
Abstract
Parliamentary party leaders have an electoral incentive to protect the informational value of their party's label by promoting unity, but recent research has shown that parties can also benefit electorally from appealing broadly through a wide distribution of candidate positions on political issues. This article suggests that party leaders with formal candidate nomination powers balance these incentives by nominating new candidates who are more congruent with the party when the distribution of issue positions among the senior candidates is wide, and, conversely, by nominating new candidates who are more divergent from the party when the senior candidate position distribution is narrow. These possibilities are tested with candidate survey data from six parliamentary democracies, and the results show that new party leader nominations are indeed conditional on the senior candidate distribution, but only on issues that are salient to the party’s electoral brand.
Keywords
How do parliamentary party leaders use their formal powers to shape the distribution of issue positions within their party? 1 This question has important implications for elite behavior and representation, but there is currently no consensus on the answer. Several studies have argued that parliamentary party leaders use their formal powers to cultivate positional unity among their co-partisan members (Cordero and Coller, 2015; Cordero et al., 2018; Ferrara, 2004; Sieberer, 2006). This strategy makes sense because parties benefit electorally from voters using their label as a policy heuristic at the ballot box (Cox and McCubbins, 1993). Party leaders thus have an incentive to enforce discipline because party unity reduces voter uncertainty about the policy signal of the party label. However, centralized party rules are not always associated with more unity (Hazan and Rahat, 2010; Shomer, 2009), so their behavioral effects remain unclear (Rahat and Cross, 2018).
This article argues that party leaders only sometimes use their formal powers to cultivate unity because parties also have a countervailing incentive to appeal broadly to different groups of voters with diverse preferences (Bräuninger and Giger, 2018; Lo et al., 2016; Somer-Topcu, 2015). The goal of the broad-appeal strategy is to increase the size of the party vote share by convincing different groups of voters that the party is ideologically closer to their preferred positions, and parties can pursue this goal by letting different candidates take divergent positions on the same issues (Tromborg, 2019). Party leaders may thus sometimes refrain from using their formal powers to cultivate unity—or even encourage their members to take divergent positions—in order to make sure that their party appeals broadly. 2
For these reasons, this article suggests that party leaders balance the incentive to appeal broadly with the incentive to appear unified when they use their formal powers. It is argued that party leaders use their formal organizational powers to reduce the variance of the issue position distribution when it gets unusually wide (to avoid the party appearing divided) but to increase the issue position variance when it gets unusually narrow (to retain a broad appeal). This theory is applied specifically to one type of party leader power—candidate nomination rules. It is costly for parties not to renominate senior candidates who have run in previous elections (Dahlgaard, 2016; Hobolt and Høyland, 2011; Kam and Zechmeister, 2013; Kotakorpi et al., 2017; Moral et al., 2015; Redmond and Regan, 2015), which motivates party leaders to nominate new candidates who diverge less from the party than the senior candidates when the senior candidates are incongruent with the party. Conversely, party leaders nominate new candidates who diverge more from the party than the senior candidates when they are congruent.
These possibilities are tested empirically with data from the Comparative Candidate Survey (CCS) from six parliamentary countries (Belgium, Denmark, Germany, Greece, Norway, and the United Kingdom). 3 The results show that party leaders with formal nomination powers do indeed nominate new candidates who are less divergent than the senior candidates when the variance of the senior candidate position distribution is high. Conversely, they nominate new candidates who are more divergent when this variance is low. However, party leaders only behave in this way on issues that are salient to the party. On non-salient issues, on the other hand, there is no discernable relationship between party leader nomination powers and the positions of new candidates. The results thus suggest that party leaders use their formal powers strategically to shape the distribution of issue positions in a way that balances the incentive to appeal broadly with the incentive to appear unified, and that they pay special attention to issues that are salient to their party’s electoral brand when doing so.
Party leader incentives
Responsible political parties are supposed to present voters with clear and unified policy positions according to one normative vision of democracy (APSA, 1950). This allows voters to make effective electoral choices and to hold governments accountable (Thomassen, 1994). Accordingly, studies on parliamentary representation and party competition have traditionally assumed that parties behave in this way (Cox, 1990; McDonald and Budge, 2005; Powell, 2000). There is also evidence that party leaders sometimes use their formal powers to cultivate unity. They use agenda-setting powers to prevent proposals they know will split the party from being voted on in the legislature (Chandler et al., 2006; Cox et al., 2008; Huber, 1992), they discipline Members of Parliament (MPs) who diverge from the party line with (the threat of) demotion or expulsion (Kam, 2009), and they use candidate selection powers to nominate ideologically congruent candidates and/or to motivate such congruence among reelection seeking MPs (Cordero and Coller, 2015; Cordero et al., 2018; Ferrara, 2004; Sieberer, 2006).
Party leaders have good reasons to behave in this way. Downs (1957) famously argued that voters use party labels as policy heuristics to vote for the most ideologically proximate party, and this proximity model of voting has withstood numerous empirical tests over time (Blais et al., 2001; Krämer and Rattinger, 1997; Westholm, 1997). A party thus benefits electorally from the informational value of its label, but disunity among party members may reduce the strength of the information signal (Cox and McCubbins, 1993). This may in turn lead voters to vote for another ideologically proximate party whose positions they are more certain about. Greene and Haber (2015) have also shown that voter impressions of disunity negatively affect their assessments of parties’ policy competencies. Accordingly, there is evidence that party disunity can influence a party’s vote share negatively as well (Lehrer and Lin, 2018). For these reasons, party leaders have an electoral incentive to promote unity to protect the informational value of the party’s label.
Centralized party decision rules are, however, not always associated with more party unity (Hazan and Rahat, 2010; Shomer, 2009). This may be because parliamentary parties also have a potentially contradictory incentive to appeal broadly (Somer-Topcu, 2015). The broad-appeal strategy can involve taking ambiguous issue positions, or it can involve taking several clear yet inconsistent positions on the same issues. Regardless of the means, the goal of the strategy is to increase the size of the party vote share by convincing different groups of voters that the party is closer to their preferred positions. An emerging literature has illustrated that parties pursue this strategy in their election manifestos (Bräuninger and Giger, 2016; Lo et al., 2016) and through the distribution of candidate positions (Tromborg, 2019).
There are several ways in which disunity among a party’s candidates can increase a party’s vote share. As Somer-Topcu (2015) points out, broad appeals can cause partisan identifiers to resolve their cognitive dissonance when their preferred party takes less preferred issue positions. It may thus help parties retain and mobilize their partisan followers. It may also lead other voters, who are not ideologically congruent with the party, to vote for a party candidate because they are ideologically congruent with a candidate from the party’s list instead of the party as a whole. If candidate divergence is related to district voter preferences, which Tromborg (2019) suggests it is, then such divergence may also cause voters in the district at large to perceive that the party is closer to them because the candidates are more visible in the districts where they run. Party leaders may thus sometimes be motivated to refrain from cultivating unity, or even to cultivate disunity, in order to appeal broadly to different groups of voters in the electorate.
Balancing the incentive to appeal broadly with the incentive to appear unified
There is a conflict between the incentive to appeal broadly through the distribution of candidate positions and the incentive to protect the informational value of the party label through unity. If a party cultivates a very wide distribution of candidate position, then it may appeal broadly, but the party runs the risk of making voters confused about what its positions are and thus reducing the informational (and electoral) value of the party label. If, on the other hand, a party cultivates a very narrow distribution of candidate positions, then the information signal of the party label will likely be strong, but the party also limits its appeals to a smaller group of voters.
Perhaps surprisingly there is to date only little published research that systematically analyzes how parties balance the incentive to appeal broadly with the incentive to appear unified. There are, however, two exceptions. Tromborg (2019) argues that parties have a stronger incentive to appear unified on issues that are more salient to their party’s electoral brand because these are the issues where they reap the greatest electoral rewards from the informational value of the party label. On less salient issues, on the other hand, political parties have an incentive to appeal broadly through a wider and district-related distribution of candidate positions. Empirically, Tromborg shows that the parliamentary candidates are indeed more unified on more salient issues, although there is some evidence of parties pursuing the broad-appeal strategy on these types of issues as well. Likewise, but in a larger sample of 14 countries, Rovny (2012) shows that parliamentary parties tend to take clear positions on issues where they hold issue ownership (Budge and Farlie, 1983; Petrocik, 1996), but blur their positions on issues that are owned by other parties in order to attract broader voter coalitions on these issues.
These findings collectively suggest that there is an optimal level of candidate divergence on each issue. This optimal level is greater than zero because parties do not want to appeal too narrowly, but it also has an upper boundary because parties do not want to make voters too uncertain about what the party’s position is. Furthermore, the optimal level of candidate divergence depends on the level of issue salience and issue ownership: It is lower on issues that are more important to the party because the potential electoral costs of divergence and ambiguity are higher. Party leaders may also be more attentive to what their positional distribution looks like on salient issues because parties are historically and ideologically more invested in these issues (Rovny, 2012: 275). Consequently, they may prioritize salient issues when (and if) they balance the incentive to appear unified with the incentive to appeal broadly.
Party leaders and candidate nomination rules
Party leaders have several formal powers that they can use to shape the issue position distribution within their party in the ways just described. This article focuses specifically on one type of formal party leader power, namely the power to nominate parliamentary candidates. The reason is that centralization of candidate nomination rules varies by party and is observable. In some parties, the nomination of parliamentary candidates is in the hand of the national party leadership, but in other parties, this decision is decentralized to the district level (Hazan and Rahat, 2010). Furthermore, the relationship between candidate nomination rules and party unity has been analyzed by several previous studies (Cordero and Coller, 2015; Cordero et al., 2018; Ferrara, 2004; Shomer, 2009; Sieberer, 2006), but no consensus has been reached so far (Rahat and Cross, 2018). Party leader nomination strategy is thus ripe for both theoretical and empirical investigation.
Given this, the key theoretical argument in this article is that when party leaders have formal candidate nomination powers, they use them to nominate candidates who have an ideological profile that allows the party to balance the incentive to appeal broadly with the incentive to appear unified. In order to understand how party leaders might achieve this goal, it is first necessary to consider what other electoral incentives and constraints are present when party leaders nominate candidates. Consequently, it is important to understand who the party leaders that can make parliamentary candidate nominations actually are.
The national party leaders who can nominate are usually organized in party agencies that include leaders in the parliamentary group and representatives from other branches of the party organization (Hazan and Rahat, 2010; Kernell, 2015). 4 The current National Executive Committee of the British Labour Party, for example, is charged with setting the party’s overall strategy in addition to ultimate authority over parliamentary candidate nominations (Kernell, 2015), 5 and it contains representatives from different sections of the party such as the Shadow Cabinet, MPs, Members of the European Parliament (MEPs), Constituency Labour Parties, and Socialist Societies. Since these leaders are charged with setting the party’s strategy, they would likely prefer to nominate the candidates who can maximize the party’s vote share. Consequently, they can be expected to pursue a nomination strategy that balances the incentive to appeal broadly with the incentive to appear unified. However, it is important to note that the heterogeneity in the types of leaders who can nominate under centralized nomination rules means that they may have heterogeneous preferences, and this could constrain their ability to respond to the party’s electoral incentives when they nominate candidates.
Another constraint that party leaders face is that it can be costly for a party not to renominate senior candidates (i.e. candidates who ran in the most recent parliamentary election or elections) because they have gained important name recognition and experience (Hobolt and Høyland, 2011; Kam and Zechmeister, 2013). Some studies have detected an incumbency effect on personal vote shares for the subset of senior candidates who have previously been elected to the parliament under proportional representation (Dahlgaard, 2016; Kotakorpi et al., 2017; Moral et al., 2015; Redmond and Regan, 2015). Other studies find no such incumbency effect (Fiva and Røhr, 2018; Golden and Picci, 2015), but there are also other potential costs associated with choosing not to renominate senior candidates such as intraparty controversy. Consistent with this possibility, Golden and Picci find that despite the lack of an incumbency effect on personal vote shares, party leaders nonetheless renominate incumbents disproportionately. This does not mean that party leaders always renominate senior candidates, but merely that refraining from doing so is, on average, more costly than not to nomine aspiring new candidates. It is thus often going to be a better strategy for party leaders to shape the distribution of candidate positions in an electorally desirable way when they nominate new candidates (i.e. candidates who did not run in the previous election) in response to senior candidates selecting out of the candidate pool. 6
For these reasons, party leaders have an electoral incentive to use their formal nomination powers (when they have them) to nominate new candidates who make up for imbalances in the issue position distribution among senior candidates.
7
More concretely, party leaders can shape the distribution of candidate positions in an electorally desirable way by nominating new candidates who are more congruent with the party when the senior candidates tend to diverge from the party’s positions (to avoid appearing divided). Likewise, party leaders have an incentive to nominate new candidates with a more personalistic ideological profile when the existing distribution of positions among the senior candidates is very narrow (to retain a broad appeal). The empirical (and representational) implications of these possibilities can be summarized in the following ways.
It is important to note that these hypotheses do not rule out constraints on party leader powers. Parties with centralized candidate nomination rules should be more likely than parties with decentralized candidate nomination rules to nominate divergent new candidates when the senior candidates are congruent, and conversely when the senior candidates are divergent. However, this does not necessarily mean that party leaders in contexts with divergent senior candidates nominate more congruent new candidates than party leaders in contexts with congruent senior candidates. This is because the same systematic constraints (e.g. party leader heterogeneity and heterogeneity in the pool of eligible party members) that led to a wide senior candidate distribution in the first place are also likely to constrain party leaders when they nominate new candidates. This means that it is typically going to be difficult for party leaders to nominate new candidates who are very congruent with the party when the senior candidates are very divergent. Yet, they can still nominate new candidates who are less divergent than their senior candidates, which steers the overall distribution of candidate divergence toward a more optimal balance between appealing broadly and appearing unified.
It is also important to note that the threshold that is mentioned in the two hypotheses represents the (perceived) optimal level of candidate divergence, and it is referred to as “some threshold” because it is not directly observable to researchers (though the empirical analysis will approximate it using the average distance among senior candidates to their party as the measure). Consequently, the testable implications from the theoretical model are simply that parties with centralized nomination rules should be more likely to nominate new congruent candidates when the issue position distribution among senior candidate is wider than some unknown threshold, and more likely to nominate new divergent candidates when the distribution is narrower than this threshold.
The theoretical model does, however, suggest that the optimal level of candidate divergence should be lower on salient issues than on non-salient issues (though still greater than zero on salient issues). As previously mentioned, this is because parties have a stronger electoral incentive to appear unified on salient issues. If party leaders perceive this incentive as well, then they should be systematically more likely to nominate congruent new candidates on salient than non-salient issues, holding constant the level of divergence in the senior candidate distribution. This possibility can be summarized in the following way:
There is also another strategic possibility. As Rovny (2012) points out, and as previously mentioned, parties are more invested in the issues that they highlight as salient (i.e. the issues that they have issue ownership over). Furthermore, these are the issues where parties get most of their votes. Consequently, it is possible that party leaders pay more attention to these types of issues when they use their nomination powers to shape the distribution of co-partisan candidate positions. If so, then the empirical implication is as follows.
Data and methods
The empirical analysis tests these possibilities with a model that analyzes issue positions among new parliamentary candidates (i.e. parliamentary candidates who did not participate in the previous election) as a function of candidate nomination rules, issue salience, and divergence among co-partisan senior candidates (i.e. co-partisan parliamentary candidates who participated in the most recent election). The data set is composed of parliamentary candidates from six parliamentary countries (eight elections from 2007 to 2015), and the unit of analysis is a political issue position for a new parliamentary candidate in an election. 8
The data on candidate positions come from the CCS. This survey project uses similar issue position questions across parliamentary democracies in two waves, which enables an analysis of candidate position taking across elections, parties, and countries. Specifically, candidates in the CCS survey waves were asked to take positions on 15 different issue statements using a five-point ordered categorical response scale ranging from “1: Strongly disagrees” to “5: Strongly agrees.” 9 These data are well suited for the empirical analysis because of their scope in terms of countries and issue dimensions, and because they include information about whether a candidate ran in the most recent election, which is necessary for testing the hypotheses. 10
The dependent variable is generated from these CCS data and measures the distance between a new candidate and the party’s issue position, which is operationalized as the modal co-partisan candidate response. Specifically, the dependent variable takes a “0” for issues where a new candidate took the same issue position as the modal co-partisan candidate response, a “1” for issues where the candidate took a position that diverged one scale point from the modal party position, and a “2” for issues where the candidate’s position diverged two scale points or more. 11 The distribution of the dependent variable is shown in Table A.1.1 in the Online Appendix.
The data on candidate nomination rules come from Kernell (2015), who has collected them from official party documents (statutes and bylaws), and interviews with party bureaucrats and representatives in several parliamentary countries. Specifically, the Kernell (2015) data set contains a variable that describes whether the rules are inclusive (party members select candidates), semi-inclusive (party members and party leaders share candidate selection authority), or exclusive (the party leadership selects the candidates). To ease the substantive interpretation of the empirical models, the three leader nomination rule categories are collapsed into a dummy variable that simply measures whether the party leadership is formally able to shape the distribution of candidate positions through nominations (“1 = semi-inclusive or exclusive candidate nomination rules”) or not (“0 = inclusive nomination rules”). Using the three-category variable instead of the dummy variable does not change the conclusions of the analysis. 12
The salience of the issues in the CCS data set is coded using expert scores from the Chapell Hill expert survey. The expert scores are measured on a 1–10 scale where a higher number means that the issue is more salient to the party. This measure of issue salience is preferable to other measures such as manifesto scores because it facilitates cross-issue comparison. This is more difficult to do with manifesto scores where the salience of each issue dimension is highly correlated with the number of subcategories that composes the issue dimension, and the number of subcategories may itself not be related to issue salience. Furthermore, the Comparative Manifesto Project (CMP) relies on proxy documents for one of the cases in the data set (Denmark), which may not be comparable across parties (Hansen, 2008).
Finally, the “senior candidate divergence” variable measures the average distance between co-partisan candidates who participated in the most recent election and their party’s position on an issue. 13 These data are obtained from the CCS issue position items described earlier in the section. A value closer to “0” (the lowest theoretical value) indicates that the senior candidates are more congruent with the party on the issue, and a value closer to “2” (the highest theoretical value) indicates that the senior candidates are less congruent with the party. The distribution of this variable is visualized at the bottom of Figures 1 and 2 below for different levels of issue salience.
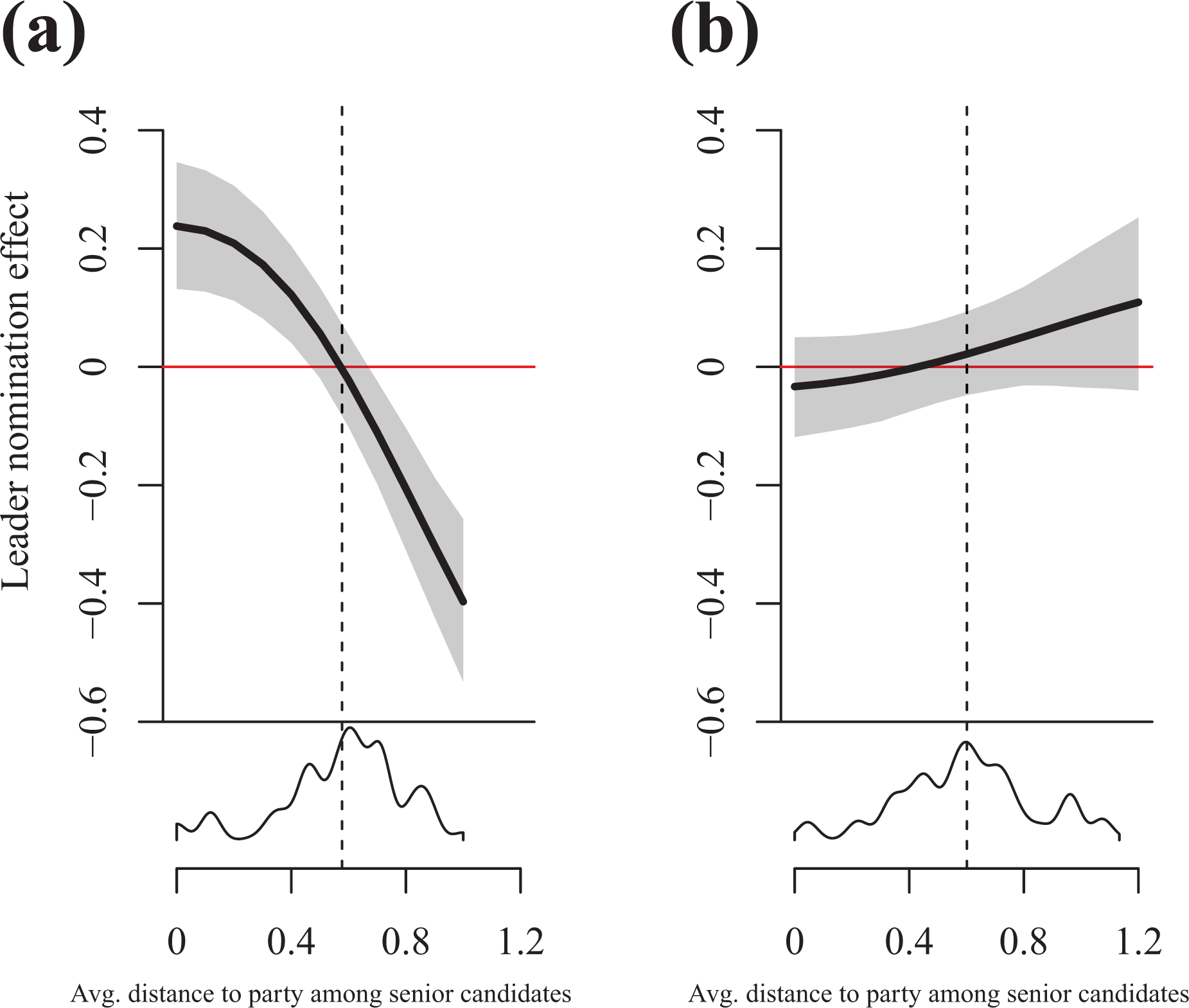
Candidate nomination rules and new candidate divergence.
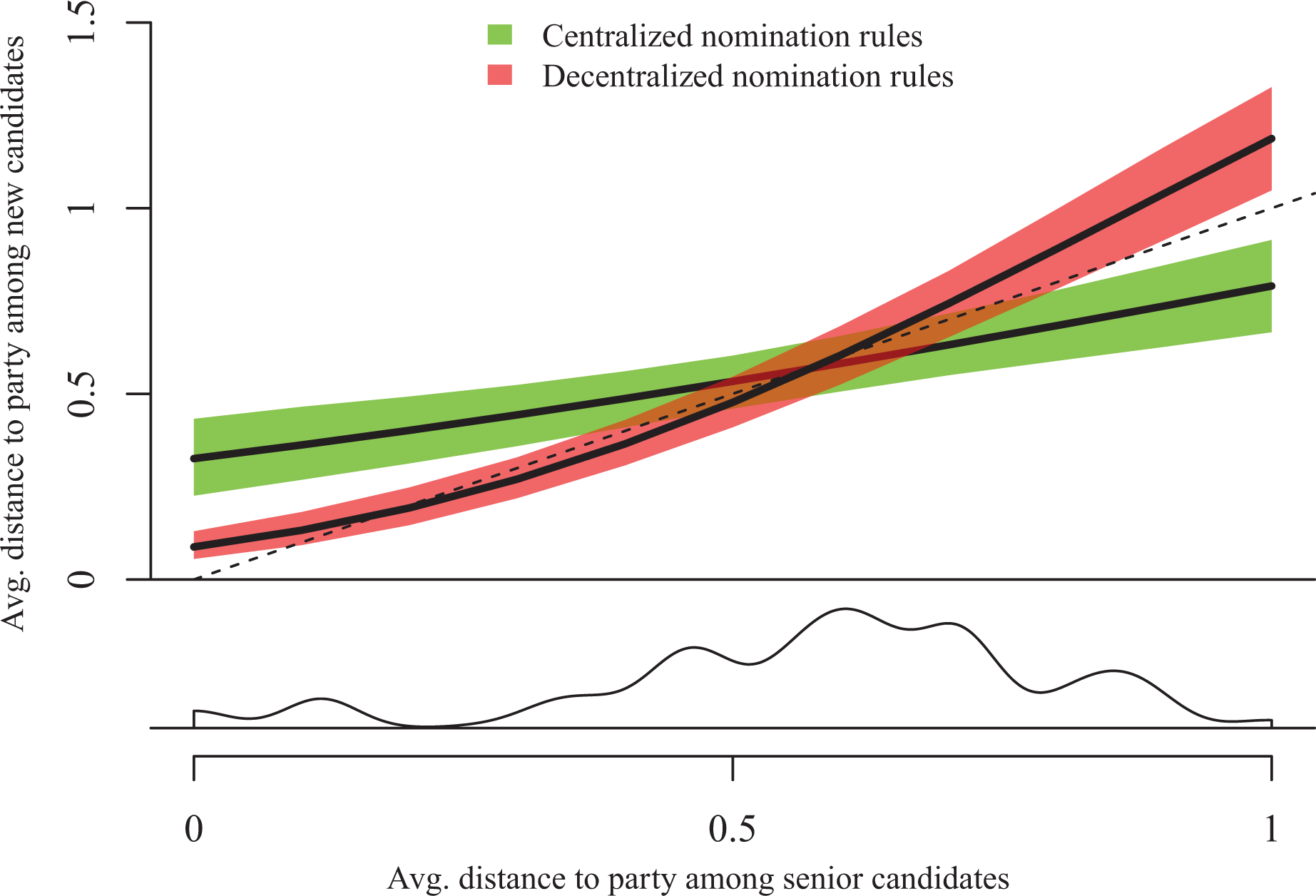
Average new candidate divergence on salient issues.
Results
Using these data, model 1.1 in Table 1 shows the parameter estimates that are obtained from regressing candidate-party divergence among new candidates on a three-way interaction composed of the three independent variables, and with an ordered probit estimator that allows the intercepts to vary at the level of candidates, issues, and parties. 14 The three-way interaction is important because of the theoretical expectation that party leaders who have formal nomination powers will use them to nominate new candidates who are more ideologically congruent with the party, but more so on salient issues where the existing divergence among senior candidates within the party is high (as well as more divergent candidates when the senior candidate distribution is narrow). Yet, the three-way interaction also makes it difficult to interpret the constituent and interaction terms, so models 1.2 and 1.3 show the results that are obtained from running the regression on a split sample composed of salient issues (above the salience mean of 5.96) and non-salient issues (below the salience mean of 5.96), respectively.
Nomination rules, senior candidate divergence and new candidate divergence.

Note: Ordered probit regression coefficients with standard errors in parentheses.
***p < 0.001; **p < 0.01; *p < 0.05; †p < 0.1
Given the three-way interaction term, the interpretation of each main constituent term in model 1.1 represents the relationship between the covariate and the dependent variable when the two moderators have a value of “0,” and the coefficients on the partial interaction terms represent the interactive effects of the two included constituent terms when the third omitted constituent term has a value of “0.” Since these are generally not realistic scenarios, the most important take-away from Table 1 is that the three-way interaction term is statistically significant. As expected, this indicates that the relationship between candidate nomination rules and new candidate issue positions is conditional on the existing distribution of senior candidate positions, and that this interactive relationship is further conditional on issue salience.
Models 1.2 and 1.3 provide some more evidence on exactly how these variables matter. The evidence is consistent with hypotheses 1 and 3 and more generally with a constrained model of party leader nominations. The positive and statistically significant coefficient on the leader nomination rules variable in model 1.2 indicates that centralized candidate nominations are associated with more new candidate divergence when the level of senior candidate divergence is very low (no divergence). The negative and statistically significant coefficient on the interaction term indicates that this effect of centralized candidate nomination rules gets reversed when the level of senior candidate divergence reaches a certain threshold. This is consistent with hypotheses 1a and 1b. Furthermore, the results are also consistent with hypothesis 3 because there is no statistically distinguishable relationship between candidate nominations and new candidate positions on non-salient issues in model 1.3.
In order to show this substantively, Figure 1 reports substantive effects from models 1.2 and 1.3. The figure reports the estimated effect of party leaders holding candidate nomination powers on the average distance to the party among new candidates (the mean of the ordered probit probability distribution) over the average distance between the party and its senior candidates. 15 The left subfigure shows these predictions for salient issues, and the right subfigure shows these predictions for non-salient issues.
The figure also includes dashed lines for the salient and non-salient means of the issue position distributions among the senior candidates. They represent an approximation of what the optimal level of divergence is. One can think of the senior candidate distribution as having a systematic and a stochastic component where the systematic component represents features of parties that lead to the desired distribution (e.g. party leader powers, socialization, etc.), and a stochastic component that represents other events that can lead the distribution to diverge from this ideal (e.g. senior candidates changing their preferences or selecting out of the party). If so, then the mean of the distribution should converge on the average ideal as the number of observations gets large according to the central limit theorem. Of course, these assumptions may be systematically violated (e.g. by issue position heterogeneity among party leaders), but the dashed lines nonetheless represent a qualified guess of what the ideal level of candidate divergence is in the absence of a direct measure. Furthermore, there is some face validity to this approximation. 16
Figure 1 reveals several interesting aspects of issue positions among new candidates that are consistent with the theoretical model. First, as indicated by the direction of the coefficients in model 1.2, the figure shows that party leaders with formal nomination powers nominate new candidates who are systematically more congruent with the party when the senior candidates are more divergent than the optimal level of divergence (hypothesis 1a). Second, and conversely, party leaders with formal nomination powers nominate new candidates who are systematically more divergent with the party when the senior candidates are more congruent with the party than the ideal level (hypothesis 1b).
Third, there is no relationship between candidate nomination rules and new candidate positions on non-salient issues as indicated by the coefficients in model 1.3. The evidence is thus not consistent with hypothesis 2. The estimated ideal level of candidate divergence (i.e. the average distance between senior candidates and the party) is slightly lower on salient than non-salient issues as expected, but party leader nomination powers are only associated with more congruent new candidates on more salient issues when the distribution of senior candidate positions gets larger than the estimated ideal level of divergence. Instead, the evidence is consistent with hypothesis 3 because it suggests that party leaders mostly (or perhaps only) pay attention to salient issues when they use their nomination powers to balance the incentive to appeal broadly with the incentive to appear unified.
Fourth, the estimated effects of leader nomination rules are substantively meaningful. This is especially true when the distribution of issue positions among senior candidates gets very wide. When this is the case, then the average divergence among new candidates is 0.4 lower on the 0–2 scale. This is quite a lot for a divergence variable that is bound between 0 and 2 (20% of the full theoretical range of the variable). The substantive effect of centralized candidate nominations on the positions of new candidates is lower when the senior candidates are congruent with the party, but centralized nominations still increase the average level of divergence with more than 0.2 on the 0–2 scale. This is not negligible against the backdrop of research on representation traditionally assuming that party leaders always use their formal powers to enforce unified positions (and thus that the effect of party leader nomination powers should always be less, rather than more, candidate divergence from the party).
The results in Table 1 are also consistent with a constrained model of party leader nominations. The positive and significant coefficient on the senior candidate divergence variable in model 1.2 indicates that more senior candidate divergence is associated with more new candidate divergence when candidate nominations are decentralized. As expected, the negative and significant interaction term indicates that this positive relationship is weaker when candidate nominations are centralized, but the size of the senior candidate coefficient is greater than the size of the interaction term, which means that there is a positive relationship between senior candidate positions and new candidate positions even when candidate nominations are centralized. This indicates that while party leaders are able to use candidate nominations to shift the overall level of candidate divergence in an electorally desirable direction, they are still constrained by the factors that were partially responsible for the wide senior candidate distribution in the first place (e.g. issue position heterogeneity among the leaders that make the nominations).
This is illustrated in Figure 2, which graphs the average new candidate divergence over the average senior candidate divergence when parties do (green color), and do not (red color), have centralized candidate nomination rules (on salient issues only). The dashed diagonal line represents the value of the horizontal axis (representing average senior candidate divergence) on the vertical axis (representing average new candidate divergence), which means that any predicted value below this line is indicative of new candidates being less divergent than the senior candidates, and any predicted value above this line indicates that new candidates are more divergent than the senior candidates. Given this, and consistent with the results so far, the figure illustrates that new candidates are more divergent than senior candidates at low levels of senior candidate divergence, and conversely at high levels of senior candidate divergence, but only when candidate nomination rules are centralized. 17 Yet the figure also illustrates that there is a positive slope on average new candidate divergence even when party leaders nominate. This positive correlation between new and senior candidate divergence suggests that party leaders may be constrained by the factors that led to a wide senior candidate distribution in the first place. Figure 2 thus suggests that while party leaders nominate new candidates in a way that steers the overall issue position distribution toward a balance between appealing broadly and appearing unified, they are also constrained in doing so. These constraints deserve attention in future research along with other variables that may influence the issue position distribution within parliamentary parties.
Conclusion
There is currently no consensus on how party leaders use their formal powers to shape the distribution of issue positions within their party due to mixed empirical findings (Rahat and Cross, 2018). In this article, it has been argued that the findings may be mixed because party leaders are faced with two contradictory incentives when deciding how to use their formal powers. On the one hand, they have an incentive to cultivate unity in order to protect the informational value of the party’s label. On the other hand, their party can benefit electorally from appealing broadly by letting their candidates take different positions on the same issues. Consequently, party leaders may use their formal powers differently in different contexts.
How, then, do party leaders resolve this electoral dilemma? This article has theorized, and illustrated empirically, that party leaders with formal nomination powers nominate new candidates who are more ideologically congruent with the party than the senior candidates when the distribution of positions among the senior candidates is wide (in order to retain the informational value of the party’s label). Conversely, party leaders with formal nomination powers nominate new candidates with a more individualistic positional profile than the senior candidates when the issue position distribution among the senior candidates is narrow (in order to make sure that the party retains its broad appeal). Furthermore, party leader nomination powers are only related to candidate positions on issues that are salient to the party’s electoral brand.
Collectively, these findings suggest that party leaders use their formal powers strategically to balance the incentive to appeal broadly with the incentive to appear unified, and that they pay particular attention to issues that are salient to their party’s electoral brand when doing so. An interesting possibility that this article has not explored, however, is that new candidate nominations are related to district specific preferences. Indeed, district voter preference effects may help explain the findings in the article for reasons that are consistent with, and extend, the theoretical model. When party leaders nominate new divergent candidates due to a narrow senior candidate issue position distribution, then they should be more likely to nominate such new candidates in districts where candidate divergence has the greatest electoral payoff. The payoff is likely to be greater in districts where voters have preferences that are more divergent from those of the party. Consequently, these are the districts where divergent new candidates should be disproportionately nominated. I encourage future research to explore this possibility with alternative data sources.
The results that the article does present contribute to the literature on candidate nomination rules and the emerging literature on broad-appeal strategies, but also to the broader literature on representation. This literature has traditionally assumed that political parties take clear, unified, and differentiated policy positions (Cox, 1990; Downs, 1957) and both the responsible government model of representation (APSA, 1950) and median mandate theory (Powell, 2000; McDonald and Budge, 2005) follow from this assumption. Yet the results presented here show that parties do not always prefer to act in this way. Rather, parliamentary party leaders cultivate a distribution of party positions on each issue that depends on issue salience as well as the institutional tools that party leaders have available to influence what candidates do and say. Uncovering other factors that determine the shape of the issue position distribution within parliamentary parties should be an exciting and important new research agenda for future research.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.