
Abstract
Aims and objectives/purpose/research questions:
Few studies have investigated different-script cognate effects in language assessment contexts. This paper examines the impact of Japanese cognates in a test of English receptive lexical knowledge that is widely used for placement purposes in second language learning contexts. Specifically, the present paper utilizes Japanese cognate frequency to predict test accuracy.
1. Does Japanese cognate frequency influence response accuracy?
2. Does the effect vary by English word frequency and/or lexical proficiency?
Design/methodology/approach:
Seventy Japanese-English bilinguals completed the multiple-choice English VLT.
Data and analysis:
Accuracy data for 150 target items and 150 distractor items were analysed separately (10,500 data points in each analysis). Generalized linear mixed-effects models were used with Japanese cognate frequency as the primary predictor and English word frequency and lexical proficiency as covariates.
Findings/conclusions:
A strong facilitatory cognate frequency effect was observed on both the selection of targets and the rejection of distractor items. This effect was marginally greater for lower proficiency learners. The English word frequency effect was also greater for lower proficiency test takers in the distractor analysis.
Originality:
The paper is the first to utilize cognate frequency to estimate the cognate effect in different-script languages in language testing.
Significance/implications:
The study provides robust evidence for the Japanese-English cognate effect in a test of lexical knowledge. This finding is broadly in line with the predictions of the bilingual interactive activation plus model of bilingual lexical processing. In addition, the paper demonstrates that the proportion of Japanese cognates in the test is significantly greater than the proportion of cognates in the language in general, indicating that it may over-estimate Japanese learners’ knowledge of English lexis. Test designers and users are thus recommended to be aware of the impact of cognates when making inferences about language ability based on such tests of lexical knowledge.
Cross-linguistic influence is a central concern for bilingual language learning, teaching and assessment, and as such continues to receive considerable interest in the psycholinguistics and applied linguistics literature (Jarvis & Pavlenko, 2008). One of the primary sources of cross-linguistic lexical influence is cognates. From an etymological perspective, cognates are words that have descended from a common source, such as father and Vater, in English and German, respectively. From a psycholinguistic perspective, cognates are words that share formal (orthographic and/or phonological) and semantic overlap across languages (e.g., Dijkstra, 2007). A key difference between these two perspectives is how they define words sharing form and meaning in languages that are etymologically unrelated and do not share script (e.g., English and Japanese). From a linguistic perspective, translation pairs such as coffee-コーヒー/koohii/ in English and Japanese are referred to as loanwords. However, from a psycholinguistic perspective, such translation pairs are cognate because they are perceived to share form and meaning, regardless of their origin. As the psycholinguistic definition is adopted in this paper, such translation pairs in Japanese and English are referred to as cognates.
Many psycholinguistic studies with languages that share script have shown that when compared to noncognates, cognates typically facilitate acquisition (e.g., De Groot & Keijzer, 2000; Tonzar, Lotto, & Job, 2009), comprehension and production of lexis in a second language (L2) (e.g., Christoffels, de Groot, & Kroll, 2006; Dijkstra et al., 2010). Studies have also shown such cognate facilitation in languages that differ in script, such as English and Hebrew (Gollan, Forster, & Frost, 1997), Korean (Kim & Davis, 2003) and Japanese (Allen & Conklin, 2013; Miwa, Dijkstra, Bolger, & Baayen, 2014).
This cognate effect is perhaps best explained by connectionist models, such as the bilingual interactive activation plus model (BIA+; Dijkstra & Van Heuven, 2002). In the BIA+ model of visual word recognition, activation spreads through orthographic, phonological and semantic levels in a network. Cross-linguistic activation occurs when features are shared at any of these levels across languages. In the case of cognates, shared orthography and/or phonology leads to cross-linguistic activation of orthographic and phonological features, followed by shared semantic features, which facilitate word recognition. In other words, the shared features across languages provide a boost to the system, resulting in faster recognition. The BIA+ model can be generalized to languages that differ in script, such as Japanese and English, where the overlap in phonology and semantics mediates cross-linguistic activation (Miwa et al., 2014).
Cognates have also been shown to influence the probability of selecting correct responses in multiple-choice tests of lexical ability (Batista & Horst, 2016; Cobb, 2000; Elgort, 2013; Laufer & McLean, 2016; Meara, Lightbown & Halter, 1994). For instance, Elgort (2013) developed a bilingual version of the Vocabulary Size Test (VST; Nation, 2006) and investigated whether Russian-English cognates influenced test takers’ responses. The VST is a paper-and-pen format, multiple-choice test of receptive lexical knowledge and includes 140 target words randomly selected from the most frequent 1000-word frequency bands in the British National Corpus-Corpus of Contemporary American English (BNC-COCA) (i.e., 10 items from each of the 1–14k bands). In both monolingual and bilingual versions of the test, cognate items were more accurately selected, suggesting that test takers used their first language (L1) knowledge of Russian when selecting the correct English response. This was so regardless of whether the L1 was present or not in the answer choices. Importantly, because the two languages do not share a script, the phonological form of the cognate translation provided the basis for noticing formal similarity across languages.
The findings of Elgort’s study are pertinent because few studies have investigated how cognates in orthographically distinct languages influence accuracy in tests of lexical knowledge. This is despite the fact that many of the world’s language learners, notably those learning English, have a L1 that does not share script with the target language (e.g., Chinese, Korean, Arabic, Hebrew and Japanese ) and even though these languages can share thousands of highly frequent cognates with the target language. Moreover, tests of lexical knowledge, such as the VST, are frequently used to place students into level-appropriate classes in language learning situations. If such tests contain large numbers of cognates in certain languages, test takers with those languages as a L1 will benefit more than other test takers. Therefore, for test users, such as teachers, administrators and the test takers themselves, the inclusion of cognates may have important consequences.
Building on the previous research discussed above, the present study investigates the cross-linguistic influence of Japanese-English cognates on the scores of one of the most widely used tests of English lexical knowledge, the Vocabulary Levels Test (VLT; Schmitt, Schmitt, & Clapham, 2001). Prior to outlining the research questions, the test and the method of identifying cognates therein are described, followed by a brief critique of previous studies investigating cognates in the Japanese context.
The Vocabulary Levels Test
The VLT was originally developed by Nation (1983, 1990) and has become established as a widely used, standard test of receptive L2 vocabulary knowledge in both classroom and research contexts. The VLT has been validated in a number of studies (Beglar & Hunt, 1999; Read, 1988) and updated versions have been produced and validated. In the present study, we use Version 2 of the revised VLT primarily because it was extensively validated by Schmitt et al. (2001) and represents a “major improvement on the old levels test” (Nation, 2001: 676).
In the VLT, test takers must select the correct synonym or definition for each target word from among a number of distractor items, as below.
business
clock ______ part of a house
horse ______ animal with four legs
pencil ______ something used for writing
shoe
wall
Target and distractor items are drawn from five frequency band levels (2k, 3k, 5k, 10k and Academic) from the following corpora: Thorndike and Lorge (1944), Kučera and Francis (1967), the General Service List (West, 1953) and the Academic Word List (Coxhead, 2000). Ten sets of six words (three targets and three distractors) are included at each frequency level. Each set has three definitions provided, and participants must select the three appropriate words from the available six. In total, there are 150 target items and 150 distractors, and each target item receives a score of 1 for a correct response. Items are sampled so that the ratio of word classes reflects that of the language as a whole (i.e., 3 (noun):2 (verb):1 (adjective)). Further information on the design of the test can be found in Nation (1990) and Schmitt et al. (2001).
Identifying Japanese cognates
To assess the number of items in the VLT that have cognates in Japanese (e.g., coffee-コーヒー/koohii/), the most expedient solution is to utilize word frequency data from corpora. The recently completed Balanced Corpus of Contemporary Written Japanese (BCCWJ) is the most comprehensive corpus of Japanese produced to date and contains approximately 104 million words (Maekawa et al., 2014) from newspapers, magazines, fictional and non-fictional texts.
Using the BCCWJ, it is possible to assess both the number of cognates that exist in the test as well as their respective frequency in Japanese. This is crucial because while there are many thousands of cognates in Japanese, many of them may be low frequency and thus may not be known. For instance, research shows that of the most frequent 10,000 headwords in the English language according to the BNC-COCA wordlists (Davies, 2008; Nation, 2012), 49% are found in the BCCWJ (Allen, 2018). However, only 22% of the cognates have a frequency of one occurrence per million words or more, suggesting that many cognates will be such low frequency that some Japanese speakers may not have encountered them before. In the present study, therefore, Japanese word frequency is used to investigate the cognate facilitation effect. By doing so, not only are cognates distinguished from noncognates (i.e., by their existence or not in the corpus), but also the frequency of the cognates provides further information with which to predict the influence of cognates on accuracy rates in the VLT.
Japanese-English cognates in lexical tests
Although a small number of studies have investigated Japanese-English cognates in tests of lexical ability (e.g., Jordan, 2012; Laufer & McLean, 2016) they have suffered from serious limitations, most notably the small number of cognates included in the analyses. For instance, Jordan (2012) conducted an English-to-Japanese translation task and observed a significant advantage in accuracy for cognate items. However, only 14 cognate items were included in the analysis and these were drawn from three different frequency bands. More recently, Laufer and McLean (2016) investigated the impact of Japanese-English cognates in a test that included three question types: recall of word form; recall of word meaning; and recognition of word form. A cognate advantage was observed in all tests and at three different levels of proficiency. The findings are not conclusive, however, because of the small number of participants at the advanced proficiency level (e.g., n = 3 for the active recall condition and n = 2 for the passive recall condition; p. 210) and because accuracy was measured for only 13 cognates, drawn from seven different frequency bands. In addition to the small number of items, both of these studies lacked any indication of the frequency of the Japanese cognates. Given that Japanese cognates vary greatly in terms of their frequency, omitting this information represents a methodological weakness.
The present study
The aim of the present study is to investigate the extent to which L1 (Japanese) cognates influence the accuracy of test takers’ responses on a test of receptive L2 (English) lexical knowledge. To this end, the following research questions were formulated.
How does L1 cognate frequency affect response accuracy in a test of receptive L2 lexical knowledge? Are L2 target words with higher L1 cognate frequencies selected more often than those with lower L1 cognate frequencies? Are L2 distractor words with higher L1 cognate frequencies rejected more often than those with lower L1 cognate frequencies?
If there is a cognate advantage for targets and/or distractors, does it vary by L2 word frequency?
If there is a cognate advantage for targets and/or distractors, does it vary by test takers’ lexical proficiency?
The primary variable of interest in this study is L1 Japanese cognate frequency, the data for which were obtained from the BCCWJ. These word frequencies were used to determine whether cognates that were more frequent in the L1 were more accurately responded to in English than those with less frequent cognates or no cognate form (indicated by zero frequencies in the corpus). Japanese word frequency thus acted as a proxy for cognate knowledge: if the L1 Japanese cognate frequency is high, participants are expected to know the word in the L1 and this is expected to be revealed in a cognate facilitation effect on responses to such words. Conversely, if the cognate frequency is very low or zero in the corpus, the cognate is unlikely to be known and therefore unlikely to affect the accuracy of responses.
In addition, because previous research (Elgort, 2013; Jordan, 2012; Laufer & McLean, 2016) has implicated both L2 word frequency and L2 proficiency as modulating factors of the cognate effect, the contribution of these two variables was investigated. English word frequency was included in the analysis to determine whether it interacted with any observed cognate effect. Specifically, words that are higher frequency are expected to show reduced cognate facilitation as a result of a ceiling effect. In other words, because accuracy rates are so high for high-frequency words, the impact of cross-linguistic similarity is expected to be minimal.
L2 lexical proficiency was included in the analysis as a control predictor with the expectation that the cognate effect may be greater for L2 users with lower language proficiency (Elgort, 2013; Van Hell & Tanner, 2012). In a similar manner to the attenuation of the cognate effect for higher frequency words, high-proficiency learners process lexical items more quickly and accurately than lower proficiency learners, thus minimizing the potential for cross-linguistic similarity to impact responses.
Method
Participants
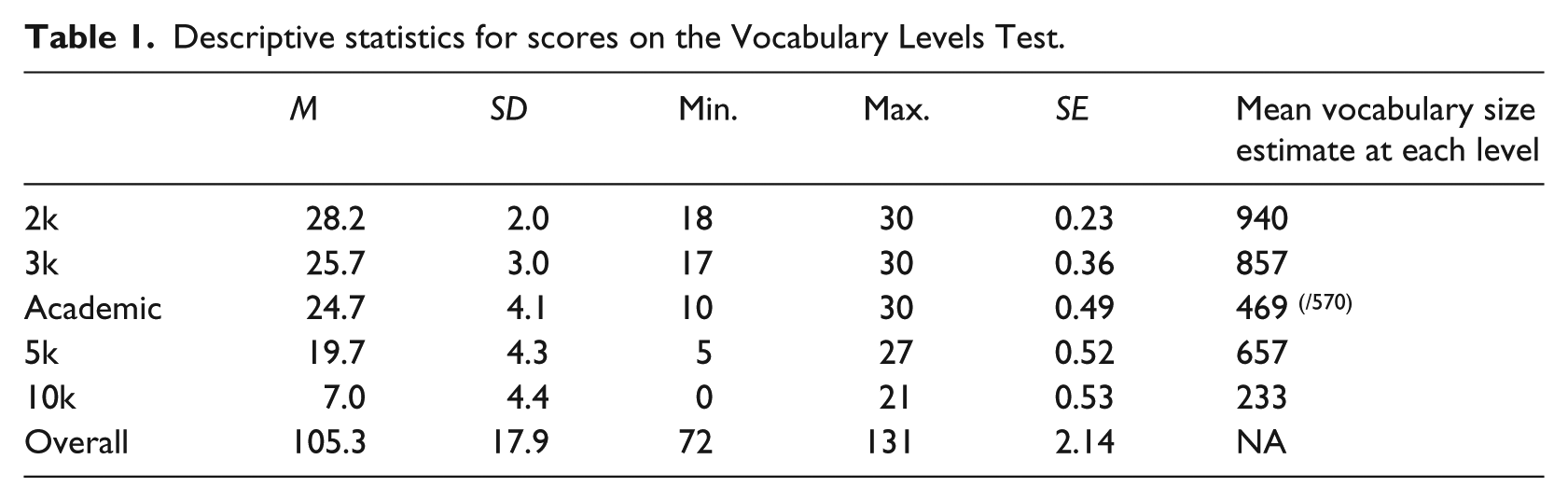
Seventy Japanese native speaker participants (42 female, mean age = 19.3, SD = .64) enrolled in English language courses at two universities in metropolitan Tokyo completed the VLT during class for course credit. Total scores were smoothly distributed across a range of 72–131 (M = 105.3, SD = 13.6). Overall, the mean scores (max = 30) 1 are lower at lower frequency bands (Table 1). Similarly, the mean estimate of vocabulary size at each level decreases.
Descriptive statistics for scores on the Vocabulary Levels Test.
Materials
For the 300 English words in Version 2 of the VLT (Schmitt et al., 2001), the Japanese cognate word frequency was extracted from the BCCWJ word frequency list (National Institute for Japanese Language and Linguistics, 2013). The database includes the English words as “lemmas” that denote the origin of Japanese cognates. For example, next to the Japanese word グロバル /gurobaru/ is the English lemma global. An exact match search using the English test items was conducted excluding derivative forms; in other words, only if the exact word form was identified in the Japanese corpus did it have an associated Japanese word frequency. If an English word had no Japanese cognate in the BCCWJ, its Japanese cognate frequency was zero.
Two proficient Japanese-English bilinguals checked the cognates to ensure that none were false friends. Five items were considered to be potentially problematic in that they may have been used in Japanese with an unrelated meaning to that of the English word. Since this comprised such a small proportion of the total items analysed (2%), it was unlikely to affect the outcome; however, to be sure, analyses were conducted with and without the five items. The resulting statistical models were close to identical. Consequently, the analyses including these items are presented.
Table 2 provides the word frequency data of target and distractor items that were found to have cognates in Japanese. Of the 150 target items, 89 (59%) had cognate frequencies of one occurrence or more, and half of these (45; 30%) had frequencies of one or more occurrences per million words. Of the 150 distractors, 89 (59%) had frequency data for cognate equivalents, with 62 (41%) occurring at least once per million words. Cognates were distributed across the English frequency levels but were more common in the highest frequency (2k, 3k) and academic bands. Table 2 also provides the descriptive data for English word frequencies (per million words) taken from the SUBTLEXUS corpus (discussed below).
Median frequency (per million words) data and number of cognates for target and distractor items.

BCCWJ: Balanced Corpus of Contemporary Written Japanese.
Procedure
The test was administered during normal class time. Thirty minutes were given to complete the test, which seemed appropriate for the present sample and was similar to the participants in Schmitt et al. (2001), who averaged 31 minutes. Participants were instructed to complete the test to the best of their ability. The test was administered under test conditions, in paper-and-pen format, and the use of dictionaries or other resources was not permitted.
Data analysis
The binary test data was analysed using generalized linear mixed models (GLMMs) with a binomial distribution, also referred to as mixed logit models. GLMMs are suitable for designs that include non-normally distributed dependent variables, multiple independent variables and random variables (Baayen, 2008). The analyses were conducted in R version 2.11.1 (R Core Development Team, 2010) using the function glmer in the package lme4 (version 1.1-7; Bates, Maechler, Bolker, & Walker, 2015).
Separate analyses were performed on the 70 participants’ responses to 150 target items and to 150 distractors (i.e., 10,500 data points in each analysis). In the target item analysis, correct responses were scored as 1 and incorrect responses were scored as 0. In the distractor item analysis, if a distractor was selected as the response it was scored as 1 and if not, it was scored as 0. If L1 cognate frequency influenced the accuracy of responses, higher selection rates should be expected for target items with more frequent L1 cognate translation equivalents. Conversely, lower selection rates (in other words, higher rejection rates) for distractors should be expected based on those that have higher cognate frequency in Japanese.
The primary predictor of interest is Japanese cognate frequency, which consisted of raw frequency data taken from the BCCWJ. In addition, two covariates were included in the models: English word frequency and lexical proficiency. English word frequency data were taken from the SUBTLEXUS corpus (Brysbaert & New, 2009), which has been shown to be a reliable predictor of lexical response behaviour in numerous psycholinguistic studies of bilingual processing. Lexical proficiency was measured using participants’ raw score on the VLT (max = 150), which provides the most relevant information about language learners’ receptive lexical knowledge and therefore is suitable for the present statistical analysis. Both the English and Japanese word frequencies were log-transformed (base e) to improve linearity and reduce random variance and all predictors were centred for the regression analyses (Baayen, 2008).
Because the word frequency predictors were correlated, each predictor was regressed against the other in a separate model. The residuals of these models, which were highly correlated with the original predictors (r = 0.9; ps < .001), were used as predictors in the analysis. All two- and three-way interactions were included in the initial model. Non-significant interaction terms were removed from the model in a backwards simplification procedure in which the simplified model was compared with the previous model using a log-likelihood ratio test (p<.05). The final models resulting from this procedure are presented. Random intercepts for items and participants and random slopes for the two frequency predictors were included. When including interactions within the random effects structure, however, the models failed to converge and thus random slopes for the interactions were omitted from the analyses. The model estimates (β) provided are log-odds ratios that demonstrate the size of each main effect or interaction (a larger estimate means a larger effect).
Because previous cognate studies have tended to utilize a binary cognate/noncognate distinction, a similar predictor was included in place of Japanese cognate frequency. The cognate status factor was created using the Japanese cognate frequency data: all English items that had a Japanese cognate in the BCCWJ were labelled “cognate” and all those without were labelled “noncognate”. However, because a very low cognate frequency may indicate that the word may be unknown in the L1, a more conservative threshold of one occurrence per million words was used in a second cognate status predictor; in this case, all words that had cognates occurring at or above 1 per million words were labelled “cognate” and those with less than that were “noncognate”. These two cognate status measures were used in turn in separate models and in place of Japanese cognate frequency.
Results
Target item analyses
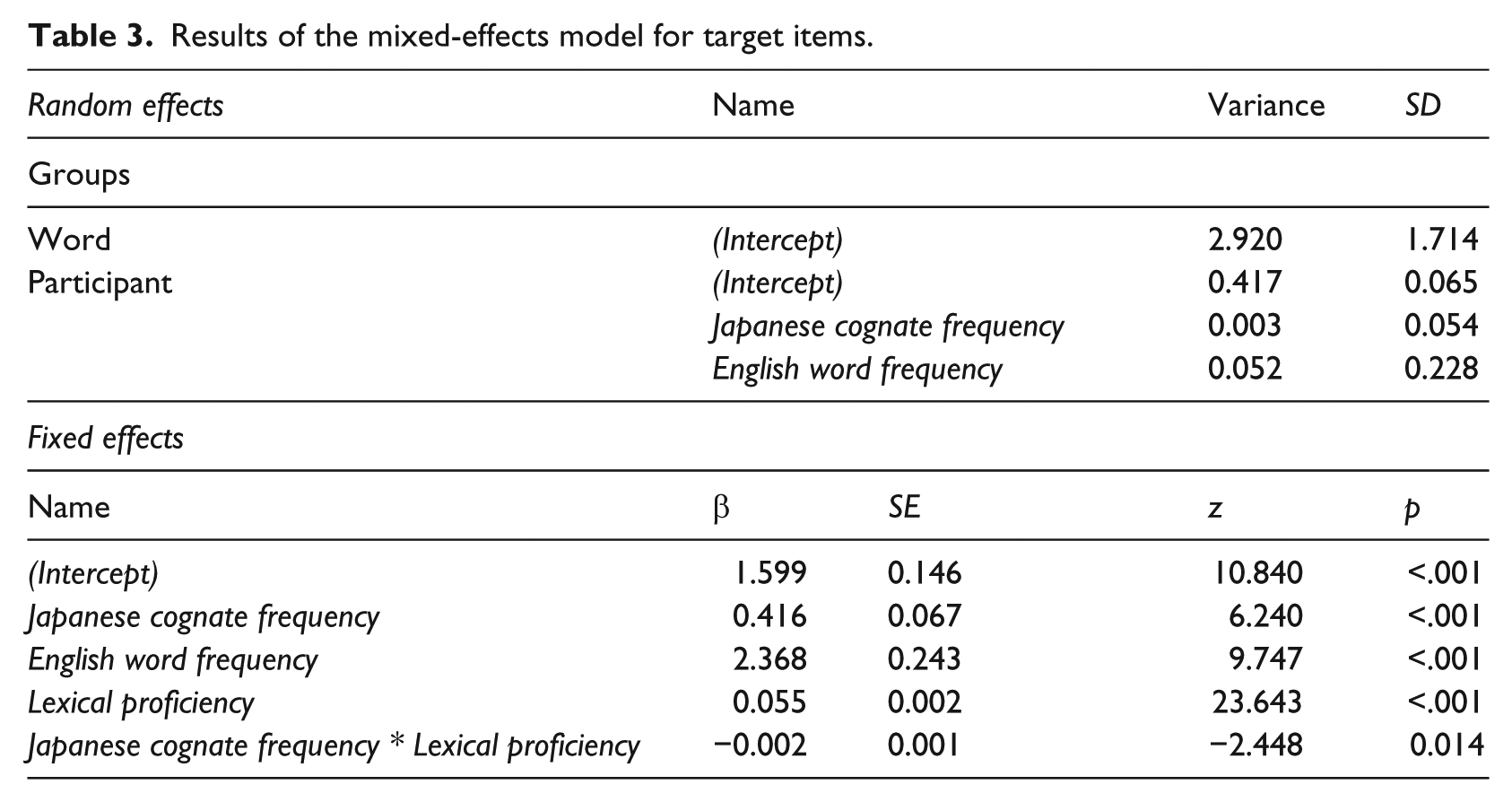
The result of the GLMM for the target items revealed a significant main effect of Japanese cognate frequency on accuracy rates. Specifically, English words with higher frequency Japanese cognates were more accurately selected than those with lower frequency cognates and those with no cognates (Table 3). The covariate English word frequency was highly significant, showing that more frequent targets were more accurately selected than less frequent targets. The second covariate, lexical proficiency, was also highly significant, showing that participants with higher lexical proficiency responded more accurately to target items than those of lower proficiency.
Results of the mixed-effects model for target items.
In addition, a significant interaction was observed between Japanese cognate frequency and participants’ lexical proficiency. This revealed that the cognate effect was greatest for lower proficiency test takers, while higher proficiency test takers were much less affected by differences in Japanese cognate frequency (Figure 1).
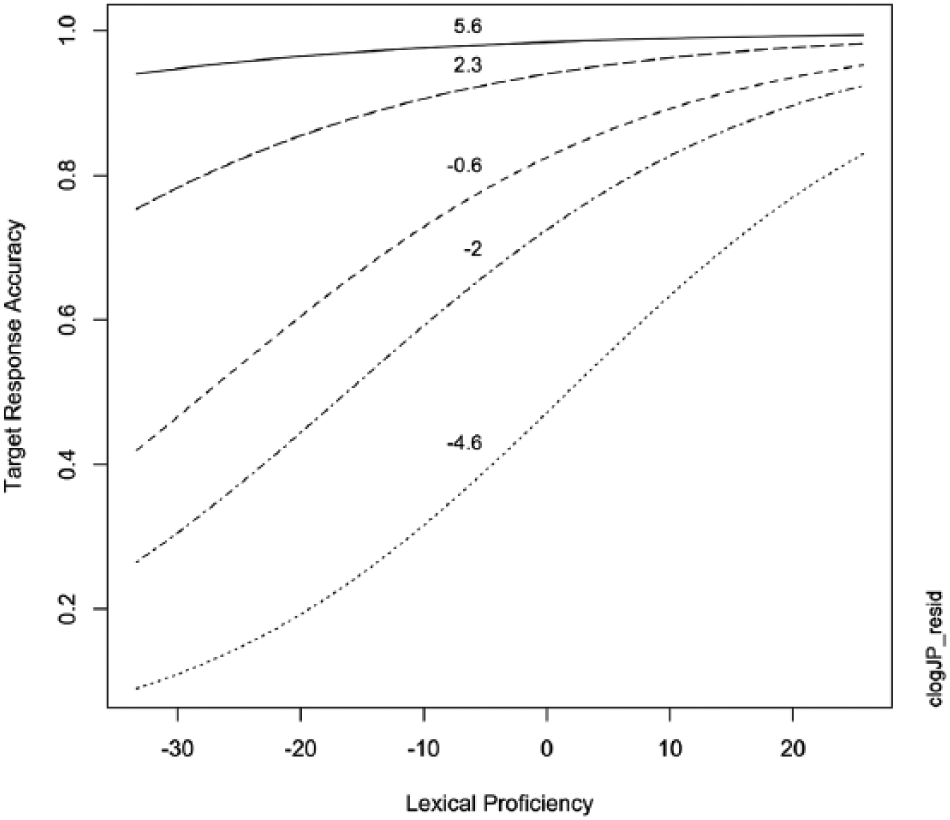
Plotted interaction of effects of log-transformed Japanese cognate frequency and lexical proficiency on target accuracy. Both measures are centred on the mean (zero), so lower values represent lower frequency/proficiency and higher values represent higher frequency/proficiency.
The above analysis was repeated replacing Japanese cognate frequency firstly with the binary cognate status predictor variable and secondly with the more restrictive cognate status predictor (⩾1 occurrence per million words). In both cases, the cognate status predictor remained significant in the final models, such that cognate items were more accurately responded to (β = −1.796, SE = .342, z = −5.251, p < .001; and β = −1.640, SE = 0.565, z = −2.903, p < .01, respectively).
Distractor item analyses
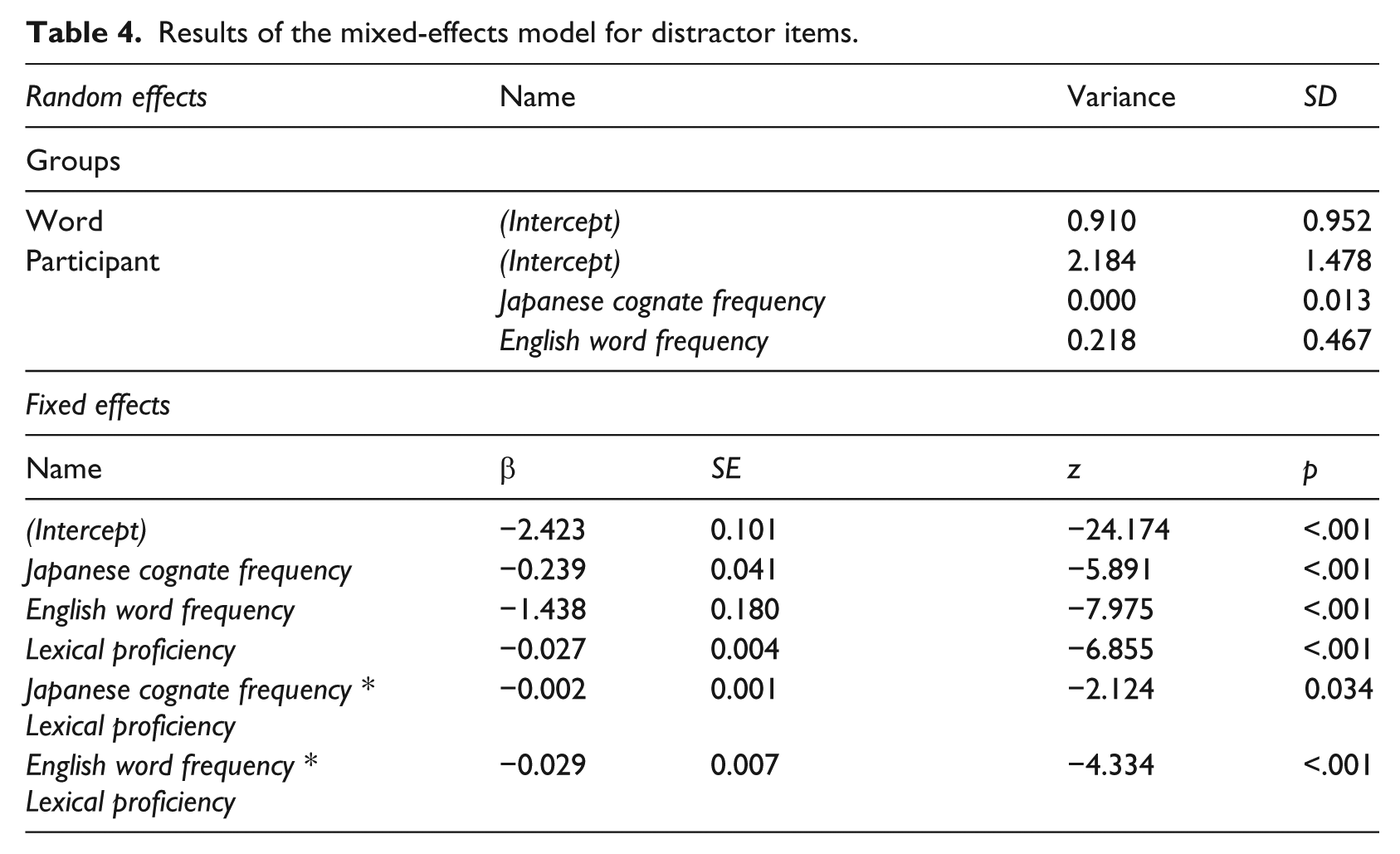
The result of the GLMM for the distractor item analyses revealed that all main effects were significant but all effects were in the opposite direction to those in the target items analysis (Table 4). That is, higher cognate frequency led to higher rejection rates, items with higher English word frequency were rejected more accurately and participants with higher lexical proficiency rejected more items accurately.
Results of the mixed-effects model for distractor items.
In addition, a significant interaction was observed between Japanese cognate word frequency and participants’ lexical proficiency, which shows that responses of lower proficiency test takers were more greatly affected by cognate frequency than those of higher proficiency learners (Figure 2). A significant interaction between English word frequency and lexical proficiency revealed that, in general, lower proficiency learners also experienced a greater word frequency effect than higher proficiency learners (Figure 3). However, Figure 3 also reveals that the lowest frequency distractors (i.e., at the 10k level) were more likely to be selected by higher proficiency participants.
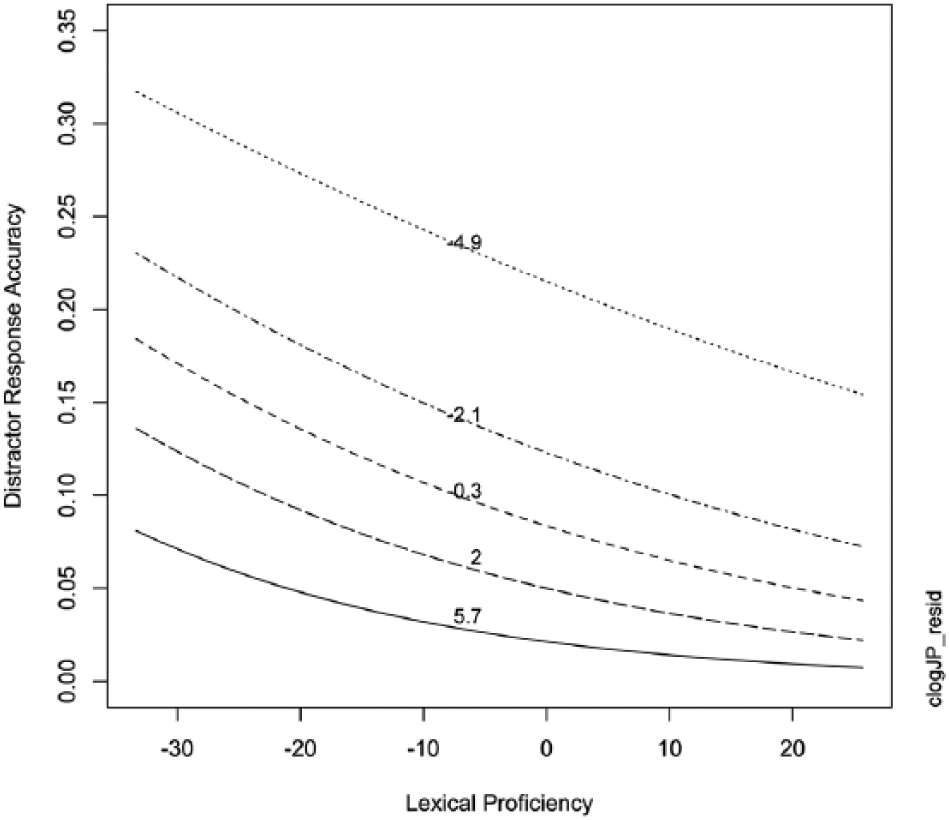
Plotted interaction of the effects of log-transformed Japanese cognate frequency and lexical proficiency on distractor accuracy. Both measures are centred on the mean (zero), so lower values represent lower frequency/proficiency and higher values represent higher frequency/proficiency.
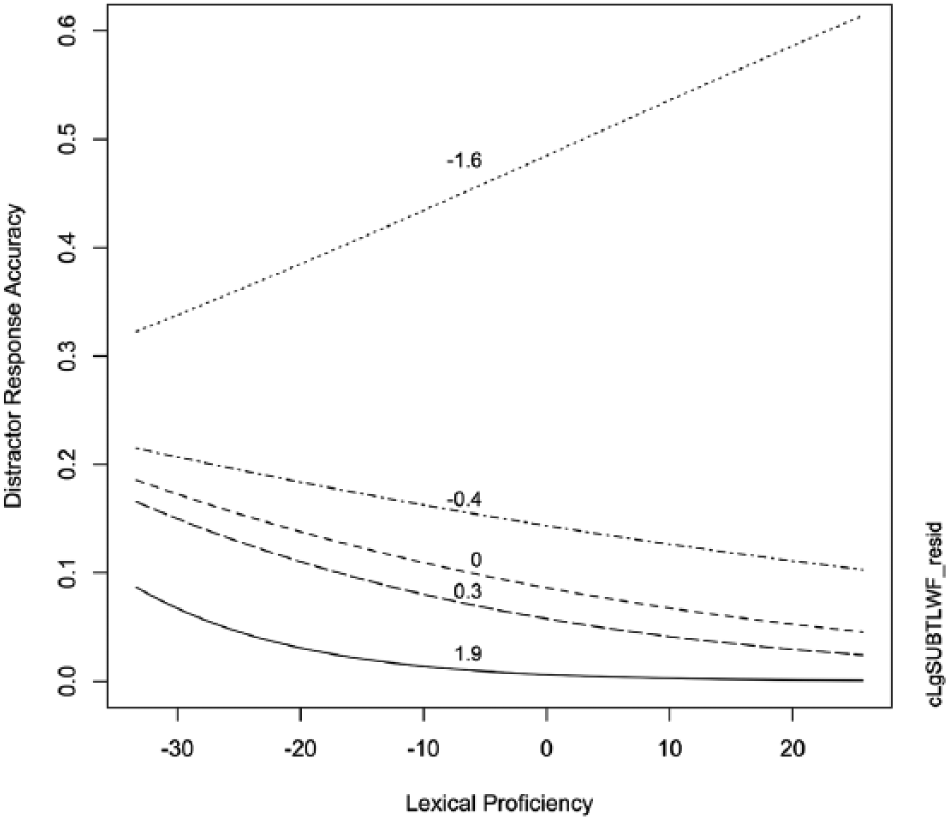
Plotted interaction of effects of log-transformed English word frequency and lexical proficiency on distractor accuracy. Both measures are centred on the mean (zero), so lower values represent lower frequency/proficiency and higher values represent higher frequency/proficiency.
Again, the above analysis was repeated replacing Japanese cognate frequency with the two cognate status predictor variables. In both cases, the cognate status predictor was significant in the final models, such that cognate distractors were more accurately rejected than noncognate distractors (β = 0.987, SE = .186, z = 5.310, p < .001; and β = 1.348, SE = .348, z = 3.499, p < .001, respectively).
Discussion
The results revealed a strong cognate advantage for Japanese test takers on a receptive test of English lexical knowledge. Japanese cognate frequency was a strong predictor of both target selection and distractor rejection, leading to higher accuracy rates for cognate items with higher L1 frequency. Furthermore, two binary cognate status measures were also strong predictors of accuracy, in line with previous findings (e.g., Elgort, 2013).
These findings are consistent with the theoretical interpretation of the BIA+ when generalized to languages that differ in script (Miwa et al., 2014). Word recognition in the test involves accessing form and meaning information in the English (L2) lexicon. As part of this process, sublexical activation of phonology of the English word is assumed to co-activate the overlapping sublexical phonology in the L1, leading to activation of phonological lexical representations in each language. This co-activation of phonological lexical representations, in addition to cross-linguistic activation at the semantic level, leads to faster lexical access and higher accuracy.
Although the size of the effect was larger for both cognate status predictors when compared to the effect of Japanese cognate frequency, it is recommended that researchers utilize the latter because it provides a more informative measure of whether cognates are likely to be known in Japanese, and thus whether they are likely to predict response accuracy. The present results do, however, support the use of a cognate status factor that is derived from cognate frequency data. Because there are so many thousands of cognates in Japanese, it is difficult to know which words exist as cognates and which are likely to be known. Utilizing frequency data is therefore clearly the most expedient method of determining which words are cognate in Japanese. There are some limitations to this approach, however, and these are discussed in the final section of the paper.
Further findings concern the interactions with cognate frequency. Firstly, the cognate effect was significantly greater for lower proficiency learners, concurring with previous studies in assessment (Elgort, 2013) and psycholinguistics (Van Hell & Tanner, 2012). While all learners benefitted from the cognate effect, the lower proficiency learners benefitted more. This is because lower proficiency learners process words more inaccurately due to weaker form–meaning associations in the lexicon, which makes the beneficial effect of cognates more apparent.
Secondly, in the distractor analysis, the L2 frequency effect upon accuracy was generally attenuated by lexical proficiency. In other words, responses by higher proficiency test takers were less affected by English word frequency than those of their lower proficiency peers. In a general sense, this may be explained by the fact that accuracy for higher proficiency test takers was much higher overall, whereas lower proficiency test takers’ responses were considerably much more accurate for high-frequency English words than for low-frequency ones. From a psycholinguistic perspective, more proficient bilinguals have used the L2 more, thereby strengthening form–meaning connections to a greater extent and for a greater number of words compared to less proficient bilinguals. This would also entail a smaller frequency effect for more proficient test takers relative to lower proficiency test takers.
However, there was also a notable difference in participants’ accuracy of rejecting distractor items at the lowest word frequency level. That is, higher proficiency test takers were more likely to incorrectly select distractor items of very low English frequency than lower proficiency test takers. This finding reflects the fact that higher proficiency participants were more likely to respond to the questions at the lowest frequency band (both accurately and inaccurately), while lower proficiency participants were more likely to leave these questions unanswered (thereby accurately rejecting all distractors). This makes sense considering the instructions of the VLT provided prior to the test, which state that test takers should not guess if they have no knowledge of the target word, but should attempt questions to which they think they know the answer (Schmitt et al., 2001). Higher proficiency learners were thus more likely to attempt lower frequency items because they believed they knew them, resulting in lower accuracy in rejecting the distractors compared to lower proficiency test takers who did not attempt the questions.
The cognate frequency effect was equally apparent for items regardless of their L2 frequency. In other words, there was no interaction between L1 and L2 frequencies. It is possible that because tests of lexical knowledge measure accuracy but not response times, subtle interactions between word frequencies are not readily observable. For instance, Miwa et al. (2014) found that in an English (L2) lexical decision task, the English frequency effect was attenuated by Japanese (L1) frequency. In other words, when words had higher Japanese frequency they were less influenced by English word frequency. In their study, eye-movements were monitored, allowing for a more precise examination of the time course of lexical processing during lexical access. In contrast, when examining the cognate effect in tests of lexical knowledge that are used for placement purposes, such as the VLT, word frequency interactions may be more difficult to observe.
Implications for assessing lexical knowledge
As demonstrated above, cognates confer an advantage to test takers relative to noncognates in this test of receptive lexical knowledge. The proportion of cognates included therefore affects the difficulty of tests. More importantly, when attempting to estimate learners’ L2 lexical knowledge, the inclusion of cognates may distort the inferences that can be drawn from the test scores. Therefore, the proportion of cognates needs to be investigated and controlled when designing and evaluating such tests.
In order to control the proportion of cognates in a test that is used with learners of a specific L1, it is important to refer to corpora to determine the prevalence of cognates shared in the languages. In the case of English and Japanese, Allen (2018) showed that the total proportion of Japanese cognates in the most common 10,000 words of the English language according to the BNC-COCA lists is 49%, and the proportion that occur once or more per million words in Japanese is 22%. The total proportion of cognates (targets and distractors) in the VLT used in the present study was 61% (176/290 items), with 37% (107/290 items) occurring at or above one per million words. 2 According to chi-square tests, the difference between the proportion of cognates occurring in the test and the proportion shared across languages in general was significant (61% versus 49%, respectively; X2(1) = 14.33, p < .001), and this difference was also significant for cognates occurring once per million words (37% versus 22%; X2(1) = 36.53, p < .001). Thus, when considering both target and distractor items, the test over-represents cognates. When analysing just the target words, which are arguably the more important items in the test, 61% were cognate (87/143 items), with 32% at or above once per million words (45/143 items). These proportions were both significantly different from those found in the reference corpus (61% versus 49%; X2(1) = 8.69, p < .01; and 32% versus 22%, X2(1) = 8.11, p < .01, respectively).
When focusing on specific levels, the difference is as much as 21% for targets at the academic word level when comparing the proportion of cognates in the test and in the Academic Word List (Coxhead, 2000) as a whole. However, because the VLT was created with reference to multiple wordlists, some items found to be in a particular band level on the test were found in other levels in the BNC-COCA lists, making a band-level comparison impractical. To facilitate such an analysis, the same corpora, preferably large representative corpora such as the BNC-COCA, must be used in both the test design and evaluation stages.
All in all, the proportion of Japanese cognates in the VLT appears to be significantly larger than that in the Japanese language in general. The VLT may therefore lead to an over-estimation of lexical knowledge when used with Japanese learners of English. It is recommended that future versions of tests that are aimed at specific populations (such as a Japanese bilingual VLT) take into account the proportion of cognates in order to provide a more reliable assessment of test takers’ English lexical knowledge. To achieve this, corpus frequency data should be used to expediently assess the number of cognates and their respective frequencies.
The implication for teachers and administrators is that the VLT may provide a somewhat different impression of a learners’ lexical ability depending on their L1. For learners with L1 Japanese, the VLT score is likely to give a slightly inflated estimation of lexical knowledge, while for learners whose L1 shares fewer cognates with the items in the test, the scores may provide a comparatively deflated estimation. Thus, it is recommended that when using lexical tests such as the VLT for placement purposes, additional information to the test score should be taken into consideration whenever possible.
Limitations and future directions
Although using corpus frequencies is recommended as the most efficient means to estimate L1 cognate knowledge, it is not a perfect solution for a number of reasons. Firstly, cognate facilitation may not be uniform for all cognates and may be attenuated for particular items or due to particular features of the test. To investigate this, an analysis of the mean response data for items organized by accuracy then cognate word frequency was conducted. It was found that there were eight cases where cognate targets featured as some of the least accurately selected items. These cognates appeared to have been inaccurately rejected due to a difference in the Japanese cognate meaning and the meaning provided in the question prompt. For example, mammoth-マンモス, which appeared at the 10k level and is a familiar although infrequent cognate in Japanese, was targeted for its non-borrowed sense (“immense”) instead of its borrowed sense (“the animal”).
Such cases are in part a reflection of the test format (only one sense can be tested) but also show the test takers’ reluctance to select a cognate target if the meaning in the test prompt was different from the meaning of the cognate in Japanese. In these instances, the existence of cognates in the L1 apparently caused difficulties for test takers. Of course, this is not simply an issue of cognates but also of depth of lexical knowledge: had the test takers known the items in more depth in the L2 (i.e., known a wider range of word senses), they would not have had such difficulty. Moreover, only eight instances were identified out of the 179 cognate items, suggesting that this issue is indeed marginal to the overall advantage afforded by cognates.
Secondly, the analysis also highlighted the margin of error inherent with using word frequencies as an indicator of lexical knowledge. In one case, a target word that was cognate according to native speaker informants did not have cognate frequency data in the BCCWJ (octave-オクターブ). Also, one target cognate was reasonably frequent but may not have been known in the L1 due to its content-specificity (bourgeois-ブルジョア, 10k). Overall, while the number of such cases was extremely small and such a margin of error may be negligible, word frequency data will never provide a perfect indication of the likelihood that speakers know a particular word, or in this case, cognate (see Allen, 2018, for further discussion on approaches to estimation).
Conclusion
In conclusion, the present study demonstrated a strong cognate advantage for Japanese L1 learners of English on the VLT. This advantage was observed in the selection of targets and the rejection of distractors, further attesting the cognate facilitation effect in tests of lexical knowledge. Most importantly, this cognate facilitation was observed using cognate frequency as the predictor of the effect and with bilinguals whose languages are orthographically distinct and unrelated. The major implication of the study for test designers is that the proportion of cognates should be controlled. To this end, L1 frequency data should be used to provide an indication of the cognate status and the likelihood that the cognate is known in the L1. The major implication for test users is that the VLT may provide a somewhat inflated (or deflated) measure of lexical knowledge depending on the test takers’ L1.
Supplemental Material
Appendix-Final – Supplemental material for Cognate frequency and assessment of second language lexical knowledge
Supplemental material, Appendix-Final for Cognate frequency and assessment of second language lexical knowledge by David Allen in International Journal of Bilingualism
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplementary material
Supplementary material is available for this article online.
Notes
Author biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.