
Abstract
We propose an iterative algorithm to select the smoothing parameters in additive quantile regression, wherein the functional forms of the covariate effects are unspecified and expressed via B-spline bases with difference penalties on the spline coefficients. The proposed algorithm relies on viewing the penalized coefficients as random effects from the symmetric Laplace distribution, and it turns out to be very efficient and particularly attractive with multiple smooth terms. Through simulations we compare our proposal with some alternative approaches, including the traditional ones based on minimization of the Schwarz Information Criterion. A real-data analysis is presented to illustrate the method in practice.
Keywords
Introduction
Quantile regression (QR) is nowadays a well-established framework in observational studies when interest is in modelling the quantiles of the response variable as a function of one or more covariates (Austin et al., 2005; Li et al., 2010). Implementation of QR was first discussed by Koenker and Bassett (1978), and since then many tutorials and books have appeared in the literature, the most notable being the one by Koenker (2005). Some advantages of QR with respect to the more usual mean regression include robustness to possible outliers and influential observations, and the ability to provide a complete picture of the response conditional distribution, see Austin et al., (2005) and Waldmann (2018) for a gentle introduction and discussion.
The linear QR model belongs to the mainstream of statistical methodology now, and the availability of specialized software makes it as simple to use as the familiar mean regression model. See the quantreg package in R, the quantreg procedure in SAS and the qreg command in Stata, all of them focusing mainly on linear QR. However, when linearity is questionable, alternative and more flexible approaches should be considered. Nonparametric or flexible modelling in QR is crucial in data analysis with important and noteworthy applications in many fields, the most famous one being growth charts (Cole and Green, 1992; Wei et al., 2006; Li et al., 2010; Muggeo et al., 2013). Here the anthropometric variable of main interest, for example, weight or height, is regressed on age, and a flexible relationship has to be fitted to obtain ‘reference’ values; the ultimate goal could be to identify observations out of such reference intervals. Unfortunately, flexible modelling of nonlinear effects within QR appears to be somewhat limited, especially when multiple smooth, yet unspecified, relationships have to be included in the same regression equation. In this context, the gap with the corresponding counterparts for mean regression, such as the generalized additive models (Wood, 2006), is somewhat substantial. A possible reason limiting the widespread usage of additive QR is the lack of efficient algorithms able to fit additive QR with automatic choice of the smoothing parameters.
Nonparametric smoothing in QR has been discussed using different techniques, such as kernel (Xiang, 1996; Yu and Jones, 1998; Liu et al., 2019), smoothing splines from both a frequentist as well as Bayesian paradigm (Thompson et al., 2010) and low rank splines with or without penalty (Wei et al., 2006; He and Shi, 1994; Ng and Maechler, 2007). Unpenalized splines strongly depend on the number and the positions of knots, and therefore these are not recommended, especially when there exist regions in the covariate range with few observations. Penalized splines are effective to deal with such “unlucky” data configurations: Bosch et al. (1995) express the problem in terms of cubic smoothing splines with an associated quadratic penalty, Koenker et al. (1994) also use smoothing splines, but with a total variation penalty on the first derivative and Ng and Maechler (2007) use splines with
To the best of our knowledge there are some R packages implementing nonparametric QR. Without the presumption of being exhaustive, we cite some options. The well-known
The goal of this article is to set up an efficient algorithm to fit additive QR models with
The rest of the article is structured as follows. In Section 2, we briefly review the P-spline framework for smoothing in QR; in Section 3, we describe the proposed algorithm in detail; and in Section 4, we present results from some simulation experiments. Section 5 is devoted to the analysis of a real dataset, and finally Section 6 reports conclusions and some discussions.
P-spline quantile regression framework
Let

where
Denoting the response quantile in (2.1) by
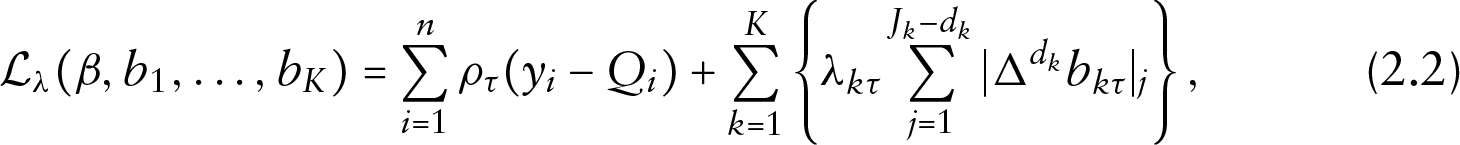
where
For fixed smoothing parameter, minimization of (2.2) is a relatively simple task since standard linear programming techniques may be used (He and Ng, 1999; Bollaerts et al., 2006; Koenker, 2011). Unfortunately, the smoothing parameter is not fixed in practice, and as briefly discussed in the Introduction, all of the current methods working with
To estimate the multiple lambda parameters of objective (2.2), we propose to use an iterative algorithm which is sometimes referred in literature as ‘Schall algorithm’. However, the approach was discussed by Fellner (1986) for robust estimation of linear mixed models based on equations of Harville (1977) and extended to generalized mixed models by Schall (1991). The algorithm has also been employed for expectile smoothing by Schnabel and Eilers (2009). The underlying idea of such ‘Harville–Fellner–Schall’ algorithm exploits the link between penalized smoothing methods and random effects models: The penalized coefficients are viewed as random effects having relevant variance parameters, see Currie and Durban (2002) and Wand (2003) for details. Viewing the penalized coefficients as random effects from a known distribution allows us to estimate the smoothing parameter as the ratio of the error variance divided by the variance of the ‘random effects’, namely of the penalized coefficients. We apply a similar idea to estimate the smoothing parameters in nonparametric QR via minimization of (2.2). We first outline the algorithm and then postpone discussion.
The proposed algorithm for additive QR (2.1) at fixed Fix a (small) value for all smoothing parameters Fit the QR (2.1) by minimizing the objective (2.2) at the fixed Compute Compute Set
Convergence in Step 5 is established throughout relative changes in the smoothing parameter values. Namely when the variation in absolute value between the current and the previous iteration of each
A theoretical justification of the iterative algorithm
Here we illustrate the rationale behind the proposed algorithm. For the sake of simplicity, we consider just one set of coefficients being penalized with a single tuning parameter
It is known that the objective function in QR may be obtained assuming an asymmetric Laplace (
Hence, given the aforementioned assumptions and
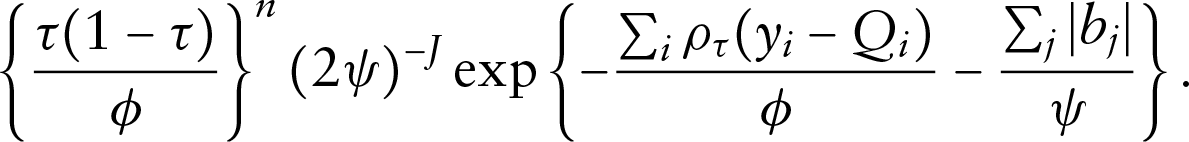
By using the simple re-parameterization

If
The partial derivatives of (3.1) are easily obtained
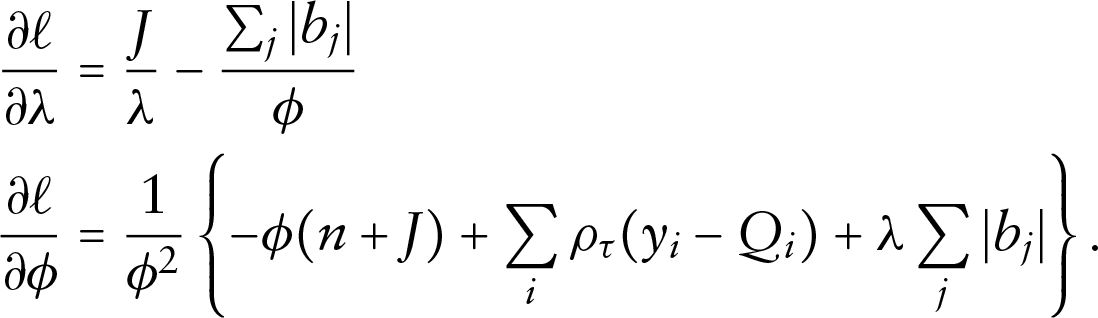
The root of
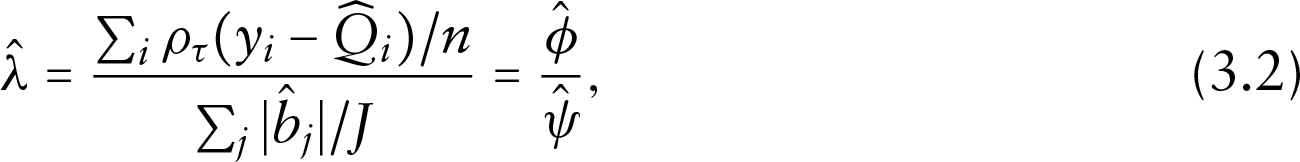
which justifies Step 4 in the aforementioned algorithm, apart from the denominators
As illustrated above, parameter estimation is justified via maximization of the joint likelihood depending on fixed and random, that is, penalized, parameters. Unlike Geraci and Bottai (2007), it should be stressed that no tentative to integrate out the random effects is carried out, and thus the objective to be optimized is the joint, rather than the marginal, likelihood. It is worth noting that in the usual mixed models framework, the variances ratio expression, that is, the counterpart of (3.2) for mean regressions, typically comes from the marginal likelihood maximization. However, as discussed by McCulloch (1997), it can be motivated under different likelihoods, including the marginal, penalized and joint likelihood of fixed and random parameters as taken in this article for smoothing QR.
The scale parameter estimate
As illustrated by (3.2) in the previous section,
The proposed algorithm straightforwardly applies to so-called varying coefficient models, that is, regression equations involving also interactions between a smooth and a linear term, such as
Quantifying the effective model dimension
The aforementioned algorithm in Step 3 requires to quantify the term-specific degrees of freedom
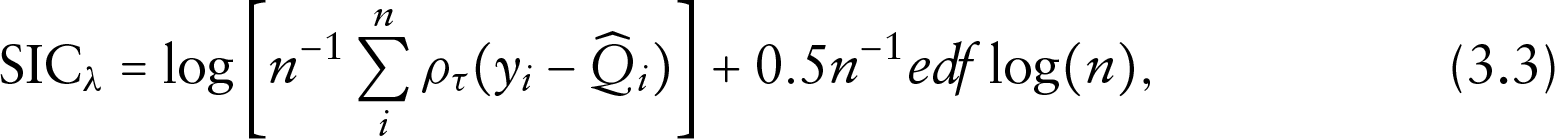
where only the total
The
The second viable approach relies on a smooth approximation of the
The least squares formulation allows to define the hat matrix whence the model degrees of freedom may be obtained. More specifically, the elements on the main diagonal of
We assess the performance of the proposed approach via some simulation experiments. We follow some settings employed in Koenker (2011), but we also consider additional scenarios. Data were generated according to
Some simulated data according to the signal curves and error distributions with constant scale function. The continuous line represents the true median signal
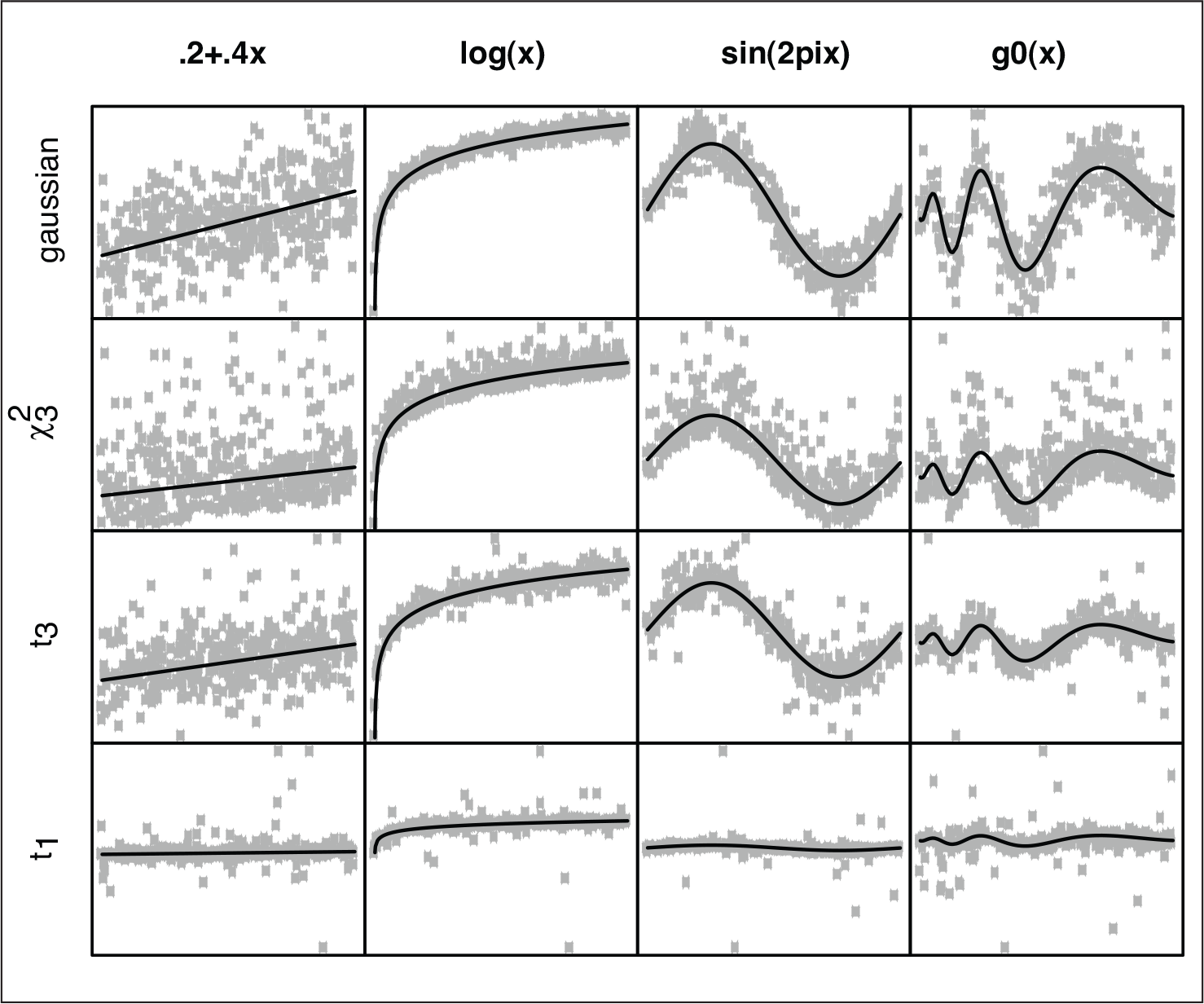
Some simulated data according to the signal curves and error distributions with constant scale function. The continuous line represents the true median signal
In the manuscript, we contrast three competitors: (a) the P-spline smoother (using
Constant scale function
. Contrasting three competitors for smoothing parameter selection in terms of MISE (on log scale) by different error distributions and signals: ‘sspline+sic ’ (light grey box), ‘pspline+sic ’ (medium grey box) and ‘pspline+hfs ’ (dark grey box)

Non-constant scale function
. Contrasting three competitors for smoothing parameter selection in terms of MISE (on log scale) by different error distributions and signals: ‘sspline+sic ’ (light grey box), ‘pspline+sic ’ (medium grey box) and ‘pspline+hfs ’ (dark grey box)
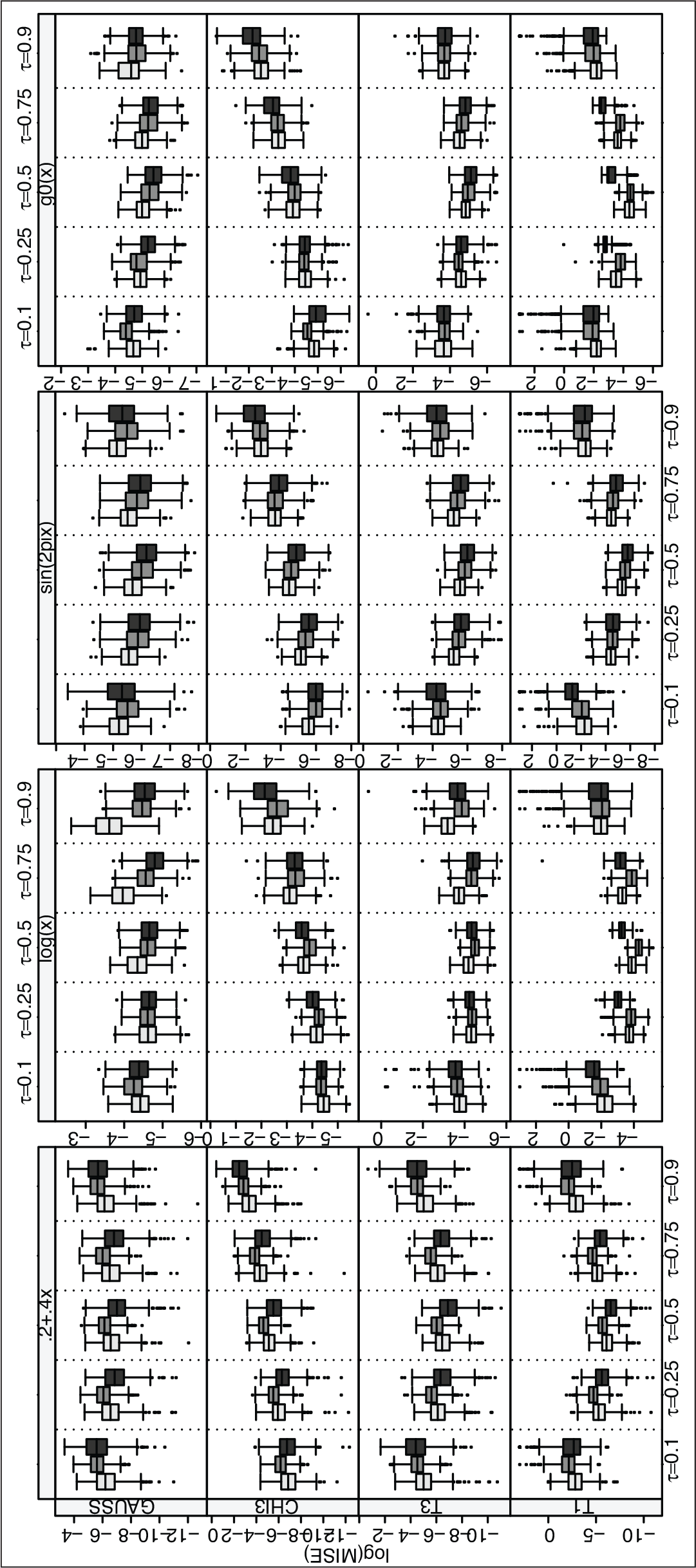
The three aforementioned main approaches are contrasted in terms of Mean Integrated Square Error (MISE) defined as the mean of squared differences between the true quantile curve and the corresponding fitted curve across 500 replicates, and also the Mean Integrated Absolute Error, similar to MISE but involving the absolute differences rather than the squares. Here we report results for the MISE values, while the MIAE results are reported in the Supplementary Material.
Figures 2 and 3 report the comparisons in terms of MISE: for all the error distributions considered and for every signal (linear, logarithmic, sinusoidal and sqrt+sinusoidal ‘
Overall, no important difference emerges across the scenarios. Occasionally, some criterion appears to perform slightly better/worse than the others: for instance, ‘sspline+
The same simulation scenarios were run with an additional linear covariate to assess possible impacts on the sampling distribution of the linear coefficient estimators. No difference was observed among the MISE values and the sampling distributions and results are not shown for shortness.
We consider the more interesting scenarios of additive models, namely more smooth relationships in the QR equation. To illustrate, we consider the true quantile function
Contrasting the three competitors (in terms of log(MISE)) for smoothing parameter selection with 2 additive terms by different error distributions and quantile curves: “sspline+sic ” (light grey box), “pspline+sic ” (medium grey box) and “pspline+hfs ” (dark grey box). Right panels: constant scale function; left panels: non-constant scale function. The true signal is
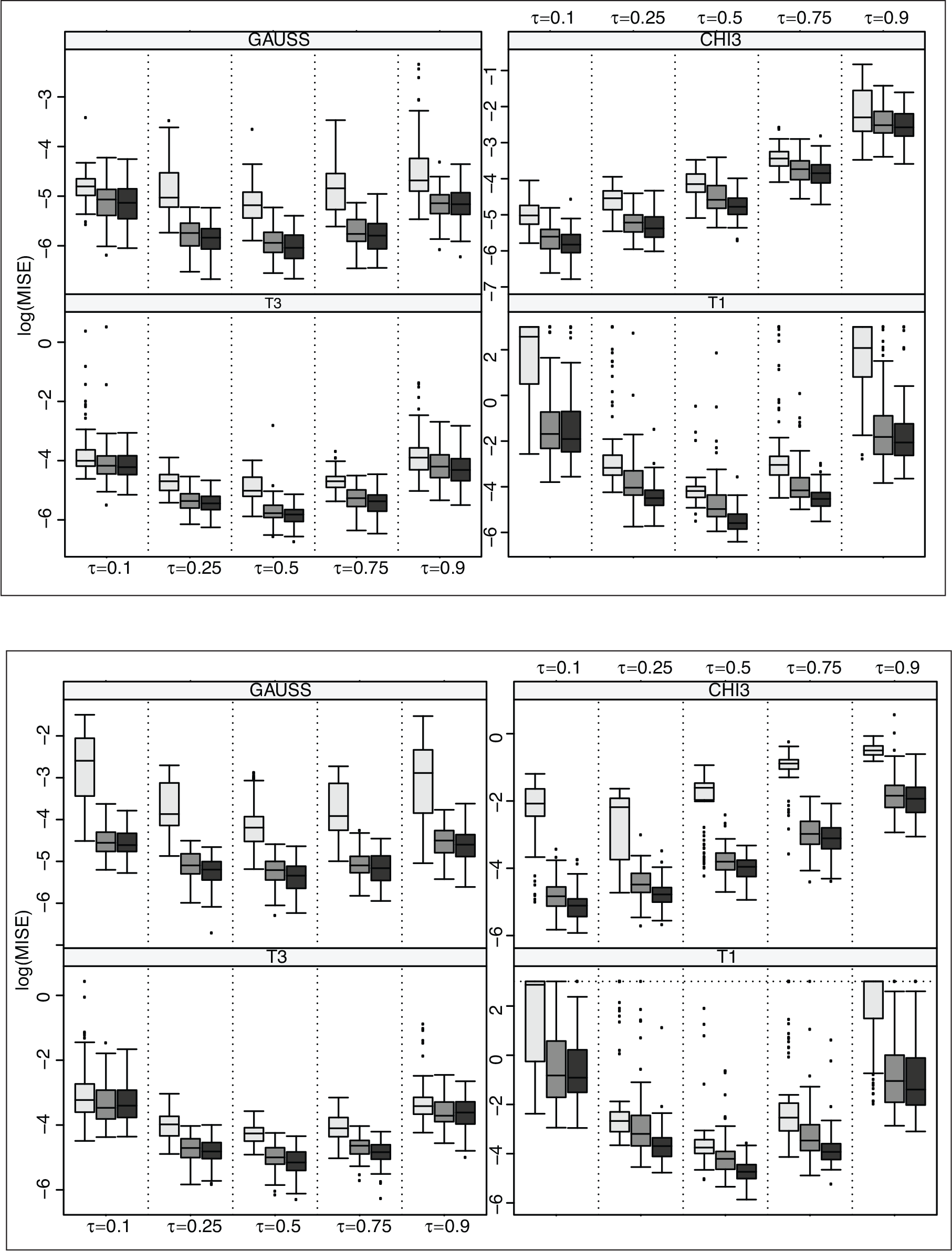
Unlike the single covariate case, here some differences are noteworthy. For the homoscedastic scenario, the traditional ‘sspline+
Differences in terms of MISE exhibit approximately the same patterns and are reported in the supplementary material which also shows comparisons relevant to smoothing parameter selection in varying coefficient models.
Computational times to fit additive quantile regresion with 1 or 2 smooth terms for
observations. Entries refer to averages (on 10 fits) of the elapsed components obtained via the system.time() function in R . Times also include building the B-spline basis and the penalty matrices. Computations run on R 3.6.1 on Windows, Intel i7-8700 CPU 3.20 GHz, RAM 16 GB.
Computational times to fit additive quantile regresion with 1 or 2 smooth terms for

To gain a rough assessment of the computational load, Table 1 reports the execution time of the aforementioned approaches when fitting additive regression quantiles with 1 or 2 smooth terms at
While for single smooth terms, all times are within reasonable ranges, differences get notable with 2 smooth terms: grid-searches show quite large times in general, but sspline+
For the sake of completeness, we mention the SIC criterion could be minimized via numerical procedures rather than grid-searches: For instance, by means of the Nelder–Mead algorithm which does not require gradient evaluation, or quasi-Newton methods which compute the gradient numerically. However, we have experienced a somewhat strong influence of the supplied starting values on the final results, making the numerical procedures substantially unreliable. One could try to run the algorithm using different starting values or probably to rely on different algorithms such as the simulated annealing, but at the cost of increasing the computational burden.
We apply the proposed algorithm to analyse data concerning the sport performance in children. Physical fitness is a powerful marker of the health condition in childhood and adolescence; for instance, fitness is negatively associated with cardiovascular risk factors for chronic disease, high blood pressure and total fatness (Kraemer and Häkkinen, 2008).
As an alternative to laboratory methods, physical fitness can be measured via the on-site fitness tests which are easy to be administered, especially when the population study involves schoolchildren. Among the different sport performance outcomes, the standing long jump (SLJ) test represents a widespread yet practical, time-efficient and cheap method for assessing the muscular fitness in children and adolescents. The schoolchildren stands at a line marked on the ground with the feet slightly apart and jumps: The SLJ performance is the horizontal distance jumped. SLJ, sometimes also known as standing broad jump, is commonly used to assess explosive leg power, but it is is also understood to be a proxy of muscular strength tests of the lower body. SLJ depends mainly on leg length, but it influenced also by neuromuscular maturation, as SLJ requires more coordination of movements and technique, for instance the so-called take-off angle (Saint-Maurice et al., 2015).
Data analysed here refer to wide survey carried out in years 2011–2013 to assess sport abilities and fitness in schoolchildren in Sicily. Data have been kindly provided by the Department of ‘Scienze Psicologiche, Pedagogiche e della Formazione’, University of Palermo. Measurements were gained by previously trained experts and include measurements on performance on several physical tests along with some anthropometric measurements collected in the major Sicilian cities in the three-year period. Here we present results relevant to
Beside the response SLJ, the main covariate is the child weight. The substantive research question is how the weight could affect the SLJ performance, namely in statistical terms the relationship SLJ—weight which is expected to be nonlinear. However, the weight is strongly correlated with age and height, which are understood to affect the response as well, possibly in a nonlinear manner. Thus, an additive QR accounting simultaneously for the three covariates flexibly appears to be the most appropriate model, namely

at fixed
We fit the additive QR model using the aforementioned algorithm; the smooth functions are expressed as identifiable cubic B-spline bases and the number of basis functions was set using the empirical rule of
Figure 5 portrays the fitted curves (centred due to identifiability constraints) along partial residuals, that is, the fitted quantile values plus the residuals from the full model. To quantify uncertainty, pointwise confidence intervals have been computed by means of the estimates covariance matrix based on bootstrap cases resampling.
The smooth effect of age, weight and height on the quantile curve
of standing long jump. In each panel, shaded areas portray the 95% pointwise confidence intervals based on bootstrap resampling and dots represent the partial residuals
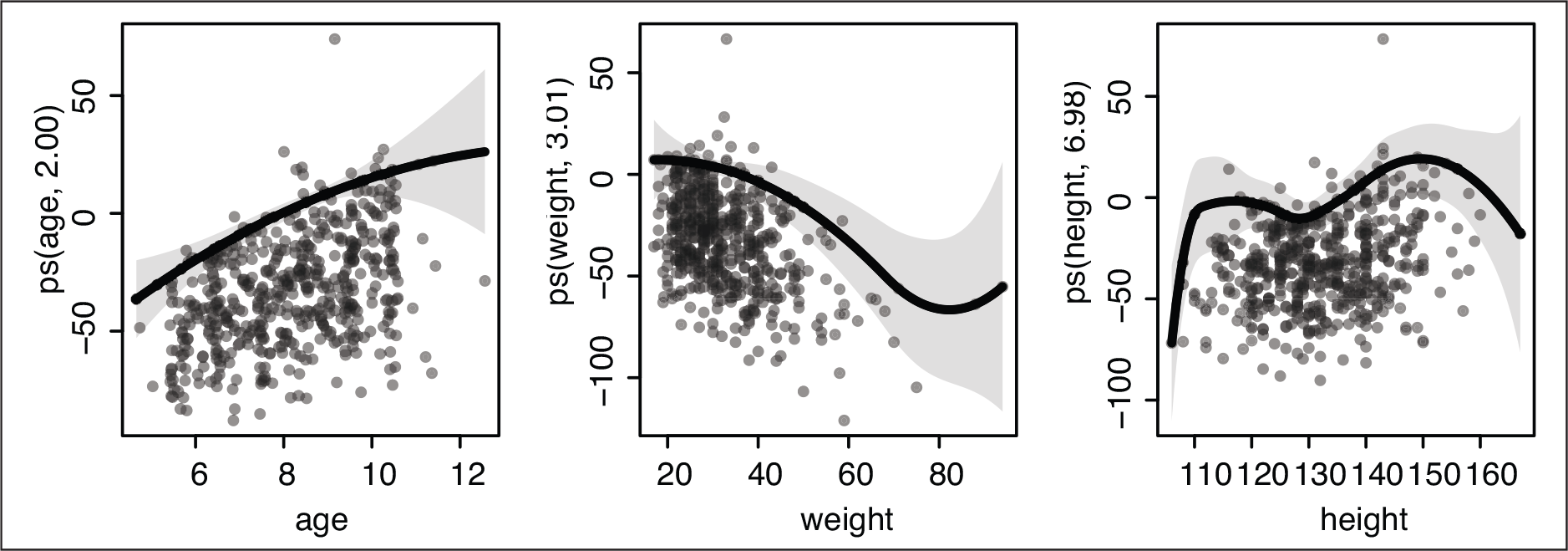
The smooth effect of age, weight and height on the quantile curve
of standing long jump. In each panel, shaded areas portray the 95% pointwise confidence intervals based on bootstrap resampling and dots represent the partial residuals
For the age term, the smoothing parameter estimate is quite large, and thus the relevant relationship with the response corresponds to a polynomial of degree 2; on the other hand, the estimated lambdas for the weight and height terms are moderate, resulting in flexible relationships with 3.01 and 6.98 degrees of freedom, respectively. Controlling for age and height, the weight effect on the SLJ is worth discussing: Until 35–40 kg, there is almost no influence on the performance, but afterwards there is an important negative effect untill about 75 kg when the relationship stabilizes. Finally, the height effect shows different phases, with steeper slopes at very low (
We have discussed estimation at single specified
We have proposed an iterative algorithm for selecting multiple smoothing parameters in additive QR models with
In addition to far better computational efficiency, simulation experiments have shown that most of the times our proposal exhibits good statistical performance as compared to the canonical approaches of smoothing splines or P-splines and tuning parameter selected by the Schwartz Information Criterion. The proposed approach returned slightly higher mean squared errors only in few scenarios at the lowest quantile (
We have focused on additive models, that is, multiple ‘univariate’ smooth terms, but generalization to bivariate smooths represents straightforward extensions where our proposal could apply. Modelling multiple quantile curves to produce growth charts for reference values can be carried out by applying the proposed algorithm at different probability values, namely with
Also, the presented algorithm could be employed in random effects QR for longitudinal data, where a few proposals have been discussed (Koenker, 2004; Geraci and Bottai, 2007; Lamarche, 2010): Comparisons with Geraci and Bottai (2007) which use explicit marginal Laplace log likelihood and Gibbs sampler appear particularly noteworthy.
Yet another possible extension of the proposed algorithm is about modelling quantiles from discrete distributions, for instance to study the student performance at university via the number of credits gained after the first academic year (Grilli et al., 2016): Here QR is applied several times at the randomly jittered response, and if the smoothing parameter has to be estimated at each perturbated dataset, the proposed approach appears quite useful due to computational efficiency.
R code to implement the methods presented in this article is currently available from the corresponding author and will be also shipped in due time with the R package
Supplementary materials
Supplementary materials for this article, including comparisons with other approaches along with further simulation results, R code and data discussed in Section 5, are available from
Footnotes
Acknowledgments
Data illustrated in Section 5 have been kindly provided by Professor M. Bellafiore, ‘Dipartimento di Scienze Psicologiche, Pedagogiche e della Formazione’ University of Palermo.We would like to thank the Editor Professor Arnošt Komárek, the Associate Editor and the referees for their suggestions and carefully reading of the manuscript which lead to a substantial improvement of the article.
Declaration of conflicting interests
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This research has been supported by the Italian Ministerial grant PRIN 2017 ‘From high school to job placement: Micro-data life course analysis of university student mobility and its impact on the Italian North-South divide.’, n. 2017HBTK5P.