterns. Three algorithms, USHPA, USHP and USHR, are proposed in the literature to effectively hide all HUSPs from quantitative sequence datasets. The proposed algorithm relies on a structure named pattern utility set for hiding (push) to hide all patterns. This structure holds the basic information needed for modification. In addition, a metric called Privacy Factor (PF) is introduced to evaluate the quality of the hidden results, and the proposed algorithm applies a separate hidden pattern that first collects HUSP sets using a mining algorithm and then modifies them, until their utility falls below a minimum threshold. USHPA is a serial algorithm, while USHP and USHR are parallel algorithms. The USHPA algorithm is for those who only consider hidden results. The USHR algorithm is for companies that consider privacy rather than utility of data. In general, USHP is the algorithm with the best performance, while USHR is the algorithm with the best privacy among the proposed algorithms.
Metrics
In addition to running time and memory consumption, there are several other evaluation metrics for evaluating the quality of high utility sequential pattern hiding algorithms. Bertino et al. [67] proposed a framework for evaluating the performance of privacy-preserving data mining. The evaluation indicators of PPUM are proposed, including hidden failure (HF), loss cost (MC) and artificial cost (AC). Concealment failure means that some information was not fully concealed after the sanitization process. Attackers may still be able to extract sensitive information from the final sanitized database. Missing itemsets means that some insensitive but frequent itemsets become infrequent after purification. Thus, the missing cost is the ratio of missing itemsets, and a lower missing cost is better for PPDM. Dinh [66] et al. mentioned database modification rate (DMR) and data integrity (DI) in addition to the above three evaluation indicators. In addition, Lin [68] et al. proposed another performance evaluation criterion, namely database structure similarity (DSS), database utility similarity (DUS) and itemset utility similarity (IUS). Huynh et al. proposed the Privacy Factor (PF) metric [66]. Rajalaxmi and Natarajan [69] also proposed a similar concept, namely the utility difference of DUS. The details of the relevant metrics are shown below.
where | HUS(DB’) | is the number of sensitive HUSP after sanitization, and | HUS(DB) | is the number of sensitive HUSP before sanitization.
This section describes the high utility sequential pattern algorithm and its hiding strategy and evaluation index. Table 6 compares the hiding strategy, key technology and metrics of hiding high utility sequential pattern algorithm.
Comparison of hidden algorithms
Comparison of hidden algorithms
The hidden pattern algorithm is generally divided into three steps. Firstly, the existing mining algorithm is used to mine high utility sequences; secondly, according to the requirements, the hidden pattern algorithm is used to modify the utility value of the sequence to be hidden so that it is lower than the minimum utility threshold; finally, the modified database is returned. Therefore, there are two different modes of hidden mining: one is to mine all high utility sequences and select the sequence to be hidden; the other is to mine a high utility sequence to determine whether to hide the sequence. Hiding means hiding directly, that is, hiding while digging, which is a dynamic hiding process. The former is usually time-consuming and takes up a lot of memory, while the latter algorithm design is more difficult.
To judge the performance of a hidden algorithm, in addition to the traditional comparison of time and memory consumption, there are many other evaluation indicators, such as HF, MC, AC, etc. A good hiding algorithm should have a good distortion rate, that is, all sensitive sequences are hidden after cleaning. For the information storage of the sequence to be hidden, the algorithms proposed so far mainly have three structures: matrix structure, chain structure and array structure. The algorithm based on the matrix structure can fully store sequence information and is easy to expand, but it will waste a lot of storage space when the data is sparse; on the kosarak10k data set, minutil is set from 35000 to 12000, and MHHUSP [63] is better than USpan+HHUSP combination 2.78, 1.87, 2.51, 3.89, 3.13, 2.55, 2.4, 2.6, 3 and 3.7 times faster. The chain structure is a new structure. The algorithm based on the chain structure is more flexible in deletion and insertion, but the access can only start from scratch; let n be the number of sequences in the original database, L is the average length of the sequence, and n1 is the number of potential HUSPs, L1 is the average number of occurrences of potential HUSPs, HUS-Hiding [64] scans the database and calculates SWU time-consuming O (n × L), constructs LQS-tree time-consuming O (n1 × L1), and modifies the utility value of HUSPs time-consuming O (n1), the time complexity of the HUS-Hiding algorithm is O (n × L + n1 × L1 + n1). The array structure can handle a large amount of data, but its insertion, deletion and other operations perform poorly and are not suitable for dynamic access. Let ns be the number of sequences, ni the average length of the sequence, np the number of potential HUSPs, n0 the average number of occurrences of potential HUSPs, nh the number of HUSPs, nj the average number of items per HUSP, nc the number of items per HUSP the average number of sequences, nr is the time required to reduce the utility of all HUSPs by θ, φ is the number of processors, USHPA [66] is divided into two parts: mining and hiding, and mining takes O (n s × n i + n p × n0/φ + n p ), hiding time-consuming O (n h × n c × n j ), then the average time complexity of the USHPA algorithm is O (n s × n i + n p × n0/φ + n p + n h × n c × n j ). The USHP [66] algorithm simultaneously hides nh HUSPs of φ processors and takes O(nh) time to synchronize the processors, then the average time complexity is O (ns × ni + (np × n0)/φ + np + (nh × nc × nj)/φ + nh), USHR needs to use random utility θ to reduce the utility value of HUSPs, then the average time complexity is O (n s × n i + (n p × n0)/φ + (n p + n h × n c × n j )/φ + n h + n r ). USHPA, USHP and USHR are composed of mining and hiding. They use the pure array structure PAS to store sequence utility. PAS is composed of three one-dimensional arrays which contain sequence, sequence utility and residual utility. Mining consumes space O (n s × n i × 3 + n p × n0 × 3 + n h × n c × (n j + 2)).
On the whole, hidden high utility sequential pattern mining is still in its infancy, and there are few related algorithms. Therefore, how to use biological heuristic algorithms to solve high utility sequential pattern mining still needs to be innovatively explored.
Dynamic high utility sequential pattern mining not only considers the order of data, but also considers the dynamic change process of data, which can be mainly divided into high utility sequential pattern mining on incremental and data streams. This chapter summarizes high utility sequential pattern mining algorithms on incremental and data streams, respectively.
High utility sequential patterns mining on incremental data
Many data in the real-world change dynamically with time, so mining high utility patterns from incremental databases has important research significance. Unlike batch algorithms, which always process the database from scratch, the incremental HUSPM algorithm updates and outputs high utility sequences in a dynamic manner, thereby reducing the cost of finding high utility items. This section summarizes and analyzes the high utility sequential pattern correlation algorithm based on the incremental database according to the different key technologies.
Using a tree structure to store utilities on tree nodes can reduce the number of data set scans, reduce memory usage, and more efficiently mine high utility patterns. The construction process of the tree structure is as follows: First, the algorithm scans the database to calculate all 1-sequences not less than the minimum threshold, and takes all 1-sequences that meet the conditions as the child nodes of the root node. Second, the algorithm constructs child nodes in a depth-first or breadth-first manner, and the child nodes are obtained by expanding candidates (I-Concatenation or S-Concatenation) from their parent nodes. After the tree is constructed, iteratively find out the high utility sequence pattern from the tree by means of pattern growth. The essence of the tree structure is to enumerate all possible candidates, representing the search space of the problem. The incremental update process of the algorithm based on the tree structure is shown in Fig. 11. If a new sequence is updated, it will be inserted into the tree structure as a candidate sequence, and the algorithm will search the candidate pattern tree again to find out the new high utility sequence and add it to the HUSP set.
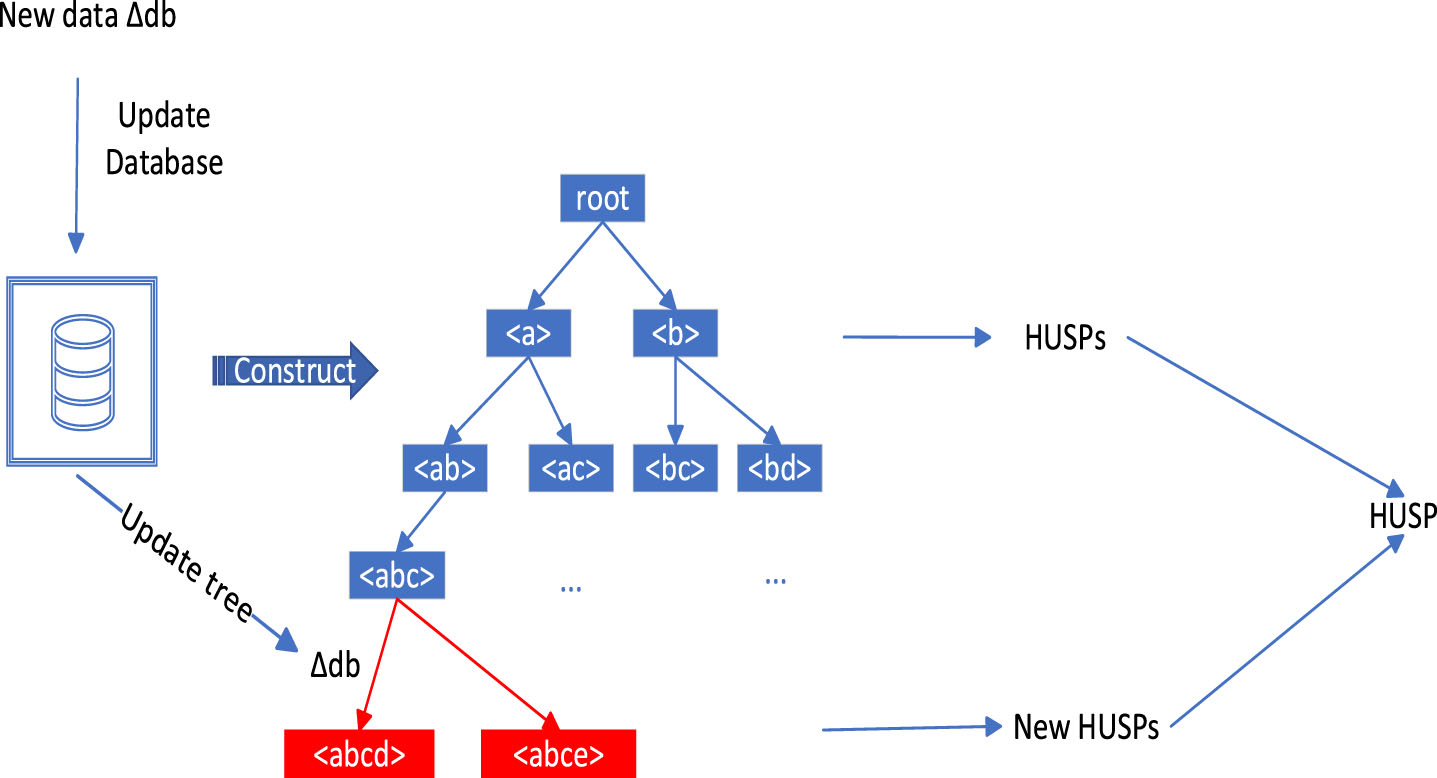
Incremental update process.
In 2010, Ahmed [10] et al. proposed a method for mining high utility web access sequences, which can perform static and incremental mining on web access sequences. By utilizing sequential pattern growth mining methods, it can successfully avoid the problems of hierarchical candidate generation and multiple database scans. The algorithm proposes two new tree-based structures called UWAS-tree (utility-based web access sequence tree) and IUWAS-tree (incremental utility-based web access sequence tree). The former is used to mine static databases. The latter is used to mine the web access sequences in the incremental database. One defect of this algorithm is that it is not suitable for sequence data in complex scenarios, it cannot handle sequence data with multiple items, and the application scenario is relatively simple.
IncUSP-Miner [22] is designed to mine HUSP in incremental databases. The algorithm designs a stricter upper bound called TUS (Tight Sequence utility), and designs a candidate pattern tree for storing utility all sequences with values not less than the threshold. In order to avoid retaining a large amount of utility information for each sequence, a set of auxiliary utility information is designed to be stored in each tree node. The author conducted experiments on the three data sets of Foodmart, Tafeng, and Music. The experiments showed that the running time of the algorithm was 30% less than that of the USpan and HUS-Span algorithms.
In 2018, Wang [71] et al. extended the IncUSP-Miner algorithm, the extended algorithm is IncUSP-Miner+, which uses a stricter upper boundary TUS to prune the search space, and uses depth-first search to recursively traverse the entire search space to find HUSPs. The author conducted comparative experiments on three aspects: utility threshold, update rate, and database scalability. When the update rate is small, IncUSP-Miner+takes 60% less execution time than USP Miner. When the update rate is large, IncUSP-Miner+performs poorly.
In 2022, Truong [72] designed an algorithm for mining frequent high average utility sequential patterns with constraints in dynamic databases, and proposed a new aumin-based three upper bounds and one weak upper bound and three pruning strategies. These upper bounds are stricter than the previously proposed upper bounds on aumax. Experiments show that the running time and memory consumed by the C-FHAUSPM algorithm depend on the size of the dataset, as well as the length and size of each itemset in the input q-sequence.
In 2022, Saleti [73] used the MapReduce framework to mine high utility sequence patterns. In the literature, a three-stage MapReduce algorithm called MR-INCHUSP was proposed, which is used to extract from the updated sequence whenever a new sequence is added to the original database. Mining high utility sequential patterns in databases. MR-INCHUSP minimizes the number of candidate sequences by utilizing information mined from the original database to reduce computational cost. In this algorithm, two new data structures, Reverse utility tree (RUTree) and Cooccurrence utility reverse map (CURMAP), are used. The former helps to retrieve utility information quickly and avoids the third stage recalculates the utility of the global HUSP, reducing the cost of recomputation, which in turn reduces the number of candidate sequences to be detected. Experiments show that due to the effectiveness of the CURMAP strategy, the MR-INCHUSP algorithm is more than 1.4 times faster than BigHUSP and more than 1.2 times faster than HUSP-Spark on different datasets.
A tree structure can be used to store previous mining results and other information to avoid redundant recalculations when the SDB is updated. However, due to the huge number of generated tree nodes, the tree structure will consume a lot of memory. Furthermore, there may be multiple instances in one supersequence of sequences, each with its own utility. When the SDB is updated, it is time-consuming to update the utility of each instance of each sequence stored in the tree structure, resulting in inefficient mining. Based on this, Ishits et al. designed a projection technique for mining regular high utility sequential patterns. In 2019, Ishita [74] proposed a regular high utility sequential pattern mining algorithm, RHusp, to mine regular high utility sequential patterns from static databases. Due to the incremental properties of processing big data, many applications in the era of big data have brought useful results, so the authors extended the algorithm and proposed an incremental algorithm RIncHUSP to mine regular high utility sequential patterns from dynamic databases. This method works efficiently by processing incremental portions of the database rather than processing the entire database. On the BIBLE dataset, the running time of the RHusp algorithm is 200s, and the running time of the RIncHusp algorithm is 50s.
A data stream is an ordered, continuous and unbounded sequence of data records, which usually arrive in a rapid manner. Data streams are not suitable for batch computing because there are many sources of data streams and their formats are complex. After processing stream data, only a small part can enter the database as static data, while other parts are directly discarded. Compared to mining HUSP from static datasets, mining HUSP on dynamic data streams requires much more information to track and requires far greater complexity to manage. The time window models in data flow mainly include sliding window and landmark window, as shown in the Fig. 12. This section summarizes and analyzes the high utility sequential pattern correlation algorithms for data streams based on different window models.
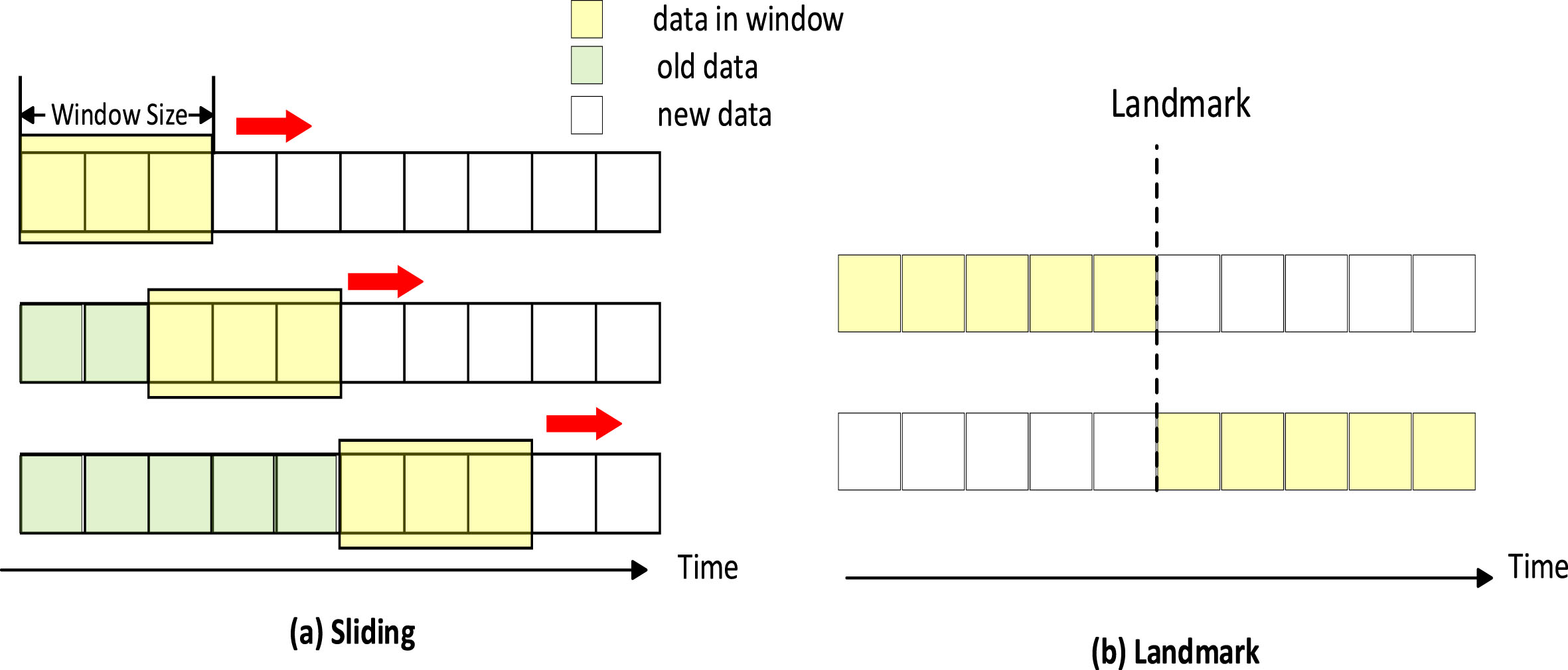
Window models.
The sliding window is only interested in the nearest few data points in the window, which is based on the first-in-first-out principle, that is, once new data points are available, the old data points in the window will be deleted, so the mining results of the sliding window depends on its window size. Two algorithms named HUSP-Miner [23] and HUSP-Stream [23] are used to discover HUSP in static and streaming sequence datasets. These algorithms use two data structures named ItemUtilList and HUSP-Tree to hold the basic information of the generated patterns in a static and streaming manner. The search space is also pruned using the Sequence-Suffix Utility cap. However, HUSP-tree is not suitable for storing information for a long time, because the main idea behind HUSP-tree is to facilitate the update process when new transactions arrive or leave the window. Therefore, the nodes in the tree are designed to store utility information for each transaction. This data structure is not efficient for mining HUSP on the entire data stream as it consumes more memory.
In 2018, Tang et al. [75] proposed an algorithm called HUSP-UT for mining HUSP in data streams. The algorithm uses a data structure called UT-tree (utility on Tail Tree) to remove obsolete data and add new data. There are two types of nodes in the structure of UT-tree, one is ordinary nodes, and the other is tail nodes. Compared with ordinary nodes, tail nodes have the utility of transactions in windows. In addition, a tail pointer table is introduced in the construction of UT-tree, which is used to delete obsolete data for updating. The proposed algorithm stores the utility of the sequence in the leaf node, which ensures that HUSP-UT obtains the actual utility value of the sequence instead of the estimated value from the UT-tree, and no candidates are generated during the mining process, effectively reducing storage consumption. When subtrees are created based on node pointers, the utility value of each item in the related sequence can be obtained, which also ensures that the utility and the new SWU value of the item in the header table can be quickly calculated (excluding processed but not in the header table item’s utility value), thus effectively reducing the running time.
In 2022, Ishita [76] et al. introduced the concept of regular high utility sequential patterns for the first time, and developed an algorithm RHusp that mines regular high utility patterns from static databases. Based on the extension of RHusp, the author extends the algorithm from static databases to mining regular high utility sequential patterns from incremental databases and data streams based on sliding windows. In incremental database, the algorithm is extended as RIncHusp, where data is continuously added to the database over time in a vertical fashion, and a new data structure DET is developed to help improve mining efficiency. In data streams, the algorithm is extended as RStreamHusp, which mines regular high utility sequential patterns from changing data streams, and the DSRHUSTrie data structure is developed to accommodate the patterns and facilitate the mining process.
Landmark windows split the data stream into discrete chunks based on events. The data from the start time 1 to the current time t is recorded as W, that is, all data points after the arrival of the landmark are equally important, and there is no difference between the past and the present. Whenever a new landmark appears, delete all data in the window and capture new data. In 2017, Zihayat et al. [77] proposed an algorithm called MAHUSP to discover HUSP on data streams. The algorithm uses a tree structure called MAS-Tree (memory adaptive high utility sequential pattern tree) to store potential HUSPs on the data stream, and once a new potential HUSP is found, the tree will be effectively updated. Two effective memory adaptation mechanisms are proposed in the literature, Leaf Based Memory Adaptation (LBMA) and Sub-Tree Based Memory Adaptation (SBMA). Handle the situation when available memory is insufficient to add new potential HUSPs to the MAS tree, and use landmark window techniques to store potential HUSPs in the data stream. The MAHUSP algorithm can efficiently discover HUSPs on data streams with high recall and precision. In order to show the effectiveness and efficiency of MAHUSP in practical applications, the authors applied the proposed algorithm to a web clickstream dataset obtained from a Canadian news portal to demonstrate users’ reading behavior, and to a real biological sequence database to identify gene regulatory sequence patterns associated with disease. The results show that MAHUSP is effective in discovering useful and meaningful patterns in both cases.
This section describes the dynamic high utility sequential pattern mining algorithm, and Table 7 summarizes the dynamic high utility sequential pattern mining algorithm from the perspectives of comparison algorithms, pruning strategies, key technologies, and algorithm advantages and disadvantages.
Comparison of dynamic high utility sequential pattern mining algorithms
Comparison of dynamic high utility sequential pattern mining algorithms
In the existing incremental algorithms, the storage and update are mainly based on the tree structure, and the algorithm only supports the insertion and deletion of a single database, and does not support the update of multiple databases, such as IUWAS-Tree [10], INCUSP-Miner [22] and INCUSP-Miner+[71]. The MR-INCHUSP [73] algorithm shows better efficiency than BigHUSP and HUSP-Spark on large datasets. For example, on Kosarak, MR-INCHUSP is 1.8x faster than BigHUSP and 1.4x faster than HUSP-Spark. On BMSWebview2, MR-INCHUSP is about 1.5 times faster than BigHUSP and 1.3 times faster than HUSP-Spark.
In the existing data stream algorithms, the window models mainly adopted are sliding window and landmark window. The sliding window does not clearly define the start and end of the window. What is defined is the length of the window. The sequences in the window have equal importance. The window will slide at a certain length and continuously output the obtained results. The landmark window fixes the starting point of the window, and the other end of the window grows with the continuous arrival of data, and continuously outputs the results. The HUSP-Stream [23] algorithm uses a sliding window model, and its time complexity consists of the construction of the Item Util List and the construction and update of the HUSP-tree. It takes O (M × Lavg) time to construct the ItemUtilList, and the construction and Updating the HUSP-tree takes O (NumPot × NumOcavg) and O (NumPot × NumOccaffavg) time, respectively, where M is the size of the dataset, Lavg is the average length of these transactions, and NumPot is the number of potentially high utility sequential patterns, NumOccaffavg is the average number of occurrences of potentially high utility sequential patterns in the sequence affected by removing old transactions and adding new transactions. The MAHUSP [77] algorithm uses the landmark window model. It takes O (Num × Lavg) time to find node N and insert it, and O (NumPot) time to initialize and update leaf nodes based on the memory adaptive mechanism. Based on memory The subtree initialization and update of the adaptive mechanism takes O (NumPot) time.
In short, in the face of the ever-changing scene information in real life, considering the diversity of data types and applications, utility mining for streaming data, dynamic data and other application scenarios is more research-intensive, more challenging, and the mining process is more complex. At present, there are few related studies, and there are many key technologies and difficulties to be solved. In addition, how to use existing technologies such as economics, deep learning, reinforcement learning, and game theory to solve utility mining problems still needs to be innovatively developed.
High utility sequential patterns have derived a series of new pattern mining methods in practical applications, such as high-average-utility sequential pattern mining, high utility sequential pattern mining with negative-item, and periodic high utility sequential pattern mining. This section summarizes and analyzes different derived pattern mining algorithms.
Since traditional HUSPM tends to look for longer patterns, under the same threshold, short patterns are not easy to be found, and its utility measure cannot guarantee fairness. In order to solve the deficiency of HUSPM, high-average-utility sequential pattern mining is carried out by normalizing the length. In order to consider the length of the sequence, and better take into account both long sequences and short sequences, Truong [78] et al. proposed a mining algorithm EHAUSM, which uses breadth pruning, strict depth pruning, reduction and compaction strategies to prune the lower and middle parts of the prefix tree. Candidate branches are averaged and utility information is stored using the EUL structure. In order to consider the cost and utility of items in sequence mining, Truong [79] et al. defined the problem of sequence mining with low cost and high average utility. A new data structure CUL (Cost Utilities List) was proposed in the literature for storage and quickly update utility and cost information for patterns. In 2022, Truong [72] designed an algorithm for mining frequent high average utility sequential patterns with constraints in dynamic databases, and proposed a new aumin-based three upper bounds and one weak upper bound and three pruning strategies. Xu [80] et al. proposed the concept of sequence average utility by considering sequence length. HAUSPM traverses the LQS tree through a depth-first search strategy. This algorithm only compares the USpan algorithm, and lacks the comparison with the similar HAUSP algorithm. Lin [81] et al. mined high utility sequential patterns from uncertain data and proposed a new mining algorithm PHAUP. The proposed algorithm is a layer-by-layer mining algorithm. The algorithm searches in a breadth-first manner to mine PHAUUBSPs. The unsatisfied sequences are pre-pruned using the PHUUBDC attribute, which significantly reduces the search space. To solve the problem that low frequency and important patterns are often overlooked, Wu [82] et al. proposed the algorithm HANP-Miner for mining high-average-utility non-overlapping sequential patterns. The algorithm consists of two steps: support calculation and candidate pattern reduction. This algorithm needs to scan the database repeatedly, so it has a high time complexity. To consider the utility of items and solve the problem of setting gaps without prior knowledge, Wu [83] proposed an efficient algorithm named HAOP-Miner, which involves two key steps: support computation and candidate pattern generation. For support calculation, a heuristic algorithm called Reverse filling (Rf) algorithm is proposed, which can efficiently calculate support by avoiding creating redundant nodes and pruning redundant and useless nodes.
In recent years, high utility sequential pattern mining has played an increasingly important role in many applications. However, current HUSPM algorithms only consider positive sequential patterns (PSP), thus limiting their ability to handle negative sequential patterns (NSP). In some applications, NSP may bring more valuable information than PSP due to missing elements. LV [84] et al. proposed a high utility sequence pattern mining algorithm EHUSN with negative items. Based on the EUCP structure of the FHM algorithm, the algorithm proposed a 2-sequence utility matrix with sizes 1 and 2 to store sequence utility. Algorithm HUNSPM [85] uses a new list structure PNU-list to mine high utility sequences containing negative items. In 2017, the high utility sequence pattern mining algorithm HUSP-NIV proposed by Xu [86] and others can mine sequence data with positive or negative external utility. The algorithm uses a utility matrix to store sequence utility information and uses an LQS tree to search High utility sequences, and use the S-cascade and I-cascade mechanisms to generate new candidate sequences. In 2020, Zhang et al. [87] introduced a comprehensive algorithm, e-HUNSR, to mine high utility negative sequence rules. The algorithm uses a new structure SLU-list to record all required information, including SID, TID, and utility of subsequences during HUSP generation, etc. This algorithm is the first algorithm for mining HUNSR. Experiments show that this algorithm is very effective in mining high utility sequence rules with negative items.
A Periodic High Utility Sequence Pattern (PHUSP) is a pattern that not only yields high utility (e.g., high profit), but also occurs regularly in sequence databases. Finding PHUSPs is useful for many practical applications such as market basket analysis, web clickstream, etc., as it can reveal sequence cycles and profitable customer behaviors [89]. Dinh [88] et al. proposed a periodic high utility sequence pattern mining algorithm PHUSPM. The PHUSPM algorithm only scans the q-sequence database once to calculate the number of sequences in the database SDB and the sequence-weighted utility of each item in I and separate the candidates Stored in i-list and s-list. Dinh [89] and others designed a new structure PUSP to mine periodic high utility sequence patterns. The algorithm PUSOM uses a utility matrix structure to store sequence utility and residual utility. Periodic High Utility Sequential Pattern Mining (PHUSPM) makes some useful sequential patterns discarded due to strict judgment thresholds, and the periodic values of some sequential patterns fluctuate greatly (i.e., are unstable). Based on this, Xie [90] and others proposed a stable periodic high utility sequential pattern mining algorithm SPHUSPM. In the literature, a new data structure PUL-list is used to record the periodic information of the sequential pattern, and the maximum instability pruning Strategy (MLPS) pruning search space, this strategy can prune a large number of unstable sequence patterns in advance, which greatly improves the mining efficiency. After using the MLPS strategy, 46.5% of the candidates can be pruned in advance on average in the six data sets, which can greatly improve the Reduce memory usage.
Future works
Through the summary and analysis of the high utility sequential pattern algorithms, it can be found that there are still many shortcomings in the existing methods. The next work of this research group will start from the following points:
(1) High utility sequential pattern mining with positive and negative values on data streams
In real life, high utility sequences with negative values contain rich utility information. However, most of the current pattern mining methods for high utility sequences with negative values stay in static data mining, and pay less attention to mining data streams. The author intends to apply the sliding window model to the high utility sequential pattern mining algorithm with negative items, set windows of different batch sizes, and use a more compact upper bound to reduce the search space, so as to improve the time efficiency and application range of the algorithm.
(2) Mining and hiding of high utility sequential patterns in incremental Databases
In incremental mining, many existing algorithms are incrementally updated based on the tree structure. However, due to the huge number of generated tree nodes, the tree structure will consume a lot of memory. In addition, when the database is updated, the utility of tree structure updating each instance of each sequence is very time-consuming and the mining efficiency is very inefficient. Based on this, the author intends to design a pruning search space with a more compact upper bound of sequence utility than SWU, and reduce the scope of database scanning. In addition, a more efficient list structure than the tree structure is proposed to be used for high utility sequential pattern mining of incremental data.
(3) High utility sequential pattern mining algorithm on uncertain data streams
At present, most algorithms are based on precise data sets for mining. In real life, due to the influence of environmental factors, the collected data sets may not be all accurate data sets. Simply apply high utility sequential pattern mining to uncertain data sets may mislead business decisions. Therefore, it is very necessary to consider the impact of uncertain data on the final result in high utility sequential pattern mining. In addition, the existing high utility sequential pattern mining algorithms based on tree structure, matrix structure, and list structure can only process static data and cannot process streaming data. In view of the above problems, the author plans to propose a sliding window-based high utility sequential pattern mining algorithm on uncertain data streams to deal with streaming uncertain data.
(4) High utility sequential pattern mining and hiding methods based on heuristics algorithms.
High utility sequential pattern mining algorithms as the order of items changes and the size of the data set increases, the problem of “combinatorial explosion” in the search space has to be considered. In the face of huge data, the heuristic-based high utility sequential pattern mining algorithm can find the optimal solution within a certain period of time according to the fitness function. Heuristic-based algorithms are fast, can solve highly complex nonlinear problems and can handle large data, such as particle swarm optimization algorithm, genetic algorithm, artificial bee colony and artificial fish swarm algorithm, etc. The next step of research will be to mine and hide high utility sequential patterns based on heuristic algorithms.
Conclusion
High utility sequential pattern mining is more and more widely used in real life, and many research results have been obtained. This survey provides a comprehensive overview of high utility sequential pattern mining and hiding methods from both static and dynamic perspectives. In the static data, the high utility sequential pattern algorithms are divided into mining algorithm and hidden algorithm, and the mining algorithm pruning strategies, key technologies, pros and cons are summarized from the perspective of serial and parallel; The adopted hiding strategies, evaluation metrics, and algorithm pros and cons are summarized. In dynamic mining, a taxonomy of the most common and the state-of-the-art approaches for incremental HUSPM is presented, including tree-based, projection-based, and data stream mining algorithms are classified into algorithms based on sliding window model and landmark window model. We further comprehensively analyze strategies, key technologies, pros and cons of each presented approach. In addition, derivative algorithms for high utility sequential pattern mining are expounded. Finally, based on the challenges faced by existing high utility sequential pattern mining and hiding, high utility sequential pattern mining with positive and negative values on data streams, the high utility sequential pattern mining and hiding in incremental databases, the high utility sequential pattern mining on uncertain data streams, and the mining and hiding based on heuristic methods are proposed as future research works.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 62062004) and the Natural Science Foundation of Ningxia (2023AAC03315).