
Abstract
Long-span cable-stayed bridges, integral to traffic infrastructure, require robust structural health monitoring(SHM) systems to withstand multi-load environments like earthquakes and wind vibrations. Traditional monitoring systems encounter challenges such as redundant sensor data, reliance on sensor quantity and quality, and a scarcity of real damage data. This study introduces a hybrid framework combining finite element model updating with deep learning to overcome these issues. Utilizing the OpenSees platform, a finite element model of the bridge is developed and refined using the Bayesian Optimization to update four critical parameters. A structural response database is created under various excitations, such as white noise, ground motions, and wind loads. A multi-head attention bidirectional LSTM (MHA-BiLSTM) network is employed, using acceleration data from main beam sensor locations to accurately predict displacements of the main beam and tower under single and cross-load scenarios, achieving an average
Keywords
Introduction
Structural health monitoring (SHM) is integral to bridge maintenance, enabling the assessment of structural damage and performance changes. Traditional SHM methods, such as visual inspections, magnetic techniques, and vibration analysis (Zinno et al., 2022), have long been employed but exhibit significant limitations. Certain bridge areas remain inaccessible for inspection, operations may need to be halted for maintenance, and internal damage often goes undetected. Additionally, human error is an unavoidable concern (Zhang et al., 2025). Another critical issue is data redundancy due to numerous sensors and high computational demands. Although various solutions have been proposed, they remain constrained by the data type and volume requirements necessary for accurate bridge health monitoring (Gao et al., 2020; Larson et al., 1994; Shan et al., 2011; Soman et al., 2013; Yi et al., 2014).
Artificial intelligence has significantly advanced technologies related to Structural Health Monitoring (SHM). Deep learning-based structural health monitoring is a promising approach to address this issue (Cha et al., 2024). In the realm of damage identification, model-based parametric techniques are commonly employed. Researchers have explored the use of artificial neural networks (ANN) and online sequential extreme learning machines (OS-ELM) for precise and efficient structural damage prediction (Hakim et al., 2015; Meruane, 2016). Abdeljaber et al. (2017) introduced a non-parametric method utilizing one-dimensional convolutional neural networks (CNN) for structural damage identification, demonstrating exceptional generalization capabilities. Real-time and continuous long-term health monitoring are key focal points in structural health monitoring. Ferguson et al. (2024) proposed a data sampling method based on traffic volume to overcome resource constraints in long-term SHM, thereby enhancing resource utilization efficiency. Entezami et al. (2024) suggested an advanced unsupervised learning approach for SHM that integrates AI, data sampling, and statistical analysis to address the challenges associated with complex data management in long-term structural health monitoring. The integration of SHM with convolutional neural networks has garnered significant attention in recent years (Azimi et al., 2020). Deng et al. (2023) addressed the challenge of missing data in traditional data-driven structural health monitoring (SHM) methods by employing a long short-term memory (LSTM) structured autoencoder (AE) framework. In a similar vein, Liu et al. (2025) introduced a CNN bidirectional LSTM(BiLSTM) network capable of effectively reconstructing long-term missing acceleration responses in SHM. Ho et al.(2025) proposed a two-step damage identification approach without pristine data, which eliminates the need for raw data of intact structures, features strong noise resistance, and low computational cost. This approach provides a reliable damage identification solution for existing bridges lacking initial health data. Nguyen-Ngoc et al. (2024) integrated deep neural networks (DNNs) with an evolved Artificial Rabbit Optimization (EVARO) algorithm for structural damage assessment. This method can effectively avoid local minima, thereby enhancing the reliability of the results. Li et al. (2023) proposed a data augmentation strategy to extract more comprehensive signal anomaly features, thereby mitigating the impact of redundant information on supervised learning efficiency. Nevertheless, obtaining authentic damage data crucial for training machine learning models in SHM applications, particularly under extreme conditions, remains a significant challenge for civil structures. The scarcity of such data, exacerbated by climate change and human activities, poses a notable obstacle, especially considering the increasing exposure of bridge structures to diverse and complex disasters (Ellingwood, 2010; Petrini and Palmeri, 2012). To address this gap, a Performance-Based Hurricane Engineering (PBHE) framework has been suggested to account for concurrent and interacting disaster sources (Barbato et al., 2013). Research focusing on extreme scenarios such as multi-loads is deemed essential (Kameshwar and Padgett, 2014; Petrini et al., 2020). The scarcity of authentic damage data for machine learning applications may result in reduced prediction and damage identification accuracy in practical SHM implementations.
In the past, finite element modeling was commonly utilized for predicting structural responses. However, the inherent complexity of structures and initial imperfections often leads to inaccuracies in ideal models, necessitating updates to enhance predictive precision (Estefen et al., 2016; Graves et al., 2023; Sharry et al., 2022). While some model updating techniques offer computational advantages, they may compromise the physical significance of the mass and stiffness matrices in the updated finite element model, thereby impacting model reliability (Kanev et al., 2007). Addressing this issue, the iterative Finite Element Model Updating (FEMU) method, also known as the deterministic parameter updating method, minimizes the disparity between measured and calculated values by iteratively adjusting model parameters. By preserving the physical interpretations of the mass and stiffness matrices, this method yields more dependable computational results and is alternatively referred to as sensitivity-based updating (Mottershead et al., 2011). The sensitivity-based updating method is limited by its disregard for noise and long-term measurement changes. Asadollahi et al. (2018) employed the FEMU stochastic method, which uses Bayes’ theorem to estimate the posterior probability density function of model parameters. This method trades some computational efficiency for the ability to account for data variability (Jang and Smyth, 2017). Han et al. (2025) constructed a lightweight surrogate model of the FE mdel using the Polynomial Chaos Expansion (PCE) model, which can reduce the computational cost of FE analysis and efficiently reflect the relationship between input parameters and system response. Similarly, the Kriging model can also be employed as a surrogate model for the finite element (FE) model (Qin et al., 2024). Qin et al. (2025) proposed a low-error two-stage adaptive weighting method based on measured static displacements and modal frequencies, thereby improving the accuracy of finite element model updating for bridge structures. These efforts have notably enhanced the reliability of structural response data generated by finite element models. Employing the updated physical model to simulate training damage data offers a viable solution to these challenges (Wang et al., 2023).
This study introduces a innovative framework that integrates a physical model with deep learning to tackle existing challenges. High-precision physical model data on structural damage are employed to train a deep learning model, resulting in a BiLSTM model that accurately predicts structural displacements. This approach addresses the lack of real damage data for large, complex structures in conventional deep learning models for structural response prediction. The framework includes a multi-task network with a BiLSTM and a multi-head attention mechanism. This mechanism, which focuses on structural modal and channel-level attention, identifies critical channels and time steps, thereby enhancing model training efficiency and prediction accuracy. In practical applications, this method reduces dependency on numerous displacement gauges in traditional bridge health monitoring systems. Instead, it utilizes accelerometer data from specific sections to derive bridge displacement data. The framework not only further incorporates the effects of complex load conditions but also fully considers compatibility with existing engineering systems, which plays a positive role in both enhancing engineering implementation efficiency and optimizing engineering cost control.
Physics-guided deep learning framework for structural response prediction
Framework overview
This study addresses the key challenge that traditional data-driven methods are difficult to consider extreme multi-loads scenarios in the SHM of long-span bridges. To this end, a physics-guided deep learning framework based on finite element model updating is proposed (as shown in Figure 1). The framework involves three main steps: (1) enhancing the accuracy of physical models through FE model updating, (2) generating extensive datasets under multiple loads, including earthquakes, strong winds, and random environmental excitations, and (3) developing a multi-head attention BiLSTM (MHA-BiLSTM) network capable of response prediction. The core innovation of this framework lies in integrating physics-guided data generation with advanced deep learning techniques, enabling robust and accurate prediction of structural responses under extreme multi-loads conditions. Structural response prediction framework for fusion of physical models and deep learning.
Updating the original finite element model addresses the issue of inadequate prediction accuracy when compared to complex real structures with initial defects. The updated model generates structural response data under multi-loads, compensating for the scarcity of damage data in large complex structures. Here, 'multi-loads’ refers to the combined action of multiple loads; specifically in this study, it denotes the load condition where white noise load, seismic load, and wind load act together. In this study, the objective function of the model updating is defined as the discrepancy between the calculated frequency from the finite element model and the measured frequency. By minimizing this error, optimal model parameters are determined. This function is expressed as:

In modal matching, a two-level approach is employed: modal type priority matching followed by frequency mean square deviation minimization. Sensitivity analysis, as outlined by Lin et al. (2020), identifies the parameters to be updated. The finite element model of the bridge is segmented into girder, tower, auxiliary pier, cable, and link support. Based on One-At-a-Time (OAT) sensitivity analysis (Mottershead and Friswell, 1993).The sensitivity coefficients could be calculated as:

MHA-BiLSTM network
This study employs the Long Short-Term Memory (LSTM) network model for data training, a specialized form of Recurrent Neural Network (RNN). Unlike traditional RNNs, LSTM addresses the issues of “gradient vanishing” and “long-term dependence” in processing long sequences through a “gating mechanism,” making it suitable for time-series analysis (Wang et al., 2019). This aligns with the focus on predicting multi-loads structural responses in this research. The fundamental component of the LSTM network is the LSTM unit, which incorporates a state transfer mechanism and a gating mechanism. The state transfer mechanism filters key information, enhancing data flow efficiency. The gating mechanism, comprising a forget gate, input gate, and output gate, regulates information inflow, storage, and outflow. Figure 2 illustrates the LSTM unit structure. Schematic diagram of the LSTM unit structure.
The steps for updating the LSTM cell state are as follows: 1. Input the hidden state

Among them, 2. Calculate the candidate value

Among them, 3. Selectively update the cell state based on the outputs of the forget gate and the input gate.

Among them, 4. Calculate the output at time step t based on the updated cell state

LSTM effectively captures temporal features and mitigates issues of gradient vanishing and long-term dependence. However, it overlooks forward and backward dependencies in temporal data. Bidirectional LSTM (BiLSTM) addresses this by capturing complete temporal dependencies in sequences (Wang and Peng, 2024). Figure 3 depicts BiLSTM’s mechanism, which incorporates a backward LSTM layer into the standard architecture, allowing bidirectional processing of temporal data. Schematic diagram of the BiLSTM network structure.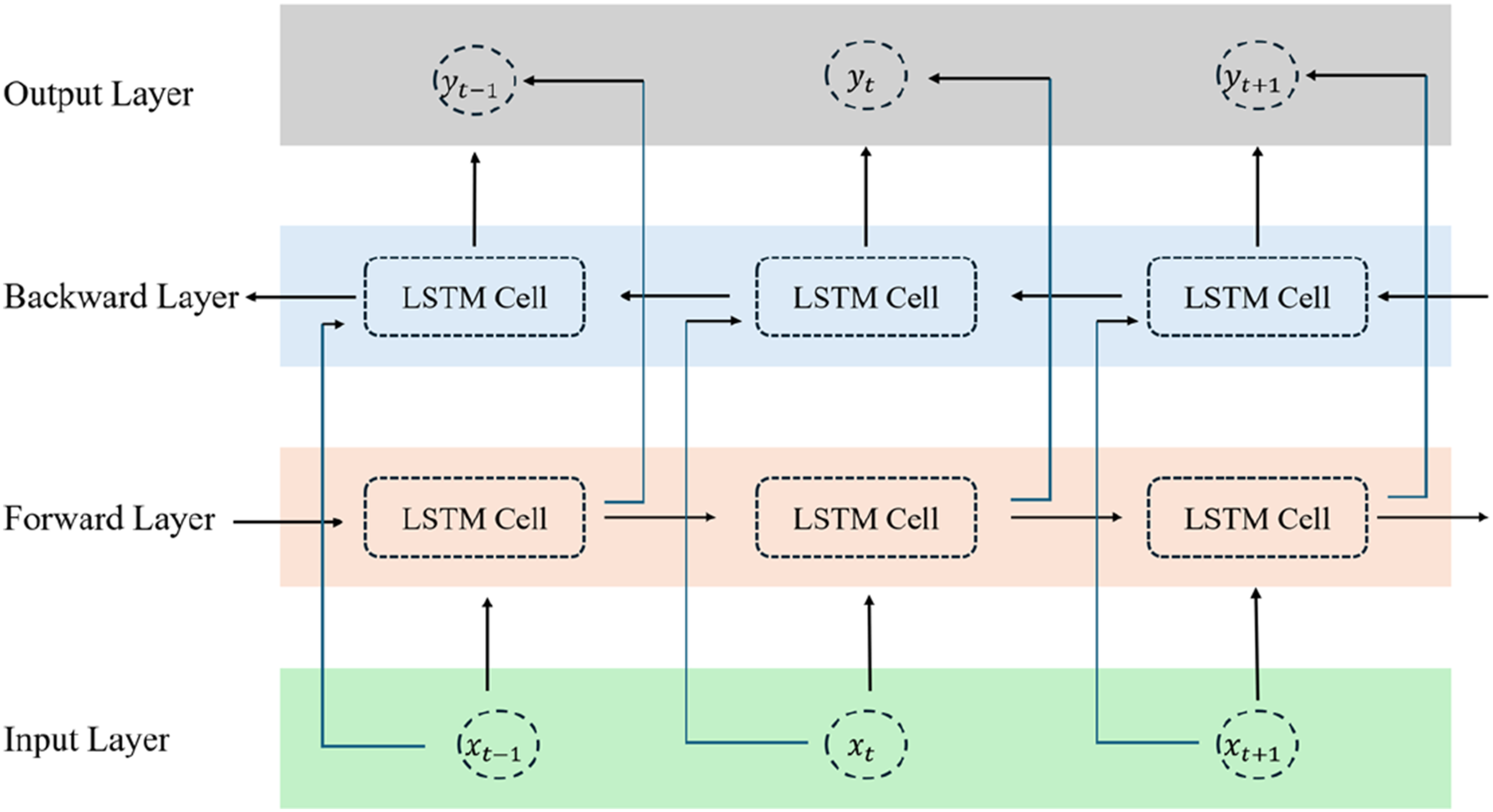
To enhance model training efficiency and prediction accuracy, a multi-head attention(MHA) mechanism is employed, incorporating several attention calculation modules. Each module computes distinct attention weights and produces unique outputs. This approach enables effective attention-allocation strategies, heightens focus on critical data components, and accurately captures interrelationships among various influencing factors (Ju et al., 2024; Philip Thekkekara et al., 2024). The proposed MHA-BiLSTM model integrates this multi-head attention mechanism. As illustrated in Figure 4, the mechanism involves transforming the input data sequence into three vector spaces: query (Q), key (K), and value (V). Each attention module independently calculates the similarity between the query and key vectors to generate attention weights. Higher weights indicate greater contributions from the corresponding value vectors. These value vectors are then weighted and summed using the attention weights, producing distinct outputs for each attention module. Multi-head attention mechanism.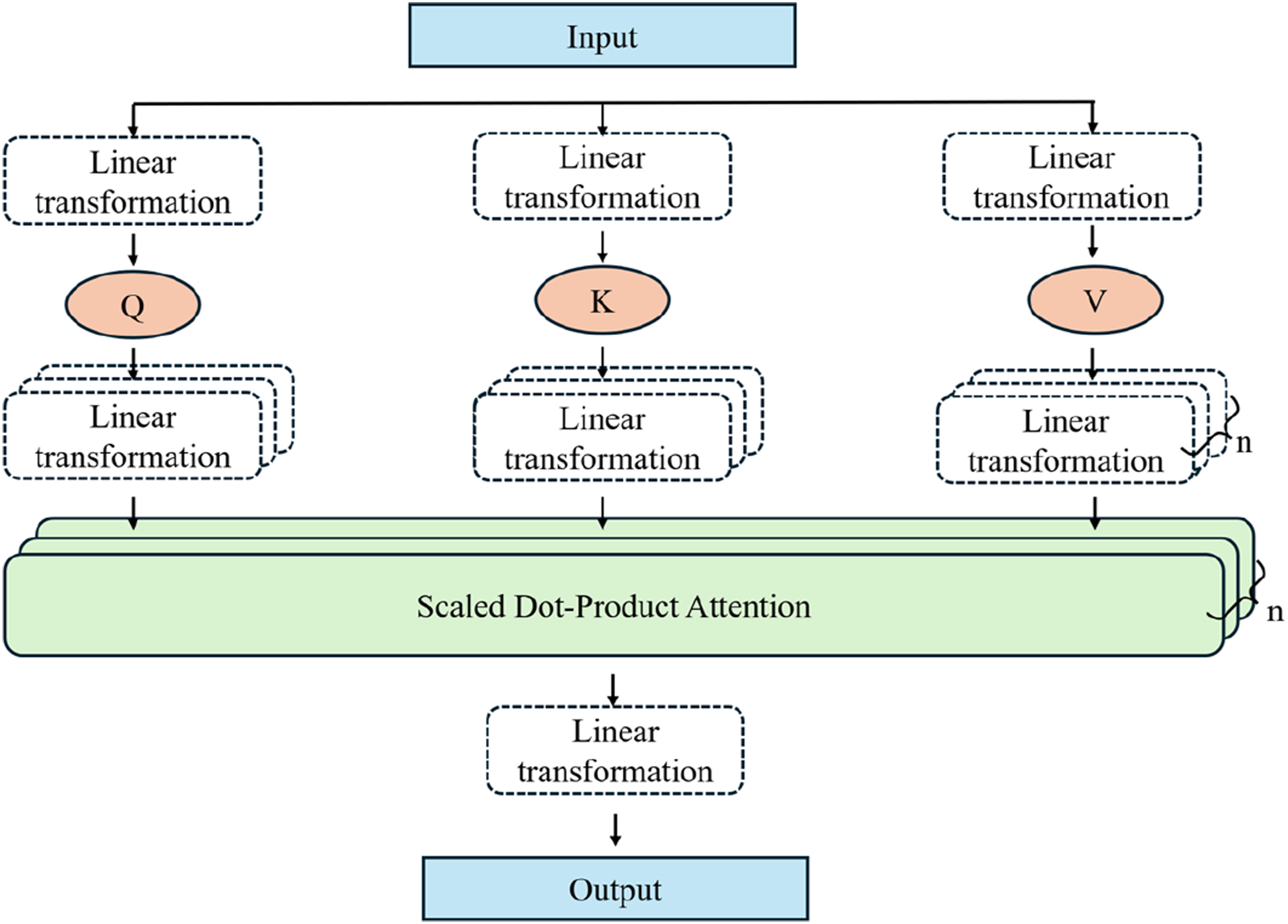
To address the core technical challenges such as real-time monitoring of dynamic responses, reconstruction of missing sensor data, and repair of abnormal signals for flexible structures like long-span bridges, relevant researchers have proposed a series of deep learning architectures. However, existing studies have not yet fully leveraged the advantage of the Multi-Head Attention (MHA) mechanism in multi-dimensional focus on key features and the ability of the Bidirectional Long Short-Term Memory (BiLSTM) network to capture long-term sequential dependencies. The Gated Recurrent Unit (GRU) is a variant of the Recurrent Neural Network (RNN) that dynamically controls information flow through the Reset Gate and the Update Gate, addressing the vanishing gradient problem in traditional RNNs and demonstrating proficiency in handling sequential data (Imrana et al., 2024; Xiao et al., 2024). In contrast, the Transformer model abandons the RNN architecture, enabling parallel computation and significantly improving training speed, while featuring a unique self-attention mechanism that can solve the long-term dependency problem of RNNs (Cao et al., 2023; Thomas et al., 2023). Both the GRU and Transformer models are applicable to the problem of interest in this study. To ensure equitable comparisons among multiple models, all models in this study were standardized with respect to sequence length, feature dimension, batch size, and dataset partition ratio. Additionally, all models underwent parametric tuning, with consistent hyperparameter settings including learning rate, optimizer type, number of learning rounds, early stopping patience, regularization parameters, and loss function. Therefore, these models and the traditional LSTM model are used for comparison with the MHA-BiLSTM model to ensure the reliability of the selected methods.
Figure 5 illustrates the architecture of the MHA-BiLSTM model presented in this study. The model processes data through the stages of input, feature extraction, attention enhancement, and output. Initially, data is processed by a two-layer BiLSTM, with each layer comprising parallel forward and backward LSTMs and a dropout rate of 0.2, resulting in a bidirectional feature vector. The hidden dimension of BiLSTM is 128. This output is then directed to the MHA module, which converts the input features into Q, K, and V vectors via three linear projections. The number of attention heads is 8. These vectors are processed by parallel scaled dot-product attention mechanisms, where each attention head independently computes association weights among sub-features and performs a weighted sum of V, yielding local features. The outputs from all attention heads are aggregated, and the output projection synthesizes them into an attention-enhanced feature. This feature is then passed to the residual connection and layer normalization module, which integrates it with the original features from the BiLSTM. Within this module, the features are combined element-wise and normalized to maintain the temporal characteristics. The extracted features proceed to the global average pooling module, which compresses the sequence length and aggregates temporal features into a global context vector. These global features are then directed to the output layer. A linear transformation adjusts their dimensionality, followed by the application of the ReLU function to introduce non-linear expressiveness to the model. A regularization layer, with a dropout rate of 0.3, enhances the model’s generalization and robustness. The dropout of the BiLSTM layer and the regularization layer is determined by adjusting the hyperparameters and based on the Schematic diagram of the MHA-BiLSTM model architecture.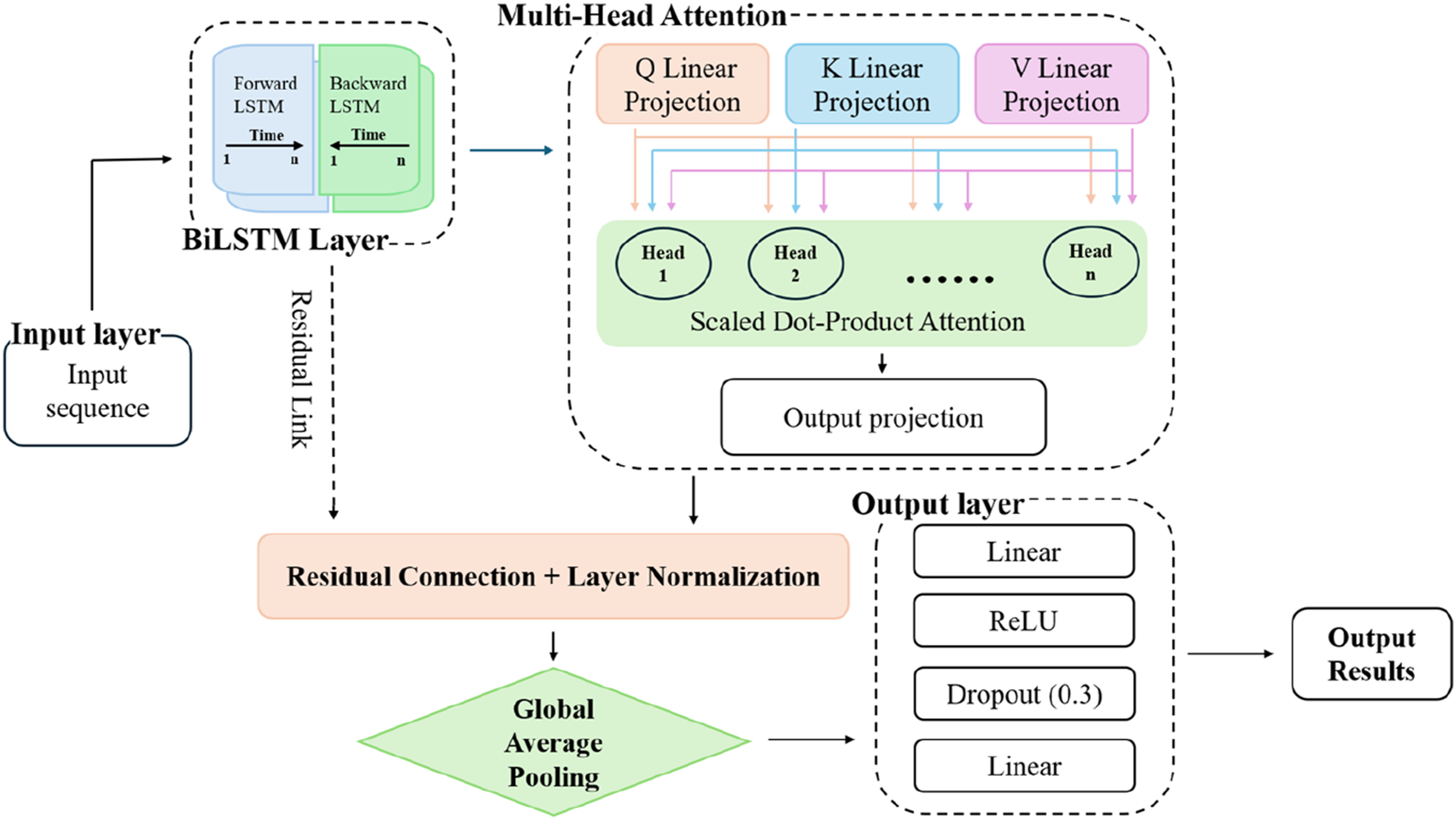
Twelve models were trained: nine single-load models (covering three directions for each excitation type) and three multi-loads models. Two primary regression metrics were employed: Root Mean Square Error (RMSE) and Coefficient of Determination (

The value range of

We trained the GRU, Transformer, and traditional LSTM models on the same dataset and equipment, comparing their prediction accuracy and efficiency with the MHA-BiLSTM model proposed in this study.
Model updating of cable-stayed bridge
Engineering background and FEM
This study is carried out taking the Sutong Bridge as the background, the longest cable-stayed bridge in China. The Sutong Yangtze River Highway Bridge has a total length of 32.4 km, and the main bridge adopts a span arrangement of 100 m + 100 m + 300 m + 1088 m + 300 m + 100 m + 100 m. The bridge uses a double-tower, double-cable-plane steel box girder cable-stayed bridge structure, with a total of 272 parallel wire cable-stayed cables.
The finite element model was established using OpenSees, an open-source software framework dedicated to earthquake and structural engineering simulations. This software offers a wide range of material models, structural elements, and analysis methods, meeting various requirements from linear analysis to nonlinear time-history analysis.
During the finite element modeling process, 523 nodes were defined along the central axis of the main girder, with a spacing of 4 m between each node. Cable anchorage nodes were defined at a distance of 17.7 m on both sides of the central axis of the main girder, with 523 nodes on each side. The spacing between the nodes along the bridge direction was also 4 m. A total of 106 nodes were defined at the cable anchorage points of the main tower and the main tower bearings, forming two cable towers. In addition, some nodes were defined at the auxiliary piers, transition piers, and the steel arms of the auxiliary piers.
The study utilizes the bilinear kinematic hardening elasto-plastic constitutive model to simulate pre-tension force and elasto-plastic deformation in stay cables. Linear elastic constitutive models are applied to main structural components like the main girder, tower body, and auxiliary piers to enable linear dynamic response analysis. Concrete behavior, including crushing and cracking of the main tower, is captured using the Kent-Scott-Park uniaxial concrete model. Additionally, Rayleigh damping with a damping ratio of 0.03 is integrated into the model.
The steel main girder is simulated using elastic beam-column elements to mimic its elastic behavior. Since the cables only bear axial forces, they are simulated using truss elements. The main tower is subjected to axial forces, bending moments, and shear forces, and the concrete material exhibits significant nonlinearity. Therefore, the main tower is simulated using fiber beam elements. Fiber beam elements can discretize the cross-section into concrete and steel fiber, enabling accurate simulation of the cross-sectional stress distribution and material nonlinearity.
During the modeling process, zero-length elements are used to simulate the bearings between the cable tower and the main girder. The equalDOF command is employed to couple the displacements of the tower and the girder, aiming to simulate the special viscous dampers with a limiting function. The same approach is applied to the bearings between the main girder and the auxiliary piers. The bottoms of the main towers and piers are fixed. The established finite element model is shown in Figure 6. Schematic diagram of the finite element model of the Sutong Bridge.
FEM updating
Sensitivity coefficients of physical parameters.

Boundaries of finite element model updating parameters.

Comparison of model frequencies after multi-algorithm updates.

Parameter update results.

Based on the sensitivity coefficients, the influence of each structural parameter on the modal frequencies was quantitatively assessed. The results indicate that the elastic modulus of the tower (0.2470), the equivalent density of the tower (0.0881), the equivalent density of the main span (0.0636) and the elastic modulus of the main span (0.0253) exhibit markedly higher sensitivities compared with the remaining parameters. These four parameters collectively dominate the frequency response and therefore were selected as the key variables for subsequent model updating. In contrast, the equivalent density of the side span (0.0023) and the elastic modulus of the side span (0.0015) present sensitivity values below 0.02, suggesting a negligible contribution to the frequency variation. It should be clarified that the sensitivity coefficients of both the damping ratio and initial cable tension are zero, which stems from the inherent synergistic effect of the theoretical nature of linear eigenvalue analysis, the core logic of OpenSees modeling, and the analysis paradigm. According to the classical theory proposed by Chopra (2017), the natural frequencies of a linear undamped system are determined by the intrinsic properties of the mass matrix and stiffness matrix, with no direct coupling to the damping matrix. In this study, the standard solution mode defaulted by the OpenSees eigen command is adopted, where the core function of damping is to attenuate the amplitude of vibration responses rather than alter the intrinsic properties of natural frequencies. Furthermore, the deviation between damped and undamped modal frequencies falls within the engineering accuracy threshold (typically<1%), so variations in the damping ratio do not exert a significant impact on the modal frequencies focused on in this research. The regulatory mechanism of initial cable tension on structural modes essentially originates from the geometric stiffness effect. Initial cable tension enhances the overall effective stiffness of the structure through “geometric stiffening,” thereby increasing the modal frequencies (Dehghani et al., 2024; Li and Chen, 2019). However, the standard linear eigenvalue analysis employed in this study only incorporates material stiffness, resulting in the geometric stiffness contribution of initial cable tension not being characterized in the modal calculation. Consequently, changes in cable tension cannot affect modal frequencies through effective stiffness, leading to a sensitivity coefficient of zero. This result does not imply that cable tension itself has no influence on structural modes, but rather reflects the inherent characteristic of linear eigenvalue analysis. This also constitutes a direction that requires improvement and expansion in subsequent research. Consequently, these parameters were excluded from further consideration to enhance computational efficiency without compromising model accuracy.
MAC values between initial model and updated model.

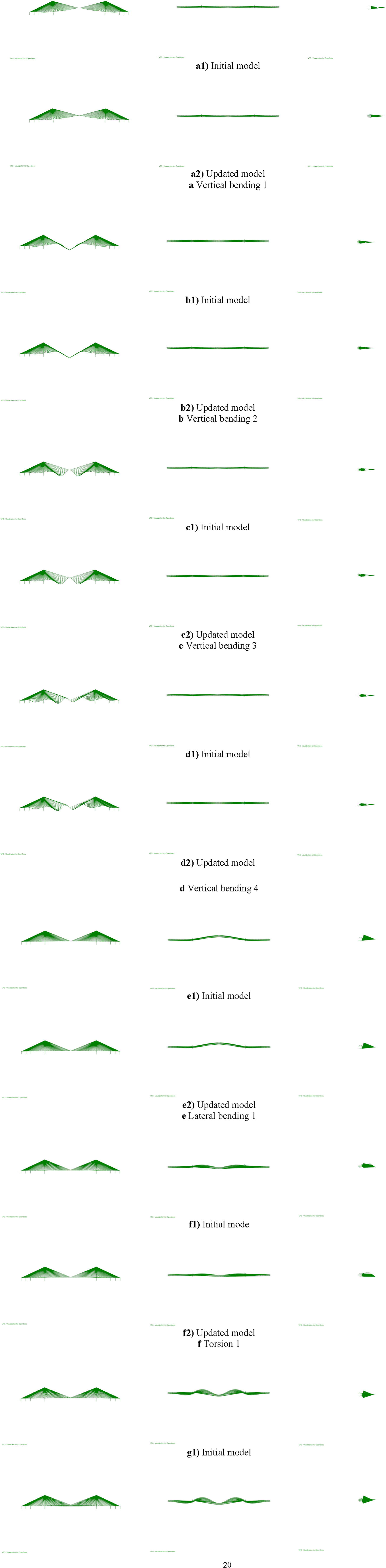
Mode shape comparison plot before and after model updating.
Structural response prediction
Structural response calculation under multi-loads
To create a structural response dataset for long-span cable-stayed bridges under multiple loads, three types of excitations were applied to the finite element model: white noise, recorded earthquake ground motion, and wind loads on all main girder nodes.
The acceleration and displacement recording nodes for the main girder are positioned according to the accelerometers specified by the Structural Health Monitoring System of the Sutong Yangtze River Highway Bridge. These sensors are placed at seven cross-sections, symmetrically distributed around the main girder’s centerline. In total, there are 14 acceleration sensors, corresponding to 14 nodes. Figure 6 illustrates the precise node locations.
Displacement recording nodes are positioned at the top, bifurcation, and the junction with the main girder of each main tower, totaling eight nodes—four per tower. These points are chosen due to their critical displacement responses and sensitivity to seismic and wind loads, as discussed in this study (Lee et al., 2021; Qiao et al., 2024). Figure 8 illustrates the node locations, with numbers outside brackets representing the north tower and those inside denoting the south tower. For the synchronization of accelerometer data acquisition, draws on the relevant research results of Fu et al.(2021) and adopts the two-stage baseline time synchronization strategy proposed by them. This strategy integrates two core links, namely clock synchronization and data synchronization, and has been experimentally verified to achieve a time synchronization error of less than 20 μs, which can fully meet the high-precision requirements for the temporal consistency of multi-sensor data in this study. Schematic diagram of the response recording nodes.
The dataset is constructed using excitation data with a time step of 0.005 seconds: white noise (100 s), earthquake (121.25 s), wind load (100.1 s), and mixed loads (321.25 s), the latter being a combination of the three types. It is important to clarify that the scenario involving the simultaneous occurrence of an earthquake and strong winds in this study is a digitally fabricated scenario. It does not directly emulate an actual disaster event but rather represents a controlled combination of numerical values. The primary objective of creating this scenario is to generate time series data reflecting the coupling of dynamic loads from multiple sources. This data is utilized to assess the learning capabilities and resilience of the MHA-LSTM model when confronted with intricate time series patterns. It is crucial to emphasize that this scenario does not simulate the genuine disaster risk posed to the Sutong Bridge. Authentic risk analysis necessitates the consideration of local historical co-occurrence records, a facet not addressed within this study.
Figure 9 presents the responses of Node 1 and Node 15 in the x-direction under different loads, encompassing main beam and tower nodes, to assess the reliability of responses from the updated finite element model. Structural response data under wind excitation.
Database construction
The original data is pre-processed using the Z-score standardization method. This normalization method can be expressed as follows: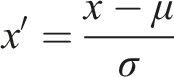
Among them, is the sample mean, and the sample standard deviation. This data preprocessing method is suitable for neural network scenarios (Wu et al., 2022).
Regarding the potential impact of sensor noise on monitoring data, this study introduces Additive White Gaussian Noise (AWGN) to corrupt the original data during the data preprocessing phase. The signal-to-noise ratio (SNR) control method introduces noise into acceleration data by calculating the necessary noise power and generating Gaussian-distributed white noise based on a specified SNR value (Marcel and Tony, 2019). The target SNR is set at 30. This Gaussian white noise is then added to the original signal to mimic real monitoring conditions and improve the model’s generalization capability.
Data segmentation was performed using a sliding window with a length of 100 and a stride of 5, which was initially adopted as the baseline configuration following the recommendations of Zhang et al. (2019, 2025). To optimize this parameter combination, an extended parameter space was constructed, with window lengths expanded to [50, 100, 200, 400, 800, 1600, 3200] and strides set as [5, 20, 50, 100] for full factorial testing. Comprehensive performance was evaluated via a balanced weighted scoring method that integrates prediction accuracy metrics (
The preprocessed single-excitation single-direction data and multi-excitation single-direction data are segmented and divided into a training set, a test set, and a validation set at a ratio of 70%, 20%, and 10%, respectively, for subsequent model training.
Prediction results
Training utilized the RTX4090, resulting in nine MHA-BiLSTM models for each direction under white noise, earthquake, and wind load excitations. Similarly, nine models were developed for each direction under multi-loads excitation, comprising MHA-BiLSTM, GRU, LSTM, and Transformer models. Original acceleration data served as input to predict full time-series data using these models. Figures 10 to 12 display the time-series comparison diagrams of the predictions. Due to space constraints, only the diagrams for node 1 and node 15 in the x-direction are shown, covering main beam and main tower data. These comparisons highlight the prediction accuracy differences among the three models under multi-loads excitation. Comparison of predicted time-series displacements in the x-direction at Node 1. Comparison of predicted values of time-series displacements in the x-direction at Node 15. Comparison of multi-model results in the x-direction under multi-loads excitation over the entire time series.

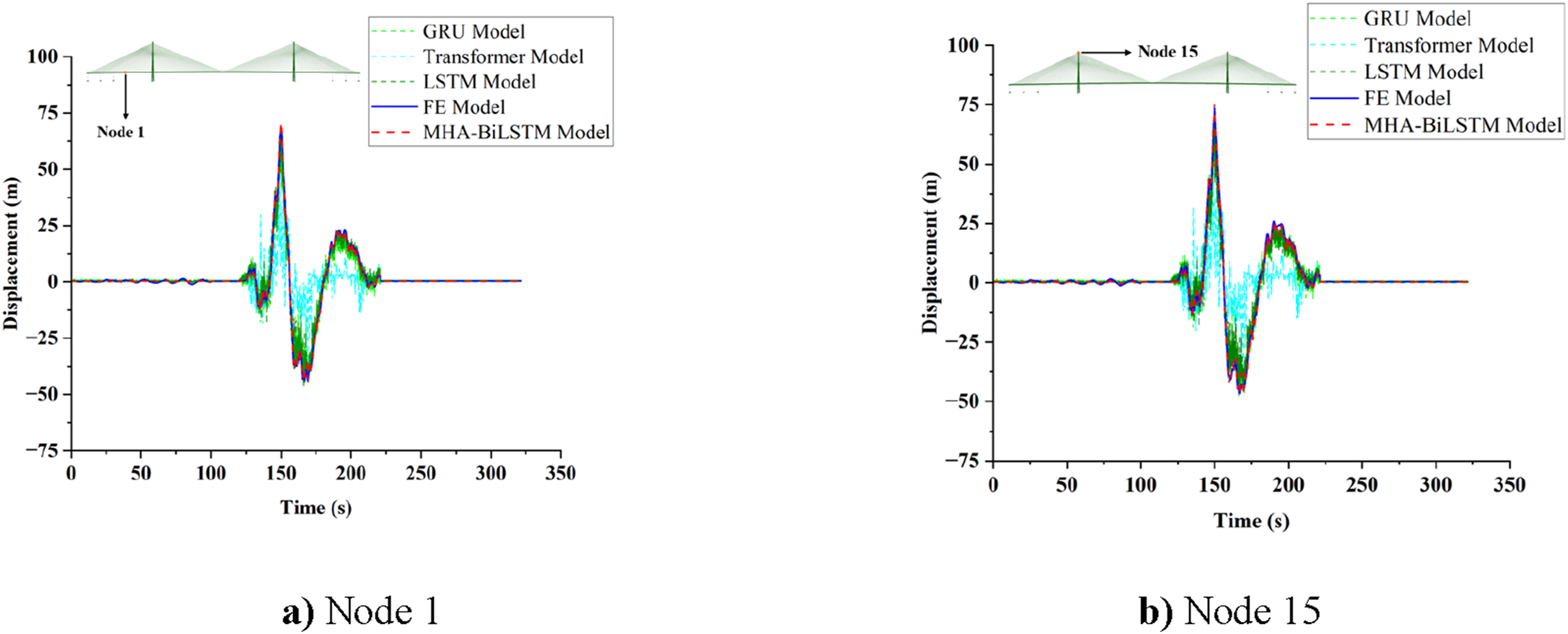
The results indicate that the proposed MHA-BiLSTM model accurately predicts structural responses under both single and multiple loads. In contrast, the LSTM, GRU, and Transformer models exhibit suboptimal prediction accuracy in the x direction under multi-loads conditions, with the Transformer model showing significant discrepancies compared to the FE model over a wide range. While the GRU and LSTM models yield results closer to the FE model, their displacement numerical errors at the same time step are considerably higher than those of the MHA-BiLSTM model.
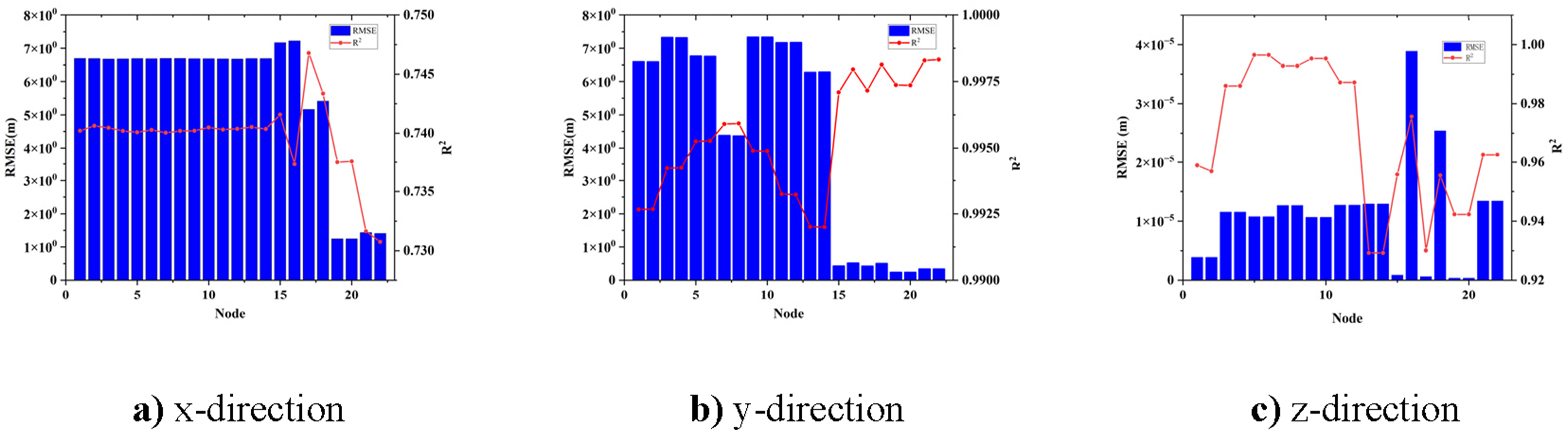
To more precisely present the differences in the prediction accuracy of each model, the RMSE and R2 of all models are shown in Figures 13 to 16. Evaluation parameters of the MHA-BiLSTM model under white noise excitation. Evaluation parameters of the MHA-BiLSTM model under seismic excitation. Evaluation parameters of the MHA-BiLSTM model for wind loads. Evaluation parameters of the MHA-BiLSTM model under multi-loads excitation.
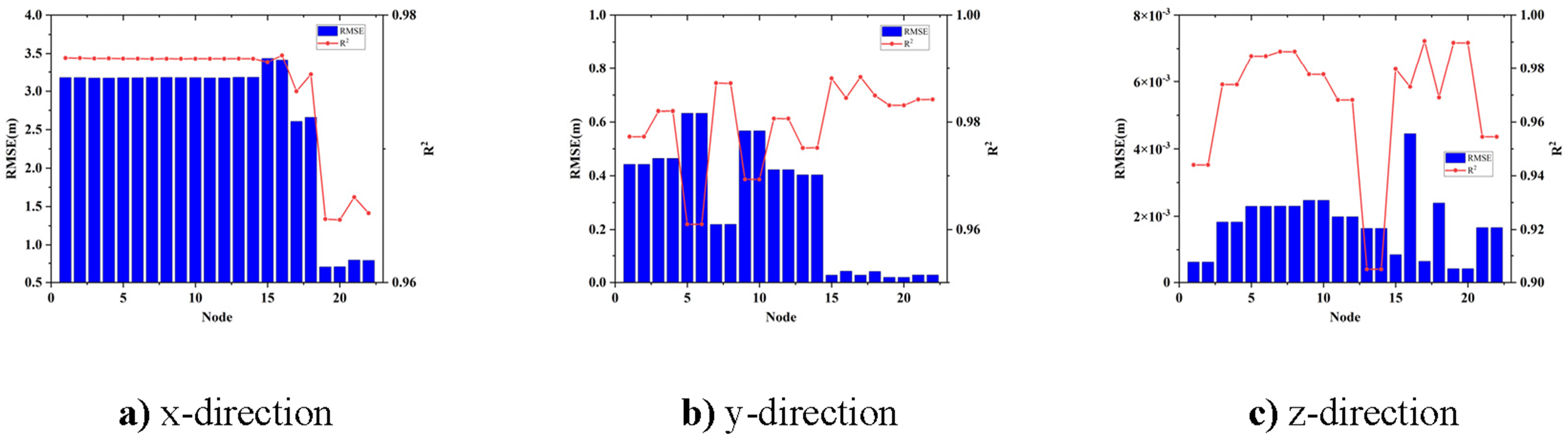
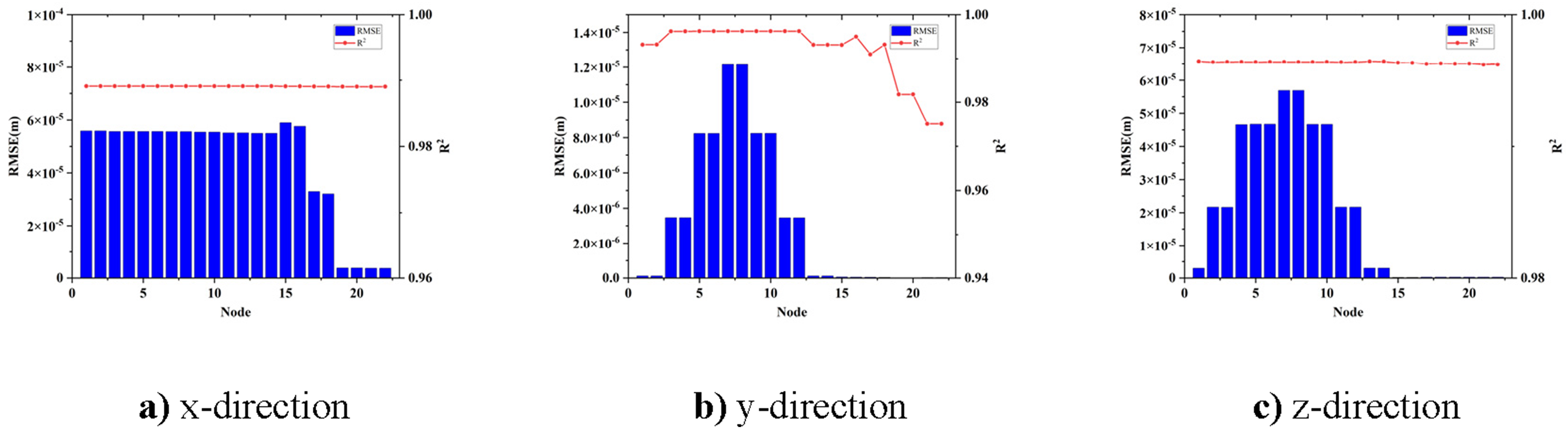

The results indicate that the MHA-BiLSTM model excels in predicting outcomes under single load scenarios, demonstrating high accuracy. Although the RMSE for the multi-loads model is higher than that for the single load model, it remains relatively low. Analysis of the data reveals that at nodes 1-14, the main beam observation nodes, the RMSE and R2 values are similar in pairs, reflecting the symmetry of these nodes about the main beam’s mid-axis. This suggests that the model effectively captures similar structural responses. However, due to the asymmetric mass distribution in the finite element model, which is based on the physical model, discrepancies exist in the parameters for the north tower top node (Node 15) and the south tower top node (Node 16). This asymmetry accounts for the observed data distribution.
The evaluation parameters of the GRU, LSTM and the Transformer model under multi - loads excitation are shown in Figures 17 to 19. Evaluation parameters of the GRU model under multi-loads excitation. Evaluation parameters of the multi-loads excitation Transformer model. Evaluation parameters of the multi-loads excitation LSTM model.

Key model evaluation parameters comparison among different models (Node 1, x-direction of main girder, multiple loads).
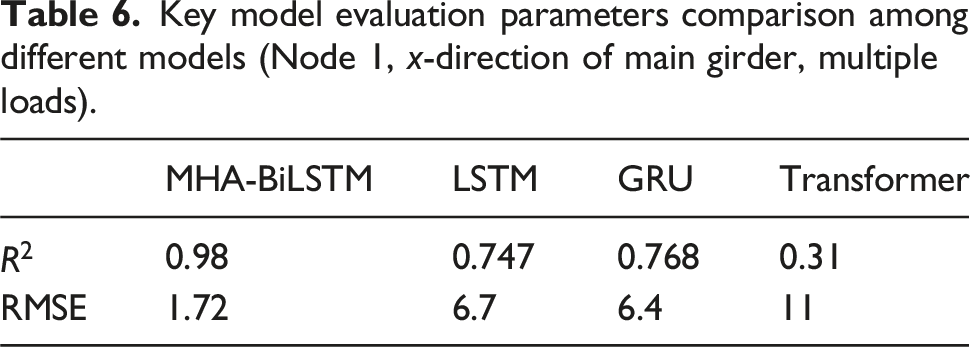
The trained MHA-BiLSTM model demonstrates strong alignment with finite element model data, accurately capturing data trends. In contrast, the GRU LSTM and Transformer models show low prediction accuracy in the X direction, limiting their practical application. Using the RTX4090 for model training, the MHA-BiLSTM model requires an average of 0.3 h, compared to 0.9 h for the GRU model, 0.86 h for LSTM model, and 1.15 h for the Transformer model, indicating higher training efficiency. This efficiency makes the MHA-BiLSTM model particularly suitable for predicting structural responses to multi-loads excitations. It effectively predicts displacement data at multiple structural points using minimal acceleration data. The model is both feasible and efficient for forecasting structural responses of large civil structures under single or multiple loads.
Conclusions
This study presents a framework for predicting the responses of long-span cable-stayed bridges by integrating physical models with machine learning. This approach combines sensor data and finite element model calculations to forecast structural responses during disasters. The Sutong Yangtze River Highway Bridge in China serves as a case study to verify the accuracy and efficiency of machine learning models in predicting structural responses. The key conclusions of this study are as follows:
A novel hybrid framework integrating finite element model updating and deep learning is proposed to address the limitations of traditional finite element models in predicting the multi-loads responses of long-span cable-stayed bridges, which arise from the scarcity of real-world damage data.
Through sensitivity analysis, the Bayesian optimization algorithm was employed to refine four critical parameters: the equivalent densities of the main girder and main tower, and the elastic moduli of steel and concrete. This adjustment significantly minimized discrepancies between modal frequencies calculated via the finite element method and those measured empirically. Additionally, a double-layer modal matching approach resolved inconsistencies between the modal orders from the finite element model and the actual observed orders.
An MHA-BiLSTM model was developed to enhance focus on critical time steps and channels. Utilizing an RTX4090, the model’s average training time was reduced to 0.3 h, thereby improving training efficiency, prediction accuracy, and generalization ability. The low resource requirements of this framework enable it to be seamlessly integrated into existing structural health monitoring (SHM) systems without the need for complex hardware upgrades.
The developed prediction model exhibited robust performance across both single-load and multi-loads scenarios. In single-load settings, the model demonstrated excellent predictive accuracy. While in multi-loads situations, the root mean squared error (RMSE) was marginally higher compared to single-load cases, it nonetheless remained at a low error level. Notably, the coefficient of determination values(R2) for the last two channels of the main beam in the Z direction were the only ones that fell slightly below 0.93. It is worth noting that after the bridge undergoes aging, it is necessary to recollect relevant monitoring data and perform model updating by combining transfer learning with model fine-tuning.
This study enhances the accuracy and efficiency of predicting responses in large civil structures under multi-loads scenarios. However, it primarily addresses single load combinations (such as white noise, earthquakes, and wind loads), leaving the generalization capability for other coupled disasters (e.g., earthquake-tsunami, tsunami-hurricane) unverified. Future research will utilize the field-measured data from full-scale bridge cases to further optimize model parameters, enrich and expand multi-loads scenarios, and conduct in-depth research on relevant real-time structural health monitoring.
Footnotes
Acknowledgements
This research work supported by the Big Data Computing Center of Southeast University and the Center for Fundamental and Interdisciplinary Sciences of Southeast University.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Natural Science Foundation of China (42430711, 52508165), Natural Science Foundation of Jiangsu Province (Grant No. BK20241337), Jiangsu transportation research project (Grant No. CT-SGZT-30, 2024QD02), and Academician special project of CCCC (Grant No. YSZX-01-2023-01-A).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.