
Abstract
Contrastive learning has become a powerful paradigm for unsupervised representation learning. However, its effectiveness largely depends on carefully designed data augmentation strategies to generate meaningful positive and negative pairs. Additionally, unsupervised clustering algorithms are typically sensitive to initialization and prone to converging to suboptimal local minima, resulting in unstable performance. To overcome these challenges, we propose HAPL, a unified end-to-end framework for short text clustering that integrates Hybrid data Augmentation with Pseudo-Label supervision. HAPL combines explicit and implicit data augmentation techniques in a synergistic strategy. It also incorporates an adaptive optimal transport mechanism for pseudo-label generation. This design provides principled supervision that stabilizes the optimization process and adapts to varied cluster distributions, thereby enhancing the model’s discriminative power. Furthermore, prototype learning is employed to reinforce the coherence of representations in the embedding space. Extensive experiments on eight benchmark datasets show that HAPL achieves state-of-the-art performance across various evaluation metrics. Comprehensive ablation experiments validate the contribution of each component to the overall effectiveness of the framework.
Introduction
Text clustering is a fundamental unsupervised learning technique widely applied in natural language processing and data mining. 1 It generally follows a three stage pipeline comprising textual representation learning, semantic similarity computation and cluster partitioning. 2 This methodological framework underpins critical applications such as topic discovery, news categorization, document organization, user opinion mining and search engine optimization. 3 The exponential growth of social media, instant messaging, and e-commerce has led to a predominance of short texts in modern data streams. These texts, typically containing no more than 50 tokens, include microblogs, chat messages, search queries, and product reviews. 4 This shift has positioned short text clustering as both an essential and challenging research frontier, where conventional methods often struggle due to data sparsity and limited contextual cues. 5
To address these issues, recent studies have prioritized enriching semantic representations for short texts. 6 Modern approaches have progressively moved beyond surface level lexical statistics toward two prevailing paradigms. One is the infusion of external knowledge through structured resources such as WordNet and domain specific knowledge graphs, which inject contextual relationships and ontological constraints. 7 The other is deep semantic encoding via pretrained language models including Word2Vec, GloVe and BERT, which produce dense feature vectors capturing compositional semantics. 8 These advances help mitigate the intrinsic information deficiency of short texts by transforming sparse lexical signals into rich distributed representations.
Nevertheless, both knowledge intensive and deep learning methods exhibit inherent limitations. Knowledge infusion approaches face domain coverage gaps and high ontology maintenance costs, whereas deep encoders generally require large scale labeled datasets to achieve optimal performance resources that are rarely available for short text scenarios. 9 To bridge this gap, recent research has explored self-supervised enhancement strategies, such as data augmentation and pseudo-label propagation. Data augmentation generates context preserving variants to alleviate sparsity, while pseudo-label propagation leverages cluster consistency to provide unsupervised supervision, jointly constructing robust feature spaces without relying on external knowledge.
Despite their promise, these techniques are not without drawbacks. For data augmentation, while effective against data scarcity, it can distort original semantics. Operations such as synonym replacement, random swapping, or insertion may introduce noise or disrupt coherence, making it challenging to preserve semantic integrity while enhancing diversity. 10 Over-augmentation may further push samples away from their true semantic space, thereby impairing discriminative capability. Advanced generative augmentation methods 11 can produce more varied samples, but their high computational cost limits practical deployment.
In the realm of unsupervised learning, pseudo-labeling has emerged as a powerful mechanism for guiding representation learning. 12 Early work such as that by DeepCluster 13 applied K-means to generate pseudo-labels for visual representation learning, albeit without a unified optimization objective. SeLa 14 addressed this limitation by formulating pseudo-label assignment as an Optimal Transport (OT) problem, minimizing cross entropy loss while ensuring theoretical convergence. Subsequently, SwAV 15 integrated this approach with contrastive learning to enable online clustering. However, both SeLa 14 and SwAV 15 rely on uniform distribution constraints for pseudo-labels, which are ineffective under real-world long tailed data distributions. More recent methods such as RSTC 16 attempt to model true class distributions to handle imbalance, while POTA 17 improves pseudo-label reliability via semantic similarity at the cost of increased computational overhead.
Motivated by recent advancements in contrastive learning and deep clustering, 18 we propose HAPL, a novel framework that integrates hybrid data augmentation with pseudo-label supervision to optimize contrastive learning. Our approach employs a hybrid augmentation strategy to enrich sample diversity while preserving semantic consistency. We introduce an adaptive OT-based pseudo-label generation mechanism that dynamically adjusts class distribution priors to address the clustering degradation problem in scenarios with varying data distributions. Additionally, the prototype learning component effectively captures intrinsic sample similarities to enhance representation quality.
The main contributions of this work are as follows:
(1) We propose a novel hybrid data augmentation strategy that synergistically integrates explicit and implicit augmentation techniques, enabling the generation of semantically enriched positive pairs that enhance the model’s discriminative capacity.
(2) We introduce HAPL, a principled end-to-end framework that leverages adaptive OT for pseudo-label generation, providing theoretically grounded supervision that simultaneously guides prototype learning and cluster assignment while ensuring stability across diverse cluster distributions.
(3) We conduct comprehensive empirical evaluations demonstrating that HAPL achieves state-of-the-art performance across multiple benchmark datasets and evaluation metrics, with systematic ablation studies rigorously validating the synergistic contributions of each architectural component.
Related work
Short text clustering
Existing short text clustering methods can be broadly classified into three categories: traditional methods, deep learning methods and deep joint clustering methods.
Traditional methods primarily rely on manually engineered features, such as Term Frequency-Inverse Document Frequency and Bag of Words models. These features are then processed using classical clustering algorithms like K-means or hierarchical clustering. While these approaches are computationally efficient and offer high interpretability, their ability to capture complex semantic representations is often limited, hindering performance on nuanced textual data.
Deep learning methods 19 leverage pre-trained language models to learn dense, semantic-aware text representations, which are subsequently clustered using traditional algorithms. Although this paradigm captures semantic information more effectively, its two-stage nature, which decouples representation learning from clustering, can lead to suboptimal results.
To overcome this limitation, deep joint clustering methods integrate representation learning and clustering within an end-to-end framework, enabling mutual reinforcement between feature refinement and cluster assignment. Among these approaches, autoencoder-based methods pioneered this direction by jointly optimizing reconstruction and clustering objectives. DEC 20 introduces a clustering layer atop the encoder and iteratively refines cluster assignments by minimizing the KL divergence between soft assignments and auxiliary target distributions. However, its simple encoder architecture limits the capacity to capture global dependencies in data. Contrastive learning methods have gained prominence by exploiting instance-level discrimination. CC 21 constructs positive pairs from augmented views of the same instance and negative pairs across different instances, enabling the model to learn discriminative features that naturally separate clusters. ProCA 22 extends contrastive learning to the prototype level by incorporating inter-class information into class-wise prototypes and adopting class-centered distribution alignment: treating same-class prototypes as positives and other-class prototypes as negatives to achieve intra-cluster compactness and inter-cluster separability. TAKE 23 employs a Transformer AutoEncoder that incorporates transformer structures to learn global features and leverages contrastive learning mechanisms to enhance feature discrimination, while introducing a convex combination loss to produce K-means-friendly feature spaces.
Despite their success, these methods still face challenges in balancing representation quality and clustering performance and handling complex and heterogeneous data distributions. In particular, the trade-off between preserving fine-grained local structures and achieving globally coherent clusters remains unresolved, often leading to suboptimal performance when applied to real-world datasets with high variability.
Data augmentation
Research has shown that single augmentation methods often yield limited performance gains, and that contrastive learning typically requires stronger augmentation strategies than its supervised counterpart. 24 This insight has spurred the exploration of various text augmentation techniques.
Early efforts focused on identifying the most effective single augmentation strategy. For instance, SCCL 25 empirically compared synonym substitution, context augmentation and back translation, identifying context augmentation as the most effective for its task. While this work provided valuable empirical insights, it remained confined to selecting among individual augmentation methods rather than systematically combining them, thereby limiting the potential for capturing multi-faceted semantic variations.
Recognizing the limitations of single-strategy approaches, subsequent research began exploring hybrid augmentation frameworks. TCL 26 proposed a dual-strategy framework combining weak (Dropout) and strong (RandAugment) augmentations to construct a more challenging learning objective. This advancement introduced the concept of augmentation composition; however, both strategies primarily operate at the architectural or token-level manipulation, lacking explicit semantic-level transformations that preserve deep contextual meaning.
Despite these advancements, a critical gap persists: existing methods typically augment data at a single semantic level–either through syntactic perturbations or shallow lexical substitutions—without strategically integrating cross-level augmentations that simultaneously ensure diversity and semantic fidelity. For tasks requiring fine-grained semantic understanding, such as short text clustering, the challenge of generating high-quality ”hard” positive pairs that are both meaningfully diverse and semantically consistent remains largely unresolved.
Methodology
The aim of this study is to design a unified model that enhances unsupervised clustering performance by integrating contrastive learning, prototype learning and pseudo-label generation. As shown in Figure 1, our framework first generates an augmented sample using an explicit augmentation strategy. Both the original and this explicitly augmented input are encoded into a shared representation space by a neural network
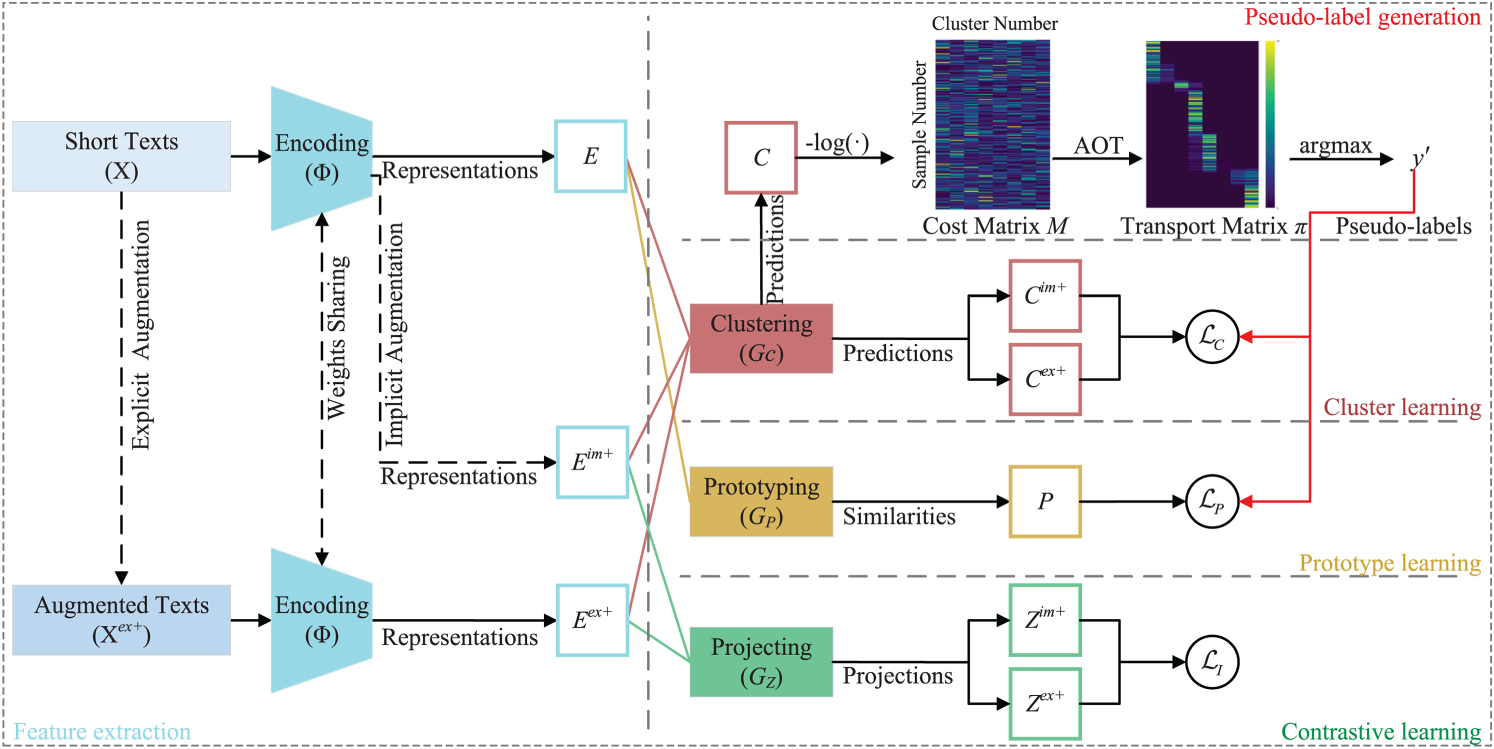
The overall training framework of HAPL, which jointly optimizes clustering loss, prototype loss, and contrastive loss.
During the feature extraction phase, HAPL employs SentenceBERT as the text encoder and combines explicit and implicit augmentation strategies to enhance sample diversity. Explicit augmentation generates extended samples
Pseudo-label generation
The pseudo-label generation module bridges feature extraction and representation learning. Its workflow can be formally described as follows: Encoder network
To enhance pseudo-label quality, this module solves a discrete OT problem to minimize cross entropy loss and generate pseudo-labels
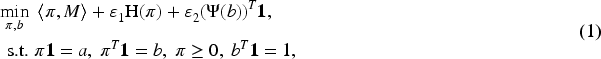
This design incorporates a dual adjustment mechanism: on one hand, the cost matrix
Ultimately, through iterative optimization, a stable transmission matrix

The objective of clustering learning is to aggregate samples belonging to the same semantic category. Specifically, two augmented text segments from the same original text form a positive sample pair; the pseudo-label serves as the supervised target for this pair. Through a hybrid augmentation strategy, the embedded representations
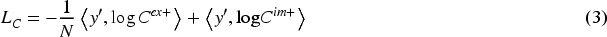
Consistent with the pseudo-label generation, the original text
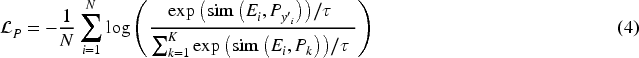
Contrastive learning aims to pull the projection representations of positive sample pairs closer together while pushing negative sample pairs apart. To achieve this, we use a fully connected layer
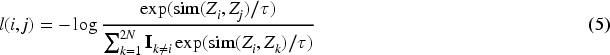
The instance comparison loss considers all positive sample pairs within a batch, including

Three loss functions work together to enhance representation quality across three levels: prototypical, categorical and instance. Prototypical loss promotes intra class compactness, category contrast loss enhances inter class discriminabilityand instance contrast loss maintains sample level discriminative power. The final objective function is:

Experiments demonstrate that when
The training process of HAPL follows a carefully designed two-stage paradigm aimed at progressively refining representations and cluster assignments. The first stage is the Warm-up Phase, whose core objective is to construct a well-structured and discriminative feature space through instance-level contrastive learning. In this phase, the model applies a hybrid augmentation strategy to each training batch of input texts, generating both explicit and implicit augmented views. These views are then encoded into feature representations, and the contrastive loss
The second stage is the Joint Optimization Phase with Adaptive Feedback. Building upon the pre-trained encoder from the first stage, this phase synchronously optimizes feature representations and cluster assignments through an iterative approach. The workflow for each iteration is as follows: First, in the Forward Propagation and Loss Calculation step, the model computes feature representations for a given batch. The clustering head

Experiments
Datasets
We evaluated our method on eight widely used real-world short text datasets, covering multiple domains including news headlines, technical forums, biomedical literature and social media under varying degrees of class imbalance. Each experiment was repeated at least 10 times to ensure statistical reliability. Table 1 summarizes the key statistics of the datasets, including vocabulary size (
Dataset details.
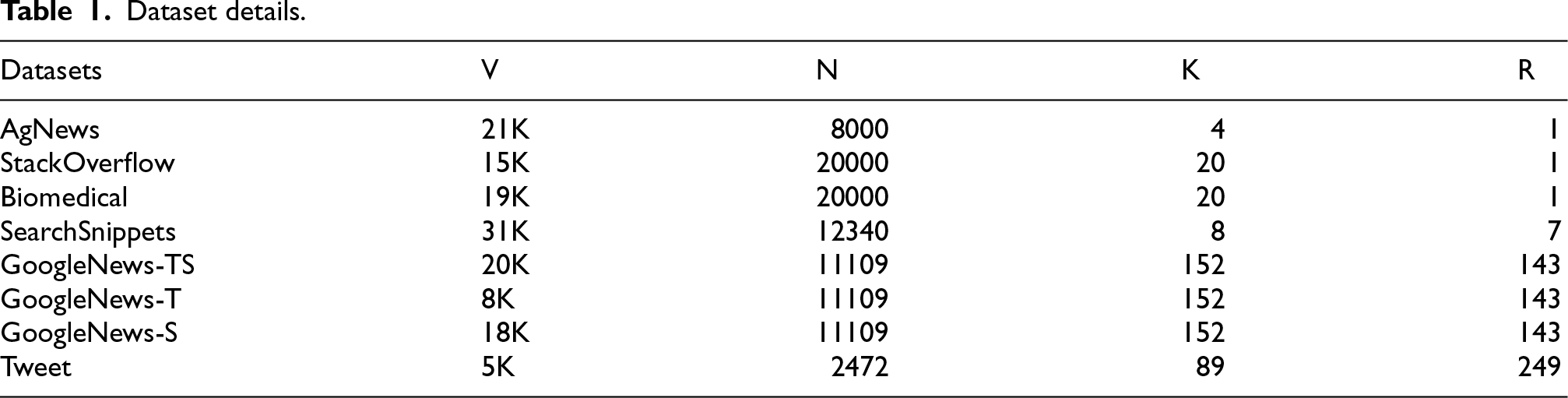
Dataset details.
Following the experimental setup of SCCL, 25 we used raw, unprocessed text as input. This allows us to assess model robustness in noisy environments while ensuring a fair comparison with baseline methods.
All experiments are conducted on a workstation equipped with an NVIDIA A40 GPU (48GB VRAM), an Intel Xeon Platinum 8380 CPU and 16GB of RAM. The model is implemented using PyTorch 2.2.1 with Python 3.9.13 and CUDA 12.0. We employ the distilbert-base-nli-stsb-mean-tokens model from the Sentence Transformers library 32 as the sentence encoder. The model is optimized using the Adam optimizer. The number of clusters is set to the ground-truth category count for each dataset. All results are averaged over ten independent runs and reported across four standard clustering metrics: Accuracy (ACC), Normalized Mutual Information (NMI), Adjusted Rand Index (ARI), and Adjusted Mutual Information (AMI).
Baselines
Among traditional methods, we adopted an approach that combines Bag of Words (BOW) or TF-IDF features with the K-means algorithm, serving as a feature engineering baseline. For deep learning methods, two representative models were included: STC
In the category of deep joint clustering methods, we selected: SCCL, 25 which builds on a SentenceBERT (SBERT) framework and incorporates instance level contrastive learning to refine text representations, combined with deep embedded clustering for joint optimization of feature learning and cluster assignment; RSTC, 16 which employs OT to generate pseudo-labels for guiding cluster learning. These baselines collectively represent state-of-the-art advancements in short text clustering and allow for a rigorous assessment of HAPL’s performance across different learning paradigms.
Accuracy(%), clustering performance comparison on eight short text datasets. The best results are in bold and the second best results are underlined.
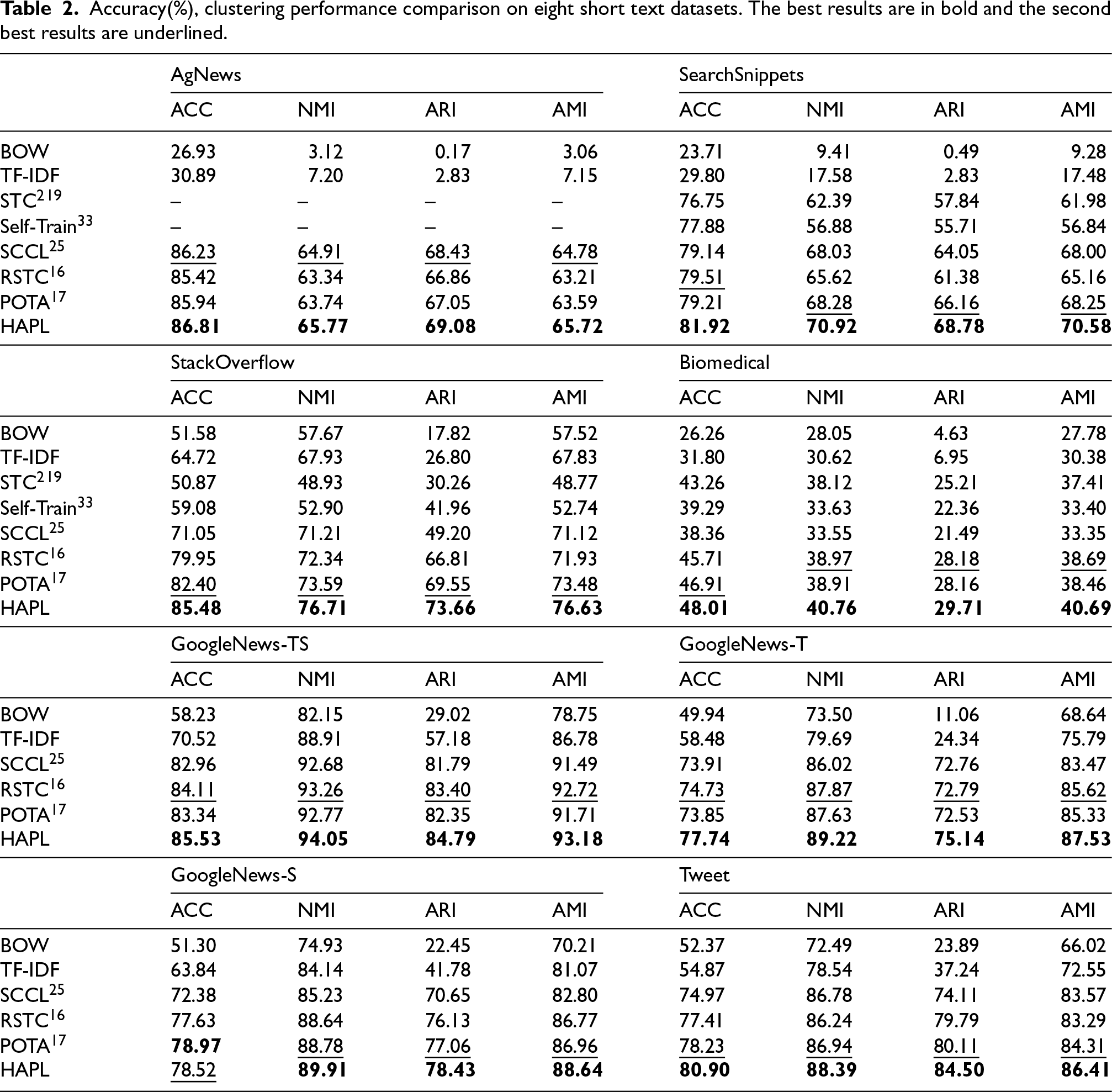
Accuracy(%), clustering performance comparison on eight short text datasets. The best results are in bold and the second best results are underlined.
Table 2 presents the experimental results of the proposed method on eight short text benchmark datasets. From the overall results, the traditional methods BOW and TF-IDF are limited by the inherent high-dimensional sparsity of short text, which is difficult to effectively capture deep semantic information, and perform poorly on all data sets. STC
The impact of hyperparameters
We investigate the effects of three key hyperparameters:
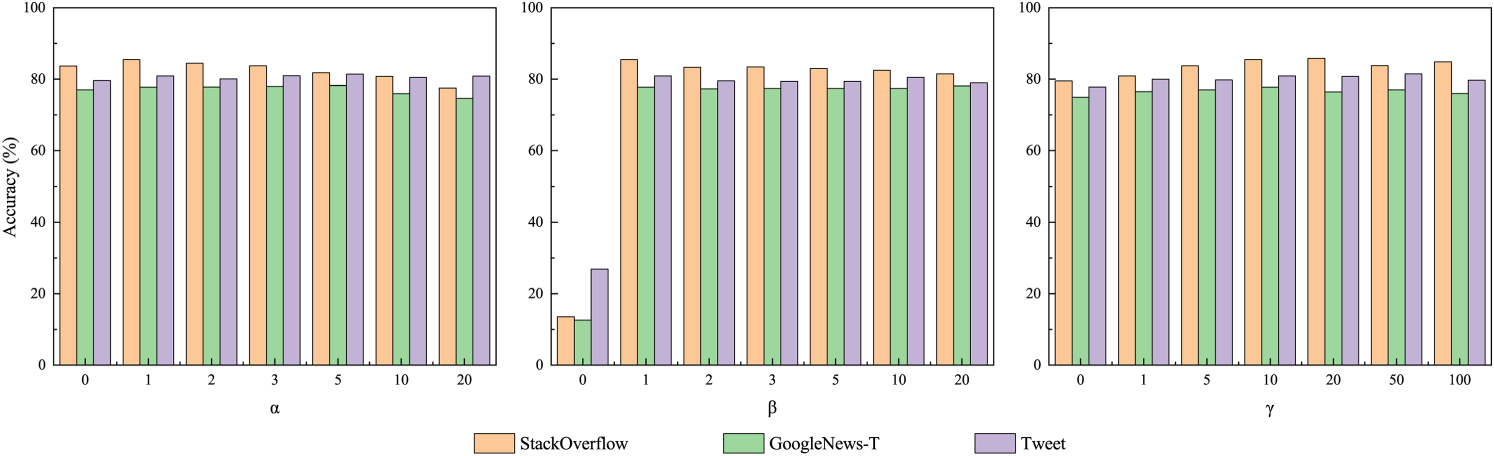
The impact of
Additionally, this paper investigates the effects of hyperparameters
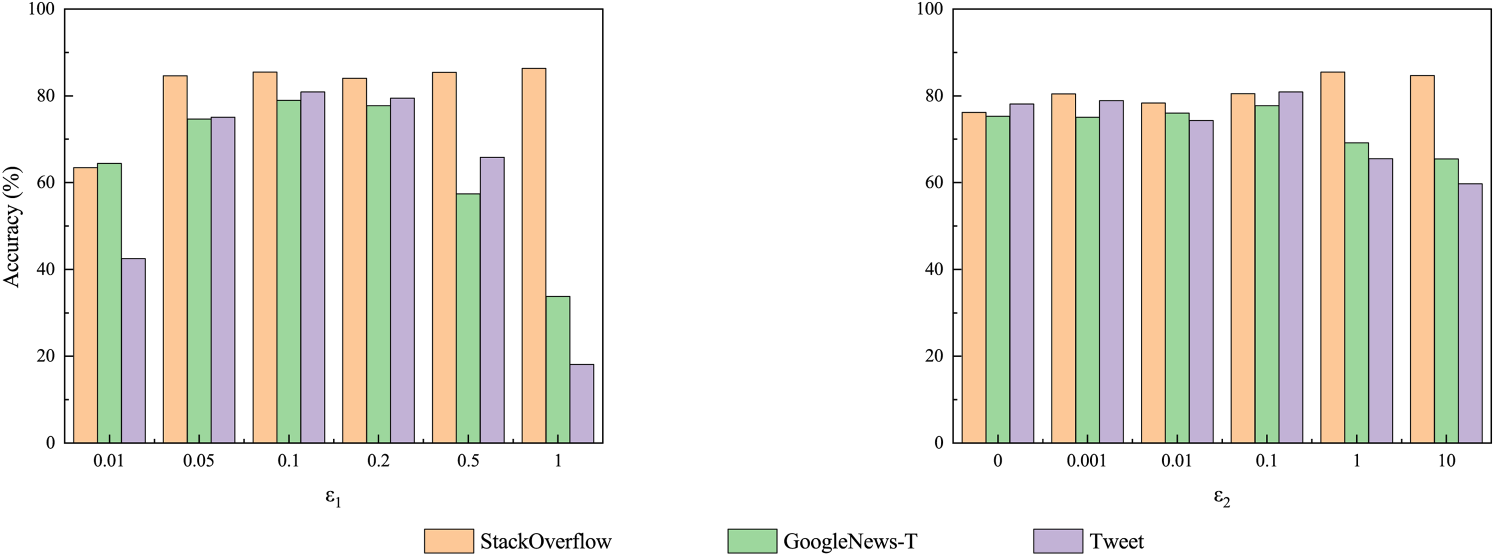
The impact of
In the experimental evaluation, the number of clusters was set to the true number of categories. All experiments were repeated ten times and their average results were reported to ensure the robustness of the conclusions.
To clarify the distinct roles of each module, we performed t-SNE visualization on the AgNews dataset, as shown in Figure 4. (a) SBERT: Raw features exhibit significant overlap with blurred class boundaries. (b) Contrastive Learning (CL): While CL substantially improves classification metrics by learning a more discriminative feature space, its effect on low-dimensional projection separation is limited. This is because CL optimizes instance-level similarity in the high-dimensional metric space, which effectively aids the classifier but does not directly enforce geometric separation in a 2D projection like t-SNE. (c) HAPL without Augmentation (HAPL
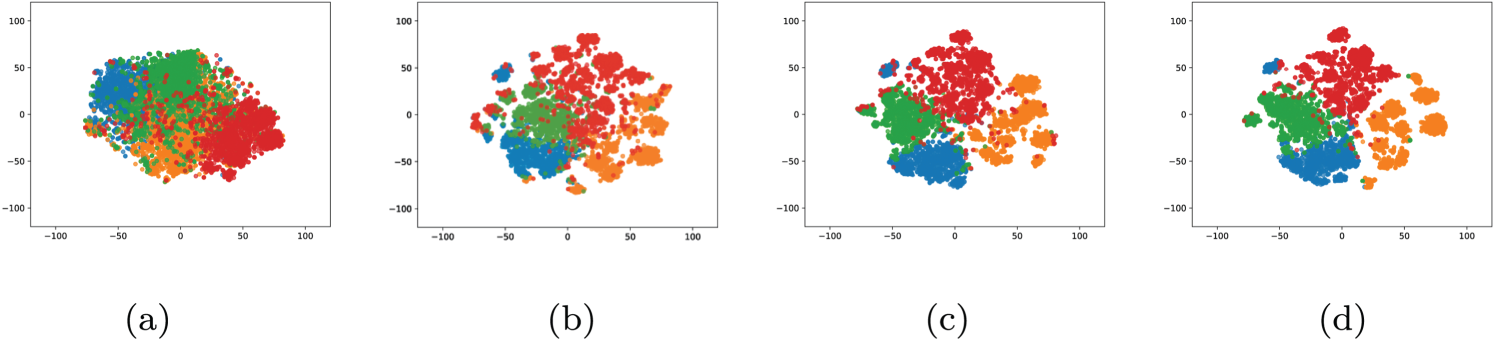
t-SNE visualization depicted on AgNews, with each color representing a true category. (a) SBERT, (b) CL, (c) HAPL
Hybrid data augmentation
This paper systematically investigates the impact of diverse unsupervised text augmentation strategies through ablation studies. Unless otherwise specified, all augmentation techniques are applied at a probability of 10%. The evaluated techniques are categorized as follows:
Explicit Augmentation: Techniques that generate new textual instances, including back-translation (bt0.1), contextual word replacement using pre-trained language models BERT (be0.1) and RoBERTa (rb0.1) and Easy Data Augmentation (eda0.1). Implicit Augmentation: Techniques that perturb input representations without generating new text, specifically random token replacement at probabilities of 10% (tr0.1) and 30% (tr0.3) and random token erasure (te0.1). Hybrid Augmentation: Combinations integrating one explicit augmentation method with one implicit augmentation method.
All augmentation strategies are applied exclusively to unlabeled training data, maintaining label consistency. Figure 5 summarizes the performance of these augmentation strategies on the StackOverflow, Biomedical and GoogleNews-T datasets. Experimental results demonstrate that hybrid augmentation methods generally outperform single augmentation techniques, with hy(be0.1,te0.1) achieving the best overall performance in terms of ACC across multiple datasets.
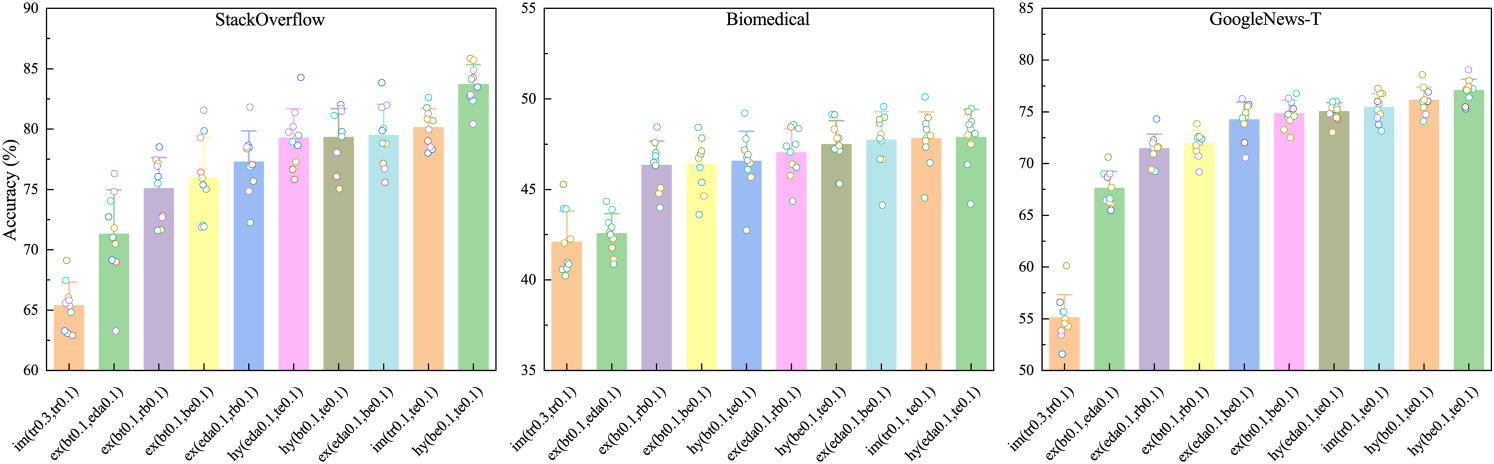
ACC metrics for ten different data augmentation strategy combinations.
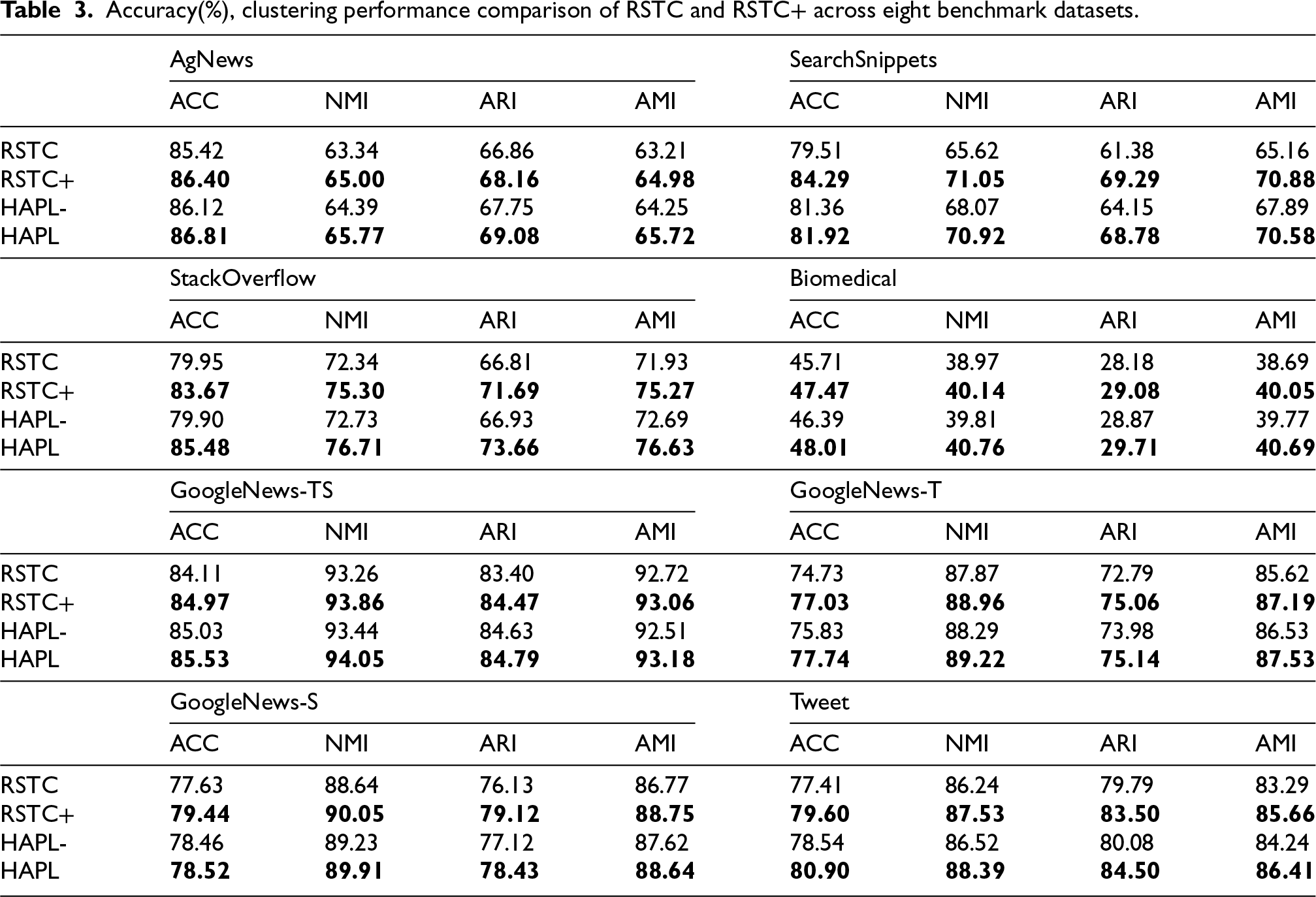
To validate the effectiveness of the proposed hybrid augmentation strategy, we integrate it into the RSTC 16 framework (RSTC+) and remove it from our HAPL model (HAPL-). As demonstrated in Table 3, RSTC+ achieves statistically significant improvements across all eight benchmark datasets, while HAPL- exhibits performance degradation. These results confirm that the hybrid augmentation strategy substantially enhances clustering performance.
Accuracy(%), clustering performance comparison of RSTC and RSTC+ across eight benchmark datasets.
This study comparatively evaluates standard OT and Adaptive Optimal Transport (AOT) methods across datasets with varying class imbalance: balanced StackOverflow, mildly imbalanced GoogleNews-T and heavily imbalanced Tweet. The methods are configured as follows: (1) OT: Employs entropy regularization
As evidenced in Figure 6, AOT (solid line) consistently achieves higher accuracy than OT (dashed line) across three datasets. Figure 7 further reveals that AOT can return to the correct number of clusters in the optimization process, contrasting with OT’s tendency toward over merging (particularly in imbalanced settings). These results demonstrate AOT’s enhanced robustness to data complexity and its effectiveness in mitigating under clustering during optimization.
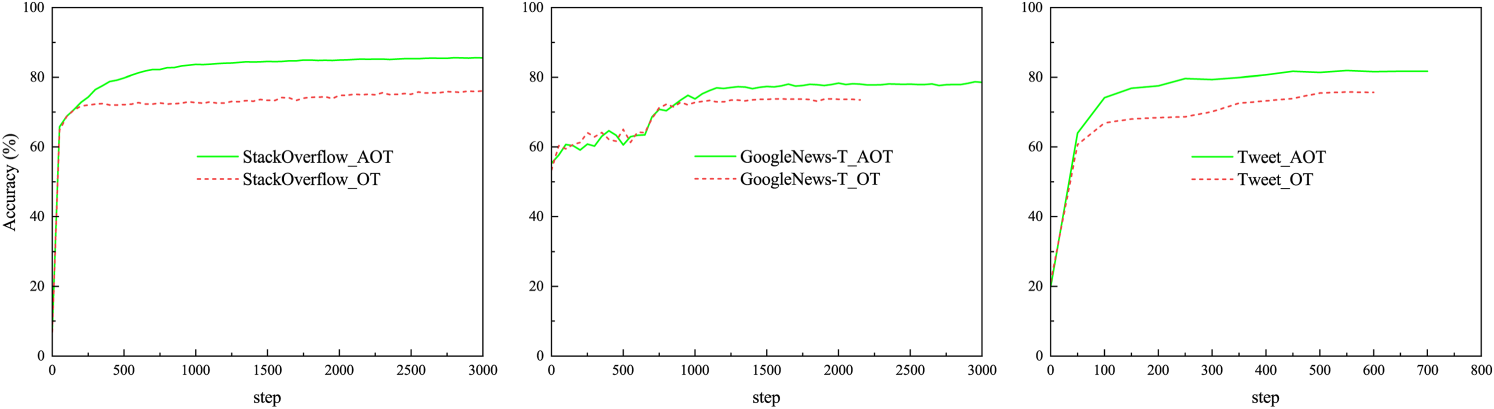
Changes in Accuracy for AOT and OT Training Across Three Datasets.
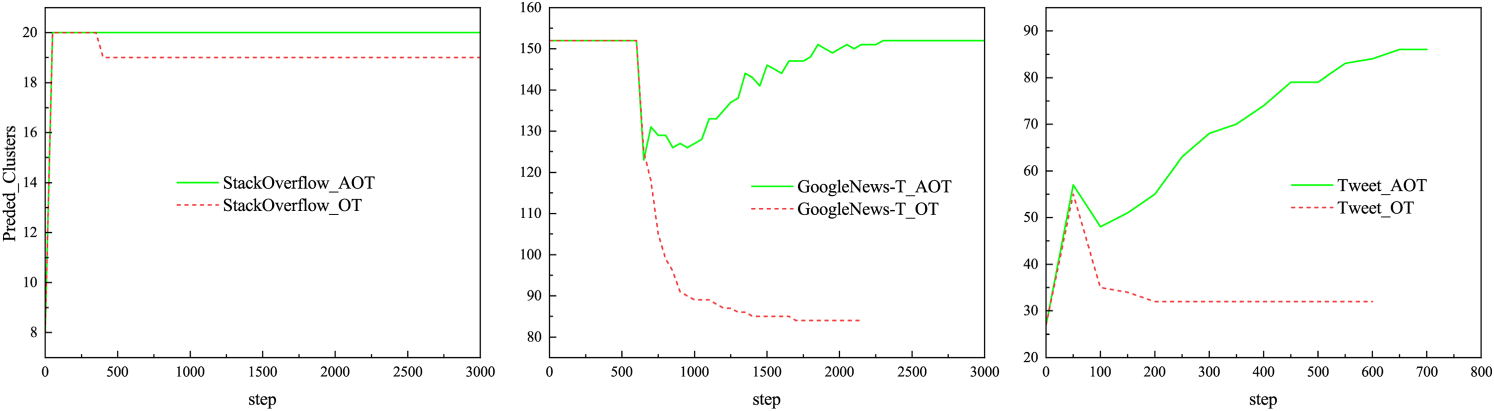
Changes in Predicted Cluster Counts for AOT and OT Training Across Three Datasets.
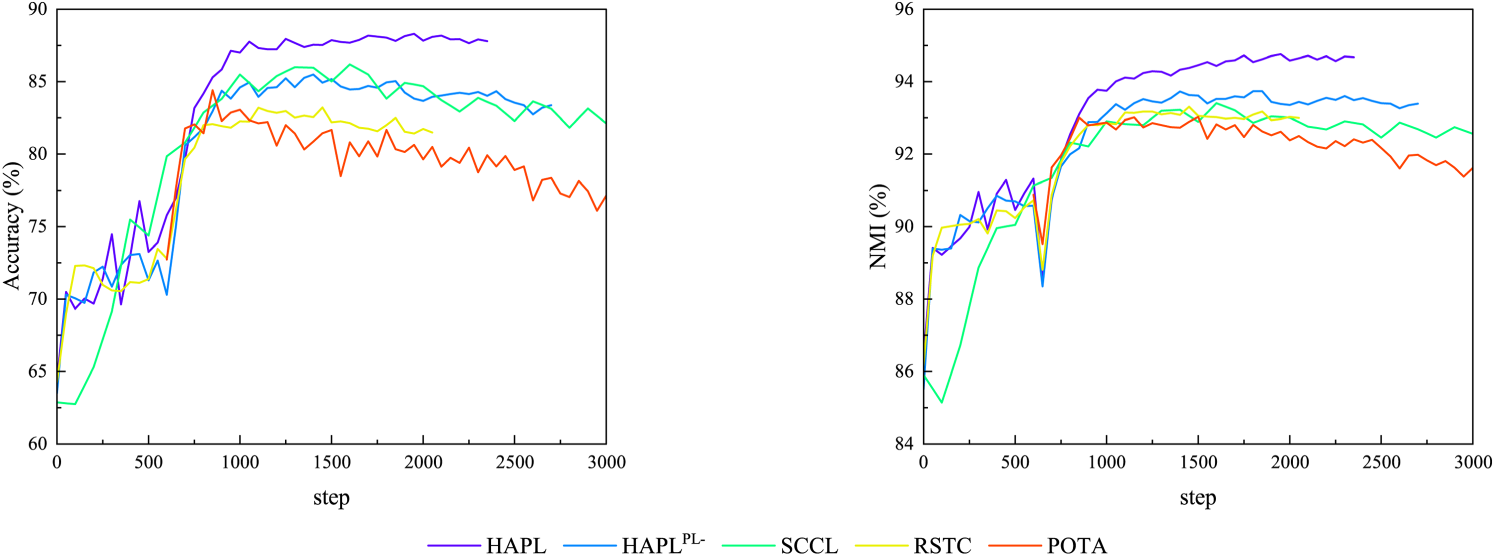
Changes in ACC and NMI during training of five models on GoogleNews-TS.
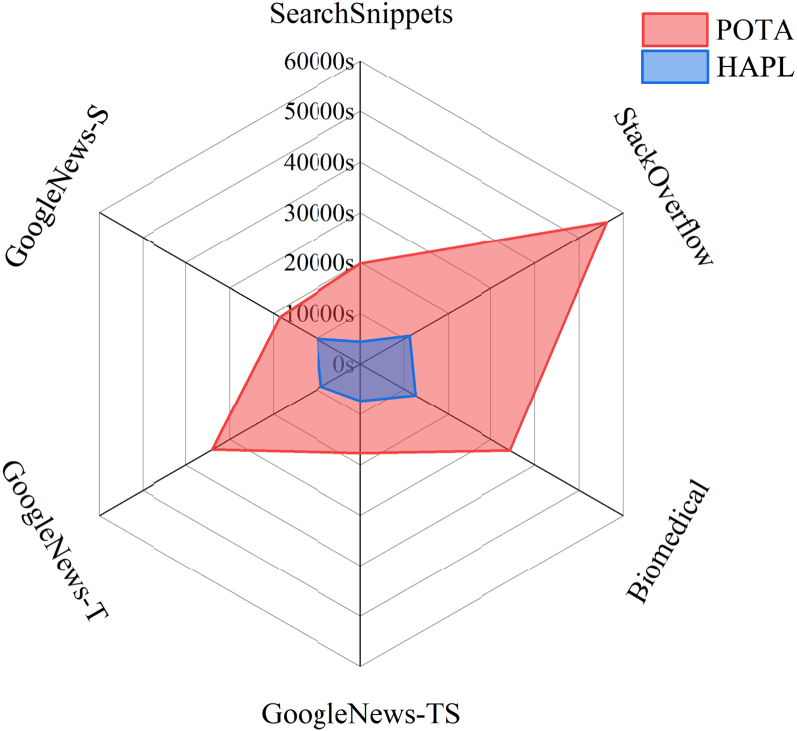
Second(s), comparison of computing overhead between HAPL and POTA across six datasets.
We design an ablation model HAPL
As shown in Figure 9, HAPL exhibits a significant reduction in computational overhead compared to state-of-the-art baseline models. Notably, the computational costs associated with the AgNews and Tweet datasets are excluded from the statistical comparison, as the model reaches convergence at an earlier stage on these datasets and the computational overhead varies considerably across different random seed initializations.
Conclusion
In this work, we present HAPL, an end-to-end framework for short text clustering that integrates feature extraction, pseudo-label generation, cluster learning, prototype learning and contrastive learning into a unified architecture. By combining explicit and implicit augmentation within a hybrid strategy, HAPL produces semantically consistent yet diverse positive pairs that strengthen representation quality. The adaptive OT module generates distribution-aware pseudo-labels that provide stable guidance for cluster assignment, while the prototype learning component further aligns sample representations with cluster prototypes, reinforcing semantic coherence and enhancing the robustness of the learned embedding space.
Ablation experiments confirm that each module contributes to overall performance, with joint optimization yielding the greatest gains. Hybrid augmentation outperforms any single strategy; the adaptive OT mechanism alleviates clustering degradation under distribution shift compared to standard OT; and prototype learning improves model stability. The complementary interplay among augmentation, adaptive pseudo-label supervision, and prototype-guided refinement validates our joint optimization design.
Two limitations remain for future work. First, HAPL currently supports single-label clustering; extending it to multi-label settings is the next step. Second, the adaptive OT module incurs O(n
Footnotes
Acknowledgements
This paper was supported by National Natural Science Foundation of China (No. 62076215, No. 62301473), Fundamental Research Funds for the Central Universities, China (No. K93
Ethical and informed consent for data used
This article does not contain studies with human participants or animals. Statement of informed consent is not applicable since the manuscript does not contain any patient data.
Authors contribution statement
Tao Yan: Writing-original draft, validation, methodology, formal analysis, data curation. Sen Xu: Writing-review, supervision, resources, project administration, funding acquisition. Shanliang Yao: writing-review, data verification, funding acquisition, Naixuan Guo: writing-review, project administration, funding acquisition. Xuesheng Bian: writing-review, funding acquisition. Xiufang Xu: Supervision, project administration. Xianye Ben: Supervision, resources, project administration. Tian Zhou: Supervision, resources.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper was supported by the National Natural Science Foundation of China (62322111, 62271289) and the Natural Science Fund for Distinguished Young Scientists of Shandong Province (ZR2024JQ007).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability and access
The datasets we used in this paper are public without private protection.