
Abstract
With the continuous development of artificial intelligence research, computer vision research has shifted from traditional “feature engineering”-based methods to deep learning-based “network engineering” methods, which automatically extracts and classifies features by using deep neural networks. Traditional methods based on artificial design features are computationally expensive and are usually used to solve simple research problems, which is not conducive for large-scale data feature extraction. Deep learning-based methods greatly reduce the difficulty of artificial features by learning features from large-scale data and are successfully applied in many visual recognition tasks. Video action recognition methods also shift from traditional methods based on artificial design features to deep learning-based methods, which is oriented to building more effective deep neural network models. Through collecting and sorting related research results found that academic for timing segment network of football and basketball video action research is relatively rich, but lack of badminton research given the above research results, this study based on timing segment network of badminton video action identification can enrich the research results, provide reference for follow-up research. This paper introduces the lightweight attention mechanism into the temporal segmentation network, forming the attention mechanism-timing segmentation network, and trains the neural network to get the classifier of badminton stroke action, which can be predicted as four common types: forehand stroke, backhand stroke, overhead stroke and pick ball. The experimental results show that the recognition recall and accuracy of various stroke movements reach more than 86%, and the average size of recall and accuracy is 91.2% and 91.6% respectively, indicating that the method based on timing segmentation network can be close to the human judgment level and can effectively conduct the identification task of badminton video strokes.
Introduction
With the development of video motion recognition technology in the field of computer vision, the research of sports motion recognition is more and more widely used in statistical motion characteristics, kinematics research, and PE teaching display. For various ball games, their structural characteristics can be divided into two types: time and score, according to the type of game [1]. Time-type sports such as basketball, football and rugby have no special area for a certain player during the game [2]. Both players are in a mixed position and win the game through teamwork within a certain time interval. The score type includes tennis, badminton, table tennis, etc. [3]. Both players always play in their own areas and confront their opponents in position. This type is usually played at their own level [4]. When watching such games, spectators tend to pay attention to the movement characteristics of the players.
In badminton competition, the movement and posture information of athletes can provide important clues for understanding the game process and discovering the movement characteristics of players [5]. Badminton has similar characteristics with volleyball, tennis and table tennis, and they all meet the Markov process conditions. Each stroke of the player in the competition is completed in an instant [6]. In order to better assist the coach or the audience to understand and grasp the key information such as the players’ movements in the badminton videos, it is meaningful to realize the intelligent recognition of the movements of the badminton players [7].
Computer vision technology has made major breakthroughs in the direction of video action recognition, but most of them are generalized action recognition for different daily movements, and lack of relevant research on badminton video action recognition. If the hitting movements in the badminton video can be regularly positioned and the types of strokes in the badminton video can be more accurately judged, the video highlights of various types of hitting movements can be provided for the audience [8]. In addition, in the field of sports video analysis, the action classification of badminton can also be transferred to tennis and other events [9].
The type of badminton stroke action can be distinguished by the flight track and landing point of the ball, and the movement track and landing point of the ball are closely related to the posture of the player when hitting the ball [10]. This research is divided into forehand hitting, backhand hitting, high, kill and pick five common categories, and on the basis of the implementation of the badminton game video action positioning and intelligent segmentation of the video, through deep learning technology to learn the characteristics of the badminton game video action, realize the identification of the video can assist the coach analysis video movements, and make users appreciate the diversity of each shot video highlights.
Current status of video action recognition at home and abroad
Current status of video action
At present, the video action recognition field is mainly divided into cutting video action recognition and long-time video action recognition. The cropping video includes only one complete action, while the long-time video includes multiple continuous actions. In the recognition of long-term video actions, action time domain segmentation is a very important step, and there are clear action switching boundaries between adjacent actions in these videos [11]. However, there is no obvious boundary information in the adjacent hitting action, so the method based on long-term video action recognition is not suitable for the positioning of badminton strokes [12]. Badminton action metavideo belongs to cropped video. In order to realize the intelligent extraction of meta video, it is necessary to locate the single shot action in badminton video, in which the single shot action video segment constitutes metavideo. In the case of a short shot action sequence, the human motion segmentation algorithm TS-WMS cannot fully learn the shot action sequence, easy to appear redundant action segmentation points [13]. Ji et al. [14] proposed a way to capture the player’s stroke action according to the inflection point of the position and flight direction of the badminton, but this method is limited to the side view of the court when the player is located on the left and right sides of the video interface, which is not applicable for the broadcast perspective of most badminton game videos. For the action time domain positioning of non-trimmed videos, Li et al. [15] proposed a multi-scale sliding window integration method on the basis of the original dual-flow convolutional neural network, which can well locate the actions in UCF101 and HMDB51 data sets and reduce the influence of background noise. However, the positioning action instance only occupies a small part of the whole video, and the other parts belong to the segments of the interference behavior recognition model, which cannot locate multiple continuous actions in the video respectively [16]. In conclusion, the existing research methods for video action positioning have been satisfied with the video with clear action boundaries or long-term video, but it is difficult to realize the action positioning of badminton video.
Current status of badminton movement recognition
Zhang and Wu [17] used a gesture-based method to extract directional gradient histogram HOG from the player’s bounding box, and classify the strokes based on support vector SVM. Literature [18] based on HOG, but the training and test data used are a single image of the shot, with different hitting movements with very similar hitting gestures, such as killing and high, drawing and hanging. Li et al. [19] classified the shots of the compressed badminton videos and identifies the hitting action by detecting the movement trajectory of the badminton. Climent-Pérez and Florez-Revuelta [20] proposed a badminton video action recognition method based on the HOG characteristics of dense trajectory and trajectory alignment, which divides player strokes into forehand, backhand, kill and other types, but HOG itself does not have scale invariance, and HOG is quite sensitive to noise due to the nature of the gradient. Literature [21] in sports video often has poor pixel quality, not static video and image resolution low background, put forward a motion descriptor, and by detecting the key audio elements to capture the player swing image, finally use the support vector machine, the three kinds of athletes typical swing action-swing, left swing, right swing for classification. Zhao et al. [22] proposed a two-layer hidden Markov Model (HMM) classification algorithm based on the body sensor network to identify the badminton stroke type, but the stroke state data captured by the sensor is not suitable to effectively identify the badminton movements in the video. You et al. [23] compared the performance of four different deep convolutional pre-training models, AlexNet, GoogLeNet, VggNet-16 and VggNet-19, when classifying the badminton images to identify different movements of athletes, which finally showed that GoogLeNet has the highest classification accuracy, but it still targeted the static image of the badminton hitting moment, and failed to classify and identify the badminton action element video. As mentioned above, it is feasible to study the action identification of badminton element video based on GoogLeNet and combined with TSN network.
Badminton video action recognition based on time network
This chapter studies a method for identify badminton movements in metavideo. The meta-video dataset was first constructed, and the dataset was preprocessed. Based on the timing segmentation network, the identification of four action elements of forehand, backhand, overhead and picking is realized.
Meta-video dataset construction
The data sample input by the sequential segment network is a meta-video (a video clip including only one action). In order to obtain high-quality meta-video training set, maximize the shooting integrity of meta-video in the training set, and ensure the training data quality of the network, the manual establishment of meta-video data set is needed. Based on the highlights of badminton videos, this section uses the fast video merge segmentation tool, and finally divides 5,160 badminton yuan videos as a data set.
With the assistance of badminton school team members, the samples in the meta-video dataset are marked according to the five actions of forehand, backhand, high, kill and picking, and the frame sampling sequence of each action meta-video is shown in Fig. 1.
Badminton action element video frame sequence sampling.
TSN network (Temporal Segment Networks) inherits the dual-stream architecture of Two-Stream CNN, in which the input of Two-Stream CNN is two parts of frame and optical flow of metavideo. The structure is composed of spatial flow convolution and temporal flow convolution, which process frame image features and optical flow features respectively. Before training the TSN network, it is necessary to decompose the RGB frames of each metavideo in the training set, randomly sample the frames and then input spatial convolution, and transmit the light extracted from these frames and adjacent frames into the temporal convolution.
Badminton match video, like ordinary video, consists of two parts: spatial flow and time sequence flow. The spatial flow section refers to the surface information of each frame forming a video, including the scene, shape, size and spatial position of the object; the temporal flow refers to the optical flow information between frames and frames, reflecting the relationship between the moving object and the surrounding environment and the direction and speed of the object movement. The motion information between the frames is described by the optical flow, the pixel matching relationship between the current frame and the previous frame based on the pixel movement in the time domain and the correlation between the adjacent frames are obtained, and the optical flow information between the adjacent frames is calculated.
In mathematical form, the optical flow is a set of displacement vectors
Where
For the badminton game video, an example of the optical flow field extracted between the adjacent frames
Schematic diagram of the optical flow extraction.
In order to better improve the model performance, introduced the attention mechanism SE (Squeeze-and-Excitation Networks) into the Inception module to achieve more ideal results [24]. SE makes neural networks focus on feature channels meaningful for the classification task and feature channels with little inhibition. However, it lacks the focus on the spatial location information. Drawing on this idea, this paper introduces the attention mechanism CBAM (Convolutional Block Attention Module) after the BN-Incepti on structure to improve the original TSN network to the CBAM-TSN network.
The CBAM structure includes two modules: channel attention mechanism CAM (Channel Attention Module) and spatial attention mechanism SAM (Spatial Attention Module). What features the CAM focuses on play a major role in the task.
The input feature F of size
SAM focuses on which regional features are more effective for the task, similar to CAM, the average and maximum pooling of F’ on channels to obtain two channel descriptors of size
The CBAM-TSN network structure is shown in the following figure. In order to effectively express the information of the whole video, the input metavideo is first divided into
The convolution predictions of each segment are then aggregated through the piecewise aggregation function, and the weighted output of the two convolutional aggregation results in space and time order is taken as the final prediction result. The whole network constructs the loss function according to the prediction results and the actual type, iteratively updates the network node parameters, and trains the network end-to-end.
The dimensions of the input features and output features at each level of the TSN network are shown in Table 1, where the principal structure is BN-Inception. BN-Inception added a normalization layer (BN) to the original Inception-vl module, which effectively prevents network performance instability due to excessive data, where the structure configuration of the initial module 0 is shown in Table 2.
CNN channel dimensions of all levels
The CBAM-TSN network structure.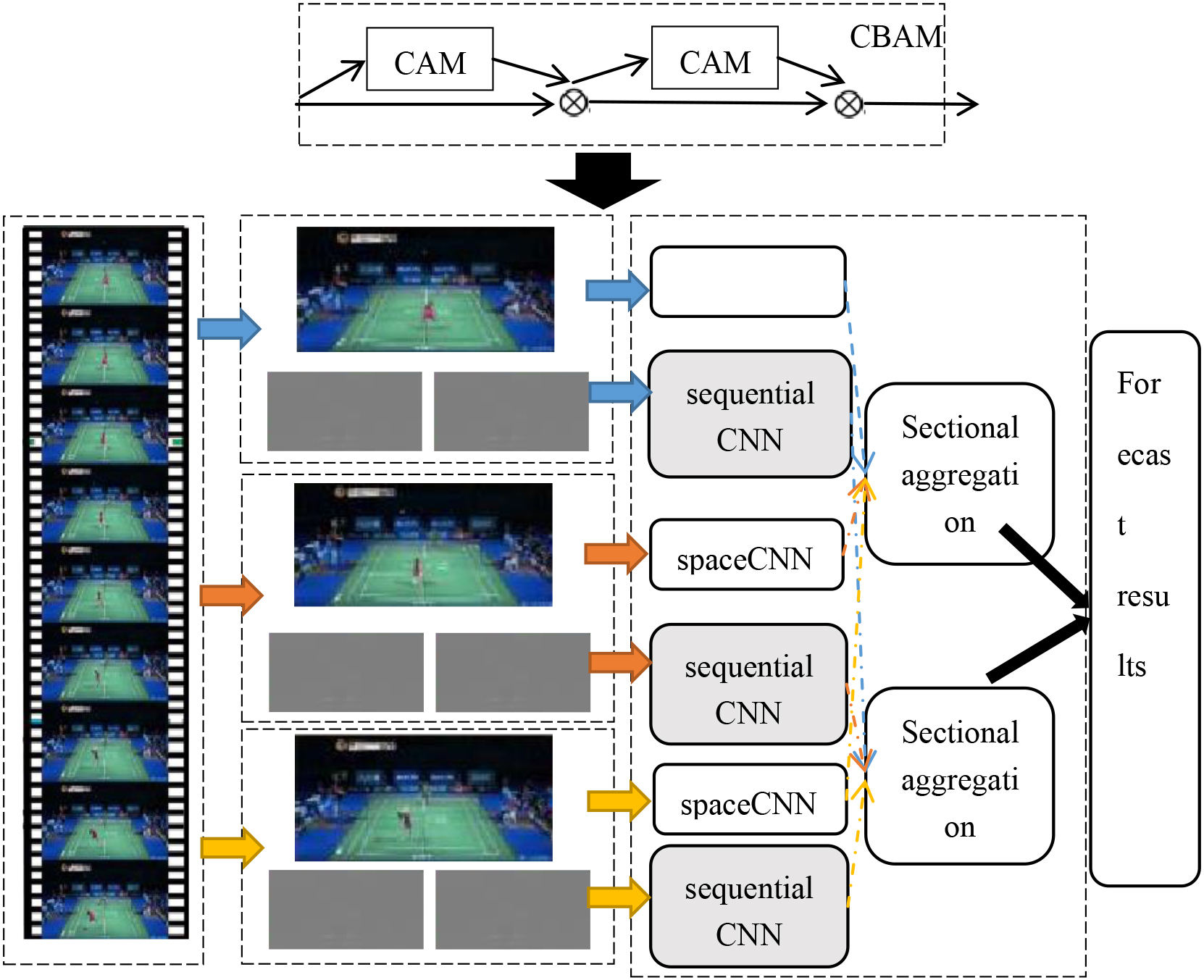
As can be seen from Table 1 above, high range ball and kill ball are highly consistent in hitting posture, and both belong to the overhead hitting category. In order to make the characteristics of different categories of metavideos show different player attitude characteristics in the training set, the high range ball and kill ball are temporarily classified as “overhead shot” in the training set.
Initial stage
The introduction of CBAM attention mechanism after BN-Inception can continue the pre-trained model for transfer learning. The characteristics of CBAM output pass through the average pooling layer (Avg Pool), Dropout layer, and the full connection layer (Linear) successively, transforming the final output feature dimension to 4, corresponding to the prediction results of the four actions of forehand shot, backhand shot, overhead shot, and pick ball.
The average pooling layer can eliminate the redundant information, compress the features, and reduce the computation and memory consumption. The Dropout layer can weaken the joint adaptability among the network nodes and enhance the robustness of the network model. The mathematical principle of normalization layer (BN) is shown in Eq. (4): can avoid the denominator of zero, here the value 1e-5, conducive to the stability of output characteristics.
For an aggregation layer in a TSN, the choice of its aggregation function
Based on this aggregation, the prediction function outputs the probability of the entire meta-video corresponding to each action. TSN models the sampled video segments as Eq. (7):
The TSN network training uses the back-propagation algorithm to combine multiple segment predictions to optimize the model parameters
Where
The choice of aggregation function
The average pooling function is that for each category, the average of all segmented predicted values is taken as the aggregation result of the entire input video, such as Eq. (9):
Where
The basic purpose of average pooling aggregation is to make full use of the information of all segments in the video, taking the average output of the predicted value of all video segments as the final prediction result. This aggregation function can model all video segments to capture information about the entire video. However, for slightly longer videos, some segment information is unrelated to the action to be identified, and evenly pooling the predicted values of these video segments can affect the accuracy of the final identification.
The maximum pooling function is that for each category, the maximum predicted value of all segments is taken as the aggregation result of the entire input video and the gradient of
The basic purpose of maximum pooling aggregation is to select a most discriminative video segment for each action category to generate the largest activation response to a certain category. For a category, it only on the video segments most relevant to that category and ignores the role of other video segments. Thus max pooling prompts TSN to learn from the segments with the largest activation response on each category, but cannot take advantage of the role of all video segments.
Linear weighted aggregation introduces the model parameter
The aggregation can be interpreted as an action can be composed of multiple parts, each part of the action recognition reflects different roles, and ultimately can learn the importance of each video segment for action recognition.
CBAM-TSN network training
The experimental hardware platform in this paper is Intel Xeon Platinum 8160Ts CPU, TITANRTX 2080 GPU 2, and memory 1T. CUDA10 and CUDNN7.6 are the GPU acceleration library, which is completed in the Ubuntu18.0 operating system using the deep learning framework PyTorch1.1. The CBAM-TSN is tested by the retention method (Hold-Out), and according to the stratified sampling method, that is, the overall data is divided into disjoint categories, a certain proportion of samples are randomly selected from all kinds of data, and the extracted samples are taken together as a sample collection. Here 10% of the samples were drawn from each category of meta-video datasets and assigned to the test set and the remaining samples to the training set.
The pre-training model adopts bninception_caffe6. During the training process, the hierarchical ten-fold cross validation is adopted. At the beginning of the training stage before each validation, each metadvideo data in the training set is divided into ten folds into the validation set, and the remaining 90 percent participate in the training process of the network.
The learning rate was reduced to 10% when training to 30Epoch and 40Epoch. An important parameter of the sparse sampling strategy followed by the CBAM-TSN network is the number of segments A. When
Experimental result
For the backbone convolutional structure (backbone) in the TSN network, this paper uses four neural network structures: AlexNet, VGG16, BN-Inception and ResNet50, and combines with the pre-training model suitable for each network.
The average recall, the average recall and the AUC of the above four network models are further compared, and the comparison results are shown in Table 3. Among them, the network model with the highest average recall on the test set is VGG16, and the network model with the highest AUC is ResNet50, while BN-Inception has the highest average recall and microaverage corresponding AUC. Through comprehensive comparison, BN-Inception is adopted as the backbone convolution structure of TSN in this paper. The test set was compared with the TSN, TSN that introduced attention mechanism SE and TSN introducing attention mechanism CBAM. The pairs of microaverage and macro-average results in the average recall, average recall, and AUC are shown in Table 3.
Ablation experiment evaluation
Ablation experiment evaluation
By comparing the test accuracy of the three aggregate functions: maximum pooling, average pooling and linear weighting introduced in the above content, the comparison results are shown in Table 4. On the test set, the average pooling achieves the best accuracy, so the average pooling is taken as the aggregation function of the network model.
Effect of different aggregation functions on the recognition accuracy
The change of test performance with
Test performance changes with the parameter k.
For the performance evaluation of hitting action classification, the ROC curves of the CBAM-TSN network model for four categories, forehand, backhand, overhead, and pick, are shown in Fig. 5 below.
The AUC metrics of the four action categories of forehand, backhand, pick and overhead are all above 0.98, with microaverage (Micro-average) and macro average (Macro-average) all about 0.99, indicating that CBAM is introduced into TSN network and trained through transfer learning has high performance.
Badminton motor recognition of the confusion matrix
Badminton movement identification and recall rate and accuracy rate statistics
Badminton action recognition ROC-AUC metric.
To further evaluate the identification performance of the model for each category sample, the metadvideo samples of the overhead shot belonging to the test set continue to be separated into high range ball and ball kill categories. The confusion matrix of the predicted results in the test set, as shown in the table. And the diagonal number of all predicted correct metavideo samples for each category, totaling 467, accounting for 91.6%, achieved good identification accuracy. But forehand and pick confusion, high ball and kill the ball is relatively more, because sometimes forehand shot and pick in the video will present a certain attitude similarity, and when the end of the video target is too small or too fuzzy, the morphological method of this paper is easy to mistake the high ball to kill ball, when the end of the video background area appear multiple strong dynamic noise, will also lead to kill easy to be misjudged as high ball.
Based on the confusion matrix, combined with the performance metrics, the recall and accuracy of the model recognition for each action can be calculated, as shown in Table 6 below.
As can be seen from Table 6, the recognition recall and accuracy of various stroke movements reach more than 86%, and the average size of recall and accuracy are 91.2% and 91.6% respectively, indicating that the method based on timing segmentation network can be close to the human judgment level to a large extent and can effectively conduct the identification task of badminton video strokes.
This paper mainly through the combination of theoretical research and experimental analysis of the badminton video clip extraction, badminton movement domain positioning and the study, the main work and conclusion is as follows: based on the timing segment network of badminton video clips, for the key movement trajectory, through the comparison of its amplitude changes. Based on the temporal segmentation network, combined with the lightweight attention mechanism, the common hitting action is classified and identified, and a video differentiation method of high distance ball and ball killing element based on image morphology processing is proposed. Combined with the experimental results, we classify and identify common hitting movements in badminton game videos, and propose a differentiation method for high distance ball and ball killing video based on image morphology processing.The experimental results show that the IoU index of the time domain positioning of badminton video is 82.6%, the AUC index of each action category is higher than 0.98, and the average recall and average accuracy rate are 91.2% and 91.6% respectively, indicating that this method can effectively realize the identification of badminton video hitting action.
Footnotes
Acknowledgments
2022 Hebei Province School Physical Education, Health and Art National Defense Education Special Task Research Project “Study on the evaluation index system of middle school students’ health literacy based on Analytic Hierarchy Process”. 2021 Hebei Higher Education Teaching Reform Research Project, No.: 2021GJJG558.