
Abstract
Recent Supreme Court doctrine rejects a narrow “moment of threat” lens in favor of evaluating police use-of-force under the totality of the circumstances. Whether expanding the temporal frame changes how reasonableness and culpability are assigned remains unclear. We test this question using a nationally stratified experiment fielded the day Barnes v. Felix was decided (N = 2,401). Participants were randomly assigned to view one of three temporally distinct dashcam clips from the Barnes incident: a four-second final frame, a thirteen-second partial-context clip, or an approximately two-minute totality-of-circumstances clip. Respondents then evaluated officer reasonableness, responsibility, criminal liability, and internal discipline. Expansion beyond the final frame reduced perceived reasonableness and increased punitiveness. However, effects were non-linear: limited additional context produced the strongest condemnation, while full context tempered reactions. Temporal framing shapes public evaluations of police use-of-force, with the direction and magnitude of effects dependent on what the selected temporal frame reveals.
Introduction
In May 2025, the Supreme Court’s decision in Barnes v. Felix (2025) marked a clear break with a “split-second” vision of police use-of-force. Before Barnes, the Fifth Circuit had instructed courts to evaluate shootings through a tightly cropped “moment of threat” lens that treated only the final seconds of an encounter as relevant. In Barnes, 1 the Court rejected that approach and reaffirmed that “objective reasonableness” under Tennessee v. Garner 2 and Graham v. Connor 3 requires assessment of the totality of the circumstances, including the officer’s conduct prior to the use of force. While the ruling settled a doctrinal debate about the time-framing that courts should use when judging use-of-force decisions, it did not resolve what members of the public actually use when they judge the same events. This is a critical distinction as research shows that public opinion can be inconsistent with legal standards on police actions (Mourtgos, 2026; Mourtgos et al., 2026; Mourtgos & Adams, 2020).
Although most members of the public do not encounter use-of-force doctrine through judicial opinions, they frequently encounter police use-of-force incidents through video, including news broadcasts, body-worn camera footage, dashcam recordings, bystander recordings, and social media clips (Barwise et al., 2020; Kalogeropoulos, 2018; Miethe et al., 2019; Mourtgos, 2026). Police agencies themselves have also recognized that video evidence has become central to public evaluations of police conduct (Newell, 2015). The same shooting can look justified to some, “lawful but awful” to others, and patently unreasonable to still others, even when watching the same event (Sommers, 2016). Prior work documents a persistent “reasonableness divide” between legal actors, lay observers, and members of the public that results in public outrage over use-of-force incidents that are both legally justifiable and within policy (Mourtgos & Adams, 2020). This divide is often structured by partisanship and baseline attitudes toward the police (Flick & Schweitzer, 2025; Marier & Goodwin, 2026). Yet these debates typically treat “the video” as fixed. In practice, what viewers see depends on how the footage is framed: which seconds are included, where the clip begins and ends, and whether it presents a split-second decision or the culmination of a longer chain of choices.
The law governing police use of force and the psychology of how observers evaluate these encounters converge on a common problem: temporal scope. “Moment of threat” analyses and the “TikTok-ification” of public video consumption encourage judgments based on brief, decontextualized clips, tending to narrow the temporal window through which force events are evaluated. Yet Barnes pushes doctrine in the opposite direction by requiring a totality-of-circumstances analysis that extends beyond the immediate instant of force, effectively demanding a longer evidentiary window than typical social-media video affords. The procedural debate over time framing therefore embeds an empirical hypothesis that remains weakly tested: public judgments about whether force was justified will shift as additional pre-force context and lead-up information are included in the video record.
Although prior studies have not directly tested the temporal-scope question raised by Barnes, they show that public evaluations of police force are sensitive to how video evidence is presented. Experimental research finds that evaluations of force shift with camera perspective and point-of-view (Korva et al., 2022; Turner et al., 2019), and with modality and audio content (Culhane et al., 2016). Related experiments indicate that judgments also vary with who is depicted, including racialized cues about the civilian and the interaction of race with officer-centered viewpoints (Bailey et al., 2021), and with what viewers bring to the encounter, including prior attitudes toward police that structure interpretation of identical evidence (Korva et al., 2022; Sommers, 2016). Existing studies have therefore mostly varied how an event is shown or who is involved, rather than the temporal scope of the encounter. Barnes is consequential precisely because it changes the legally relevant temporal window, while the corresponding behavioral response of observers to expanded temporal context remains under-identified in the empirical record.
This study addresses that gap by aligning an experimental manipulation of time-framing with the competing legal frames in Barnes itself. We recruited a nationally stratified sample of 2,401 U.S. adults on Prolific on the day the Court issued its holding in Barnes v. Felix. Participants were randomly assigned to watch one of three clips drawn from the dashcam footage in Barnes: a four-second final-frame segment that begins immediately before the shooting; a thirteen-second partial-context clip that shows a brief lead-up; or a roughly two-minute totality-of-circumstances clip that includes the broader sequence of officer and driver behavior leading to the shooting. After viewing their assigned clip, respondents evaluated the officer’s conduct on four dimensions: reasonableness of the force, attribution of responsibility between the officer and driver, support for criminal charges (against the officer), and support for internal discipline.
Across the primary evaluative and sanctioning outcomes, expanding the temporal frame shifted judgments in a non-linear pattern, although responsibility attributions were comparatively stable. Any additional context, whether partial or full, reduced perceived reasonableness relative to the final-frame condition. However, a limited amount of extra information produced the strongest condemnation: respondents who saw the thirteen-second partial-context clip rated the officer’s conduct as least reasonable and expressed the highest support for criminal charges and internal discipline. When shown the full two-minute context, respondents still judged the force as less reasonable than in the final-frame condition, but their punitive reactions softened relative to the partial-context condition. In other words, a small expansion of the frame heightened criticism; a fuller expansion tempered it.
The article makes three contributions. First, it provides a direct experimental test of the temporal framing dispute that animated Barnes using the very incident that gave rise to the Supreme Court’s ruling. Second, it shows that public judgments of “reasonableness” are not only structured by individual characteristics and prior attitudes, but also by how much of the encounter is presented for review, and that more information does not simply move opinions in a single direction. Third, it extends work on video evidence and body-worn cameras by demonstrating that temporal truncation and partial context can systematically shape lay judgments relative to those formed under full context. Taken together, the findings suggest that neither legal standards nor public opinion can be understood without attention to the informational frames through which police use-of-force is seen and evaluated (Mourtgos, 2024, 2026), a concern long raised by scholars who have argued that “objectivity” in force assessments is constructed through selective attention to particular moments and omissions in the chain of events (Alpert & Smith, 1994).
Legal and Empirical Background
Fourth Amendment Standards and the Temporal Scope of Reasonableness
Modern U.S. jurisprudence on police use-of-force is anchored in the Fourth Amendment, as articulated by the Supreme Court in Tennessee v. Garner (1985) and Graham v. Connor (1989). Garner limited the use of deadly force against fleeing suspects, holding that deadly force may not be used unless it is necessary to prevent escape and the suspect poses a threat of serious physical harm. Graham then supplied the broader doctrinal framework, requiring excessive-force claims to be evaluated under the Fourth Amendment’s “objective reasonableness” standard.
Under Graham, reasonableness must be judged from the perspective of a reasonable officer on the scene, not with “20/20 hindsight,” and the Court identified several non-exhaustive factors that may inform the reasonableness inquiry: the severity of the suspected crime, whether the suspect poses an immediate threat of physical harm, and whether the suspect is resisting or fleeing. In practice, these factors seek to frame the reasonableness inquiry; the “perspective of a reasonable officer on the scene,” for example, excludes information unavailable to the officer at the time, such as evidence discovered after the shooting, later-developed forensic findings, or facts about the civilian’s intent that the officer could not have known, bracketing them off as irrelevant. That framework, however, cannot be applied without some additional temporal framing, as relevant information and the reasonableness of actions can change throughout an encounter. That is, an action that may be reasonable based on the information available at one point in the encounter may not be reasonable based on the information available at a different point in the encounter. Whether the suspect poses an immediate threat, then, may depend not just on what one looks at, but on when one looks.
Scholars have long argued that this supposed objectivity is inherently fragile. Alpert and Smith (1994) noted that assessments of “objective reasonableness” are unavoidably shaped by the information decision makers choose to consider and by their prior beliefs about crime and authority. Judgments about police conduct depend not only on the immediate facts of the encounter, but also on observers’ experiences, attitudes toward the police, and broader cultural narratives (Mourtgos & Adams, 2020; Sommers, 2016). The legal standard aspires to impartiality; its application is mediated by information, time, and viewpoint.
The Final-Frame Doctrine and Officer-Created Jeopardy
The central doctrinal dispute that culminated in Barnes v. Felix concerns how tightly to crop the temporal frame. Should courts evaluate an officer’s conduct only at the instant force is used, or should they consider the decisions and tactics that set up that moment?
Returning to Garner, the Court noted, the constitutional question is “whether the totality of the circumstances justified a particular sort of. . . Seizure.” 4 The Court later repeated that language in Graham, while also reminding lower courts that “[t]he calculus of reasonableness must embody allowance for the fact that police officers are often forced to make split-second judgments—in circumstances that are tense, uncertain, and rapidly evolving—about the amount of force that is necessary in a particular situation.” 5 This injected a degree of doctrinal confusion into the temporal scope of Fourth Amendment analysis: should courts look broadly at the “totality of the circumstances” or narrowly at officers’ “split-second judgments?”
Over the next thirty-five years, the federal circuits answered that question in different ways. Most federal circuits—the First, 6 Third, 7 Sixth, 8 Seventh, 9 Ninth, 10 Tenth, 11 Eleventh, 12 and D.C. circuits 13 —adopted a “totality of the circumstances” approach that permitted, if not required, courts to look beyond the instant in which the officer used force. Referring to the actions of an officer prior to initiating a seizure with the use of force, the First Circuit wrote, “Pre-seizure conduct may be relevant in the reasonableness analysis,” 14 and, in a separate case, that an officer’s actions “need not be examined solely at the moment of the shooting.” 15 The Sixth Circuit, similarly, looked at officer behaviors that occurred in “the preceding seconds or minutes” so long as there was “some causal connection” to the officer’s ultimate use of force. 16
The remaining minority of circuits—the Second, 17 Fourth, 18 Fifth, 19 and Eighth 20 circuits—adopted a narrower time frame for Fourth Amendment review in excessive force cases, looking only at the circumstances as they existed at the moment the officer actually used force. This more limited framing, the Fourth Circuit explained, was based on a reading that emphasized Graham’s reliance “upon the ‘split-second judgments’ that were required to be made and focused on the reasonableness of the conduct ‘at the moment’ when the decision to use certain force was made.” 21 Under that reading, “conduct prior to that moment [in which the officer used force] is not relevant.” 22 The Fifth Circuit, similarly, held that the Fourth Amendment inquiry simply did not permit courts to look at “any of the officers’ actions leading up to [a] shooting.” 23
Critics argue that this final frame focus systematically strips out the context that directly influences whether a use of force was reasonable or unreasonable. Scharf and Binder (1983) described the use of deadly force as contingent on the sequence of events that preceded it. Fyfe (1988, 1997) described the inclination to ignore the iterative nature of use-of-force situations as the “split-second syndrome,” in which deadly force decisions are portrayed as instantaneous reactions in a way that insulates officers from scrutiny for their own role in creating the peril. 24 In his account, many shootings are not the product of malice but of poor tactics: officers closing distance unnecessarily, abandoning cover, or escalating interactions in ways that leave no safe options. As the Seventh Circuit described, for example, “an officer acted unreasonably because he created a situation where deadly force became essentially necessary.” 25 Evaluating only the final moments turns a sequence of choices into a single “split-second” event and erases responsibility for those choices.
Subsequent legal scholarship developed the concept of “officer-created jeopardy” to capture this dynamic. Stoughton et al. (2021) argue that a strict moment-of-threat rule frustrates reform because it “immunizes” poor tactical decisions as long as the final trigger pull looks proportionate in isolation. Lee (2021) similarly documents that trial courts often instruct juries to confine their attention to the moment of force, despite Graham’s directive to consider the “totality of the circumstances.” She contends that excluding antecedent conduct is both doctrinally mistaken and normatively troubling because it severs accountability for the decisions that made an unjustified and avoidable violent confrontation likely.
Feldman (2017) pushes this critique further, arguing that federal reasonable force jurisprudence has constructed a “legal grey hole” around police use-of-force through layered legal temporalities. By banning hindsight, compressing the officer’s time horizon, and channeling disputes into qualified immunity, courts narrow the time frame available for judgment and thereby help insulate police use-of-force from meaningful review. In Feldman’s reading, the problem is not only which facts count, but which stretches of time law is willing to see.
Barnes v. Felix 26 brought this temporal dispute to the Supreme Court. The case arose from a Fifth Circuit decision that evaluated a fatal traffic-stop shooting through the narrow moment-of-threat frame, excluding earlier events from the Fourth Amendment reasonableness analysis. The Supreme Court unanimously rejected that approach and held that courts must consider the totality of the circumstances, including “facts and events leading up to the climactic moment.” In the Court’s words, a use-of-force analysis cannot proceed with “chronological blinders.” Doctrinally, then, Barnes moved the law away from the final-frame approach and toward a broader temporal lens. Empirically, however, the ruling leaves open the question that motivates this study: whether lay observers evaluate the same use-of-force incident differently when the temporal window expands from the final seconds, to a partial lead-up, to a fuller account of the encounter.
The facts of Barnes illustrate why temporal scope matters. The case arose from a traffic stop involving unpaid tolls. During the encounter, the officer learned that the driver did not have a valid license and that the vehicle had been rented by the driver’s girlfriend. The officer also observed the driver moving inside the vehicle and noted the odor of marijuana. The encounter escalated when the officer instructed the driver to exit, the driver restarted the vehicle, and the officer moved onto the driver’s door sill as the car began to move. From that position, the officer fired into the vehicle, killing the driver. Viewed only in its final seconds, the shooting appears as an officer firing from the side of a moving vehicle. Viewed with more of the lead-up, the same shooting becomes part of a longer sequence involving both the driver’s conduct and the officer’s tactical decisions.
The Public’s Lens and the Expectations Gap
Legal doctrine is only one forum where reasonableness is contested. Public reactions to police use-of-force often diverge sharply from official findings. Internal investigations and courts may classify a shooting as justified under Garner and Graham, and some observers may agree with that assessment, while others view the same event as avoidable, unnecessary, or excessive. Mourtgos and Adams (2020), using nearly three decades of General Social Survey data, show that a substantial and growing share of Americans disapprove of uses of force that legal doctrine would likely treat as reasonable. They describe this as an expectations gap between legal and community standards. That gap is not uniform. It varies across demographic groups and is strongly structured by political attitudes and baseline trust in the police (Flick & Schweitzer, 2025; Marier & Goodwin, 2026).
From the officers’ perspective, these disagreements often appear as misunderstanding or hostility toward policing. Classic work by Niederhoffer (1967) and more recent research (Mourtgos et al., 2020) suggest that many officers see the public as insufficiently appreciative of the risks they face and too willing to condemn split-second decisions. From the public’s perspective, repeated findings of “justified” uses of force in controversial incidents look like a failure of administrative or legal accountability mechanisms. The result is a cycle in which each side views the other as unreasonable, with predictably negative consequences for legitimacy (Wise et al., 2025).
One reform impulse has been to move legal standards closer to lay intuitions. Fyfe (1997, 1988) argued that departments should reduce avoidable shootings by training officers in tactics that preserve distance, cover, and options. Stoughton et al. (2021) go further, proposing that evaluators ask not only whether force was reasonable, but whether it was necessary and proportional to the threat. They argue that incorporating necessity and proportionality would narrow the gap between constitutional reasonableness and what communities see as morally justified. Critics of this expansion warn that increased hindsight scrutiny may encourage hesitation, increasing risks to officers and bystanders (National Police Association, 2025). The tradeoff between officer safety and public accountability lies at the core of current debates.
From Doctrinal Frames to Lay Judgments
Barnes v. Felix resolves a specific legal question about how courts should frame police encounters. It does not resolve how members of the public process those encounters, particularly when they encounter them as video rather than as written opinions. Most people experience police use-of-force through visual media, not case reports. They see dashcam footage, body-worn camera clips, and bystander videos circulating on news and social media platforms. The same incident can appear lawful and justified to some, “lawful but awful” to others, and plainly criminal to still others, even when they are watching the same event.
Existing empirical research shows that these judgments are sensitive to information and time. Attitudes toward the police and partisanship shape how people interpret identical vignettes or videos (Flick & Schweitzer, 2025; Marier & Goodwin, 2026; Mourtgos & Adams, 2020). Experimental work indicates that pre-video information and the time allowed for appraisal can change the likelihood that viewers label force as excessive: when participants receive contextual information before viewing, longer appraisal time reduces “excessive force” judgments (Baker & Reysen, 2020). A separate line of experiments shows that, holding the underlying event constant, camera perspective and point-of-view can shift inferences about intent and agency (Turner et al., 2019) and can change perceived appropriateness of the officer’s actions across viewing angles (Korva et al., 2022). Related work indicates that modality and audio content alter evaluations of the same incident, including judgments that map onto blame and excessiveness (Culhane et al., 2016). Finally, officer-centered perspectives can also shape evaluative judgments through identification mechanisms that affect attribution and blame (Bailey et al., 2021). Taken together, this work suggests that police-video judgments are not passive reactions to recorded facts. Viewers interpret video through frames that direct attention toward particular actors, moments, and causal explanations. Extending the temporal window may therefore change judgments not simply by adding information, but by changing which part of the encounter is treated as the relevant event.
What remains untested is the effect of the specific temporal question at the center of Barnes: whether and how public judgments change when observers see only the final seconds of a shooting, a short clip that includes some lead-up, or a more complete account of the encounter. If the informational frame is itself an input into judgments of reasonableness, then changes in doctrine that demand broader temporal narratives may interact in complex ways with how lay observers understand and evaluate police use-of-force.
The present study speaks directly to this intersection. By experimentally varying the temporal scope of a real dashcam video from Barnes and measuring responses on reasonableness, responsibility, criminal liability, and discipline, we connect constitutional debates over “totality of the circumstances” and “moment of the threat” to the psychology of viewing. In doing so, we treat Barnes not only as a doctrinal turning point, but also as a natural case for testing how informational frames shape the public’s verdict.
Design and Method
We designed an experiment that mirrors the competing legal frames at the heart of Barnes v. Felix. Participants were randomly assigned to view versions of the same police encounter that differed only in the temporal scope of information: a short “final-frame” clip, a brief “partial-context” clip, or a longer “totality-of-circumstances” clip. Random assignment allows us to interpret differences in average outcomes across conditions as causal effects of informational framing.
Our expectations are straightforward. Let the “final-frame” condition serve as the control. The partial-context and totality conditions each expand the temporal frame and provide additional information about the officer’s and driver’s behavior.
This hypothesis follows from attribution logic applied to the moment-of-threat structure of the Barnes encounter. The final-frame condition closely approximates a moment-of-threat perspective: viewers see the officer standing on the door sill of a moving vehicle immediately before firing. In that narrow frame, the officer’s conduct is presented primarily as a reaction to an apparent immediate threat, limiting the antecedent conduct available for causal attribution. Expanding the temporal window reveals prior choices that are excluded or minimized by the final-frame view, including the officer’s commands, the driver restarting the vehicle, and the officer’s decision to move onto the door sill as the vehicle begins to move. Under the officer-contributed jeopardy logic discussed above, making those pre-force choices visible should reduce perceived reasonableness and increase support for sanctioning, because viewers can attribute the shooting not only to the immediate threat presented in the final seconds, but also to the sequence of tactical decisions that helped produce that moment.
This hypothesis reflects the possibility that temporal scope changes not only how much information viewers receive, but how they organize the event itself. Event segmentation theory suggests that people parse continuous action into discrete episodes, and that boundaries between those episodes shape what viewers encode as the relevant event and who appears causally central to it (Zacks et al., 2007; Zacks & Tversky, 2001). Framing theory makes a related point: frames do not simply add or subtract facts, but organize information in ways that define problems, assign responsibility, and guide moral evaluation (Entman, 1993; Iyengar, 1991; Stone, 2012). Applied to Barnes, the partial-context clip may create an event frame centered on the officer’s tactical choices immediately before the shooting, while the fuller totality clip may embed those same choices in a broader sequence that includes the driver’s conduct and the officer’s evolving perception of risk. The expected non-linearity is therefore incident-contingent: partial context should produce the strongest condemnation when it foregrounds officer-contributed jeopardy without simultaneously restoring mitigating context. In a different incident, or with a different temporal cut, the direction of the effect could differ.
Sample and Data Collection
Data come from an online survey fielded in May 2025 (N = 2,401). The study was conducted on Prolific, an online research platform that supports stratified sampling. To approximate the adult U.S. population, Prolific recruited respondents using strata defined by age, sex, race and ethnicity, and partisanship (Democrat, Republican, Independent), based on U.S. Census benchmarks and platform profile data. Prolific also employs a naivety distribution system that limits repeated exposure to similar studies, and in head-to-head comparisons with alternate platforms has been shown to provide higher quality panels (Douglas et al., 2023).
Sample Demographic Composition Compared to U.S. Population Benchmarks
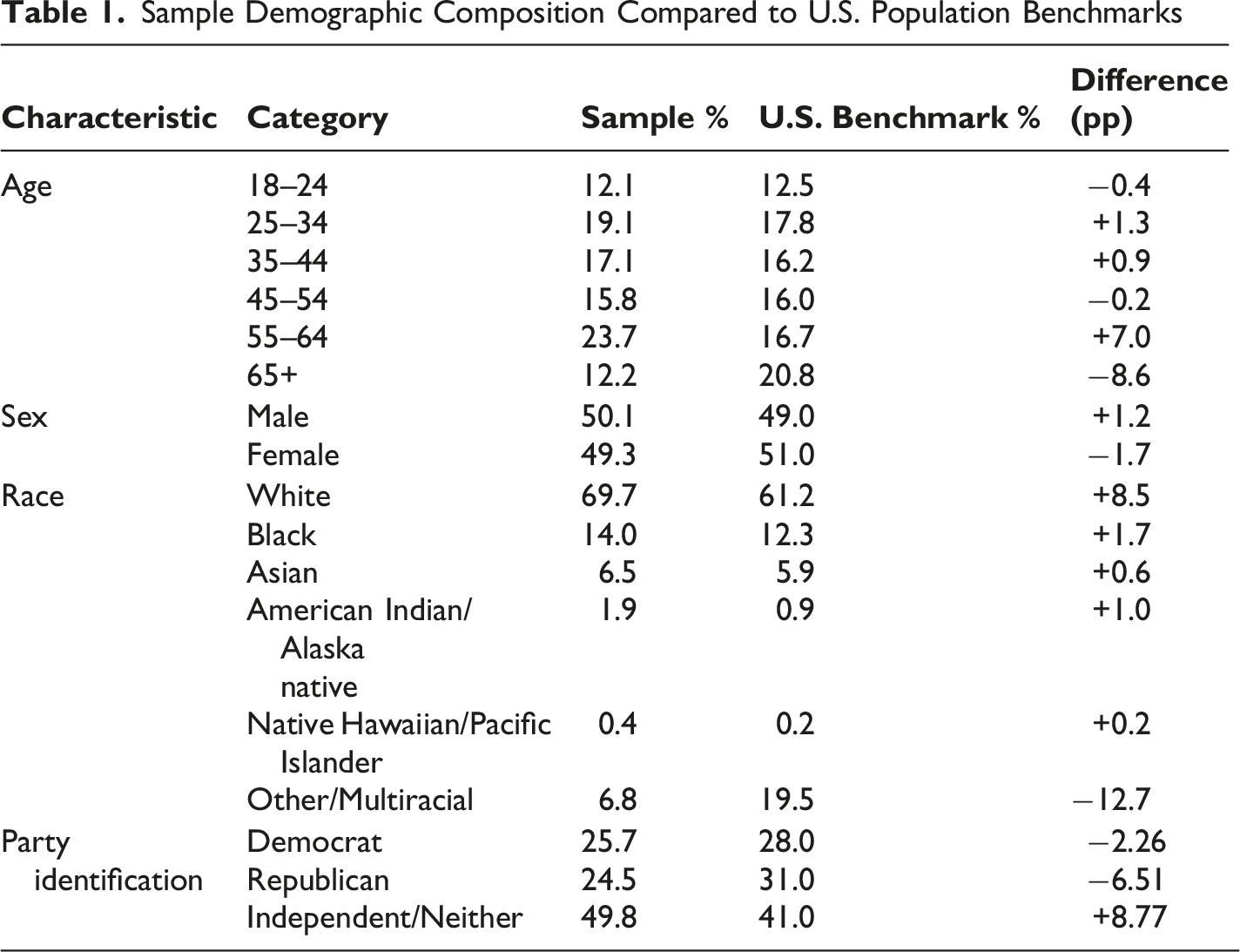
The timing of data collection coincided with the Court’s decision in Barnes v. Felix. This allowed us to situate responses to the video stimuli in the same legal moment that reframed how courts are expected to evaluate police use-of-force.
Experimental Design and Procedures
We implemented a between-subjects design. Respondents were told that they would view dashcam footage from a real encounter between a police officer and a driver and then evaluate the officer’s actions. They were randomly assigned to one of three conditions that varied in the temporal scope of information. Before viewing the video, participants saw a brief, condition-specific description of the encounter drawn directly from the Fifth Circuit opinion in Barnes and edited only for clarity. The descriptions and videos always matched in content and temporal scope with their respective condition.
In the final-frame control condition, respondents viewed a four-second clip showing the officer standing on the driver’s door sill as the vehicle accelerates; the officer twice yells “Don’t fucking move” and fires two shots into the vehicle. In the partial-context condition (treatment 1), respondents viewed a 13-s clip that includes all footage from the control condition plus the immediately preceding sequence, showing the officer instructing the driver to exit the car, the driver restarting the vehicle, and the officer jumping onto the door sill as the car begins to move. In the totality-of-circumstances condition (treatment 2), respondents viewed a 1-min, 39-s clip that encompasses the entire encounter captured on dashcam. This version includes all footage from the first two conditions and additional context: the initial reason for the stop (unpaid tolls), the driver’s admission that he lacks a valid license and has rented the vehicle under his girlfriend’s name, the officer observing the driver reaching around inside the car, repeated commands to stop the vehicle, the officer noting the odor of marijuana, and the driver stating that his identification is in the trunk. All video segments were taken directly from the Barnes dashcam recording. We standardized resolution and audio levels across clips and pilot-tested the materials to confirm that they played smoothly, were understandable, and did not differ in technical quality.
The design trades some experimental abstraction for ecological realism. In actual legal proceedings, jurors do not evaluate a use-of-force incident based only on a short, written vignette or a decontextualized image; they see video, receive narrative context, and then render judgments. We therefore paired each video clip with a brief written description matched to the same temporal scope. The purpose was not to create a separate textual-framing manipulation, but to ensure that respondents had enough factual orientation to understand the assigned clip. This was especially important because the final-frame clip lasted only 4 seconds and because some contextual details in the longer clips, including portions of the audio, could be difficult to process without brief orientation. By pairing condition-specific textual descriptions with video clips that varied in temporal scope, we approximate how final-frame, partial-context, and totality-of-circumstances presentations of the same event may shape evaluations of reasonableness.
All respondents first completed an online consent form describing the study and warning that the video would depict a real police shooting. They then received instructions, viewed their assigned clip, and answered outcome measures and background questions. The survey concluded with demographic items and political and attitudinal measures, including feeling thermometers toward the police and major political groups, which were used to assess randomization balance and in covariate-adjusted robustness checks rather than as focal outcomes.
Randomization Check
To assess whether random assignment produced comparable groups, we tested for differences in both pre- and post-treatment covariates across conditions. Table A1 in the appendix reports descriptive statistics and balance tests. No statistically significant differences emerged for any demographic or attitudinal variable except two baseline feeling thermometer measures reported in Table A1. Even there, the differences were small in substantive terms, ranging from 3.2 to 5.6 points on a 0–100 scale. Because these thermometer items are not focal outcomes and all main results are robust to covariate adjustment, we do not interpret these isolated balance differences substantively. We therefore treat the groups as comparable at baseline. All main results are robust to controlling for these covariates (reported in the Appendix).
Outcome Measures
All outcome measures were collected immediately after participants viewed the assigned video. Full wording of the condition-specific descriptions and links to the video segments are provided in the appendix.
We focus on four outcomes that map closely onto legal and organizational evaluations of police use-of-force: 1. 2. 3. 4.
Descriptive Statistics for Primary Outcome Measures Collapsed Across Experimental Conditions
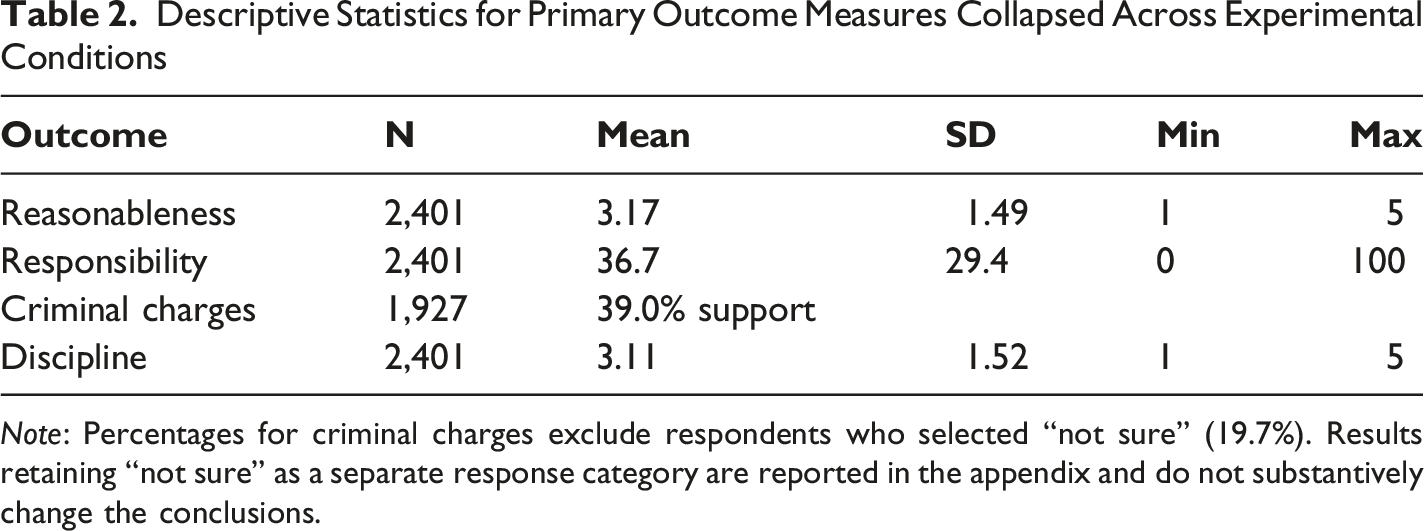
Note: Percentages for criminal charges exclude respondents who selected “not sure” (19.7%). Results retaining “not sure” as a separate response category are reported in the appendix and do not substantively change the conclusions.
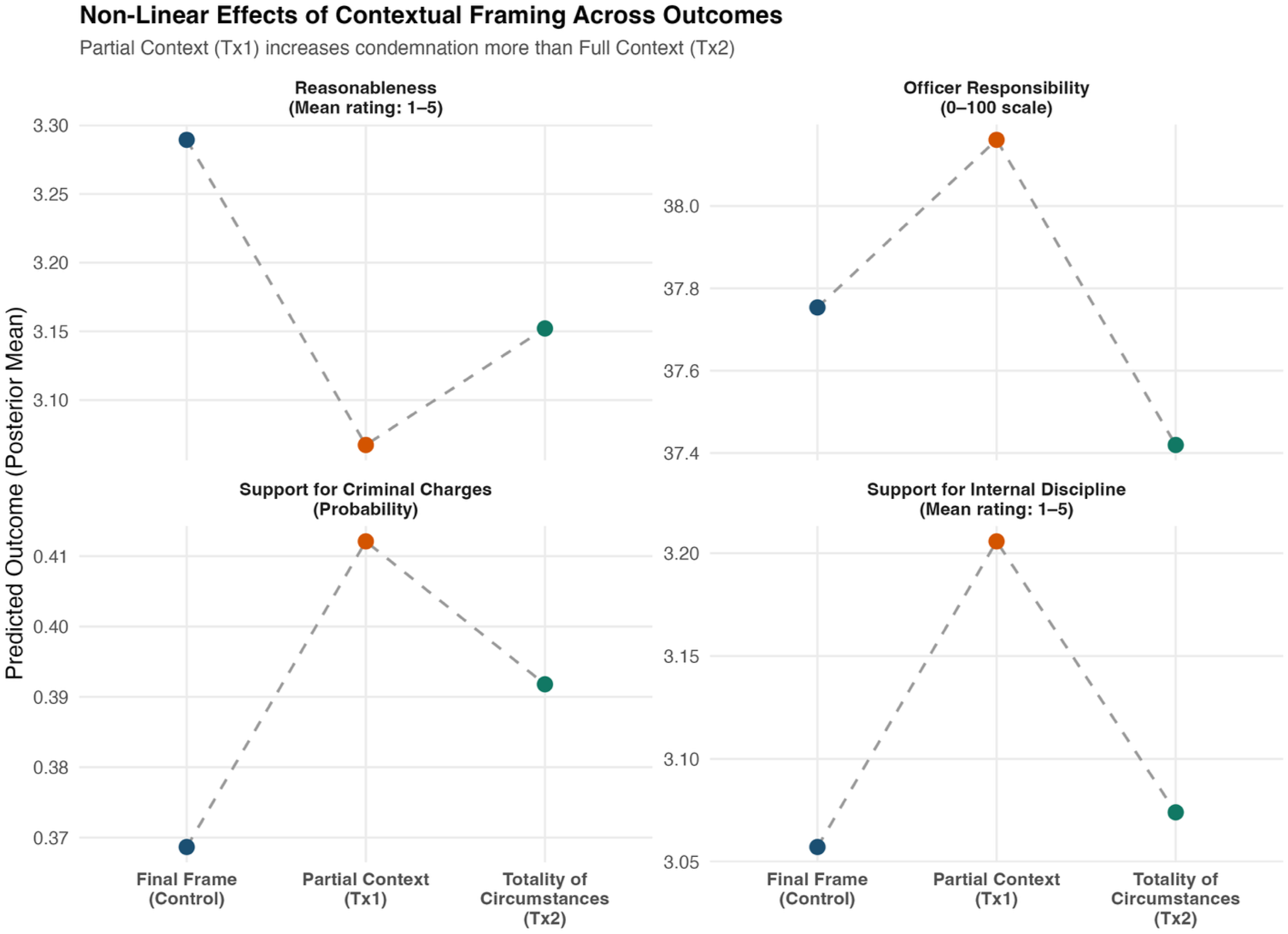
Predicted evaluations across temporal framing conditions: Posterior mean predicted values are shown for each experimental condition across the four outcome measures. Points represent model-estimated predictions, and dashed lines connect posterior means across framing conditions. The Partial Context (Tx1) condition produced the strongest shifts for reasonableness, criminal charges, and internal discipline, although the magnitude and substantive importance of the shifts varied by outcome. The Totality of Circumstances (Tx2) condition attenuated or moderated those shifts. Officer-responsibility attributions varied little across conditions, while still following a non-monotonic pattern
Analytic Strategy
We analyze all outcomes in a Bayesian regression framework. This approach lets us model each outcome with a likelihood that matches its scale and summarize uncertainty in terms of posterior intervals and probabilities rather than binary significance tests (Blair et al., 2025; Mourtgos, 2026).
Additional details regarding the Bayesian setup can be found in the Appendix. Readers mainly interested in the substantive results can think of what follows simply as a set of regression models that estimate average treatment effects across conditions, just as in other design-based experiments.
Our analytic goal is to estimate how informational framing (Final-Frame, Partial-Context, Totality-of-Circumstances) affects evaluations of the officer’s conduct across four outcomes: perceived reasonableness, attribution of responsibility, support for criminal charges, and support for internal discipline. Because the experiment randomly assigns respondents to conditions, differences in outcomes across conditions can be interpreted as causal effects of the temporal frame.
Model Specification
For each outcome, we estimate a regression of the form.
For reasonableness and support for internal discipline, both measured on 5-point ordered scales, we use cumulative logit models with proportional odds. For officer responsibility, measured on a 0–100 scale, we use a continuous outcome model with a skew-normal likelihood truncated at the bounds. For support for criminal charges, coded as 1 for support and 0 for non-support, we use a Bernoulli–logit model. Robustness checks that include the response “Not sure” are reported in the appendix.
In all models, treatment indicators enter linearly, so coefficients for Partial-Context and Totality can be interpreted as treatment effects relative to the Final-Frame condition. We used weakly informative priors that regularized implausibly large effects while leaving substantial room for the data to update the posterior. For the ordinal reasonableness and discipline outcomes, we used cumulative-logit models with weakly informative priors on the treatment effects. For the binary criminal-charges model, the prior specification was centered on a 50% baseline probability of support for charges. For the bounded officer-responsibility outcome, priors were chosen through prior predictive simulation to generate plausible values on the 0–100 scale without concentrating mass at impossible or extreme values. By “prior predictive simulation,” we mean that we simulated possible outcome values from the priors before fitting the models to the observed data, then verified that those simulated values fell within plausible ranges for each outcome scale while still allowing substantial uncertainty. As a sensitivity check, we also re-estimated the primary models using flat/uninformative priors; the substantive conclusions were unchanged. The sensitivity check results, and full likelihoods and prior specifications, are reported in the Appendix.
All models are estimated via Hamiltonian Monte Carlo using four chains with 5,000 iterations per chain (1,000 warm-up). Standard convergence diagnostics (trace plots,
We also examined whether respondents spent enough time on their assigned condition page to have viewed the video. The survey platform recorded total time on the condition page. Page-submit times shorter than the assigned video length indicate that the full video could not have been viewed. No respondents in the final-frame or partial-context conditions submitted the page before the assigned video length. In the full-context condition, 19 respondents, or 2.5% of that condition, submitted before the 99-s video length. As a robustness check, we re-estimated all primary models excluding these respondents. The substantive results were unchanged. We also re-estimated the models after excluding respondents who failed a pre-treatment instructed-response attention check. Attention-check passage rates were very high across conditions: 99.6% in the final-frame condition, 99.4% in the partial-context condition, and 99.3% in the totality condition. Those results likewise did not alter the substantive conclusions. Full timing and robustness results are reported in the Appendix.
Presentation of Effects
For each outcome, we summarize treatment effects using posterior medians and 95% credible intervals for the contrasts between conditions. To aid interpretation, we transform posterior draws into predicted outcome distributions by condition. We also report the posterior probability that each treatment effect is positive or negative (for example,
Substantively, we focus on two quantities. First, we examine the effect of “any context” (Partial-Context and Totality) relative to the Final-Frame condition, which indicates whether expanding the temporal frame changes evaluations of reasonableness and culpability. Second, we compare Partial-Context to Totality, which speaks to the non-linear pattern hypothesized in the Introduction: whether a small amount of additional context maximizes condemnation, with full context tempering that reaction. Results are robust to the inclusion of pre- and post-treatment covariates (demographics and baseline attitudes), which sharpen interval estimates but do not alter the pattern or magnitude of treatment effects; those specifications are reported in the appendix.
Results
Figure 2 presents the posterior distributions for the two framing contrasts—Partial-Context (Tx1) and Totality-of-Circumstances (Tx2)—relative to the Final-Frame (control) across all four outcomes. Reported effects represent differences on the log-odds or raw-scale, depending on outcome family, with posterior probabilities (Pr Δ ≠ 0) indicating the proportion of posterior mass supporting a directional effect. For readers less familiar with Bayesian inference, these probabilities can be read as the degree of confidence, given the data and model, that the true effect is positive or negative; for example, a value of .99 indicates that nearly all plausible effect values imply a shift in the same direction, whereas a value near .50 indicates that positive and negative effects are about equally likely. Posterior Distributions for Framing Effects on Evaluations of Officer Conduct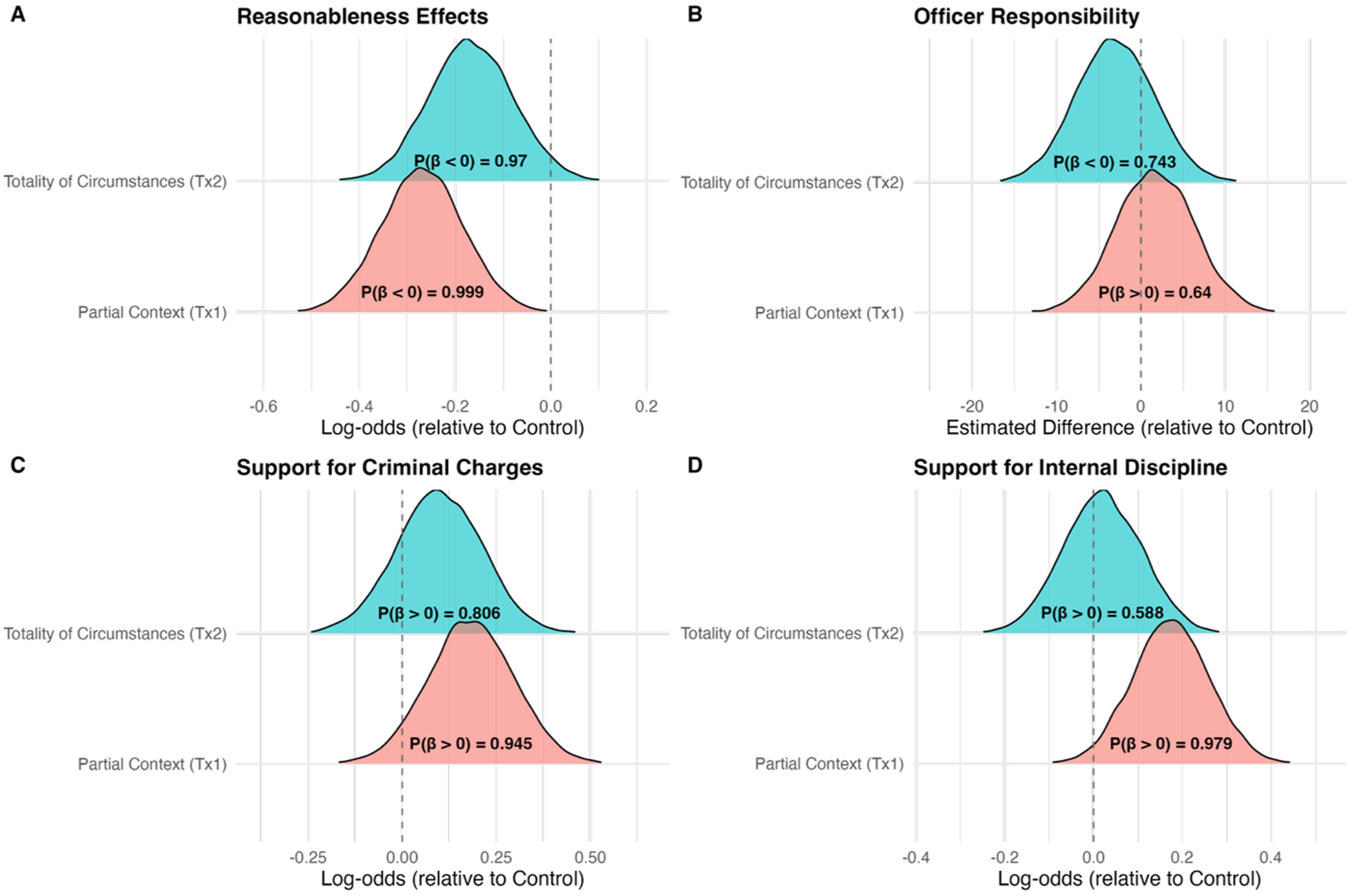
Reasonableness
Both contextual framings led participants to view the officer’s actions as less reasonable than when they saw only the final seconds of the encounter, although the evidence was stronger for the Partial-Context frame than for the Totality frame. The Partial-Context frame produced the strongest shift (Median = −0.27, SD = 0.09, 95% CrI [−0.44, −0.10], Pr Δ <0 = .999, OR = 0.76), while the Totality frame also likely reduced perceived reasonableness though to a somewhat lesser extent and with greater uncertainty (Median = −0.17, SD = 0.09, 95% CrI [−0.34, 0.01], Pr Δ <0 = .97, OR = 0.85). On the original 1–5 reasonableness scale, these effects correspond to a decline from 3.29 in the control condition to 3.07 under the Partial-Context frame and to 3.15 under the Totality frame. Thus, providing any contextual information tended to decrease perceptions of reasonableness, with the partial (13-s) clip exerting the strongest effect.
Officer Responsibility
Providing complete contextual information did not meaningfully shift attributions of responsibility to the officer. Under the Totality frame, respondents attributed somewhat less responsibility (Median = −3.09, SD = 4.65, 95% CrI [−12.22, 6.08], Pr Δ <0 = .743, Δ ≈ −0.18), whereas the Partial-Context frame yielded no consistent directional shift (Median = 1.66, SD = 4.67, 95% CrI [−7.39, 10.97], Pr Δ >0 = .64). On the original 0–100 responsibility scale, mean attributions were 37.8 in the Final-Frame condition, 38.2 under the Partial-Context frame, and 37.4 under the Totality frame. Overall, temporal framing did not meaningfully shift respondents’ allocation of responsibility between the officer and driver. Descriptively, however, responsibility attributions still followed a non-monotonic pattern, with partial context slightly increasing responsibility assigned to the officer and full context producing the only below-control responsibility estimate.
Support for Criminal Charges
The Partial-Context frame increased support for criminal prosecution relative to the control condition, while the Totality frame produced a smaller and less certain increase. The Partial-Context effect was the stronger of the two (Median = 0.18, SD = 0.11, 95% CrI [−0.04, 0.41], Pr Δ >0 = .945, OR = 1.20). The Totality effect was positive but more uncertain (Median = 0.10, SD = 0.11, 95% CrI [−0.13, 0.32], Pr Δ >0 = .806, OR = 1.10). On the original probability scale, mean support for criminal charges was 0.369 in the control condition, 0.412 under the Partial-Context frame, and 0.392 under the Totality frame. In other words, the shorter contextual clip elicited the strongest punitive response, while the full-context clip produced a more modest shift that should be interpreted more cautiously.
Because 19.7% of respondents selected “Not sure,” we also estimated a robustness model that retained the full three-category response distribution. We used a multinomial logit specification treating “No,” “Not sure,” and “Yes” as separate outcomes, rather than imposing an ordinal structure in which uncertainty is assumed to fall between opposition and support. The results, reported in the Appendix, closely parallel the binary analysis: the Partial Context condition increased support for criminal charges, the Totality condition produced a smaller and less certain positive shift, and neither condition meaningfully changed the probability of selecting “Not sure.”
Support for Internal Discipline
The pattern for internal discipline resembled criminal charges for the Partial-Context condition but differed for the Totality condition. The Partial-Context frame increased recommended disciplinary severity (Median = 0.17, SD = 0.09, 95% CrI [0.01, 0.34], Pr Δ >0 = .979, OR = 1.19), whereas the Totality frame produced no meaningful shift (Median = 0.02, SD = 0.09, 95% CrI [−0.15, 0.19], Pr Δ >0 = .588, OR = 1.02). On the original 1–5 scale, mean support for internal discipline was 3.06 in the control condition, 3.21 under the Partial Context frame, and 3.07 under the Totality frame. Participants who viewed the full encounter did not differ appreciably from the Final-Frame control, but those who saw only limited additional context were more punitive.
Posterior Estimates for Framing Effects on Evaluations of Officer Conduct
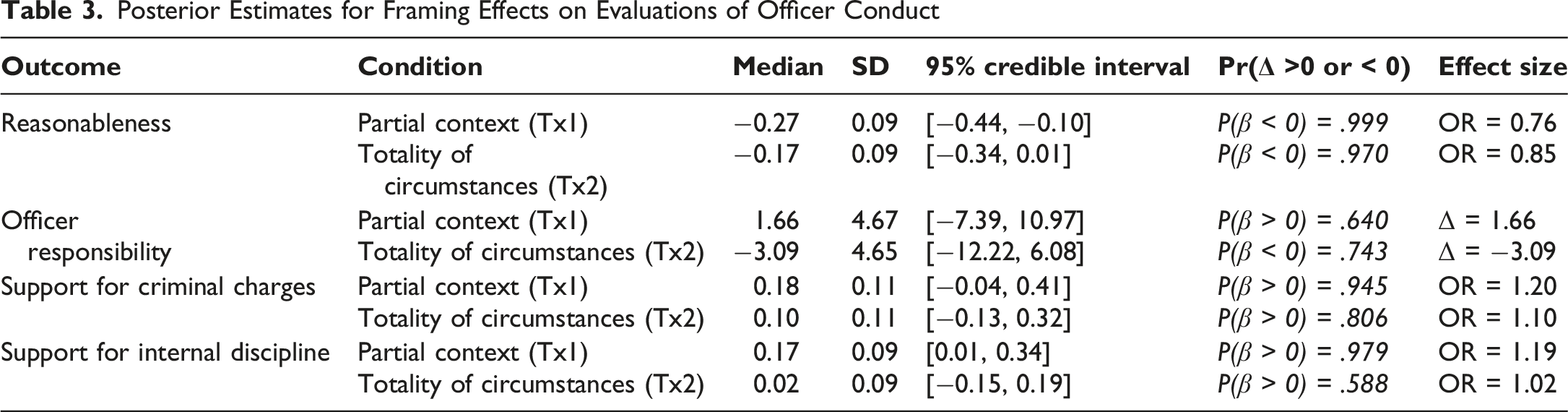
Figure 1 summarizes posterior mean predicted values of each outcome across conditions to illustrate how contextual framing operates non-linearly across evaluative domains. Because several outcomes are measured on ordinal scales, the vertical distance between points should be interpreted as directional change rather than as a cardinal unit shift with a fixed substantive meaning. What constitutes a “large” or “small” movement on such scales is inherently judgment-dependent and varies by construct, baseline level, and distributional compression (although a nearly 5% change in support for criminal charges seems notable). Accordingly, the figure is intended to highlight relative patterns across conditions, particularly the tendency for partial context (Tx1) to move predicted outcomes farther from the final-frame baseline than full contextualization (Tx2), while recognizing that the responsibility differences are substantively small.
Practical significance depends on the institutional decision context. We therefore do not treat posterior probabilities as self-interpreting evidence of importance. A small shift on a five-point reasonableness scale may be negligible for some purposes, while a several-point shift in support for criminal charges may matter in contexts involving public legitimacy, media framing, charging discretion, or jury-pool attitudes. This logic is consistent with decision-focused Bayesian approaches that distinguish statistical uncertainty from practical importance (Mourtgos, 2026), but the present study does not impose a single region of practical equivalence. Those thresholds would necessarily differ across courts, prosecutors, police agencies, media organizations, and community stakeholders. We therefore interpret the results as evidence that temporal framing can shift public judgments, while treating the practical importance of those shifts as context-dependent rather than universal.
Discussion
Barnes v. Felix settled a doctrinal dispute over the proper time-framing of an analysis of a use-of-force incident. Implied within this dispute is a hypothesis that viewing an incident across various time frames will shift judgment of the incident. This hypothesis has implications beyond the legal analyses that will inevitably follow the Barnes ruling. The rise of publicly accessible body-camera and dashcam footage, combined with short-form social media video, has increased the likelihood that lay audiences encounter police use-of-force incidents as brief excerpts rather than complete evidentiary records, with potential implications for police legitimacy and public trust (Barwise et al., 2020; Kalogeropoulos, 2018; Miethe et al., 2019; Newell, 2015; Wise et al., 2025). In that sense, the hypothesis at the core of the doctrinal dispute in Barnes also applies to potential shifts in public sentiment over use-of-force incidents reviewed through the lens of TikTok, Instagram Reels, and other short-form social media.
To test the accuracy of the hypothesis, we used the publicly available dashcam video from the original incident of concern in Barnes. We then edited the footage to provide three separate time-framings of the officer-involved shooting. A survey randomly assigning this footage was then administered to a large sample of participants, stratified along national-level demographic benchmarks. Our findings demonstrate that time-framing can meaningfully shift individuals’ views of use-of-force incidents, but that these impacts may be non-linear.
The descriptive pattern is generally consistent but not identical across outcomes. Compared to the four-second final-frame clip, both contextual frames lowered perceived reasonableness of the officer’s conduct. The partial-context condition produced the largest shift; the totality-of-circumstances condition also reduced reasonableness, but less sharply. A similar non-monotonic pattern appeared with support for criminal charges, with the thirteen-second clip producing an increase in support for criminal charges and the full-context condition returning preferences closer to the control. Internal discipline followed a more limited version of that pattern: the thirteen-second clip generated the most severe disciplinary recommendations, but the full-context condition returned disciplinary preferences close to the final-frame baseline. Officer responsibility assignments were relatively flat, with little meaningful movement across conditions. Descriptively, however, they still followed a non-monotonic pattern: partial context slightly increased officer responsibility, while full context was the only condition in which responsibility assigned to the officer fell below the final-frame control. Taken together, the results are consistent with a non-monotonic framing: a small amount of additional context maximizes condemnation, while full context softens it. The responsibility and internal discipline findings, however, suggest that this pattern does not operate equally across all evaluative judgments.
This variation across outcomes is important because responsibility attribution behaved differently from the other outcomes. Temporal framing changed how respondents evaluated the officer’s conduct, but it did not meaningfully change how they allocated causal responsibility for the outcome between the officer and driver. This dissociation likely reflects the structure of the responsibility measure. Respondents were asked to divide responsibility across two actors on a constrained 0–100 scale, whereas the other items asked whether the officer’s conduct crossed a threshold. Those are related but not identical judgments. A respondent can believe that the officer’s actions were less reasonable, or more deserving of discipline, without substantially reducing the driver’s share of responsibility for the encounter. Conversely, respondents may recognize that the officer was causally involved in the outcome simply because he fired the shots, while still judging the use of force as reasonable within the narrow final-frame threat context. This distinction is especially important in Barnes because the broader footage contains both aggravating information about the officer’s tactical choices and mitigating information about the driver’s behavior. In that setting, temporal context may alter judgments about whether the officer’s conduct warrants sanction without producing a corresponding shift in zero-sum blame attribution.
The remaining framing effects are not mechanistic, but they already tell us something important. The informational environment does not simply add or subtract “sympathy” for the officer in proportion to the number of seconds shown. Consistent with event segmentation and framing theories, temporal cuts appear to organize the encounter into different causal narratives (Entman, 1993; Iyengar, 1991; Zacks et al., 2007; Zacks & Tversky, 2001). The short final frame presents a stylized split-second decision. The partial-context clip adds just enough lead-up to make the officer’s tactical choices visible but does not fully foreground the driver’s behavior, including the broader sequence of noncompliance, resistance, or flight that viewers may treat as relevant to both legal reasonableness and perceived threat. The full clip restores those elements and seems to generate a more mixed narrative: the officer still looks less reasonable than in the final frame condition, but respondents become less eager to punish than when they see only the limited context.
The modest size of these effects should also be interpreted in light of the incident itself. Barnes is not a case in which the available footage points cleanly in only one direction. The partial-context clip makes the officer’s tactical choices more visible, particularly the decision to move onto the door sill as the car begins to move. At the same time, the fuller clip restores information that some viewers may interpret as increasing uncertainty or risk, including the driver’s lack of a valid license, movements inside the car, the odor of marijuana, and the back-and-forth about identification. In this sense, the Barnes footage contains both aggravating and mitigating cues. That ambiguity likely limits the size of the observed treatment effects. A more polarizing incident, or one in which a temporal cut more clearly foregrounds either officer misconduct or civilian threat, could produce larger shifts. The key point, then, is not that partial context will always increase condemnation or that full context will always moderate it. Rather, temporal framing matters because each cut changes which causal story is most available to viewers. Put differently, these estimates should not be read as universally large or small; their practical significance depends on the institutional setting in which temporally edited video is used and on how ambiguous the underlying incident is.
One way to read this pattern is in light of the “split-second syndrome” critique that motivated much of the prior literature. Fyfe (1988, 1997) argued that judicial and administrative reviews often treat deadly force decisions as instantaneous reactions and ignore the chain of decisions that produced the crisis. Our results suggest that ordinary viewers do something similar when they see only the last seconds of an encounter. The officer’s behavior is evaluated as a reaction to an immediate threat, and average judgments of reasonableness look relatively favorable. Partial context disrupts that narrative. Once viewers see the officer order the driver out, watch the car restart, and see the officer jump onto the door sill, it becomes much easier to attribute causal responsibility to the officer’s own choices and to interpret the shooting as the culmination of poor tactics rather than an unavoidable split-second response. Full context then complicates the story again. The unpaid tolls, the driver’s lack of a valid license, the rented vehicle, the movements inside the car, the odor of marijuana, and the back-and-forth about identification all supply cues that can be read as risk, ambiguity, or both. The officer’s actions still look questionable, but the situation no longer looks simple. In the language of the Barnes Court, moving from a partial glimpse to the “totality of the facts (Barnes v. Felix, 2025)” appears to pull some respondents back from the most punitive positions.
Theoretical implications follow directly. The “objective reasonableness” standard in Graham v. Connor (1989) presumes a stable observer: a reasonable officer on the scene evaluating a fixed set of circumstances. In practice, both law and public opinion are sensitive to how those circumstances are framed in time. Feldman’s (2017) account of “legal temporalities” and the construction of a “legal grey hole” around police use-of-force emphasizes how some appellate courts narrowed the time horizon for judgment by banning hindsight and compressing the officer’s time frame. Our experiment indicates that lay judgments are also temporally contingent, but not in a simple monotonic fashion. When we expand the frame, we do not observe a linear march toward greater condemnation or greater exoneration. We observe a peak in punitive sentiment at partial context, with full context producing something closer to ambivalence. That is a different sort of temporal vulnerability than the one Feldman describes, but it reinforces the basic point: reasonableness depends on which slice of time the law and institutions choose to display.
The results also speak to the gap between legal reasonableness and lay evaluations of police use-of-force. Prior work has shown that many Americans reject some uses of force that are likely to be found constitutional, and that this expectations gap is structured by partisanship and baseline attitudes toward the police (Flick & Schweitzer, 2025; Marier, 2024; Marier & Goodwin, 2026; Mourtgos & Adams, 2020). Our findings show that the size and even the direction of that gap can depend on how much of the incident people see. When the public sees only the final-frame clip, their judgments may align more closely with a narrow Graham analysis that focuses on the perceived threat at the moment of firing. When they see partial context, they move away from that legal standard and toward a broader moral assessment that treats tactical decisions as central. When they see full context, they partially revisit that condemnation. In that sense, informational time framing thus becomes a third term in the relationship between doctrine and public opinion, alongside demographics and attitudes.
The practical implications are immediate. Courts, prosecutors, and defense counsel control which segments of video are entered into evidence and emphasized at trial. Media outlets and advocacy organizations often present excerpted or edited versions of police video, sometimes through shortened clips, still frames, blurred or frozen images, audio excerpts, or narrated summaries, rather than the full sequence of events that preceded the use of force (Miethe et al., 2019; Newell, 2015; Sommers, 2016). Police agencies themselves also release critical-incident videos, which may truncate the lead-up or foreground some contextual details (Cheng, 2021). Our results do not tell us which of these practices is normatively correct. They do show that each practice is empirically consequential. In this incident, a few additional seconds one way or the other can move average support for criminal charges and disciplinary severity by non-trivial margins. Transparency that consists of partial video is therefore not neutral; it is a form of temporal framing whose consequences depend on what the selected segment reveals.
The implications for juries should be understood cautiously. Our respondents evaluated the video individually, outside the structure of a trial, and without legal instructions, attorney argument, witness testimony, expert interpretation, cross-examination, repeated viewing, or deliberation. Those features may reduce the influence of any single temporal cut by giving jurors a fuller evidentiary record and competing interpretations of the same footage. At the same time, trials do not eliminate temporal framing. Courts decide which portions of video are admitted, attorneys select which clips to emphasize, and jurors often encounter video evidence through narrative accounts that direct attention to particular moments. Thus, while our design should not be treated as a direct model of jury decision making, it suggests that temporal framing may remain consequential whenever factfinders evaluate police video through selected segments rather than the full encounter.
For body-worn camera policy, the lesson is similar: video evidence is not self-interpreting, and the temporal boundaries placed around footage can shape how it is understood. Much of the debate has treated cameras as devices that produce “objective” evidence that will discipline both officers and critics. Empirical work has already complicated that view by documenting mixed behavioral effects of cameras on force and complaints and by showing that camera perspective and audio tracks shape evaluations of the same event. This study adds a temporal dimension. Even when the camera is fixed, selectively truncating the footage can tilt viewer interpretations. In the context of Barnes, the law now requires consideration of the full encounter. Agencies and courts that employ body-worn or dashcam footage while showing only curated segments may comply formally with transparency norms while generating predictable distortions in how jurors and the public allocate responsibility.
The study also has limits that matter for interpretation. We examine a single incident, one captured by a dashcam and decided by the Supreme Court at a particular political moment. The treatment arms consist of three specific temporal cuts, and the direction of the effects depends on what those cuts reveal. Barnes is also an ambiguous case: the partial-context clip foregrounds the officer’s tactical choices, while the full-context clip restores information about the driver’s behavior and the officer’s evolving perception of risk. Other incidents, including cases that appear clearly reasonable or clearly unreasonable ex ante, or clearly justified or unjustified in legal or administrative terms, might generate different patterns. In such cases, temporal framing effects may be smaller, more linear, or differently directed because additional context may reinforce rather than complicate the initial interpretation. A temporal cut that foregrounds civilian threat could make additional context more favorable to the officer, while a cut that foregrounds avoidable escalation or officer misconduct could make additional context more damaging. The shooting of Adam Toledo by the Chicago Police Department provides one possible example. Media depictions of the incident commonly showed images of Toledo facing the officer with his raised hands empty, clearly demonstrating that the officer shot an unarmed teenager. On the other hand, a fuller context video shows Toledo running with a gun in his hand, dropping it just seconds before quickly turning around and raising his hands. It is certainly possible that if we had conducted a similar experiment using that footage instead of the Barnes footage, the final-frame analysis may have been more critical, rather than more favorable, of the officer than a partial or totality edit of the footage.
Beyond the singular incident, our respondents are drawn from an online, stratified sample rather than from actual jurors, and they evaluate the footage without live testimony, cross-examination, or deliberation. These are standard constraints in experimental work on legal decision making, but they mean that the results should be understood as proof-of-concept evidence rather than universal claims about all uses of force. We also did not directly measure respondents’ prior familiarity with Barnes or prior exposure to the dashcam footage. Random assignment should distribute such familiarity across conditions in expectation, but prior knowledge may still shape how respondents interpret what they see. Future work should measure prior exposure to the incident or experimentally vary background information before video exposure.
These limitations point directly to the next steps. Future research should vary not only the length of clips but also the type of incident, the camera perspective, and the presence or absence of audio, building on existing work on video evidence and juror decision making (Baker & Reysen, 2020; Miethe et al., 2019). It would also be useful to embed temporal framing manipulations in deliberative settings, where group discussion might either magnify or dampen the non-linear pattern we observe. A further question is whether temporal framing interacts with individual priors about the police: for example, whether partial context especially inflames respondents who already distrust the police, or whether full context primarily moderates views among those inclined to give officers the benefit of the doubt.
What this study establishes is narrower but firm. Under a clean experimental manipulation grounded in an actual Supreme Court case, the temporal framing of a police shooting altered public judgments of reasonableness and sanctioning. In Barnes, those changes were non-linear: a brief extension beyond the final seconds of the encounter produced the harshest evaluations of the officer, while a fuller accounting of the encounter softened those evaluations. In a post-Barnes environment, where courts are instructed to see more of the story, institutions that control how much of that story is shown to lay audiences are, in effect, shaping what counts as reasonable force. That influence need not always run in the same direction; it depends on what the selected temporal frame reveals.
Conclusion
This study asked whether changing the temporal frame of a police encounter changes how people judge it. We used real dashcam footage from Barnes v. Felix and randomly assigned respondents to three versions of the same shooting: a four-second final frame, a thirteen-second partial-context clip, and a roughly two-minute totality-of-circumstances clip. After viewing their version, respondents rated the officer’s conduct on reasonableness, responsibility, criminal liability, and internal discipline.
In this incident, the core pattern is not linear, with the Barnes footage producing something like a “Goldilocks” effect. Any context beyond the final 4 seconds lowers perceived reasonableness. The thirteen-second partial-context clip is where condemnation peaks. In that condition, respondents evaluate the officer as least reasonable and are most willing to endorse criminal charges and severe discipline. The full, two-minute clip still depresses reasonableness relative to the final frame, but it pulls punitive attitudes back toward the baseline. In Barnes, limited context maximized criticism, while full context tempered it.
These results matter for how Barnes is implemented in practice. The decision instructs courts to move from a narrow moment-of-threat lens to a broader totality-of-circumstances analysis. Our findings suggest that what factfinders see on video will shape how that standard is applied. Temporal framing is therefore a practical lever in what counts as “objective reasonableness.”
The same logic carries over to media and transparency practices. News outlets, advocacy organizations, and police agencies frequently present police video through excerpted or edited formats rather than full evidentiary records. These clips are often presented as neutral disclosure. Our estimates indicate that, in this case, a short contextual clip pushed public opinion toward harsher evaluations compared to both bare final-frame footage and the fuller recording. Transparency without completeness is itself a form of framing, and one that can magnify or soften perceptions of culpability depending on what the selected segment reveals.
Supplemental Material
Supplemental material - Assessing “Reasonable” Police Uses of Force after Barnes v. Felix: How Time Framing Affects Public Perceptions
Supplemental material for Assessing “Reasonable” Police Uses of Force after Barnes v. Felix: How Time Framing Affects Public Perceptions by Scott M. Mourtgos, Ian T. Adams, Kyle McLean, Seth Stoughton and Geoffrey P. Alpert in Police Quarterly.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.