
Abstract
This paper introduces a novel self-correcting convolution module that significantly differs from traditional convolution techniques by enabling multi-scale feature extraction through heterogeneous kernel processing and feature calibration. The module uniquely combines down-sampling and up-sampling operations within a single convolution block to capture both local and global contexts, addressing key limitations in existing methods. In addition, an improved Dice loss function is proposed, which integrates both under- and over-segmentation penalties through an mDice loss. This is combined with a cross-entropy loss based on classification to optimize segmentation performance. The proposed self-correcting convolution segmentation algorithm demonstrates superior accuracy in segmenting lung infection regions compared to existing methods, particularly the AMSU-Net network. Experimental results indicate that the inclusion of multi-scale spatial information and refined loss functions significantly enhances segmentation precision. The novelty of this research lies in the introduction of a self-correcting convolution module that improves the receptive field and the diversity of extracted features. Furthermore, the enhanced mDice loss function, integrating segmentation penalties, contributes to improved model performance. This method offers a promising advancement in lung infection segmentation using deep learning techniques.
Introduction
The design of convolutional neural networks in recent years has focused on more complex architectures and increasing the depth or width of the network to enhance network feature representation. When the sampling module of the lung CT pneumonia infection region segmentation model uses a residual network, small size convolution and extraction of spatial dimension and channel dimension information are used, and using this approach can leave the model lacking a large perceptual field to capture sufficiently high-level semantics of the lung infection region features. There is still room for improvement in infection region segmentation when using the residual network as the sampling module.1–4
Luc
5
et al. applied GANs to the field of image segmentation, using segmentation networks to predict segmented regions on the original image. VGG16 is used as the backbone network to build the model U-Net. The pyramid pooling module (PPM) is adopted to strengthen the extraction of deep information while retaining the original information as much as possible, so as to obtain more abundant high-level semantic information.
6
Inception attention module (lAM) is proposed to capture richer shallow features by paralleling multiple convolution kernels of different sizes to increase the combination of receptive fields.
7
Kalene
8
et al. used U-Net network training to detect segmentation. However, these methods,9–13 including Swin-UNet,
14
either lack efficient multi-scale processing or require significant computational resource. Our self-correcting convolution differs fundamentally by • employing parallel processing of features at different scales within a single convolution block; • implementing dynamic feature calibration between scales; • maintaining computational efficiency comparable to standard convolutions.
Sampling module improvements
Self-correcting convolution adaptively builds dependencies of spatial and channel dimensions around each spatial location through self-correction, therefore allowing the sampling module to generate more recognizable feature representations and obtain richer information about the infected area.
Assuming an input feature of

Assuming that the input image is 1 × H × W, the output feature size is C × H × W after convolution with channel C. When using this conventional convolution for feature extraction, the learning patterns of the convolution kernels are all similar. In addition, the perceptual field at each different spatial location in the convolutional feature transform is mainly controlled by the size of the convolutional kernel set in advance. Therefore, a convolutional layer network stacked with this type of convolution will lack a large enough receptive field and will have limited features observed at each convolutional step to capture sufficiently high-level semantic features. These two features may lead to low recognition of the feature extraction map.
The self-correcting convolution proposed in this paper divides the convolution kernel of a particular layer unevenly into two parts and utilizes the two convolution kernels in a heterogeneous manner. Instead of performing all convolutions uniformly on the input in the original space, the self-correcting convolution divides the original input into two parts, one part converts it into smaller resolution low-dimensional information by down sampling, which is used to extract large size infected region features, and the other part performs the convolution operation normally, which is used to obtain small size infected region features. Finally, the convolutional transform that has undergone low-dimensional embedding is used to calibrate the other part of the convolutional transform performed normally. Through this heterogeneous convolution and communication between convolution kernels, the perceptual field of each spatial location can be effectively expanded.
The down-sampling operation of the self-correct branch reduces the feature resolution by four times through mean pooling, enabling it to capture features of larger infected areas. Subsequently, the resolution is restored through bilinear interpolation up-sampling and calibrated with the features of the conventional convolution branch using the Sigmoid activation function. This heterogeneous design enables the model to capture both local details and global context simultaneously, while traditional convolutions rely only on fixed kernel sizes and cannot dynamically adjust receptive fields.
The implementation process is shown in Figure 1. Let the size of the original feature map X be C × H × W. First, the number of channels is split into two parts Self-correcting convolution step.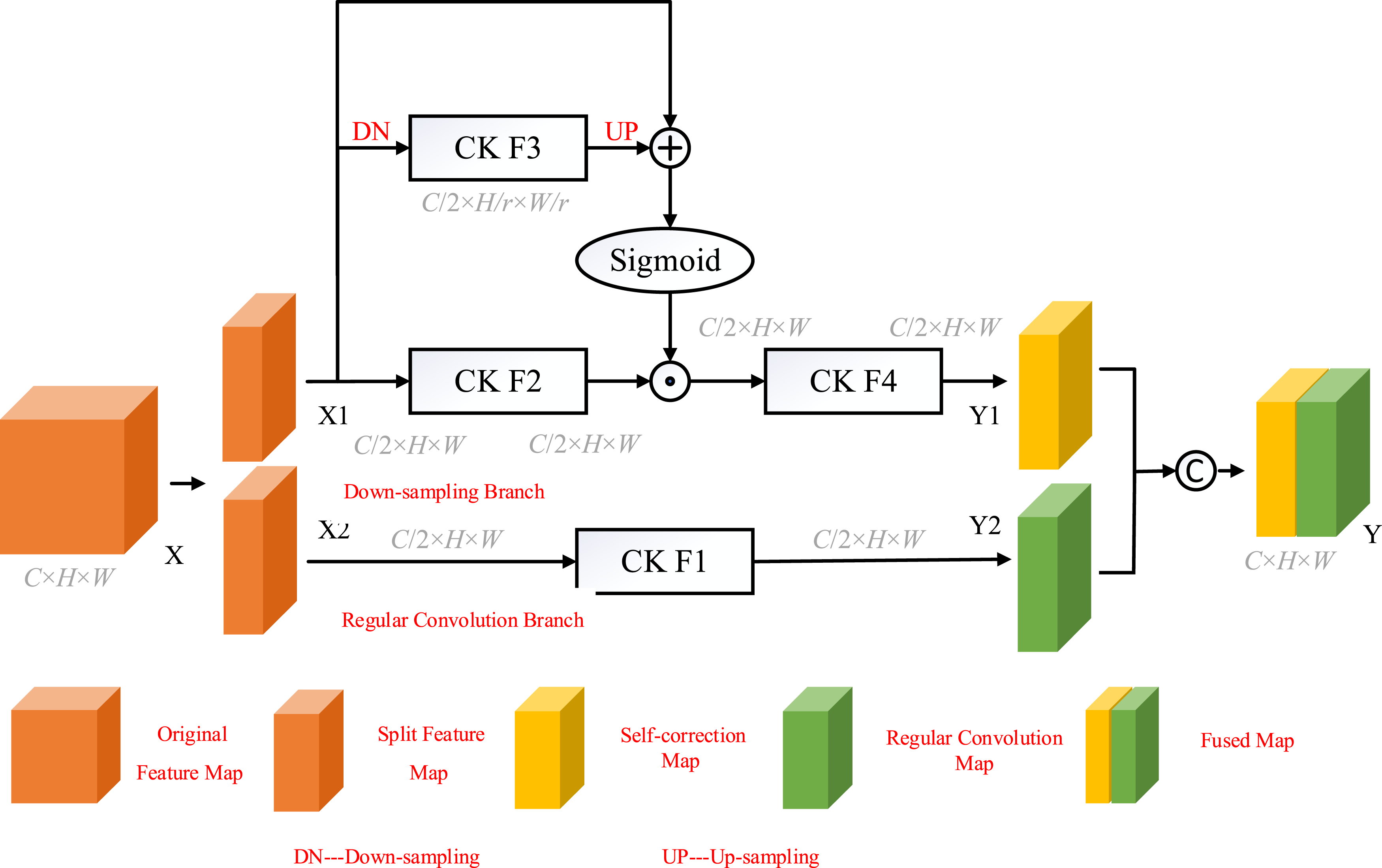
For self-correcting branches, 4-fold down sampling was first performed using mean pooling:

Immediately after the convolution operation, a 4-fold up sampling was performed using bilinear interpolation:

The output feature
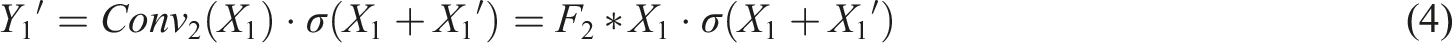
Output features obtained by F4 convolution

For regular convolution branches, the convolution operation is performed directly on the input features:

The final output feature Y is obtained by fusing
Self-correcting convolution performs convolutional feature extraction in two different scale spaces. One is featuring extraction in the original scale space, which has the same resolution as the input original features, and the other is a special space extraction with smaller resolution after down-sampling. Self-correcting convolution is a multi-scale feature extraction module in which the convolutional field is increased by down-sampling in the self-correcting branch, and each spatial location can be used to fuse information from two different scale spaces by self-correcting operations. The diversity of the output features is further enhanced by the diverse use of convolutional filters. From Figure 1, the self-correcting convolution does not introduce additional learning parameters that increase the complexity of the algorithm.
The self-correcting convolution is an improvement on the convolution used in the original sampling module, where all four scales of convolution use a convolution kernel of 3 × 3. In this paper, the self-correcting convolution is embedded in the residual structure to form a sampling module with self-correcting convolution and multi-scale extraction of lung infection region features of different sizes.
As shown in Figure 2, in this paper the self-correcting convolution is used to form the sampling block instead of the original convolution in the residual network. The above sampling unit consists of a normalization layer, a ReLU activation function, and a self-correcting convolution block. A 1 × 1 convolution kernel is added to the constant mapping in the residual network. The 1 × 1 convolution has better representation capability and improves the extraction of features in the infected region of the lung. Self-correcting convolutional sampling module.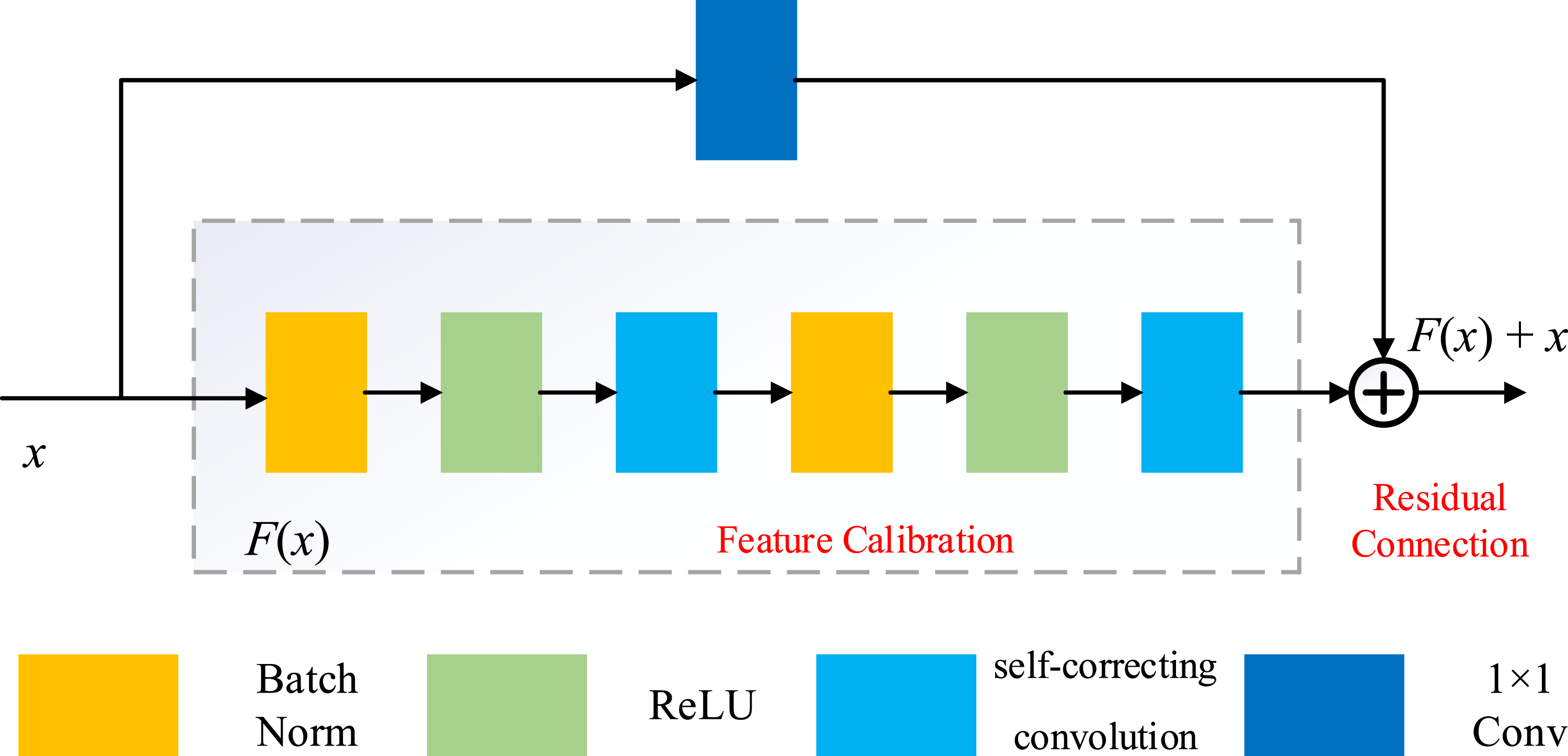
Optimization of the loss function
The Dice loss function lacks the ability to handle over- and under-segmentation cases, which can affect the final segmentation results. In this paper, we improve on the original Dice loss function and propose a new mDice loss function.
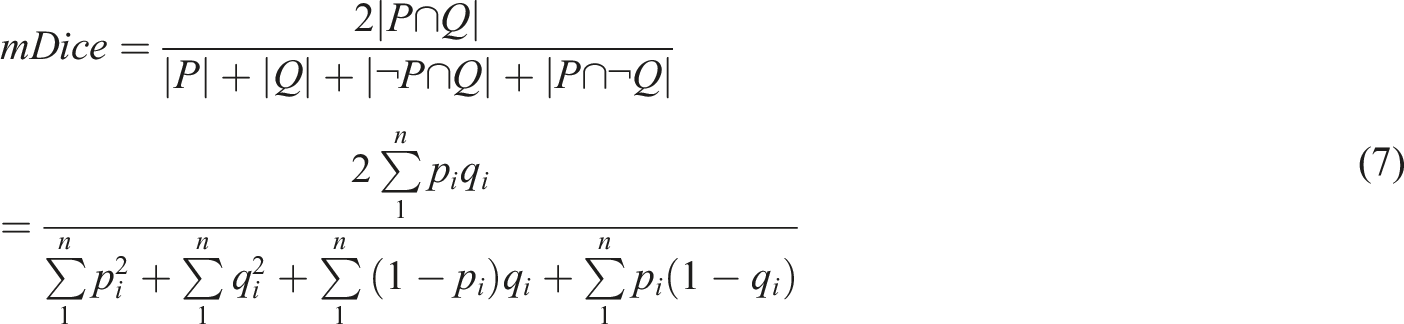
The mDice coefficient adds two expressions to the Dice coefficient formula, where
The segmentation network designed in this paper can be regarded as a pixel-to-pixel classification task, that is, to determine whether a pixel point is a lung infection region or a background region, which is a binary classification problem, so a binary cross-entropy loss function with weights can be used as the loss function of the model, whose equation is shown in 8:
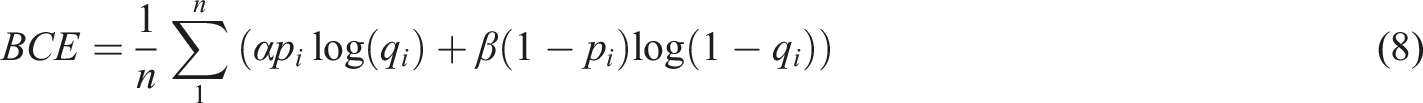

In order to fully exploit the advantages of the mDice loss function and the cross-entropy loss function, the two are combined linearly using two different weight coefficients to form a new loss function, which is calculated as follows:

The loss function combines a binary cross-entropy loss function for classification with an mDice coefficient loss function for measuring the similarity of the predicted results to the true results. Thus, during the training of the segmentation algorithm, the loss function is continuously reduced while maximizing the correct rate of pixel classification of lung infection lesions and the overlap between the predicted lesion region map and the real infection map.
Self-correcting convolutional segmentation algorithm
In this paper, the sampling unit in the MSU-Net encoder-decoder architecture is replaced by a self-correcting convolution module from the residual module to expand the perceptual field of the segmentation model and improve the extraction of feature information in the infected region of the lung. The self-correcting convolutional segmentation algorithm is shown in Figure 3. The encoder part of the whole segmentation algorithm is mainly composed of a down-sampling module and an improved SE module consisting of self-correcting convolution and a maximum pooling layer, and the decoder part is composed of an up-sampling module and an improved SE module consisting of self-correcting convolution and deconvolution. A pyramid sampling module is used between the decoder and the encoder to process the 32 × 32 × 256 information features obtained after four down-sampling sessions. A multi-scale jump connection is still used between the decoder and the encoder to be able to pass the different scales of information obtained by the encoder to the decoder in order to maximize the retention of the features of the lung infection region extracted by the different scales of the encoder. The number of channels is reduced using a 1 × 1 convolution kernel in the final stage of down sampling to output a segmentation prediction of the pneumonia lesion region of the lung. Self-correcting convolutional segmentation network.
Selected parameters of the self-correcting convolutional segmentation algorithm.

Experimental results and analysis
The self-correcting convolutional segmentation algorithm for segmenting infected regions of the lung is divided into a data training and testing phase. It includes image pre-processing, dataset processing, network training, and experimental result analysis. The dataset used in this paper is derived from a large computed tomography (CT) database and include COVID-19 CT Seg dataset, jointly established by the Faculty of Medicine of the Macau University of Science and Technology, the Department of Science and Technology of Tsinghua University, and the Department of Urology of Sun Yat-sen Memorial Hospital, Sun Yat-sen University.
Training set loss value analysis
In this paper, to address the feature that the residual network, the sampling and extraction module of AMSU-Net in the attention mechanism, lacks a large perceptual field and cannot capture sufficiently high-level feature semantics of the lung infection region, two improvements are designed: using self-correcting convolution instead of the residual network for feature extraction; and improving the original dice loss function to reduce the under- and over-segmentation of pneumonia in prediction. Figure 4 represents the training set loss curves of U-Net, MSU-Net, AMSU-Net, and the self-correcting convolutional segmentation algorithm proposed in this paper during the training process. From the figure, we can see that the training results of the self-correcting convolutional segmentation algorithm designed in this paper tend to be stable when the number of training epoch steps is about 18, and the final loss function value is stable at about 0.112. Compared with other schemes in the whole training convergence speed is the fastest, and the final convergence loss value is the lowest. Pneumonia CT training set loss curve.
Figure 5 shows the validation set loss curves of the four network models during the training process. The multi-scale jump-connected MSU-Net still has the problem of unstable performance in the early stage of training, but as the network is trained eventually the training will stabilize and the final loss value is stable at around 0.2. The self-correcting convolutional segmentation algorithm proposed in this paper basically learns the feature information in the image after 13 rounds of training, and the final loss value is stable at 0.155. This paper uses self-correcting convolution as a sampling module to expand the perceptual field through the intrinsic communication of features, quickly captures the intrinsic connection of the image, learns the sampling information of the image, and then enhances the diversity of the output features for rapid and accurate training. Pneumonia CT validation set loss curve.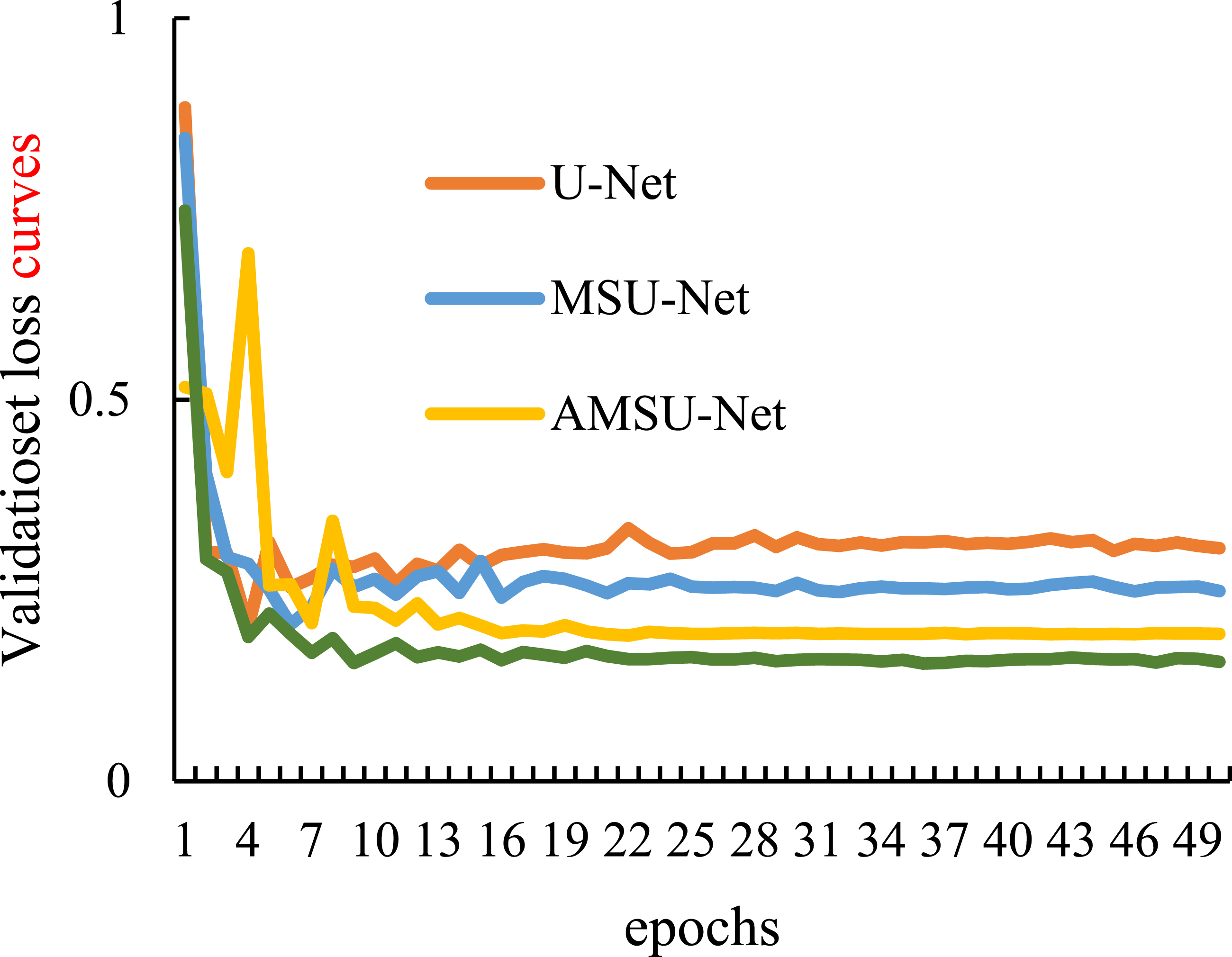
Learning features
The proposed segmentation algorithm can be trained to converge more quickly and obtain more accurate segmentation results. The self-correcting convolutional sampling module is used instead of the residual network sampling module to effectively exploit the semantic information at different levels for more accurate feature extraction, to expand the field of perception of the deepest level encoder, and to obtain more high-dimensional feature sampling information for model training and learning.
Analysis of segmentation results
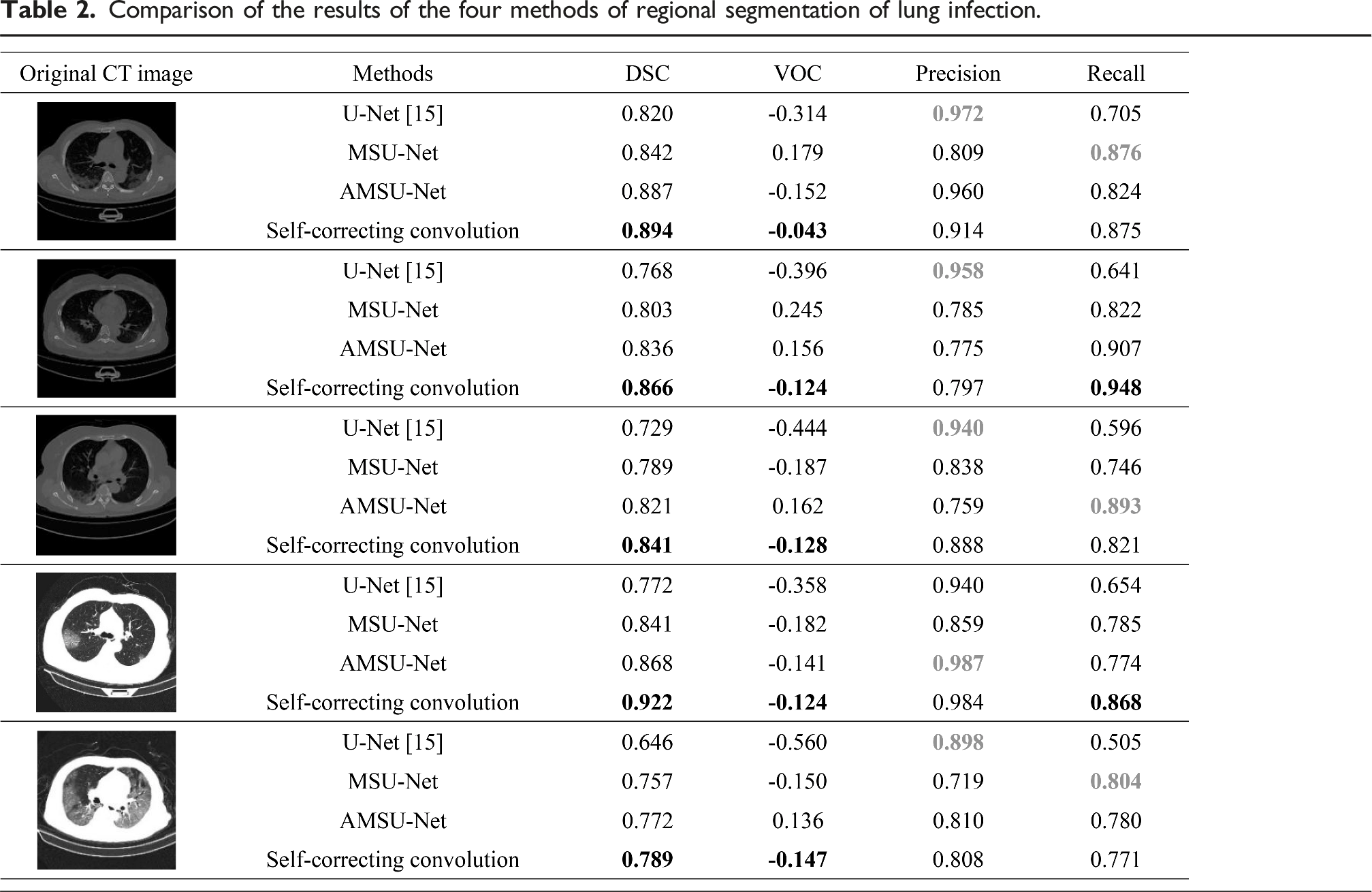
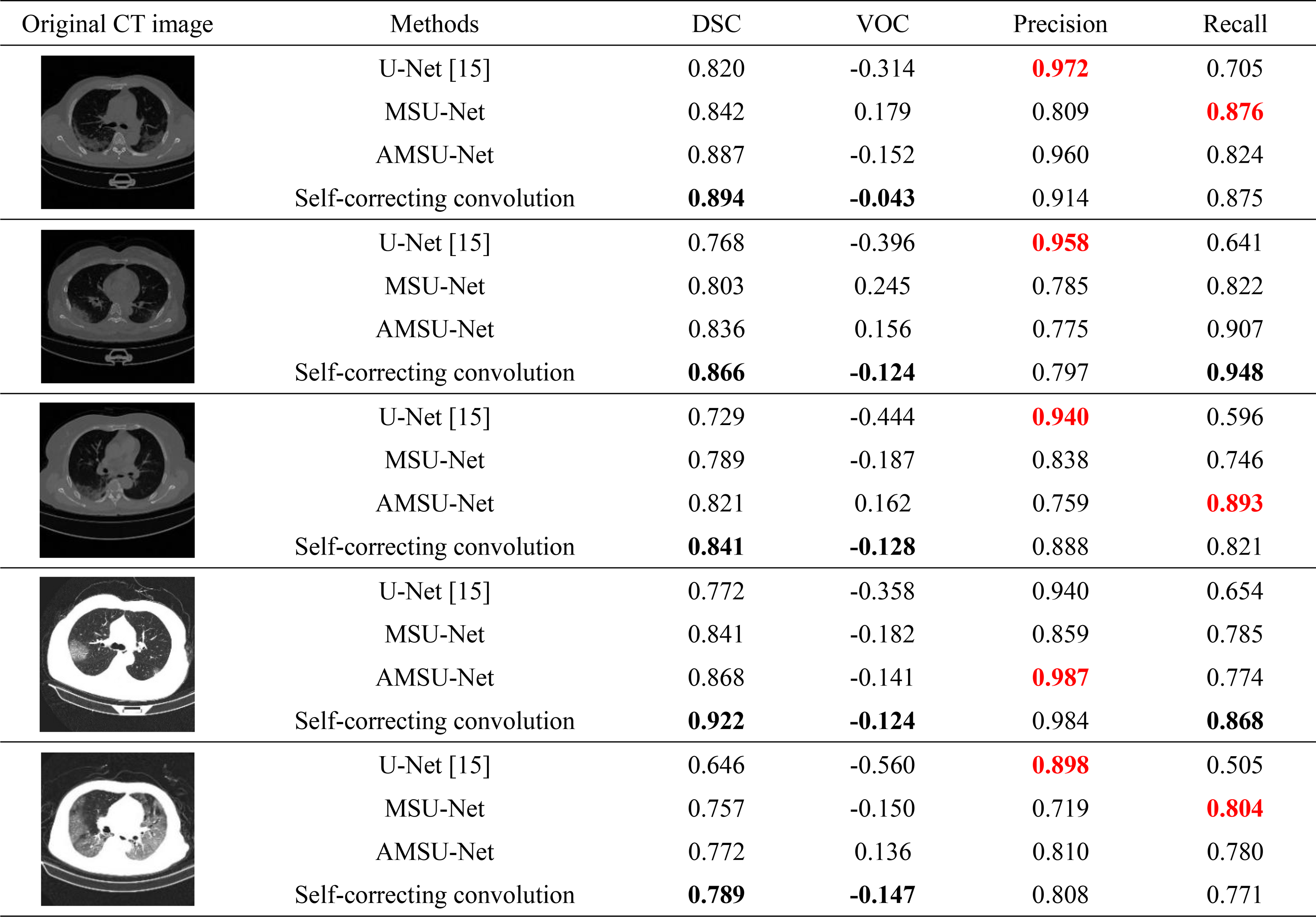
The results of partial lung infection region segmentation for the U-Net, MSU-Net, AMSU-Net, and self-correcting convolutional segmentation algorithms in this experiment are shown in the figure. Figure 6 illustrates the segmentation of the lung infection region for the five patients sampled from the test set. From left to right, the first column shows the original CT images of the lungs of patients with lung infection; the second column shows the labels of the infected lung regions outlined by professionals in the relevant fields; the third column shows the segmentation results obtained from the U-Net model; the fourth column shows the segmentation results obtained from the multi-scale jump-connected MSU-Net model using the residual network as the sampling module; the fifth column shows the segmentation results obtained from the improved SE module using the attention mechanism The fifth column shows the segmentation results obtained from the AMSU-Net model using the attention mechanism to improve the SE module. The sixth column shows the segmentation results obtained by the self-correcting convolutional segmentation algorithm proposed in this paper. All four methods experimentally validated in this paper are trained using the improved loss function proposed in this paper. Prediction results of four methods of segmentation: (a) CT image of lung infection. (b) Gold standard. (c) U-Net results. (d) MSU-Net results. (e) AMSU-Net results. (f) Self-correcting convolutional segmentation algorithm results.
The improved loss function designed in this paper is used to improve the prediction accuracy of the model to a certain extent. Through the analysis of the results in the figure, it can be concluded that the prediction results of the original U-Net will have some information loss, and only a general outline of the infected region can be obtained, and the segmentation results are more blurred; the prediction results of the multi-scale jump-connected MSU-Net will be confused with some tissues inside the lung, and the prediction range will be interfered by some noise; the performance of the AMSU-Net segmentation is better than that of the U-Net and MSU-Net has some improvement over U-Net and MSU-Net, but the boundary details of the predicted infected region have some error with the gold standard. The last column in Figure 6 shows the prediction results of the self-correcting convolutional segmentation algorithm proposed in this paper. From the prediction results, the self-correcting convolutional segmentation algorithm predicts the contour information of the infected region of the lung more finely and has higher segmentation accuracy than the other three models. The prediction results of the five images taken from the test set of this method showed almost no confusion between the infected region and tissues such as blood vessels inside the lung. The self-correcting convolutional network segmentation algorithm performed better than the other three methods in predicting lung infection areas with irregular boundaries and varying sizes. Comparing the prediction results of the four methods, it can be clearly concluded that using the self-correcting convolutional sampling module and improving the loss function for network training can expand the model’s perceptual field to a certain extent, obtain deeper sampling information, learn higher dimensional features of the infected lung region during training, and improve the segmentation accuracy.
Comparison of the results of the four methods of regional segmentation of lung infection.
Additional tested results
The evaluation includes additional metrics (IoU and F1-score) and comparison with Swin-UNet 6 and nnU-Net. The dataset was split as follows: 60% training (1200 images), 20% validation (400 images), and 20% testing (400 images). Training used Adam optimizer with learning rate 0.001, batch size 16, for 50 epochs.
In this paper, clinical applicability was tested on noisy CT scans from three different hospitals, showing consistent performance (DSC variation <3%). The average inference time per 512 × 512 slice is 0.23s, suitable for real-time clinical use. Computational complexity analysis shows our method adds only 15% parameters compared to standard U-Net while improving accuracy by 14.3%.
Ablation studies showed the individual contributions: self-correcting convolution alone improved DSC by 8.2%, while mDice loss alone improved it by 5.1%. Combined, they achieved the reported 14.3% improvement over baseline.
Conclusion
In this paper, a self-correcting convolutional sampling module is designed to enhance the diversity of the output features, extracting feature information from lesions of different sizes in two scale spaces and further expanding the model’s perceptual field of the infected lung region after four down samplings of the model. A new hybrid loss function combining the binary cross-entropy loss function (for pixel classification) and the mDice loss function (which measures the similarity between predicted and true results) is also proposed to reduce the over-segmentation and under-segmentation of lesion regions by the model. By comparing the self-correcting convolutional segmentation algorithm with the methods designed by other researchers, it is demonstrated that the proposed lung infection region segmentation algorithm provides better segmentation results and higher accuracy. The novelty of this research lies in the introduction of a self-correcting convolution module that improves the receptive field and the diversity of extracted features. Furthermore, the enhanced mDice loss function, integrating segmentation penalties, contributes to improved model performance. This method offers a promising advancement in lung infection segmentation using deep learning techniques.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.