
Abstract
Named Entity Recognition (NER) plays a vital role in Natural Language Processing (NLP) tasks, extracting valuable information from textual data. This study addresses a gap in NER research by comparing the effectiveness of cloud-based NER tools (Azure NER and Google Cloud NER) and a popular open-source tool (SpaCy) for recognizing named entities in both English and Polish text. Text data is imported into a PostgreSQL database and processed by each NER tool. The extracted entities and their labels are stored in a dedicated SQL Entity table, enabling performance evaluation across different languages and entity types. This research contributes to the field of NLP by investigating the suitability of cloud-based NER tools for multilingual tasks, particularly those involving Polish text, which presents unique linguistic challenges. By analyzing the performance of these NER approaches, the study provides valuable insights for selecting the most effective NER technique for specific NLP applications, especially when dealing with multilingual content.
Introduction
In the era of big data, the ability to extract valuable information from textual content is crucial for diverse applications in Natural Language Processing (NLP). Named Entity Recognition (NER) plays a vital role in this endeavor, automatically identifying and classifying named entities such as locations, organizations, and people within text data. The process of extracting stop words is crucial for enhancing the performance of various NLP tasks, including sentiment analysis,1,2 topic modeling,3,4 and text summarization.5,6 Stop word lists generated from this process can significantly improve the accuracy and efficiency of these tasks.
One key application of NER lies in information retrieval systems. By identifying named entities within a document, NER facilitates more precise searches.7,8 For instance, searching for news articles related to a specific historical figure. NER can pinpoint the relevant entities (e.g., “Nicolaus Copernicus”) within the text, enabling the search engine to return more accurate and relevant results compared to keyword-based searches alone.
Furthermore, NER plays a crucial role in building intelligent question answering systems.9,10 When a user asks a question like “What is the capital of Poland?”, NER can identify the entity “Poland” as a location. This information can then be used by the system to retrieve the correct answer “Warsaw” from a knowledge base.
Finally, accurate NER is essential for high-quality machine translation. By identifying named entities in the source text (e.g., organizations, locations, people), NER allows the translation system to handle them appropriately in the target language. This ensures a more accurate and natural-sounding translation by preserving the intended meaning of the named entities. These examples showcase the multifaceted role of NER in empowering various NLP applications to extract valuable information from text data, ultimately leading to improved performance and functionality.
Several studies have shown that existing NER tools primarily focus on English language data (e.g. Won et al., 11 Ehrmann et al., 12 Jehangir et al. 13 and Krechowicz 14 ). However, languages like Polish, with their inherent complexities, can pose challenges for these tools. This study aims to bridge this gap by examining the effectiveness of NER tools across both English and Polish text.
Dadas (2018) also achieved high performance in Polish NER using a deep learning model with knowledge-based features from Wikipedia. 15 Their model surpassed others in PolEval 2018 (22.4% error reduction). The evaluation combined exact match (0.2 weight) and overlapping entity scores (0.8 weight). Notably, incorporating Wikipedia and lexicons further improved their model’s performance (scores up to 89.6). This suggests knowledge-based techniques can be highly effective, especially when enriched with external resources.
Choosing the most effective NER tool depends on the task and data at hand. Schmitt et al. 16 compared popular open-source options like StanfordNLP, SpaCy, and others. 16 Their evaluation, using the CoNLL 2003 and GMB corpora, revealed that StanfordNLP achieved the highest overall F1-score (81.05) on CoNLL 2003, potentially due to its default classifier being partially trained on that data. However, the performance gap narrowed significantly on the GMB corpus (StanfordNLP F1-score: 70.88), with SpaCy even showing improvement (F1-score: 59.66) compared to CoNLL 2003 (F1-score: 54.33). This underlines the importance of considering both the chosen tool’s training data and its suitability for your specific corpus to achieve optimal NER performance.
A study by Roy 17 highlighted the shift towards deep learning architectures in NER due to the availability of large amounts of computer-readable textual data and hardware that can process the data. 17 The study reviewed significant learning methods employed for NER and how they evolved from linear learning methods.
Regarding the Polish language, a study by Telenyk et al. 18 evaluated the coherence of Polish texts using neural network models. 18 Although not specifically focused on NER, their work demonstrates the applicability of advanced machine learning techniques to the Polish language, which could potentially extend to NER tasks.
Another comprehensive study by Pakhale 19 offered an exhaustive exploration into the evolving landscape of NER methodologies, blending foundational principles with contemporary AI advancements. 19 The study spanned a spectrum of techniques from traditional rule-based strategies to the contemporary marvels of transformer architectures, particularly highlighting integrations such as BERT with LSTM and CNN. The narrative accentuated domain-specific NER models, tailored for intricate areas like finance, legal, and healthcare, emphasizing their specialized adaptability.
In terms of specific tools, a study by Otto et al. 20 introduced a novel task, corpus, and baseline for Scholarly Entity Extraction focused on Machine Learning Models and Datasets. 20 Their work underscores the crucial role of NER models in various NLP tasks, including information extraction (IE) and text understanding.
Research by Tamla et al. 21 introduces a novel cloud-based Information Extraction system (CIE) designed for Named Entity Recognition (NER) in the medical domain. Their system offers a comprehensive solution, managing cloud resources and providing functionalities for both ML practitioners and medical experts to develop and train their own NER models. Evaluation results demonstrate promising performance, with their model achieving F1-scores of 0.853 and 0.842 on Azure and AWS platforms, respectively, surpassing their baseline model (GERNERMED). This research highlights the potential of cloud-based NER systems to enhance performance and accessibility of NER tasks within the medical field.
Wang et al. 22 propose a novel approach to multilingual and multimodal named entity recognition (2M-NER) with their 2M-NER model. 22 Recognizing the limitations of existing datasets, they introduce a large-scale 2M-NER dataset encompassing four languages and text-image combinations. The 2M-NER model tackles this challenge by aligning text and image representations through contrastive learning and incorporating a multimodal collaboration module to capture the interactions between the two modalities. Their evaluations demonstrate the effectiveness of this approach, with the 2M-NER model achieving the highest F1-scores on the 2M-NER tasks for all four languages (English: 69.99, French: 63.13, Spanish: 71.21, German: 62.16) compared to benchmark models. These findings highlight the potential of combining multilingual and multimodal information to improve NER performance.
The field of NER is rapidly evolving, with new models and techniques continually being developed and refined. These advancements are not only enhancing the performance of NER tasks but also expanding their applicability across various domains and languages. However, it’s important to note that the choice of the most effective NER tool depends on the specific task and data at hand.
A review of Named Entity Recognition (NER) systems revealed a research gap: the lack of focus on cloud platforms and the Polish language. This gap motivated a comparative analysis in this area. Publicly available open-source algorithms and tools dominate current NLP research. Therefore, this study will compare the performance of cloud platforms (Azure and Google Cloud) with a popular open-source tool, SpaCy, for both English and Polish NER tasks.
Several factors might explain the limited research on Polish NER within cloud platforms. The dominance of English-language research in NLP is a significant factor. Many cloud-based NER services and benchmark datasets primarily cater to English text. This can lead to a bias towards English-centric solutions.
Furthermore, the inherent complexity of the Polish language itself presents a challenge. Polish boasts a rich inflectional morphology, complex syntax, and a unique alphabet with additional characters. These characteristics necessitate specialized approaches that might not be readily available in existing cloud-based NER solutions designed primarily for simpler languages.
By comparing the performance of these NER approaches across different languages and entity types, this research seeks to provide valuable insights into their strengths and weaknesses. This information can aid in selecting the most suitable NER technique for specific NLP applications, particularly when dealing with multilingual content.
Research methodology
This research investigates the effectiveness of Named Entity Recognition (NER) within cloud platforms compared to open-source tools. The study hypothesizes that cloud-based NER systems, such as Azure Text Analytics and Google Cloud Natural Language API, will achieve superior performance due to their potential access to more extensive and diverse language corpora for training. These corpora are critical for NER models to learn the intricacies of language and identify named entities accurately. Open-source tools, while readily available and often customizable (e.g., SpaCy), might be limited by the size and scope of the training data they utilize.
Furthermore, this research explores the potential influence of language complexity on NER performance. The hypothesis is that the English language will be more effectively recognized compared to Polish. This can be attributed to several factors: English, as a more widely used language, benefits from a larger pool of training data, leading to more robust and mature NER models. Additionally, English possesses a relatively simpler grammatical structure compared to Polish. Polish boasts a rich inflectional morphology, complex syntax, and a unique alphabet with additional characters. These characteristics can pose challenges for NER models, particularly those not specifically trained on the intricacies of the Polish language.
To investigate these hypotheses, a comparative analysis will be conducted. This analysis will evaluate the performance of NER systems offered by leading cloud platforms (e.g., Azure Text Analytics, Google Cloud Natural Language API) alongside a popular open-source tool (e.g., SpaCy with pre-trained Polish models) for both English and Polish text. Text data for evaluation will be sourced from publicly available datasets. To ensure consistency and focus on relevant entities, the analysis will concentrate on three commonly targeted named entity types in NER research: “location”, “organization”, and “person”.16,22 This multifaceted approach will allow for an assessment of the impact of cloud-based resources and language complexity on NER accuracy specifically for these key entity types.
By comparing performance across these platforms and languages, this study aims to contribute valuable insights to the field of NLP. The findings can inform researchers and practitioners on the strengths and limitations of cloud-based NER tools, particularly for languages like Polish that might require specialized approaches.
Datasets
One of the significant challenges encountered during this research was the limited availability of suitable datasets, especially for the Polish language. This scarcity was most pronounced for datasets containing organizations, evident in both languages, and locations, particularly for Polish due to the lack of publicly available annotated location data. The lack of diverse datasets containing these entities necessitated additional effort in data preparation.
To address this challenge, the chosen approach went beyond utilizing solely ready-made linguistic corpora. In addition to existing datasets, articles freely available on the Internet were also included. This approach ensured a broader and more comprehensive representation of contemporary Polish language use, considering the variety of sources and the overall size of the data. Data cleaning steps were applied to the internet articles to remove noise and maintain consistency with the existing datasets.
Data for the Polish language are summarized in Table 1, detailing the sources and characteristics of the corpus used in the research. Table 1 also includes the size (number of characters) of the datasets for both languages. The total size of texts was: 252504 characters for the English dataset, and 235430 characters for the Polish dataset.
Polish and English corpora.
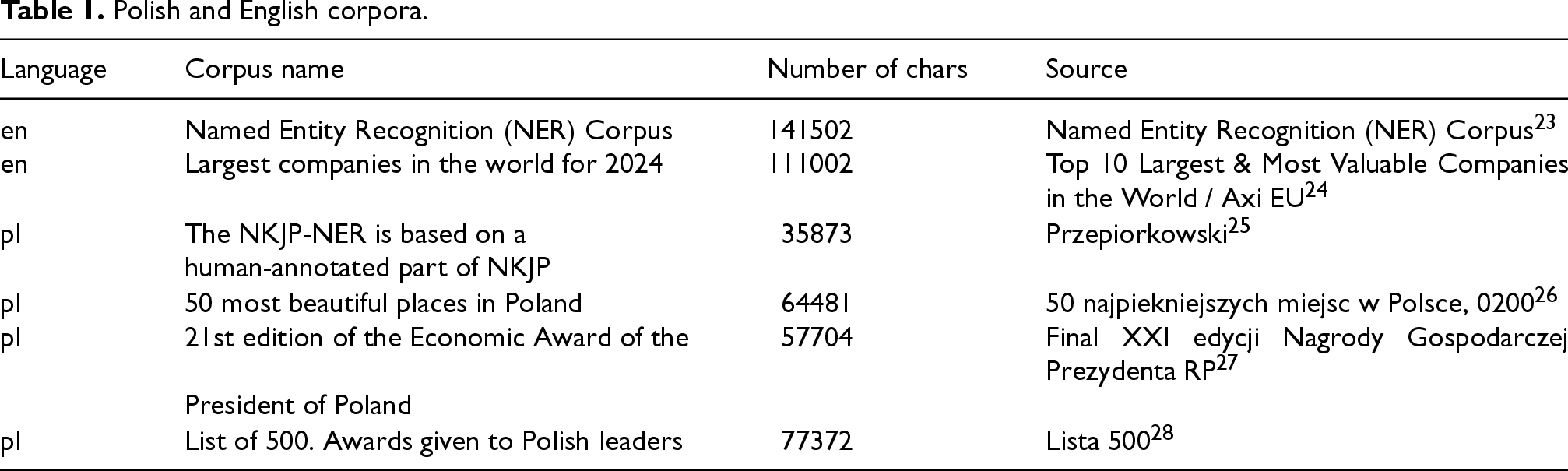
Polish and English corpora.
Table 2 details the number of named entities identified and manually labeled within the Polish and English corpora used for this research. The labels correspond to the three targeted entity types: “location”, “organization”, and “person”.
Number of named entities by type in Polish and English corpora.

This research investigates the performance of three popular named entity recognition (NER) tools: Azure NER (ANER), Google Cloud NER (GNER), and SpaCy NER (SNER). This study evaluates their effectiveness on both English and Polish text, analyzing their capability to recognize three entity types: “location”, “organization”, and “person”.
The research leverages tools from two cloud service providers and an open-source framework. Azure AI Language 29 service provides pre-built models for various NLP tasks. The recognize entities function is used to identify entities within the provided content.
Google Cloud Natural Language API 30 offers a comprehensive suite of NLP functionalities. The analyze entities function is used to detect named entities in the text data.
SpaCy 31 is the open-source library that provides pre-trained statistical models for various NLP tasks. A SpaCy model is loaded based on the document language to recognize named entities in text. The study used the en_core_web_lg model 32 for English and pl_core_news_lg 33 for Polish.
Due to the inherent variation in naming conventions across the tools, all entity labels were converted to a lowercase format and mapping was performed to establish a base label for each entity type, as presented in Table 3.
Mapping entity labels to base labels for English and Polish in different NER tools.
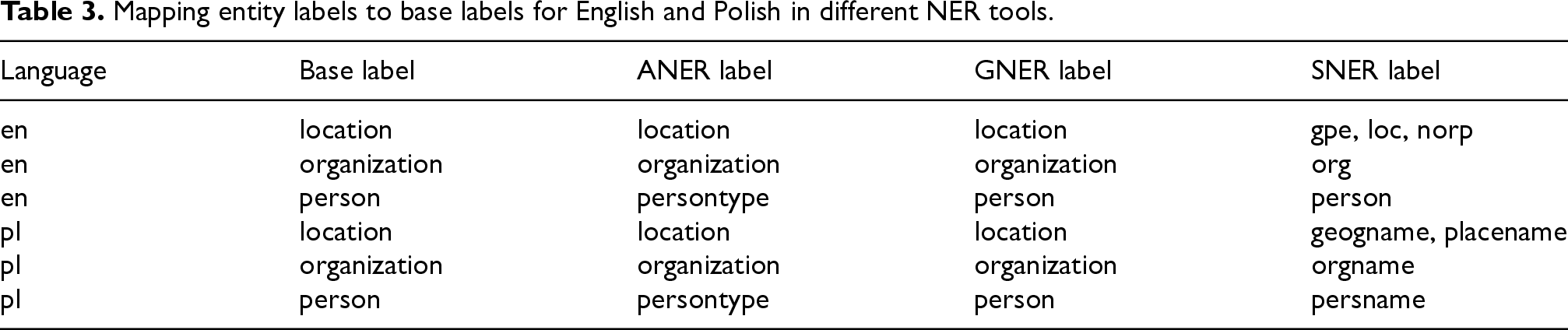
Mapping entity labels to base labels for English and Polish in different NER tools.
To assess the performance of the NER tools, this research employed standard metrics used in NER evaluation: Precision, Recall, and F1-score.16,21 Precision measures the proportion of identified entities that are actually correct, while Recall reflects the proportion of actual entities that are correctly identified. F1-score provides a harmonic mean that balances these two measures.
After importing data from the sources presented in Table 1, any necessary cleaning or pre-processing steps were performed on the text data. This might include removing punctuation, converting to lowercase, or handling special characters to ensure consistency for the NER models. The pre-processed text data was then imported into the PostgreSQL database for further analysis.
To perform a comparative assessment of NER accuracy for Azure Named Entity Recognition (ANER), Google Cloud NER (GNER), and SpaCy NER (SNER) on Polish and English content, a custom research environment was developed using Python. This environment integrates with both Azure Cloud, Google Cloud, and SpaCy to access the appropriate functions required to run each NER model (Figure 1).
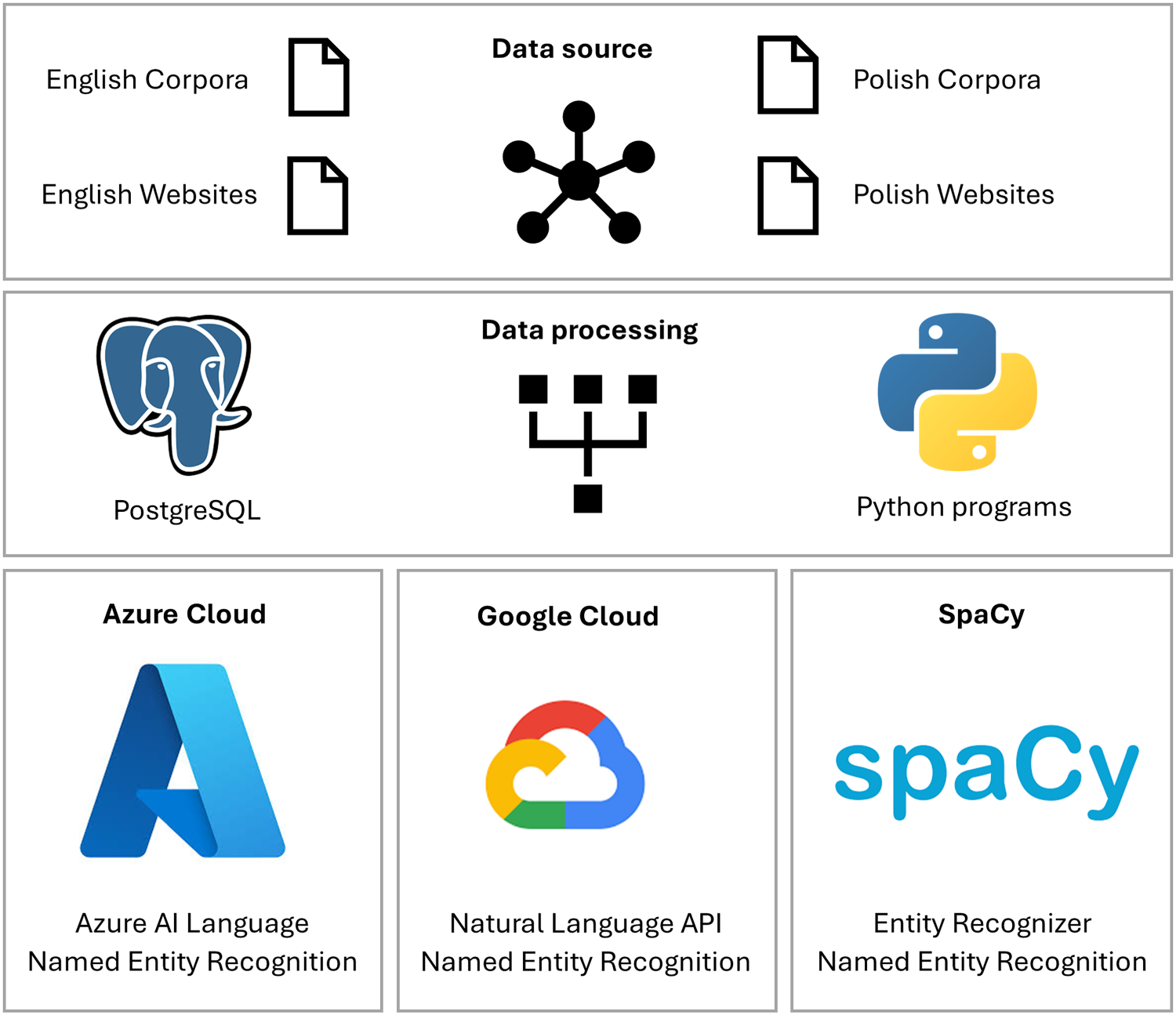
Named entity recognition research environment.
The text data obtained from the sources listed in Table 1 was imported into a PostgreSQL database for analysis. Each text entry, limited to a maximum of 250 characters, is stored within an SQL Document table. This table schema includes the following fields: (1) Document Id (integer): A unique identifier assigned to each text record. (2) Language (text): This field specifies the language of the text (“en” for English, “pl” for Polish). (3) Source (text): This field indicates the origin of the text data, such as the dataset name or website URL. (4) Content (text): This field stores the actual text content that will be analyzed for named entities. Sample data from this SQL Document table is presented in Table 4.
Sample data in the SQL Document table.

The implemented program iterates through each record in the SQL Document table. For each record, the program interacts with the chosen NER tool (ANER, GNER, or SNER) depending on the document language. The output from each NER tool, which consists of the identified named entities and their corresponding labels, is then parsed.
During parsing, the program extracts relevant information from the NER tool’s output, such as the identified entity phrase and its assigned label. This information is then stored in a separate SQL Entity table. This SQL Entity table includes the following fields: (1) Document Id (integer): Foreign key referencing the corresponding record in the SQL Document table. This establishes a link between the identified entity and the original text it was found in. (2) Phrase (text): The actual text phrase identified as a named entity. (3) Actual label (text): The ground truth label assigned to the entity based on the data source (“location”, “organization”, or “person”). (4) ANER label (text): The label assigned to the entity by the Azure NER tool (ANER). (5) GNER label (text): The label assigned to the entity by the Google Cloud NER tool (GNER). (6) SNER label (text): The label assigned to the entity by the SpaCy NER tool (SNER).
This structure allows for efficient storage and comparison of the named entities identified by each NER tool for the same text record. By analyzing the data in the SQL Entity table, the research can evaluate the performance of each NER tool and assess their effectiveness in recognizing different entity types across both English and Polish text. Sample data from this SQL Entity table is presented in Table 5.
Sample data in the SQL Entity table.
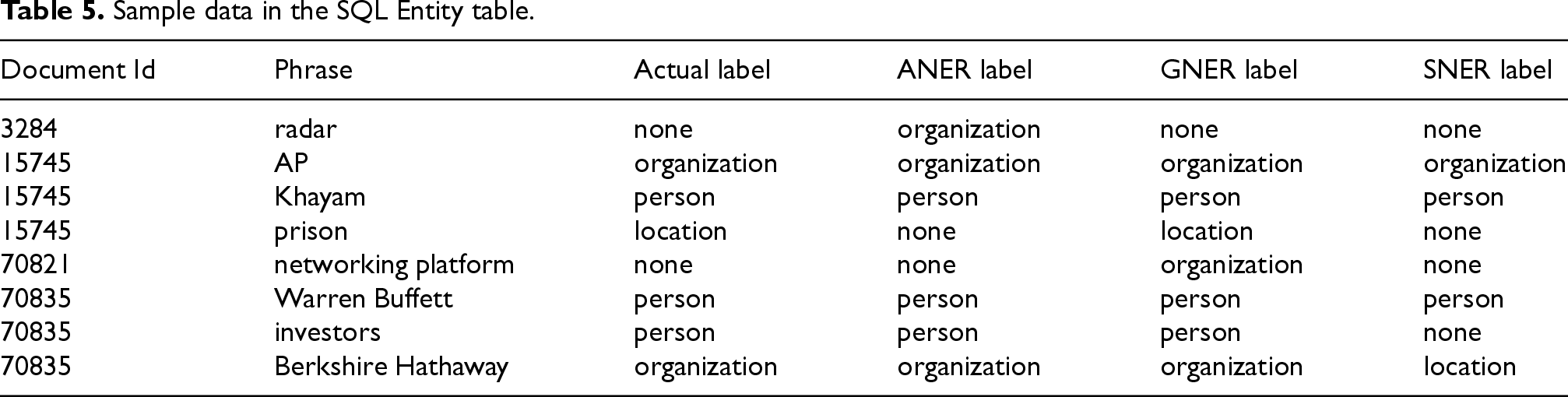
The NER tool’s (ANER, GNER, SNER) logic for identifying true positives, false positives, and false negatives can be described as follows: (1) True Positive: Both the actual label and the NER label accurately categorize a named entity as a “location”, “organization”, or “person”. (2) False Positive: The NER label erroneously classifies a named entity as a “location”, “organization”, or “person”, while the actual label is “none”. (3) False Negative: The actual label designates a named entity as a “location”, “organization”, or “person”, but the NER label fails to recognize it. (4) True Negative (Not Applicable): Given that the phrases were exclusively labeled as “location”, “organization”, or “person”, the concept of a “true negative” does not apply to the NER tool’s evaluation. A True Negative would occur if an entity were correctly identified as something other than these three categories, which was not possible based on the available labels.
NER performance
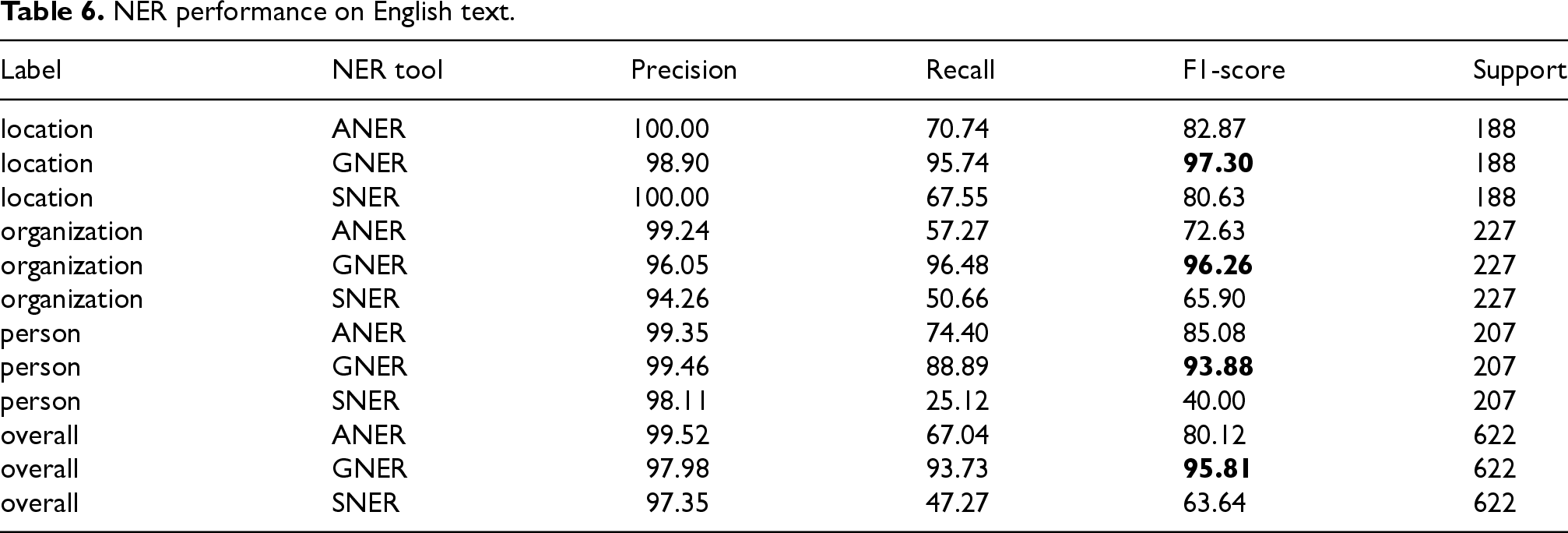
Based on the conducted experiments, Precision, Recall, and F1-score metrics were calculated for each tool (ANER, GNER, SNER) across different entity labels and overall. The results for English are presented in Table 6, and for Polish in Table 7.
NER performance on English text.
NER performance on English text.
NER performance on Polish text.
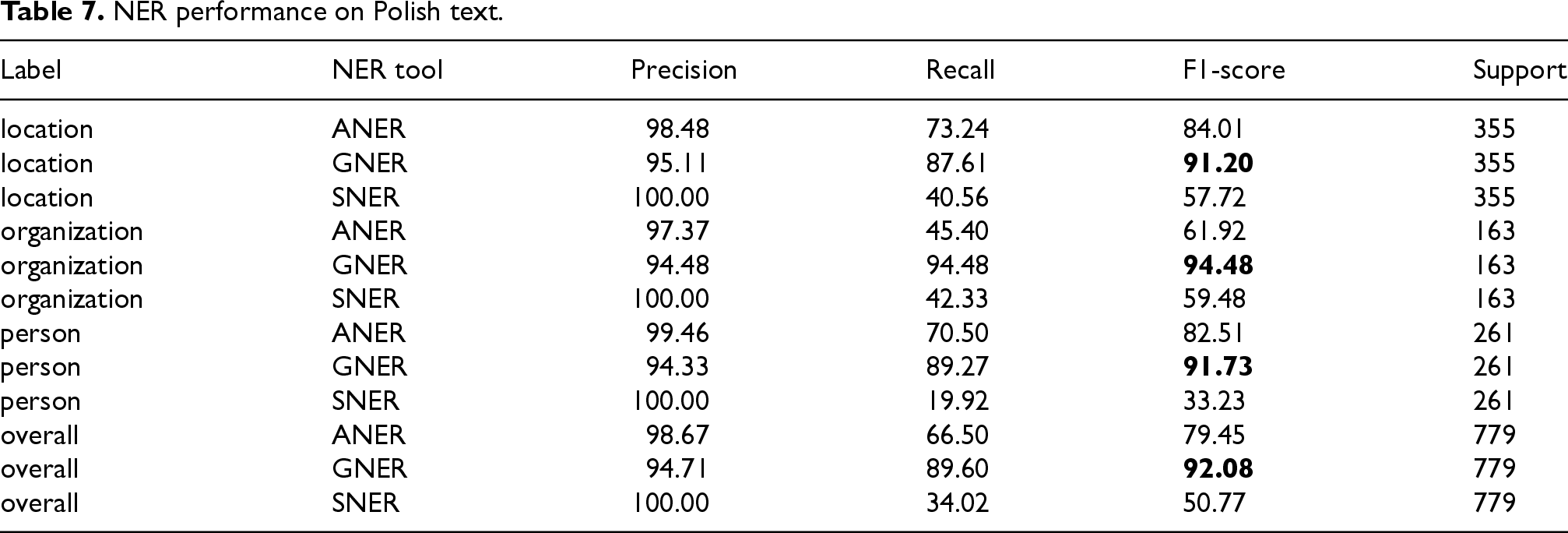
In English, for each entity label, the GNER tool achieved the best F1-score results: 97.30 for the “location” label, 96.26 for the “organization” label, 93.88 for the “person” label, and 95.81 overall. The ANER tool performed 15.69 points lower overall, and the SNER tool was 32.17 points lower overall compared to GNER.
In English, for each entity label, the GNER tool achieved the best F1-score results (Table 6). The overall F1-score for GNER was 95.81, with individual entity label scores of 97.30 (“location”), 96.26 (“organization”), and 93.88 (“person”). The ANER tool achieved an overall F1-score of 80.12, while SNER achieved 63.64. This indicates that GNER outperformed both ANER (by 15.69 points) and SNER (by 32.17 points) in English.
Similar to English, the GNER tool achieved the best F1-score results for each entity label in Polish (Table 7). The overall F1-score for GNER was 92.08, with individual entity label scores of 91.20 (“location”), 94.48 (“organization”), and 91.73 (“person”). The ANER tool achieved an overall F1-score of 79.45, while SNER achieved 50.77. Here again, GNER demonstrated superior performance compared to ANER (by 12.63 points) and SNER (by 41.31 points).
As initially hypothesized, the comparison of English and Polish results (Figures 2 and 3) revealed that English generally yielded better performance across all tools. GNER showed the smallest difference between languages (3.73 points higher in English), while ANER displayed a slightly higher overall F1-score in English (0.67 points). Notably, SNER exhibited a significant performance gap between languages, with English results being 12.87 points higher.
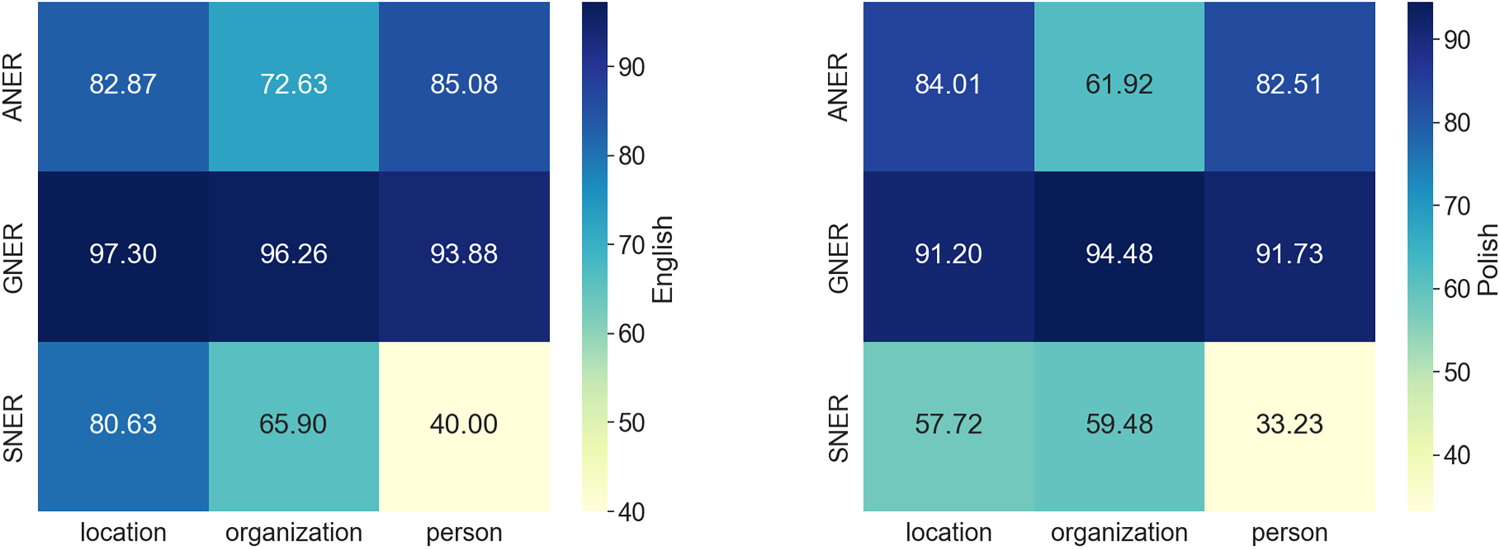
Comparison of F1-score by entity label (English vs. Polish).
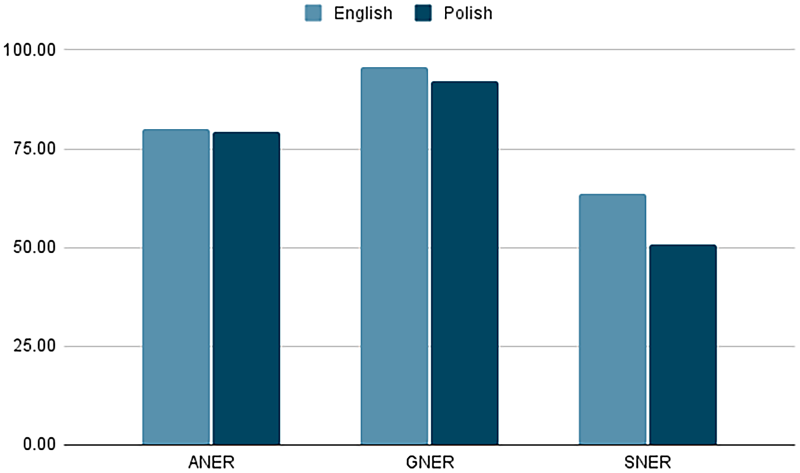
Overall F1-score comparison (English vs. Polish).
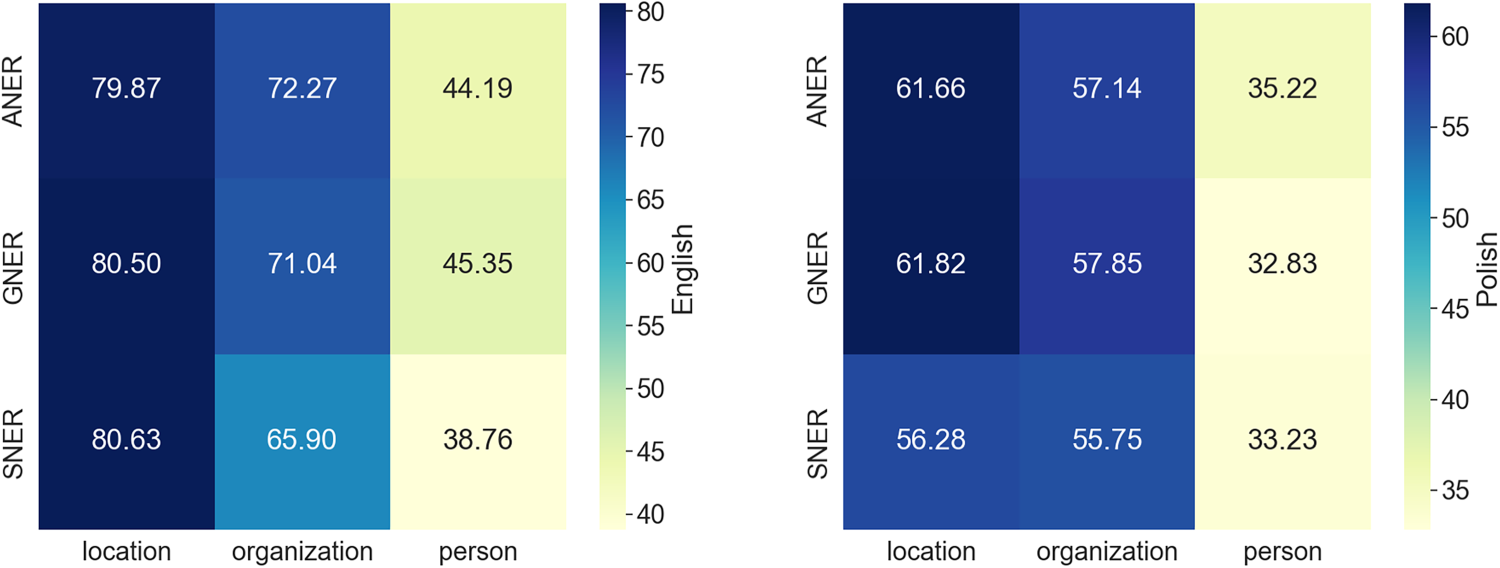
Comparison of F1-score by entity label (English vs. Polish) on identifying proper nouns.

Overall F1-score comparison (English vs. Polish) on identifying proper nouns.
An unexpected finding was the consistently lower performance of the ANER tool compared to GNER for both English and Polish. To understand this better, a closer examination of the entities correctly identified by GNER but missed by ANER and/or SNER is planned for the next step of the analysis. This investigation will focus on specific cases where ANER and/or SNER misclassified entities that GNER identified correctly. A deeper examination of these discrepancies aims to uncover the reasons behind ANER’s underperformance and identify potential areas for improvement in these NER tools.
The initial analysis of NER tool performance revealed a potential bias. GNER demonstrated a stronger ability to recognize common nouns compared to proper nouns (Table 8). This could have influenced the overall results. To isolate the performance on proper nouns specifically, the methodology was refined.
Sample NER performance on common nouns compared to proper nouns.
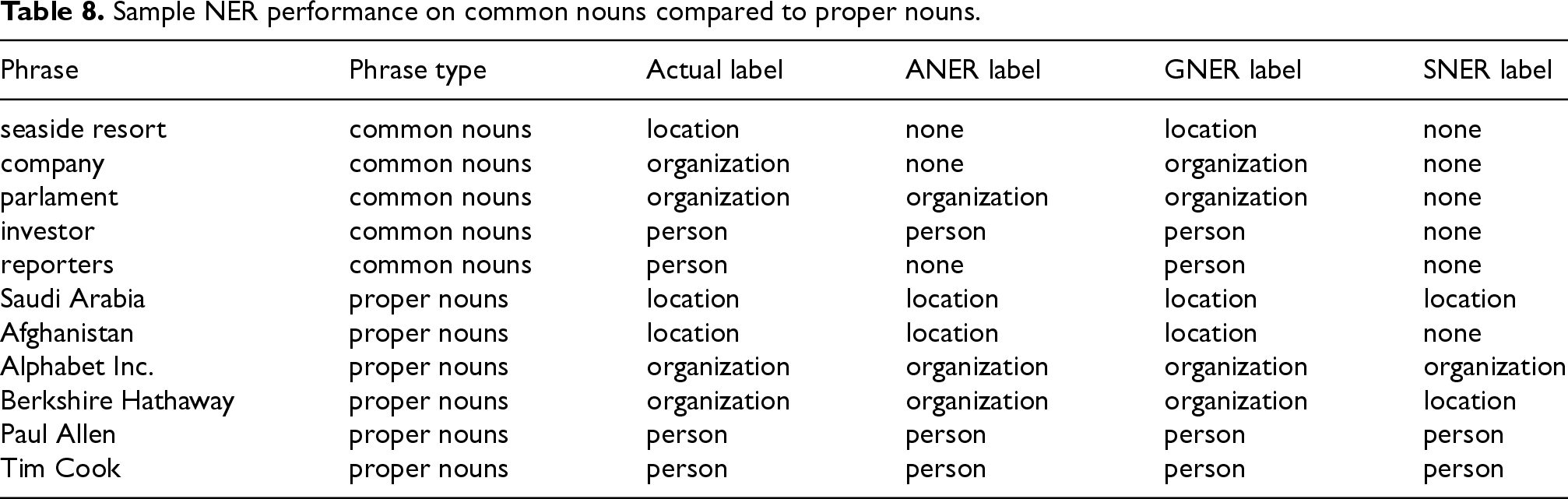
Sample NER performance on common nouns compared to proper nouns.
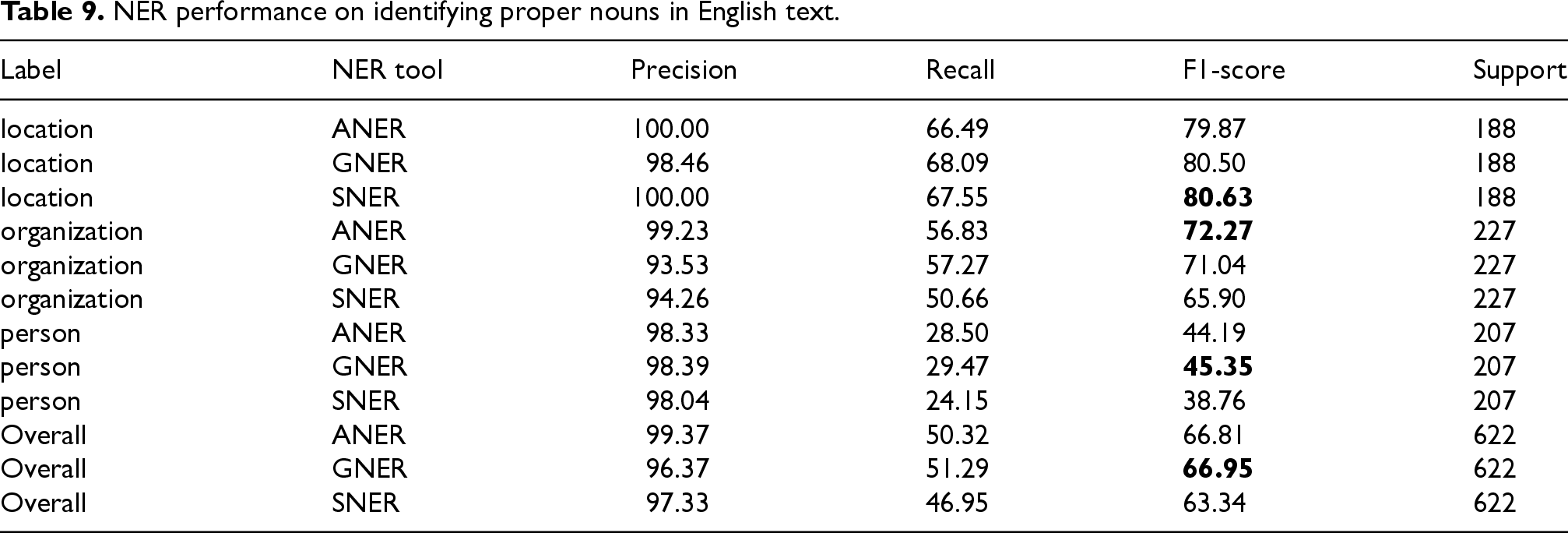
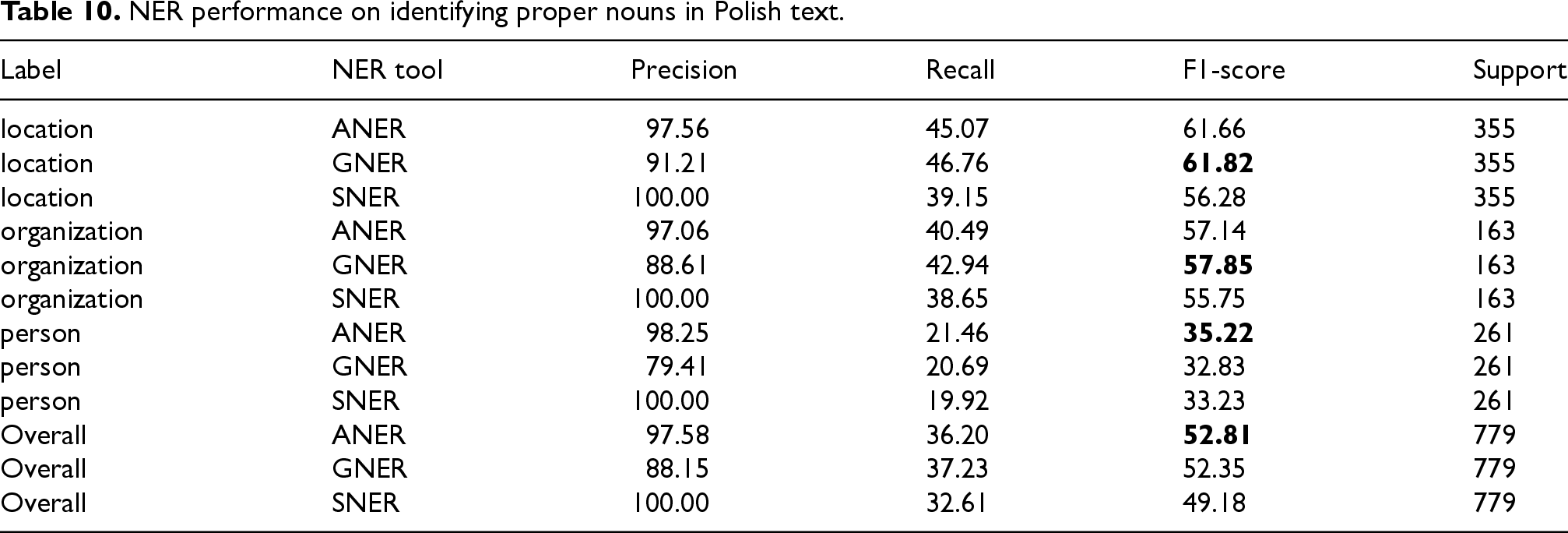
First, an additional field named “phrase type” was introduced to the SQL Entity table (Table 8). This new field allowed for the distinction between common and proper nouns within the data. With this distinction in place, the experiments were then repeated, but this time considering only phrases that were identified as “proper nouns” based on the new field. This ensured a more focused analysis on the NER tools’ ability to recognize proper nouns. The refined results for English and Polish are presented in Tables 9 and 10, respectively.
NER performance on identifying proper nouns in English text.
NER performance on identifying proper nouns in Polish text.
When focusing on proper nouns in English text (Table 9), SNER emerged as the leader for “location” labels, slightly outperforming GNER and ANER by 0.13 points and 0.76 points respectively. However, for “organization” and “person” labels, SNER’s performance significantly dropped, lagging behind GNER by 6.37 for “organization” and ANER by 6,59 points for “person”. Overall, ANER and GNER exhibited nearly identical F1-scores, with a difference of 0.14 points. SNER performed considerably worse overall (by 3.61 points behind GNER) due to its weaknesses in recognizing “organization” and “person” entities as proper nouns.
Analyzing proper noun identification in Polish text (Table 10) revealed a different pattern. GNER slightly outperformed ANER for “location” (0.16 points) and “organization” labels (0.71 points). However, the trend reversed for “person” labels, where ANER outperformed GNER by 2.39 points. SNER’s performance was worse for “location” labels (5.54 points behind GNER). Surprisingly, for “organization” and “person” labels, SNER achieved results comparable to the best tools, with a difference of only 2.10 points and 1.99 points from the leaders, respectively. Overall, ANER emerged as the top performer for proper noun identification in Polish, surpassing GNER by 0.46 points and SNER by a substantial margin of 3.63 points.
Statistically significant differences in the results (Figures 4 and 5) for all three tools (ANER: 14.00, GNER: 14.60, SNER: 14.16) confirm the hypothesis of greater tool effectiveness in processing the English language. The obtained results indicate a clear advantage of the models over the Polish language.
This refined analysis revealed GNER as the most effective tool for English, while ANER demonstrated superior performance for Polish, especially when considering the overall F1-score. Furthermore, SNER exhibited competitive results compared to the other tools.
The initial hypothesis that cloud-based NER systems outperform open-source systems needs to be considered in the context of the specific application. When dealing with both common and proper nouns, GNER emerges as the top performer (95.81 for English and 92.08 for Polish), followed by ANER (80.12 for English and 79.45 for Polish). SNER, on the other hand, consistently yields the lowest results (63.64 for English and 50.77 for Polish). This suggests that the SpaCy tool may not be well-suited for this type of application. However, when the task is limited to proper nouns, the performance of all tools becomes comparable. For English, the F1-scores are ANER: 66.81, GNER: 66.95, SNER: 63.34; and for Polish, they are ANER: 52.81, GNER: 52.35, SNER: 49.18. In this case, the choice of tool depends solely on the specific application context. The second hypothesis, regarding the superiority of NER performance in English over Polish, was confirmed. The results for Polish were consistently lower than those for English, with the smallest difference being 14.00 points and the largest being 14.60 points. This trend indicates a general advantage for English.
The conducted research led to additional, unforeseen conclusions. There is a clear distinction between the NER tools in their approach to named entity recognition. GNER excels at identifying both proper and common nouns as named entities, while ANER performs noticeably worse in this regard, and SNER is essentially not suitable for recognizing common nouns. This highlights the importance of selecting the right tool for the specific application, and the conducted research has implications for this decision-making process.
It is evident that tools like ANER exhibit very high precision, while GNER, despite its high F1-score, often has lower precision. This is particularly evident in Polish text, where GNER achieved a Precision of 94.71 for all nouns and 88.15 for proper nouns, which are significantly lower than those of ANER and SNER. This should also be considered when choosing a tool for specific needs and applications.
Future research should explore several avenues for improving named entity recognition. One direction is to analyze other open-source tools, particularly for handling common nouns. Additionally, it is worth investigating how to control the types of named entities recognized within individual NER tools (e.g., restricting recognition to only proper nouns). Furthermore, the study could examine the impact of punctuation removal on entity recognition accuracy, with a particular focus on SpaCy. While this study has shed new light on the relationship between common nouns and proper nouns, further research is needed to explore this issue in greater depth, particularly in relation to the individual performance of NER tools on different datasets and the impact of noise corpus quality on identification accuracy.
Overall, the research findings provide valuable insights into the performance of cloud-based and open-source NER tools, highlighting the strengths and limitations of each approach. The recommendations for future work aim to address these limitations and further enhance the effectiveness of named entity recognition in various applications.
Footnotes
Acknowledgments
Not applicable.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.