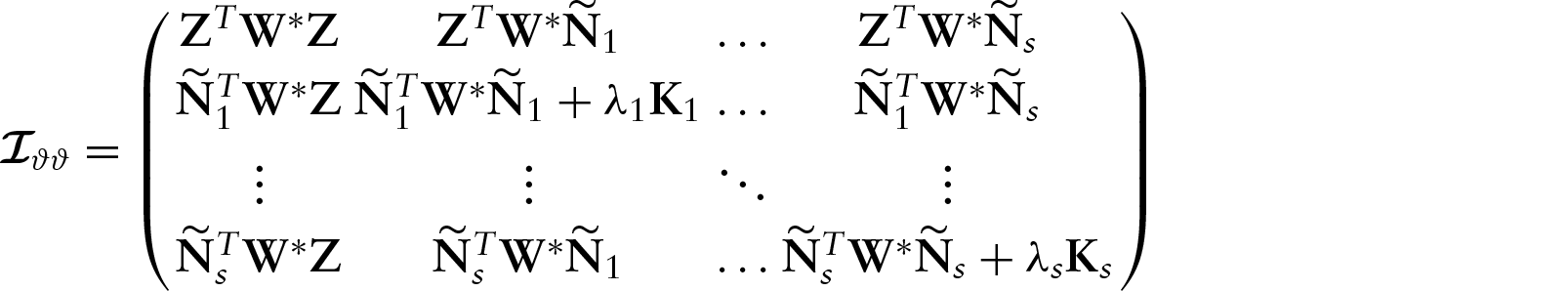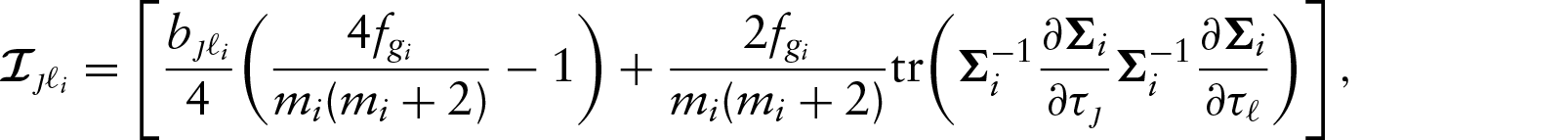Abstract
In this article, we extend varying-coefficient models with normal errors to elliptical errors in order to permit distributions with heavier and lighter tails than the normal ones. This class of models includes all symmetric continuous distributions, such as Student-t, Pearson VII, power exponential and logistic, among others. Estimation is performed by maximum penalized likelihood method and by using smoothing splines. In order to study the sensitivity of the penalized estimates under some usual perturbation schemes in the model or data, the local influence curvatures are derived and some diagnostic graphics are proposed. A real dataset previously analysed by using varying-coefficient models with normal errors is reanalysed under varying-coefficient models with heavy-tailed errors.
Keywords
Introduction
Diagnostic methods for parametric regression models have been largely investigated in the statistical literature. The majority of the works have given emphasis in studying the effect of eliminating observations on the results from the fitted model, particularly on the parameter estimates. This approach has also been extended to nonparametric and semiparametric models. For example, Wei (2004) presented some influence diagnostic and robustness measures for smoothing spline. Kim et al. (2002) derived influence measures for the partial linear models (LMs) based on residuals and leverage for the estimates of the regression coefficients and the nonparametric function. Fung et al. (2002) studied influence diagnostics for normal semiparametric mixed models with longitudinal data. Li et al. (2009) derived influence measures and outlier test for partially varying-coefficient mixed model.
Case deletion does not directly reflect the impact of other perturbations in the model. Alternatively, Cook (1986) has proposed an interesting method, named local influence, to assess the effect of small perturbations in the model (or data) on the parameter estimates. The local influence analysis does not involve recomputing the parameter estimates for every case deletion, so it is often computationally simpler. Several authors have extended the local influence method to various regression models. For example, Galea et al. (1997) and Díaz-García et al. (2003) extended the local influence methodology to elliptical linear regression models. Galea et al. (2005) applied the local influence method in functional and structural comparative calibration models under elliptical distributions. Paula et al. (2003) developed local influence for symmetrical nonlinear models.
In context of nonparametric and semiparametric regression models, Thomas (1991) constructed local influence diagnostics for the smoothing parameter and Zhu et al. (2003) extended the works by Cook (1986) to provide local influence measures under different perturbation schemes in normal partially LMs. Ibacache-Pulgar and Paula (2011) extended the local influence methodology to Student-t partial LMs. Ibacache-Pulgar et al. (2012, 2013) developed local influence for elliptical semiparamteric mixed model and semiparametric additive model under symmetric distributions respectively. Recently, Zhang et al. (2015) derived local influence measures for varying-coefficient LM.
The aim of this article is to apply the approach of local influence in partially varying-coefficient models (PVCMs) under elliptical distributions. This article is organized as follows. Section 2 contains one motivating example analysed under normal PVCM. In Section 3, the PVCMs under elliptical distributions are presented and a penalized log-likelihood function is considered for the parameter estimation. A discussion on the process to obtain maximum penalized likelihood estimators, the derivation of a back-fitting algorithm, some inferential result and discussions on degrees of freedom (df) estimation and selection of the smoothing parameter are given in Section 4. In Section 5, the main concepts of local influence are considered and normal curvatures for some perturbation schemes are derived. An illustration of the methodology is presented for dataset in Section 6. Finally, in Section 7, some concluding remarks are given.
Motivating example
In our application we will consider the house prices dataset that has been reported by Harrison and Rubinfeld (1978). The aim of the study is to assess the association of house prices with the air quality of the neighbourhood by using regression models. The outcome variable LMV (logarithm of the median house price in US$ 1 000) is related with 14 explanatory variables; 6 of them are defined from census track and the remaining variables are defined for clusters. Altogether, there are 506 observations. We will work, for the purpose of motivating the PVCMs, with four explanatory variables, LSTAT (% lower status of the population), ROOM (average number of rooms per dwelling), CRIM (per capita crime rate by town) and TAX (full-value property-tax rate per US$ 10 000).
Scatter plots: LMV versus TAX (a), LMV versus LSTAT, (b) LMV versus ROOM × LSTAT (c) and CRIM × LSTAT (d)
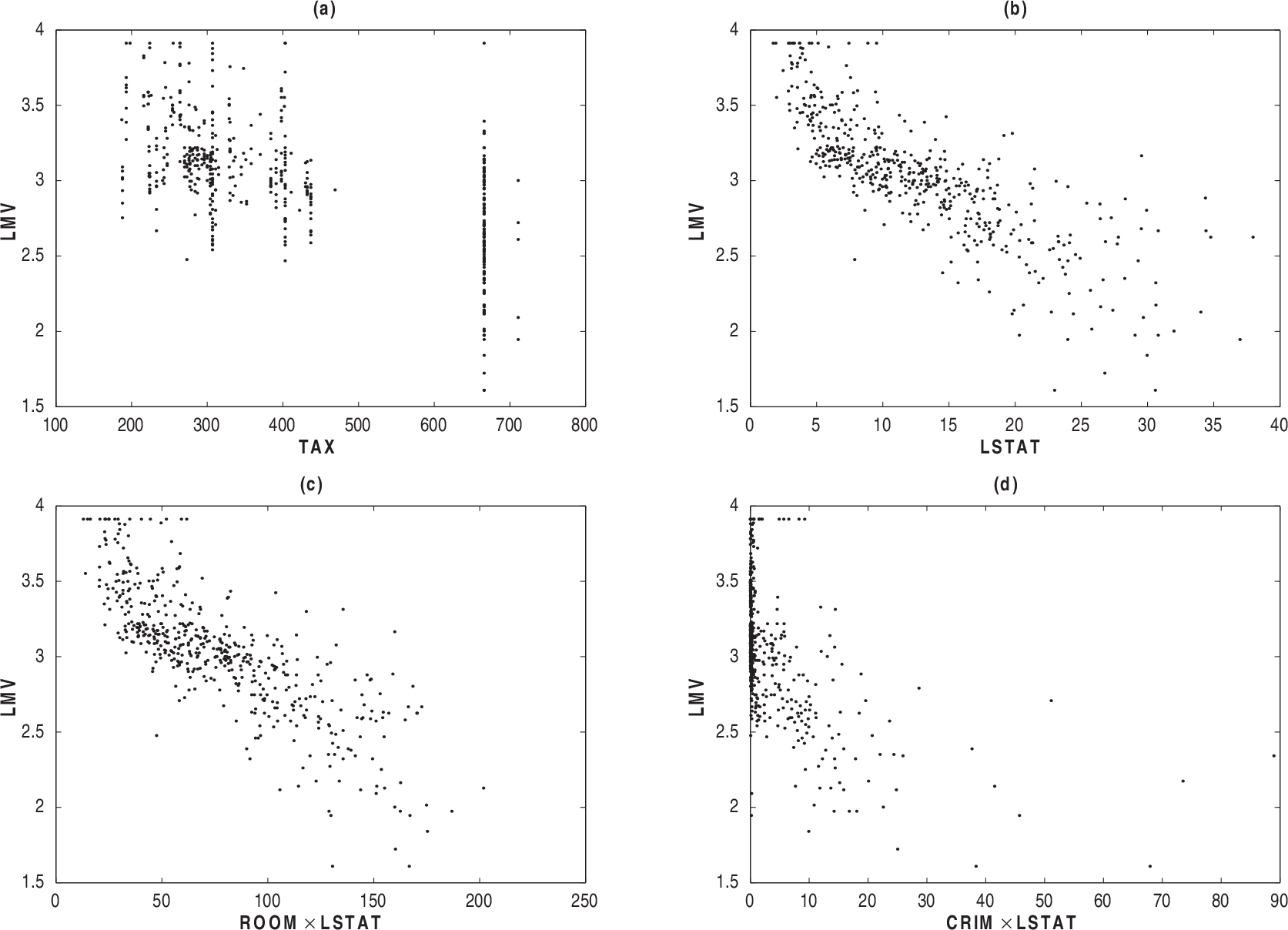
Scatter plots: LMV versus TAX (a), LMV versus LSTAT, (b) LMV versus ROOM × LSTAT (c) and CRIM × LSTAT (d)
We see in Figure 1(a) that the relationship between LMV and the explanatory variable TAX is linear, whereas the relationship between LMV and LSTAT appear in nonlinear ways (Figure 1(b)). On other hand, Figures 1(c) and 1(d) suggest that the explanatory variables ROOM and CRIM might be interacting with the variable LSTAT in nonlinear fashion. These tendencies suggest a PVCM among LMV and the explanatory variables. First, we adjust a Student-t and normal PVCM. In order to identify outlying observations, the index plots of the Mahalanobis distance is performed in Figures 2(a) and 2(b).
Index plots of the Mahalanobis distance under normal (a) and Student-t (b) models and between the estimated weights and Mahalanobis distance under Student-t model (c)
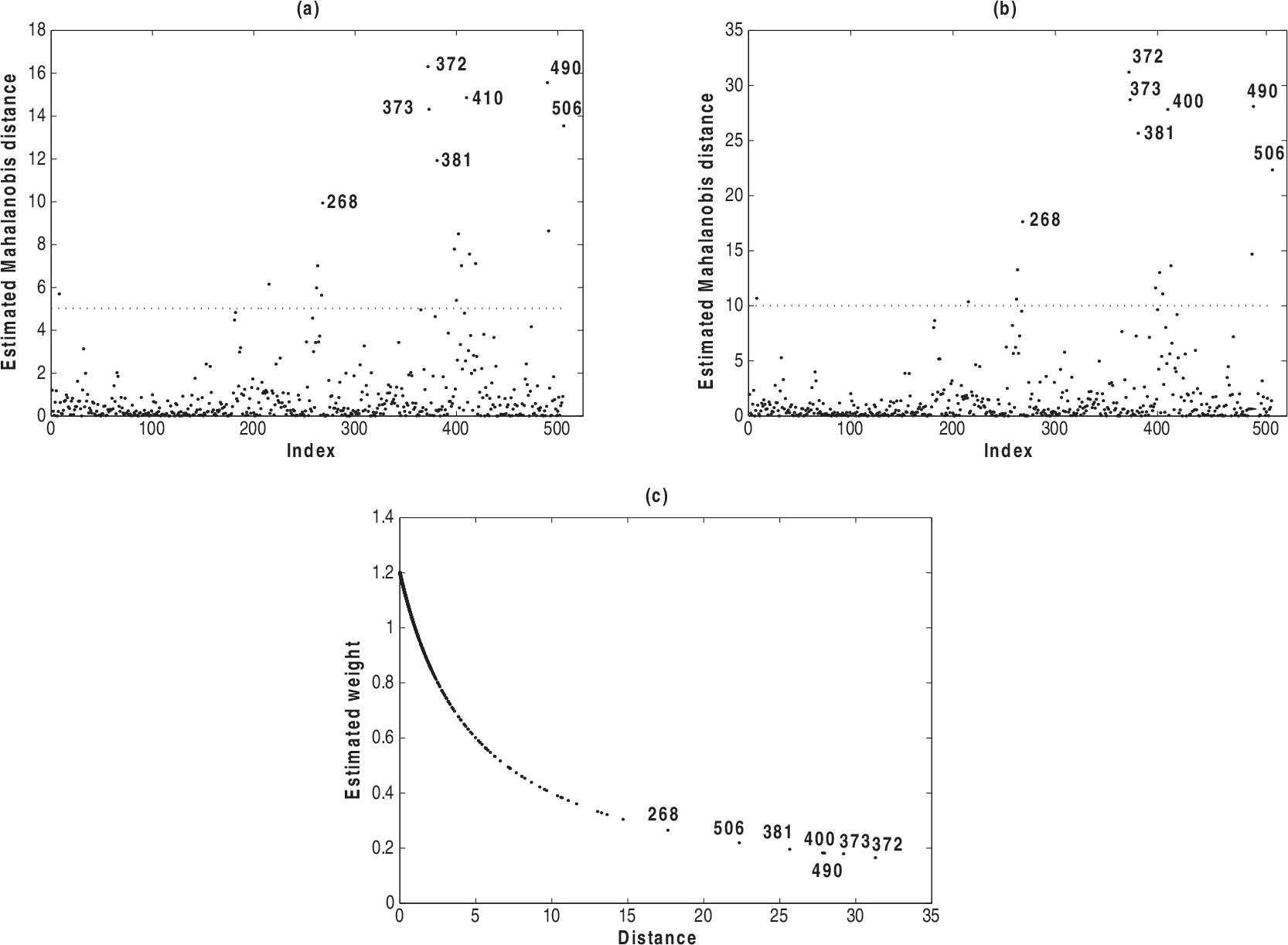
In Figures 2(a), 2(b) and 2(c), we see seven observations albeit with discrepant values. These observations correspond to case 268, 372, 373, 381, 410, 490 and 506. Figure 2(c) displays the estimated weights under the Student-t model and we notice that the estimated weights for the observations described above take the smaller values. In Section 6, we reanalyse this example under heavy-tailed errors for which the maximum penalized likelihood estimates (MPLEs) appear to be less sensitive to the outliers and to some perturbations in the model or data than the estimate from the normal PVCM.
The PVCMs emerge as a powerful tool in statistical modelling because of their flexibility to model explanatory variables effects that can contribute in a parametric way and explanatory variables effects in which the coefficients are allowed to vary as smooth functions of other variables (e.g., time variable). These models are often used in research related to longitudinal, clustered, spatial and hierarchical sampling schemes. In this class of models, usually it is assumed that random errors follow a normal distribution. However, it is well known that in many cases the normal distribution is not appropriate and that the least-squares estimates are sensitive to outlying observations. A possible alternative for dealing with this deficiency is to assume, for example, heavy-tailed distributions for the errors. A class of distributions containing distributions with such features is the class of elliptical distributions. The elliptical class includes all elliptical contoured distributions such as normal, Student-t, power exponential and contaminated normal, among others. The variety of error distributions with different kurtosis coefficients gives more flexibility for analysing datasets from light- and heavy-tailed distributions.
The model
The PVCM assumes that the relationship between the response variable and the explanatory variables can be represented as
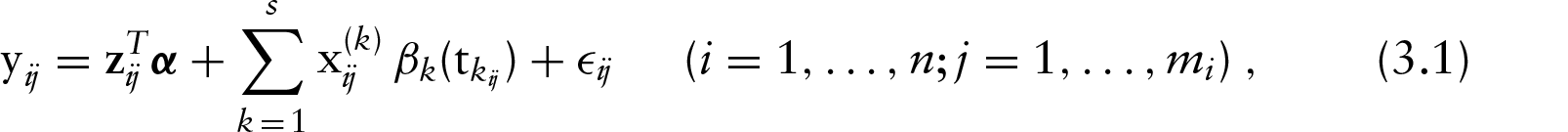
In order to write model (3.1) in a matrix form, we obtain
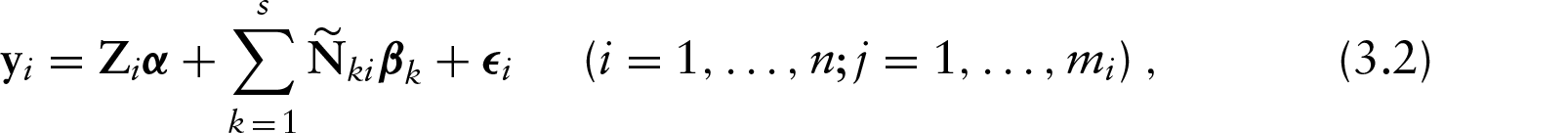

We will assume that εi follows an elliptical distribution with location parameter 0 and scale matrix Σi (see, e.g., Fang et al., 1990). Consequently, the distribution of yi is given by
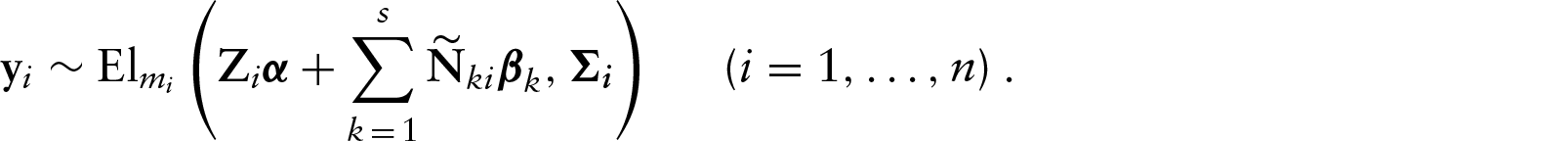
In order to ensure that the random vector y
i
admits a density for all

Penalized function
Let

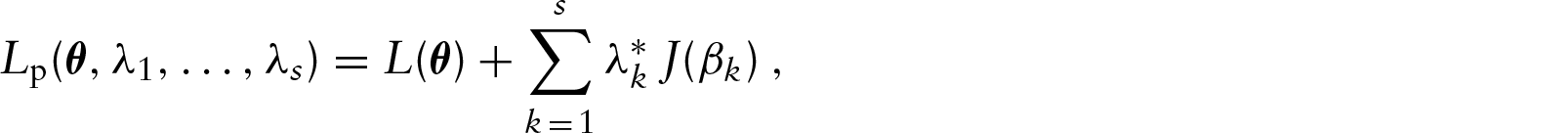

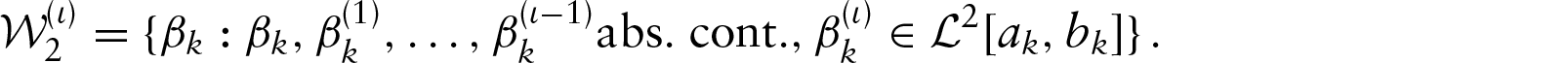
When


In this section, we discuss some aspects of estimation and inference in elliptical PVCMs. In the first subsection, we discuss the estimation of
Maximizing the penalized log-likelihood function
Because

The determination of the MPLE First, we maximize the function Here, Then, we maximize Now, we maximize Finally, we maximize
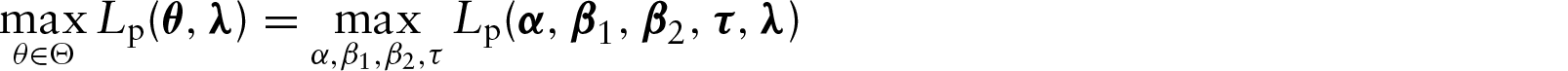
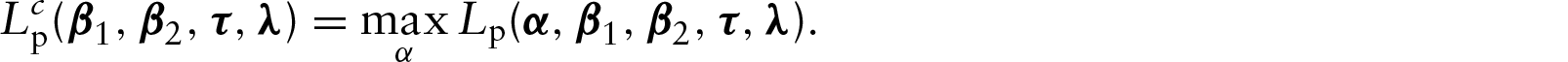


The four-step procedure can be generalized for
Fisher score and weighted back-fitting algorithms
Let



The solution of the estimating equation system (4.1) to obtain the MPLE of Initialize:
a. Fitting a PVCM under normal errors to get b. Getting starting value for c. From the current value Step 1: Iterating repeatedly by cycling between the following equations:
Step 2: For current values Iterating between 2 and 3 by replacing
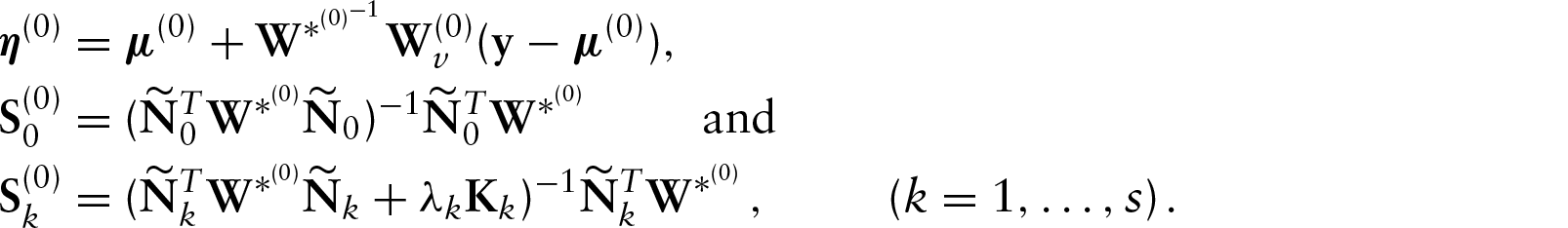
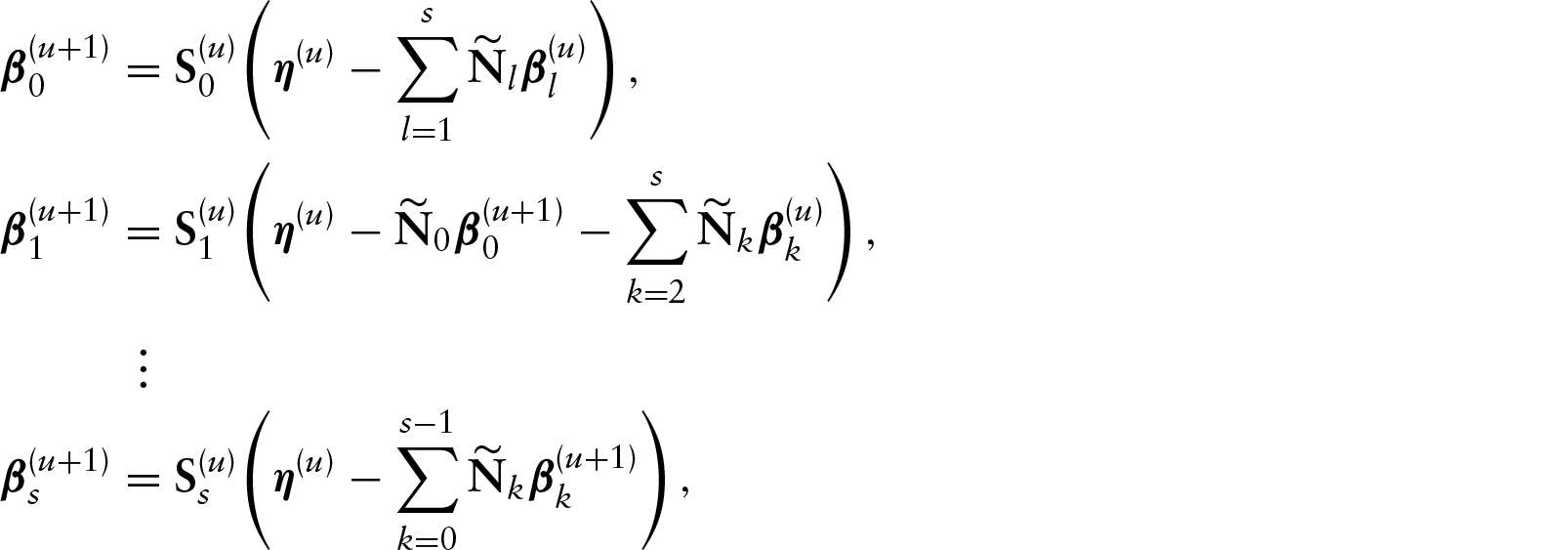

Note that under Student-t distribution (df
Approximate standard errors
In this work, we derive the covariance matrix of

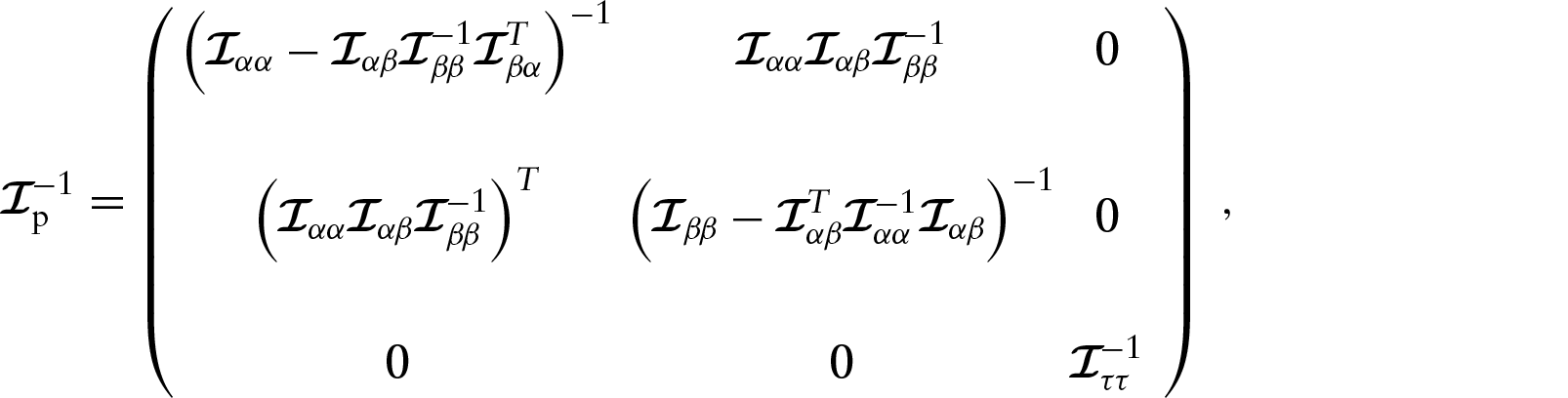

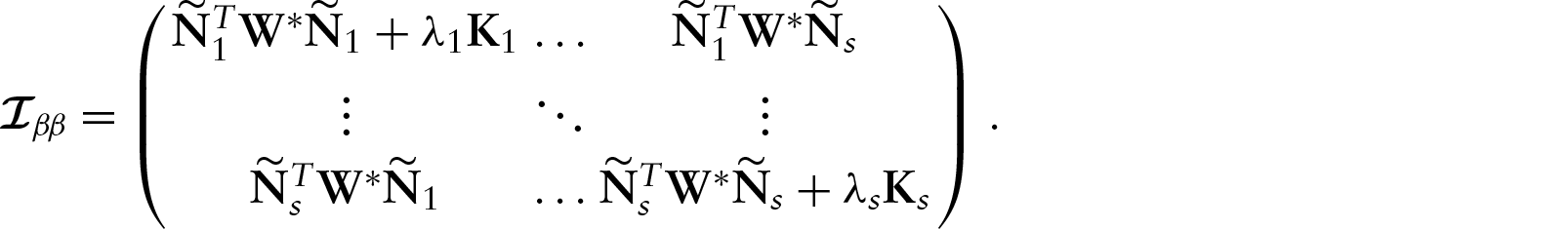

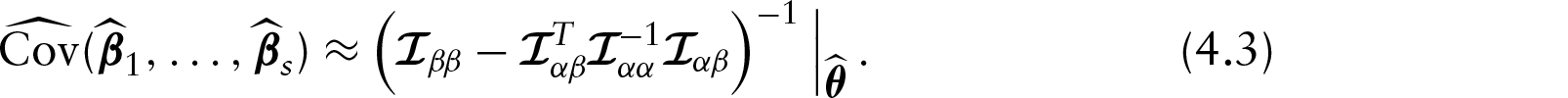
By using variance–covariance matrix (4.3), we can construct an approximate pointwise SEB for
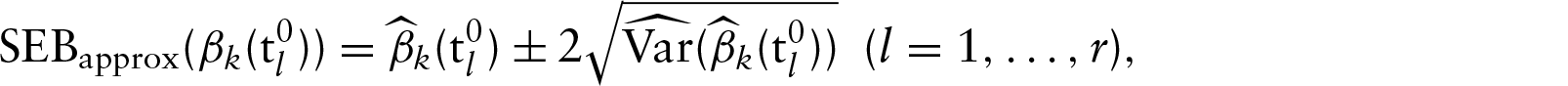
On degrees of freedom
In the elliptical PVCM, the df associated with the

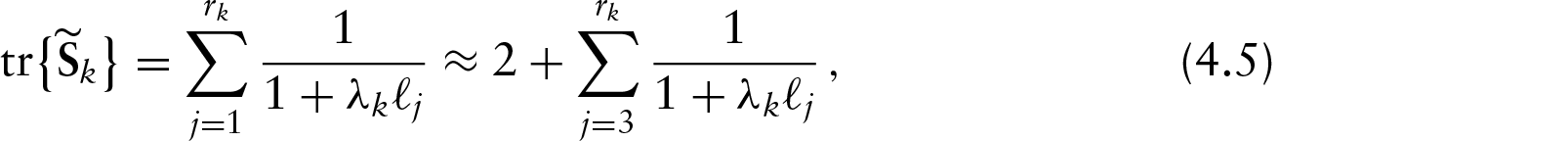
In the previous subsections, the smoothing parameters For simplicity, consider Select a range for the smoothing parameters.
a. Obtain an appropriate regression obtaining the fitted equation b. Since the relationship between Minimize the The suggestion is to select a grid of values from the range
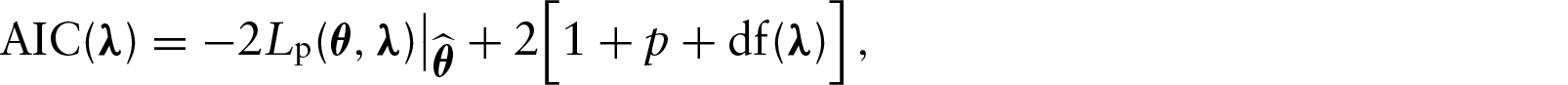
Local influence measure
In this section, we present the local influence method and derive the perturbation matrix for different perturbation schemes under elliptical PVCM.
The method
Let
Conformal normal curvature
In order to have a curvature invariant under uniform change of scale, Poon and Poon (1999) proposed the conformal normal curvature defined as
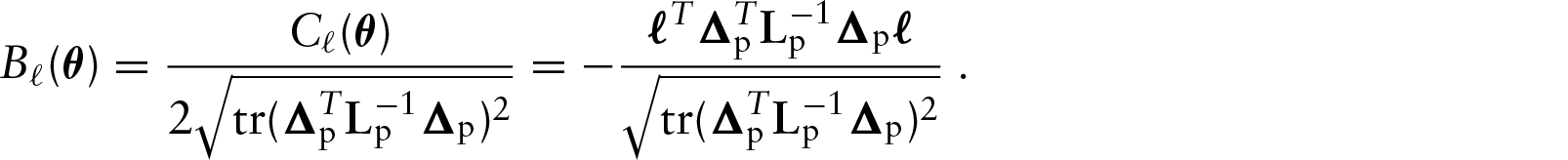
Normal curvature derivation
In this subsection, we present the expressions of the elements of the (
Case-weight perturbation
Let us consider the attributed weights for the observations in the penalized log-likelihood function as
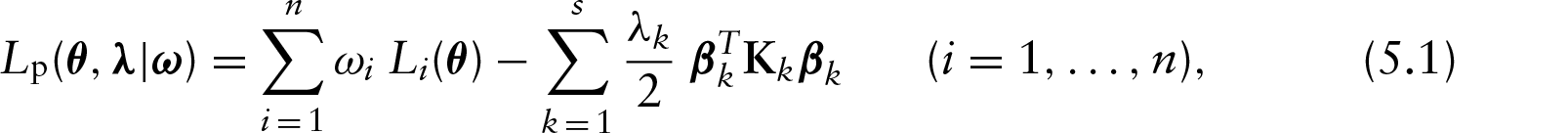
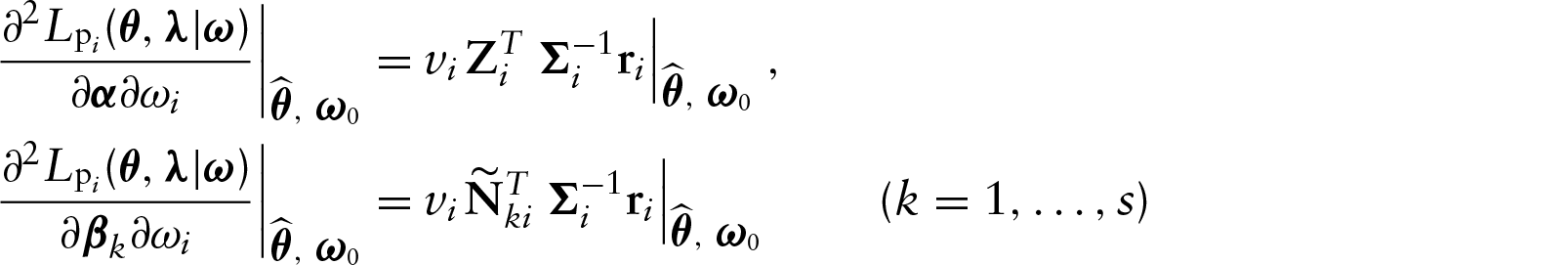
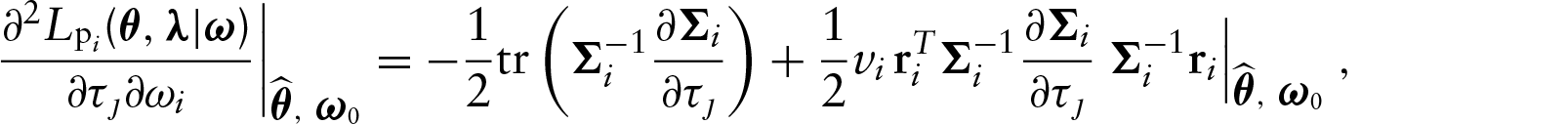
Under the scale parameter perturbation scheme, we assume that
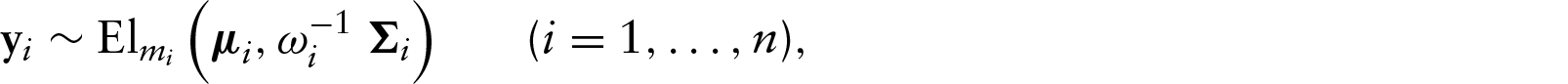


Explanatory variable perturbation
Here, the
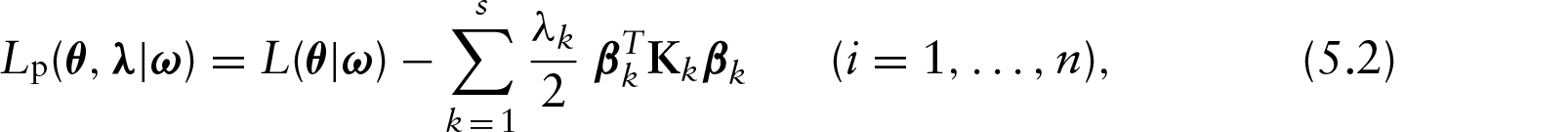
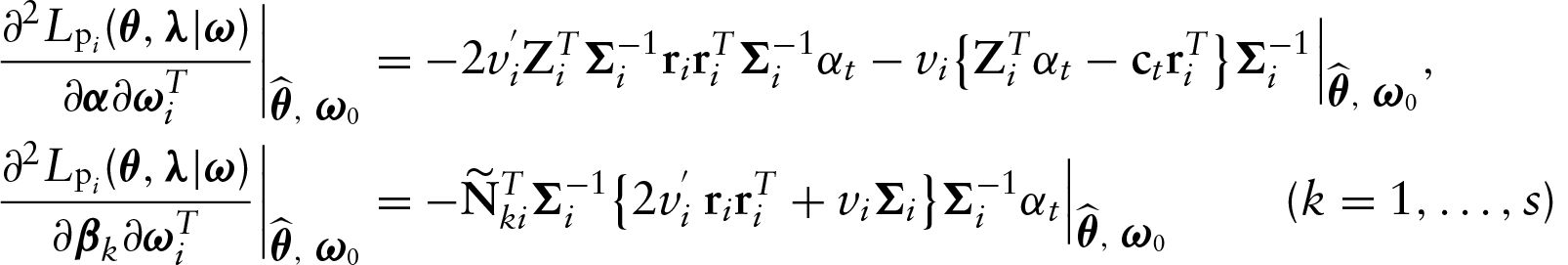
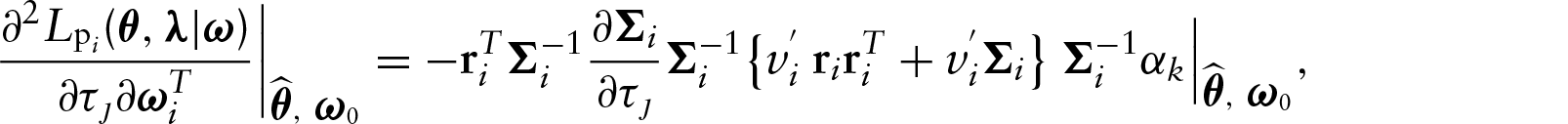
The dataset reported by Harrison and Rubinfeld (1978) has been analysed by various authors using different models; see, for instance, Belsley et al. (1980) and Ibacache-Pulgar et al. (2013). The descriptive analysis of Section 2 suggests that the relationship between LMV and the explanatory variable TAX is linear (see Figure 1(a)), whereas the relationship between LMV and LSTAT appears in non-linear ways (see Figure 1(b)). On other hand, Figures 1(c) and 1(d) suggest that the explanatory variables ROOM and CRIM might be interacting with the variable LSTAT in nonlinear fashion. These tendencies suggest a PVCM among LMV and the explanatory variables. Specifically, we will assume the following model:

We will compare in the sequel the fits based on normal and Student-t errors. The df
MPLEs, estimated standard errors and AIC values under normal and Student-t (
) models fitted to house prices data
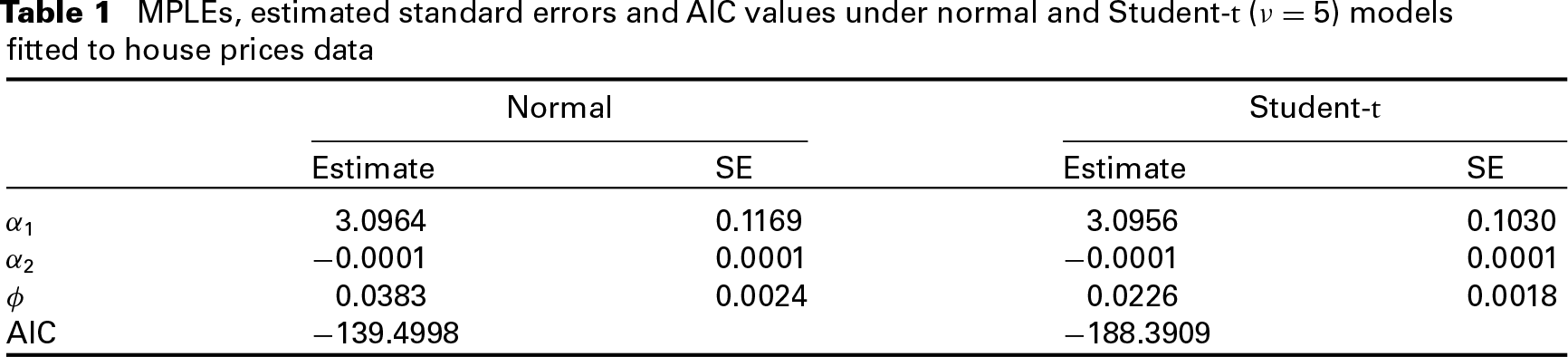
MPLEs, estimated standard errors and AIC values under normal and Student-t (
) models fitted to house prices data
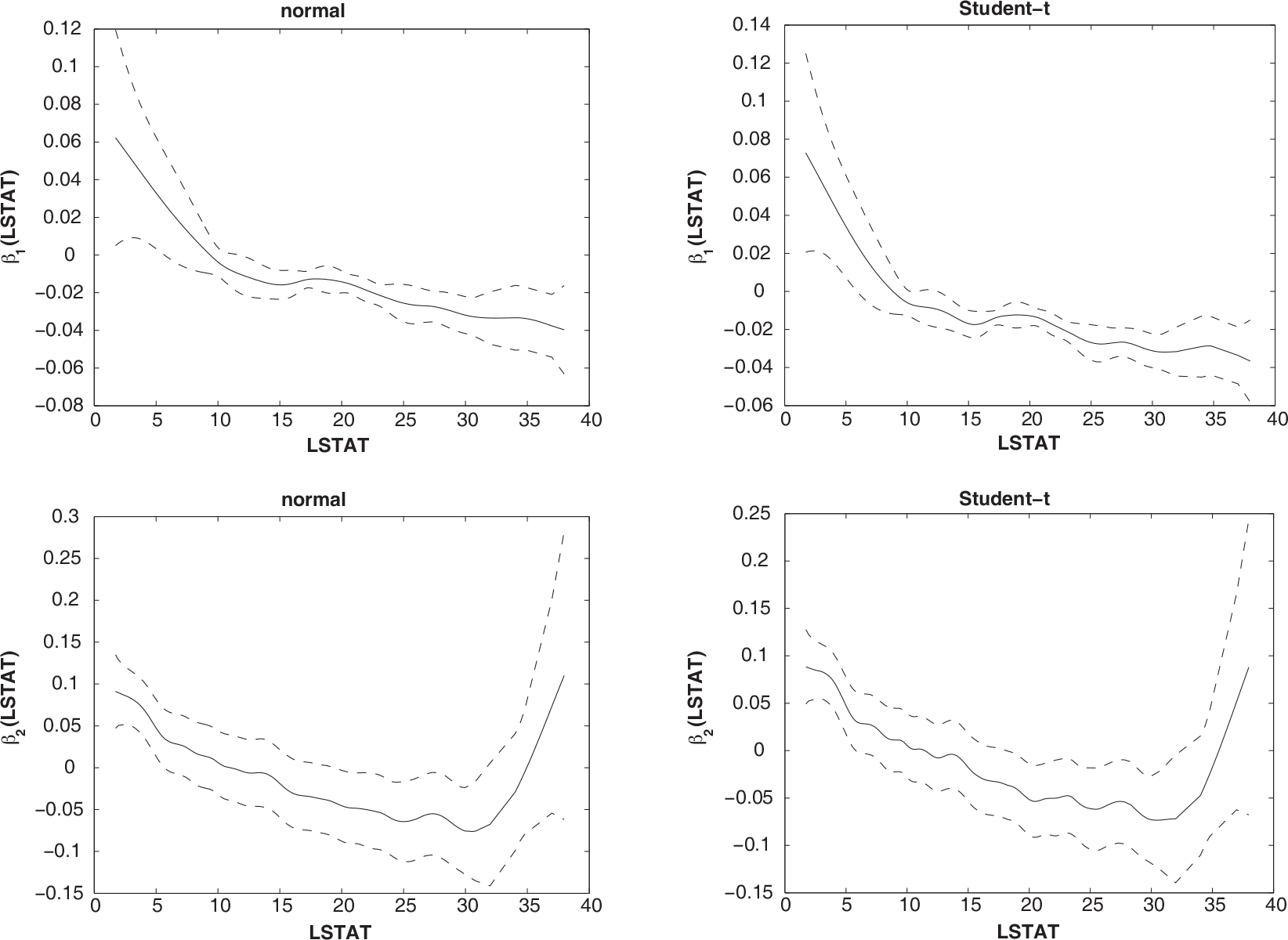
Comparing these results, we may notice a similarity between the estimates Plots of estimated coefficient functions for the house prices data, and their approximate pointwise SEB denoted by the dashed lines
Scatter plots of LMV versus fitted LMV: normal (a) and Student-t models (b)
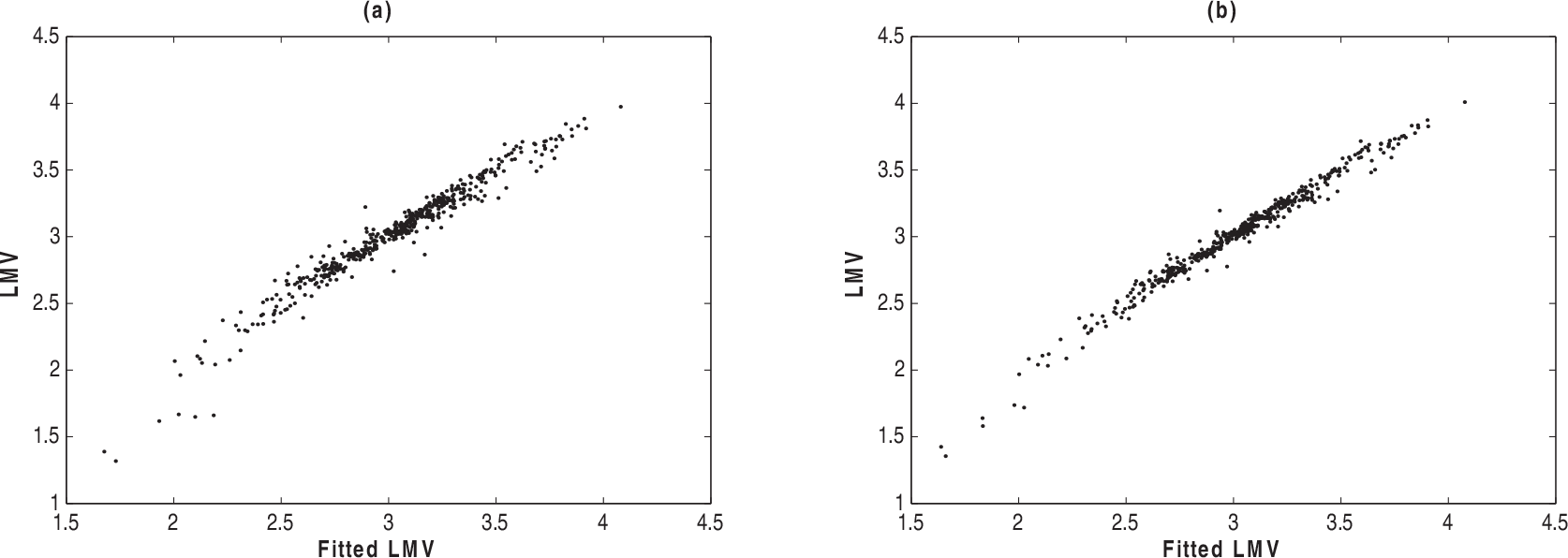
Figure 4 displays the graphics of the LMV versus the fitted LMV from tho models, indicating suitable fits for both models.
It is important to mention that the observations 372, 490, 410, 373, 506, 381 and 268 that appear as possible outliers under Student-t and normal models (see Figures 2(a) and 2(b)), the estimation process under Student-t model assigns them small weights, confirming the robust aspects of the MPLEs against outlying observations under heavier-tailed error models; see Figure 2(c).
Now, in order to identify influential observations, we present some index plots of
Index plots of B
i
for assessing local influence on α under case-weight perturbation for normal and Student-t models fitted to house prices data
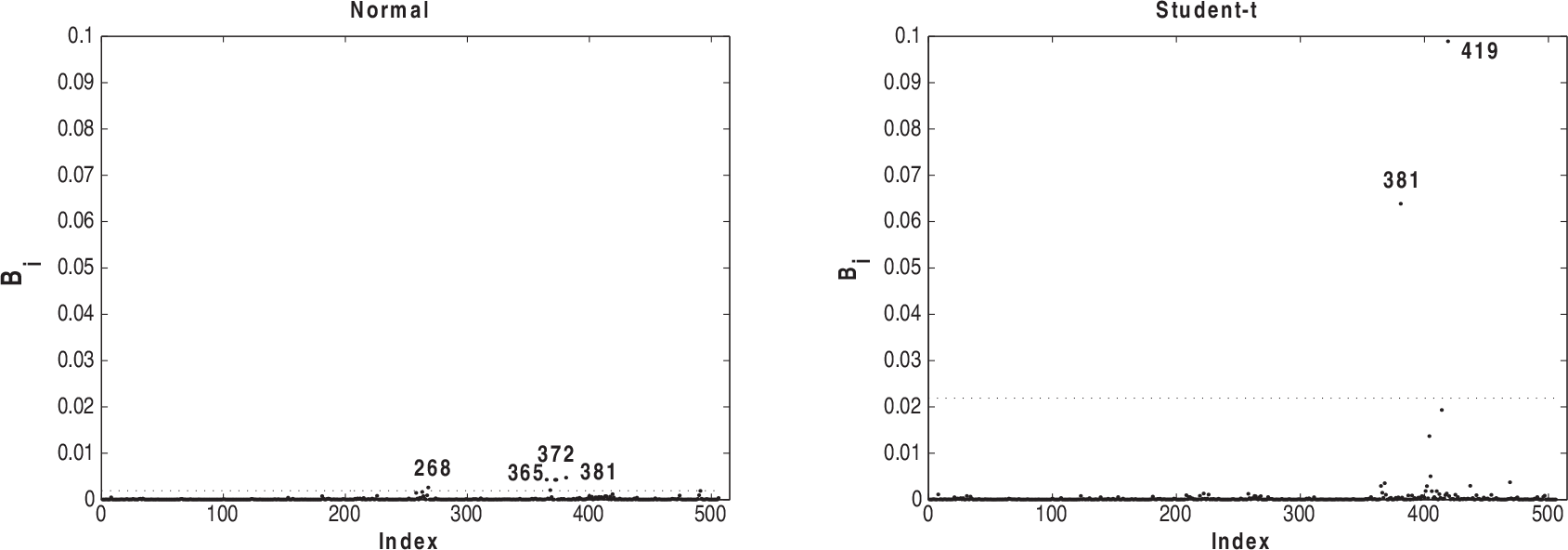
Index plots of B i for assessing local influence on α under case-weight perturbation for normal and Student-t models fitted to house prices data
Index plots of B i for assessing local influence on β1 under case-weight perturbation for normal and Student-t models fitted to house prices data

Index plots of B i for assessing local influence on β2 under case-weight perturbation for normal and Student-t models fitted to house prices data
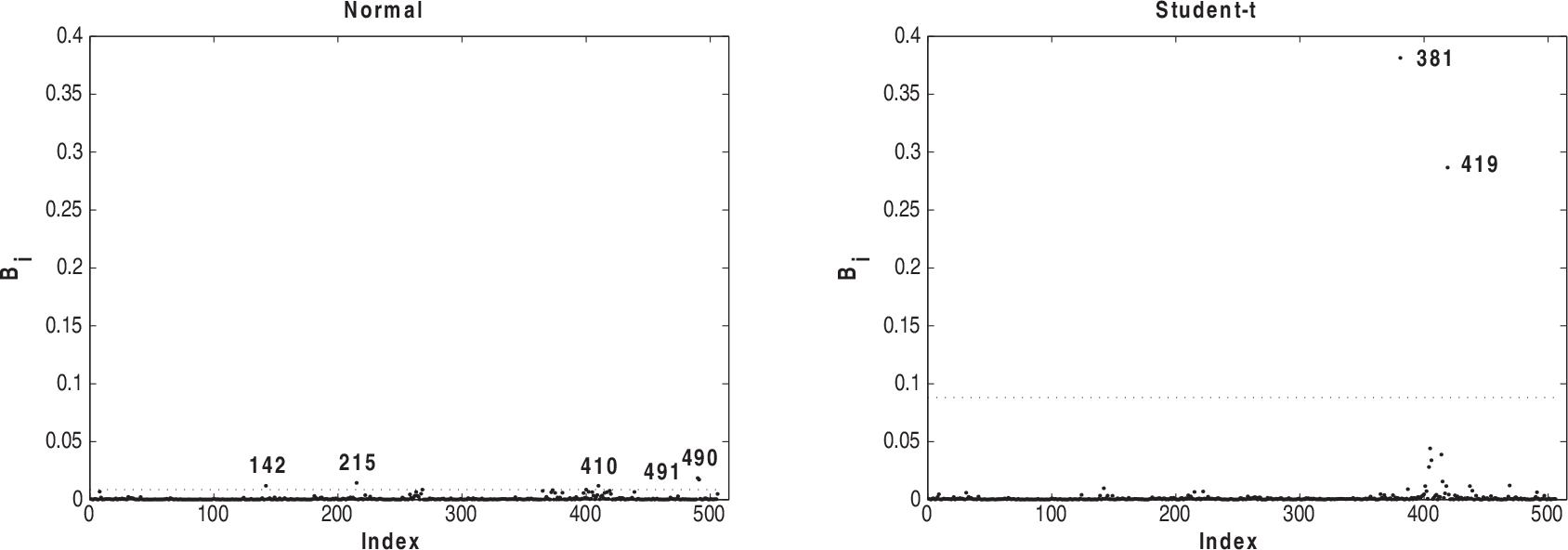
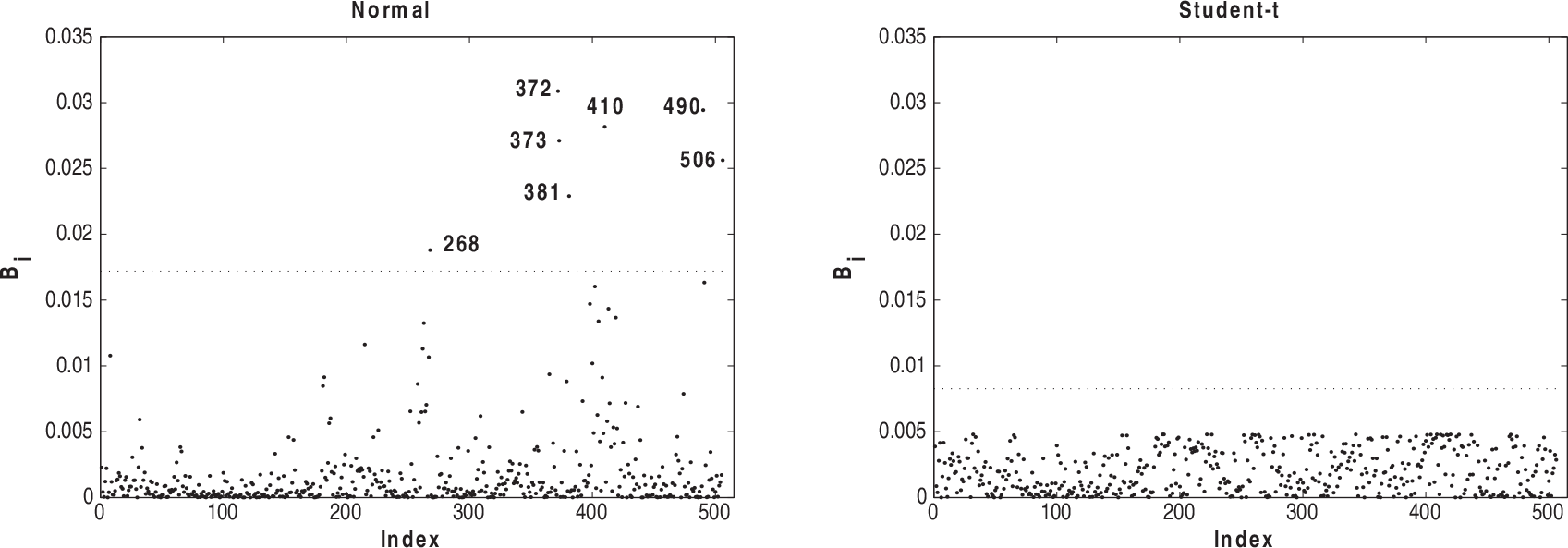
Figures 5–8 present the index plots of B i for the case-weight scheme under the two fitted models. Considering Figure 5, we notice that 381, 365, 372, 268 and 369 are pointed out under the normal model and observations 419 and 381 have the greatest values under Student-t model. Based on Figure 6, we notice that observations 381, 419 and 405 are more influential under the normal model, whereas observations 405, 381 and 406 appear as influential under the Student-t model. Looking at Figure 7, we observe that the observations 490, 491, 215, 410 and 142 appear with a small influence under the normal model, whereas the observations 381 and 419 have the greatest influence under Student-t. From Figure 8, we notice that observations 372, 373, 410 and 506 are more influential under normal model and the observations 419, 381 and 406 have the greatest values under the Student-t model.
Index plots of B
i
for assessing local influence on ϕ under case-weight perturbation for normal and Student-t models fitted to house prices data
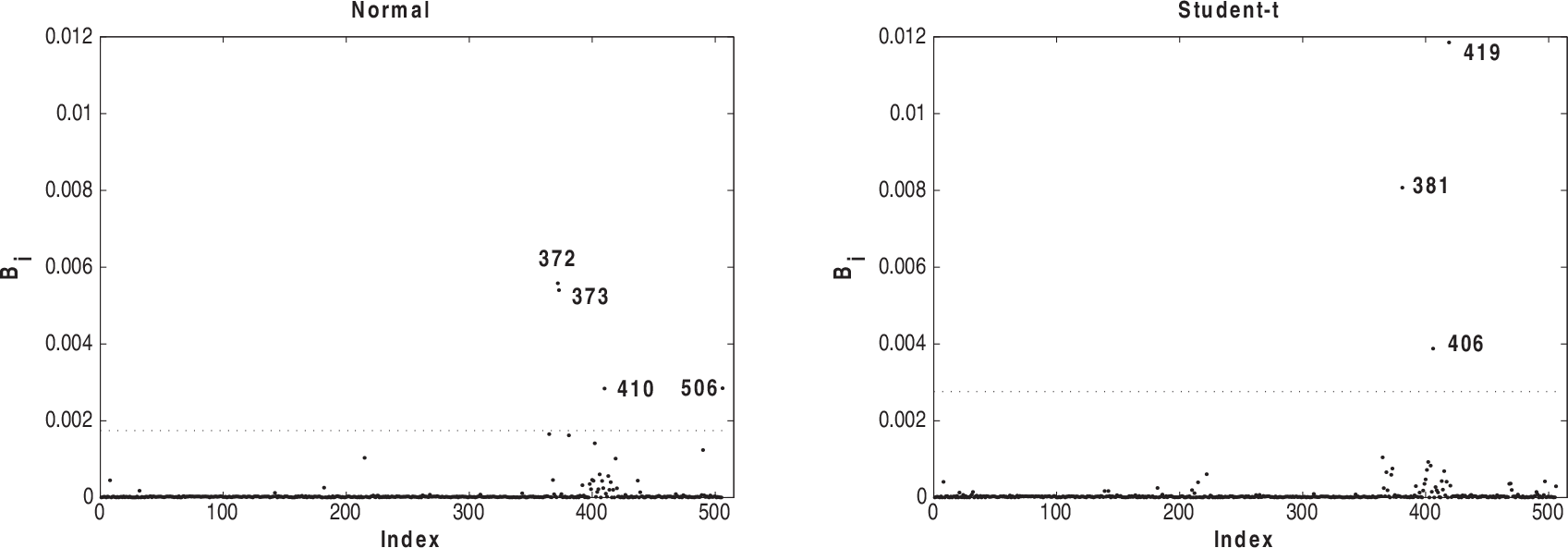
Index plots of B i for assessing local influence on ϕ under case-weight perturbation for normal and Student-t models fitted to house prices data
The index plots of
Index plots of B
i
for assessing local influence on α under TAX perturbation for normal and Student-t models fitted to house prices data
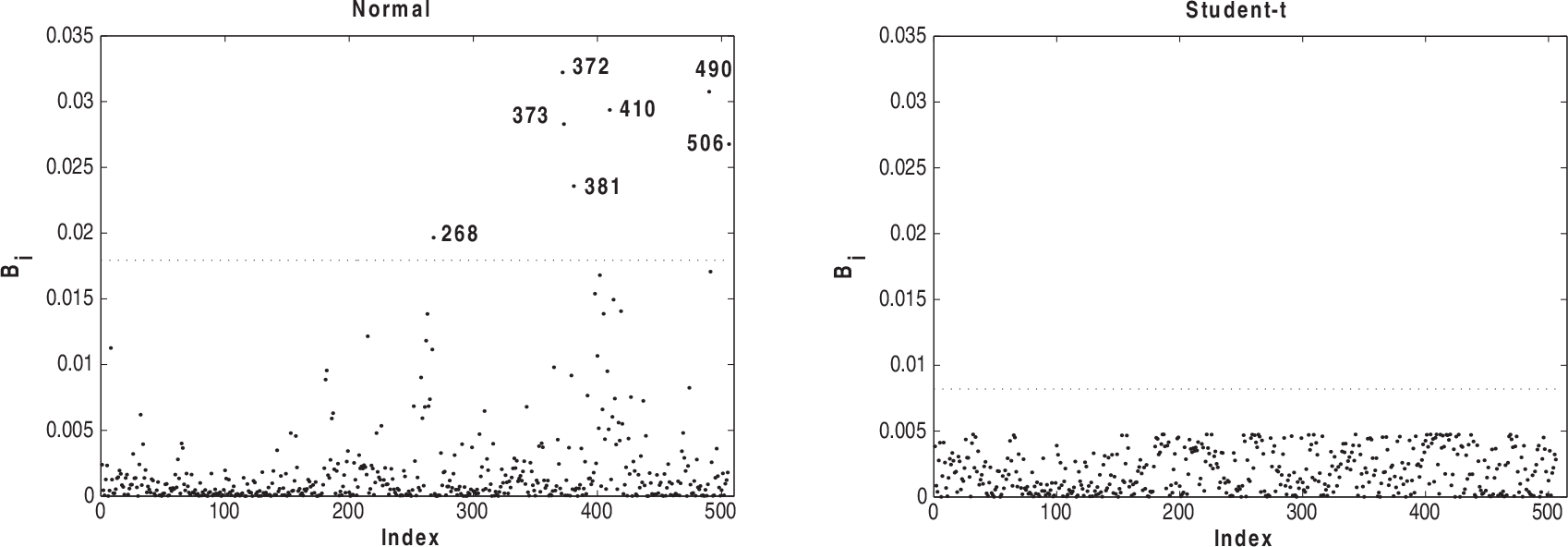
Index plots of B i for assessing local influence on α under TAX perturbation for normal and Student-t models fitted to house prices data
Index plots of B i for assessing local influence on β1 under TAX perturbation for normal and Student-t models fitted to house prices data

Index plots of B i for assessing local influence on β2 under TAX perturbation for normal and Student-t models fitted to house prices data
Index plots of B i for assessing local influence on ϕ under under TAX perturbation for normal and Student-t models fitted to house prices data
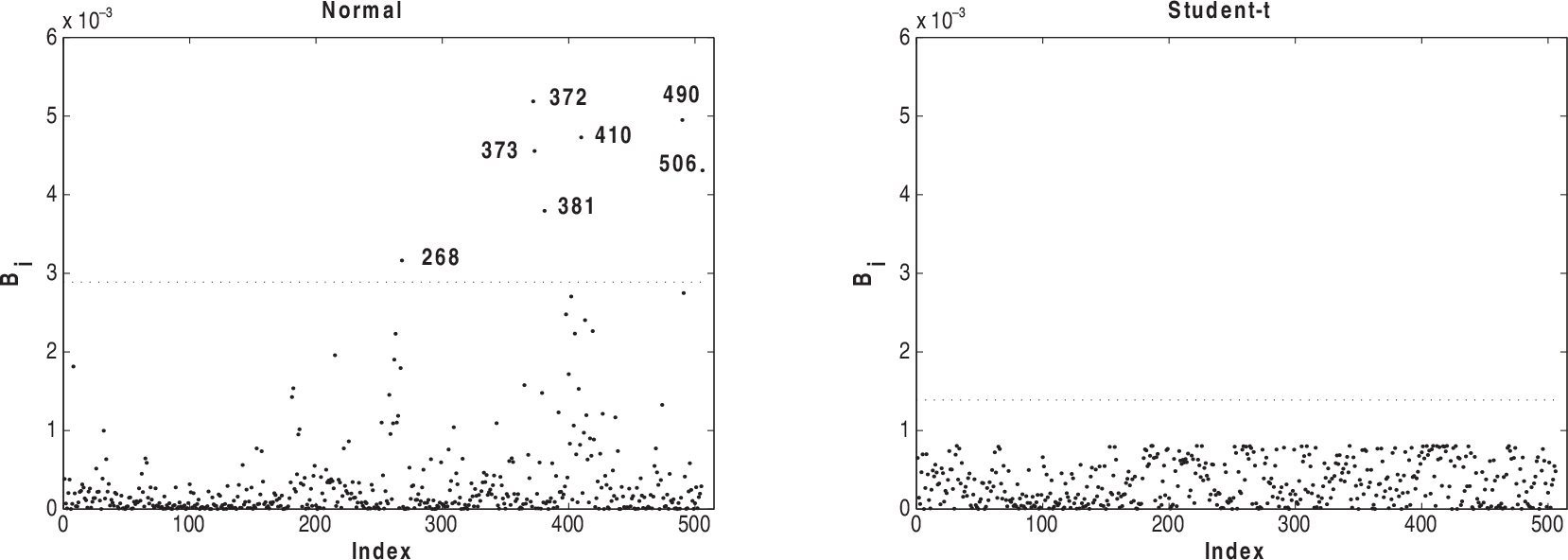
Based on these local influence graphics, we can conclude that the MPLEs for the regression coefficient
In this article, we discuss parameter estimation and some statistical diagnostics for PVCM under elliptical errors. Local influence approaches for the proposed model under case-weight, scale parameter and explanatory variable perturbations are developed. Closed-form expressions are obtained for the penalized observed and expected information matrices. A real dataset previously analysed under normal errors is reanalysed under Student-t errors by assuming the smoothing parameter fixed and by applying the AIC to choose a df parameter estimate. The study provides evidences on the robust aspects of the MPLEs from Student-t PVCM with small df against outlying observations, as pointed out by Ibacache-Pulgar et al. (2013) in the context of symmetric semiparametric additive models. However, these robust aspects do not seem to be extended to all perturbation schemes of the local influence approach, indicating the usefulness of the normal curvatures derived in this article for assessing the sensitivity of the MPLEs from the elliptical PVCMs. Thus, we can recommend Student-t PVCMs as an option to fit symmetric datasets with partially varying-coefficient and indications of heavy tails. The codes in MATLAB used in the application may be obtained from the authors by request.
Acknowledgements
This work was supported by Project FONDECYT 11130704, Chile.
Score function
Assuming that (3.3) is regular with respect to 
In particular, we obtain
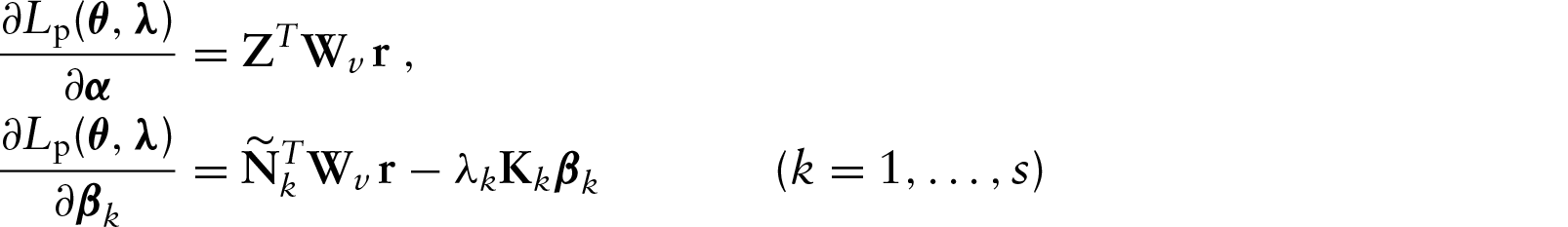
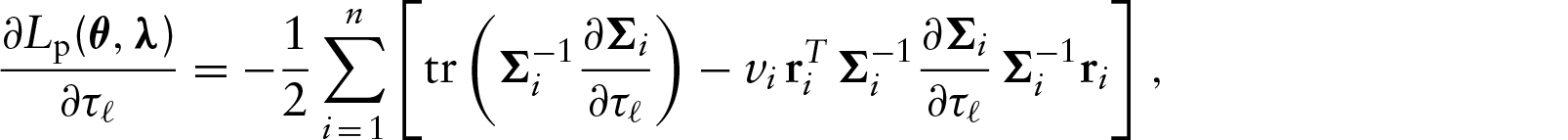
Hessian matrix
Let 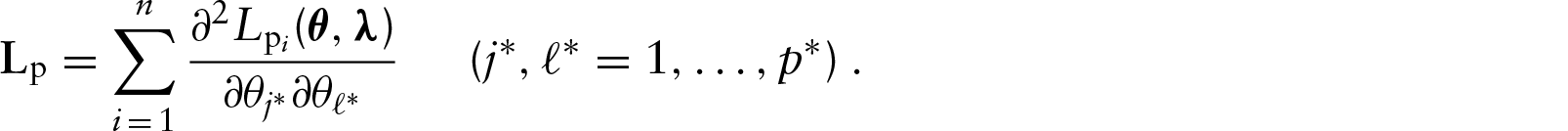
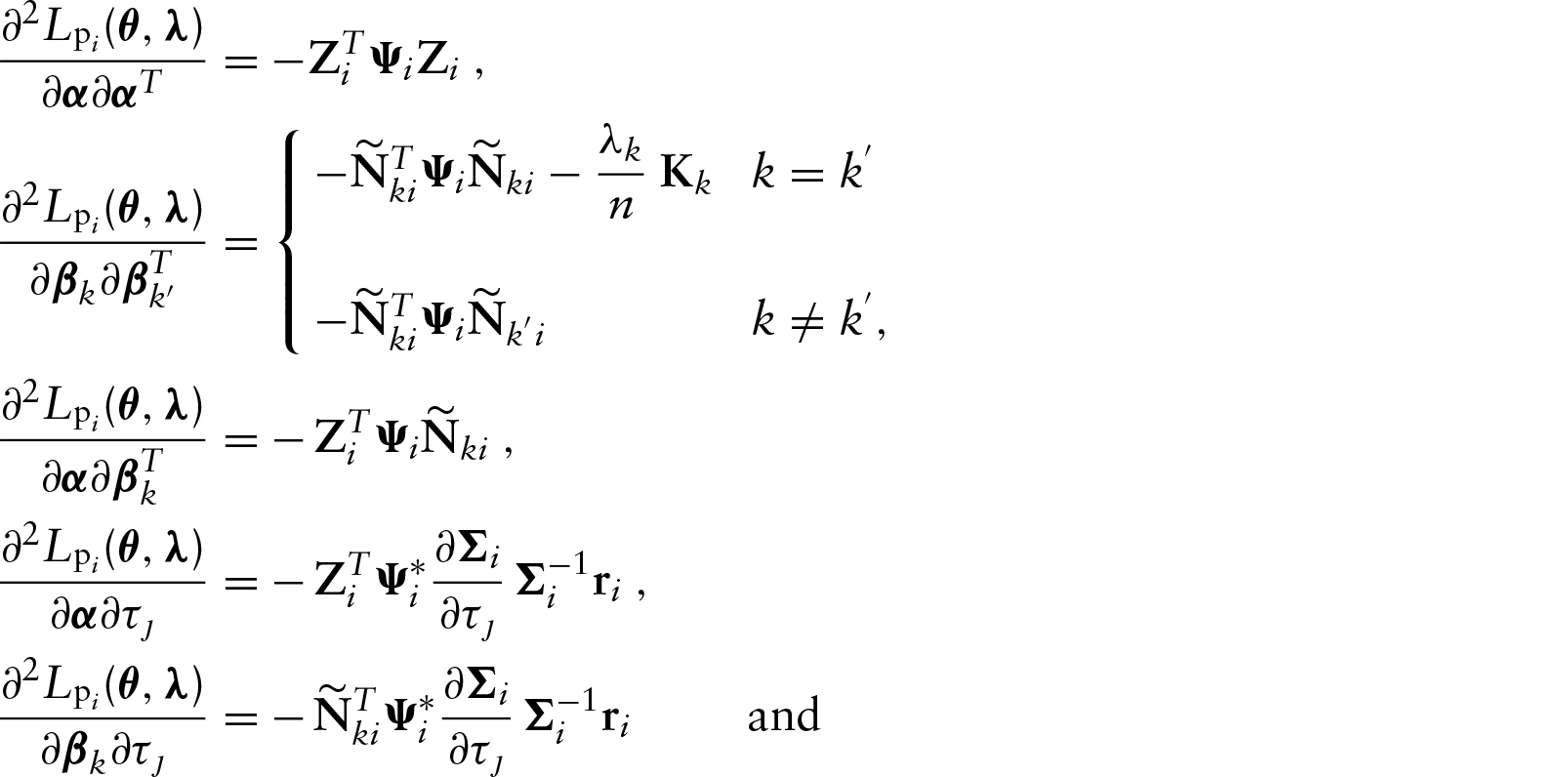

Expected information matrix
In general, by calculating the expectation of the matrix 

Let