
Abstract
As the most valuable area in the telecommunications industry, wireless communication has shown great potential for development in the 21st century. With the massive popularity of smartphones and 5G technology, how to create a high-quality wireless communication transmission network gradually becomes a key problem that needs to be broken through urgently at present. The study proposes a corresponding greedy reinforcement learning algorithm based on the establishment of an interference-resistant wireless communication model, which performs direct retention of high-value actions as a way to avoid extensive network computation. The results show that the algorithm achieves a fitness value of 99.1 and converges to 99.9 at about 19 iterations in the handwritten digital image set. It indicates the algorithm has a fast convergence speed in incorporating the dual network structure and empirical recovery, which can effectively enhance the learning efficiency of the anti-interference of wireless communication system and provide a new reference method for the development of anti-interference technology of wireless communication.
Introduction
As the boost of communication technology, wireless communication (WC) is being used more and more in various fields and the communication space is facing a more complex electromagnetic environment. A stable and secure environment in the frequency band of WC is always the goal sought after by technical experts, as various environmental interferences or malicious man-made attacks are always constantly affecting normal communication. 1 The result is that more and more research is focused on anti-jamming technologies for WC. Among the current anti-jamming techniques, the overall can be divided into three types: time domain, frequency domain and air domain. 2 Among them, the time domain anti-jamming techniques include instantaneous communication, etc., which is mainly based on the sequential change of the signal in the time attribute for anti-jamming in the time domain. Instantaneous communication techniques reduce the chance of a communication signal being detected by reducing the duration of the signal in the channel in order to raise the threshold for interference in communication transmissions.3,4 With the diffusion of this technology, the probability of communication messages being jammed is considerably lower and therefore the applications are widespread. Although a number of anti-jamming methods have emerged from the time, frequency and air domains, they still struggle to overcome a number of inherent problems. Firstly, current methods usually fail to obtain an optimal policy and tend to fall into a locally optimal policy. Secondly, due to the poor computing power of communication devices, the algorithms used today are far beyond the tolerance threshold of the devices and cannot be scaled up on a large scale, and too much computation increases the communication latency and the communication quality tends to degrade. 5 To add insult to injury, deep learning-based channel analysis techniques are beginning to be used to attack WC, and general anti-jamming techniques have become difficult to combat, with more efficient anti-jamming algorithms needing to be proposed. Recently, the application of reinforcement learning in decision problems has provided new ideas for updating anti-jamming techniques in the field of communications. Therefore, the study constructs an anti-jamming model and designs greedy reinforcement learning algorithms in order to further provide the effectiveness of the application of anti-jamming techniques in communications. The main content of the study is divided into four parts. The second part is a literature review on WC techniques and reinforcement learning. In the third section, the design process of the anti-interference WC system model and the greedy reinforcement learning algorithm is presented. In the fourth section, the greedy reinforcement learning algorithm and the practical tests on communication interference immunity are conducted to verify the method. The final concludes a summary and suggestions for future.
Related works
To more comprehensively deal with attacks from malicious interferers in WC, numerous studies and experiments have been carried out by scholars at home and abroad. Gandhi et al. proposed a network clustering and fuzzy reinforcement learning based scheme for maximizing network lifetime. The results showed that the method has superior function compared to traditional research methods. 6 Ranjan et al. used the interference index (II) as the interference minimization key to minimize the interference between secondary nodes in order to maximize the system capacity. For validating the outcomes, an efficient greedy algorithm is incorporated and the final result confirms that it can provide a 60% gain in CR network capacity with the introduction of II. 7 Liu et al. proposed a method based on generalized complementary coding scrambling multiple access (and named it GCCSMA) to improve the operating efficiency of radio spectrum technology. This coding method combines complementary codes and multiple-input multiple-output technology to overcome the problem of code duplication during use. The results verified that this method has certain effectiveness. 8 Wang et al. proposed a distributed RA algorithm in view of coordinated Q learning to address the interference to the channel during RA and improve the communication quality. The outcomes demonstrate that the method has superior convergence performance, while the network transmission capability is better than existing methods; the overhead of RA can be effectively reduced by coordinated Q learning. 9 Scholars such as Zhao et al. proposed a new technology based on the TACS architecture to achieve safer and more efficient train autonomous detour systems. And introduce 5G technology into this framework to make up for the shortcomings of existing communication technology. Comparing this algorithm with traditional methods, the convergence speed of this algorithm is significantly faster. 10
With the rapid development of reinforcement learning technology, many scholars began to apply it directly to the powder of network communication and RA. Yan et al. proposed a deep learning based communication security anti-interference decision method to better enhance the communication anti-interference ability in the process of smart city development. The process integrates the analysis of interference strength and channel gain aspect functions. The results showed that the algorithm has a network capacity of 960 bits when the number of links is 300 and also has a high reliability of autonomous decision making. 11 Liang et al. proposed a transfer learning model based on convolutional neural network to reconstruct the compressed signal to cope with the situation where the current deep learning algorithm cannot adapt to large sample data. The experiment selected ultra-wideband radar echo signals and the Modified National Institute of Standards and Technology handwriting dataset to compare the performance of the constructed model. The results showed that the model has superior performance under different noise levels. 12 Mu et al. propose a machine learning-based allocation scheme for intelligent spectrum partitioning to better analyze the interference immunity of wireless body area networks (WBANs). The results show that the research method is able to adapt more quickly to the rapidly changing WBAN in the topology, while the system has excellent anti-interference performance and system stability. 13 Lu et al. proposed a reinforcement learning framework based on drone-assisted anti-jamming cells to improve the performance of cellular systems against smart jammers. UAVs are combined with deep reinforcement learning and transfer learning to improve the intelligent interference capabilities of cellular systems. Simulation shows that this algorithm can significantly reduce the bit error rate and save drone consumption. 14
In summary, with the rapid development of communication technology, wireless networks are facing increasingly severe interference problems, which include not only interference caused by natural factors, but also security threats caused by malicious attacks. In order to improve the anti-interference ability of wireless communication systems, researchers have proposed a variety of algorithms and methods. At present, reinforcement learning algorithms have been widely used in wireless communication networks. Most of the research focuses on the allocation of communication resources and network attacks. Few studies have integrated greedy algorithms into reinforcement learning to improve reinforcement learning, thereby better solving the problem of wireless communication anti-interference. In addition, the greedy algorithm performs well in scenarios such as resource allocation and power control due to its simple and efficient characteristics. Through the local optimal selection strategy, the greedy algorithm can quickly find the approximate optimal solution, which is suitable for real-time systems that require fast response. In view of this, the study proposes a wireless communication anti-interference technology based on greedy reinforcement learning algorithm. First, an anti-interference wireless communication model based on deep learning is constructed, and then the communication anti-interference model is optimized in combination with the greedy learning algorithm to achieve efficient operation of anti-interference wireless communication data tasks, and it is expected that it can effectively improve communication performance.
Anti-interference techniques for WC incorporating greedy-reinforcement learning algorithms
For improving the anti-interference capability of WC, the research is based on reinforcement learning algorithm and combined with greedy algorithm to form a new effective anti-interference technique for WC in view of greedy-reinforcement learning algorithm, and this section is divided into two parts to explain.
Deep learning-based model for interference-resistant WC systems
In this WC model, the sender sends information to the receiver over the transmission channel under the influence of multiple interfering attackers. At the moment
At the same time, there will be Model of a jam-resistant WC system.
As can be seen in Figure 1, for defending against jamming attacks, it is essential for the sender to select an unblocked secure channel
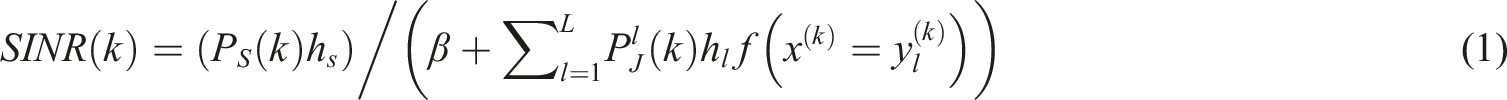
In equation (1),
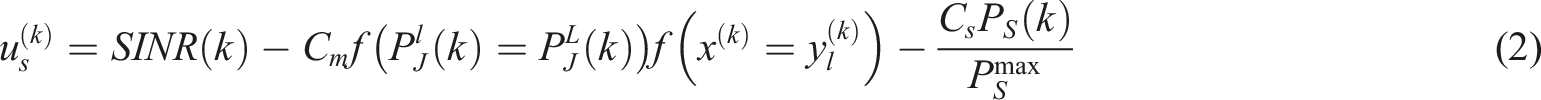
In equation (2), Specific implementation process of the reinforcement learning algorithm.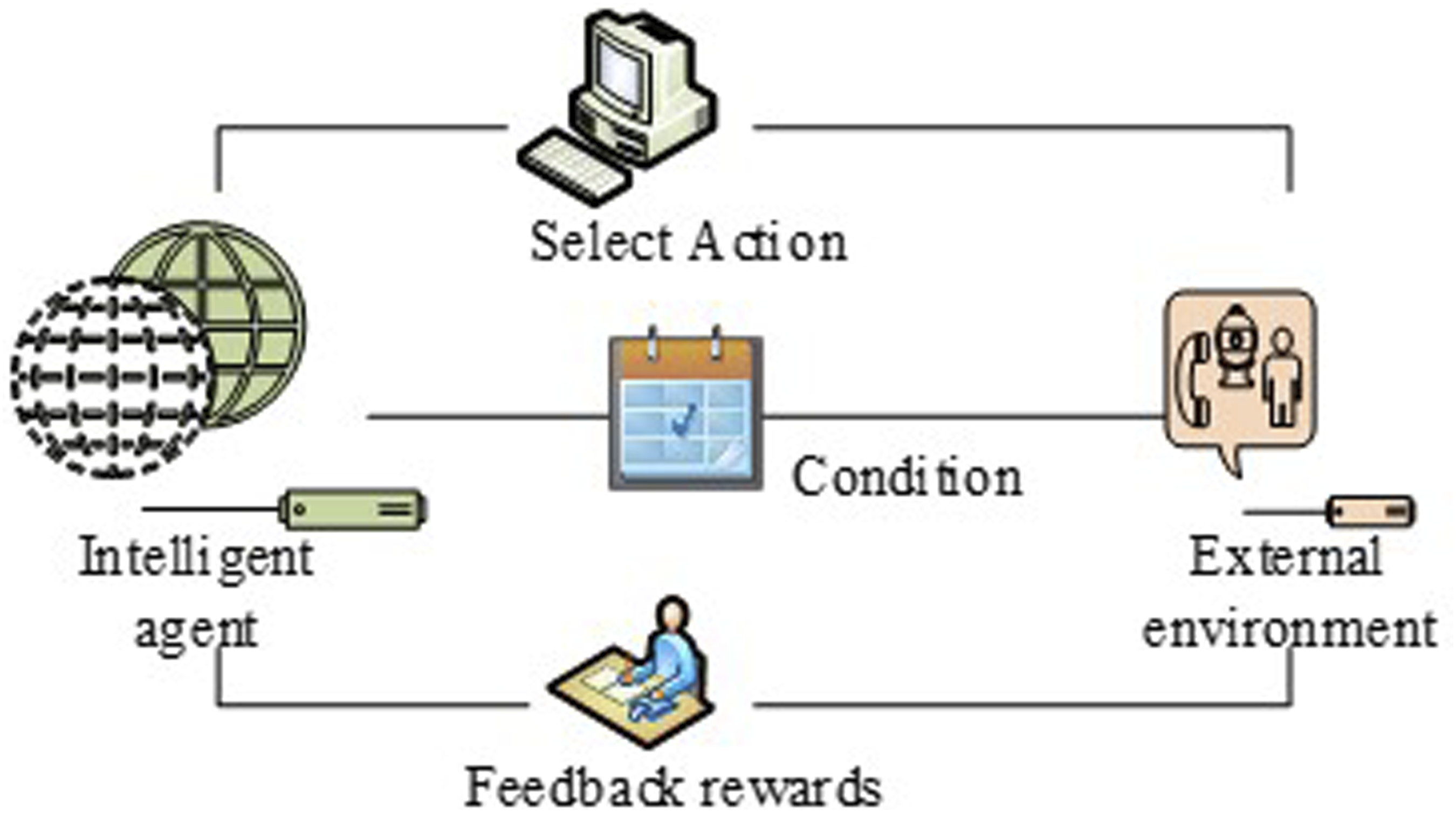
In the reinforcement learning model, the intelligence constantly interacts with its surroundings, where at each time point it receives feedback from the environment indicating its current state, which is used to update its strategy. The sum of the rewards of this process is expressed in equation (3).

In equation (3),

In equation (4),

In equation (5),
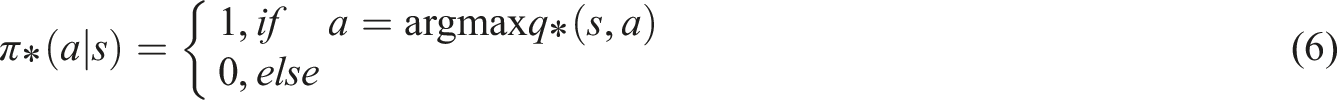
Combined with the above analysis, the resulting deep reinforcement learning structure is shown in Figure 3. Deep reinforcement learning architecture.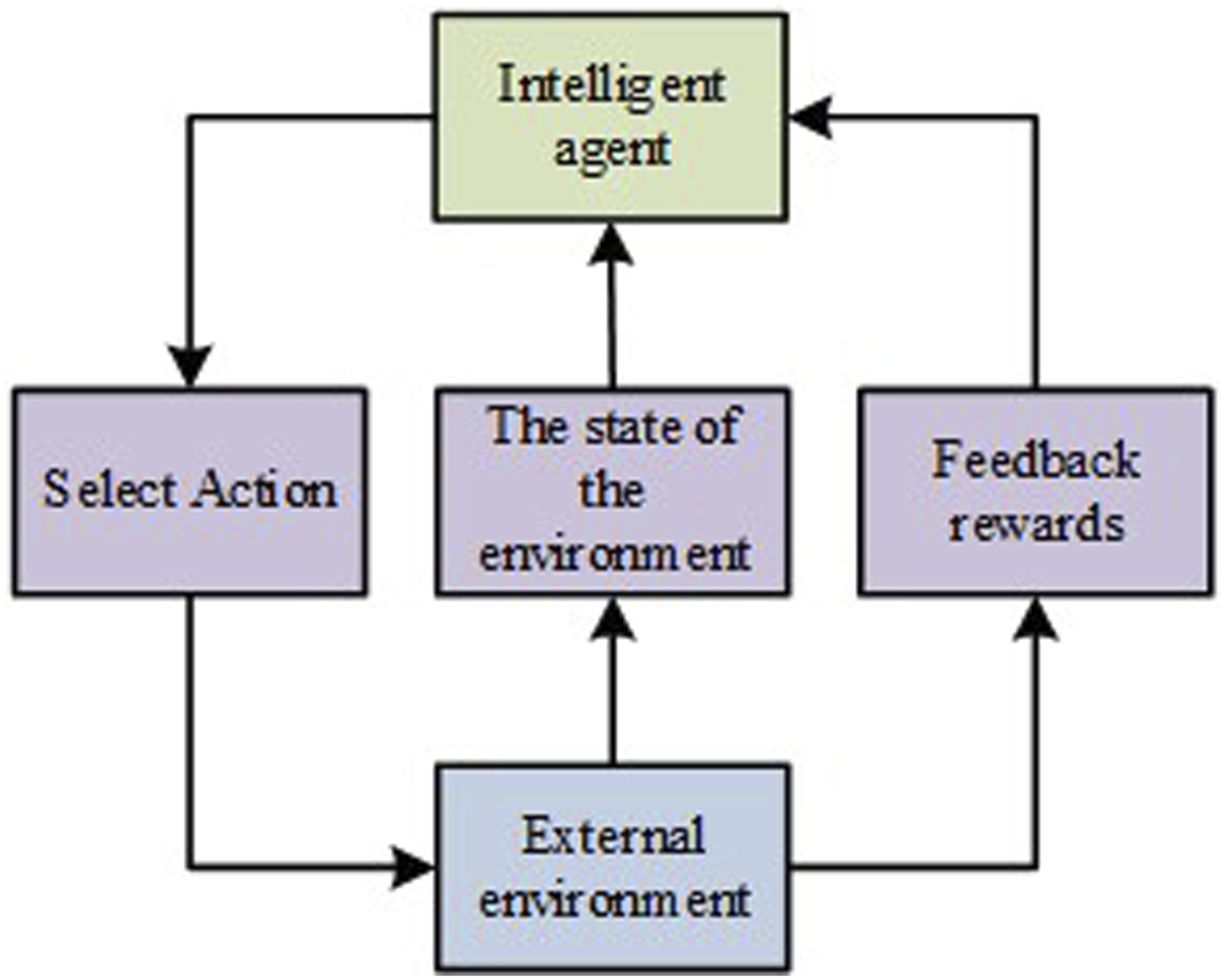
Design of anti-interference model for WC in view of greedy-reinforcement learning algorithm
In WC jamming engineering, the processing of large amounts of data is a highly comprehensive and systematically fraught large scale project for researchers. In order to better achieve efficient operation of jam-resistant WC data tasks, the research proposes to combine greedy algorithms with reinforcement learning algorithms to form a Specific architecture of the greedy reinforcement learning algorithm.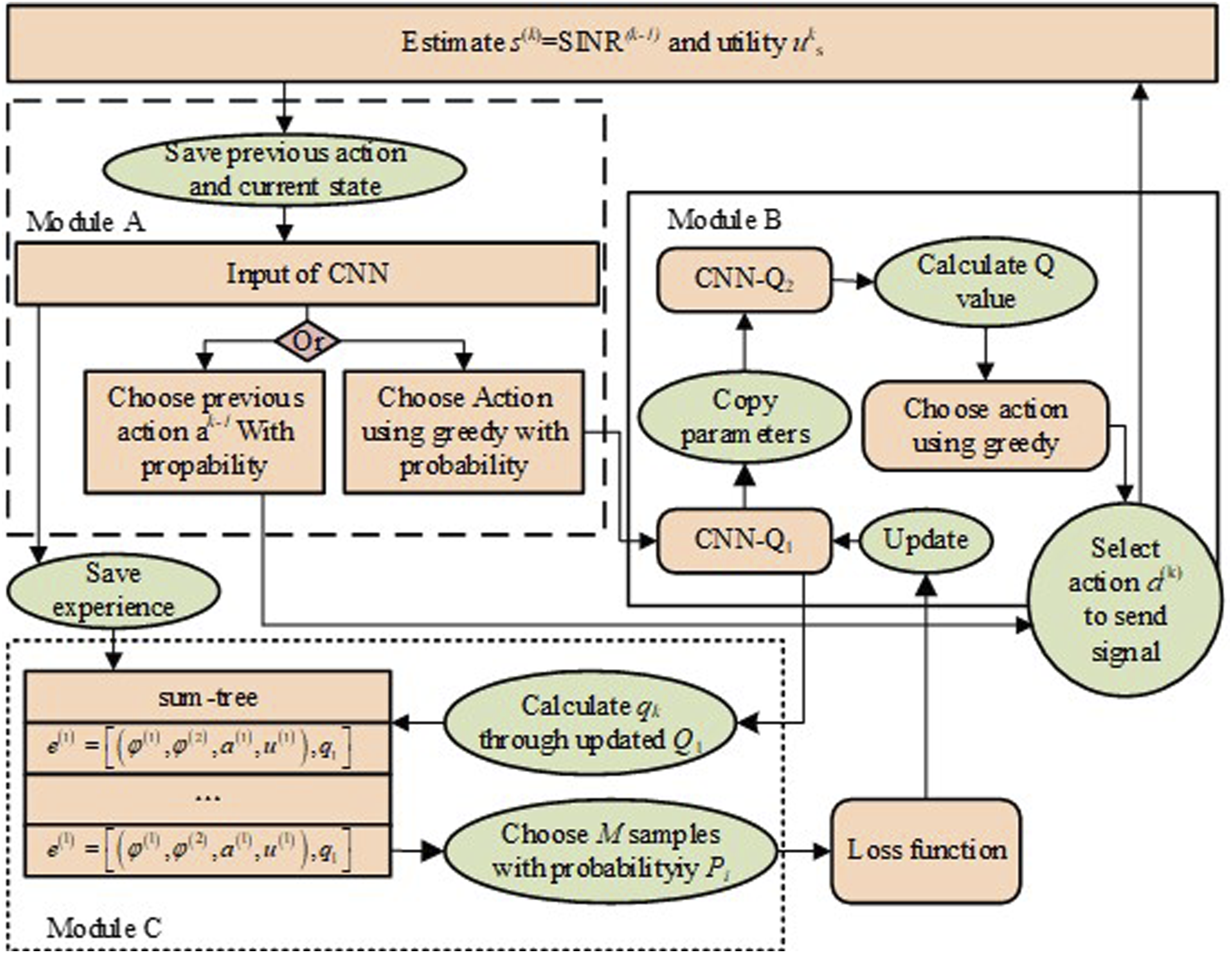
As can be seen in Figure 4, module A is used to save actions and states, and to input the resulting parameters into the network, ultimately determining whether to save the previous signal with value or to calculate the highest value action according to the network. Module B reduces the coupling of the network data through a dual network structure, calculates the
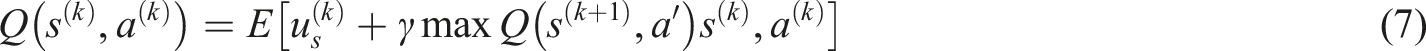
In equation (7),
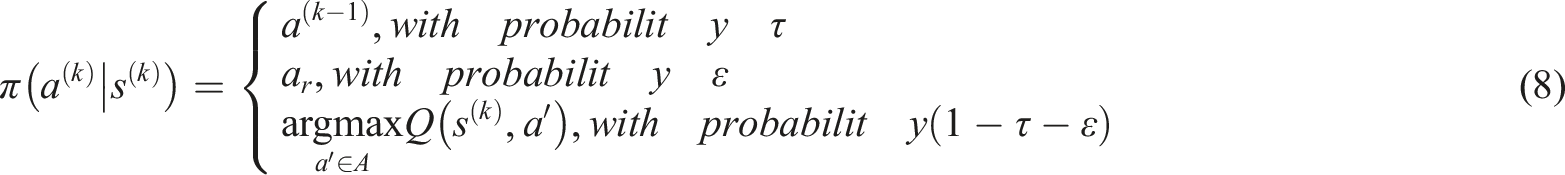
In equation (8),

In equation (9), the value of the action

In equation (10), Structure of CNN model.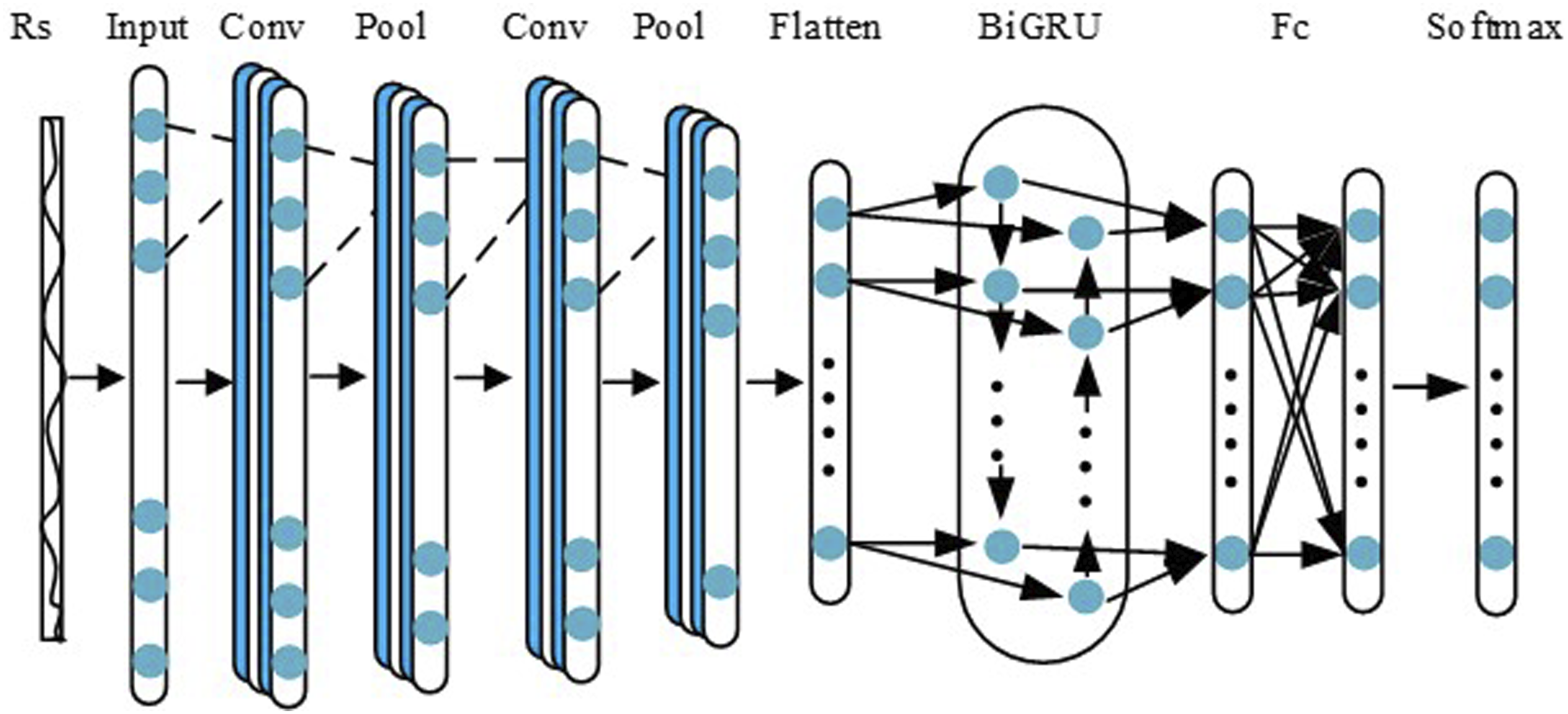
In view of the output of the CNN, the sender can choose the optimal transmit power and channel.
19
In the research method, two convolutional neural networks with the same structure are constructed, which are served as
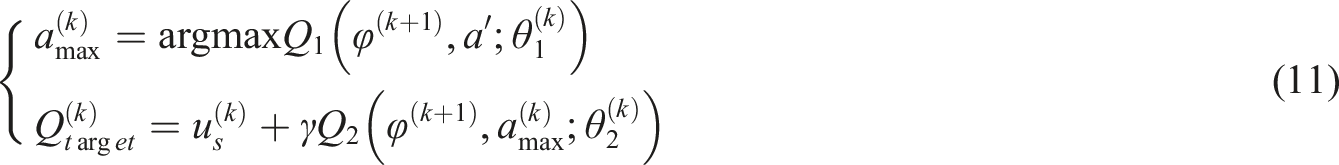
In equation (11),

Also when evaluating the priority of the empirical samples, the value of the Temporal Difference (TD) needs to be calculated, which is shown in equation (13).

In equation (13),

In equation (14),

In equation (15), Basic flow of the PDDQN.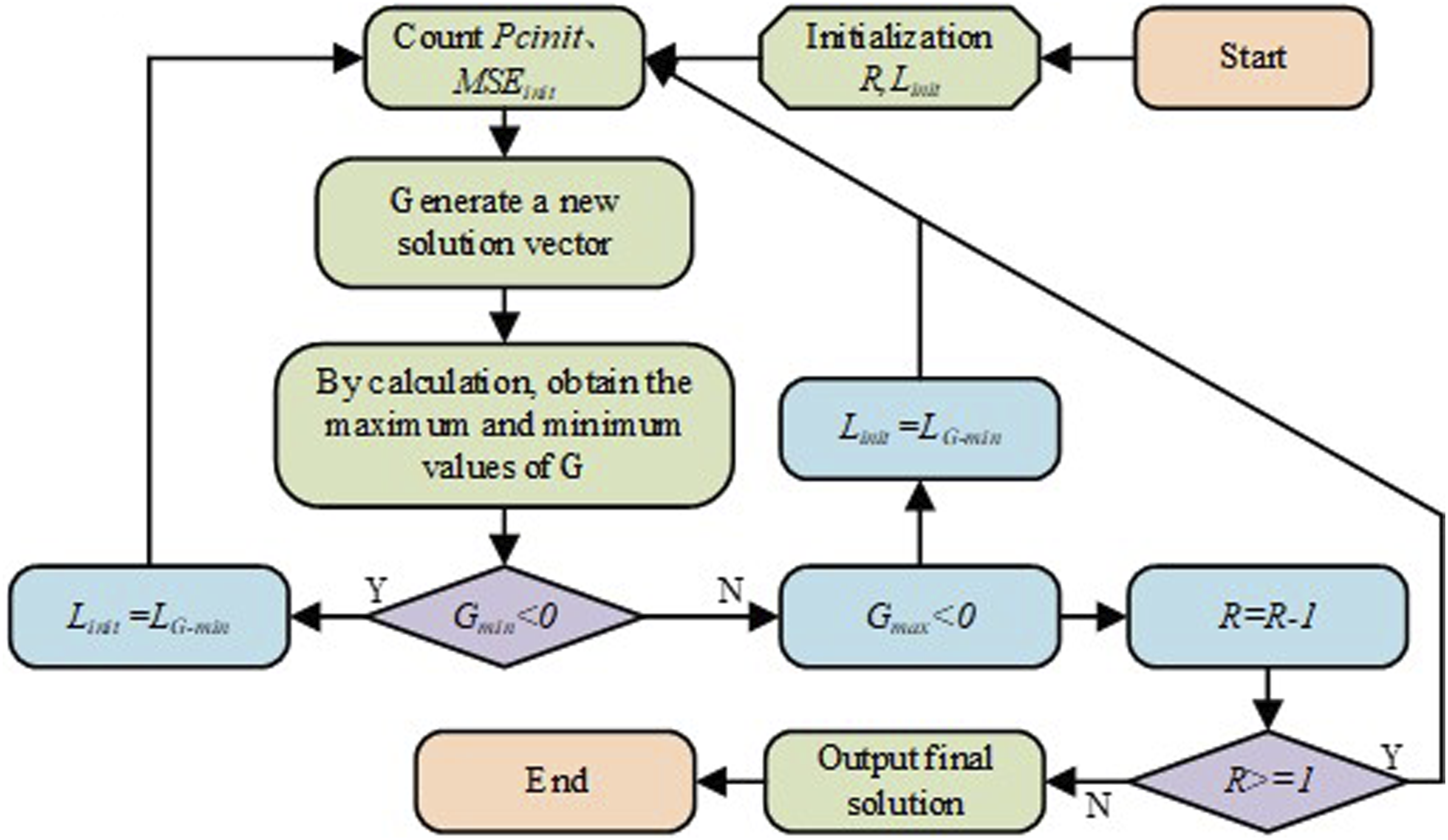
In Figure 6, the PDDQN model uses a greedy algorithm to solve the resource allocation problem in wireless communication and control the power. It also uses a deep learning algorithm to dynamically adjust the communication parameters and can adapt to the ever-changing communication environment, optimizing the communication performance through continuous learning. In the wireless communication anti-interference problem, the greedy reinforcement learning algorithm can be used to adjust the communication parameters to resist external interference and quickly respond to strategy implementation.
Performance test and application effect of anti-interference system for WC
In order to better analyze the functionality of the system constructed in this study, the performance of the WC anti-jamming system and the actual simulation results of this technology are analyzed in this section.
Performance testing of anti-interference systems for WC
The experimental basic environmental parameters.
To ensure that the overall experiments are conducted in a reasonable manner, the relevant parameters in the performance simulation experiments are set as follows: Comparison of convergence of different algorithms. (a) ImageNet dataset, (b) MNIST dataset.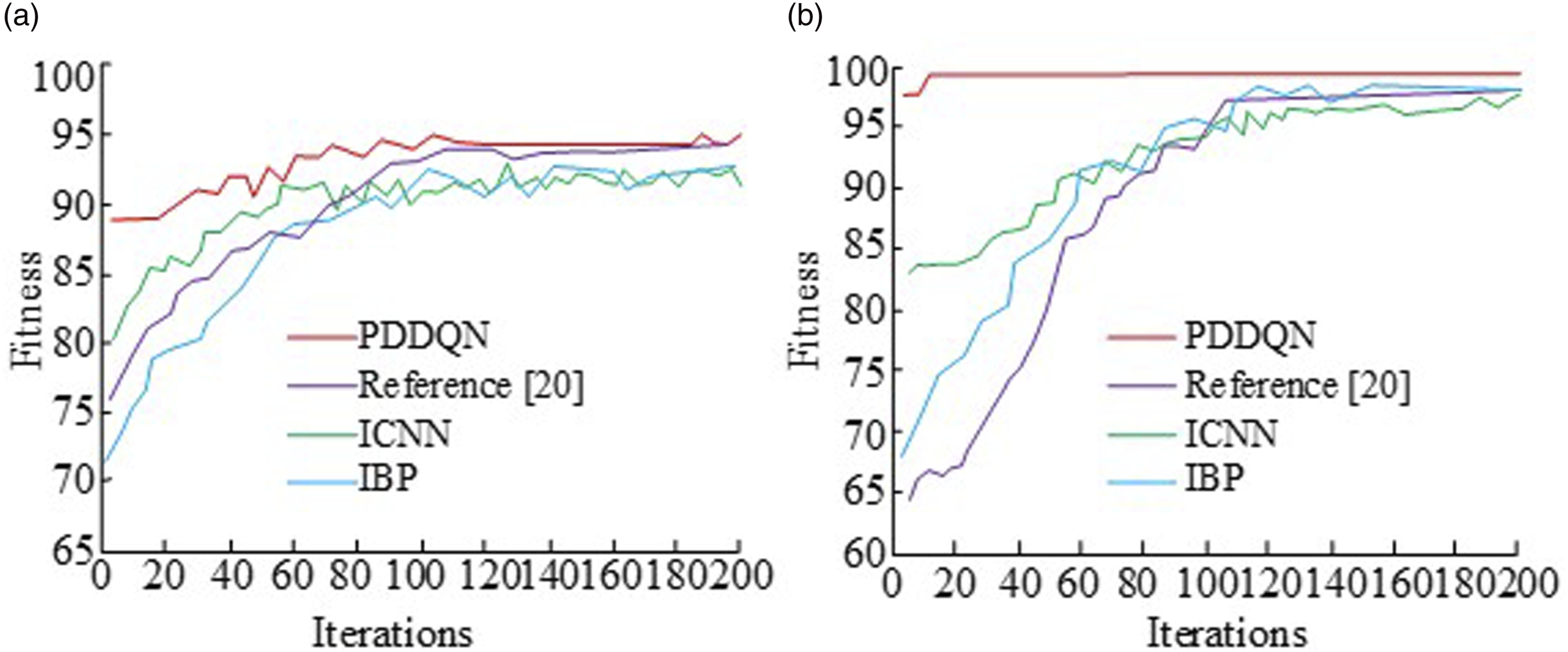
Figure 7(a) shows a comparison of the change in fitness on the ImageNet dataset. With the number of runs, the fitness values of all four algorithms show a fluctuating trend of zigzag changes and never appear to be stable values; while when the number of iterations is 120, the research method has the largest fitness value of 94.8, which also indicates a faster convergence and better merit finding ability. Figure 7(b) shows a test of convergence on the MNIST dataset. When the number of iterations is around 19, the fitness value of the research method reaches 99.1 and converges infinitely to 99.9; while it is at 140 iterations that the remaining three algorithms slowly start to show equilibrium fitness, but the values are smaller than the research method. All of these results indicate that the research method has a better fitness effect and is able to reach a convergence state more quickly and start to find the optimal parameters. The four algorithms were then compared and the accuracy of the runs in the two datasets is shown in Figure 8. Accuracy of the four algorithms running on different datasets. (a) ImageNet dataset, (b) MNIST dataset.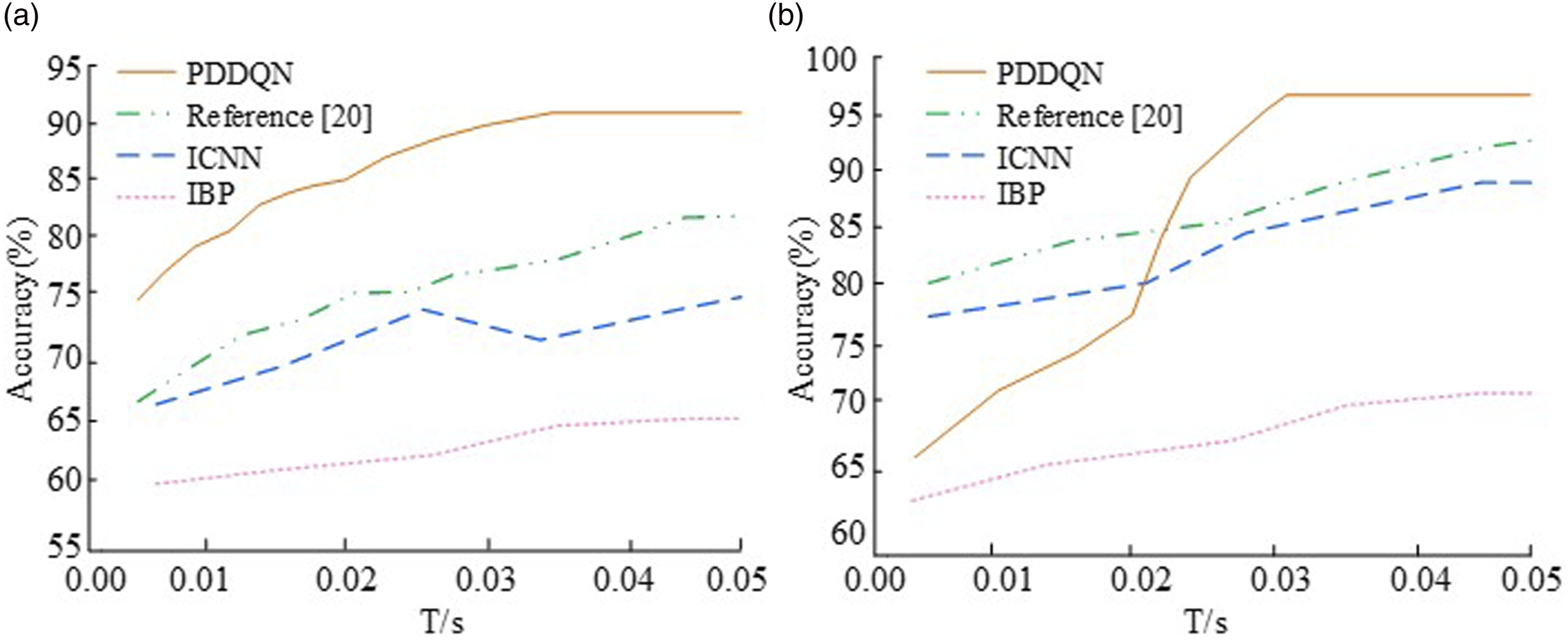
In Figure 8(a), the highest accuracy rates for the four methods PDDQN, literature (20), ICNN, and IBP are 92.1%, 82.3%, 74.2%, and 65.3%, respectively when the run time is 0.05 s. The maximum accuracy of the studied methods starts to be reached when the run time reaches 0.035 s. Figure 8(b) illustrates that the accuracy of the IBP method is still low in the dataset and increases as the run time increases, but not by much in fact, with the highest value being around 70.0%. The running accuracy of the study method shows a cliff-like increase and has a maximum accuracy of 96.2% at around 0.032 s. The above results indicate that the research method has a higher running accuracy under the same experimental conditions and also has the performance of reaching steady state more quickly. A comparison of the time taken by the different algorithms to reach steady state on the two datasets is then presented in Figure 9. Time taken by different models to reach steady state. (a) ImageNet dataset, (b) MNIST dataset.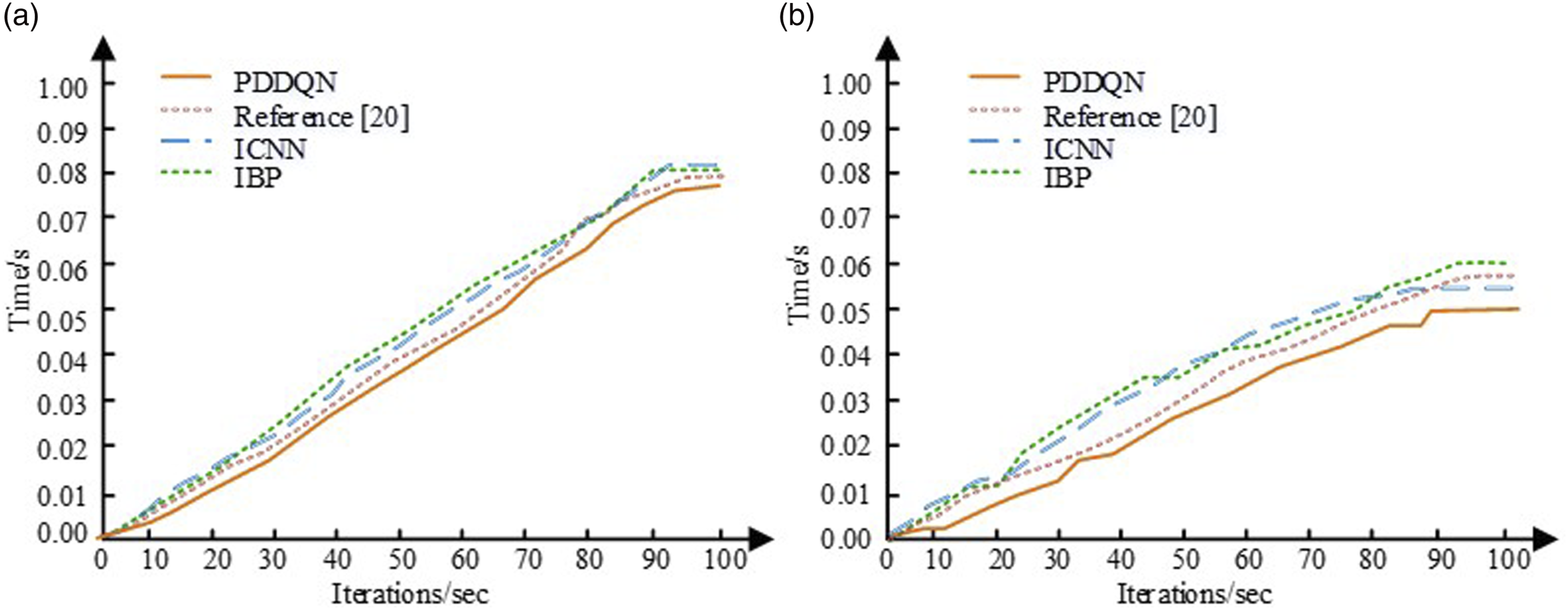
In Figure 9(a), when the number of iterations is 91, the running times of PDDQN, literature (20), ICNN, and IBP start to stabilize, with 0.0768 s, 0.0791 s, 0.0801 s, and 0.0823 s, respectively. The time taken by the four methods to reach a stable state is 0.0501 s, 0.0571 s, 0.0556 s, and 0.0601 s, respectively, and the time taken by the four methods to reach a stable state is significantly smaller than that of the other algorithms, which is to a certain extent faster than the operational efficiency of WC anti-interference.
Analysis of simulation results of anti-interference experiments
Based on the above analysis of the performance of the model, the study then proceeded to conduct an experimental simulation of the interference immunity and to compare it with different algorithms. Firstly, the S/N performance of the variable and constant transmit power models were compared in practice with the same average power Comparison of different reinforcement learning algorithms. (a) Comparison of SINR values of different algorithms when N = 32 and L = 2, (b) comparison of SINR values of different algorithms when N = 32 and L = 8.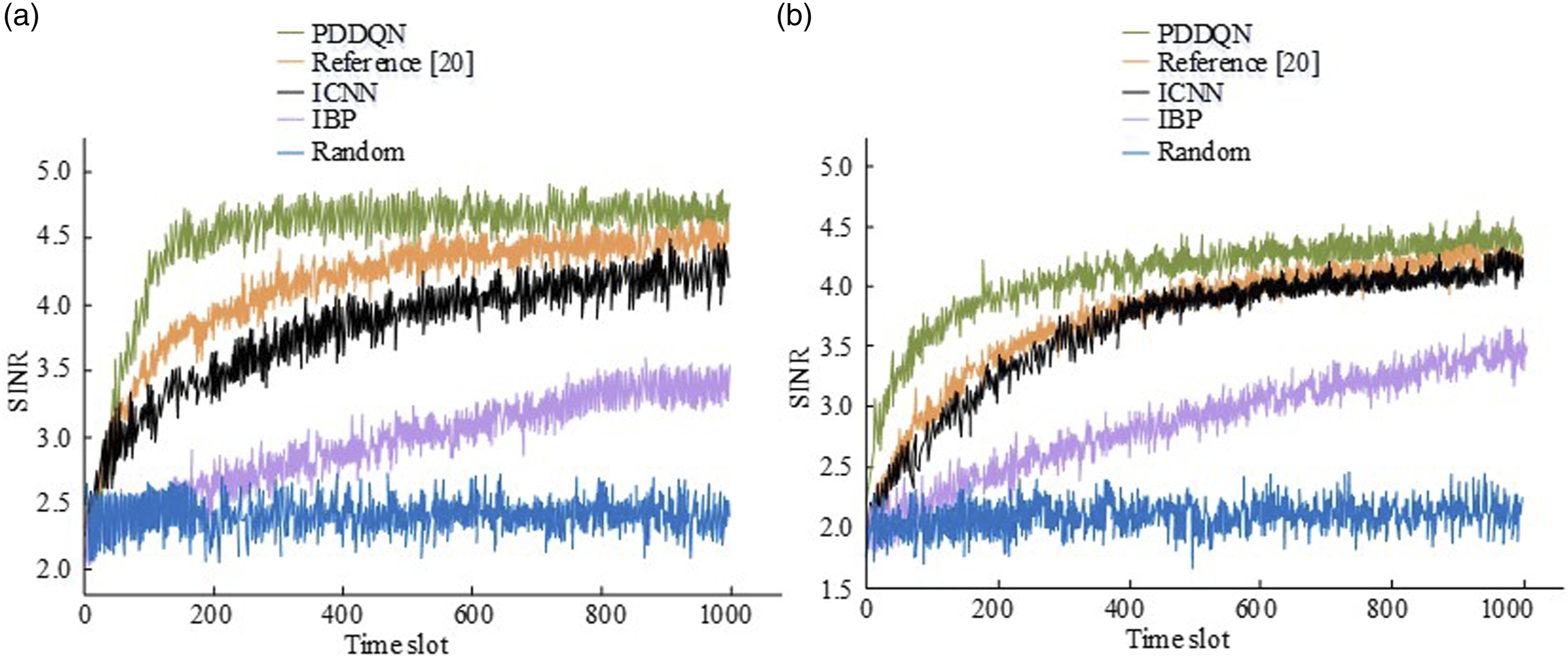
In Figure 10(a), parameter N is equal to 32, parameter L is equal to 2, and the SINR of the research method reaches 4.53 at time node 200, while the SINR of ICNN and literature (20) are only 3.41 and 3.82, respectively. In terms of convergence speed, the research method reaches convergence at time node 200, while the other three methods start converging after time node 1000. In Figure 10(b), parameter N is equal to 32 and parameter L is equal to 8; it can be observed that the performance of all methods has been reduced. The study method still has a maximum SINR value at time node 200, reaching 400, while the corresponding values for the literature (20), ICNN, and IBP are 3.41, 3.23, and 2.54, respectively. This indicates that the convergence rate of the study method starts to decrease when the number of interfering attackers increases, but is still faster than the rest of the algorithms. The incorporation of the dual network structure and empirical recovery in the research method can effectively improve the performance and learning efficiency of the WC system against interference. Finally, the research method is compared with a reinforcement learning algorithm based on Comparison of SINR for different greedy reinforcement learning algorithms. (a) Comparison of SINR of different algorithms when N = 32 and L = 2, (b) comparison of SINR of different algorithms when N = 32 and L = 8.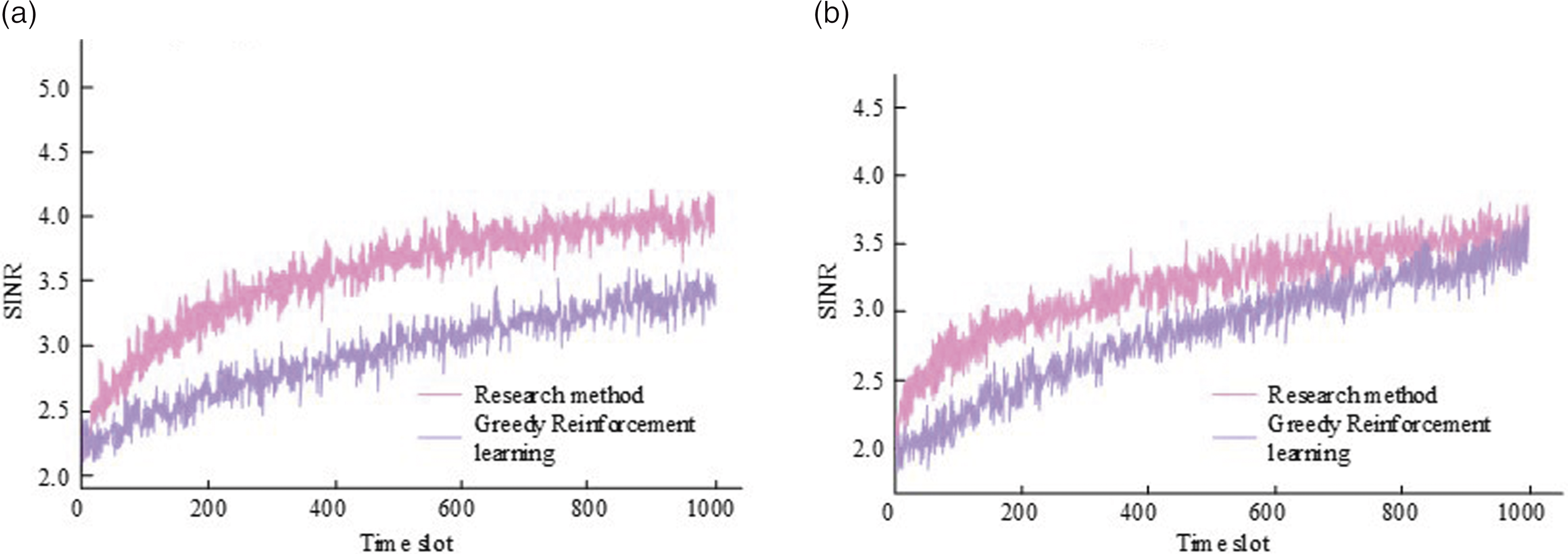
The selectable communication bands and interfering attackers in Figure 11(a) are 32 and 2, respectively, that is,
Conclusion
The development of WC technologies such as 5G has placed higher demands on communication security. The study constructs an anti-interference model for WC in this context and uses it to design a greedy action retention algorithm for improving the convergence speed of the algorithm and the utilization of communication computing resources. The results show that the algorithm has a maximum fitness value of 94.8 in the ImageNet dataset, with a high convergence speed and superiority seeking capability. In the MNIST dataset, the highest value of the IBP method is at 70.0%, and the proposed method shows a cliff-like increase in operational accuracy and has a higher accuracy with a maximum accuracy of 96.2% near 0.032 s. Moreover, when the number of iterations is around 89, the running time of the three methods PDDQN, ICNN and IBP starts to reach a stable state, with 0.0501 s, 0.0556 s, and 0.0601 s, respectively. The time taken by the designed methods to reach a stable state is significantly smaller than that of other algorithms, which to a certain extent can be faster in the running efficiency of WC anti-interference. The SINR values of ICNN and IBP at the 200 time node are 3.23 and 2.54 for the number of channels and jammers of 32 and 8, respectively, while the proposed method has a maximum value of 400. With the selectable communication bands and jamming attackers of 32 and 2, respectively, the reinforcement learning algorithm incorporating the greedy algorithm improves the SINR value from 2.61 to 3.32 in a very short period of time and greatly accelerates the convergence rate, which is a significant enhancement to the anti-interference capability of WC when the time node is 200.
However, the study did not consider the consumption of computing resources by deep learning, and the future needs to be combined with wireless-driven edge computing to enhance the application capability of low-power networks.
Statements and declarations
Footnotes
Conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.