
Abstract
This paper investigates feature selection methods based on hybrid architecture using feature selection algorithm called Adapted Fast Correlation Based Feature selection and Support Vector Machine Recursive Feature Elimination (AFCBF-SVMRFE). The AFCBF-SVMRFE has three stages and composed of SVMRFE embedded method with Correlation based Features Selection. The first stage is the relevance analysis, the second one is a redundancy analysis, and the third stage is a performance evaluation and features restoration stage. Experiments show that the proposed method tested on different classifiers: Support Vector Machine SVM and K nearest neighbors KNN provide a best accuracy on various dataset. The SVM classifier outperforms KNN classifier on these data. The AFCBF-SVMRFE outperforms FCBF multivariate filter, SVMRFE, Particle swarm optimization PSO and Artificial bees colony ABC.
Keywords
Introduction
Feature selection (FS) selects an optimum subset of features from the huge features available. The FS algorithms can be divided in three main categories: filter, wrapper and embedded methods. The filter methods are independent of any classification algorithm and evaluate the usefulness of feature, or a set of features, through measures of distance, dependency, correlation on data. Feature ranking are applied for high dimensionality problems [1]. The best ranked features are selected as input of a classifier.
Multivariate feature selection methods measure the interaction between features and select the best subset of features [2, 3]. In contrast, univariate methods evaluate each feature individually. Furthermore, due to the computational cost of the search algorithms used in feature selection, feature ranking methods are widely used in practice [4].
Popular filter methods include Relief [5, 6] Correlation based feature selection [7], Minimum Redundancy Maximum Relevance [8], fast correlation based filters [9], T-score, which is based on t-statistics measuring correlations between input features and output class labels. The filters are fast, computationally simple, evaluated based on criteria like entropy, correlation, mutual information, probabilistic distance measures [10, 11]. The principal filters drawback is they do not interact with the classifier and the majority of proposed methods ignores features dependency which affect classification performance negatively when compared to other FS techniques [1].
The wrappers are computationally expensive [1] and find feature subset that achieves higher accuracies by embedding classifier into the feature selection phases. Popular wrapper and embedded methods include support vector machines recursive feature elimination [2] and its variants Random forest RFE [12]. Classifiers such as boosting algorithms, SVM are applied to rank the features and distinguish relevant samples for classification [2]. The embedded methods incorporate the classifier in a FS construction process, but less computational expensive than filters.
Various evolutionary computation (EC) techniques have proved their performance for FS such as Genetic algorithm (GA) [13, 14], Particle swarm optimization (PSO) [15, 16], Ant Colony Optimization (ACO) [17], Artificial Bee Colony [18] and Differential evolution (DE) [19].
Hybrid FS methods combine two or more FS approaches in multiples stages including filter-wrapper, wrapper-wrapper, or filter inside wrapper, wrapper inside filter. The wrapper could be an evolutionary or swarm algorithm. For high dimensional dataset, applying filter is required to reduce the computational cost, after that, wrapper is performed to enhance the quality of selected features previously.
Kai et al. [20] described multiple SVM-RFE approach, where the SVM was trained on multiple subsets of data and the genes were ranked using statistical analysis, and demonstrated its effectiveness in choosing genes in microarray data. From the experiments, it was found that SVM-RFE (Correlation) outperformed SVM-RFE (mRMR) in terms of classification accuracy.
The proposed FS method [21] hybridized artificial bee colony (ABC) and differential evolution (DE) algorithm and described a new binary neighborhood search mechanism. The experimental results show that the proposed hybrid method is better than ABC and DE.
Akadi et al. [22] designed a two stages FS algorithm by combining the minimum Redundancy and maximum Relevance (mRMR) filter approach and GA in gene selection. Firstly, the mRMR discards irrelevant genes. Secondly, GA selects the highest discriminative gene subset. The results indicate that the proposed method finds the smallest efficient gene subset compared to GA and mRMR.
Filter-wrapper feature selection algorithm is proposed in [23]; the filter measure encodes the position of each particle in particle swarm and the classifier evaluates the solution in the fitness function. The experiments validate that the proposed method slightly outperforms a binary PSO based filter method.
Jiang et al. [24] designed a novel approach measuring the correlation between a continuous and discrete feature. An efficient filter FS algorithm named efficient correlation measure based filter (ECBMF) removes irrelevant features. Comparative studies were carried out on twenty UCI dataset and show that the proposed algorithm outperforms the others FS methods in both accuracy and dimensionality reduction.
The proposed approach is based on embedded method SVMRFE incorporated in multivariate filter FCBF. The FCBF filter identifies the predominant features but unable to guarantee high accuracy; SVMRFE is an efficient FS method in term of accuracy and weak for discarding redundant features.
The present work combines both multivariate filter FCBF and embedded method SVMRFE for feature selection task to benefit from them. We propose a hybrid algorithm with FCBF and Support Vector Machine recursive feature elimination SVMRFE by searching relevant and complementary features and discarding noisy features.
The adapted FCBF-SVMRFE incorporates inside FCBF filter the embedded SVMRFE method to find complementary features. Firstly, filter is used at the first stage; the idea consists of taking every feature and removes all correlated features with it, then; the SVMRFE method is applied to evaluate the impact on the performance. If the results are better, we test the next feature and so on, if not, the features are restored and then avoid decreasing the performance. The main objectives addressed in this work are:
Obtain the highest accuracy by machine learning algorithm, identify the smallest subset of relevant features, discard all redundant features and modify SVMRFE algorithm to remove worst features instead of only one at each execution for original algorithm. Increase the performance by finding complementary features and compare the hybrid proposed method with existing methods: GA, PSO, and SVMRFE.
This paper is organized as follows. Section 2 describes filter ranking methods FCBF, SVM-RFE methods and presents a related work on FS algorithms. Section 3 explains the proposed architecture. The numerical experiments are demonstrated on medical datasets from UCI database in Section 4. The performance of the proposed algorithm are validated and compared with existing approaches in Section 5. Finally, the results were discussed followed with conclusion in Section 6.
Fast correlation-based filter
Filters Ranking Methods assign a weight to each feature and rank it accordingly. Filter techniques assess the relevance of the features based only on the properties of the data. In general, a feature relevance score is computed and low scoring features are removed [4].
The fast correlated based filter method [9] is a multivariate algorithm (FCBF) based on relevance redundancy approach and was conceived with two main phases: FCBF starts by selecting a set of features characterized by high correlation with the class using symmetric uncertainty (SU) defined Eq. (1), then, sorts these values into a list. It applies heuristics that removes the redundant features and keep the features that are more relevant to the class. SU is the ratio between the information gain and the entropy of two features. FCBF is effective to remove redundant and irrelevant features. The experimental results [9] validate the efficiency of the FCBF method, faster than both Correlation Feature Selection (CFS) and ReliefF.
where
Guyon et al. [2] proposed an embedded FS algorithm Support vector machine recursive feature elimination (SVM-RFE). SVM-RFE is a FS method that uses SVM weights as the ranking criterion of features. It has two versions: linear and nonlinear. The non linear SVMRFE uses a specific kernel strategy and is more appropriate for non linear decision function [25]. This method starts with all features, uses criteria from SVM models coefficients to assess features, and recursively removes features that have small values.
Related work
Yu and Liu [2] present a filter ranking method based on symmetrical uncertainty measure. The proposed algorithm searches the predominant features first; then, removes the redundant features from that set. In this paper, the authors show that feature relevance alone is insufficient for efficient feature selection of high-dimensional data. They define feature redundancy and propose to perform explicit redundancy analysis in feature selection.
Zhang et al. [25] propose a novel hybrid approach by correlation-based filters and Support Vector Machine Recursive Feature Elimination (SVM-RFE) method for robust feature selection. In the first stage, they incorporate correlation-based filters to identify predominant Features and Complementary Features, and generate multiple groups for robustness; in the second stage, they aggregate multiple groups with SVM-RFE into a compact feature subset for high classification accuracy. Experimental results on both UCI data sets and microarray data sets have proved the effectiveness of the proposed approach.
Djellali et al. [26] designed two hybrid FS methods: multivariate filter fast correlation based filter FCBF and PSO (FCBF-PSO) and FCBF with genetic algorithm (FCBF-GA), FCBF-PSO combines in two phases particles swarm PSO and In first stage, FCBF filter is applied and provides a subset of features (relevant and no redundant), in the second stage, PSO is performed with previous selected features and executed on five UCI datasets. The experiments show that FCBF-PSO and FCBF-GA (genetic algorithm replace PSO) are competitive.
Authors [27] designed a framework based on a genetic algorithm (GA) for feature subset selection that combines various existing feature selection methods. This approach can find small subsets of features that perform well. The experiments were conducted using three existing feature selection methods entropy, T-statistics, and SVM-recursive feature elimination (RFE) on three datasets. The experimental results demonstrate that this approach is a robust and effective approach to find subsets of features with higher classification accuracy and smaller size compared to each individual feature selection algorithm.
Ferreira et al. [28] constructed two feature selection ranking filters for high-dimensional datasets, with a relevance-redundancy approach working in unsupervised or supervised mode. The experimental evaluation validated the efficiency of this method. According to authors, as compared to wrapper approaches, the selected features of this approach may not be the best for any classifier.
Baretta et al. [6] proposed modified filter ranking ReliefF called sReliefF and sTurRF to identify relevant features. Simulation analysis demonstrated that in presence of gene interactions these methods efficiently scale down large scale datasets to improve the computational cost of data mining algorithms and extract optimal features from genetic datasets.
Freeman et al. [29] examined a number of filter-based feature subset evaluation measures with the aim of assessing their performance to specific classifiers. This work tests 16 filter measures with K-nearest neighbors KNN and SVM classifierson 20 real and 20 artificial datasets. The results indicate that KNN classifiers work well with subset based RELIEF, correlation feature selection, whereas Fisher’s interclass separability criterion and conditional mutual information maximization work better for SVM. For KNN classifiers, the best filter measures are Correlation based feature selection CFS, and subset RELIEF.
Tapia et al. [30] described a method for performing sparse and stable gene selection from a number of unstable, but low cost, SVM-RFE units. It was shown that the introduction of a consensus constraint with respect to variations in the policy of gene removal improves gene selection precision. This method is validated on three benchmark microarray datasets.
Piyushkumar et al. [31] investigated filter approaches to gene selection to improve computational complexity and stability. In backward elimination method, a modified logistic regression loss function selects relevant samples. Tscore ranks the genes. The stability and computational complexity are improved compared to SVM based methods without reducing the accuracy.
Moldonado and Weber [32] introduced a novel wrapper algorithm using support vector machines with kernel functions. This method performs a sequential backward elimination of features. This approach has been tested on four datasets, outperforms other filter and wrapper techniques and provides high classification performance.
Apolloni et al. [33] investigated two new hybrid FS algorithms, called respectively Binary Differential Evolution BDE Xrank and BDE XRankf. The information gain values ranks the features in a first stage; the second stage, the BDE based wrapper method performs a search for a best solution. All initial solutions are generated with a reduced number of features. Four classifiers (KNN, C4.5, Naïve Bayes, SVM) have been used on six high dimensional microarray data. This approach reduces the size by 90% and achieves highly results.
Cadenas et al. [34] proposed hybrid FS approach based on fuzzy random forest, it can work with both crisp and uncertain data and integrated a filter and wrapper method into a sequential search procedure with improved classification accuracy of the features selected. This method achieves good performance with smaller number of features.
Maka et al. [35] investigated various wrapper and filter techniques for reducing the feature dimension of pairwise scoring matrices and demonstrated that these two types of selection techniques are complementary to each other. Two fusion strategies used to combine the ranking criteria of filter and wrapper methods. It was shown that feature subsets selected by the fusion methods are superior to those selected by the individual on microarray dataset.
Proposed adapted fast correlation SVMRFE based feature selection method
The embedded Support vector machine recursive feature elimination (SVMRFE) algorithm is incorporated in the Fast correlation based feature selection FCBF as shown in Fig. 1. The main idea is to evaluate both symmetrical uncertainties for features then measures the accuracy with classifier. The comparison between two accuracies at iteration I and I-1 before removing these features and after, if the current accuracy decreases that means, even if these features are redundant, they are complementary and then we restore them. The key idea is to remove for each relevant feature j its redundant features
Flowchart of the proposed adapted feature selection.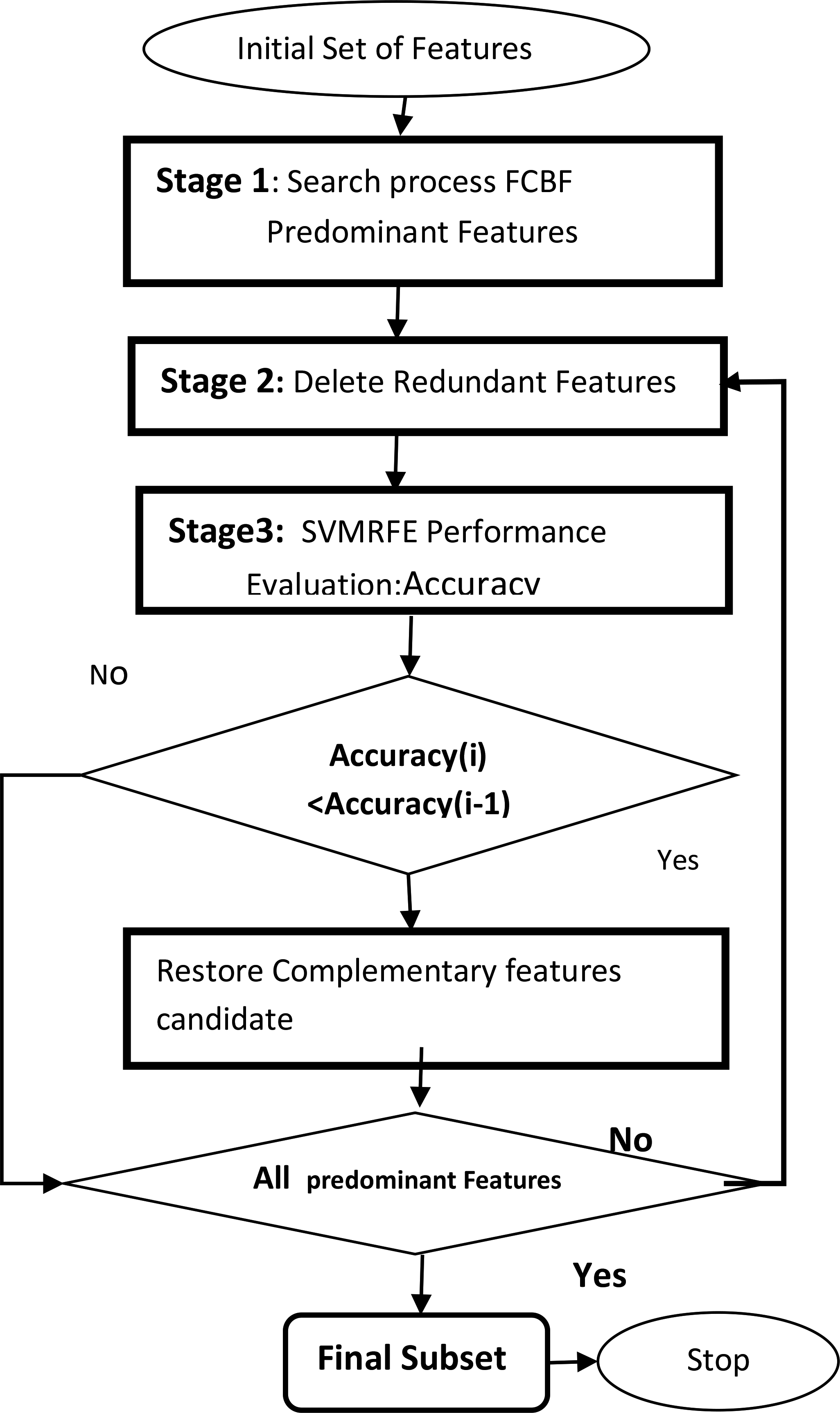
The Adapted fast correlation based filter algorithm (Fig. 1) consists of three stages:
Stage 1 The first stage is the relevance analysis, aims at ordering the input variables depending on relevance scores which is computed as the symmetric uncertainty with the respect to the target output. This phase discards irrelevant variables, which have a ranking score below a predefined threshold. Stage 2 The redundancy analysis phase selects predominant features from the relevant set obtained in the first stage. Each predominant feature has its redundant features removed. Stage 3 The third stage apply SVMRFE algorithm to evaluate the impact of removed features on accuracy. However, if the accuracy at iteration I decrease in comparison to accuracy at iteration I-1, it indicates that these features are complementary and cannot be removed. Consequently, deleted features are restored in the list of selected features. This process is repeated (stage 2 and 3) for all predominant features.
To avoid high computational time due to excessive SVMRFE execution for each predominant feature, the number of redundant feature removed is counted. If this number is greater than ten 10% percent of total number of features, we apply SVMRFE. This choice ensures:
Reduce the number of execution of SVMRFE algorithm. All complementary features obtained contribute to improve accuracy. However, we know that only a subset of these features improves the performance, the proposed solution is to perform a function SearchComplementary.
The adapted FCBF-SVMRFE tests the previous and current accuracy depending on the size of features: the restoration stage (if Cp
The procedure SVMRFE is a FS method that uses SVM weights as the ranking criterion of features. It was proved that removing more than one feature at each execution is more accurate [2]. The previous resulted subset is used as input for SVMRFE method. It has three steps:
Experimental results
In this section, we first describe the experimental settings, we empirically evaluate the performance of the proposed feature selection method Adapted FCBF-SVMRFE on different classifiers: Support vector machine, K nearest neighbors (KNN). We also compare the proposed algorithms AFCBF-SVMRFE with five FS methods (Table 1).
List of tested algorithms
List of tested algorithms
ABC and PSO are employed as wrapper approach using accuracy of classifiers SVM, KNN respectively as fitness function: We employ ABC-KNN; ABC-SVM and PSO-KNN, PSO-SVM.
To assess the performance of the proposed feature selection algorithms, we choose the dataset from UCI [40] machine learning repository. The datasets properties are summarized in Table 2.
Datasets used in the experimental study
Datasets used in the experimental study
The quality of the subsets of features obtained from the proposed method is validated using two machine learning algorithms: Knearest neighbors (KNN), Support Vector Machine (SVM) on eight UCI dataset.
Support Vector machine is a robust supervised learning method [36] and generalize well in different applications. For multiclass problem, one versus all classification technique is applied [37]. K nearest neighbors KNN [38] is an efficient algorithm that stores all cases and classifies new cases based on a majority vote of its neighbors (distance measure). KNN is used in pattern recognition and machine learning.
Parameters setting of FS algorithms
We describe the parameters setting of different FS algorithms: PSO, ABC, SVMRFE and hybrid FCBF-SVMRFE. All algorithms are implemented by using MATLAB 7.0. Each dataset is split into training and test set. Classification accuracies of AFCBF-SVMRFE, PSO, ABC, SVMRFE are measured by the standard k
Setting parameters
Setting parameters
Different existing methods were studied to compare the effectiveness of the proposed method. Five methods were applied: ABC, PSO, FCBF, SVMRFE, hybrid FCBF-SVMRFE.
Regarding PSO, the position of particle is encoded using binary digits. Each bit set to 1 or 0 represents selected or unselected feature. The particles are initialized randomly.
The hybrid two stages FCBF-SVMRFE method consists of applying FCBF filter method on all features then the resulted subset of features are used as input of SVMRFE embedded method. The threshold is set to zero and X% of features removed for SVMRFE at each execution.
Experiments on proposed FS methods
The results of numerical experiments are summarized in Table 4. SVM and KNN classifier are used to evaluate the accuracy on the selected feature subset.
WDBC and hepartitis performance
WDBC and hepartitis performance
The experiments on WDBC data (Table 4) show that Adapted AFCBFSVMRFE accomplishes the best SVM accuracy (97.059%) and 25 features in comparison with ABC (95.30% and 15 features), PSO (96.86%; 17 features).
As can be learned from hepatitis in Table 4, the hybrid AFCBF-SVMRFE algorithm and FCBF achieve best SVM classification accuracy with 100% and 13 features selected. PSO realizes less accuracy 83.33% with SVM than AFCBFSVMRFE but provides minimal number of features (9). ABC (86.50% and 12 features). Lung Cancer as shown in Table 5, PSO achieves (94.44% SVM accuracy, 27 features) and outperforms the proposed AFCBFSVMRFE with accuracy of 79.40% on SVM classifier and FCBF-SVMRFE algorithm (88.89%). The proposed method AFCBFSVMRFE is better than both FCBF and SVMRFE. PSO realizes the best accuracy for KNN (
Lung cancer and arrythmia
The results on Arrythmia shown in Table 5 demonstrate that PSO (84.61% and 159 features) outperforms the proposed AFCBFSVMRFE and ABC (83.45% and 170 features). However, AFCBFSVMRFE with SVM accuracy 79.08% and 237 features is more efficient than FCBFSVMRFE which realizes the accuracy of 68.55% with 171 features, FCBF (68.88% and 2010 features) and SVMRFE (70.50% and 210 features).
The lung cancer has 4 restored features with 79.4% SVM accuracy, 12 restored for arrhythmia (79.08%) and 455 features restored for colon cancer (94.44%) increasing accuracy.
Colon cancer as shown in Table 6, AFCBFSVMRFE performs well with accuracy of (94.44%) on SVM classifier better than ABC (88.81%), FCBF (83.30%), SVMRFE (81.25%) and 87.10% for FCBF-SVMRFE algorithm. In contrast, ABC achieves minimal number of features (981) compared to other methods. ABC accomplishes the best performance for KNN (
Colon cancer and DLBCL performance
The results on DLBCL in Table 6 demonstrate that AFCBFSVMRFE outperforms all FS methods (100.00% accuracy and numbers of features 2293) on SVM classifier better than FCBF (85.70%), SVMRFE (91.30%) and FCBF-SVMRFE (100.00%) and ABC (88.75%). However, ABC realizes minimal number of features (1541).
As can be learned from Fig. 2, the minimal number of features is realized with adapted AFCBFSVMRFE on leukemia Fig. 2f and prostate Fig. 2h. The hybrid approach FCBFSVMRFE accomplishes 5 features on WDBC Fig. 2a where PSO succeed to reach the minimum subset in Fig. 2b on hepatitis (9); arrhythmia (159) Fig. 2d and DLBCL (2068) Fig. 2g. The best result is achieved with ABC on lung cancer Fig. 2c and colon Fig. 2e.
Comparison of FS methods of number of features on different datasets on SVM classifier.
For leukemia data, the AFCBFSVMRFE method provides the best performance in SVM accuracy 100.00% and less numbers of features 366 as shown in Table 7. AFCBFSVMRFE achieves the best performance (85.70%) for KNN with
Leukemia and prostate performance
The experiments carried out demonstrate that the adapted AFCBF-SVMRFE method with KNN classifier outperforms the feature selection methods: FCBF, SVMRFE and FCBF-SVMRFE for all datasets.
The SVM classifier performs well than KNN classifier for all FS methods including existing approaches and proposed method like shown in Tables 5–7.
It has been found that the proposed method Adapted FCBF-SVMRFE is more accurate than the exiting FS methods (FCBF, SVMRFE, FCBF-SVMRFE, PSO and ABC) for classifying the hepatitis, WDBC, colon, DLBCL, leukemia and prostate.
The two stages FCBF-SVMRFE method is more efficient than FCBF filter method and embedded approach SVMRFE. The SVMRFE performs well than FCBF filter approach.
Restored features constitute a subset of features from the set of complementary features with random selection and classifier accuracy that are efficient for increasing the performance in term of accuracy and feature size reduction.
The complementary features when restored partially and well selected with classifier criterion is a good technique to restore the best features randomly. The proposed method is relevant with high size. However, some parameters influence the performance like the size of limit variable (chosen 10% of the feature size).
The adapted FCBF-SVMRFE method provides a list of restored features that are dependent of the size of redundant features. This number is critical; the reason is the restoration of features depends on the improvement of accuracy. If this number is high, it means that some features might be irrelevant. The tradeoff must be conducted between keeping complementary features and removing irrelevant features to guarantee the best choice of features subset.
Conclusion
In this paper a hybrid approach called adapted AFCBF-SVMRFE based on filter method FCBF and embedded SVMRFE was proposed. The SVMRFE is incorporated in FCBF filter. The experiments conducted validated the novel algorithm in term of SVM and KNN classification accuracies and number of features better than existing method.
Restored features from the set of complementary features with random selection and classifier accuracy provide an optimal subset of features. To avoid high computational cost, the proposed algorithm does not restore only complementary features but might restore irrelevant features. This drawback is acceptable because of the increase of the classifier accuracy. The future work intends to enhance the ability of AFCBFSVMRFE for features restoration.