
Abstract
Recently, Graph Neural Networks (GNNs) using aggregating neighborhood collaborative information have shown effectiveness in recommendation. However, GNNs-based models suffer from over-smoothing and data sparsity problems. Due to its self-supervised nature, contrastive learning has gained considerable attention in the field of recommendation, aiming at alleviating highly sparse data. Graph contrastive learning models are widely used to learn the consistency of representations by constructing different graph augmentation views. Most current graph augmentation with random perturbation destroy the original graph structure information, which mislead embeddings learning. In this paper, an effective graph contrastive learning paradigm CollaGCL is proposed, which constructs graph augmentation by using singular value decomposition to preserve crucial structure information. CollaGCL enables perturbed views to effectively capture global collaborative information, mitigating the negative impact of graph structural perturbations. To optimize the contrastive learning task, the extracted meta-knowledge was propagate throughout the original graph to learn reliable embedding representations. The self-information learning between views enhances the semantic information of nodes, thus alleviating the problem of over-smoothing. Experimental results on three real-world datasets demonstrate the significant improvement of CollaGCL over state-of-the-art methods.
Introduction
Recommendation has been extensively utilized to alleviate information overload issues [9]. Among various methods, Collaborative Filtering (CF) directly digs user preference from historical user-item interactions, which serves as a popular architecture for recommendation [6, 10]. Many existing popular methods have achieved significant improvement by combining with CF paradigm [19, 40]. However, CF methods require high-quality interaction information to learn users and items representations [5]. Graph Convolutional Networks (GCNs) are effective in recommendation by stacking multiple convolutional layers to extract local collaborative signals [4, 13]. Various neural network GCNs [33] learn reliable user and item representations, such as graph auto-encoder [2, 3] and attention mechanism [38]. Most GCN-based models require sufficient quality labeled data for model training. However, in practical scenarios, data is extremely sparse, making it challenging for GCNs-based models to capture high-quality users and items interaction information [26]. Contrastive learning (CL) acquires general features from unlabeled data has been substantiated as an efficient strategy for tackling data sparsity [16]. Due to its consistent requirement, contrastive learning has achieved significant success in numerous recommendation tasks [15, 28].
Graph Contrastive Learning (GCL) is the application of CL in graph-based recommendation. The primary idea of GCL for enhancing users and items representation is to capture the consistency between different augmentation views [35]. Most current GCL methods focus on constructing efficient graph augmentation views. SGL [22] has been proposed to generate graph augmentation by applying stochastic strategies that destroy the structural information of user-item interactions, such as node dropping and edge perturbation. LightGCL [34] utilizes singular value decomposition (SVD) augmentation to preserve critical information within graph structure. Some studies have proposed contrastive learning methods that differ from graph augmentation. SimGrace [30] constructs augmented view by randomly perturbing the parameters of graph neural network. To improve performance in graph contrastive learning, SimGCL [31] and XSimGCL [39] proposed adding uniform noise to user and item embeddings as an alternative approach to graph augmentation for constructing perturbed views. XSimGCL optimized the model on a single view, which provides a feasible way to simplify contrastive learning. The combination of contrastive learning with other recommendation methods has also achieved great success, such as sequential recommendation [42] and reinforcement learning-based recommendation [43].
Despite the effectiveness of these methods, GCL-based recommendation suffer from several problems: i) Current GCN-based recommendations are limited by the issue of over-smoothing [14, 20] and noise interactions [25]. ii) Graph augmentation with structural perturbation may lead to the disruption of structure information, which misleads the learning of embeddings [31]. iii) It is difficult for current GCL methods to extract valuable information from global collaborative relations. To alleviate the problem above, an effective graph contrastive learning method To mitigate the impact of structural perturbation, CollaGCL introduces global collaborative information into the learning process of perturbed views. The extracted meta-knowledge was propagated throughout the original graph to optimize recommendation and contrastive learning tasks. The joint-view representation learning module was designed to allow perturbed view to actively aggregate effective collaborative information from the main views. This helps mitigate the negative effects of over-smoothing and graph augmentation. Experiments conducted on both baselines and CollaGCL have confirmed the improved recommendation performance of CollaGCL. Further experiments validate the robustness of CollaGCL.
Related work
GCN-based methods
The current mainstream recommendation models make recommendations by learning embedding representations of users and items. Efficiently learning high-quality representations is an important research focus. GCN [31] pioneered the application of convolutional neural network (CNN) concepts to graph structures for learning neighborhood information of nodes. Leveraging their simplicity and ease of implementation, GCN has gradually become a core component of recommendation models, such as NCF [6] and NGCF [10]. However, GCNs face challenges such as high complexity with large-scale datasets and issues like over-smoothing after multiple convolution layers. LightGCN [18] significantly reduces complexity by removing feature transformation and non-linear activation modules from GCN. However, the issue of over-smoothing still persists. ResGCN [11] constructs a residual connection convolutional network to strengthen self-information and alleviate the over-smoothing problem. This allows the model to maintain a healthy learning trend even after 56 layers. However, the self-information of nodes originates from a single view and cannot capture diverse information. SVD-GCN [32] directly calculates the final embeddings of LightGCN using a low-rank method based on singular value decomposition, eliminating the need for convolution operations. This effectively alleviates over-smoothing but lacks a certain level of interpretability.
Although these methods have made significant contributions to alleviating the issues of over-smoothing and high-complexity in GCNs, there is still a need for further research on addressing the challenges that GCN faces in graph contrastive learning (GCL).
Contrastive learning for recommendation
Contrastive learning, owing to its self-supervised [12, 27] nature, is effective in learning features from unlabeled samples [24], serving as a valuable approach to mitigate the data sparsity issues in recommendation. Learning embedding representations from diverse graph structures and constructing a contrastive learning framework for optimization is a recent research hotspot in recommendation. To the best of our knowledge, SGL [22] employs a strategy of random dropout to enhance nodes and edges, constructing an effective CL framework. However, the random approach may discard some crucial structural information, making it challenging for the model to learn information between different views. Introducing multiple perturbed views also further increases the model’s complexity. AutoGCL [36] uses the learned embeddings to automatically deploy different graph augmentation strategies for each node. However, AutoGCL does not take into account edge augmentation strategies. SimGCL [31] and XSimGCL [39] introduce uniform noise to the embedding spaces of users and items, achieving feature augmentation. XSimGCL proposes a single-view CL framework, optimizing SimGCL’s multi-view framework and providing new ideas for the simplification of graph contrastive learning. The CL strategy of LightGCL involves reconstructing the adjacency matrix using truncated SVD. However, it does not take into account the impact of lost structural information. AdaptiveGCL [41] employs a variational graph autoencoder to generate existing edges and learn a parameterized mask for removing noisy edges in the graph. This method dynamically generates suitable perturbation views but may face complexity issues due to a large number of parameters and frequent graph generation.
Current GCL methods employ various augmentation strategies [21], but these approaches often fail to preserve crucial structural information from the original graph and optimize the negative impact of the augmentation.
Methodology
As depicted in Fig. 1, CollaGCL builds contrastive learning framework using LightGCN (View 1) and SVD augmentation (View 2). It is recommended to deploy LightGCN in the module of Graph Encode and normalization in the module of Norm. In the Joint-View Learning module, a fully-connected layer and aggregation function are used to learn collaborative information from main view (View 1). The Global Learning module should be able to capture global collaborative information and generate appropriate embeddings for subsequent tasks.
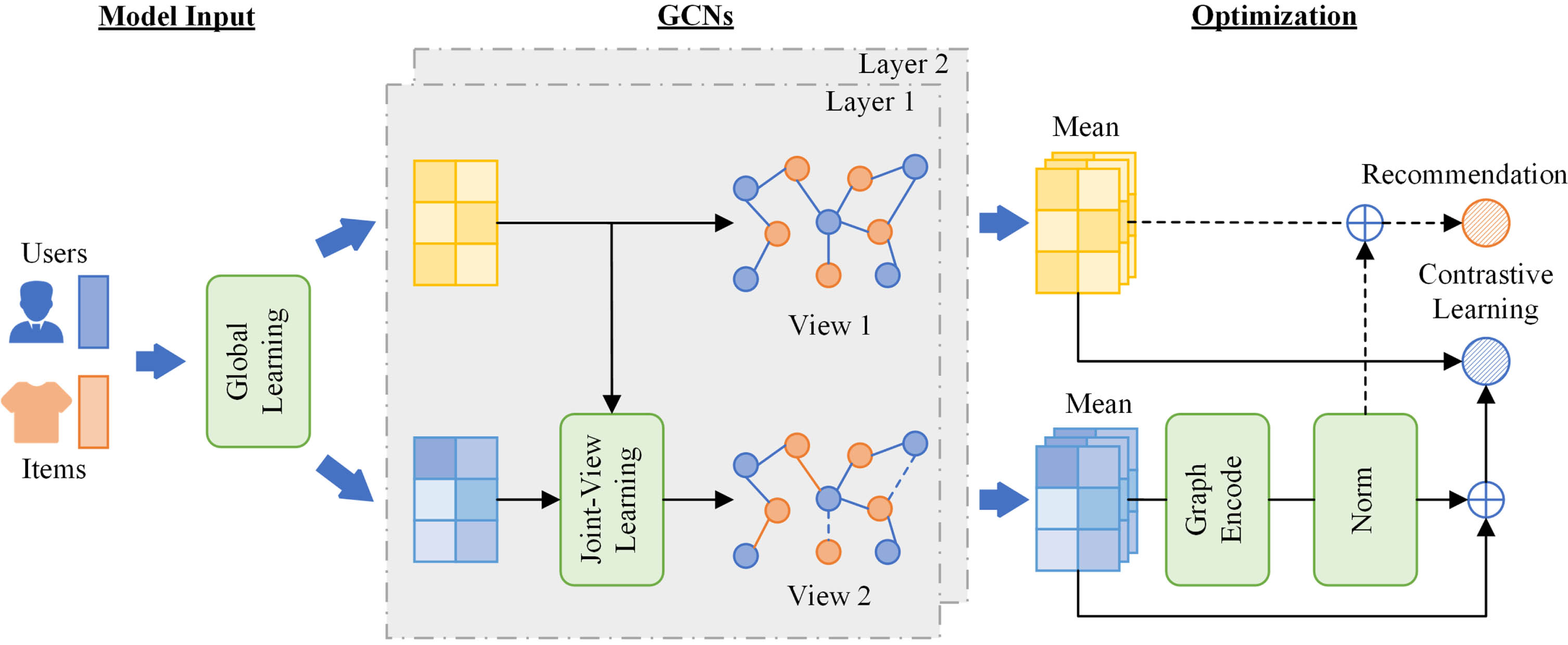
Overall structure of CollaGCL.
As a common practice of CF,
Graph augmentation with random perturbation may remove important structure information, which misleads the representation learning. In addition, removing important nodes or edges from the graph structure may compromise the integrity of the connected graph, resulting in a lack of learnable consistency among contrastive views [31]. As shown in Fig. 2, to alleviate the negative impact of graph structure perturbation, CollaGCL captures the first-hop neighborhood information of the original graph structure. The reason is that first-layer embeddings capture smooth user-item interaction information and the embeddings will be over-smoothing with the increasing of layers. In accordance with the common practice, users and items are represented as d-dimensional embeddings to learn neighborhood representations. Then, a single-layer LightGCN is employed to capture collaborative information:
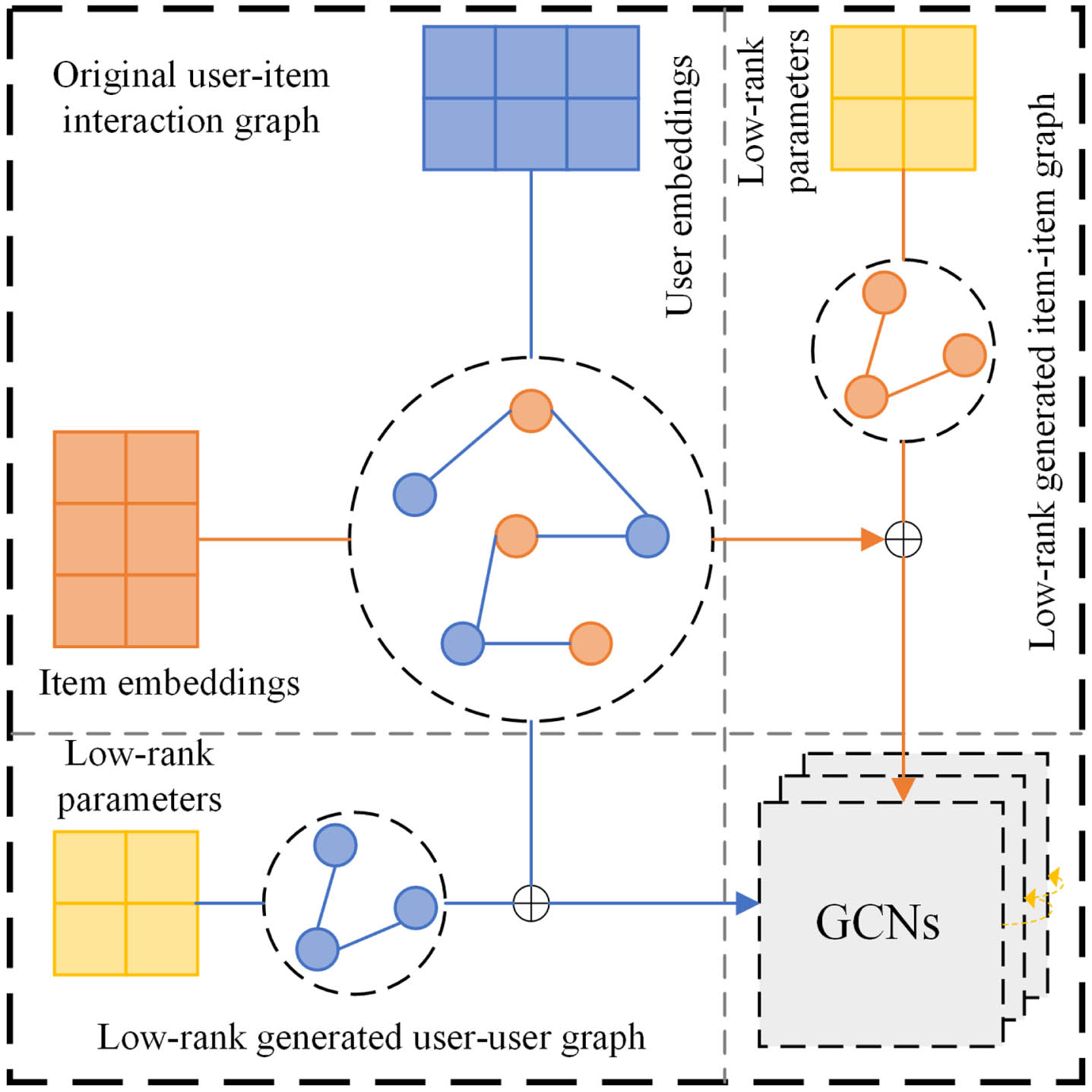
The framework of global learning module.
where
Subsequently, the user and item embeddings generated by the low-rank constructed graph can be represented as
Finally, the collaborative information is aggregated with the generated graph information to enhance the embedding representations. The embeddings from the global learning layer serve as inputs for the main view and perturbed view, replacing randomly initialized embeddings
where
Main view propagation
To better aggregate global collaborative information, a two-layer LightGCN was adopted to encode the neighborhood information for each node in the main view. In the l-th layer, the aggregation process is expressed as
To construct a better contrastive learning paradigm and extract important structure information, SVD method is used to reconstruct the graph structure as the perturbed view. Firstly, SVD is performed on the adjacency matrix
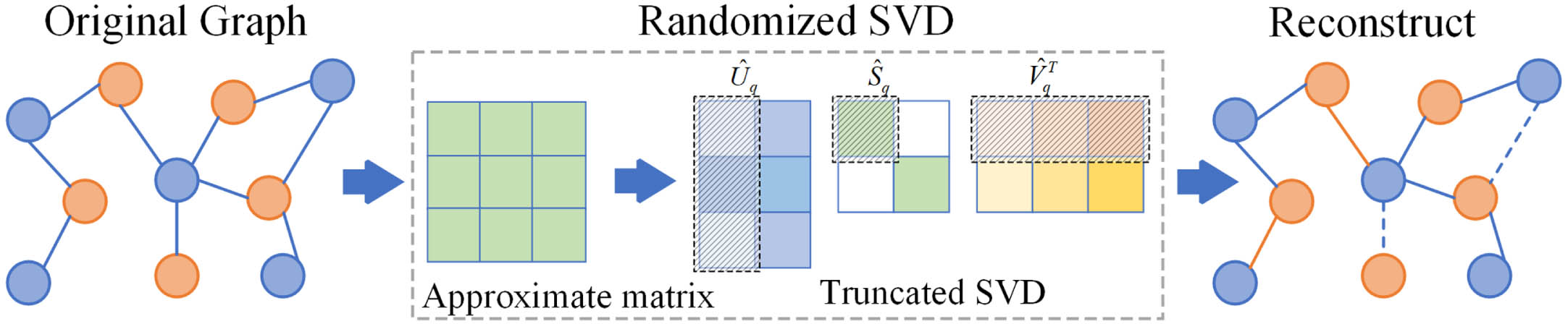
The process of graph augmentation.
GCNs aggregate too much information from high-order neighborhood after stacking multiple layers, making embeddings hard to distinguish and leading to the over-smoothing problem [8]. In contrastive learning, the over-smoothing problem still exists due to the construction of multiple views. Different contrastive views capture various collaborative information, and joint-view connections is utilized to incorporate self-information to emphasize the semantics of the centric node. However, directly connecting different views embeddings could potentially amplify the impact of noise. Therefore, fully-connected layers are used to reintegrate the main view embeddings to learn suitable information. Embeddings from different views are combined to mitigate the issue of over-smoothing. The specific implementation of message aggregation is as follows:
where f (·) is fully-connected function, mapping the embedding into a d-dimensional space. The perturbed view preserves the essential graph structure information to learn important and reliable embedding representations. In each layer, the perturbed view propagation aggregates the joint-view messages m(u) and m(v) as the embeddings for that layer:
This module is designed to capture reliable information (meta-knowledge) to propagate throughout the entire graph structure to optimize embedding representations. The embeddings learned during the propagation process in the perturbed view contain essential structural information and less noise. Layer aggregation with weight is used to extract reliable information as meta-knowledge from each layer. This method captures various semantic information from different layers and uses weights to learn uniform feature representations. The extracted meta-knowledge is as follows:
Setting the aggregation coefficient as
where d(u) and d(v) denote user and item embeddings through which meta-knowledge diffuses in the entire graph structure. In order to better optimize the CL loss, it’s necessary to extract the feature information form different views. The embedding for the main view directly uses the meta-knowledge extraction method to aggregate layer information. For the perturbed view, the diffused knowledge d(u) and d(v) needs to be aggregated with the meta-knowledge k(u) and k(v). This effectively preserves the information in the perturbed view, and the diffused knowledge from the original graph further helps optimize the insufficiently learned embeddings in the perturbed view to alleviate information loss caused by dimension reduction in the SVD process. Therefore, the calculation for the final embeddings used for CL loss in the two views is as follows:
where e(u) and g(u) represent the final user embeddings of main view and perturbed view for contrastive learning, respectively. e(v) and g(v) are represented in the same way. The embeddings used for recommendation tasks should aggregate information from different views. Due to the presence of partially insufficiently trained node information in the perturbed view embeddings, directly aggregating this information onto e(u) and e(v) would impact the embedding consistency. Therefore, using the embeddings d(u) and d(v), optimized on the original structure, as perturbed view information for recommendation tasks is a better choice. The embedding representations z(u) and z(v) for recommendations are
Cross-view meta-knowledge diffusion serves as an embedding optimization module, providing high-quality embeddings for the loss function. The construction of this module has two benefits: i) it compensates for the missing information caused by structural perturbations and helps contrastive learning better distinguish positive and negative instances. ii) it assists the recommendation task in making more accurate predictions. Both aspects work together to improve the model’s performance.
To enhance recommendation performance, a multi-task joint optimization strategy was employed for contrastive learning. Including both BPR loss
where σ (·) and log(·) represent the sigmoid and logarithm function, respectively. Items i+ and i- are positive and negative instance. The traditional CL models like SGL and SimGCL contrast node embedding by constructing two additional views, while the embeddings generated from the main view are not directly involved in the InfoNCE loss. In CollaGCL, the embeddings from the two views are directly used as the comparison objects for InfoNCE loss:
where s (·) and τ denote cosine similarity and temperature, respectively. The InfoNCE loss
The recommendation performance of CollaGCL is assessed through several representative experiments, aiming to address the following questions: RQ1: How does the recommendation performance of CollaGCL compare to baseline methods? RQ2: How does the complexity of CollaGCL? RQ3: How does the uniformity of learned embedding by CollaGCL? RQ4: How does the key component of CollaGCL improve recommendation performance? RQ5: How does CollaGCL perform against popularity bias? RQ6: How does the configuration of hyperparameters affect the performance of CollaGCL?
Experimental settings
Datasets and evaluation metrics
Three real-world datasets were used to assess model performance in the experiments, and the detailed information about the datasets is presented in Table 1. Yelp is a dataset containing user rating information, Gowalla consists of users’ check-in records, and Amazon is a dataset of users’ ratings on products with book category. The datasets is partitioned into training, testing, and validation sets in a 7:2:1 ratio and employed Recall@N and NDCG@N as evaluation metrics [10, 23], where N={20, 40}.
Statistics of experimented datasets
Statistics of experimented datasets
Some popular baseline methods are compared with CollaGCL in terms of performance, including CF and CL methods, and below is a brief introduction to these baselines: NGCF [10] employs collaborative filtering methods to extract high-order collaborative signals between users and items. LightGCN [18] adopts a simplified GCN structure without matrix transformation and non-linear activation. HCCF [29] employs CL on a hypergraph to capture users and items information. SGL [22] introduces random elimination of nodes and edges to construct contrastive views. NCL [37] combines users (items) graph structural and semantic space neighbors to construct contrastive learning task. SimGCL [31] adds uniform noise to user and item embeddings as an alternative approach to graph augmentation for constructing perturbed views. XSimGCL [39] builds single view CL tasks with uniform noise perturbation on user-item embeddings. It improves training efficiency compared to SimGCL. LightGCL [34] adopts SVD augmentation to construct perturbed view.
Hyperparameter settings
All baseline methods strictly followed the parameter settings as instructed in the original paper and were adjusted for optimal performance. The parameter information for CollaGCL is presented in Table 2, and these parameters are tuned within reasonable ranges to search for the best performance. The optimization strategy for model parameters involves using the Adam optimizer.
The parameter information for CollaGCL
The parameter information for CollaGCL
All baseline methods and CollaGCL were trained on the datasets, and detailed results are provided in Table 3. By comparing the results, it can be noticed that contrastive learning methods (SGL, SimGCL, etc) consistently outperform collaborative filtering methods (NGCF, LightGCN), primarily because self-supervised learning effectively mitigates the data sparsity issue. Compared to contrastive learning methods with structural perturbation (SGL, LightGCL, etc), approaches that retain graph structural information (SimGCL, XSimGCL) achieve better results, indicating that preserving graph structure information is beneficial for enhancing contrastive learning performance. In comparison to other baseline methods, CollaGCL exhibits significant advantages on all three datasets. This is mainly attributed to CollaGCL’s mitigation of the negative effects of structural perturbation and the design of modules to reduce over-smoothing problem in graph neural networks. The improvement in the Yelp dataset, which has less data and more interactions compared to the Gowalla and Amazon datasets, is relatively lower. The reason for this phenomenon may be that the increase in the number of node interactions limits the advantages of contrastive learning to a certain extent. Nodes with a large number of interactions will affect their performance with neighboring nodes due to the fusion of noisy information. The significant improvement on the Gowalla and Amazon datasets highlights the superiority of CollaGCL in handling sparse data. This is mainly attributed to the construction of the contrastive learning framework and the SVD augmentation.
Performance comparison with baselines on different datasets
Performance comparison with baselines on different datasets
GCL methods suffer from computational cost due to the need to construct additional views. The definitions of parameters are provided in Table 2. In addition, E and M represent interaction number and node number in a batch, respectively. The complexities of baselines are shown in Table 4. SVD is performed in the pre-processing stage which takes
Complexity comparison of baseline methods
Complexity comparison of baseline methods
The uniformity of learned embedding representations is an intuitive method for evaluating the performance of graph contrastive learning. It is closely related to the model’s recommendation performance, but excessive uniformity can also lead to a decrease in performance. In order to demonstrate the uniformity of embeddings, users and items are ranked by the interactions, defining the top 10% as hot and the bottom 80% as cold. Subsequently, 500 users and items were sampled from each of the hot and cold groups to learn embedding representations. To clarify the presentation, t-SNE is utilized to learn a 2-dimensional representation, and Gaussian kernel density estimation curves are then plotted (arctan (feature y /feature x )).
The experimental results are shown in Fig. 4, all methods on the Yelp have learned clustered embedding features. In all examples, the density curves of popular users and items exhibit a certain degree of steepness. The proportion of highly interactive nodes in Yelp is much higher than in the other two datasets. Therefore, the Yelp dataset is more prone to over-smoothing and noise problem of hot groups, and it may be beneficial to limit the interactions of high interaction nodes to alleviate this problem. LightGCN, compared to CL methods, learns a more clustered distribution, possibly due to the sparsity of the data. Compared to other CL methods, SGL exhibits poorer uniformity, possibly due to the random dropout strategy making the learning process challenging for certain nodes. CollaGCL, XSimGCL, and SimGCL have learned more uniform embedding representations, indicating that contrastive learning mitigates data sparsity. CollaGCL exhibits local clustering to prevent excessive uniformity, which could make features difficult to distinguish.
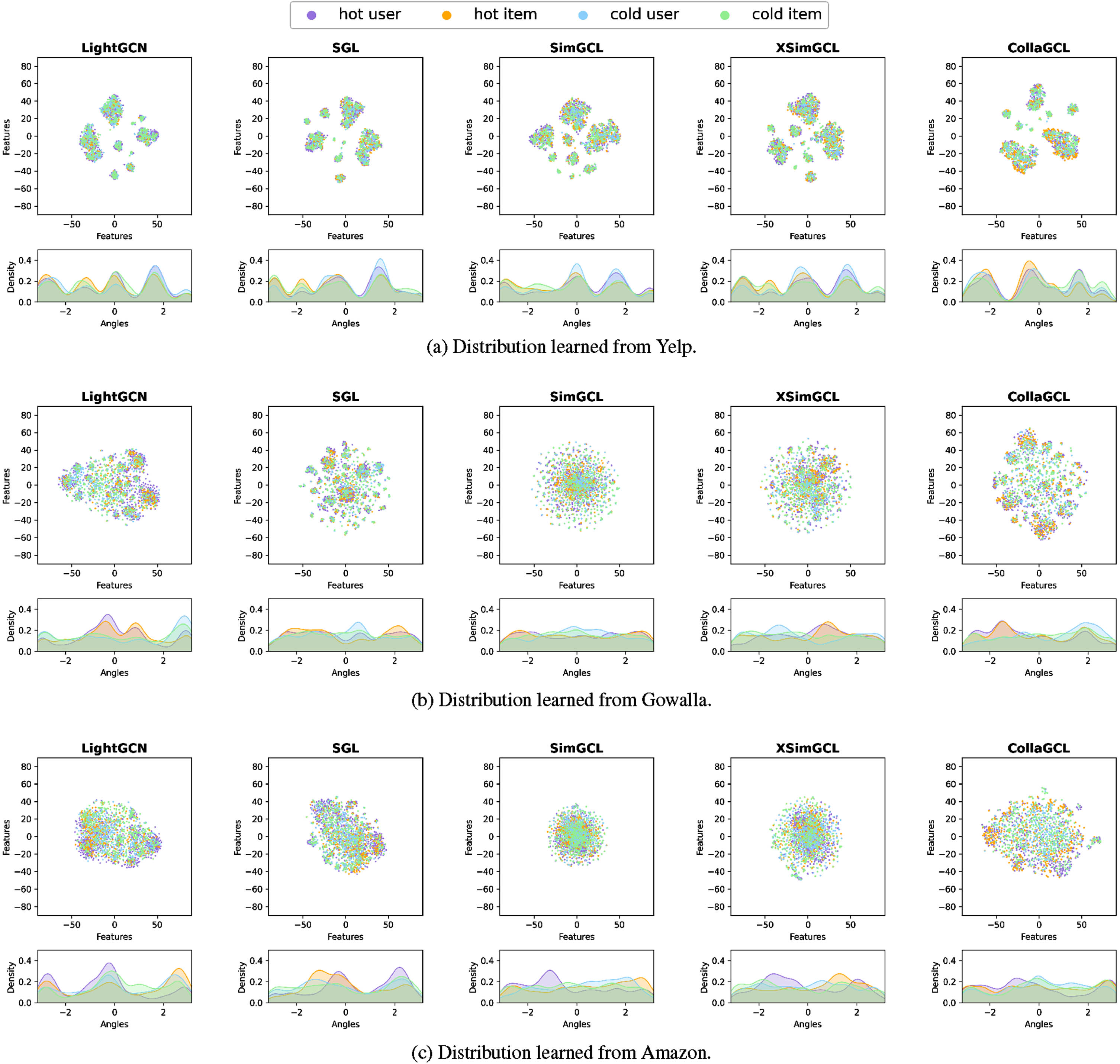
The distribution of representations learned from three datasets.
To examine whether the proposed modules have a positive impact, ablation experiments are conducted on different variants. Brief descriptions of all variants are as follows: baseline: contrastive learning using only SVD augmentation. w/o-gcr: at the model input stage, the module of global learning is removed. w/o-jrl: in the graph convolution stage, the module of joint-view learning is removed. w/o-meta: in this variant, meta-knowledge diffusion is eliminated.
In comparison to the results presented in Table 5, CollaGCL outperforms all variants on different datasets. w/o-gcr and w/o-meta have a significant impact on all three datasets, highlighting the importance of global collaborative information for perturbed view learning and the optimization role of meta-knowledge for recommendation tasks. w/o-jrl has a greater impact on datasets with relatively fewer data and less influence on larger and sparser datasets. This could be because the sparsity of data affects the effectiveness of graph convolutional networks, making it challenging for perturbed views to learn valuable information from the main view. CollaGCL and all its variants outperform the baseline, indicating that all the combinations of modules have a beneficial effect.
Ablation study on key components of CollaGCL
Ablation study on key components of CollaGCL
To investigate the model’s ability to mitigate popularity bias, the data is grouped based on interaction counts, with each group having an interaction count range of {0-5, 6-10, 11-15, 16-20, 21-25}, and items with fewer interactions are defined as long-tail items. The decomposed Recall@20 is used as the evaluation metric for the experiment is
The experimental results are shown in Fig. 5, CollaGCL effectively mitigates the popularity bias on both datasets and provides good recommendations for nodes with few interactions. This is because CollaGCL effectively learns the diversity of features from different views and mitigates the issue of data sparsity. As the interaction count increases, CollaGCL gradually approaches the performance of other baseline methods. This phenomenon occurs because increased interactions lead to more thorough training of these nodes. It is noteworthy that in certain groups, SGL performs worse than LightGCN, possibly due to the random dropout strategy disrupting the graph structure and affecting connectivity, resulting in suboptimal embedding for some groups. The multi-perturbed view structure in SimGCL allows the learning of more diverse features for the long-tail items, leading to better performance than XSimGCL in certain groups. The application of contrastive learning in recommendation models helps optimize embeddings for long-tail items, alleviating the problem of popularity bias and data sparsity.
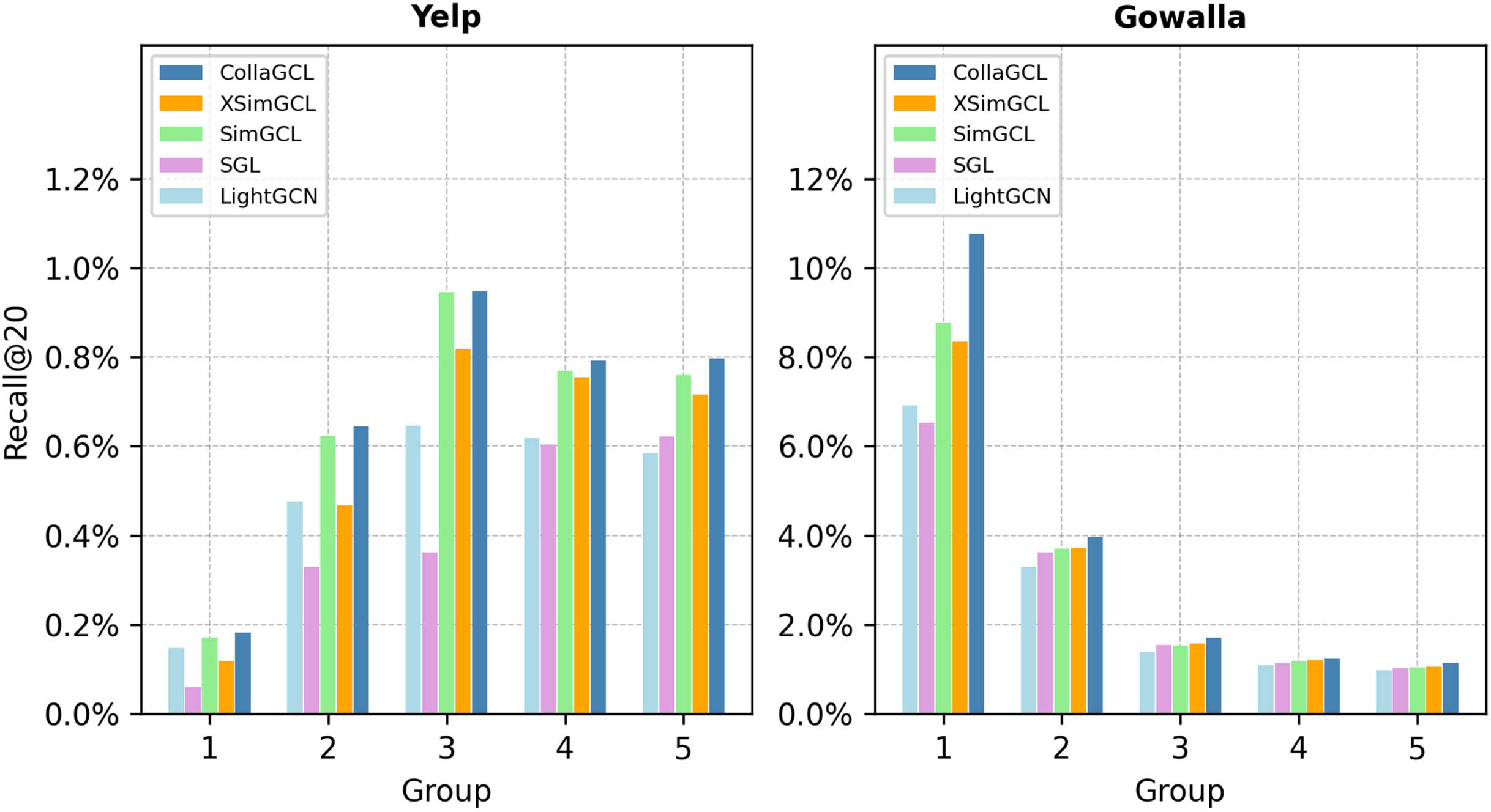
The ability to promote long-tail items.
Experiments were carried out to assess how key parameters influenced the overall performance of CollaGCL. The parameter adjustments were made while keeping the other parameters at optimal values. As shown in Fig. 6, the relatively flat trend across all three datasets is due to the effective preservation of important information. On the Amazon dataset, excessively large values of q introduce noise issues, while too small values of q struggle to retain crucial information, both leading to a sharp decline in performance. According to experimental results, the optimal value for q on the three datasets is 5.
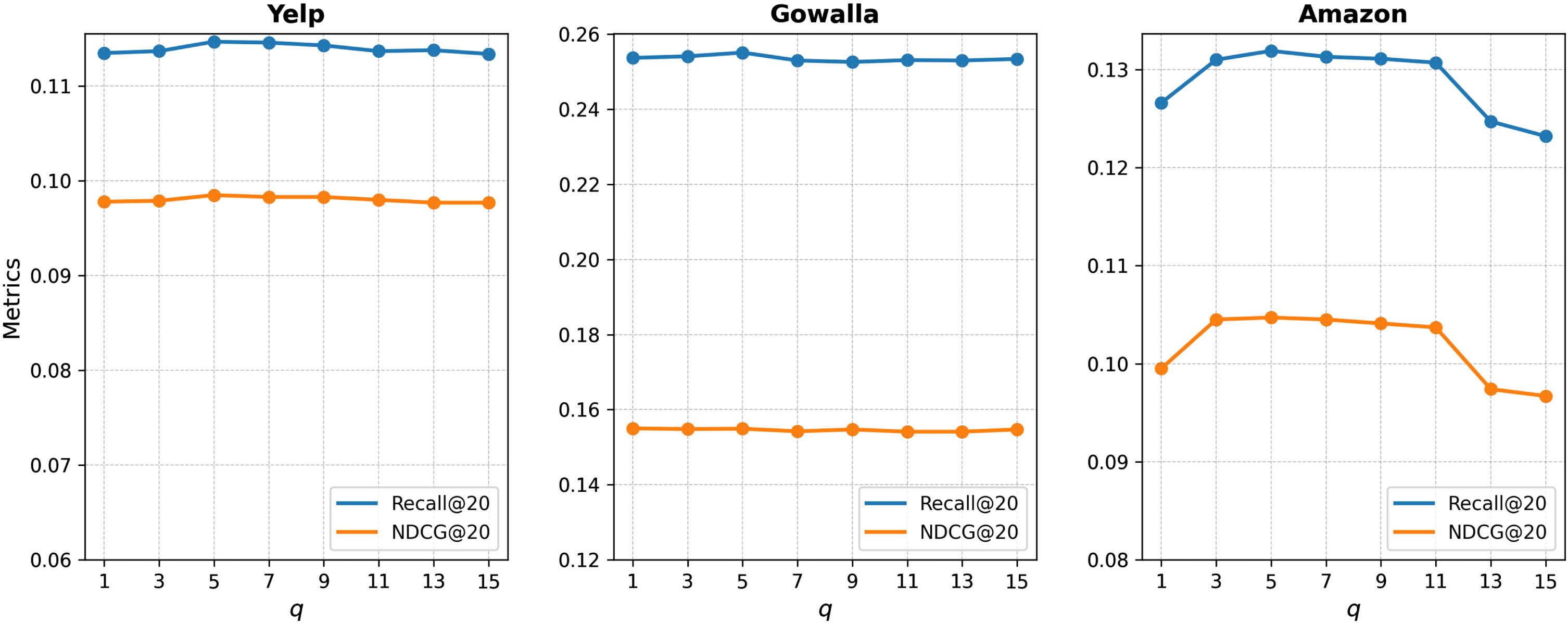
The impact of q.
The temperature coefficient τ is used to control the model’s discrimination against negative samples. Setting a larger τ leads to a more uniform distribution, where the model treats all negative samples equally. On the other hand, a smaller τ sharpens the distribution, making the model pay more attention to hard negative samples. As shown in Fig. 7, CollaGCL is highly sensitive to the parameter τ, and the optimal value for τ across the three datasets is found to be 0.2.
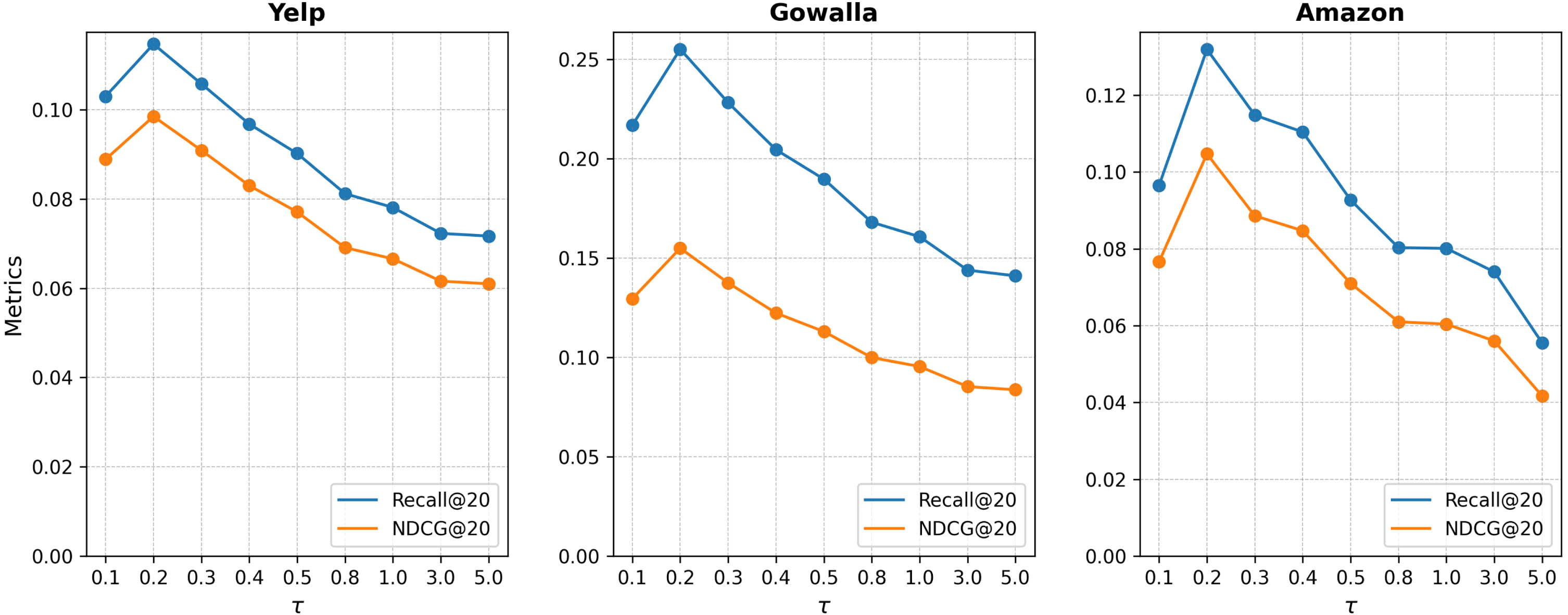
The impact of τ.
The parameter λ1 is used to control the influence of the CL loss on the model. As shown in Fig. 8, on the large and relatively sparse Gowalla and Amazon datasets, CollaGCL tends to prefer larger weights for optimizing the model, with the optimal value being 0.8. On the other hand, for the relatively smaller Yelp dataset, CollaGCL tends to favor smaller weights for model optimization, and the optimal value is found to be 0.2. It can be observed that when λ1 takes a value of 1.0 on Yelp, the performance sharply declines. The reason for this phenomenon may be that the model is overly sensitive to the contrastive learning loss, leading to issues such as training instability.
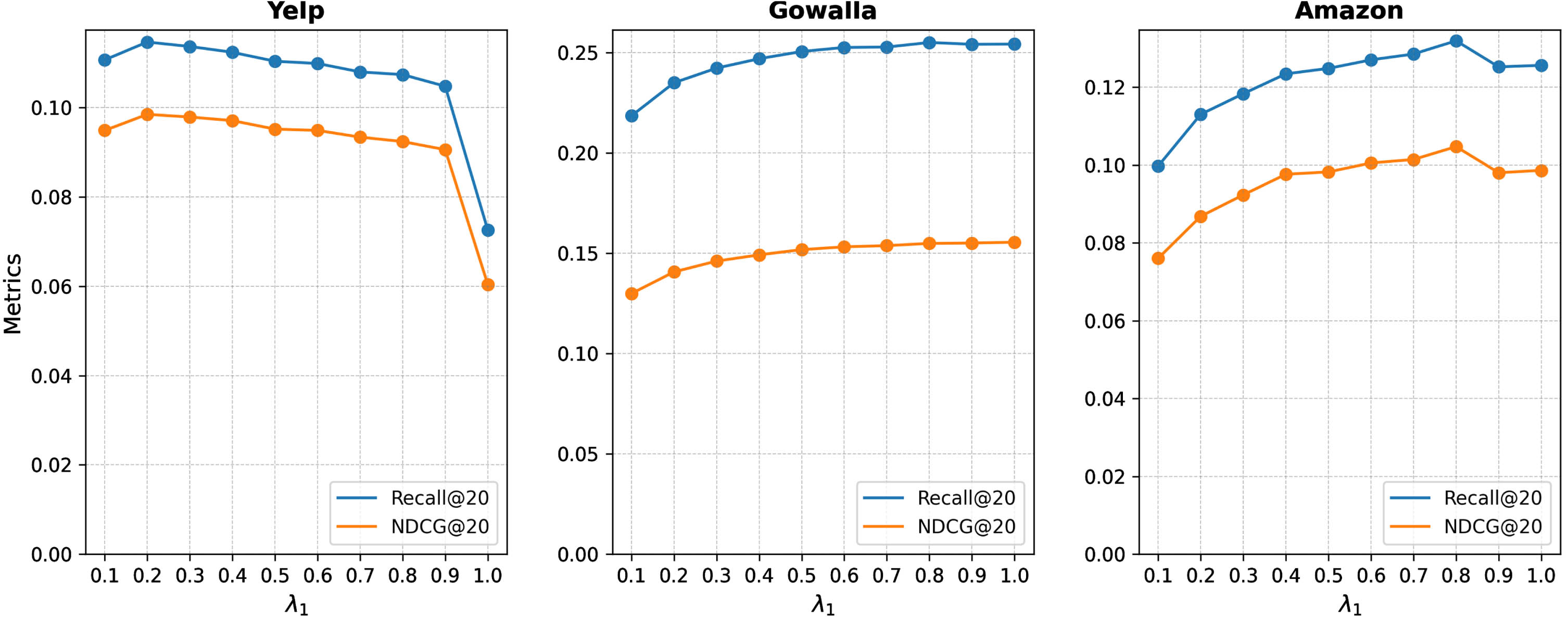
The impact of λ1.
This paper proposed an effective contrastive learning method based on SVD approach for constructing perturbed views. Given that graph structural perturbations result in missing connectivity information in the original graph, CollaGCL considered incorporating global collaborative information as view input signals. To mitigate the impact of over-smoothing, the joint-view representation learning module reorganized the main view information and applied self-connections to emphasize the node’s self-information. To better optimize the training task, cross-view meta-knowledge diffusion module extracted meta-knowledge based on the properties of singular value decomposition and propagated it within the graph structure, improving the embeddings of both views. Experimental results demonstrate that CollaGCL has improved recommendation performance and mitigated popularity bias. In future work, consideration is given to utilizing auto-encoders to optimize the model performance and proposing suitable single-view propagation schemes.
Footnotes
Acknowledgments
This work was supported by the Postgraduate Research & Practice Innovation Program of Jiangsu Province [KYCX23_3078].