
Abstract
Long-term time series forecasting (LTSF) has become an urgent requirement in many applications, such as wind power supply planning. This is a highly challenging task because it requires considering both the complex frequency-domain and time-domain information in long-term time series simultaneously. However, existing work only considers potential patterns in a single domain (e.g., time or frequency domain), whereas a large amount of time-frequency domain information exists in real-world LTSFs. In this paper, we propose a multi-scale hierarchical network (MHNet) based on time-frequency decomposition to solve the above problem. MHNet first introduces a multi-scale hierarchical representation, extracting and learning features of time series in the time domain, and gradually builds up a global understanding and representation of the time series at different time scales, enabling the model to process time series over lengthy periods of time with lower computational complexity. Then, the robustness to noise is enhanced by employing a transformer that leverages frequency-enhanced decomposition to model global dependencies and integrates attention mechanisms in the frequency domain. Meanwhile, forecasting accuracy is further improved by designing a periodic trend decomposition module for multiple decompositions to reduce input-output fluctuations. Experiments on five real benchmark datasets show that the forecasting accuracy and computational efficiency of MHNet outperform state-of-the-art methods.
Keywords
Introduction
Time series forecasting has been widely used in various fields such as electricity, energy, climate, and transportation [11,34,7]. Long-term time series forecasting (LTSF), in particular, is challenging due to the uncertainty of forecasting increasing as the forecast horizon extends [32,25,47]. It is crucial for many different types of applications, e.g., transportation participants’ long-term trajectory estimates, long-term renewable energy policies, planning for electricity consumption, environmental monitoring [29,27], etc. Factors like trend changes, structural changes, and external disturbances in long-term time series further complicate forecasting [5].
Making an accurate LTSF model is a difficult undertaking, as both time-domain information (i.e., the sensor data over time) and frequency-domain information (i.e., the information about each frequency component of the sensor data) need to be considered jointly. The equivalent transformation of the two is realized by the Fourier transform. To address this issue, conventional techniques, e.g., Seasonal Auto-Regressive Integrated Moving Average (SARIMA) [37], Gaussian Process (GP) [18], Bayesian Temporal Matrix Factorization (BTMF) [3], and Vector Autoregression Moving-Average with Exogenous Regressors (VARMAX) [12], often cling to the rigid stationary assumption and are unable to account for the non-linear relationships between variables. Over the past few years, deep learning-based methods like recurrent neural networks (RNNs) [21,19], long short-term memory networks (LSTMs) [16,35,48], and transformer-based methods [32,47,41,20,8,46] have made significant innovations in time series forecasting. However, transformer-based methods, due to their computational complexity and memory requirements, struggle with modeling long sequences. Recently, a linear model called DLinear [44] has shown competitive performance in transformer-based methods. However, PatchTST [32], a new transformer-based model to shorten sequence length by patch, achieves awesome results in long-term time series forecasting. Despite the success of various LTSF models, the existing work overlooks two crucial aspects.
Firstly, existing time-domain work [26,24,33] only takes into account time correlations at one time scale, which might not adequately capture the variations found in a wide range of real-world situations. In fact, long-term sequences often exhibit multiple time patterns at different time resolutions (e.g., seconds, minutes, hours), and different time scales are typically associated with different periodic patterns present in the data. For instance, in electricity load forecasting, different hours within a day exhibit different periodicities, and the load also varies from week to week, as shown in Fig. 1. Rich information is provided by these multiscale time patterns for LTSF modeling. Therefore, efficiently capturing long-term dependencies and decomposing multiscale time patterns in time series data is an important challenge for LTSF models.
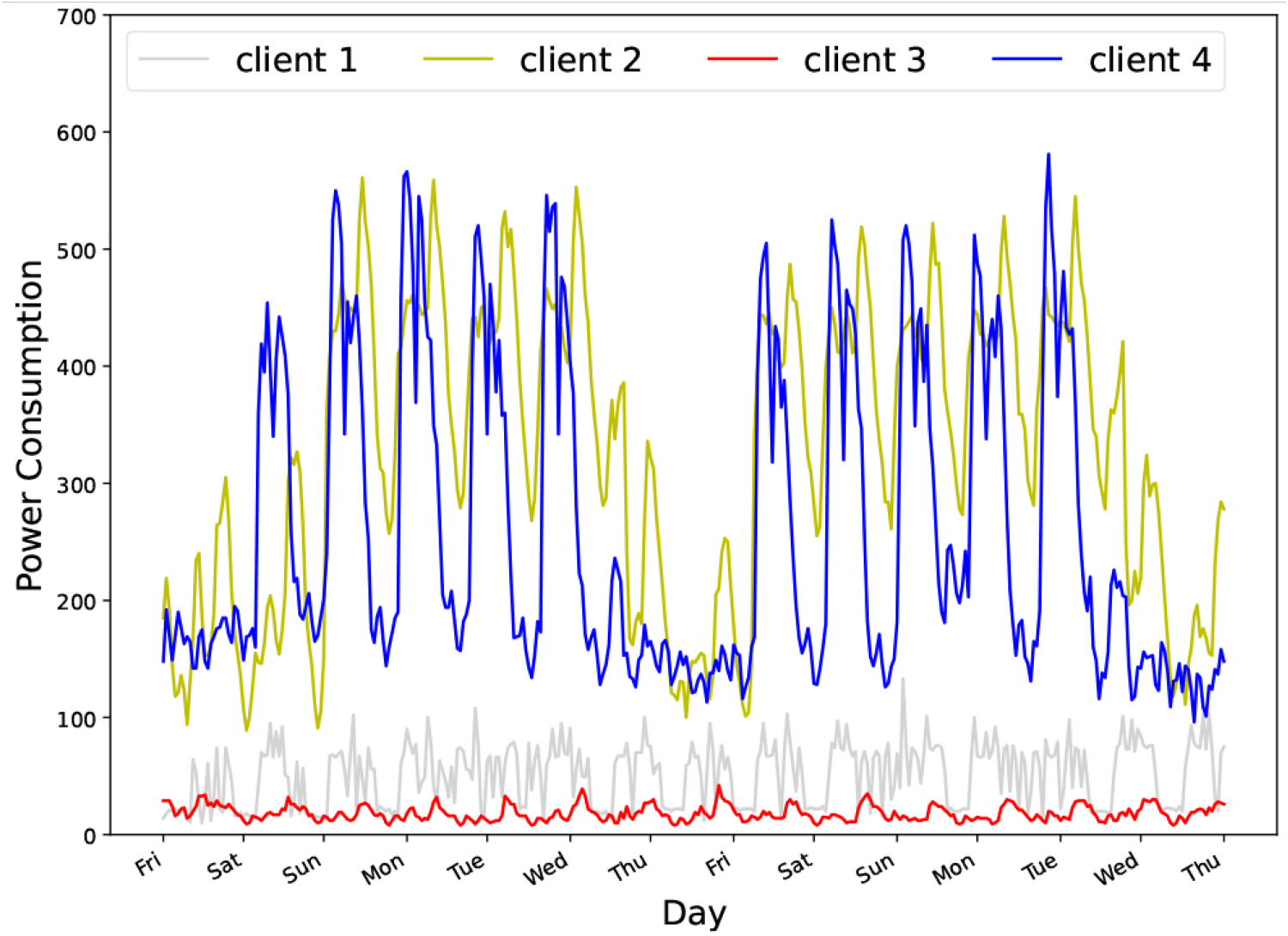
The pattern of power consumption was repeated daily and weekly for client 1 and 3 and weekly for client 2 and 4 in the Electricity dataset during the two-week period from 2:00 on Friday to 23:00 on Thursday.
Secondly, the time-frequency information of long-term time series has not been thoroughly researched. Most existing solutions focus on processing information in a single domain, such as the time domain or the frequency domain. For instance, Autoformer [41] and PatchTST [32] only consider time periodicity and perform semantic learning with an enhanced Transformer structure, while FiLM [46] and FEDformer [47] only focus on the frequency domain. In order to analyze and forecast time series, both time and frequency information are necessary. Time-related periodicity and correlations are captured in the time domain, while global features and potential time series changes are captured in the frequency domain. Thus, integrating time and frequency information in long-term time series to discover interactions between time patterns and frequency components at different time scales is another problem that needs to be urgently addressed in this paper.
In order to address the abovementioned challenges, this paper introduces a multi-scale hierarchical network (MHNet) based on time-frequency decomposition, dedicated to LTSF. MHNet consists of the frequency-enhanced information representation module and the multi-scale time-domain feature extraction module. In the multi-scale time-domain feature extraction module, we adopt a multi-scale hierarchical representation [9] of long-term time series in the time domain. We use window slicing to decompose the data into sub-sequences at multiple scales, extract features, and represent each sub-sequence. This not only allows for the gradual establishment of a global understanding and representation of the time series with different time scales but also enables handling long-term time series data with lower computational complexity and memory overhead. In the frequency-enhanced information representation module, we introduce a transformer based on frequency-enhanced decomposition [47]. It has two advantages: first, it employs a hybrid expert module for seasonal trend decomposition to extract features in the frequency domain, better capturing the global features of the time series. Multiple decompositions can also reduce input-output fluctuations, further improving forecasting accuracy. Second, it is also possible to lower the computational complexity of the transformer by choosing a fixed number of Fourier components at random. By integrating these two ideas, we design a multi-scale window mechanism in MHNet to capture time patterns at different time resolutions, achieving joint modeling of time and frequency domains in long-term time series. The main contributions of this paper are as follows:
Through joint processing of long-term time series in the time and frequency domains, we propose a multi-scale hierarchical network (MHNet) based on time-frequency decomposition for robust and efficient LTSF. To improve the efficiency of transformers on long sequences, we introduce multi-scale hierarchical representation and Fourier component random selection mechanisms, significantly reducing the computational complexity and memory requirements of the model. We use five actual benchmark datasets in our extensive experimentation. According to the experimental findings, MHNet performs better in terms of computational efficiency and forecasting accuracy than other methods.
The rest of this paper is arranged as follows:. In the second section, we introduce related work, and in the third section, we provide a detailed explanation of the proposed MHNet framework. In the fourth section, we present the experimental design and settings of the proposed framework. The fifth section concludes the paper.
Long-term time series forecasting (LTSF) [17] refers to the forecasting and analysis of data over an extended future time range, often involving forecasts spanning multiple quarters, years, or even longer timeframes. Such forecasts require consideration of various factors, including seasonal changes, trends, periodicity, and the possibility of outliers. In the following paragraphs, we first present the recent developments in the field of time series forecasting. Then, we describe existing research on multi-scale hierarchical representation strategies that are based on the information domains (such as time and frequency domains) and LTSF models.
Long-term time series forecasting
The effectiveness of LTSF depends on the capacity of the model to demonstrate significant predictive ability and accurately represent intricate interactions between input and output. Deep learning methods, a type of machine learning approach utilizing neural network models for advanced pattern recognition and automatic feature extraction, have achieved remarkable success in long-term forecasting in recent years.
Common deep learning models include RNN, CNN, Transformer, and hybrid models [5]. However, traditional RNN models may encounter challenges in capturing long-sequence dependencies due to training-related issues such as gradient vanishing and explosion. But variants of RNNs such as LSTM, BiLSTM [28], and GRU [30] can effectively mitigate the aforementioned issues. Convolution kernels, which are usually employed to learn local patterns, limit CNN models’ capacity to capture global trends and periodicity. According to current research, transformer-based forecasting approaches perform better when predicting long sequences. This superiority is mostly attributed to their self-attention mechanism, which dynamically apprehends remote dependencies and thereby enables them to proficiently navigate intricate patterns and protracted temporal relationships.
In the task of time series prediction, the Transformer model treats the time steps of the input sequence as location information, represents the features of each time step as vectors, and employs an encoder-decoder framework for forecasting. Reformer [15] enhances efficiency, accuracy, and scalability by introducing separable convolutional and invertible layers. LogTrans [31] proposes an improvement for Transformer-based time series prediction, addressing two main weaknesses: position-independent attention and memory bottlenecks. However, the computational costs of both aforementioned models still remain relatively high, especially when compared to some lightweight models. Informer [45] adopts a generative decoder, self-attention refinement, and ProbSparse self-attention mechanism, reducing computation time by calculating a portion of the attention matrix. However, it still exhibits significant errors in predicting the peaks and valleys of the curves, making it challenging to meet the increasingly high precision requirements for long sequences. Autoformer [41] introduces a time series decomposition module, enhancing the self-attention module with a self-correlation mechanism to explore data patterns more effectively. However, it overly relies on identifying the periodic characteristics of time series data, making it unsuitable for training on datasets with weak periodicity. FEDformer [47], a model designed from a time-frequency perspective. This model incorporates two attention modules that utilize Fourier and wavelet transforms to process time series data. By applying attention operations in the frequency domain, FEDformer enhances the transformer’s capability to capture features of time series data in the frequency domain.
This paper proposes a time series prediction method that leverages a hierarchical multi-scale representation, fully utilizing temporal and frequency information. The model is designed to capture both time and frequency domain features effectively, considering the importance of capturing features from both perspectives.
Representation in time-frequency domain
Time series analysis and forecasting heavily depend on time-related correlations and periodicity. In recent years, numerous transformer-based solutions have been put forth in an attempt to capture the temporal and long-range dependencies. For example, Informer [45] introduces the ProbSparse self-attention extractive technique based on KL divergence to reduce model complexity. Autoformer [41] changes the Transformer into a deep decomposition structure and designs self-correlation mechanisms to learn subsequence-level time periodicity. FEDformer [47] uses a Fourier-enhanced structure for linear complexity. Pyraformer [20] applies pyramid attention modules with both inter-scale and intra-scale connections, achieving linear complexity. Non-stationary transformers [22] propose the attention of series stationarity and de-stationarity to over-stabilization. TimesNet [40] analyzes temporal changes within 2D spatial regions across multiple periods. LogTrans [31] reduces spatial complexity by capturing local information through the use of LogSparse [15] design and convolutional self-attention layers.
Bais patterns in the frequency domain are also essential for time series forecasting as they can capture global features and underlying variation patterns within the time series [36]. Therefore, various methods have been developed in recent years that leverage frequency-enhanced structures for time series forecasting. For instance, FEDformer [47] uses a Fourier-enhanced structure for frequency domain mapping. ETSformer [39] replaces the self-attention mechanism in Transformers by using exponential smoothing attention and frequency attention. FiLM [46] utilizes Legendre polynomial projection, and [38] uses Fourier projection to approximate historical information, eliminating any external noise. To directly learn features in the frequency domain, STFNets [43] incorporate the short-time Fourier transform into data processing. Fredo [36] learns in the frequency domain based on the periodic AverageTile model. Floss [42] employs periodic offset and spectral density similarity measures to learn representations with consistent periodicity. To efficiently extract time dependencies, JTFT [4] makes use of the sparsity of time series in the frequency domain along with a limited number of learnable frequencies. However, all the above transformer-based solutions have certain limitations, since the majority of models concentrate on creating new mechanisms to simplify the original attention mechanism in an effort to improve forecasting performance, particularly over longer forecasting horizons. Nonetheless, most models only consider time correlations at a single time scale, overlooking the importance of multi-scale time patterns in time series data with complex periodicity.
Multi-scale hierarchical representation
In this section, we review various multi-scale hierarchical representation strategies in different domains. Unlike the symbols in language data processing with Transformers, language data are generated by humans, which are highly semantic and information-dense, whereas time series data are naturally redundant. In general, Transformers can only learn feature representation of a fixed scale, making it challenging to capture features at different scales in the time series. Therefore, the hierarchical structure of time series data has two advantages: firstly, multi-scale hierarchical processing can utilize information at different time scales to progressively extract and learn features of the time series, building up a global understanding and representation of the time series, and secondly, this hierarchical strategy significantly reduces the computation length in the encoder, saving a considerable amount of computation cost.
Recently, there has been a significant increase in methods that utilize hierarchical strategies for multi-scale feature extraction. Swin Transformer [23] introduces a universal Transformer backbone that constructs hierarchical feature maps. It starts with small-sized patches and progressively merge adjacent patches in deeper Transformer layers to construct hierarchical representation, and achieve linear computational complexity related to the image size. HiFormer [9] proposes a structure based on a CNN Transformer that effectively combines global and local information. It uses a new Transformer-based fusion method to maintain the richness and consistency of feature representation between different scales for the segmentation task of 2D medical images. By generating feature maps at different scales, MA-CNN [2] applies multi-scale convolution to capture information at different scales along the time axis, so as to capture short-term, medium-term, and long-term dependencies in time series. By learning representations for time series using various scales, Formertime [6] addresses the limitation of Transformer models that can only generate fixed-scale sequence input representations, and can extract local features of time series. Additionally, adopting hierarchical strategies can significantly reduce computational costs. Motivated by Formertime, this paper utilizes window slicing to decompose long-term time series data into sub-sequences at multiple scales and extract features and representations for each sub-sequence.
The proposed scheme
Figure 2 introduces the overall framework of the MHNet model. The model consists of two main components: one is the Frequency enhanced Information representation module (FI), inspired by FEDformer [47], and the other is the Multi-scale time-domain Feature Extraction module (MFE). The advantage of FI is its strong ability to capture global features of time series in the frequency domain. However, this module can only learn features at a fixed scale, which is not conducive to learning latent information in time series. MFE addresses such a limitation by progressively extracting and learning features of time series in the time domain with hierarchical multi-scale processing, gradually building a global understanding and representation of time series using information at different time scales.
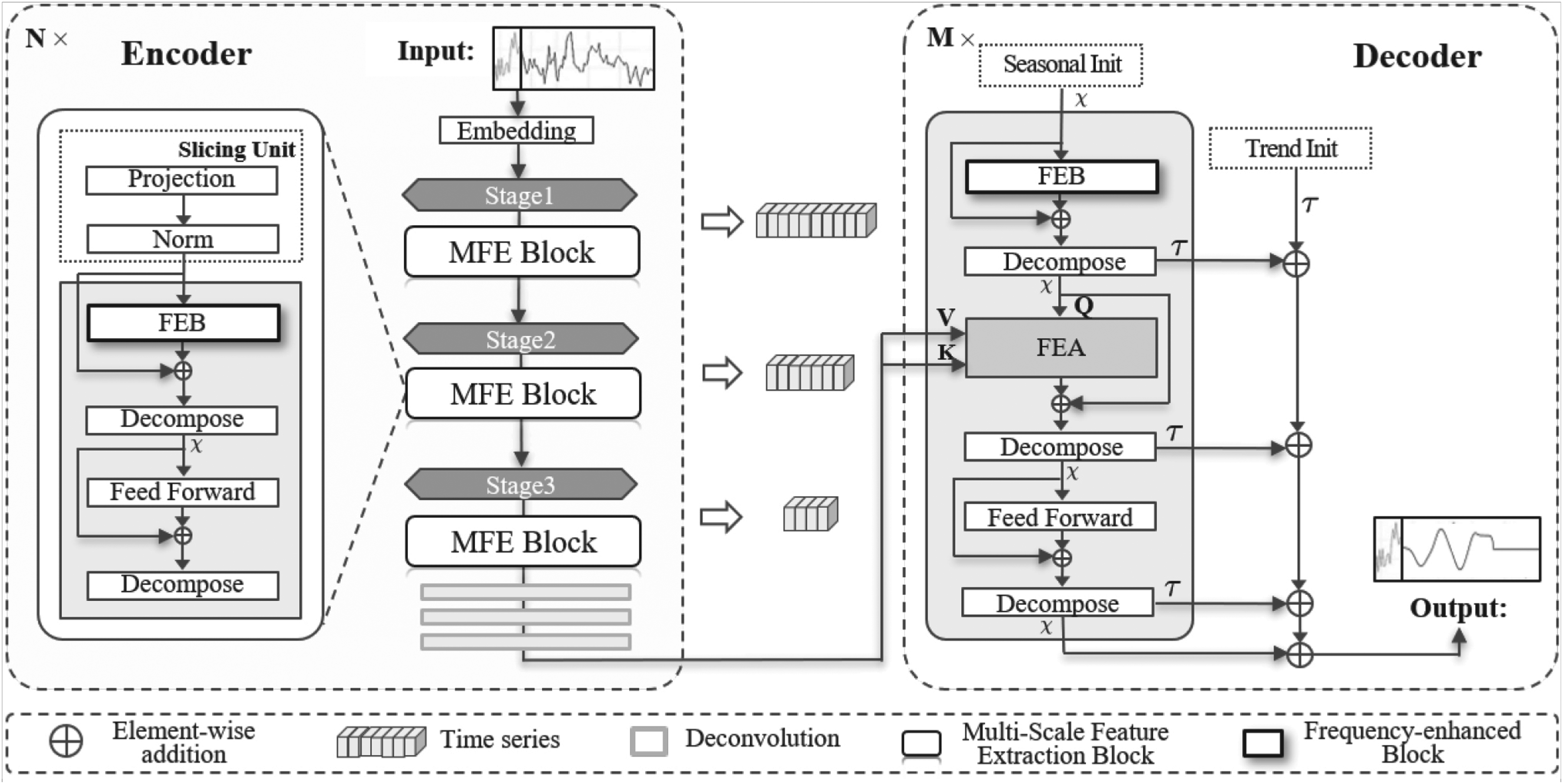
Illustration of the proposed Multi-scale Hierarchical Network (MHNet) based on time-frequency decomposition. MHNet has two primary sections: (a) a multi-scale hierarchical representation, extracting and learning features of time series in the time domain. (b) a Transformer based on frequency-enhanced decomposition to model global dependencies.
MFE is illustrated in Fig. 3. A collection of multivariate time series involving numerous channels makes up the model’s whole input. The time series have the same sequence length for every channel. To produce multi-scale representations of time series data, we utilize a hierarchical framework. Specifically, we partition the entire deep neural network architecture into multiple similar stages to generate features across different temporal scales. For the sake of simplicity, each stage’s architecture is analogous, composed of consecutive temporal slice processing operations and our designed time-frequency enhancement decomposition network. In the first stage, our method applies temporal slicing to multivariate time series, with the specific slicing method detailed in Section 3.1.1. Sliced data is then fed into the time-frequency enhancement decomposition module, and the processed data re-enters stage 2 for similar operations, repeating in stage 3 as well. This hierarchical structure enables the effective extraction of time series representations at different scales. Our proposed machine translation model comprises two components: data pre-processing and multi-scale feature extraction module.

The detailed architecture of the multi-scale time-domain feature extraction module.
The data pre-processing phase primarily involves time series slicing, which is the aggregation of consecutive time points, facilitating subsequent operations. Suppose the time series input at stage j, where j is selected from the set 1, 2, 3, is presented as

After processing through the projection ction, the input for stage 1 is l*c1, the input for stage 2 is l/s1*C1, the input for stage 3 is l/s1/s2*C2, and the output is l/s1/s2/s3*C3.
This systematic procedure ensures an efficient transformation of the raw time series into a format suitable for subsequent stages, optimizing the representation of temporal information in the computational pipeline.
In the proposed approach, multi-scale feature extraction mainly focuses on the encoder part of the model, which divides the model into three stages. Each stage processes time series data at different scales and uses the output of the previous stage as input to extract features. For example, assuming the input sequence has a size of l in the first stage, we first aggregate
There are two advantages of introducing hierarchical multi-scale representation in time series forecasting: firstly, hierarchical multi-scale processing can make use of information at different time scales, progressively extract and learn time series features, and gradually build a global understanding and representation of time series. Secondly, through this hierarchical strategy, the length of the entire time series before input to the encoder can be significantly reduced, saving a considerable amount of computational costs.
Frequency enhanced information representation
This section provides a detailed explanation of a frequency-domain enhancement information representation method based on Transformer, mainly consisting of typical encoder-decoder structure, frequency-domain enhancement mechanism, and time series decomposition mechanism.
Encoder-decoder
Our approach uses a three-stage encoder to learn global feature representations, with each encoder applying the same processing procedure. The encoder adopts a multi-layer structure and can be represented as
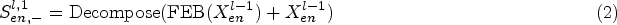
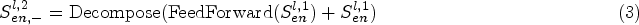

In the above equation,
Additionally, the decoder also uses a multi-layer architecture to processes the seasonal components and trend components of the time series. The structure is represented as
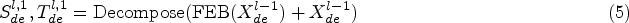
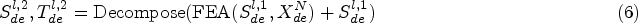
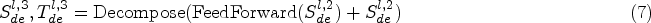

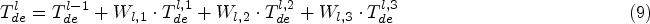
Similar to FEB, FEA is also implemented using a discrete Fourier transform mechanism and can replace the cross-attention module. The final forecasting result is the sum of the two fine decomposition components, i.e.,
In our plan, the frequency-domain enhancement mechanism consists of two parts, as shown in Fig. 4: the Frequency Enhancement Block (FEB) on the left and the Frequency Enhancement Attention Block (FEA) on the right. They are explained as follows.
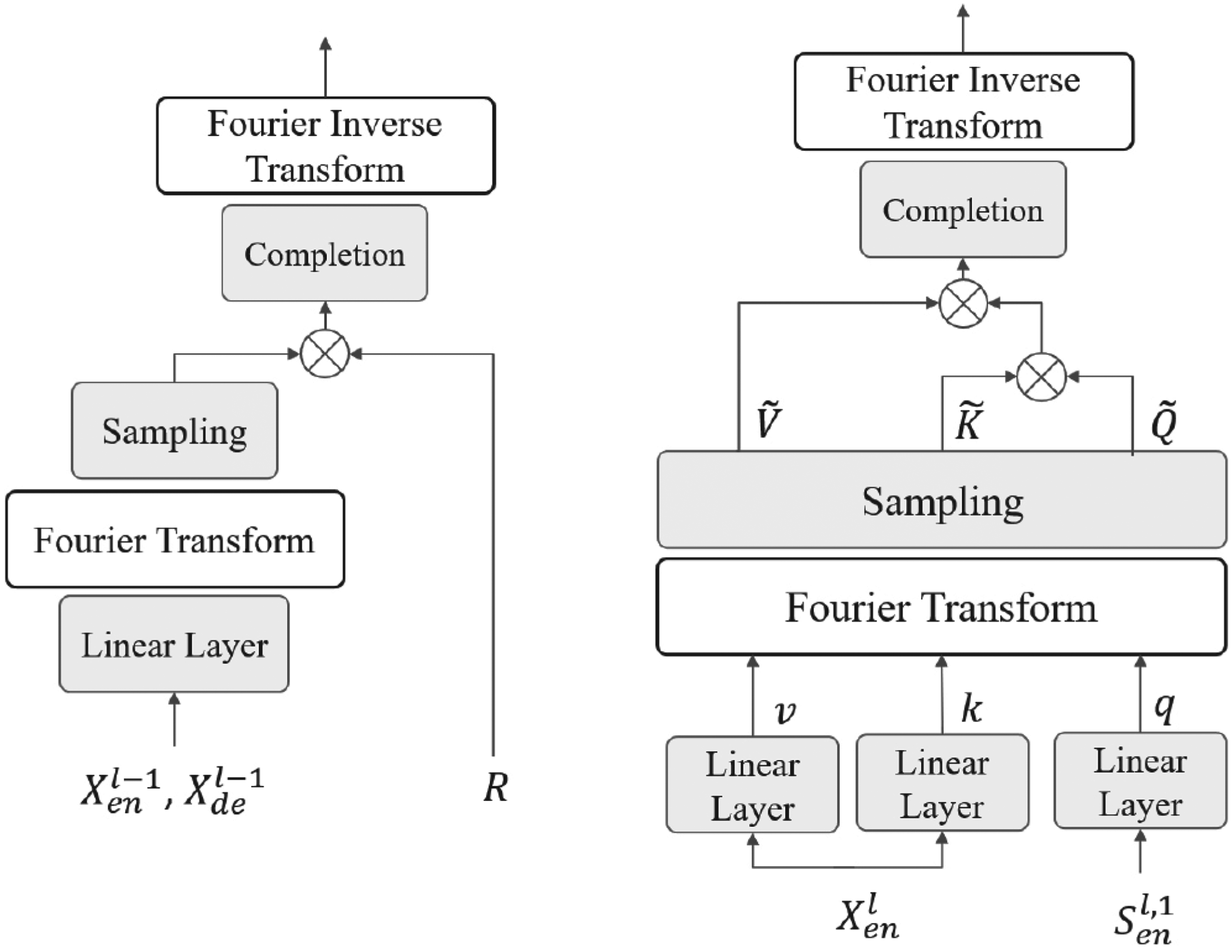
Left: The Frequency Enhancement Block (FEB), Right: The Frequency Enhancement Attention Block (FEA). In FEB, the Fourier transform is used to convert time series into the frequency domain, and the inverse Fourier transform is used to return the sequence to the time domain.
In the Frequency Enhancement Block (FEB), we use the Fourier transform to convert time series into the frequency domain, so as to enhance sequence information. Specifically, a one-dimensional Fourier transform is used to convert the sequence first into the frequency domain. Then, the frequencies are weighted to enhance the relevant information of the sequence. The enhanced sequence is then obtained by applying an inverse Fourier transform to the sequence to return it to the time domain. Replacing the self-attention module with the FEB module can better extract global features of time series. The calculation formula for FEB is as follows:

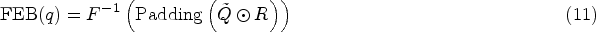
In the above equation, represents the Fourier transform, and represents the inverse Fourier transform. The Fourier transform of q is represented as Q,
The Frequency Enhancement Attention Block (FEA) is an attention mechanism that enhances sequence information using Fourier transform. Unlike traditional attention mechanisms, FEA maps the sequence to the frequency domain and calculates attention weights in that domain to enhance sequence information. Replacing the traditional cross-attention block with FEA can further improve sequence modeling capability. Specifically, we process the data in a way similar to FEB. The sequence is first transformed into the frequency domain using one-dimensional Fourier transform. Then, attention weights in the frequency domain are calculated, and then the sequence is transformed back into the time domain to obtain the enhanced sequence. The formula for calculating cross attention in the known Transformer is as follows:
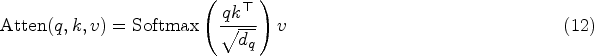
In the FEA module, we define the frequency domain enhanced attention module as follows:




In the above equation, q, k, v represent query, key, and value, and

Time series decomposition method has been a very useful method in time series analysis. This method assumes that a time series is often a superposition or coupling of various forms of changes: Secular Trend (T), which refers to the overall trend or state that develops and changes over a long period; Seasonal Variation (S), which refers to regular changes in a time series due to seasonal variations; Cyclical Variation (C), which refers to cyclist continuous variations with no strict regularity over several years or cycles; Irregular Variation (I), which is the influence of various accidental factors on the development of time series.
To learn complex time patterns in long-term time series, we introduce the concept of time series decomposition in this paper, where we decompose the input data into seasonal components and trend components, allowing us to process different parts of the data accordingly. When calculating the trend component, we can obtain:

The above explanation covers the frequency-domain feature extraction based on FEDformer. The following section will provide a detailed explanation of the overall flow of the model.
This section provides a detailed explanation of the overall architecture of our proposed MHNet, as shown in Algorithm 1. Assuming historical time series input data
First, MHNet performs feature extraction in the time domain based on multi-scale hierarchical representation. The consecutive
Differences compared to FEDformer
As we employ FEDformer as the baseline architecture for the encoder-decoder framework, this section accentuates the divergences between our experiment and FEDformer. In FEDformer, the authors seamlessly integrate a seasonal trend decomposition method into the Transformer-based approach, merging Fourier analysis with Transformer-based methodologies to capture global features of time series in the frequency domain. However, FEDformer exclusively processes time series at a fixed scale, thereby falling short in capturing the local features inherent in time series data.
However, in addressing time series forecasting problems, an excessive emphasis on frequency domain features might result in the oversight of temporal information. In FEDformer, due to the model’s requirement for extracting frequency domain features, time series are trained with the original scale. However, the temporal redundancy of time points in time series poses challenges, and the information at the original scale may not always be conducive to effectively extracting features at various temporal scales. MHNet leverages a multi-scale hierarchical structure to comprehensively capture temporal features in the time domain, enabling us to better utilize information from different temporal scales and establish an effective representation of both global and local features in time series. This characteristic enhances the model’s performance on long sequences, while the hierarchical processing method significantly reduces computational costs. Specifically, the reduction in time series length during input decoding not only improves computational efficiency but also leads to substantial cost savings.
Performance evaluation
Datasets and settings
Dataset:
We experiment on five public benchmark datasets (ETT, electricity, exchange-rate, traffic, and weather) to assess MHNet’s performance. The dataset statistics are summarized in Table 1, and the following information is provided regarding the public benchmark datasets that have been fixed:
ETT: This dataset is a temperature dataset of electric power Transformers in a county in China collected by Beihang University. It is divided into four types of datasets, namely ETTm1/m2 and ETTh1/h2. Among them, ETTm1/m2 means collecting data once every 15 minutes, and ETTh1/h2 means collecting data once every hour. All datasets include records from July 1, 2016 to June 26, 2018. There are six electric load features and the target value “oil temperature” in each record. Electricity: The dataset involves power consumption data from 321 users, including 26,304 data records from January 1, 2012 to December 31, 2014, with an interval of 1 hour. Exchange-Rate: Exchange-Rate contains eight countries’ daily exchange rates between 1990 and 2016. Traffic: The Traffic dataset records road occupancy rates. It gathers hourly data from 2015 to 2016 that was captured by sensors on San Francisco highways. Weather: This dataset contains local climate data from nearly 1600 regions in the United States. It includes over 35,000 data records from January 1, 2010 to December 31, 2013, with an interval of 1 hour. Each record consists of the target value “wet bulb” and 11 climate features.
The five datasets are divided, in chronological order, into a training set (70%) and a validation set (10%), in accordance with previous works.
Dataset statistics.

Experimental Settings:
MHNet is trained on a single GPU (an NVIDIA GeForce RTX 3080 GPU) and implemented in Python using PyTorch 1.9.0. For experimental settings, the Using the Adam optimizer [13], back-propagation can be used to optimize any parameter that is trainable. The learning rate is set to 1e-3. The number of epochs is set to 10, the dropout rate is 0.05, and the GELU has been chosen as the activation function. To monitor training progress, we implemented an early stopping mechanism, terminating training if there was no evidence of loss degradation on the validation set for three consecutive epochs. To make a fair comparison, all these models are trained under similar settings.
Evaluation Metrics:
Mean Absolute Error (MAE), Mean Square Error (MSE) and R-squared (


The following are the techniques used in our comparative analysis and the search spaces of their important hyper-parameters:
Deep learning-based Methods:
LSTM [10]: It is based on RNN, LSTM establishes internal loops within the unit through input gates, output gates, and forget gates, which solves many problems of RNNs models.
LSTNet [14]: It finds long-term patterns of time series trends and extracts short-term local dependency patterns between variables using CNN and RNN. Additionally, it employs traditional Autoregressive (AR) model to address the scale insensitivity issue of neural network models.
TCN [1]: It is a CNN-based time convolutional network architecture. It introduces causal convolution and residual connections, which ensure the implementation of CNN in the field of time series prediction with lower memory consumption and parallelism.
Transformer-based Methods:
Reformer [15]: It uses LSH (Locality Sensitive Hashing) technology to accelerate the self-attention mechanism, which makes it more efficient and scalable in processing long sequence data
LogTrans [31]: It proposes a logarithmic sparse Transformer, which, in the case of a constrained memory budget, raises the time series’ prediction accuracy that have strong long-term dependencies. and fine granularity.
Informer [45]: It adopts the generative decoder, self-attention refinement, and ProbSparse self-attention mechanism.
Autoformer [41]: It adds a time series decomposition module. It modifies the self-attention module and proposes a self-correlation mechanism that can better explore data patterns.
FEDformer [47]: It is a frequency-enhanced decomposed Transformer with a mixed expert mechanism for decomposing periodic and trend components. It replaces the self-attention module and cross-attention module with Fourier-enhanced and Wavelet-enhanced modules. The module can better capture the global features of time series.
MHNet: It is our proposed method.
On ETT, Electricity, Exchange-Rate, Traffic and Weather, most baselines (LSTM, LSTNet, TCN, Reformer, Informer, Autoformer, and FEDformer) have been compared in the existing literature. The recurrent layers, convolutional layers, and recurrent-skip layers of LSTM and LSTNet are selected from
The experimental results of all the methods on the five datasets are reported in Tables 2–4, where the following tendencies are apparent.
Results summary (in terms of MSE) of all methods on five datasets.
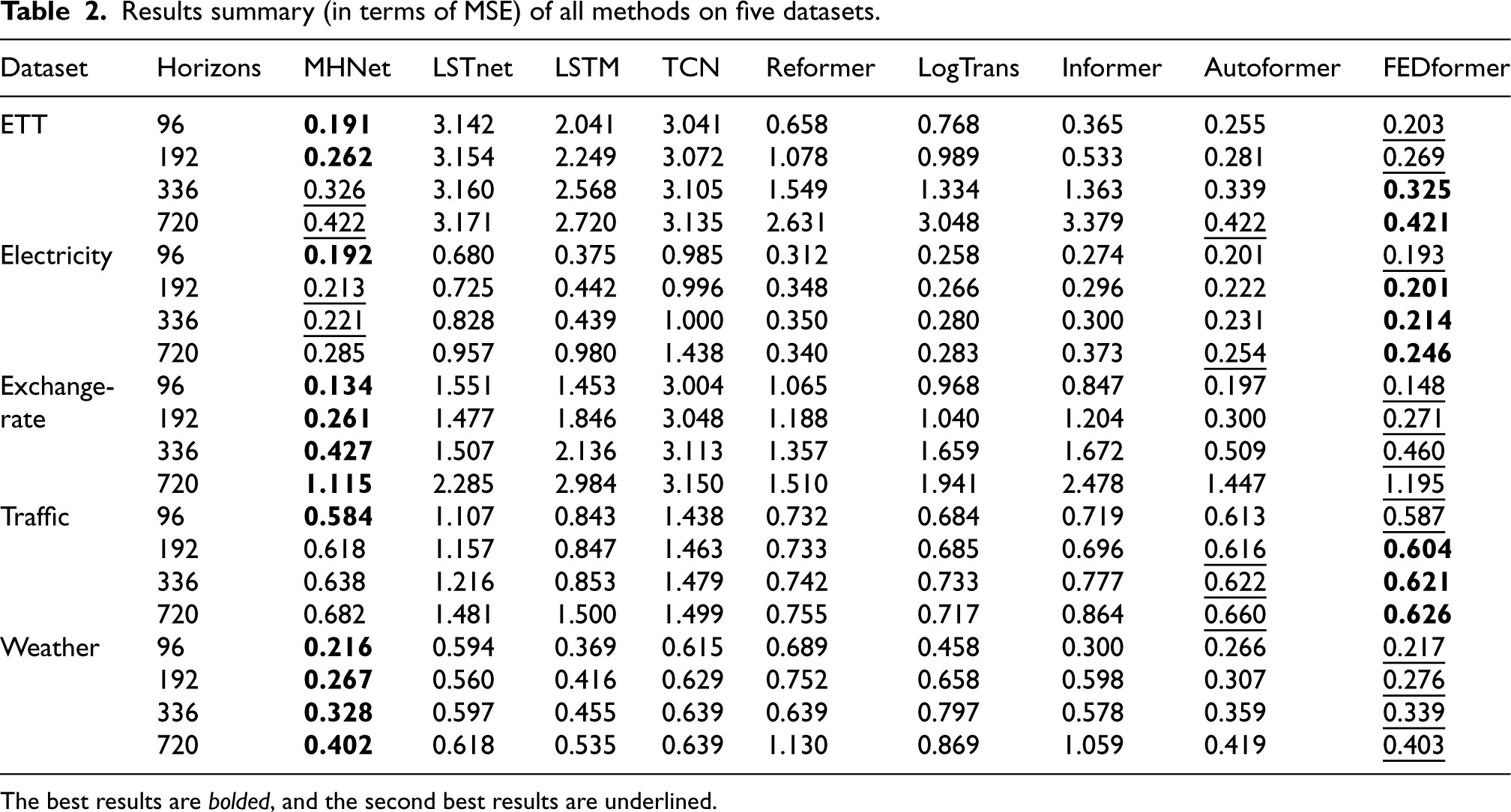
Results summary (in terms of MSE) of all methods on five datasets.
The best results are bolded, and the second best results are underlined.
Results summary (in terms of MAE) of all methods on five datasets.
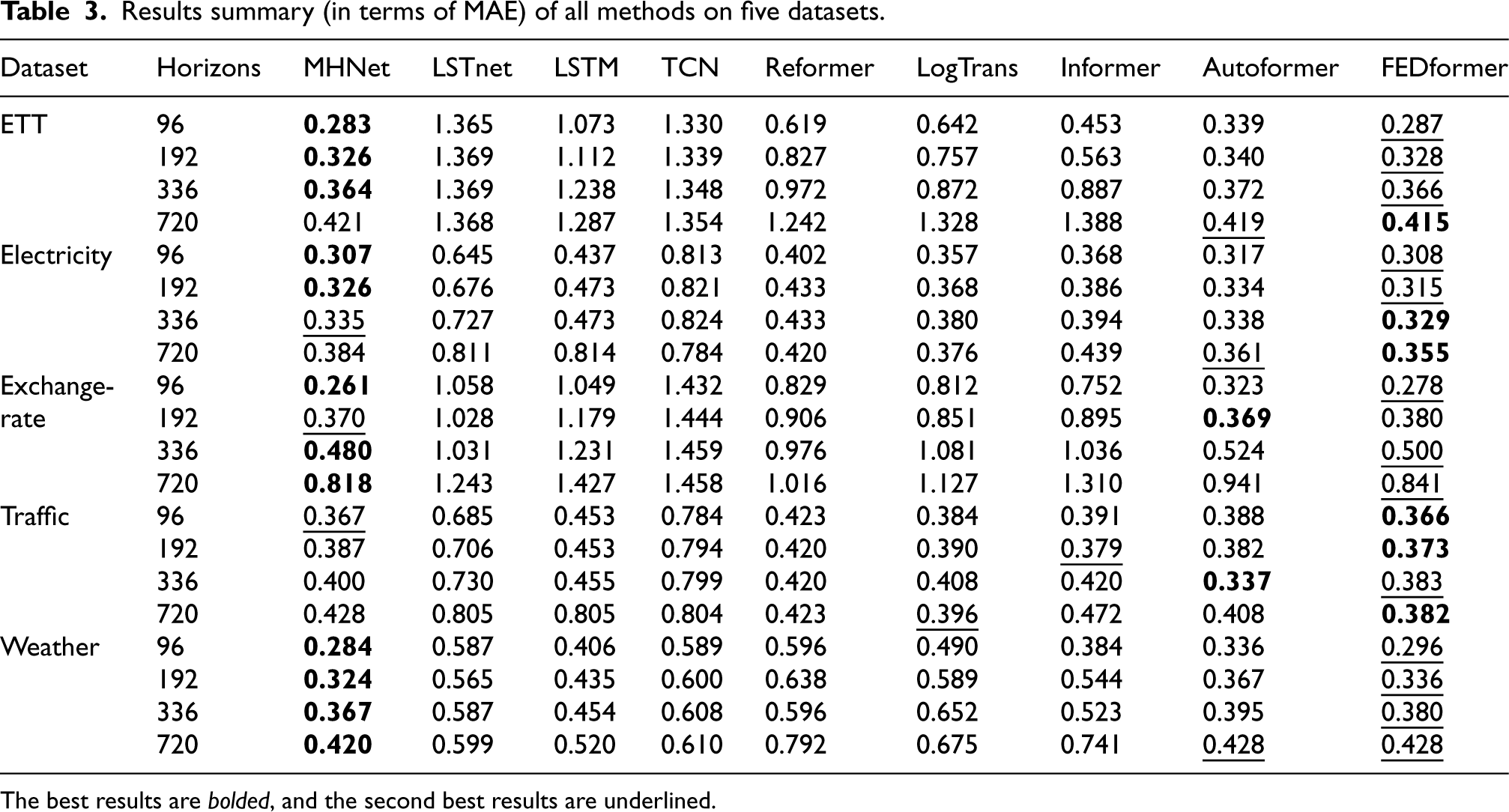
The best results are bolded, and the second best results are underlined.
Results summary (in terms of R-squared) of all methods on five datasets.
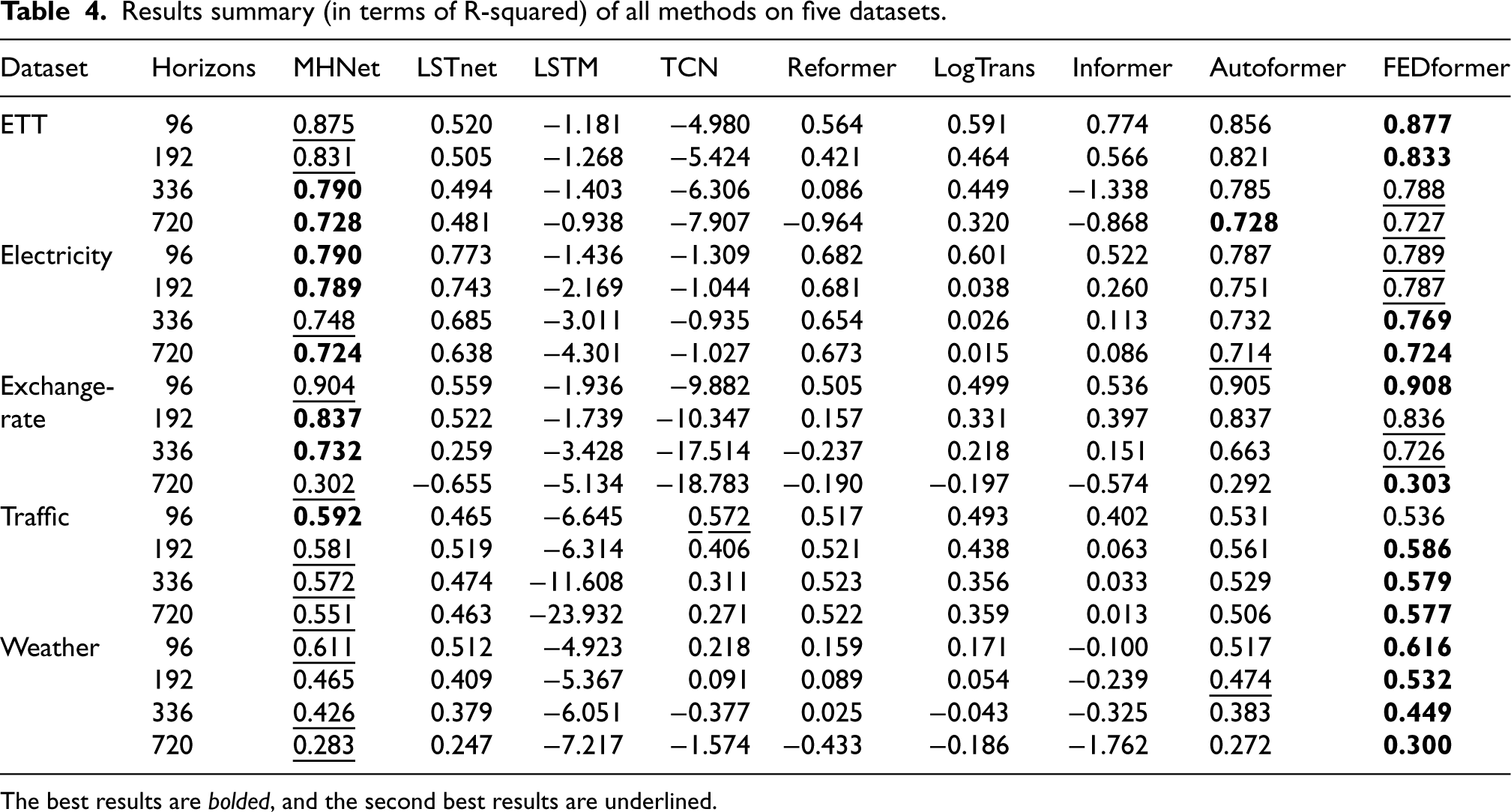
The best results are bolded, and the second best results are underlined.
Our method (MHNet) produces the state-of-the art results. Specifically, MHNet outperforms the current methods on all horizons and all metrics on the Exchange-Rate and Weather datasets. The Exchange-Rate and Weather data, which demonstrate an overall upward or downward trend change with multi-scale structural changes, may be the reason why they are so well suited for our assumption. One possible explanation for this could be the seasonal trend decomposition module. On the Traffic dataset, however, MHNet performs marginally worse than other approaches. The autocorrelation graphs of sample variables from the Exchange-Rate and Traffic datasets are displayed in Fig. 6 to help investigate the causes. We can plainly see the trend and structural changes in the Exchange-Rate dataset. In contrast, for Traffic dataset, we can hardly see the trend changes. In addition, as demonstrated in Table 4, our model exhibits strong performance in terms of the
Deep learning-based methods (LSTM, LSTNet, TCN) get worse results then Transformer-based methods, as they cannot capture long-term temporal dependencies. Specifically, when it comes to long-range feature capture ability, the RNN-based LSTM and LSTNet outperforms the CNN-based TCN model by a huge margin. This is due to CNN’s convolutional kernel and receptive filed, which limits its capacity to extract long-range features. Based on the frequency feature extraction ability, the Transformer models outperform the RNN- and CNN-based models by a significant margin.
Transformer-based methods (Reformer, LogTrans, Informer, Autoformer, FEDformer) are the state-of-the-art methods that extend attention modules to learn long-term temporal dependencies. Among them, FEDformer outperforms Informer in all the cases (5 datasets
Visualization of results under
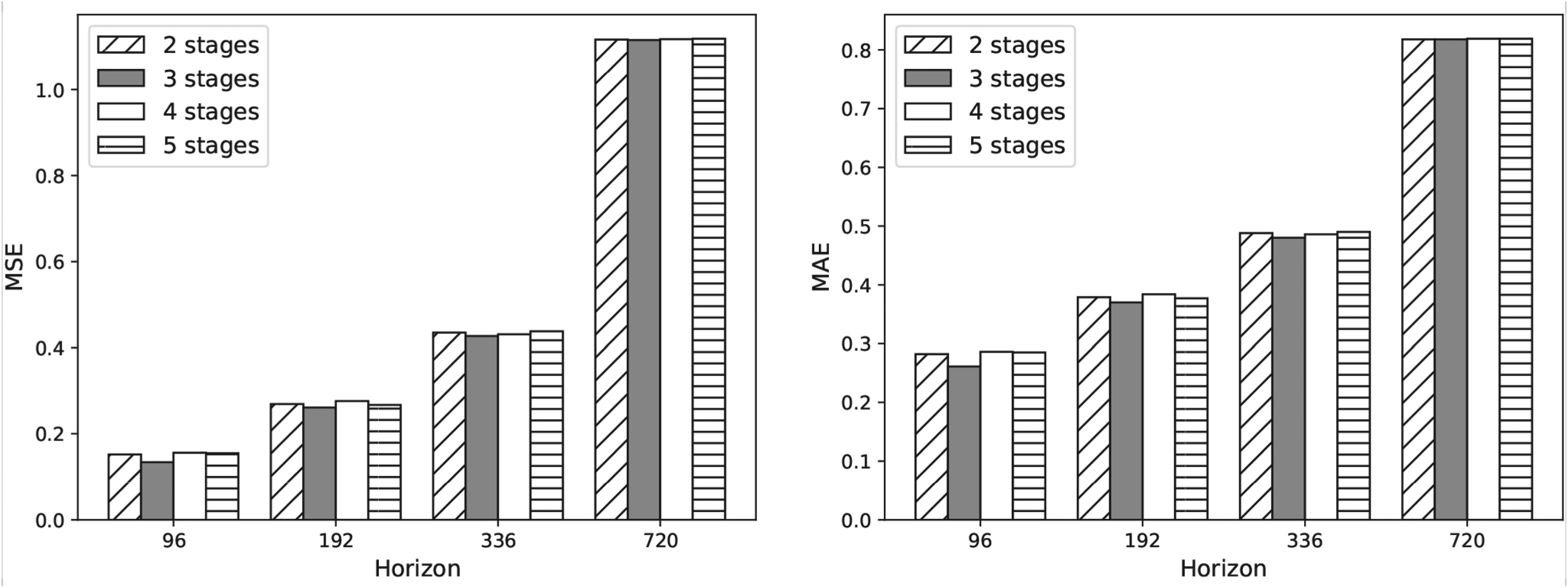
In order to examine the impact of multi-scale modeling, we assess the performance of MHNet across a range of scales (i.e., 2 scales, 3 scales, 4 scales, and 5 scales), and the prediction length ranged from 96 to 720. The Exchange-Rate dataset’s MHNet results under various scale numbers are displayed in Fig. 5. It is evident that MHNet performs better than other scales when the number of scales is increased to three. This is due to MHNet’s increased capacity to identify a wider range of both short- and long-term patterns.
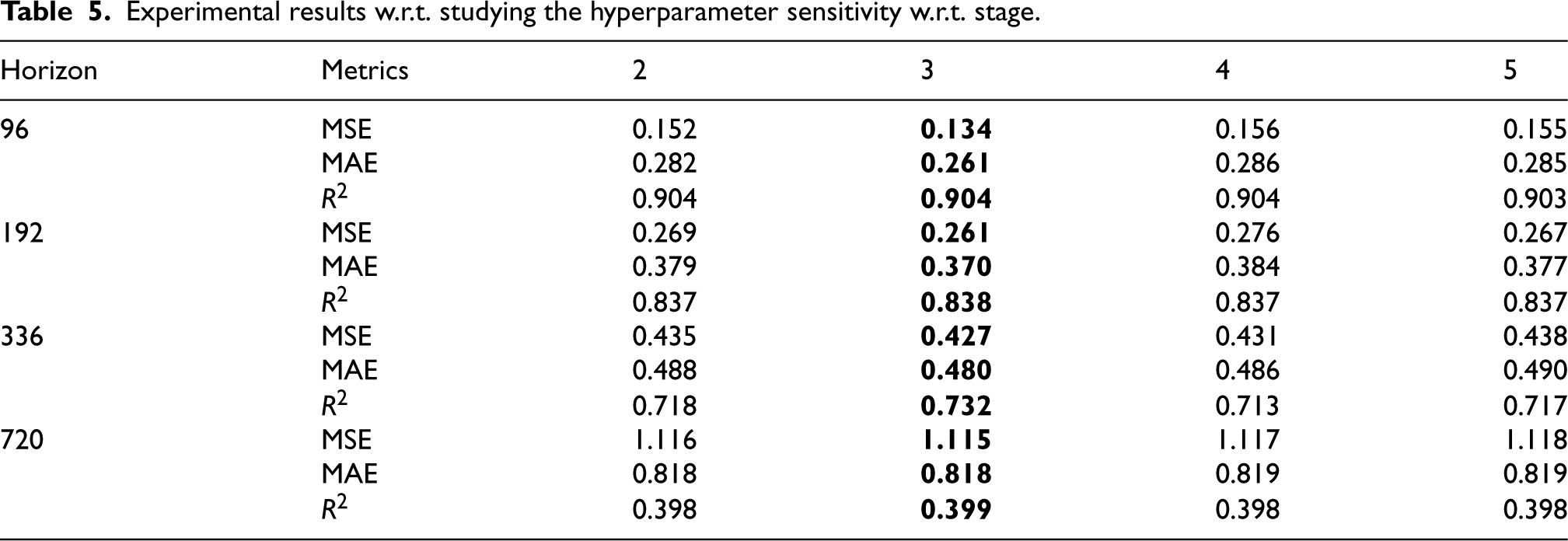
It demonstrates that feature extraction is performed properly using the three-level hierarchical structure. The accuracy of the predictions varies little between the various stages as the prediction length grows. Table 5 displays the specific evaluation values. It is clear that the addition of a hierarchical structure significantly increases the efficiency of the existing time series forecasting model, hence raising the forecasting results’ accuracy. The prediction performance is mediocre when the number of stages is 2, which may be because insufficient parameters will impede the effective information extraction. The performance of MHNet does not improve when the number of stages is increased to 4 or 5, which may be because the task’s requirements for the number of stages have already been satisfied, and over-fitting is easily caused by using too many parameters.
Experimental results w.r.t. studying the hyperparameter sensitivity w.r.t. stage.
In this section, we examine the two crucial variables (i.e., window slice sizes and learning rate), which could influence the performance of MHNet. Firstly, through a sensitivity study of the hyperparameter window slice size, we validate the value of the multi-scale representation. The window slice sizes for the three stages were set to five different combinations using the ETTh1 and ETTh2 datasets. The predictive performance peaks with the middle three slice sizes, as shown in Table 6, and the highest performance is attained when the slice sizes are
Experimental results w.r.t. studying the hyperparameter sensitivity w.r.t. temporal slice size.
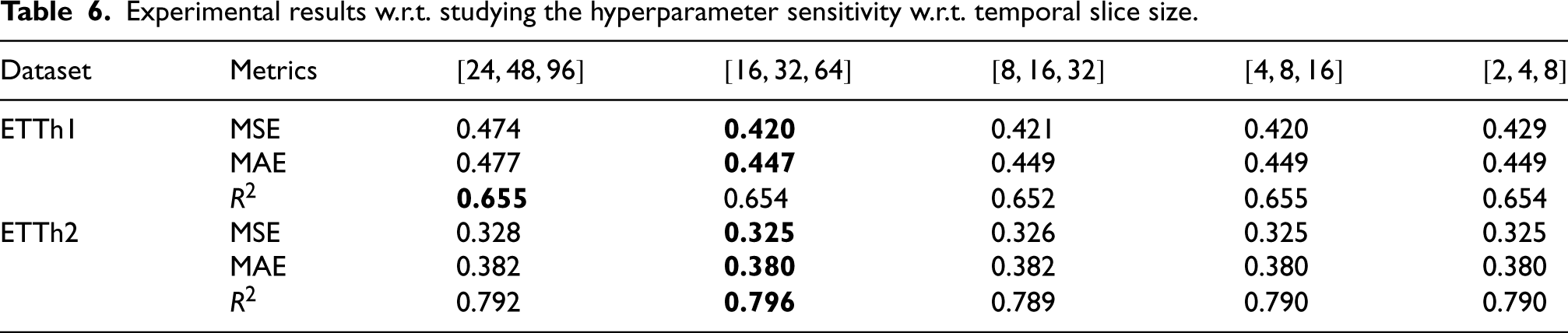
Experimental results w.r.t. studying the hyperparameter sensitivity w.r.t. temporal slice size.
Experimental results w.r.t. studying the hyperparameter sensitivity w.r.t. learning rate.
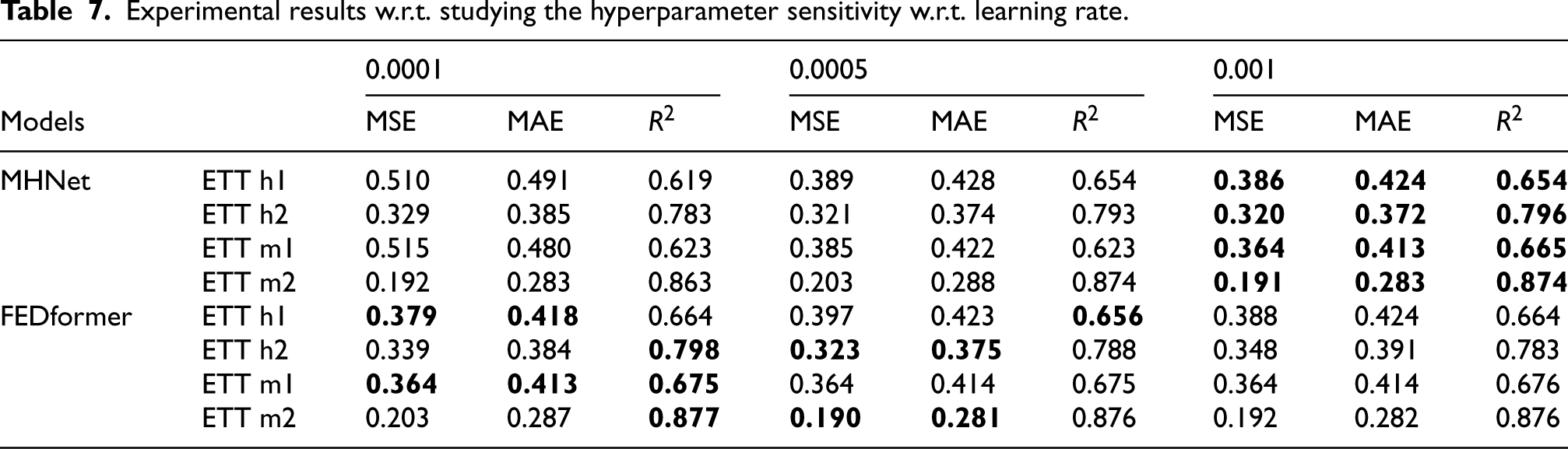
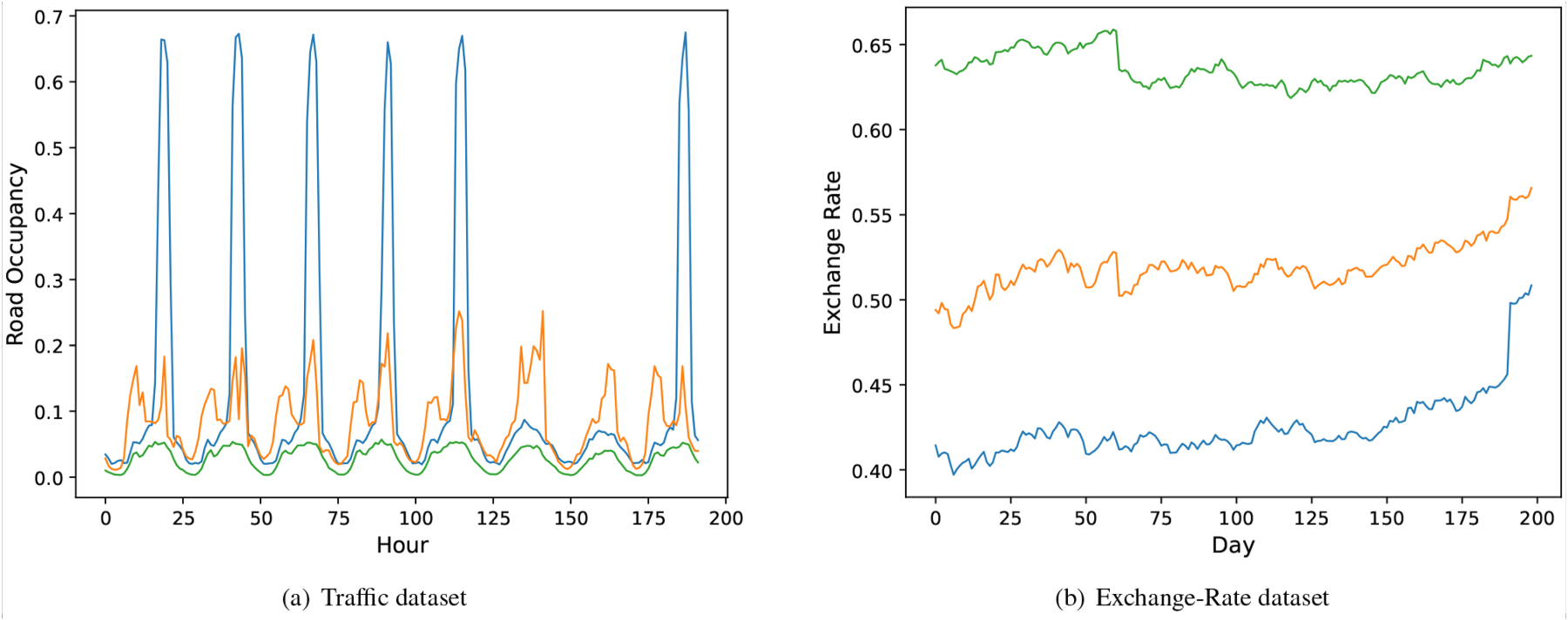
The autocorrelation graphs based on (a) Traffic dataset and (b) Exchange-Rate dataset.
The results of the experiments at various learning rates are then contrasted. We run experiments using the ETTh1 and ETTh2 benchmark datasets in order to assess the performance of MHNet. We discovered that our model operates most effectively when the learning rate is changed to 0.001, as indicated in Table 7, thus we made this choice. When the learning rate is 0.0001, the baseline model operates most effectively. As a result, we decided to use 0.0001 as the baseline model’s learning rate in the experiments.
Figure 7 presents a visualization of the prediction results produced by MHNet on five datasets. The ground truth is represented by the blue line, while our predictions are depicted by the orange line. It is observable that the predictive trend of MHNet largely aligns with the original trend analysis. Notably, there are fluctuations in the predictions for the dataset, which we hypothesize may be attributed to the time-frequency transformation mechanism employed in our approach.
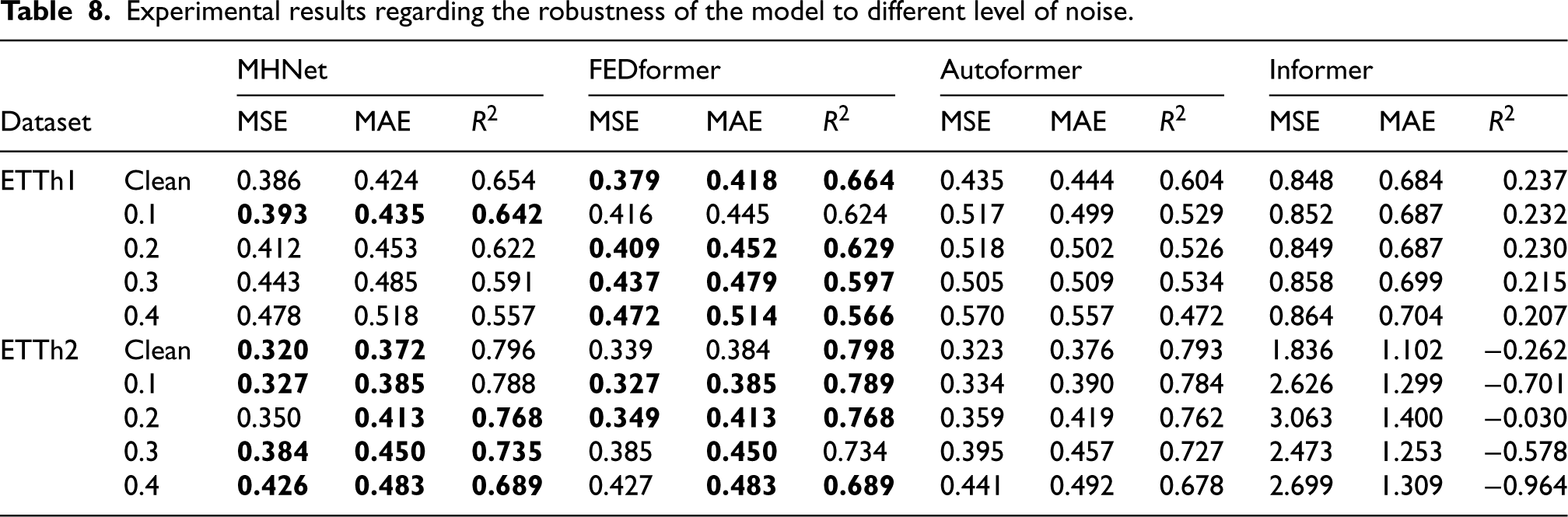
Evaluation of model robustness to noise
The noise robustness experiment was conducted using the ETTh1 and ETTh2 datasets. We added Gaussian noise to the original datasets, selecting four standard deviations [0.1, 0.2, 0.3, and 0.4] as the noise levels. A larger standard deviation indicates more noise added. The results, as shown in the Table 8, demonstrate that while the performance of our model declines with increasing noise levels, the overall change remains minimal. This indicates that our model is robust to noise. We hypothesize that transforming time series data into the frequency domain can more effectively capture the intrinsic frequency characteristics of the series, thereby enhancing the model’s ability to resist noise. We hypothesize that the model struggles to capture the overall trend of the weather data accurately. Nonetheless, MHNet demonstrated a level of performance that rivals the best models.
Illustration of the prediction performance using MHNet on five datasets. Experimental results regarding the robustness of the model to different level of noise.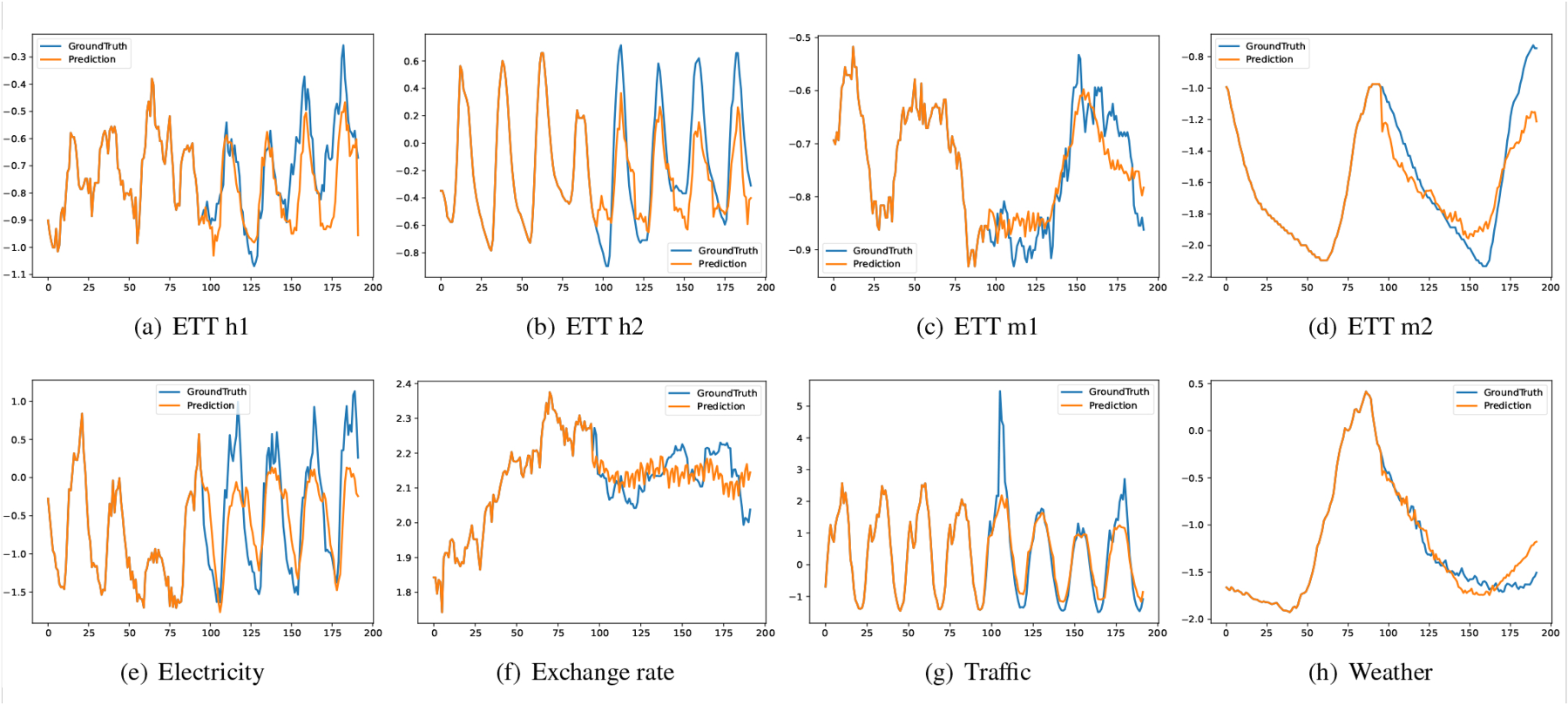
In models for forecasting time series using Transformers, computational cost has been a significant problem. A high number of parameters are needed for Transformer computing because of the unique characteristics of attention matrix calculation in Transformer models. In order to assess the computational expense, we evaluate the parameter numbers, training time, storage usage and prediction performances of MHNet, FEDformer, Autoformer and Informer on Exchange Rate dataset in Table 9. In these methods, the autoformer has the fewest parameters and operates quickly. However, the forecasting outcomes worsen. Compared with FEDformer and Informer, MHNet runs fastest and gets best forecasting performance improvement and the computation cost. This is because we model the original time series with a hierarchical structure, which greatly reduces the length of the sequence for attentional computation. MHNet demonstrates the superiority over existing methods.
The computation cost of different methods.

The computation cost of different methods.
In this paper, we propose a multi-scale hierarchical network (MHNet) based on time-frequency decomposition. In order to deal with long time series with lower computational complexity, MHNet first introduces multi-scale hierarchical representations. Then, through a gradual process of extraction and learning of the local dependencies of the time series, it uses the local information of different time scales to gradually build up the global understanding and representations of the time series. This makes it possible for the proposed model to reduce the computational burden of managing long time series. The Transformer then establishes the long-term dependence based on frequency-enhanced decomposition, and the periodic trend term decomposition module is meant to further increase prediction accuracy by reducing input and output fluctuation through numerous decompositions. To strengthen the robustness against noise, attention mechanisms are also used in the frequency domain. Tests conducted on five real-world datasets demonstrate that MHNet performs better in different scenarios than alternative Transformer-based and hybrid approaches. We believe that MHNet can accurately capture the trend changes and structural changes for long-term time series forecasting through theoretical analysis and experimental validation.
Currently, we are still working on extending the hierarchical multi-scale structure. However, adaptively selecting suitable segment sizes for different phases of time series remains a challenge. In our future work, we will further investigate adaptive selection of scales for different stages.
Footnotes
Acknowledgments
This work has been supported by the Jiangsu Provincial Program for Innovation & Entrepreneurship under Grant No.JSSCBS20220406, the Natural Science Research of Jiangsu Higher Education Institutions of China under Grant No.22KJD520004, the General Project of Philosophy and Social Science Research in Jiangsu Colleges and Universities under Grant No.2022SJYB0243.