
Abstract
Traditional athlete training data classification and prediction models have low accuracy, poor processing of high-dimensional data, and weak dynamic adaptability. Before applying the ARIMA model for classification and prediction, the first step is to use an automated data acquisition system to connect sports devices, collect and clean athlete training data in real time, and securely store and backup it on a central server. The second step is to preprocess the collected data and divide it into training and test sets to ensure the accuracy and generalization ability of the model. The third step is to conduct time-series analysis to identify the time-dependent and seasonal components of athlete training data. The fourth step involves fitting the ARIMA model through differential analysis, stationarity testing, model parameter optimization, residual analysis, rolling forecasting, and ensemble learning, and predicting and classifying athlete training data, so as to improve the accuracy and robustness of the model. The experimental results show that the accuracy of data classification using ARIMA model is the highest, all exceeding 92%, and the average classification accuracy is 2%–16.7% higher than that of other models. Moreover, the prediction errors of the ARIMA model are all below 1.0%. In summary, the application of ARIMA models to classification and prediction of the athlete training data is highly reliable.
Keywords
Introduction
As sports science and big data technologies develop, the analysis and prediction of athlete training data are becoming increasingly critical. Traditional classification and prediction models are significantly deficient in processing high-dimensional data and in dynamic adaptability, which makes it hard to accurately capture complex patterns and trends in athlete training data. The ARIMA model is an advanced time series analysis method that can effectively handle data with time-dependent and seasonal components, providing more accurate prediction and classification results. Therefore, by applying the ARIMA model to classify and predict athlete training data, not only the accuracy of the model can be improved but also its robustness in practical applications can be enhanced.
The main contributions and innovations of this article are as follows: (1) proposing a method for classification and prediction of athlete training data based on the ARIMA model, which ensures the high quality of data and the reliability of the model through a systematic data acquisition and preprocessing process; (2) combining time-series analysis methods to deeply explore the time-dependent and seasonal components in data; (3) fine-tuning model parameters to ensure the best fitting effect of the model. Finally, through experimental verification, it is demonstrated that the ARIMA model has significant advantages in classification accuracy, prediction error, and high-dimensional data processing, which provides a reliable basis for the analysis and decision-making of athlete training data.
Related work
Classifying and predicting athlete training data is beneficial for comprehensively understanding their performance, progress, and potential problems, revealing potential patterns and trends, so scientific basis can be provided for training and management.1,2 Classifying and predicting training data is also beneficial for identifying the performance of athletes in high-pressure environments, providing corresponding psychological counseling and intervention measures, and improving their psychological resilience and emotional stability.3,4 Giles 5 used athlete tracking data combined with machine learning models for feature extraction and classification. This method effectively detected directional changes during tennis sports, but it had shortcomings such as high data processing complexity and poor model interpretability. Jauhiainen 6 introduced a novel machine learning method for detecting injury risk factors in young team athletes. By integrating multiple machine learning algorithms, it could accurately identify potential injury risk factors. However, his research had shortcomings in sample size and data diversity. Bunker 7 proposed a machine learning framework for sports result prediction, which combined multiple machine learning algorithms to improve the accuracy of competition result prediction. However, his research had limitations in terms of applicability to specific sports and the generalization ability of the model. Meng 8 proposed a dual feature fusion neural network model for sports injury estimation. By integrating multiple features, the prediction accuracy of the model was improved. Although this method performed well in experiments, it faced high requirements for data processing and computational resources in practical applications. In Musa 9 research, artificial neural networks and k-nearest neighbor classification models were applied to complete the selection task of high-performance archers. By combining the physical fitness and skill parameters of athletes, the accuracy of selection was improved. However, there was still room for improvement in feature selection and model stability in his research. From the above references, it can be seen that different machine learning methods have performed well in improving sports data analysis and prediction, but each still has shortcomings in terms of data processing complexity, model interpretability, universality, and computational resource requirements.
The ARIMA model is different from some complex machine learning models, as it does not require complex assumptions or preprocessing of data.10,11 Many scholars have utilized the advantages of ARIMA models to predict different data.12,13 Abonazel 14 study used the ARIMA model to predict Egypt’s Gross Domestic Product (GDP). The data stationarity was ensured through ADF (Augmented Dickey–Fuller) test, and the model order was determined using ACF (autocorrelation function) and PACF (partial autocorrelation function) graphs. The optimal ARIMA model was ultimately selected for prediction. The results indicated that this model had a good prediction effect on Egypt’s GDP and provided high prediction accuracy. Wang 15 proposed a distributed ARIMA model for processing ultra-long time series data. His research adopted a distributed computing framework, dividing ultra-long time series into multiple subsequences. ARIMA models were constructed for local prediction and then the results were merged to obtain global prediction. The results showed that the distributed ARIMA model had high efficiency and scalability in processing large-scale data. Sahai 16 used the ARIMA model to model and predict the COVID-19 epidemic situation in the five most affected countries. In his research, model parameters were estimated using the ordinary least squares method. The results indicated that the ARIMA model could effectively capture the trend of epidemic development and provide short-term predictions. Poongodi 17 applied the ARIMA model to predict Bitcoin prices and conducted time-series analysis on historical Bitcoin price data. The results showed that the ARIMA model had high accuracy in predicting Bitcoin prices. Nath 18 used the ARIMA model to predict wheat yield in India. Firstly, differential processing was performed on the wheat yield data to ensure stationarity, and then the model parameters were determined through ACF and PACF graphs. After estimating and testing the model parameters, the best ARIMA model was ultimately selected for prediction. The results indicated that the ARIMA model performed well in predicting wheat yield and had high prediction accuracy. The ARIMA model is often used to predict heart rate data, detect heart rate abnormalities, and provide early warning of heart attacks or other cardiovascular diseases. The research of the above scholars has shown excellent prediction performance of the ARIMA model. Therefore, this article aims to apply the ARIMA model to classify and predict athlete data.
Application of the ARIMA model
Collection of athlete sports data
The data in this article is sourced from the official database provided by the General Administration of Sport of China. It contains detailed training records of multiple athletes during different training cycles, including key indicators such as training intensity, duration, heart rate, and energy consumption. The specific collection process is shown in Figure 1. Collection process of athlete sports data.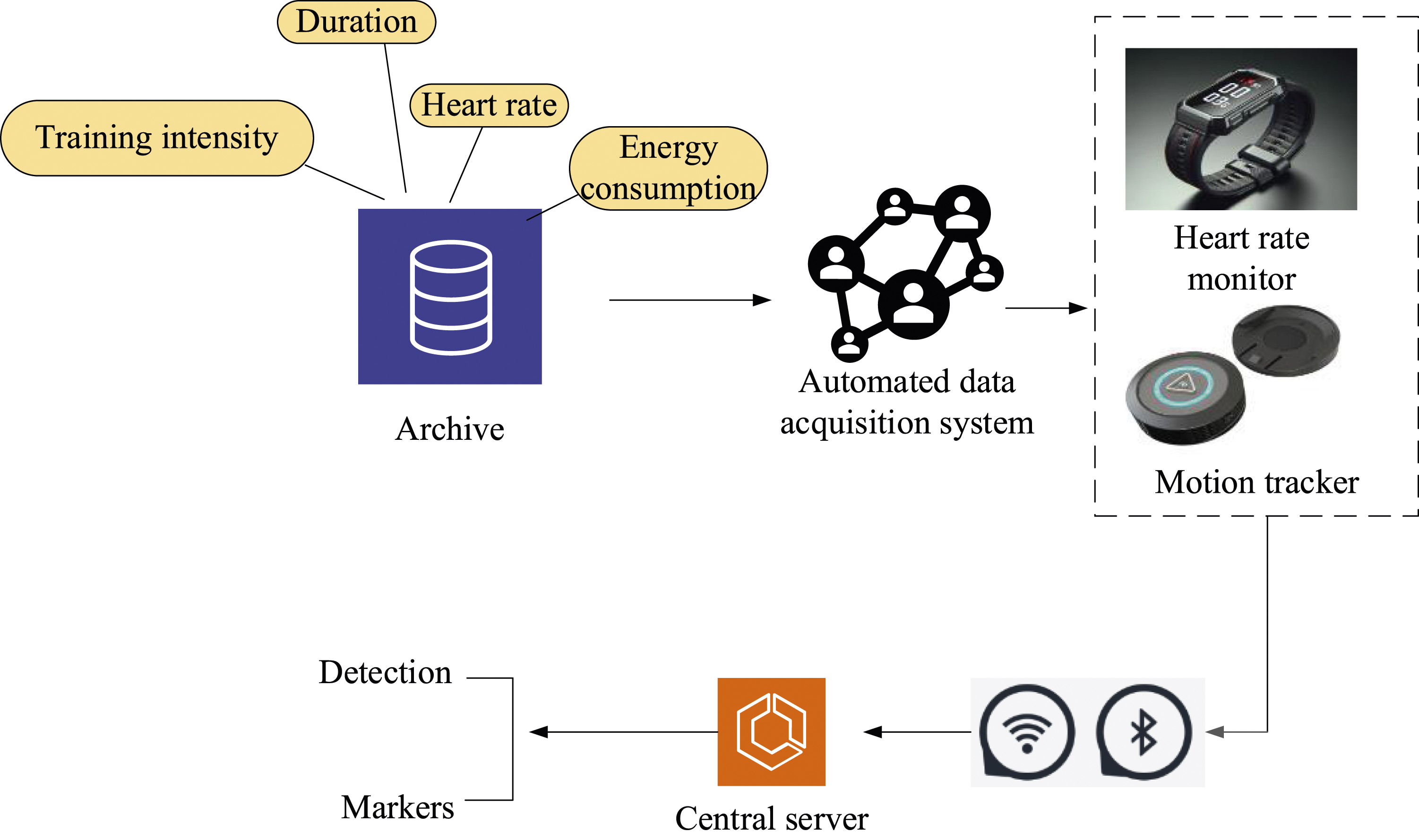
In Figure 1, an automated data acquisition system is used to connect training devices such as heart rate monitors (the model is Polar H10, an electrode heart rate sensor, collecting once per second) and motion trackers to collect real-time training data. These devices are connected to the central server via Bluetooth and Wi-Fi, ensuring real-time data upload and storage. Strict data quality control measures are implemented during the data acquisition process. This includes real-time monitoring of data flow, automatic detection, and labeling of abnormal data points. Heart rate values or unreasonable exercise intensity records that exceed the normal range are manually reviewed, and whether to retain or remove them is decided based on the review results. By implementing measures such as data encryption, access control, data anonymization and de-identification, regulatory compliance, and security training and awareness, the privacy and security of collected data are effectively safeguarded.
Data from different devices and time periods is integrated, and data cleaning techniques are used to remove duplicate records, correct formatting errors, and unify data units to ensure data consistency and availability. All collected data is stored in a secure server, using distributed storage technology to improve data access speed and reliability. At the same time, regular data backup strategies are implemented to ensure the security and integrity of data.
Data preprocessing
Missing values are a common issue in athlete training data, and improper handling can seriously affect the performance of the model.19,20 Therefore, a preliminary analysis of the data is conducted to identify the location and quantity of missing values using descriptive statistical methods. For continuous data, use mean imputation method to handle missing values:

Variable interpretation of the formula for processing missing values.

For categorical data, the mode imputation method is used, which replaces missing values with the most frequently occurring category. This method can maintain the distribution characteristics of categorical variables and avoid bias caused by missing values.
Outlier types include data input errors, device faults, and abnormal motion events. The presence of outliers can have a negative impact (increased sensitivity and reduced generalization) on the training and prediction results of the model, so box-plots and interquartile range (IQR) methods are used to identify outliers. The first quartile and third quartile are calculated, and then the IQR21,22 is calculated to determine the upper and lower bounds of outliers: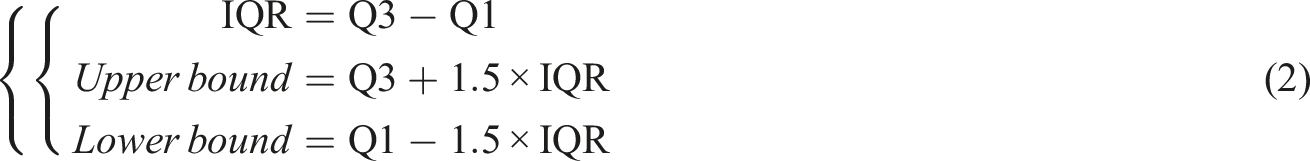
Variable interpretation of formulas related to outliers.

Values that exceed the upper and lower bounds are considered as outliers and are replaced with the corresponding bound values. In order to handle scale differences in data, Z-score normalization is applied to all numerical features, so that different features have the same measurement scale.
For features that exhibit nonlinear relationships with output variables, logarithmic transformation is performed to improve their distribution characteristics. The formula is as follows:
Among them,
The moving average method is used to adjust for seasonal fluctuations in athlete training data23,24:
Among them,
The moving average is subtracted from the raw data to obtain adjusted seasonal data, thereby removing seasonal components. The adjusted seasonal data better reflects the trend and changes in training effectiveness.
Finally, the dataset is divided into training and test sets in chronological order. The impact of different data segmentation strategies on model performance is significant. Random segmentation is suitable for non-time series data, but it may lead to time series data leakage. Time series segmentation is suitable for time series data, which can preserve temporal dependencies and avoid data leakage. The training set is used for model training, and K-fold cross-validation is used during the training process. The test set is used to validate the prediction performance of the model. To ensure the generalization ability of the model, it is necessary to ensure the continuity of the training and test sets in time, and to avoid data leakage.
Time-series analysis
The goal of time-series analysis is to identify the time-dependent and seasonal components of data, laying the foundation for the application of ARIMA models. Compared with traditional moving average method, exponential smoothing method, and modern STL (Seasonal and Trend decomposition using Loess), it can be found that STL has significant advantages in processing athlete training data. It can accurately capture long-term trends and seasonal variations in data, as well as effectively handle outliers and noisy data. Athlete training data is visualized using time series data graphs, observing the trends, seasonality, and periodicity of the data. The data from January 1, 2022 to January 1, 2023 is taken as an example, as shown in Figure 2. In Figure 2, the moving average is calculated and plotted to smooth time series data and further identify long-term trends and periodic fluctuations. The window size of the moving average is 7 days. Time series data graph.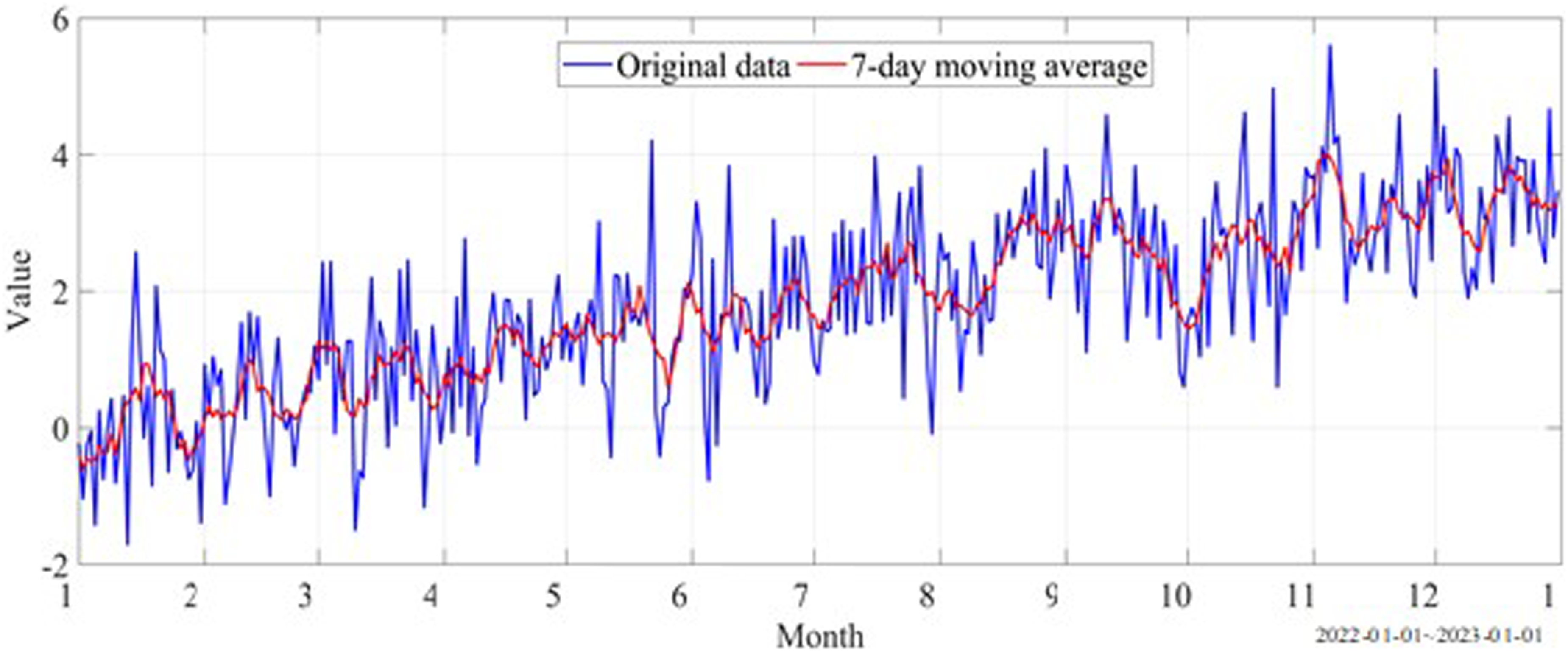
The ADF statistic and corresponding p-value are calculated using the ADF test to determine whether the sequence is stationary.25,26 The formula is as follows: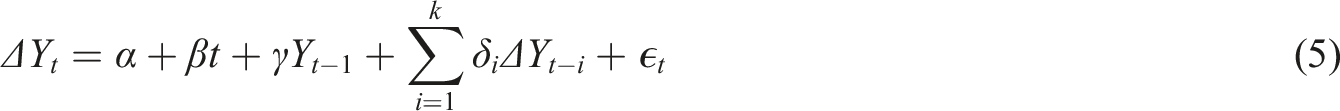
If the p-value is less than the significance level (0.05) and the null hypothesis is rejected, the sequence is stationary. KPSS (Kwiatkowski–Phillips–Schmidt–Shin) test is used: calculating KPSS statistics and corresponding critical values to determine whether the sequence is stationary. If the KPSS statistic is greater than the critical value and the null hypothesis is rejected, then the sequence is non-stationary.
If the sequence is unstable, differential transformation is used for stationarization. By calculating first-order and second-order differences to eliminate trend and seasonal components in the data, the sequence satisfies the assumption of stationarity.
After analyzing the stationarity of the sequence, ACF and PACF are used to analyze the autocorrelation characteristics of the sequence. ACF is used to display the correlation between the sequence and its lag value, and to identify the MA (moving average) component in the sequence27,28:
PACF is used to display the partial correlation between a sequence and its lag value, and to identify the AR (autoregressive) components in the sequence. Based on the significant peaks in the ACF and PACF graphs, the order of the ARIMA model, that is, the values of AR (p) and MA (q), is preliminarily determined. When the ACF graph gradually decays after a certain lag order, and the PACF graph is truncated at that lag order, the AR model is selected; on the contrary, the MA model is selected.
For seasonal time series, seasonal difference method is applied to eliminate seasonal components. Time series with structural mutations should be detected using CUSUM (cumulative sum) and Pettitt tests. First, the cumulative sum statistic is calculated and a CUSUM graph is drawn to determine whether there are significant mutation points in the sequence. Then, the Pettitt statistic and its corresponding significance level are calculated to detect mutation points in the sequence. If the p-value is less than the significance level (0.05), there is a mutation point in the sequence. For complex time series, STL (Seasonal and Trend decomposition using Loess) is applied to decompose the sequence into trend, seasonality, and residual components by specifying the window size. The decomposed components are observed, and trend changes and periodic fluctuations in the data are identified. In contrast, ARIMA models have stronger predictive ability and higher flexibility, and they can be adapted to various time series data through parameter adjustment, especially performing well in predicting future data.
Model fitting and prediction classification
When applying the ARIMA model to classify and predict athlete training data, selecting appropriate model parameters (p, d, and q) is crucial. p controls the use of the number of past observations to predict the current value. High p-values increase model complexity and may lead to overfitting. d controls the number of data differentials to make the sequence stationary. Appropriate d-values can eliminate trends, but excessively high d-values may lead to excessive noise. q controls the use of past prediction errors to predict the current value. High q-values increase model complexity and may lead to overfitting.
The first-order differencing is performed on the raw data, and the ADF test is used to perform stationarity test on the difference data. If the data is still non-stationary, second-order differencing is continued to be used. Non-stationary data can undergo logarithmic transformation to reduce its volatility and make it closer to a stationary state. When the differentiated data meets the stationarity requirements, the number of differences (d) is recorded. The values of (p) and (q) are determined by observing significant lag orders through ACF and PACF graphs.
ACF and PACF graphs are used to determine the initial order of the model. AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) are used to further optimize the order selection, ensuring a balance between the complexity and accuracy of the model.
The maximum likelihood estimation (MLE) method is used to set initial parameter values and calculate the initial logarithmic likelihood function value. The numerical optimization algorithms are used to gradually adjust parameter values to maximize the logarithmic likelihood function.29,30 Optimizing and converging to the optimal estimate of parameters are continued iteratively, completing parameter estimation. The formula is as follows: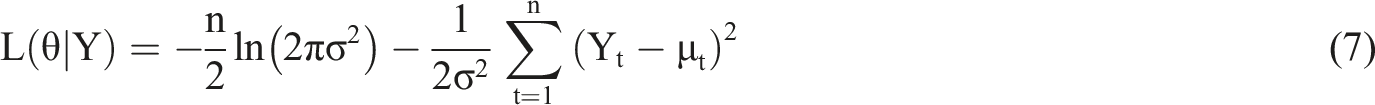
The estimated parameters are substituted into the ARIMA model, and the least squares method is used for model fitting. PCA (Principal Component Analysis) is used to reduce the dimensionality of high-dimensional training data, extract main features, and reduce computational complexity, while maintaining the main information of the data.
The fitting effect of the model is tested through residual analysis. The histogram is used to determine whether the residual satisfies the normal distribution. For residuals that do not meet the normal distribution, data transformation, model adjustment, outlier processing, and non-parametric methods are used to improve the normality of residuals and improve the prediction effect of the model. A residual sequence diagram is drawn and if the residual is white noise (mean is zero, and variance is constant, without autocorrelation) is checked. Ljung–Box test is used to perform autocorrelation test on residuals, ensuring that there is no significant autocorrelation in the residual sequence. Based on residual analysis and model validation results, the model parameters are adjusted for iterative optimization until the model reaches the best fitting effect.
After completing the fitting of the ARIMA model, athlete training data is predicted and classified. Fitted ARIMA models are used for short-term and long-term prediction of training data. At each prediction step, the model is updated with the previous predicted values, which is rolling forecasting. During the prediction process, the predicted and actual values of each step are recorded for subsequent analysis of prediction errors. Inverse differential transformation is applied to restore the predicted results to the original scale, ensuring that the predicted results are consistent with the actual data. The selection of prediction error indicators includes mean-square error, root mean squared error, and mean absolute error.
Statistical features of time series (mean, variance, and autocorrelation coefficient) are extracted, and training data is converted into feature vectors suitable for classification. Grid search and cross-validation techniques are used to find the optimal combination of model parameters. Comparing the performance of the model with default parameters and optimized parameters, the accuracy of the model with default parameters is 70%. The model performance with optimized parameters has an accuracy rate of 85%. It is evident that the performance of the model improves after using grid search and cross-validation techniques. The extracted feature vectors are input into the model for classification tasks. Combining prediction and classification results, the features of categories with high classification errors are analyzed, and feature engineering and model parameter adjustment are performed. Finally, ensemble learning techniques (stacking and voting) are used to integrate the prediction results of multiple classification models, improving the accuracy and robustness of classification. The training data characteristics of different sports events may vary. The ARIMA model has good applicability in handling training data with regular periodicity and gradual improvement, but its limitations are more obvious for sports projects affected by multiple external factors and high-dimensional data.
Improving overall model performance also requires ensemble learning. In this article, Bagging (Bootstrap Aggregating) is selected to extract multiple subsets from the raw dataset with replacement. Then a base learner is trained for each subset (set to 100). Finally, the prediction results of these base learners are combined through voting or averaging.
Evaluation of performance tests
Classification accuracy
To verify the effectiveness of using ARIMA model (M1) for classifying and predicting athlete training data, random forest model (M2), support vector machine model (M3), convolutional neural network model (M4), and long short-term memory model (M5) are selected for comparison. Random forests can handle high-dimensional data and have good robustness to outliers and noise. Support vector machines have demonstrated strong classification capabilities in handling small sample, nonlinear, and high-dimensional pattern recognition and can flexibly handle nonlinear problems through different kernel functions. Convolutional neural networks effectively extract local features from time series data through one-dimensional convolution. As a deep learning model, they can automatically learn complex data representations and are suitable for high-dimensional time series data. Long short-term memory models are adept at processing sequential data, capturing long-term dependencies in time series, and effectively avoiding gradient vanishing problems through their unique memory unit structure, making them suitable for long-term sequence prediction. By comparing these models, the performance of different types of models in athlete training data classification and prediction tasks can be comprehensively evaluated.
As the sample size increases, the performance of the model gradually improves. Training data is randomly selected from 250 athletes, with 10 features including heart rate, step count, speed, training time, calorie consumption, blood oxygen level, sleep time, body fat rate, heart rate variability, and sports type. The time span is 1 year, and the data is recorded once a day. The dataset is divided into training sets (70%) and test sets (30%) to ensure the temporal continuity of the training and testing data.
According to the training performance of athletes, the data is manually labeled into three categories: efficient training (L1), moderate training (L2), and inefficient training (L3). The imputation of missing values, processing of outliers, standardization, and adjustment of seasonal data are performed on training data (section 3.2, data preprocessing, shows details). To ensure fairness in comparison, all models use the same preprocessed data, and each model is trained using the training set. Each model undergoes 10 rounds of cross-validation to avoid overfitting and evaluation bias.
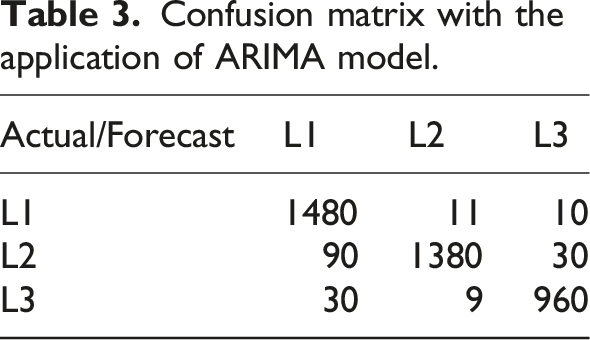
Confusion matrix with the application of ARIMA model.
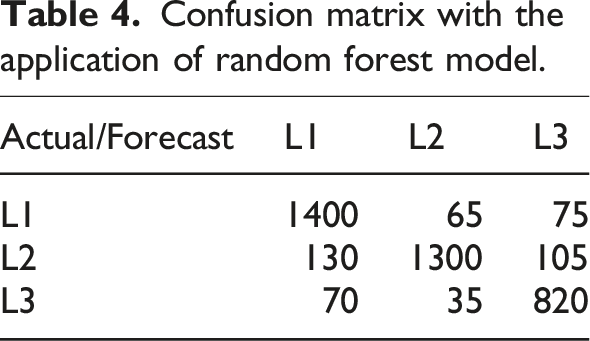
Confusion matrix with the application of random forest model.
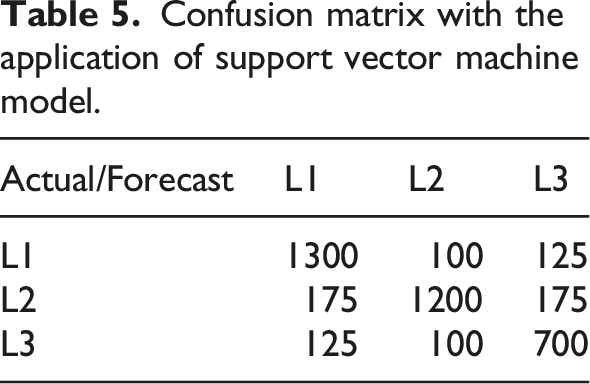
Confusion matrix with the application of support vector machine model.
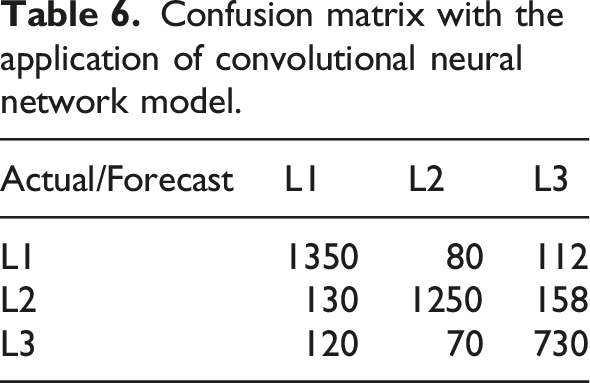
Confusion matrix with the application of convolutional neural network model.
Confusion matrix with the application of long short-term memory model.
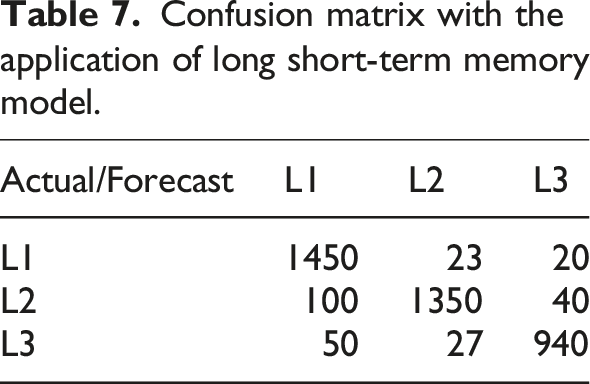
Table 3 shows that among the 4000 data points included in the test set, out of 1600 data points of L1, 1480 are correctly classified; 90 are misclassified as L2; 30 are misclassified as L3. Out of 1400 data points in L2, 1380 are correctly classified; 11 are misclassified as L1; 9 are misclassified as L3. Out of the 1000 data points in L3, 960 are correctly classified; 10 are misclassified as L1; 30 are misclassified as L2.
Table 4 shows that out of 1600 data points in L1, 1400 are correctly classified; out of 1400 data points in L2, 1300 are correctly classified; out of the 1000 data points in L3, 820 are correctly classified.
Table 5 shows that out of 1600 data points in L1, 1300 are correctly classified; out of 1400 data points in L2, 1200 are correctly classified; out of 1000 data points in L3, 700 are correctly classified. Specifically, the accuracy of the support vector machine model in classifying and predicting athlete training performance is lower than that of the random forest model and ARIMA model, and it has significant errors in distinguishing between efficient training, moderate training, and inefficient training.
Table 6 shows that out of 1600 data points in L1, 1350 are correctly classified; out of 1400 data points in L2, 1250 are correctly classified; out of 1000 data points in L3, 730 are correctly classified. The misclassified data points in L1 and L3 are both above 100.
In Table 7, out of 1600 data points in L1, 1450 are correctly classified; out of 1400 data points in L2, 1350 are correctly classified; out of the 1000 data points in L3, 940 are correctly classified. These data indicate that the long short-term memory model has high accuracy in classifying and predicting athlete training data, significantly outperforming random forest, support vector machine, and convolutional neural network models.
The classification accuracy of different models is calculated based on the data from Tables 3–7, as shown in Figure 3. Classification accuracy of different models.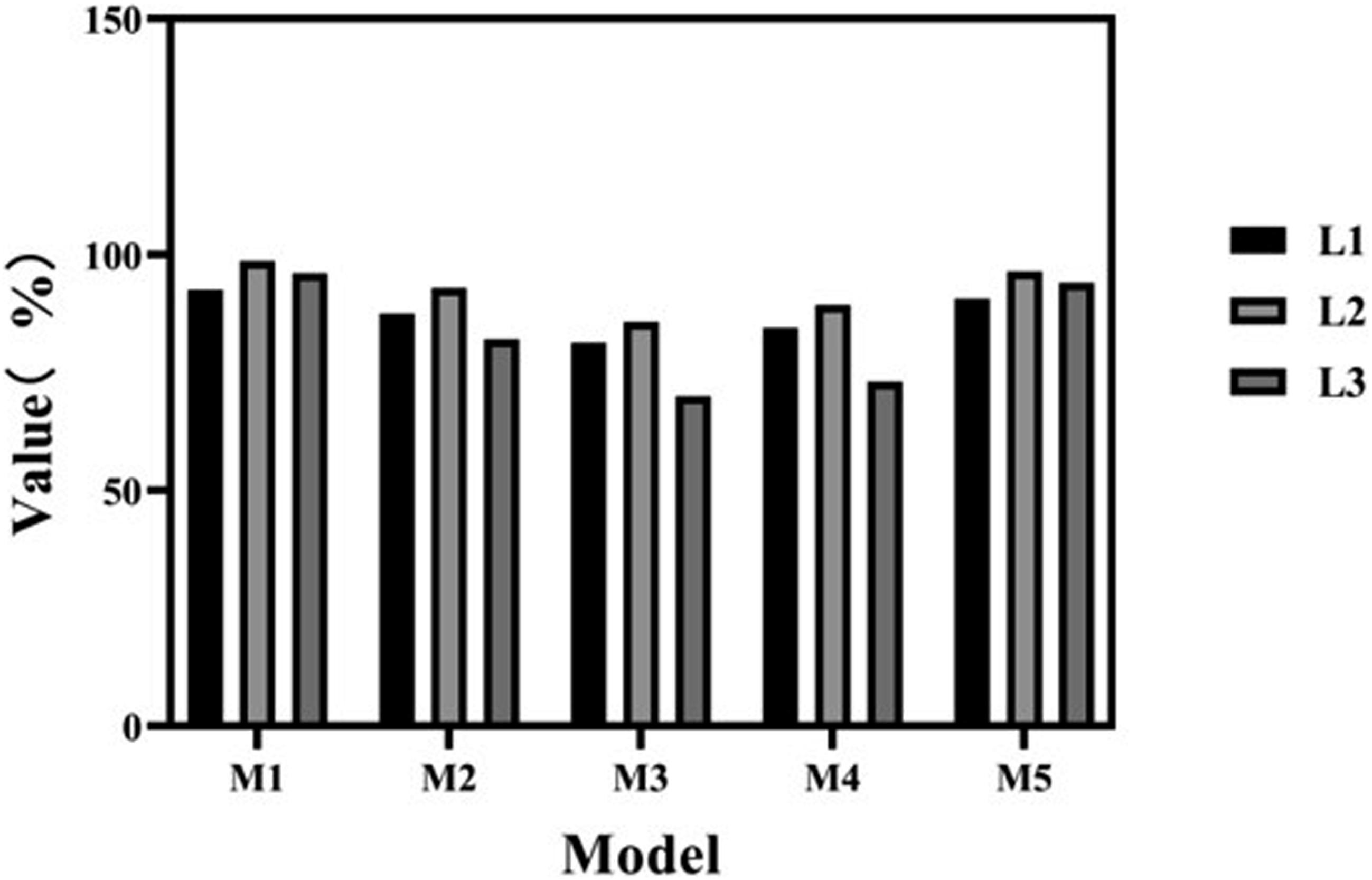
In Figure 3, M1 has the highest accuracy in data classification, all exceeding 92%, followed by M5 with an accuracy of over 90%. The accuracy of data classification in M3 is the lowest.
The average classification accuracy is calculated based on the data in Figure 3, as shown in Figure 4. Average classification accuracy of different models.
In Figure 4, the average classification accuracy of M1 is the highest at 95.7%, followed by M5, with an average classification accuracy of 93.7%. The average classification accuracy of M3 is the lowest, with 79%. The data shows that the application of ARIMA model ensures the classification of athlete training data. Compared to other models, its classification accuracy is 2%–16.7% higher.
Athlete training data is real-time. To ensure the effectiveness of the experiment, the dataset is expanded by selecting athlete data from different sports events (football, basketball, athletics, swimming, and gymnastics), with 500 athletes selected for each sports event to ensure the representativeness of the data sample. As with the above operation, it can be calculated that the average classification accuracy of M1 is still the highest, at 93.68%. Then they are sorted by high and low, M5, M2, M4, and M3 in sequence, with 91.93%, 90.53%, 88.97%, and 85.23%, respectively.
Prediction accuracy
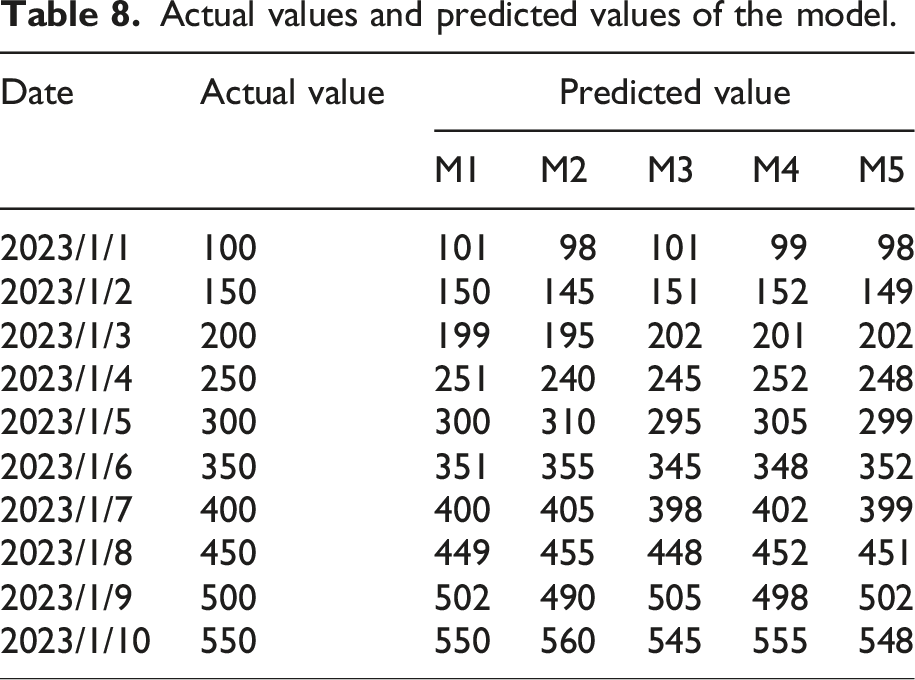
Actual values and predicted values of the model.
Prediction errors of each model.
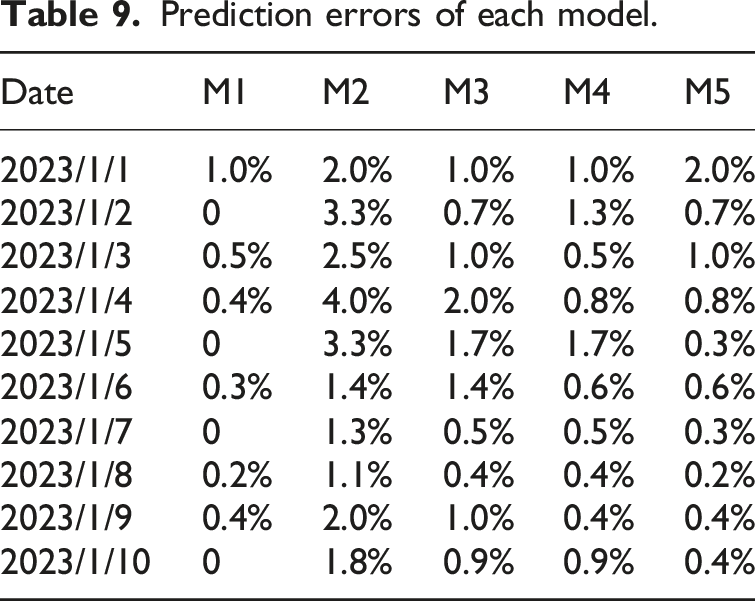
Table 9 provides a detailed calculation of the prediction errors for each model within 10 days. The prediction error of M1 on all dates is below 1.0%. In contrast, M2 has a larger prediction error, exceeding 1.5% on many dates. The prediction error of M3 is relatively stable, with only 2 days of error exceeding 1.5%. The prediction error of M4 and M5 is mostly within 1.5%. Through comparative analysis, it can be seen that M1 has the smallest prediction error and more accurate prediction results, and it can better reflect the actual training data.
The average prediction error of each model is calculated based on the data in Table 9, as shown in Figure 5. Average prediction error of each model.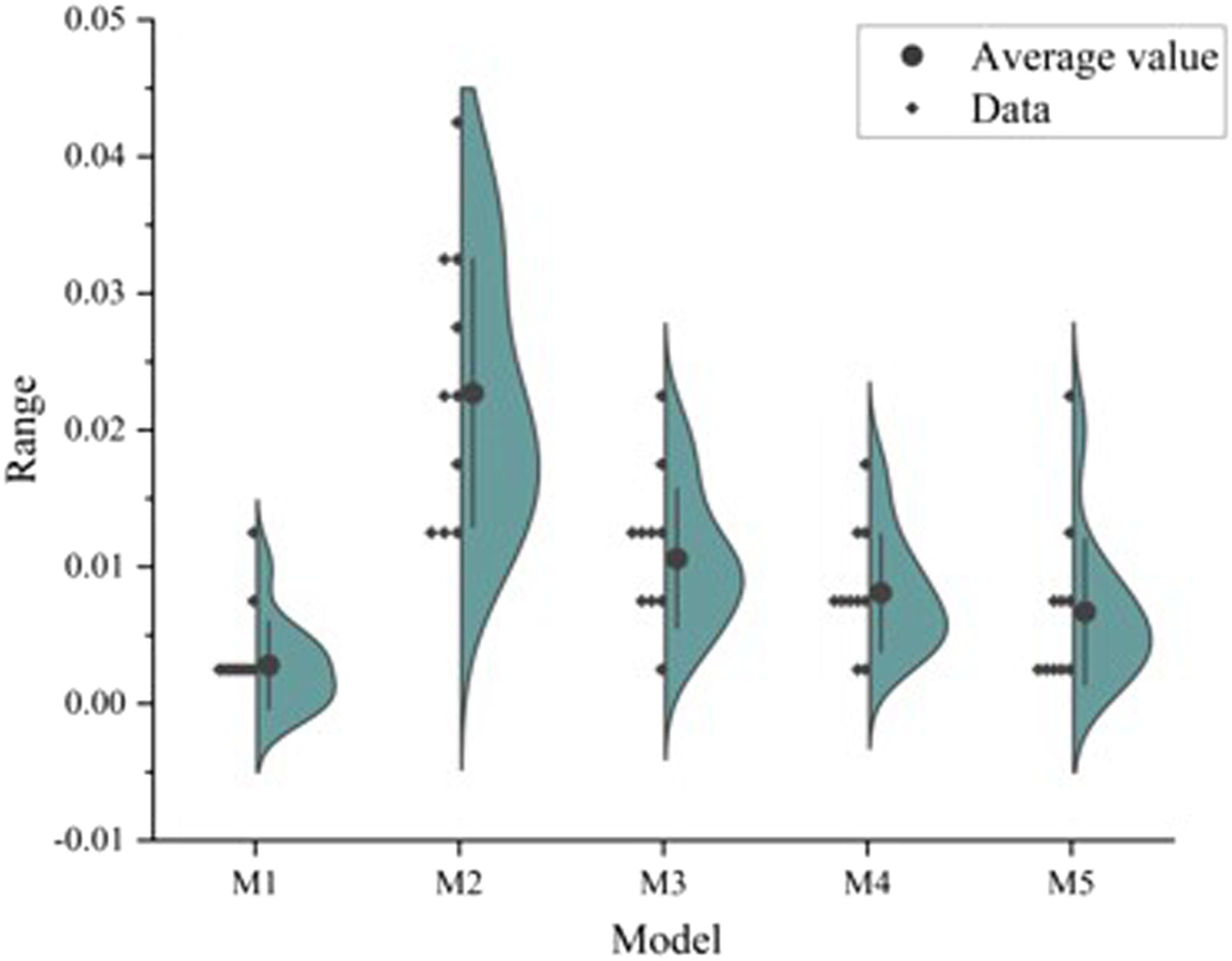
Prediction accuracy of each model.

Table 10 clearly shows that M1 has the highest prediction accuracy, reaching 100%, followed by M4 and M5, both at 90%, while M3 has an accuracy of 80%, showing relatively good performance. M2 has the lowest prediction accuracy, only 30%. These results indicate that M1 is the most reliable prediction model, followed by M4 and M5, while M2 has lower prediction accuracy and needs further improvement.
In addition to evaluating the accuracy and prediction error of the ARIMA model, the stability of the model on different time windows and datasets is good and does not require improvement.
High-dimensional data processing
High-dimensional data processing situations.
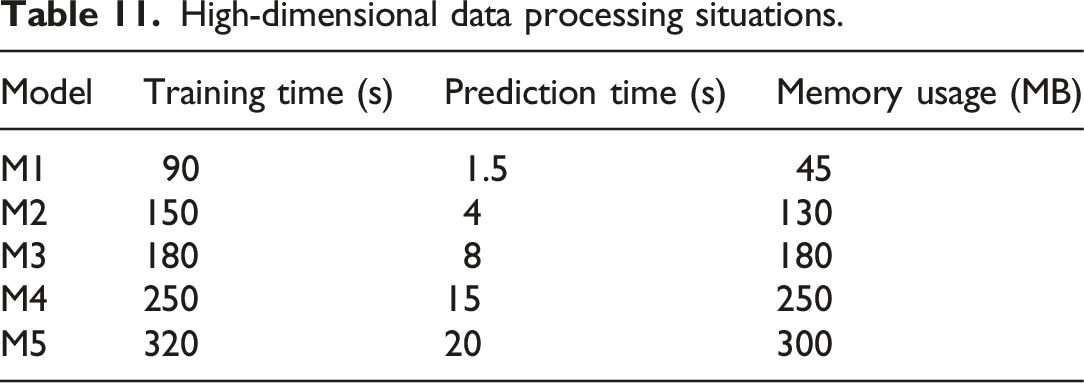
In Table 11, M1 has the shortest training time of only 90 seconds, which is significantly better than other models, indicating its high efficiency in high-dimensional data processing. The training time of M2 and M3 is relatively short, with 150 seconds and 180 seconds, respectively. The training time of M4 and M5 is relatively long, with 250 seconds and 320 seconds, respectively.
M1 has the shortest prediction time, only 1.5 seconds, demonstrating its fast prediction ability. The prediction time of M2 and M3 is 4 seconds and 8 seconds, respectively, showing good performance. The prediction time of M4 and M5 is relatively long, with 15 seconds and 20 seconds, respectively.
M1 has the least memory usage, only 45 MB, which is a significant advantage in resource-limited environments. The memory usage of M2 and M3 is 130 MB and 180 MB, respectively. M4 and M5 use more memory, with 250 MB and 300 MB, respectively.
From the above results, it can be seen that M1 has significant advantages in processing high-dimensional data. It not only has shorter training and prediction time but also has the least memory usage, making it suitable for classifying and predicting training data in environments with limited computational resources. Although other models perform well in certain aspects, overall, M1 is more efficient and resource friendly.
Conclusion
This article uses the ARIMA model-based athlete training data classification and prediction method to collect and preprocess athlete training data, and uses time-series analysis to identify the time-dependent and seasonal components of the data. Finally, the best parameter fitting model is selected for classification and prediction. Experiments have shown that the ARIMA model significantly outperforms other models in classification accuracy, with small prediction errors and strong high-dimensional data processing capabilities. However, the ability of this article to handle extreme outliers and nonlinear trends is limited. The ARIMA model performs well in classifying and predicting athlete training data, helping coaches and athletes understand training effectiveness and optimize training plans, thereby preventing overtraining and injuries, improving performance and recovery efficiency. Future research directions include deep learning feature extraction to enhance model predictive ability, multi-source data fusion to provide comprehensive support, and the application of more nonlinear and hybrid models to better capture complex data patterns and trends. Optimizing model parameters and improving data collection systems can further enhance the accuracy and practicality of the model.
Statements and declarations
Footnotes
Conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Hunan Provincial Department of Education (Key projects): Reform and practice of mixed teaching of badminton course in colleges and universities under the teaching mode of “split class” in the new era (No: HNJG-2022-0279).