
Abstract
Due to recent developments in deep learning models, the field of time series forecasting has undergone significant advancements related to forecasting accuracy and reliability across various industrial sectors. Unfortunately, traditional deep learning models often encounter long-term and multivariate forecasting challenges due to complex temporal patterns. To overcome this, decomposition-based approaches have been proposed. However, there have been few attempts to utilize an appropriate network type for each decomposed component. In this paper, we propose the two-stage decomposition-based hybrid deep neural network (TSDNet) for enhancing the accuracy of long-term time series forecasting. To effectively manage complicated time series data with varying periodicities, TSDNet accommodates a single linear layer for forecasting smooth trend components and a convolutional module for complex seasonal components. Extensive experiments on various benchmark and real-world financial datasets show that TSDNet mostly improves the forecasting accuracy compared to the existing methods considered, particularly in long-term forecasting scenarios. Furthermore, ablation studies were conducted to examine the impact of the number of decomposition stages and the implementation of different modules on the decomposed elements, suggesting the effectiveness of the proposed approach.
Keywords
Introduction
Time series analysis has increasingly gained much attention across various real-world decision-making domains, such as energy, transportation, finance, economics, meteorology, and healthcare.1–5 This analytical process plays a crucial role in forecasting future scenarios by focusing on understanding past and present trends. For instance, precisely forecasting real-time demands and supplies in the energy sector is essential for efficient resource allocation. 6 In finance and economics domains, time series forecasting forms the foundation for understanding market volatility and predicting future trends. 7
Different from image and text data analytics, traditional models such as autoregressive integrated moving average (ARIMA) 8 and state-space models were widely utilized in the time series forecasting domain. These models were demonstrated for their robustness in handling univariate data and effectiveness in capturing linear relationships over time. Despite their effectiveness, these traditional models might pose limitations in managing the complexities of modern time series forecasting tasks and understanding correlation, seasonality, and trends.9–11 Moreover, they usually require extensive manual tuning to adjust internal components such as trends and seasonality.
In recent decades, remarkable advances in deep learning networks have introduced a new dimension in time series forecasting. Specifically, deep learning models such as feedforward neural networks, recurrent neural networks (RNNs), convolutional neural networks (CNNs), and Transformers have shown outstanding performance. 12 Yet, since most existing models focused on short-term and univariate forecasts based on past data, they face challenges in forecasting long-term and multivariate time series. 13 Moreover, they often inadequately capture the complex interactions among different types of input data in multivariate time series. 14
To address the shortcomings of standard deep learning models in time series forecasting, the following two major approaches were introduced. First, several researchers proposed new network architectures that are specifically designed for accommodating long-term dependencies and multivariate time series data. For example, time convolutional network models were devised to adapt CNNs for time series data. 15 The authors in Wu et al. 16 introduced the dimension transformation of time series analysis, which enables more sophisticated interpretations by navigating the complex scales and correlations inherent to multivariate data.
Second, time series decomposition approaches were adopted to address the limitations of traditional deep learning models in time series forecasting. In general, these approaches are performed by dividing time series into trends and seasonal components to analyze these elements separately as inputs for a forecasting model. 17 From the perspective of combining deep neural networks and decomposition techniques, some studies utilize both the original and decomposed elements for predictions using complex networks.18,19 More pertinently, DLinear 20 demonstrated the effectiveness of linear feedforward neural networks by utilizing seasonal and trend elements of multivariate time series data.
In this paper, we propose a novel two-stage decomposition-based hybrid deep neural network (TSDNet) that decomposes a single time series into four separate time series for long-term time series forecasting. Motivated by DLinear 20 and TimesNet Wu et al., 16 TSDNet utilizes both simple linear layers and a specialized convolutional module to effectively accommodate complex time series data with varying periodicities. Specifically, a single linear layer and a convolutional module are employed to forecast smooth trend components and complex seasonal components, respectively. Furthermore, TSDNet employs a parallel structure similar to DLinear for multivariate time series forecasting, enabling independent forecasts for each univariate series obtained from multivariate time series. Extensive experiments on six benchmarks and five real-world financial datasets demonstrated that the proposed method mostly outperformed the forecasting accuracy compared to existing time series forecasting methods.
The key contributions of this paper are listed as follows:
The proposed TSDNet treats multivariate time series as a collection of univariate series, each of which is then decomposed into multiple univariate sequences to enhance forecasting accuracy. The effectiveness and validity of TSDNet are analyzed by conducting two ablation studies related to time series decomposition stages and deep learning modules. The proposed approach demonstrates the superior performance over the recent long-term time series forecasting methods on several ETT and Weather datasets, along with five real-world financial datasets, while providing ease of implementation.
This paper is organized as follows. A review of recent advancements in time series forecasting models is provided in Section 2. In Section 3, we define the problem considered in this paper and introduce the structure of the proposed TSDNet. Section 4 presents the experimental design, including the datasets, evaluation metrics, and comparison models. Experimental results and their analysis are presented in Section 5, and finally, the conclusion is drawn in Section 6.
Related work
Traditional methods in time series forecasting
The field of time series prediction has attracted substantial interest due to its wide-ranging applications across various sectors. For instance, linear models such as exponential smoothing 21 and the ARIMA model were foundational methods in time series analysis for decades, which are acclaimed for their simplicity and effectiveness in certain scenarios. However, these traditional linear models pose inherent limitations when they are confronted with nonlinear patterns in data as well as high-dimensional and multivariate time series. These limitations become more complicated as the complexity and volume of data increase. To overcome these limitations, more advanced models were developed and investigated, including the vector autoregressive moving average model, 22 support vector regression, 23 ridge regression, 24 and nonparametric methods such as the Gaussian process. 25 Although these approaches can successfully deal with nonlinear and multidimensional data, there are still two challenges that need to be addressed. First, they often encounter computational complexity and difficulty in managing high-dimensional data. Second, their performance is highly likely to depend on the time-intensive feature engineering that is done by the domain experts.
Deep learning-based models for time series forecasting
In response to the challenges of the traditional time series forecasting models, there have been substantial attempts to develop deep learning-based models. In particular, RNN-based models such as the long short-term memory (LSTM) 26 and gated recurrent units 27 are known to be effective for extracting latent features from high-dimensional data. These models are recursively trained and updated at each time step for capturing temporal dependencies within the data. To further enhance the capability of a model by focusing on the significant interval of time series data, dual-stage attention-based recurrent neural networks 28 and dual self-attention temporal point processes recurrent neural networks 29 were proposed.
On the other hand, CNN-based models have gained significant attraction in time series analysis. These models offer a distinct approach to time series analysis, emphasizing the importance of spatial relationships and patterns in data interpretation. The authors of Borovykh 30 proposed the dilated CNN, which is characterized by its stacks of dilated convolutions to encompass a broad historical range. The dual self-attention network 31 was designed to handle complex and nonlinear dependencies inherent in time series data. The sample convolution and interaction network (SCINet), which was introduced in Liu et al., 32 employs a series of connected convolutional and activation operations, allowing for the extraction of features from multiple perspectives. In a study by Silva et al., 33 the original SCINet model was improved by incorporating skip connections into the structure. Building upon these developments, recently, TimesNet 16 showcased an impressive performance, marking a significant advancement in time series forecasting. This model employed a modular architecture that effectively transforms one-dimensional time series data into two-dimensional tensors, utilizing multi-periodicity to capture and model complex temporal variations.
To take advantage of RNN and CNN-based approaches, several studies proposed hybrid deep learning models, such as a convolutional recurrent neural network, 34 by incorporating the unique capabilities of CNNs and RNNs. The network proposed in Lai et al. 35 aims to combine long and short-term patterns of time series data to support a more sophisticated analysis. Similarly, memory time series network 36 was designed to handle complex temporal patterns and dependencies in time series data. Gu et al. 37 proposed a novel hybrid approach that amalgamates RNNs, temporal convolutional neural networks, and neural differential equations to overcome the individual limitations of these techniques by integrating their strengths.
Recently, Transformer-based models and self-attention mechanisms 38 have been widely employed 12 due to their ability to capture long-term dependencies and balance predictability and model capability. Li et al. 39 proposed the LogSparse Transformer, which enhances the Transformer architecture with convolutional and sparse attention for improved efficiency. The Reformer 40 improved the original model by devising locality-sensitive hashing and reversible layers for computational efficiency. The authors in Zhou et al. 41 proposed the Informer that employs prob-sparse self-attention and distilling techniques to reduce computational demands. The model proposed in Lim et al. 42 utilized specialized components for feature selection and adopted gating layers to suppress unnecessary information. Further innovations were made by Pyraformer, 43 which utilizes a pyramidal attention structure to balance the analysis of short-term and long-term dependencies while minimizing computational complexity. The ETSformer 44 improved upon traditional Transformers by incorporating exponential smoothing, enhancing accuracy and interoperability. The authors of Chowdhury et al. 45 enhanced the Transformer model by focusing on task-aware data reconstruction to augment end-task performance. In addition, 46 proposed the non-stationary Transformers, which is a versatile framework characterized by making series stationary and adjusting attention modules. Finally, the CLformer was developed by Wang et al., 47 which integrates convolution and locally grouped autocorrelation into the Transformer framework. More recently, by operating on variate tokens instead of temporal tokens, iTransformer 48 aims to enhance multivariate correlation modeling and achieves state-of-the-art performance in real-world forecasting.
In contrast to Transformer-based models, several studies proposed more straightforward approaches such as linear layers and multi-layer perceptron (MLP) block stacking to achieve forecasting performances comparable to those of Transformer-based models. N-Beats, 49 NBEATSx by Olivares et al., 50 and N-Hits by Challu et al. 51 initially verified the effectiveness of block stacking structures in streamlined MLP-based frameworks. Further emphasizing this trend, 52 introduced LightTS, which utilizes a streamlined MLP structure with dual down-sampling strategies. These models demonstrated that complexity is not always a prerequisite for high performance in time series analysis.
Decomposition approaches for time series forecasting
Generally, the decomposition of time series data is achieved by separating the original data into several components. The decomposition-based approaches have been known to be highly effective for isolating and analyzing elements such as seasonal patterns, underlying trends, and residual factors in time series datasets. 53 One of the most prevalent decomposition methods is seasonal-trend decomposition using loess (STL) 17 that aims to separate the time series into trend, seasonality, and residual parts. Additionally, advancements in decomposition techniques that employ Fourier transforms and wavelet-based multi-resolution analysis54,55 offered alternative perspectives in decomposing time series data.
Due to the effectiveness of deep neural networks, there have been increasing attempts to integrate deep learning models with time series decomposition techniques. 56 This integration aims to harness the proficiency of deep learning in identifying complex patterns, particularly when employed to the decomposed trends and seasonal components of time series data. In this context, innovative models such as Autoformer 18 and Fedformer 57 have emerged. Autoformer integrates a decomposition-based approach with an auto-correlation mechanism to significantly enhance long-term time series forecasting capabilities. Similarly, Fedformer combines seasonal-trend decomposition with frequency enhancement within a Transformer framework to capture global and detailed patterns for extended forecasting.
Another decomposition-based approach was introduced by utilizing contrastive learning methods for learning disentangled seasonal-trend representations. 58 The authors of Huang et al. 59 proposed a dual-channel network model designed explicitly for long-term forecasting in time series data. They employed a deep cross-decomposition method to effectively separate and extract features from seasonal and trend-cyclical components, demonstrating their adeptness in managing complex time series data. Building on these advancements, DLinear, which demonstrates its simplicity and robustness, has been recently proposed by Zeng et al. 20 This model, which is capable of predicting long sequences through a single time series decomposition, verified the potential of straightforward linear approaches in tackling complex time series forecasting tasks. As a result, the development of DLinear underscored the growing recognition of simpler yet effective models in time series forecasting. Thus, decomposition approaches were demonstrated to be instrumental since they contribute to understanding the inherent complexities of time series data and creating more accurate and efficient forecasting models. The proposed two-stage decomposition approach will be described in Section 3.2.
Methods
Problem definition and notations
We introduce the definition and notations for the proposed time series forecasting model. Let
Let denote the part of the time series from the first to the

In this paper, we address the time series forecasting problem where
The overview of TSDNet
Figure 1 provides a comprehensive overview of the proposed TSDNet. The core feature of TSDNet is a two-stage decomposition in which the input time series is split into four distinct subseries. Each subseries is individually processed through customized deep learning architectures to enhance forecasting accuracy. When TSDNet conducts multivariate time series forecasting with
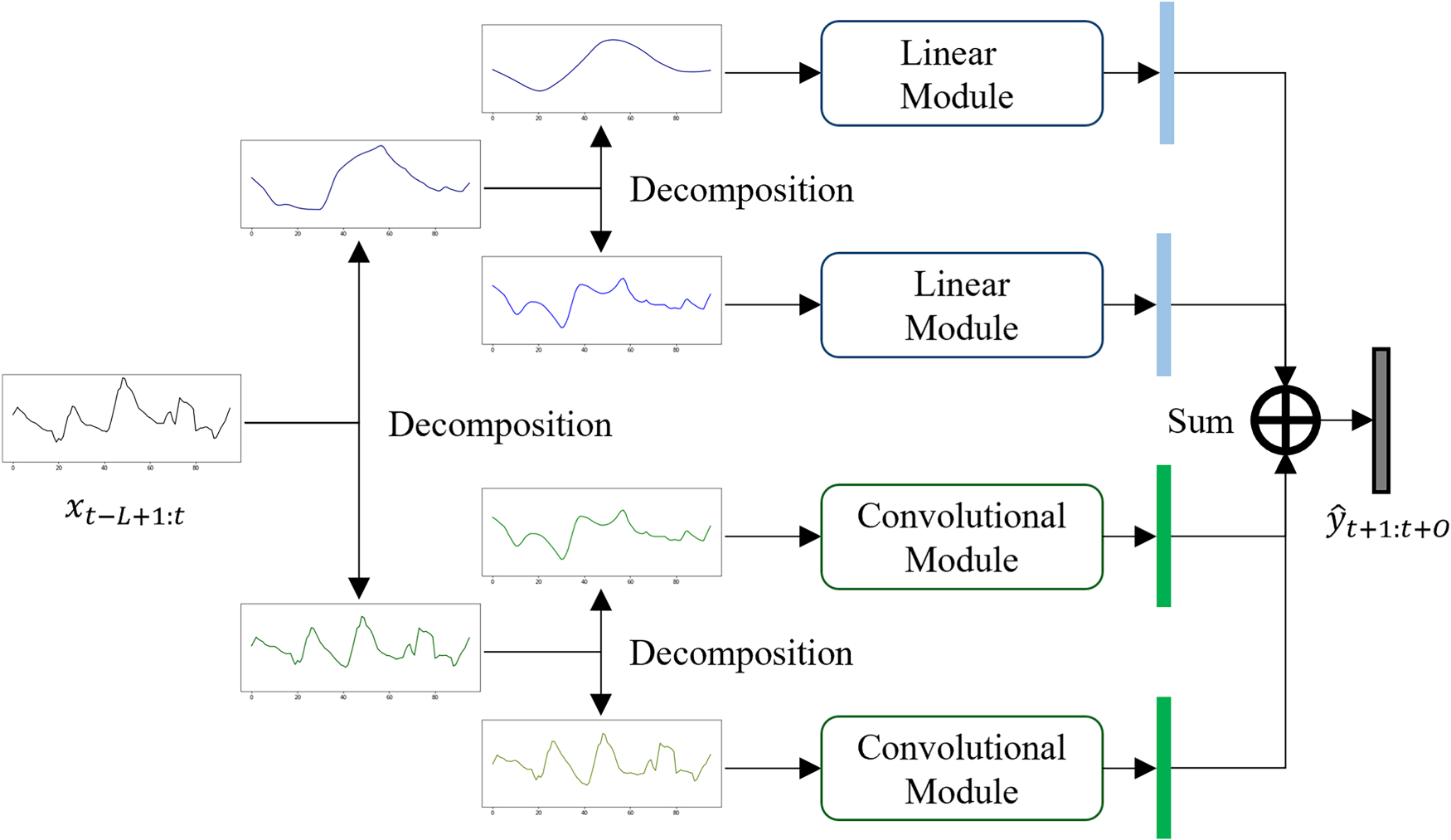
Simple overview of TSDNet architecture.
To alleviate the impact of the scale for individual instances, we utilize instance normalization
60
in which the input data is normalized for each instance separately rather than the entire batch. This process is performed on the input



Time series forecasting poses significant challenges due to factors such as seasonality and unpredictable fluctuations. To address these challenges, this paper proposes a systematic decomposition of time series, which identifies and isolates fundamental components to simplify the underlying structure and enhance the precision of subsequent predictive models. Drawing on the principles of DLinear, 20 we employ a two-stage procedure that extracts trends from seasonal components using a moving average and then repeats this process for more refined decomposition. Through the proposed two-stage decomposition, we can dissect the time series into elemental parts and elucidate different data characteristics, thereby enhancing the stationarity within the series. 53 The implementation of this two-stage decomposition is illustrated in Figure 2.
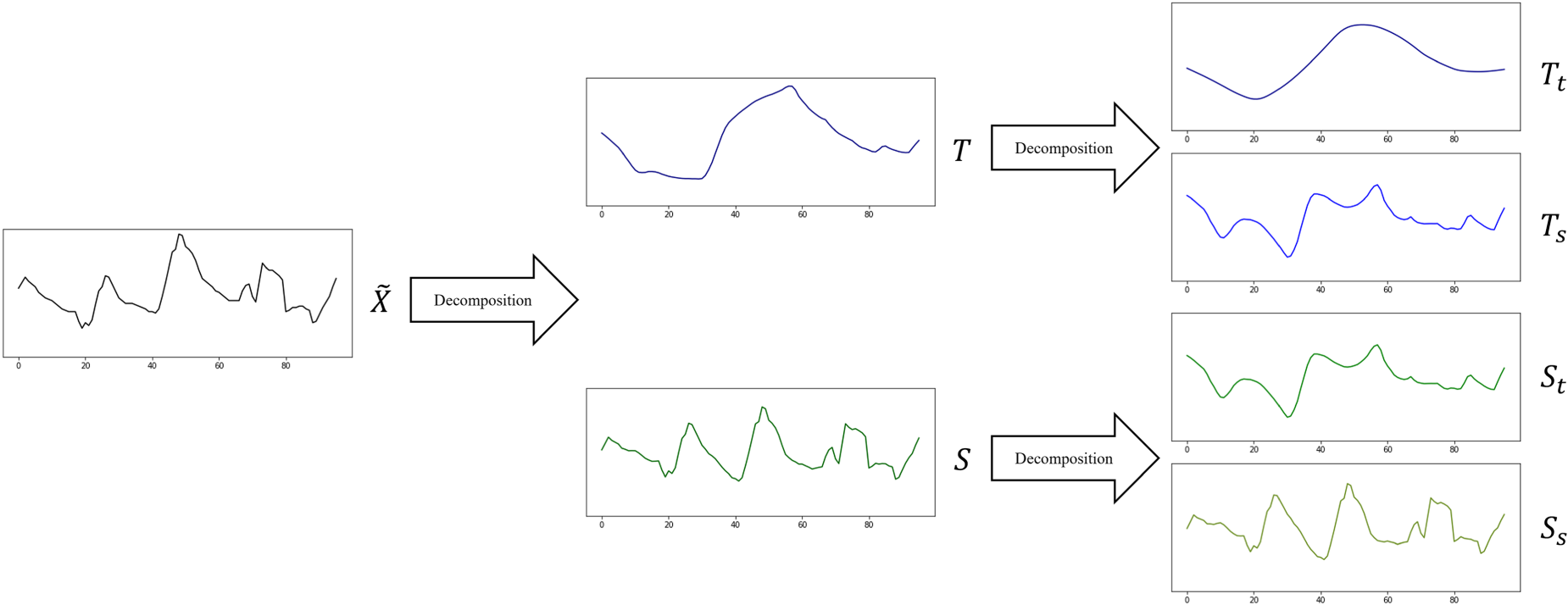
The example of two-phase time series decomposition.
First,




Based on the findings from Zeng et al.
20
and Li et al.,
14
it was demonstrated that utilizing a linear model structure can significantly enhance the forecasting accuracy of cyclical, long-term time series. Inspired by these insights, we adopt a linear module to the trend components of the time series, which is typically characterized by their smoother and more periodic natures. Let
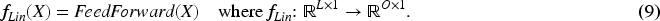
Different from trend components, seasonal components often contain various intricate and irregular patterns that are not fully addressed by trend decomposition. Therefore, these seasonal components are dealt with in a convolutional module to effectively capture their complex characteristics. To effectively accommodate these seasonal aspects, we utilize the
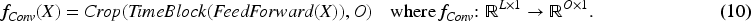
Data length extension
To effectively extract the relevant information from time series data, a data length extension is applied to the input of
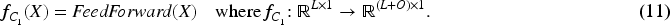
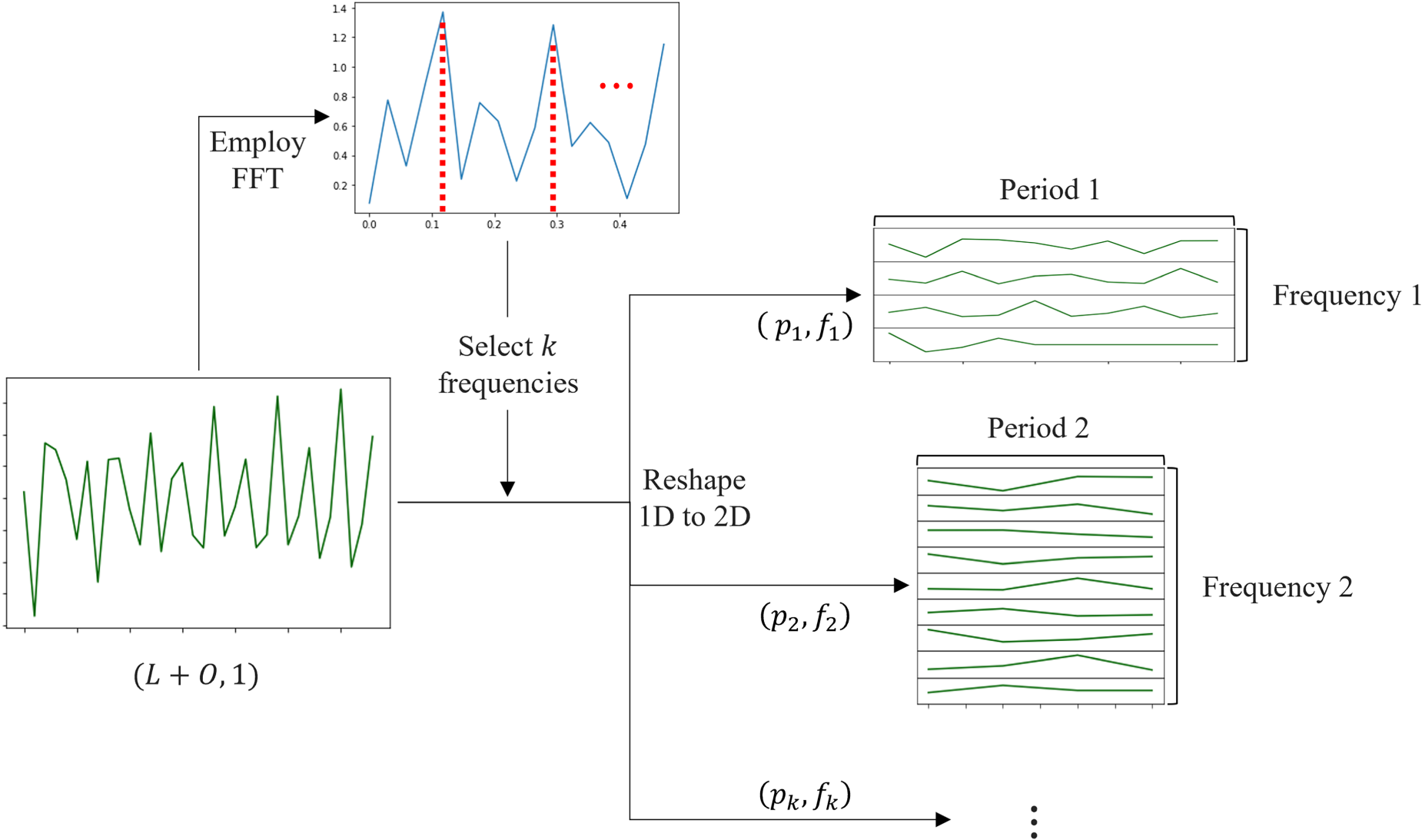
Implementation of TimeBlock
CNNs are generally acclaimed for their proficiency in capturing two-dimensional (2D) variations using 2D kernels. However, the input of TSDNet corresponds to a one-dimensional (1D) form. To exploit the advantages of CNNs for time series forecasting, we incorporate
In

FFT-based 2D transformation procedure.
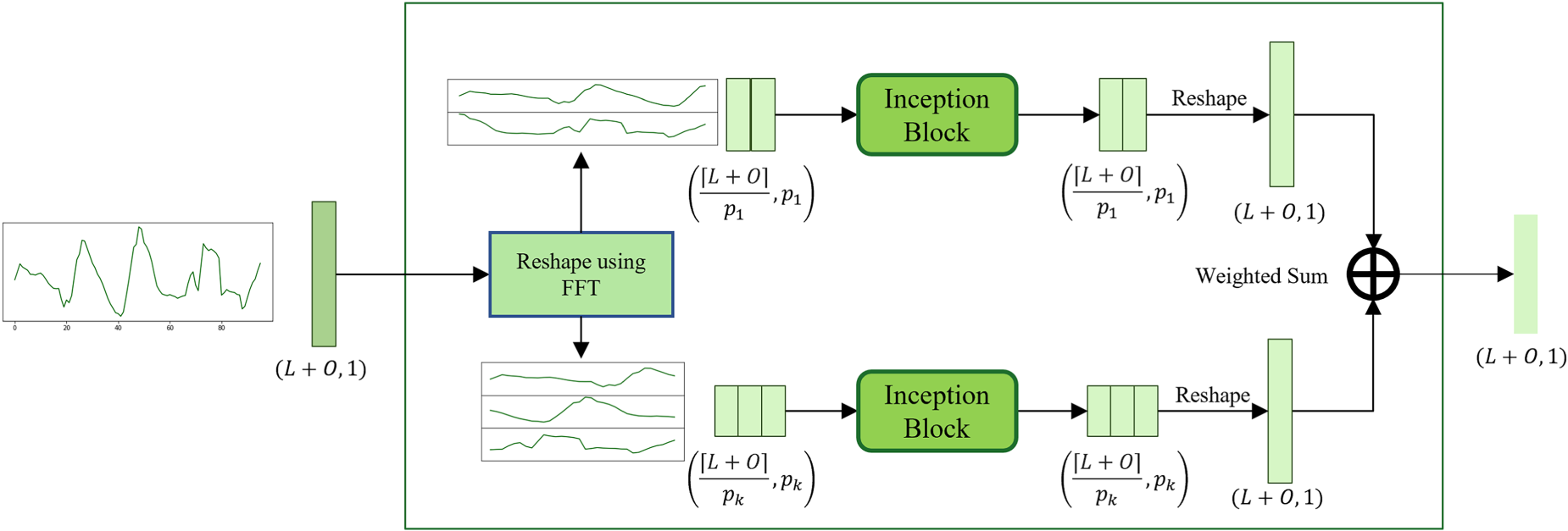
After implementing
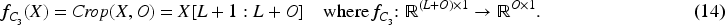
Finally, the convolutional module used in this paper, as previously defined in equation (10), can be summarized as follows:
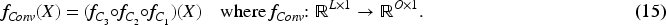
The entire forecasting process of TSDNet is summarized in equations (16) to (18).

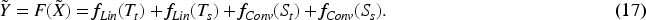

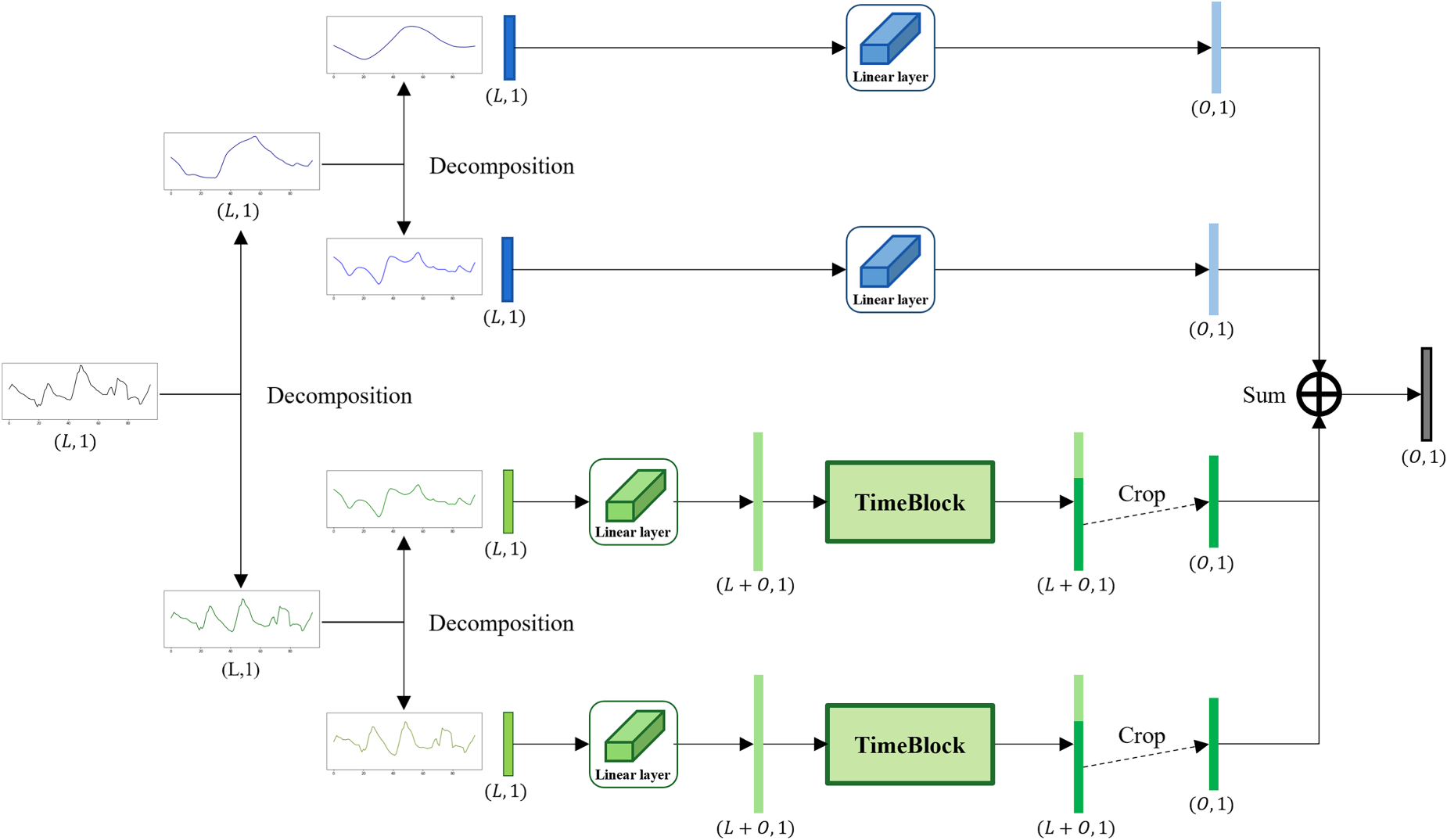
Entire structure of TSDNet.
The rationale behind the proposed two-stage decomposition approach is to effectively isolate stable long-term trends and short-term fluctuations, while reducing noise by separately handling residual elements. The trend subseries, which are characterized by their simple and repetitive structures, are processed using a linear module. This choice ensures efficient and accurate modeling of gradual and stable patterns that demand lower computational resources. On the other hand, the seasonal subseries, having been stripped of the trend component, retain irregular and complex fluctuations. A convolutional module is employed to better capture these intricate and diverse temporal dynamics. This module allows for extracting a broader range of features from the seasonal subseries, facilitating a deeper understanding of short-term variations. As a result, TSDNet provides the robust and accurate long-term forecasts
Datasets
Benchmark time series datasets
We prepared 6 datasets, where 4 datasets were collected from real-world datasets for long-term time series forecasting, and the others were from public benchmarks. The details of 6 datasets are described as follows:
Table 1 lists a brief description of 6 datasets. In Table 1 the dataset size indicates the numbers of the training, validation, and test datasets, respectively.
Dataset descriptions.

Dataset descriptions.
U.S. Stock dataset information.
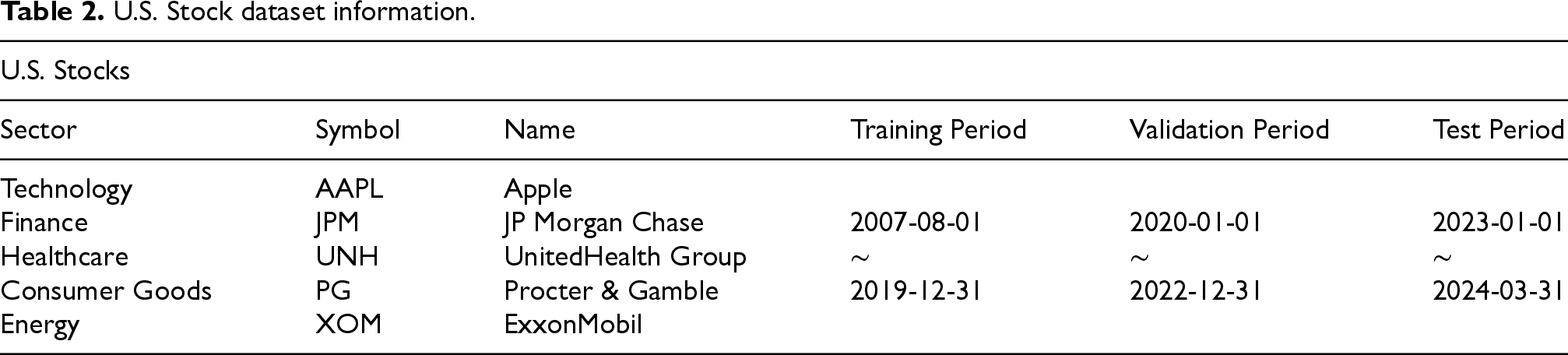
The U.S. stock datasets utilized in this study consist of five major sectors—Technology, Finance, Healthcare, Consumer Goods, and Energy—featuring representative companies such as Apple (AAPL), JP Morgan Chase (JPM), UnitedHealth Group (UNH), Procter & Gamble (PG), and Exxon Mobil (XOM). Each of the datasets is partitioned to reflect diverse economic conditions, with a training period from August 1, 2007, to December 31, 2019, a validation period from January 1, 2020, to December 31, 2022, and a test period from January 1, 2023, to March 31, 2024. Details of the dataset are presented in Table 2.
Experiment configurations of TSDNet
In the experiments, TSDNet was implemented by using the PyTorch and trained with the ADAM optimizer
64
and MSE loss. Specifically, the batch size and initial learning rate were set to 32 and
Evaluation metrics
The two representative metrics, mean square error (MSE) and mean absolute error (MAE), are used to evaluate the performances of time series forecasting models. Generally, MSE is known to be more sensitive to outliers, while MAE provides a more linear perspective of errors. MSE is a common metric used to measure the average squared differences between the predicted and actual values, calculated using the following formula:


To provide a broad perspective on current advancements and various methodologies in time series forecasting, the performance of the proposed method was compared with 16 models from existing literature. This selection spans a range of methodologies, from classical statistical techniques to modern deep learning approaches, facilitating diverse comparisons in both univariate and multivariate time series forecasting. Specifically, the baseline methods evaluated in this paper include ten transformer-based models: Transformer, 38 Reformer, 40 LogTrans, 39 Informer, 41 Pyraformer, 43 Autoformer, 18 Stationary, 46 Fedformer, 57 ETSformer, 44 and iTransformer. 48 Each model showcases unique adaptations and innovations within the transformer architecture. In addition, we compared two RNN-based models, LSTM 26 and LSSL, 37 known for their capability to capture time-dependent patterns in time series data. Furthermore, recent approaches, including TimesNet 16 two MLP-based models, LightTS 52 and DLinear, 20 were also included in the performance comparison.
Results
Performance comparison on multivariate and univariate time series forecasting
This section presents the results of time series forecasting experiments conducted on six diverse datasets, covering both univariate and multivariate scenarios. Throughout these experiments, a consistent input length (
For multivariate time series forecasting, TSDNet was assessed using six datasets, including four ETT datasets, along with Exchange and Weather data. Table 3 illustrates the performance of TSDNet in terms of MSE and MAE, compared with other methods. MAE and MSE values for comparison models were obtained from Wu et al. 16 and Liu et al. 48

TSDNet excelled in most datasets, particularly the ETT datasets. On ETTm2 and ETTh2 datasets, TSDNet achieved the best performance across all prediction lengths for both MSE and MAE metrics. Specifically, TSDNet showed a 3% improvement in MSE (from 0.288 to 0.280) on ETTm2 and a 1% improvement (from 0.383 to 0.380) on ETTh2, averaged across the four prediction lengths. On the ETTm1 dataset, TSDNet ranked first for prediction lengths of 336 and 720 and achieved the best performance in MAE when considering the average across the four lengths. On the ETTh1 dataset, TSDNet showed weaker performance for shorter prediction lengths. On the other hand, TSDNet performed well at the 336-length prediction for MAE and at 720-length predictions for both MSE and MAE.
In the Weather dataset, TSDNet ranked second in both MSE and MAE for the 720-length prediction but led in most other lengths, achieving the best performance across the four prediction lengths. On the other hand, TSDNet showed weaker performance on the Exchange dataset compared to the other datasets. This may be attributed to the high level of uncertainty and lack of long-term repetitive patterns in financial data, which makes it more complicated to forecast long-term time series. 35
Table 4 presents the univariate time series forecasting results on all ETT datasets: ETTm1, ETTm2, ETTh1, and ETTh2. In Table 4, since TimesNet primarily provides multivariate forecasting results, we implemented and tested several baseline models, including TimesNet, iTransformer, DLinear, Autoformer, Informer, and Transformer for univariate forecasting. The hyperparameters of baseline models were the same as those in Wu et al. 16
MSE and MAE results of TSDNet and the other methods for univariate time series forecasting.
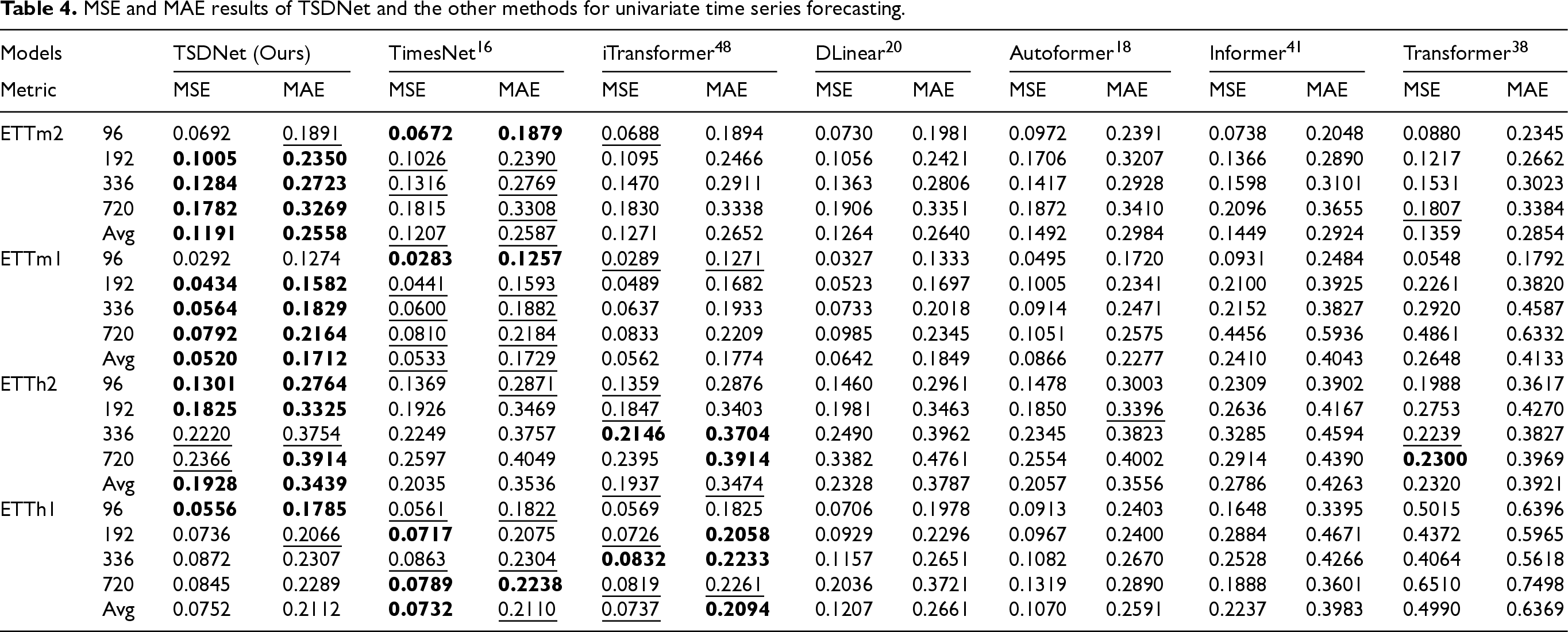
For the ETTm2 dataset, TSDNet achieved the second-best performance for the 96-length prediction and the best for all other lengths, achieving a 1% improvement in mean performance across all four lengths in terms of MSE (from 0.1207 to 0.1191). Similarly, for the ETTm1 dataset, TSDNet ranked third for the 96-length prediction and first for all other lengths, which leads to a 2% improvement in average MSE (from 0.0533 to 0.0520). On the ETTh2 dataset, TSDNet ranked first in both metrics for the 96 and 192 lengths, second for the 336-length prediction, and second in MSE but first in MAE for the 720-length prediction, improving the mean MSE from 0.1937 to 0.1928. Finally, for the ETTh1 dataset, TSDNet demonstrated top performance for the 96-length prediction but ranked third across the remaining lengths, resulting in third-place performance on average for both MSE and MAE. Based on the above observations, TSDNet consistently yielded near-top performance across all datasets and prediction lengths, which demonstrates the robustness and adaptability of the proposed method in various forecasting scenarios.
Table 5 presents the performance of TSDNet and baseline methods in U.S. stock price forecasting. Each method was evaluated for forecast horizons of 10, 20, 30, 60, and 120 days. A 60-day input sequence was used for each method. TSDNet consistently outperformed the other baseline models on AAPL and PG in both MSE and MAE. On the other hand, TSDNet ranked first in MAE for JPM and in MSE for XOM while ranking second in both MSE and MAE for UNH. Among the comparison models, iTransformer yielded the lowest MAEs and MSEs for UNH and XOM, while TimesNet ranked first in MSE for JPM. TSDNet demonstrated stable performance across all forecast horizons and robust adaptability to various stocks, which suggests its efficiency and reliability for U.S. stock price forecasting.
MSE and MAE results of TSDNet and the other methods for U.S. stock closing price forecasting.
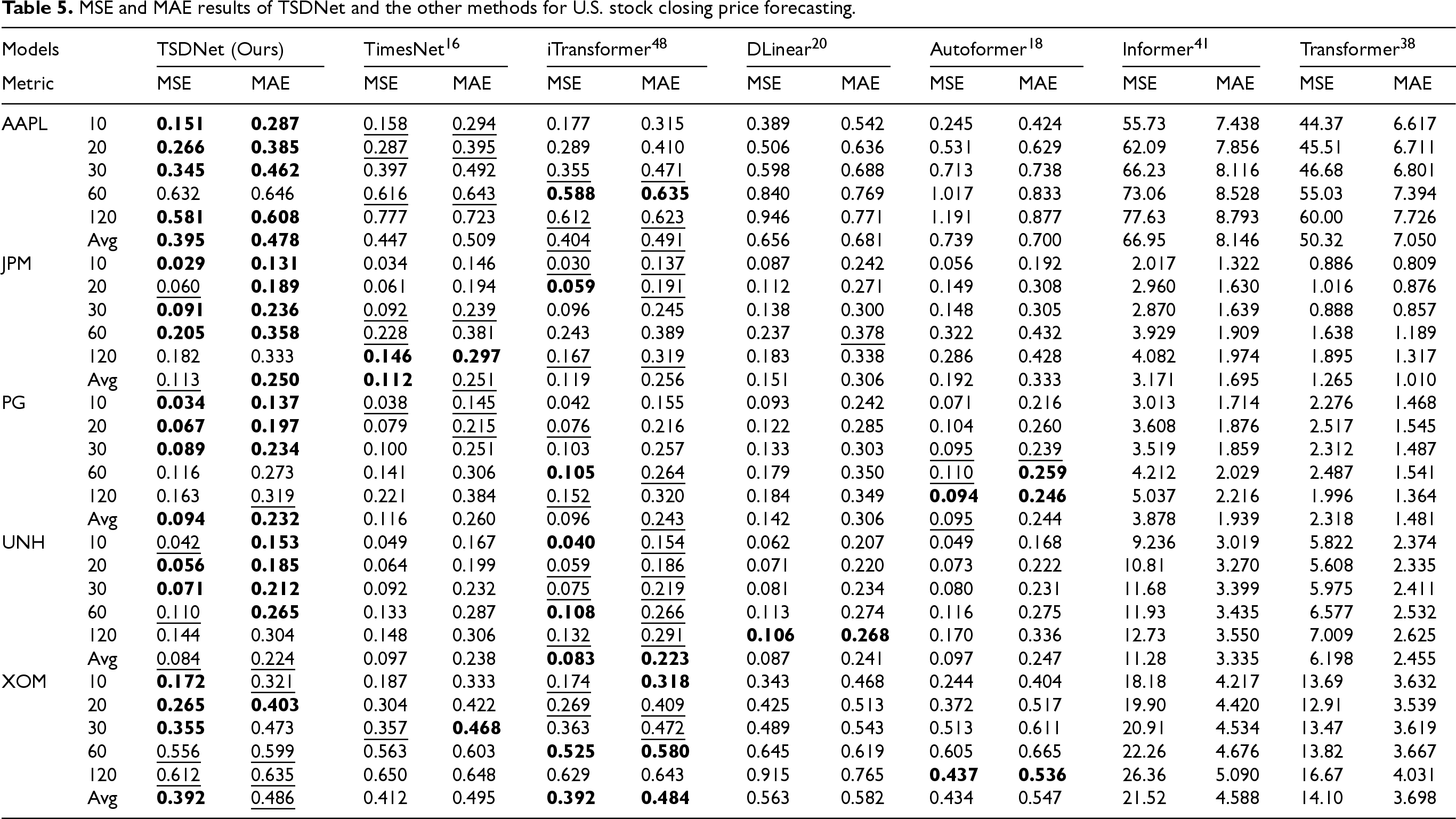
MSE and MAE results of TSDNet and the other methods for U.S. stock closing price forecasting.
We conducted a hyper-parameter sensitivity analysis on the ETTh1 dataset to evaluate the effects of optimizers and loss functions on the performance of TSDNet. To investigate the effectiveness of each optimizer, we tested the three well-known optimizers, including Adam, RMSprop, 64 and Adagrad, 65 while keeping the loss function fixed as MSE. As shown in Table 6, Adam consistently performed better than the others.
Comparison of optimizers based on MSE and MAE.
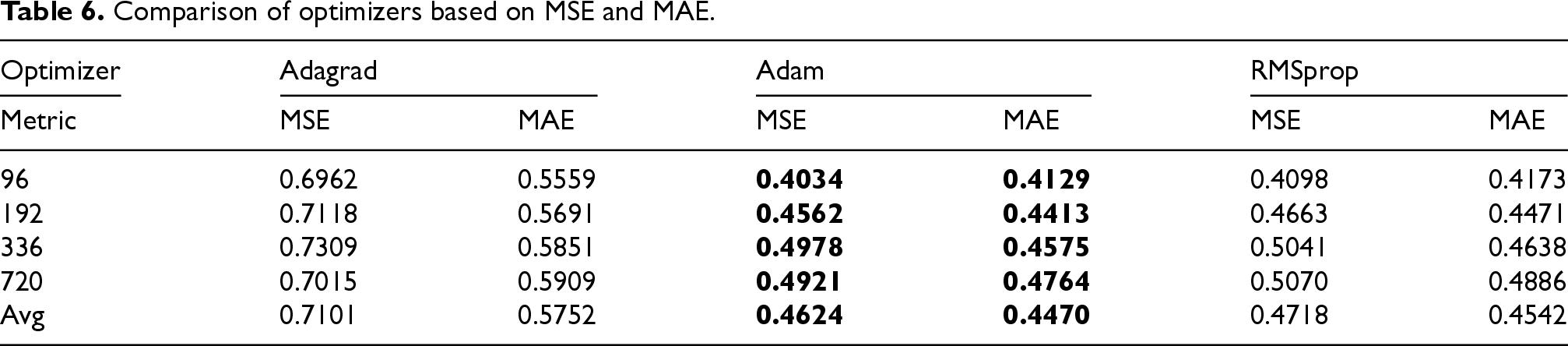
Comparison of optimizers based on MSE and MAE.
Next, we evaluated the loss functions MSE, MAE, and Huber 66 by setting the optimizer to Adam based on the above results. Table 7 shows that MSE provided the best results among the tested loss functions. Based on these findings, the combination of Adam and MSE was used for TSDNet in the other experiments.
Comparison of loss functions based on MSE and MAE.
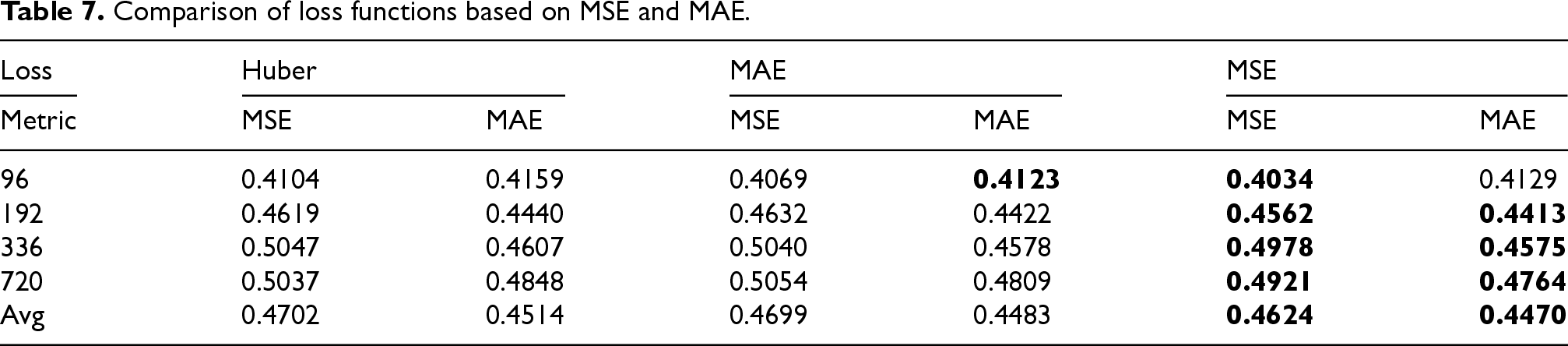
Table 8 presents the training time and memory complexity of four representative methods, including TSDNet, TimesNet, DLinear, and iTransformer. The computational complexity of each model depends on three main parameters:
Comparison of computational complexity across forecasting models.

Comparison of computational complexity across forecasting models.
Ablation of decomposition
To analyze the effects of employing time series decompositions and different modules on TSDNet, we carried out the two ablation studies in this subsection. In ablation studies, we utilized the ETTh2 dataset for both multivariate and univariate scenarios, with each experiment maintaining an input length of 96 and prediction lengths of 96, 192, 336, and 720. The first ablation study was carried out by changing the number of decompositions from 0 to 2, and the decompositions were performed on either trend or seasonal components as presented in Table 9. To investigate only the effects of decompositions on TSDNet, we note that only the linear module
Configurations for an ablation study to evaluate the effects of time series decomposition frequency.
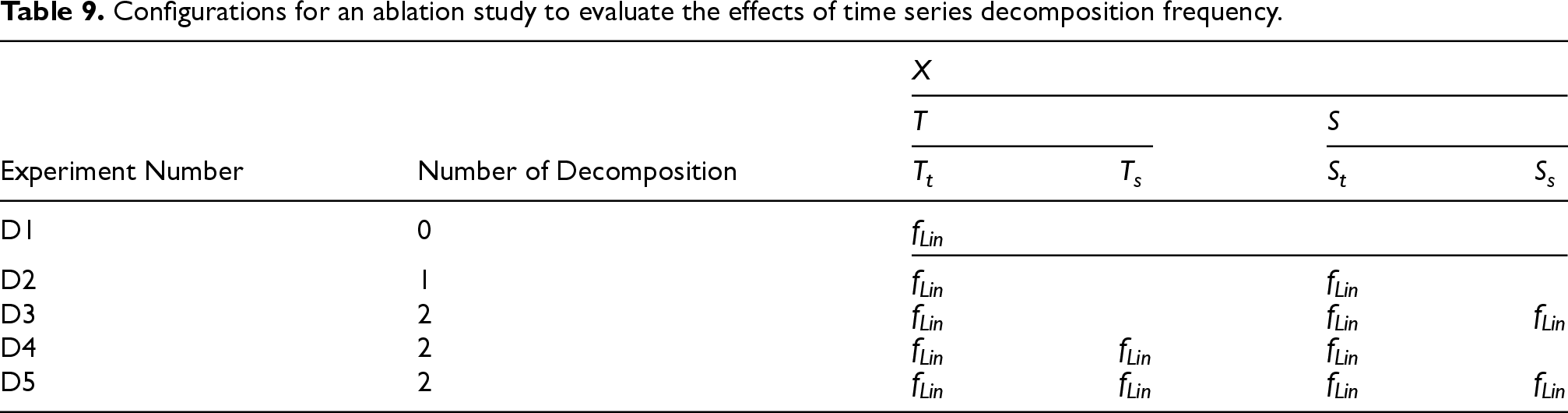
Configurations for an ablation study to evaluate the effects of time series decomposition frequency.
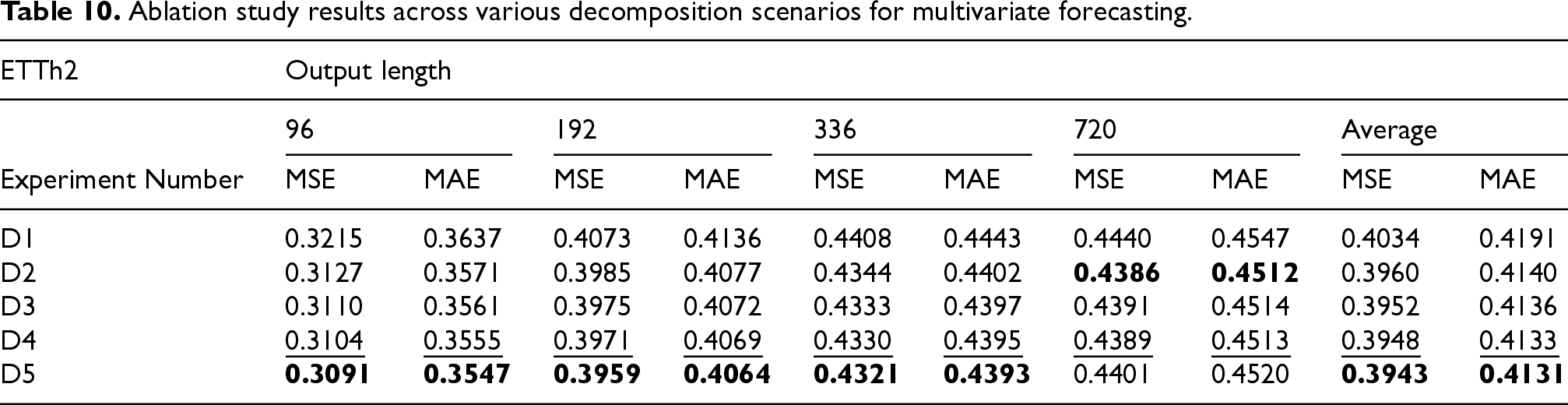
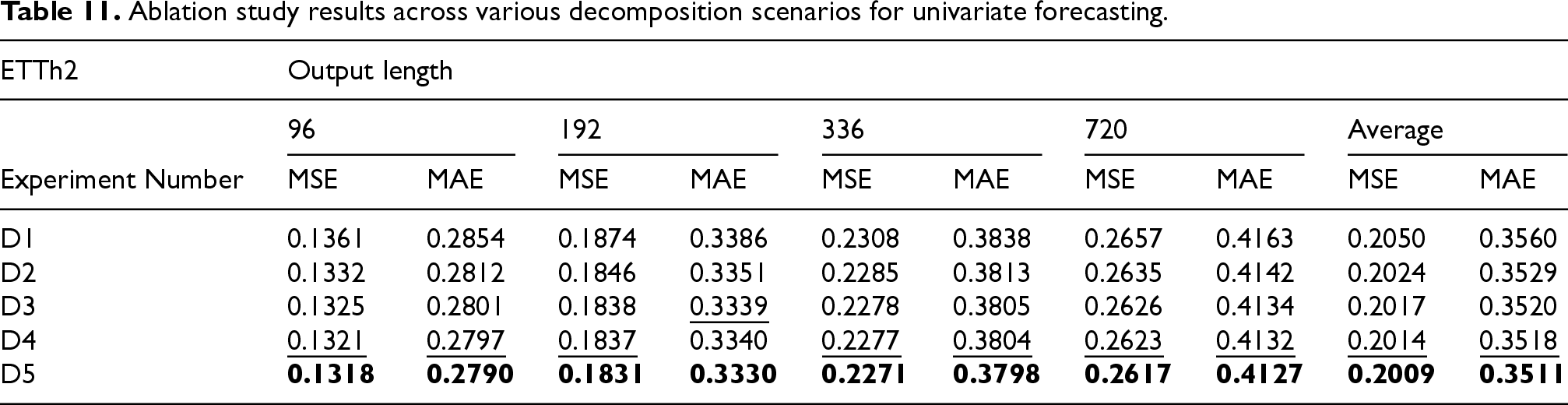
Tables 10 and 11 display the ablation study results for multivariate and univariate predictions, respectively. Interestingly, a single decomposition was more effective for
Ablation study results across various decomposition scenarios for multivariate forecasting.
Ablation study results across various decomposition scenarios for univariate forecasting.
Next, we investigate the effects of employing different modules on the decomposed components. Based on the superiority of the two-stage decomposition shown in Tables 10 and 11, we evaluated the impact of using linear and convolutional modules on trend and seasonal components, Table 12 lists the experiment settings for the second ablation study, where
Configurations for an ablation study for analyzing the impact of module combinations.
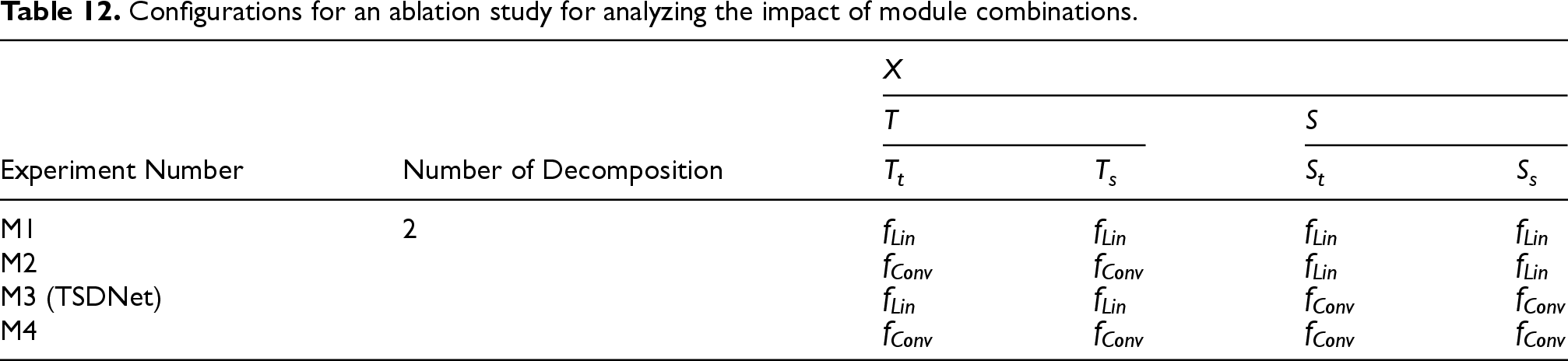
Configurations for an ablation study for analyzing the impact of module combinations.
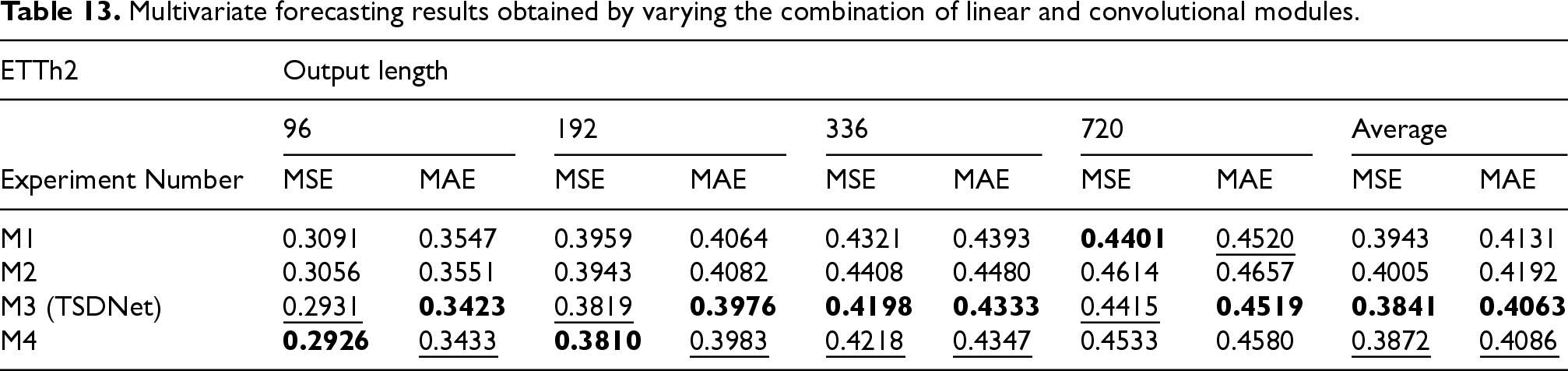
Tables 13 and 14 present the results of the second ablation study. As shown in Table 13, the performances achieved by M1 and M4 were the near-best in 720-length predictions and shorter predictions, respectively. Nevertheless, it was observed that M3, which corresponds to the proposed TSDNet, exhibited the best average performance.
Multivariate forecasting results obtained by varying the combination of linear and convolutional modules.
Univariate forecasting results obtained by varying the combination of linear and convolutional modules.
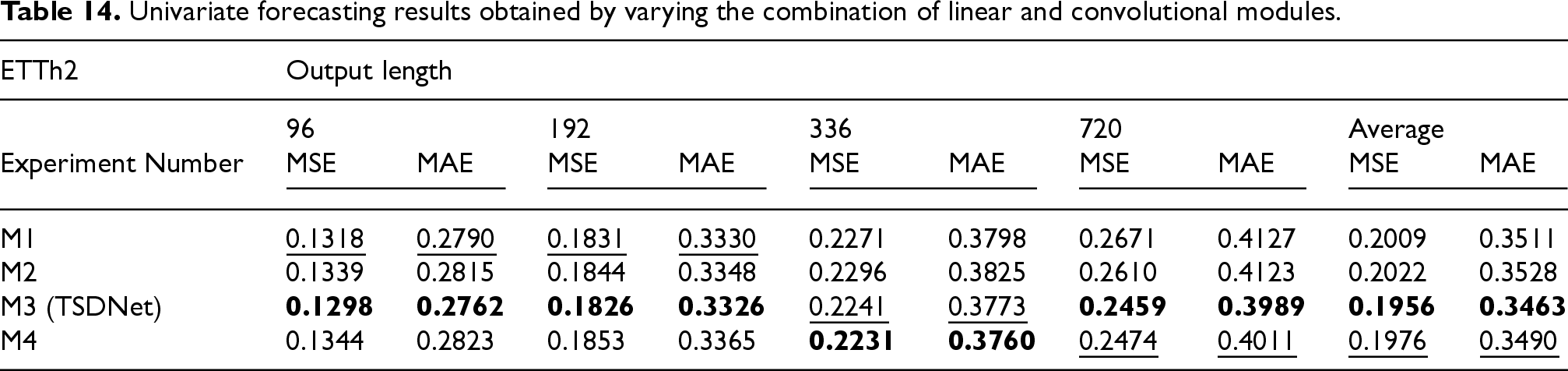
Besides, Table 14 shows that M1 outperformed M4 when
In this paper, we proposed a novel two-stage decomposition-based hybrid deep neural network for long-term time series forecasting. The proposed approach incorporates a two-stage time series decomposition into four distinct categories of trends and seasonalities. Specifically, we employed a single linear layer for the trend component, while for the seasonal component, we utilized a convolutional module based on
We conducted extensive experiments using six benchmark datasets and five real-world univariate financial datasets to compare the performance of the proposed method with the other baseline methods for both multivariate and univariate time series forecasting. For multivariate predictions, the proposed method outperformed other methods in four out of six benchmark datasets. For univariate predictions, it outperformed other methods in three out of four benchmark datasets. In the real-world financial datasets, our method ranked highest on two datasets, achieved either first or second place depending on forecast length for two datasets, and ranked second on one dataset. Furthermore, ablation studies were conducted to validate the effectiveness of the model, focusing on the number of decomposition stages and the implementation of different modules on the decomposed elements.
In future work, we plan to investigate the potential benefits of further decomposition stages on model performance. Additionally, as our experiments used a fixed moving average size for time series decomposition, future research will aim to understand how varying the moving average size impacts different datasets and decomposition stages. We also intend to reduce the computational complexity of TSDNet. In particular, optimizing the decomposition process and enhancing the efficiency of model components are promising directions for improving the proposed method.
Footnotes
Acknowledgements
This work was supported in part by the National Research Foundation of Korea (NRF) grant funded by the Korea Government (MSIT) (No. NRF-2022R1F1A1066744), and in part by the Smart Manufacturing Innovation R&D program funded by the Korea Ministry of SMEs and Startups in 2024 (Project No. RS-2024-00433001).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Research Foundation of Korea (NRF) grant funded by the Korea Government (MSIT) (No. NRF-2022R1F1A1066744), and in part by the Smart Manufacturing Innovation R&D program funded by the Korea Ministry of SMEs and Startups in 2024 (Project No. RS-2024-00433001).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.