
Abstract
With the advent of the big data era, anomaly detection becomes increasingly crucial for ensuring the security and reliability of systems. This paper investigates large-scale anomaly detection based on the Isolation Forest algorithm, enhancing the algorithm’s performance in the context of big data by introducing the method of adaptive feature selection. The proposed approach is a fusion of the Isolation Forest and adaptive feature selection, dynamically adjusting feature weights to adapt more flexibly to the contributions of different features. Experimental results on large-scale datasets demonstrate that adaptive feature selection significantly improves the anomaly detection performance of the Isolation Forest algorithm. This method provides a new perspective for enhancing anomaly detection techniques and addressing the challenges posed by large-scale, high-dimensional data. Its practical implications are crucial for real-world applications.
Keywords
Introduction
With the rise of the big data era, the security and reliability of large-scale systems have become critically important. The rapid growth of massive data has brought unprecedented opportunities to various industries, while also presenting significant challenges. As a key technical approach, anomaly detection is widely used to ensure the normal operation of systems and the security of data. Its goal is to identify anomalies that significantly deviate from normal patterns within large-scale data, thereby preventing potential risks and failures. However, traditional anomaly detection methods often exhibit high computational complexity, poor adaptability, and difficulties in handling data imbalance when faced with large-scale, high-dimensional data.
Traditional anomaly detection methods are typically based on statistical, 1 clustering, 2 or machine learning techniques. 3 For example, statistical-based methods (such as Z-score and Grubbs test) rely on assumptions about data distribution, making them unsuitable for complex high-dimensional data 4 ; clustering-based methods (such as K-means and DBSCAN) incur significant computational overhead when processing large-scale data and are sensitive to parameter settings 5 ; while supervised learning-based methods (such as support vector machines and neural networks) require large amounts of labeled data, making them less effective in addressing data imbalance issues. 6 These limitations restrict the applicability of traditional methods in big data environments.
To address the challenges of anomaly detection in large-scale, high-dimensional data, the Isolation Forest algorithm has garnered significant attention due to its efficient computational performance and superior capability in handling anomalous data. By randomly selecting features and split points to construct isolation trees, Isolation Forest can quickly identify anomalies, making it particularly suitable for high-dimensional data and large-scale datasets. However, despite its outstanding performance in anomaly detection, Isolation Forest still faces several challenges in practical applications. 7 For instance, high-dimensional data may contain many redundant or irrelevant features, which can affect the algorithm’s detection accuracy. Additionally, data imbalance issues may reduce the algorithm’s ability to detect minority-class anomalies.
To further enhance the performance of the Isolation Forest algorithm in big data environments, this paper focuses on introducing an adaptive feature selection method. By dynamically adjusting the weights of features, the algorithm can more flexibly adapt to the contribution of different features to anomaly detection, thereby addressing the limitations of the existing Isolation Forest in the context of big data. This improvement not only enhances the detection accuracy of the algorithm but also strengthens its adaptability to high-dimensional and imbalanced data, providing new perspectives and solutions for the further optimization of anomaly detection methods.
This paper is organized as follows: In Section 2, we review related work on big data anomaly detection. Section 3 presents model of the proposed methodology. In Section 4, we present the adaptive feature selection algorithm. In Section 5, we present the experimental setup and results analysis, and we conclude the paper in Section 6.
Related work
In the fields of anomaly detection and feature selection, researchers have proposed various methods and techniques that have been widely applied in different scenarios. Below, we review related research from four aspects: anomaly detection methods, feature selection techniques, applications of Isolation Forest, and advancements in adaptive feature selection.
Anomaly detection methods
Anomaly detection is a crucial research direction in data mining and machine learning, aiming to identify data points that significantly deviate from normal patterns. Traditional anomaly detection methods can be broadly categorized into the following types. (1) Statistical-based methods: Such as Z-score, Grubbs test, and Gaussian distribution-based methods.
8
These methods rely on assumptions about data distribution and are suitable for low-dimensional data but perform poorly on high-dimensional data. (2) Machine learning-based methods: Such as Support Vector Machines (SVMs), K-Nearest Neighbors (KNNs), and clustering algorithms (e.g., K-means and DBSCAN).
9
These methods identify anomalies by constructing models or calculating distances between data points. However, they face challenges such as high computational complexity and parameter sensitivity when applied to large-scale data. (3) Deep learning-based methods: Such as Autoencoders and Generative Adversarial Networks (GANs).10,11 These methods extract data features through nonlinear mappings and can handle complex high-dimensional data but require large amounts of labeled data and computational resources.
Although these methods have achieved certain success in different scenarios, they still face challenges such as low computational efficiency and insufficient model robustness when dealing with large-scale, high-dimensional data.
Feature selection methods
Feature selection is a critical step in improving the performance of anomaly detection. Its goal is to select the most representative features from the original feature set to reduce computational complexity and enhance model performance. Traditional feature selection methods mainly include the following three categories. (1) Filter methods: Such as Chi-square test, mutual information, and information gain.12–14 These methods evaluate the relevance between features and target variables for feature selection, offering high computational efficiency but ignoring interactions between features. (2) Wrapper methods: Such as Recursive Feature Elimination (RFE) and genetic algorithm-based feature selection.15,16 These methods iteratively train models to evaluate the performance of feature subsets, achieving high accuracy but at the cost of significant computational overhead. (3) Embedded methods: Such as Lasso regression and decision tree-based feature selection.17,18 These methods integrate feature selection into the model training process, balancing efficiency and performance.
However, these methods often face trade-offs between efficiency and accuracy when dealing with large-scale, high-dimensional data.
Applications of isolation forest in anomaly detection
Isolation Forest is a tree-structure-based anomaly detection algorithm that has gained widespread attention due to its computational efficiency and suitability for high-dimensional data. Its core idea is to construct isolation trees by randomly selecting features and split points, isolating anomalies on shorter paths, thereby effectively detecting anomalies.
7
The advantages of Isolation Forest include. (1) High computational efficiency: Its time complexity is (2) No assumptions about data distribution: It can handle complex high-dimensional data. (3) Sensitivity to anomalies: It can quickly identify data points that significantly deviate from normal patterns.
In recent years, Isolation Forest has been widely applied in fields such as network security, financial fraud detection, and industrial fault diagnosis.19–22 However, Isolation Forest may be affected by redundant features when processing high-dimensional data, leading to reduced detection performance.
Advancements in adaptive feature selection
Adaptive feature selection methods are a class of emerging techniques proposed in recent years to address feature selection challenges.23–25 These methods dynamically adjust feature weights or selection strategies, allowing for more flexible adaptation to changes in feature contributions to models. Examples include. (1) Weight adjustment-based methods: These methods dynamically adjust feature weights by evaluating their importance, thereby improving model robustness. (2) Reinforcement learning-based methods: These methods optimize the feature selection process using reinforcement learning algorithms, enabling efficient feature selection in complex data environments.
Adaptive feature selection methods offer significant advantages in improving model robustness and accuracy, particularly in scenarios involving large-scale, high-dimensional data.
In summary, the current research trend is to introduce more intelligent and adaptive methods into anomaly detection to address the challenges posed by large-scale, high-dimensional data. This paper combines Isolation Forest with adaptive feature selection techniques to propose an improved anomaly detection method. By dynamically adjusting feature weights, the method aims to enhance the algorithm’s performance on high-dimensional and imbalanced data, providing new research insights for further optimization of anomaly detection methods.
Isolation forest algorithm model
Isolation Forest is a tree-structure-based anomaly detection algorithm, whose core idea is to isolate anomalies by randomly partitioning the feature space. Since anomalies typically exhibit significantly different feature distributions compared to normal points, they tend to have shorter path lengths within the tree structure. Specifically, the Isolation Forest constructs multiple isolation trees by randomly selecting features and split points. Due to their sparse distribution and distinct characteristics, anomalies can be isolated in fewer partitioning steps, resulting in shorter path lengths within the tree structure. By calculating the average path length of a sample across all trees, the Isolation Forest effectively measures its anomaly score: the shorter the path length, the higher the degree of anomaly. This mechanism, based on random partitioning and path length, enables the Isolation Forest to achieve high efficiency and robustness when handling high-dimensional data and large-scale datasets.
Mathematical model of isolation forest
Assume there is a dataset
Subsampling
A subset S of size

Tree Building
A binary tree is constructed recursively. At each node, a feature dimension

Path length calculation
For each sample

Anomaly scoring
The anomaly score for each sample is measured based on the average path length and its standard deviation. Typically, samples with shorter path lengths are considered more likely to be anomalies. The anomaly score



Algorithm flow of isolation forest
The algorithm flow of the Isolation Forest is shown in Figure 1. Algorithm flow of isolation forest.
The Isolation Forest algorithm operates as follows: First, the dataset
Adaptive feature selection algorithm
The core idea of the adaptive feature selection algorithm is to dynamically adjust the weights of features, enabling the model to better adapt to the varying contributions of different features to anomaly detection. This algorithm integrates the Isolation Forest model with adaptive feature selection methods, iteratively optimizing feature weights to improve the accuracy and robustness of anomaly detection.
The adaptive feature selection algorithm dynamically adjusts feature weights to optimize the anomaly detection performance of the Isolation Forest model. The algorithm begins by initializing the weights of each feature, typically setting them to equal values or based on prior knowledge. Subsequently, the algorithm constructs an Isolation Forest model using the current weights and calculates the anomaly scores of the samples. Based on the model’s output, the contribution of each feature is computed, usually measured by the number of splits or information gain of the feature in the tree structure. The feature weights are then dynamically updated according to their contributions, increasing the weights of high-contribution features and decreasing the weights of low-contribution features. Finally, the above steps are repeated until the feature weights converge or a predetermined number of iterations is reached, thereby achieving continuous optimization of anomaly detection performance.
Mathematical model of the adaptive feature selection algorithm
Assume there is a dataset
Initialize feature weights
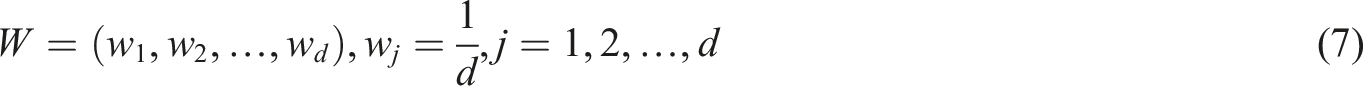
Build isolation forest model
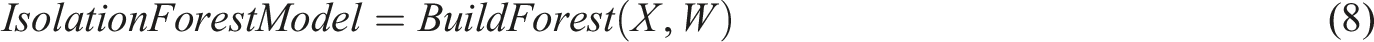
Calculate feature contribution
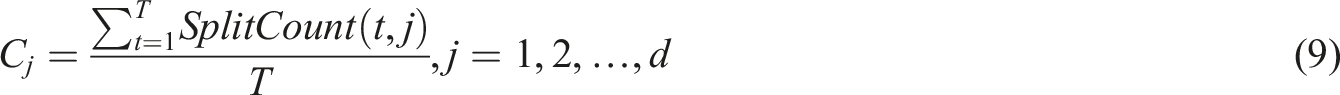
Update feature weights

Iterative optimization
Repeat steps 2–4 until convergence or the maximum number of iterations is reached.
Pseudocode of the adaptive feature selection algorithm
The pseudocode for the adaptive feature selection algorithm is described as follows:

The overall time complexity of the adaptive feature selection algorithm is:
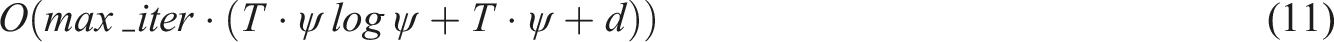
Optimization of the adaptive feature selection algorithm
Although the adaptive feature selection algorithm demonstrates excellent performance in enhancing the anomaly detection capabilities of the Isolation Forest model, it still faces challenges in computational efficiency and robustness when dealing with high-dimensional data and large-scale datasets. To further optimize the algorithm’s performance, this paper proposes the following two optimization directions: optimization of feature contribution calculation and optimization of the weight update strategy.
Optimization of feature contribution calculation
In the current algorithm, the feature contribution is measured by counting the number of splits of each feature in the tree structure. Although this method is simple and intuitive, calculating the split counts for all features in high-dimensional data can lead to high computational complexity. To address this, this paper proposes the following optimization methods.
Introduction of information gain and gini index
The feature contribution can be measured using information gain or the Gini index, which can more accurately reflect the contribution of features to anomaly detection. Specifically, the contribution

Approximation and sampling techniques
To reduce computational costs, random sampling techniques can be employed to calculate contributions for only a subset of trees or features. For example, randomly select T′ trees (T′≪T) and d′d′ features (d′≪d) to compute the approximate contribution:

This approach significantly reduces computational complexity while maintaining calculation accuracy.
Optimization of weight update strategy
The current algorithm updates feature weights by normalizing feature contributions. Although this method is simple, it may not fully capture the complex relationships between features and is susceptible to noise in the data. To address this, this paper proposes the following optimization strategies.
Introduction of regularization terms
We introduce an L2 regularization term during the weight update process to prevent overfitting of the weights. The updated feature weights WW can be calculated using the following formula:

Dynamic adjustment of update step size
To accelerate the convergence of weight updates, introduce a dynamically adjusted step size η. Specifically, the step size η can be adjusted based on the rate of change in feature contributions:

Consideration of feature correlations
We also introduce a feature correlation matrix R during the weight update process, where

This optimization method can better capture the interactions between features, improving the accuracy of weight updates.
Experimental design and data analysis
To comprehensively evaluate the performance of the adaptive feature selection algorithm and its optimization methods, this paper designs five sets of performance experiments and conducts comparative analyses on multiple public datasets. The following sections elaborate on the experimental setup, comparison methods, experimental results, and data analysis.
The experimental environment includes hardware configurations with an Intel Core i7-10750H @ 2.60 GHz CPU, 16 GB DDR4 RAM, and an NVIDIA GeForce GTX 1660 Ti GPU. The software environment consists of the Ubuntu 20.04 LTS operating system, Python 3.8 programming language, and major libraries such as Scikit-learn, NumPy, Pandas, and Matplotlib. Experiments are conducted on multiple public datasets, including KDD Cup 1999, 26 Credit Card Fraud Detection, 27 MNIST, 28 and NSL-KDD, 29 to comprehensively evaluate the algorithm’s performance.
The experimental parameter settings include the number of trees (n_estimators) in the Isolation Forest model set to 100, subsample size (max_samples) set to 256, maximum tree depth (max_depth) set to 10, and minimum sample split size (min_samples_split) set to 2. For the adaptive feature selection algorithm, the maximum number of iterations (max_iter) is set to 10, and the convergence threshold (epsilon) is set to 0.01. In the optimization methods, the regularization coefficient (lambda) is set to 0.1, and the initial step size (eta_0) is set to 0.01, ensuring consistent and comparable performance evaluation across different datasets.
The comparison methods include the traditional Isolation Forest, the original adaptive feature selection algorithm, the optimized adaptive feature selection algorithm, Local Outlier Factor (LOF), 30 and One-Class Support Vector Machine (One-Class SVM). 31 The traditional Isolation Forest does not use feature weight adjustment, the original adaptive algorithm calculates feature contributions based on split counts, the optimized algorithm introduces information gain and dynamic step size for weight updates, LOF detects anomalies based on density, and One-Class SVM separates anomalies by constructing a hyperplane. These methods are used together to comprehensively evaluate the performance of the proposed algorithm.
The experiments evaluate the performance of each method in terms of accuracy, recall, F1 score, and runtime.
Experimental design for model accuracy and generalization ability
To evaluate the accuracy and generalization ability of the adaptive feature selection algorithm and its optimization methods, this paper designs the following experiments. The experiments test the performance of the models on multiple datasets and analyze their performance under different data distributions to verify the robustness and generalization ability of the models.
First, the Isolation Forest, the original adaptive feature selection algorithm, and the optimized adaptive feature selection algorithm are trained using the KDD Cup 1999 dataset, and their performance on the training set is recorded. Then, the trained models are applied to the NSL-KDD, Credit Card Fraud Detection, and MNIST datasets to test their generalization ability under different data distributions. Additionally, 5% random noise is introduced into the NSL-KDD and Credit Card Fraud Detection datasets to test the robustness of the models under noisy data. Finally, the accuracy, recall, and F1 score of each model on the training set, test set, and noisy data are compared to evaluate the accuracy and generalization ability of the models.
Comparison of model accuracy and generalization ability of different algorithms.
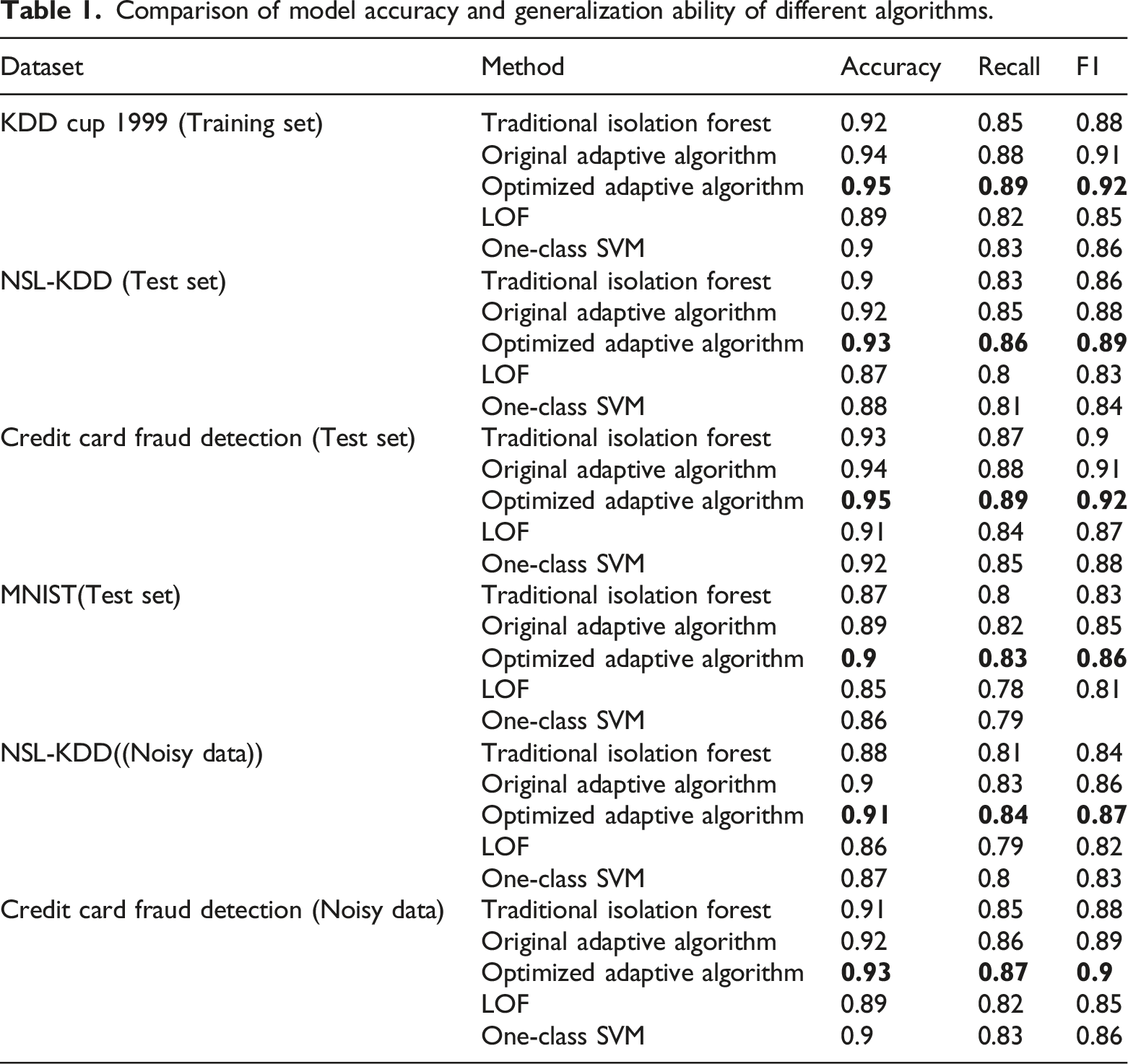
From Table 1, it can be observed that the optimized adaptive feature selection algorithm outperforms both the traditional Isolation Forest and the original adaptive algorithm in terms of model accuracy and generalization ability. On the training set, the F1 score of the optimized algorithm reaches 0.92, which is 1% higher than that of the original algorithm and 4% higher than that of the traditional Isolation Forest. In cross-dataset testing, the F1 score of the optimized algorithm on the NSL-KDD dataset is 0.89, representing a 1% improvement over the original algorithm and a 3% improvement over the traditional Isolation Forest. In noisy data testing, the F1 score of the optimized algorithm is 0.87, demonstrating higher robustness.
The optimized adaptive feature selection algorithm surpasses the Isolation Forest, the original adaptive algorithm, LOF, and One-Class SVM in both model accuracy and generalization ability. This algorithm not only achieves higher accuracy under known data distributions but also adapts well to different data distributions and noisy environments, exhibiting strong generalization ability and robustness. This provides a more reliable solution for anomaly detection in large-scale, high-dimensional data.
Comparison of model algorithm training time and inference time
This experiment evaluates the training time and inference time of the Isolation Forest, the original adaptive feature selection algorithm, the optimized adaptive feature selection algorithm, Local Outlier Factor (LOF), and One-Class Support Vector Machine (One-Class SVM) on large-scale datasets. The experiment involves training and testing these algorithms on the KDD Cup 1999, Credit Card Fraud Detection, and MNIST datasets, recording their training and inference times, and conducting a comparative analysis of the computational efficiency of each algorithm.
Comparison of Model Training and Reasoning time.

From Table 2, it can be observed that the optimized adaptive feature selection algorithm outperforms the Isolation Forest, the original adaptive algorithm, LOF, and One-Class SVM in both training time and inference time. On the KDD Cup 1999 dataset, the training time of the optimized algorithm is 35.2 seconds, which is 27.7% less than that of the original algorithm and 22.3% less than that of the Isolation Forest. On the Credit Card Fraud Detection dataset, the inference time of the optimized algorithm is 0.7 seconds, representing a 22.2% reduction compared to the original algorithm and a 12.5% reduction compared to the Isolation Forest. This indicates that the optimized algorithm achieves higher computational efficiency during both the training and inference phases, significantly reducing time consumption and providing better real-time performance. It offers a more efficient solution for anomaly detection in large-scale datasets.
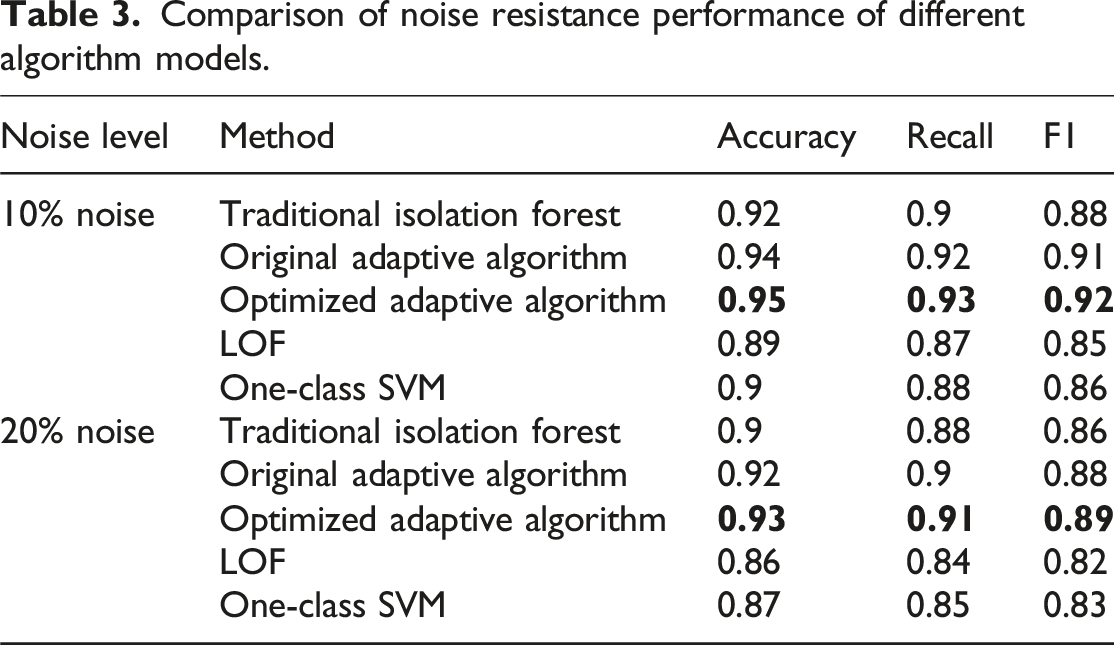
Comparison of model noise resistance capability
To evaluate the stability and accuracy of different algorithms in noisy environments, this paper designs a noise resistance capability experiment. The experiment compares the performance of Isolation Forest, the original adaptive feature selection algorithm, the optimized adaptive feature selection algorithm, Local Outlier Factor (LOF), and One-Class Support Vector Machine (One-Class SVM) in noisy data environments by introducing varying levels of noise into the data.
The experiment begins by preprocessing the UCI KDD Cup 99 dataset and adding 10% and 20% random noise, respectively. Next, the Isolation Forest, the original adaptive feature selection algorithm, the optimized adaptive feature selection algorithm, LOF, and One-Class SVM are trained on datasets with no noise, 10% noise, and 20% noise. Then, the accuracy, precision, recall, and F1 score of each algorithm under different noise levels are recorded. Finally, by comparing the performance differences of the algorithms under different noise levels, their noise resistance capabilities and stability are analyzed.
Comparison of noise resistance performance of different algorithm models.
Comparison of model parameter sensitivity
To evaluate the sensitivity of different algorithms to hyperparameters, this paper designs a parameter sensitivity experiment. The experiment analyzes the impact of key hyperparameters on algorithm performance by adjusting those of the Isolation Forest, the original adaptive feature selection algorithm, the optimized adaptive feature selection algorithm, Local Outlier Factor, and One-Class Support Vector Machine.
Comparison of model parameter sensitivity of different algorithm models.
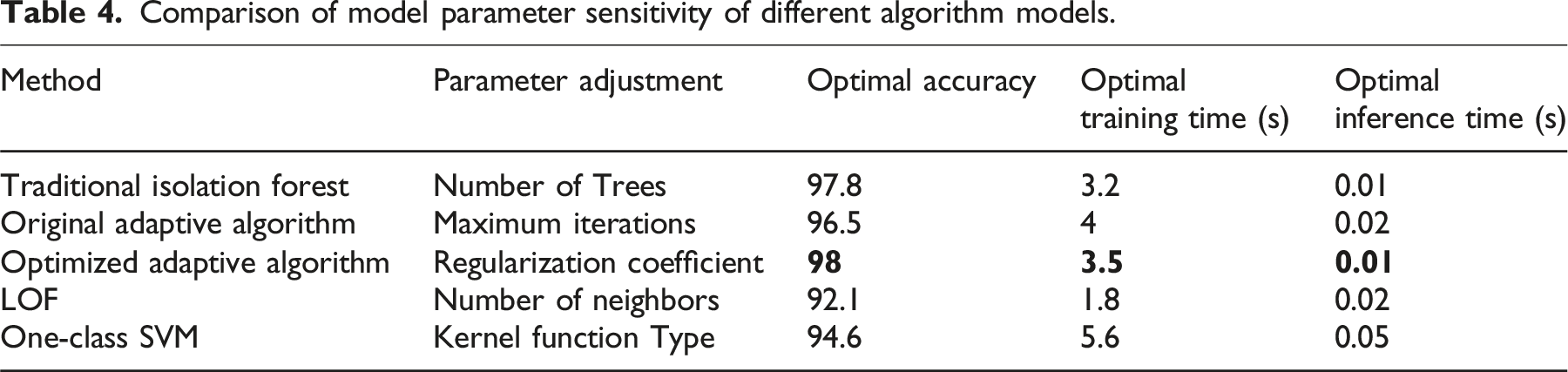
Additionally, the original adaptive algorithm is sensitive to the maximum number of iterations. Increasing the number of iterations can improve accuracy but significantly increases training time. Overall, each algorithm demonstrates different characteristics in parameter optimization. Optimizing appropriate parameter configurations can effectively enhance model accuracy and efficiency, especially when dealing with large-scale data, where reasonable parameter selection is particularly crucial.
Conclusion
This paper proposes an adaptive feature selection method based on the Isolation Forest algorithm to enhance anomaly detection performance in big data environments. Traditional Isolation Forest algorithms face challenges such as feature redundancy and computational inefficiency when handling high-dimensional and large-scale data. In contrast, the adaptive feature selection method improves the model’s sensitivity to anomalies by dynamically adjusting feature weights. Experimental results demonstrate that the proposed improved method significantly outperforms the traditional Isolation Forest algorithm on multiple large datasets, particularly in handling high-dimensional data, showcasing strong adaptability and robustness.
Despite the achievements of this study, some limitations remain. First, the current method primarily focuses on optimizing feature selection. Future work could explore integrating other anomaly detection algorithms to develop a more accurate and efficient comprehensive anomaly detection framework. Second, the performance of the proposed method on real-time data streams has not been thoroughly investigated. Therefore, future research could explore algorithm improvements from the perspectives of online learning and incremental learning to adapt to dynamic data changes. Finally, the experiments in this paper are limited to specific datasets. Future work could extend the evaluation to broader application scenarios to validate the algorithm’s generalizability and scalability.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.