
Abstract
Modelling football outcomes has gained increasing attention, in large part due to the potential for making substantial profits. Despite the strong connection existing between football models and the bookmakers’ betting odds, no authors have used the latter for improving the fit and the predictive accuracy of these models. We have developed a hierarchical Bayesian Poisson model in which the scoring rates of the teams are convex combinations of parameters estimated from historical data and the additional source of the betting odds. We apply our analysis to a nine-year dataset of the most popular European leagues in order to predict match outcomes for their tenth seasons. In this article, we provide numerical and graphical checks for our model.
Introduction
In recent years, the challenge of modelling football outcomes has gained attention, in large part due to the potential for making substantial profits in betting markets. This task may be achieved by adopting two different modelling strategies: the ‘direct’ models, for the number of goals scored by two competing teams; and the ‘indirect’ models, for estimating the probablility of the categorical outcome of a win, a draw, or a loss, which will hereafter be referred to as a ‘three-way’ process.
The basic assumption of the direct models is that the number of goals scored by the two teams follow two Poisson distributions. Their dependence structure and the specification of their parameters are the other most relevant assumptions, according to the literature. The scores’ (goals’) dependence issue is, in fact, the subject of much debate, and the discussion cannot yet be concluded. As one of the first contributors to the modelling of football scores, Maher (1982) used two conditionally independent Poisson distributions, one for the goals scored by the home team, and another for the away team. Dixon and Coles (1997) expanded upon Maher's work and extended his model, introducing a parametric dependence between the scores. This also represents the justification for the bivariate Poisson model, introduced in Karlis and Ntzoufras (2003) in a frequentist perspective, and in Ntzoufras (2011) under a Bayesian perspective. On the other hand, Baio and Blangiardo (2010) assume conditional independence within hierarchical Bayesian models, on the grounds that the correlation of the goals is already taken into account by the hierarchical structure. Similarly, Groll and Abedieh (2013) and Groll et al. (2015) show that, up to a certain amount, the scores’ dependence on two competing teams may be explained by the inclusion of some specific team covariates in the linear predictors. However, Dixon and Robinson (1998) note that modelling the dependence along a single match is possible: in such a case, a temporal structure in the 90 minutes is required.
The second common assumption is the inclusion in the models of some teams’ effects to describe the attack and the defence strengths of the competing teams. Generally, they are used for modelling the scoring rate of a given team, and in much of the aforementioned literature they do not vary overtime. Of course, this is a major limitation. Dixon and Coles (1997) tried to overcome this problem by downweighting the likelihood exponentially overtime in order to reduce the impact of matches far from the current time. However, over the last 10 years the advent of some dynamic models allowed these teams’ effects to vary over the seasons, and to have a temporal structure. The independent (or double) Poisson model proposed by Maher (1982) has been extended to a Bayesian dynamic independent model, where the evolution structure is based on continuous time (Rue and Salvesen, 2000), or is specified for discrete times, such as a random walk for both the attack and defence parameters (Owen, 2011). Instead, the non-dynamic bivariate Poisson model is extended in Koopman and Lit (2015) and Koopman et al. (2017), and is expressed as a state space model where the teams’ effects vary in function of a state vector.
For our purposes, the scores’ dependence assumption may be relaxed, and in this article we assume conditional independence. From a purely conceptual point of view, we have several reasons for adopting two independent Poisson: (a) as discussed by Baio and Blangiardo (2010), assuming two conditionally independent Poisson hierarchical Bayesian models implicitly allows for correlation, since the observable variables are mixed at an upper level; (b) as noted by McHale and Scarf (2011), there is empirical evidence that goals of two teams in seasonal leagues display only slightly positive correlation, or no correlation at all, where as goals are negatively correlated for national teams; (c) bivariate Poisson models (Karlis and Ntzoufras, 2003), which represent the most typical choice for modelling correlation, only allow for non-negative correlation. Moreover, the independence assumption allows for a simpler formulation for the likelihood function and simplifies the inclusion of the bookmakers’ odds in our model. Concerning the dynamic assumption of the team-specific effects, we use an autoregressive model by centring the effect of seasonal time
Whatever the choices for the two assumptions discussed earlier, the models proposed in this context were built with both a descriptive and a predictive goal, and their parameters’ estimates/model probabilities were often used for building efficient betting strategies (Dixon and Coles (1997); Londono and Hassan, 2015). In fact, the well-known expression ‘beating the bookmakers’ is often considered a mantra for whoever tries to predict football—or more generally, sports—results. As mentioned by Dixon and Coles (1997), to win money from the bookmakers requires a determination of probabilities, which is sufficiently more accurate than those obtained from the odds. On the other hand, it is empirically known that odds of the bookies are the most accurate source of information for forecasting sports performances (Štrumbelj, 2014). However, at least two issues deserve a deep analysis: how to determine probability forecasts from the raw betting odds, and how to use this source of information within a forecasting model (e.g., to predict the number of goals). Concerning the first point, it is well known that the betting odds do not correspond directly to probabilities; in fact, to make a profit, bookmakers set unfair odds, and they have a ‘take’ of 5–10%. In order to derive a set of coherent probabilities from these odds, many researchers have used the ‘basic normalization’ procedure, by normalizing the inverse odds up to their sum. Alternatively, Forrest et al. (2005) and Forrest and Simmons (2000) propose a model-based approach, where the betting probabilities are the dependent variables of a regression model, with a historical set of betting odds and match outcomes as independent variables. However, Štrumbelj (2014) shows that Shins procedure (Shin, 1991, 1993) gives the best results overall, being preferable both to the basic normalization and regression approaches. Concerning the second issue, a small amount of literature focused on using the existing betting odds as ‘part’ of a statistical model for improving the predictive accuracy and the model fit. Londono and Hassan, 2015 use the betting odds for eliciting the hyperparameters of a Dirichlet distribution, and then update them based on observations of the categorical three-way process. No researcher has tried to implement a similar strategy within the framework of direct models.
In this article we try to fill the gap, creating a bridge between the betting odds and betting probabilities, on the one hand, and the statistical modelling of the scores, on the other hand. After transforming the inverse betting odds into probabilities, we develop a procedure to (a) infer from these the implicit scoring intensities, according to the bookmakers, and (b) use these implicit intensities directly in the conditionally independent Poisson model for the scores, within a Bayesian perspective. We are interested in both the estimation of the models parameters, and in the prediction of a new set of matches. Intuitively, the latter task is much more difficult than the former, since football is intrinsically noisy and hardly predictable. However, we believe that combining the betting odds with an historical set of data on match results may give predictions that are more accurate than those obtained from a single source of information.
In Section 2, we introduce two methods, proposed in the literature, for transforming the three-way betting odds favoured by bookmakers into probabilities. In Section 3, we introduce the full model, along with the implicit scoring rates. The results and predictive accuracy of the model on the top four European leagues—Bundesliga, Premier League, La Liga and Serie A—are presented in Section 4, and are summarized through posterior probabilities and graphical checks. Moreover, some model assumptions are checked via predictive measures. Some profitable betting strategies are briefly presented in Section 5. Section 6 concludes our analysis.
Transforming the betting odds into probabilities
The connection between betting odds and probabilities has been broadly investigated over the last decades. The odds of any given event are usually specified as the amount of money we would win if we bet one unit on that event. The inverse odds—usually denoted as 1:2.5—correspond to the imprecise probability associated to that event. In fact, as is widely known, the betting odds do not correspond directly to precise probabilities: the sum of the inverse odds for a single match needs to be greater than one (Dixon and Coles (1997)) in order to guarantee the bookmakers’ profit. Here,
There is empirical evidence that the betting odds are the most accurate available source of probability forecasts for sports (Štrumbelj, 2014); in other words, forecasts based on odds probabilities have been shown to be better, or at least as good as, statistical models, which use sport-specific predictors and/or expert tipsters.
However, some issues remain open. Among these, there is a strong debate over which method to use for inferring a set of probabilities from the raw betting odds. We can transform them into probabilities by using the two procedures proposed in the literature: the ‘basic normalisation’—dividing the inverse odds by the booksum, that is, the sum of the inverse betting odds, as broadly explained in Štrumbelj (2014)—and ‘Shin's procedure’ described in Shin (1991, 1993). Štrumbelj (2014), Cain et al. (2002, 2003), and Smith et al. (2009) show that Shins probabilities improve over the basic normalization: In Štrumbelj (2014), this result has been achieved by the application of the ranked probability score (RPS; Epstein, 1969), which may be defined as a discrepancy measure between the probability of a three-way process outcome and the actual outcome.
In this article we will not focus on comparing these two procedures; rather, we are interested in using the probabilities derived from each of them for statistical and prediction purposes, as will become clearer in later sections.
(A) Basic normalization

where
(B) Shin's procedure
In the model proposed by Shin (1993), the bookmakers specify their odds in order to maximize their expected profit in a market with uninformed bettors and insider traders. The latter are those particular actors who, due to superior information, are assumed to ‘already’ know the outcome of a given event—for example, football match, horse race, etc.—before the event takes place. Their contribution in the global betting volume is quantified by the percentage
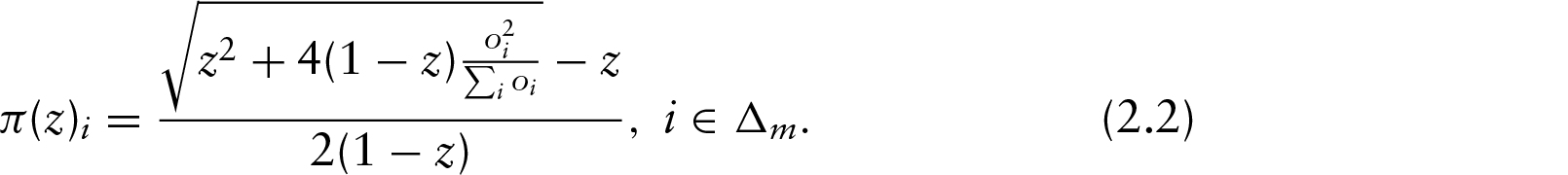
The current literature refers to these as Shin's probabilities. The earlier formula is a function depending on the insider trading rate

The value obtained here may be defined as the minimum rate of insider traders that yields probabilities corresponding to the vector of inverse betting odds
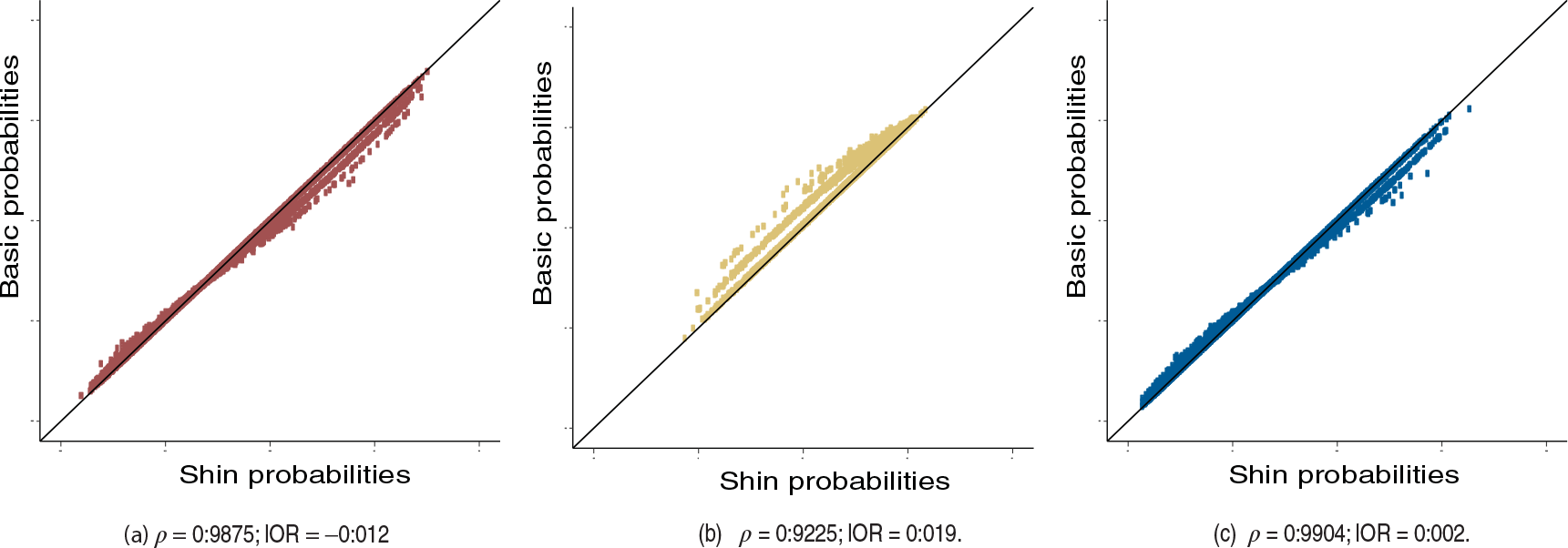
Figure 1 displays the three-way betting probabilities obtained through the two procedures described earlier for English Premier League, from the season 2007–2008 to the season 2016–2017; the single captions report the Pearson's correlation coefficients and a global log-odds ratio. As may be noted, the draw probabilities obtained with the basic normalization tend to be higher than those obtained with Shin's procedure. Conversely, as a home win and an away win tend to become more likely, Shin's procedure tends to favour them.
Comparison between home (Panel (a)), draw (Panel (b)) and loss (Panel(c)) Shin probabilities (
-axis) and the corresponding basic normalized probabilities (
-axis) for the English Premier League (seasons from 2007–2008 to 2016–2017), according to seven different bookmakers. For each three-way outcome,
is the Pearson's correlation coefficient and
a global log-odds ratio between basic and Shin probabilities over all the matches and all the different bookmakers
Model for the scores
Here,

where


Now, from Equation (3.1) we move to the following specification:

where
The model introduced in (3.3) still relies on the conditional independence assumption, but the rates are now convex combinations accounting for different information sources. Roughly speaking, this approach presents some similarities with the Bayesian model averaging perspective (Hoeting et al., 1999), with the first model
Equation (3.3) introduced a convex combination for the Poisson parameters, accounting for both the scoring rates



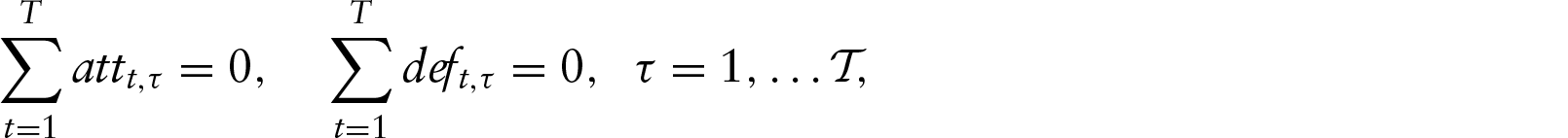
where as
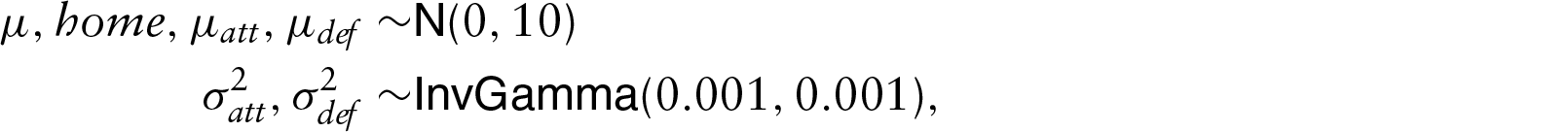
where

where

Data
We collect the exact scores for the top four European professional leagues—Italian Serie A, English Premier League (hereafter, EPL), German Bundesliga, and Spanish La Liga—from season 2007–2008 to 2016–2017. Moreover, we also collected all the three-way odds for the following bookmakers: Bet365, Bet&Win, Interwetten, Ladbrokes, Sportingbet, VC Bet, William Hill. All these data have been downloaded from the public available page http://www.football-data.co.uk/. We are interested in both (a) posterior predictive checks in terms of replicated data under our models, and (b) out-of-sample predictions for a new dataset. According to point (b), which appears to be more appealing for fans, bettors and statisticians, let
Parameter estimates
As broadly explained in Section 3, the model in (3.3) combines historical information about the scores and betting information about the odds. We acknowledge that the scoring rate is a convex combination that ‘borrows strengths’ from both sources of information. Figure 2 displays the posterior estimates for the attack and the defence parameters associated with the teams belonging to the EPL during the test set season 2016–2017. The larger is the team-attack parameter, the greater is the attacking quality for that team; conversely, the lower is the team-defence parameter, the better is the defence power for that team. As a general comment, after reminding the reader that these quantities are estimated using only the historical results, the pattern seems to reflect the actual strength of the teams across the seasons. For example, Chelsea and Manchester City register the highest effects for the attack and the lowest for the defence across the nine seasons considered: consequently, the out-of-sample estimates for the tenth season mirror previous performance. Conversely, weaker teams are associated with an inverse pattern: see for instance Hull City, Middlesbrough, and Sunderland, all relegated at the end of the season. It is worth noting that some wide posterior bars are associated to those teams with fewer seasonal observations: in fact, some teams have been observed for less than 10 seasons due to relegations/promotions.
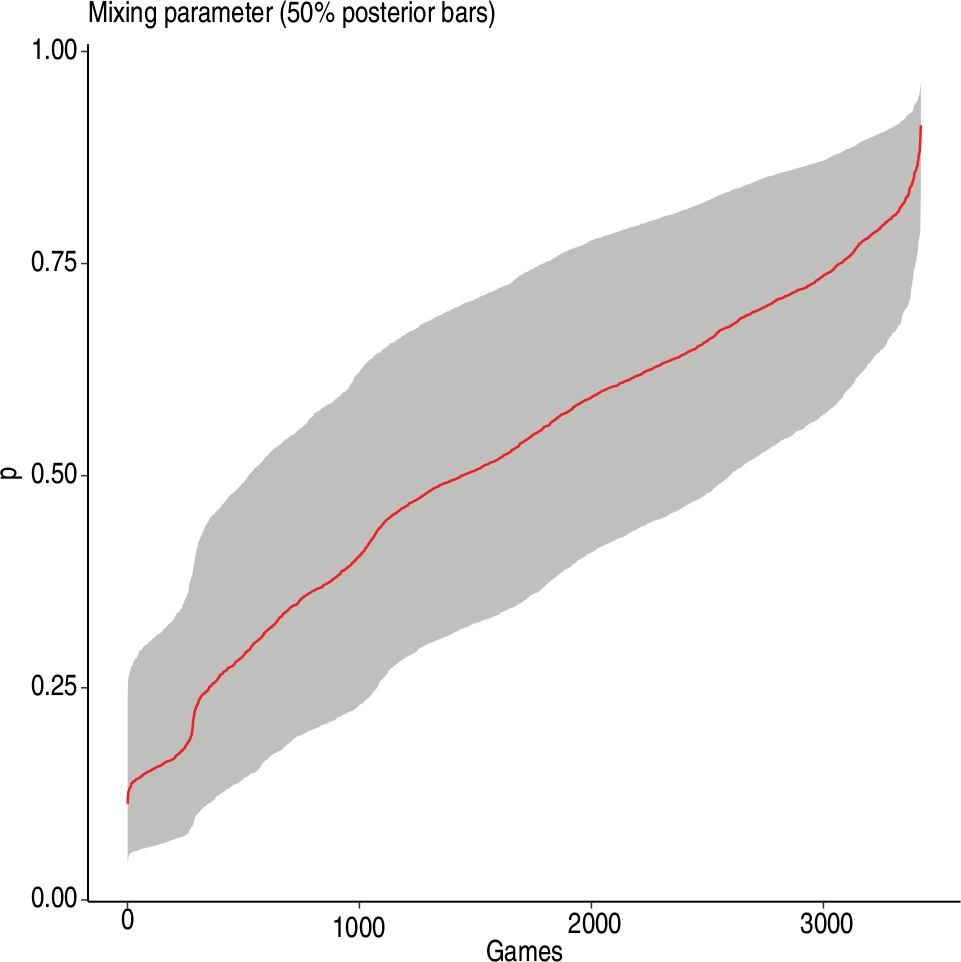
Figure 3 displays the ordered 50% credible bars for the marginal posteriors of the mixing parameter
Posterior 50% credible bars for the attack (red) and the defence (blue) effects along the 10 seasons for the teams belonging to the EPL 2016–2017. Wider posterior bars are associated with teams reporting fewer observations

Posterior 50% credible bars for the attack (red) and the defence (blue) effects along the 10 seasons for the teams belonging to the EPL 2016–2017. Wider posterior bars are associated with teams reporting fewer observations
As broadly explained in Gelman et al. (2014), once we obtain some estimates from a Bayesian model we should assess the fit of this model to the data at hand and the plausibility of such model, given the purposes for which it was built. The principal tool designed for achieving this task is ‘posterior predictive checking’. This post-model procedure consists of verifying whether some additional replicated data under our model are consistent with the observed data. Thus, we draw simulated values
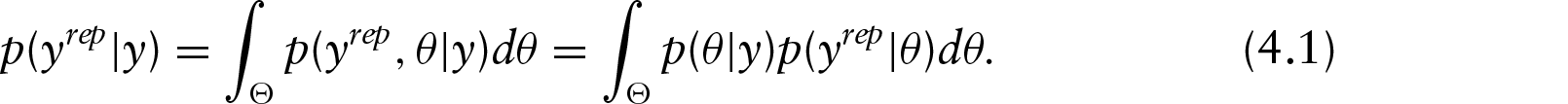
Then, we define a test statistic

Rather than comparing the posterior distribution of some statistics with their observed values (Gelman et al., 2014), we propose a slightly different approach, allowing for a broader comparison of the replicated data under the model. Figure 4 (Panel (a)) displays the replicated distributions
Figure 4 (Panel (b)) displays the 50% and 95% credible uncertainty intervals (dark yellow and yellow, respectively) for the ordered estimated goal differences. Blue points are the observed goal differences. About 95.1% of the observed points fall within the 95% uncertainty intervals, and this suggests a good model calibration.
Ordered posterior 50% credible bars for mixing parameter p for EPL (from 2007–2008 to 2015–2016), 3420 matches
Overall measure of goodness of fit
In Bayesian statistics, it is usual to compare competing models through some criteria based on trade-off between the fit of the data to the model and the corresponding complexity of the model (Spiegelhalter et al., 2002), such as deviance information criterion (DIC). Denoted with

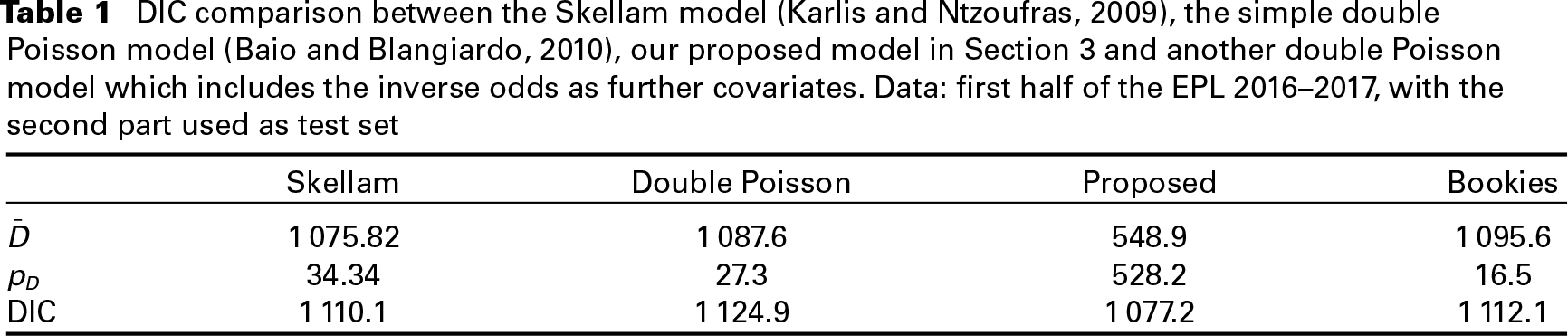
The lower is the DIC, and the better is the model supported by the data. Of course, DIC may be negative as well. Table 1 shows the posterior mean deviance, the effective number of parameters and DIC for four competing models, considering the EPL 2016–2017. For the sake of brevity, we do not report here the results for the other leagues, which are quite similar to those obtained for the EPL. Still, according to a simpler DIC interpretation, we focused here on the 2016–2017 season only; in fact, considering more seasons, as we did in the previous sections, just yields an increase of the model complexity, but mirrors the same DIC pattern observed for one season only. The four models considered are: the Skellam model (Karlis and Ntzoufras, 2009), a simple double Poisson model (Baio and Blangiardo (2010)), our proposed model and a further model (marked with the term Bookies) which includes the bookies inverse odds as model covariates in the scoring rates in the following way:
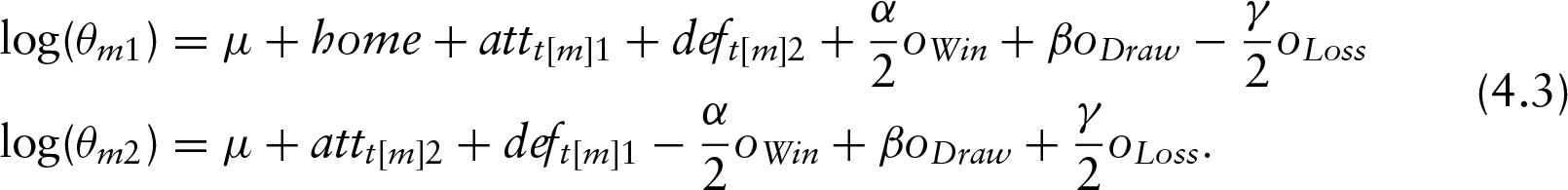
As it is evident, our model yields the lowest DIC (1077.2) and the lowest
DIC comparison between the Skellam model (Karlis and Ntzoufras, 2009), the simple double Poisson model (Baio and Blangiardo (2010)), our proposed model in Section 3 and another double Poisson model which includes the inverse odds as further covariates. Data: first half of the EPL 2016–2017, with the second part used as test set
In this section, we quickly assess whether the main assumptions for our proposed model hold. The strategy is to use posterior predictive tools for detecting possible conflicts between the model and the data. But the diagnostic measures developed here may also act as a sort of inverse tool, revealing that replicated data exhibit some unexpected features.
Conditional independence
Considering
PP checks for the goal difference
in EPL against the replicated goal difference
. Panel (a): goal differences distribution (grey areas) conditioned on the observed probability (blue segments). Panel (b): 95% posterior intervals (light yellow) and 50% posterior intervals (dark yellow) for estimated goal difference
. Blue points are the ordered observed goal differences

PP checks for the goal difference
in EPL against the replicated goal difference
. Panel (a): goal differences distribution (grey areas) conditioned on the observed probability (blue segments). Panel (b): 95% posterior intervals (light yellow) and 50% posterior intervals (dark yellow) for estimated goal difference
. Blue points are the ordered observed goal differences
Draw inflation
As already mentioned, predicting less draws than the actual ones is a well-known problem in modelling football outcomes. Poisson based models may suffer from this underestimation, and for this reason Karlis and Ntzoufras (2009) propose a zero inflated model for favouring the draw outcome. Nonetheless, this is not the case for our proposed model, which actually overestimates the number of draws, as suggested by Figure 4 (Panel (a)).
Overdispersion
As it is well known, Poisson based models do not allow for overdispersion. In many cases, the variance for a discrete set of data may be greater than its mean, and the Poisson distribution is not well suited in such situations. As broadly documented in the supplementary material, we found that replicated variances are greater than the replicated means; analogously as the interpretation for the conditional dependence, MCMC replications suggest there is no need for explicitly modelling the marginal overdispersion.
The main appeal of a statistical model relies on its predictive accuracy. As usual in a Bayesian framework, the prediction for a new dataset may be performed directly via the posterior predictive distribution for our unknown set of observable values. Following the same notation of Gelman et al. (2014), let us denote with 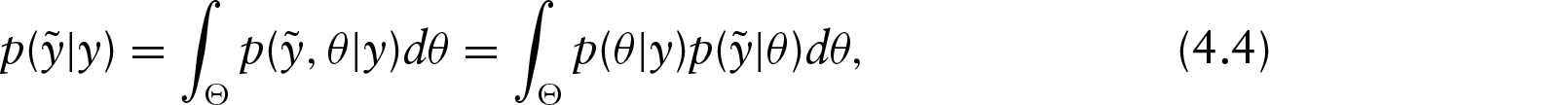
where the conditional independence of
Figure 6 displays the posterior predictive distributions for the following matches: Eintracht Frankfurt-RB Leipzig, German Bundesliga 2016–2017; Hull-Middlesbrough, EPL 2016–2017; Real Madrid-Barcelona, Spanish La Liga 2016–2017; Sampdoria-Juventus, Italian Serie A 2016–2017. The red squares indicate the observed results. Darker regions are associated with higher posterior probabilities. According to the model, the most likely result for the first and the second game is (0,0), with an associated posterior probability about 0.1 and 0.15, respectively, where as the most likely result coincides with the actual result (0,1) for the fourth game. These plots provide a picture that acknowledges the large uncertainty of the prediction. We would not be much interested in a model that often indicates a rare result that has been observed as the most likely outcome; the outcome (2,3) in Real Madrid-Barcelona had a low probability to arise, and a model which would suggest such an outcome as more likely than (1,1) or (1,0) could suffer from some predictive inefficiency. Thus, being aware of the unpredictable nature of football, we would like to grasp the posterior uncertainty of a match outcome in such a way that the actual result is not extreme in the predictive distribution.
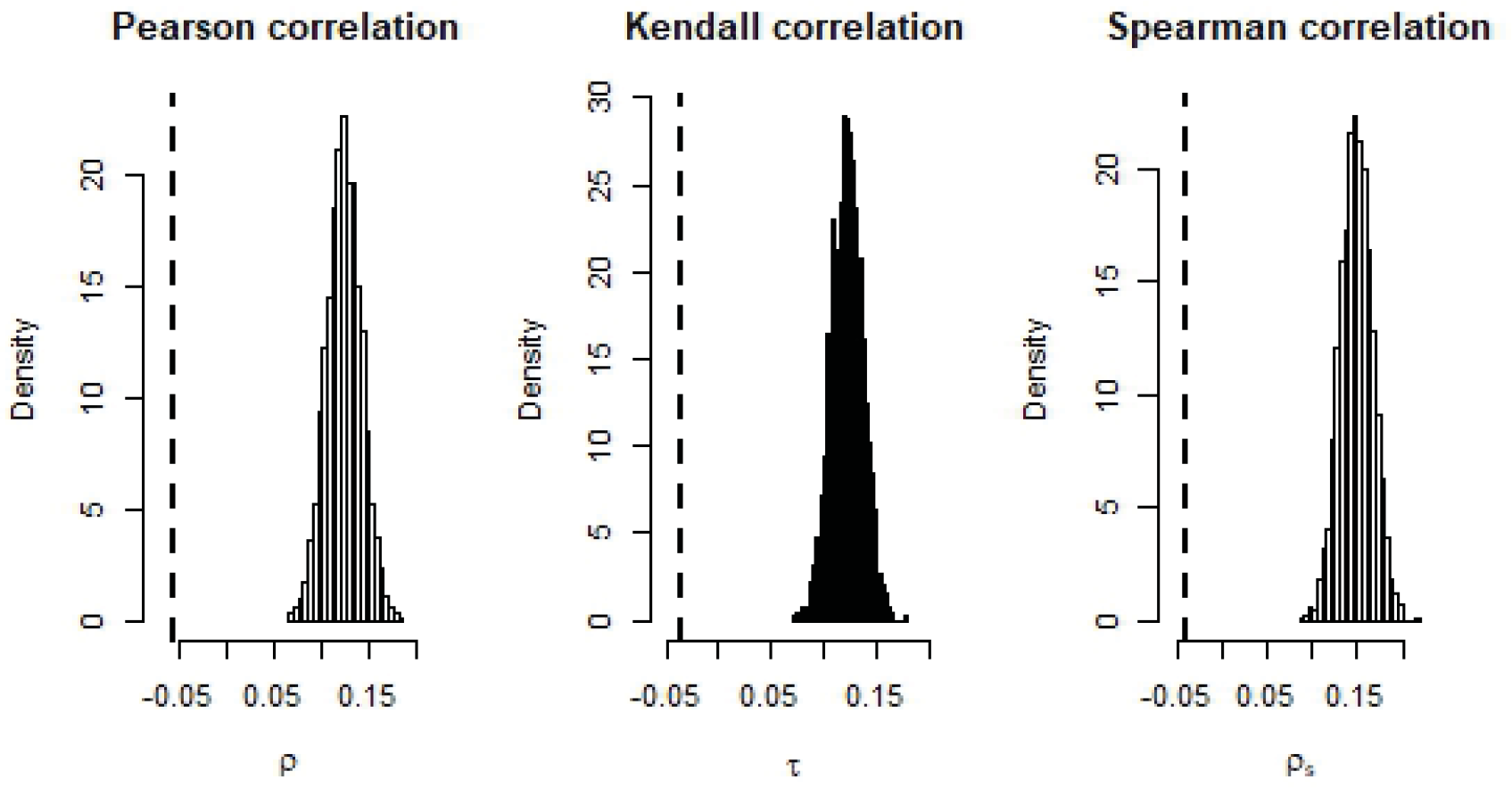
MCMC distribution for the Pearson correlation coefficient
, the Kendall correlation coefficient
and the Spearman correlation coefficient
between the replicated scores
and
for
for the EPL. The dashed black line denotes the observed correlations between the marginal distributions of the observed scores
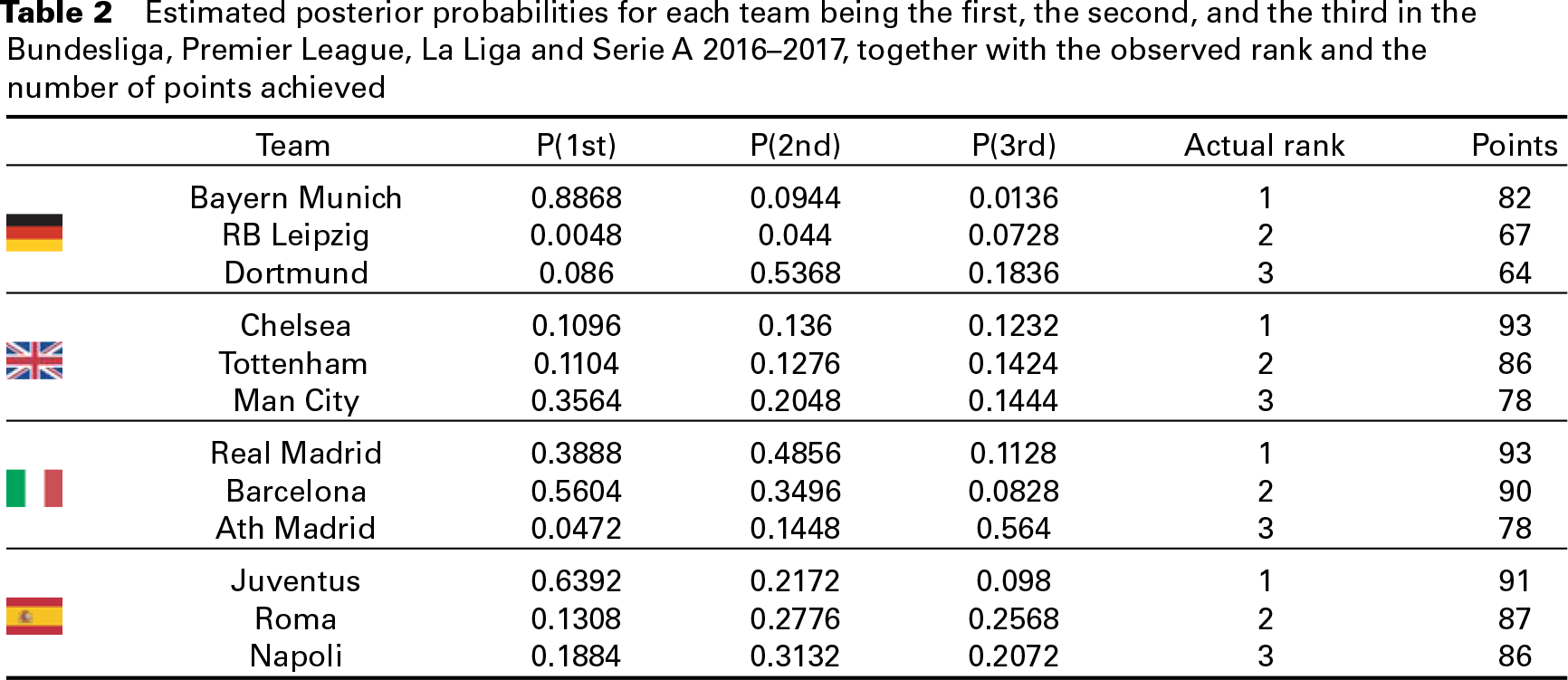
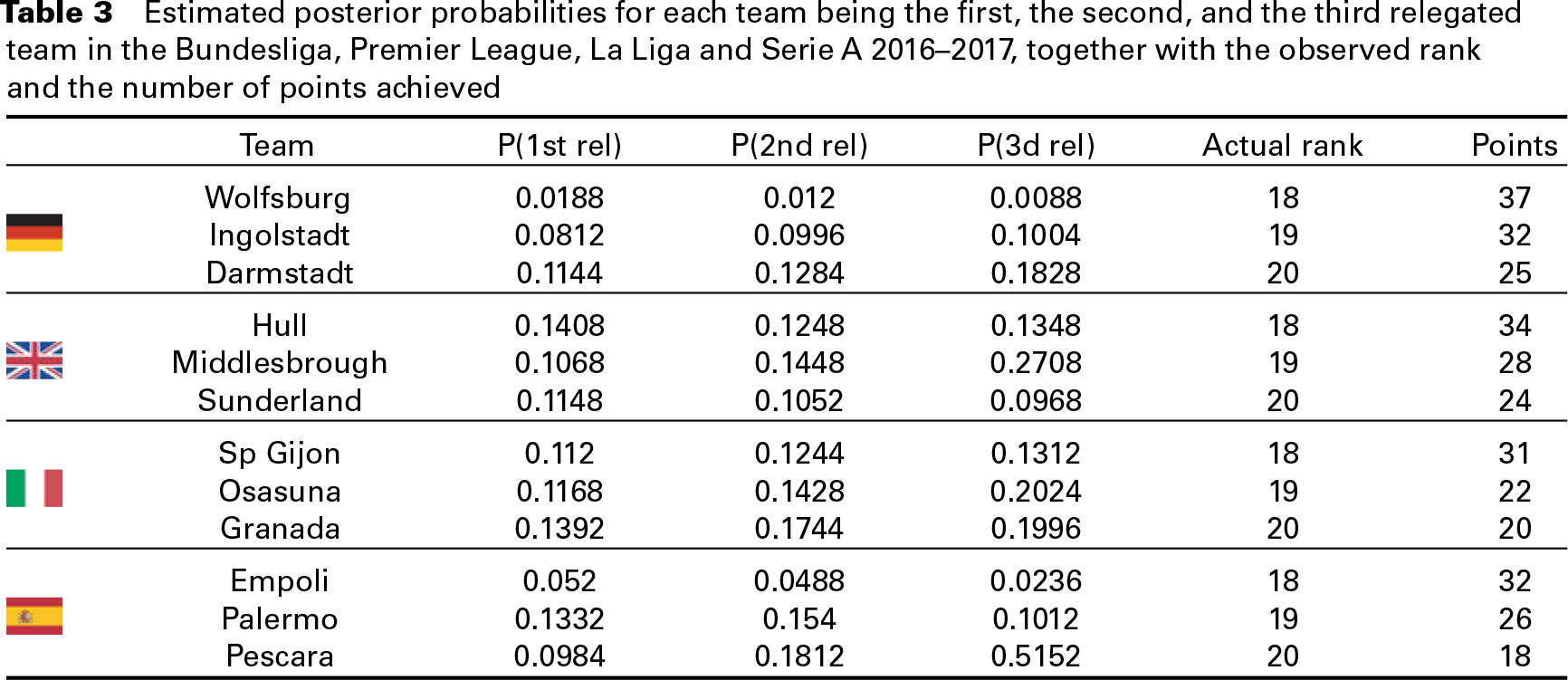
Tables 2 and 3 report the estimated posterior probabilities for each team being the first, the second, and the third; the first relegated, the second relegated, and the third relegated for each of the top four leagues, together with the observed rank and the achieved points, respectively. According to the fit of the previous seasons, Bayern Munich has an estimated probability 0.89 of winning the German league in 2016–2017, which it actually did; in Italy, Juventus has an high probability of being the first (0.64) as well. Conversely, Chelsea has a low associated probability to win the EPL (0.11), and this is mainly due to the bad results obtained by Chelsea in the previous season. Of course, the model does not account for the players’/managers’ transfer market occurring in the summer period. In July 2016, Chelsea hired Antonio Conte, one of the best European managers, who won the EPL on his first attempt. For the relegated teams, it is worth noting that Pescara in Serie A has high estimated probability to be the worst team of the Italian league (0.51). Globally, the model appears able to identify the teams with an associated high relegation's posterior probability.
Estimated posterior probabilities for each team being the first, the second, and the third in the Bundesliga, Premier League, La Liga and Serie A 2016–2017, together with the observed rank and the number of points achieved
Estimated posterior probabilities for each team being the first, the second, and the third relegated team in the Bundesliga, Premier League, La Liga and Serie A 2016–2017, together with the observed rank and the number of points achieved
Posterior predictive distribution of the possible results for the following matches: Eintracht Frankfurt-RB Leipzig, German Bundesliga 2016–2017; Hull-Middlesbrough, English Premier League 2016–2017; Real Madrid-Barcelona, Spanish La Liga 2016–2017; Sampdoria-Juventus, Italian Serie A 2016–2017. All the plots report the posterior uncertainty related to the exact predicted outcome. Darker regions are associated with higher posterior probabilities and red square corresponds to the observed result

Figure 7 provides posterior 50% credible bars (grey ribbons) for the predicted achieved points for each team in top four European leagues 2016–2017 at the end of their respective seasons, together with the observed final ranks. Displaying 50% credible bars results to be cleaner than 95% bars, and highlights the predictive power of the model in terms of 50% out-of-sample calibration. At a first glance, the four predicted posterior ranks appear to detect a pattern similar to the observed ones, with only a few exceptions. As may be noticed for Bundesliga (Panel (a)), Bayern Munich's prediction mirrors its actual strength in the 2016–2017 season, where as RB Leipzig performance was definitely underestimated by the model. Still, the model does not take into consideration the budget of each team, and the fact that RB Leipzig was one of the richest teams in the Bundesliga in 2016–2017. In the EPL (Panel (b)), Chelsea is underestimated by the model, where as Manchester City is the favourite team. The predicted pattern for the Spanish La Liga (Panel (c)) is extremely close to the one we observed, apart from the winner (our model favoured Barcelona, second in the observed rank). The worst teams (Sporting Gijon, Osasuna and Granada) are correctly predicted to be relegated. Also, for the Italian Serie A, the predicted ranks globally match the observed ranks. The outlier is represented by Atalanta, a team that performed incredibly well and qualified for the Europa League at the end of the last season. As a general comment, we may conclude that these plots show a good model calibration, since more or less half of the observed points fall in the posterior 50% credible bars.
In this section we provide a real betting experiment, assessing the performance of our model compared to the existing betting odds. In a betting strategy, two main questions arise: it is worth betting on a given single match? If so, how much is worth betting? In Section 2, we described two different procedures for inferring a vector of betting probabilities

where
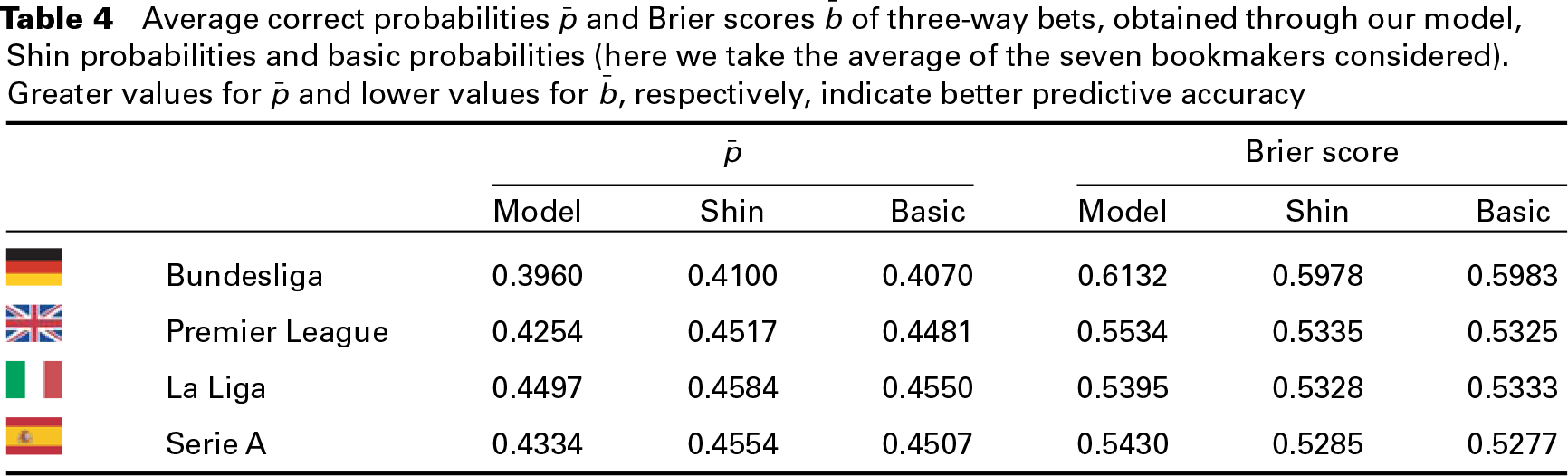
Average correct probabilities
and Brier scores
of three-way bets, obtained through our model, Shin probabilities and basic probabilities (here we take the average of the seven bookmakers considered). Greater values for
and lower values for
, respectively, indicate better predictive accuracy
Moreover, we may compute the Brier score (Brier, 1950), another index used for the predictive accuracy and previously used by Spiegelhalter and Ng (2009) for assessing football predictive accuracy:

The Brier score is a sort of mean squared error of the forecasts, ranging from 0 to 2. The lower is the Brier core, and the better is the model predictive accuracy. As reported in Table 4, our model is very close to the bookmakers’ probabilities (Shin's method and basic procedure) for what concerns both
Posterior 50% credible bars (grey ribbons) for the achieved final points of the top-four European leagues 2016–2017. Black dots are the observed points. Black lines are the posterior medians. At a first glance, the pattern of the predicted ranks appears to match the pattern of the observed ones, and the model calibration appears satisfying

According to the second definition, ‘beating the bookmaker’ means earning money by betting according to our model's probabilities. One could bet one unit on the three–way match outcome with the highest expected return (Strategy A), or place different amounts, basing each bet on the match's profit variability, as suggested in Rue and Salvesen (2000) (Strategy B). Denoted with 
The expected profits (percentages divided by 100) for our model and according to the bookmakers’ probabilities are reported in Figure 8 in terms of their mean
We have proposed a new hierarchical Bayesian Poisson model in which the rates are convex combinations of parameters accounting for two different sources of data: the bookmakers’ betting odds and the historical match results. We transformed the inverse betting odds into probabilities and we worked out the bookmakers’ scoring rates through the Skellam distribution. A wide graphical and numerical analysis for the top four European leagues has shown a good predictive accuracy for our model, and surprising results in terms of expected profits. These results confirm on one hand that the information contained in the betting odds is relevant in terms of football prediction; on the other hand that, combining this information with historical data allows for a natural extension of the existing models for football scores.
Further work should be done in order to include a parametric dependence in the proposed model.
Distribution of the expected profits (%/100)
, expressed in terms of mean
standard deviations for the seven bookmakers considered, for each of the top four European leagues

Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.