
Abstract
It is increasingly common to test hypotheses combining moderation and mediation. Structural equation modeling (SEM) has been the favored approach to testing mediation hypotheses. However, the biggest challenge to testing moderation hypotheses in SEM was the complexity underlying the modeling of latent variable interactions. We discuss the latent moderated structural equation procedure (LMS) approach to specifying latent variable interactions, which is implemented in Mplus, and offer a simple and accessible way of testing combined moderation and mediation hypotheses using SEM. To do so, we provide sample code for six commonly encountered moderation and mediation cases and relevant equations that can be easily adapted to researchers’ data. By articulating the similarities in the two different approaches, discussing the combination of moderation and mediation, we also contribute to the research methods literature.
Both moderation and mediation are commonly used analytical approaches in the organizational sciences, as evidenced by the number of publications in which these approaches have been used. In some publications, moderation or mediation are the means to an end; that is, they are the primary analytical tools to test hypotheses in some substantive context with said substantive context being the primary focus of the publications (e.g., Kulik & Perry, 2008). In other publications, moderation or mediation is the end; that is, they are the topics of interest with the focus on addressing some methodological or statistical aspect underlying them (Edwards, 2009; Mathieu, DeShon, & Bergh, 2008).
Recently, there has been renewed interest in the research literature to use mediation and moderation together. Similar to Edwards and Lambert (2007), we used the PsycInfo database to locate articles using the terms moderate, moderating, or moderation and the terms mediate, mediating, or mediation. From 2008 to 2013, our search yielded 264 articles, out of which 75 used a single-level model combining moderation and mediation while 33 more used a multilevel model that combined moderation and mediation. Renewed emphasizes that their simultaneous treatment is not a novel, contemporary idea as the topic was discussed in earlier publications such as Baron and Kenny (1986) and James and Brett (1984). Contemporary interest in the topic, however, is driven by both conceptual needs and methodological developments. Conceptually, areas of research interest have matured to such a degree that moving these areas forward requires posing increasingly complex theoretical questions—the types of questions necessitating the use of complex analytical tools such as the simultaneous application of moderation and mediation (e.g., Thau & Mitchell, 2010). Methodologically, the renewed interest is driven by a recognition that weak or inappropriate analytical practices underlying the simultaneous use of mediation and moderation had been emerging in the research literature over the past 20 years, necessitating the explication of the appropriate steps to undertake such analyses; that is, “course corrections” were needed so that the complex conceptual questions could be appropriately addressed on an empirical basis.
There were two “course correcting” publications, one by Edwards and Lambert (2007) and the other by Preacher, Rucker, and Hayes (2007), which discussed simultaneous mediation and moderation strategies. Further, the recent book by Hayes (2013) has created a definitive contribution to the combined use of moderation and mediation. Hayes demonstrates 74 different models that illustrate different moderation, mediation, and simultaneous moderation and mediation models, which can be adapted to different research questions. The Edwards and Lambert (2007) and Hayes (2013) approaches are fundamentally consistent with each other, and Table 1 demonstrates how the two terminologies map onto each other in different models. All of the moderation and mediation models are illustrated by both sets of authors using regression-based path analysis on observed variables.
Table of. Equations for Different Models.

The goal of the current article is to extend mediation-moderation into a structural equation modeling (SEM) framework. Specifically, in addition to providing a “one-stop” source for models, the primary purpose of the current article is to step outside of the regression-based analyses used by Edwards and Lambert (2007), Preacher et al. (2007), and Hayes (2013) to illustrate how the models may be addressed through SEM. The advantages of using SEM over ordinary least squares regression are well known and documented (Bollen, 1989; Kaplan, 2000). Foremost among the advantages is that unlike regression, where it is assumed that the scores on the variables are measured without error, SEM permits the incorporation of measurement error into the analyses. To this end, we mapped six models from Hayes onto the Edwards and Lambert framework of mediation-moderation models. The set of models from these sources constitutes some of the most commonly encountered models found in the research literature. We used the Edwards and Lambert equation system because it allows us to calculate intercepts and error terms, which can then be used for interaction plotting purposes.
The current article is more of a teaching note because we are not altering or adding to the equations that have been so eloquently explained in Edwards and Lambert (2007), Preacher et al. (2007), and Hayes (2013). Rather, using Mplus SEM software (L. K. Muthén & Muthén, 1998-2012), we map the equations into a latent variable approach including latent interaction terms for moderation. We start with a very brief review of moderation combined with mediation. Given that it is at the core of specifying latent interaction terms in the Mplus package, the article turns to an explanation of the latent moderated structural equation procedure (LMS) approach to latent variable interaction specification including some potential issues in its application. We then articulate the six different models combining moderation and mediation using one database across the examples. The emphasis here is purely on application with less emphasis on the technical aspects.
Moderation and Mediation Combined
As illustrated in Figure 1a, moderation takes place when a third variable, M (the moderator variables), affects the strength of the relationship between X (the predictor variables) and Y (the outcome variables). In other words, the strength of the relationship between two variables (X and Y) varies as a direct function of a third moderator variable. Figure 1b and 1c illustrate mediated relationships. Full mediation (Figure 1b) occurs when the effect of X on Y is transmitted via an intermediate variable or mediator (M), and partial mediation (Figure 1c) occurs when the effect of X on Y is transmitted both directly and indirectly through M (LeBreton, Wu, & Bing, 2009).

a-d: Moderation, mediation and moderation + mediation.
Figure 1d shows an example of moderation combined with mediation where both the paths from X to M and X to Y are moderated. While Preacher et al. (2007) refer to the combinations of mediation and moderation tests collectively as general indirect effects, Muller, Judd, and Yzerbyt (2005) make a distinction between mediated moderation, where there is overall moderation of the relationship between X and Y, and moderated mediation, where the indirect effect between the antecedent and the outcome depends on the moderator. Edwards and Lambert (2007) also make a distinction between moderated-mediation and mediated-moderation. According to Edwards and Lambert (2007), moderated-mediation denotes that the mediated effects are dependent on the levels of a moderator variable, M. By contrast, mediated-moderation means that only the X to M relationship (coefficient a) varies significantly as a function of Z but the M to Y relationship does not (coefficient b). Viewing moderated-mediation and mediated-moderation in terms of path analysis reveals that, when moderated-mediation refers to moderation of the path from X to M but not of the path from M to Y, moderated-mediation and mediated-moderation are equivalent from an analytical standpoint, and any distinction between them is a matter of conceptual framing [italics added]. (Edwards & Lambert, 2007, p. 7)
Latent Variable Interactions
While most of the published moderated mediation research to date used regression analysis to evaluate the hypothesized paths, we extend the analyses to incorporate SEM capabilities. Unlike regression models, SEM accounts for measurement error in the observed variables. Ignoring measurement errors can lead to biased parameter estimates (paths) between the variables. This issue becomes even more severe for interaction terms (Dimitruk, Schermelleh-Engel, Kelava, & Moosbrügger, 2007; Moosbrügger, Schermelleh-Engel, Kelava, & Klein, 2009) or with any estimator produced from a product term such as testing the indirect effect within mediation models (Preacher et al., 2007). However, the use of latent variables to create interaction terms within SEM creates particular challenges in this regard as outlined in the review of the five approaches to specifying latent variable interactions by Cortina, Chen, and Dunlap (2001).
When Cortina et al. (2001) was published over a decade ago, the primary difference between their reviewed approaches was how many of the observed variables from the X latent predictor variable were multiplied with the observed variables from the Z latent moderator variable to operationalize the latent interaction effect on the Y latent outcome variable. Kenny and Judd (1984), for example, stated that all pairwise product terms between the observed X and Z variables be created, whereas Jöreskog and Yang (1996) stated that only one product term between one X and one Z observed variable was required. Yet in another example, Algina and Moulder (2001) used mean centering of the indicator variables to calculate the product terms and further simplified the Jöreskog and Yang (1996) approach. Regardless of the approach, the biggest challenge associated with product terms is that they are inherently nonnormal (Cortina et al., 2001; Moosbrügger et al., 2009). Yet, estimation procedures such as maximum likelihood (ML) estimation (the primary estimation procedure in SEM) assume multivariate normality. While Cortina et al. recognized the research suggesting that ML is fairly robust in the presence of some nonnormality, they succinctly noted that “this work notwithstanding, there have been suggestions that ML will produce incorrect standard errors when the multivariate normality assumption is violated (Bollen, 1989)” (p. 326). This is due to the fact that the observed indicators of the predictor variables (the Xs) and the error/disturbance terms of the latent variables (ζ) are no longer uncorrelated and the error/disturbance terms are not normally distributed—basic assumptions within any SEM application. Besides inappropriate standard errors, other issues include having over- or underestimated values for the parameter estimates representing the main and interaction effects on the Y latent outcome variable. Excellent reviews on these and other issues (e.g., inappropriate goodness-of-fit tests, imposing multiple constraints to properly identify estimates of the product terms, etc.) using a product approach to specifying latent interaction terms and ML estimation are provided by Bollen (1989, starting p. 403), Klein and Moosbrügger (2000, starting p. 457), and Schumacker and Lomax (2000, starting p. 338).
In recognition of these issues, a number of alternative procedures for specifying latent interaction terms were developed. The earliest technique to emerge was the asymptotic distribution free estimation procedures (ADF). ADF procedures were developed as an alternative to ML estimation of the product models and included, for example, weighted least squares (WLS; Browne, 1982), mean adjusted weighted least squares (WLSM; B. Muthén, 1993), mean and variance adjusted weighted least squares (WLSMV; B. Muthén, 1993), and weighted least square with elliptical estimator (Bollen, 1989). The main advantage of ADF estimators was also one of their primary disadvantages. The advantage was in minimal assumptions about the distribution of the observed variables including the product terms among them (Bollen, 1989). However, the latter also meant that ADF estimation did not exploit the specific unique distributional properties of those variables and as such lowered the efficiency and power to estimate the parameters in which these variables are used, particularly in the presence of small sample sizes (Klein & Moosbrügger, 2000). Sample size requirements for ADF estimation are much larger than ML to achieve consistent convergence of the models (Bollen, 1989). Additionally, because these procedures are asymptotic distribution free, the computational requirements are larger than those for ML (Bollen, 1989). For example, with just 10 observed variables, WLS requires the inversion of a 55 × 55 matrix (Bollen, 1989), and the matrix grows exponentially larger with the addition of each observed variable. Even with today’s high-powered computers, it may not be feasible to estimate a model with even a moderate number of observed variables.
In light of these computational inefficiencies, the unconstrained (Marsh, Wen, & Hau, 2004, 2006) and residual centering approaches (Little, Bouvaird, & Widaman, 2006) were introduced. The unconstrained approach (Marsh et al., 2004, 2006) simplifies the approach by omitting the constraints after mean centering the indicator variables (i.e., allowing the factor loadings and error components of interaction terms to be freely estimated). The residual centering approach (Little et al., 2006) uses a two-step procedure where the indicator product terms are regressed on the X and Z variables to generate residuals, and these residuals are used as indicators of the latent interaction term in accordance with the unconstrained approach. While these approaches show promise, their ability to mitigate the nonnormality issues need further testing, and the approaches have yet to be refined enough to the point where they can be easily adopted by researchers.
Despite the excellent review provided by Cortina et al. (2001; see also Algina & Moulder, 2001), the article appeared to have little impact on researchers’ actual practices for testing interaction effects using a latent variable approach for the next decade. The vast majority of organizational science researchers throughout the first decade of the 2000s and now into the second one appear to have skipped the latent variable approach and relied primarily on a regression-based approach. Even though SEM software was readily available, the proper specification of latent interactions required using aspects of the software that was beyond the typical user’s knowledge such as identifying and properly specifying the extra constraints needed to model the parameters around the product terms and latent interaction variable. Further, there were other issues such as its computational complexity, large sample size requirements, and lack of convergence that distanced researchers even further from applying a latent variable approach to specifying interaction effects. Not surprisingly, among the 75 articles since 2008 that used a combination of moderation and mediation, all except 6 articles used regression or ANOVA based tools for testing the moderation effect, and even among those 6, only 2 used some form of latent variable interaction.
At about the same time as the Cortina et al. (2001) publication, Klein and Moosbrügger (2000) published an article on a latent variable approach to specifying interaction effects that mitigated many of the issues presented earlier and that they had been developing since the mid-1990s. Like many such new approaches, though, it was not “consumable” at that point in time because the software tools had not yet been developed to make it widely available. Further, it needed to undergo the requisite scrutiny by experts to evaluate its viability. Klein and Moosbrügger (2000) presented the LMS approach, which utilizes maximum likelihood (ML) procedures based on expectation maximization (EM) developed specifically to exploit the specific unique distributional properties of the variables in the interaction (Klein & Muthén, 2007).
Unlike other approaches, “LMS uses the raw data of indicator variables directly for estimation, and does not require the forming of any products of indicator variables” between the predictor, X, and moderator, Z, latent variables to create the latent interaction variable (Klein & Moosbrügger, 2000, p. 467). As explained succinctly in Kelava et al. (2011), LMS is a distribution analytic approach. With one major exception, the distribution analytic approach makes the same assumptions about most of the properties of the latent exogenous (predictor) and endogenous (outcome) variables (e.g., ξ and δ, ε and ζ are multivariate normally distributed with means equal to 0) as the product indicator SEM approaches reviewed by Cortina et al. (2001). The exception is an important distinguishing factor, however, between them and the LMS procedure. Specifically, based on Kenny and Judd (1984) and others, it has been demonstrated that if a significant interaction or other nonlinear term is truly present and impacting the latent endogenous (outcome) variable, η, as hypothesized, then η and its observed manifest variables (the y’s) will be nonnormally distributed (Kelava et al., 2011; Mooijaart & Satoora, 2012) in the presence of those nonlinear effects. The typical SEM approaches (product indicator) assume that η and its observed variables are normally distributed, and this is why the use of product indicator approaches to evaluate models with interactions and other nonlinear terms remains problematic (see Mooijart & Satoora, 2012, p. 65).
In contrast, the distribution analytic approaches, such as LMS, account for the nonlinearity in estimating the parameters of the model. LMS is based on the research demonstrating that much more information than just the means and covariances need to be brought into the analyses when testing for interaction effects in the models (Kelava et al., 2011; Mooijart & Satoora, 2012). To do so, LMS relies on two core statistical techniques: (a) the notion of a mixture distribution such that a nonnormal distribution may be represented by mixtures of normal distributions with different means and variances and (b) the notion of conditional distribution, which is a distribution of a variable holding one or more variables constant. As stated by Kelava et al. (2011): To illustrate these ideas, consider the distribution of the height of adults in the United States which is nonnormal. Males have a distribution that is approximately normal (μ = 69:41, σ = 4:48 inches) and females have a distribution that is approximately normal (μ = 63:86, σ = 4:39 inches; McDowell, Fryar, Ogden, & Flegal, 2008) as well. In other words, there are two conditional normal distributions, one for gender = male and one for gender = female. Combining these two conditional distributions into one distribution represents the nonnormal distribution in the entire population. Statisticians often use this idea and combine several normal distributions to represent complex nonnormal distributions. The challenge is to find a conditioning variable like gender in the preceding example that identifies the mean and variance of the specific conditional normal distributions to be combined. The LMS procedure builds on these two central ideas. First, although overall interaction (ξ1ξ2) and quadratic (ξ1
2, ξ2
2) effects are nonlinear, the conditional effects are linear when a variable is controlled that causes the nonlinearity. Second, the multivariate distribution of the observed indicator variables (x1; x2;:::; xq; y1; y2;:::; yp) can be approximated by a weighted combination of conditionally normal distributions. For both parts, the challenge is in finding the proper variable on which to condition. (p. 473)
Here the term ξ1ξ2 symbolizes the interaction between two latent variables. Instead of computing product terms from the observed variables of each latent variable, LMS identifies an appropriate conditioning vector to capture the nonlinearity of moderation effects. In other words, LMS does not require creation of indicator interaction terms nor does it require the researcher to specify a conditioning variable. Instead, based on the joint vector of indicators associated with the interacting predictor latent variables, LMS procedures identifies a vector of conditioning variables using a matrix operation called Cholesky decomposition (Kelava et al., 2011). To achieve this representation, the vector of predictor variables is eventually decomposed into two vectors representing the linear and nonlinear (z1) components within both the structural and the measurement model. This z1 vector of nonlinear components is used for conditioning whereby the joint distribution of the original predictor and outcome variables is multivariate normal (Klein & Moosbrügger, 2000). The multivariate distribution of X and Y variables can be represented as a mixture distribution in which the z1 vector is used to determine the means, variances, and covariances of the set of normal distributions used in the mixture. As LMS takes into account nonnormality of interaction by representing the nonnormal distribution as a mixture of conditionally normal distributions, there is no need to specify any product terms among the indicator variables for X and Z.
Based on the z1 vector, the multivariate normal distributions of predictor and outcome variables are summed and weighted using a numeric approximation procedure (Hermite-Gaussian quadrature). To reiterate, as the nonnormality of the distribution is approximated as a mixture of conditionally normal distributions, we do not need to specify any indicator product terms. LMS uses the expectation maximization algorithm to calculate maximum likelihood estimates and standard errors for each of the parameters. LMS uses the complete raw data to calculate the parameters. Moreover, the approach generates robust estimates of the standard errors using the Fisher information matrix based on ML procedures. Thus, another advantage to LMS besides not having to specify product terms among indicators is that it provides ML estimators, and as such, “they are consistent, asymptotically unbiased, asymptotically efficient, and asymptotically normally distributed” (Klein & Moosbrügger, 2000, p. 467).
Since its introduction, the performance of the LMS approach has been evaluated in comparative studies with other approaches to specifying latent interaction terms. In one of the earliest studies, Klein and Moosbrügger (2000) compared LMS to the product indicator approach to specifying the latent interaction using WLS and normal ML estimation procedures. Along all evaluation criteria, the LMS approach was the stronger one. Similar comparative outcomes were reported by Marsh et al. (2004); Schermelleh-Engel, Werner, Klein, and Moosbrügger (2010); and Jackman, Leite, and Cochrane (2011). Jackman et al. (2011) also found that the LMS approach possessed greater power in detecting latent interaction effects. Given the favorable evaluations, the LMS approach to specifying latent interaction effects was built into the Mplus software package (L. K. Muthén & Muthén, 1998-2012) under the estimation procedure called MLR (maximum likelihood robust errors). The syntax to specify the interaction term is intuitive, typically requiring one line. Most importantly, because it does not require the user to specify product terms among the X and Z indicator variables, there is also no need to write the multitude of user-specified constraints needed to identify all of the components underlying the interaction.
Interaction effects, which by definition are nonnormal, may require larger sample sizes. In general, the sample size required to detect effects with sufficient power may depend on many factors including complexity of the model, distributions of the variables, as well as effect sizes and missing data. Based on the approach outlined in L. K. Muthén and Muthén (2002), here we provide example code of estimating sample size using Monte Carlo simulation in the context of LMS process accompanied by an Excel sheet implementing the key formulas based on L. K. Muthén and Muthén .
While relatively easy to implement, the LMS approach is not a panacea to all the challenges associated with latent variable interactions. While the LMS approach is robust to nonnormality of outcome variables, like all maximum likelihood approaches, it relies on the assumption of normality of predictor variables (Schermelleh-Engel et al., 2010). Therefore, like other nonlinear SEM approaches, the effectiveness of the approach diminishes when the sample size is small (<100), the reliability of measurements is poor (<.65), and when the predictor variables are severely nonnormal (Harring, Weiss, & Hsu, 2012). While testing certain complex moderated mediation models, when the mediator variable (M) is already influenced by an interaction of two predictor variables, M may not be normally distributed, and this can become an issue in calculating interactions involving M. As the models combining mediation and moderation get increasingly complex (e.g., multistage multi-mediator models), it is unknown at this stage how effective the LMS approach may be given that it has not been evaluated under those conditions.
LMS relies on numerical integration and raw data, allowing it to compute the conditioning vectors from the data. However, this feature also makes it a computationally intensive process. As the model gets more and more complex, the computational burden increases and may exceed the computation capacity of even the most powerful computers. Complex models may take long periods of time to come to a final solution. It has been the authors’ personal experience that when the two latent variables in the interaction term have a large number of indicators, the capacity of even our most powerful computer to derive a final solution is exceeded.
Given the computational intensity of complex moderated mediation models, researchers may start with a simpler, less complex model with a smaller number of latent variables and interactions and add to it in small steps. Additionally, it may be possible to start by estimating model parts and use those results to specify appropriate starting values for the full model. Another option would be to use parceling to reduce the number of indicators per latent variable. Before the researcher makes the choice of using parceling, our recommendation is to start with a full model using all observed variables. It is often the case, however, that a warning is received that the number of required integration points exceeds the capacity of the computer. While less frequent, the syntax will execute, but the full model may be computationally too intensive to derive a solution even when the computer is permitted to run for hours. Thus, the researcher may need to create parcels among the observed variables. Parceling is an important methodological consideration, and appropriate care must be taken to create parcels. As Little and coauthors (Little, Cunningham, Shahar, & Widaman, 2002; Little, Rehmtulla, Gibson, & Schoemann, 2013) point out, researchers need to take into account several factors, including scale type and dimensionality of the construct, to use parceling effectively. As Little et al. (2013) suggest, there are several advantages to using parceling, and while parceling can be an efficient tool, its effectiveness is dependent on the use it is put to. In the case of computational intensity of large models, the parceling may allow a researcher to test relationships that otherwise would be computationally impossible to test with the current computers. However, appropriateness of parceling in each case will depend on several factors, including dimensionality of the scale, the approach to parceling, and scale type.
It has been our experience, however, that these limitations are a function of model complexity and that under most “normal” circumstances, the LMS procedure performs as expected as and better than any other approach to specifying latent interaction terms to date. The syntax for its specification is very simple, and unlike the product-based approaches does not require the specification of any extra constraints to properly identify the parameters. It also allows the researchers to use SEM to incorporate measurement error in models that combine moderation and mediation. The following demonstrations utilize the LMS approach within the Mplus software package. Given current interest in tests of moderated mediation, the demonstration illustrates six different moderated-mediation models but from a SEM perspective.
Demonstration
Models and Data
We present six different models, which simultaneously combine moderation and mediation. Figures 2a through 2d illustrate the models according to Hayes’s (2013) format on the left side and according to Edwards and Lambert’s (2007) format on the right side. There are no equivalents to Hayes’s Models 21 and 11 in the Edwards and Lambert (2007) format. To demonstrate each model, we used the Edwards and Lambert (2007) fictitious example whereby feedback (predictor variable) influenced commitment (outcome variable) through job satisfaction (the mediator variable) and family centrality (continuous moderator variable) or gender (binary moderator). The first model, Hayes Model 7, illustrated in Figure 2a, is also the “First Stage Moderation model” in the Edwards and Lambert (2007) article. The second model, Hayes Model 8, shown in Figure 2b, is the model combining “Direct and First Stage Moderation effects” in Edwards and Lambert’s terminology. The third model is Hayes Model 14 (Figure 2c), which is also the “Second Stage Moderation model” in Edwards and Lambert’s terminology. The fourth model, Figure 2d, is Model 58 in Hayes’s terminology, and it corresponds to Edwards and Lambert’s “First and Second Stage Moderation model.” Model 21 (Figure 2e) from Hayes (2013) is similar to Edwards and Lambert’s “First and Second Stage Moderation model.” However, in Model 21, the first and the second path are moderated by different variables. Finally, we also demonstrate a more complex Hayes Model 11 (Figure 2f), whereby the first stage effect is moderated by two moderators. There is no equivalent to Models 11 and 21 in Edwards and Lambert’s terminology, though the equations can be extended to these models.

a-f: Six illustrated models.
We tested the models using simulated data developed from the data set provided by Edwards and Lambert (2007). The original data included responses from 1,307 respondents who were surveyed on work and family issues. A full description of the variables is provided in their article. In general, though, feedback was measured with five items, satisfaction was measured with three items, commitment was measured with eight items, and family centrality was measured with six items, and all were on a 7-point response scale (1 = strongly disagree, 7 = strongly agree). Gender was coded as 0 = men and 1 = women. To create the current database, Monte Carlo simulation was used to generate 10 databases with 1,307 observations each. Given that this was a demonstration, we created a data set with three items for each scale in order to reduce model complexity. We picked one database with values most similar to the original data set.
Given that much of the following is illustrating how to conduct the analyses with more focus on syntax than the actual outcomes, only the analyses of Hayes Model 7 (First stage moderation), and Hayes Model 11 are illustrated in the following sections. We limited it to these two models simply because there is a great deal of repetition from one model to the next. The analyses of all of the remaining models except 11 are sufficiently similar to Model 7 that the reader should be able to understand the differences in syntax by examining the syntax files for those other models. Model 11, though, is sufficiently different because it encompasses a three-way latent variable interaction. Therefore, it warrants separate attention. All the sample data and code are accessible at https://drive.google.com/#folders/0BypX-E-3GQYxSVBBQ1JpX29WbUE.
The latent variable interactions were defined using the XWITH statement in Mplus syntax. The XWITH option in Mplus needs to be used with TYPE=RANDOM and ALGORITHM=INTEGRATION to define latent variable interactions. XWITH option is not limited to only latent variable interactions and can also be used to define interactions between latent and observed variables, both binary and continuous. XWITH is paired with the symbol | to define the interaction variables. We then calculate the indirect and total effect based on equations from Edwards and Lambert (2007) using model constraint statements in Mplus. Since all the effects are calculated using the MLR estimator (the LMS estimation) in Mplus, the standard errors are known to be robust.
Analysis of Hayes Model 7—First Stage Moderation Model
As seen in Figure 2a, this model specifies that feedback (X) influences commitment (Y) via an indirect effect through satisfaction (M), and centrality moderates the relationships between feedback and satisfaction. This model is akin to Model 7 in Hayes (2013) and the First Stage Moderation model in Edwards and Lambert (2007).
To specify latent variable interactions, we need to use the following Mplus commands before specifying the measurement and path models. Per the explanation in the introduction, underlying the LMS approach is a numerical integration process, and these lines of syntax are the ones that evoke it.
ANALYSIS:
TYPE = RANDOM;
ALGORITHM = INTEGRATION;
As with all SEM models, the first step is to define the latent variables using a measurement model. This required the four lines of code in the following, where the provided names for the latent variables (e.g., fbk, sat, etc.) are to the left of the “by” command and the corresponding observed variables underlying each latent variable is to the right. The letter following the exclamation mark is a reminder as to which variables were the X, M, Y, and W.
fbk BY feed1-feed3; ! X
sat BY sat1-sat3; ! M
com BY commit1-commit3; ! Y
cen BY cent1-cent3; ! W
Specifying the actual latent variable interaction between feedback and centrality in the model is completed using the XWITH command.
fbkccenc | fbk XWITH cen;
The term fbkcenc is the label the user gives to the latent interaction variable. The pike key (|) is the Mplus command denoting that the latent interaction is defined by the terms to the right of it. Specifically, that the latent variable fbk is to be crossed with (XWITH) the other latent variable cen, both of which were defined in the measurement model.
Again, as with all SEM models, the next step is to test the proposed path model. For the main effects, the structural path model was estimated by regressing satisfaction (M) on feedback (X) and centrality (W) and commitment (Y) on feedback (X) and satisfaction (M).
sat ON fbk;
sat ON cen;
com ON sat;
com ON fbk;
Testing the effect of the latent interaction term is also simply done with an “ON” statement. Specifically, the following line of syntax was used:
sat ON fbkccenc (axw5);
Assuming the reader is looking at the actual syntax file while following this text, you will notice two other major characteristics about the file. First, many of the lines of syntax are followed by parenthetical markers such as the (axw5) in the previous line. Recall that we mapped the models onto the equations presented by Edwards and Lambert (2007). The axw5 is the latent interaction effect per Equation 5 from Edwards and Lambert (2007). In this manner, the user can go to their article and see what value belongs to the many functions underlying their equations. Following an estimated parameter with parentheses in Mplus assigns the obtained value to that marker.
The aforementioned is important because of the second major characteristic of the syntax files. Namely, using the MODEL CONSTRAINTS feature of Mplus permits the user to create new terms and values. As can be seen in the syntax, we used the constraints for two primary purposes. The first was to execute the Edwards and Lambert (2007) equations and test the differences between low and high values of the moderator. In the case of Model 7, this was the difference in First Stage Moderation at the low and high values of the moderator. The second purpose was to calculate the predicted values at the low and high values of the moderator so that we could plot the interaction. Table 3 shows results for all the calculated effects. A few example lines of syntax from the main syntax file illustrating each of these two purposes are presented in Table 4, and the plots for Model 7 are illustrated in Figure 3.
Fit Indices and Unstandardized Coefficients for All Models.

Note: N = 1,307. All the coefficients are unstandardized.
aThe term estimated paths refers to number of free parameters in the output. Including the option TECH1 on the output line also gives more detailed information on the number of parameters estimated.
**p < .01.
Direct, Indirect, Total Effects for the Models.

Note: N = 1,307. All the coefficients are unstandardized.
*p < .05. **p < .01.
Model Constraint Command Examples for Calculating Effects and Plotting Points.

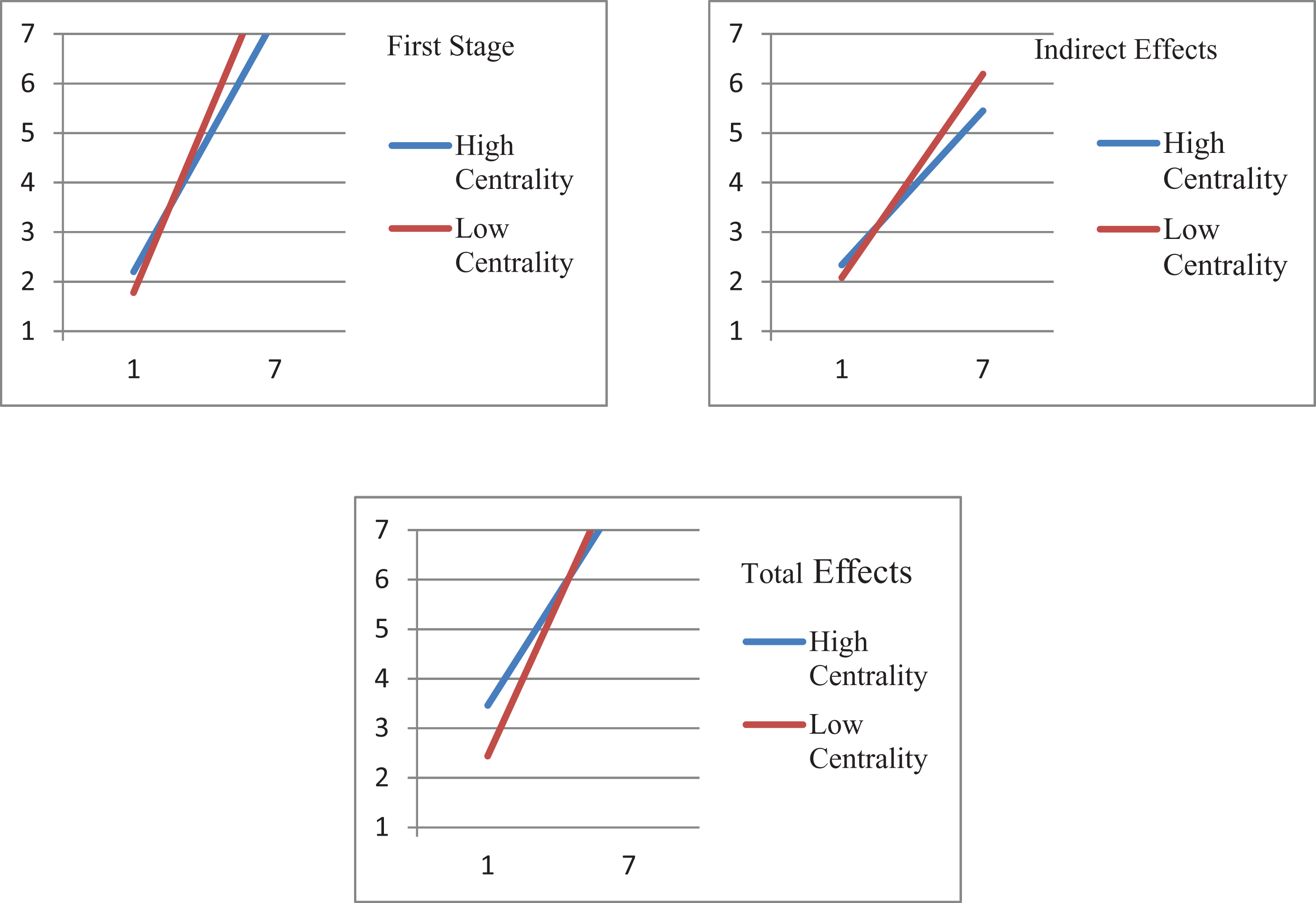
Model 7 first stage, indirect and total effects.
We are optimistic that by studying the Hayes Model 7 (Edwards and Lambert first-stage moderation only model) syntax file along with the notes we provide in that file, the reader should be able to follow the changes in syntax the represent the other models. For example, the primary difference between Hayes Model 7 and Hayes Model 58 (the first- and second-stage moderation model) is the additional syntax to operationalize the second-stage moderation effect and to generate the values for plotting that interaction. Similarly, the Hayes Model 14 (Edwards and Lambert second-stage only moderation model) excludes the syntax for first-stage moderation and only includes that for second-stage moderation. While it may take some effort to understand the syntax itself, every attempt was to take a modular approach so that the operationalization of different stages or the full model are readily apparent.
Analysis of Hayes Model 11—Two Moderators for the First Stage Effect Only
This model has no equivalent in the Edwards and Lambert (2007) article. It specifies that feedback (X) influences commitment (Y) via an indirect effect through satisfaction (M), centrality (W) moderates the relationship between feedback (X) and satisfaction (M), and gender (Z) moderate the relationships between centrality (W) and satisfaction (M) such that there is a three-way interaction between X, W, and Z. This model is illustrated in Figure 2f.
For Model 11, the measurement model was the same as previously described. The latent variable interactions differ from the previous model in that there are two-way interactions (the first three lines of syntax in the following) in addition to the theoretical three-way interaction (the last line of syntax in the following).
fbkccenc | fbk XWITH cen; ! XW
fbkcgen | fbk XWITH gen;! XZ
cencgen | cen XWITH gen;! WZ
fbkcengen |fbkccenc XWITH gen;! XWZ
Note that the interaction of a binary variable (gender) with a latent variable is defined the exact same way we define interactions between two latent variables.
As the next step, we provide syntax to test the proposed path model. For the main effects, the structural path model was estimated by regressing satisfaction (M) on feedback (X), centrality (W), and gender (Z) and commitment (Y) on feedback (X) and satisfaction (M).
sat ON fbk (ax5);
sat ON cen (aw5);
sat ON gen (az5);
com ON fbk (bx20);
com ON sat(bm20);
Testing the effect of the latent interaction term is also simply done with an “ON” statement. Specifically, the following lines of syntax were used to test the effects of the two-way interactions (the first three lines of syntax in the following) in addition to the theoretical three-way interaction (the last line of syntax in the following).
sat ON fbkccenc (axw5);
sat ON fbkcgen (axz5);
sat ON cencgen (awz5);
sat ON fbkcengen (axwz5);
Similar to the Model 7 file, we use parenthetical markers such as the (axw5) in the previous lines that are extensions of the Edwards and Lambert (2007) notations to the current model. Following an estimated parameter with parentheses in Mplus assigns the obtained value to that marker. We then used the markers and manipulated them using the MODEL CONSTRAINTS feature of Mplus to create new terms and values. Similar to the previous example, we used the constraints for two primary purposes, to execute the extensions based on the Edwards and Lambert (2007) equations and test the differences between low and high values of the moderator. Table 3 shows results for all the calculated effects. A few lines of syntax illustrating each of these two purposes are presented in the bottom half of Table 4, and the plots for Model 11 are illustrated in Figure 4.
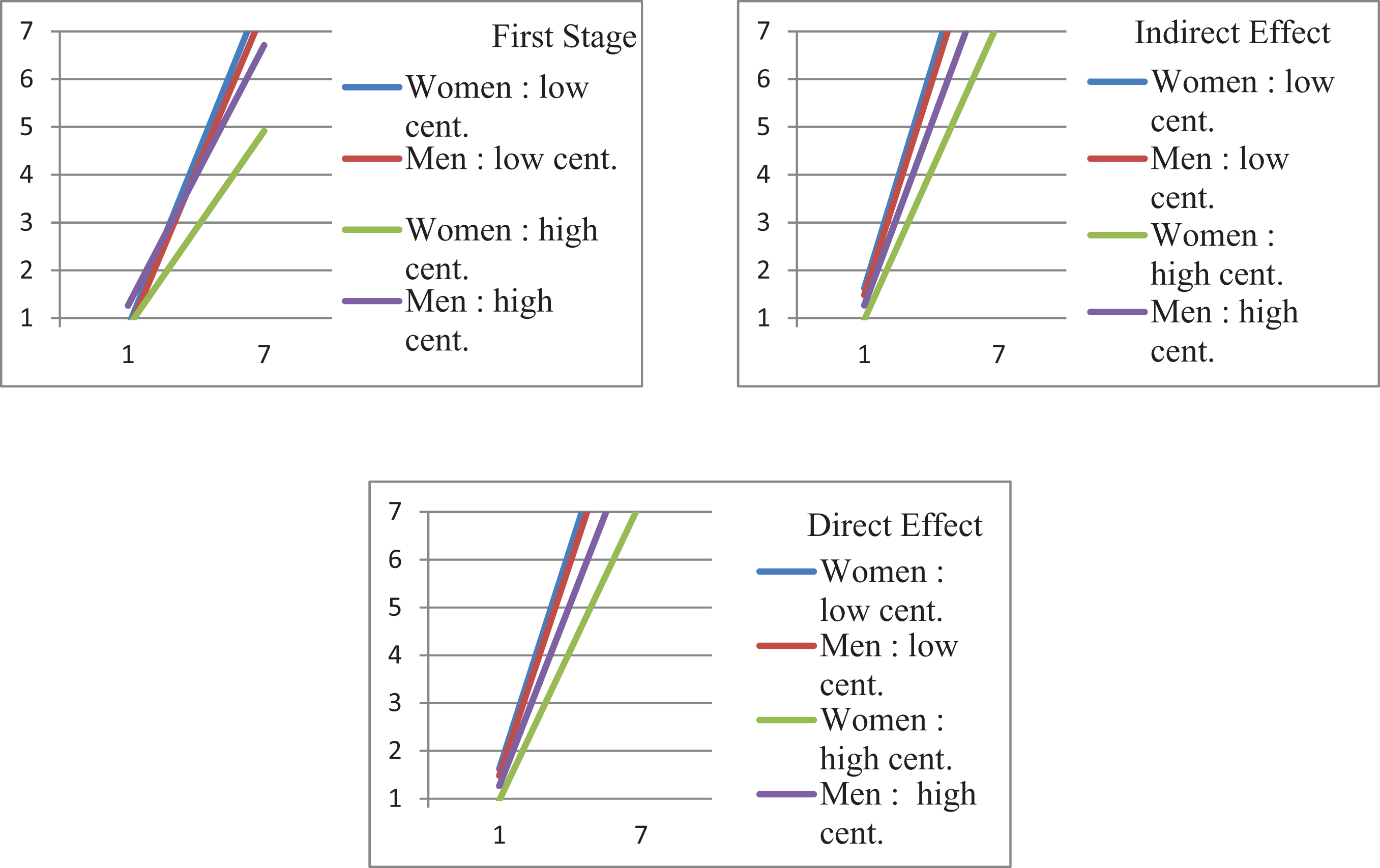
Model 11 first stage, indirect and total effects.
Interpreting Moderation
Similar to regression-based moderation approaches, a significant interaction term indicates that the effect of the key independent variable on the dependent variable differs across the range of the moderator. It can be further probed by investigating if the coefficients, which represent slopes of the relationship between independent and dependent variable, differ across different values of the moderator. In our case, moderation of first, second, direct, indirect, and total effects means that these paths may differ at different levels of the moderator. Based on Edwards and Lambert (2007), these effects can be calculated at different values of the moderator. Overall, interpretation of moderation will be based on (a) statistical significance of the interaction term and (b) statistical significance of the difference values of first, second, direct, indirect, and total effects. Further, simple slopes for each path and effect can be plotted. We provide code for plotting all the effects based on the Edwards and Lambert (2007) paper. Further, based on the graphing capabilities in Mplus, we also provide simple code for plotting indirect effects.
Endogeneity and Calculation of ρ
As Antonakis, Bendahan, Jacquart, and Lalive (2010) point out, endogeneity is an important consideration in understanding mediation models. The point 9 in their 10 commandments recommends that researchers calculate correlations between the disturbances of the mediator and the outcome variable. Similarly Imai, Keele, and Tingley (2010) and Imai, Keele, and Yamamoto (2010) point out that correlation between the mediator and outcome variable (in the example case, satisfaction and commitment) can be treated as a sensitivity parameter to violation of the sequential ignorability assumption of causal mediation. Under the sequential ignorability assumption, the correlation between mediator and outcome disturbance terms (ρ) should be 0. In our model, it is very easy to calculate ρ by adding one line of code:
sat with com;
Tables 5 and 6 list results for the models, which include estimation of the correlation between the disturbances of mediator and the outcome variable (satisfaction and commitment). Estimating such a parameter may not always be possible given the identification issues, and some models may not converge when the correlation between disturbances of mediator and outcome variables are estimated. We found that for some models, including the correlation between residuals of the mediator and outcome variable produced errors and inconsistent estimates (e.g., Model 14), which may indicate potential model misspecification. However, since the purpose of this paper is to illustrate how the models could be adapted, we have included the results in this paper. For substantive papers, it is important to specify appropriate models.
Fit Indices and Unstandardized Coefficients for All Interaction Models After Correlating Disturbances of M and Y.

Note: N = 1,307. All the coefficients are unstandardized.
aThe term estimated paths refers to number of free parameters in the output. Including the option TECH1 on the output line also gives more detailed information on the number of parameters estimated.
**p < .01.
Direct, Indirect, Total Effects for All Models After Correlating Disturbances of M and Y.

Note: N = 1,307. All the coefficients are unstandardized.
*p < .05. **p < .01.
Model Fit Involving Latent Variable Interaction
When using the LMS approach within Mplus the first time, the user will see that none of the “typical” fit indices are reported such as the chi-square goodness of fit, Tucker-Lewis Index (TLI), Comparative Fit Index (CFI), and the like. Rather, only the information criteria, Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), and sample adjusted BIC (SABIC), are reported. The “typical” fit indices are based on normal theory, and as explained previously, the LMS approach is not. The developers of Mplus recognized this and purposely did not program those fit indices in to avoid giving the impression that they are accurate and okay to use. One method to get a sense as to how well the model would fit is to run a baseline model where the moderator is included, but only its main effects are specified (paths from it to the dependent variable), and the model is evaluated using the traditional maximum likelihood estimation procedure; that is, the latent interaction term (using the XWITH statement) is not included. It is after this then that the model with the latent interaction term is estimated. One can then compare the latter interaction model to its baseline using the information criteria. In most cases, the fit of the baseline model should meet all of the usual criteria for judging a well-fitting model. If it does not fit well, then adding the interaction to it does not make sense. Assuming it fits well, one can then evaluate whether the inclusion of the interaction term changes the information criteria between the baseline and interaction models. When hypothesizing a disordinal interaction, it is likely that the baseline structural model may not fit very well, in spite of a good measurement model. In such cases, addition of the latent variable interaction model dramatically reduces the information loss, leading to a smaller information criteria numbers.
In practice we prefer, and therefore recommend, the AIC over the BIC for these comparisons (Vandenberg & Grelle, 2009). Both Burnham and Anderson (2002) and Yang (2005) demonstrate that the BIC is based on some unrealistic assumptions and over-penalizes for the inclusion of more parameters. For example, the BIC assumes that the population of alternative models for a given model is known when that is rarely if ever the case within the organizational sciences (Vandenberg & Grelle, 2009). Also, the AIC is asymptotically optimal, the BIC is not, in identifying the model with the smallest or least mean square error under the commonly made assumption that the true population model is infinite dimensional (Yang, 2005). Infinite dimensionality is not an unreasonable assumption as it implies that the processes that generate the data are rarely represented exactly by a fixed finite dimensional model (Kuha, 2004). While the absolute values of AIC are not useful for interpretation, the differences in the AIC values of different models are of key importance (Burnham & Anderson, 2002). Ideally, the model with the smallest AIC is selected as the optimal one as larger AIC indicates larger information loss.
However, we would like to interject a word of caution in that the goal here is not about finding the optimal model from among a number of alternatives. Rather, the goal is simply to ask whether the inclusion of the latent interaction term with its paths to other variables results in a dramatic loss of information relative to the baseline, namely, increases the value of AIC. Further, the AIC does penalize for model complexity, and the inclusion of the interaction terms increases model complexity a great deal. While comparing AIC values, the smaller value is preferred over the larger value. According to Burnham and Anderson (2002), difference in the AIC (Δi = AICi – AICmin) can be very important and useful in determining the better model. Δi = 4 – 7 can indicate that the model with smaller AIC is considerably better fitting, and Δi > 10 can rule out the worse fitting model. One sees this in Table 2, where all of the interaction models except Models 21 and 11 had smaller AIC values than the baseline models. Models 21 and 11, however, were the most complex interaction models in the set tested. Thus, their respective AIC values were larger than those of their respective baseline models. Further, in Table 5, which tested the same models after including the correlation of disturbances of outcome and mediator, Model 14 showed inconsistent estimates and also a poorer fit index (high AIC) as compared to other models, flagging the model misspecification. Maslowsky, Jager, and Hemken (2015) recently proposed another method for evaluating the fit of the model with the latent interaction variable. Like the previous approach, the relative contribution of the latter model is compared to a baseline model without the latent interaction variable. However, instead of comparing the AIC values from both models, Maslowsky et al. recommend the log-likelihood ratio test; that is, computing the difference between the log-likelihood functions from both models and treating the difference as a chi-square value.
Bootstrapping
In the older versions of Mplus, it was not possible to bootstrap the latent variable interaction models. However, the more recent 7.2 version of Mplus also allows the users to use ML estimator and bootstrapping. In our analysis, the confidence intervals from both the processes were identical. While the bootstrapped processes take a lot longer to run, many researchers may prefer bootstrapped results. To bootstrap the latent variable interaction models, it needs two additional lines of syntax to specify the estimator and the number of bootstrap draws. So the analysis syntax now would be:
ANALYSIS:
TYPE = RANDOM;
ALGORITHM = INTEGRATION;
ESTIMATOR = ML;
BOOTSTRAP = 500;
PROCESSORS = 4;
To generate the bootstrapped output, we also specify one additional syntax command in the output line:
OUTPUT: samp CINTERVAL (BCBOOTSTRAP);
Both LMS and bootstrapping are computationally intensive, and therefore it may take several hours for a bootstrapped complex moderated mediation model to run and generate output. However, depending on how many core processors your own computer has, processing speeds can be dramatically increased by instructing Mplus to use all of the computer’s core processors by inserting the PROCESSORS = command.
Discussion
Using a simulated data set, we demonstrate how researchers may be able to use latent interaction models in the context of a combination of moderation and mediation models. We do so by drawing parallels between Edwards and Lambert’s (2007) and Hayes’s (2013) approach and attempt to introduce the LMS procedure in the organizational literature.
While moderation and mediation are commonly used techniques to understand complex organizational phenomena, the statistical techniques have advanced since the Baron and Kenny (1986) article. Commonly used techniques for combining moderation and mediation include the Edwards and Lambert (2007) approach as well as the approach by Hayes (2013) and coauthors (e.g., Preacher et al., 2007). However, these approaches are regression based. Our literature search demonstrated that out of the 75 articles that combined moderation and mediation, only 2 articles used latent variable interactions. The important advantage SEM has over regression is SEM allows the researchers to incorporate measurement error and offers greater power to detect effects (Steinmetz, Davidov, & Schmidt, 2011). Such advantages of SEM are even more important for interaction terms. SEM also offers confirmatory factor analysis capabilities that can improve our models (LeBreton et al., 2009). While researchers have acknowledged the advantages of SEM over regression, SEM product indicator calculation procedures for interaction effects have been rather complex and inaccessible. The goal of the current article was to provide a single one-step approach to combine moderation and mediation analysis and extend it into a SEM framework. We do so using the simple and accessible syntax using the Mplus software package ( L. K. Muthén & Muthén, 1998-2012), which implements the efficient and unbiased (Klein & Moosebrugger, 2000; Marsh et al., 2004; Schermelleh-Engel et al., 2010) LMS approach for latent variable interactions.
As organizational researchers attempt to answer increasingly complex questions, these theoretical questions also need appropriate methodological tools to answer them better. Along with better tools of analysis, there is an increasing need for better measures and incorporating good measures into analysis. SEM techniques allow the researchers to incorporate measurement error into the analysis, improving the quality of results in the process. By creating opportunities for incorporating measurement error in such analysis, this article contributes to the organizational literature by improving the quality of findings.
While this teaching note was designed to demonstrate the technique for several different models combining moderation and mediation, for substantive research papers, theoretical support is essential to understand the causal effects and to specify which paths should be interpreted. Additionally, to keep our demonstration as simple as possible, we used three indictor variables to define the latent variables. Our syntax can be easily adapted to situations where each latent variable is defined through more observed/manifest variables. However, as pointed out earlier, it may not be possible for a model to converge if there are a large number of interactions or indicator items in an interaction, and the researcher may have to use parceling methods to arrive at a solution. Also, as the complexity of the interactions increases, it may take a long time for the model to converge. Finally, this technique may not be applicable in a long and complex chain of mediation and moderation models.
This teaching note attempts to extend the regression-based approaches to combine moderation and mediation to SEM, discussing the combination of moderation and mediation, namely, Edwards and Lambert (2007) and Hayes (2013), and identifying parallels between the two approaches. To do so, we demonstrate use of the latent variable interaction techniques implemented in Mplus. However, this article does not provide code for all the different combinations moderation and mediation as identified by Hayes. Moderated mediation models are complex models, and using the computationally intensive LMS process may require researchers to use strategies like parceling to simplify the model. However, we do not know the implications of using parceling in such a moderated mediation model, and a simulation analysis of different parceling practices on efficiency and bias of results can further contribute to this area of research. This article also does not take into account the emerging perspective on causal inferences or other approaches such as instrumental variable approach. While calculation of ρ may flag issues with the causal model at the data analysis stage, it is important to take into account endogeneity concerns during study design. SEM processes indeed help counter some sources of endogeneity such as measurement error. However, unmeasured measurement error is just one form of endogeneity, and the researchers may choose to use instrumental variables to mitigate other sources of endogeneity (Antonakis et al., 2010). However, use of instrumental variables is beyond the scope of this article, and we refer our readers to Antonakis et al. (2010) for more details.
Conclusion
The purpose of this article is to extend the Edwards and Lambert (2007) approach to integrating moderation and mediation to SEM. The complexity of the product indicator approaches was one of the biggest challenges in testing moderation hypothesis in regression models. However, by using the recent advances in nonlinear SEM as incorporated in the Mplus program, we provide a one-step approach to test the moderation and mediation hypotheses together using SEM. We discuss the LMS approach and also provide sample code and relevant equations to help management scholars easily adopt this technique for their data. We also contribute to the literature by outlining parallels between the approaches to combining moderation and mediation, namely, Edwards and Lambert (2007), Preacher et al. (2007), and Hayes (2013).
Footnotes
Acknowledgments
We thank Prof Andrew F. Hayes and Guildford Press for allowing us to use parts of the moderation and mediation figures from http://www.processmacro.org and from Hayes (2013). We also thank Profs Jeff Edwards and Lisa Lambert, and APA press for allowing us to use parts of the moderation and mediation figures from ![]() .
.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.