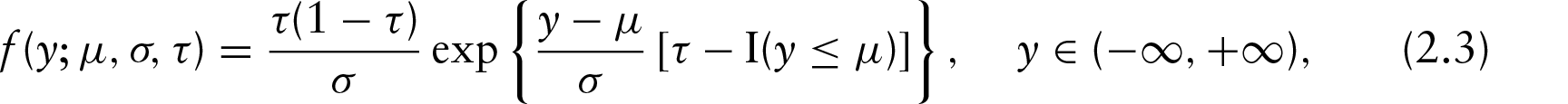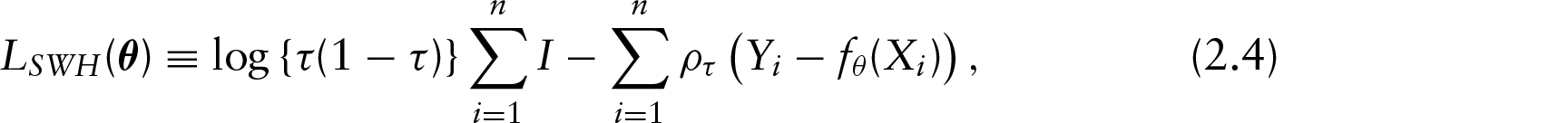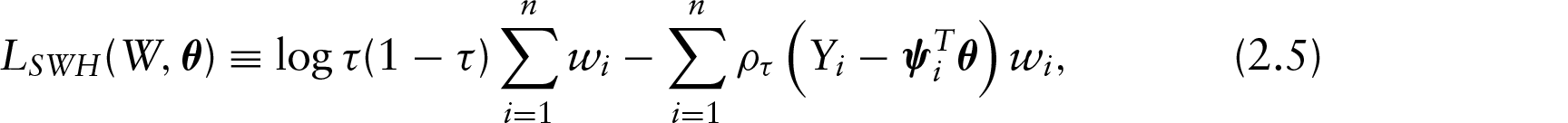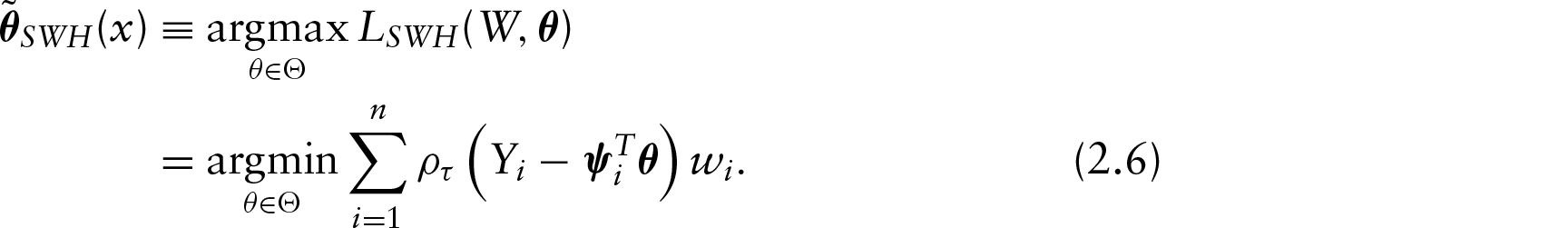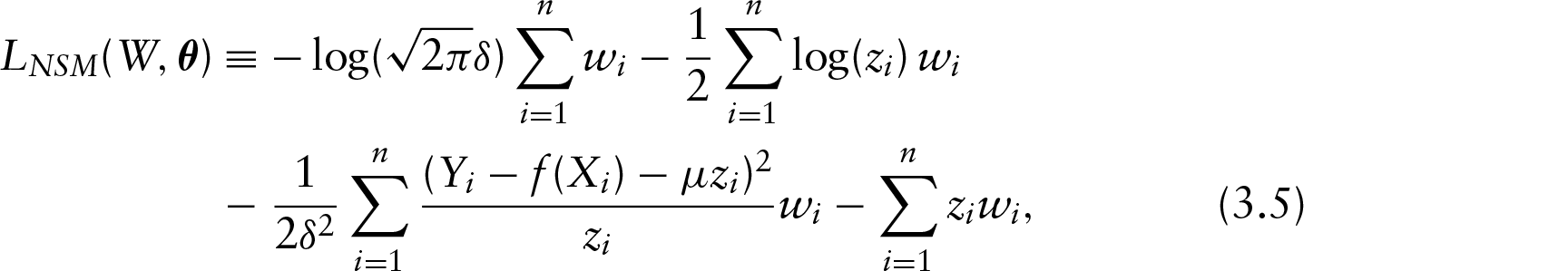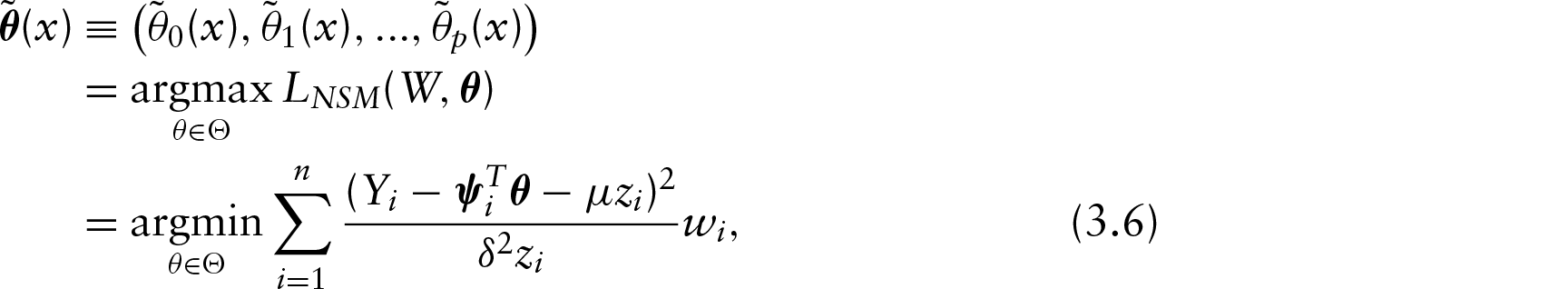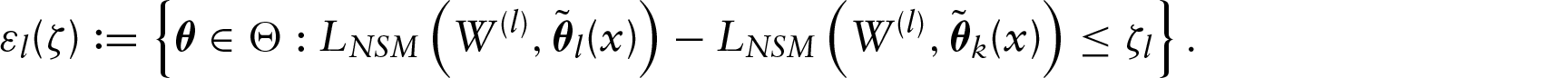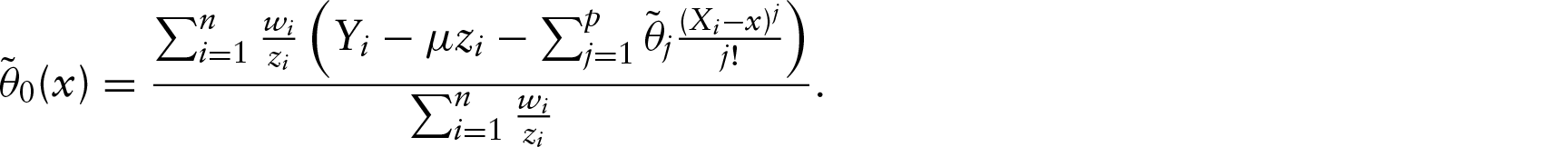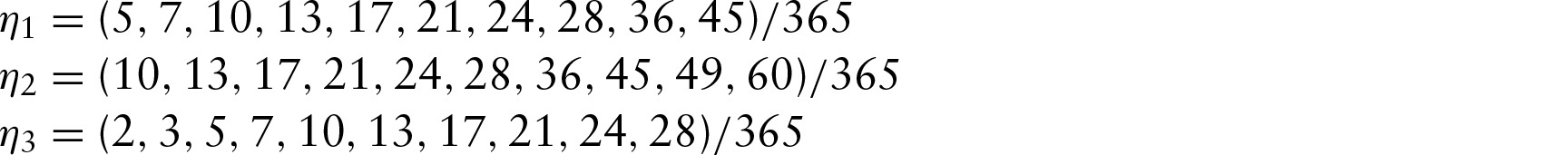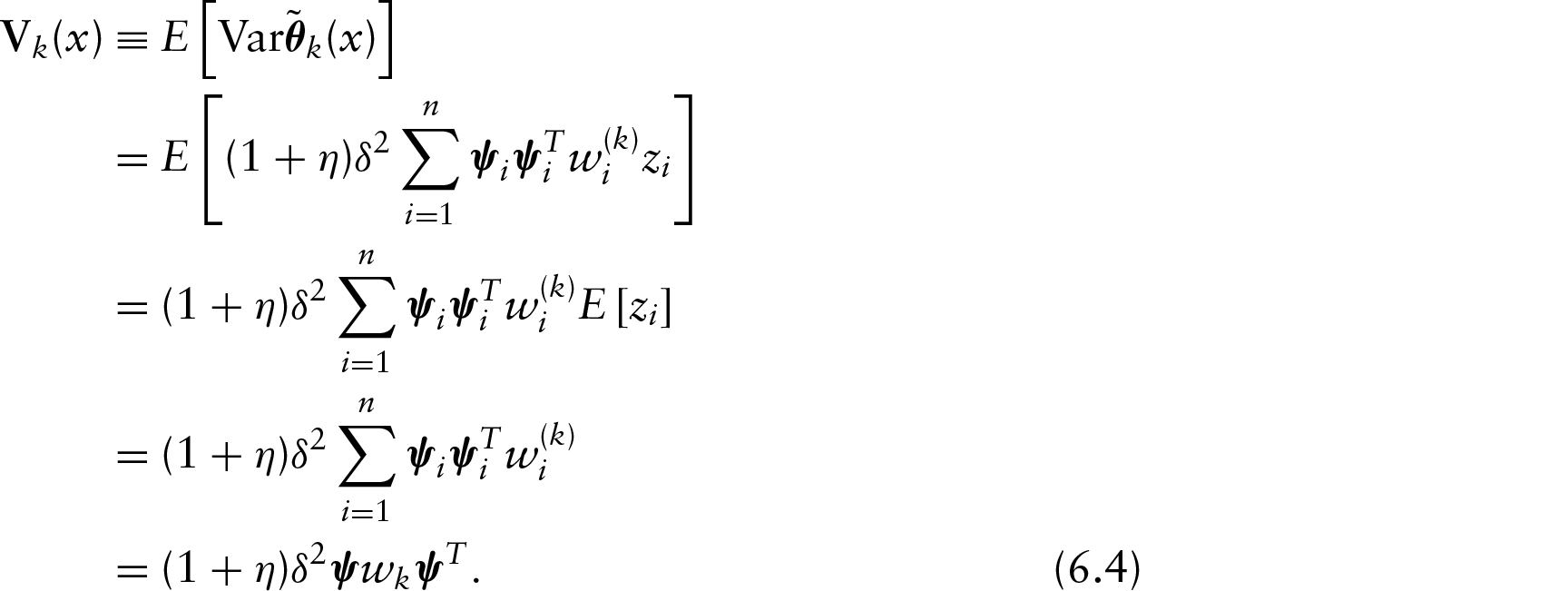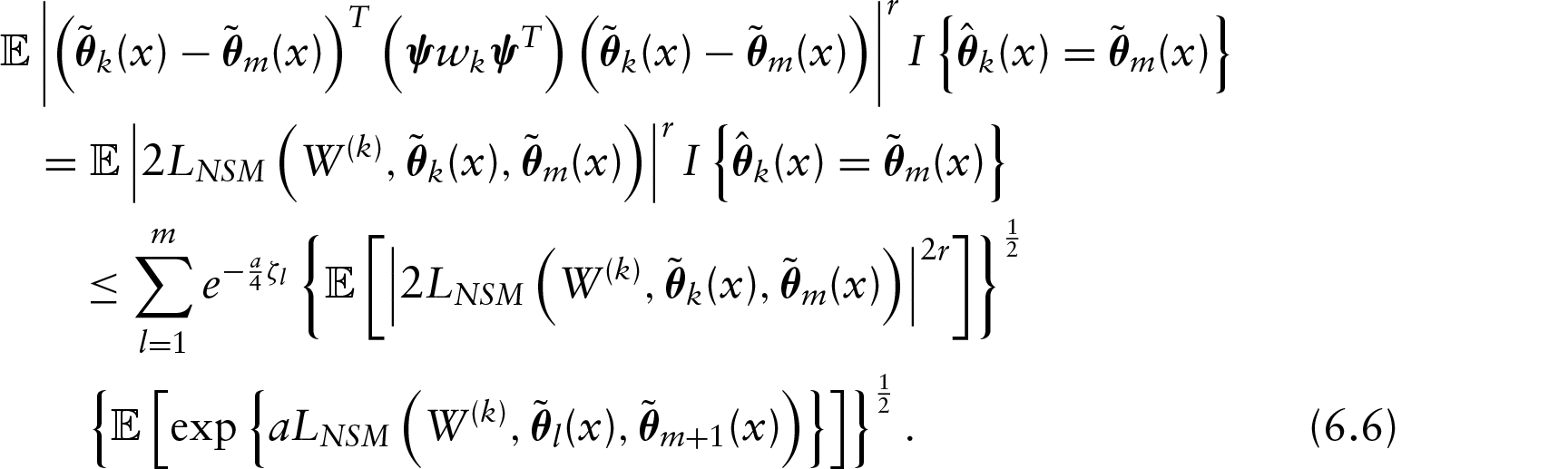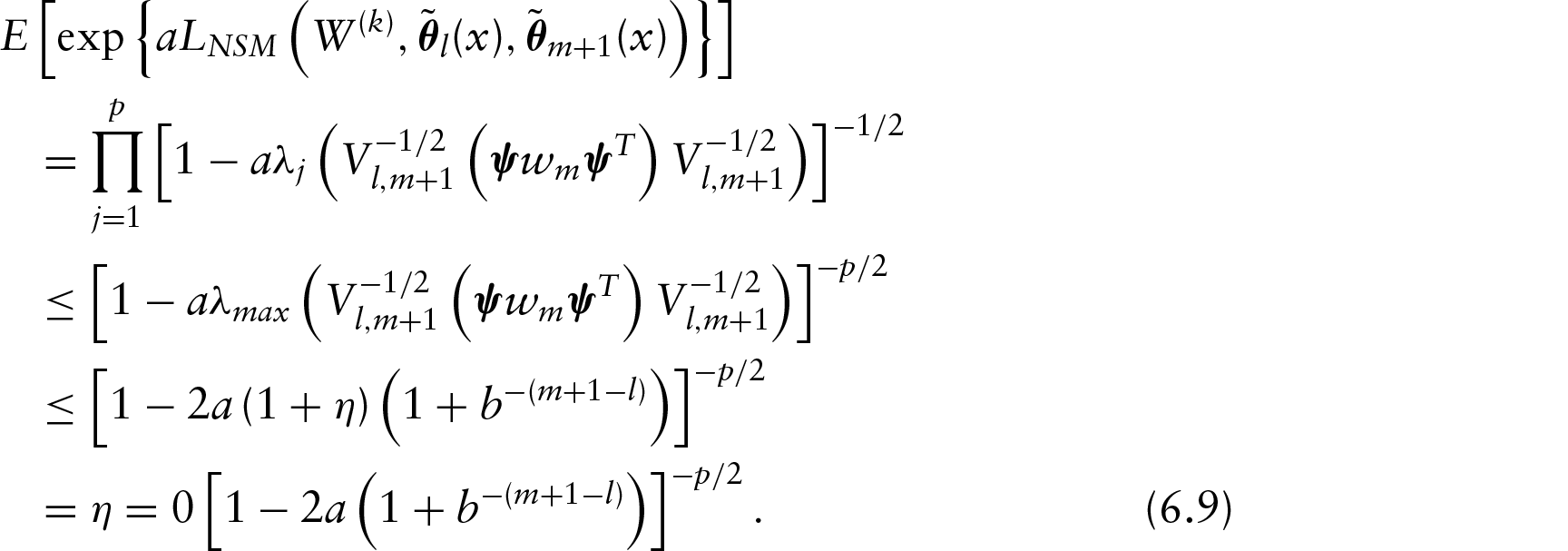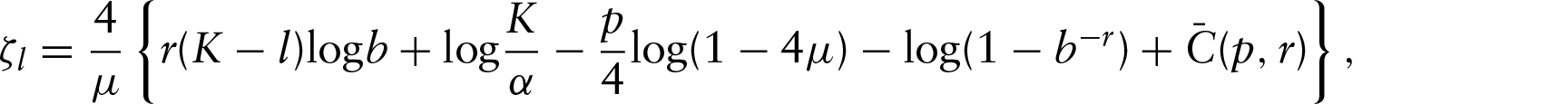We investigate a new kernel-weighted likelihood smoothing quantile regression method. The likelihood is based on a normal scale-mixture representation of asymmetric Laplace distribution (ALD). This approach enjoys the same good design adaptation as the local quantile regression (Spokoiny et al., 2013, Journal of Statistical Planning and Inference, 143, 1109–1129), particularly for smoothing extreme quantile curves, and ensures non-crossing quantile curves for any given sample. The performance of the proposed method is evaluated via extensive Monte Carlo simulation studies and one real data analysis.
Parametric quantile regression (Koenker, 2005) has been used in a number of disciplines to explore the relationship between the response and covariates at both the centre and extremes of the conditional distribution and obtain a more comprehensive analysis of the relationship between variables. While a parametric model is possibly misspecified, non-parametric models, on the other hand, require fewer assumptions about the data and offer a more flexible way of modelling a relationship than parametric models, consequently avoid model misspecification when a parametric model is not available, which is common in wide applications (wand, 1995; fan, 1996; takezawa, 2005). One of the popular non-parametric smoothing techniques is kernel smoothing. Non-parametric kernel smoothing quantile regression has attracted much attention in the literature (Chaudhuri, 1991; Hardle, 1993; fan, 1996; Yu, 1998; Cai, 2008; Dette, 2008; Dabo-Niang, 2012; Schaumburg, 2012; Kong, 2017).
However, the performance of kernel smoothing techniques, in spite of their advantages over parametric models in dealing with model misspecification, depends on smoothing parameter or bandwidth selection. While a global bandwidth such as the rule of thumb (Yu, 1998) is generally useful, a point-wise bandwidth, which depends on the values of covariate or the design set should be considered for the complexity of the underlying regression functions. In particular, bandwidth selection in non-parametric smoothing quantile regression requires not only design adaptation but also quantile adaptation. Spokoiny, Wang and Hrdle (henceforth SWH) (Spokoiny, 2014) developed a kernel-weighted likelihood quantile regression with point-wise bandwidth selection and promising performance in practice.
But SWH's approach may not guarantee non-crossing quantile curves for any given sample (calculated for various percentile , which is a common problem in the estimation of conditional and structural quantile functions due to lack of monotonicity. Note that monotonicity (for each in the design set, it is a monotone function of percentile value ) guarantees non-crossing quantile curves, but not vice versa. Such a phenomenon violates the basic principle of probability theory, that is, the associated distribution functions should be monotone increasing. Various methods were presented to address or avoid the quantile crossing in parametric quantile regression, but with few on non-parametric quantile regression. Recently, (Jones, 2007) improved double kernel smoothing for quantile regression; (Bondell, 2010) and (muggeo, 2013) used spline-based constraints to incorporate non-crossing conditions; (qu, 2015) applied inequality constrains to ensure the monotonicity over quantiles; and (liu, 2011) dealt with this issue via simultaneous multiple quantile smoothing.
In this article, we explore a local likelihood-based quantile regression based on a normal scale-mixture (NSM) representation of asymmetric Laplace distribution (ALD) and show that this method has the similar property of SWH's procedure but a much better adaptation for smoothing extreme quantile curves. Moreover, a theoretical justification of the estimated non-crossing quantile curves, that is, estimated quantile function is monotone with respect to for all , is given by our proposed method. Therefore, the proposed method enjoys both design adaptation and non-crossing quantile curves simultaneously. This article is organized as follows. We first review SWH's approach in Section 2, then propose a new local likelihood smoothing based on an NSM representation of ALD and show that this approach satisfies the propagation condition (PCs Spokoiny, 2009) in Section 3. In Section 4 we elaborate the proposed adaptive bandwidth selection rule and point out that the rule is able to avoid the problem of quantile curves crossing, especially for estimating extreme quantiles. Section 5 illustrates the numerical performance of the proposed method. Section 6 provides concluding remarks and discusses future work.
Kernel-weighted likelihood for local quantile regression
(Spokoiny, 2014) developed an interesting non-parametric quantile regression method: local quantile regression, which provides point-wise bandwidth selection and exhibits promising performance in practice. SWH claimed that their bandwidth selection rule is adaptive and novel, although the regression estimator named qMLE in their Equation (8) is simply equivalent to a local polynomial quantile regression or a type of kernel-based weighting ‘check function’ approach, such as the local linear single-kernel approach of Yu, 1998.
Let be the random variables, where is a continuous random variable and is a univariate regressor . Let be the cumulative distribution function of given . Let be the inverse function, which is also the value of that minimizes the expected loss function:
where, and is an asymmetric loss function that satisfies where is an indicator function.
Under the quantile non-parametric model , given data in the form , where and are independent scalar observations of and , respectively. The th conditional quantile of given is estimated by
SWH took advantage of the link between the minimization of the sum of the loss function in Equation (2.2) and the maximum likelihood method based on an ALD. For a random variable , its density function can be written as
where is skew parameter, is scale parameter and is location parameter.
Based on an ALD log-likelihood, SWH considered
where is the level of the quantile. Then they fit at point by the local polynomial approach , with basis and . Therefore, the local log-likelihood at is given by
where the weights is chosen via a kernel function , while is a bandwidth controlling the degree of localization. Note that Equation (2.5) is similar to the global log-likelihood in Equation (2.4), but each summand in is multiplied with the weight , so only the points from the local vicinity of contribute to .
The corresponding local quantile MLE (they named it as qMLE) at is then given via the maximization of in Equation (2.4)
Local quantile regression with an alternative likelihood for smoothing
Figure 1a displays the performance of SWH's approach, showing the bandwidth sequence (upper panel) and the smoothed 50% quantile curve (lower panel) based on the Lidar dataset (available in R package SemiPar), which adapts the data well. And this is also true for other moderate or central quantile curves. However, it can be seen from smoothing extreme quantile curves in Figure 1 that the proposed bandwidth selection rule lacks good adaptation and then results in the over-smoothing phenomenon. Figures 1b and 1c display the smoothed 1% and 99% quantile curves using SWH's method and show that when the curves start to switch smoothness, the rule is not adaptive so that the estimated curves are too smoothing out of the data ranges. A possibly theoretical interpretation for this problem is: when , the weighted ‘check function’ takes constant 0, if (also, when and if ). This may result in that the proposed significant test always picks constant bandwidth for smoothing extreme quantile curves, although this is not a problem for the local quantile regression estimation equation. We want to point out that this over-smoothing problem will be solved by a new version of adaptive bandwidth selection rule.
The bandwidth sequences (upper panels) and smoothed quantile curves (lower panels) for the Lidar dataset using SWH's kernel-weighted likelihood
Moreover, there is no guaranteed of this approach to avoid quantile crossing. Therefore, we propose an alternative adaptive bandwidth selection rule based on a NSM representation of ALD and show that this alternative version has the similar property to SWH's procedure but much better-adaptation for smoothing extreme quantile curves.
(Reed, 2010) and (Kozumi, 2011) noted that under the assumption of ALD-based ‘working likelihood’, the quantile regression model error can be represented as a scale mixture of normal variables, that is,
where , , and , and and are independent. Hence, SWH's model (1) could be re-written as
That is, for given ,
that is, the joint conditional density of is given by
Clearly, if is fixed in advance, then the local log-likelihood (SWH's Equation (7)) can be replaced by a NSM representation of ALD:
where the weights is chosen via a kernel function , while is a bandwidth controlling the degree of localization. Similar to Equation (2.5), the local log-likelihood in Equation (3.5) depends on the central point via the structure of the basis vectors and via the weights .
Now, once a local th-degree polynomial is used to approximate at , the corresponding local qMLE at could be defined via maximization of earlier:
where estimates , and estimates the derivative of . Further, let and , we have
where the design matrix consists of the columns .
We note that the involves in a specification of vector , and we point out that could be fixed in advance via a sample from a data-driven inverse Gaussian distribution, and our extensive experiments in Section 5 show that the selection of the sample has no effect on the estimation. In fact, note that the joint likelihood function of is given by
Therefore, the conditional density of is given by
That is, are i.i.d. with a generalized inverse Gaussian (GIG) distribution:
where and .
Performance of adaptive bandwidth selection and non-crossing estimation
Adaptive bandwidth selection
There are several methodologies for automatic smoothing parameter selection. One class of methods chooses the smoothing parameter value to minimize a criterion that incorporates both the tightness of the fit and model complexity. Such a criterion can usually be written as a function of the error mean square, and a penalty function designed to decrease with increasing smoothness of the fit. Examples of specific criteria are generalized cross-validation (Craven, 1979) and the Akaike information criterion (AIC)(Akaike, 1973). These classical selectors have two undesirable properties when used with local polynomial and kernel estimators: they tend to under-smooth and tend to be non-robust in the sense that small variations in the input data can change the choice of smoothing parameter value significantly. (Hurvich, 1998) obtained several bias-corrected AIC criteria that limit these unfavourable properties and perform comparably with the plug-in selectors (Ruppert, 1995).
The adaptive bandwidth selection rule in SWH's paper is different from the rule of thumb of (Yu, 1998) and AIC rule of (Cai, 2008). It does add a nice option to the bandwidth selection menu for practitioners. In this article, we perform the local quantile curve estimation following the similar bandwidth selection procedures, but based on a NSM representation of ALD.
First, we fix a finite ordered set of candidates of bandwidth , where is very small. According to SWH, the bandwidth sequence can be taken geometrically increasing of the form with fixed , , and for . For each , an ordered weighting scheme is chosen via a kernel function leading to the local quantile estimator at , , as:
Then, we start with the smallest bandwidth . For any , compute the local qMLE and check whether it is consistent with all the previous estimators for . We use a localized likelihood ratio test, that is, the difference to reject , where maximize the log-likelihood defined in Equation (3.5) where bandwidth and is the other local likelihood under with bandwidth . The difference checks whether belongs to the confidence set of :
If the consistency check is negative, the procedure terminates and selects the latest accepted estimator.
The adaptation algorithm can be summarized as follows:
The adaptive estimator is the latest accepted estimator after all steps:
Moreover, all the estimators should be consistent to each other and the procedure should not terminate at any intermediate step . This effect is called as ‘propagation’. Hence, under the assumptions (A1)–(A3) in Appendix, and then according to (Serdyukova, 2012), the propagation conditions (PCs) for this approach also satisfies:
Theorem 1. (Theoretical choice of the critical values.) Assume (A1)–(A3), given and , the critical values satisfy
for all , where , with the choice of the critical values of the form
where is an arbitrary constant, and . The critical values are selected to ensure the desired PCs which effectively means a ‘no alarm’ property, that is, the selected adaptive estimator coincides in the most cases that the estimator corresponding to the largest bandwidth. An advantage of the proposed alternative normal scale-mixture likelihood function over SWH's method is that the derived bandwidth has better adaptation when tends to 0 or 1. Figure 2 displays the bandwidth sequence (upper panel) and smoothed quantile curves for quantiles 1% (2a) and 99% (2b) based on the Lidar dataset, which provides much better fitting than those curves presented in Figure 1. The dependency structure changing on smoothness is more adaptive than the bandwidth sequence in Figure 1. This alternative normal scale-mixture likelihood method also works well for other moderate or central quantile curves. Figure 2 shows that the method gives quite similar estimates to SWH's method for (2c) and (2d) quantile curves.
The bandwidth sequences (upper panels) and smoothed quantile curves (lower panels) for the Lidar dataset using the alternative normal scale-mixture likelihood
Non-crossing quantile curve estimation
The proposed bandwidth selection rule in SWH's method seems to have no quantile crossing phenomenon when several smoothed quantile curves are provided together. This indicates the advantage of the local bandwidth selection rule. Whereas most of published articles on this topic, which include constrained smoothing spline (He, 1997; Bondell, 2010), double-kernel smoothing (Yu, 1998; Jones, 2007) and monotone constraint on conditional distribution function (Hall, 1999; Dette, 2008), among others, focus on the development of new methods rather than adaptive bandwidth selection for avoiding quantile crossing. SWH showed that even working with ‘local constant’ kernel smoothing quantile regression via
adaptive bandwidth selection rule may not have quantile crossing either. This may be true practically, but without a theoretical justification. Under our proposed approach, the justification of non-crossing quantiles could be outlined in the following equation.
Recall the non-parametric quantile regression model , where . Given data , and under the local polynomial approach, estimates , with
where the likelihood function is expressed in Equation (3.5) and estimate the derivative of .
That is, the derivative of over satisfies . Therefore, can be expressed as,
For each , we aim to check the derivative of over . If , then is an increasing function of .
Note that , therefore, we have
That is, is a strictly monotonic function of over .
Numerical examples
In this section, we implement the proposed method via extensive Monte Carlo simulation studies and one real data analysis. All numerical experiments are carried out on one Inter Core i5-3470 CPU (3.20GMHz) processor and 8 GB RAM.
Simulation 1
In this simulation study, we aim to summarize our numerical results on choosing the critical values by the PCs as described in Section 4.1. We generate data of size from an , which does coincide with the likelihood () taken to simulate critical values. We mainly check the critical values at different quantile levels , and for different choices of and . We also study how bandwidth sequence affects the critical values.
Table 1 shows the critical values with several choices of and with and Monte Carlo samples, and a bandwidth sequence scaled to the interval . Critical values decrease when increases, and increase when increases.
Critical values with different and ()
Critical Values
0.05
10.357
7.605
4.888
1.248
0.000
0.000
0.25
15.782
11.332
8.440
4.354
0.908
0.000
0.50
21.714
15.427
10.351
3.594
0.000
0.000
0.75
15.283
10.932
8.396
3.949
0.840
0.000
0.95
10.789
7.686
4.943
1.208
0.000
0.000
Table 2 shows the critical values for different s with and Monte Carlo samples, and a bandwidth sequence scaled to the interval . Critical values behave similarly for symmetric .
Critical values with different ()
Critical Values
0.25
0.5
16.971
11.539
8.133
3.584
0.044
0.000
0.25
0.75
20.218
13.743
9.336
3.131
0.000
0.000
0.25
1
24.676
16.270
9.308
4.214
1.561
0.000
0.5
0.5
12.823
9.619
7.205
3.703
0.949
0.000
0.75
0.5
11.249
7.222
4.244
0.181
0.000
0.000
Table 3 shows the critical values for the following alternative bandwidth sequences, with and Monte Carlo samples.
Although the critical values differ for different bandwidth sequences, they indicate the same patterns (finite and decreasing).
Critical values with different bandwidth sequences ()
Critical Values
11.002
6.508
3.089
0.000
0.000
0.000
23.187
13.810
7.775
3.690
0.000
0.000
6.871
4.737
2.046
0.389
0.000
0.000
Overall, although the critical values differ for different bandwidth sequences, , and , the same finite and decreasing patterns indicate that the adaptation algorithm can be completed in maximum steps, as the values of critical values decrease to zero in 6 step.
Simulation 2
In this simulation study, we compare the performance of our proposed approach to SWH's method as well as two other bandwidth selection techniques. One proposal comes from (ng, 2007), in which they considered constrained quantile estimations using linear or quadratic splines (implemented with R function cobs in Package cobs), and the other is from (Yu, 1998), in which they considered a rule of thumb bandwidth (implemented with R function lprq in Package quantreg).
We generate one training data of size 2 000 and 500 test datasets of size 500 from the model
where the univariate input follows a uniform distribution on and is a non-linear function of
and the scale factor is linearly increasing in with the form
Therefore, Equation (5.1) is a heteroskedastic model.
In this simulation, we consider three different types of random errors for : , and , respectively. Therefore, the true -th conditional quantile function of given can be expressed as
where is the -th quantile of . Figure 3 presents the training data generated under this scenario with their true -th conditional quantile functions . Note that the non-linear function in the right figure is not identical to the true conditional median function as the random error is an asymmetric distribution.
Simulated training data and true conditional quantile functions with
We aim to compare the prediction power of the aforementioned four methods for the prediction of the conditional quantile function by 500 test datasets, in terms of three measurements, namely, the root mean square error (RMSE), the mean absolute errors (MAE) and the Theil-U statistic, which is a relative accuracy measure that compares the forecast results with the nave forecast (Theil, 1966):
where is the prediction of the true conditional quantile . The smaller the measurement value is, the better the method is. The three measurements are implemented with R function av.res in package AnalyzeTS.
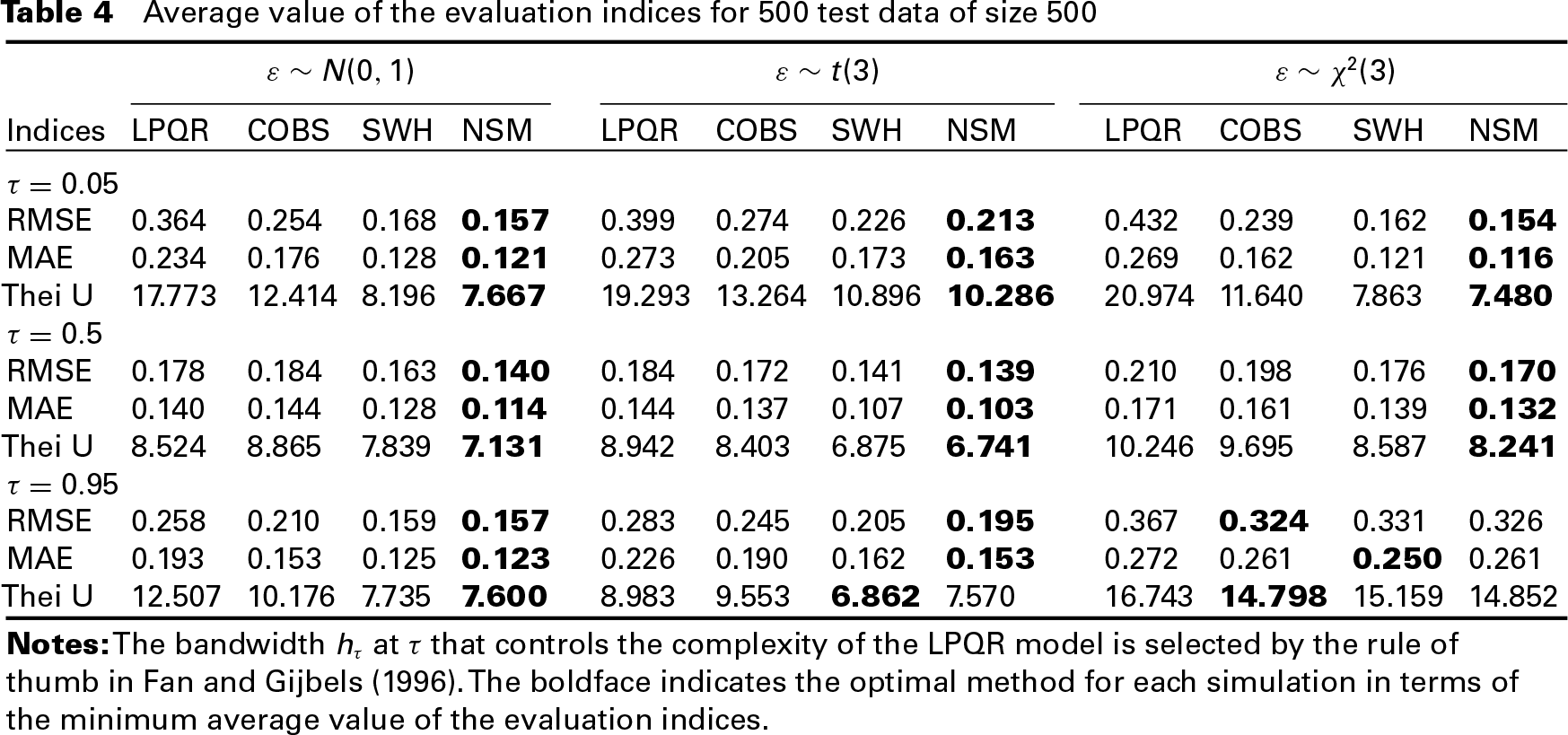
The superiority of the proposed NSM approach is demonstrated in Table 4 which summarizes the results for three values of s: 0.05, 0.50 and 0.95, based on the 500 replications. Note that Simulation 2 is implemented with critical values (5,7,10,13,17,21,24,28,36,45)/365, simulated from (coincide with the likelihood) with , . The bold face values show that both SWH's method and the proposed NSM approach are superior to LPQR and COBS, while the proposed approach performs slightly better than SWH. It is encouraging to see that the proposed approach approximates well under Gaussian error and also provides excellent results under the circumstance of heavy tail and asymmetric distributions, such as and .
Average value of the evaluation indices for 500 test data of size 500
Indices
LPQR
COBS
SWH
NSM
LPQR
COBS
SWH
NSM
LPQR
COBS
SWH
NSM
RMSE
0.364
0.254
0.168
0.157
0.399
0.274
0.226
0.213
0.432
0.239
0.162
0.154
MAE
0.234
0.176
0.128
0.121
0.273
0.205
0.173
0.163
0.269
0.162
0.121
0.116
Thei U
17.773
12.414
8.196
7.667
19.293
13.264
10.896
10.286
20.974
11.640
7.863
7.480
RMSE
0.178
0.184
0.163
0.140
0.184
0.172
0.141
0.139
0.210
0.198
0.176
0.170
MAE
0.140
0.144
0.128
0.114
0.144
0.137
0.107
0.103
0.171
0.161
0.139
0.132
Thei U
8.524
8.865
7.839
7.131
8.942
8.403
6.875
6.741
10.246
9.695
8.587
8.241
RMSE
0.258
0.210
0.159
0.157
0.283
0.245
0.205
0.195
0.367
0.324
0.331
0.326
MAE
0.193
0.153
0.125
0.123
0.226
0.190
0.162
0.153
0.272
0.261
0.250
0.261
Thei U
12.507
10.176
7.735
7.600
8.983
9.553
6.862
7.570
16.743
14.798
15.159
14.852
Notes: The bandwidth at that controls the complexity of the LPQR model is selected by the rule of thumb in (fan, 1996). The boldface indicates the optimal method for each simulation in terms of the minimum average value of the evaluation indices.
Real-world data application
In this section, we demonstrate the efficacy of our the proposed alternative approach with one benchmark example that comes from the second and third health examination surveys of the United States (National Center for Health Statistics, 1970, 1973). Taken together these provide data on the anthropometry of children between the ages of 6 years and under 18 years, with from 400 to 600 children of each sex seen in each year of age (cole, 1988). Here, along with (Yu, 1998), the weights and ages of 4 011 US girls were analysed.
The scatter plot in Figure 4a displays weight against age for a sample of 4 011 US girls, where age is a univariate regressor for simplicity. It is evident that the distribution is left skewed and presents long tails, suggesting that focusing on the centre is not sufficient for a comprehensive description of a weight distribution. Such observation motivates the use of quantile regression, where a complete picture of weight distribution is captured by conditional quantiles.
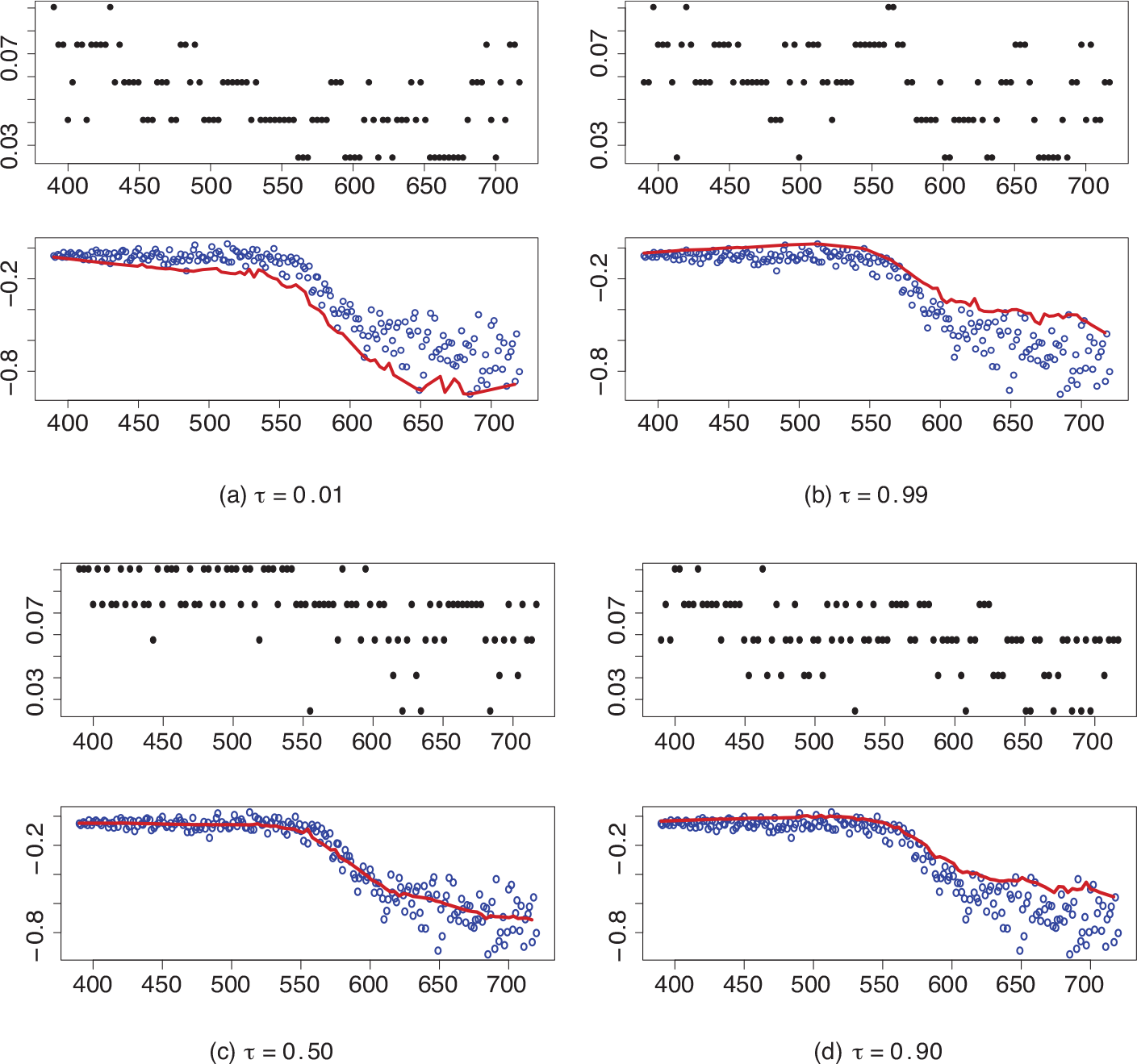
We then continue by inspecting the relation between weight and age in the sample. In Figure 4, we display the bandwidth sequence (upper right panels), boxplot of adapted bandwidth (lower right panels) showing the relationship between the adapted estimator and the bandwidth index, and smoothed quantile curves for quantile 99% (4b) and 1% (4a), respectively, by using the alternative NSM likelihood function. Both adaptations show that the proposed bandwidth selection is well adapted over the data distribution, which provides smooth fitting and better adaptation when tends to extreme quantiles. Furthermore, Figure 5 shows that the non-quantile crossing property holds for the rule in Section 4.2, which is based on the alternative normal scale-mixture likelihood function.
Smoothed quantile curves (in red) for US Health Examination Surveys with and via alternative normal scale-mixture likelihood (left panel). The bandwidth sequence (upper right); boxplot of adaptive bandwidth (lower right)
Smoothed quantile curves for US Health Examination Surveys with via alternative normal scale-mixture likelihood function
Discussions and concluding remarks
The kernel-weighted likelihood function Equation (2.5) in SWH's paper is a local ALD-based likelihood function. The ALD-based inference has nowadays become a powerful tool for formulating different quantile regression techniques, particularly for the development of different Bayesian inference techniques for quantile regression. The ALD-based inference for non-Bayesian methods includes (taylor, 2016) in financial risk analysis and (geraci, 2007) in longitudinal data analysis and among others. The local ALD-based likelihood approach in the paper uses an alternative ALD-type of likelihood. The resulting automatic bandwidth selection rule not only enjoys the PCs of SWH (which postulates that the risk is smaller than the upper bound for the risk of the estimator ) but also guarantees non-quantile curve crossing. Theoretical results also claim that the proposed adaptive procedure performs well, which would minimize the local estimation risk for the problem at hand. We illustrate the performance of the procedure by comparing the Lidar dataset with SWH's approach and analysing an extended real data application. In particular, we show that the performance of the adaptive procedure is promising in practice, especially for smoothing extreme quantile curves.
Moreover, the proposed approach can also be extended to the -dimensional case with , under the non-parametric additive modelling framework (yu, 2004). That is, let be a real-valued dependent variable and is a vector of explanatory variables. Let be a -dimensional th quantile regression function of given . Suppose that the th quantile function is modelled as an additive function of ,
where each can be fitted by the proposed approach in Section 3 and the whole can be further derived via backfitting algorithm used in (yu, 2004). For example, without of generality, consider a local linear regression with , for ,
where is a kernel function and is the bandwidth for estimating in the earlier setting.
Acknowledgements
We thank the editor, the associate editor and two anonymous reviewers for their constructive comments, which helped us to improve the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article
Funding
The authors declared: The research was partially supported by Major Program of the National Natural Science Foundation of China (Grant No. 71490725) and the BUL Research Leave funding, the National Science Foundation of China (No 11261048).
Appendix
Recall: .
Assumption Consider a finite sequence of scales , where the matrix is of full row rank.
Assumption For any fixed and the method of localization with , the following relation holds:
Assumption Assume that the true regression model
considering the regression model (3.2), where stands for the unknown true covariance matrix, where is the true value of Equation (3.2), there exists such that
Assuming (A3), the true covariance matrix , and the conditional variance of the estimate is bounded with : as follows:
According to the basic property of quadratic equation, consider a simple example and there always holds , with . The same procedure may be easily adapted to Equation(6.2) as follows:
Therefore, the unconditional variance of the estimate as follows is bounded with
Proof of Theorem 1.
The event happens if for some , . Hence,
Further, combined with the Cauchy–Schwarz inequality, for any positive :
Among which,
and
Therefore, we obtain
For any , with an arbitrary constant , the choice of the threshold of the form
where provides the required PC bounds.
References
1.
AkaikeH (1973) Information theory and an extension of the maximum likelihood principle. In Second International Sympo- sium on Information Theory, edited by PETROVB. N.CSAKIF. pages 267–281. Budapest: Akademiai Kiado.
CaiZXuX (2008) Nonparametric quantile estimations for dynamic smooth coefficient models. Journal of the American Statistical Association, 103, 1595–1608.
4.
ChaudhuriP (1991) B Nonparametric estimates of regression quantiles and their local Bahadur representation. The Annals of Statistics, 19, 760–777.
5.
ColeT (1988) Fitting smoothed centile curves to reference data. Journal of the Royal Statistical Society, Series A (Statistics in Society), 151, 385–418.
6.
CravenPWahbaG (1979) Smoothing noisy data with spline functions: Estimating the correct degree of smoothing by the method of generalized cross-validation. Numerical Mathematics, 31, 377–403.
DetteHVolgushevS (2008) Non-crossing non-parametric estimates of quantile curves. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 70, 609–627.
9.
FanJGijbelsI (1996) Local Polynomial Mod- elling and Its Applications: Monographs on Statistics and Applied Probability 66. CRC Press.
10.
GeraciMBottaiM (2007) Quantile regres- sion for longitudinal data using the asymmetric Laplace distribution. Biosta- tistics, 8, 140–154.
11.
HallP, WolRCYaoQ (1999) Methods for estimating a conditional distribution function. Journal of the American Statistical Association, 94, 154–163.
12.
HardleWMammenE (1993) Comparing nonparametric versus parametric regression fits. The Annals of Statistics, 21, 1926–47.
13.
HeX (1997) Quantile curves without crossing. The American Statistician, 51, 186–192.
14.
HurvichC, SimonoJSTsaiC (1998) Smoo- thing parameter selection in nonparametric regression using an improved Akaike information criterion. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 60, 271–293.
15.
JonesMYuK (2007) Improve double kernel local linear quantile regression. Statistical Modelling, 7, 377–389.
16.
KoenkerR (2005) Quantile Regression. New York, NY: Cambridge University Press.
17.
KongEXiaY (2017) Uniform Bahadur representation for nonparametric censored quantile regression: A redistribution-of- mass approach. Econometric Theory, 33, >242–261.
18.
KozumiHKobayashiG (2011) Gibbs sampling methods for Bayesian quantile regression. Journal of Statistical Compu- tation and Simulation, 81, 1565–1578.
19.
LiuYWuY (2011) Simultaneous multiple non-crossing quantile regression estimation using kernel constraints. Journal of Nonparametric Statistics, 23, 415–437.
20.
MuggeoVMSciandraMTomaselloACalvoS (2013) Estimating growth charts via nonparametric quantile regression: A practical framework with application in ecology. Environmental and Ecological Statistics, 20, 519–531.
21.
NgPMaechlerM (2007) A fast and efficient implementation of qualitatively constrained quantile smoothing splines. Statistical Modelling, 7, 315–328.
22.
QuZYoonJ (2015) Nonparametric estimation and inference on conditional quantile processes. Journal of Econome- trics, 185, 1–19.
23.
ReedCYuK (2010) Efficient Gibbs sampling for Bayesian quantile regression (Technical report). London: Brunel University London.
24.
RuppertDSheatherSWandM (1995) An effective bandwidth selector for local least squares regression. Journal of the American Statistical Association, 90, 1257–1270.
25.
SchaumburgJ (2012) Predicting extreme value at risk: Nonparametric quantile regression with refinements from extreme value theory. Computational Statistics & Data Analysis, 56, 4081–4096.
26.
SerdyukovaN (2012) Spatial adaptation in heteroscedastic regression: Propagation approach. Electronic Journal of Statistics, 6, 861–907.
27.
SpokoinyVVialC (2009) Parameter tuning in pointwise adaptation using a propagation approach. The Annals of Statistics, 37, 2783–2807.
28.
SpokoinyVWangWHärdleWK (2013) Local quantile regression. Journal of Statis- tical Planning and Inference, 143, 1109–1129.
29.
TakezawaK (2005) Introduction to Nonpara- metric Regression. Vol. 606. John Wiley & Sons.
30.
TaylorJWYuK (2016) Using auto-regressive logit models to forecast the exceedance probability for financial risk management. Journal of the Royal Statistical Society: Series A (Statistics in Society), 79, 1069– 1092.