
Abstract
During the process of capturing infrared and visible images, the presence of inconsistent illumination poses a challenge that adversely affects the visual quality of the fused paper. In this paper, we propose a novel method for infrared and visible fusion, termed SelectiveFusion, which effectively addresses the issue of inconsistent illumina-tion in the process of capturing infrared and visible light images. This method consists of three key elements: en-coder, fusion strategy, and decoder. Firstly, the source images are fed into the encoder to extract multi-scale deep features. Subsequently, a new fusion strategy is employed to merge features from each scale. In our fusion strate-gy, we develop a selective channel attention fusion module that allows for selective channel weighting of the dif-ferent input features from infrared and visible image. Finally, the fused features are subjected to feature recon-struction through a nested decoder. Additionally, we formulate a novel loss function to guide the training of the fusion network. Our experiments were conducted on publicly available datasets, and compared to existing methods, both quantitatively and qualitatively, demonstrating the effectiveness and versatility of SelectiveFusion. Our code is publicly available at [https://github.com/ISCLab-Bistu/SelectiveFusion].
Introduction
Due to the limitations of hardware imaging equipment, images obtained from single-modal sensors are unable to present complete and detailed scene information. For example, in poor lighting conditions, images acquired by visible light sensors struggle to effectively differentiate objects from the background. 1 Therefore, the emergence of image fusion technology addressed this issue. 2 It refers to the complementary integration of images captured by different modal sensors in the same scene, resulting in a fused image. 3 The fused image exhibits superior scene representation and visual perception capabilities, making it suitable for various subsequent visual tasks. 4
Over the past few decades, researchers have proposed a plethora of algorithms for the fusion of infrared and visible images. These algorithms can be broadly categorized into two types: traditional methods 5 and deep learning-based methods. 6 Traditional image fusion methods require activity level measurements in either the spatial or transform domain, and manual design of fusion rules 7 to achieve image fusion. A typical approach involves applying mathematical transformations to convert source images into a transformed domain, 8 followed by the designing of fusion rules within this domain. Examples of such methods include fusion frameworks based on multi-scale transforms, sparse representation, and saliency-based fusion frameworks. 9
While traditional image fusion algorithms have achieved decent results, they still suffer from issues such as feature extraction methods lacking generality and the complexity of manual fusion strategy design. 10 As a result, traditional image fusion methods are facing developmental bottlenecks. 11 In recent years, the thriving development of deep learning has led to the emergence of numerous deep learning-based algorithms in the field of image fusion. These algorithms leverage the powerful feature extraction and representation capabilities inherent in deep learning, giving them a significant advantage over traditional methods. 12 As research on deep learning-based image fusion methods has progressed, they can currently be classified into four main categories: those based on autoencoders, convolutional neural networks, generative adversarial networks, and transformer-based image fusion frameworks. 13 Presently, deep learning-based fusion algorithms have become the dominant trend in the field of image fusion. Introducing these fusion techniques into an end-to-end framework 14 can further optimize the training process and yield superior image fusion results.
While algorithms based on deep learning have shown significant advancements compared to traditional methods, we have observed that existing deep learning-based image fusion methods still have limitations when dealing with the issue of uneven input image quality, which is common in practical applications. Especially during the acquisition of infrared and visible images, significant illumination imbalances arise due to varying lighting conditions, 15 such as daytime, nighttime, or adverse weather. This poses a significant challenge for effectively fusing high-quality visible images and low-quality infrared images. Existing methods often struggle to distinguish and effectively utilize the different quality characteristics of the two modalities, potentially leading to fusion results being compromised by low-quality images and failing to fully leverage the advantages of high-quality images. 16 Therefore, selective feature fusion in situations with uneven input image quality is a critical problem that urgently needs to be addressed in the field of image fusion.
Uneven input image quality is a significant challenge for existing deep learning-based fusion methods, particularly in infrared-visible fusion under varying illumination. This issue hinders the effective utilization of different modality characteristics, potentially compromising fusion results. Addressing selective feature fusion in such scenarios is critical. We propose SelectiveFusion, an end-to-end method for effective multi-scale feature fusion and quality-based selective fusion, maximizing complementary information. Our contributions are:
An end-to-end image fusion framework comprising an encoder, fusion network, and decoder. It leverages global and local features, with the encoder extracting multi-scale features, the fusion network performing selective fusion at the feature level, and the decoder reconstructing the image. This adaptively learns the fusion strategy for superior complementary feature integration. A selective channel fusion module, SCFusion. It employs a learnable attention mechanism to adaptively weight channels based on visible and infrared quality differences. By explicitly modeling quality, it enhances high-quality modality contributions and suppresses low-quality noise, effectively extracting and fusing complementary features and improving robustness in uneven illumination. A loss function based on complementary information. It guides the model to preserve both overall quality and complementary texture details. This is achieved by explicitly encouraging the network to capture the unique details visible in each modality where the other is less informative, yielding richer textures and clearer details than traditional losses. Comprehensive evaluation on benchmark datasets demonstrates SelectiveFusion's significant competitive advantages across multiple metrics compared to existing methods, fully verifying the framework's effectiveness and advancements.
In this section, we will categorize image fusion into two types: traditional methods and deep learning-based image fusion methods. We will provide detailed explanations of each in the following subsections.
Traditional methods
In the field of image fusion, image transformation and feature fusion are key aspects addressed by traditional algorithms. Traditional algorithms can be broadly categorized as follows:
Transform Domain Methods: These methods perform image fusion by transforming images into specific domains and then applying fusion rules. 17 Examples include transform methods such as Discrete Cosine Transform (DCT), Discrete Wavelet Transform (DWT), and Curvelet Transform (CVT). Scale Transform Fusion: This category approaches fusion by decomposing source images into multi-scale representations using pyramid techniques and performing fusion based on rules. Subspace-based Methods: These techniques aim to reduce redundancy and extract key information by projecting images into lower-dimensional spaces. Examples include Principal Component Analysis (PCA), Independent Component Analysis (ICA), and Non-negative Matrix Factorization (NMF). Sparse Representation Fusion Methods: These methods achieve fusion by sparsely encoding image blocks using learned dictionaries and reconstructing the fused image. Sparse Representation (SR) is a common method in this category. Saliency-based Methods: These methods focus on extracting salient regions from source images using saliency models and reconstructing the fusion image based on these salient features.
However, in the field of image fusion, traditional methods face challenges such as limited adaptability to complex scenes and are sensitive to parameter settings. This limits the versatility and flexibility of traditional fusion approaches, leading to increasingly complex and challenging design processes. 18 As a result, the complexity and difficulty of traditional fusion methods have been on the rise.
Deep learning-based image fusion method
With widespread applications and rapid developments of deep learning in computer vision tasks, some limitations of traditional methods have been addressed. Deep learning-based methods can leverage large-scale data for training, enhancing the model's generalization ability, and demonstrating excellent performance on images of different scales. Currently, the most widely used approach is the image fusion framework based on auto-encoders. Simultaneously, various deep learning algorithms have been extensively applied in the field of image fusion. These include the utilization of convolutional neural networks, generative adversarial networks, and transformer-based image fusion frameworks. Inspired by its success in computer vision, Transformer-based fusion methods leverage self-attention mechanisms to model long-range dependencies and facilitate effective feature integration. The rapid progress in the field of deep learning has also led to a sharp increase in the performance of image fusion. 19
For instance, Li et al. proposed an encoder-decoder model named RFN-Nest. 20 It employs an encoder network to preserve features and a decoder to reconstruct the fusion result. Additionally, a two-stage training strategy is employed to achieve better fusion results for different source images. Prior to this, Li et al. proposed DenseFuse, 21 a novel deep learning architecture for image fusion. Ma et al. proposed FusionGan, 22 a generative adversarial network, to address the problem of the fusion of infrared and visible light images. This method retains most of the infrared pixel-level information and gradient features from the visible light image. Ma et al. also proposed a fusion network called U2Fusion, 23 which can be applied to various fusion tasks. The Elastic Weight Consolidation algorithm can enable a single model to address different fusion tasks without the need for weight decay. Furthermore, transformer-based approaches like SwinFusion, 24 YDTR, 25 MixFuse 26 and CrossFuse 27 have been applied in the field of image fusion, leveraging the popularity of transformer technology in computer vision. There are also novel fusion algorithms such as MFEIF, 28 which designs an edge-guided attention mechanism on multiscale features to attenuate noise while restoring details. STDFusionNet 29 extracts salient target features to assist in image fusion, whereas LRRNet, 30 based on low-rank representation, forms the foundation of a highly lightweight fusion network, with matrix multiplication as the core solution. TextFusion 31 introduces a novel paradigm for controllable image fusion, leveraging coarse-to-fine association and an affine unit to guide multi-modal feature fusion.
Proposed method
This section will provide a detailed introduction to the fusion network framework we proposed. It covers the network model's architecture, the encoder-decoder structure, the SCFusion fusion module, the two-stage training approach, and the loss function design.
The architecture of the fusion network
The architecture of the fusion network is shown in Figure 1 below. Given the input source images, the framework proceeds through three parts: feature extraction, feature fusion, and feature reconstruction, ultimately producing the fused image. The feature extraction component comprises a multiscale feature extraction network consisting of four encoder blocks. It conducts shallow-to-deep level feature extraction on the input source images. The feature fusion segment is composed of four identical SCFusion fusion modules. SCFusion employs the same fusion approach across the four different scales obtained from feature extraction, resulting in richer and more accurate fusion information. The feature reconstruction component consists of three layers of decoder blocks, remapping the fused features back into the image space to generate a new composite image. This image comprehensively utilizes information from both the infrared and visible light images, leading to a synthesized image with enhanced visual effects and information integration.
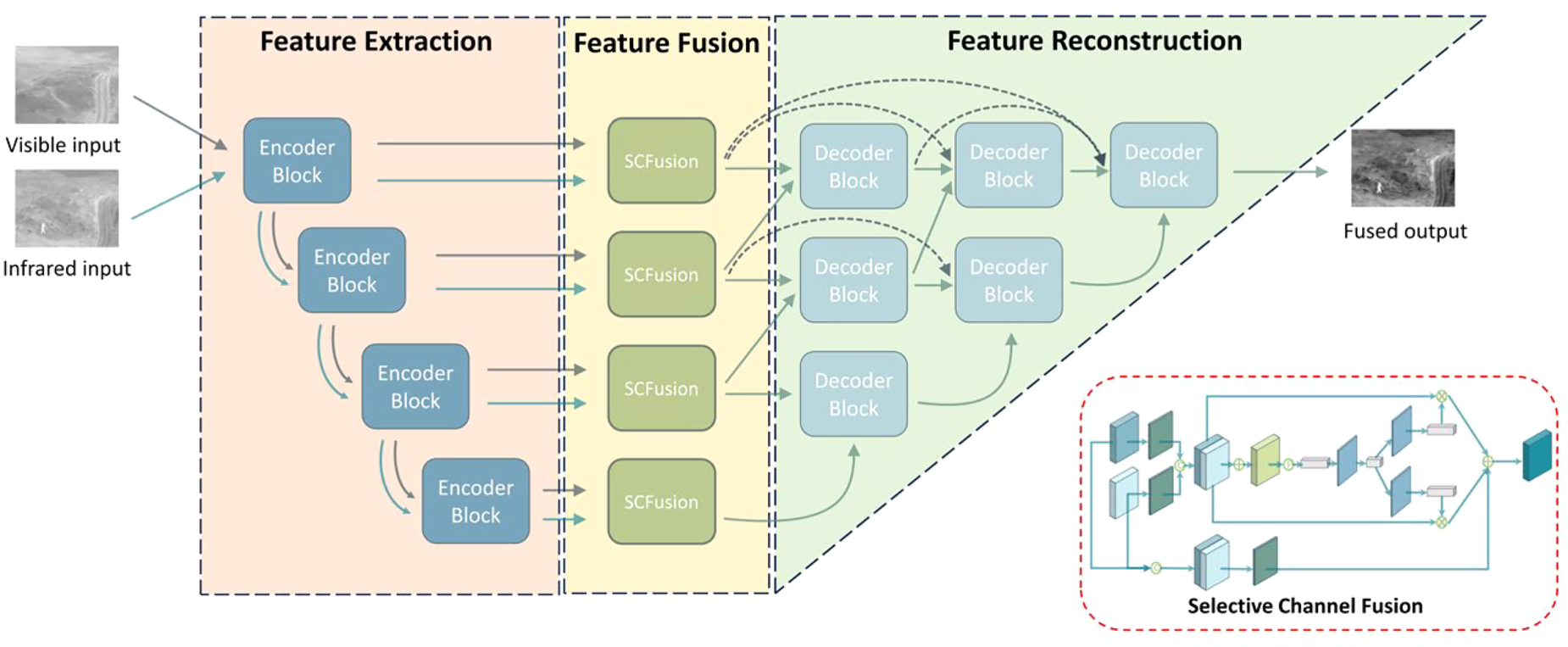
The framework of the proposed SelectiveFusion, consisting of feature-extracting encoder block, fusion-oriented SCFusion block, and feature-reconstructing decoder block.
The specific implementation process involves the following steps: First, the visible and infrared images are inputted into the feature extraction network. The features of the image pair are extracted using pre-trained weights from the one-stage model. The features of the visible and infrared images at the same scale are then fed into the SCFusion fusion module for feature fusion. Finally, the fused features are passed through a bottom-up feature reconstruction network to generate the reconstructed image. The weights of the feature reconstruction network are also pre-trained beforehand.
The entire network model consists of three components: feature extraction, feature fusion, and feature reconstruction, as shown in Figure 2 underneath. First, we will describe how to implement the encoder and decoder parts for feature extraction and reconstruction. These two parts are trained simultaneously in the first stage and their weights remain unchanged in the overall architecture when we introduce the feature fusion network. These together form our one-stage training. In the first stage, the encoder and decoder parts are trained to develop the capability to extract features at multiple scales and reconstruct multi-scale deep features.
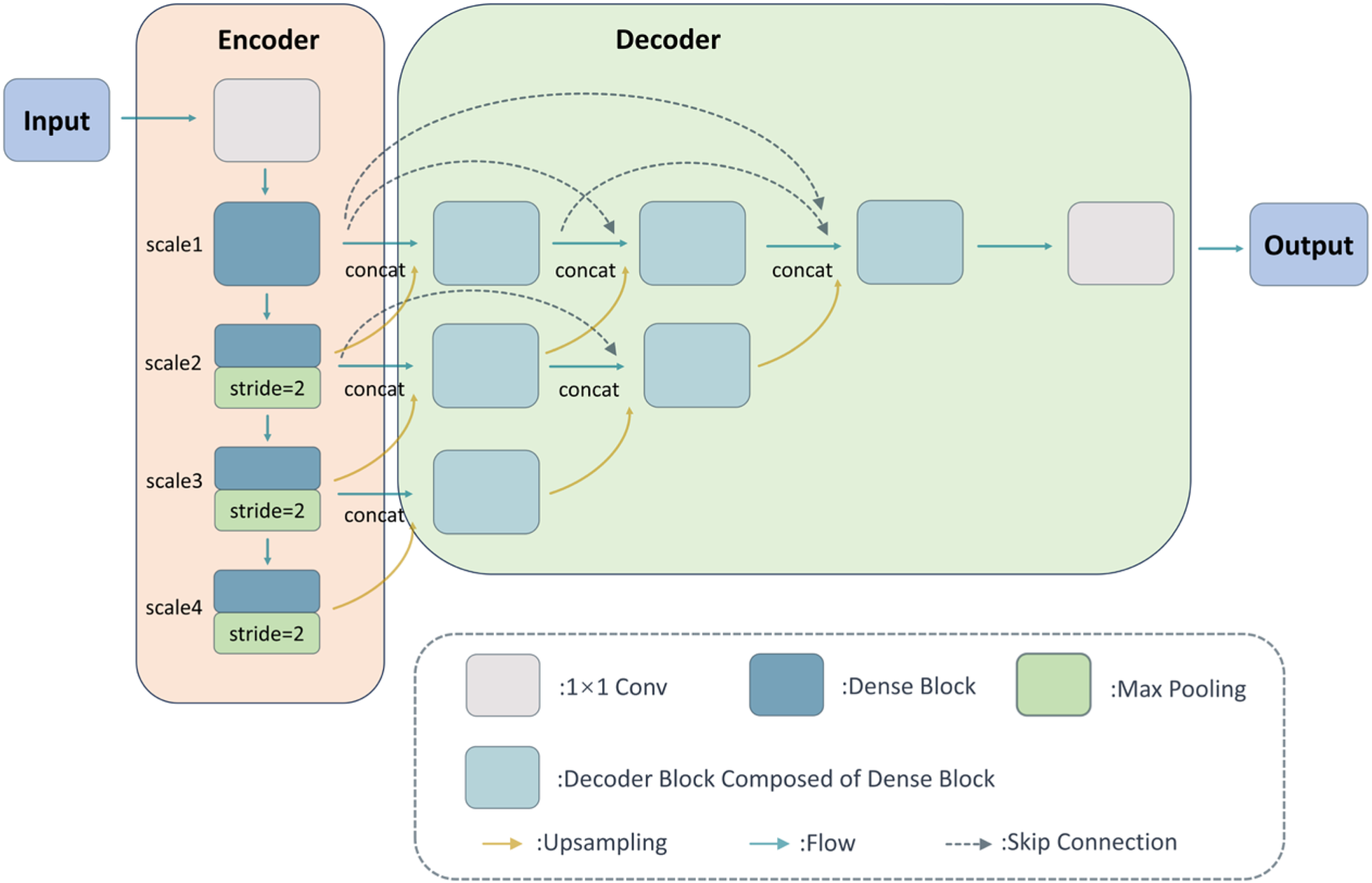
One-stage training procedure composed by the encoder-decoder architecture.
The Encoder part processes the input visible and infrared images through a 1 × 1 stem convolution, introducing an initial feature representation for the multi-scale encoder network. It then undergoes three down-sampling operations composed of dense blocks and max-pooling, obtaining four different scales of features. Each dense block consists of a 3 × 3 convolution and a 1 × 1 convolution. The output channels of the first convolution are half of the input channels, while the second convolution restores them.
The structure of each block in the Decoder part is identical to that in the Encoder part. However, the bottom-up fusion is inspired by the design of Unet ++. 32 Each deep-level feature is upsampled to the same scale as the previous layer and fused through feature concatenation. Low-level features primarily focus on the basic edge and texture information in the image, while high-level features pay more attention to abstract shape and structural semantic information. By progressively fusing low-level and high-level features, the fusion model gains the ability to perceive and understand features at different scales, enabling global perception and discrimination of multi-scale images. Additionally, blocks at the same level are fused with each preceding block through skip connections. This allows the model to learn global feature information at the same scale, fuse semantic information from different layers, and enhance the model's perception and feature representation capabilities. Finally, a 1 × 1 convolution is applied to produce a more information-rich and visually appealing reconstructed image.
The one-stage training model architecture consists of both the encoder and decoder parts. The model structures for these two parts correspond entirely to the sections mentioned earlier in the SelectiveFusion overall training architecture. However, we first conduct training on this section to obtain the weights, which are then utilized in the second stage to train the SCFusion Block. Finally, during inference, we use the one-stage trained encoder, the two-stage trained fusion module, and the one-stage trained decoder to achieve the fusion of infrared and visible images.
The Encoder and Decoder parts are simultaneously trained as part of the one-stage training framework. This design is aimed at achieving better feature extraction and reconstruction capabilities. The COCO2014 dataset is used for training. After extracting features at four different scales in the encoder part, a feature loss function is computed using the encoded features of the input images. In the decoder part, after completing feature reconstruction, a structural loss function is calculated using the input encoded features. These two loss functions will be detailed in the following section on loss functions. The entire loss function for the one-stage network is composed of these two components. It's worth noting that once the weights of the one-stage network are obtained, they will only be used for assisting in the training of the second-stage fusion module, which will be described in the subsequent discussion. During the training of the fusion module, the weights of the one-stage framework remain unchanged.
The SCFusion fusion module is predicated on the principle of merging and reweighting feature channels within the fused feature map, thereby enabling effective fusion through the discrimination and weighting of feature maps originating from distinct modalities. Furthermore, the residual pathway preserves global features of the fused image, resulting in an enriched representation of critical fusion features. The SCFusion module is primarily realized through three operators: Fuse, Select, and Residual. The specific details are illustrated in Figure 3 below.
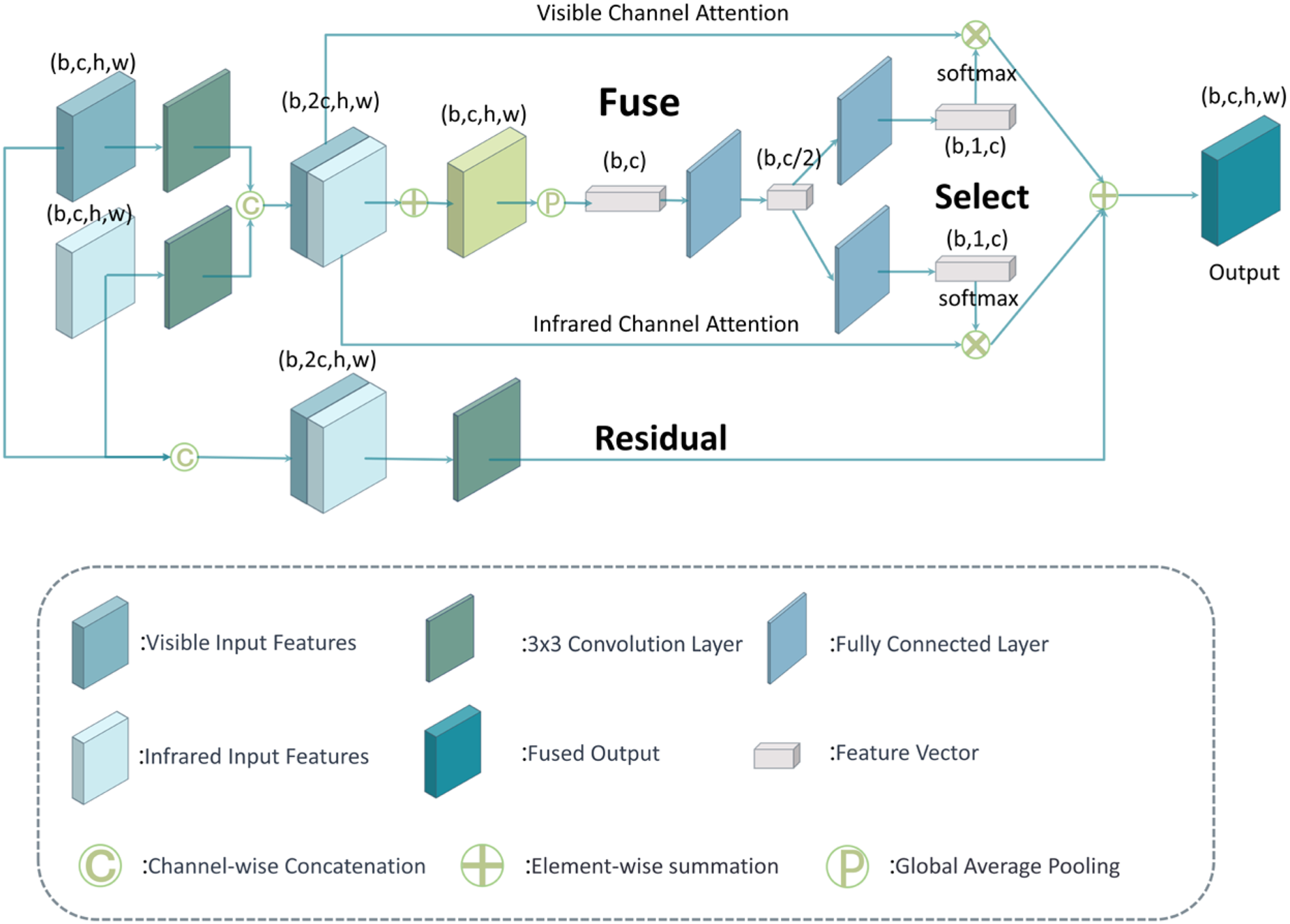
The architecture of SCFusion block.


Through the global average pooling operation defined in the Equation, the 3D fused feature map F is compressed into a 1D channel-wise feature vector S. This vector S effectively captures the global response magnitude of the fused feature map along each channel and can be regarded as a global channel descriptor, serving as the input to the subsequent channel attention selection module.


The final output of SCFusion is composed of the fusion features from the Fuse-Select branch and the features from the Residual branch, added together:

The entire process of the SCFusion module consists of the Fuse-Select branch and the Residual branch. In the Fuse-Select branch, both visible and infrared undergo a preliminary 3 × 3 convolution for individual feature processing. Then, they are fused using summation, followed by compression into a channel feature vector of shape
The loss function used in the first stage of network training is identical to the fusion framework we proposed. After feature extraction, the obtained features serve as the feature loss function, while the fused output after feature reconstruction serves as the structural loss. Since the first-stage network takes only one image input, the training process involves calculating the loss based on the feature encoding of the input image.
During the training of the entire fusion framework, even though there are two inputs, visible light and infrared light, for feature extraction and feature reconstruction, the network architecture remains exactly the same. At this stage, the weights acquired during the initial stage are unchanged . This allows simultaneous feature extraction from both visible and infrared light. Unlike the one-stage training, the extracted features are fed into the fusion module. When calculating the loss, the output of the fusion module is used as the feature loss. The fused output is then passed through the pre-trained feature reconstruction network to obtain the final fused image feature. This final feature is used for the structural loss along with the feature encoding of the input visible image.
From Figure 4 above, it can be observed that employing the same loss function, we derived distinct sets of weight parameters in two stages. Through the first-stage network training, weight parameters for both feature extraction and feature reconstruction components were obtained. In contrast, the second-stage network yielded weight parameters specific to the fusion module.
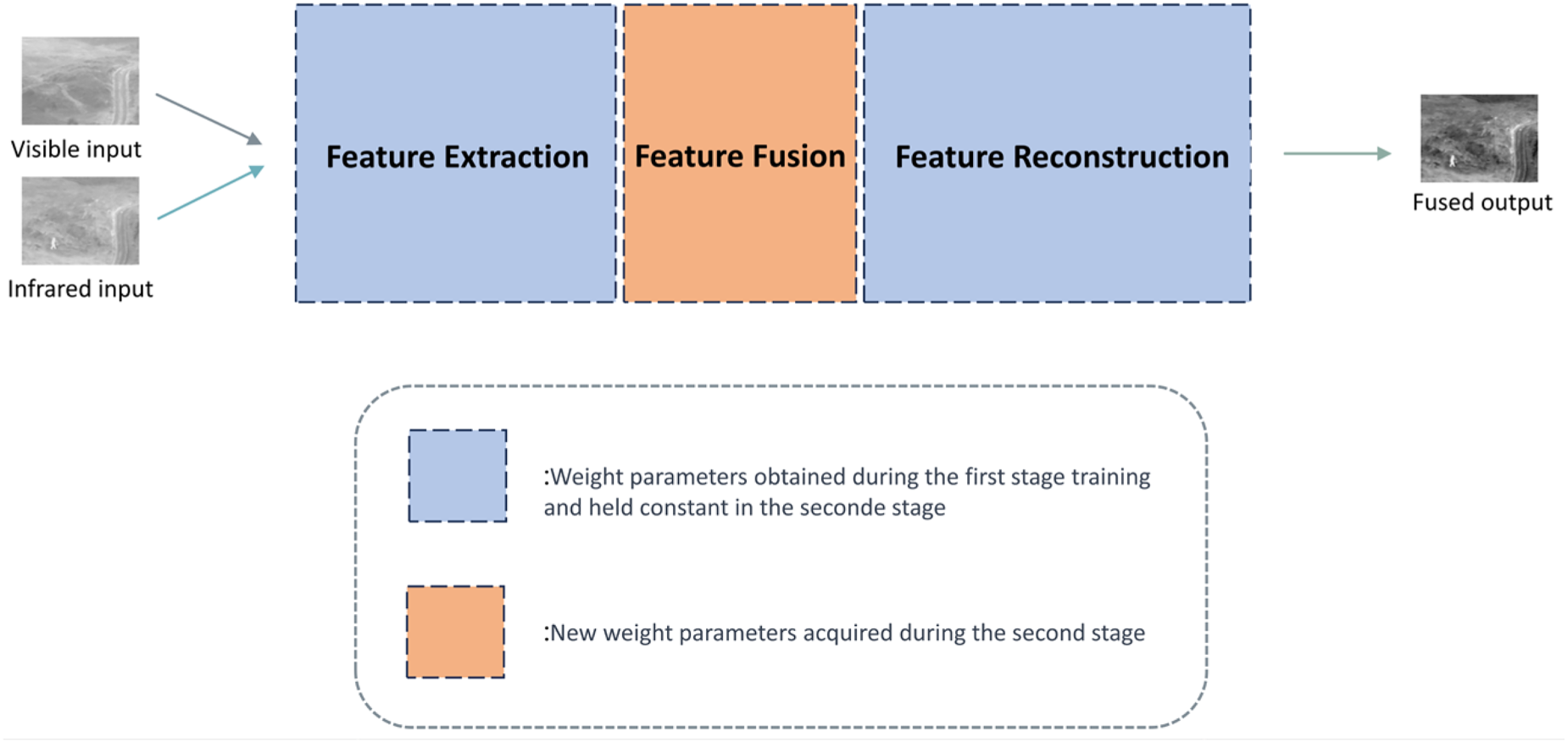
The schematic diagram of the two-stage training strategy.
Due to the absence of ground truth in the infrared and visible image fusion algorithm, 33 the impact of the loss function on fusion performance is crucial. 34 In order to preserve both texture and structural information in the fused image, the loss function of the proposed framework consists of a feature loss function during the fusion process and a structural loss function after fusion output.
The feature loss function computes the sum of encoded feature elements for the fused image with respect to both infrared and visible light, as well as the mean squared error loss between the fused image and the maximum encoded feature element set of both infrared and visible light. Additionally, optimization is performed on the fused images of different scales with respective weights. The specific implementation is as follows:
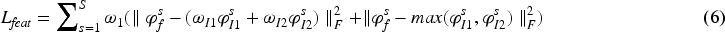
This loss design guides the model to generate fusion results that are as similar as possible to real images. Due to the amplification of larger error terms in the MSE Loss, the model pays more attention to pixels that deviate significantly from real images during the training process, thus preserving more detailed information as much as possible. However, considering that our fusion framework incorporates diverse feature information at multiple scales, we further design the loss function from a complementary perspective, introducing additional constraints to guide the fusion features with more information.
35
Complementary loss is formulated as follows:

The structural loss function involves applying a multi-scale structural similarity MS-SSIM loss to the output of the fusion network after feature extraction, feature fusion, and feature reconstruction, compared with the output of visible light. The specific implementation is as follows:
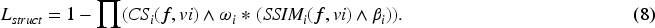
By introducing the MS-SSIM Loss, differences between the fused image and the visible image are optimized in terms of luminance, contrast, and structure. Weighting the information at different scales allows for a more comprehensive assessment of the quality of the fused image. This enables the output image to better retain the characteristics of the original image, making the fused image perceptually more similar to the visible image. This leads to an improvement in the quality of image fusion and the preservation of more details, while reducing the potential introduction of visually noticeable artifacts or false details.
The loss function for the entire network model training is defined as:
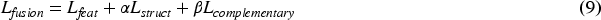
In this section, we experimentally validate the proposed fusion method. We will provide detailed explanations regarding dataset selection, evaluation metrics, experimental configurations, ablation experiments on the proposed network, as well as performance comparisons with other fusion methods. Through both quantitative and qualitative perspectives, we aim to thoroughly validate the effectiveness of the fusion approach. Finally, we explore the application of fused images in the domain of semantic segmentation.
Dataset
Regarding the dataset, for the first stage training, we utilized the COCO2014 dataset, 37 which includes 82,783 training images and 40,504 validation images, to train our feature extraction network and reconstruction network. In the second stage training process, we selected the KAIST 38 dataset to train our fusion module. The KAIST dataset encompasses diverse typical traffic scenarios, including daytime and nighttime campus, street, and rural scenes. The KAIST dataset contains 95,328 pairs of images, and we chose 80,000 pairs of infrared and visible images from it. We split these 80,000 pairs into training and validation sets with a ratio of 9:1, specifically using 72,000 pairs for training and 8000 pairs for validation. We resized the images to a shape of 256 × 256 and converted them into grayscale for training our fusion network.
For the test set, we selected three representative datasets: TNO, 39 RoadScene, 40 and VOT-2020. 41 From each of these datasets, we selected 50 pairs of infrared and visible images for fusion testing. The TNO dataset is one of the most common datasets in the field of image fusion, containing infrared and visible light images in military-related scenarios. RoadScene includes vehicles, pedestrians, and traffic signs, allowing us to evaluate the fusion performance of the model in complex scenarios. The VOT-2020 dataset is a benchmark for short-term tracking of visual objects in RGB. By evaluating our proposed model on these three test sets, which represent different scenarios and lighting conditions, we can comprehensively assess the performance of our model.
Evaluation metrics
We have selected the following metrics to evaluate the performance of image fusion: Entropy (EN): Higher entropy indicates a richer information content in the fused image. Mutual Information (MI): Higher MI implies that more information from the source images has been transferred to the fused image. Spatial Frequency (SF): Higher SF indicates that the fused image contains richer edge and texture details. Standard Deviation (SD): The main subject reflects the contrast and distribution of the fused image. The human visual system is often attracted to regions with higher contrast, so a higher SD indicates better contrast. Visual Information Fidelity (VIF): A higher VIF indicates that the fusion result is more consistent with human visual perception. Multi-scale Structural Similarity Index Measure (MS-SSIM): MS-SSIM models the information loss and distortion during the fusion process, reflecting the structural similarity between the fused image and the source images. Therefore, a higher value of this metric indicates less information loss and distortion.
Comparative methods
We compared our method with nine mainstream approaches, including DenseFuse, FusionGan, LRRNet, MFEIF, RFN-Nest, STDFusion, SwinFusion, U2Fusion, and YDTR. All competitive methods have publicly available code. We conducted inference on the test set using the original parameters provided in the respective papers and the model weights provided by the authors.
Experimental configurations
In terms of network model parameter settings, given the ample richness of image pairs in the training set, we set the number of epochs to 2. The batch size and learning rate were respectively set to 4 and
In the feature extraction network, we performed three downsampling operations on the extracted features to obtain four different scales of feature maps. These maps were then fed into the feature fusion module for training. During training, we assigned weights
Furthermore, when calculating the Mean Squared Error Loss between the fusion input and the encoded features of visible and infrared light, we assigned weights
The weighting parameters
Settings of loss function parameter in the training framework.

Settings of loss function parameter in the training framework.
The proposed fusion network was implemented in a Python 3.7 programming environment using PyTorch 1.12.0 on an RTX 3090 GPU, running on a system with an Intel Core i7 processor, 32GB of RAM.
Given that the fusion framework proposed in this paper can be viewed as a two-stage framework from a training perspective, this section will investigate how to adjust the weight parameter settings to enhance the performance of the fusion module, thereby improving the overall performance of the fusion framework.
Since the first stage trained the encoder-decoder network and its weights were fixed, the ablation experiments focused on the SCFusion fusion module at four different scales. To determine the optimal settings for the weight parameters in our proposed loss function, defined as:
Setting
When
The average values of the objective metric obtained with different values of
while keeping
constant on the TNO dataset.
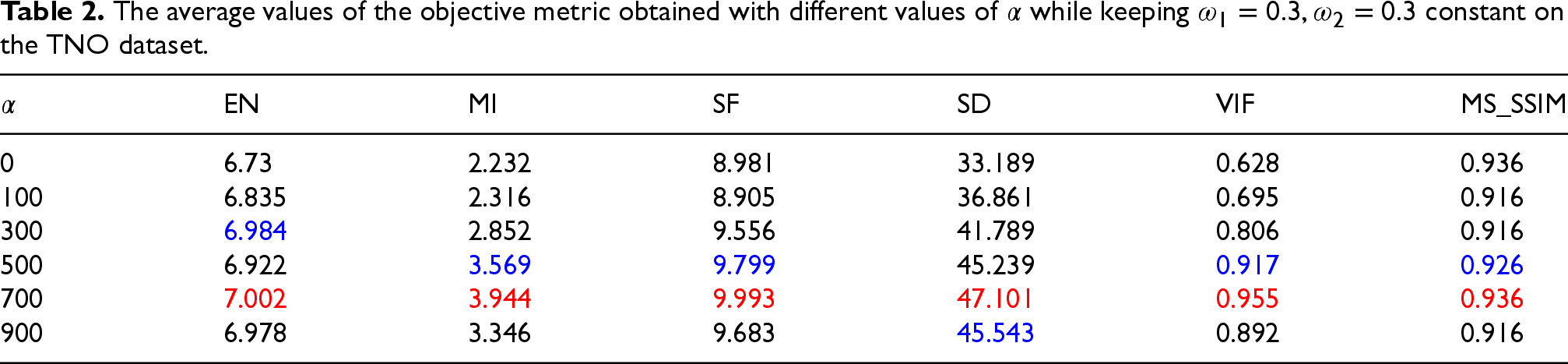
The average values of the objective metric obtained with different values of
The second detail we need to study through ablation experiments is the setting of
According to Table 3, we can observe that when the structural loss function is incorporated, i.e., when
The average values of the objective metric obtained with different parameters (
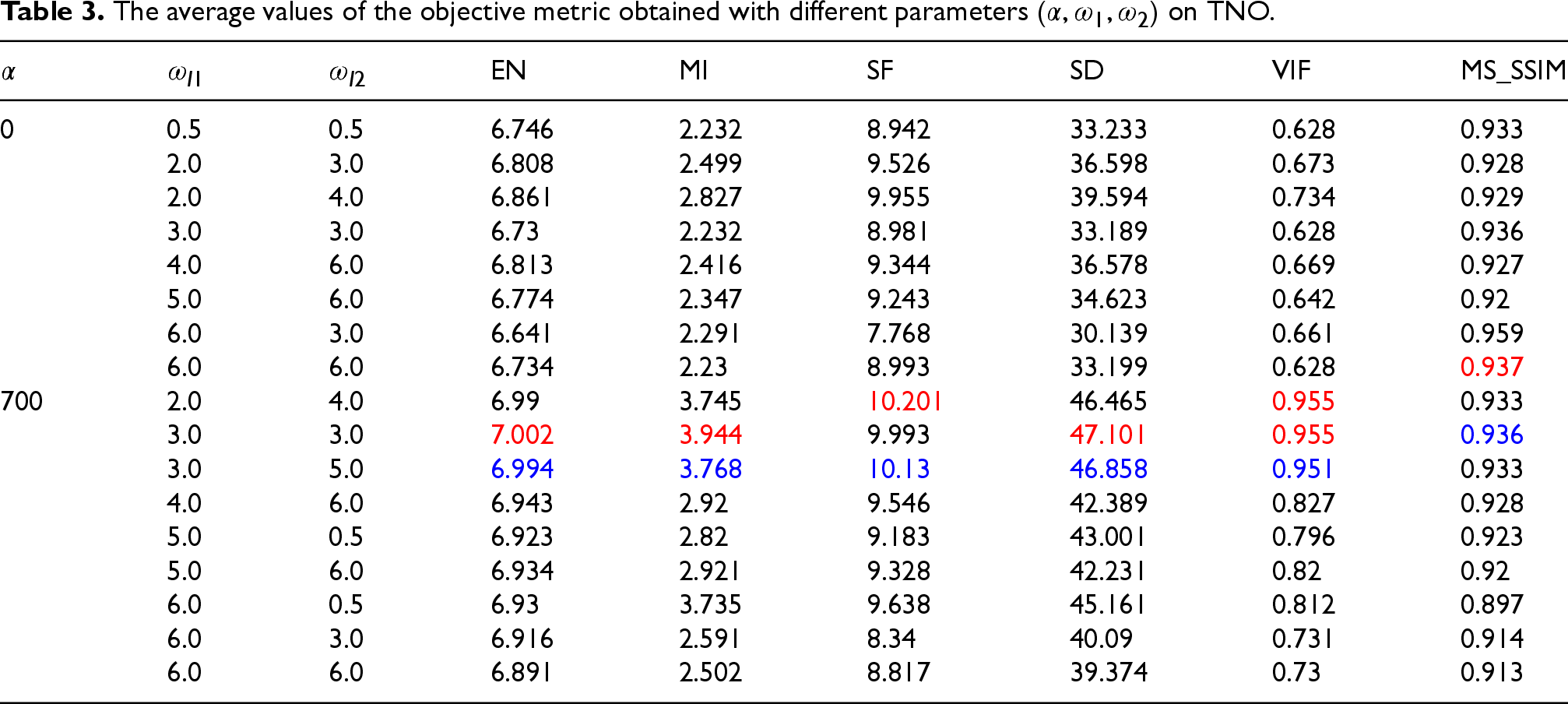
In terms of testing the feature loss function, our ablation experiments have revealed that equal weighting or slightly greater weighting towards visible light yields better fusion performance when compared to other weight settings. This implies a higher priority for visible light in our fusion algorithm. The experimental result aligns with our initial hypothesis, as the human eye is highly sensitive to visible light. Visible light carries more abundant environmental information, which is crucial for the fusion algorithm. On the other hand, infrared light is relatively weaker in terms of color and detail. Assigning a higher weight to visible light enhances the richness of information in the image, which is in line with the original design concept of our attention fusion module.
Following the determination of the optimal settings for the structural loss weight
Table 4 presents the results of our ablation study investigating the impact of the weight parameter
The average values of the objective metric obtained with different values of while keeping
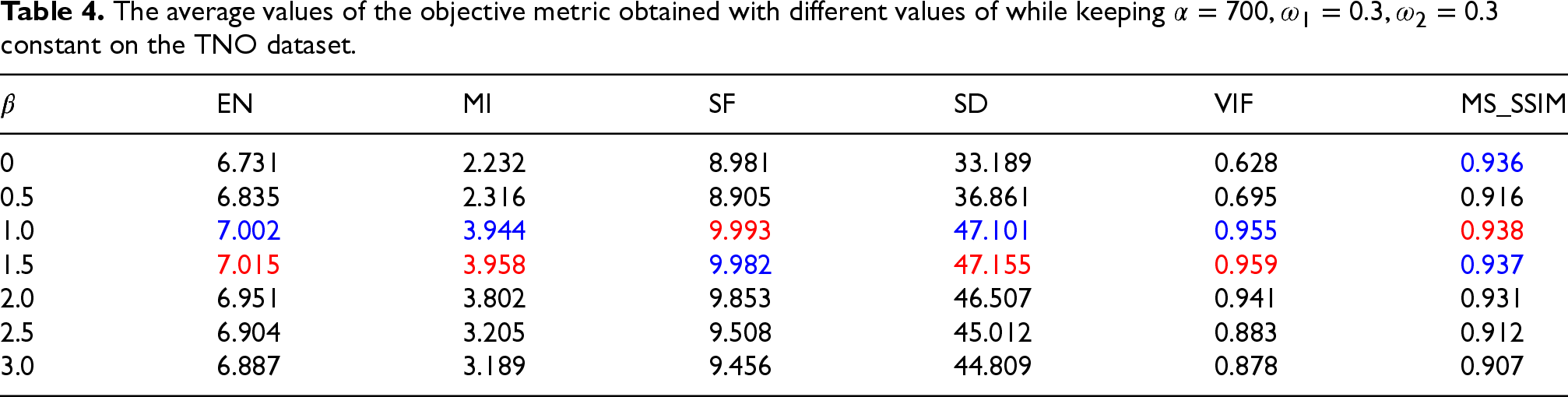
We achieved promising results on the TNO test set. SelectiveFusion employs a selectively attentive mechanism to suppress background noise and selectively enhance fusion features. Information regarding this can be gleaned from Table 4, our model consistently outperforms in both the SD and VIF metrics. The SwinFusion algorithm leverages CNN for local information extraction and Swin Transformer for global information extraction, yielding excellent results in quantitative metrics as well. (Table 5)
Quantitative results on infrared and visible images collected from TNO.
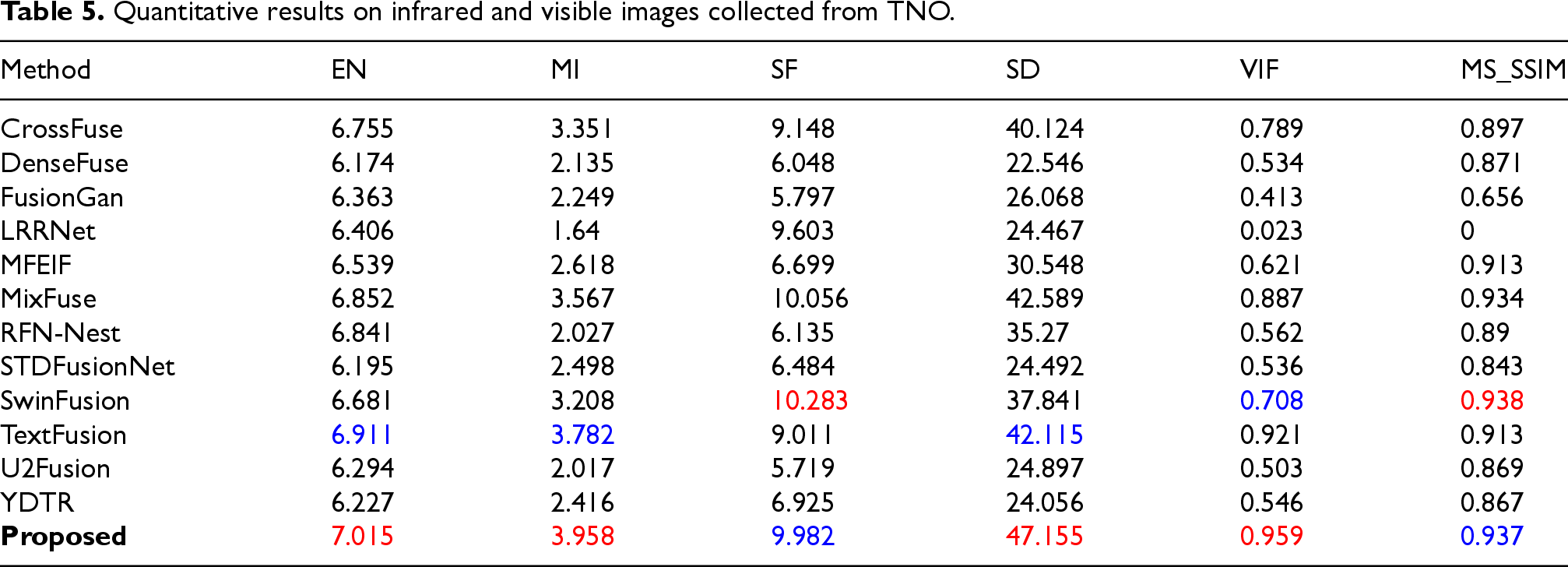
Quantitative results on infrared and visible images collected from TNO.
Based on the qualitative analysis of the fusion results on TNO from the Figure 5 below, we can observe our emphasis on the pedestrian portions of the dataset. In the infrared image, we can discern the outlines and approximate body postures of two pedestrians. However, in the visible light image, due to dim lighting conditions, obtaining clear information about both individuals is challenging. Most fusion methods tend to produce results closer to the infrared source image, focusing more on outline information regarding the two pedestrians, resulting in a relatively blurry fusion outcome. Moreover, fusion results from other algorithms fail to preserve details such as the pedestrian's backpack on the right, and often exhibit white artifacts. In contrast, our SelectiveFusion algorithm's fusion results align more with human visual habits. The details and texture of the backpack are clearly visible in SelectiveFusion ‘s fusion result.

The experimental results on the TNO dataset. (a) Infrared; (b) Visble; (c) CrossFuse; (d) DenseFuse; (e) FusionGan; (f) LRRNet; (g) MFEIF; (h) MixFuse; (i) RFN-Nest; (j) STDFusionNet; (k) SwinFusion; (l) TextFusion; (m) U2Fusion; (n) YDTR; (o) Proposed.
Table 6 provides specific insights into our model's performance on the RoadScene test set. Our model achieves the first rank in quantitative metrics, specifically MI, SD, and VIF, and secures the second position in EN and SF. Simultaneously, SwinFusion, RFN-Nest, MFEIF and MixFuse also demonstrate their strengths in performance metrics on this test set.
Quantitative results on infrared and visible images collected from RoadScene.
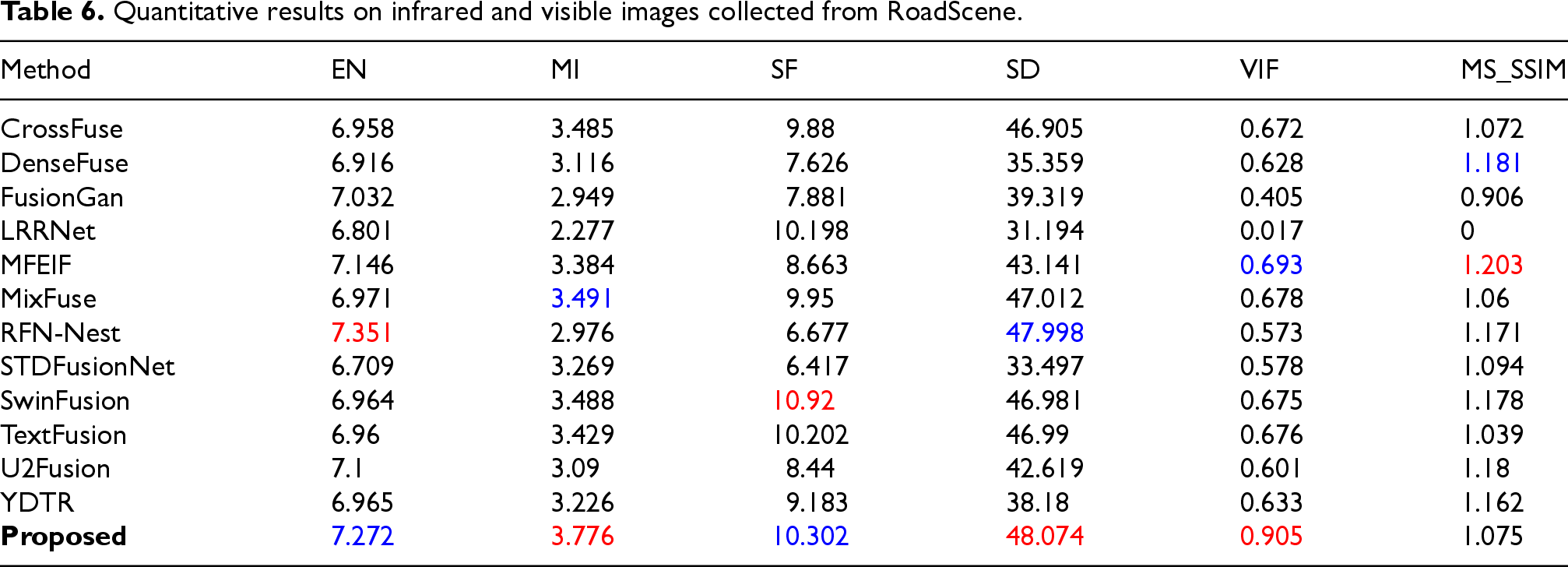
Quantitative results on infrared and visible images collected from RoadScene.
We can conduct a qualitative analysis using a representative image from the test set, which primarily depicts roadside buildings with complex structures. Additionally, the uneven illumination from nearby and distant streetlights results in uneven brightness distribution in the image. The fusion results can be observed in Figure 6. Certain fusion results from methods like FusionGan, LRRNet, and STDFusion fail to distinctly differentiate the transitions between light and dark areas. SwinFusion, MFEIF and MixFusion outperform other algorithms in fusion quality. However, these algorithms, although they distinguish light and dark areas, exhibit some light distortion in the fusion results, which may not entirely align with human visual perception. The MixFusion method integrates more infrared information, resulting in slightly blurred edges. RFN-Nest demonstrates commendable fusion results in this particular image.In contrast, SelectiveFusion provides superior details in the window illuminated by the streetlight in the upper left corner, and the light transition on the wall illuminated in the lower right corner appears more natural.

The experimental results on the roadScene dataset. (a) Infrared; (b) Visble; (c) CrossFuse; (d) DenseFuse; (e) FusionGan; (f) LRRNet; (g) MFEIF; (h) MixFuse; (i) RFN-Nest; (j) STDFusionNet; (k) SwinFusion; (l) TextFusion; (m) U2Fusion; (n) YDTR; (o) Proposed.
In the more challenging VOT-2020 test set scenarios, our model quantitatively continues to exhibit excellent performance. Table 7 illustrates that it achieves the top rank on four key metrics (MI, SD, VIF, and MS-SSIM) and is ranked second on EN.
As shown in Figure 7, high exposure has led to the complete loss of the car's contour information in the visible light image. SwinFusion and STDFusion nearly lose detailed information, FusionGan and RFN-Nest capture more infrared information, but may obscure the texture details of pedestrians. LRRNet, which is based on low-rank representation, is designed for effective image information extraction. Nevertheless, its fused output appears somewhat underexposed under high-exposure conditions. While MixFuse excels in information transmission, further improvement is needed in detail retention and the overall visual quality of the fusion. In contrast, SelectiveFusion's fusion result not only retains pedestrian information under visible light but also preserves the contour information of the car from the infrared image.
Quantitative results on infrared and visible images collected from VOT-2020.
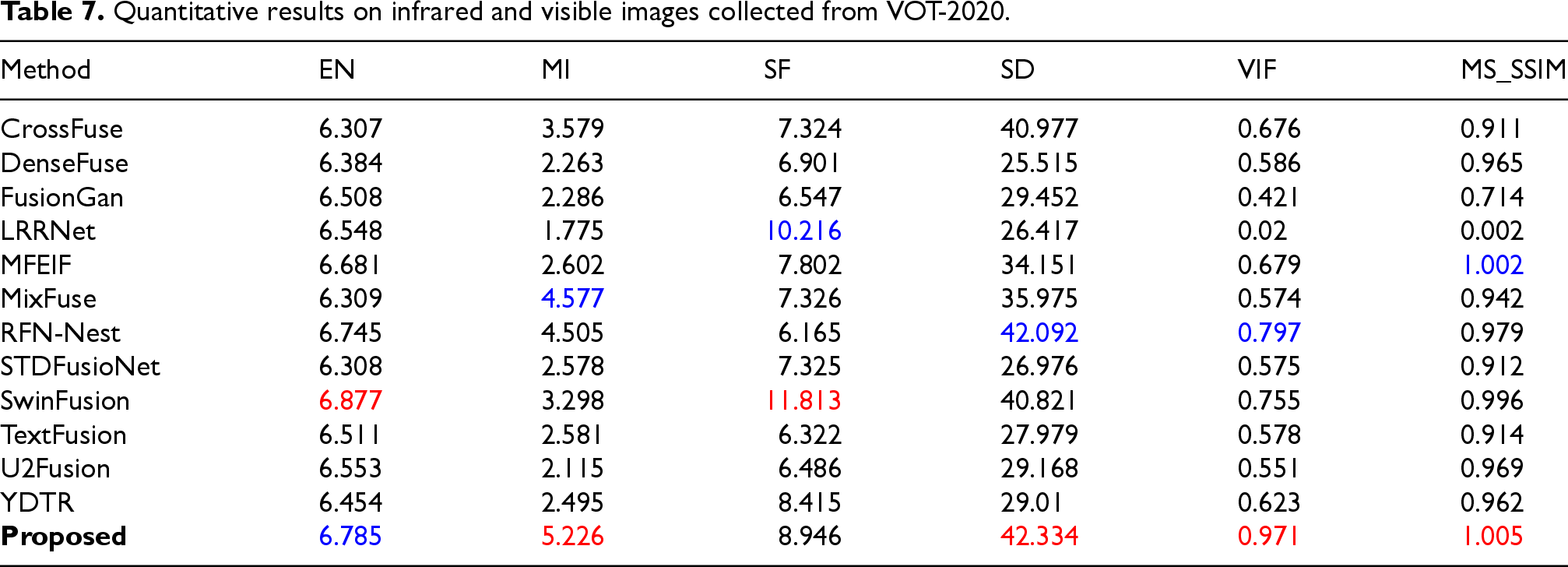
Quantitative results on infrared and visible images collected from VOT-2020.

The experimental results on Vot-2020 (a) infrared; (b) visble; (c) CrossFuse; (d) DenseFuse; (e) FusionGan; (f) LRRNet; (g) MFEIF; (h) MixFuse; (i) RFN-nest; (j) STDFusionNet; (k) swinFusion; (l) TextFusion; (m) U2Fusion; (n) YDTR; (o) proposed.
We conducted research on the affirmative application of fused images in the field of semantic segmentation. In particular, we selected 1000 pairs of infrared and visible image sets from the MSRS dataset. 42 The image sets were fused using our SelectiveFusion fusion network, forming three distinct sets that were employed as separate training datasets. These sets were employed to train the lightweight semantic segmentation network, BiSeNet v2. 43 Subsequently, testing was performed on 360 images, and the quantitative and visual results are presented in Table 7 and Figure 8, respectively. It can be observed that BiSeNet v2 trained with fused results successfully segments pedestrians and vehicles that cannot be accurately identified in single-modal images. The adaptive selection fusion introduced by our proposed SelectiveFusion ensures the meaningful integration of information from low-quality source images. Consequently, the segmentation performance for pedestrians and vehicles surpasses that of single-modal images. (Table 8)

Segmentation results for infrared, visible and fused images on the MSRS dataset.
In this paper, we propose a fusion model named Selective Fusion, which follows a two-stage training framework. Additionally, we introduce a novel fusion module called Selective Channel Fusion, designed for the selective weighting of channels in two modalities. Finally, we introduce a new loss function that constrains training from the perspective of compensating information. Through extensive experiments involving representative algorithms and evaluation on six metrics, we demonstrate the superiority of our Selective Fusion fusion algorithm. It exhibits adaptability to diverse lighting conditions and fusion environments across the TNO, RoadScene, and VOT-2020 test sets. The algorithm demonstrates strong competitiveness in handling different scenes and illumination scenarios.
Upcoming research is anticipated to explore the nuances within the image fusion domain, aiming to seamlessly integrate the attributes of infrared and visible light through the application of deep learning technologies. These investigations will specifically address challenges posed by significant illumination imbalances in diverse lighting conditions. The outcomes of such research endeavors are poised to significantly contribute to refining and enhancing image fusion methodologies.
Segmentation performance(mIoU) of infrared, visible and fused images on the MSRS dataset.

Footnotes
Acknowledgements
This research was funded by the Program of Promoting the Development of University—Diligence Talents (Beijing Information Science and Technology University, grant no. 5112111145).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.