
Abstract
Abstract
In the fast-moving field of Natural Language Processing (NLP), making lexicons is still a method for many text analysis applications. This process of generating lexicons has traditionally used techniques such as semantic matches, word embeddings, and tools like EMPATH. With the arrival of Large Language Models (LLMs) including GPT-3.5, GPT-4 and Mistral 7b 0.1, we have new ways to create lexicons. This study takes a close look at how these older methods stack up against the newer options brought by LLMs. We carried out a detailed analysis, looking at how well different methods could create lexicons, focusing on their precision, scalability, and concluding on how efficiently they can be used in real-world settings. By using standard NLP tasks like document classification, emotion classification and sentiment analysis, this research prove itself on a variety of datasets to test how well the lexicons worked. This discovery, along with others from our study, aims to help professionals and researchers find the best approaches to lexicon creation today, setting the stage for more research in the NLP field.
Keywords
Introduction
The purpose of this research is to compare established and emerging methodologies for generating lexicons. Lexicons have various applications in research, such as subject analysis, emotion detection, social media analysis, and semantic analysis. Large-scale lexicon approaches can enable a wide range of daily life applications, such as classifying tweets, evaluating customer feedback on a product, automating online harassment detection, sentiment analysis, and more. For new developers, using large lexicons for word detection is a popular and intuitive method in natural language processing. Creating lexicons often requires human interaction, especially in data labeling, which can be time-consuming and costly, as Mohammad and Turney 1 stated when using Mechanical Turkers for generating their lexicons. As language is also constantly evolving, being able to dynamically generate news lexicon can prevent the problem of having current lexicons become irrelevant in the future.
With a focus on automating lexicon generation based on various inputs ranging from a single word to a lexical field, our research undertakes a comparative analysis of different lexicon generation approaches. These approaches encompass traditional methods like semantic matches inspired by the S-match algorithm, 2 word-embedding, including EMPATH, 3 and another technique involving Doc2Vec 4 combined with UMAP. 5 In contrast, the emerging Large Language Models (LLMs) including BERT 6 and GPTs iterations developed by OpenAI, 7 with a spotlight on the latest entrant, GPT-4, our research also inlcuded Mistral 7b Instruct v0.1 as a local LLM. 8 These models stem from transformers, introduced by Vaswani et al. 9 in 2017, which opened a new horizon in NLP capabilities.
In our experiment, we ventured to craft various systems utilizing these diverse methodologies to generate lexicons. Following the development phase, we did a comparative analysis of the performance of these systems utilizing the same word detection algorithm to evaluate their efficacy in the same settings. Our system was tested on several tasks: a Document Classification task using the 20 newsgroups dataset, 10 which contains around 18,000 articles across 20 categories; an Emotion Classification task using the SMILE dataset, 11 consisting of 3000 tweet reviews from British Museums, as well as the CARER dataset 12 first one labeled with five of Paul Ekman's six emotions 13 and the second one with five similar; and a Sentiment Analysis task using Yelp dataset reviews. 14
Related work
The domain of lexicon generation has traditionally been anchored in manual creation and the use of semantic matching algorithms. However, the advent of word embeddings, such as Word2Vec, 15 an example of these techniques, provide dense vector representations, marked a significant shift. These techniques provide dense vector representations of words, capturing their semantic nuances based on their surrounding words. As a result, lexicon generation benefited from embeddings that were more contextually relevant and semantically rich, reducing the need for extensive human intervention.
These models, adept at processing the sequential nature of text, such as RNNs 16 and LSTMs, 17 paved the way for more advanced architectures like transformers. However, the transformer architecture, with models like BERT, set new benchmarks in various NLP tasks. These models, especially when pre-trained on large corpora, have been instrumental in lexicon generation, offering superior performance in understanding contextual relationships between words. Generative Large Language Models, such as GPT, Llama, 18 and Falcon, 19 have further advanced the field by excelling in a broad spectrum of tasks, from the generation of lexicon, sentences, or the classification of documents. Despite these advancements, challenges like the dynamic nature of language persist, pointing towards the need for continuous research and innovation in the field.
Previous research has also proposed alternative methods for generating lexicons. For instance, Qadir and Riloff 20 used hashtags and labels on tweets to identify expressions of emotions, leading to the creation of a lexicon and subsequent classification of different tweets, it's a kind of reverse engineering our methods; from a label extract a lexicon. Muppidi et co., 21 when developing a Bibliographic Citation Sentiment Analysis system, were able to extract words related more likely to be present in a specific polarity, therefore generating a lexicon based on learned label. Despite several limitations, such as a limited coverage, polysemy, ambiguity or the negation detection, lexicons remain widely used in sentiment analysis and classification research, as evidenced by surveys on sentiment analysis by Hussein 22 or on sentiment classification by Zhang. 23 Recently, those limitations could have been considered answered by Large Language Model, as those models can capture more complex patterns and dependencies in language, capable of understanding a context a word can be used in based on its surroundings. However, deploying Large Language Models in daily applications poses challenges due to their resource-intensive nature. They require vast amounts of training data and GPU, limiting access for independent developers and even smaller organizations. Research have also been made on lexicon comparison, as it is the case in Sentiment Analysis, Garcia-Pablo et al. 24 compared polarity of words present in different lexicons while Musto 25 compared them on a same task, or still in a same task in Emotion Classification by Tabak. 26
Our contribution
In this study, we present a contribution to the field of Natural Language Processing by conducting a comprehensive comparative analysis of traditional lexicon generation techniques against the backdrop of emerging Large Language Models like BERT, GPT-3.5, and GPT-4. Our research is among the first to systematically assess the efficacy of these new models against conventional methods such as semantic matching, Doc2Vec and Empath in the specific task of lexicon creation. We delve into the nuances of automating lexicon generation, a process traditionally marked by labor-intensive manual efforts, and offer an in-depth evaluation based on precision, scalability, and applicability in real-world NLP tasks such as document classification, emotion, and sentiment analysis.
Our findings reveal a nuanced landscape where each method exhibits distinct advantages and limitations. We underscore the potential of LLMs to revolutionize lexicon generation with their sophisticated understanding of language nuances, despite their current limitations in generation time and accessibility. Conversely, traditional methods like Doc2Vec maintain relevance due to their consistency and efficiency, particularly when enhanced with pre-trained models.
Furthermore, our research contributes to the discourse on the practical applications of automatically generated lexicons in NLP, highlighting their flexibility and adaptability for tasks like text data labeling, topic modeling, and emotion analysis. Through a meticulous literature review and experimental validation, we offer insights into a range of automated systems employing techniques from semantic matching algorithms to advanced word-embedding methodologies, thereby paving the way for future advancements in automated lexicon generation and its applications in the expanding domain of NLP.
Methods
Semantically generated lexicon
Our first lexicon is generated using a simplified concept of semantic match. Given an input, that can be one or many words, we searched through every word definition in a dictionary until we find a definition that includes this input. Once we located a corresponding definition, we added it to a tree structure that resulted in multiple semantic fields. These fields are defined by Griffiths et al. 27 as distinct areas of meaning within the lexicon around one or many words. For generating those lexicons, we used the Oxford English Dictionary (OED), edition June 2013. Because we wanted to decide the size of our lexicon, we decide to introduce the idea of layer. Going on a further layer means repeating the previous search but using the words found on the previous layer as an input. Later, to evaluate the quality of the lexicons, we decided to use measurement: we called a word relevant when it was directly related to our input. To determine the accuracy of the lexicon based on the input layers, we measure the size/relevance ratio of layers and use that layer, we called this ratio “efficiency”. By doing so, we compared the amount of word related to our input (relevant words) with the total amount of unique words (size). Based on our analyses, we obtained the results presented in Table 1 for an input “joy”.
Efficiency per layer for a word “joy” for all words.

Efficiency per layer for a word “joy” for all words.
The results after the layer 1 were not satisfying. Through our analysis, we found that non-relevant words are often contain in examples for other relevant words definitions, and therefore generate unrelated words, which can lead to errors propagating throughout the lexicon. Additionally, we observed a clear relationship between efficiency and layers, with higher layers having lower efficiency due to error propagation and the multiple meanings of words.
To improve the efficiency of the generated lexicons, we introduced a relevance score (1) for each word found by our system. By selecting the highest-ranked words, we sought to generate more efficient lexicons, as redundancy is highly likely to occur with words related to the first input. We found that the lexical field of the first input was over-represented through layers and counting occurrences of a specific word is likely to highlight it. The formula to compute the relevance score for a word “a” is:

Efficiency per layer for a word “joy” using relevance score to select high ranked words.

For this part of our system, we used methods introduced by Top2Vec, designed by Angelov,
28
using Doc2vec and multidimensional reduction with UMAP, it's possible to extract similarities among words depending on their context based on multiple documents. Doc2Vec first calculates the vector representation of the input word. It then searches through the entire vocabulary to find other words with similar vector representations. This is done using a similarity measure, cosine similarity. Cosine similarity measures the cosine of the angle between two vectors, with a value of 1 indicating that the vectors are identical and a value of 0 indicating that they are completely dissimilar. This allows us to consider words that are more similar and therefore have a better use of our word count algorithm, as a value is associated with every word. To bring a better overview of Doc2Vec, the Eq. (2) represents the training objective of the model. It aims to maximize the likelihood of predicting surrounding words given a central word and a document ID.
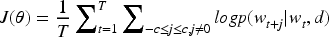
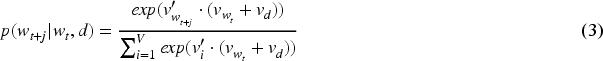

BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained deep learning model developed by Google; it is a Large Language Model. By processing the text in both directions, it allows him to capture the context and meaning of each word based on its surrounding words and the overall sentence structure. This has been made possible because it's using a transformer architecture, which is a neural network that can process sequences of data and find patterns thanks to its attention. BERT can be fine-tuned for specific tasks by adding a few additional layers on top of the pre-trained model, therefore we can use it to generate lexicons. BERT required text data to be trained and learn the relationships words have with each other's, so we had to train our model. We did the same as the previous method, which is using the first 15,000 news. We used BERT to create vectors for each word and document, the Eq. (5) shows how numerical values are first calculated when using transformers.


We decided to use BERT as a reference for a transformer encoding architecture, making it an intermediary step between GPT and Mistral, whom have decoder only architecture.
GPT (Generative Pre-trained Transformer) operates based on a transformer architecture and is pre-trained on an extensive corpus of text data before being fine-tuned for tasks. The GPT series, especially through iterations like ChatGPT, has exhibited impressive performance across a broad spectrum of NLP assignments, thus gaining substantial recognition. For our experiment, we used the OpenAI API, which necessitated setting up an account and obtaining an API key, to dynamically request python lists of synonyms for specific input words, with the list size varying based on the input. However, this service comes at a financial cost, highlighting the accessibility of Large Language Models for small entities is somewhat restricted due to development complexities and ownership by private institutions.
We utilized both GPT-3.5 and GPT-4 in our experiment, to compare them with each other's and also to bring a real reference into our different comparisons; GPT being the most known LLM. We incorporated different prompts for each to request synonyms pertinent to the given task. For GPT-3.5, our prompt was “Give me x words similar to [input]”, whereas with GPT-4 we specified “Give me x words that are more likely to be found in [task]”, where “x” represents the lexicon size, and “task” refers to the context — for example, for list a 20 words in a document discussing space in the case of space news document classification we asked “Give me 20 words that are the more likely to be found in a text talking about space”. An essential dimension of our analysis was the consideration of execution time, measuring the duration between posing a request and receiving a response. We conducted the experiment from the Nagoya Institute of Technology, documented through the Ookla speed test referenced by Bauer et al. 30 — boasting a download speed of 930Mbps, upload speed of 912Mbps, and a latency of 9 ms.
EMPATH
EMPATH is a tool designed to analyze text across 194 predefined categories, from emotions to themes such as “violence” or “family”. It operates based on a lexicon bootstrapped from crowd-sourced data and was constructed using a two-step process: First, a seed set of terms for each category was established. For each of these seed terms, the tool utilizes word embeddings from large text corpora to locate similar words. This expansion process can be represented by the Eq. (7):

Mistral 7B stands out within the landscape of large language models (LLMs) for its unique combination of open-source availability, efficient parameter size (7 billion), and competitive performance. This positioning makes it a compelling candidate for research in local LLMs. Local LLMs refer to the deployment of LLMs on personal or local hardware as opposed to relying on centralized cloud services.
The relatively small parameter count of Mistral 7B allows for such deployments while achieving performance gains through innovations like the FlashAttention mechanism and a rolling buffer cache. Current limitations of current local LLMs are the GPU required to run them; in float16, Mistral 7B instruct 0.1 requires 18GB of GPU. We reduced the risk of hallucination by providing example of generated lexicon in our prompt, so our model could understand the data expected in output.
Experimental setting
Word detection
Word detection can be considered a way to identify the features that distinguish one document from another. As a same word can have different forms based on its context, such as its tense or pluralization, it exists methods able to simplify word, like stemming, used to normalize words to their base or root form. This involves stripping words of their affixes, such as -ed or -s, to obtain the base form of the word. Additionally, POS (part-of-speech) tagging is used to identify the grammatical roles of words in a sentence, such as nouns, verbs, adjectives, and adverbs. Doing so we can gain time and focus on the relevant word in a document. We also added a list of stop-words to this selection functions, it also allows use to ignore words that don’t have significant meanings. By leveraging stemming and POS tagging, we can identify important features in a document that are relevant for classification. The NLTK (Natural Language Toolkit) 31 library provides various functions and algorithms for both stemming and POS tagging, making it a useful tool for our experiment.
Document classification
In document classification, the task is to assign a label to a document based on its content. The approach we had was to accomplish it while using lexicons by counting the number of words in certain categories that are related to a specific topic. We generated lexicons related to those categories and considered a word as related if it was included in one of those lexicons. For example, if we wanted to identify topics related to ‘sci.space’, one of the 20 newsgroups categories, we counted words such as “NASA”, “rocket”, “planet”, and “stars”. By counting the frequency of these words in a document, we can assign a score to each topic. The topic with the highest score was considered the topic of the document.
For our experiment, we used the articles we didn’t use when generating our models from the 20 newsgroups dataset. The categories of the 20 newsgroups dataset are the following: ‘alt.atheism’, ‘comp.graphics’, ‘comp.os.ms-windows.misc’, ‘comp.sys.ibm.pc.hardware’, ‘comp.sys.mac.hardware’, ‘comp.windows.x’, ‘misc.forsale’, ‘rec.autos’, ‘rec.motorcycles’, ‘rec.sport.baseball’, ‘rec.sport.hockey’, ‘sci.crypt’, ‘sci.electronics’, ‘sci.med’, ‘sci.space’, ‘soc.religion.christian’, ‘talk.politics.guns’, ‘talk.politics.mideast’, ‘talk.politics.misc’, ‘talk.religion.misc’. The relative distance between each category being different from one another, there is difference between having the wrong guess between two categories: as comp.windows.x being semantically closer to comp.os.ms-windows.misc than it is to sci.space for example. Therefore, we decided to group similar categories to overcome this limitation and obtain more accurate results. The groups of categories were defined as follows:
Group 1: ‘comp.graphics’, ‘comp.os.ms-windows.misc’, ‘comp.sys.ibm.pc.hardware’, ‘comp.sys.mac.hardware’, ‘comp.windows.x’ Group 2: ‘rec.autos’, ‘rec.motorcycles’ Group 3: ‘rec.sport.baseball’, ‘rec.sport.hockey’ Group 4: ‘sci.crypt’, ‘sci.electronics’, ‘sci.med’, ‘sci.space’ Group 5: ‘talk.religion.misc’, ‘soc.religion.christian’, ‘alt.atheism’ Group 6: ‘talk.politics.guns’, ‘talk.politics.mideast’, ‘talk.politics.misc’ Group 7: ‘misc.forsale’
The Figure 1. shows the F1 score we had per groups of categories. F1 scores are calculated as follow (8):

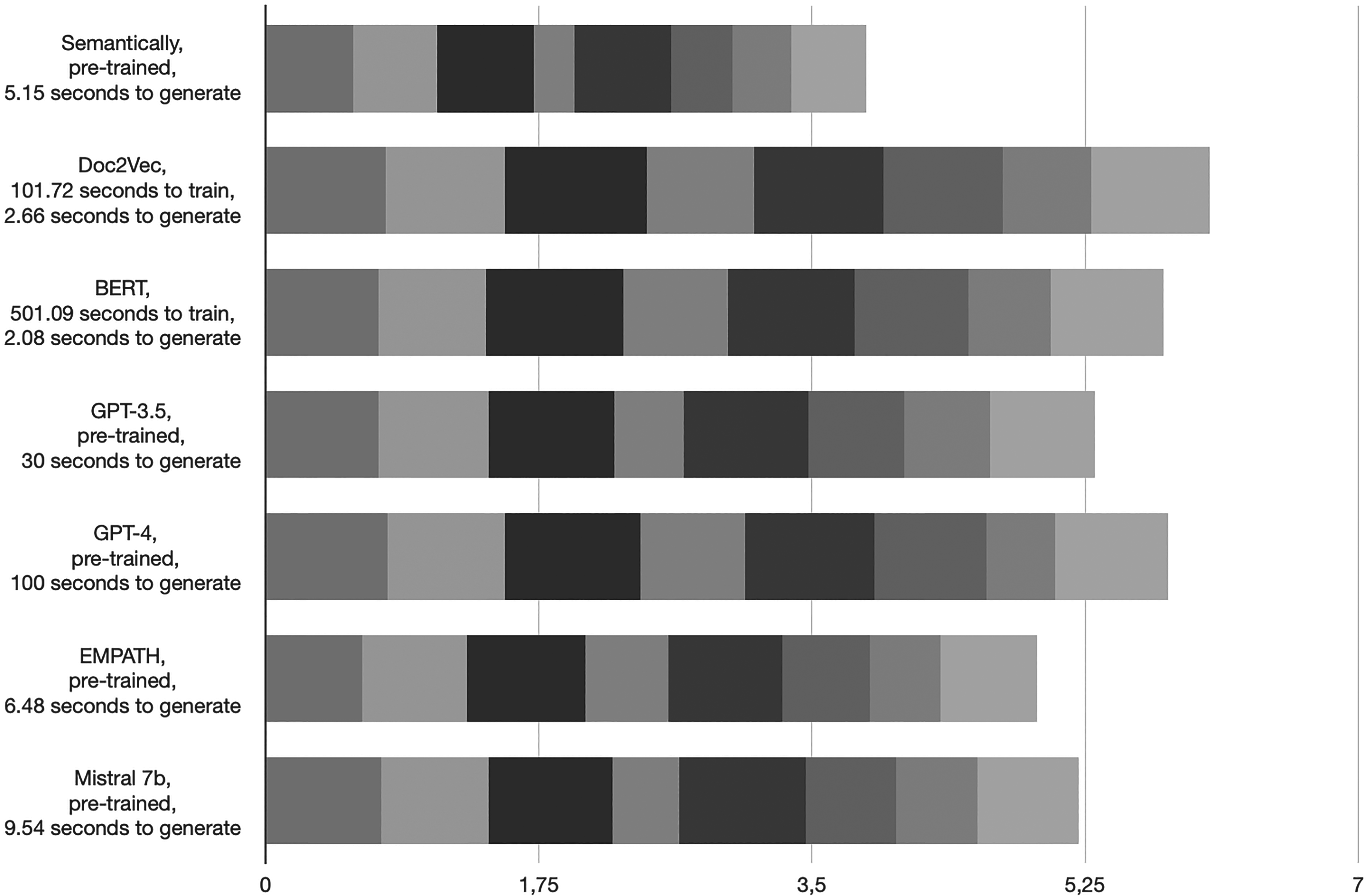
F1 score obtained with our lexicons for each category represented by the different shades.
Where TP means True Positive, which is the amount of correct prediction, FP and FN are respectively the amount of False Positive and False Negative.
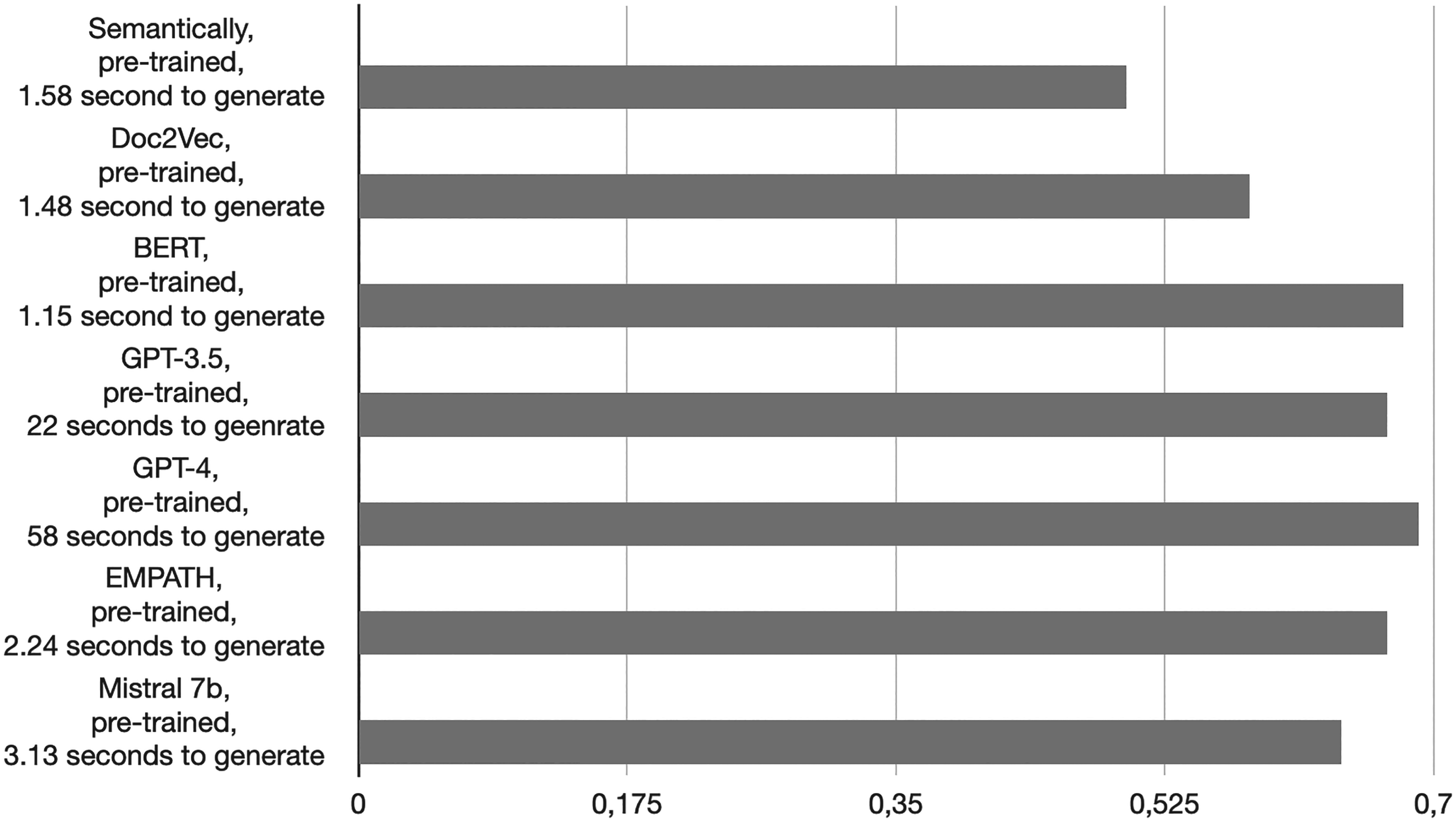
In examining the time efficiency of lexicon generation techniques, both traditional methods and Large Language Models (LLMs) have demonstrated distinct characteristics. Doc2Vec showed a marked difference in the time taken to train the models, necessitating a notably extended period. The BERT model required five time more time for training; however, it showed efficiency in the processing time. On the other hand, GPT-3.5 and GPT-4 offered a considerable advantage owing to their pre-trained nature, thus removing the need for a separate training time, but the remote nature of GPT brings a higher time to process the generation of lexicons. EMPATH, while being a contender in the processing speed against other non-pre-trained models, demonstrated a commendable processing time, but show the advantage to not require training time, aligning almost with the Semantically method as well as Mistral 7B timewise.
Moving on to the evaluation based on the F1 score, it is important to note the varied performances across different groups, illustrating the relative strengths and weaknesses of each method. Here, Doc2Vec is showcasing the highest average score, affirming its place as a reliable tool in lexicon generation. BERT didn't lag far behind, asserting its utility with competitive scores. The GPT demonstrated both highs and lows, presenting a layered picture of their applicability. EMPATH, although not leading, demonstrated a stable and consistent performance across groups, showing its reliability, even if it achieved slightly lower results than Mistral 7b. Semantically generated struggles to reach a decent score; it might be due to its nature, as the lexicons are generated based on dictionary definition, a lack of context learning leading to less efficiency.
An analyze of group data shows that group 3 responded well to most methods, likely thanks to a technical and distinct vocabulary in its article that aligns with context and semantic, indicating a favorable alignment with the lexicon generation strategies employed. Group 4 and 7 proved to be a challenging domain for several approaches; as group 7 deals with sales, it's likely to be complicated to find patterns of word or object related to it, while group 4 contains specific categories, such as encryption that were challenging for all methods (EMPATH generated a lexicon of words related to Dungeons and Dragons for example). These observations point towards an essential understanding that the choice of lexicon generation method should be closely tied to the nature of the task at hand.
For this experiment we used the Yelp reviews dataset, 32 which is made of restaurant reviews, with a text and the number of stars attributed. In our sentiment analysis with the Yelp reviews, we are trying to figure out if a review is positive, negative, or neutral. We use two lists of words for this: one list has positive words and the other one has negative words. If a Yelp review has a rating of 4 to 5 stars, we consider it positive. If it has 3 stars, it's neutral. And if it has 1 or 2 stars, it's negative. We then look at the words in each review. If it has significantly more words from the positive list, we say the review sounds positive, if it has more from the negative list, we say it sounds negative. If the difference is not significant enough, then the review is detected as neutral. This way, we can match our word lists with the star ratings to see if they agree. We used the first 50,000 reviews to train our two models and tested them on the next 100,000. The challenge encountered in this task was the inclusion of a third neutral category, which is detected when the difference between the positive and negative lexicons is not significant enough. The results can be seen on the Figure 2.

Second to generate/train lexicons and their F1 score obtained for our sentiment analysis.
In emotion classification, the task is to identify and assign an emotion label to a piece of text based on the words and phrases it contains. Like how we tackled document classification, we used lexicons representing various emotions to achieve this. In the context of this study, we generated lexicons pertaining to different emotions — for example, a lexicon for “happiness” might contain words like “joy,” “elated,” and “pleased.” To discern the prevailing emotion in each text, we analyzed the frequency of words from our emotion lexicons appearing in that text. The emotion represented most prominently through the appearing words was then designated as the primary emotion of the text, in case of no words detected, then the text is considered normal. The challenge when using lexicons for emotion classification is when an expression is expressed without a word explaining it, for example “What a day!”. This method allows us to automate the process of detecting emotions in text by using lexicon-based approaches to identify and categorize emotional content.
To process this task, we used the SMILE dataset previously mentioned, containing around 3000 tweets, and the CARER dataset, that can be found on Kaggle, for that last we changed the “disgust” emotion into “love”. For those tasks, we used the emotion as they were labeled in the datasets, so for the SMILE dataset; anger, disgust, happiness, surprise and sadness, as for the CARER dataset; anger, fear, joy, love, sadness, and surprise.
However, our initial test did not yield the results we hoped for when generating similar words; the words used in input, despite being in our documents, were not known well enough by our models and therefore the generated lexicons not accurate. The size of the dataset was the issue, as a larger dataset usually helps models learn word embeddings better. Therefore, we decided to use the sentiment analysis model, which was trained on a more extensive dataset.
Except for Doc2Vec and GPT-4, we relatively keep the same ranking for the F1 score. For Doc2Vec it is probably because of the complexity between emotions; while it's able to keep semantic information thanks to paragraph ID, when asked to generate a lexicon related to “happiness”, it was generating pronouns, we didn’t find this problem when using BERT for word embedding. Analyzing emotions in tweets is like trying to read a story from just one line. Tweets are often super short, with just a sentence or two, which doesn't give much to deduce emotions. Moreover, Twitter is full of slang and abbreviations, making it more difficult for lexicons to approach this task (“lmao” being “laughing my ass off” for example). Adding to the challenge, it's often hard to tell if a tweet is a joke, sarcasm, or a genuine feeling because of their brevity. Despite all the challenges enumerated we can notice that our results are relatively like the one we previously had. For all those enumerated reasons, Mistral also struggled, but it is highly possible that better results could have been achieved by asking him to generate such lexicons in the context of using it for tweets Figure 3.
Second to generate/train lexicons and their F1 score obtained for our emotion recognition.
The efficiency-accuracy trade-off of all results can be found on the Figure 4.
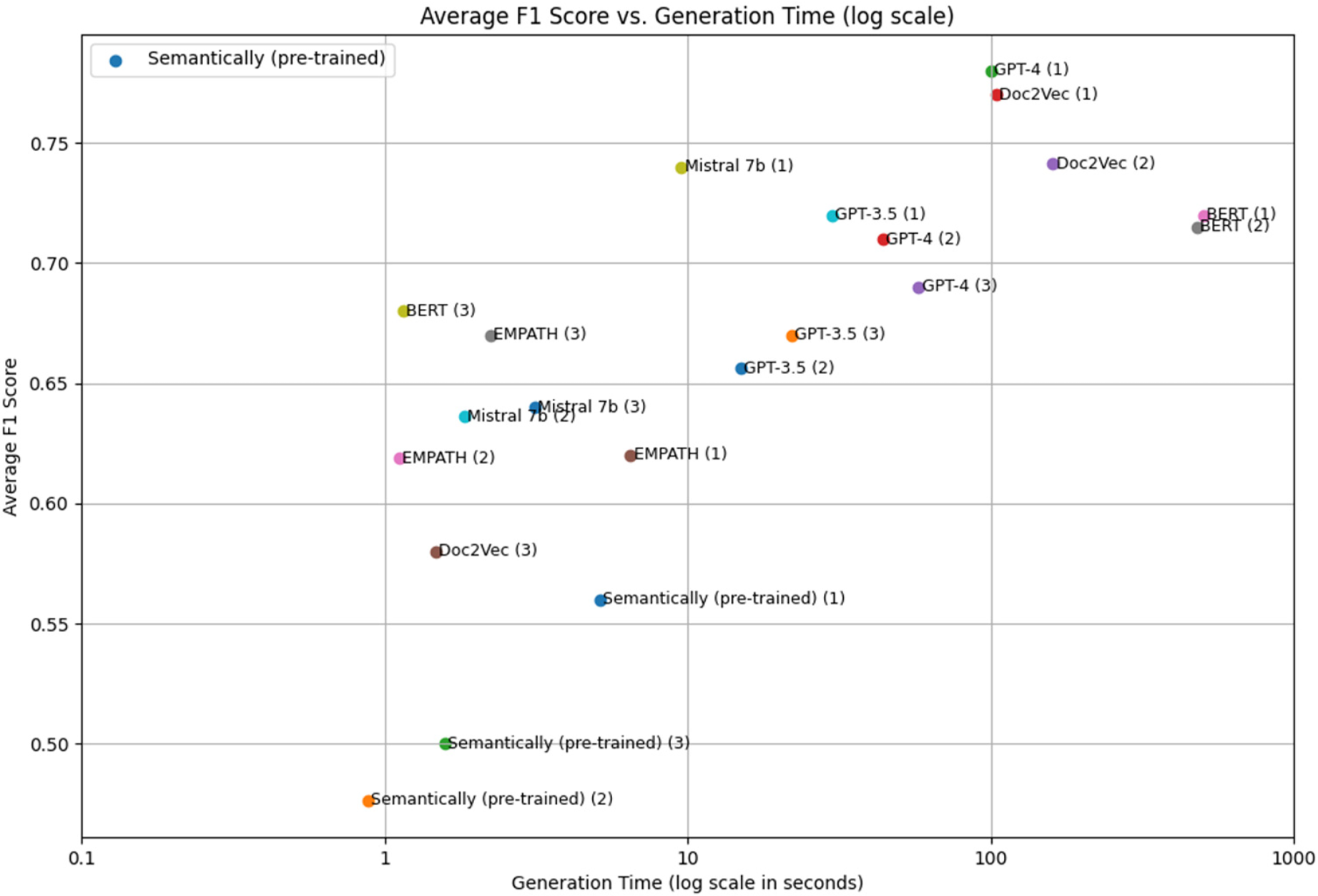
Efficiency-accuracy trade-off based on a log of generation time.
Parentheses correspond to the experiment (1) being the task of Document classification for example. The figure confirmed our previous analysis; GPTs are showing good results on the F1 average but struggle in the generation time. EMPATH and Mistral prove to be the methods with the best compromises, showing speed and good F1 score.
Our research shows a nuanced landscape in which different methods for lexicon generation come with their own sets of strengths and weaknesses. Lexicons offer a valuable means of data labeling due to their inherent flexibility and the fact that they usually don't necessitate training. This distinguishes them from traditional supervised machine learning models which require labeled datasets. Lexicons, being pre-defined lists of words associated with specific sentiments or categories wanted by the user, allow for quick and adaptable data annotation, enhancing the selection and quality of training data, therefore allowing better results as shown in previous research, where 2% of the dataset were enough to train efficiently a mental disorder identification model. 33 Furthermore, with the rise of fine-tuned Language Models (LLMs) and their need in quality data, the use of lexicons for labeling text becomes even more relevant.
Regarding our experiments, readers must keep in mind that we made them to compare the generated lexicons, not to achieve great performances, explaining the limited results. An important factor for all three methods were the words used in input when generating lexicons. Doc2Vec shows consistency and quality, while keeping a decent time to process the task when the generation is done. This is presumably owed to its design that maintains the structure of documents by utilizing paragraph IDs, thereby preserving their semantics. Its performance could be even better with the use of a pre-trained model built on a more substantial dataset. Despite taking a more considerable amount of training time, BERT has demonstrated scalability and precision, particularly in processing tasks swiftly, a feature that posits it as a potentially preferable option in high-scale systems, it also achieved the highest average in its results. On the other hand, while pre-trained models such as EMPATH exhibit reliability and flexibility, they are not devoid of weaknesses. A noted limitation is their partial lexicon, a shortfall not shared by GPT and semantically lexicons, which comprehend a more extensive vocabulary. Another determinant of the outcomes for GPT is also the quality of the prompts used; a factor significantly influencing the generation time for lexicons. Mistral 7b, our local language model performs great, falling short from GPT 3.5 sometimes, the downside of it would be the high GPU required, necessitating good setup (18GB of RAM if not quantized).
To conclude, all methods have their pros and cons. While Doc2Vec showcases the best results when it comes to Documents Classification, it necessitates training and couldn’t keep those results on the two other tasks. BERT, using the same structure, shows a better overall result, maybe also due to the training time, by requiring more computation it can capture better the context of words. Consequently, pre-trained models such as EMPATH and Mistral offer the benefits of reliability and flexibility, while GPT also shows those qualities it struggles with the generation time, making it difficult to scale on a dynamic Topic Modeling task. Overall, EMPATH and Mistral are the methods that is showing the more flexibility, keeping consistent results while having a low generation/processing time, however, BERT once trained showcase the best results and processing time. It highlights once again the ability for encoding transformers to capture the semantic of words. In the realm of lexicon generation, traditional methods continue to hold their ground against LLMs, notably due to their accessibility problem, as GPT would have been one of the best solutions if it was not for its generation time. Nonetheless, LLMs are still emerging, and further improvements are anticipated to eventually surpass traditional approaches in all the measured aspects.
Limitation
Despite the comprehensive analysis presented in this study, several limitations must be acknowledged. First, estimating the optimal number of experiments required to reach clear and definitive results proved challenging. The vastness of possible configurations and parameters in lexicon generation methods made it impractical to exhaustively explore every option within the scope of this research. This limitation may have affected the ability to fully capture the nuances and performance variations across different methods.
Second, the resource-intensive nature of Large Language Models (LLMs) posed significant constraints. Utilizing models with over 100 billion parameters was beyond the capacity of our local computational resources. As a result, we relied on services like ChatGPT to access these larger models. This dependency introduces variables such as network latency and service availability, which could impact the consistency and reproducibility of the results. Moreover, models like Mistral 7B required substantial GPU memory (up to 18GB of RAM when not quantized), highlighting the accessibility challenges for researchers without high-end hardware setups.
Lastly, while our experiments aimed to compare the generated lexicons objectively, the limited performance results indicate that further tuning and optimization are necessary. Factors such as prompt quality for GPT-based methods significantly influenced generation time and overall effectiveness, suggesting that our findings might be sensitive to these variables. Future research should consider these aspects to enhance the reliability and applicability of lexicon generation methods in real-world settings.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
