
Abstract
In professional basketball games, athlete action recognition is an important part of sports performance analysis and intelligent assisted training. The complex scene background, frequent target occlusion, and varied motion patterns pose challenges to traditional detection and recognition methods in terms of accuracy and real-time performance. In view of this, the study proposes an improved object detection model for single shot multi-box detectors by combining pyramid feature integration module and dual axis convolutional perception module. At the same time, an action recognition model based on an improved 3D convolutional network is designed through adaptive weight fusion and attention mechanism. In the testing of the object detection model, when the number of iterations reached 500, the average accuracy improved by 6.14% and the frame rate decreased by 8.56%. The missed detection rate under low light conditions was 7.3%, the false detection rate was 8.7%, and the detection time was 30.8 ms. The highest detection accuracy of the action recognition model in complex backgrounds was 89.3%, and the robustness score was 91.9. The results indicate that the proposed model can maintain high accuracy and efficiency in complex backgrounds and fast movements in professional basketball game scenarios. The research model significantly improves the performance and robustness of action recognition, which can provide certain technical support for intelligent sports training systems.
Introduction
The rapid development of the global intelligent sports industry, accompanied by the increasing demand for high-level competitive events and training, has promoted in-depth research on precise motion analysis and intelligent assisted training technology.1,2 As an important component of intelligent sports systems, action recognition plays a crucial role in improving performance analysis and training efficiency. 3 However, action recognition in professional basketball games still faces many challenges. Especially in high-intensity competitions and complex background scenes, the rapid movement changes and frequent occlusions of athletes make it difficult for traditional detection algorithms to effectively capture target features, thereby affecting recognition accuracy and real-time performance. 4 As a classic One-stage object detection algorithm, single shot multi-box detector (SSD) is widely used in real-time object detection tasks due to its efficient detection speed and strong small object localization ability. 5
Literature review
Wang et al. proposed an improved model based on feature pyramid and SSD. By integrating multi-scale feature maps and introducing attention mechanisms, the detection ability of small targets was enhanced. The experimental results showed that on the PASCAL VOC2007 test set, the average accuracy of the algorithm reached 78.3%, which was 1.1% higher than the original algorithm. 6 Sogabe et al. identified the position and type of instruments in ophthalmic surgical microscope images through the SSD model to detect the main surgical tools in cataract surgery, overcoming the image distortion caused by gas-liquid interface refraction and viewpoint scaling. The results showed that the average accuracy of this method in surgical images was 0.75. 7 Basit et al. proposed a deep learning method based on SSD, combined with the lightweight neural network architecture MobileNet v2, to address the challenge of improving accuracy in brain tumor detection. Even in low resolution MRI scans, this method could detect the smallest tumor spots. The results showed that the accuracy of the model reached 98%. 8 Yang et al. proposed a new object detection framework to address the shortcomings of the SSD model in detecting small objects. The backbone network of the original model was replaced. A partially convolutional network was adopted to reduce computational complexity. The feature extraction capability was enhanced through a multi-scale fusion network. The results showed that the model achieved an average accuracy of 80.38%, with a complexity only half that of SSD. 9 Zhang et al. proposed a flight trajectory tracking method based on video signal filtering to address the issue of motion tracking in basketball games. Specifically, the adaptive median filtering algorithm is used to filter the basketball flight video signal. After median filtering, select the image difference to enhance the basketball flight trajectory image, and then use Harris corner detection algorithm to enhance the image. The experimental results have demonstrated the effectiveness of this method. 10
In the field of basketball detection and recognition, various methods have been proposed to improve detection accuracy and action recognition ability. Ye et al. proposed a comprehensive action recognition system for tennis serve training based on inertial sensors, aiming to assist in tennis serve training by collecting athlete action data using multiple inertial sensors. The system adopts small dataset data preprocessing and convolutional neural network method based on local attention mechanism for recognition. The experimental results show that this method is effective. 11 Pengyu et al. proposed a fast skeleton extraction and model segmentation method to address the accuracy issue of target recognition in basketball player detection technology. Starting from the characteristic information of basketball target states, this study compared and analyzed various detection methods. A new strategy for constructing dynamic ellipsoid bounding boxes was proposed to replace traditional bounding box methods. 12 Li et al. proposed a hybrid system for recognizing basketball players’ movements under complex backgrounds and inconsistent lighting conditions. The enhanced You Only Look Once (YOLO) was used for player detection, combined with long short-term memory networks and fuzzy logic for action classification. The results showed that the system achieved a recognition accuracy of 99.3% for 8 types of actions on different basketball videos.13,14 Facchinetti et al. proposed an algorithm based on athlete tracking data to automatically identify active periods in basketball games, addressing the issue of alternating between active and inactive periods. The data from GPS sensors was utilized and the performance was evaluated through ROC. The algorithm accurately identified the active period of the game by setting thresholds applicable to player motion parameters. 15 Liu et al. proposed a universal jersey number detector to address the challenges of player location and identity recognition. The detector predicted the bounding boxes, keypoints, and jersey number categories of players through an end-to-end model, rather than generating numerical suggestions based on preset anchor points. The results showed that the model had good detection performance.16,17
In summary, traditional methods perform poorly in small object detection and temporal motion capture, resulting in low recognition accuracy in scenarios such as rapid movement, complex backgrounds, and frequent occlusions during professional basketball training action recognition. In view of this, this study designs a Multi-scale Feature Enhanced SSD (MSA-SSD) that combines multi-scale feature integration with dual attention mechanism, and an action recognition model based on Dual scale 3D Convolutional Network (DS-3DNet). The innovation of the research lies in achieving multi-scale feature fusion and global contextual information enhancement through the Pyramid Feature Integration Module (PFIM) and the Global Information Integration Module (GIIM). At the same time, the DS-3DNet architecture combines adaptive weight fusion and attention mechanism to enhance the ability of athletes to extract spatial details and temporal features of their movements. The research aims to solve the technical difficulties of action recognition in complex basketball game scenarios, and provide more efficient solutions for sports performance analysis and intelligent assisted training in practical applications.
Methods and materials
Design of object detection algorithm based on improved SSD
The accuracy and real-time performance of action recognition technology are crucial for sports performance analysis and intelligent assisted training systems in professional basketball games and training scenarios. 18 SSD detects targets simultaneously on feature maps of different scales, avoiding the process of generating candidate boxes using the Two-stage algorithm and significantly improving detection efficiency.19,20 However, considering that in professional basketball games, due to the varied movements of athletes and frequent target occlusion, it will further exacerbate missed and false detections in the SSD model. Therefore, in order to improve its detection performance in the complex environment of professional basketball games, the research attempts to introduce PFIM and GIIM to enhance its shortcomings in occlusion and small object detection, and provide more accurate object detection results for subsequent action recognition.
Firstly, in the PFIM module, traditional convolutional networks struggle to fully capture multi-scale semantic features. Therefore, a Multi-path Parallel Residual Module (MPRM) is designed, as shown in Figure 1. Residual unit structure and MPRM structure. (a) Residual unit structure, (b) MPRM structure.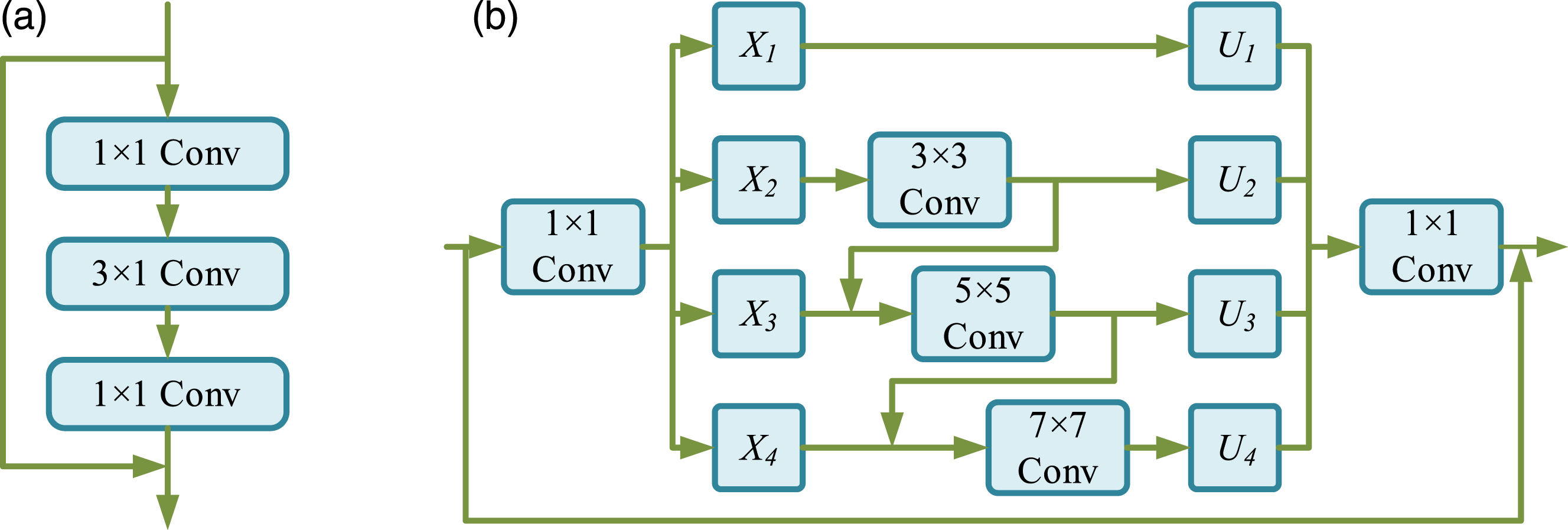
Figure 1(a) shows the basic residual unit structure diagram, which includes 1 × 1 convolutional layer, 3 × 3 convolutional layer, and ReLU activation function. The gradient vanishing problem in deep networks is alleviated through skip connections. Figure 1(b) shows the structure diagram of the MPRM, which has multiple convolution kernels of different sizes such as 3 × 3, 5 × 5, and 7 × 7 for parallel feature extraction, in order to increase the receptive field and multi-scale feature fusion ability. Compared to the basic residual unit, the MPRM module can capture richer contextual information and detailed features, making it more suitable for small object detection tasks in complex backgrounds.
Subsequently, in order to perform more accurate upsampling and improve the image’s detail preservation ability, Sub-pixel Convolution (SPC) is used to enhance the resolution of basketball game images. Compared to upsampling and deconvolution, SPC not only improves computational efficiency, but also enhances image detail representation. Therefore, the final PFIM module structure is shown in Figure 2. PFIM module structure.
As shown in Figure 2, in the PFIM module, the input feature map undergoes convolutional and compression operations to extract preliminary multi-scale features, and preserves shallow positional information and deep semantic information through skip connections. Subsequently, the module uses multiple convolution kernels of different sizes to process the features, extracting rich multi-scale features. The feature maps are gradually fused after downsampling to improve detection performance in small targets and complex backgrounds.
Subsequently, GIIM aims to supplement the global contextual information that is not captured in the PFIM module. Its core is the Dual-axis Convolutional Perception Module (DCPM), which enhances the depth of input features through spatial and channel dual convolution attention mechanisms. DCPM performs dual attention enhancement on the input feature map. By jointly modeling the spatial and channel dimensions, significant regions in the feature map are precisely focused to enhance the fusion effect of contextual information. By calculating Global Average Pooling (GAP) and Global Max Pooling (GMP), spatial and channel features are obtained. The convolutional layer is used to fuse spatial information. Spatial weight matrices
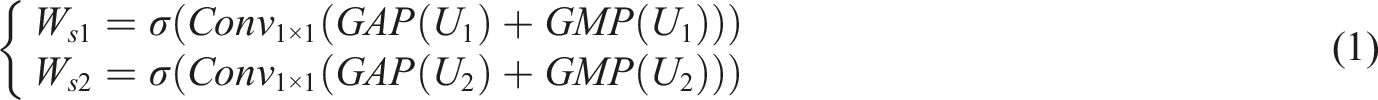
In equation (1),
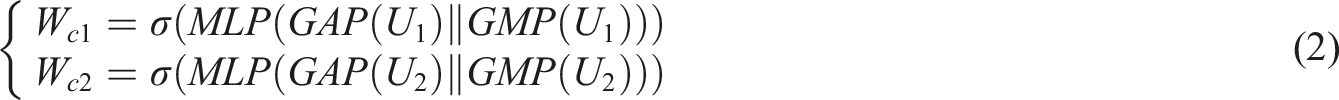
In equation (2),

In equation (3), MSA-SSD module structure. (a) 2D convolution operation, (b) 3D convolution operation.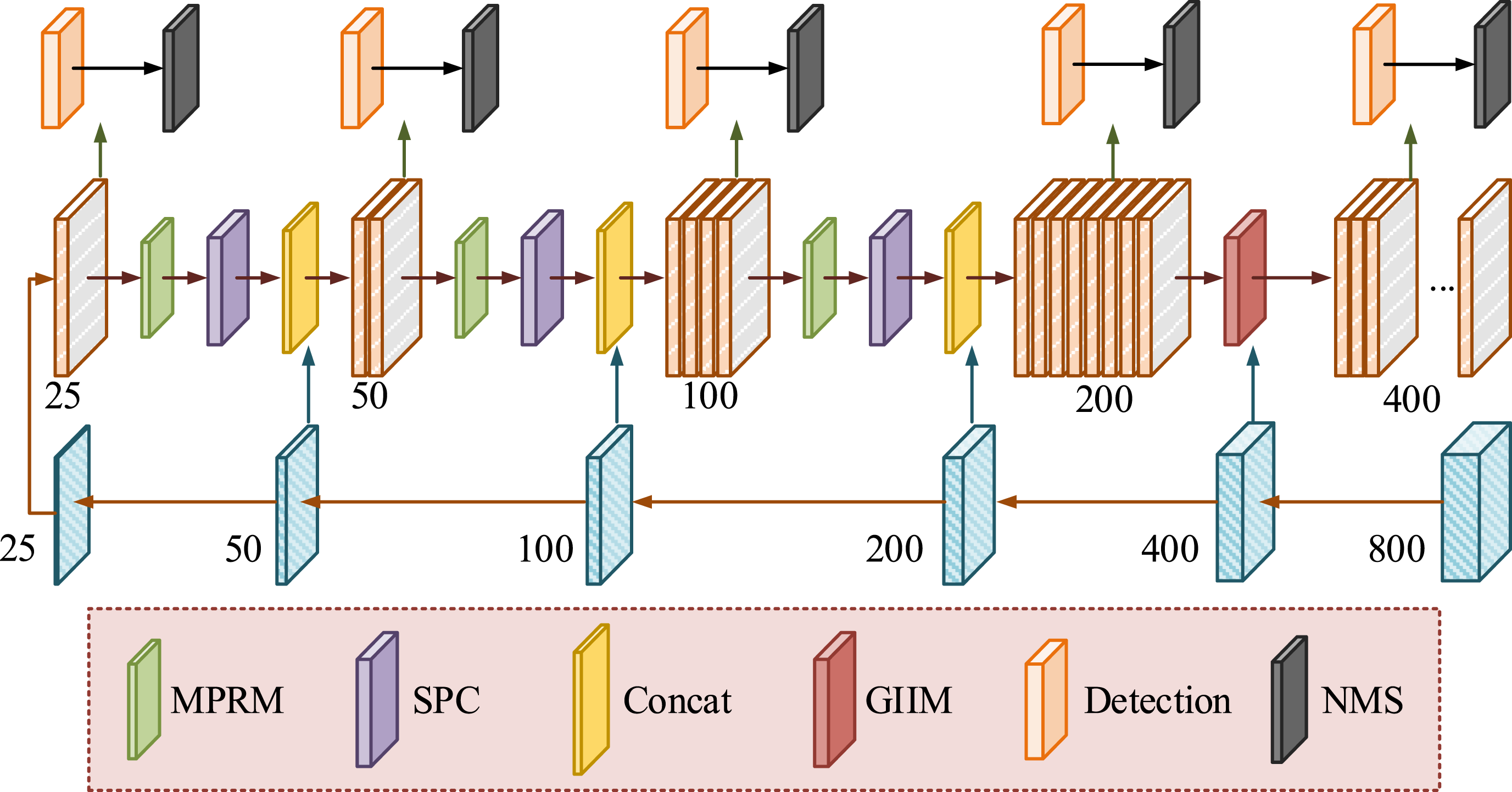
As shown in Figure 3, the overall structure of the MSA-SSD model includes a basic feature extraction network, PFIM, and GIIM, through which multi-scale feature fusion and contextual information enhancement are achieved. PFIM receives feature maps of different scales as input, extracts rich semantic features through multi-path parallel convolution, and generates fused output feature maps; GIIM further processes these features, enhances the expressive power of feature maps through spatial and channel attention mechanisms, and finally outputs enhanced contextual information. These enhanced feature maps are then used in the final stage of object detection to achieve high-precision object recognition and localization.
Construction of training action recognition model based on 3D convolution
After completing the target detection part of basketball game training, the extracted athlete action areas need further temporal feature analysis to accurately identify complex action sequences. In professional basketball games and training scenarios, athlete action recognition not only needs to focus on spatial features, but also needs to capture temporal variation information of consecutive frames in the video.
21
3D Convolutional Neural Network (3D-CNN) is used to process spatial and temporal features in video data, especially for capturing detailed changes in athlete movements and recognizing training movements. Its structure is shown in Figure 4.22,23 2D and 3D convolution operations.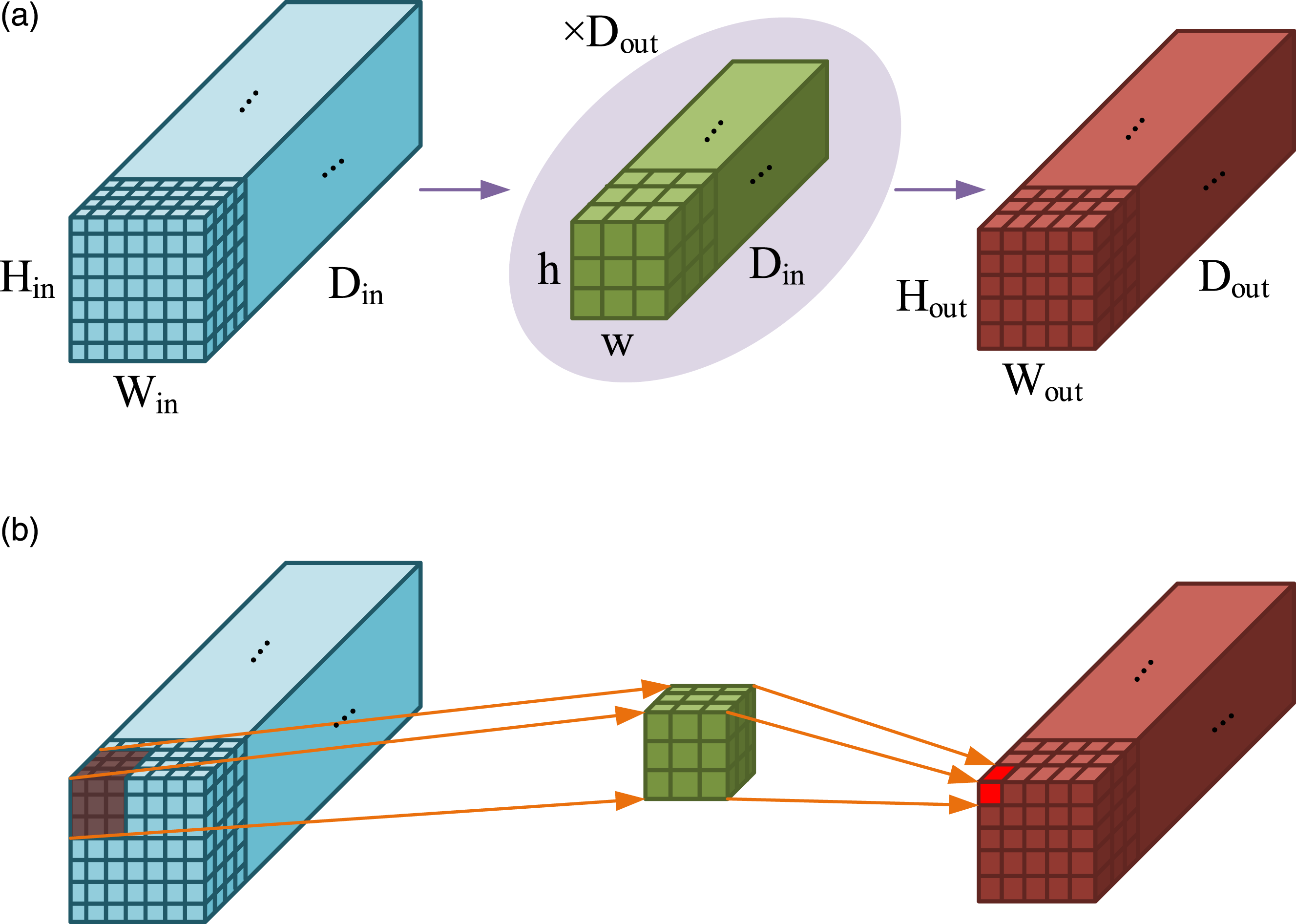
In the 2D convolution of Figure 4(a), the convolution kernel slides along the height and width dimensions of the input feature map to extract local spatial features of the image through spatial convolution, which is suitable for single frame image processing. In the 3D convolution of Figure 4(b), the convolution kernel slides in the three dimensions of height, width, and time, which can simultaneously capture spatial and temporal variation features in video data.24,25 However, considering the significant computational and memory consumption issues of standard 3D convolutional networks when processing high-resolution videos, a dual scale 3D-CNN architecture is designed. By combining high and low resolution branches, a feature fusion strategy is used to capture fine-grained spatial details and global temporal information of athlete movements, in order to better capture fine-grained spatial details and global temporal information and reduce computational costs.
Firstly, to address the potential issues of gradient vanishing and exploding caused by random initialization, the study adopts a mixed initialization strategy of Xavier initialization and He initialization to ensure a reasonable weight distribution in each layer of the network. In shallow convolutional networks, due to the relatively uniform number of input and output nodes, using Xavier initialization can maintain the variance stability of weights, as shown in equation (4).

In equation (4),

In equation (5),

In equation (6),

In equation (7),

In equation (8),

In equation (9), Schematic diagram of SVM.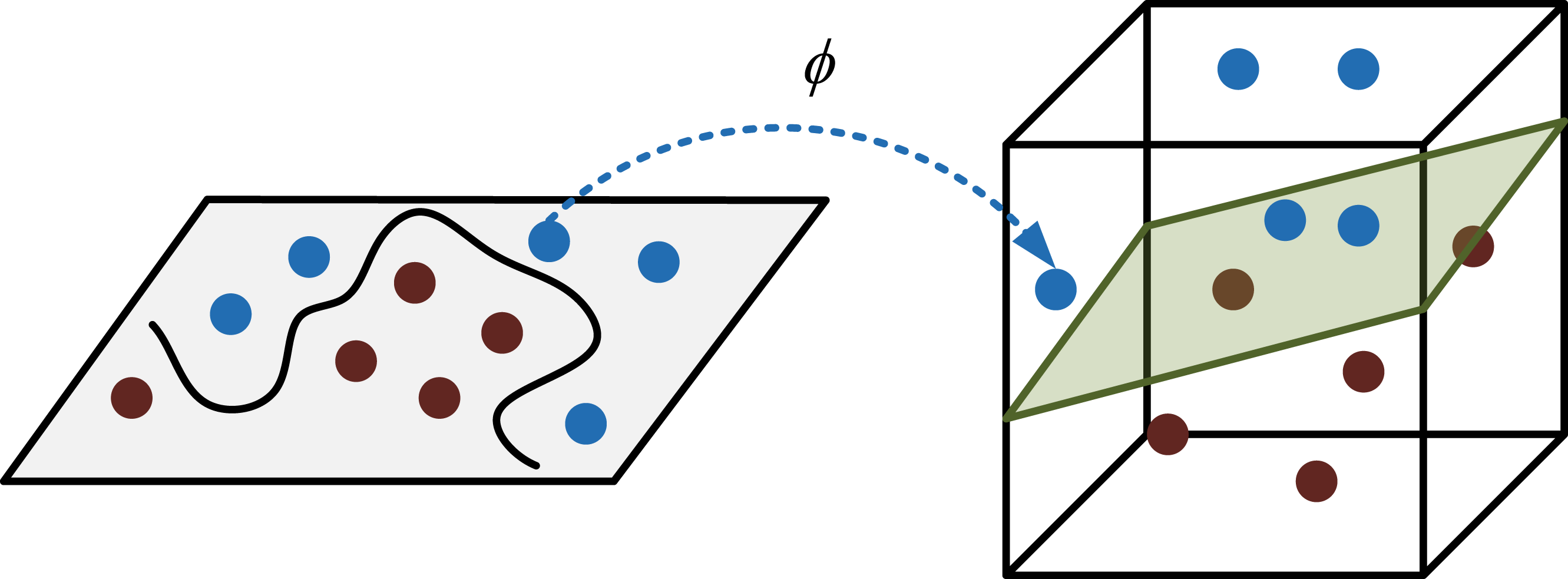
As shown in Figure 5, the input features may be nonlinear and inseparable in the original space. SVM maps these features to a high-dimensional feature space through kernel function DS-3DNet module structure.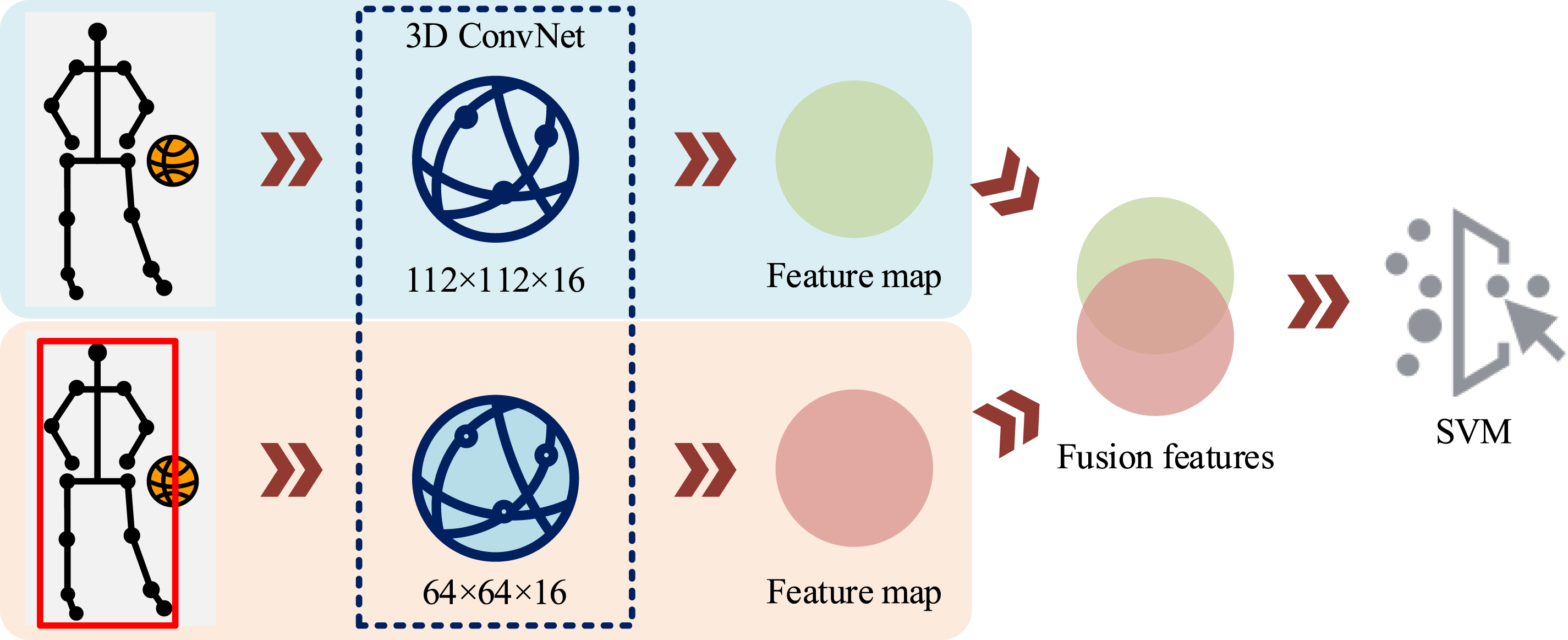
As shown in Figure 6, the DS-3DNet training action recognition model first uses two types of input feature maps, high-resolution, and low resolution, which are 112 × 112 and 64 × 64, respectively, and input them to two parallel 3D convolutional neural network branches. The high-resolution branch is used to extract fine-grained spatial features of athlete movements in video clips and capture small changes in movements. The low-resolution branch is used to capture global temporal features, adapting to the modeling requirements of long-term action sequences while reducing computational costs. Secondly, the feature maps extracted by the two branches are fused through the feature representation module, integrating spatial details and temporal information. Subsequently, the fused feature vectors are input into SVM for action classification, and the final decision result is output.
Methodology
Based on the above theory, the MSA-SSD model is proposed to improve the recognition and detection accuracy of athlete movements in professional basketball games. The entire process of the proposed method is shown in Figure 7. Flow chart of basketball game training action recognition technology.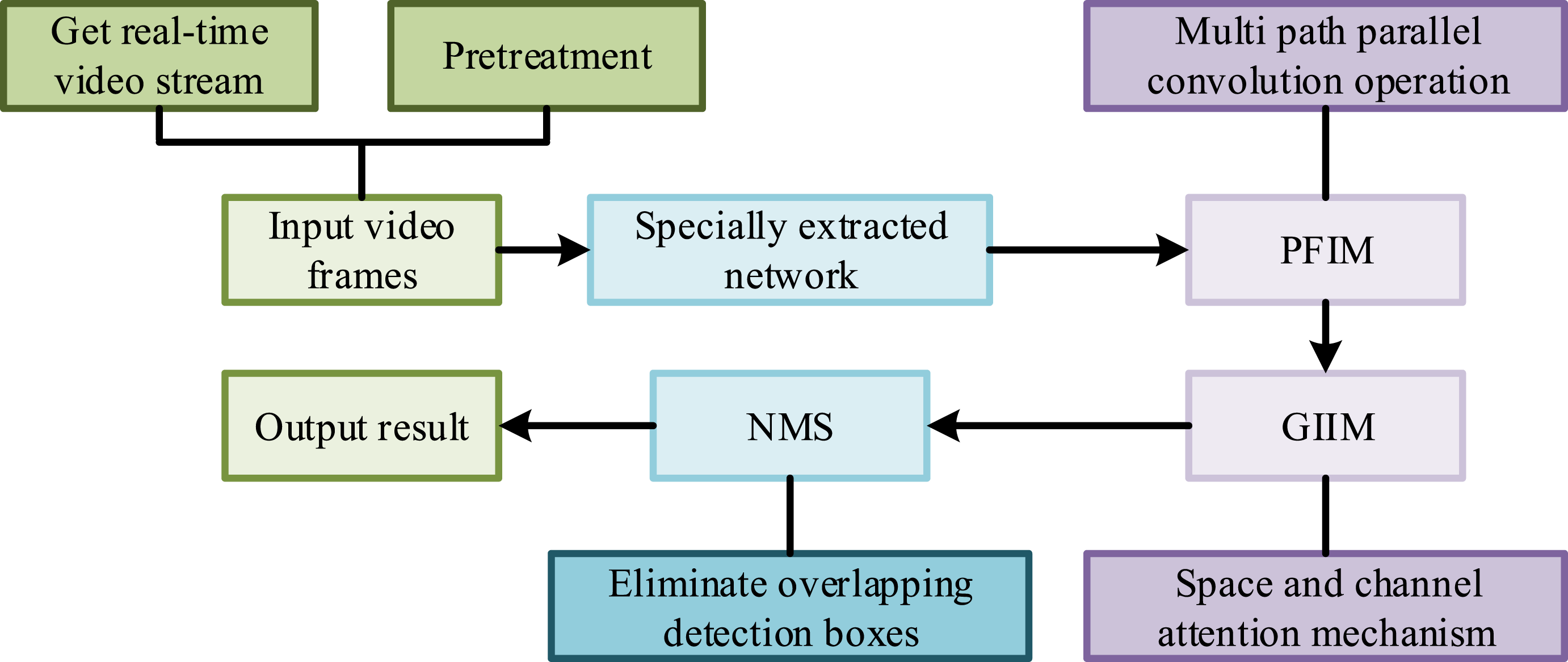
As shown in Figure 7, this process achieves efficient object detection by gradually passing the input video frames to different processing modules. Firstly, the video frames are processed through a feature extraction network to generate preliminary feature maps, which are then passed on to PFIM. In this module, multi-scale semantic information is extracted through multi-path parallel convolution to enhance feature expression. The fused features are input into GIIM, and spatial and channel attention mechanisms are used to further optimize the features. Finally, the most representative detection boxes are selected through NMS, and the final detection result containing category labels and bounding box coordinates is output.
Results
Performance testing of MSA-SSD object detection model
Ablation test results.

*:p < 0.05, **:p < 0.01, ***:p < 0.001.
In Table 1, the indicators include Mean Average Precision (mAP) and Frame Per Second (FPS). The mAPs of the basic SSD, SSD + PFIM, SSD + GIIM, and MSA-SSD models were 87.9%, 90.7%, 89.9%, and 93.3%, respectively. The FPS of the basic SSD, SSD + PFIM, SSD + GIIM, and MSA-SSD models were 39.7, 38.1, 37.6, and 36.3, respectively. The improved model incorporating PFIM and GIIM modules showed significant improvement in accuracy throughout the entire training process. The PFIM module enhances the detection ability of small targets and complex backgrounds through multi-scale feature fusion, while the GIIM module improves the model’s feature expression ability by capturing global contextual information. The final MSA-SSD model combines these two improvements, demonstrating the highest detection accuracy. The statistical test results show that the single component models SSD + PFIM and SSD + GIIM have significant improvements in mAP, while the combined model MSA-SSD has a more significant improvement in mAP, and also shows a statistically significant decrease in FPS. Subsequently, SSD, Convolutional Encoder Network (CENet), and Adaptive Convolutional Neural Network (ACNet) are selected as comparison models. To further validate the detection capability of the model in actual basketball game scenarios, especially in complex situations where the target is partially occluded, a qualitative analysis experiment is designed. By displaying the detection results of people and basketballs under different degrees of occlusion, the robustness performance of the model in fine-grained object detection and complex scenes is shown in Figure 8. Target detection qualitative analysis results. (a) SSD, (b) CENet, (c) ACNet, (d) MSA-SSD.
Comprehensive evaluation of multiple environments and conditions.
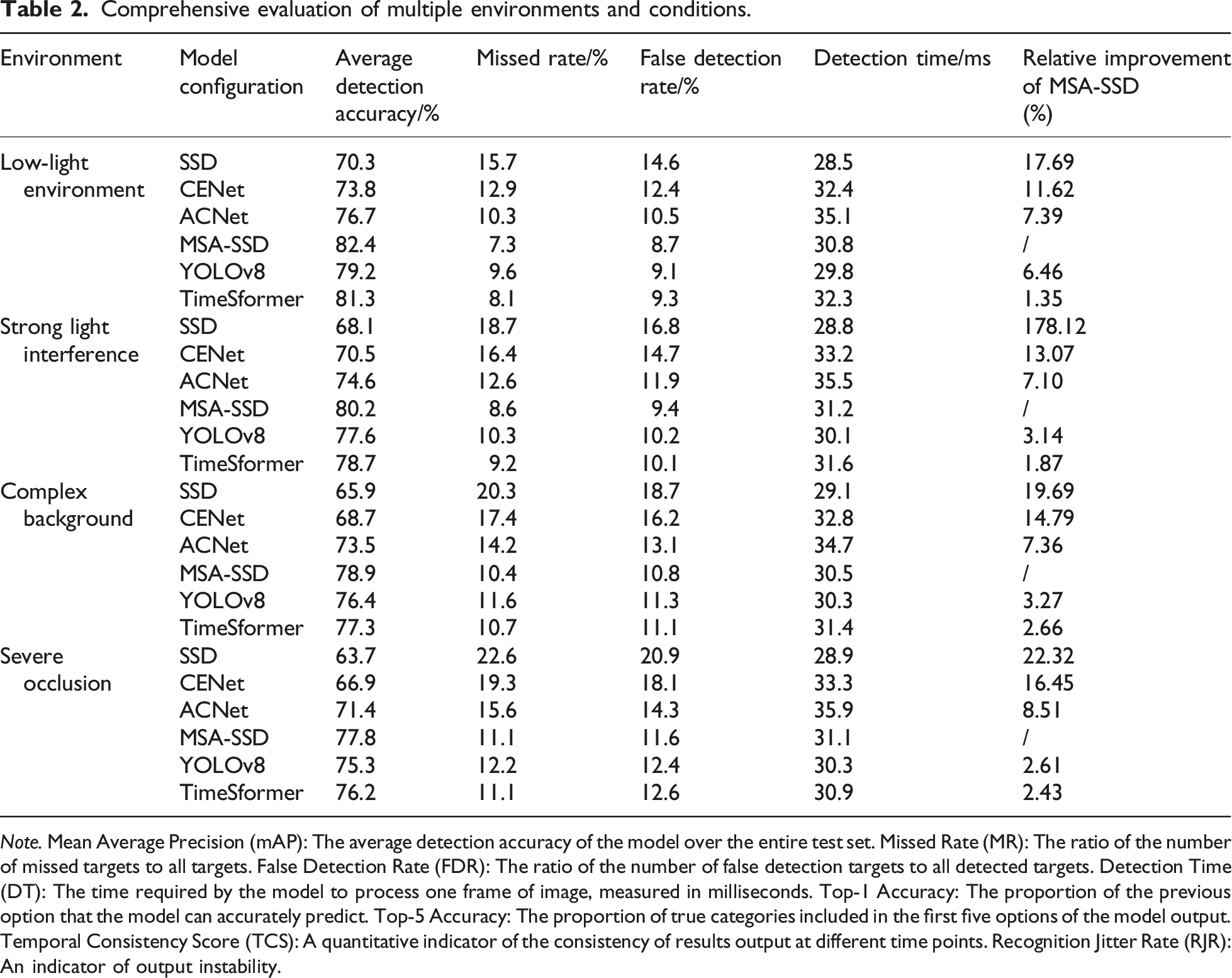
Note. Mean Average Precision (mAP): The average detection accuracy of the model over the entire test set. Missed Rate (MR): The ratio of the number of missed targets to all targets. False Detection Rate (FDR): The ratio of the number of false detection targets to all detected targets. Detection Time (DT): The time required by the model to process one frame of image, measured in milliseconds. Top-1 Accuracy: The proportion of the previous option that the model can accurately predict. Top-5 Accuracy: The proportion of true categories included in the first five options of the model output. Temporal Consistency Score (TCS): A quantitative indicator of the consistency of results output at different time points. Recognition Jitter Rate (RJR): An indicator of output instability.
As shown in the Table 2, under low light conditions, the average detection accuracy of MSA-SSD reached 82.4%, with a missed detection rate of only 7.3%. This performance is attributed to the PFIM module’s ability to enhance detailed features under low light conditions, thereby improving detection accuracy. In strong light interference and complex background environments, the false detection rates of MSA-SSD were 9.4% and 10.4%, respectively. The main reason is that the GIIM module can capture global contextual information and effectively distinguish between targets and backgrounds. In addition, MSA-SSD exhibited strong robustness in severely occluded environments, with a missed detection rate of 11.1%, which was 4.5% lower than ACNet. Although the detection time is slightly higher than SSD, its improved accuracy and robustness make it more suitable for real-time object detection tasks in complex basketball game scenes.
Application analysis of DS-3DNet training action recognition model
The experimental environment is the same as the previous section, using NVIDIA A100 GPU for model training and testing. The comparative models are Inflated 3D ConvNet (I3D), Temporal Relationship Network (TRN), and Slow Fast Network (SFNet). The study collects live videos of 20 professional basketball games, including central field perspective, sideline perspective, and audience perspective. There are a total of 1500 video clips with an average duration of about 20 s, covering various movements of athletes during the competition, including different lighting conditions, occlusion situations, and background interference. The video segments in the dataset are sliced, key frames are extracted, and standardized to a uniform resolution of 112 × 112, with a frame rate of 30FPS maintained. All video clips are professionally annotated, including detailed action categories, time intervals, and athlete target box information, to ensure the accuracy and consistency of data annotation. Firstly, the results of Top-1 and Top-5 accuracy tests on each model are shown in Figure 9. Top-1 and Top-5 test results. (a) Top-1 accuracy test, (b) Top-5 accuracy test.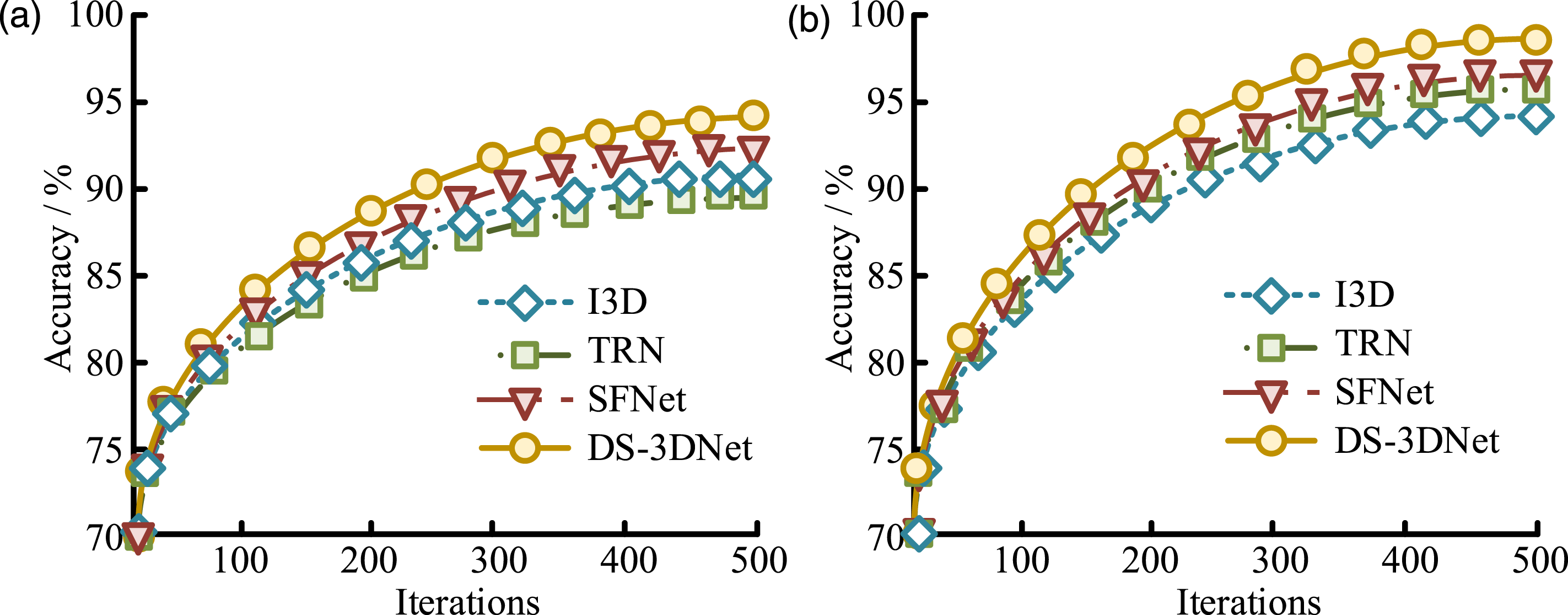
Figures 9(a) and (b) show the Top-1 and Top-5 results of each model, respectively. In Figure 9(a), when the number of iterations was 500, the Top-1 accuracy of I3D, TRN, SFNet, and DS-3DNet was 91.1%, 89.3%, 93.2%, and 94.5%, respectively. In Figure 9(b), when the number of iterations was 500, the Top-5 accuracy of each model was 94.2%, 96.4%, 96.9%, and 98.2%, respectively. The advantages of DS-3DNet are mainly attributed to the optimization of feature fusion strategy and temporal modeling module, which effectively enhances the robustness of the model to uncertain action categories. In addition, although SFNet and TRN have certain advantages in temporal modeling, their feature extraction capabilities are insufficient, resulting in slightly inferior overall performance compared to DS-3DNet. The Top-1 accuracy of 94.5% was obtained under specific training and testing conditions, so its accuracy may decrease in unseen teams or different camera angles. Subsequently, to test the stable performance of the model in long-term videos, 200 video clips with a duration of more than 20 s are collected from the dataset for testing. The results are shown in Figure 10. TCS and RJR test results. (a) TCS test, (b) RJR test.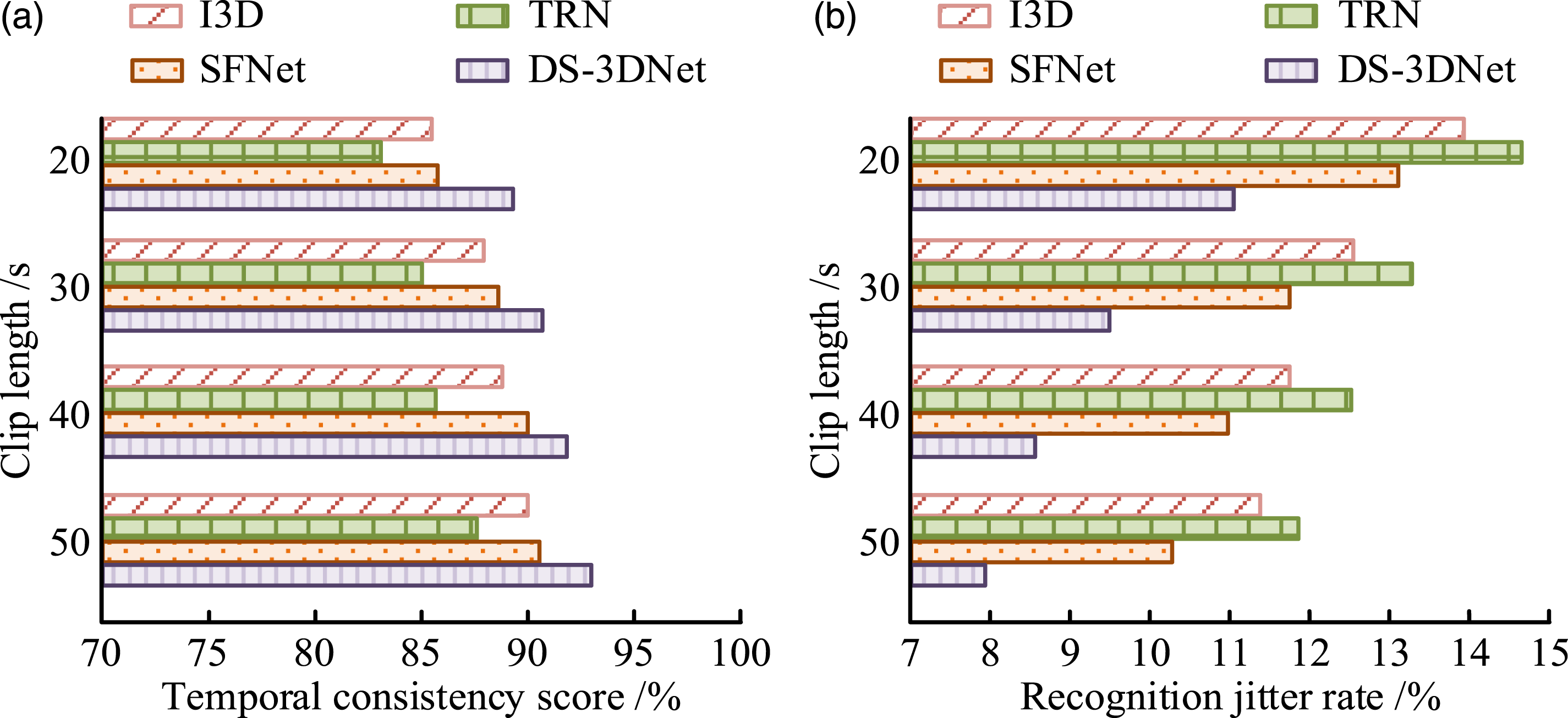
Basketball action detection results of the model under different backgrounds.
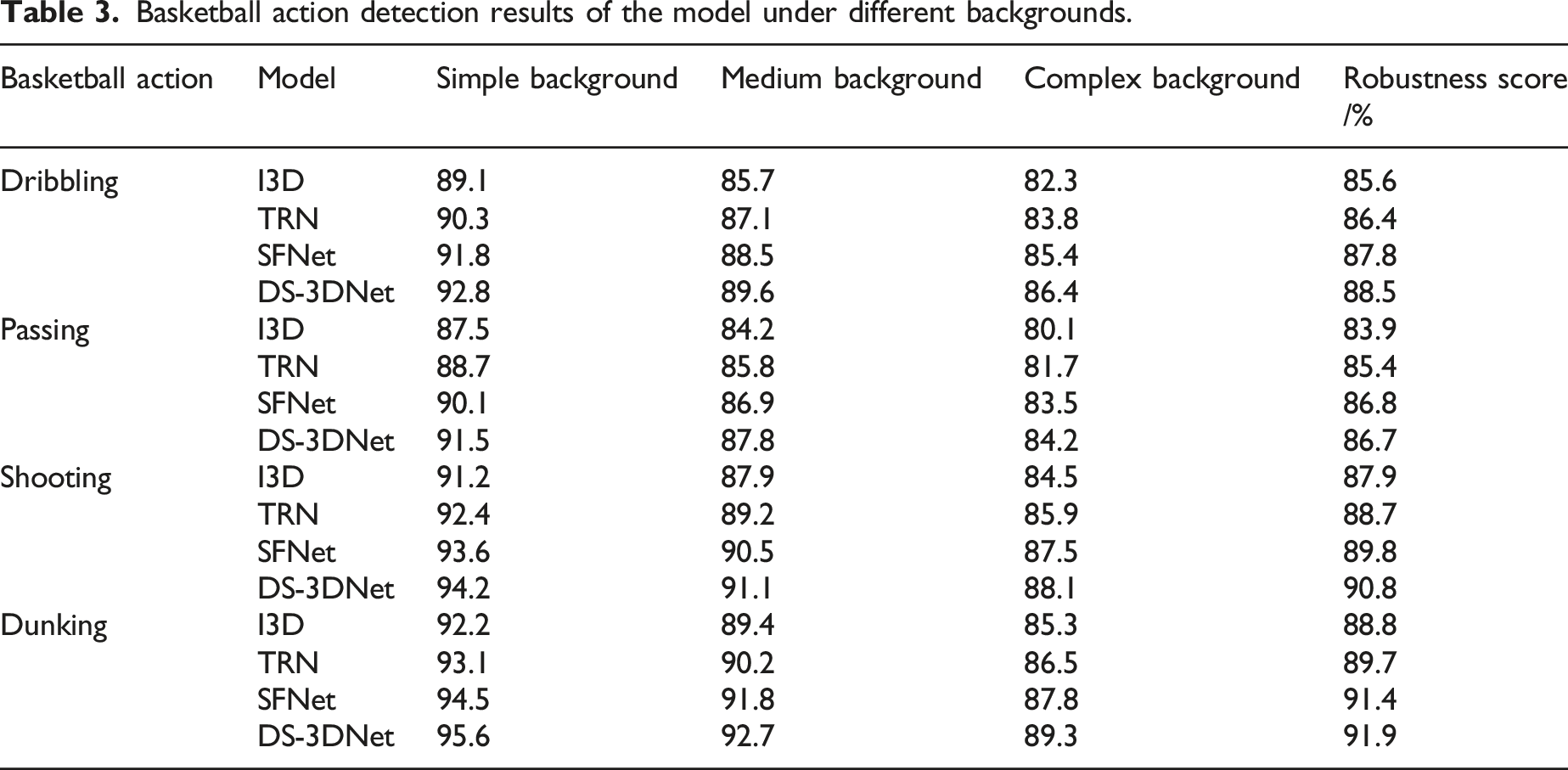
As shown in Table 3, DS-3DNet outperformed other models in terms of detection accuracy and robustness scores under all background conditions, especially in complex backgrounds. The dual scale architecture of DS-3DNet significantly enhanced the model’s adaptability to background noise and accuracy in capturing subtle motion features. Specifically, the robustness score of DS-3DNet in complex backgrounds reached 91.9%, which was about 3%–5% higher than models such as I3D and TRN. In contrast, models such as I3D and TRN had poor adaptability to complex backgrounds and were easily affected by background noise, resulting in a significant decrease in detection accuracy and robustness scores. This indicates that DS-3DNet has stronger adaptability to complex scenarios in practical applications, which is suitable for high demand action recognition tasks.
Conclusion
In response to the low accuracy and poor real-time performance of action recognition in professional basketball games and training scenarios, the MSA-SSD object detection model and DS-3DNet action recognition model were proposed. The performance test results of the MSA-SSD model showed that when the number of iterations was 500, the mAP and FPS of the MSA-SSD model were 93.3% and 36.3, respectively. In qualitative testing, players and basketballs that could detect 4 images without missed or false detections were superior to the comparison model. Finally, its average detection accuracy under low light conditions was 82.4%, with a missed detection rate of 7.3% and a false detection rate of 8.7%. The detection time was 30.8 ms, achieving a balance between high accuracy and computational efficiency. In the DS-3DNet application test, when the number of iterations was 500, its Top-1 and Top-5 accuracy was 94.5% and 98.2%, respectively. On a video detection with a duration of 50 s, its TCS and RJR were 93.8% and 7.9%, respectively. The highest action recognition accuracy in a simple background was 95.6%, with a robustness score of 92.7. The highest action recognition accuracy in complex backgrounds was 89.3%, with a robustness score of 91.9. The results showed that the MSA-SSD and DS-3DNet models exhibited excellent detection and action recognition performance in complex basketball game videos, with excellent recognition accuracy and robustness.
However, there are still shortcomings in the research, namely, there is still room for improvement in detection time and computational complexity. Future work will focus on exploring lightweight network structures and multi-modal fusion strategies to further enhance the model’s generalization ability and computational efficiency, and explore the application effects of the model in other types of motion. In addition, the real-time deployment of the model may be affected by computational resource limitations, especially when running on low-end devices. Future research can explore extending this model to other team sports fields and consider making the relevant code and supplementary materials public to promote transparency and reproducibility of the study. The generalization ability of the proposed model can be further explored by testing it on out-of-distribution data, including unseen teams and different camera angles.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data generated or analyzed during this study are included in this article.