
Abstract
With the widespread application of deep learning technology in image analysis, visual-based data processing and action recognition have become current research hotspots. To improve the accuracy and real-time evaluation of the quality of aerobics actions, a new lightweight OpenPose network is developed to extract key points of athletes’ skeletons. At the same time, the adaptive multi-scale optimization is carried out on the spatiotemporal graph convolutional network to grasp the temporal characteristics of actions. Finally, a new aerobics action quality evaluation model is designed by integrating Siamese network. The accuracy of the proposed model reached 96.8%, which was 5.3% higher than existing methods. The highest action evaluation matching degree was 89.7%, the highest action improvement rate was 21.34%, the highest action similarity evaluation was 92.17%, and the shortest evaluation time was 0.71 seconds. Its efficiency and effectiveness in the detection and evaluation process are significantly higher than other advanced models. From this, the proposed method for evaluating the quality of aerobics actions has strong application potential while ensuring efficiency and accuracy, and can provide certain technical support for aerobics competitions and actions training.
Introduction
With the deep popularization of the concept of national fitness, aerobic exercise, as a fitness method that combines music rhythm and body movement, has been widely promoted and applied worldwide. Especially in the fields of sports competition, fitness exercise, and entertainment performance, aerobic exercise not only helps to improve the participants’ cardiorespiratory function, coordination, and strength endurance but also becomes an important criterion for assessing the level of motor skills in programs such as competitive aerobics. 1 In competitive sports, the execution of high-quality aerobic movements directly affects the score and performance of the competition, while in the field of public fitness and recreation, standardized and regulated movement instructions can effectively improve the effect of exercise and reduce the risk of sports injuries. Therefore, accurate assessment of aerobic movement quality not only has important competitive value but also has a wide range of social application needs. However, at this stage, aerobic movement quality assessment still mainly relies on the subjective judgment of professional referees or coaches, which has the problems of inconsistent judgment standards, strong influence of subjective factors, and limited real-time feedback capability. With the development of intelligent sports and sports health field, how to realize the objective, efficient, and real-time assessment of aerobic movement with the help of advanced technology has become an important topic to be solved. 2 Especially in the fast and changeable scenarios with rich movement details such as competitive aerobics, the traditional methods have significant deficiencies in the recognition of movement details, dynamic coherence capture, and complex posture adaptability, which seriously constrain the standardization and automation process of movement quality assessment. To address this problem, many researchers at home and abroad have successively explored it. Liu Q believes that the traditional aerobic exercise recognition judgment model has the challenges of limited cost and insufficient recognition accuracy, for this reason, the scholar proposes a novel recognition judgment model that integrates Convolutional Neural Networks (CNN) and long and short-term memory networks. The experimental results show that the model recognizes fewer training parameters and has higher subsequent judging accuracy, and performs well in static or short-time action recognition, but there are still some limitations in dealing with complex dynamic action sequences and scenarios with high real-time requirements. 3 Lv D et al. In order to improve the quality assessment effect of aerobics exercise, the researchers combined the infrared target imaging system and monocular detection algorithm to propose a novel assessment model. The experimental results show that the model can effectively track the athlete’s body posture and accurately assess the quality of movement with good tracking accuracy, but it is sensitive to the environmental lighting conditions and weakly adapted in multi-character interaction scenarios. 4 Cao T attempted to enhance the effectiveness of wireless sensor networks in aerobics training posture assessment in the scholar combined the deep learning method and multiple inertial measurement units to The scholar combined the deep learning method and multiple inertial measurement units to construct an aerobics training posture evaluation system. The experimental results show that the system has lower classification error and higher real-time performance than the existing methods, and is suitable for single training in controlled environment, but it is more equipment-dependent, which restricts its generalization to large-scale free-motion scenarios. 5 Zuo N et al. In order to overcome the problem of low success rate of tracking and decomposition of the traditional aerobics movement, the researchers combined the binary classifiers and convolution filters, and proposed a new action evaluation model. A novel movement evaluation model. The experimental results show that the method has a significant improvement in tracking and decomposition success rate compared with the traditional method, which is suitable for fast processing of action segments, but there is still room for improvement in the modeling of action continuity and the capture of detailed features. 6 Zhang Y proposed a frame bounding box smoothing non-maximum suppression strategy to strengthen the stability of aerobic quality assessment, which integrates multiple prediction frames by integrating the information to obtain the results. Experimental results show that the method effectively improves the stability and tracking quality of motion quality assessment localization, and performs well in scenes with high action coherence, but there are still some limitations on the adaptability to drastic posture changes and abnormal movements. 7 Through skeletal joint point extraction, spatio-temporal feature modeling, and action similarity analysis, deep learning methods are able to more accurately capture the fine changes in locomotor actions and achieve automated, real-time action evaluation. However, there are still many limitations in the existing deep learning-based assessment methods, such as the high consumption of computational resources in the skeleton feature extraction phase, insufficient temporal modeling of complex dynamic actions, and the lack of efficient matching mechanism for action quality determination, which leads to the difficulty of balancing the assessment accuracy and real-time performance, and the robustness of the assessment in the diversified action scenarios needs to be improved.
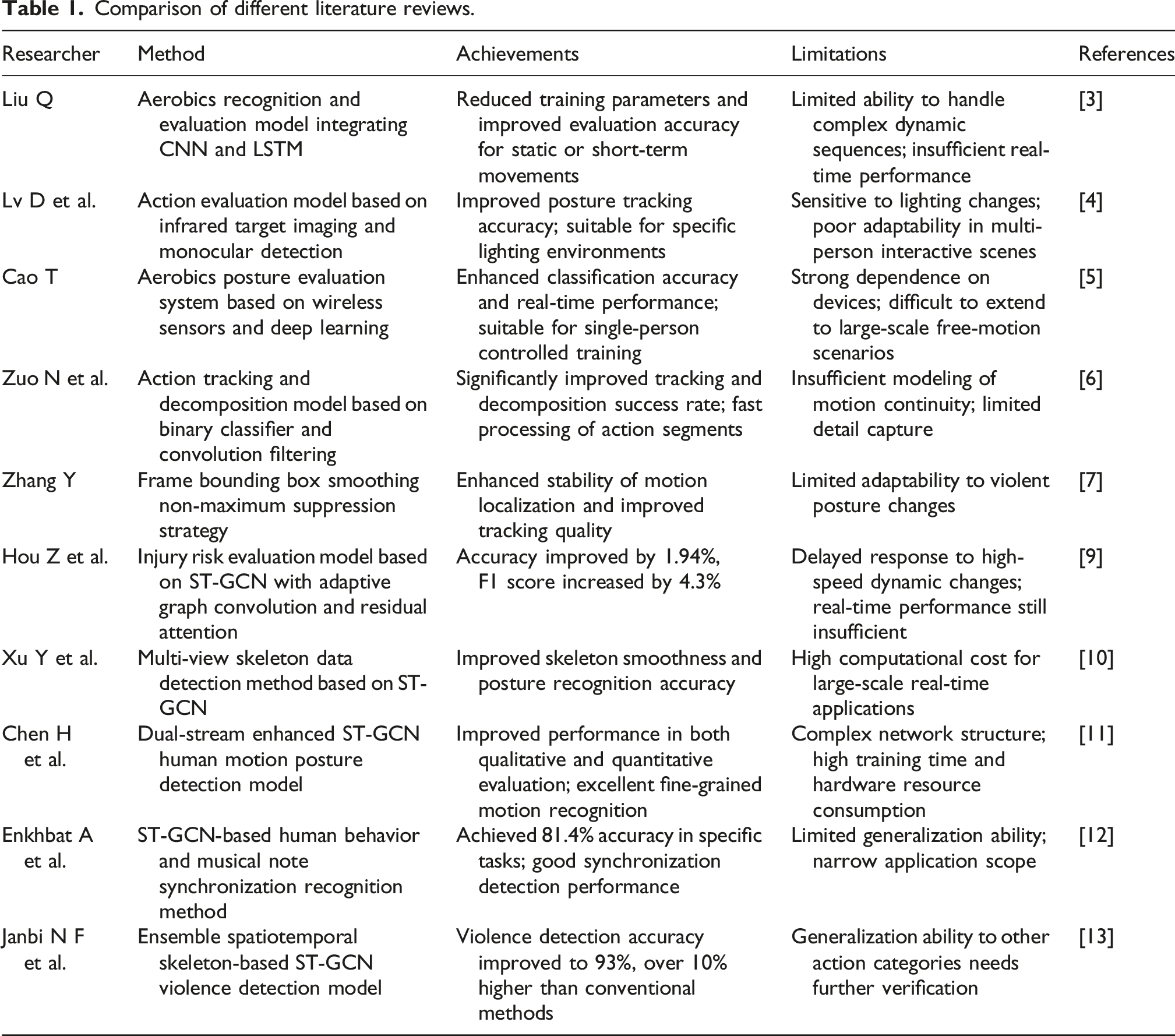
Comparison of different literature reviews.
In summary, despite the improvement in the accuracy of aerobics quality assessment, these methods still have certain limitations, including insufficient adaptability to complex dynamic movements and challenges in real-time. In order to solve these problems, an efficient, accurate, and widely adaptable aerobics movement quality assessment model is constructed. The study proposes an innovative movement quality assessment method based on deep learning techniques. Specifically, compared with the existing techniques, the study significantly reduces the number of model parameters and inference latency and improves the real-time processing capability by introducing a lightweight OpenPose network while maintaining the accuracy of skeleton key point extraction; on this basis, an adaptive multi-scale spatio-temporal graph convolution network (AMS-ST-GCN) is proposed to dynamically adjust the spatial relationship modeling between skeleton joints, and fully captures different levels of movement change features through multi-scale temporal convolution; in addition, the fusion twin network (Siamese Network, SN), which realizes efficient matching and quality quantification between standard and actual movements in the movement feature space, fills the gap of traditional movement recognition methods that make it difficult to accurately assess the movement accuracy and fluency. The study aims to provide an efficient and accurate solution for quality assessment in aerobics, and also provides a reference for action recognition and assessment in other fields.
Methods and materials
To improve the quality evaluation accuracy of aerobics actions, an aerobics action analysis framework based on lightweight OpenPose and adaptive multi-scale ST-GCN is built. First, the lightweight OpenPose network is applied to extract the skeletal features of athletes, capturing changes in joint positions and skeletal structures. Subsequently, an adaptive multi-scale ST-GCN model is adopted to enhance the spatiotemporal feature extraction capability, to comprehensively reflect the complexity of actions and athlete performance. Finally, combined with SN, the current action is compared with the standard action library to evaluate the similarity of actions, and the action quality score is optimized through a spatiotemporal error minimization comparison loss function.
Skeleton feature extraction of aerobics athletes based on OpenPose
The quality assessment of aerobics actions relies on the accurate capture and analysis of athletes’ actions. Skeleton feature extraction can provide position information of action joints and changes in skeleton structure during dynamic and complex action processes, helping to analyze athlete posture, action accuracy, and coordination.14,15 OpenPose, as an efficient multi-body pose estimation algorithm, can extract real-time and accurate joint position information of athletes from images or videos, and generate corresponding skeleton structure maps. OpenPose uses CNN to process images, locate key points, and generate skeleton maps through the connections between key points. The processing results of each frame of the image include the 2D or 3D coordinates of various joints of the athlete, such as shoulders, knees, ankles, etc.16–18 However, in practical applications, due to the dynamic characteristics and rapid changes of aerobics actions, the skeletal information of a single frame image is not sufficient to fully characterize the athlete’s performance throughout the entire action process. In addition, due to the rapid changes in athletes’ posture, factors such as joint occlusion, posture changes, and interactions between athletes may affect the accuracy of skeleton extraction.19–21 Therefore, a lightweight OpenPose network model is proposed, and its structure is shown in Figure 1. Lightweight OpenPose network model structure.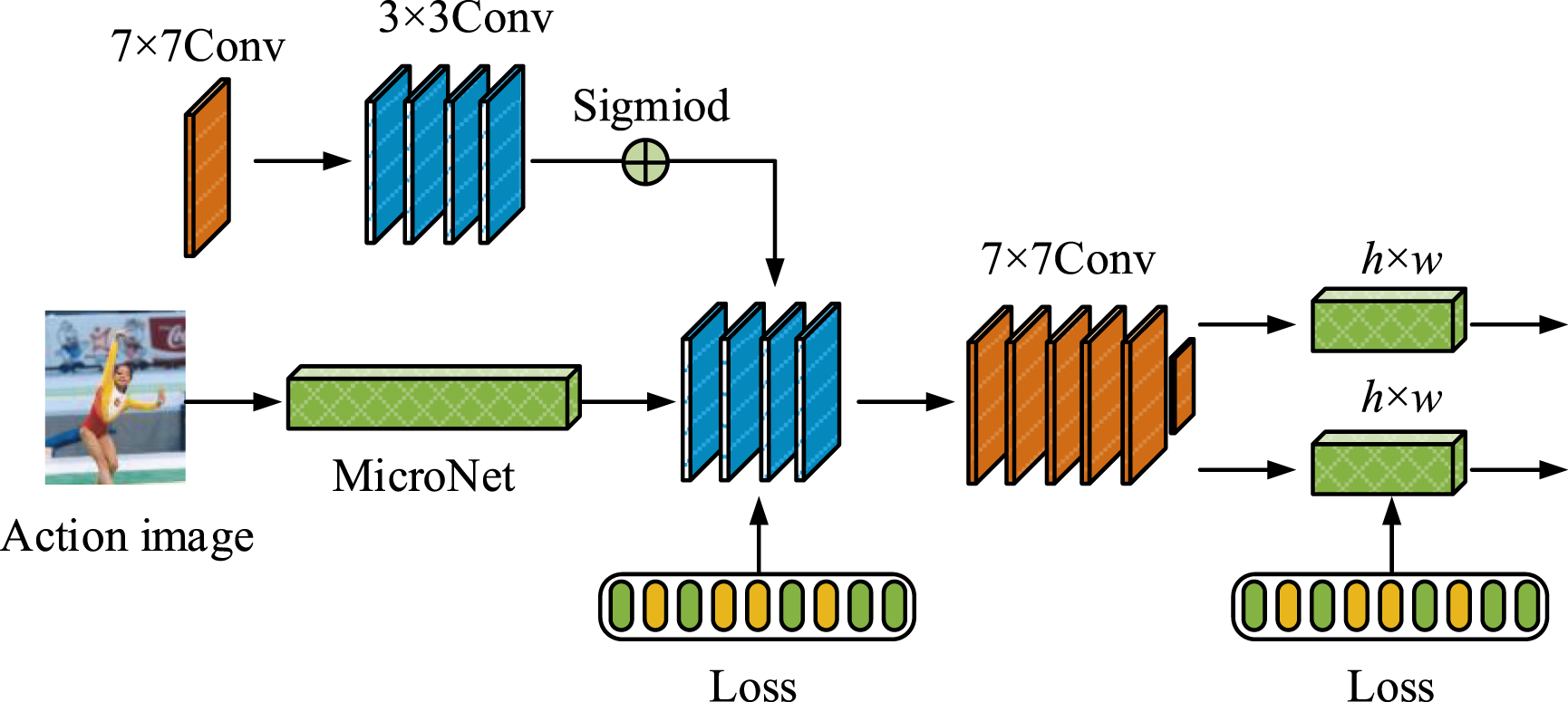
In Figure 1, the entire lightweight OpenPose receives video action information from the MircoNet network, and then extracts the action information into inference feature 1 and inference feature 2 through 5 rounds of 7×7 convolution operations. During this period, the Loss function is used to predict the confidence level of skeletal joints, partial affinity domain fields, and image features of the Visual Geometry Group (VGG19) in the output image. After completion, deeper convolutional feature extraction is performed in the pose refinement stage. Similarly, inference features 3 and 4 are extracted. Compared to the traditional OpenPose network model, this lightweight OpenPose uses a more lightweight MircoNet network to front-end VGG19, reducing running parameters, distinguishing channels and regions more finely during runtime, and reducing computational resources. Second, the pose refinement stage is used to replace the dual branch multi-stage CNN repeated convolution extraction, reducing redundant calculations. The network unit structure of MircoNet is displayed in Figure 2.22–24 Network unit structure of MircoNet.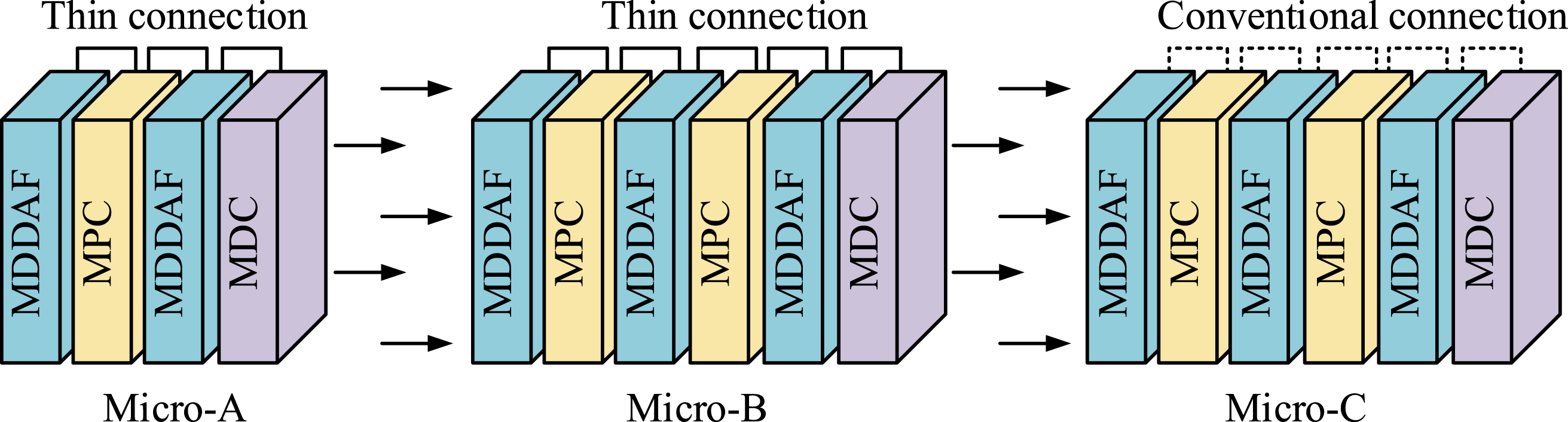
As shown in Figure 2, MircoNet consists of three basic units, namely Mirco-A, Mirco-B, and Mirco-C. Among them, Miro-A consists of two layers of Maximum Dynamic Displacement Activation Function (MDDAF), one layer of Micro-decomposition Point Convolution (MPC), and one layer of Micro-decomposition Deep Convolution (MDC). Miro-B consists of three layers of MDDAF, two layers of MPC, and one layer of MDC. The structure of Mirco-C is similar to that of Mirco-B, but the decomposition between layers is done through conventional connections. Compared to Mirco-A and Mirco-B, conventional connections can reduce computational complexity in simpler or resource limited situations. Assuming Schematic diagram of micro-decomposition point convolution.



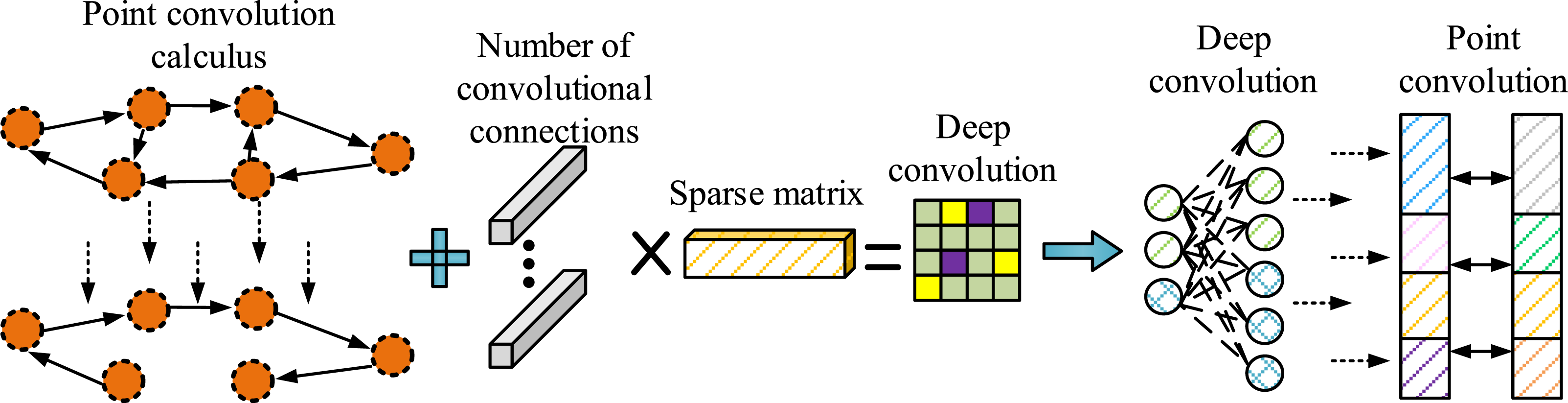
As shown in Figure 3, MPC decomposes high-dimensional calculations into multiple low dimensional operations through data permutation matrices, greatly reducing the model’s demand for computational resources. MDC is decomposed into multiple convolution kernels, which reduces the complexity. The MPC and MDC are connected. By combining micro-decomposition methods, the number of channels in the spatial filter of the convolution operation is first increased, thereby expanding the coverage range of the receptive field. Assuming the size of the input convolution kernel is 

Construction of aerobics action extraction and quality evaluation model based on adaptive multi-scale ST-GCN
After constructing the lightweight OpenPose network model, the lightweight OpenPose network can successfully extract skeletal features of aerobics athletes, and obtain joint position information and changes in skeletal structure. However, to achieve precise extraction and quality evaluation of aerobics actions, relying solely on static skeletal features is not sufficient to fully reflect the complexity of the actions and the performance of the athletes.32,33 Therefore, the study further introduces the ST-GCN model. The spatiotemporal feature maps of athlete skeletons in the ST-GCN model and conventional Kinect are displayed in Figure 4.
34
Skeleton spatiotemporal feature maps of ST-GCN and conventional Kinect. (a) Kinect (b) ST-GCN.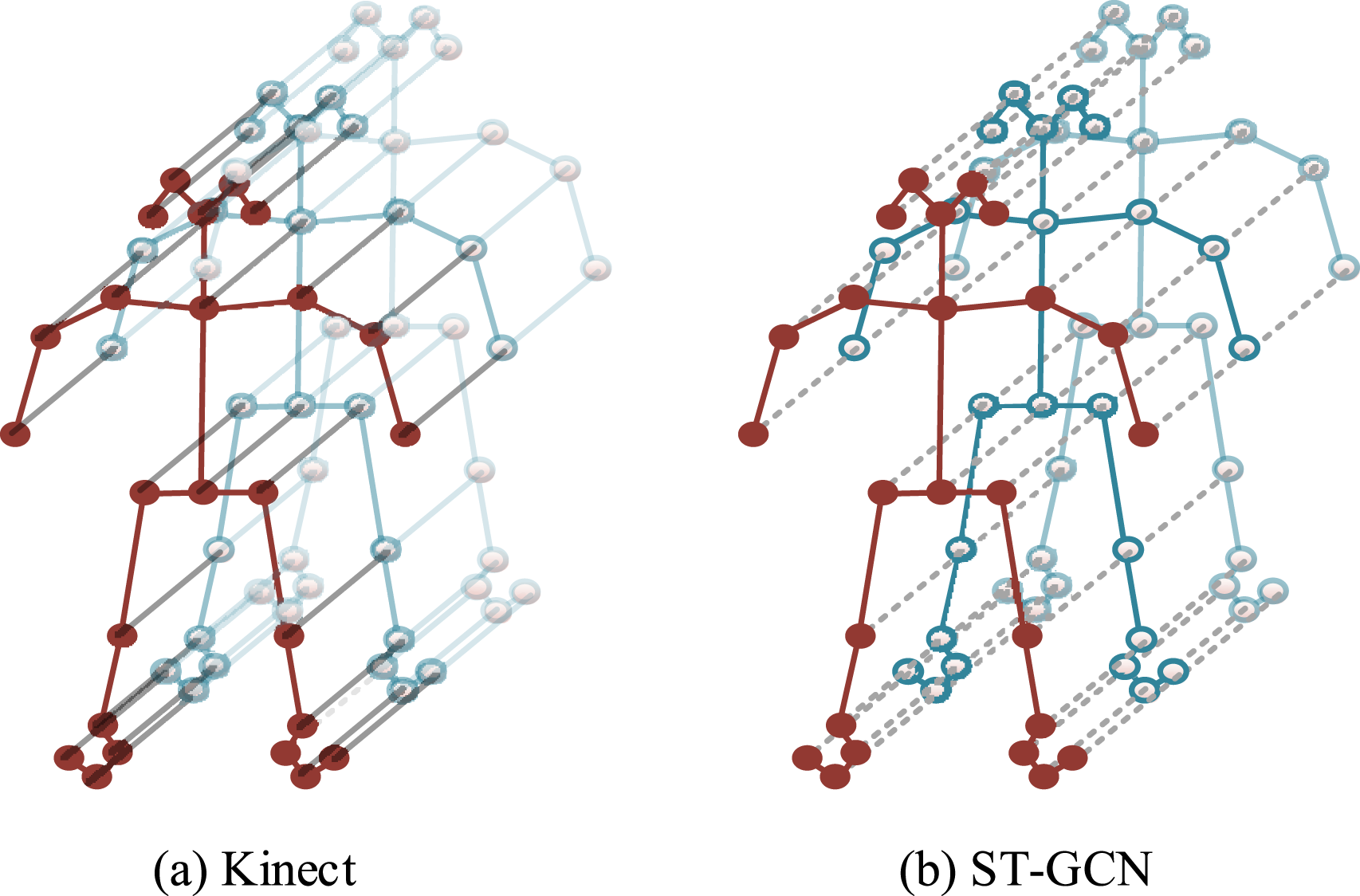
Figure 4(a) shows the spatiotemporal feature map of the human action skeleton in the conventional Kinect. Figure 4(b) shows the spatiotemporal feature map of the human action skeleton in the ST-GCN model. In Figure 4, ST-GCN can effectively capture the spatiotemporal features of athlete skeletons through graph convolution and temporal convolution operations. Unlike ST-GCN, the skeleton extraction method adopted by Kinect mainly relies on depth sensors to obtain the three-dimensional position coordinate information of athletes. Although it can accurately obtain joint positions in space, it is relatively simple in temporal processing. To this end, an Adaptive Multi-Scale Spatial Temporal GCN (AMS-ST-GCN) model is proposed. The structure of AMS-ST-GCN is shown in Figure 5. Structure of AMS-ST-GCN.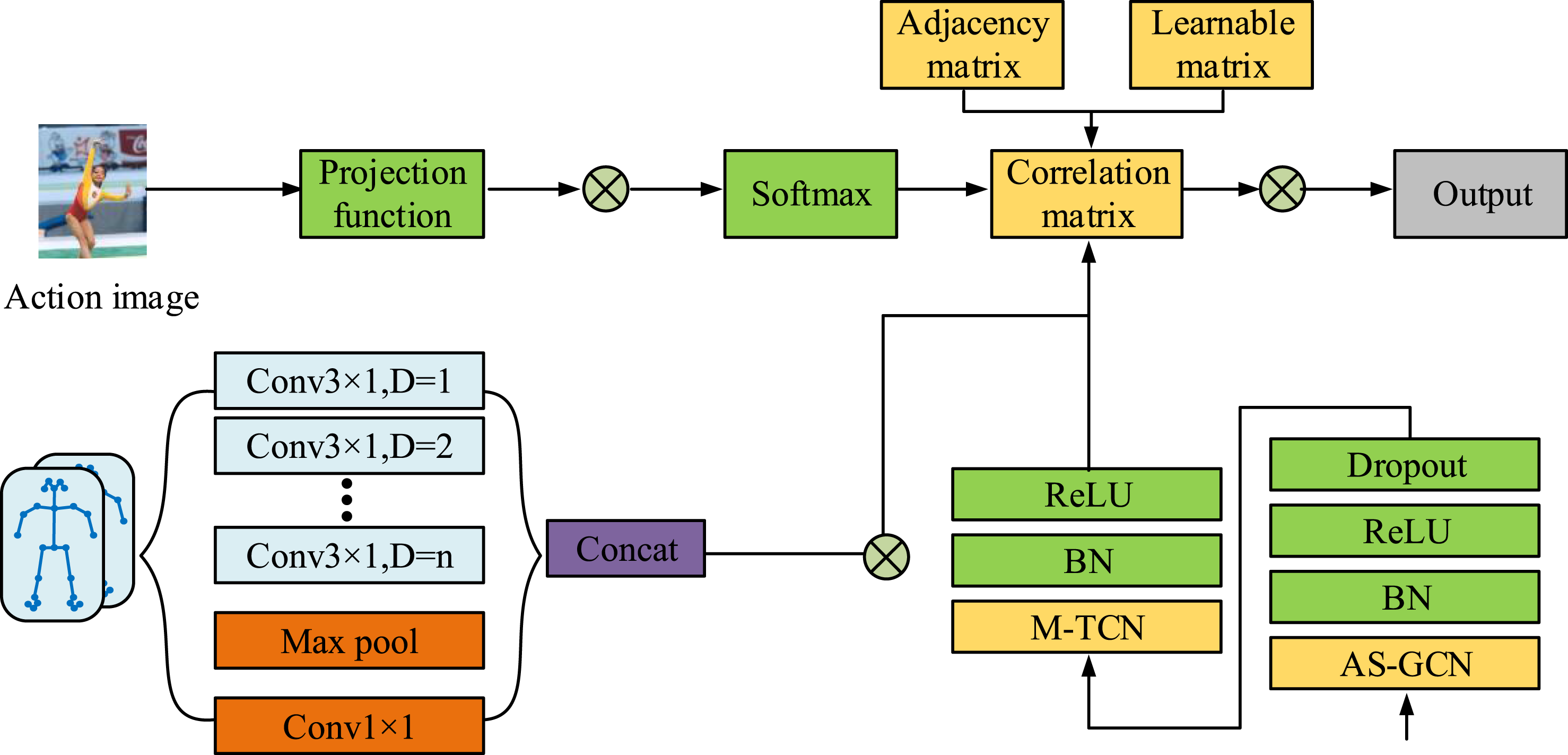
In Figure 5, the AMS-ST-GCN mainly includes Adaptive Semantic Graph Convolutional Networks (AS-GCN), Multi-scale Time Graph Convolution (M-TCN), and Adaptive Multi-channel Graph Convolutional Networks (AM-CGN). In the process, first, the input human skeletal data is modeled as a spatio-temporal graph, where nodes represent joint point locations and edges connect spatially adjacent joints to the same joint trajectory in time. The model uses a Spatial-Temporal Graph Convolution (STGC) structure for feature extraction in the spatial and temporal dimensions, respectively. Spatial convolution is used to capture the local relationships between joint points, while temporal convolution is used to model the dynamic properties of action evolution over time. To further enhance the feature representation, the study introduces an adaptive neighbor matrix mechanism based on the traditional ST-GCN. Compared with the fixed-skeleton topology, the improved model is able to dynamically adjust the connection strength between nodes according to the distribution characteristics of the input data, thus enhancing the adaptability to different action patterns and individual differences. In addition, the model is designed with multi-scale convolutional branches, and different branches perform convolutional operations on the first-order, second-order, and farther-neighborhoods, which can effectively fuse the local fine-grained action features with the global action trend information. Through adaptive neighbor optimization and multi-scale feature fusion, the overall network shows better results in detail discrimination and action dynamic modeling. Finally, after feature fusion, the output layer completes the action category evaluation and score prediction based on the extracted multiscale spatio-temporal features, which provides reliable support for downstream performance analysis. For a given skeleton graph, the graph convolution operation of AS-GCN is displayed in equation (7) Structure of action similarity evaluation model based on SN.


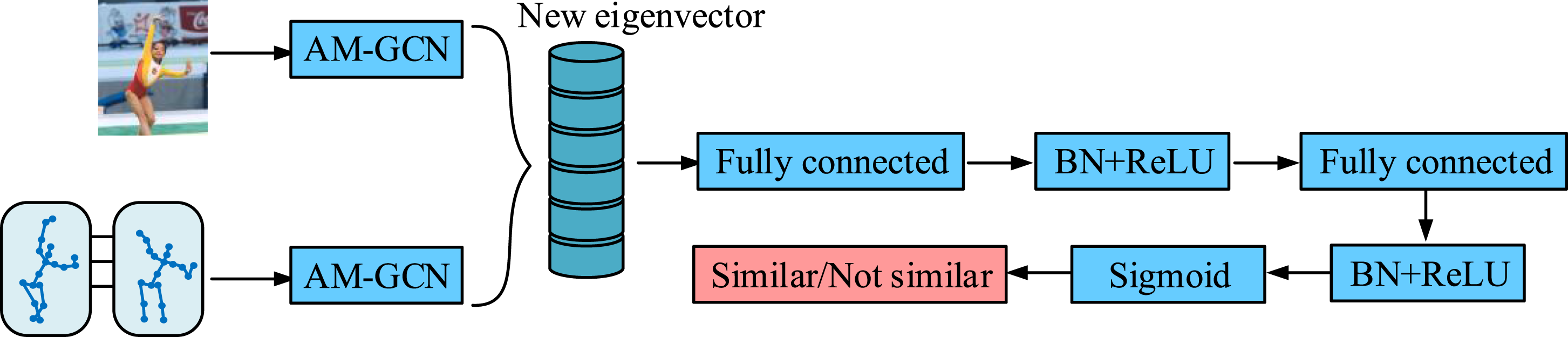
As shown in Figure 6, the model is mainly composed of two sub-networks that share weights. These two sub-networks, respectively, receive input action features, process them through the same network structure, and generate corresponding action embedding vectors. Then, by calculating the similarity between the embedding vectors of these two actions, the model can evaluate the similarity between the current action and the standard action. Specifically, the input action features first pass through a feature extraction layer, which encodes the spatiotemporal features extracted by adaptive multi-scale ST-GCN, mapping the spatial and temporal features of the action to a low dimensional space. Subsequently, the two sub-networks share the same convolutional and fully connected layers, ensuring that the comparison of action features during processing can be performed in the same parameter space, improving the consistency and generalization ability. Specifically, an adaptive weighting mechanism is used to generate embedding vectors for each action. These embedded vectors capture the spatiotemporal features of actions. In order to measure the similarity between two action features, a weighted similarity measurement formula is proposed, as shown in equation (10) New aerobics action quality evaluation model flow.
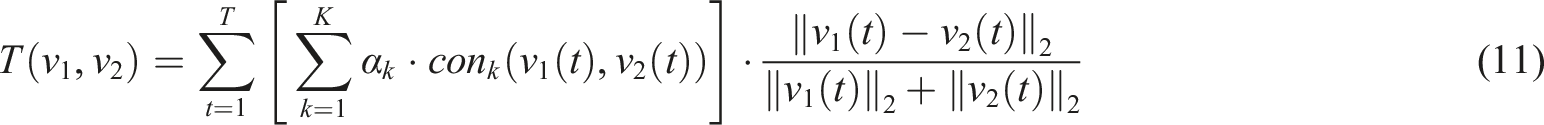
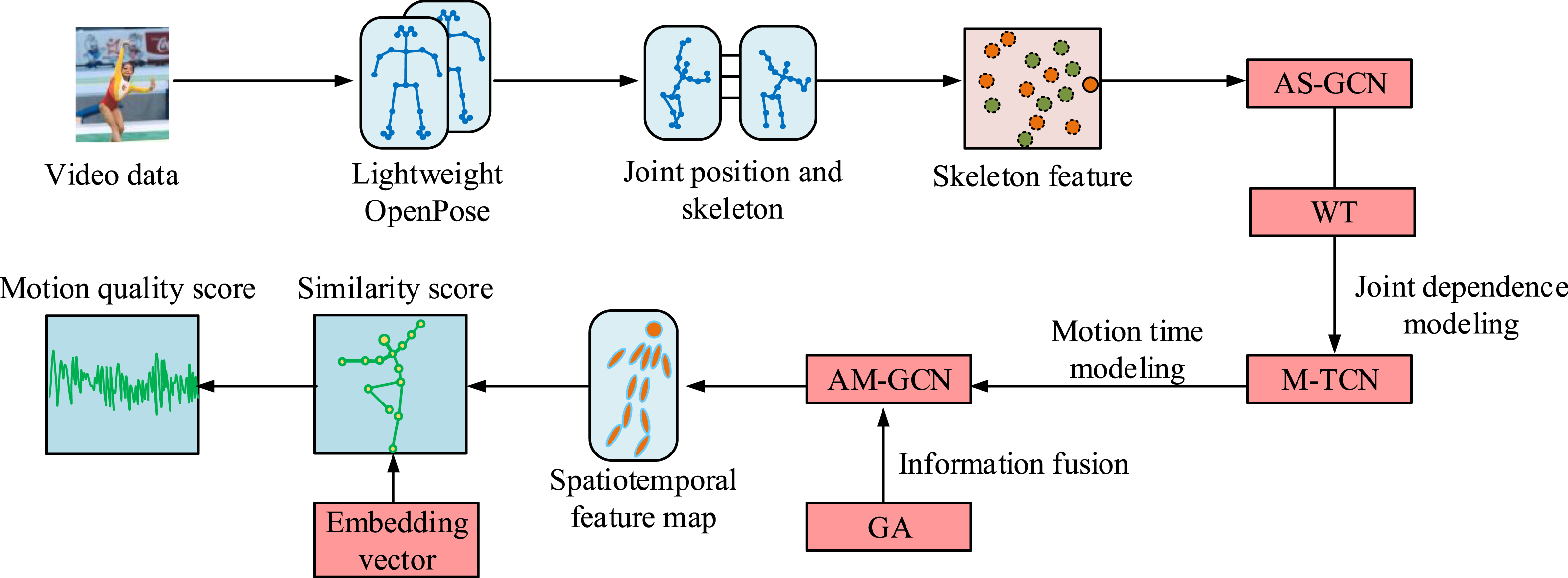
As shown in Figure 7, firstly, the lightweight OpenPose network extracts the skeletal joint features of athletes and obtains the spatiotemporal coordinate information of each joint during the action process. Next, the adaptive multi-scale ST-GCN captures the spatiotemporal dynamic features of the skeleton, enhancing the recognition ability of action details and coherence. Then, SN is used to compare the athlete’s current action with the standard action library. The similarity of actions is evaluated by calculating the similarity between embedded vectors. Finally, by introducing a spatiotemporal error minimization contrastive loss function, the model is optimized, taking into account the accuracy, coordination, and fluency of the actions. The final output is the athlete’s action quality score, which guides the athlete to improve their action execution.
Results
The study first constructs an experimental environment and conducts optimization tests on key hyper-parameters, with action accuracy and evaluation time as the core indicators for optimization. Multiple performance tests are conducted using two types of publicly available datasets, including ablation testing, comparative testing, and action feature extraction evaluation. At the same time, multiple advanced models are introduced for comparative testing, with action improvement rate, action similarity, and action quality as indicators, to verify the superiority and reliability in existing methods.
Performance testing of the quality evaluation model for aerobics actions
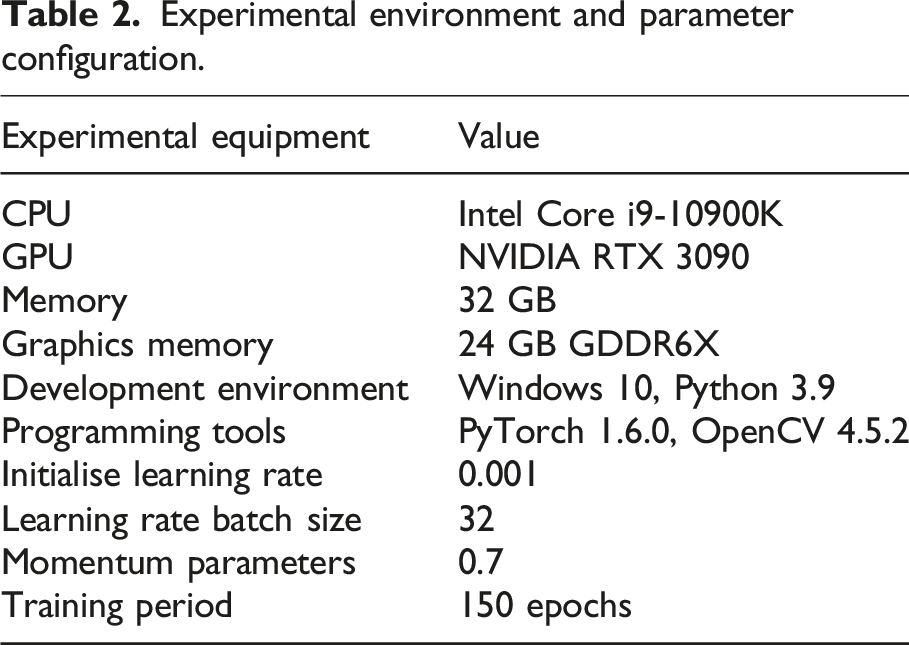
Experimental environment and parameter configuration.
The study first conducts value selection tests on two types of hyper-parameters that have a significant impact on the final model performance, namely the number of channels Hyper-parameter selection test. (a) Test the number of channels in the input feature map (b) Action adaptive weight test.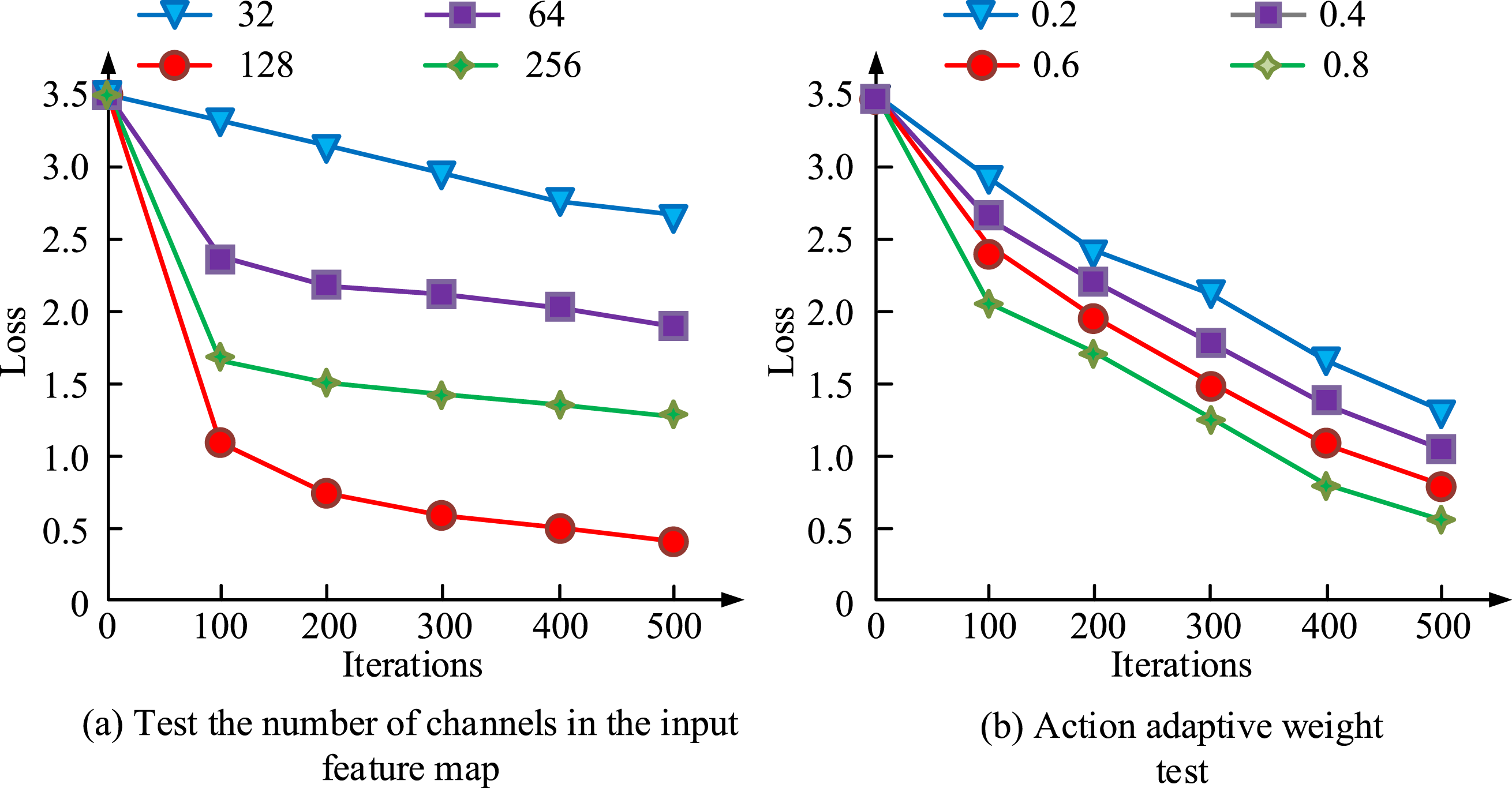
Figure 8(a) shows the channel count test of the input feature map. Figure 8(b) displays the action adaptive weight test. In Figure 8(a), the Loss value of the model shows an overall decreasing trend as the number of input feature map channels is gradually increased from 32 to 128. Specifically, when the number of channels is set to 32, the Loss value is initially about 3.5, and then decreases to about 2.7 with training; when the number of channels is increased to 64, the Loss value further decreases to 2.0; and when the number of channels reaches 128, the Loss value decreases to about 0.5, which shows a more significant convergence effect. When continuing to increase the number of channels, the decrease in the Loss value tends to slow down, while the model training time increases significantly and the computational overhead is aggravated. From Figure 8(b), it can be seen that there are differences in the Loss decline rate of the model under different action adaptive weights. The larger the weight value, the faster the Loss value decreases and the final convergence value is lower. Among them, when the weight is set to 0.8, the final Loss value of the model is the lowest, which is about 0.6; and when the weight is 0.2, the final Loss value is only reduced to about 1.4, which is not ideal for both convergence speed and effect. From a comprehensive point of view, a reasonable increase in the number of channels of the feature map can effectively improve the model’s ability to perceive the details of the action, but the computational burden brought by too many channels should not be ignored; at the same time, a moderate adjustment of the action adaptive weights can help to optimize the balance of the features between the actions during the training process, which can further reduce the Loss value and improve the overall training effect. The ablation test is conducted on the proposed model, as displayed in Figure 9. Ablation test results. (a) Human3.6M (b) CMU MoCap.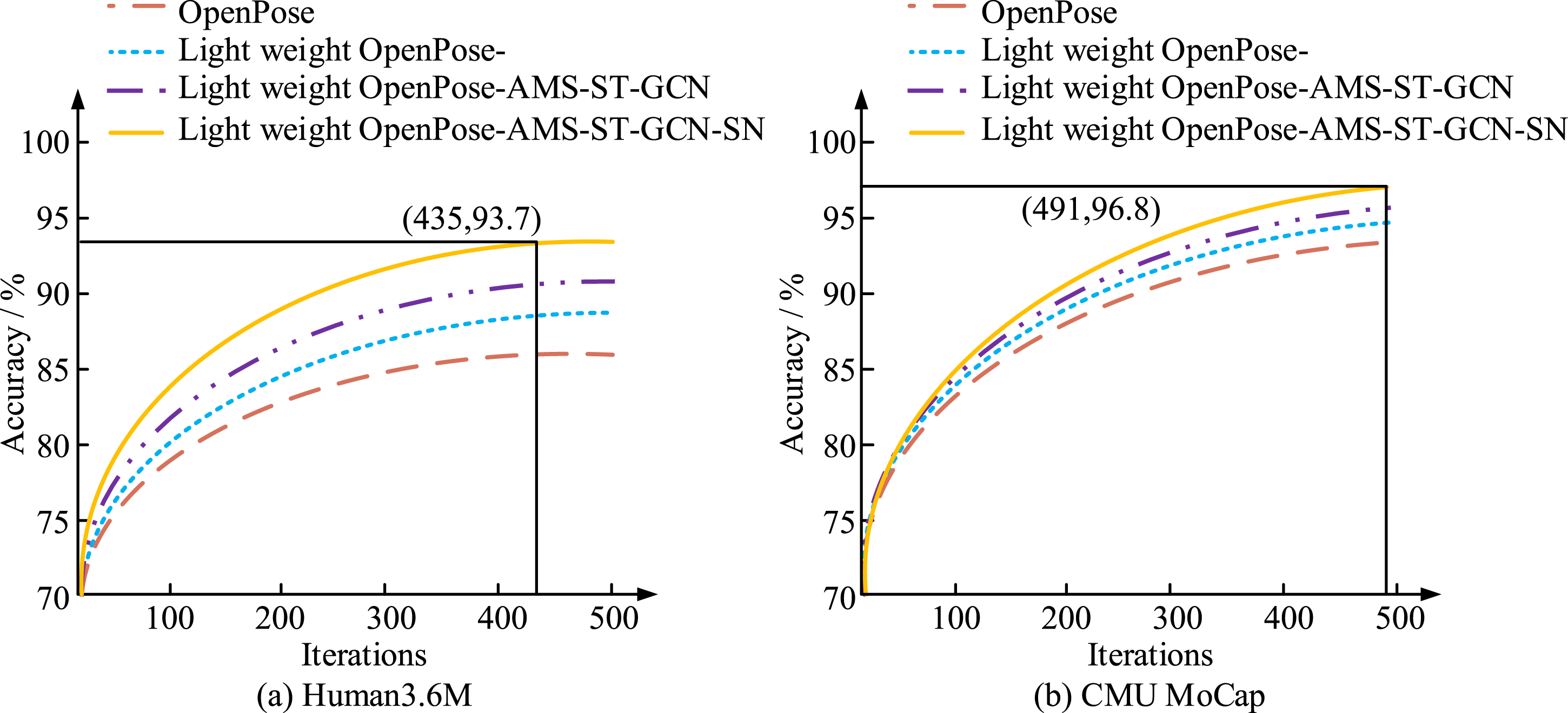
The results of multi-index testing of the model.
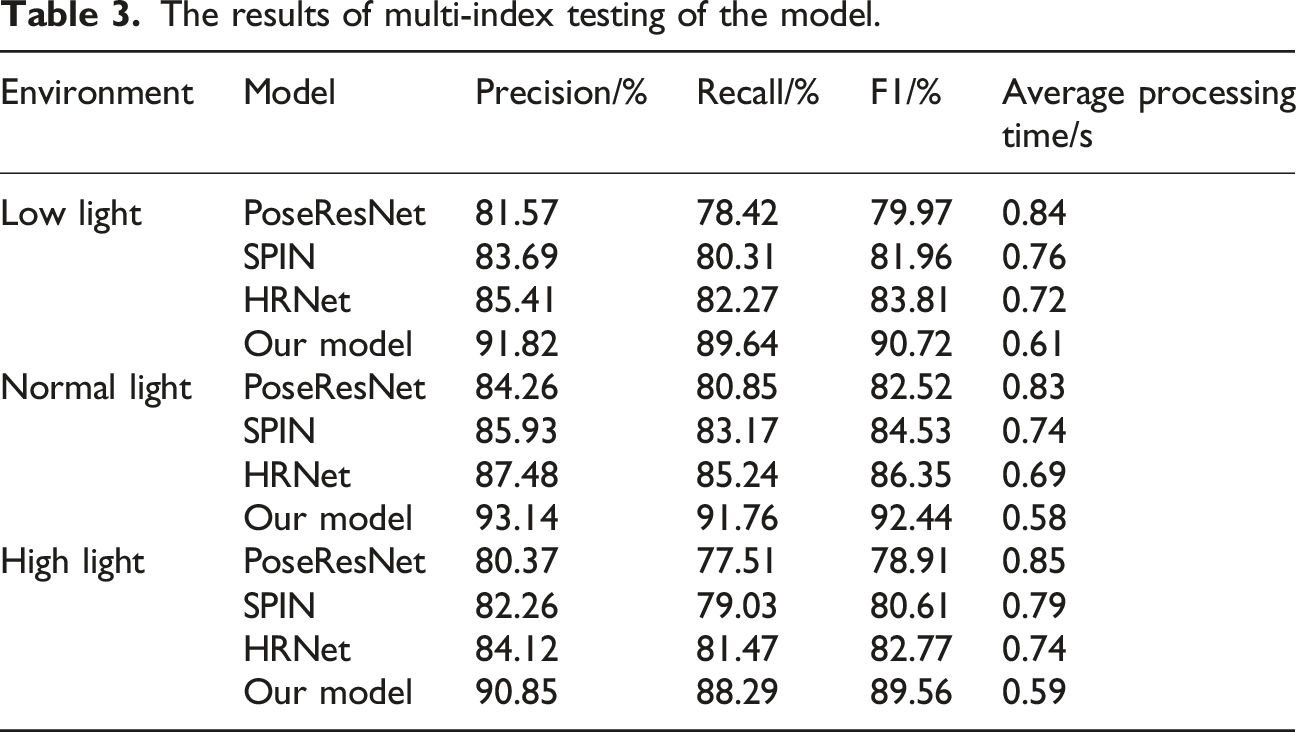
As can be seen in Table 3, under different lighting environments, the proposed model significantly outperforms the comparison methods in the three metrics of Precision, Recall and F1 value, and keeps the lowest average processing time. Specifically, in low-light environment, Our model’s Precision reaches 91.82%, Recall is 89.64%, and F1 value is 90.72%, which are higher than that of PoseResNet, SPIN, and HRNet, and the average processing time is only 0.61 seconds, which reflects good real-time performance and robustness. Under normal lighting conditions, the indexes of our model are further improved, in which the F1 value reaches 92.44%, which is more than 6% higher than that of HRNet, and the average processing time is shortened to 0.58 seconds, which verifies the stability and high efficiency of the model in the standard environment. And in the strong light environment, despite the overall recognition difficulty, Our model still maintains 90.85% Precision and 89.56% F1 value, the performance is ahead of other baseline methods, and the inference time is controlled within 0.59 seconds. In summary, the research method shows high accuracy and excellent processing efficiency in action recognition under different light intensities, and has good scene adaptability and practical promotion potential.
Simulation testing of the quality evaluation model for aerobics actions
To verify the effectiveness in action recognition detection and quality evaluation, 8 types of basic aerobics actions are randomly selected from the Human3.6 M dataset for testing. The selected actions are displayed in Figure 10. 8 types of basic actions of aerobics. (a) Propelling forward (b) Upthrow (c) Forward downward (d) Forward upward lift (e) Lateral raise (f) Side down (g) Side upward (h) Backward downward lift.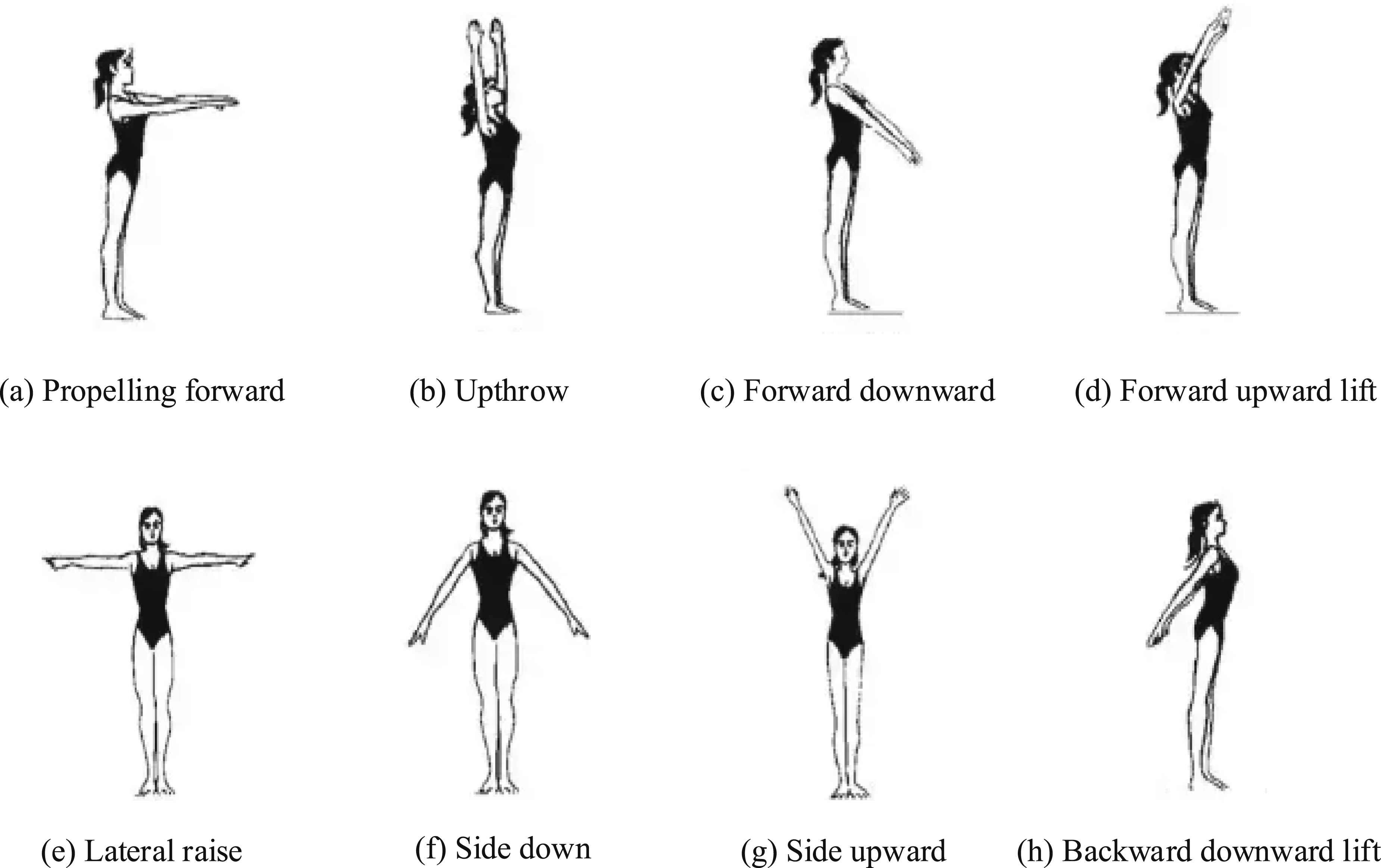
Figure 10(a) shows the propelling forward action, Figure 10(b) shows the upthrow action, Figure 10(c) shows the forward downward action, Figure 10(d) shows the forward upward lift action, Figure 10(e) shows the lateral raise action, Figure 10(f) shows the side ward action, Figure 10(g) shows the side upward action, and Figure 10(h) shows the backward downward lift action. Combining the above 8 types of aerobics actions, taking the Percentage of Correct Keypoints (PCK) as the detection indicator, as displayed in Figure 11. PCK detection results of 8 types of actions by different models. (a) PoseResNet (b) SPIN (c) HRNet (d) Our model.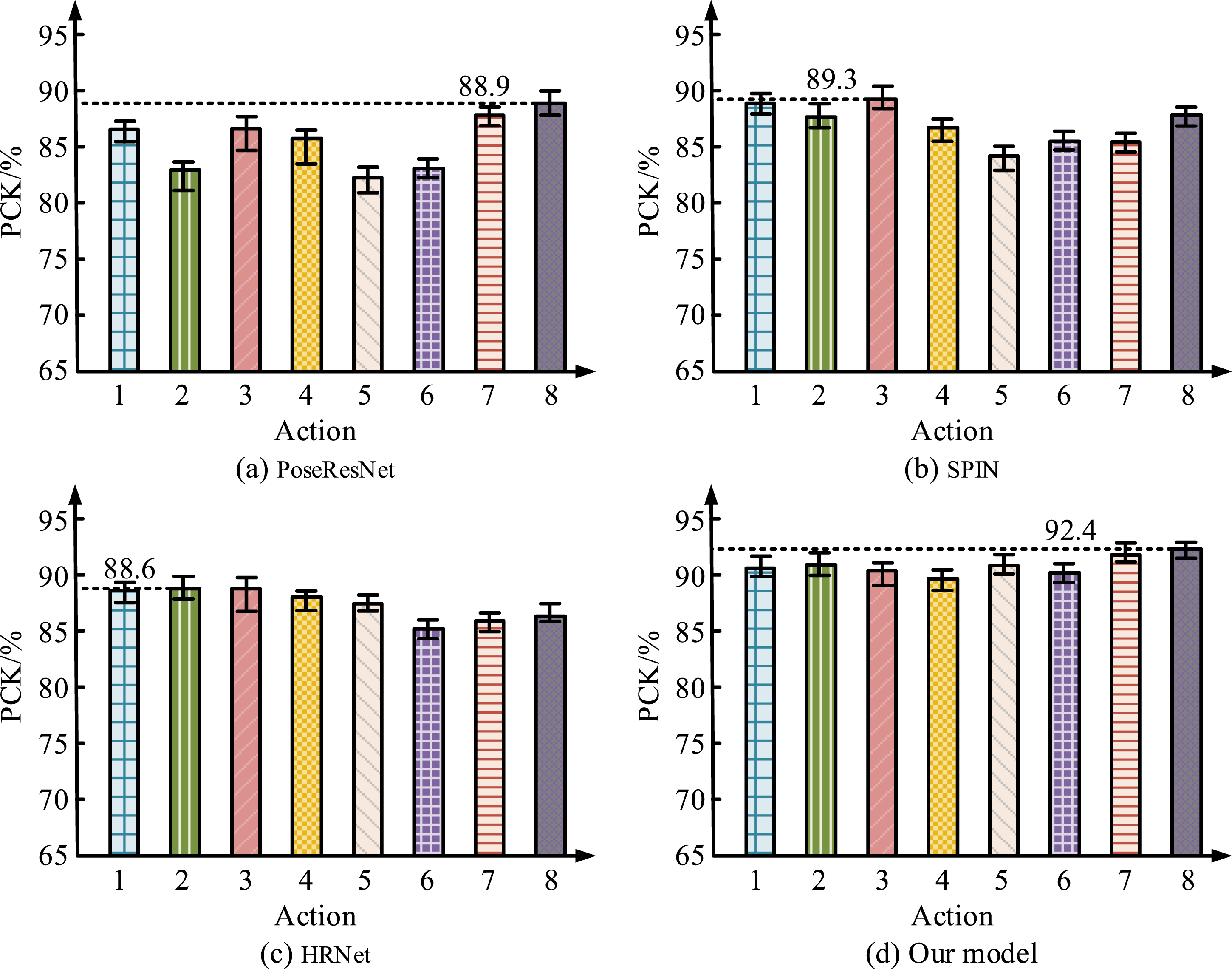
Figure 11(a) shows the PCK detection results of 8 types of actions in the PsoeResNet model, SPIN model, PsoeResNet model, and the proposed model. From Figure 11, the proposed model performed well in PCK detection results, especially in actions such as propelling forward, upthrow, and lateral raise, with significantly higher PCK values than other models. For example, in the “propelling forward” action, the PCK of the proposed model reached 95.2%. In contrast, the PoseResNet model accounted for only 85.2%, the SPIN model for 88.5%, and the HRNet model for 91.3%. This gap was also reflected in other actions, and the proposed model maintained high accuracy in most actions, especially in the complex actions of “forward upward lift” and “side upward,” with PCK of 92.5% and 93.3%, respectively. The proposed model has stronger robustness and accuracy in handling details and complex actions. Compared to traditional models such as PoseResNet and SPIN, it can better capture key point information and adapt to the action characteristics of different athletes. The study randomly selects four types of actions and tests the action evaluation matching degree of the four evaluation models in the process of action feature extraction and matching. The results are shown in Figure 12. The matching test results of action evaluation of different models. (a) Propelling forward (b) Upthrow (c) Lateral raise (d) Backward downward lift.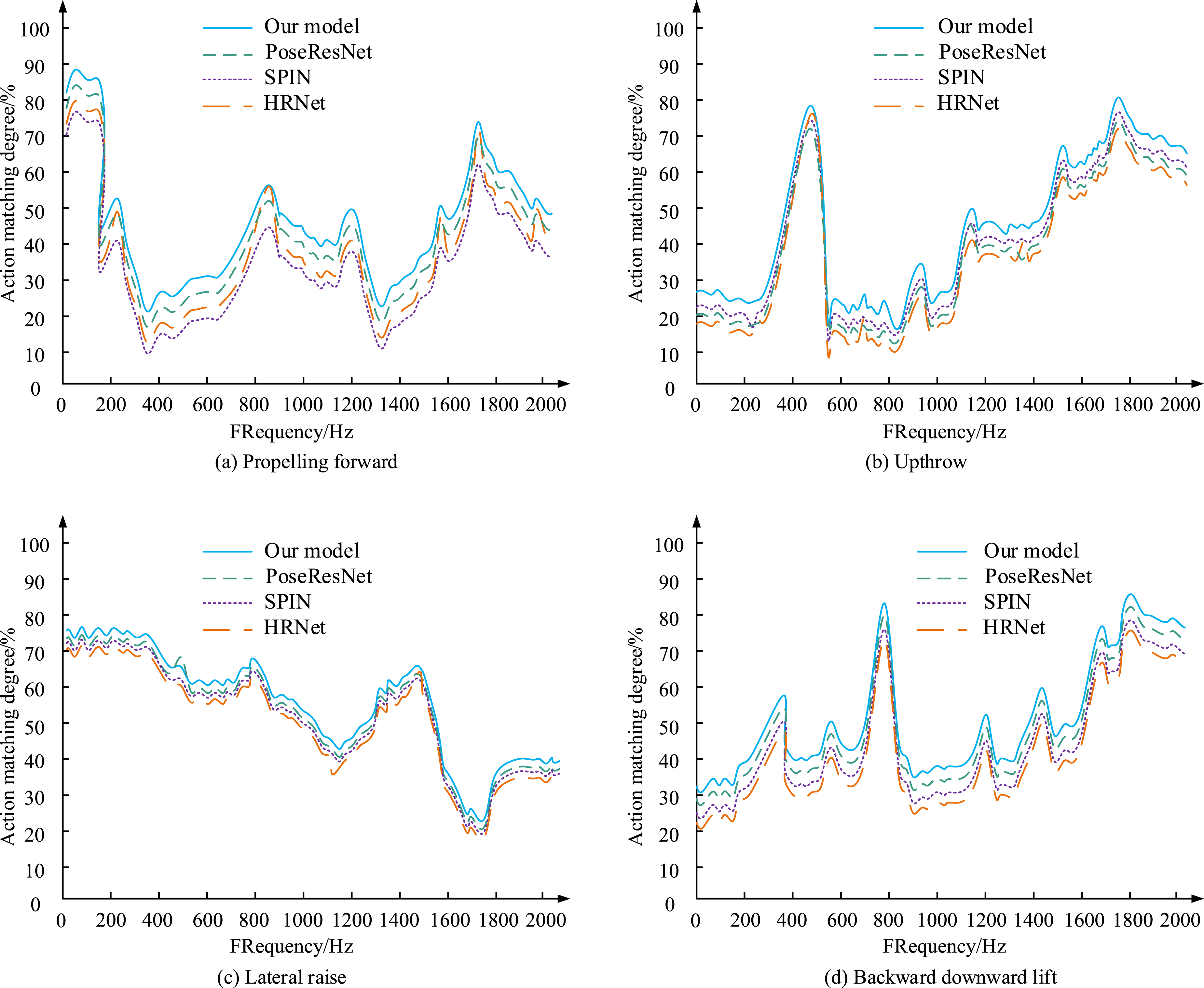
Action evaluation results of different models.
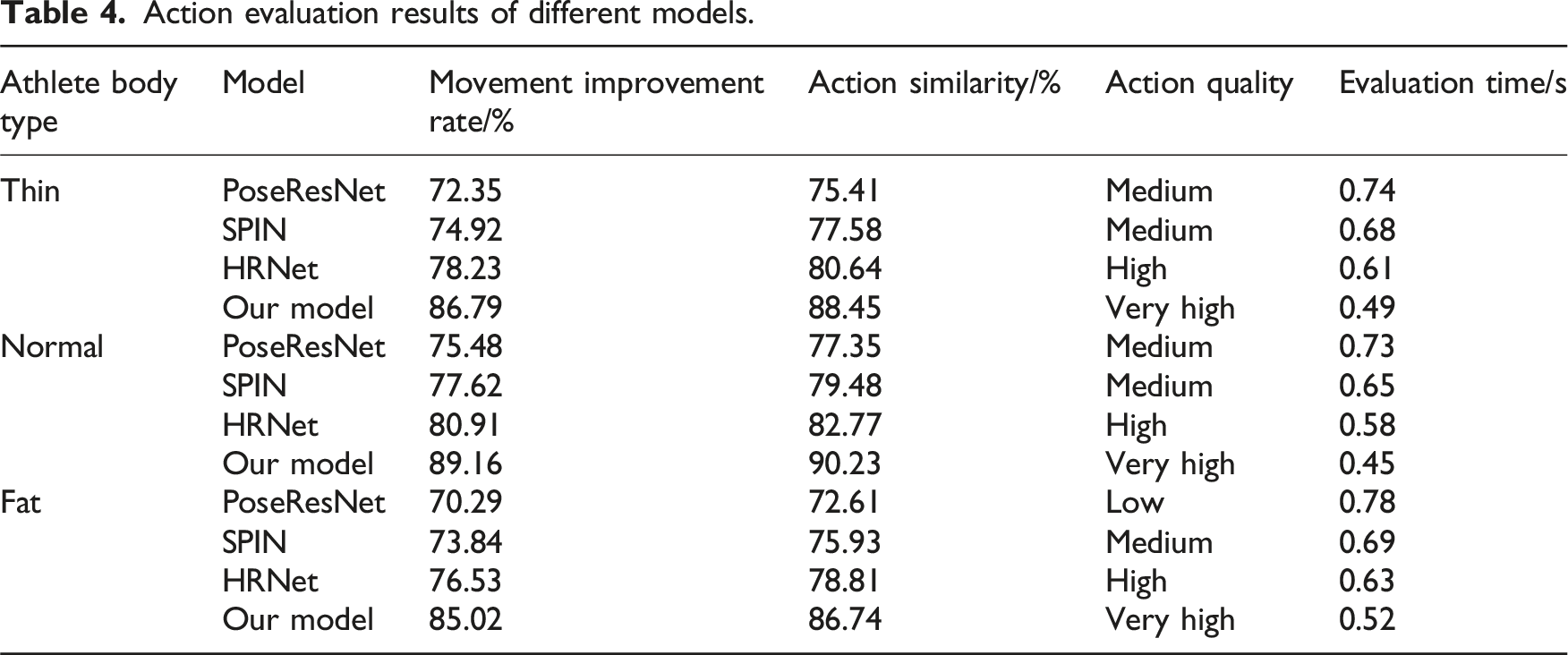
As can be seen from Table 4, the proposed model shows significant advantages in terms of action improvement rate, action similarity and action quality rating in the action assessment task for athletes of different body types, and the shortest assessment time. Specifically, in the group of lean athletes, our model achieved a movement improvement rate of 86.79% and a movement similarity of 88.45%, with a movement quality rating of Very High, and an evaluation time of only 0.49 seconds, which is superior to baseline methods such as PoseResNet, SPIN and HRNet. In the test with normal-sized athletes, our model also achieved 89.16% improvement rate and 90.23% similarity of movements, with the quality of movements maintained at Very High level, and the average evaluation time shortened to 0.45 seconds, which demonstrated high efficiency and accuracy. Even in the group of obese athletes, our model still maintains 85.02% of movement improvement rate and 86.74% of movement similarity, the movement quality level is much higher than that of other methods, and the evaluation time is 0.52 seconds, which is significantly better than that of other models. In summary, the proposed model shows higher action optimization effect and action recognition accuracy under different athletes’ body type conditions, and has good generalization ability and practical application potential.
Discussion
Aiming at the problems of computational complexity, inadequate dynamic modeling and inefficient action matching in aerobics action quality assessment, the study proposes an efficient assessment model that combines lightweight OpenPose, adaptive multi-scale ST-GCN and twin network. The experimental results show that the model achieves excellent performance on both Human3.6 M and CMU MoCap datasets, with a detection accuracy of 96.8%, an action evaluation matching of 89.7%, and an average evaluation time of only 0.71 seconds, which is significantly better than the mainstream methods such as PoseResNet, SPIN, and HRNet. The computational overhead is significantly reduced by the lightweight design of MircoNet, AMS-ST-GCN enhances the extraction of complex spatio-temporal features of actions, and the twin network structure improves the accuracy and consistency of action similarity assessment. Compared to the CNN-LSTM fusion model proposed by Liu Q, this study further strengthens the ability to recognize and model complex dynamic actions 3 ; compared to the infrared imaging-based method of Lv D et al, the proposed method does not rely on specific lighting conditions and is more adaptable 4 ; compared to the sensor-based scheme of Cao T, this study achieves wider applicability without the need for external hardware with real-time feedback capability. 5 In addition, compared with the traditional tracking model proposed by Zuo N et al. and Zhang Y’s NMS strategy approach, this study is more advantageous in terms of detail capture and temporal coherence.6,7
The model has a broad application potential in the fields of sports training, health monitoring, and dance recognition. The evaluation results can provide technical feedback for competitive aerobics and gymnastics programs, as well as automated movement specification monitoring in home fitness and rehabilitation training, supporting public health management and intelligent physical education. The combination of multimodal data, 3D visual inputs and incremental learning mechanisms is expected to further improve the dynamic adaptability and cross-individual generalization ability of the model. Nonetheless, the research still has shortcomings. The current training samples are mostly derived from standardized datasets, which have not been extensively validated in complex environments with multiple background disturbances. Meanwhile, the model still suffers from performance fluctuations when facing pose occlusion or non-standardized movements. The robustness and generalization ability of the model in real applications can be improved by introducing more real scene samples and fusion of multi-source information in the future.
Conclusion
Aiming at the problem of insufficient accuracy and real-time performance in aerobics movement quality assessment, the study proposes an assessment method based on lightweight OpenPose and ST-GCN model. Experiments show that the model Loss is reduced to 0.5 when the number of input feature map channels is 128 and the action adaptive weight is 0.8. By improving the OpenPose, ST-GCN and SN modules, the detection accuracy reaches 96.8%, and each module effectively improves the model performance. Under different lighting environments, the proposed model achieves the highest Precision 91.82%, 93.14%, and 90.85%; Recall 89.64%, 91.76%, and 88.29%; and F1 values 90.72%, 92.44%, and 89.56%, and the average detection time is shortened to less than 0.61 seconds, which is overall better than the PoseResNet, SPIN, and HRNet. In the movement assessment of athletes of different body types, the model achieved the highest movement improvement rates of 86.79%, 89.16%, and 85.02%, and the highest movement similarity of 88.45%, 90.23%, and 86.74%, and the movement quality was rated as Very High, and the assessment time was controlled at 0.49–0.52 seconds, showing excellent adaptability and robustness. Nevertheless, the study still has limitations. The current training data is mainly based on standard action samples, which lacks extensive validation in diverse and complex environments, which may affect the generalization ability of the model; there is still room for improvement in feature extraction and recognition stability in extreme occlusion or background interference scenarios; in addition, the model relies on a single skeleton input and lacks multimodal information fusion. Future research can consider: (1) optimizing the AMS-ST-GCN structure and introducing dynamic adjacency and attention mechanisms to improve the ability of complex action modeling; (2) fusing multi-source data such as images and IMUs to enhance the comprehensiveness and robustness of the evaluation; (3) applying on-line incremental learning to improve the adaptability to individual differences; and (4) carrying out large-scale extensive testing in real environments to further validate and expand the value of the model application. Model application value.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statements
The data will be made available on the request.