
Abstract
This study proposes a security detection algorithm based on convolutional neural networks (CNNs) to enhance anomaly detection in API call sequences, addressing the challenges of capturing complex temporal relationships and nonlinear features in high-dimensional sparse API data. The proposed algorithm includes several preprocessing steps, such as deduplication to reduce redundancy, feature extraction using the TF-IDF (term frequency-inverse document frequency) algorithm, and logarithmic transformation to mitigate the impact of high-frequency APIs. An importance scoring mechanism is introduced to quantify the role of each API in anomaly detection. A customized TextCNN architecture is designed for API sequences, incorporating input layers, word embedding, multi-size convolution and pooling layers, attention layers, and fully connected layers. The attention layer is particularly applied to enhance the detection efficiency of evasion features. The model is trained using the Sigmoid activation function, CrossEntropyLoss loss function, and optimized via the Adam algorithm. The Softmax function is utilized to transform the feature vector into a probability distribution, with a threshold of 0.5 for anomaly detection. Clustering and auxiliary information are integrated to further improve classification accuracy and guide security strategy formulation. Experimental results demonstrate that the optimized TextCNN anomaly detection algorithm achieves an average accuracy of 95.88%, a recall rate of 91.23%, a false positive rate of 2.34%, and a false negative rate of 1.78%. These findings highlight the algorithm’s ability to enhance feature extraction accuracy, improve high-dimensional data processing, and provide an effective solution for real-time security monitoring, thus strengthening the security of the development environment.
Introduction
In today’s digital age, APIs play a pivotal role in connecting different software systems and web services.1,2 As cloud computing, mobile applications, and IoT (Internet of Things) technologies develop rapidly, API calls have become a vital means of data exchange and service interaction. Attackers may launch attacks by manipulating API calls, such as injecting malicious code, stealing sensitive information, or abusing service resources, posing a serious threat to enterprise and user security.3,4 However, traditional security detection methods, such as rule-based matching and traditional machine learning models, have many limitations when dealing with API call sequences. These approaches rely on predefined features and patterns, making it difficult to capture complex long-range dependencies. Meanwhile, in the face of high-dimensional and sparse API call data, their processing efficiency is not high; their response to new or unknown attacks is slow, and their accuracy is low. To address these issues, this study utilizes a CNN-based security detection algorithm to improve the anomaly detection effect in API call sequences. As a deep learning technology, CNN can automatically extract features, reduce manual intervention, and learn deeper data representations, thereby improving the learning ability and detection accuracy of complex patterns.5–7 This study explores the design of a CNN architecture suitable for the characteristics of API call sequences, including steps such as data preprocessing, feature extraction, model training, and anomaly detection. This study can not only enhance the detection capability of unknown attack patterns but also optimize the efficiency of high-dimensional data processing and provide a real-time security monitoring solution. This study provides developers with more reliable security guarantees and provides valuable references for exploring new security detection algorithms and technologies.
This study proposes a CNN-based security detection algorithm to address the inefficiency, slow response, and low accuracy of traditional security detection methods when processing high-dimensional, sparse API call data. The algorithm comprehensively optimizes the data preprocessing, feature extraction, model training, and anomaly detection processes by designing a CNN architecture suitable for API call sequences. Experimental results show that the CNN model performs well in multiple tests, with high accuracy and recall and low false positive rate. The high efficiency of the algorithm ensures real-time and scalability, providing a solution for real-time security monitoring, strengthens the security of the development environment, and proves its reliability and superior performance. The innovation of this study is that CNN is used for API call sequence anomaly detection for the first time; deep learning is used to automatically capture features; preprocessing steps are applied to improve the model’s effectiveness and stability; attention mechanism is added to improve the detection efficiency of malicious evasion samples.
This study aims to address several key challenges in the field of cybersecurity: (1) Traditional security detection methods struggle to handle high-dimensional data, especially when the data is sparse, as is often the case with API calls. By leveraging CNNs, which are particularly well-suited to extracting relevant features from such data, the study seeks to improve detection accuracy and reduce false positives, leading to more reliable security systems. (2) One of the primary goals of the algorithm is to enhance real-time detection capabilities in security monitoring. The high efficiency of the CNN model ensures that it can process and analyze large volumes of API call data swiftly, which is critical for timely detection and response to potential threats. (3) Through advanced preprocessing, feature extraction, model training, and anomaly detection techniques, this study seeks to enhance the overall performance of security detection systems. The addition of an attention mechanism is a particularly innovative step, improving the detection efficiency for malicious evasion attempts, which often go unnoticed by traditional methods.
The choice to use CNNs for anomaly detection in API call sequences reflects a growing trend in cybersecurity to employ deep learning models for complex, high-dimensional tasks. CNNs, known for their ability to capture spatial hierarchies in data, are well-suited for identifying patterns in sequential data such as API calls. This approach represents a significant departure from traditional security detection methods, which often rely on simpler statistical techniques or rule-based systems. The innovation of using deep learning to automatically extract features from raw data, without the need for extensive manual feature engineering, is a key contribution of this study.
Furthermore, the integration of an attention mechanism highlights an important aspect of this research: improving detection efficiency. In real-world scenarios, malicious actors often attempt to evade detection by disguising their behavior to appear normal. An attention mechanism allows the model to focus on the most relevant parts of the input data, thereby improving its ability to detect subtle signs of malicious activity and reducing the chances of false negatives.
Another objective discussed in the study is enhancing the stability and effectiveness of the model through preprocessing steps. These steps ensure that the raw API call data is cleaned and transformed into a format that maximizes the performance of the CNN model. By applying such preprocessing techniques, the study aims to demonstrate the importance of preparing data in ways that improve both the training process and the robustness of the detection system.
The research objectives are centered around the development of a more efficient, accurate, and real-time security detection system capable of handling high-dimensional API call data. The incorporation of deep learning techniques, such as CNNs and attention mechanisms, marks a significant advancement in the field of cybersecurity, addressing key challenges in anomaly detection and real-time threat monitoring. The successful implementation of these objectives could pave the way for more effective security systems that can detect sophisticated attacks in development environments with greater speed and accuracy.
Related works
API call sequence anomaly detection can identify and prevent potential security threats. By monitoring abnormal API calls, it can prevent malware and attacks, protect system security, improve the intelligence of security systems, and respond to network security challenges faster and more accurately.8,9 To address the issue of API call sequence anomaly detection, many scholars have proposed different solutions. In response to the security challenges of API in encryption, authentication, and anomaly detection, Kaul Deepak used artificial intelligence to achieve data-driven and real-time response, and built a deep anomaly detection system that discovered API traffic pattern deviations, helping to protect enterprise APIs from increasingly complex threats. 10 In response to the problem of low accuracy in detecting malicious program behavior in new power system edge applications, Li Nige proposed a detection model based on API call sequences, which combined rule matching and deep learning technology. Experimental results showed that the proposed detection model could effectively identify malicious samples and distinguish malicious program behaviors. 11 Zhang Jie analyzed malicious evasion samples and summarized a set of common malicious evasion sample functions. Combined with machine learning technology, he designed a new feature vector that could effectively avoid malicious evasion samples. The results showed that the detection accuracy of this method for malicious evasion samples exceeded 95%. 12 To improve the detection accuracy and efficiency of mobile terminals, Yao Ye proposed a mobile terminal malware detection method based on API call sequence. This method used API call sequence as a feature and adopted a series of feature preprocessing techniques to eliminate redundant processing of API call sequence. Experimental results showed that the detection accuracy of this method was high. 13 The research of the above scholars shows the cutting-edge application of artificial intelligence and machine learning in API call sequence anomaly detection. However, the research is mostly based on specific environments or data, with limited generalization ability and adaptation to new attack patterns, and the efficiency of processing high-dimensional sparse data needs to be improved. In practical applications, balancing false positives and detection rates is still a challenge.
CNN learns normal behavior patterns to identify abnormal activities and improve the accuracy of abnormal software detection or classification. It can process complex high-dimensional data, capture deep features, and effectively classify and warn unknown or complex attacks.14,15 To overcome the limitations of traditional methods, more and more scholars have applied CNN to malware detection or classification in order to improve detection accuracy. Shallow learning architectures in machine learning still have shortcomings in identifying complex malware. SL Shiva Darshan proposed a Windows malware detector based on CNN, which used the execution time behavior characteristics of portable executable files to detect and classify ambiguous malware. The proposed method was effective in discovering malware portable executable files through experiments, and its detection accuracy was extremely high. 16 To cope with the increasingly serious IoT (Internet of Things) security threats, Lin Qianguang proposed an algorithm based on CNN to classify IoT malware using API call sequences. The algorithm application execution was represented by a continuous API call sequence, and the data time series was analyzed and filtered based on improved information gain. The results showed that the algorithm had practical applicability in IoT malware classification, and had high accuracy and low computational overhead. 17 The research of scholars has shown the powerful performance of CNN in malware detection, which improves detection accuracy and classification effect and reduces computational cost. However, most of the methods are targeted at specific platforms or malware, and the generalization and cross-platform application are limited. The adaptability to new attacks needs to be verified. Although CNN is good at processing high-dimensional data, the problems of real-time performance and false positive rate still need to be solved.
Implementation of anomaly detection algorithm for API call sequence based on CNN
Data preprocessing and feature extraction
Data preprocessing
To evade detection, malicious code often inserts many repeated actions into normal behavior, resulting in multiple repeated APIs or API sequences in the sequence.18–20 This redundant information causes the obtained API sequence to be too long, which not only interferes with analysis but also hides the code and increase training time.21,22 To address this problem, this article deduplicates the API call sequence to reduce its complexity, thereby obtaining an API call sequence that is more in line with actual applications.
For functions with the same function but different names in the API, the strategy of removing the suffix is adopted. When processing the API sequence in the sample, the API with different function names but the same function is first processed, and then the continuous repeated API or API sequence segments are removed to achieve the purpose of deduplication.
This article counts the number of APIs before and after deduplication for 10647 samples. The statistical results before and after deduplication are shown in Figure 1. Statistics of sample numbers before and after deduplication. (a) Before deduplication. (b) After deduplication.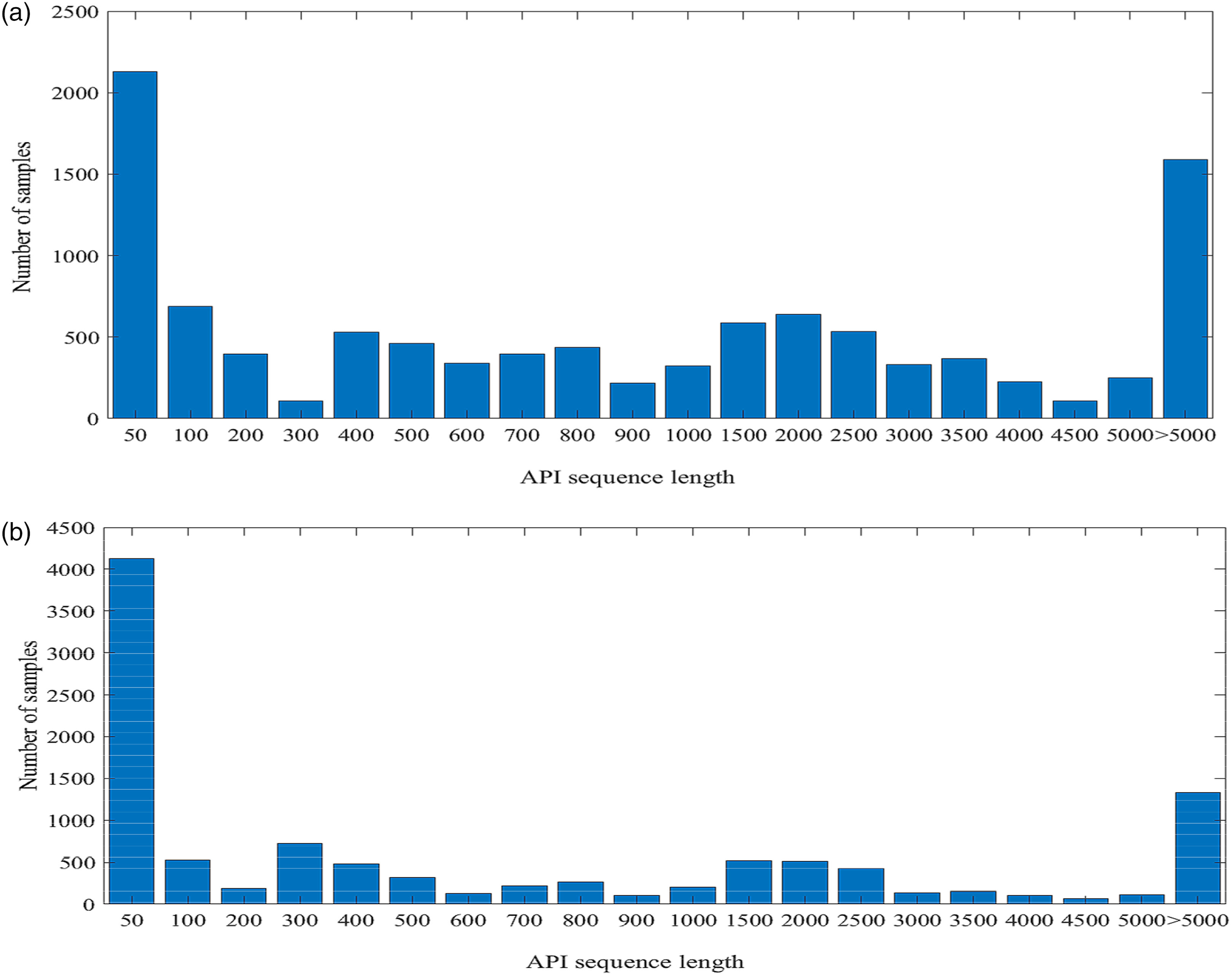
As shown in Figure 1(a) and (b), most samples are concentrated in the lower number of calls. However, after deduplication, the number of samples under each number of calls has changed. The number of samples with 300 calls increases from 108 to 723, while the number of samples with more than 5000 calls decreases from 1587 to 1335, showing the effectiveness of deduplication. This deduplication not only reduces the amount of data and improves the efficiency of computing resources, but also reduces the interference of repeated patterns on model training and improves the accuracy of anomaly detection. At the same time, the distribution of samples after deduplication is more uniform, which helps CNN better learn the features of API sequences of different lengths and enhance its generalization ability. From the above statistical analysis, it can be seen that deduplication can effectively reduce the length of the API, thereby improving the efficiency of subsequent analysis.
Feature extraction
Because machine learning algorithms cannot directly learn the sequence characteristics of functions from APIs, they must be converted into mathematical forms that can be learned. This article performs a uniform lowercase conversion on the API call sequence and uses the TF-IDF algorithm to extract features from the API call sequence.
TF-IDF is a statistical method for evaluating the importance of words to documents, combining word frequency and inverse document frequency.23–25 TF-IDF can identify representative words for a specific document and has been used for feature extraction in malicious code detection, especially in API call sequence analysis to find the key APIs that distinguish normal from malicious programs.26,27 However, this method has limitations, focusing mainly on the frequency of a single API and ignoring the timing and context information of the call sequence. Although TF-IDF is still useful in simple text feature extraction, in complex tasks such as malicious code detection, it has gradually been replaced by methods such as Word2Vec and deep learning that can better understand data structure and context to improve detection accuracy and robustness. 28
Assuming that a sequence set S of API calls contains malicious evasion samples and ordinary malicious samples, the sequence set contains M API call sequences. The TF-IDF algorithm first deduplicates the API names in the API call sequence to obtain a dictionary containing the API names. The dictionary is used to convert them into M-dimensional vectors, where each dimension is the number of times the API name appears in the API call sequence, and the word length matrix is normalized using the inverse document frequency. The TF-IDF formula can be expressed as:


The TF-IDF algorithm multiplies the word frequency in the text by the inverse document frequency to obtain the inverse vector on each dimension. In this way, through TF-IDF, a set of datasets that can be used to learn and describe machine learning algorithms can be obtained.
Feature engineering
This article uses TF-IDF to extract feature vectors from API call sequences. Although this vector contains global information of API calls, some general information cannot distinguish malicious escape samples well. To eliminate this general information disturbance, it is necessary to filter the API call information related to the technology and with identification ability, so as to find anomalies in the API call sequence. However, when measuring the importance of API functions, the TF-IDF method only uses the number of times the API appears as a feature vector. Such a linear relationship cannot well reflect the importance of API functions. This article optimizes the calculation of API function feature values in word frequency processing, highlights the characteristics of typical abnormal APIs, and constructs and implements an API call sequence anomaly detection algorithm combined with CNN.
In the word frequency optimization process, a specific API can be called tens of thousands of times, while others are only a few or even none. From the word frequency matrix, it can be seen that the API is cited up to 12000 times, but its importance is not more than 12000 times that of other APIs. Formula (3) is used in this article to process the number of API calls. The formula is as follows:

By logarithmic transformation, the impact of frequent calls on the API can be reduced, making the API call characteristics more balanced. In practical applications, the frequent calls of certain API functions have a great impact on the detection of abnormal API call sequences. By optimizing the number of API calls, the number of calls is made more uniform. The data distribution before and after the optimization of the number of API calls is shown in Figure 2: Data distribution before and after optimization of API call times (a) Data distribution before optimization of API call times.(b) Data distribution after optimization of API call times.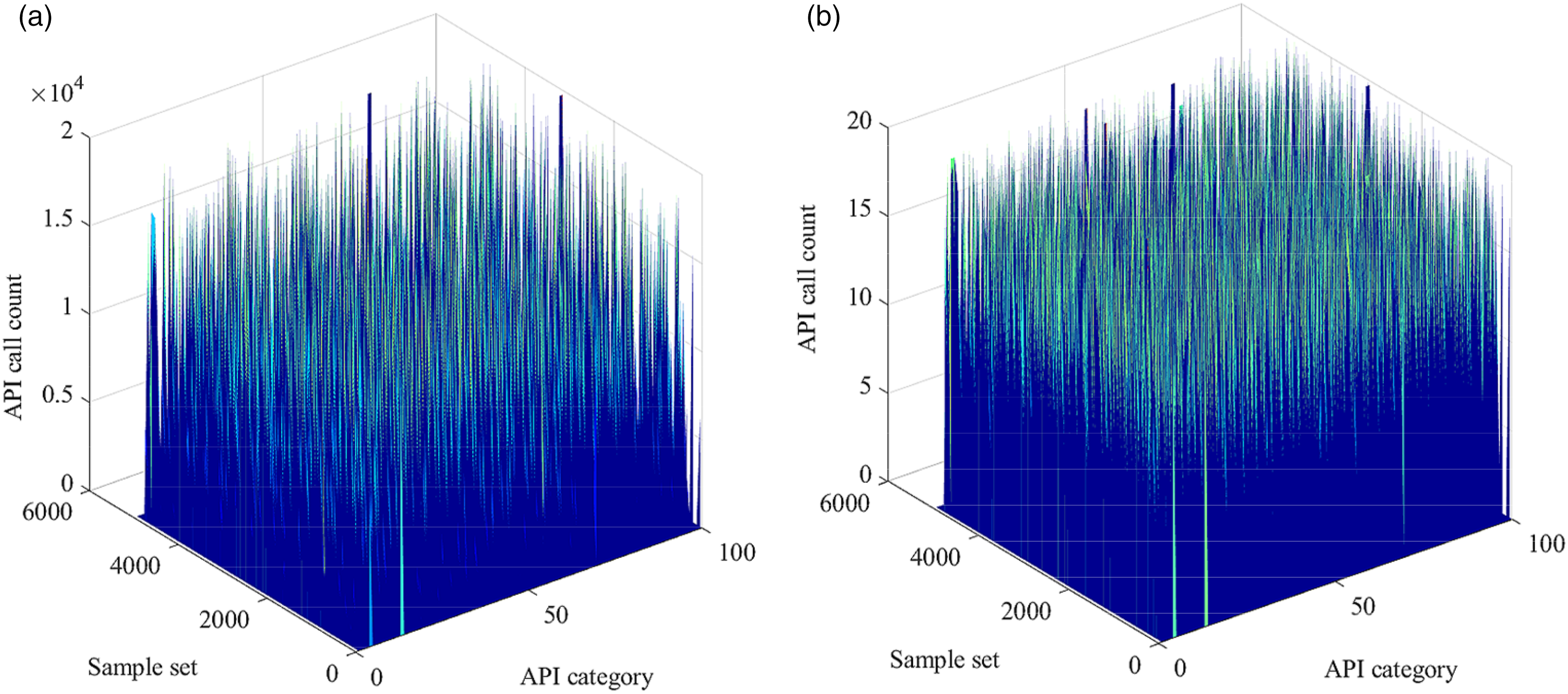
Figure 2 compares the distribution of API call times before and after optimization. Figure 2(a) shows that the API call times before optimization are unevenly distributed, and some API calls are abnormally frequent, interfering with malicious sample detection. In Figure 2(b), after logarithmic transformation and data remapping, the API call times are compressed to 0–20 times; the data distribution becomes uniform; the visualization effect is better. After optimization, the extreme values in the data disappear, and the call differences between samples and APIs are smoothed, providing a more stable foundation for subsequent analysis and feature extraction. This optimization method significantly improves the quality of data processing and helps to improve the accuracy of malicious sample detection.
API call abnormal sequence function.

Among the 14 abnormal sequence functions, different API functions play different roles in determining whether a sample is an abnormal sample. To quantify the role of different API functions in determining abnormal samples, this article proposes a weight calculation method based on the importance scoring mechanism. First, the API set closely related to abnormal behavior is identified through statistical analysis, and then the feature selection algorithm is used to evaluate its distinguishing ability. Then, the machine learning model is trained, and the generated feature importance score is used as the initial weight. Combined with the sensitivity of convolutional neural networks to local patterns, the weight is further adjusted to reflect the context and location information of the API sequence. Finally, the weight is optimized through cross-validation, so that the model can accurately capture the evasion characteristics of malware, thereby improving the detection effect. The algorithm can finely characterize the characteristics of different types of evasion behavior and accurately calculate their weights, thereby significantly improving the model’s detection efficiency for malicious evasion samples.
The function weight set is obtained through algorithm operation, and then the ratio of normal and malicious evasion samples in the evasion API function is calculated. If the difference between the two is large, the weight of this API function should be increased. On this basis, the Pearson correlation coefficient is used to establish the relevant Formula (4) to measure the difference in the evasion API functions between samples. The formula is:
After the above process, different weights can be assigned to API functions according to their importance. On this basis, a CNN-based API call sequence anomaly detection algorithm is studied. The algorithm successfully achieves accurate detection of malicious samples and provides strong support for improving network security protection capabilities.
CNN model architecture design
Detection model framework
The core of anomaly detection is to identify API sequence features that can distinguish normal programs from malicious codes.29–31 These API call sequences reveal the behavior and logic taken by malicious codes to achieve destructive purposes, and there is a temporal relationship between API functions. This article previously uses the TF-IDF algorithm to extract features, but this method fails to capture the similarity and connection between malicious code contexts. To this end, the Word2vec technology32,33 is applied to convert API sequence features into vector form. This method uses the spatial distance between word vectors to characterize the semantic relationship between APIs. Compared with traditional machine learning methods, deep learning methods are more efficient. They only need to input processed data into the neural network to achieve automatic feature extraction, which greatly simplifies the feature processing process and has better performance. To this end, this article uses CNN to automatically extract API sequences. The entire detection model process includes four stages, as shown in Figure 3. CNN-based API call sequence anomaly detection.
In the data preprocessing part, by extracting the API sequence, deduplication is performed on it, and effective information of the API call is extracted. On this basis, Word2vec is used to realize vectorized expression, so that the information can be transformed into a form that can be processed by the neural network. Word2vec can not only use spatial distance to measure the dependency between APIs, but also generate a one-dimensional fixed dense matrix compared with one-hot encoding, which greatly saves memory. 34 When building the model, TextCNN is selected for text classification. The network uses convolution kernels of different sizes to extract features and cooperates with the pooling layer to reduce the dimension. To enhance the model’s performance, a custom attention layer is specially applied to increase the weight of key features. At the same time, the dropout strategy is used to prevent overfitting.35,36 After training, the model is saved for subsequent prediction.
TextCNN model
This article uses CNN to extract the features of the API sequence and optimizes the network structure on this basis. The optimized TextCNN model includes input layer, word embedding layer, convolution and pooling layer, attention layer, and full connection and output layer, which improves the efficiency of TextCNN in feature extraction and classification. The optimized TextCNN model is shown in Figure 4. Optimized TextCNN model structure.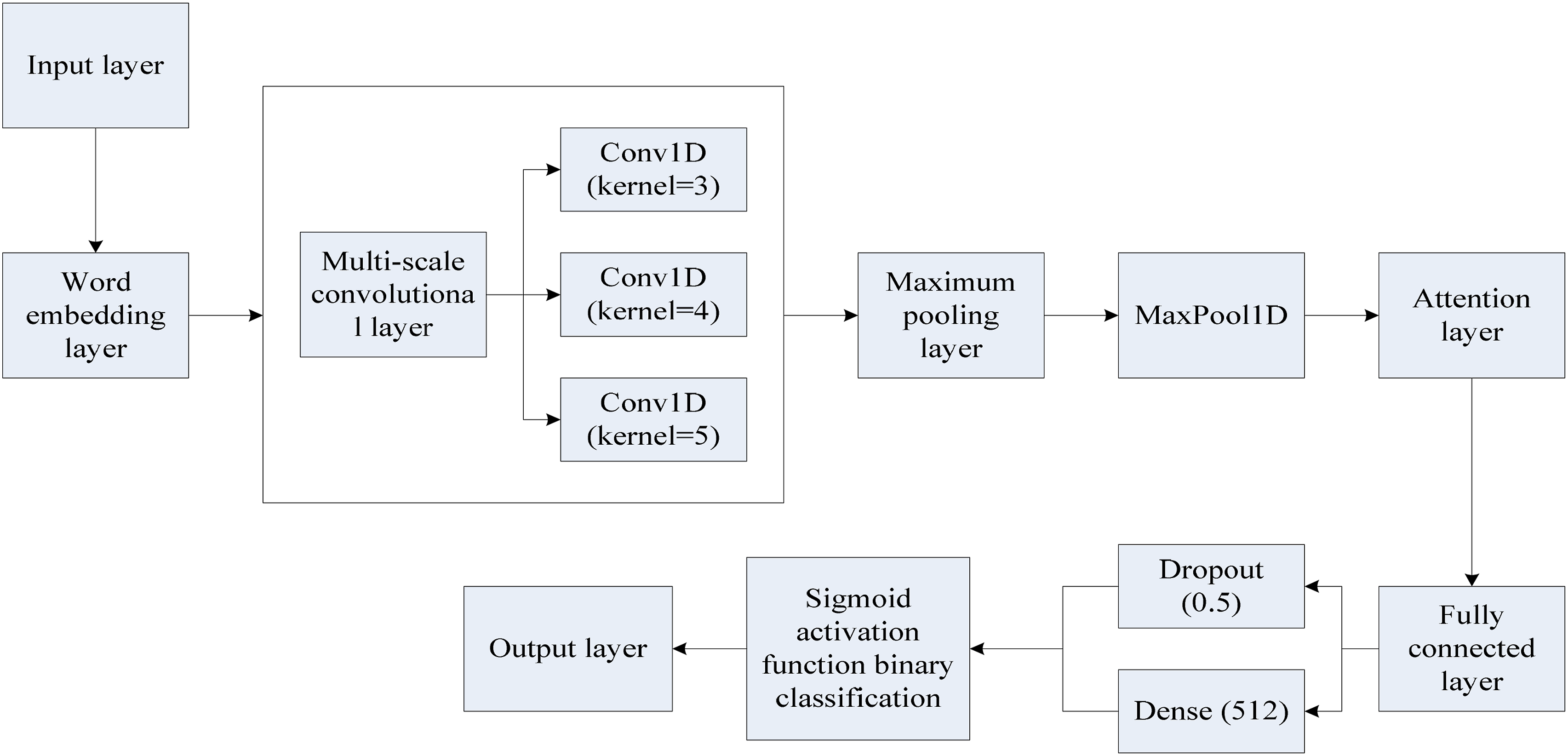
Based on Figure 4, this article uses the API sequence after deduplication preprocessing as the training set and uses the Word2vec model to train the word vector. In the word vector vector space, the expression of each sampling point is converted into a two-dimensional matrix, and the multi-layer neural network is used to realize the feature extraction of the API sequence.
The key issue of the application of TextCNN in time series analysis is to use convolution kernels to express time series information. In view of the fact that single-length convolutional neural networks are prone to lose certain features, this article uses a TextCNN model with multi-scale convolution kernels to extract features from multiple angles and obtain more complete features. This study finds that the convolution kernel size of TextCNN is between 1 and 10, so ReLU is used as the activation function. The convolution data after each convolution is reduced in dimension through the TextCNN algorithm, and the concatenate function is used to fuse multiple convolution layers and pooling.
In CNN, the role of each convolution filter is to capture the local characteristics of the overall region. 37 Considering that different attributes contribute differently to sample classification, this article applies the attention layer into the underlying convolutional neural network and assigns corresponding weights to each feature. The determination of attention weights includes two key steps: the first step is to obtain the distribution of attention based on the input data; secondly, a specific attention value is obtained by weighted average of the attention distribution. In this article, the perceptron function is used to measure the correlation between words, and different attention levels are assigned to each feature based on this, thereby improving the network’s ability to recognize key features and optimizing the classification effect.
This article uses the Keras architecture and defines an attention class, which mainly relies on four parts. The first is the init function, which is used to initialize the required parameters; the second is the build function, which determines the shape of other variables by the shape of the input; the next is the call function, which is the center of the attention mechanism. In the call function, after a series of complex vector operations, the attention value of the input information is finally calculated; the last function is the compute_output_shape function, which calculates the size of the output. In the implementation of the call function, the perceptron function is first used to calculate the weight of each word in the input information. Then, the softmax function is used to normalize the score results to ensure that the sum of all attribute weights is 1. Finally, the final attention value is calculated by the weighted sum of each weight. By continuously training the input data, the attention mechanism can automatically adjust the weight value so that the features with strong category distinction ability get a larger weight, thereby improving the model’s classification performance.
The fully connected layer plays an important role in the neural network. It can have one or more layers, which is equivalent to transforming the feature space. Through the combination of weight matrices, the fully connected layer can reintegrate local features obtained from the convolutional layer, etc.
The application of activation function improves the model’s nonlinear expression ability, and the network can learn more complex patterns. In this article, a two-layer fully connected layer structure is used. The first layer consists of 512 neurons, and the training unit uses ReLU as the activation function to improve the nonlinearity of the neural network; in the second layer, two neurons are configured, and the sigmoid activation function is used to effectively distinguish normal samples from malicious samples. The dropout strategy is used to enhance the model’s anti-fitting ability. During training, according to a certain probability, a part of the neurons are randomly discarded to ensure that each training is performed by a different network structure.
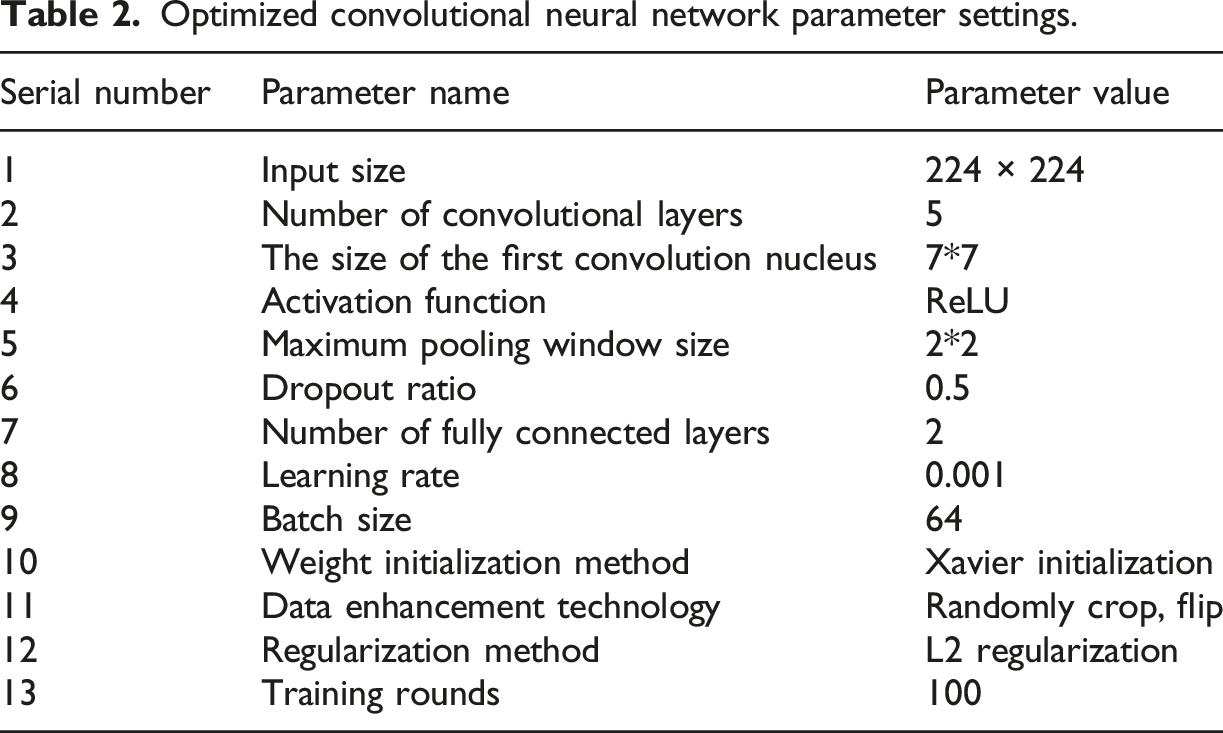
Optimized convolutional neural network parameter settings.
Model training and optimization
The optimized convolutional neural network anomaly detection model uses the Sigmoid activation function and the CrossEntropyLoss loss function. The Sigmoid function is continuous, smooth, and easy to differentiate. It can map real numbers in the range of (0, 1) and is often used in secondary classification.
38
The Sigmoid function can effectively increase the features representing abnormal API call sequences while reducing the gain of non-abnormal API call sequences. Therefore, it has significant advantages in mapping the features of abnormal API call sequences. Under the premise of not knowing whether it is an abnormal API call sequence, it can push the features representing the abnormal API call sequence to the middle and the atypical features to both sides, thereby learning the characteristics of the abnormal API call sequence more precisely. The calculation of the Sigmoid function is shown in Formulas (5) and (6). Among them, Formula (6) is the derivative of Formula (5).

The Sigmoid activation function enhances the model’s complexity and improves the ability to learn from complex data by outputting nonlinear mapping. This function can effectively map the features of malicious code to a new feature space through linear transformation, so that the model can more deeply explore the characteristics of malicious code, thereby improving the accuracy of the optimized CNN model in API call sequence anomaly detection. The loss function used in this article is CrossEntropyLoss, which has the advantage of being only proportional to the difference between the model output and the true value. In Formula (7), c represents the model’s output vector, and class represents the real label data.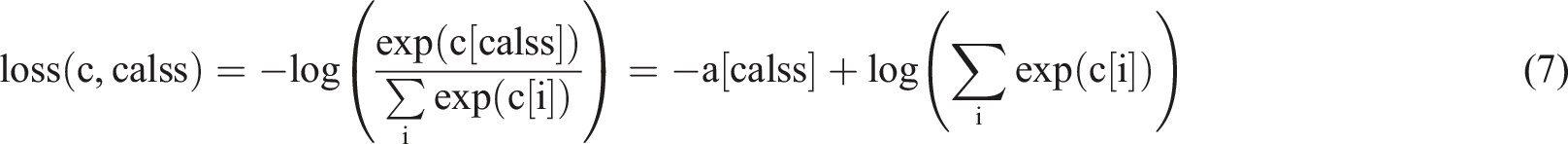
The parameters in the CNN model are optimized with the help of an optimizer to further improve the learning ability of the model as well as the model’s performance to achieve better recognition results. To improve the model’s accuracy, this article selects Adam to optimize the model parameters. The Adam optimization algorithm combines the sparse gradient of the adaptive gradient algorithm with the RMSProp (root mean square propagation) algorithm suitable for non-steady-state conditions and online situations, and has significant advantages in large-scale data optimization. 39
Anomaly detection and classification
Anomaly detection
Anomaly judgment is the core link in the security detection of API call sequences. Its accuracy plays a crucial role in ensuring the safe and stable operation of the entire system. When using CNN for API call sequence anomaly detection, this article uses the softmax function to perform anomaly judgment, and the formula can be expressed as:
The softmax function plays a crucial role in neural networks. It performs exponential operations on the output values of each node and further normalizes them to generate a distribution representing the probability of each category. This probability distribution actually reveals the possibility that the input feature vector belongs to each category. The softmax function has a significant feature that it has the ability to transform any real number vector into a complete probability distribution, and the sum of all probability values in the distribution is always equal to 1. By carefully comparing these probability values, it is possible to precisely determine whether the API call sequence is abnormal. The realization of this judgment process depends entirely on the fine processing of the feature vector by the softmax function. The softmax function can keenly output completely different probability distributions based on the slight differences in the feature vectors, thus providing a basis for accurate judgment of abnormal behavior.
To precisely determine whether the API call sequence is abnormal, it is crucial to set an appropriate abnormal threshold. The determination of this threshold is based on the model training results and actual needs. In the output of the softmax function, high probability values usually indicate the category to which the input feature vector belongs. However, in anomaly detection, this article focuses more on the probability of abnormal categories. This article chooses to regard the category with the lowest probability as an anomaly; then, a threshold of 0.5 is set to define whether the API call sequence is abnormal. When the probability of the abnormal category of the API call sequence exceeds this threshold, it is judged as abnormal behavior; otherwise, it is considered normal.
Classification processing
In the security detection of API call sequences, the softmax function is used to identify abnormal sequences that deviate from the normal pattern. Once the softmax function detects an anomaly, the system responds immediately and records the abnormal details such as API sequence, time, and IP, into the security log for subsequent analysis; then, the security team is quickly notified by email, SMS (short message service), etc., to ensure timely response; finally, after confirming the threat, the system automatically or manually blocks the anomaly after confirmation to prevent the damage from expanding. However, these are only preliminary measures. To more comprehensively evaluate the threat and deploy targeted strategies, fine-grained classification of anomalies and revealing the attack type or pattern behind them are the key to subsequent work.
This article adopts a combination of cluster analysis and auxiliary information to improve the accuracy of abnormal behavior classification. Cluster analysis can classify abnormal behaviors into different categories based on the similarity of API call sequences, which helps to discover new abnormal patterns or attack types. This article selects the K-means algorithm for clustering. At the same time, it combines network traffic, system logs and other security information to provide a more comprehensive context of abnormal behavior and accurately determine its type and intention. By combining cluster analysis with auxiliary information, the characteristics and patterns of abnormal behaviors are better understood, and targeted security strategies can be formulated. Moreover, as data and models are updated, this method can be continuously optimized to improve the accuracy and timeliness of classification.
Anomaly detection performance evaluation
Experimental design
To evaluate the performance of the optimized TextCNN anomaly detection algorithm proposed in this study, two datasets were utilized: Dataset 1, sourced from the Alibaba Cloud Security Malicious Program Detection Competition, contains approximately 90 million API call records, while Dataset 2 is publicly available on Kaggle. Following data cleaning, deduplication, and standardization procedures, the preprocessed datasets were divided into 20 separate test case groups.
To comprehensively assess the algorithm’s effectiveness, several evaluation metrics were chosen, including accuracy, recall, false positive rate, false negative rate, and operational efficiency. For comparison purposes, two baseline algorithms—Isolation Forest and LOF (Local Outlier Factor)—were selected. The Isolation Forest algorithm, based on random forests, detects anomalies by constructing isolated trees, offering high efficiency without the need for labeled data. On the other hand, LOF is a density-based anomaly detection method that identifies outliers by evaluating the local density of data points, making it particularly sensitive to local anomalies.
Experimental results
Accuracy and recall
In the anomaly detection of API call sequences, accuracy and recall are important indicators for evaluating the model’s quality. Accuracy reflects the accuracy of the model’s prediction, while recall reflects the model’s ability to find all truly abnormal cases. Considering the two together, the quality and reliability of the model can be more comprehensively evaluated. Testing these two indicators can more accurately evaluate the system’s ability to detect malicious behavior, which is conducive to better reducing false positives and false negatives, making the system’s security protection more powerful. This article first tests the accuracy of the three algorithms on 10 test cases. The results are shown in Figure 5: Accuracy results.
According to the display of Figure 5, the average accuracy of the algorithm in this article reaches 95.88% in all 20 test cases; the average accuracy of the Isolation Forest and LOF algorithms in 20 test cases is 88.84% and 83.53%, respectively. The algorithm in this article is significantly higher than the other two comparison methods. Specifically, in the first test case, the accuracy of this algorithm is 96.71%, while the accuracy of Isolation Forest and LOF algorithms are 87.91% and 84.31%, respectively. In the 10th test case, the accuracy of this algorithm is 95.78%, while the accuracy of Isolation Forest and LOF algorithms are 89.22% and 85.26%, respectively. In the 20th test case, the accuracy of this algorithm is 96.45%, while the accuracy of Isolation Forest and LOF algorithms are 90.70% and 83.18%, respectively. This series of data not only confirms that the improved algorithm based on CNN has higher classification accuracy in detecting API call sequence anomalies, but also highlights its ability to effectively identify potential malicious behaviors.
Recall rate results.

Table 3 shows that compared with Isolation Forest and LOF, the algorithm proposed in this article has a significant advantage in recall rate. In the first test case, the recall rate of the algorithm proposed in this article is as high as 90.88%, far exceeding the 85.51% of the Isolation Forest algorithm and the 75.18% of the LOF algorithm. This trend remains consistent in subsequent test cases. In the 10th test case, the recall rate of the algorithm proposed in this article is 93.67%, while the Isolation Forest and LOF algorithms are 85.76% and 77.78%, respectively; in the 20th case, the recall rate of the algorithm proposed in this article is 90.13%, while the Isolation Forest and LOF algorithms are 83.49% and 80.72%, respectively, which once again proves its superiority. Overall, the average recall rate of the algorithm proposed in this article is 91.23%, while the average recall rates of the Isolation Forest and LOF algorithms are 84.76% and 77.96%, respectively. The comprehensive data show that the improved algorithm based on CNN not only improves the accuracy of malicious behavior detection, but also effectively reduces false positives and false negatives, thereby greatly enhancing the system’s security protection capability. Therefore, this study confirms that compared with the traditional Isolation Forest and LOF algorithms, the performance of the CNN-based API call sequence anomaly detection method is significantly improved, laying a solid foundation for future optimization.
False positive rate
The false positive rate affects system reliability and user experience. Too high a false positive rate causes legitimate API calls to be mislabeled as abnormal, causing dissatisfaction and inconvenience in operation, and increasing the burden on the security team. The results are shown in Figure 6: False positive rate test results.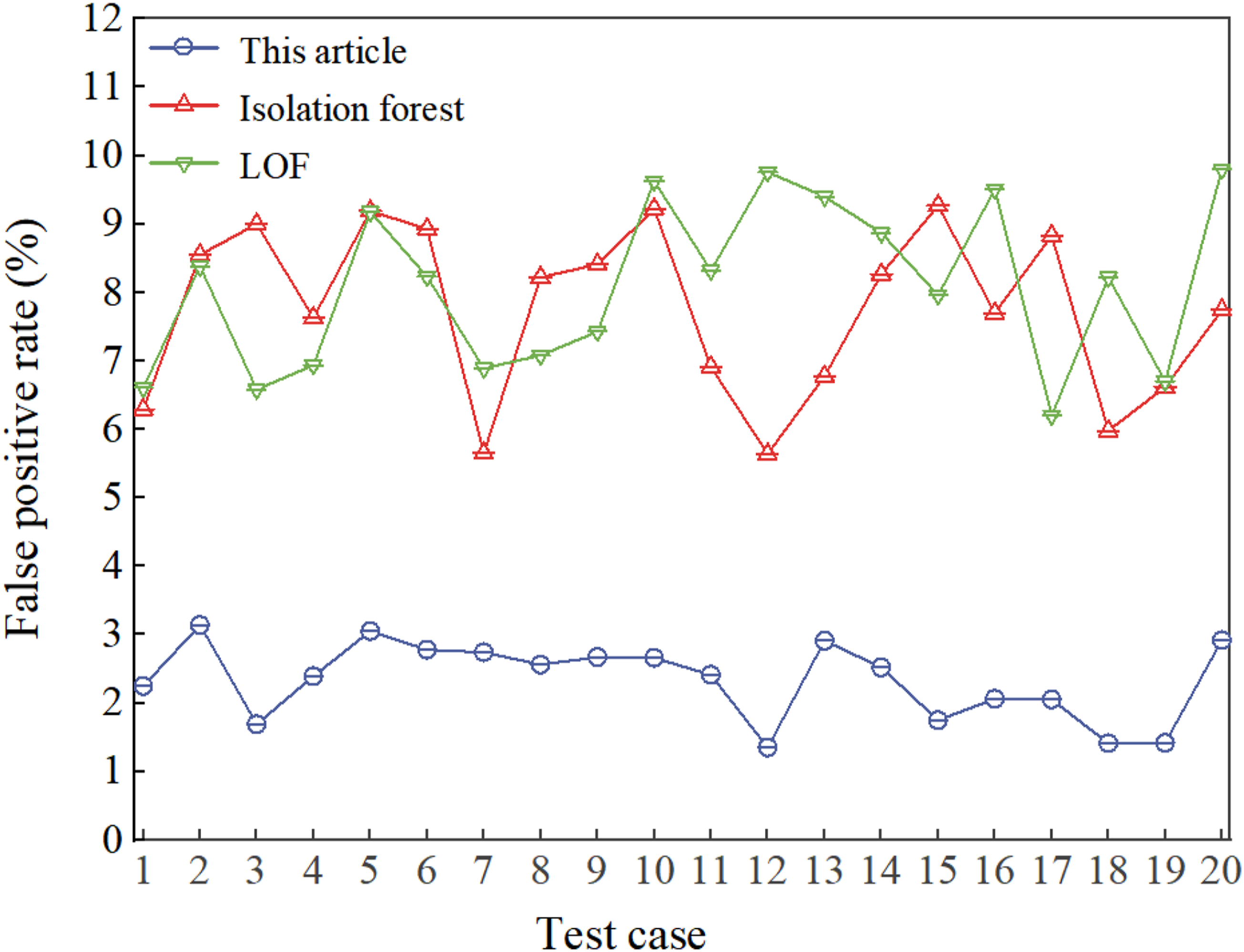
Figure 6 shows that the false positive rate of the algorithm in the test case is significantly lower than that of Isolation Forest and LOF. In the first test case, the false positive rate of the algorithm in this article is only 2.25%, while the other two algorithms are 6.29% and 6.61%, respectively. By the 10th test case, the false positive rate of the algorithm in this article is 2.66%, while the other two algorithms are 9.22% and 9.63%, respectively, which is much lower than the other algorithms. By the 20th test case, the false positive rate of the algorithm in this article is only 2.92%, while the other two algorithms are 7.74% and 9.80%, respectively. These data prove the effectiveness and superiority of the algorithm in processing complex API call sequences. Overall, for 20 test cases, the average false positive rate of the algorithm in this article is 2.34%, and the average false positive rates of the other two algorithms are 7.74% and 8.08%, respectively. The security detection algorithm based on CNN improvement has excellent performance in false positive rate, can more precisely identify anomalies, reduce interference with normal operations, and improve system performance.
False negative rate
The false negative rate is a key indicator to measure whether the system can effectively identify security threats, which directly affects system security. Reducing the false negative rate is extremely important for ensuring system security and preventing malicious activities, and is also the key to improving the reliability of the detection algorithm. In addition to the false negative rate, specificity is also an important indicator to measure its false negative rate. High specificity means that the model can more accurately identify normal cases, reduce false positives, and thus improve the accuracy of anomaly detection. The test results of the false negative rate and specificity of the three different algorithms are shown in Figure 7: False negative rate test results. (a) False negative rate results. (b) Specificity results.
By comparing Figure 7(a) and (b), it can be clearly seen that the false negative rate of the improved CNN-based algorithm proposed in this article is significantly lower than that of the other two algorithms in 20 test cases. The false negative rate of the algorithm in this article is between 1.10% and 2.43%, and its average false negative rate is 1.78%; the specificity is between 90.82% and 95.20%, and the average specificity is 93.14%. The false negative rate of the Isolation Forest algorithm is between 6.46% and 10.11%, and its average false negative rate is 8.25%; the specificity is between 83.23% and 88.22%, and the average specificity is 85.63%. The false negative rate of the LOF algorithm is between 6.79% and 11.31%, and its average false negative rate is 9.15%; the specificity is between 77.22% and 84.93%, and the average specificity is 81.28%. These data prove the effectiveness and superiority of the algorithm in this article when processing complex API call sequences, which is of great significance for improving network security protection capabilities. Overall, the security detection algorithm based on CNN improvement performs well in reducing false negative rate and improving specificity, can precisely identify anomalies, reduce interference with normal operations, and improve system performance. This improvement is crucial to enhancing network security protection and provides a reference for future research. Continuous optimization is expected to detect anomalies more intelligently and efficiently.
Operation efficiency
Operation efficiency is crucial to system response and resource utilization. Efficient algorithms can quickly process large amounts of API data, ensure real-time and scalability, and are critical to dealing with complex security threats. For a comprehensive evaluation, this article uses two indicators, average processing time and number of calls processed per second, for testing. The results are shown in Figure 8: Operation efficiency results. (a) Average processing time results. (b) Number of calls processed per second.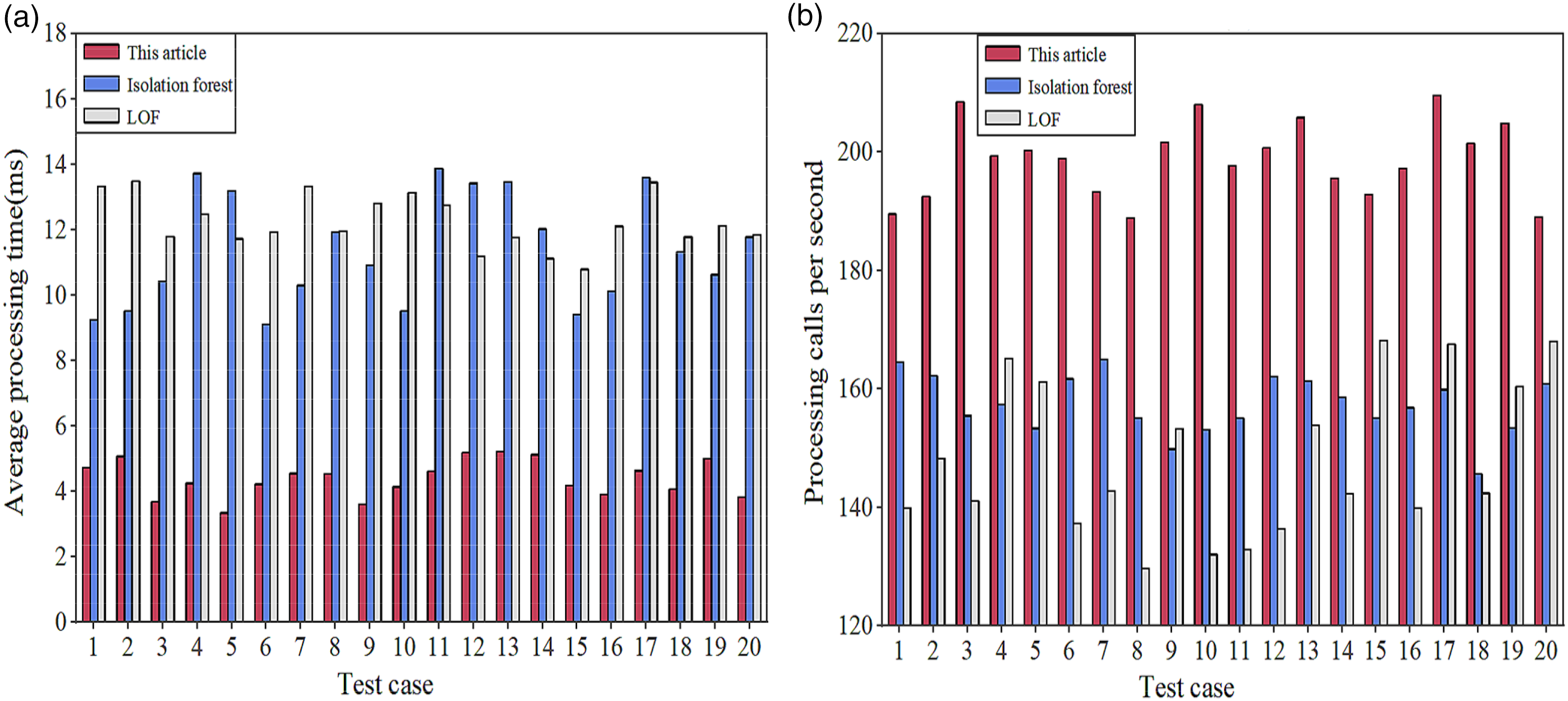
As shown in Figure 8(a) and (b), the performance of the proposed algorithm in 20 test cases is significantly better than the other two comparison algorithms. In the first test case, the average processing time of the proposed algorithm is only 4.72 milliseconds, and it can process 189.51 calls per second; the Isolation Forest and LOF algorithms require 9.25 milliseconds and 13.33 milliseconds, respectively, and the number of calls processed per second is 164.56 and 139.91, respectively. This advantage is maintained in multiple test cases. In the 10th and 20th test cases, the average processing time of the proposed algorithm is 4.14 and 3.83 milliseconds, and the number of processing calls per second is 208.02 and 188.97 times, respectively; the average processing time of the Isolation Forest algorithm is 9.52 and 11.78 milliseconds, and the number of processing calls per second is 153.10 and 160.84 times, respectively; the average processing time of the LOF algorithm is 13.14 and 11.85 milliseconds, and the number of processing calls per second is 132.04 and 168.00 times, respectively. The data shows that the improved algorithm based on CNN not only has a fast processing speed, but also has a significantly higher number of processing calls per second. Overall, the overall average processing time and number of processing calls per second for the 20 test cases of the algorithm in this article are 4.39 milliseconds and 198.76 times, respectively; the overall average processing time and number of processing calls per second of the Isolation Forest algorithm are 11.37 milliseconds and 157.30 times, respectively; the overall average processing time and number of processing calls per second of the LOF algorithm are 12.24 milliseconds and 148.10 times, respectively. This shows that the algorithm can quickly process a large amount of API call data while ensuring high detection accuracy, and has excellent real-time and scalability. In practical applications, this means that it can reduce operating costs and enhance the system’s feasibility and competitiveness.
Conclusions
This article designs a CNN algorithm to detect anomalies in API call sequences to improve the system’s recognition ability and detection accuracy for unknown attack patterns. The results show that the CNN model is significantly better than the Isolation Forest and LOF algorithms in multiple tests. It performs well in terms of accuracy and recall, while maintaining a low false positive rate. In addition, the efficient operation of the algorithm also ensures real-time and scalability. These results show that the improved CNN model not only improves the learning ability and feature extraction accuracy of complex patterns, but also optimizes the efficiency of high-dimensional data processing, providing an effective solution for real-time security monitoring, and further enhancing the security of the development environment. In addition to the optimization of the algorithm itself, this study also performs preprocessing steps such as deduplication, feature extraction, and word frequency processing on the API call sequence, which further improves the model’s effectiveness and stability. However, current research still focuses on API call sequences in specific environments, and the model’s generalization ability and cross-platform application need to be improved. At the same time, the adaptability to new attack patterns and the balance between false positive rate and detection rate are also important directions that need to be paid attention to and studied in the future.
This study introduces a CNN-based algorithm for anomaly detection in API call sequences, aiming to enhance the system’s recognition capabilities and detection accuracy for previously unseen attack patterns. The experimental results demonstrate that the proposed CNN model outperforms both Isolation Forest and LOF algorithms across multiple tests, excelling in accuracy and recall while maintaining a low false positive rate. Moreover, the algorithm’s high operational efficiency ensures both real-time performance and scalability, making it a viable solution for real-time security monitoring and further strengthening the security of the development environment.
In addition to optimizing the core algorithm, this study also incorporated preprocessing techniques, such as deduplication, feature extraction, and word frequency processing, to improve the model’s stability and overall performance. Despite these advancements, the current research remains limited to analyzing API call sequences within specific environments, highlighting the need for further exploration into the model’s generalization capability and its applicability across diverse platforms.
Future research should focus on enhancing the model’s adaptability to new, evolving attack patterns and exploring methods to balance false positive rates with detection accuracy more effectively. Additionally, expanding the generalization ability of the model to handle a wider variety of data environments and attack scenarios will be critical for ensuring the robustness and versatility of the security detection system in real-world applications. Another promising direction involves investigating transfer learning or multi-platform integration techniques to improve the model’s performance in diverse contexts. Furthermore, addressing the scalability of the model to handle even larger datasets and ensuring its computational efficiency at scale could provide significant benefits for large-scale security monitoring systems.
Statements and declarations
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.