
Abstract
We propose an estimation approach to analyse correlated functional data, which are observed on unequal grids or even sparsely. The model we use is a functional linear mixed model, a functional analogue of the linear mixed model. Estimation is based on dimension reduction via functional principal component analysis and on mixed model methodology. Our procedure allows the decomposition of the variability in the data as well as the estimation of mean effects of interest, and borrows strength across curves. Confidence bands for mean effects can be constructed conditionally on estimated principal components. We provide
Keywords
Introduction
Advancements in technology allow today's scientists to collect an increasing amount of data consisting of functional observations rather than single data points. Most methods in functional data analysis (fda) (see, e.g., Ramsay and Silverman 2005) assume that observations are (a) independent and/or (b) observed at a typically large number of the same (equidistant) observation points across curves.
Linguistic research is only one of the numerous fields in which the data often do not meet these strong requirements. Our motivating data come from a speech production study (Pouplier et al. 2014) on assimilation, the phenomenon that the articulation of two consonants becomes more alike when they appear subsequently in spoken language. The data consist of audio recordings of nine speakers repeating the same 16 target words, including the two consonants of interest, each five times. The recorded acoustic signals during the duration of the two consonants were summarized by the phoneticians in a functional index over time (shown in Figure 1) varying between
We propose a model and an estimation approach that extend existing methods by accounting for both (a) correlation between functional data and (b) irregular spacing of—possibly very few—observation points per curve. The model is a functional analogue of the linear mixed model (LMM), which is frequently used to analyse scalar correlated data.
We use functional principal component analysis (FPCA; see, e.g., Ramsay and Silverman 2005) to extract the dominant modes of different sources of variation in the data. The functional random effects are expanded in bases of eigenfunctions of their respective auto-covariances, which we estimate beforehand using a novel smooth method of moments approach represented as an additive, bivariate varying coefficient model. FPCA is a key tool in fda as it yields a parsimonious representation of the data. It is attractive as the eigenfunction bases are estimated from the data and have optimal approximation properties for a fixed number of basis functions. It also allows for an explicit decomposition of the variability in the data.
We propose two ways of predicting the eigenfunction weights. We either compute them directly as empirical best linear unbiased predictors (EBLUPs) of the resulting LMM or we alternatively embed our previously estimated eigenfunctions and ’ values in the general framework of functional additive mixed models (FAMMs) introduced by Scheipl et al. (2015). The first approach is straightforward and computationally much more efficient; it does not require additional estimation steps as a plug-in estimate is used, and is thus almost a by-product of the eigenfunction estimation. The latter has the advantage that all model components are estimated/predicted in one framework, allowing for approximate statistical inference conditional on the FPCA.
There is previous work on dependent functional data as well as on functional data that is irregularly or sparsely observed, but with few exceptions noted below, existing work has not addressed both issues simultaneously.
First, methods for dependent functional data differ in their generality and in their restrictions on the sampling grid. Brumback and Rice (1998) consider a smoothing spline-based method for nested or crossed curves, which are modelled as fixed effect curves. They allow for missing observations in equal grids but do not consider any covariate effects. A Bayesian wavelet-based functional mixed model approach is introduced by Morris et al. (2003) and extended by Morris and Carroll (2006), Morris et al.(2006) and subsequent work by this group. While this approach is quite general in the possible functional random effects structure, and fixed and random effects are estimated within one framework allowing for full Bayesian inference, it assumes regular and equal grids with at most a small proportion of missings and a reasonable number of completely observed curves. Di et al. (2009), Greven et al.(2010) and Shou et al. (2015) consider functional linear mixed models (FLMMs) with a functional random intercept (fRI), with a fRI and functional random slope, and with nested and crossed fRIs, respectively. While following a similar approach to estimation of these models, all three are restricted to data sampled on a fine grid, and fixed effects are estimated under an independence assumption, not allowing for the statistical inference we provide. Di et al.(2014) extend the random intercept model of Di et al. (2009) to sparse functional data; the correlation structure, however, remains less general than ours and the estimation approach cannot easily be generalized to more complex structures. Also motivated by an application from linguistics, Aston et al. (2010) perform an FPCA on all curves ignoring the correlation structure, and then use the functional principal component (FPC) weights as the response variables in an LMM with random effects for speakers and words. Only linear effects of scalar covariates are considered, FPC bases are restricted to be the same for all latent processes, and it is assumed that the data are sampled on a common grid. Brockhaus et al. (2015) propose a unified class for functional regression models including group-specific functional effects, which are represented as linear array models, and are estimated using boosting. The array structure requires common grids and boosting does not provide inference. Other approaches concentrate specifically on spatially correlated functional data on equal grids, for example, Staicu et al. (2010). Scheipl et al. (2015) develop a flexible class of functional response models, allowing for various functional random effects with flexible correlation structures. Both spline-based and FPC-based representations are considered, and densely as well as sparsely sampled data are allowed. In the case of the FPC-based representation, they assume that appropriate FPC estimates are available. Yet, the estimation of the auto-covariances is challenging for correlated functional data with complex correlation structures, especially when observed on unequal grids, and no estimation approach is currently available. We combine our newly proposed FPC estimation with this general framework to obtain estimates, and approximate point-wise confidence bands (CBs) for the mean and covariate effects. In addition to providing an interpretable variance decomposition, our FPC-based approach reduces computation time by orders of magnitude compared to the spline-based estimates from Scheipl et al. (2015) (compare Section 5), allowing the analysis of realistically sized data in practice. Estimation errors and CB coverage also compare favourably.
Second, a number of approaches allow for irregularly or sparsely sampled functional data but assume that curves are independent. (Guo 2002, Guo 2004) first introduces the term functional mixed effects models for his model. The model does not capture between-function correlation as only curve-level random effect functions are included, which are modelled using smoothing splines. The approach is not restricted to regularly sampled grid data. Chen and Wang (2011) propose a spline-based approach that is suitable for sparsely sampled data, but similar to Guo (2002); Guo (2004), they only consider curve-level random effects. James et al. (2000), Yao et al. (2005) and Peng and Paul (2009) among others propose FPCA approaches for sparsely observed functional data with uncorrelated curves. For functional data with independent curves, there is a direct relationship to the longitudinal data literature as well, too extensive to cover here.
For an extensive overview and further references for functional regression approaches, including functional response regression, see Morris (2015).
The remainder of the article is organized as follows. Section 2 introduces the general FLMM and presents an important special case which is used to analyse the motivating linguistic data on assimilation. Section 3 develops our estimation framework. Our method is evaluated in an application to the assimilation data and in simulations in Sections 4 and 5, respectively. Section 6 closes with a discussion and outlook. Theoretical results and supplementary material including estimation details as well as additional results for application and simulations are available in the online appendix, where we also provide
Functional linear mixed models
The general model
The general FLMM is given by

For our application in speech production research (Section 4), we use an FLMM with a crossed design structure to account for correlation between measurements of the same speaker and between measurements of the same target word.
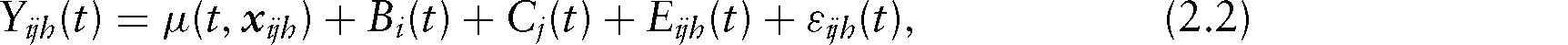
Let us now assume that for our general model (2.1), we have observed
Estimation
We base our estimation on FPCA, which provides the dimension reduction so important for functional data and allows an explicit decomposition of the variability. Compared to other basis approaches, for example, using splines, FPCA has the advantage that the eigenbases are optimal in the sense of giving the best approximation for a given number of basis functions, and thus typically small numbers of basis functions give good approximations. To pool information across observations, which is particularly important in the case of irregularly or sparsely sampled functional data, we use smoothing of the auto-covariances of We estimate the mean We use a smooth method of moments estimator based on the centred curves to estimate the auto-covariances of the functional random effects. We conduct an eigen decomposition of each estimated auto-covariance matrix evaluated on a pre-specified, fine grid. Using the Karhunen-Loève (KL) expansion (Loève 1945; Karhunen 1947), we represent the functional random effects in truncated bases of eigenfunctions. We propose two ways of predicting the random basis weights.
Step 1, Step 3 and the first option for Step 4 are analogous to the estimation proposed in Di et al. (2009), Greven et al. (2010) and Shou et al. (2015) for functional data sampled on an equal, fine grid and in Di et al. (2014) for a simpler model. Step 2 is new and leads to a new combination with the FAMM approach of Scheipl et al. (2015) in the second option for Step 4. For simplicity, we focus in the remainder of this section, where we describe the four steps in detail, on model (2.2).
We estimate the mean

We estimate the auto-covariances using a smooth method of moments estimator. Whereas for data sampled on an equal, fine grid, estimation can be done point-wise, this is not possible for irregularly or sparsely sampled data, which makes the estimation of the auto-covariances more challenging and requires a new approach. We exploit the fact that for centred data, the expectation of the cross products corresponds to the auto-covariance, which can be decomposed as follows:

We use bivariate tensor product P-splines (see, e.g., Wood 2006 sec. 4.1.8) for the estimation of the auto-covariances, where low rank marginal bases for each
For the practical implementation of Step 1 and Step 2, we build on existing software and use
Based on Mercer's Theorem, the eigen decompositions of the auto-covariances are
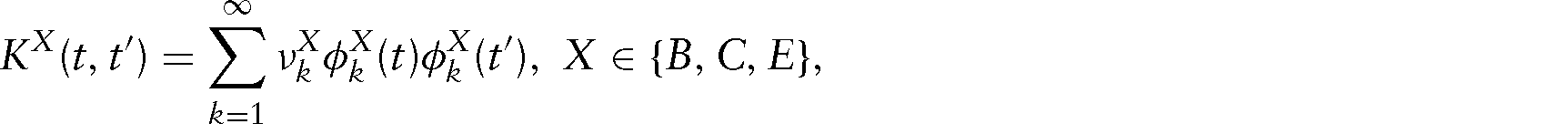
Truncation of the FPCs: While in theory, there is an infinite number of eigenfunctions, dimension reduction achieved by the selection of the number of FPCs for each random process is necessary in practice. This truncation has a theoretical justification and can be seen as a form of penalization (see, e.g., Di et al. 2009; Peng and Paul 2009). Among the multiple proposals in the literature (see for an overview Greven et al. 2010), we base our choice on the proportion of variance explained. This allows us to quantify the contribution of the random processes to the variation in the observed data. It is based on the variance decomposition of the response
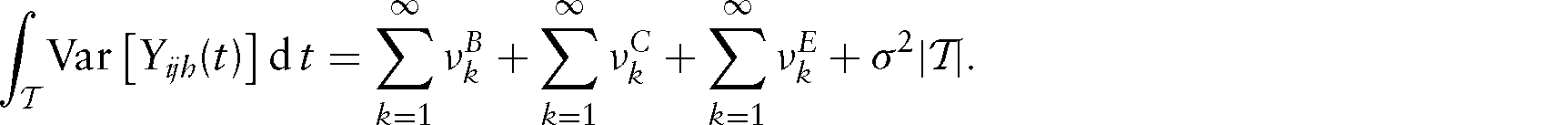
Approximation of the functional random processes: Based on the truncation, we use KL expansions to obtain parsimonious basis representations for the random processes
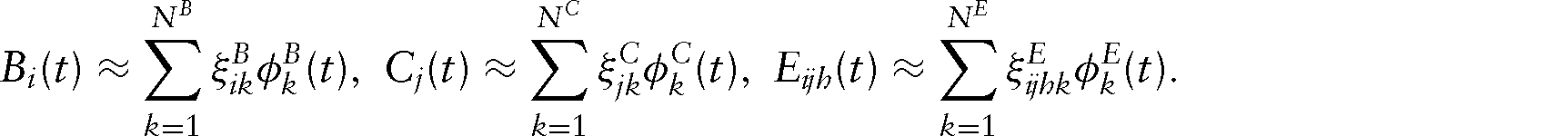
For prediction of the FPC weights, we first linearly interpolate the chosen eigenfunctions such that they are available on the original observation points. Due to the smoothness of all model components, this leads to a small error which could be further decreased, if desirable, by further increasing the number of grid points
See Online Appendix B for further details, including the rescaling of the FPCs, and Online Appendix A for the derivation of the variance decomposition.
Step 4: Prediction of the basis weights
The basis weights for a centred random process
These considerations motivate our two proposals for the prediction of the basis weights. The first is straightforward and computationally very efficient. It is almost a by-product of the FPC estimation, taking only a few seconds for our large phonetics data. It generalizes the conditional expectations introduced by Yao et al. (2005). The second involves higher computational costs but has the advantage that the mean is re-estimated in the same framework, allowing for approximate statistical inference, for example, for the construction of point-wise CBs conditional on the FPCA. Depending on the sample size of the data and the main question of interest, one or the other may be preferred. Further details for both, such as concrete matrix forms, can be found in Online Appendix A.
Prediction of the basis weights as EBLUPs: Using the truncated KL expansions of the random processes, we can approximate model (2.2) by
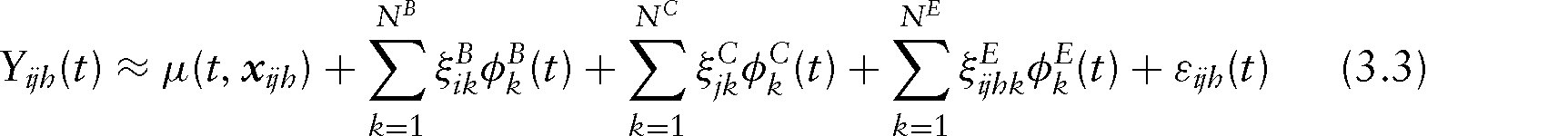
Let
The EBLUP for the basis weights in model (2.2) in the usual form (see Online Appendix A) requires the inversion of the estimated covariance matrix of

This computationally efficient way of predicting
Prediction of the basis weights using FAMMs: The second option uses the fact that model (3.3) together with the distribution of the basis weights implied by the KL expansion falls into the general framework of a FAMM (Scheipl et al. 2015) using suitable marginal bases and penalties. We combine our FPC estimation with the FAMM idea, and write model (3.3) using estimated eigenfunctions and -values as

The estimation quality can be further improved, if desirable, by applying the four estimation steps iteratively. Several possibilities are described in Online Appendix B, where further details on the estimation and implementation can also be found.
Background and scientific questions
In linguistics, the term assimilation refers to the common phenomenon whereby a consonant becomes phonetically more like an adjacent, usually following consonant. Assimilation commonly occurs in English phrases such as ‘Paris show’ in which the word-final /s/-sound is, in fluent speech, pronounced very similar to the following, word-initial /sh/-sound (Pouplier et al. 2011). Assimilation patterns are conditioned by a complex interaction of perceptual, articulatory and language-specific factors, and are therefore a central research topic in the speech sciences. In order to investigate assimilation in German, Pouplier et al. (2014) obtained audio recordings of
Index curves of the consonant assimilation data over time. Left [right]: Curves of order /s#sh/ [/sh#s/]. Positive values approaching
indicate a reference /s/ [/sh/] acoustic pattern, while negative values approaching
indicate a reference /sh/ [/s/] acoustic pattern.
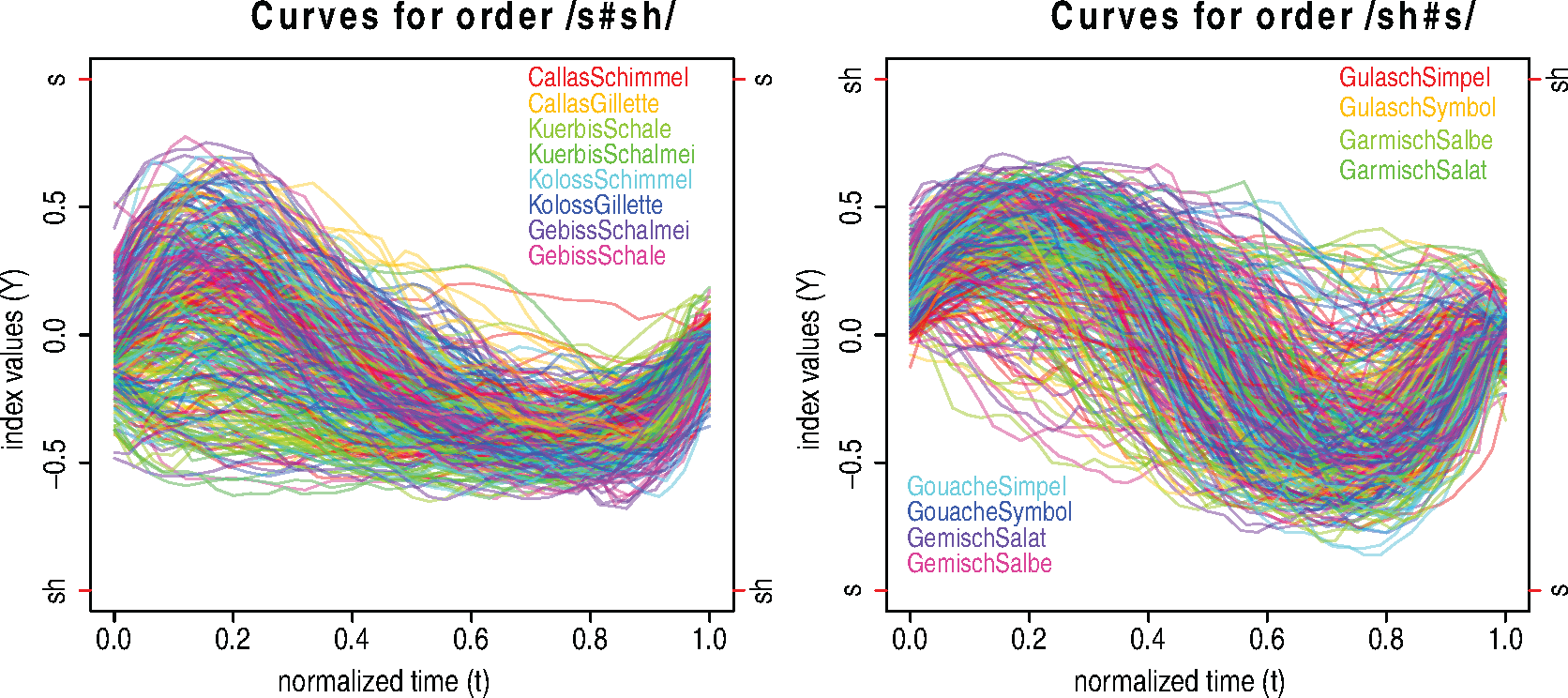
Index curves of the consonant assimilation data over time. Left [right]: Curves of order /s#sh/ [/sh#s/]. Positive values approaching
indicate a reference /s/ [/sh/] acoustic pattern, while negative values approaching
indicate a reference /sh/ [/s/] acoustic pattern.
A special focus lies on the asymmetry arising from the order of the consonants. We investigate under which conditions (order, syllable stress, vowel context) the two consonants assimilate, and whether assimilation is symmetric with respect to the orders /s#sh/ and /sh#s/. A common approach is to extract curve values at pre-defined points on the time axis (e.g., 25%, 50%, 75%) which are subsequently used in multivariate methods (e.g., Pouplier et al. 2011 ). Such analyses fail to capture the continuous dynamic change characteristic of speech signals. Applying our fda-based method allows us to take into consideration the temporal dynamics and to account for the complex correlation structure in the data which arises from the repeated measurements of speakers and of target words. Moreover, we can quantify the effect of covariates and interactions and obtain a variance decomposition.
All utterances were recorded with the same sampling rate (32 768 Hz) and then standardized to a [0,1] interval as the speaking rate, and hence the target consonant duration, differs across experiments. After standardization, measurements are unequally spaced for different curves. In some data settings, registration can be used to account for variation in time. For this application, however, registration cannot replace the standardization of the time interval as different transition speeds between the two consonants are part of the research question of interest and thus a change relative to the length of the time interval is of interest. Registration would remove the main source of information on the assimilation process and flat curves, arising from (near) complete assimilation, would render registration problematic.
In order to account for the repeated measurements of speakers and target words, we fit an FLMM with crossed fRIs, model (2.2), to the consonant assimilation data. The number of measurements per curve
Covariate effects: We consider four dummy-coded covariates: consonant order (order), stress of the final (stress1) and of the initial (stress2) target syllable, which can be strong or weak and vowel context (vowel), which refers to the vowels immediately adjacent to the target consonants and is either of the form ia or ai, for example, Call
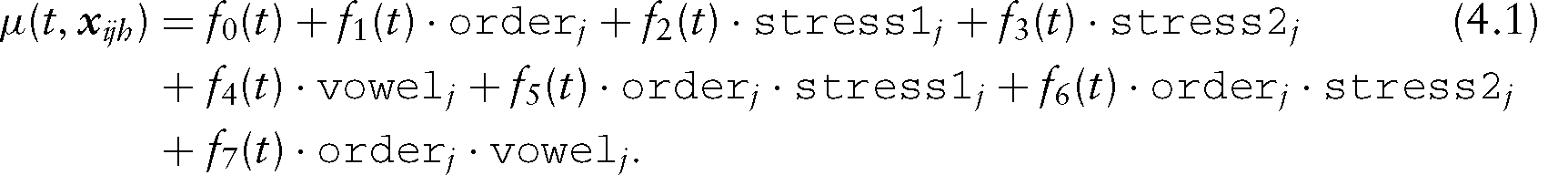
Our estimation yields two and three FPCs for the fRI for speakers and for the smooth error, respectively. No FPC is chosen for the fRI for target words. It is likely that the eight covariate and interaction effects describe the target words sufficiently, as confirmed by obtaining one FPC for the fRI for target words in the model without covariate effects. Most variability (67.29%) is explained by the three chosen FPCs for the curve-specific deviation which also captures interactions between speakers and target words. The two chosen FPCs for speakers explain 20.45% of the estimated variability.
The left panel of Figure 2 shows the effect of covariate order (
Left: Effect of covariate order (red solid line) with point-wise confidence bands (dashed lines). Right: Mean function (solid line) and the effect of adding (
) and subtracting (
) a suitable multiple (
) of the first FPC for speakers.
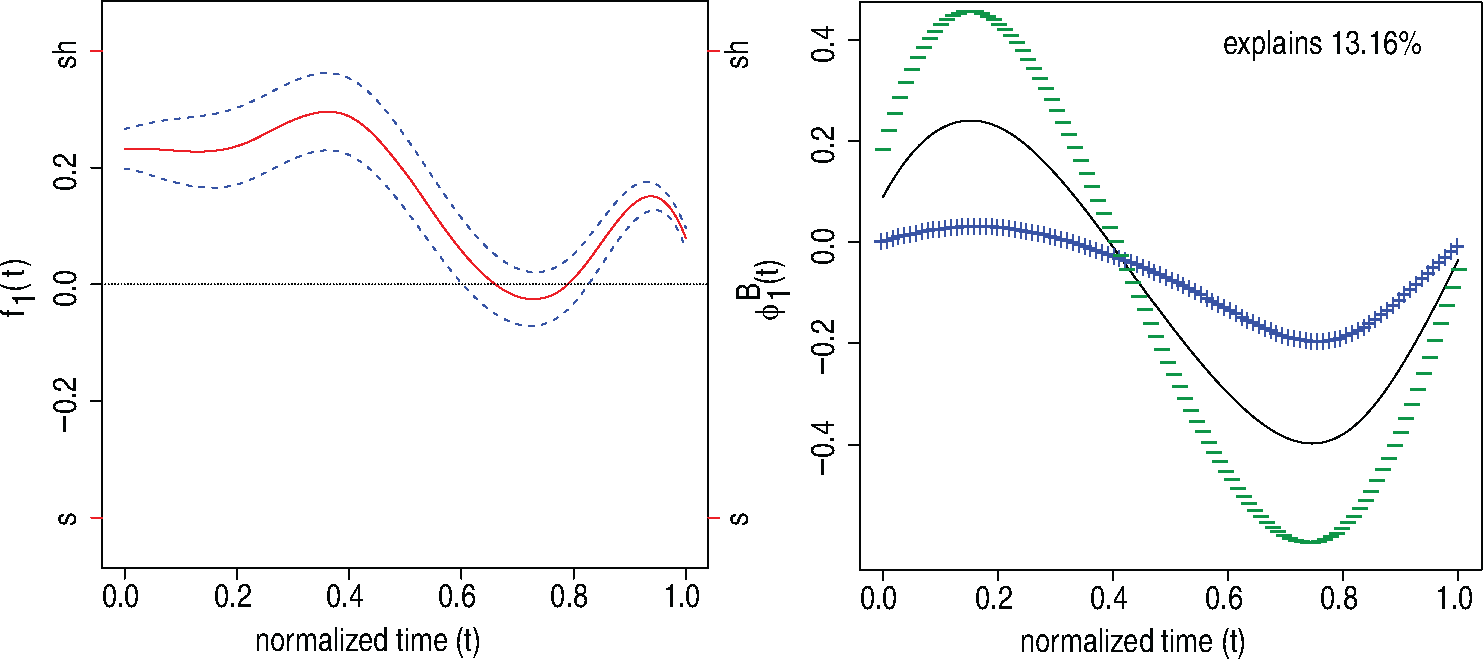
Left: Effect of covariate order (red solid line) with point-wise confidence bands (dashed lines). Right: Mean function (solid line) and the effect of adding (
) and subtracting (
) a suitable multiple (
) of the first FPC for speakers.
Moreover, we find that assimilation is stronger for target words with unstressed final syllables (
In the right panel of Figure 2, we show the effect of adding (
Simulation designs
We conduct extensive simulation studies to investigate the performance of our method. The data generating processes can be divided into two main groups: (a) data that mimics the irregularly sampled consonant assimilation data and (b) sparsely sampled data with a higher number of observations per grouping level but fewer observations per curve. For all settings, we generate 200 data sets.
Application-based simulation scenarios: We consider two application-based scenarios, one with an fRI for speakers and covariate mean effects (fRI scenario) and another with crossed fRIs for speakers and for target words, respectively, but no covariate mean effects (crossed-fRIs scenario). We generate the data based on the estimates of model (2.2) for our consonant assimilation data with
Sparse simulation scenario: In order to investigate the estimation performance in the sparse case, we additionally generate data with crossed fRIs as in model (2.2) consisting of observations that are sparsely sampled on [0,1]. The number of observation points per curve is drawn from the discrete uniform distribution
For all scenarios, we centre the FPC weights such that the weights of each grouping variable also empirically have zero mean. Moreover, we decorrelate the basis weights belonging to one grouping variable and assure that the empirical variance corresponds to the respective eigenvalue. This is done to obtain data that meet the requirements of our model. It allows us to separate the effect of unfavourably drawn weights and of the estimation performance. This adjustment gains importance for small sample sizes
We fix the number of FPCs in order to separate the effect of the truncation from the estimation quality. We use five marginal basis functions each for the estimation of the auto-covariances and eight basis functions for the estimation of the mean. We predict the FPC weights as EBLUPs for all scenarios, and additionally compare with the computationally more expensive FAMM prediction (FPC-FAMM) for the fRI scenario with covariates.
We compare our FPC-based approach to a spline basis representation of the functional random effects (using eight basis functions) within the FAMM framework of Scheipl et al. (2015) (spline-FAMM). To the best of our knowledge, the work of Scheipl et al. (2015) is the only competitor to our approach as all other methods are either restricted to equal, fine grids or do not allow for a crossed structure. Due to the high computational costs of Scheipl et al. (2015), we restrict our comparison to the fRI scenario, in which we can compare estimation quality and CBs coverage for covariate effects.
Simulation results
We focus our discussion on the FPC-based results for the application-based scenario with crossed fRIs and compare with the other settings and estimation approaches. We use root relative mean squared errors (rrMSE) as measures of goodness of fit which are of the general form
Simulation results for the crossed-fRIs scenario: Figure 3 shows the true and estimated FPCs of the two fRIs as well as of the smooth error term. As expected, the better the FPCs are estimated, the more independent levels are there for the corresponding grouping variable which can enter the estimation of the auto-covariance. The FPCs of the smooth error term (707 levels) are estimated best, followed by the FPC of the fRI for target words (16 levels). Most variability in the estimates is found for the FPCs of the fRI for speakers due to the small number of speakers (
Table 1 lists the rrMSEs averaged over 200 simulation runs for all model components. It shows that the mean function is reconstructed very well, which is also the case in the sparse scenario. The covariate effects for the fRI scenario are discussed below. The auto-covariances and their eigenvalues have similar low average rrMSEs for both application-based scenarios. For the sparse scenario, the eigenvalues are estimated even better with average rrMSEs between 0.02 and 0.05. For the auto-covariances for the sparse scenario, we obtain average rrMSEs of 0.06 for each of the crossed fRIs and an average of 0.14 for the smooth error which is due to the complex eigenfunctions mentioned above. The error variance has similar low average rrMSEs for the two application-based scenarios. For the sparse scenario, the average rrMSE is higher, which is due to the estimation inaccuracies in the auto-covariance of the smooth error.
rrMSEs averaged over 200 simulation runs for all model components by random process. Rows 1-3: Number of grouping levels LX and average rrMSE for
,
and
and their covariance decompositions. Last row: Average rrMSEs for
,
, and
.

rrMSEs averaged over 200 simulation runs for all model components by random process. Rows 1-3: Number of grouping levels LX and average rrMSE for
,
and
and their covariance decompositions. Last row: Average rrMSEs for
,
, and
.
The prediction quality of the basis weights clearly depends on the estimation quality of the FPCs and of the eigenvalues, as well as of the error variance, as evident from equation 3.4). Also important for the prediction of the basis weights is the number of curves with the given weight entering the prediction. Thus, the basis weights of
For all scenarios, we obtain good results for the functional random effects as well as for the functional response. The rrMSEs for the functional response are lowest, which is due to the fact that even if the FPC bases are not perfectly estimated, they can still serve as a good empirical basis. Thus, the data can be reconstructed very well.
We found considerably more outliers of the relative errors for the sparse scenario than for the other two scenarios, which is most probably due to an unfavourable distribution of the few observation points across the curves in a few data sets.
True and estimated FPCs of the crossed fRIs
and
(top row), as well as of the smooth error
(bottom row). Shown are the true functions (red solid line), the mean of the estimated functions over 200 simulation runs (black dashed line), the point-wise 5th and 95th percentiles of the estimated functions (blue dashed lines) and the estimated functions of all 200 simulation runs (grey).
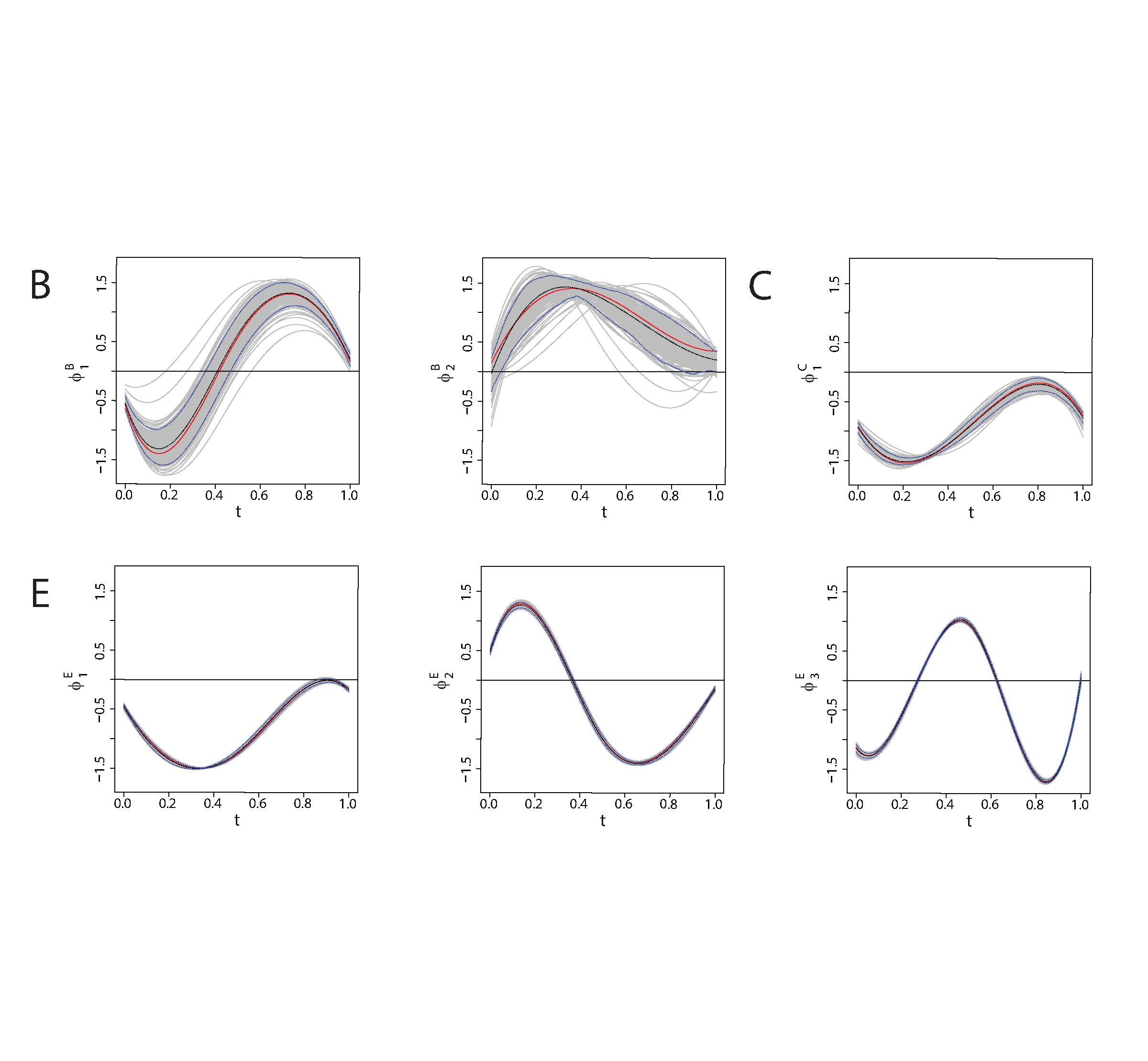
Overall, we can conclude that all components are estimated well and especially for the functional response we obtain very small rrMSEs across all simulations.
Comparison of the different estimation results for the fRI scenario: We find that the functional random processes and the functional response are estimated equally well for the two options of the basis weights prediction. The functional response is again estimated very well with an average rrMSE of 0.09 for both EBLUP and FPC-FAMM estimation. The spline-FAMM results are considerably worse for the random processes (almost three (smooth error) and almost seven (fRI) times higher average rrMSEs), which results from the fact that the constraint
For the covariate effects, the FPC-FAMM estimation gives better results than the estimation under an independence assumption (between 1 and 1.28 times lower average rrMSEs) and considerably better results than the spline-FAMM estimation (between 2.8 and six times lower average rrMSEs). In spite of ignoring the variability of the estimated FPCA, the average point-wise coverage of the point-wise CBs is very good for most effects for FPC-FAMM (between 91.18% and 95.54%) and the simultaneous coverage is reasonable. Both are considerably better than the spline-FAMM alternative (point-wise coverage between 35.12% and 41.67%). The coverage for the latter would most probably improve by increasing the number of spline basis functions which is, however, limited by the high computation time.
Computation times: Our simulations show that the FPC-based approach has clear advantages in terms of computational complexity, despite the computational cost of the auto-covariance estimation. We compare times for one simulation run of the fRI scenario for each estimation option obtained under the same conditions (without parallelization in function
We propose an FPC-based estimation approach for FLMMs that is particularly suited to irregularly or sparsely sampled observations. To pool information, we smooth both the mean and auto-covariance functions. We propose and compare two options for the prediction of the FPC weights and obtain conditional point-wise CBs for the functional covariate effects. Our simulations show that our method reliably recovers the features of interest. The parsimonious representation of the functional random effects in bases of eigenfunctions outperforms the spline-based alternative of Scheipl et al. (2015) with which we compare, both in terms of error rates and coverage as well as in terms of computation time. To the best of our knowledge, there is no other competitor to our approach as all other methods are either restricted to regular grid data or simpler correlation structures. In our application to speech production data, we show that our method allows conclusions to be drawn about the asymmetry of consonant assimilation to an extent which is not achievable using conventional methods with data reduction.
Building on existing methods for our estimation approach allows us to take advantage of robust, flexible algorithms with a high functionality. The computational efficiency, however, could potentially be improved by exploiting the special structure of our model. In future work, we plan to improve the estimation of the auto-covariances in order to better account for their symmetry and positive semi-definiteness and for the fact that the cross products in model (3.2) are not homoscedastic. Moreover, it would be interesting to compare the different options for iterative estimation in detail.
The construction of point-wise and simultaneous CBs that account for the variability of the estimated FPC decomposition is beyond the scope of this work, but would be of interest. For uncorrelated functions, Goldsmith et al. (2013) propose bootstrap-based corrected CBs for densely and sparsely sampled functional data. However, it remains an open question how to extend their non-parametric bootstrap to our correlated curves, and computational cost is another issue.
Acknowledgments
We thank Fabian Scheipl and Simon Wood for making available and further improving their extensive software at our requests, for technical support and for fruitful discussions. Sonja Greven and Jona Cederbaum were funded by the Emmy Noether grant GR 3793/1-1 from the German Research Foundation. Marianne Pouplier was supported by the ERC under the EU's 7th Framework Programme (FP/2007–2013)/Grant Agreement n. 283349-SCSPL. We thank the referees, the associate editor, and the editor for their useful comments.