
Abstract
Multilevel methods allow researchers to investigate relationships that expand across levels (e.g., individuals, teams, and organizations). The popularity of these methods for studying organizational phenomena has increased in recent decades. Methodologists have examined how these methods work under different conditions, providing an empirical base for making sound decisions when using these methods. In this article, we provide recommendations, tools, resources, and a checklist that can be useful for scholars involved in conducting or assessing multilevel studies. The focus of our article is on two-level designs, in which Level-1 entities are neatly nested within Level-2 entities, and top-down effects are estimated. However, some of our recommendations are also applicable to more complex multilevel designs.
Keywords
Many organizational phenomena are multilevel (ML) because they involve variables that reside at different levels of analysis. To investigate relationships that span across levels, ML 1 modeling methods are needed. Thus, researchers interested in ML phenomena need to know how to deal with several key aspects involved in an ML study. Moreover, considering the increasing use of ML methods in our field (González-Romá & Hernández, 2017), reviewers need to be prepared to evaluate manuscripts that implement these methods. This requires understanding certain important issues and knowing some appropriate ways to handle them. Fortunately, research on ML methods is ripe enough to offer a set of recommendations (summarized in Table 1), several tools and resources (see Table 2), and an evaluation checklist (see Table 3), which can be useful to researchers who plan to conduct a ML study and reviewers and journal editors who frequently evaluate ML studies. Thus, the goal of the present article is to provide a set of recommendations and resources. We hope to contribute to the field by (a) offering a comprehensive approach that covers the initial stages to the final stages of ML studies; (b) helping researchers to make sound decisions when planning ML studies; (c) increasing the rigor of ML studies; and (d) facilitating reviewers’ work when evaluating ML manuscripts. Due to space limitations, we focus on two-level designs in which Level-1 (L1) entities are neatly nested within Level-2 (L2) entities (e.g., employees nested within teams; departments nested within firms), and top-down effects are estimated. We do this because these are the most frequently used designs in our field (Molina-Azorín et al., 2020).
Multilevel Topics and Their Corresponding Recommendations.

The specific interpretation of the associated intercept depends on the specific model being tested and the centering procedure used.
For a primer on MLSEM with Mplus syntax and examples, see Vandenberg and Richardson (2019).
GMC(M): Grand-Mean Centering with cluster means introduced as L2 predictors.
Contextual = between–within. Thus, regardless of the centering option, both between and contextual effects can be obtained and tested.
Multilevel Tools and Resources.

Checklist for Evaluating Multilevel Studies.

Note. Checklists are useful tools. However, they must be used with some flexibility because some items may not apply to some specific situations.
The specific interpretation of the associated intercept depends on the specific model being tested and the centering procedure used.
L2 predictors can only be centered by using GMC (this should be done if zero has not a meaningful interpretation).
For example, a non-significant effect should be trusted more or less depending on whether the power is high enough or not (e.g., Mathieu et al., 2012), in combination with the effect size (LaHuis et al., 2019). If the effect is considered relevant in practice, and power is low, studies should cross-validate the results with larger samples. Some indirect ways of increasing power (e.g., adding relevant covariates, using more reliable measurement instruments) can also be used (Mathieu et al., 2012; Pituch & Stapleton 2012; Scherbaum & Ferreter 2009).
When and Why We Use ML Methods
Typically, researchers use ML modeling methods when the relationships investigated involve variables that reside at different levels. In these cases, researchers collect data about the study variables in a sample of L1 entities (e.g., individuals, departments) that belong to the sampled L2 units 2 (e.g., teams, firms, respectively). This results in a database with a nested structure.
Due to several factors (e.g., social interaction), employees in the same unit tend to have similar work experiences. Thus, nested data tend to show some degree of non-independence. Analyzing nested data by means of ordinary least squares (OLS) regression at the lower level can have undesirable consequences because the OLS assumption of independence of observations is violated (Heck & Thomas, 2015). In this regard, Bliese and Hanges (2004) showed that (a) estimating the relationship between an L2 variable and an L1 variable by using OLS regression leads to an increase in Type I error and (b) estimating the relationship between two L1 variables using OLS regression and nested data leads to an increase in Type II error and a loss of statistical power (Bliese & Hanges, 2004). Furthermore, Bliese et al. (2018) showed that even a very low degree of non-independence (as indicated by an intraclass correlation coefficient [ICC] = 0.013) affects the standard errors of parameter estimates. Thus, we recommend that researchers use ML modeling methods when analyzing data with a nested structure (Bliese et al., 2018).
Construct Meaning
Generally, ML studies involve constructs specified at higher levels. It is extremely important to clarify the meaning of these constructs before formulating the study hypotheses and conducting the analyses (Chen et al., 2004; Jak, 2019; Preacher et al., 2010). Without this clarification, it is not possible to fully and precisely interpret the empirical results obtained for these constructs and draw the subsequent conclusions.
Unfortunately, current practices in published studies do not reflect the importance of construct clarification. Kim et al. (2016) review concluded that “explicit discussions of how researchers conceptualize the constructs in their studies … at each level are lacking” (p. 892). ML researchers should take the construct meaning issue seriously. Hence, we propose that researchers address the following points:
Provide an explicit definition of all the study constructs, especially those residing at higher levels (Chen et al., 2005). Specify the nature of higher-level constructs. Higher-level constructs can be of different types. A useful typology was proposed by Kozlowski and Klein (2000), who distinguished among: (a) global unit properties, which are properties of the unit as a whole (e.g., unit size); (b) shared unit properties, which describe characteristics that are common to unit members and originate in lower-level properties (e.g., team climate); and (c) configural unit properties, which also originate in lower-level properties, but convey the pattern of individuals’ experiences and attributes within a unit (e.g., climate uniformity). When necessary, explain how higher-level constructs emerge. Some higher-level constructs originate in individuals’ properties (e.g., perceptions, affect, and behaviors). The latter combine through certain processes (e.g., social interaction) to yield higher-level constructs that have some features (e.g., sharedness, synergy, and complementarity) that are not present in the corresponding individual elements (Eckardt et al., 2021). In these cases, it is necessary to explain how higher-level constructs emerge from individual properties to fully understand the nature and foundation of the former.
3
Unfortunately, this explanation is frequently missing in research manuscripts (Eckardt et al., 2021; González-Romá, 2019). This explanation requires (a) specifying the type of emergence involved and (b) explaining the processes and factors involved in the emergence of higher-level constructs. Kozlowski and Klein (2000) proposed an emergence typology with two general types, composition and compilation. The composition processes of emergence explain how convergence and within-unit agreement develop to yield a shared unit property. One of the psychosocial processes that explain convergence and within-unit agreement is social interaction (Ashforth, 1985). Compilation processes promote variability and configuration, and they explain how different types or amounts of individual-level properties combine to yield higher-level configural properties. One factor that may explain variability and configuration within units is demographic diversity (González-Romá & Hernández, 2014). Explaining how higher-level constructs emerge helps to understand the relationship between higher-level constructs and their individual-level counterparts. This relationship can also be clarified by using Chan’s (1998) composition models. When ML models include isomorphic constructs, test for isomorphism. ML isomorphism means that (a) “higher-level constructs have similar meanings and properties as their lower-level counterparts” (Tay et al., 2014, p. 78) and (b) both types of constructs show similar relationships with other constructs within an ML nomological network (Kozlowski & Klein, 2000). Generally, isomorphic constructs appear in homologies (i.e., ML models positing parallel relationships between constructs across levels). An often overlooked point is that ML isomorphism requires psychometric isomorphism or measurement equivalence across levels (Jak, 2019; Tay et al., 2014). Psychometric isomorphism is crucial when higher-level constructs are formed following the composition models of direct-consensus and referent-shift consensus (Chan, 1998). However, it is not required for additive, dispersion, or process composition models (see Tay et al., 2014, p. 85). Psychometric isomorphism involves ascertaining whether (a) the same dimensions underlie the investigated construct at different levels and (b) factor loadings are invariant across levels. This isomorphism can be tested by ML factor analysis (see Tay et al., 2014). Note that if different dimensions underlie the studied construct at different levels, the dimensions used to describe the involved entities at different levels cannot be the same. If the factor loadings change across levels, the defining characteristics of the studied construct change across levels, and the construct cannot have the same interpretation across levels. Finally, we recommend taking the validity of constructs across levels seriously and implementing some of the different approaches proposed in the literature (see Chen et al., 2004; Tay et al., 2014).
Formulating ML Hypotheses
Hypotheses specify the expected relationships between variables (Bacharach, 1989). When formulating hypotheses, researchers have to be aware of (a) the precise meaning of the variables involved in the statistical analysis conducted for hypothesis testing and (b) what this analysis really does. This will ensure that the hypothesized relationships are aligned with the estimated relationships. This is especially important when formulating ML hypotheses because the variables and relationships mentioned in the hypotheses often do not completely match the variables and relationships modeled in the statistical analysis. In fact, current practice shows that we (researchers) frequently fail to formulate ML hypotheses that are fully aligned with the estimated relationships (see Bliese et al., 2018; LoPilato & Vandenberg, 2015). To avoid this, a deeper understanding of what ML modeling methods really do in four specific cases can be helpful. We focus on these cases because they are quite common in ML research and offer room for improvement.
Hypotheses involving an individual-level predictor centered within cluster. Centering is a common practice that helps to interpret variable values by setting a reference zero point. When an L1 (e.g., individual) predictor's influence is of interest and a cross-level interaction effect is examined, the general recommendation is to center L1 predictors (X) around the group mean
4
(Aguinis et al., 2013b; Enders & Tofighi, 2007; this practice is called centering within cluster [CWC] or group-mean centering). In these cases, centered values indicate subjects’ standings on X relative to the unit mean, rather than an absolute value. CWC changes the meaning of values in L1 predictors. The associated ML hypotheses should acknowledge this change (Bliese et al., 2018). Thus, instead of hypothesizing that “at L1, X is positively/negatively related to Y,” we should hypothesize that “at L1, subjects’ relative X is positively/negatively related to subjects’ relative Y.” Hypotheses about cross-level direct effects. The intercept-as-outcome ML model is popular among researchers. It is used to estimate cross-level direct effects (relationships between an L2 predictor and an L1 outcome). This model can be represented as follows: Yij is the score on the outcome of subject i from unit j, Xij is the score on an L1 predictor of subject i from unit j, Pj is the score on an L2 predictor for each unit, β0j and β1j are the regression intercept and slope, respectively, estimated in each unit (j), γ00 and γ10 are regression intercepts, γ01 is a regression slope, and rij, U0j, and U0j are residual terms. Frequently, γ01 is interpreted as estimating the relationship between an L2 predictor (Pj) and the L1 outcome (Yij). However, this interpretation is not accurate (Bliese et al., 2018; LoPilato & Vandenberg, 2015). As equation (2) shows, γ01 estimates the relationship between an L2 predictor (Pj) and an L2 outcome (β0j). Thus, to interpret γ01 accurately, the meaning of β0j must be clarified. In this model, β0j is a unit mean in the outcome (Yij), adjusted after controlling the effect of the unit mean in the predictor. Specifically, Mediation hypotheses involving a higher-level variable. In nested data, the variance of variables measured at L1 can be decomposed into two orthogonal components: a between-cluster component and a within-cluster component
6
(Preacher et al., 2010). Variables measured at L2 (e.g., unit size) only have between components of variance. “Because Between and Within components are uncorrelated, it is not possible for a Between component to affect a Within component or vice versa” (Preacher et al., 2010, p. 210). Therefore, “any mediation effect in a model in which at least one of X, M, or Y (i.e., the predictor, the mediator, or the outcome) is assessed at Level 2 must occur strictly at the between-group level” (Preacher et al., 2010, p. 210). Thus, when researchers formulate mediation hypotheses that involve an L2 variable, the hypothesized relationships among the between components of the involved variables should be specified. Moderation Hypotheses. As L1 variables have between- and within-cluster components, when they appear in interaction terms, it is extremely important to specify the component involved in the interaction. Depending on this component, the meaning of the interaction term and the corresponding moderation hypothesis may change (see Preacher et al., 2016). Fortunately, being aware of all the possible moderation effects in an ML design offers opportunities for theoretical development because it helps to uncover “hidden” moderations. Thus, we suggest that researchers think carefully about all the possible moderation effects existing in a given ML design, specify the within and between components involved, and focus on the ones dictated by their theoretical framework.
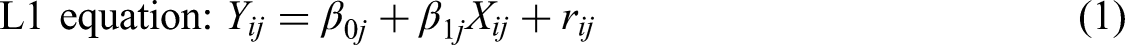


Deciding on Conventional ML Modeling or ML Structural Equation Modeling
Although Conventional ML modeling (CMLM) and ML Structural Equation Modeling (MLSEM) are valid routes in ML research, the latter has several advantages. First, MLSEM can simultaneously account for measurement and sampling error (Marsh et al., 2009), whereas CMLM ignores both types of errors, which can bias the parameter estimates (Lüdtke et al., 2008, 2011; Muthén & Asparouhov, 2011). Second, MLSEM provides goodness-of-fit indices for each level of analysis (Ryu, 2014), whereas judging fit in CMLM is troublesome (Hox, 2010). Finally, MLSEM partitions the variance of L1 predictors into two orthogonal (between and within) latent components (Asparouhov & Muthén, 2019), whereas in CMLM the effects operating at different levels are conflated (e.g., Preacher et al., 2011; Zhang et al., 2009). The two sources of variance can be deconflated by CWC the L1 predictors and reintroducing the cluster means at L2 (a procedure known as CWC(M); Zhang et al., 2009). However, this latter approach still assumes that the observed means are perfectly reliable indicators of the L2 scores.
Despite the advantages of MLSEM, we do not suggest that MLSEM should replace CMLM. In fact, MLSEM has a major drawback: due to its complexity, it only performs well with larger samples. MLSEM shows more convergence problems (Li & Beretvas, 2013; Ludtke et al., 2011) and requires larger samples to reach similar power levels as CMLM (McNeish, 2017a; Zigler & Ye, 2019). In fact, small samples can often be more simply and effectively analyzed with CMLM (McNeish, 2017a). In addition, the choice may also depend on the types of variables modeled (Chen et al., 2004). For example, correcting for sampling error is an issue of concern when L1 variables are aggregated to operationalize L2 constructs (e.g., unit climate), but not for global L2 variables that have no L1 analogue (e.g., firm size). Similarly, measurement error is of particular concern when modeling constructs operationalized with several items responded to by individuals (e.g., unit culture), but it may be less important for variables such as salary or sales. Finally, neither CMLM nor MLSEM adequately deals with measurement error in dispersion constructs.
Thus, the choice between MLSEM and CMLM depends on sample size, model complexity, and the types of effects researchers want to test. MLSEM can generally be recommended if samples are large enough (i.e., a minimum of 100 L2 units with 15 subjects per unit; González-Romá & Hernández, 2017) or measurement and/or sampling error is an issue. For small samples, CMLM is recommended (McNeish, 2017a). However, if the model is too complex to be tested with CMLM, Bayesian MLSEM is recommended (Asparohouv & Muthén, 2019; Hox et al., 2012), especially with informative priors (e.g., Holtmann et al., 2016; McNeish, 2017a).
Data Preparation and Sample Size
Before testing the study hypotheses, researchers need to consider several important issues: mean centering predictors, outliers, missing data, and sample size.
Mean-centering. When centering L1 predictors (including mediators and covariates), it is advisable to disentangle the between- and within-cluster components (Zhang et al., 2009). As mentioned earlier, in CMLM, this is typically accomplished with CWC(M) (Enders & Tofighi, 2007; Zhang et al., 2009), which allows researchers to test and quantify the effects at both levels of analysis (Enders, 2013; LaHuis et al., 2019). If the interest is in directly estimating contextual effects (whether the relationship between the predictor and the outcome differs across levels), L1 predictors should be grand-mean centered,
7
and their cluster means introduced at L2 (GMC(M)). The L2 slope captures the contextual effect, and the L1 slope represents the unconflated within effect (Enders, 2013; Kreft et al. 1995; Hoffman, 2019). Regardless of the centering option, modeling the cluster means at L2 prevents bias due to omitted L2 variables (Antonakis et al., 2021; Bell et al., 2019). It is important to point out that the fact that cross-level and between-level (and contextual) effects can be analyzed by mean centering the L1 predictors and reintroducing the cluster means at L2 does not imply that an L2 construct exists (although this may be the case). L2 constructs that are operationalized from L1 data require a composition model to justify how higher-level constructs emerge and specify how the lower-level data should be combined to compose the higher-level construct (Kozlowski & Klein, 2000; van Mierlo et al., 2009). When using MLSEM, the between and within variance components of L1 predictors are disentangled by latent mean centering (Asparouhov & Muthén, 2006a, 2019; Lüdtke et al., 2011). A simpler hybrid option is sometimes used for complex models, where only the between variance is modeled as a latent component (to correct for sampling error), while the L1 predictor is kept uncentered (Asparouhov & Muthén, 2019). Because centering occurs behind the scenes in MLSEM, researchers need to be aware that the default options may change depending on the estimation methods, software, and ML models (Asparouhov & Muthén, 2019, 2021; Hoffman, 2019). Thus, we strongly advise researchers to find out what these options are, in order to interpret the effects correctly. Outliers. They can occur at different levels and bias ML results (Kloke et al., 2009; Pinheiro et al., 2001). Thus, outliers must be identified to assess whether they are errors to be corrected (e.g., sampling or coding errors) or meaningful outliers that influence ML results (Aguinis et al., 2013a; Langford & Lewis, 1998). In the latter case, researchers can delete outliers or use robust methods to reduce their impact (e.g., bootstrapping, heavy-tailed, or rank-based methods) (e.g., Aguinis et al., 2013a; Finch, 2017), but this impact should be assessed and explained (Aguinis et al., 2013a; Loy & Hoffman, 2013). Missing data. Missing data models should be consistent with the specific ML statistical models tested; the former should include the effects considered in the latter (van Buuren, 2018; Grund et al., 2016, 2019). Consistency is achieved by employing estimation methods that use all the available data when fitting a model, such as full information maximum likelihood (FIML) (see Grund et al., 2019),
8
fully Bayesian methods (Asparouhov & Muthén, 2019, 2021), or multiple imputation (MI). ML extensions of traditional MI work well for random intercepts and contextual effects (see Mistler & Enders, 2017). However, for random slopes, fully Bayesian MI is recommended (Enders et al., 2020; Goldstain et al., 2014). These methods are available in MI packages such as BLIMP (Keller & Enders, 2019) or JOMO (Quartagno et al., 2019). Sample size recommendations. Deciding on the best combination of L1 and L2 sample sizes is a complex issue because it depends on many factors, such as the level of dependency in the data (ICC), the effect size, the estimation method, or the type of effect, among others. In general, simulations suggest that it is better to have more groups of fewer individuals than the other way around, for both CMLM and MLSEM. However, the latter is more demanding in terms of sample size. The reader can consult several reviews on sample size guidelines for different conditions and types of effects (González-Romá & Hernández, 2017; McNeish & Stapleton, 2016a; Hox & McNeish, 2020). These reviews show that CMLM typically offers unbiased and precise parameter estimates with samples as small as 20–30 L2 units of 5–10 cases each. However, it is more demanding in terms of power, especially for cross-level interactions. For example, Arend and Shäfer (2019) showed that, for medium ICCs, effect sizes, and slope variance components, adequate power levels (≥ 0.80) were reached with L2/L1 sample sizes of 40/3 or 30/5 (for L1 effects), and combinations ranging from 150/3 to 90/25 and from 200/9 to 125/25 (for cross-level direct effects and interactions, respectively). For MLSEM, the reviews mentioned above suggest that although 50 groups may suffice for small models, a minimum of 100 L2 units of 15–20 L1 units each is typically required to reach convergence and accurate estimates. If samples are smaller, Bayesian estimation is recommended (Asparohouv & Muthén, 2021; Zitzmann et al., 2016) with carefully selected priors (Depaoli & Clifton, 2015). Although sample size guidelines are useful, they are based on specific conditions that may not generalize to the researcher's case. Thus, it is advisable to carry out power analysis to establish the sample sizes required at different levels (Scherbaum & Pesner, 2019).
9
Although software based on approximate formulas can be used for simple models with fixed effects, Monte-Carlo-based simulation is the recommended strategy (e.g., Arend & Shäfer, 2019; Lane & Hennes, 2018; Sagan, 2019). In a priori analysis, different scenarios with different effects and sample sizes can be simulated to make a more informed decision about recommended sample sizes to reach enough power (see Arend and Shäfer (2019) for examples, guidelines, and recommendations). However, we acknowledge that a priori power analyses may be very hard to run with complex models.
Fitting an ML Model
ML models are typically estimated using maximum likelihood methods (Hox et al., 2018). 10 Particularly, in CMLM, FIML and restricted maximum likelihood (REML) can be used, which are robust against mild violations of assumptions (e.g., non-normal residuals) when samples are large. With large samples, FIML is preferable to REML because it allows nested models that differ in fixed and/or random parts to be compared by means of chi-square tests (Hox, 1998). However, if the number of L2 units is small (i.e., less than 50 plus the number of L2 predictors; Snijders & Bosker, 2012), REML is recommended because it shows less bias in variance components (Hox et al., 2018; Hox & McNeish, 2020). Results of REML improve further if the Kenward–Roger correction is applied (McNeish, 2017a, 2017b).
In MLSEM, the conventional method is FIML (Hox et al., 2018). FIML is often combined with robust chi-squares and standard errors (Robust Maximum Likelihood [RML]) if distributional assumptions are unmet (Hox et al., 2010). In fact, when normality is seriously violated, robust standard errors are more precise, provided that samples are large (100 groups) (Maas & Hox, 2005). However, Hox et al. (2010) warned against the practice of using RML with small samples without testing distributional assumptions. When assumptions hold and data are continuous, RML only performs well with a large number of clusters (i.e., 200). This can be generalized to ordinal data with five or more categories (which are often assumed to be continuous and analyzed by RML; see Padget & Morgan, 2020). With fewer categories, other robust methods such as Diagonally Weighted Least Squares are preferred (Asparahouv & Muthén, 2007; DiStefano & Morgan, 2014; Heck & Thomas, 2015).
When samples are small, models are intractable with maximum likelihood (e.g., random slopes and categorical items), or they show convergence issues, Bayesian estimation is recommended, 11 for both CMLM and MLSEM. However, although Bayesian methods improve convergence rates (Depaoli & Clifton, 2015), the use of uninformative priors does not generally overcome maximum likelihood estimates in terms of bias and power (McNeish, 2016), and it may even make them worse (McNeish, 2017a). Thus, informative priors should be chosen carefully (Bolin et al., 2019). However, informative priors do not have to be strong to be useful (McNeish, 2016). Weak priors are even preferred if it is unclear how to form strong ones (Depaoli & Clifton, 2015). 12
One advantage of using MLSEM is that SEM programs provide a variety of indices to assess model fit. However, well-known fit indices designed for the single-level case present two important problems in ML models: (a) model fit assessment is dominated by model fit at the lower level because the sample size at this level is much larger and (b) when the indices indicate a poor fit, it is not possible to determine the level where the reason for the model misfit resides. This situation led methodologists to derive procedures to obtain level-specific indices of model fit (e.g., Ryu & West, 2009; Yuan & Bentler, 2007). Some of them have been implemented in software packages (e.g., Mplus [Muthén & Muthén, 2017]; OpenMx [Rappaport et al., 2020]). We strongly recommend that researchers compute the available level-specific indices to assess the fit of MLSEM models.
Testing ML Effects
Before testing ML effects such as cross-level direct effects and interactions, it is common to test whether there is enough variability across intercepts and slopes, respectively (Gavin & Hofmann 2002). When testing variability, the one-tail likelihood ratio test (see Hox et al., 2018) and the confidence intervals created around the variance estimated by Residual Bootstrap or Bayesian methods (see Aguinis et al., 2013b) are recommended. However, their results should not keep researchers from testing cross-level hypotheses (Aguinis et al., 2013b; LaHuis & Ferguson, 2009) due to low statistical power (Berkhof & Snijders, 2001; LaHuis & Ferguson, 2009). Instead, ICC(1) and ICC(β) (Aguinis & Culpepper, 2015) can help to quantify the amount of variance attributed to intercept and slope differences, respectively.
Fixed effects are typically tested by means of the Wald test. 13 When cross-level interactions are significant, Preacher et al. (2006) tools are helpful for analyzing and interpreting the conditional effects. When the interest is in ML mediation, different types of indirect effects of a predictor X on an outcome Y via a mediator M are possible (depending on whether the variables reside at L1 or L2) (Bauer et al., 2006; Krull & MacKinnon, 2001; Zhang et al., 2009). Regardless of the mediation model, indirect effects (which involve products of coefficients) do not distribute normally. The Monte-Carlo-based confidence interval method is typically recommended to test for significance of the indirect effect (Fang et al., 2019; Tofighi & MacKinnon, 2011). Bayesian estimation (especially with informative priors) is also promising when samples are small (Yuan & MacKinnon, 2009; Fang et al., 2019). These recommendations also apply to ML conditional mediation models when conditional indirect effects are tested across different levels of the moderator (see Hayes & Rockwood, 2020). Table 2 shows a number of useful tools for these additional tests and plots for both CMLM and MLSEM.
Reporting ML Analysis
To foster transparency and replicability, authors should provide information about their methodological decisions and justify their soundness. The recommendations provided in this paper should be considered. Moreover, when reporting ML results, researchers should strive to provide confidence intervals (Tonidandel et al., 2014), effect sizes (see Hamaker & Muthén, 2020; LaHuis et al., 2019; Rights & Sterba, 2019), and power levels (Scherbaum & Pesner, 2019). For more recommendations on reporting ML research, see Ferron et al. (2008), Jackson (2010), Monsalves et al. (2020), and Luo et al. (2021).
Conclusion
A limitation of this article is that we focused on a typical two-level design and did not consider other alternatives (e.g., designs with three levels, cross-classification of L1 entities, and bottom-up effects; see Heck et al., 2013; Preacher et al., 2010). However, because the two-level designs considered are quite popular in our field, we think the recommendations, tools, and resources presented will help to improve the quality of ML studies and facilitate reviewers’ and editors’ work.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Author Biographies
Vicente González Romá is Professor of Work and Organizational Psychology at the University of Valencia and director of the Research Institute of Personnel Psychology, Organizational Development and Quality of Working Life (Idocal). His research has been published in leading journals. Some of his research topics are organizational and team climate, leadership, job burnout and engagement, work teams, career development, and research and measurement methods. He has served as editor of the European Journal of Work and Organizational Psychology (2008–2011) and an associate editor of the Journal of Applied Psychology (2014–2020).
Ana Hernández is Associate Professor of Methodology of the Behavioral Sciences at the University of Valencia. She chairs the Spanish Test Commission and is the current vice-president of the executive committee of the European Association of Methodology. Her research has been published in leading journals. Her main research interests are work teams, leadership, job quality, validity of measurement instruments, and multilevel analysis.
Appendix
Conventional Multilevel Modeling Centering Within Cluster Centering Within Cluster with reintroduction of cluster means Full Information Maximum Likelihood Grand Mean Centering Grand Mean Centering with reintroduction of cluster means Intraclass Correlation Coefficient Level-1 Level-2 Multiple Imputation Multilevel Multilevel Structural Equation Modeling Ordinary Least Squares Restricted Maximum Likelihood Robust Maximum Likelihood Structural Equation Modeling