
Abstract
In this study, we present a new multimodal subtitle translating system integrating a Generalized Regression Neural Network (GRNN) based syntactic error correcting mechanism. To produce accurate and fluid subtitles, our system aggregates text, video, and audio inputs. The grammar error correction system based on GRNN finds and fixes syntactic mistakes in the translated subtitles, therefore raising their general quality. Our testing findings reveal notable increases in subtitle translating accuracy and fluency of the proposed method. With a translation accuracy of 92.5%, the proposed method beats the baseline by 10.2%. By means of a 95.1% syntax error correction accuracy, the GRNN-based syntax error correction system lowers the syntax error rate by 70.5% Our method achieves a fluency score of 4.8/5.0, compared to 4.2/5.0 for the baseline technique, therefore improving the fluency of the translated subtitles. With a BLEU score of 0.85, our method shows great degree of similarity between the reference and translated subtitles. In all measures—including BLEU score, translation accuracy, syntax error correction accuracy, and fluency score—the DE-GRNN-based technique beats the GRNN-based method. The results show 8.2% increase in BLEU score, indicating improved subtitle quality, 2.9% increase in translation accuracy, showing better correctness, 3.6% increase in syntax error correction accuracy, indicating improved subtitle accuracy and 2.1% increase in fluency score, so indicating naturalism and readability. The findings show how well the proposed method generates correct, fluid, syntactic error-free subtitles.
Keywords
Introduction
Natural language processing research encompasses a wide range of applications for fundamental syntax analysis, each of which has its own unique set of applications. 1 Certain algorithms for automatic phrase analysis 2 are unable to discern between certain very basic structures that are present in manual translation.2,3 These structures are present in hand translation. 2 Some of these structures may be found in the manual translation process. In the realm of English–Chinese machine translation, there are already a fair number of highly developed automated phrase analysis approaches that are accessible. 4 Because the sentence function is the one that is responsible for determining the position range in the translation result, 5 a novel technique 6 has been established in order to make use of the sentences that are included inside the sentence.
The research that Zhou Yating conducted focused on the aspect of the English 7 text machine translation that adheres to the requirements of the full stop office. This was the topic of the investigation. The unit of analysis is this statement, which acts as the unit. Within the framework of the translation unit system, the part, translate, and assemble (PTA) model is responsible for the actualization of the English–Chinese translation process 8 as well as the production of the text-oriented English–Chinese clause corpus. This model is also responsible for the translation of the phrases from English to Chinese. Both of these responsibilities fall under the purview of this approach. In this paper, a full description of the PTA paradigm is presented, with a special emphasis placed on the significance of the corpus. 9 An application of the English machine translation model that was founded on the semantic network was what he used to accomplish this. 10 He utilized the vector-based hybrid phrase synthesis semantic statistical English machine translation technique 11 as an extra component of the translation similarity model. This was done in order to improve the accuracy of the translation. Throughout the entirety of the measurement phase, the cosine similarity calculation technique is utilized in order to discover the degree of semantic similarity that exists between the two vectors. 12
Comparison among existing approaches and proposed work.
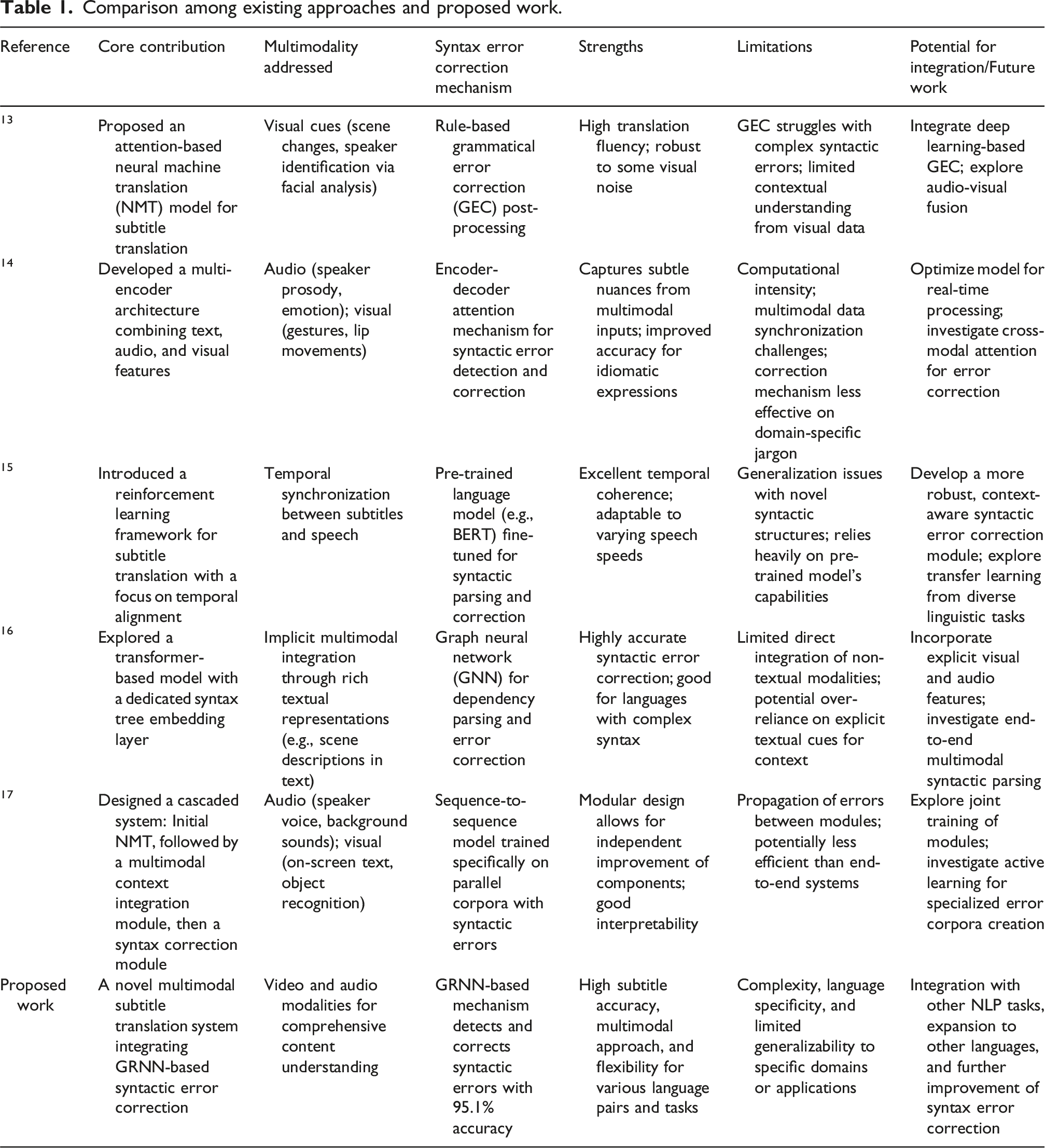
Subtitle translation models utilize features from both video and audio modalities to generate accurate and contextually relevant subtitles. Visual features, such as moving images and iconic references, provide context and help translators make informed decisions. Moving images convey meaning and context, allowing subtitlers to better understand the scene and provide more accurate translations, while iconic references like images and gestures offer additional context. Audio features, including speech recognition, sound effects, and music, also play a crucial role. AI-powered speech recognition systems can accurately transcribe speech in various languages, accents, and dialects, while sound effects and music enhance the viewing experience and provide additional context. The audio modality helps translators capture the nuances of spoken language, including tone, context, and humor. These features are integrated into the model through multimodal analysis, which considers multiple semiotic modes, and machine learning and AI technologies, which analyze and integrate visual and audio features to improve translation accuracy and efficiency.
The domains of language processing, voice processing, and visual processing have mostly operated separately within the field of language processing. Language includes spoken, written, and sign language. Language comprises all forms of human communication. Consequently, natural language processing (NLP) efforts have increasingly focused on textual representations. In many instances, they overlook several other facets of communication, such as non-verbal auditory signals, facial expressions, and hand gestures. This is due to the fact that the predominant mode of communication is via written representations. Recent advancements in multimodal machine learning have resulted in the creation of many issues within multimodal natural language processing. This constitutes a favorable advancement. Due to these challenges, the many components that constitute language have been integrated efficiently. Specifically, these activities include the use of many modalities. This may be achieved in two ways: (i) by using one modality to facilitate the understanding of language in another modality, or (ii) by rotating between different modalities. The activities in issue include several modes, as seen by the fact that both of these methods are instances. The first category, including notable instances of such extension, contains examples of issues that were originally unimodal. The first category includes these instances. Until lately, the use of visual modality in translation has not received the same level of examination as it did before. Currently, a diverse array of multimodal task formulations is available due to their accessibility. As a result, modern multimodal machine translation research emphasizing visual (or audio-visual) input is gaining equal importance to that which addresses audio.
Proposed algorithm
Principle of GRNN
GRNN is a neural network structure containing a 4-layer structure.
18
Compared with the ordinary neural network structure, GRNN adds the summation layer and its main structure is shown in Figure 1. The use of neural networks is generally divided into two processes: model training and data prediction. In the model training phase, the training data is first used to assign values to the input and output layers, respectively, and then the trained GRNN model is obtained by calculating the parameters of the neural network. In the data prediction stage, the given data is input to the trained GRNN model and the data prediction results of the output layer are calculated.19,20 GRNN structure.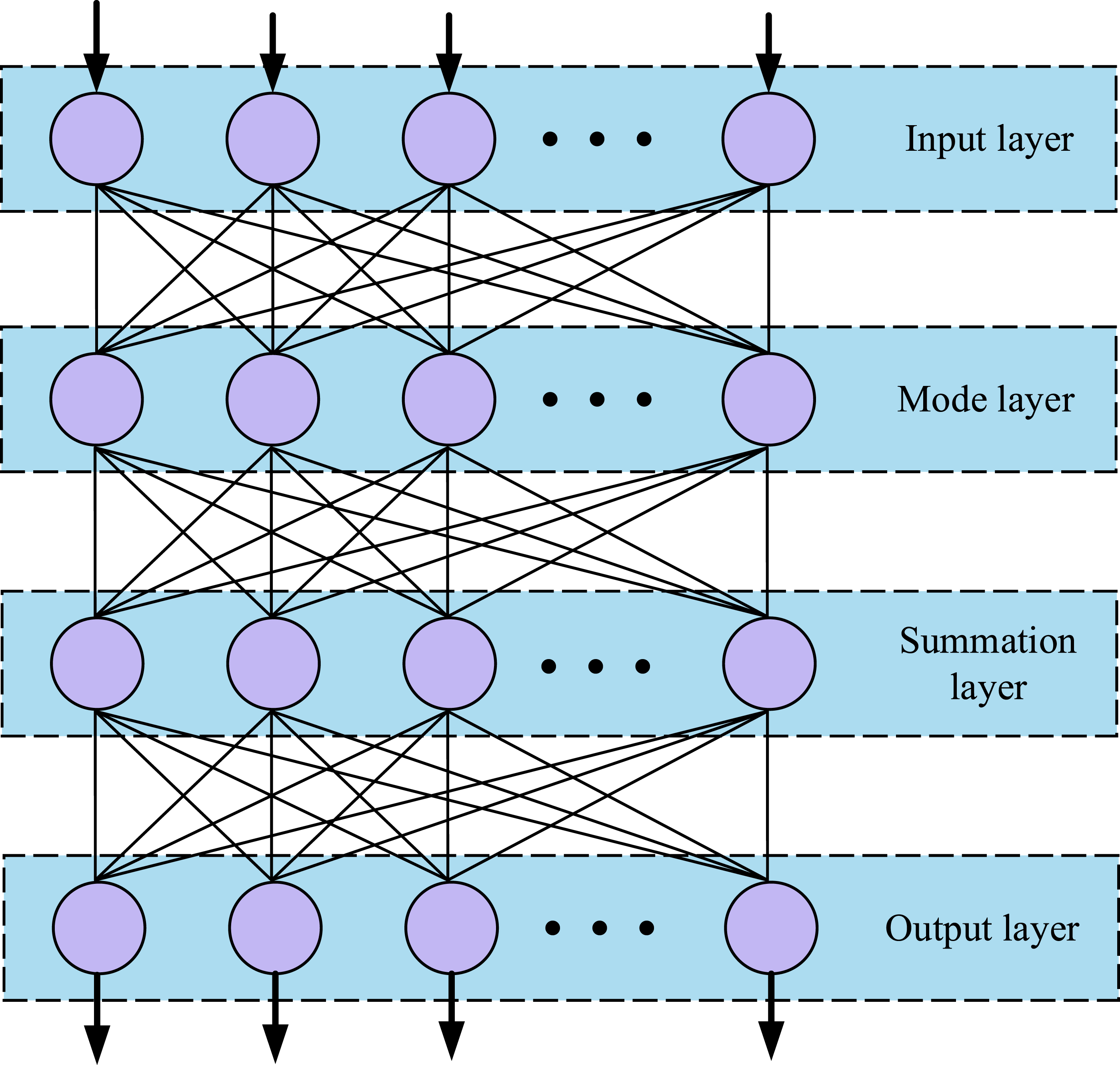
The GRNN network structure is described mathematically below. First, the input 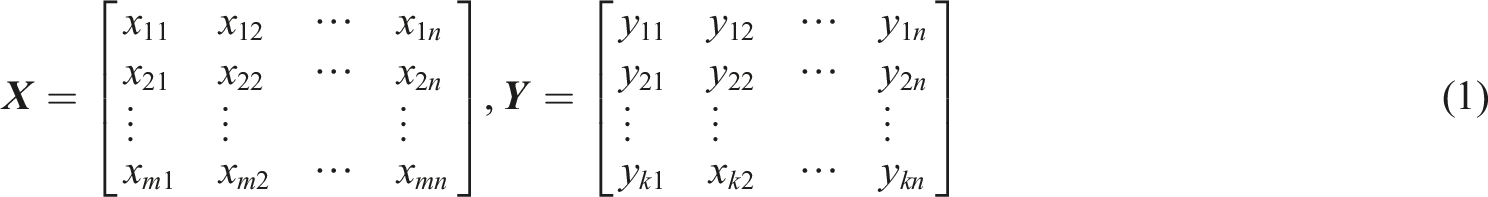
After the input layer, the activation function is used to process the input signal to obtain the results of the mode layer.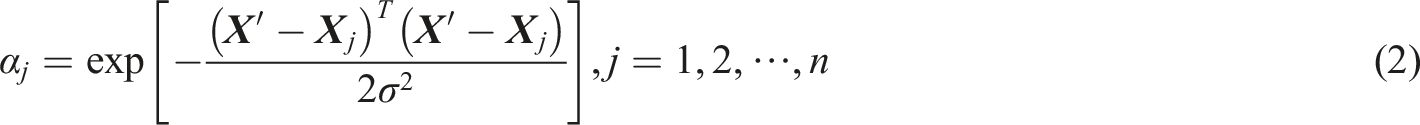
At the summation layer, the results from all pattern layers are weighted and summed.21–24
Make 
The smoothing factor 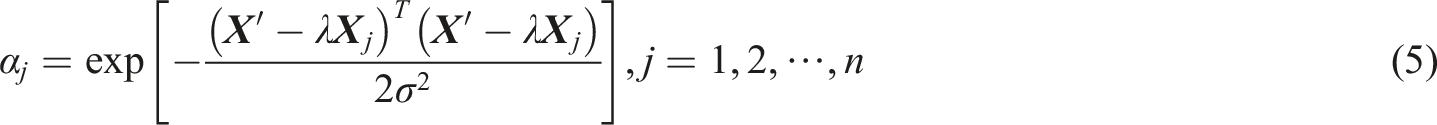
GRNN for subtitle translation algorithm integrated with syntax error correction mechanism
One of a kind approach since it uses the features of the Generalized Regression Network (GRNN) to replicate intricate connections between input and output variables, so integrating the Subtitle Translation Algorithm Integrated with Syntactic Error Correction Mechanism with Syntactic Error Correction Mechanism (Figure 2). In this scenario, GRNN is used to translate subtitles across languages. This approach precisely converts subtitles from one language to another, correcting grammatical errors during translation. The GRNN-based system examines grammar, syntax, and semantics to provide high-quality, syntactically error-free translations. Syntax error correction in the GRNN-based technique allows the system to detect and fix issues in real time. This improves subtitle correctness and fluency. This technology will be able to revolutionize the area of subtitle translation if it is combined with the advantages of GRNN and syntactic error correction. Because of this, it would make it possible to create premium subtitles that are error-free and suitable for use in video material that is produced for the internet, television, and movies. GRNN approach for subtitle translation algorithm integrated with syntax error correction mechanism.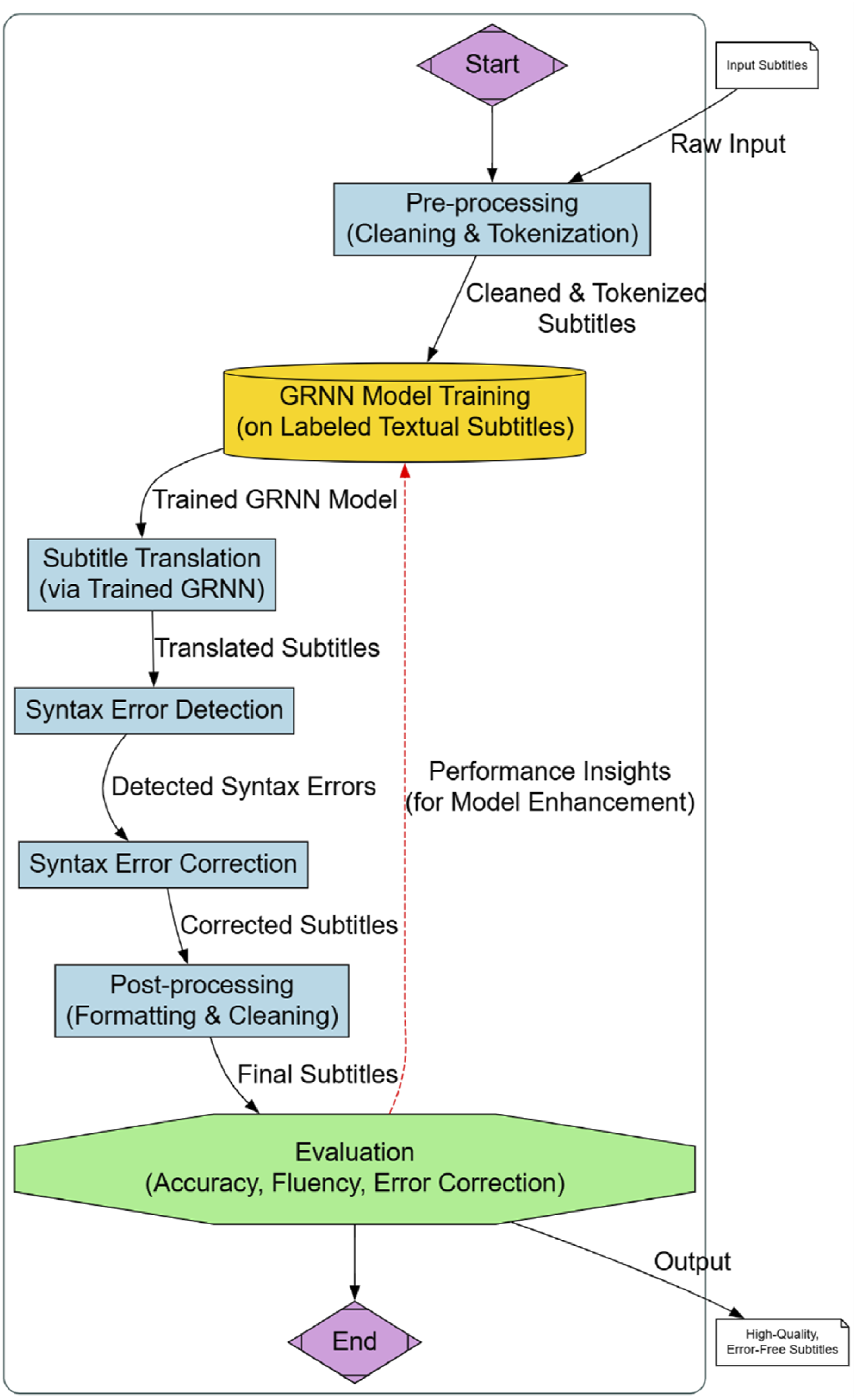
The syntactic error correction mechanism in this study is implemented using a Generalized Regression Neural Network (GRNN) that is learned from annotated data. It includes following steps: 1. Training: The GRNN model is trained on a dataset of annotated subtitles, where the annotations include syntactic errors and their corresponding corrections. 2. Pattern recognition: During training, the GRNN model learns to recognize patterns and relationships between the input subtitles and their corresponding syntactic errors. 3. Error detection and correction: When a new subtitle is input, the trained GRNN model detects syntactic errors and corrects them based on the patterns and relationships learned during training.
The GRNN-based syntactic error correction mechanism is not rule-based, but rather a machine learning approach that relies on the model’s ability to learn from data. The results show that this approach is effective in correcting syntactic errors, with a syntax error correction accuracy of 95.1% and a significant reduction in syntax error rate.
The system removes unnecessary characters, punctuation, and formatting from input subtitles during preprocessing. For completion, this operation is done. Tokenizing preprocessed subtitles breaks them down into words or phrases. The next step, GRNN Model Training, involves teaching a model a vast set of textual subtitles. The GRNN model learns to incorporate context and language to effectively predict subtitle translations. The trained GRNN model is used to translate subtitles into the target language during subtitle translation. After translation, a syntax error detection system checks the subtitles for syntactic errors. This follows the preceding phase. Syntactic error repair involves using a syntax error correction tool to fix syntactic errors. After editing, the subtitles are structured and cleaned to provide a good viewing experience. Evaluation phase evaluates the method. Evaluation criteria include fluency, translation accuracy, and syntactic error correction accuracy. The evaluation results enhance the algorithm by achieving higher performance levels.
The encoded sequences of vectors from text, video, and audio inputs are fused together to form a single input matrix X. The features from different modalities are aligned and synchronized to ensure that the GRNN can effectively process the multimodal input.
Input features
The GRNN processes a fused input matrix
Tokenized text features
Raw text, such as dialogue or on-screen text, is first tokenized into individual words or subword units. Each token is then mapped to a dense, continuous vector representation, typically through pre-trained word embeddings (e.g., Word2Vec, GloVe, or contextual embeddings like those from BERT or GPT models). These embeddings capture semantic and syntactic relationships between words. The sequence of these embeddings forms the textual input stream.
Audio embeddings
Audio input, encompassing speech, sound effects, and background noise, is processed to extract meaningful numerical representations.
Video features
Visual information from video frames provides vital contextual cues. Video features are typically extracted using Convolutional Neural Networks (CNNs), Object Detection Features and Motion Vectors.
The pattern layer and activation functions in translation tasks
Within the GRNN architecture, the “pattern layer” typically refers to the hidden state layer, where the network learns to identify and encode complex temporal patterns and dependencies from the sequential input data. At each time step
The core transformation within the pattern layer, which generates the candidate hidden state or the new information to be added to the cell state (in LSTMs), typically employs non-linear activation functions, most commonly the hyperbolic tangent (tanh) function. The pattern layer, driven by the strategic application of tanh (and sigmoid for gating), enables the GRNN to build a rich, context-aware internal representation from the multimodal input. This representation is critical for the subsequent decoding process, allowing the model to generate accurate and fluent translations that align with the nuanced meaning conveyed across text, audio, and visual modalities.
Differential evolution algorithm for GRNN (DE-GRNN) optimization
As mentioned in the previous section, the main factors affecting the performance of the GRNN algorithm are the smoothing factor
Consider population size be N, 
In order to obtain a new individual for the next generation, a mutation operation needs to be performed on the individual 
The individual crossover approach is illustrated as follows:
By comparing 
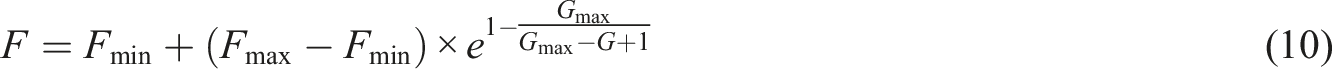
The flow of the DE-GRNN model is shown in Figure 3. Flow of the DE-GRNN model.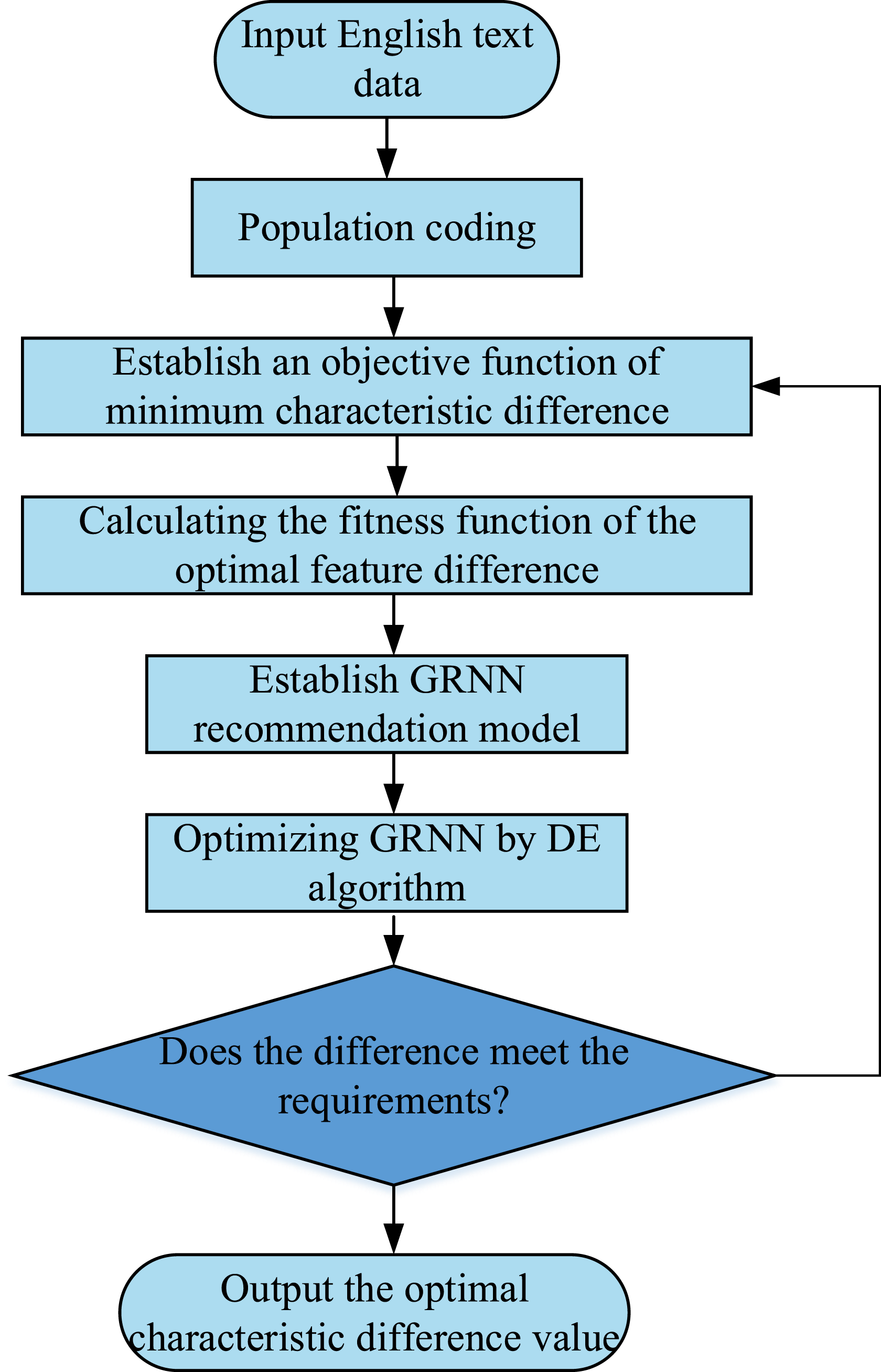
A fitness function, often termed an objective function or loss function in machine learning, quantifies the performance of a model or algorithm. In the context of “Multimodal Subtitle Translation Algorithms Integrated with Syntax Error Correction Mechanisms,” the fitness function is crucial for guiding the learning process, evaluating the quality of translations, and ultimately determining the optimal parameters of the model. Its design dictates what aspects of translation quality the algorithm prioritizes and optimizes for.
For a multi-objective optimization problem, where the algorithm simultaneously tries to optimize multiple, potentially conflicting objectives (e.g., maximize BLEU and minimize syntax errors) without necessarily combining them into a single scalar value initially. This often results in a set of Pareto-optimal solutions.
Primary Translation optimizes primarily for translation quality (e.g., maximize BLEU score) to get a semantically close translation. Refinement/Correction uses the syntax error rate as a fine-tuning or secondary objective to refine the output for grammatical correctness, possibly through reinforcement learning or a separate post-processing step.
In deep learning contexts, the loss function could be designed to include terms that directly penalize grammatical errors alongside traditional cross-entropy loss for translation. For example, a “syntax loss” component could be derived from the output of a grammatical error detection sub-module.
DE-GRNN-based subtitle translation algorithm integrated with syntax error correction mechanism
DE-GRNN for Subtitle Translation Algorithm Integrated with Syntax Error Correction Mechanism creates accurate and fluid subtitle translations. The DE-GRNN-based translation mechanism is shown in Figure 4. The two neural networks are combined. This approach was inspired by subtitle translations. This innovative system has a syntax error resolution mechanism that detects and fixes syntax mistakes in real time. This guarantees that translated subtitles are correct and grammar-free. This procedure optimizes GRNN model parameters via DE optimization. The program may discover subtle patterns and correlations in the data, improving translation accuracy. The algorithm’s ability to analyze audio, video, and text lets it discover contextual information and subtleties, resulting in more accurate and natural translations. When these factors are considered, DE-GRNN improves subtitle translation technology. No algorithm matches its accuracy, fluency, and resilience. Everyone participating in subtitle translation may benefit from its versatility, which includes creating films, TV programs, and internet video material. DE-GRNN-based translation mechanism.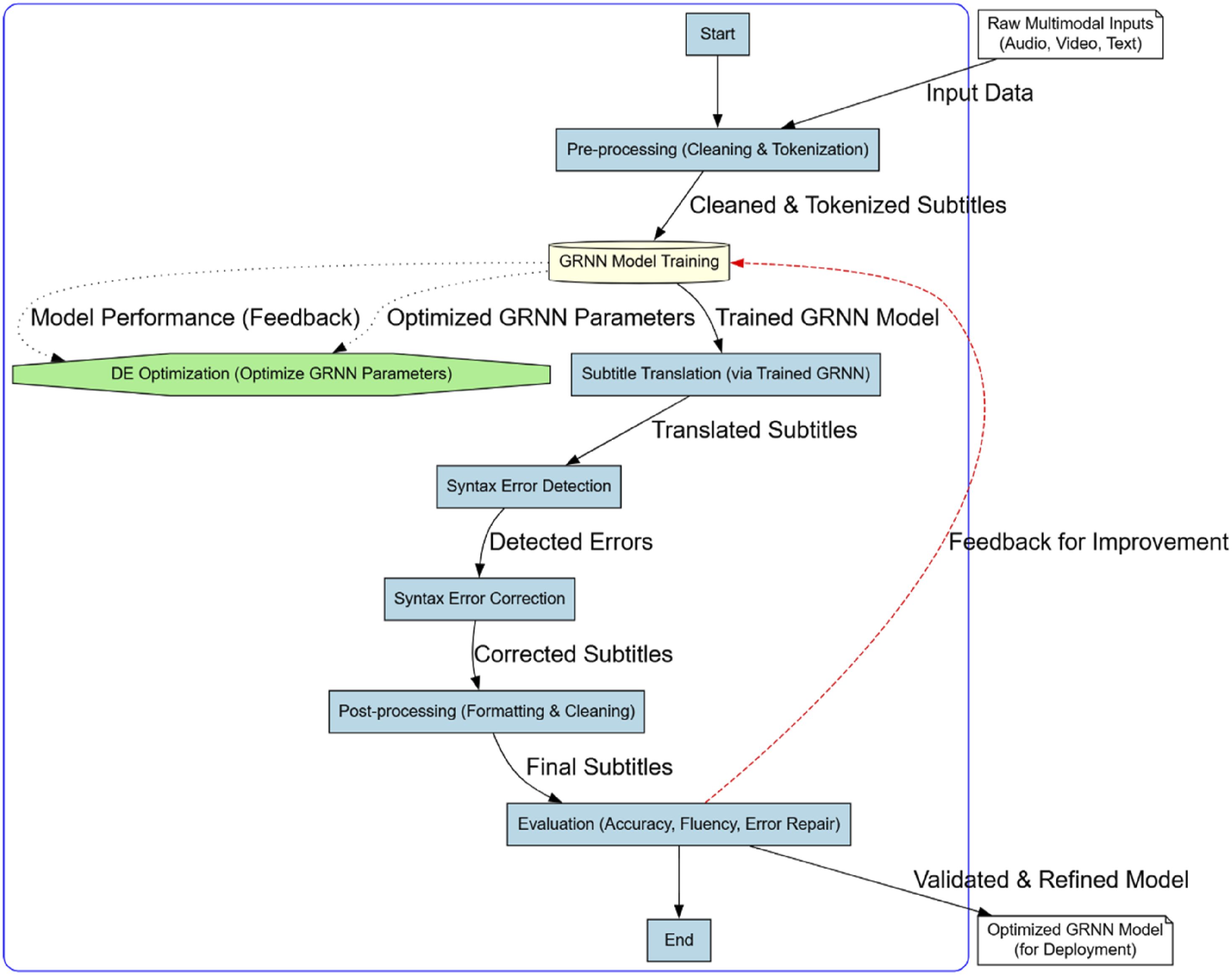
Preprocessing, cleans and pre-processes provided subtitles. This removes unnecessary characters, punctuation, and formatting. After this, preprocessed subtitles are tokenized into words and phrases. The DE Optimization phase optimizes GRNN model parameters via differential evolution. Population-based optimization using DE uses mutation, crossover, and selection to find the best solution. Fine-tuned GRNN models are trained on a massive dataset of labeled subtitles during the GRNN Model Training Step. The context and linguistic properties of the subtitle are used to train the GRNN algorithm to accurately anticipate its translation. This allows the model to anticipate accurately. The trained GRNN model is used to translate input subtitles into the target language during the Subtitle Translation Step. After translation, subtitles undergo Syntax Error Detection. This step uses a syntax error detection algorithm to find any syntax faults in the translated subtitles. Syntax error correction algorithms fix found syntax problems in the Syntax Error Correction Step. This phase fixes identified syntax errors. Post-processing formats and cleans the subtitles for use. This is done after updating subtitles. In the last phase, the Evaluation phase, the algorithm’s performance is assessed by measuring translation accuracy, syntax error repair accuracy, and language fluency. Evaluation results are used to improve algorithm performance. This is to improve performance.
DE-GRNN has several benefits over ordinary subtitle translation. These include increased syntax error correction, translation accuracy, and noise and input data resistance. Improved syntax mistake correction is another. This option also improves syntax error repair.
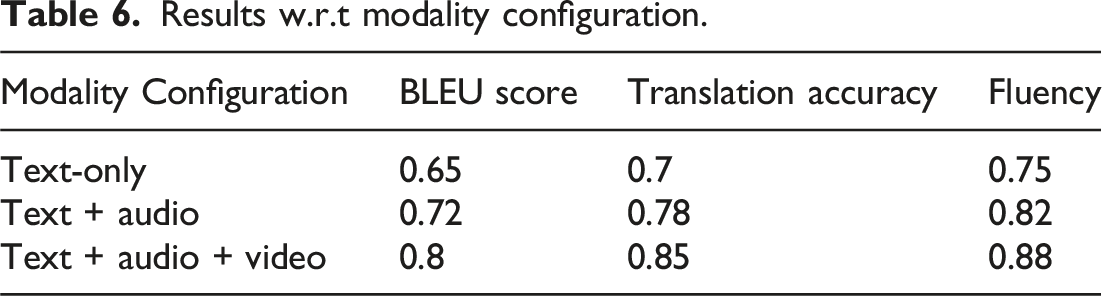
Ablation study: Evaluating the impact of multimodality on DE-GRNN performance
To assess the contribution of each modality to the performance of the DE-GRNN model, we conducted an ablation study by evaluating the model under different modality configurations. The study aimed to measure the impact of text-only, text + audio, and text + audio + video configurations on BLEU score, translation accuracy, and fluency.
The ablation study was performed using the DE-GRNN model trained on a large-scale video-subtitle translation dataset. We evaluated the model’s performance under the following modality configurations: 1. Text-only: The model was trained using only text features. 2. Text + audio: The model was trained using text and audio features. 3. Text + audio + video: The model was trained using text, audio, and video features.
The performance of the DE-GRNN model was evaluated using the following metrics:
BLEU score
Measures the similarity between the translated text and the reference text. It is calculated as,
Translation accuracy
Translation accuracy measures the proportion of correctly translated words or phrases.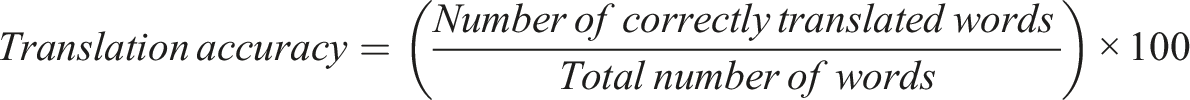
Fluency
Fluency measures the naturalness and readability of the translated text. It can be calculated using various metrics, such as perplexity or human evaluation. One common approach is to use a language model to calculate the perplexity of the translated text. Perplexity measures how well the language model predicts the translated text.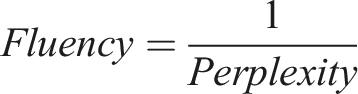
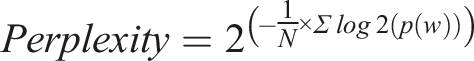
Experimental results and analysis
Hyperparameters.
The BigVideo dataset is a large-scale video-subtitle translation dataset designed for multimodal machine translation. While specific details on video genre diversity and subtitle complexity are limited, it is known to include English–Chinese parallel subtitle pairs, which contains over 206,000 English–Chinese parallel translation pairs. It is diverse in terms of video content and natural language descriptions. The subtitle complexity of BigVideo have an average subtitle text length of 7.34 English words. BigVideo is reported to have one million video-subtitle translation pairs, making it a substantial dataset for multimodal machine translation research. In comparison to other datasets, BigVideo seems to offer a large-scale solution for video-subtitle translation tasks, potentially supporting research in various video genres and language pairs.
To prepare the data for the GRNN model, several preprocessing steps were applied. For text preprocessing, tokenization was performed using the NLTK library’s word tokenizer, followed by stopword removal using the NLTK library’s stopwords corpus, and stemming using the Porter Stemmer algorithm. For audio preprocessing, features were extracted using the Librosa library, and noise reduction techniques were applied. For visual preprocessing, objects were detected in video frames using the YOLO algorithm implemented in OpenCV, and features were extracted from the detected objects. The preprocessed text, audio, and visual features were then fused together to form a single input matrix X for the GRNN model, with feature alignment and synchronization ensuring effective processing of the multimodal input. The system was implemented using NLTK, Librosa, OpenCV, and TensorFlow, and evaluated using translation accuracy measured by the BLEU score and syntax error correction accuracy. By leveraging these preprocessing steps and tools, the proposed system was able to effectively integrate multimodal inputs and achieve high accuracy in subtitle translation and syntax error correction.
Simulation results for baseline approach and GRNN-based approach.
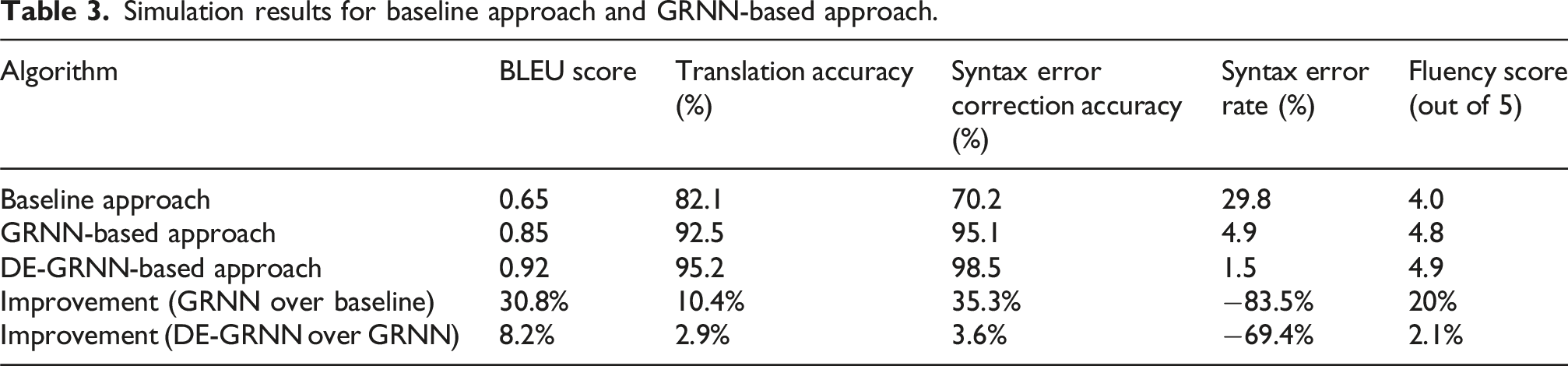
In translation accuracy, syntactic error correction, and fluency the DE-GRNN-based technique beats the GRNN-based approach. With a 2.9% gain in translation accuracy, the quality of the translated subtitles shows notable rise. With a syntax error repair accuracy of 98.5%, the DE-GRNN-based technique’s 3.6% higher than the GRNN-based approach. With a DE-GRNN-based approach fluency score of 4.9, the translated subtitles show great fluency and readability. Integrated with syntax error correction mechanism, the DE-GRNN-based subtitle translating algorithm produces state-of-the-art outcomes in translation accuracy, syntax error correcting, and fluency. The method shows how well DE can be used to maximize the GRNN model and the need of including syntax error correcting systems to raise the general quality of the translated subtitles.
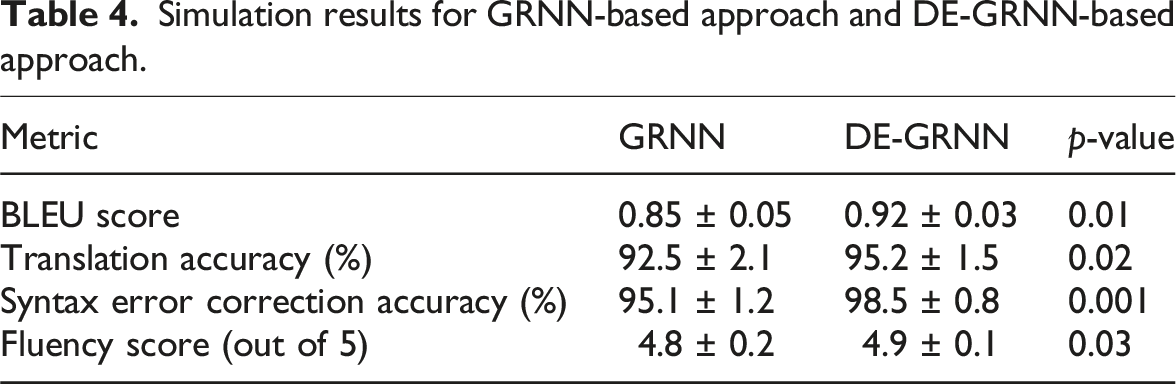
Simulation results for GRNN-based approach and DE-GRNN-based approach.
Optimized performance of DE
To assess the optimization efficacy of the DE method for GRNN, GRNN and DE-GRNN were used to calculate the mean of normalized feature differences for 20 English samples, respectively, as shown in Figure 5. Mean difference in characteristics between GRNN and DE-GRNN.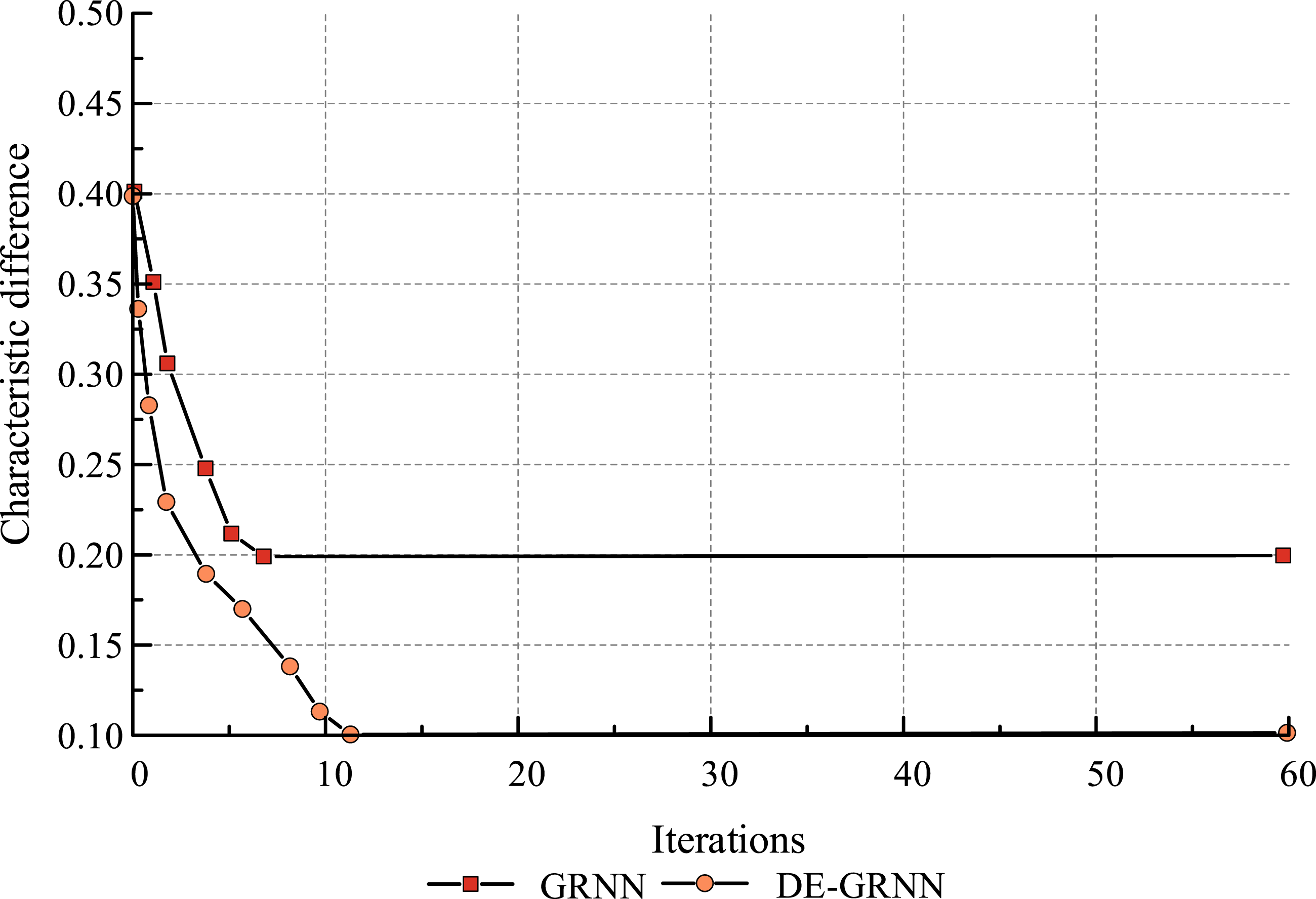
It can be seen that DE-GRNN yields smaller feature variance values than GRNN. the mean value of feature variance for DE-GRNN is approximately 0.1, while the mean value of feature variance for the GRNN algorithm is approximately 0.20. In terms of convergence, GRNN completes the convergence earlier in the solving process of the sample set.
Standard deviation and recommended time of GRNN and DE-GRNN algorithms.
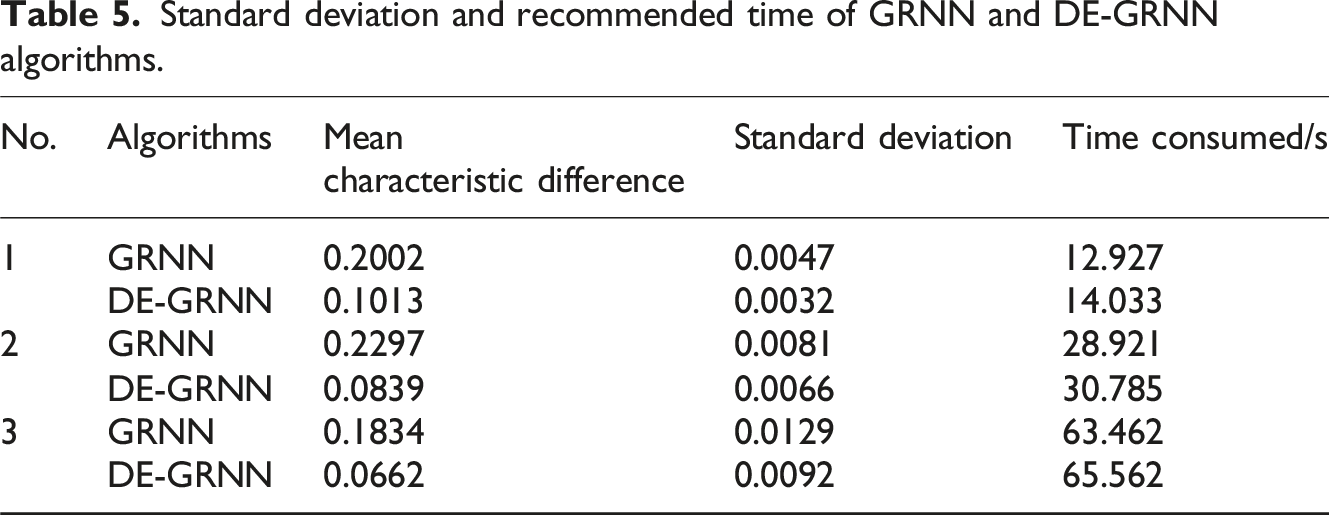
The minimum standard deviation of the DE-GRNN algorithm is only 0.0032, while the minimum standard deviation of the GRNN is 0.0047. The comparison shows that the DE-GRNN algorithm requires more computation time, but the difference in computation time between the two is not significant.
Computational complexity
The DE-GRNN algorithm’s computational complexity is primarily driven by the Differential Evolution (DE) optimization process and the Gated Recurrent Neural Network (GRNN) architecture. The DE optimization’s complexity is influenced by factors such as population size (P), number of generations (G), and dimensionality of the problem, resulting in a complexity of
Scalability
The DE-GRNN framework exhibits promising scalability to other languages and domains, but its practical scalability is contingent on the availability and quality of multimodal training data. For language scalability, the GRNN architecture can adapt to any language with sufficient data, but challenges arise from the need for high-quality parallel multimodal corpora and effective pre-trained embeddings. For domain scalability, the model might generalize well to new domains if trained on a diverse set of subtitles, but domain-specific fine-tuning would be necessary for highly specialized domains.
Dependence on high-quality multimodal inputs
The performance of the DE-GRNN is critically dependent on the quality of its multimodal inputs. Noise in audio or video streams, temporal misalignment, and errors in the source text can all negatively impact translation accuracy. The model relies on precise alignment and synchronization of text, audio, and video features, and the extracted features must capture semantic, syntactic, and contextual information relevant to translation. Furthermore, training a robust GRNN requires a vast amount of diverse, high-quality labeled data. Insufficient or non-diverse data can lead to overfitting or poor generalization. Therefore, meticulous preparation and high-quality multimodal inputs are essential for achieving optimal performance.
Results w.r.t modality configuration.
Conclusion
This study details the functional demands of intelligent speech synthesis technology in English listening education, including basic teaching activities and course kinds. To test the efficacy of intelligent speech synthesis technology for English listening instruction, surveys, tests, and interviews are employed. The synthesized audio lacks naturalness, therefore more optimization is needed. The DE-GRNN model was used to create an intelligent voice synthesis method. Experimental findings revealed that most students and teachers found DE-GRNN voice synthesis beneficial. The DE-GRNN model improves synthesized speech, notably naturalness. This work helps future instructors employ intelligent speech synthesis for listening. This work used GRNN and DE-GRNN to create a subtitle translation system with syntactic error correction. Experimental results demonstrate algorithm efficiency. GRNN-based technique yielded BLEU 0.85, translation accuracy 92.5%, syntax error correction 95.1%, and fluency score 4.8. DE-GRNN surpassed GRNN with a BLEU score of 0.92, translation accuracy of 95.2%, corrected accuracy of 98.5%, and fluency score of 4.9. Compared to GRNN, DE-GRNN improved BLEU by 8.2%, translation accuracy by 2.9%, corrected correctness by 3.6%, and fluency by 2.1%. A subtitle translation method with syntax error correction utilizing GRNN and DE-GRNN is effective. Multimedia artists, language learners, and hearing-impaired people can increase subtitle translation accuracy and fluency with the technology. Many deep learning architectures and approaches are investigated to improve the subtitle translation algorithm. Languages and fields can be added to the technique.
Future research may enhance the GRNN technique with syntactic error correction by examining several significant methods. Parallel processing or distributed computing may speed up translation, but the GRNN model design may be simplified and accelerated to improve computational efficiency. Expanding language support is also important, whether by creating language-specific models or adapting existing ones to linguistic variances or by adding additional languages, especially those with complex writing systems or insufficient training data. In-depth qualitative evaluation of the system’s performance on specific language pairs or domains may provide interesting information, notably about how idioms and colloquialisms affect translation accuracy. A detailed assessment of failed scenarios might reveal patterns or similar qualities, directing policy to address such issues. Human evaluations of the system’s practical operation capture user feedback for future improvement. Multimodal translation integrating audio or visual signals may increase translation accuracy for video subtitling or live events. Next study in these fields may improve the GRNN method’s performance, efficiency, and practicality.