
Abstract
This study disproves the following six common misconceptions about coefficient alpha: (a) Alpha was first developed by Cronbach. (b) Alpha equals reliability. (c) A high value of alpha is an indication of internal consistency. (d) Reliability will always be improved by deleting items using “alpha if item deleted.” (e) Alpha should be greater than or equal to .7 (or, alternatively, .8). (f) Alpha is the best choice among all published reliability coefficients. This study discusses the inaccuracy of each of these misconceptions and provides a correct statement. This study recommends that the assumptions of unidimensionality and tau-equivalency be examined before the application of alpha and that structural equation modeling (SEM)–based reliability estimators be substituted for alpha when one of these conditions is not satisfied. This study also provides formulas for SEM-based reliability estimators that do not rely on matrix notation and step-by-step explanations for the computation of SEM-based reliability estimates.
Keywords
Although many methods for estimating the reliability of test scores have been proposed (for a complete review of the estimation methods, see, e.g. Feldt & Brennan, 1989; Haertel, 2006), this study focuses on Cronbach’s (1951) coefficient alpha (hereinafter referred to as “alpha”), which estimates reliability by using data from a single test administration. Alpha, conceived as an “internal consistency” coefficient, is the most frequently used reliability coefficient (which is to be interpreted as an estimator or an estimate of reliability, depending on the context) in organizational research.
Previous studies such as Cortina (1993) and Schmitt (1996) have played an important role in providing a better understanding of alpha for organizational researchers. The influence of their seminal articles is remarkable; Cortina (1993) and Schmitt (1996) appear within the list of the 10 most cited articles among all the papers that were published during the past 20 years in the Journal of Applied Psychology and Psychological Assessment, respectively (Harzing, 2013). While their comprehensive reviews still provide valuable guidance for organizational researchers, there is an increasing need for a review that discusses the latest studies and that offers an updated perspective on the issue.
The influence of Cronbach (1951) has not been overshadowed. His groundbreaking paper has been cited by more than 22,000 studies, which is the largest number of citations for any paper published in Psychometrika (Harzing, 2013). Cronbach (2004) declared it to be “[another sign] of success” that “there were very few later articles by others criticizing parts of my argument” (p. 393). Despite the optimistic assessment provided by Cronbach (2004), criticisms of alpha have been actively published in the past decade.
However, such research does not offer a practical aid to organizational researchers for several reasons. First, the latest theoretical reviews of alpha can only be found in psychometrics journals, such as Psychometrika. As Sijtsma (2009a) noted, psychometricians, who are theorists of measurement, have been distanced from other social scientists, who are practitioners of measurement. Studies in psychometrics are increasingly using advanced mathematics that most social scientists cannot easily understand. Second, previously published papers in psychometrics have typically focused on specific subjects within the field, and these papers are thus less helpful for understanding the broader outline of the field. Therefore, a comprehensive study on the historical background of alpha and the practical issues arising from using it as a reliability coefficient would be particularly helpful to organizational researchers.
The current study seeks to respond to such a research need. In the next section, we develop our analyses on test score reliability by focusing on six common misconceptions about alpha that are frequently held by organizational researchers. For example, one may believe that Cronbach first proposed alpha because it is named “Cronbach’s alpha”; one may also contend that alpha should be regarded as the best available reliability coefficient because so many researchers use it in practice. Disproving such misconceptions will enable organizational researchers to make better decisions on fundamental issues such as what to call, how to use, and even whether to use alpha. After the “misconception” section, we present the formulas and procedures of alternatives to coefficient alpha for reliability estimation when the prerequisite assumptions for alpha are suspected to be violated. In presenting this information, we show that reliability estimators based on structural equation modeling (SEM) may be effectively used for all of the situations in which violation of the assumptions for alpha is suspected.
Before addressing the misconceptions about alpha, however, we first note the true score modeling of the test score

Given sample data from a single administration of a test, alpha estimates the reliability of test scores for a population of examinees of interest, as defined in Equation 1.
Common Misconceptions About Alpha
Common Misconception: Alpha Was First Developed by Cronbach
Although subsequent researchers provide more elaborate interpretations, newer proofs, and more meaningful modifications to earlier works, academia recognizes the researcher who originated a formula to the greatest extent. In our field, it is difficult to imagine not using the originator’s name for a formula. Thus, Cronbach is commonly considered to have initially proposed the formula in question.
The Spearman-Brown formula was presented approximately 100 years ago. The formula was so named because it was published independently by Spearman (1910) and Brown (1910) in the same issue of the same journal, the British Journal of Psychology. Let

The Spearman-Brown formula is based on the assumption that the half tests are parallel and thus that the score variances of the split-halves are equal. General formulas that are applicable when the variances differ were independently proposed by Flanagan (1937), Rulon (1939), and Mosier (1941).
However, these split-half reliability formulas yield different results depending on how the halves are split. To resolve this issue, Kuder and Richardson (1937) proposed a reliability formula (called “KR-20”) that can be used for data on dichotomously scored items (e.g.,

Guttman (1945) believed that the preceding studies set too many assumptions to obtain a reliability coefficient and thus presented six reliability estimators. The only assumption required for Guttman’s estimators was the independence between the error scores of the items (i.e.,



Cronbach (1951) proposed alpha, as expressed in Equation 5, which enables KR-20 to be applied to polytomously scored item data (e.g.,
As we have shown previously, Guttman’s (1945)
This argument does not suggest that Cronbach intercepted the achievements of previous researchers. Although the coefficient is typically called Cronbach’s alpha, Cronbach never named the coefficient after himself. In fact, Cronbach (2004) shied away from the name Cronbach’s alpha, stating the following: “To make so much use of an easily calculated translation of a well-established formula scarcely justifies the fame it has brought me. It is an embarrassment to me that the formula became conventionally known as ‘Cronbach’s
It is the users (or, rather, the “consumers”) of the formula who credited Cronbach (1951) rather than Hoyt (1941) or Guttman (1945), both of whom preceded Cronbach in introducing algebraically equivalent formulas. Different positioning strategies of these studies could have led users to perceive the formulas to be different even though they yielded the same results. First, alpha was positioned as a general reliability coefficient. Cronbach (1951) mathematically proved that alpha, the general formula of KR-20, can also be the general formula for split-half reliability formulas. That is, Cronbach’s proof that the formulas that were previously thought to be unrelated are actually connected to each other led alpha to be positioned as a representative and comprehensive formula, not merely one of many reliability coefficients. Such positioning of alpha sharply contrasts with that of
Interestingly, alpha was not the best reliability coefficient even at the time of Cronbach’s (1951) publication. To find a better alternative than alpha, it is natural to assume that recent studies on reliability should be cited. Contrary to such expectations, a superior alternative already existed even before the name of alpha was proposed by Cronbach (1951). Guttman (1945) referred to
Common Misconception: Alpha Equals Reliability
In the current organizational research literature, alpha is often considered to be the equivalent of the reliability of test scores. However, it is difficult to find explanations as to whether alpha is larger or smaller than reliability when the prerequisites for alpha to be the reliability coefficient are not fulfilled. Therefore, alpha can be easily misconceived to always be equal to reliability or at least to be an unbiased estimator of reliability.
Under the Assumption of Uncorrelated Item Errors
Guttman (1945, p. 274) proposed that
In the classical true score model, the observed score for item

where
Now consider another expression of alpha that is based on the average of all

This expression is simply derived from the fact that
Alpha has typically been referred to as a reliability coefficient rather than a lower-bound estimate; however, the latter is a more correct description in a strict sense. The concept of lower bound enables us to better understand the characteristics of alpha, which might seem counterintuitive if we considered alpha to be a reliability coefficient.
First, we rethink the meaning of Cronbach’s (1951) mathematical proof. The average of the split-half reliability estimates that are acquired from all possible split-halves is an intuitively attractive concept. However, human intuition is occasionally deceived. One important point is usually overlooked: Guttman’s
Second, alpha is negative when the average of the interitem score covariances is negative (see Equation 8; Cronbach & Hartmann, 1954). Many textbooks explain that alpha has a value between zero and one. Upon reading this explanation, one may assume that it is impossible for alpha to have a negative value, irrespective of any prerequisite condition. However, in practice, alpha may have a negative value in some situations, for example, where an item is negatively worded but is accidentally not reversely scored in a personality scale (Sijtsma, 2009a) or where an item has a negative discrimination in a multiple-choice achievement test. All reliability coefficients do not have the same problem as alpha; we will show later that SEM estimators of reliability (i.e., Equation 16 and 19) are always non-negative.
Third, alpha may be smaller than one even when no measurement error exists. By definition, the reliability of test scores must be one when no measurement error exists. Thus, one might assume that alpha will also be one when the measurement error variance is zero. To examine this statement, let us take an exemplary case in which homogeneity (i.e., unidimensionality) across items is satisfied but in which the essentially tau-equivalent condition is not satisfied. Consider a three-item test. The following variance-covariance matrix for the three-item scores is one such matrix that meets the homogeneous condition:

The computation of alpha based on this matrix results in
Without the Assumption of Uncorrelated Item Errors
Thus far, we have assumed that item errors (

Thus, test score reliability should be expressed as follows:

Lucke (2005) developed the idea expressed in Equations 9 and 10 into more sophisticated proofs, which generate the following implications. First, correlated item errors affect alpha and classical reliability in the opposite direction. Positively correlated item errors decrease the value of reliability but make alpha overestimate (i.e., inflate) the true reliability.
Second, the impact of correlated item errors on alpha and classical reliability strictly occurs through the sum of interitem error covariances. The internal structure of interitem error covariances (e.g., autocorrelated, moving average) is irrelevant. The similarity between the items (e.g., parallel, tau-equivalent, congeneric) is also irrelevant.
Third, the necessary and sufficient condition for alpha to be equivalent to classical reliability should be that the sum of interitem error covariances equals the deviance from tau-equivalency. If the former is smaller than the latter, alpha underestimates reliability. If the former is greater than the latter, alpha overestimates reliability.
Correlated errors may arise from various sources, such as common stimulus materials, consistency response sets, and transient errors (Green and Yang, 2009a). Under the assumption of uncorrelated item errors, alpha is a lower bound estimate of reliability, which implies that a high value of alpha ensures a high value of reliability. Without such an assumption, a high value of alpha no longer guarantees the level of reliability. Positively correlated item errors reduce the level of reliability but increase the value of alpha. Thus, an alternative method that substitutes for alpha and provides a reliability estimate that is not overly distorted by correlated item errors is needed.
Multiple-factor model
Before discussing an alternative, we first define the reliability of test scores by using the multiple-factor model, also known as the hierarchical factor model (Lord & Novick, 1968, p. 535; McDonald, 1999), and introduce two “omega” coefficients based on the model. With the hierarchical factor model, the vector of

where g is a general factor (common to all items),

This equation suggests that all components except

McDonald (1999) also identified the proportion of variance in the test scores that is accounted for by a general factor, called the hierarchical omega
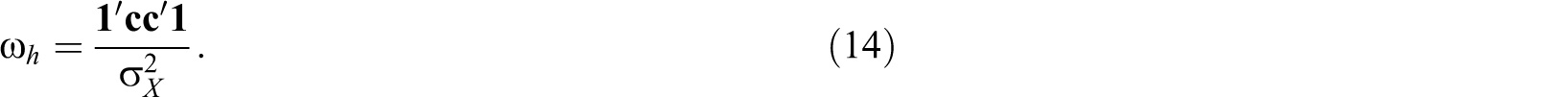
The omega coefficient can be used as a general formula for computing reliability that does not require the assumption of uncorrelated item errors. Let us denote the variance-covariance matrix of item errors (
Figure 1 illustrates the differential effects of interitem error correlations on alpha and
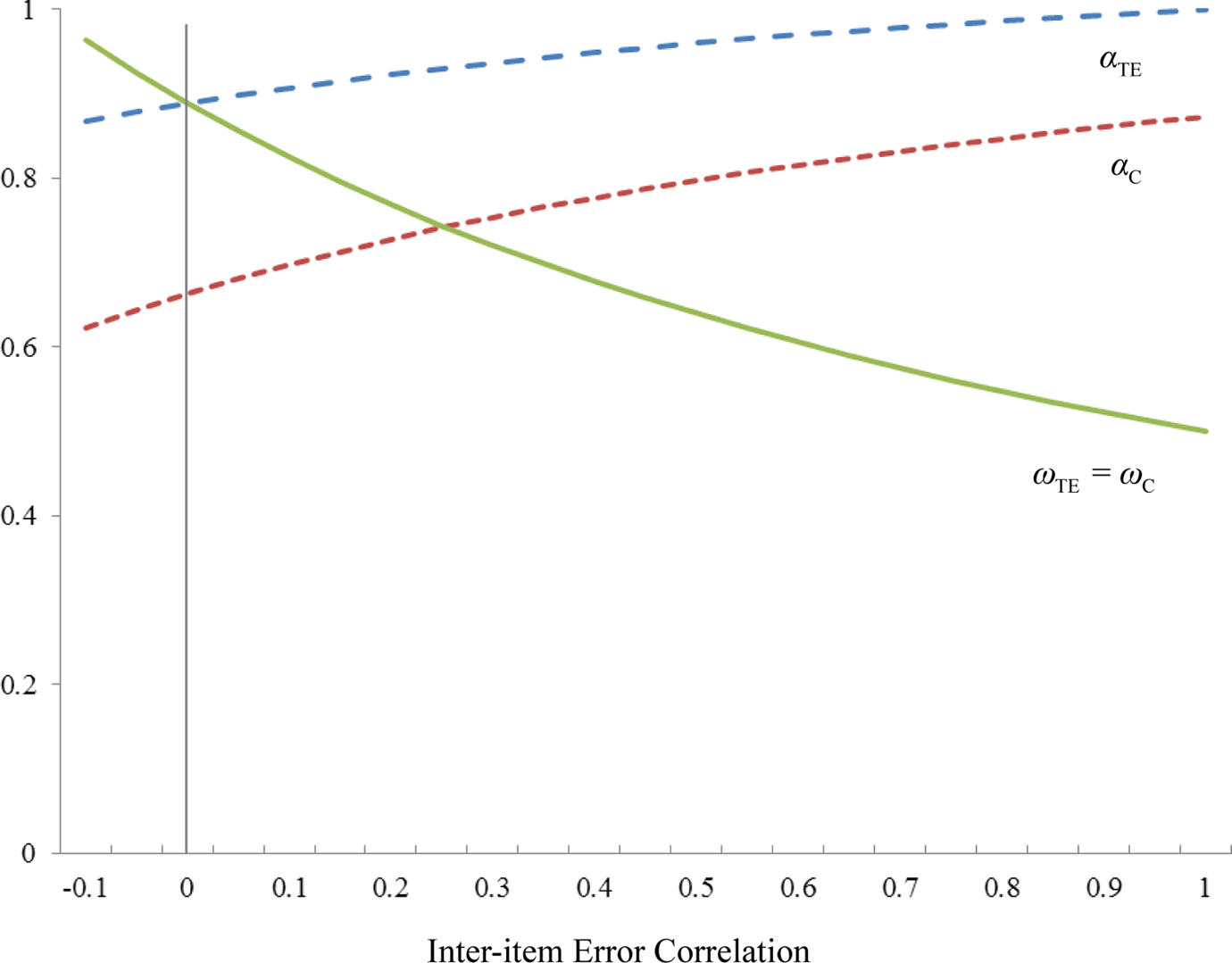
Influence of interitem error correlation on
Common Misconception: A High Value of Alpha Is an Indication of Internal Consistency
Alpha has a seemingly inextricable connection with internal consistency. Prestigious psychometricians refer to alpha as “a measure of internal consistency” (Nunnally & Bernstein, 1994, p. 290) or “an internal consistency estimate” (Thompson, 2003, p. 10). Popular textbooks on research methods offer more detailed descriptions of alpha, for example, “the most commonly reported index of internal consistency” (Christensen, Johnson, & Turner, 2011, p. 144) or “the most common and powerful method used today for calculating internal consistency reliability” (Rubin & Babbie, 2008, p. 184). The cognitive bond between the two terms is so strong that considerable empirical studies substitute the expression internal consistency for alpha when reporting reliability information (Hogan, Benjamin, & Brezinski, 2000).
Despite its frequent use, surprisingly little consensus exists about the precise meaning of internal consistency. This study identifies three different definitions of internal consistency that can be either explicitly or implicitly found in the literature: homogeneity, interrelatedness of a set of items, and general factor saturation.
When we consider the definitions of internal consistency, secondary or tertiary definition problems arise. The present study defines homogeneity as the unidimensionality of a set of items, based on previous studies (Cortina, 1993; Green, Lissitz, & Mulaik 1977; McDonald, 1981; Schmitt, 1996; Sijtsma, 2009a). Unidimensionality refers to the existence of one latent trait underlying a set of items (Hattie, 1985). The interrelatedness of a set of items is defined as the arithmetic mean of interitem correlation coefficients, that is,
The definition of internal consistency as homogeneity stems from Cronbach (1951), who used the two terms interchangeably (Schmitt, 1996). He also proposed that a high value of alpha is indicative of homogeneity. Green et al. (1977) and McDonald (1981) noted logical problems in the argument provided by Cronbach (1951), and other studies (e.g., Cortina, 1993; Schmitt, 1996; Ten Berge & Sočan, 2004) demonstrated that alpha cannot be an indication of homogeneity or unidimensionality by offering counterexamples. Nevertheless, such an interpretation persists (Green & Yang, 2009a).
The fact that alpha cannot evidence homogeneity may be demonstrated through another counterexample. Consider four tests, each consisting of eight items (V1–V8), whose observed variance-covariance matrices (
Four Variance-Covariance Matrices With Different Internal Structures.

The definition of internal consistency as the interrelatedness of a set of items has been accepted by many experts (Cortina, 1993; Green et al., 1977; McDonald, 1981; Schmitt, 1996; Sijtsma, 2009a). First, a high level of alpha does not indicate internal consistency in this definition. Alpha is a function of both item interrelatedness and the number of items in the set. Even when the average of interitem correlation coefficients is as low as .1, a satisfactory level of alpha can be obtained if there are a sufficient number of items (e.g., if
Second, this definition is not congruent with the dictionary meaning of consistency in a situation in which strong group factors exist. According to the definition, we must declare that matrices
The definition of internal consistency as general factor saturation was suggested by Revelle (1979). A notable point about this definition is that alpha is no longer closely related to internal consistency when strong group factors and a weak general factor exist. In matrices
In summary, alpha does not indicate internal consistency in any definitions of psychometric properties. In addition, there is little utility in using the term internal consistency from the perspective of clarity and usefulness. What internal consistency exactly means is ambiguous. The use of more descriptive terms such as item interrelatedness is more helpful for understanding content and context.
Common Misconception: Reliability Will Always Be Improved by Deleting Items Using “Alpha if Item Deleted”
Equation 8 clearly illustrates that given the observed test score variance
Kopalle and Lehmann (1997) suggested that deleting items with lower interitem correlations can lead to an overstatement of alpha, or “alpha inflation,” in which the sample-level alpha is more highly reported than the population-level alpha. They raised the need to separate the calibration sample, which determines the scale, and the cross-validation sample, which calculates reliability, and suggested that the deletion of items must follow a theoretical and logical basis.
Raykov (2007, 2008) revealed a more critical problem associated with reducing the number of items by the “alpha if item deleted” information. Raykov (2007) proposed that the actual reliability of a scale may decrease even though alpha appears to increase after the number of items is reduced, and Raykov (2008) proved that predictive validity can also decrease. Raykov (2008) proposed a latent variable modeling approach that produces point and interval estimates of criterion validity as well as reliability after the deletion of individual components. While Raykov (2008) raised the possibility that an increase in the sample-level value of alpha might be obtained at the expense of predictive validity, the potential tradeoff between reliability and content validity will be discussed in the next section.
We have no intention of discouraging the use of the “alpha if item deleted” function itself. It can be helpful for the identification and remedy of dysfunctional items within a scale. However, we generally discourage mechanical reliance on the output of statistical software. Researchers should be well versed in the substance of what they are studying and use that knowledge in conjunction with statistical indices to make judgments about the makeup of a measure.
Common Misconception: Alpha Should Be Greater Than or Equal to .7 (or, alternatively, .8)
The works of Nunnally (Nunnally, 1967, 1978; Nunnally & Bernstein, 1994) are the second most cited documents, with only the Bible having more citations. Interestingly, the broad-ranging remarks of Nunnally’s works across hundreds of pages are not cited nearly as often as their references to acceptable levels of alpha (.7 or .8). Nunnally most likely offered concrete numbers purely with the intention of providing his readers with some practical aid. Such advised levels create various problems, however.
First, the advised levels of alpha are neither the result of empirical research (Churchill & Peter, 1984; Peterson, 1994) nor the consequence of clear logical reasoning; instead, they were derived from Nunnally’s personal intuition. For example, there is no evidence that .7 is a better standard than .69 or .71.
Second, people use Nunnally’s authority as an immunity standard, which “legally” excuses them from having to think further about reliability when alpha values above .7 or .8 are obtained. There are two intriguing facts that demonstrate that Nunnally’s work (1967, 1978) is cited for its usefulness in providing a “hall pass” or “certificate” rather than for its content. First, in the first edition of the work, Nunnally (1967) stated that a reliability of .5 or .6 is sufficient for exploratory research; however, the standard applied to exploratory research was increased to .7 in the second edition (Nunnally, 1978). People choose which edition of Nunnally’s work to cite depending on whether their alpha is above or below .7 (Henson, 2001). Second, the second edition is still the most widely cited version of the work despite the existence of a third edition (Nunnally & Bernstein, 1994).
Third, the artificial effort to increase alpha above a certain level may harm reliability and validity. The strategy of deleting items by using the “alpha if item deleted” information to increase alpha may reduce both reliability (Raykov, 2007) and criterion validity (Raykov, 2008). Another common strategy to increase alpha is to repeatedly present slightly different items that essentially measure the same component of a particular construct. Each item must correctly represent its whole to obtain high content validity. Therefore, sacrificing the diversity of items to increase alpha hinders content validity. The phenomenon in which an increase in reliability is obtained at the cost of validity is also known as the attenuation paradox (Humphreys, 1956; Loevinger, 1954). This phenomenon is referred to as a paradox because a test with perfect reliability, despite seemingly being the epitome of an ideal test, is not valid. For example, all examinees who take a test with a reliability of unity will have either a score of zero or a perfect score, as an examinee who gives a correct/wrong answer to an item will also give correct/wrong answers to any other items. In a similar context, Streiner (2003) also argued that although a higher alpha is desirable, an excessively high level of alpha is not desirable because it accompanies unnecessary repetition and overlap.
Some scholars further argued that a high level of alpha is fundamentally undesirable. For example, Kline (1986) asserted that “high internal consistency can be … antithetical to high validity[;] … the importance of internal-consistency reliability has been exaggerated” (pp. 118-119). Boyle (1991) criticized researchers’ obsession with a high level of alpha, stating that “it may often be more appropriate to regard estimates such as the alpha coefficients as indicators of item redundancy and narrowness of a scale” (p. 291).
We recommend against mechanistically or automatically applying a cutoff criterion. When the importance of a decision made on the basis of a test score increases, the standard for reliability should also increase. Cortina’s (1993) advice that “the finer the distinction that needs to be made, the better the reliability must be” (p. 101) captures the essence of such a guideline. However, Lance, Butts, and Michels (2006) found that such a guideline is rarely followed; most empirical studies have used .70 as a universal standard of reliability regardless of the stage or purpose of research. One size does not fit all. The nature of the decision being made on the basis of a test should be the guide for the acceptable level of reliability. 1
Common Misconception: Alpha Is the Best Choice Among All Published Reliability Coefficients
Although alpha’s presence overwhelmingly overshadows many other reliability coefficients, McDonald (1981) claimed that “coefficient alpha cannot be used as a reliability coefficient” (p. 113). A number of reliability coefficients (i.e., estimators) have been proposed in an attempt to overcome the limitations of alpha, and several authors have compared the performance of these estimators. Osburn’s (2000) simulation study included 11 reliability coefficients and reported Max (
In all of these studies, there was a common finding that alpha received relatively poor scores. A more striking fact is that five different reliability coefficients were ranked first by five comparison studies. The results of such studies give an impression that even among experts, there is no consensus on which methodology is superior to others. Until there is an explicit statement about which alternative method should replace alpha, users will continue to use it.
To overcome this situation, Sijtsma (2009a, p. 107) recommended the use of the greatest lower bound (glb) (Jackson & Agunwamba, 1977; Woodhouse & Jackson, 1977), declaring that his paper is “meant to invite debate on” the issue. His intention of stimulating debate was successfully realized; in 2009, four comments on his paper (Bentler, 2009; Green & Yang, 2009a, 2009b; Revelle & Zinbarg, 2009), as well as his rejoinder (Sijtsma, 2009b), were published in Psychometrika. However, the recommendation for the glb in Sijtsma (2009a) was not easily accepted. Revelle and Zinbarg (2009) criticized how the glb, unlike its name, yields a smaller value than McDonald’s
Such reactions to Sijtsma (2009a) indicated what top psychometricians have been considering to be substitutes for alpha; all four comments proposed approaches based on SEM. Several authors have proposed methods for computing SEM estimates of reliability (Green & Yang, 2009b; Jöreskog, 1971; Miller, 1995; Raykov, 1997; Raykov & Shrout, 2002), including McDonald’s (1999)
A Framework for Choosing a Reliability Estimator
Examinations of the Assumptions of Unidimensionality and Tau-Equivalency
Alpha should no longer be an unconditional and automatic choice for reliability estimation. As Cortina (1993) noted and as our previous discussion suggests, alpha should be used for reliability estimation when the following conditions are met: (a) the test measures a single factor, (b) the test items are essentially tau-equivalent in statistical similarity, and (c) the error scores of the items are uncorrelated. However, all of these conditions are rarely met in practice; one or more of the assumptions regarding unidimensionality, essential tau-equivalency, and uncorrelated errors may be violated to some degree. This study does not devote further attention to the detection and correction of correlated errors; interested readers are referred to Kim and Feldt (2011) and Raykov (2004). Nevertheless, regarding the selection of a reliability estimator, we recommend that the assumption of unidimensionality and tau-equivalency be examined before the application of alpha and that SEM-based reliability estimators be substituted for alpha when one of these conditions is not satisfied. Figure 2 summarizes our guidelines.
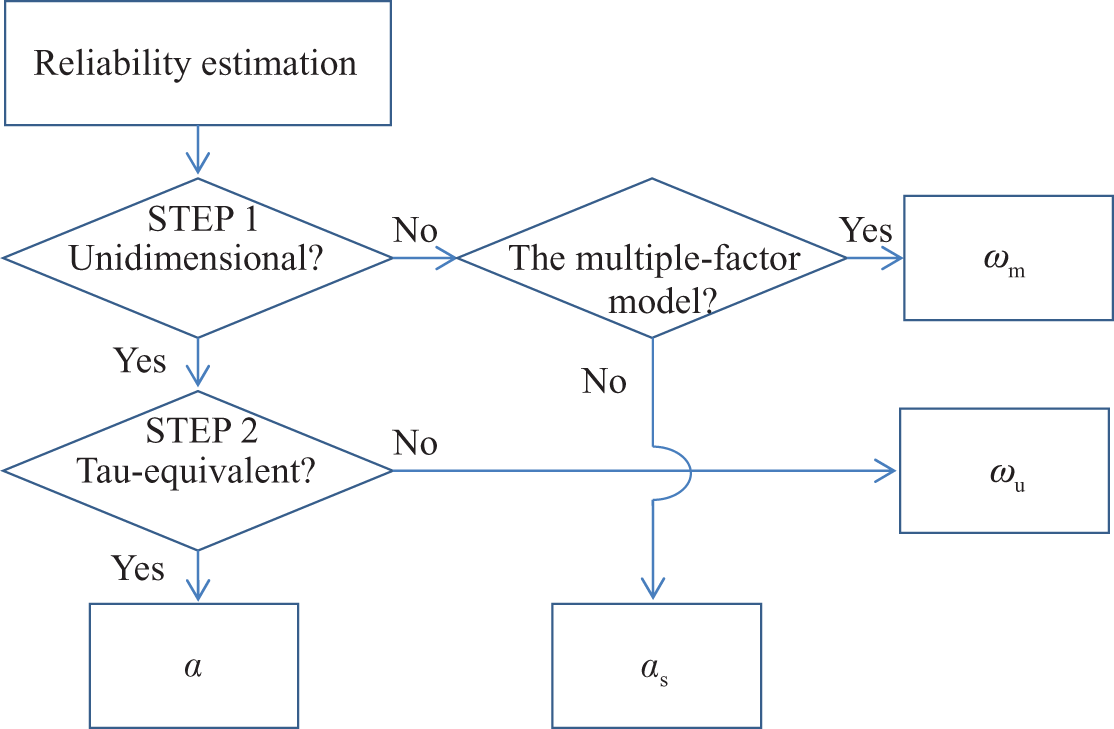
A framework for choosing a reliability estimator.
Unidimensionality
While various methods have been developed to test unidimensionality (Hattie, 1985), this study focuses on SEM approaches. The unidimensional model is nested within the multidimensional model in SEM, and the chi-square difference is usually used to test for statistical significance. Three models can be employed to conceptualize multidimensionality in SEM: the correlated factors model, the higher-order factor model, and the multiple-factor model (Figure 3).
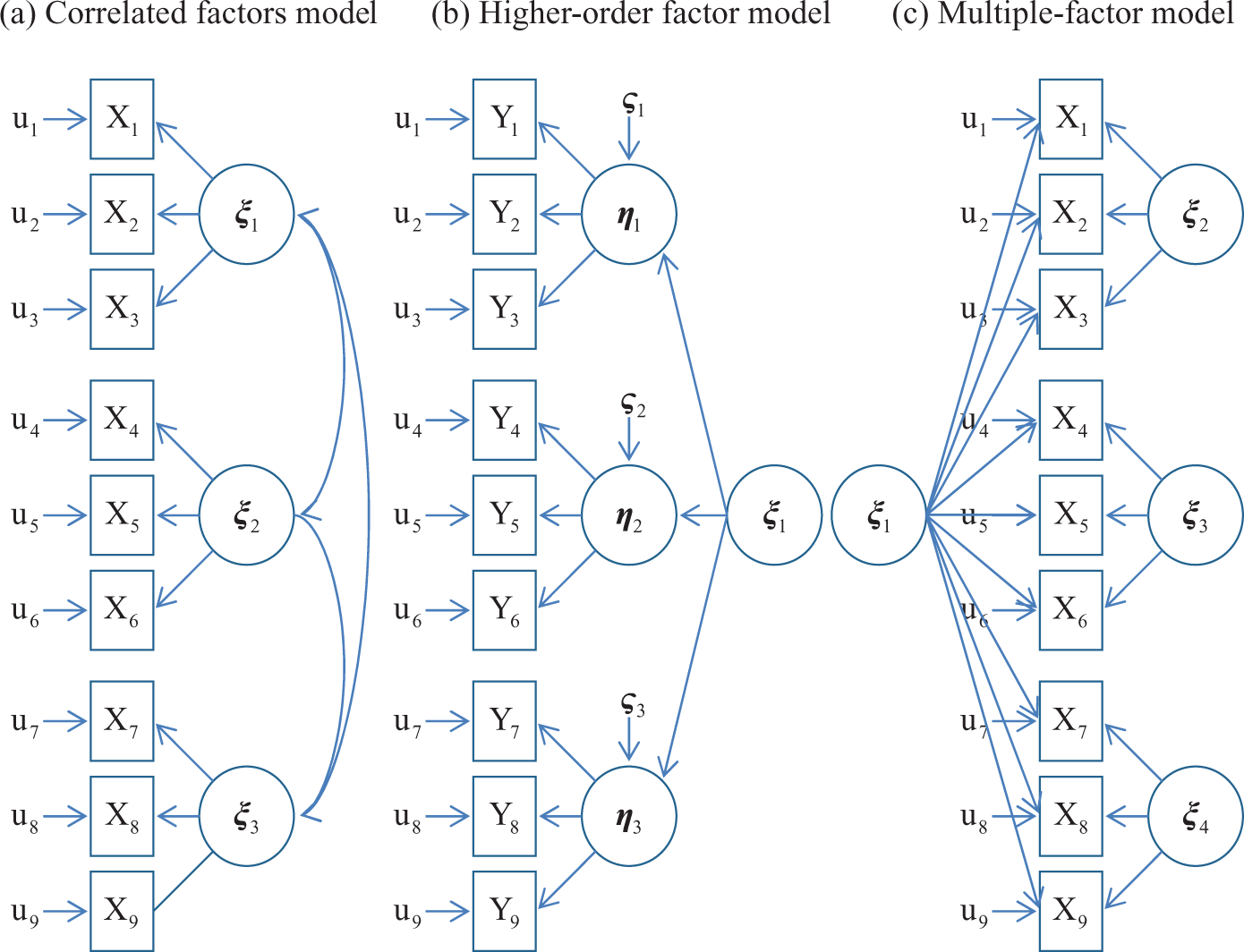
Three models of multidimensionality in structural equation modeling.
Although the correlated factors model is most frequently used among organizational researchers, its popularity is not an indication of its superiority. As the exact opposite of the unidimensional model, the correlated factors model includes only subdomain constructs and omits a common construct, which is a hidden influencer that causes the latent variables to correlate with each other. Moreover, paradoxically, the construct that most scale developers originally design to measure (Reise, 2012) and that most researchers primarily intend to study is excluded from the measurement model.
The higher-order factor model and the multiple-factor model, also known as the hierarchical factor model or bifactor model, share a commonality; they consider both subdomain factors and a common factor. While a general factor (i.e.,
The two models nevertheless have some interesting differences. While a higher-order factor subjugates the lower-order factors, a general factor competes with the group factors in explaining the variances of the manifest variables. Whereas a general factor is directly linked with the manifest variables, a higher-order factor’s connections with the manifest variables must be mediated by the lower-order factors (Reise et al., 2010).
Although the multiple-factor model is the least understood and least used model by organizational researchers, it has several advantages over the higher-order factor model (Chen, West, & Sousa, 2006). Multiple-factor models can easily detect a nonexistent domain-specific factor because such a factor will cause an identification problem and a nonsignificant factor loading for the group factor; however, higher-order factor models are insensitive to signal such anomalies because nonsignificant variances of the disturbances of lower-order factors usually do not cause any estimation problems and can be easily overlooked by researchers. While group factors can be predicted by external variables independently of the general factor, estimating paths between the disturbances of first-order factors and external variables is difficult with second-order factor models. Because the higher-order model is nested within the multiple-factor model (Yung et al., 1999), the multiple-factor model functions as a baseline model for testing whether the chi-square differences between the models are statistically significant (Chen et al., 2006).
Let us describe the typical constraints of the multiple-factor model. Every manifest variable is assumed to have one general factor and one (and only one) group factor. A general factor is orthogonal to or uncorrelated with group factors by definition. Group factors are also generally constrained to be orthogonal to or uncorrelated with each other for identification and interpretability (Reise, 2012). In other words, the variance-covariance matrix of the latent variables (i.e.,
Tau-Equivalency
More restrictions are placed on the tau-equivalent model than on the congeneric model. In the latter model, either the variance of the latent variable or a factor loading of one of the manifest variables must be fixed at a non-zero value (typically 1.0) to determine the scale of the latent variable. The former model adds the constraint of equal factor loadings (i.e.,

The tau-equivalent model and the congeneric model in structural equation modeling.
Reliability Estimators for Multidimensional Data
Among the statistical procedures that have been presented for estimating the reliability of multidimensional test scores, two estimators can be recommended for organizational researchers: the multidimensional version of
This study offers formulas and computation examples of


where
Let us consider an illustrative example. If we apply the orthogonal factor solutions to the matrix
Stratified Alpha (
)
Our plan B is to use
To address the score reliability of stratified tests, Rajaratnam, Cronbach, and Gleser (1965) derived

where
Let us illustrate the
Reliability Estimators Based on the Congeneric Measurement Model
When the tau-equivalency assumption is violated, an SEM-based congeneric reliability estimator is recommended as an alternative to coefficient alpha. The SEM-based congeneric reliability, presented by Jöreskog (1971) and McDonald (1999, p. 89), is simply the unidimensional version of

which is numerically equal to Equation 14. The estimate of

or

Organizational researchers usually refer to these formulas as “composite reliability” (Peterson & Kim, 2013), which is supposedly a shorthand for the reliability of composite scores. This designation is a misnomer, however, because the dictionary meaning of the term is too general to be limited to a specific method, and it can encompass broad categories of reliability estimators, including alpha. Using such a designation is similar to calling a proper noun (e.g., Chicago) by a common noun (e.g., city). Composite reliability is commonly abbreviated to CR. If this acronym should be used, the term congeneric reliability describes the characteristics of this reliability coefficient better than composite reliability or construct reliability do.
Examples of the Computation of Omega Coefficients
This section offers two examples that allow interested readers to replicate our computations. 2 Readers who are familiar with R, a free open-source statistical software platform, will consider the psych package (Revelle, 2014) to be the most convenient tool for obtaining omega coefficients because its Omega function estimates them spontaneously. We will assume that our typical readers use one of the SEM packages (e.g., LISREL, Mplus, and AMOS) that do not offer automated calculations of omega coefficients. Our LISREL program codes are displayed in Appendix 2.
Table 2 presents an examination of the assumption of unidimensionality. The fit indices for the unidimensional model indicate unacceptable fit, suggesting that more than one latent trait is underlying this set of items. The chi-square difference between the unidimensional model and the multiple-factor model is significant at
An Examination of the Unidimensionality Assumption.
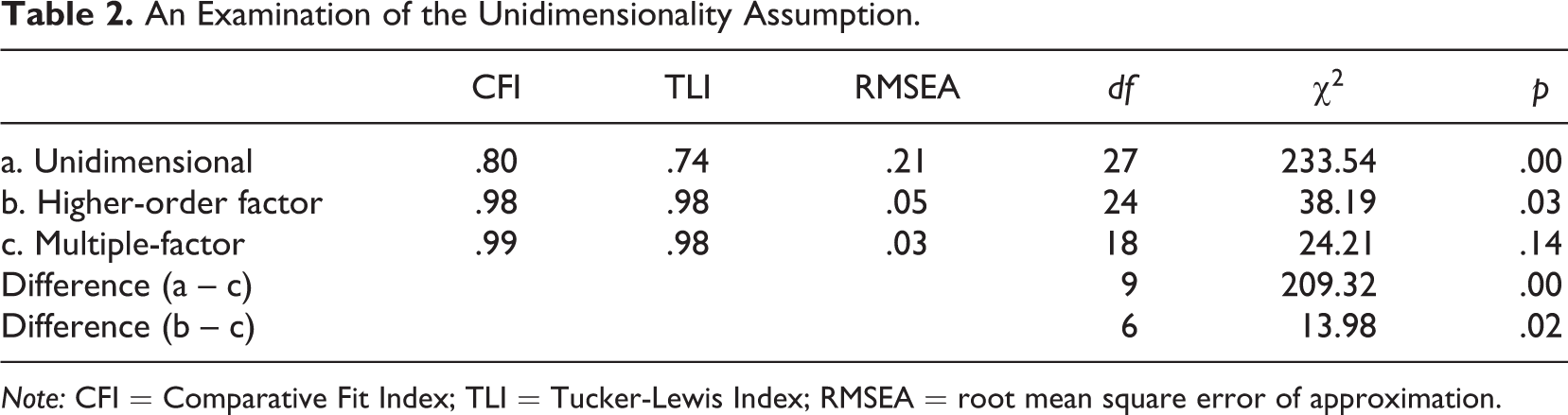
Note: CFI = Comparative Fit Index; TLI = Tucker-Lewis Index; RMSEA = root mean square error of approximation.
Table 3 displays a step-by-step explanation of the computation of
A Computation of

Table 4 presents an examination of the assumption of tau-equivalency. The fit indices for the tau-equivalent model indicate poor fit, and its chi-square value is significantly greater than that of the congeneric model at
An Examination of the Tau-Equivalency Assumption.
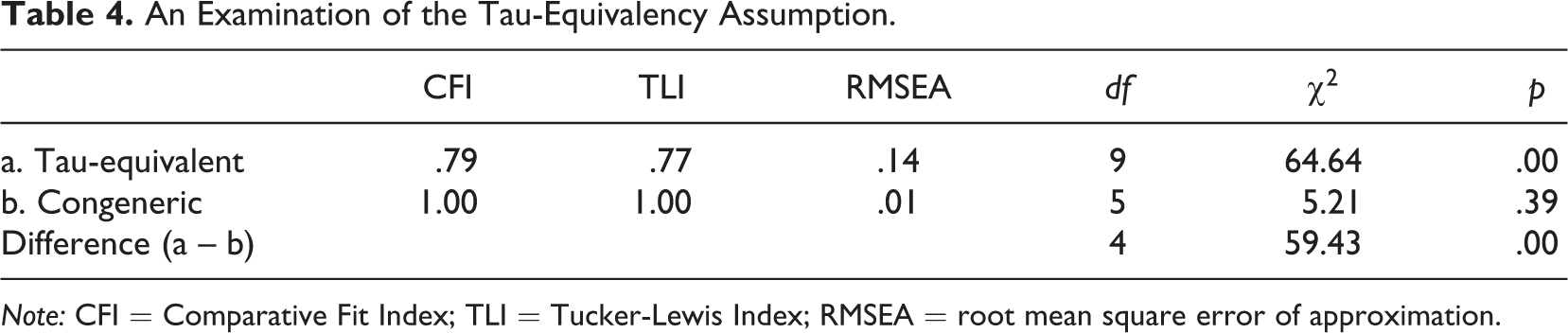
Note: CFI = Comparative Fit Index; TLI = Tucker-Lewis Index; RMSEA = root mean square error of approximation.
Table 5 displays the computation of
A Computation of
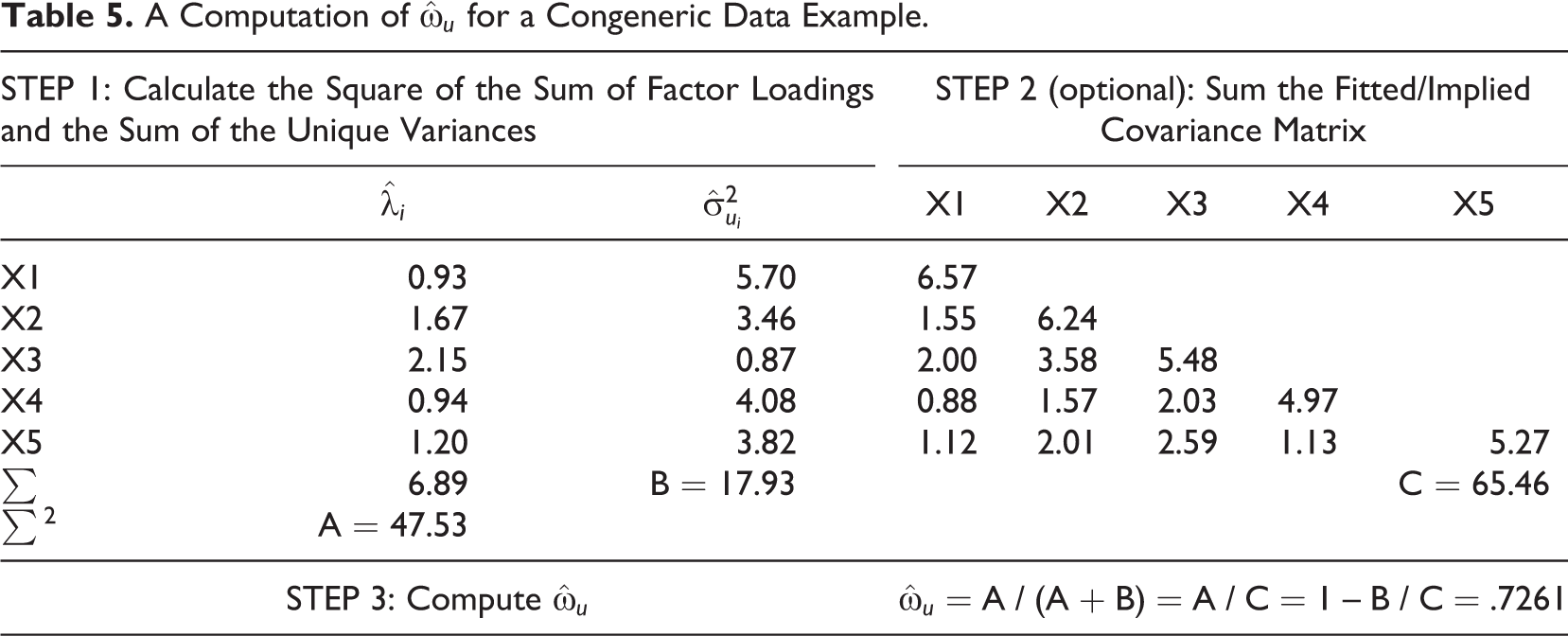
Conclusion
We commonly observe cases in which the best-selling products are not the products with the best quality. When the switching cost is higher, consumers tend to choose a more familiar alternative (e.g., the QWERTY keyboard layout) even though they know of a more efficient alternative (e.g., the Dvorak keyboard layout). Because of network externalities, in which other people’s choices affect the utility of an individual, in some situations, the winner may take all. For example, an individual may face a considerable disadvantage if he or she uses a different spreadsheet program while everyone else uses Microsoft Excel.
Alpha is a good example of how such marketing concepts may be applied to the choice of statistical analysis methods. Alpha is a relatively inferior method despite its widespread use. Even if users are aware of alpha’s inferiority, they may be unwilling to invest effort into becoming familiar with other reliability coefficients. Moreover, although they may be willing to tolerate personal costs from switching to another reliability coefficient, they may fear penalties incurred from not using the alpha coefficient in their studies because dissertation committees and editors are likely familiar with alpha but may not be familiar with its alternatives. In the perspective of network externality, substituting alpha with a superior alternative is not merely a matter of personal choice but a matter of academia consciously responding to the issue. It would be prudent for the editors of various academic journals on organizational research to recommend that their contributors use superior alternatives with or in place of alpha in their works.
Footnotes
Appendix 1
The computation uses Lucke’s (2005, p. 117) compound symmetric item error covariance model, which requires errors to be equally correlated among items. The item error variances are
Note that XTE with XC with
The values of
Appendix 2
| MULTIDIMENSIONAL DATA | ||||||||
| DA NI=9 NO=213 MA=CM | ||||||||
| CM SY ! CM=KM | ||||||||
| 1 | ||||||||
| 0.828 | 1 | |||||||
| 0.776 | 0.779 | 1 | ||||||
| 0.439 | 0.493 | 0.46 | 1 | |||||
| 0.432 | 0.464 | 0.425 | 0.674 | 1 | ||||
| 0.447 | 0.489 | 0.443 | 0.59 | 0.541 | 1 | |||
| 0.447 | 0.432 | 0.401 | 0.381 | 0.402 | 0.288 | 1 | ||
| 0.541 | 0.537 | 0.534 | 0.35 | 0.367 | 0.32 | 0.555 | 1 | |
| 0.38 | 0.358 | 0.359 | 0.424 | 0.446 | 0.325 | 0.598 | 0.452 | 1 |
| MO NX=9 NK=4 PH=FI ! CODE FOR MULTIPLE-FACTOR MODEL | ||||||||
| VA 1 PH 1 1 PH 2 2 PH 3 3 PH 4 4 | ||||||||
| FR LX 1 1 LX 2 1 LX 3 1 LX 4 1 LX 5 1 LX 6 1 LX 7 1 LX 8 1 LX 9 1 | ||||||||
| FR LX 1 2 LX 2 2 LX 3 2 LX 4 3 LX 5 3 LX 6 3 LX 7 4 LX 8 4 LX 9 4 | ||||||||
| OU ME=ML RS EF ND=4 | ||||||||
| CONGENERIC DATA | ||||||||
| DA NI=5 NO=270;CM SY | ||||||||
| 6.57 | ||||||||
| 1.67 | 6.24 | |||||||
| 2.06 | 3.56 | 5.48 | ||||||
| 0.71 | 1.79 | 1.98 | 4.97 | |||||
| 0.63 | 1.94 | 2.62 | 1.25 | 5.27 | ||||
| MO NX=5 NK=1; VA 1 PH 1 1 ! CODE FOR THE CONGENERIC MODEL | ||||||||
| FR LX 1 1 LX 2 1 LX 3 1 LX 4 1 LX 5 1 | ||||||||
| ! EQ LX 1 1 LX 2 1 LX 3 1 LX 4 1 LX 5 1 ! DELETE THE FIRST ! IF TAU-EQ | ||||||||
| OU ME=ML RS EF ND=4 | ||||||||

Acknowledgments
The authors are deeply grateful to Professor Meade and the two anonymous ORM reviewers for their invaluable guidance and constructive comments. They also acknowledge the support provided by Kyung Su Liu.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The present research has been conducted by the Research Grant of Kwangwoon University in 2014.