
Abstract
As aerobics becomes an increasingly popular form of exercise, the demand for precise movement standards has grown. Traditional human pose recognition models no longer meet the practical requirements of aerobics scenarios. To address this, the study is based on open pose estimation technology, optimized with attention mechanisms and graph neural networks, and proposes a hybrid human pose recognition model. Performance validation and ablation experiments show that the model have an accuracy of 95% and a loss value as low as 0.0089. The highest score for human key points is 7.5, with angle error and position error reduced to 4.9% and 5.4%, respectively, outperforming the base algorithm. This highlights the success of the proposed optimization and enhancement techniques. In practical application comparison experiments, the recognition model achieves a running time of 8 ms when recognizing 150 images, significantly outperforming the comparison models. In multi-person recognition experiments, the proposed model reaches an accuracy of 93%. Additionally, the model shows superior performance in visualizing human pose recognition in practical scenarios. These results indicate that the model has high recognition accuracy and robustness, and can adapt to various real-world applications, meeting the high demands for human pose recognition in aerobics.
Introduction
Aerobics is a lightweight sport that integrates entertainment, fitness, and leisure. It has gained widespread popularity due to its lack of restrictions in terms of venue, equipment, and fitness level. Aerobics is crucial for enhancing the public’s physical fitness. It not only strengthens muscle strength, improves rhythm, and fosters teamwork awareness, but also conveys rich cultural information through gymnastic dance, enhancing cultural confidence.1,2 Due to its numerous benefits, experts and scholars domestically have conducted various levels of research on it. Masagca et al. studied the impact of aerobics on muscle endurance by conducting a two-and-a-half-month aerobics training experiment on over 100 university students without prior athletic experience. The results demonstrated significant improvements in their scores in push-ups, planks, and wall sit tests after the training. 3 To explore whether aerobics has a positive effect on the performance of football players, Panihar et al. randomly divided a group of football players into two groups for a comparative experiment. Following the experiment, physical fitness tests were administered to both groups. The results revealed that the exercise group outperformed the control group in areas such as speed, agility, flexibility, and other fitness metrics. 4 These studies indicate the positive impact of aerobics on improving public physical fitness and health.
The most widely used approach for human pose recognition relies on the dynamic movements of body joints. With the development of deep learning technology, methods using human skeletal key points for pose recognition have made significant progress.5,6 For instance, Xu et al. addressed the issue of current human pose recognition models failing to capture all the poses needed during training and testing phases. They proposed a method to extract human skeletal data from multiple perspectives using deep learning networks, and verified its high accuracy in simulation experiments. 7 Juang et al. innovatively proposed a classification system for four human postures: standing, bending, sitting, and lying. This system combines the advantages of Gaussian mixture models, contour intersection methods, and support vector machines, improving the interpretability and robustness of human posture classification. 8 These studies optimize and improve human pose recognition using deep learning techniques, but still face limitations such as large model computation and high hardware requirements.
OpenPose technology marks a significant breakthrough in multi-person 2D pose estimation. It is capable of detecting key points across different body parts, including the hands, legs, and face, all at once. Additionally, it is compatible with multiple operating systems. OpenPose has found practical applications in areas such as human-computer interaction, security surveillance, and sports analysis. 9 The open-source nature of OpenPose has attracted many experts and scholars both domestically and internationally to research and improve it. For example, Osawa and other scholars designed a remote rehabilitation system for elderly individuals who cannot undergo professional rehabilitation training in hospitals. This system uses a monocular camera to capture user motion images and applies OpenPose technology to recognize poses, providing professional remote guidance. Experimental results show that the system’s accuracy and feasibility meet practical application requirements. 10 Hsiao et al. proposed a low-cost, markerless system for evaluating push-up movements based on OpenPose, Python code, and fuzzy inference techniques. The system demonstrated good reliability in experiments and is expected to be applied in rehabilitation exercises and industrial safety. 11 Jeongzh et al. addressed smoking behavior in non-smoking areas in public places by combining OpenPose technology with smoke detection hardware, proposing a smoking behavior recognition system. The system demonstrated a recognition rate of over 70%, providing a new approach for identifying smoking behavior in public spaces. 12 The development of automobile automation has raised higher demands for intelligent vehicle interiors. To address this, Walocha et al. used OpenPose and electrocardiogram data to capture driver states in real-time, dynamically adjusting driving modes or interior lighting to help drivers operate vehicles more safely and intelligently. 13 Overall, OpenPose has been successfully applied in various fields and has achieved notable results. However, there is still a lack of research on applying OpenPose technology to aerobics.
In summary, although OpenPose technology is widely used in fields such as human-computer interaction and rehabilitation training, it has not been specifically adapted to the rhythmic and continuous movements unique to aerobics. As a result, it cannot accurately recognize the dynamic characteristics and standard postures of aerobics movements. Aerobics teaching and training scenarios often require multi-perspective and multi-person recognition simultaneously. However, the original OpenPose model has a large computational load and requires high-performance hardware, making it difficult to perform real-time motion analysis on ordinary terminals. This limits its widespread adoption in popular fitness settings. The research is based on OpenPose technology, integrating depthwise separable convolution, attention mechanism and adaptive graph convolutional network to construct an aerobics human pose recognition model. This technology integration fills the application gap of OpenPose in the field of aerobics, balancing computational efficiency and recognition accuracy, providing an innovative technical path for aerobics teaching and training, and has great practical value.
Methods and materials
Construction of multi-person pose estimation model based on OpenPose
OpenPose is a bottom-up human pose estimation method, which mainly includes the backbone feature extraction network, multi-stage iterative refinement module, and fusion parallel output section.14,15 The core principle involves first identifying the key points of the human body in the target figure, and then infer the specific posture based on the relationships between these key points.16,17 Due to its dual-stream joint prediction mechanism, this algorithm has proven effective in applications such as human-computer interaction, video surveillance, and more.18,19 The specific implementation process is shown in Figure 1. OpenPose model for human pose recognition.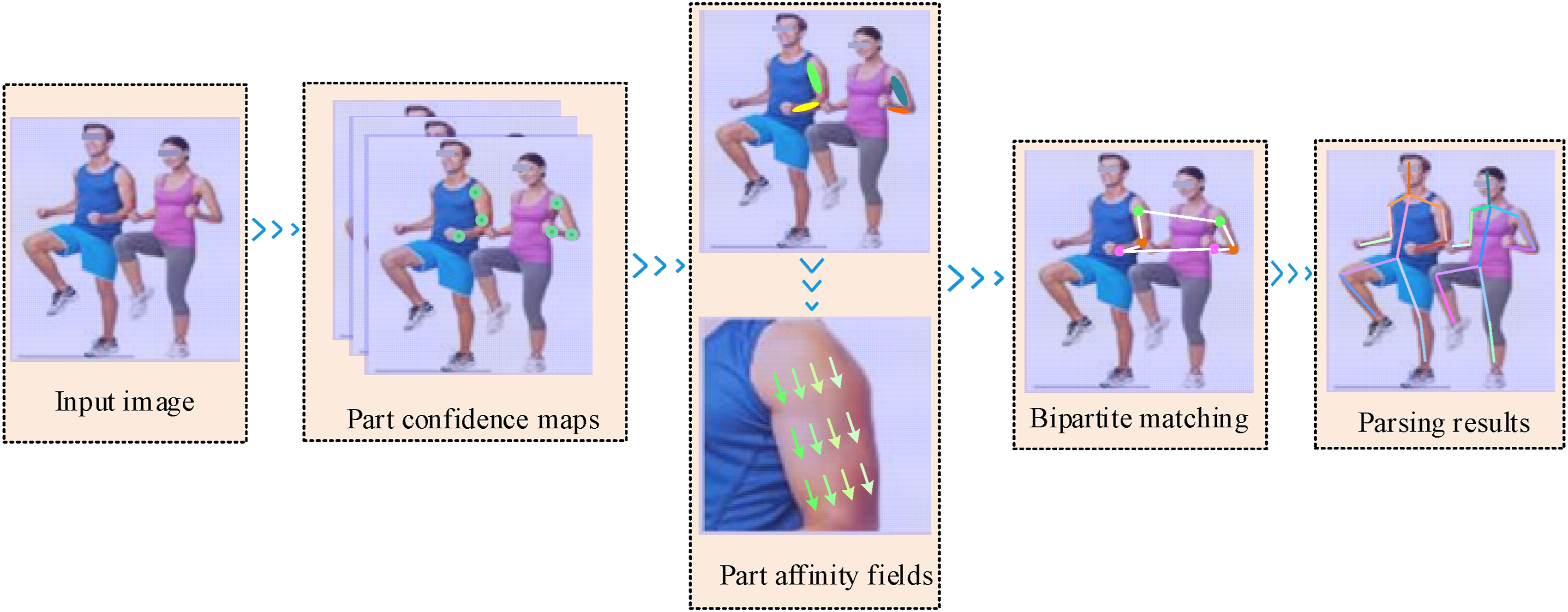
As shown in Figure 1, the OpenPose algorithm initially extracts multi-level features from the raw input image for human pose recognition. It outputs confidence maps and part affinity fields based on these features, and then uses these feature maps as input for the next stage to detect human key points and the relations between key points, thus recognizing the human pose. The output representation for the confidence maps and part affinity fields in the initial stage of the feature map is given by equation (1) Depthwise separable convolution layer workflow.


As depicted in Figure 2, the depthwise separable convolution layer is composed of two components: depthwise and pointwise convolution. To ensure that the depthwise convolution effectively extracts features in a higher-dimensional space, the study uses pointwise convolution before the depthwise convolution for dimensionality expansion. After expanding the dimensions, the channels can be extended to any appropriate size, allowing the depthwise convolution to capture more effective information. The convolution parameter scale is shown in equation (3)


After performing feature extraction within the same layer, the challenge of minimizing interference features while emphasizing the capture of important features emerges. The study addresses this issue by incorporating an attention mechanism, which learns the importance weights of each feature map channel to further suppress the interference from insignificant channels or pixels.22,23 However, the attention mechanism requires weight calculation in the fully connected layer, which increases the model’s parameter count and computational dimensions, thus impacting the model’s running speed. To minimize the time cost of training and inference, the study introduces an ultra-lightweight subspace attention mechanism (ULSAM), which attempts to improve the neural network’s efficiency using subspace attention mechanisms, thus promoting the application and development of compact CNNs. The structure of ULSAM is shown in Figure 3. Schematic diagram of the structure of ULSAM.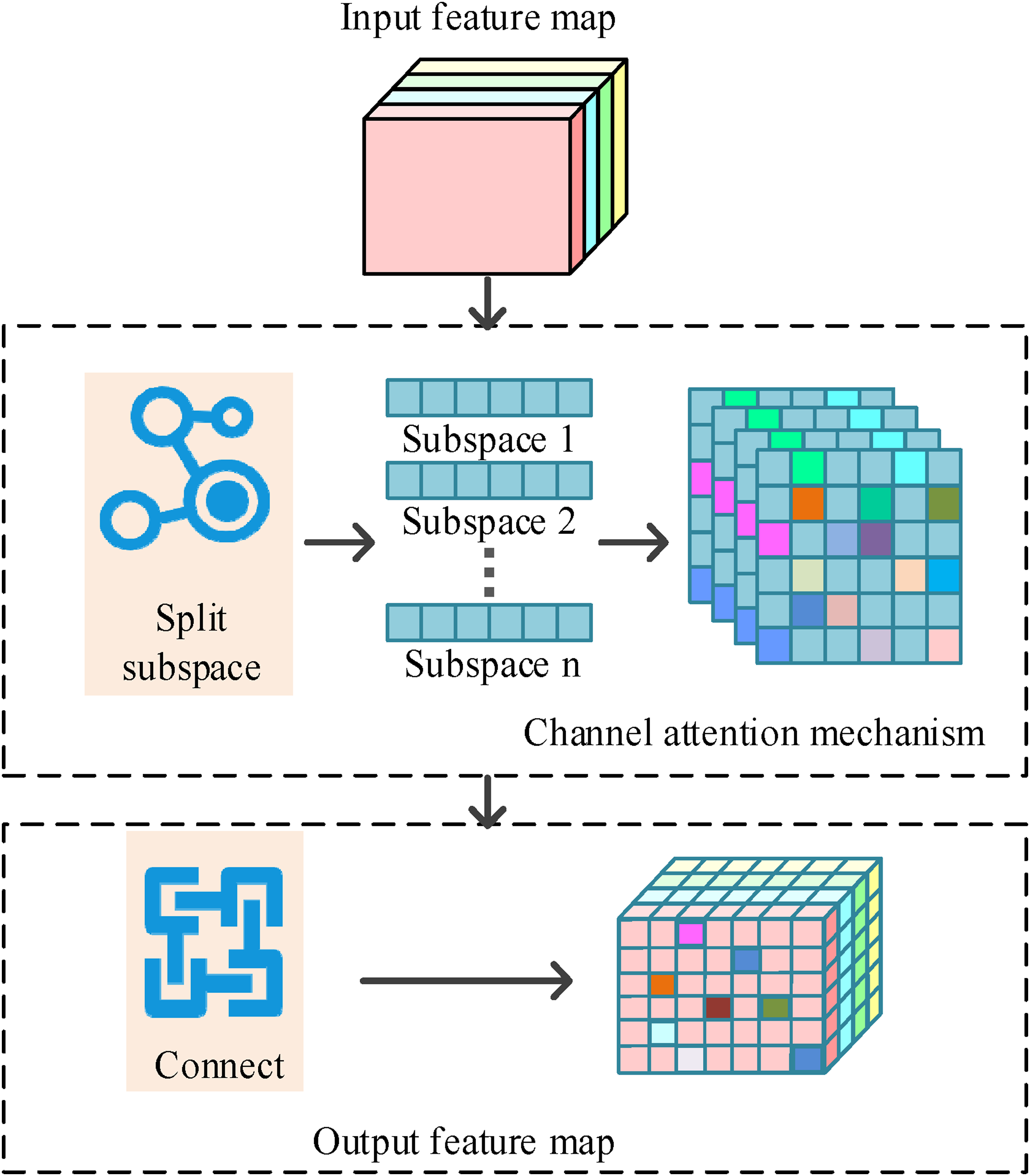
As shown in Figure 3, ULSAM mainly consists of three parts: the input, channel attention mechanism, and output layer. The input layer receives the human pose feature maps extracted by convolutional layers, and the channel attention mechanism layer treats feature maps extracted from convolution kernels at different scales as subspaces. It then learns the importance weights for each subspace feature and performs weighted adjustment on the feature maps at the output layer to enhance the feature representation. The final output is a set of feature maps with different importance values. The ULSAM processing ensures focus on important information and prevents interference from irrelevant features. The expression for attention assignment of one group of subspace features is shown in equation (5)
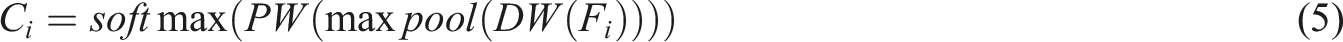

As shown in equation (6), the attention feature map

After concatenating all the feature maps using equation (7), the final attention feature map group Schematic diagram of DC-ULSAM model structure.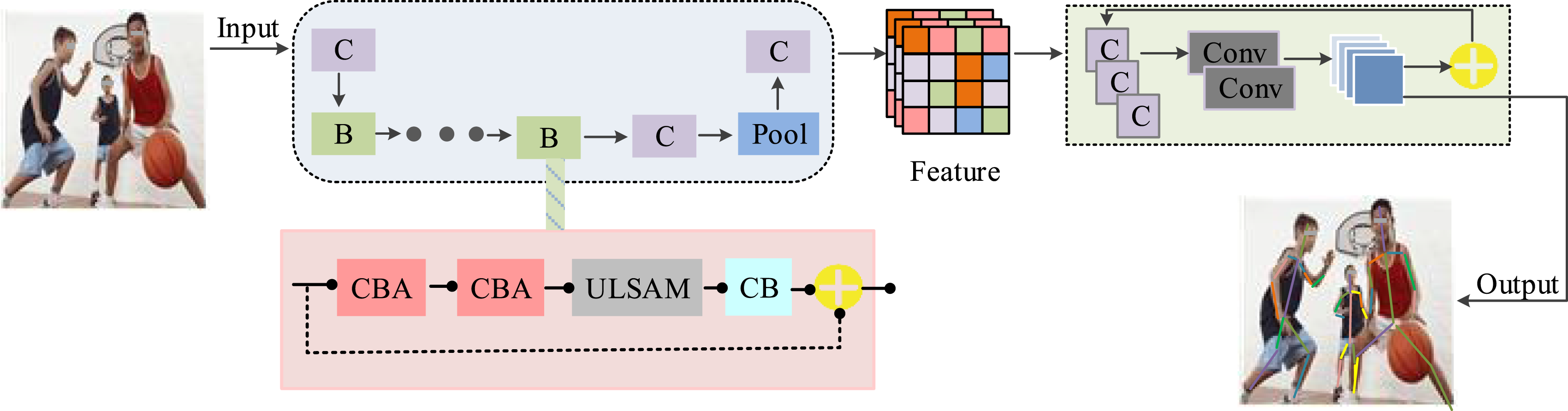
As illustrated in Figure 4, the DC-ULSAM model for aerobics pose estimation begins by extracting features from the original image, generating a set of feature maps. These maps are then passed through convolutional neural networks for an initial estimation. In subsequent stage, the estimation results from the previous stage are combined with the feature maps, which leads to a more refined final estimation. After multiple iterations, confidence maps for key points and part affinity fields are generated, and human pose skeleton diagrams are generated based on these key point confidence maps and part affinity fields.
Construction of multi-person pose recognition model for aerobics
To address the accuracy bottleneck and insufficient generalization of action classification in traditional aerobics human pose recognition models in multi-person scenarios, a multi-person pose estimation model based on OpenPose is proposed in this study. On this basis, in order to improve the classification performance of the model for diverse aerobics movements, the Adaptive Graph Convolutional Networks (AGCN) were introduced in the study to adapt to different types of data.24,25 Therefore, based on AGCN, the study extracts keypoint coordinates, bone lengths, directions, and motion information from the human skeleton map. The Space-Time-Channel (STC) attention module is incorporated to improve the extraction of key features. By combining AGCN with the STC attention module, a human pose recognition model called AGCN-STC is developed.
26
The structure of this recognition model is depicted in Figure 5. Structure of the AGCN-STC recognition model.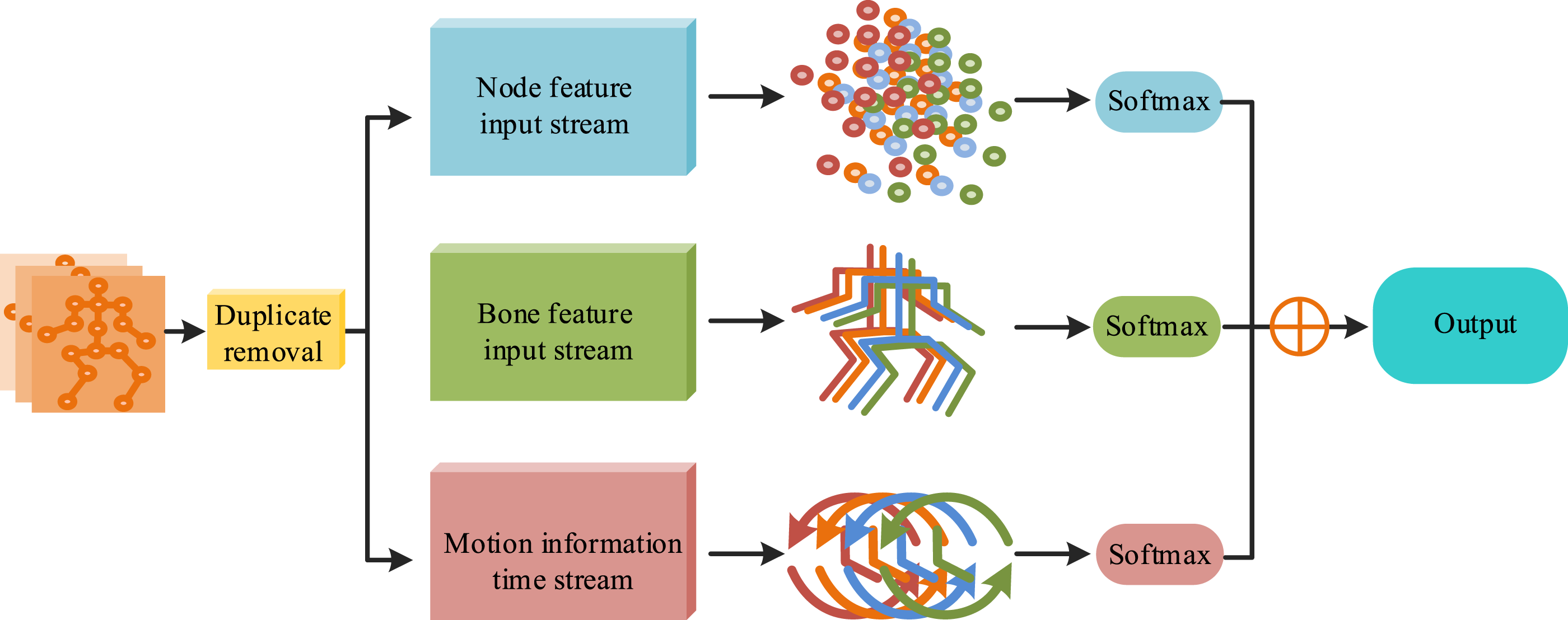
In Figure 5, the AGCN-STC action recognition model first preprocesses the pose information upon receiving the human pose skeleton map, removing redundant pose information. The preprocessing method used is to deduplicate the pose information through the Non-Maximum Suppression. The last pose information of each pose is first obtained, as shown in equation (8) STC attention module structure diagram.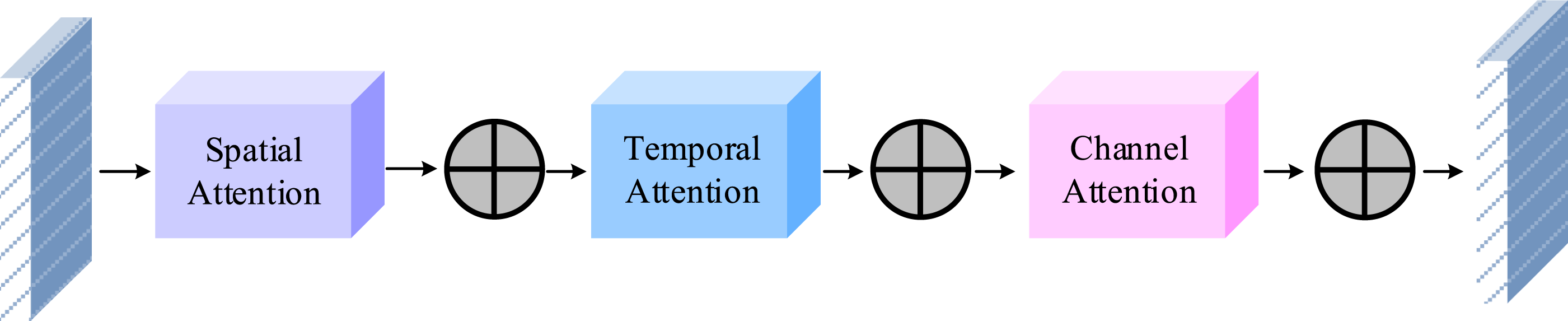





As shown in Figure 6, the STC module is composed of three components: the spatial attention module, the temporal attention module, and the channel attention module. The spatial attention module enables the neural network to assign different levels of attention to different joints.
28
With the attention calculation expression shown in equation (13)




The role of the ReLU activation function is to limit the input values to a non-negative range. By introducing the STC module, the model can strengthen feature extraction from three directions: time, space, and channel, avoiding the omission of important information and improving the accuracy of human pose recognition. Finally, the study combines the DC-ULSAM human pose estimation module and the AGCN-STC recognition module to build a human pose recognition model based on OpenPose technology, named AA-OP. The specific structure of this recognition model is shown in Figure 7. AA-OP human pose recognition model structure diagram.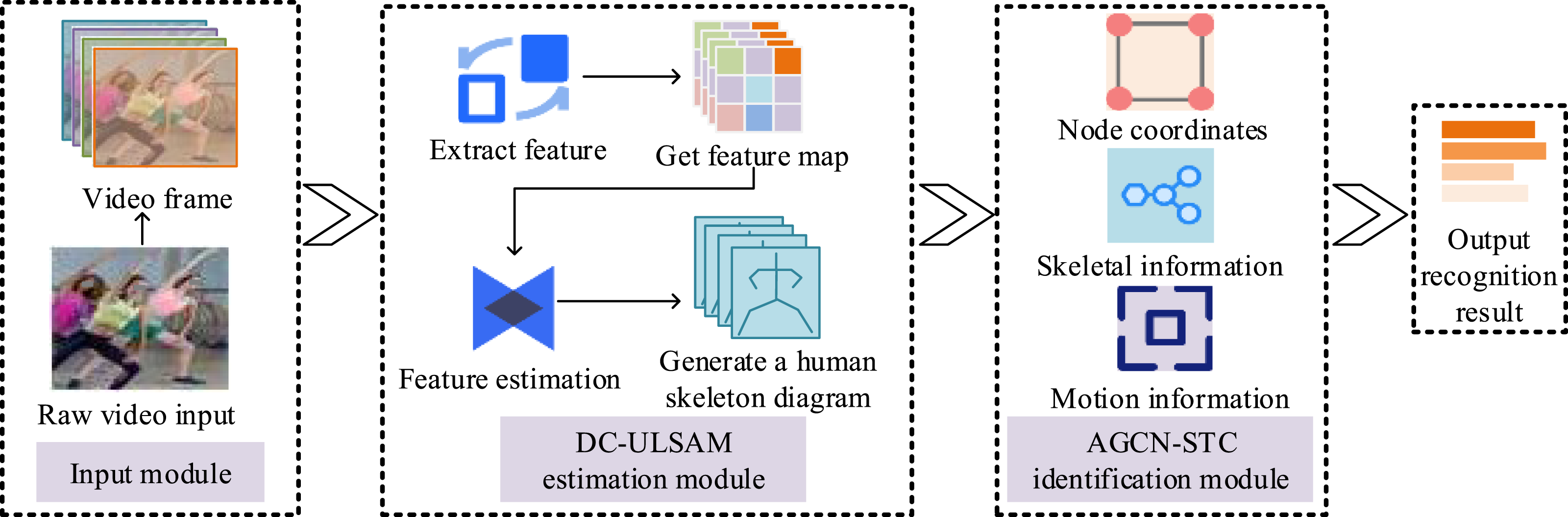
As shown in Figure 7, the AA-OP human pose recognition model first preprocesses the aerobics video to extract static frame images from the motion video, which serve as the input for the DC-ULSAM estimation module. The DC-ULSAM estimation module extracts features from the image and generates the human skeleton map. Upon receiving the skeleton map, the AGCN-STC recognition module extracts features from the skeleton map through joint feature input flow, bone feature input flow, and motion time information flow. Attention mechanisms are used to enhance the focus on important features, and the final human pose recognition result is obtained by weighted fusion. The AA-OP human pose recognition model is based on OpenPose technology and has been optimized to enhance its feature extraction capabilities and fully leverage the advantages of different data streams.
Results
Experimental setup
Experimental environment parameters.
Performance verification of AA-OP human pose recognition model
Based on the above experimental setup, the study first performed model performance validation on the AA-OP human pose recognition model using the training and test sets from the Human3.6 M dataset as the target images. The evaluation metrics for model performance validation were accuracy and loss. The AA-OP model was tested for accuracy and loss on both the training and test sets, and the experimental results are shown in Figure 8. Accuracy and loss value experiment results.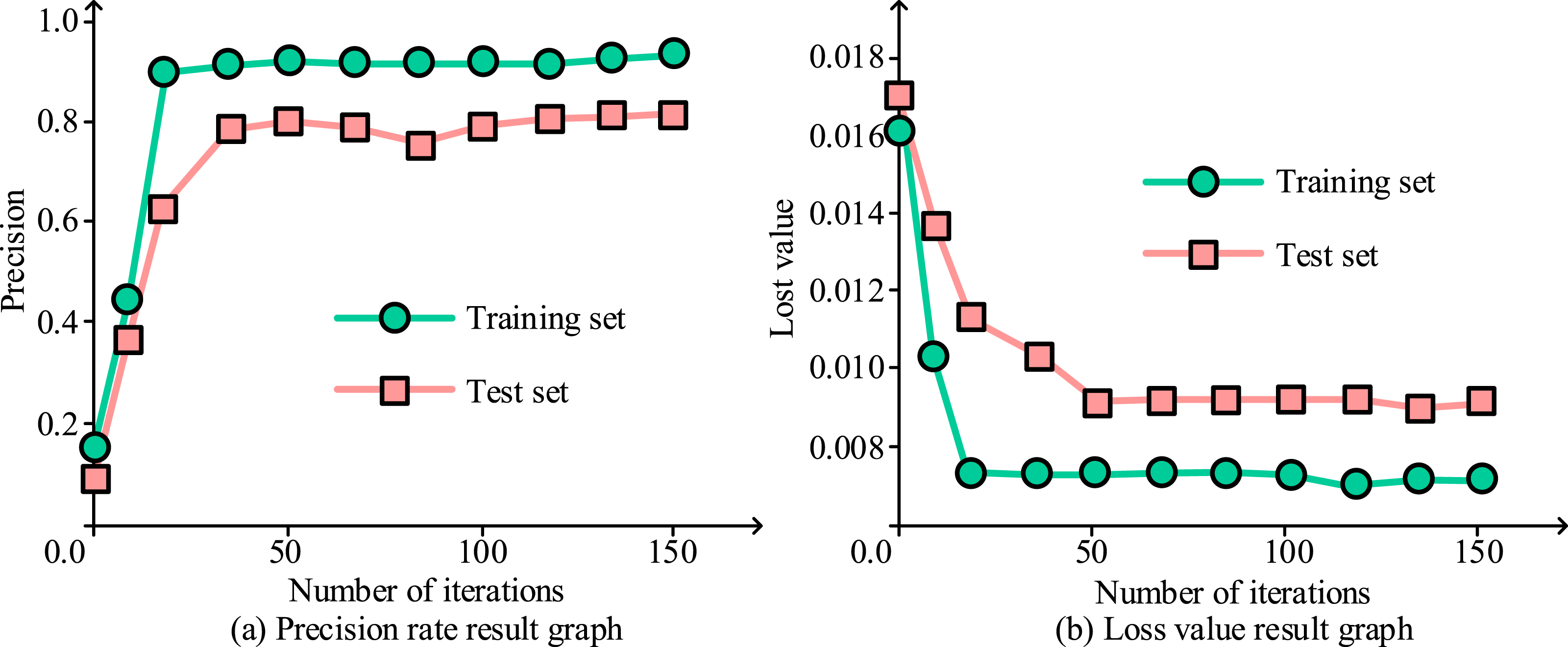
As shown in Figure 8(a), with an increasing number of model iterations, the accuracy on both the test and training sets stabilized. After 150 iterations, the accuracy on the training set stabilized at 0.91, while the accuracy on the test set stabilized at 0.89, with the training set’s accuracy slightly higher than that of the test set. As shown in Figure 8(b), after 23 iterations, the loss value on the training set reached a steady state at 0.0072, and after 51 iterations, the loss value on the test set stabilized at 0.0089. These results demonstrate that the AA-OP model achieved good performance in terms of both accuracy and loss after training. To further verify the feasibility of the AA-OP model, the study conducted verification experiments on the light and moderately crowded image sets, with the results shown in Figure 9. Accuracy results for images with different levels of crowding.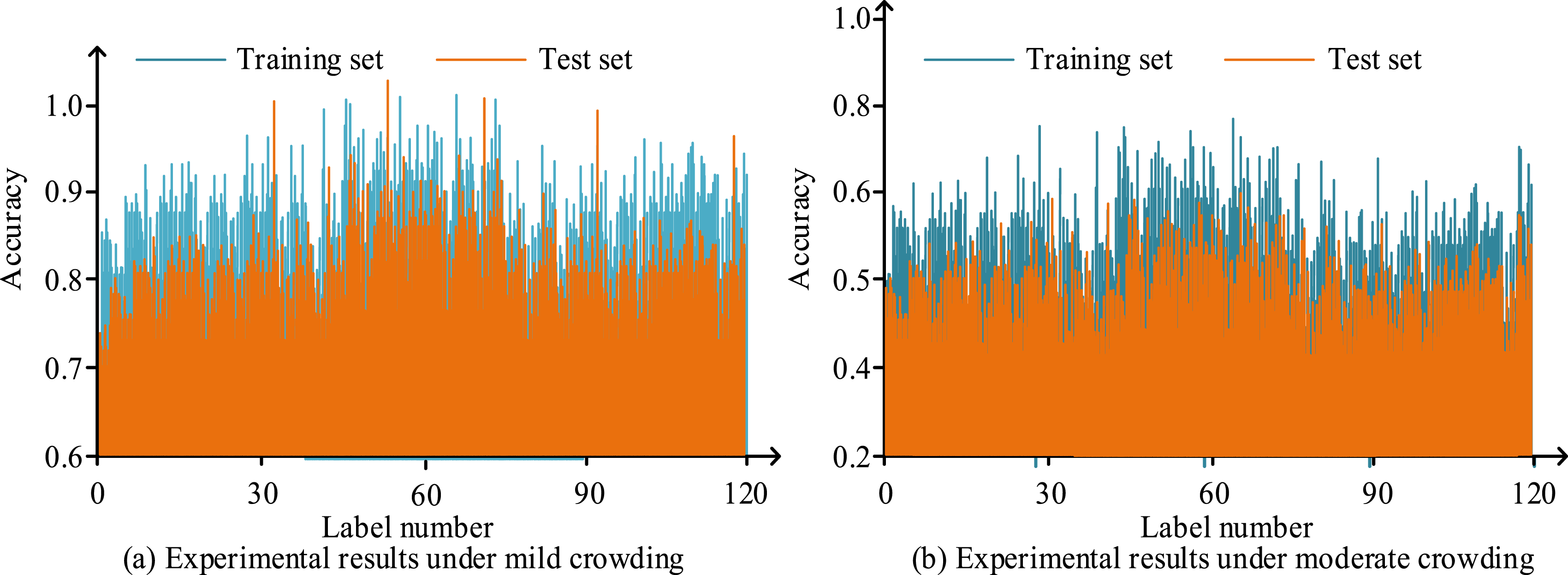
In Figure 9(a), it can be seen that for lightly crowded images, the recognition difficulty was relatively low. The minimum accuracy on the test set was 0.75, and the maximum accuracy was 0.95. The minimum accuracy on the training set was 0.79, and the maximum accuracy was 0.98. In Figure 9(b), the recognition target was moderately crowded images, the accuracy on both the training and test sets decreased, but it remained above 0.7. The highest accuracy on the different sets reached 0.92 and 0.94. Overall, despite the increased difficulty of the recognition target, the AA-OP model still maintained high accuracy, proving the superiority of the model’s performance.
Ablation experiment of AA-OP model
To assess the impact of the improvements made to the OpenPose algorithm, the study conducted additional ablation experiments to confirm the effectiveness of these modifications and the superior performance of the AA-OP model. The ablation experiments used the Human3.6 M dataset, with evaluation metrics being keypoint scores and accuracy. First, the study conducted experiments on the keypoint scores for OpenPose, DC-ULSAM, AGCN-STC, and AA-OP models on images with different Signal-to-Noise Ratios (SNRs). The results of the keypoint score experiments are shown in Figure 10. Keypoint score experiment results.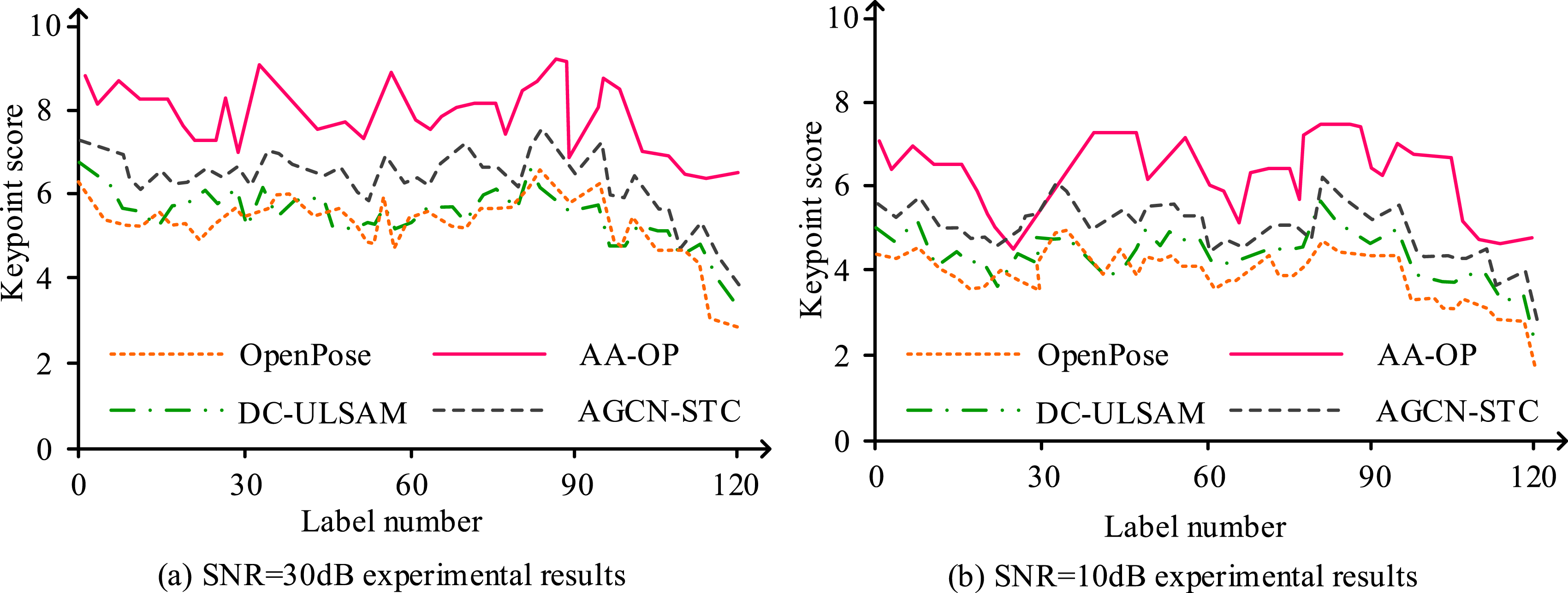
As shown in Figure 10(a), when the SNR of the recognition image was 30 dB, indicating good image quality, the highest keypoint score for OpenPose was 6.3, for DC-ULSAM it was 6.4, for AGCN-STC it was 7.8, and for AA-OP it was 9.0. In Figure 10(b), when the SNR dropped to 10 dB, indicating lower image clarity, the highest keypoint score for OpenPose was 5.1, for DC-ULSAM it was 5.8, for AGCN-STC it was 6.0, and for AA-OP it was 7.8. These results demonstrate that, at different SNRs, the AA-OP model outperforms the other three models in terms of keypoint recognition, validating the effectiveness of the improvements made to the OpenPose algorithm for enhancing human pose recognition. After comparing the keypoint scores, the study continued with angle and position error experiments on the four models. The experimental results are shown in Figure 11. Angle and position error experiment results.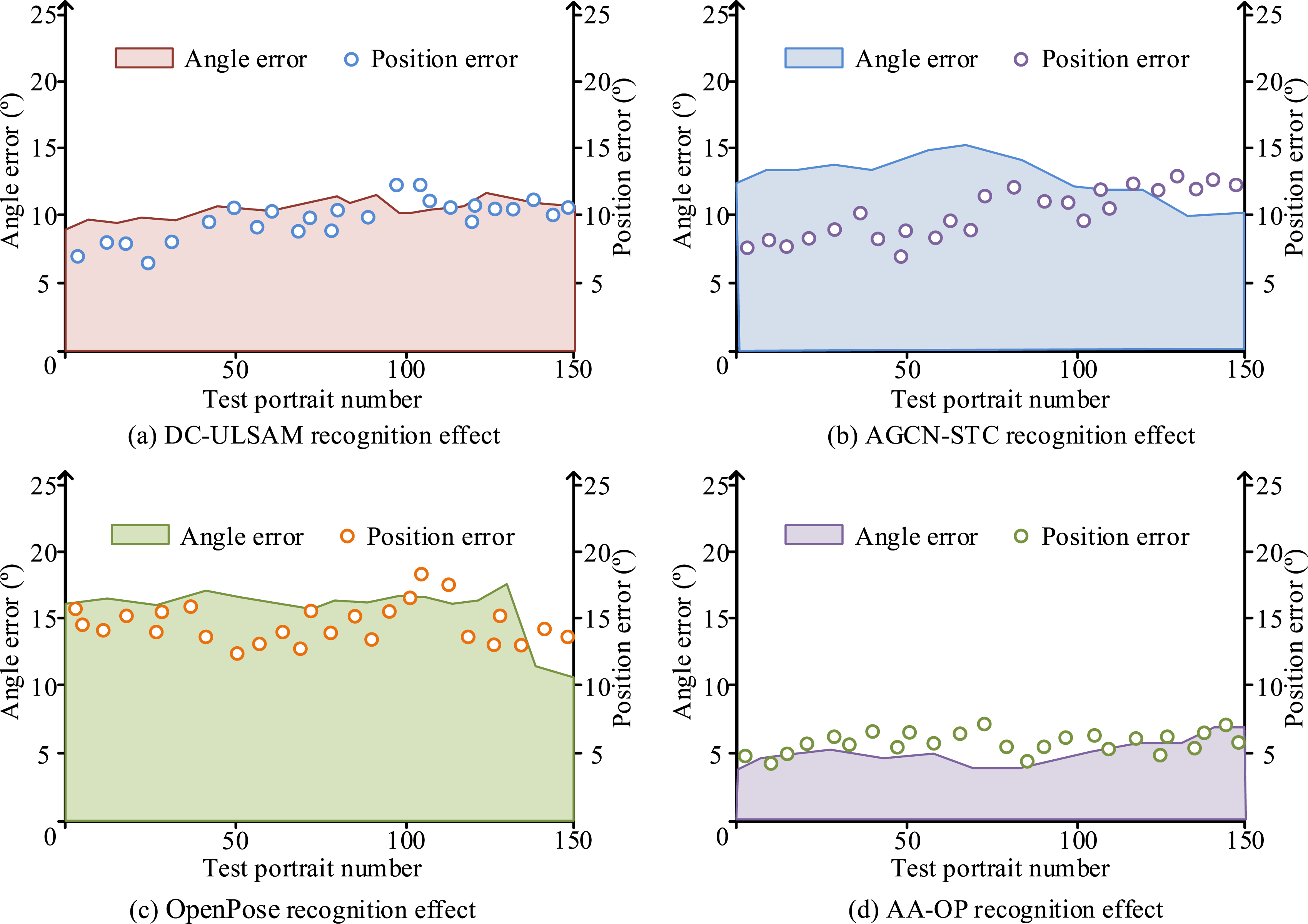
Figures 11(a), (b), (c), and (d) show the angle and position errors for OpenPose, DC-ULSAM, AGCN-STC, and AA-OP models when recognizing target human bodies. It can be seen that the recognition error for DC-ULSAM and AGCN-STC models did not vary significantly. Specifically, the average angle error for AGCN-STC was 10.1%, with a position error of 9.5%. For DC-ULSAM, the average angle error was 9.8%, with a position error of 9.7%. The average angle error for AA-OP was 4.9%, and the position error was 5.4%. The error variation for OpenPose was larger, with an average angle error of 14.3% and a position error of 14.1%. In comparison, AA-OP demonstrated higher and more stable recognition accuracy, showing superior practicality. This experiment further confirmed the effectiveness of the improvements made in the research.
Validation of AA-OP model in practical applications
To further validate the performance of the AA-OP model in real-world application scenarios, the study conducted comparison experiments with mainstream models. The comparison models included Cascaded Pyramid Network (CPN), Convolutional Pose Machines (CPM), and High-Resolution Network (HRNet). The AP dataset was used, and the study first conducted a comparison of the recognition times for the four models. The results are shown in Figure 12. Running time results under different SNRs.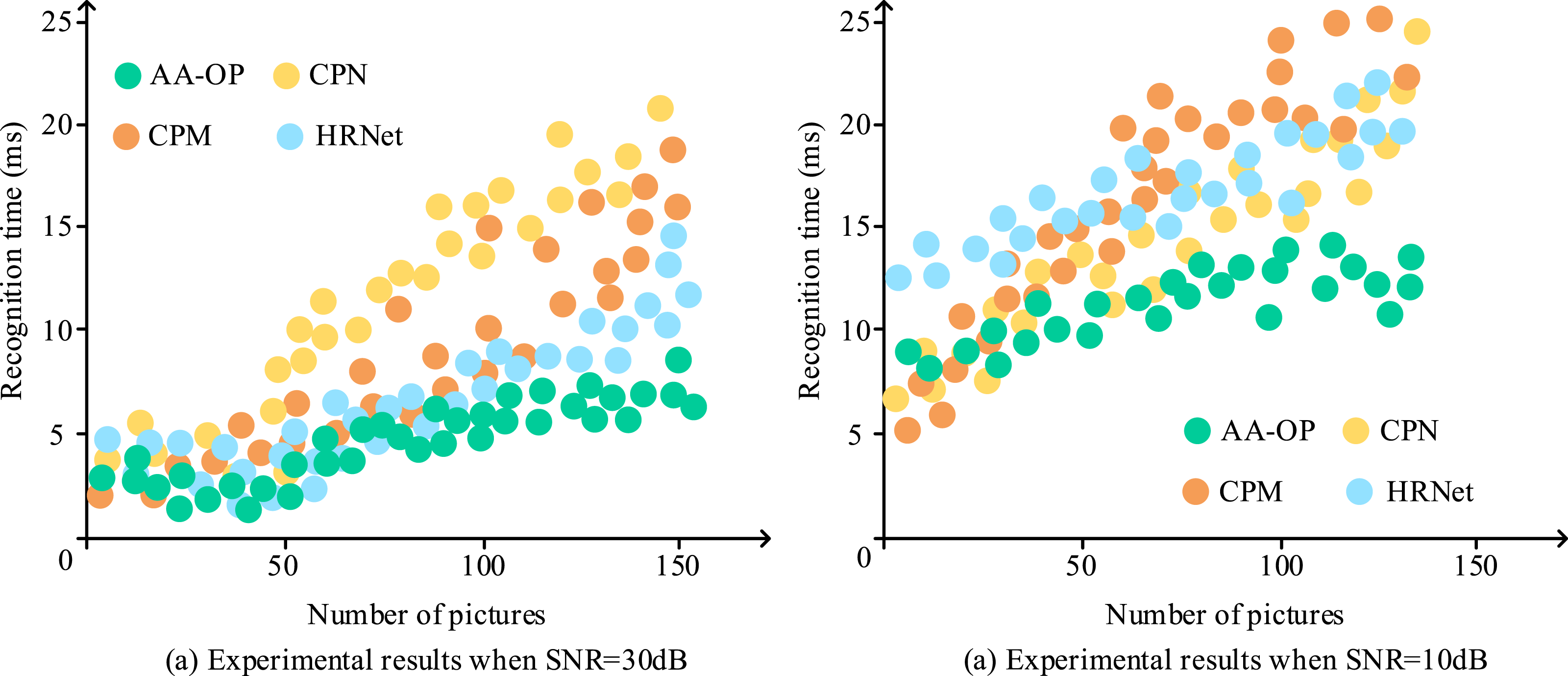
In Figure 12(a), when the image clarity was relatively high, with an SNR of 30 dB, the recognition time for all four models increased as the number of images grew. When the number of images reached 150, the recognition times for CPN, CPM, HRNet, and AA-OP were 20 ms, 18 ms, 14 ms, and 8 ms, respectively, with AA-OP performing the best. In Figure 12(b), when the image clarity decreased, all four models experienced a decrease in recognition efficiency. However, AA-OP maintained the highest efficiency, with the recognition times for CPN, CPM, and HRNet increasing by 5 ms, 8 ms, and 8 ms, while AA-OP’s recognition time only increased by 4 ms. The experimental data indicate that AA-OP maintained a fast recognition speed even with target images of varying clarity, validating its superior robustness and adaptability. The study continued by conducting comparison experiments on the recognition accuracy for single-person and multi-person images across the four models. The experimental results are given by Figure 13. Recognition accuracy results for single-person and multi-person images.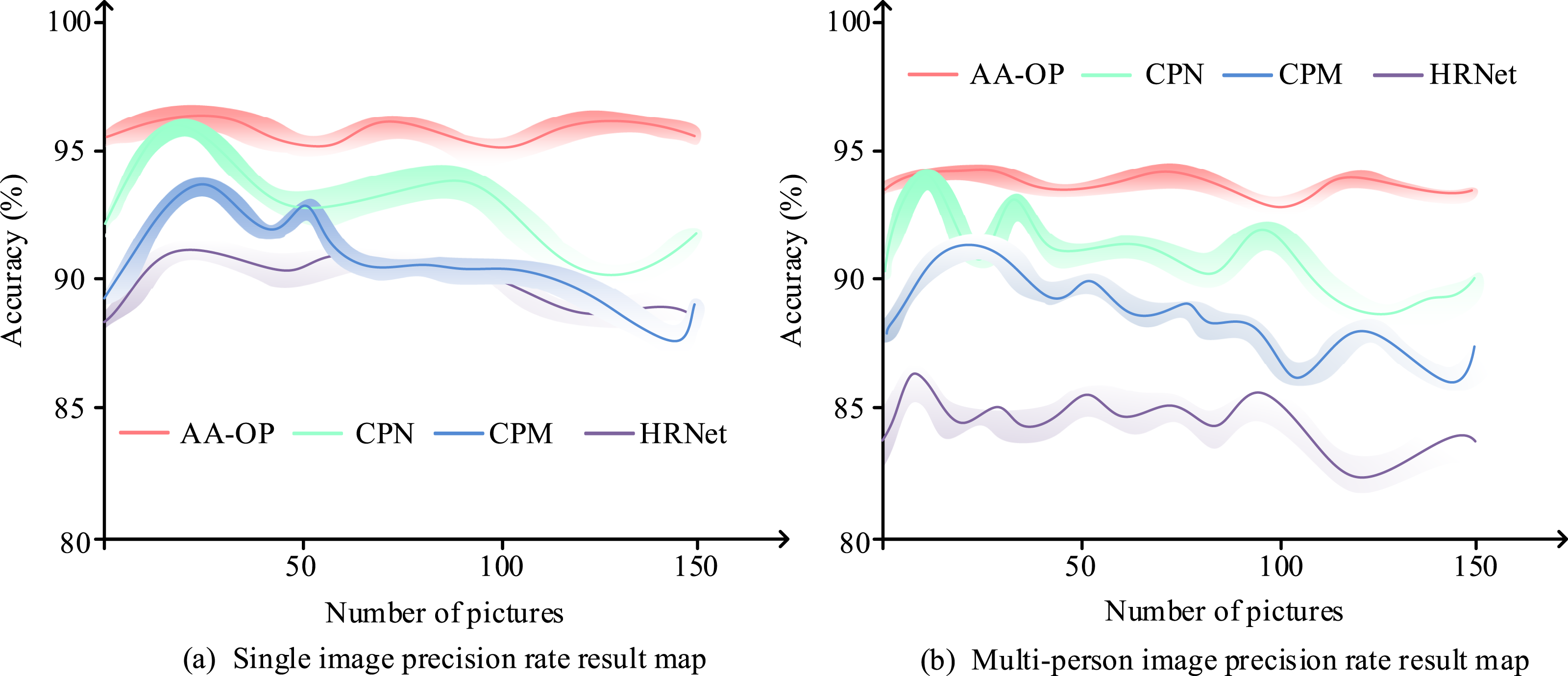
As seen in Figure 13(a), when the target was a single person, the recognition accuracy for all four models exceeded 85%. The highest accuracy for CPN was 96.3%, for CPM it was 93.2%, for HRNet it was 92.1%, and for AA-OP it was 96.7%, making AA-OP the best-performing model. However, when the target was a multi-person image, the accuracy of the three comparison models dropped significantly, with the highest accuracy for CPN, CPM, and HRNet being 94.1%, 91.3%, and 86.2%, respectively. In contrast, the AA-OP model maintained an accuracy above 93%, with a highest accuracy of 94.8%. This demonstrated that the AA-OP model could maintain high accuracy even for multi-person scenarios, indicating its suitability for real-world aerobics applications. Finally, the study conducted a comparison experiment on the AA-OP model’s performance in real human pose recognition. The visual results are shown in Figure 14. Human pose recognition results.
From Figures 14(a) and 11(b), it can be observed that CPM and CPN failed to recognize details such as the feet and occluded parts of the human body in the image. In Figure 14(c), HRNet misidentified a baseball bat as part of the human body and erroneously recognized a human from the background audience as the target human, without filtering out interference. In contrast, the AA-OP model provided a more complete recognition, accurately recognizing only the pose of the baseball player, excluding interference from the audience and sports equipment. Moreover, AA-OP outperformed the comparison models in terms of handling fine details. This experiment demonstrated the superior recognition performance of the AA-OP model.
Discussion
The research optimized the AA-OP human pose recognition model based on the OpenPose algorithm to improve its applicability in aerobics. The experimental results show that the AA-OP model performs excellently in performance and ablation experiments. After training, the accuracy reaches 95% and the loss value is 0.0089. Both its key point score and Angle position error test results are superior to those of the original OpenPose algorithm. The AA-OP model can still maintain a key point score of 7.5 under low-quality images, demonstrating good robustness and environmental adaptability, which is mainly attributed to the introduced attention mechanism. Shuai’s research also enhanced the model’s adaptability by fusing image features through the attention mechanism. 29 In crowded multi-person scenarios, the AA-OP model also demonstrated superior recognition performance, with the highest accuracy reaching 96.7%. The visual results in real human pose recognition also showed superior recognition performance. This might be related to the use of CNNs, which aligns with Purohit’s view on the role of neural networks in pedestrian action recognition. 30 Lauer also employed deep neural networks to develop a pose estimation toolbox, which also showed high precision. 31 In the comparison experiment on the running speed under different SNRs, the AA-OP model’s running times were 8 ms and 4 ms, faster than the other three comparison models. This was mainly due to the reasonable network structure of the AA-OP model, which was consistent with the research results of Samkari’s team on human pose recognition models. 32 The results confirmed that the AA-OP model could meet the requirements of human pose recognition for aerobics, providing more professional assistance to aerobics enthusiasts, while also offering a new direction and insight for the field of human pose recognition.
The AA-OP model proposed in the study combines a lightweight network structure with an adaptive attention mechanism, breaking through the performance bottleneck of the traditional OpenPose algorithm in complex scenarios, while maintaining efficient recognition. In response to the professional needs of aerobics in practical applications, the AA-OP model achieved fine joint angle recognition through a hierarchical feature fusion strategy and captured continuous movements accurately in rhythmic actions. The research findings not only contribute to enhancing the scientific and standardized nature of mass sports and fitness, aligning with the United Nations Sustainable Development Goals (SDGs) of “ensuring healthy lifestyles for the well-being of people of all ages” (SDG 3) but also reduce computing resource consumption through lightweight technology, promoting green technological innovation. In response to “Taking Urgent Action to Address Climate Change and Its Impacts” (SDG 13).
Conclusion
Aerobics has become increasingly popular among the general public due to its many advantages and is now a mainstream fitness activity. Recognizing the movement poses in aerobics can help fitness enthusiasts perform their exercises more accurately. However, traditional human pose recognition models, limited by the quality of the target images, cannot meet the needs of human pose recognition in multi-person aerobics scenarios. Therefore, the study innovatively proposed an aerobics human pose recognition model based on OpenPose technology. The final experimental results showed that the model outperformed the basic algorithms in recognition performance. Additionally, the model demonstrated excellent recognition accuracy and robustness across different recognition scenarios. The results proved that the AA-OP aerobics pose recognition model proposed in the study can meet the requirements for human pose recognition in actual aerobics exercises. The operational efficiency of the model is closely related to the hardware configuration, but systematic tests on its performance in different hardware environments have not yet been conducted, which may affect its applicability on low-configuration devices. Although the model performs well in experimental scenarios, its recognition accuracy may decline in complex situations such as extreme lighting conditions, dense crowds or high-speed movement. In the future, research and test models need to improve their operational efficiency on different hardware platforms and explore lightweight improvement solutions. Meanwhile, by integrating multimodal data or time series modeling methods, the stability of the model in complex motion scenarios can be enhanced.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.