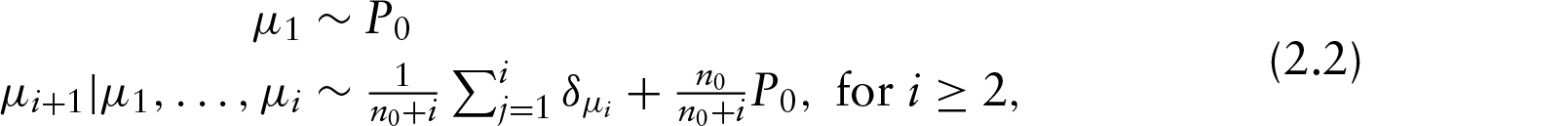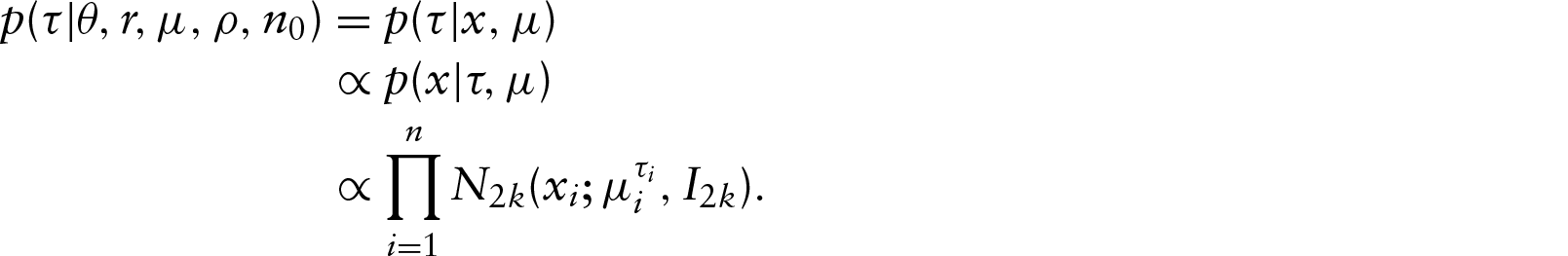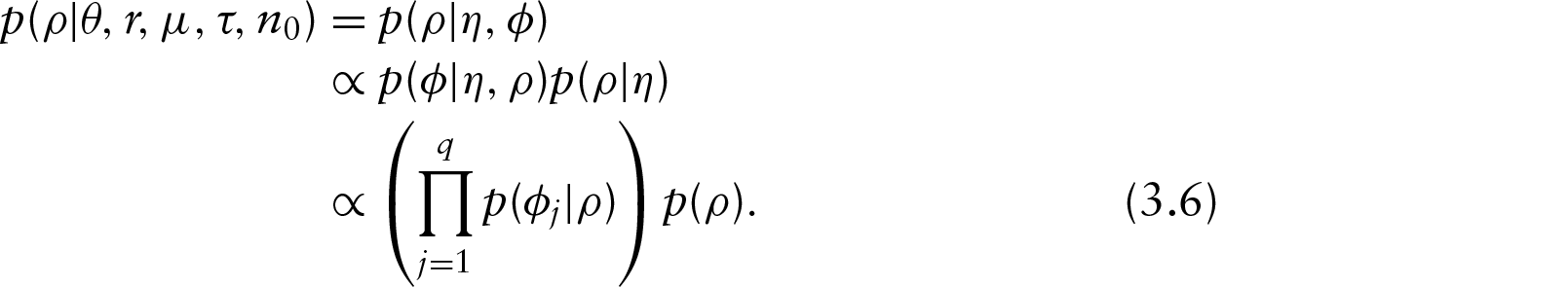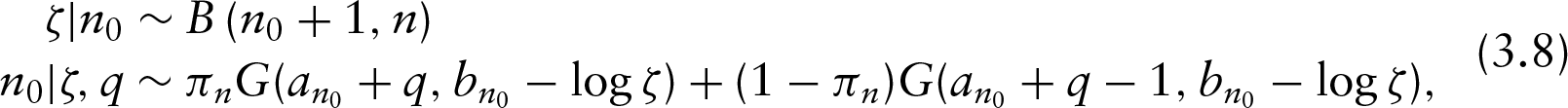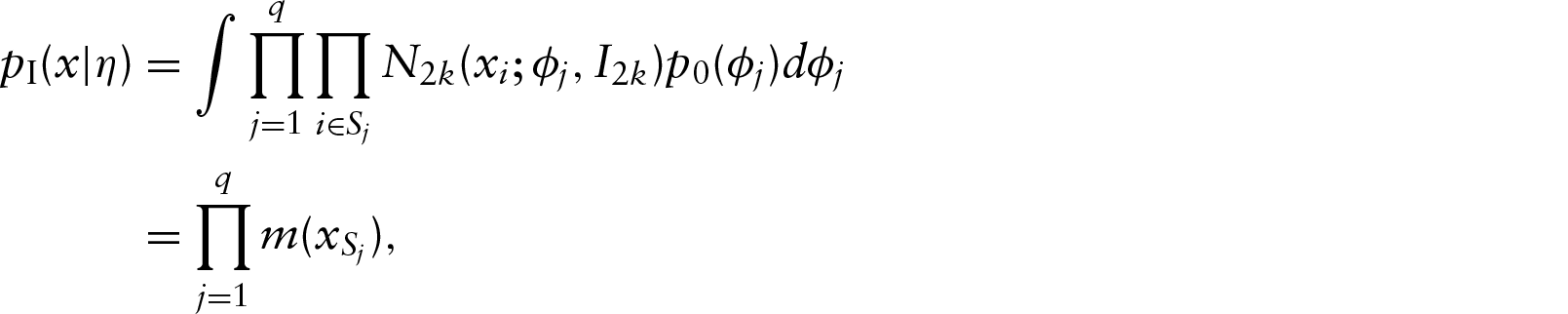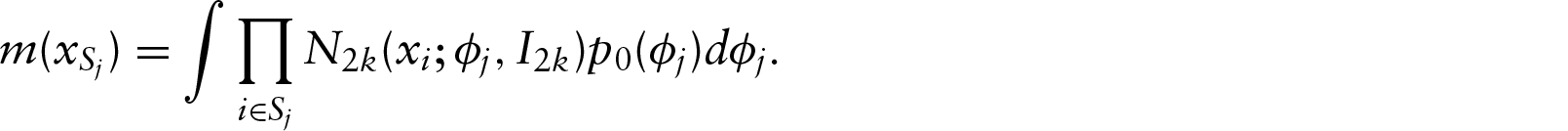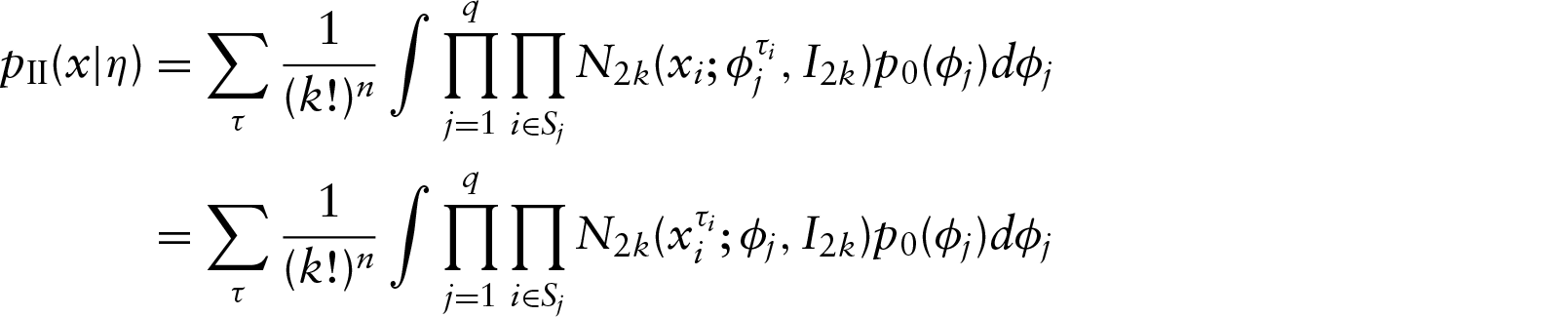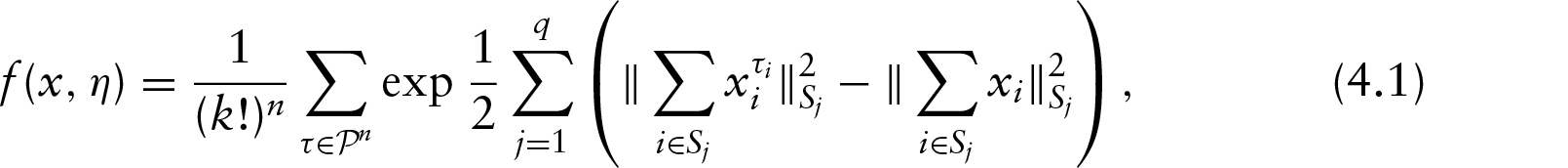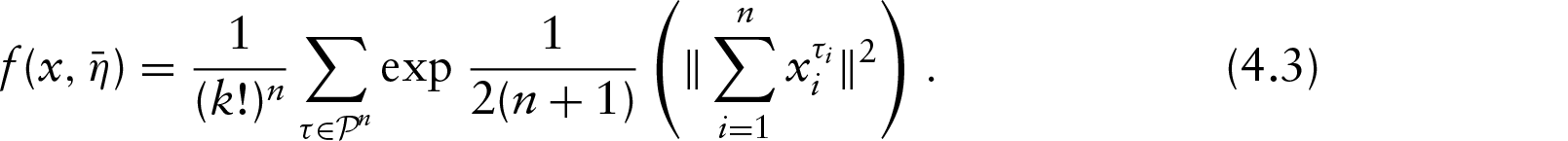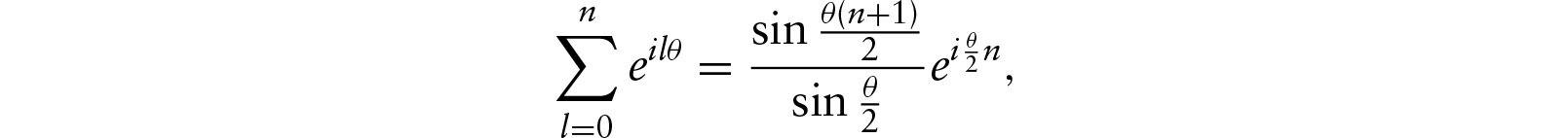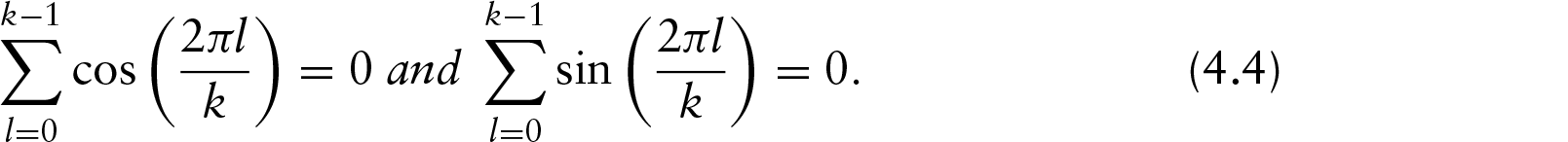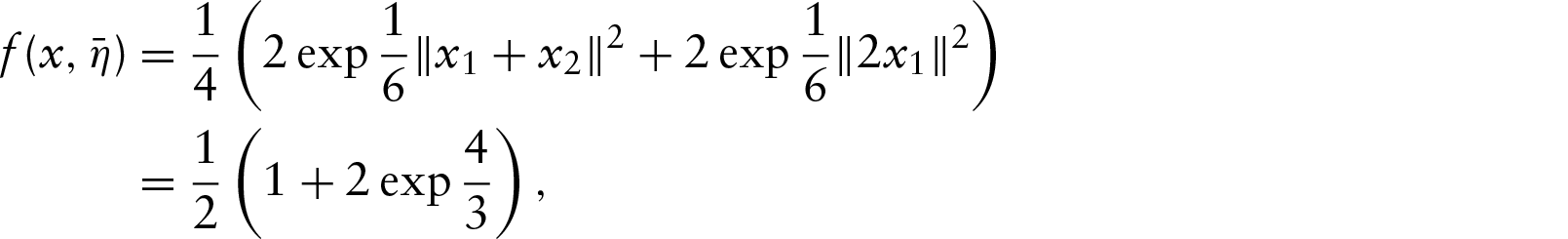This article presents a Bayesian model for the clustering of non-ordered multivariate directional or circular data. The particular trait of our data is that each single observation is made up of non-ordered points on the circle. We introduce a hierarchical model that combines a symmetrization technique, projected normal distributions and a Dirichlet process. One parameter is introduced to model the non-ordered trait and another one to control the variability of the angles on the circle. An informative prior on the relative locations of the angles is also provided. The gain of the symmetrization is highlighted by a theoretical study. The parameters of the model are then inferred using a Metropolis–Hastings-within-Gibbs algorithm. Simulated datasets are analysed to study the sensitivity to hyperparameters. Then, the benefits of our approach are illustrated by clustering real data made up of the positions of five separate radiotherapy X-ray beams on a circle.
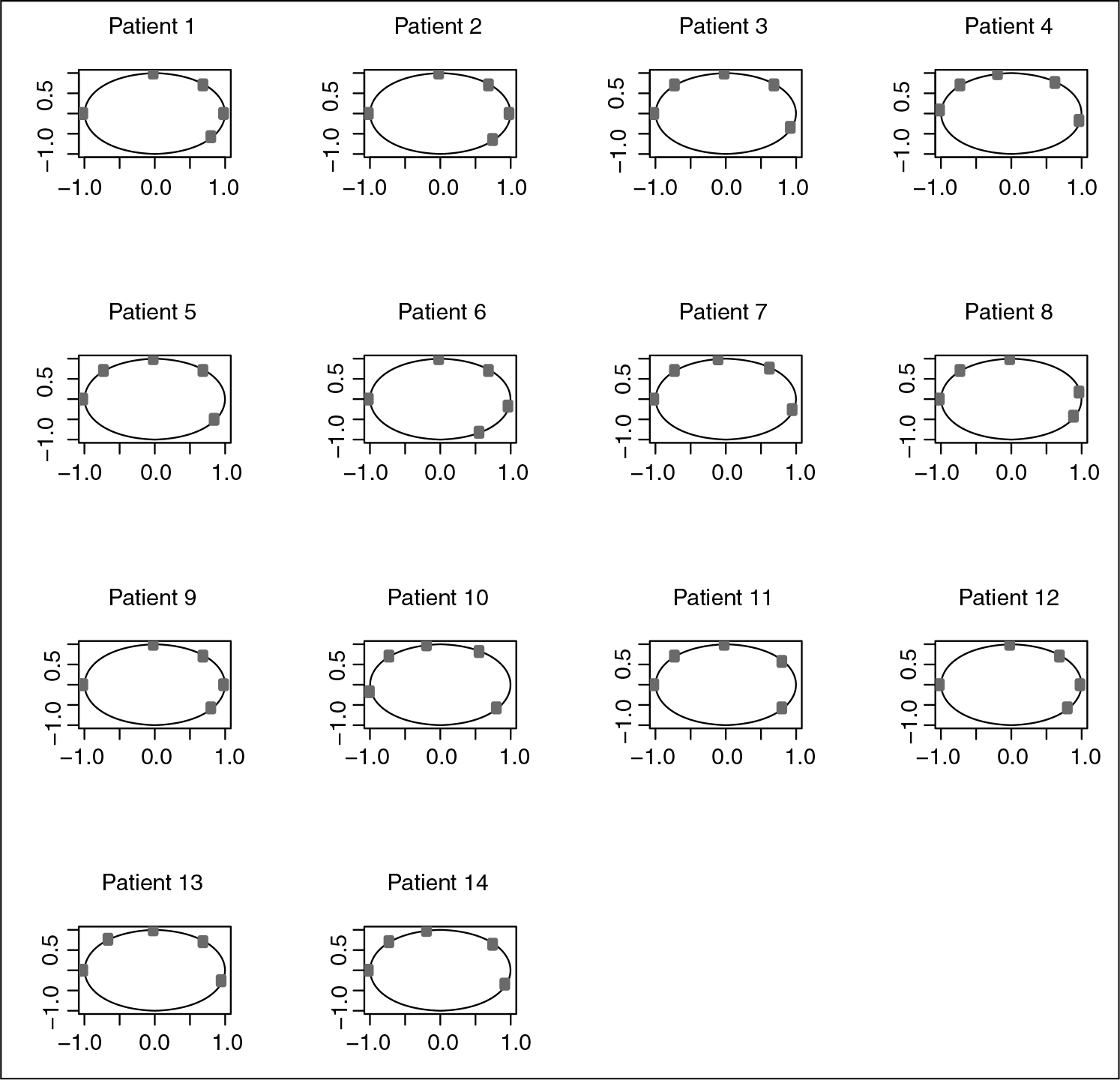
Circular and directional data arise in a number of different fields such as oceanography (wave direction), meteorology (wind direction) and biology (animal movement direction). The present article is motivated by circular data in medicine. Nowadays, intensity modulated radiation therapy (IMRT) has demonstrated its effectiveness for cancer treatment. The latest generation of radiotherapy machines projects multiple rays. Multiplying beams allows to concentrate radiation on the tumour while avoiding the massive irradiation of healthy areas. However, the selection of the incident angles of the treatment beams may be a crucial component of IMRT planning. Due to variations in tumour locations, size and patient anatomy, repositioning for the multiple beams takes a long time and is based on the planner's experience to find an optimal set of beams. So, establishing a small set of standardized beam bouquets for planning could be of valuable help. The set of beam bouquets could be determined by learning the beam configuration features from previous IMRT datasets. The multiple beams are fixed on a circle in the transverse plane around the patient. Consequently, an observation is composed of the beams of a patient, that is, circular measurements. A real dataset from post-operative treatment of liver cancer at the Institute of Sainte Catherine in Avignon, France, is represented in Figure 1. One actual observation consists of a (non-ordered) set of angles rather than of a vector (ordered) of length but to cope with the technical difficulty of dealing with sets, it is convenient to store the angles of each patient in a vector in increasing order (or in any other given order). Of course, the derived vectors may be very different even for similar sets of angles. This is easily seen by considering a simple case of two patients with angles and : the two patients should share the same cluster as the sets of angles are very similar (modulo 360), although the derived vectors are very different and, if any classical clustering method was applied, are not likely to share the same cluster.
Real dataset of 14 patients with angles. A point on the circle represents the location of a treatment beam
Abraham et al. (2013) proposed a first tool to assist the selection of beam orientations to enhance the therapist's experience. A suitable distance on the circle was defined and, for a fixed number of clusters, an algorithm based on simulated annealing was proposed. Yuan et al. (2015) generalized the precedent approach using -medoids to cluster beam configuration features with different numbers of beams. These methods suffer from some major flaws. First, the number of clusters has to be supplied by the user. An additional procedure of model selection (AIC, BIC, RIC, silhouette index, ) can be used to select the number of clusters, but an appropriate methodology that automatically finds this number would be very useful. Second, the final result is only one unique clustering, whereas there are probably other clusterings that could be acceptable. A final result with all possible clusterings and a probability of appearance for each could be of great help for the practitioner. These problems can naturally be solved with a Bayesian clustering method based on Dirichlet Process as it does not require a preselected number of clusters and provides different clusterings (possibly with different numbers of clusters) with their posterior probabilities. Also note that the Bayesian framework is well adapted to our application as the sample size is low and can be compensated to some extent by prior information.
Circular data have first been studied using classical non-Bayesian approaches. Three main models for circular data can be found in the litterature: the von-Mises distributions, the wrapped distributions and the projected normal distributions. The von-Mises distributions, first introduced by Von Mises (1918) and extended by Singh et al. (2002) and Mardia et al. (2008), are the natural analogues of the normal distribution on the sphere. The wrapped distributions (Mardia and Jupp, 2009) are based on a simple fact that a probability distribution on a circle can be obtained by wrapping a probability distribution defined on the real line. Projected normal distributions are obtained by projecting multivariate normal random variables radially onto the sphere (Presnell et al., 1998). These latter distributions allow for asymmetric and possible bimodal models. We refer the reader to Mardia and Jupp (2009) for a complete review on probability distributions of circular data.
Bayesian literature on circular data is more recent. Von Mises distributions are used in the univariate case in Damien and Walker (1999) and are applied to a change-point problem in SenGupta and Laha (2008). Wrapped distributions appear in Ravidran and Ghosh (2011), with a data augmentation algorithm to overcome some computational difficulties, and in Jona-Lasinio et al. (2012), to handle structured dependences between spatial measurements. Nuñez-Antonio and Gutiérrez-Peña(2005), Wang and Gelfand (2013) adapted the projected normal distributions in a Bayesian framework. A more sophisticated model was considered in Wang and Gelfand (2014) to capture structured spatial dependence for modelling directional data at different spatial locations. This model was then upgraded to capture joint structured spatial and temporal dependence (Wang et al., 2015). Then, it was extented to the important spherical case and to any dimension (Hernandez-Stumpfhauser et al., 2017). Also, it was adapted to a multidimensional time series forecasting framework coupled with a Dirichlet process by Mastrantonio et al. (2018).
Note that, for all the models cited earlier, each observation is simply a point on a circle or on a sphere while in our case, a single observation is made up of () non-ordered points on the circle. For this reason, these models cannot straightforwardly be adapted to our dataset. We propose an extension of the projected normal distribution to our data. This extension does not reduce to a simple projection of a multivariate normal distribution but enables us to model the multivariate and the non-ordered features of our data. We also provide an informative prior distribution on the relative locations of the angles on the circle. This prior distribution expresses that the angles are a priori regularly spaced on the circle. A new parameter is also introduced to control the variability of the angles on the circle. Inference on the variabiliy of the angles is of particular interest for a clustering purpose as an inadequate value of this parameter can alter the final results. The projected normal distribution is then associated with a Dirichlet process to perform clustering. Therefore, the proposed method includes an automated selection for the number of clusters.
In the present article, the Bayesian model is described in the next section. Section 3 is devoted to the inference of the parameters of the model. Section 4 provides a theoretical study to highlight the adaptability of our model to the multivariate and the non-ordered features of the data. Sections 5 and 6 provide empirical results first on simulated data and then on the real dataset that motivated the present work. A short conclusion is given in Section 7.
Model
A simple way of generating distributions on the -dimensional unit sphere is to radially project probability distributions originally defined on the -dimensional space (Presnell et al., 1998).. Let be a random -dimensional vector, then is a random point on . If has a -variate normal distribution , then is said to have a projected normal distribution, denoted by . The literature has been first confined to the special case where and (Presnell et al., 1998; Nuñez-Antonio and Gutiérrez-Peña, 2005; Nuñez-Antonio et al., 2011). Then, Wang and Gelfand (2013) studied the projected normal family with a general covariance matrix and refer to this richer class as the general projected normal distribution. This general version allows asymmetry and bimodality (see Figure 2 in Wang and Gelfand, 2014). The general projected normal distribution is not identifiable because is invariant to scale transformation. To overcome this problem, Wang and Gelfand (2013) fixed some variance parameters in to provide identifiability.
In a first step of simplification, we assume that the th of the observations is given by a vector of angles instead of a non-ordered set . Using a projected normal distribution, we denote by a random vector with distribution , where is defined as the radial projection of on the unit circle of . In other words, we have for all and all where denotes the Euclidean norm of . Note that is observed while is not and is treated as an unknown parameter. We denote by the joint distribution of . Clustering analysis will be based on a Dirichlet process mixture (DPM) model described as follows:
where and where denotes the Dirichlet process (DP) introduced by Ferguson (1973) with centre and precision parameter . The clustering properties of the DP are well known and date back to Blackwell and MacQueen (1973). It is shown that the parameter follows the Pólya urn scheme:
with indicating the point measure on . So, may be equal to one of the previous ’s or may be drawn from . This results in a positive probability of sharing the parameter value with previous observations; hence the clusters. In the sequel, we will denote by the distribution of given by (2.2). Although the DPM is very popular for Bayesian clustering, other model-based cluster methods exist. For a review of these methods, we refer the reader to Quintana (2006); Lau and Green (2007); Fritsch and Ickstadt (2009) and references therein. Note that the DPM model does not require choosing the number of clusters. On the other hand, it is well known that the number of clusters can be controlled by . Learning about from the data may be addressed by assuming a Gamma prior distribution (Escobar and West, 1995).
Now recall that the actual th observation consists of a (non ordered) set of the form rather than of a vector (ordered) . The impact of this simplification is quite easy to understand. Using model (2.1), two observations and with the same angles but in different orders would have a very low posterior probability of sharing the same cluster, that is . We treat the observations as vectors for convenience, but we have to introduce a permutation parameter to compensate this simplification. More precisely, for all and all permutation of , we set ; can be viewed as a random permutation of the coordinates of . Therefore, the clustering model becomes:
where and . The permutations are assumed to be a priori independent with a uniform distribution UP on the set P of permutations of . The posterior probability that two observations and with the same angles but in different orders would share the same cluster is increased with model (2.3) as there exist some values of and such that . A theoretical study of the impact of the symmetry introduced by is given in Section 4.
Prior information It is natural to assume that the angles are a priori distributed so that the radial projections are roughly equally spaced on the unit circle. As can be seen as a random change of , this prior information can be incorporated into the covariance matrix of as follows. From (2.3), it is well known that the marginal distribution of is . Denote by the -matrix of the rotation in with angle and centre and by , , random variables with distribution . Assume that are independent and set where is a positive number and for . It is important to note the influence of on the distribution of . First, it is shown in the Appendix that the expected value of is for and for and that the components become more correlated and equally spaced as increases. Furthermore, if we denote by the radial projection of onto the unit circle, it is shown that tends to almost surely as and tends to almost surely as where are independent and identically distributed random variables with distribution . In other words, the radial projections of the components of are highly correlated and equally spaced for large values of but approximately independent and uniformly distributed for small ones. The influence of is also studied through some simulations in the sequel (see Subsection 5.1 and Figure 2).
Inference on can be performed using an inverse gamma prior for which the full posterior conditional distribution will be calculated in the following section.
It is worth pointing out that the weak dissymmetry introduced in the definition of between and the other components of leads to a convenient closed-form expression of from which closed-form expressions of the inverse and the determinant can be obtained as well. Such closed-form expressions and the full posterior conditional distribution of could not have been obtained so easily with a perfect symmetric distribution . The calculations of , and are given in the Appendix. To highlight the dependence on , will be also denoted by in the sequel.
Finally, the complete Bayesian model can be expressed as follows:
where . By convention, it is assumed that the random variables at a stage of the hierarchy are independent.
Inference
We set , , , and . Thus, the parameter is and the observation is . We sample from the posterior distribution of with a Metropolis–Hastings-within-Gibbs algorithm. In what follows, stands for a generic notation for a density distribution.
agraph Simulations of We can restrict our attention to model (2.3) instead of the full model (2.4) for the simulations of as every component of except remains fixed. An alternative parameter setting of , and will prove useful. Denote where . First, note that the full conditional distribution of reduces to the conditional distribution of given as there is a natural bijection between and . Second, if we denote by the value of the density of at , it is easy to check that:
where is the permutation such that . Consequently, if we set , sampling from the posterior distribution of in the DPM model (2.3) reduces to sampling from the posterior distribution of in the following conjugate DPM model:
a set partition for where each represents a cluster, that is, if there exists such that and if there exist , such that , ,
a vector composed of the distinct values of , that is, for all .
Then, the conjugate DPM model (3.2) may be expressed as:
where is the cardinal of , is the indicator function for the event , denotes the gamma function and stands for the generic notation for any density. We can integrate over the cluster location parameter analytically in (3.3) as is conjugate to the normal distribution of given and . Then, we run the SAMS sampler of Dahl (2003) for simulating . This sampler may improve the merge-split sampler initially proposed by Jain and Neal (2004). Once a simulation of is obtained, it is easy to simulate the cluster location parameter from its full conditional which reduces to sample independently each from a distribution with . As recommended by the previous authors, we combine three runs of the Metropolis–Hastings update of the SAMS sampler with a full scan of Gibbs sampling for (see MacEachern, 1994, for a presentation of this particular Gibbs sampler). Some details of the SAMS and the Gibbs samplers used in this article are given in the Appendix.
agraph Simulations of It is shown in the Appendix that the are independent given with density:
with . If we denote by the univariate normal distribution truncated to , we remark that (3.4) is close to the value of the density of at . It is then natural to simulate from (3.4) by a Metropolis–Hastings step with a as the proposal distribution. Clearly, the probability of acceptance reduces to the ratio where and are, respectively, the current and the proposed values of in the algorithm. Alternative methods of simulations could have been used at this step such as, for example, the slice sampler proposed by Hernandez-Stumpfhauser et al. (2017).
agraph Simulations of As the prior distribution of is uniform, we have:
Thus, given , the are independent with density (with respect to the counting measure on the set of permutations of ):
agraph Simulations of
From (2.4), it is clear that the full conditional distribution of reduces to the conditional distribution of given . Then, using the parametrization of in terms of and (3.3), we note that and are independent and that:
We show in the Appendix that and that the components of the matrix are independent (constant) of except the components of the first 2 by 2 diagonal submatrix (lines and columns 1 and 2). As this submatrix is equal to , it is easily seen that
where ‘constant’ stands for a generic notation for an expression independent of . Since and , we have:
and it is easy to conclude from (3.6) that the full conditional of is
agraph Simulations of Using the arguments of Escobar and West (1995), under the prior, is updated at each Gibbs iteration by sampling first an additional variable from a Beta distribution and then a new value of from a mixture of Gamma distributions as follows:
with weights defined by .
The whole procedure is summarized in Algorithm 1.
Algorithm 1
Require: Dataset .
Require: Hyperparamaters
Repeat:
Simulate
(a) Run the SAMS sampler three times.
(b) Run the Gibbs sampler.
Simulate for each cluster .
Propose , accept with probability .
Simulate new from 3.5.
Simulate new from 3.7.
Simulate from 3.8.
Theoretical study of the symmetrized model
To investigate the impact of the symmetrization induced by the variables , we consider a simple model of the following form:
and its symmetrized version:
where is obtained by random permutation of the coordinates of . In both models, and is any distribution of the partition of . Such distributions include the distribution derived from the Dirichlet process given by (3.3). Model (II) can be viewed as a simplified and reparametrized version of (2.4). Now consider an idealized sample for which every observation is simply a random permutation of one unique observation ; in other words, for every , there exists a permutation such that . As the coordinates of all the are the same but in a different order, it is expected that all the observations are put together in one unique cluster. The aim of this section is to study whether model (4.1) is more appropriate than model (4.1) for this purpose.
Let and denote respectively the density of and the conditional density of given for model (I). We have:
where and
Denote by the conditional density of given for model (II). By (3.1) and noting that , we have:
where the earlier sum is taken for all the values of in , and . Therefore, models (I) and (II) reduce to
and
For all partition and all observation , we set
where for all subset and for all .
Proposition (a) For all partition and all observation ,
we have:
(b) For all distribution , there exists a positive number
such that:
for all partition and all observation .
(c) For all distribution , all partition and all observation , we have:
where the maximum is taken over all partitions of .
From of Proposition 1, we see that is the likelihood ratio of models (II’) and (I’). From , we know that the posterior odds ratio is large when is large. It would be of interest to know whether this ratio is greater than one. Unfortunately, this is not an easy task except for a few particular cases given further. Indeed, although the factor is actually known (see the proof of Proposition 1 in the Appendix), it is rather intractable. From , we deduce that the posterior odds is actually greater or equal to one at least for the partition that maximizes . This partition does exist for any observation and is independent of . In other words, for any , there exists a partition such that for all prior . Finally, we can remark from the proof of the theorem that the equality in (4.2) is obtained when is a Dirac distribution; a meaningless prior.
Consider the partition with a single cluster: and . From (4.1), the posterior odds ratio when is likely to be large when and small when all the for all . Assume from now that and that . Remember that models the prior information about the mutual positions of the angles on the circle. Therefore, can be viewed as a non-informative prior. In this case, for all and we have:
Example 1 provides a typical sample for which the posterior probability of a unique cluster is greater with model (II) than with model (I) independently of the prior distribution .
Example 1 First, by noting that:
for all , we deduce that:
Assume and set for and . In other words, is made up of consecutive points on the unit circle separated from an angle of , is obtained by a rotation with angle of each point of and so on. Therefore, it is easy to see from (4.4) that . Our conjecture is that for all integer which implies, from of Proposition 1, that the probability of a unique cluster is greater for model (II) than for model (I) for any distribution . For the conjecture reduces to for a single partition . As for all and , it is easily seen from (4.1) that . On the other hand, as and , we see from (4.3) that
hence the proof of the conjecture for . We also proved the conjecture for with a rather large amount of calculations (not given here) to take into account all the partitions and all the permutation . We are not in a position to provide general proof of the conjecture for .
Simulations
With small datasets, a misspecification of the prior could have a strong negative impact on the final results. Therefore, special attention has to be paid to the prior and the hyperparameter specifications. Consequently, we test our algorithm on two simulation studies to evaluate the influence of some hyperparameters.
The performances of our method are investigated using the adjusted Rand index (ARI), proposed by Hubert and Arabie (1985), to compare our obtained partition to the actual one. The Rand index (Rand, 1971) is a well-known measure of the similarity between two partitions. If we denote by the numbers of pairs that are in the same cluster in both partitions and by the number of pairs that are in different clusters in both partitions, then the Rand index is defined by the ratio . The ARI is a corrected-for-chance version of the Rand index. Its expected value (under the generalized hypergeometric model) is equal to 0 and its maximum is 1, while the expected value of the Rand index depends on the number of clusters. For a presentation of the different criteria for clustering comparison and for a study investigating the usefulness of the adjusted measures, we refer the reader to Fritsch and Ickstadt (2009) and Nguyen et al. (2009).
Influence of the precision parameter
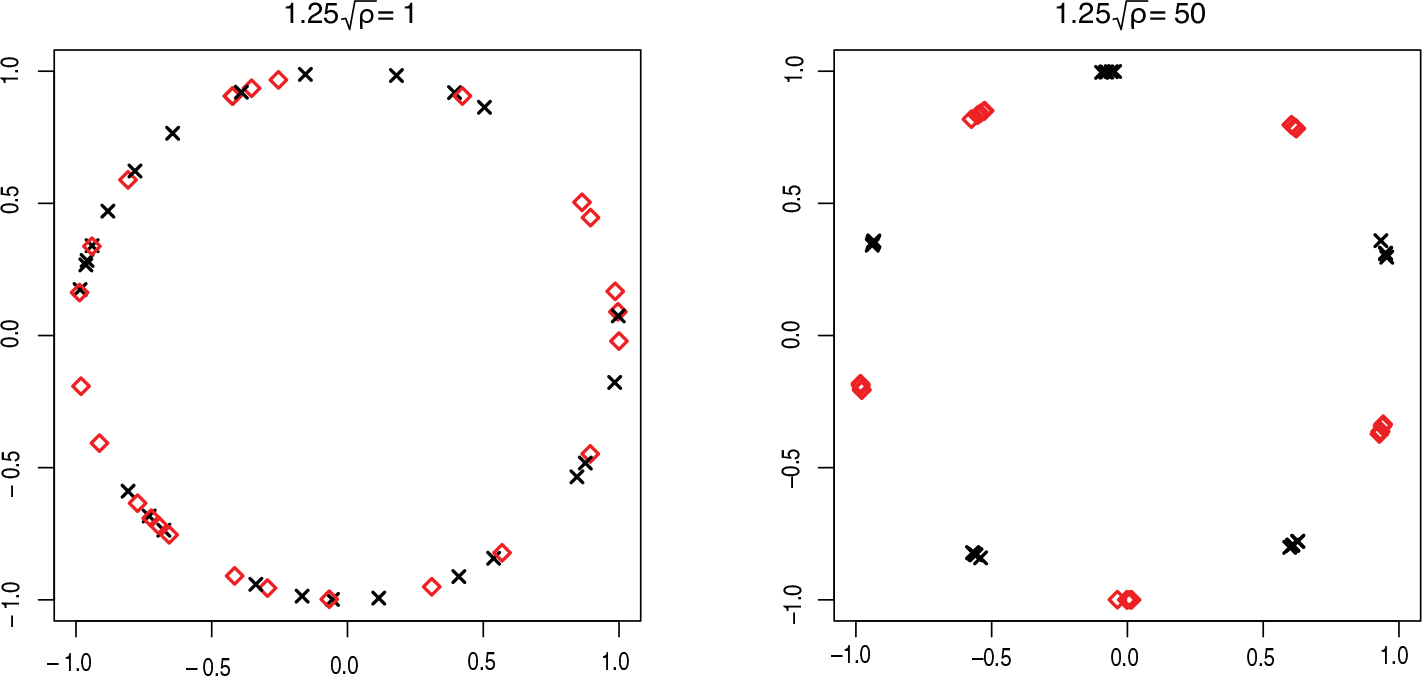
First, we choose to simulate data using a procedure which is close to our model in order to investigate the influence of the precision parameter . We set clusters of 10 data. We simulate the coordinates of each centre approximately on a circle with a fixed radius. Since it is shown in Section 2 that , the first coordinate is simulated according to a uniform distribution on the circle with radius . The other coordinates () are generated according to a noisy rotation with angle of . For each cluster , we generate 10 data according to . A comparison of the generated data is provided in Figure 2 with different values for ; for the clarity of the picture, we choose to represent only clusters of 5 observations. It is clear from Figure 2 that large values of provide small variability for the projected observations. This observation can be confirmed by a simulation study. We simulate some datasets according to the earlier procedure with different values for . For each value of , a hundred datasets are simulated. Then, our Bayesian methodology is applied using and . The mean values for the ARI are given in Table 1.
Adjusted Rand index according to
0.0064
0.1024
0.64
5.76
256
ARI
0.35
0.39
0.45
0.62
0.78
As expected, this parameter has an important influence on the obtained results. We choose a non-informative prior for by setting . This prior is close to the Jeffreys prior for the model whose density reduces to .
Two datasets are generated with two different values for the parameter to highlight the influence of this parameter. Two clusters of five data are represented on each plot. Each data is composed of angles on the circle. One cluster is represented by the black cross, the other by the red square
Robustness to the Hperparameters and
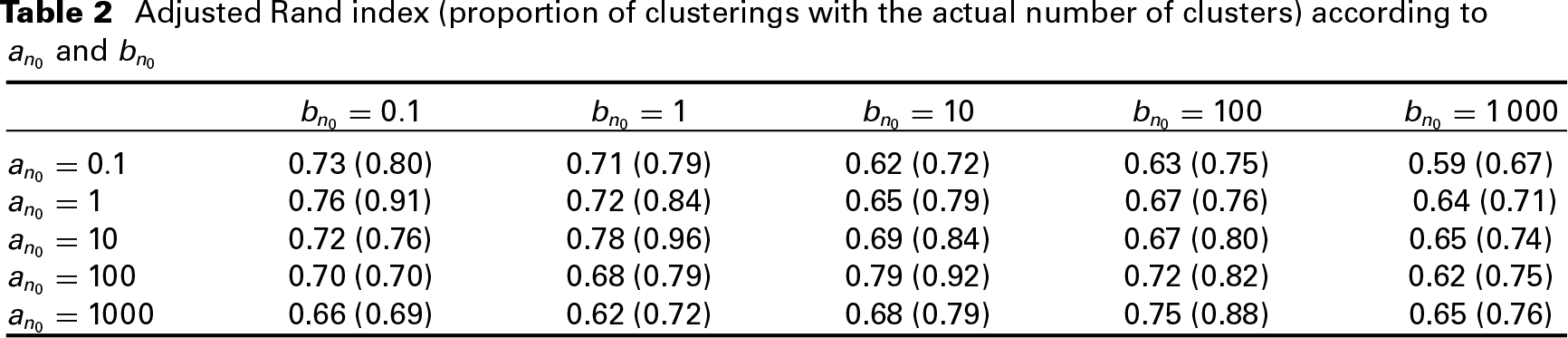
It is well known that the number of clusters does depend on whose prior distribution is fixed by the hyperparameters and . In this subsection, we investigate the sensitivity of the ARI with respect to these hyperparameters. We apply the same simulation strategy as in the previous subsection with a fixed value of such that . Note that the parameters and are not at all involved in the simulation of the dataset. The mean values for the ARI over 100 simulated datasets are given in Table 2.
Adjusted Rand index (proportion of clusterings with the actual number of clusters) according to and
0.73 (0.80)
0.71 (0.79)
0.62 (0.72)
0.63 (0.75)
0.59 (0.67)
0.76 (0.91)
0.72 (0.84)
0.65 (0.79)
0.67 (0.76)
0.64 (0.71)
0.72 (0.76)
0.78 (0.96)
0.69 (0.84)
0.67 (0.80)
0.65 (0.74)
0.70 (0.70)
0.68 (0.79)
0.79 (0.92)
0.72 (0.82)
0.62 (0.75)
0.66 (0.69)
0.62 (0.72)
0.68 (0.79)
0.75 (0.88)
0.65 (0.76)
Table 2 suggests that a choice of approximately between and provides good and similar results.
Influence of the number of clusters
Using the previously fixed hyperparameters, a simulation study is provided with different numbers of clusters. For each number of clusters, 100 datasets are simulated according to the earlier procedure. Each cluster has a number of points randomly chosen between and . The results are gathered in Table 3.
Adjusted Rand index according to the number of clusters
Number of clusters
1
3
5
8
10
ARI
0.97
0.74
0.71
0.66
0.60
The results are rather good even with a high number of clusters.
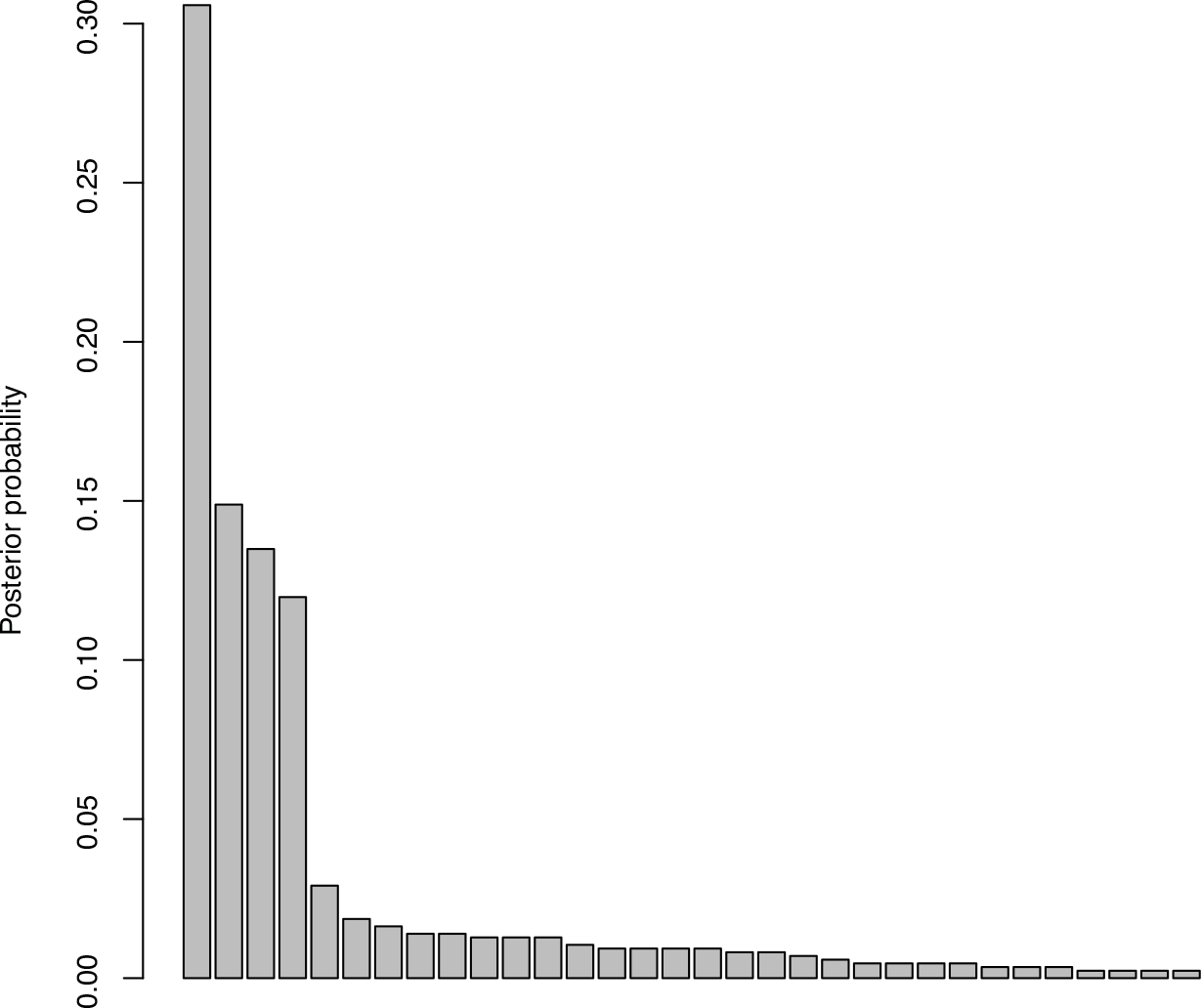
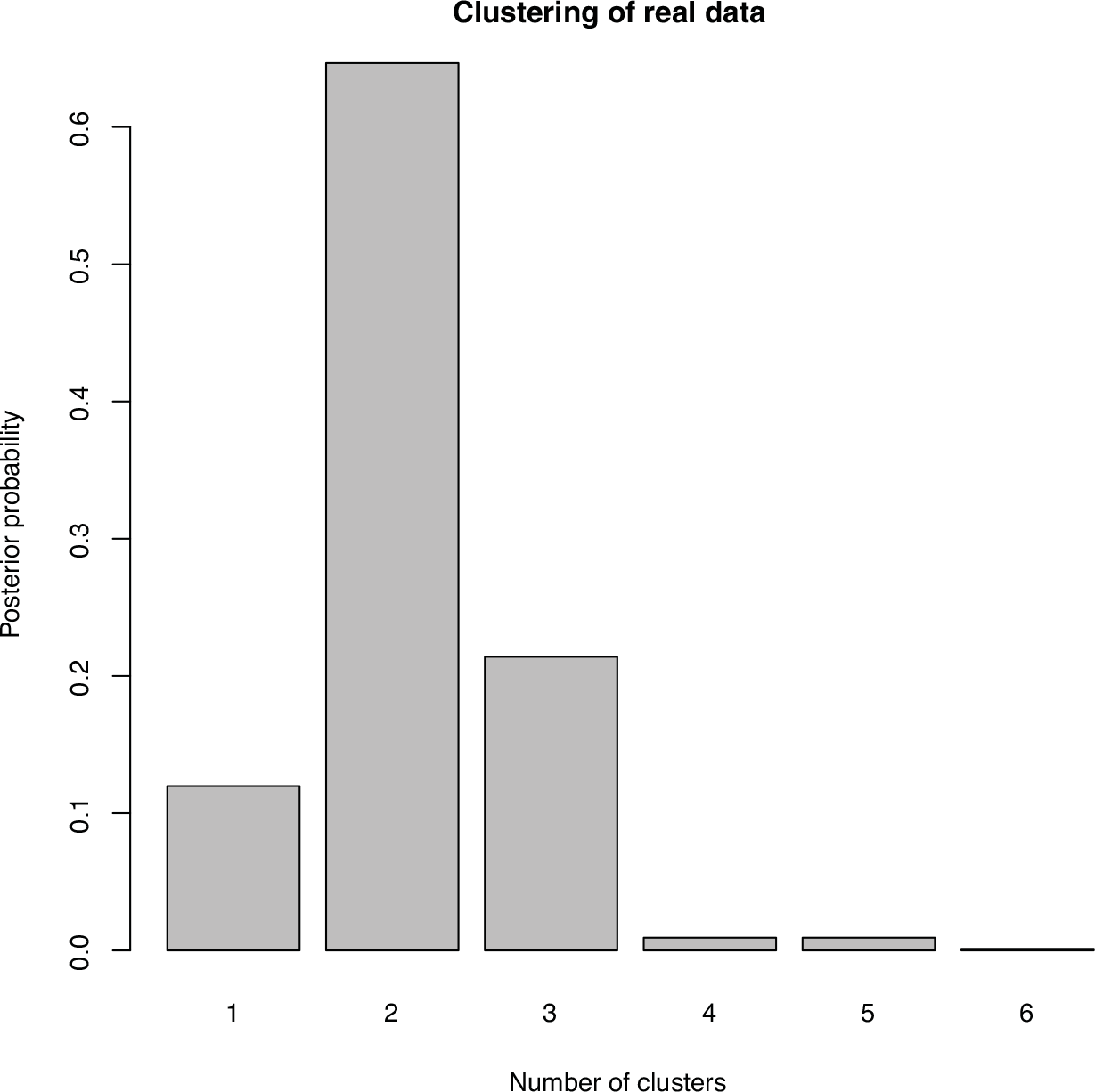
Barplot of the proportion of 32 more probable clusterings. For a better apprehension, the clusterings that have a posterior probability lower than 0.02% have been omitted
Real data
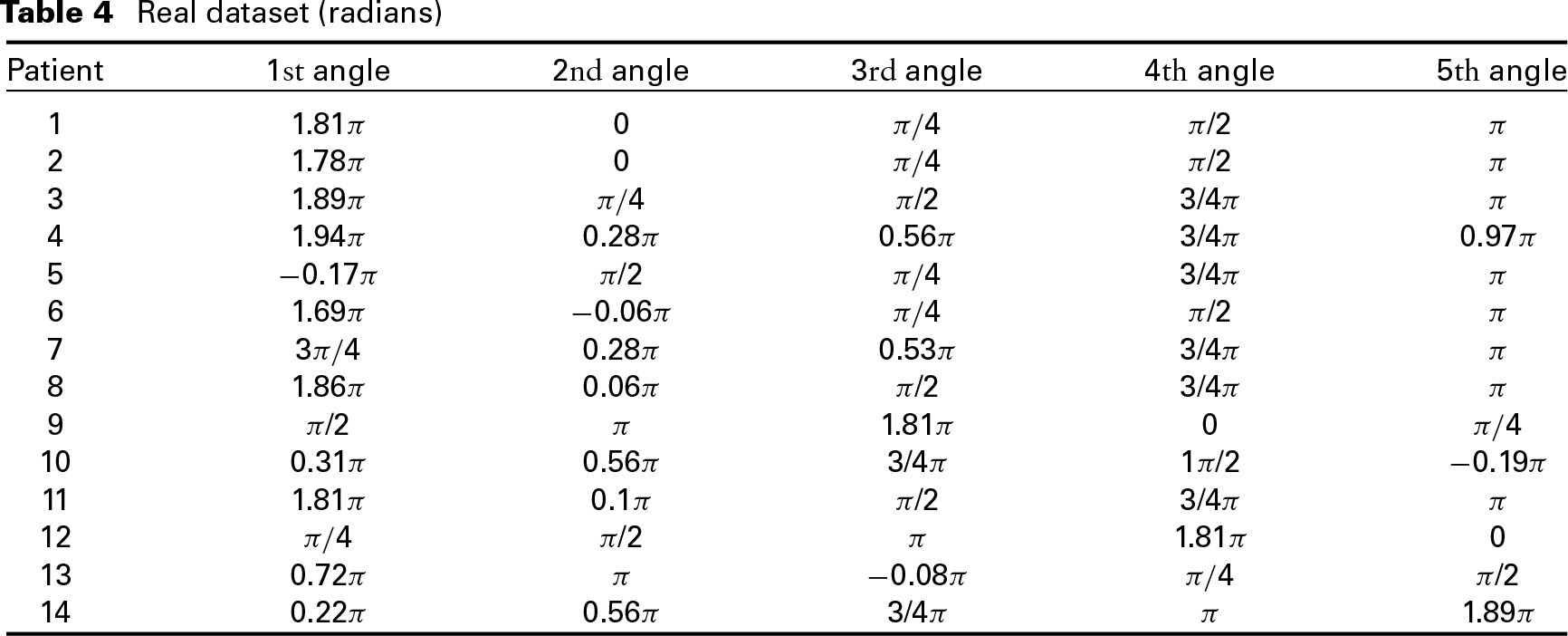
We then apply the methodology to a real dataset from post-operative treatment of liver cancer at the Institute of Sainte Catherine in Avignon, France (see Figure 1 and Table 4). Let us recall that no other competing methods exist for these kind of multivariate circular data except the method described in Abraham et al. (2013) with a fixed number of clusters. Consequently, our results are compared to those of Abraham et al. (2013) in which the number of clusters was preselected to .
Let us remind you that the a priori distribution of is a gamma distribution with parameter and with an expected value equal to (if ) and a variance equal to (if ). Remember that the expected number of clusters given is approximately equal to (Teh, 2010). According to the results of Section 5, the results are robust with respect to the choice of the hyperparameters and with . We choose a rather non-informative prior by setting and which leads to a distribution of centred around with a large variance. Other values for and have been tested and give nearly the same results. As in Section 5, we choose a non-informative prior by setting .
Posterior distribution of the number of clusters
MCMC convergence diagnostics was investigated with the clustering entropy
Traceplots for this quantity and for other parameters of the model suggest a good mixing and the convergence of our chain. On a classical personal laptop and using a nonoptimized code, the time of mixing was approximately 12 minutes, whereas the whole procedure lasts 90 minutes.
The majority clustering (mode of the posterior distribution of the clusterings) is the same as in Abraham et al. (2013) (two clusters: one containing data 1, 2, 6, 9 and 12, the second containing data 3, 4, 5, 7, 8, 10, 11, 13 and 14) with a posterior probability equal to 30.5%. This result was awaited and is coherent with the choice of 2 clusters in the previous method. But the real gain from our Bayesian approach is to look beyond this majority clustering. Here there are 3 more clusterings that are significant and that could give some information on this real dataset. The second majority clustering is nearly the same as the previous one: the clusters are the same but data 6 is alone in a third cluster. Indeed, this data is very atypical because it is the only one that contains an angle near 1.69. The posterior probability for this clustering is 14.9%. The third majority clustering gives nearly the same information with a posterior probability of 13.5%. There are two clusters: one with data 6 and a second with all the others. Finally, another clustering with a posterior probability of 12.0% is made up of only one cluster. Even with other choices for the hyperparameters and , the posterior probability of this clustering remains high. It highlights the fact that all the data share some common traits and the main difference in the two clusters of the majority clustering only concerns one angle. All the clusterings are included in Figure 3 sorted by their posterior probabilities. It can be noted that a credible region with a posterior probability of 71% is composed of the four previous clusterings.
We give in Figure 4 the posterior distribution of the number of clusters. The posterior probabilities of 1, 2 or 3 clusters are respectively 12%, 65% and 21%. Consequently, the number of clusters is certainly (with probability 98%) less than or equal to 3.
As expected, these results are in line with the clusterings obtained in Abraham et al. (2013). The final choice of two clusters (that is not made here a priori) could provide, using the centres of the clusters, preset positions for praticians. As explained earlier, these two centres share only one main difference on one unique angle. This is highlighted by the important posterior probability of the clustering with only one cluster. Thus, using these preset positions should be fairly easy for praticians, with four fixed values and only two choices for the last one. Furthermore, the results suggest another preset position that should be added and tested if the two previous one do not fit: the beam angles of data 6. As explained in Yuan et al. (2015), the definition of such presets will help to save time (at least 30 minutes for each patient) and will allow more people to be treated with this technology; it is also shown that the beams generated with our methodology show dosimetric qualities comparable to their manually generated clinical counterpart, even if no adjustments were allowed around the fixed presettings.
Real dataset (radians)
Patient
angle
angle
angle
angle
angle
1
1.81
0
/2
2
1.78
0
/2
3
1.89
/2
3/4
4
1.94
0.28
0.56
3/4
0.97
5
0.17
/2
3/4
6
1.69
0.06
/2
7
3
0.28
0.53
3/4
8
1.86
0.06
/2
3/4
9
/2
1.81
0
10
0.31
0.56
3/4
1/2
0.19
11
1.81
0.1
/2
3/4
12
/2
1.81
0
13
0.72
0.08
/2
14
0.22
0.56
3/4
1.89
Conclusion
We present a full Bayesian framework for the clustering of multivariate circular and non-ordered data. It is based on a hierarchical model that combines projected normal distributions and the Dirichlet Process. Two original parameters are also introduced in this model: the parameter to infer the variance of the angles and the symmetrization parameter to model the non-ordered feature of the data. The parameters of the model are then inferred using a Metropolis–Hastings-within-Gibbs algorithm and a theoretical study of the impact of the symmetrization parameter is provided. The simulation study and the real data example show the benefits of this approach. Indeed, the number of clusters is chosen automatically by the method and the final result is much more complete than the majority clustering which is usually provided by classical clustering algorithms. However, some improvements could be considered, such as incorporating covariates (shape or size of the tumour, stage of the cancer, sex, age,...) to preselect the beam positions.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
AbrahamCMolinariNServienR (2013) Unsupervised clustering of multivariate circular data. Statistics in Medicine, 32, 1376–82.
2.
BlackwellDMacQueenJB (1973) Ferguson distributions via Polya urn schemes. The Annals of Statistics, 1, 353–55.
3.
DahlDB (2003) An improved merge-split sampler for conjugate Dirichlet process mixture models (Technical Report No. 1086). Madison, WI: University of Wisconsin, 1–32.
4.
DamienPWalkerS (1999) A full Bayesian analysis of circular data using the von Mises distribution. The Canadian Journal of Statistics, 27, 291–98.
5.
EscobarMDWestM (1995) Bayesian density estimation and inference using mixtures. Journal of the American Statistical Association, 90, 577–88.
6.
FergusonTS (1973) A Bayesian analysis of some nonparametric problems. The Annals of Statistics, 1, 209–30.
7.
FritschAIckstadtK (2009) Improved criteria for clustering based on the posterior simi- larity matrix. Bayesian Analysis, 4, 367–92.
8.
GriffinJHolmesC (2010) Computational issues arising in Bayesian nonparametric hierarchical models. In Bayesian Nonpa- rametrics, edited by HjortNHolmesCMllerPWalkerSG pages 208–22. Cambridge: Cambridge University Press.
9.
Hernandez-StumpfhauserDBreidtFJvan der WoerdMJ (2017) The general projected normal distribution of arbitrary dimension: Modeling and Bayesian inference. Bayesian Analysis, 12, 113–33.
10.
HubertLArabieP (1985) Comparing part- itions. Journal of Classication, 2, 193–218.
11.
JainSNealRM (2004) A split-merge Markov chain Monte-Carlo procedure for the Dirichlet process mixture model. Journal of Computational and Graphical Statistics, 13, 158–82.
12.
Jona-LasinioGGelfandAJona-LasinioM (2012) Spatial analysis of wave direction data using wrapped Gaussian processes. The Annals of Applied Statistics, 6, 1478–98.
13.
LauJWGreenPJ (2007) Bayesian model-based clustering procedures. Journal of Computational and Graphical Statistics, 16, 526–58.
14.
MacEachernSN (1994) Estimating normal means with a conjugate style Dirichlet process prior. Communications in Statistics: Simulation and Computation, 23, 727–41.
15.
MacEachernSN (1998) Computational methods for mixture of Dirichlet process models. In Practical Nonparametric and Semipara- metric Bayesian Statistics, edited by DeyDMller andPSinhaD pages 23–44. Lecture Notes in Statistics 133. New York, NY: Springer-Verlag.
16.
MardiaKVHuguesGTaylorCCSinghH (2008) A multivariate von Mises distri- bution with applications to bioinformatics. The Canadian Journal of Statistics, 36, 99–109.
17.
MardiaKVJuppP (2009) Directional Statistics. New York, NY: John Wiley & Sons.
18.
MastrantonioGPolliceAFedeleF (2018) Distributions-oriented wind forecast verification by a hidden Markov model for multivariate circular-linear data. Stochastic Environmental Research and Risk Assessment, 32, 169–81.
19.
NealRM (2000) Markov chain sampling method for Dirichlet process mixture models. Journal of Computational and Graphical Statistics, 9, 249–65.
20.
NguyenXEppsJBaileyJ (2009) Information theoretic measures for clustering comparison: Is a correction for chance necessary? ICML’09: Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, Canada, 14–18June 2009, pages 1073–80.
21.
Nuñez-AntonioGGutiérrez-PeñaE (2005) A Bayesian analysis of directional data using the projected normal distribution. Journal of Applied Statistics, 32, 995–1001.
22.
Nuñez-AntonioGGutiérrez-PeñaEEscarelaG (2011) A Bayesian regression model for circular data based on the projected normal distribution. Statistical Modelling, 11, 185–201.
23.
PresnellBMorrisonSPLittellRC (1998) Projected multivariate linear models for directional data. Journal of the American Statistical Association, 93, 1068–77.
24.
QuintanaFA (2006) A predictive view of Bayesian clustering. Journal of Statistical Planning and Inference, 136, 2407–29.
25.
RandW (1971) Objective criteria for the evalu- ation of clustering methods. Journal of the American Statistical Association, 66, 846–50.
26.
RavidranPGhoshSK (2011) Bayesian analysis of circular data using wrapped distributions. Journal of Statistical Theory and Practice, 5, 547–60.
27.
SenGuptaALahaAK (2008) A Bayesian analysis of the change-point problem for directional data. Journal of Applied Statistics, 35, 693–700.
28.
SinghHHnizdoVDemchukE (2002) Probabilistic model for two dependant circular variables. Biometrika, 89, 719–23.
29.
TehYW (2010) Dirichlet processes. In Ency- clopedia of Machine Learning. Springer.
30.
Von MisesR (1918) Über die ganzzahligkeit der atomgewicht und verwandte fragen. Physikalische Zeitschrift, 19, 490–500.
31.
WangFGelfandAE (2013) Directional data analysis under the general projected normal distribution. Statistical Methodology, 10, 113–27.
32.
WangFGelfandAE (2014) Modeling space and space-time directional data using projected Gaussian processes. Journal of the American Statistical Association, 109, 1565–80.
33.
WangFGelfandAEJona-LasinioG (2015) Joint spatio-temporal analysis of a linear and a directional variable: Space-time modeling of wave heights and wave directions in the adriatic sea. Statistica Sinica, 25, 25–9.
34.
YuanLWuQJYinFLiYShengYKelseyCRGeY (2015) Standardized beam bouquets for lung IMRT planning. Physics in Medicine & Biology, 60, 1821–43.