
Abstract
Virtual Reality (VR) transforms second language acquisition by immersing learners in interactive, context-rich environments that foster cognitive engagement and enhance phonemic competence. This research explores the neurocognitive enhancements induced by VR-based English phoneme learning through multimodal bio-signal analysis and advanced machine learning (ML) techniques. A total of 450 English learners participated in immersive VR scenarios designed to target challenging English phonemes within authentic conversational tasks. Two types of datasets were collected: one in the form of a CSV file containing EEG signals and eye-tracking data, and the other comprising audio signal data. EEG and eye-tracking data were preprocessed using Z-score normalization to ensure consistency. Audio data were denoised using the Savitzky–Golay filter, which effectively preserves phonetic information while removing environmental noise. The cleaned data were fed into the feature extraction process. For the EEG and eye-tracking data, feature extraction was carried out using Independent Component Analysis (ICA), while Mel-frequency cepstral coefficients (MFCCs) were extracted from the audio data to capture detailed phonetic features essential for phoneme classification. This approach ensures accurate classification of phonemic performance and prediction of neurocognitive load in immersive VR-based phoneme learning. A feature-level fusion technique was employed to integrate the normalized event-log features and audio-based MFCCs into a unified, high-dimensional feature space, enabling comprehensive multimodal analysis. The Manta Ray Foraging Optimized Light Gradient-Boosting Machine (MRFO-LGBM) was introduced to optimize the LGBM model, enabling accurate classification of phonemic performance and prediction of neurocognitive load. The proposed method was implemented using Python 3.10.1. Experiments demonstrate that the proposed VR-enhanced cognitive phoneme recognition framework significantly outperforms other models, achieving superior results in terms of accuracy, F1-score, precision, and recall, with all metrics ranging from 95% to 96% in predicting neurocognitive states during immersive language acquisition. This research introduces a novel, scalable VR-based system that integrates bio-signal fusion and intelligent modeling to deliver personalized, measurable improvements in phonemic competence.
Keywords
Introduction
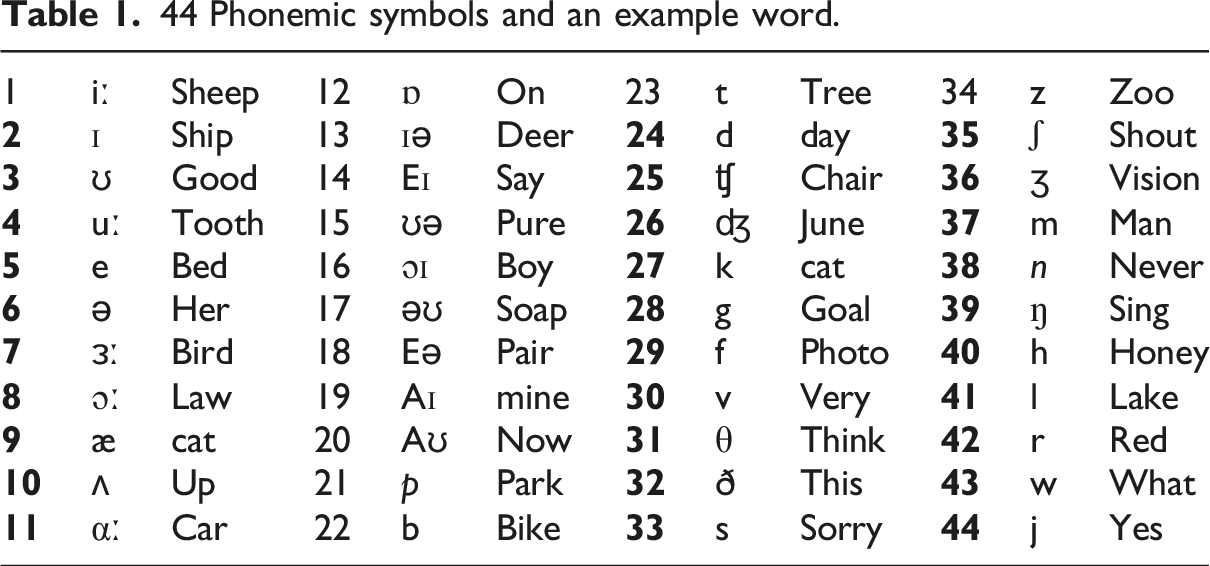
Phonemics, an important subfield of linguistics, focuses on identifying and examining phonemes, which are minimal units of sound in a language that distinguish meaning. 1 In English, there are approximately 44 phonemes, which vary slightly across dialects and accents of spoken English, including consonants and vowels. A comprehensive understanding of all phonemes is necessary to achieve intelligible pronunciation, good listening comprehension, and fluent speech production. 2 As a component of English phonemic competence, the ability to appropriately perceive, produce, and distinguish these units of sound when communicating is a valuable skill for second language learners. 3
44 Phonemic symbols and an example word.
With its unique ability to create realistic environments, VR has become an increasingly important medium in educational technologies.
8
VR creates the possibility of transformative experiences in language learning contexts by engaging students in rich sensory input that resembles authentic communication situations.
9
Unlike the static context of a traditional language classroom, VR immerses users in a living and dynamic environment that allows for practice using contextualized interactions, experiential learning, and embodied cognition.
10
The power of VR could enhance neurocognitive functions corresponding to English phonemic competence, due to VR’s capacity to enhance sensory engagement and cognitive processing in immersive, interactive language learning environments.
11
VR allows for contextually authentic simulations and immediate feedback to assist learners in practicing and developing their phonemic awareness, auditory discrimination, and pronunciation. This research investigates the neurocognitive benefits of VR-based English phoneme learning using sophisticated ML algorithms and multimodal bio-signal analysis. The LGBM model was refined with the introduction of the Manta Ray Foraging Optimized Light Gradient-Boosting Machine (MRFO-LGBM), which allowed for precise phonemic performance classification and neurocognitive load prediction. The main contributions of this work are. • Designed an engaging VR-based system for the development of English phonemic competence through interactive and contextualized scenarios. • Applied Z-score normalization on the EEG and eye-tracking samples, and S-G filtering on audio signals, as suitable methods to ensure clean and consistent input. • Used ICA on the EEG and eye-tracking data to obtain relevant neurocognitive features, and used MFCCs for all audio samples to extract relevant phonetic features. • Developed a feature-level fusion approach and applied a tuned MRFO-LGBM model, which achieved 96.81% accuracy in classifying phonemic performance and predicting neurocognitive loading.
Related works
This section examines a range of immersive and neurocognitive techniques—including electroencephalography (EEG), functional near-infrared spectroscopy (fNIRS), virtual reality (VR), augmented reality (AR), and artificial intelligence (AI)—employed to enhance phonemic learning, pronunciation, and language acquisition across diverse learner demographics.
Yang et al. 12 assessed the efficiency of high variability phonetic training (HVPT) for enhancing the phonological decoding skills of Chinese learners. Their study, involving 40 undergraduate students, utilized a modified phonics screening test, a WeChat application, and an fNIRS device to track network connectivity and brain activity. Despite observing inhibition in the learners’ right fusiform gyrus, Yang et al. 12 reported significant improvement in performance on 5-phoneme pseudo words. Their research findings indicated that Mobile Multisensory Visual Phonetic Training (MVPT) successfully assisted learners in segmentally evaluating novel, challenging words using phonetic patterns. LaRocco et al. 13 developed a phoneme-based imagined speech EEG-based brain–computer interface (BCI) for paralyzed or physically disabled individuals. They identified gamma power (GP) on channels F3 and F7 as the key distinguishing feature among phonemes. LaRocco et al. 13 suggested that with modifications to classifier algorithms, trial window duration, and feature selection, the technique could be adapted for practical applications. Juyal et al. 14 investigated how language proficiency affects EEG signals during imagined conversation in both native English speakers and non-native Chinese speakers. Analyzing signals from 16 participants using the 14-channel EEG for the Imagined Speech dataset, they employed various connectivity metrics and fusion approaches to increase the reliability of imagined vowel phoneme recognition. Juyal et al. 14 found that combining the imagined phase and rest state correlations with phase slope index (PSI) features yielded the best accuracy for both native and non-native speakers. Ge et al. 15 investigated the effects of integrating the Accent Method Rhythm and Pitch (AMRP) with phonemic contrast on speech production in Mandarin-speaking stroke patients with dysarthria. Their results demonstrated that this combination significantly improved the production of targeted words, sentence clarity, and the standard deviation of amplitude. Duraivel et al. 16 addressed communication loss in patients with neurodegenerative disorders by employing high-quality µECoG brain recordings during speech production to re-establish communication. Their approach improved decoding accuracy by 35% by acquiring signals with a 48% higher signal-to-noise ratio and a 57x higher spatial resolution. Duraivel et al. 16 concluded that future neural speech prostheses might achieve high-quality speech decoding using high-density µECoG. Heidlmayr et al. 17 examined phonological deafness among second language (L2) learners, linking it to neuroplastic alterations in the phonological system. Their EEG investigation revealed three event-related potential (ERP) effects that improved with L2 ability: the left frontal auditory N100 component, smaller fronto-central phonological mismatch negativity (PMN) effects, and the semantic N400 effect. Heidlmayr et al. 17 suggested these findings indicate neuroplasticity in the human brain may support the acquisition of hard-wired linguistic features, such as the capacity to recognize phonetic variations in an L2. Tolba et al. 18 presented an interactive AR system combining AI speech recognition with AR to teach phonetics. Their technology enhanced reading skills by incorporating a 3D animated model of speech systems onto a 2D image. Additionally, it utilized a customized AI-based phoneme recognition system to provide real-time pronunciation feedback. A user evaluation with 83 adult participants indicated that the system enhanced comprehension and mastery of specific phonemes, suggesting its potential utility in conventional classroom environments.
Yuan et al. 19 aimed to enhance English language learning for international trade using project-based activities aided by VR and speech recognition technologies. Their approach employed time-delay neural networks (TDNN) to record temporal data in speech within virtual reality environments simulating actual trading situations. Yuan et al. 19 reported that the virtual experiment system lowered costs while enhancing comprehension, with results indicating improved critical thinking, communication, and creative abilities. Xue and Wang 20 investigated the incorporation of virtual worlds and wireless sensing microprocessors to improve English listening abilities, focusing on phonetic mastery in junior and senior high school education. Participants explored effective phonics teaching strategies due to the perceived ineffectiveness of traditional methods. Xue and Wang 20 also analyzed findings from interviews and walkthrough tests. Xie et al. 21 examined the effect of immersive virtual reality (IVR) on primary school pupils’ language memory. They divided 77 students into two groups: one using PowerPoint and the other using IVR. While both methods effectively promoted vocabulary retention, PowerPoint proved superior for instantaneous retention. However, IVR demonstrated better long-term retention, indicating that incorporating language learning theory into IVR settings improved vocabulary acquisition. Ultrasound-enhanced pronunciation training techniques increase articulation learning effectiveness by visualizing the articulatory system as biofeedback. Mozaffari and Lee 22 addressed associated challenges by developing a novel ultrasound-enhanced multimodal pronunciation training system that fuses AI and ultrasound technologies. This technology enhanced user flexibility, system engagement, and autonomy by enabling users to move their heads freely. Bahameish et al. 23 examined the effectiveness of an AR smartphone application in improving vocabulary learning outcomes for children with Autism Spectrum Disorder (ASD). Their study involved nine participants aged 8 to 12 with mild ASD recruited from a local special needs center. Findings revealed significant individual variation in vocabulary learning abilities, with some participants showing notable improvements. Watthanapas et al. 24 investigated the effectiveness of a multilingual VR learning evaluation system for teaching grammatical structures to Thai learners. In a 5-week teaching experiment, participants practiced Thai word order for 20 minutes per session. Results indicated that Thai language anxiety negatively impacted learning retention and task value, while Thai language self-efficacy positively correlated with both conditions. Pellas and Christopoulos 25 explored the effectiveness of the machinima method, developed using Open Simulator and Scratch4SL, in supporting vocabulary acquisition among students with developmental dyslexia. They presented empirical evidence of its influence on language acquisition, along with standards for machinima construction and insights into its educational implications. Wang and Liu 26 examined the usefulness of songs and rhymes as teaching tools for phoneme segmentation and categorization among 11th-grade English as a Foreign Language (EFL) underachievers in Taiwan. Results showed that phoneme segmentation improved somewhat, but not significantly. Their project proposes investigating the potential benefits of song lyrics education for English listening skills.
Recent advancements in immersive and neurocognitive language learning techniques, such as EEG, VR, and AR, have demonstrated significant potential for improving phonemic acquisition and auditory processing. However, several persistent challenges remain evident in the current literature. (1) Limited Generalizability of EEG Systems: Most EEG-based phoneme recognition systems, while accurate, primarily rely on gamma power (GP) derived from limited scalp regions (e.g., F3 and F7). This reliance limits their generalizability across broader cognitive states and diverse individuals.
13
(2) Neglect of Real-time Engagement in Imagined Speech: Language learning experiments utilizing imagined speech EEG signals predominantly focus on classification accuracy. They often overlook real-time cognitive engagement and its correlation with phonemic retention within naturalistic learning settings.
14
(3) Lack of Integrated Bio-signal Assessment in Mobile Training: Mobile phonics training platforms emphasize performance improvement metrics but lack integration with real-time multimodal bio-signals (e.g., EEG combined with eye-tracking) necessary to assess the underlying dynamics of phonemic awareness and decoding during learning.
12
To address these limitations, this study proposes a framework designed to enhance immersive language acquisition by quantifying VR-induced neurocognitive adaptations related to English phonemic competence. The framework enables the integration of multimodal bio-signals, including EEG and eye-tracking data, gathered within immersive VR learning contexts to measure phonemic decoding processes and cognitive engagement. Complementing the predictive ability of the Light Gradient-Boosting Machine (LGBM) classifier, we introduce the Manta Ray Foraging Optimized Light Gradient-Boosting Machine (MRFO-LGBM). This optimized model aims to characterize learners’ neurocognitive adaptations and phonological processing within immersive settings, achieving high accuracy with real-time performance.
Methodology
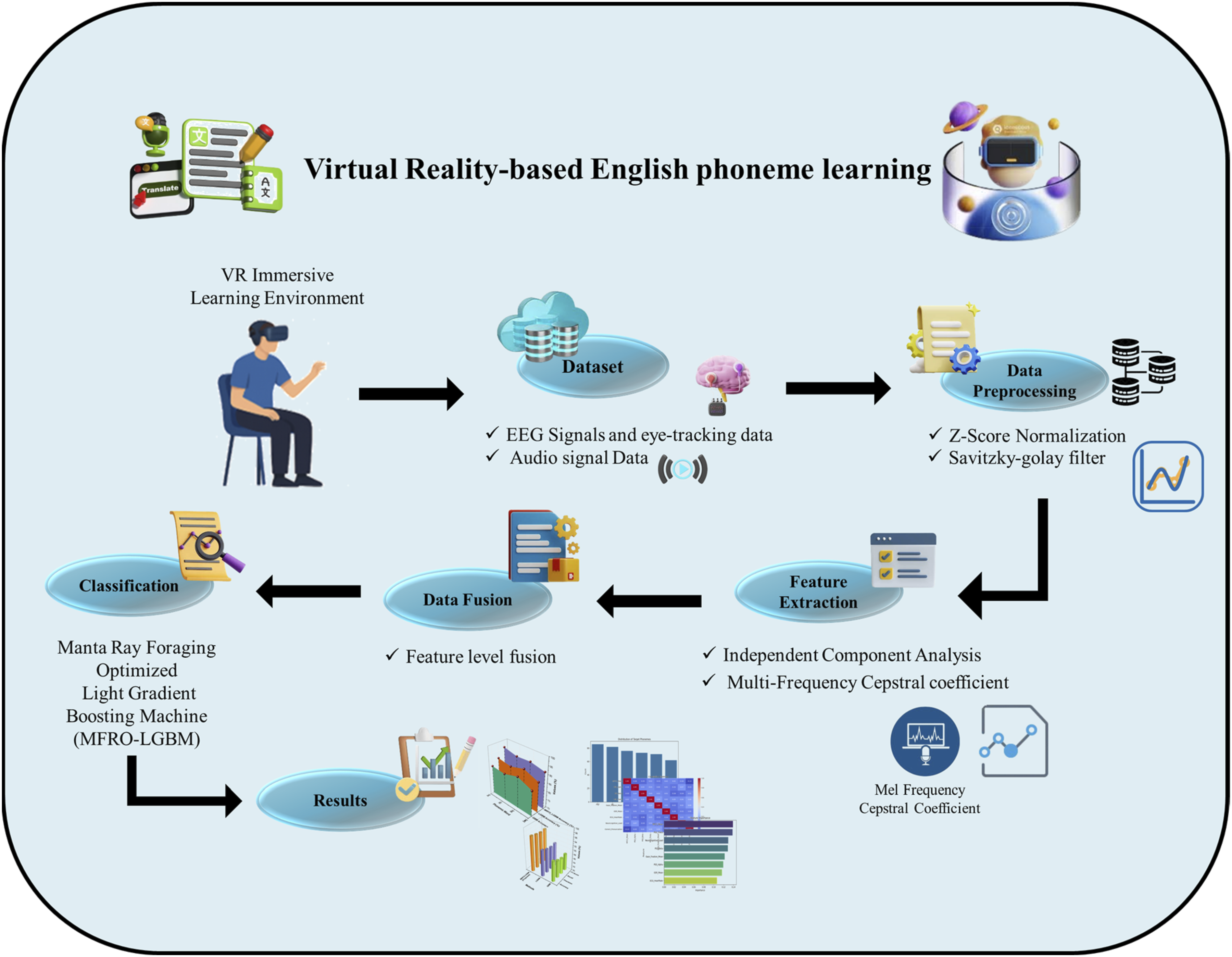
EEG, eye-tracking, and audio streams were collected and preprocessed using Z-score normalization. The audio data were denoised using the S-G filter to maximize phonetic quality. Feature extraction was conducted using ICA for bio-signals and MFCCs for audio streams. Feature-level fusion technique was used to combine the normalized event-log features and MFCCs into a unified high-dimensional feature space. An adaptation of the Manta Ray Foraging Optimized Light Gradient-Boosting Machine (MRFO-LGBM) was proposed to find optimal classifications. This integrated approach enables the prediction of phonemic performance and neurocognitive load in immersive VR-based language learning environments. Figure 1 shows the overall process of the VR-based learning environment. Overall process of phonemic performance and prediction of neurocognitive load.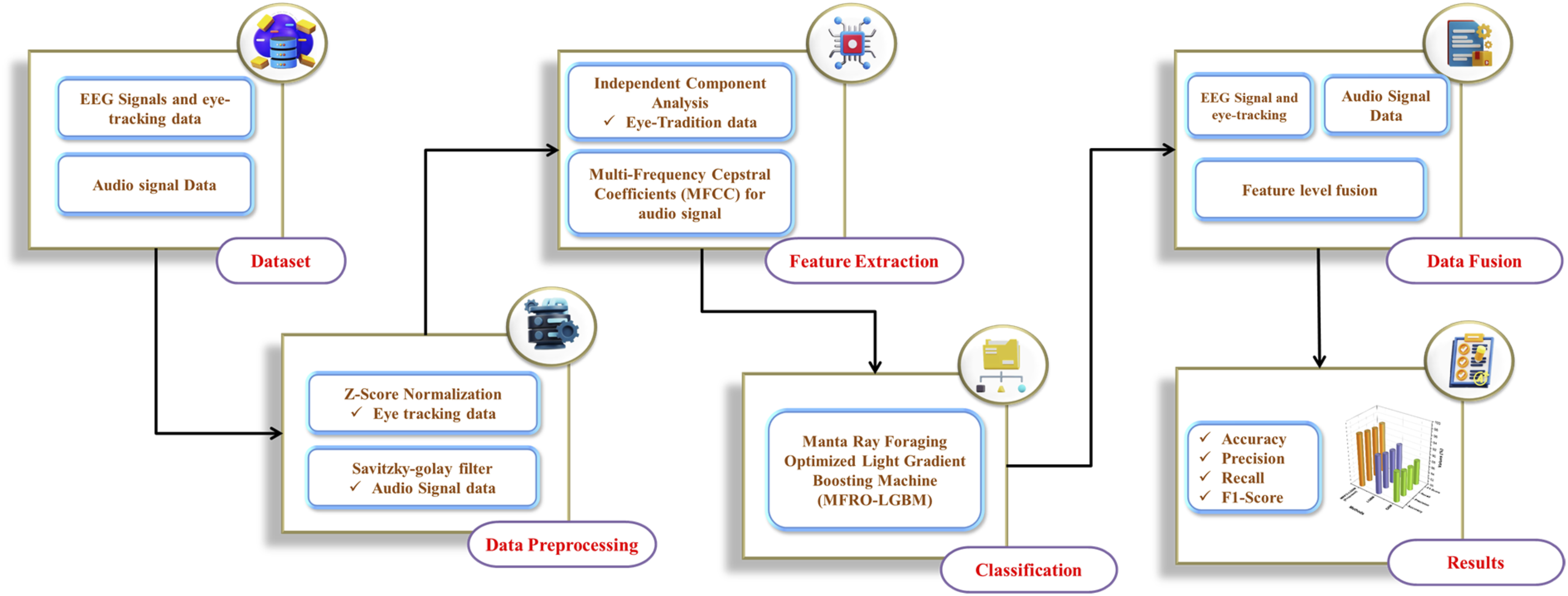
Dataset
The VR English Phoneme Learning dataset was collected from Kaggle. This dataset includes neurocognitive and behavioral data from 450 participants who participated in immersive VR environments to improve English phonemic competence. The data includes EEG-derived PSD features for cognitive state monitoring, speech-derived MFCC features for phoneme articulation assessment, eye-tracking metrics, GSR and ECG data for physiological arousal and heart rate analysis, and audio file references for individual English phoneme pronunciations.
Source: https://www.kaggle.com/datasets/programmer3/vr-english-phoneme-learning-dataset
Data preprocessing
Data preprocessing involved two key steps: Z-score normalization was applied to EEG and eye-tracking data to standardize signal scales, while the Savitzky–Golay filter was used to denoise audio signals, preserving critical phonetic information.
Z-score normalization
Z-score normalization was a technique used to transform the EEG and eye-tracking features that were recorded for English learners in immersive phoneme learning scenarios. This processing step ensured uniform scaling across all data points, eliminating variances caused by differing signal magnitudes and enabling the classifier. This transformation centers the data around a mean of zero and a standard deviation of one, which increases the comparability and stability of multimodal features. The Z-score is calculated using equation (1):
Savitzky–Golay filter (S-G)
The S-G filter was a low-pass filter that resembled an FIR filter in structure and a generalized average movement filter. Additionally, it is perfect for operating smoothing signals to improve signal-to-noise ratios without causing signal distortion. This smoothing approach was accomplished by a convolution process that uses the linear minimum squares technique to replace successive neighboring measurements with a low-degree polynomial. The S-G filter was utilized to smooth the audio signal to remove noise, which improves the clarity of phonemic features, imperative for accurate classification and neurocognitive load prediction in VR-based phoneme learning during VR-based phoneme learning.
The S-G filter smooths the signal by fitting a polynomial of degree o to a window of M consecutive data points using least squares. The central point of this fitted polynomial replaces the original data point at the center of the window. This process iterates across the signal. Key parameters are the window size M, controlling the smoothing strength (larger M = more smoothing), and the polynomial order o, affecting the fit’s flexibility. The core polynomial fitting concept is represented by equation (2):

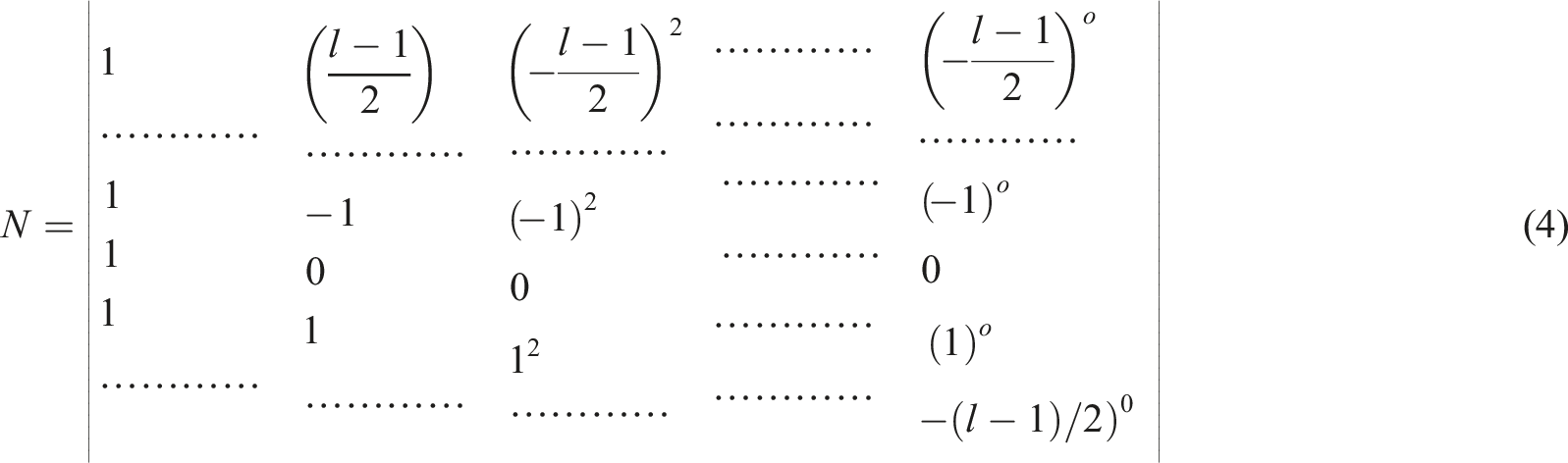
Equation (5) can be employed to denote the vector of the polynomial coefficients 

Equation (7), which uses the matrix’s variables’ least squares approach, can be used to find the vectors of polynomial coefficients.
The linear combination of row values of
Feature extraction
Feature extraction was performed using ICA on the EEG and eye-tracking data to isolate meaningful neural components, and MFCCs were extracted from audio data to capture essential phonemic features.
Independent Component Analysis (ICA)
EEG and eye-tracking data gathered during immersive VR-based phoneme learning were subjected to ICA to extract features. This method reliably separates neural and ocular signals associated with phonological processing and attentional engagement. ICA enables the identification of source signals while extracting the features for better and more accurate classification of neurocognitive states. ICA has been used extensively for blind sources and signal separation because it can recognize statistically independent components from highly correlated and high-dimensional data. ICA has been widely used to monitor intricate industrial operations. Because ICA can extract non-Gaussian features, which are thought to be dominant in contemporary processes, it outperforms many conventional techniques.
A linear combination of signals originating from an assortment of independent sources or concealed variables can be regarded as the process being tracked for process monitoring. Assume that the normal operating conditions of a process produce a process data matrix 



The vector of the 

The subsequent objective function is then repeatedly maximized to yield 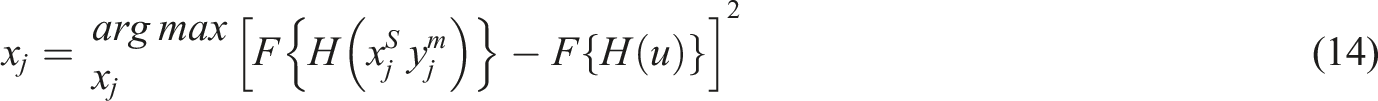
Mel-frequency cepstral coefficients (MFCC)
To facilitate the correct classification of phonemic performance and the inference of neurocognitive load, MFCCs were used to extract the relevant phonetic features based on the preprocessed audio signals collected during the immersive VR-based English phoneme learning. MFCCs, widely used in phonetic and speech-emotion recognition, were extracted. MFCCs are derived from the Mel filter bank, which models the nonlinear perception of sound in the human auditory system of sound. The Mel filter considers how humans produce and perceive speech, which is beneficial to improving the feature representation for learning models. The relation between the real frequencies of speech and the Mel frequencies, which account for the human auditory perception, is provided in equation (15):
The audio signal is segmented into overlapping frames. For each frame
FFT is applied to convert each time-domain frame into the frequency domain: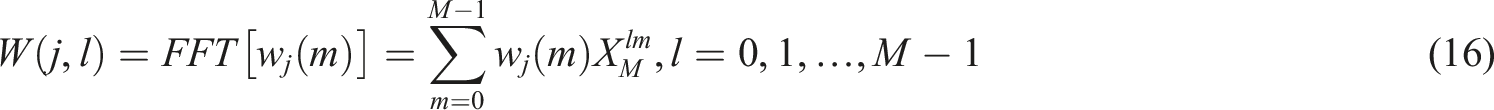


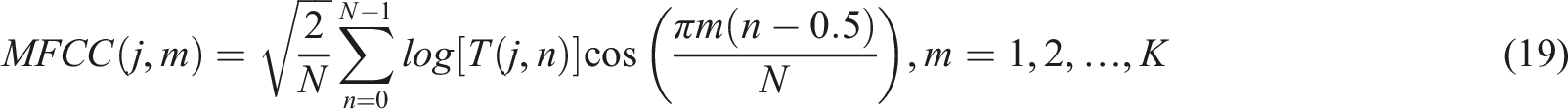
Data fusion
Feature-level fusion
This approach forms a unique feature vector by combining the features extracted from various modalities. The main benefit of this approach is that measuring multimodal data correlations at an early stage yields higher accuracy. This approach allows us to fuse EEG, eye-tracking, and audio-based phonemic features during immersive VR-supported English learning. The features from the different modalities were converted into the same format before the feature fusion process. Feature-level fusion provided the best results for multimodal integration. It also showed improvement in processing time from previously used approaches. Consequently, this enables real-time assessment of phonemic decoding and the students’ neurocognitive responses in real time for improved language acquisition.
Manta ray foraging optimized light gradient-boosting machine (MRFO-LGBM)
The MRFO-LGBM is a hybrid predictive model used to improve both the accuracy and speed in the classification of phonemic performance and the prediction of neurocognitive load. The MRFO algorithm is a bio-inspired optimization method that performs well for both exploration and exploitation of the search space to identify an optimal solution. The study employed the MRFO algorithm to optimize the hyperparameters for phonemic classification accuracy and neurocognitive prediction. The GBM procedure sequentially executes ensemble learning. When sequentially building models, GBM minimizes the prediction error through gradient descent. This procedure combines weak learners, usually decision trees, to build a strong prediction model. LGBM is a very effective and scalable implementation of GBM that uses histogram-based algorithms and leaf-wise growth for trees. LGBM was used to classify phonemic performance and neurocognitive load from combined multimodal datasets. The hybrid MRFO-LGBM model leverages MRFO’s optimization and LGBM’s predictive capabilities to build a precise, flexible learning framework. The MRFO determines optimal hyperparameters for LGBM, improving overall model performance across EEG, eye‐tracking, and audio-derived features. The hybrid approach allows for precise classification of learner responses and performance in immersive VR experiences, mitigating the drawbacks of traditional phoneme training activities. Algorithm 1 shows the pseudocode for MRFO-LGBM.

Gradient-boosting machine (GBM)
In the domain of immersive language learning, the GBM algorithm was deployed to improve the classification of phonemic performance while also predicting neurocognitive load from VR learning environments. Assumed 

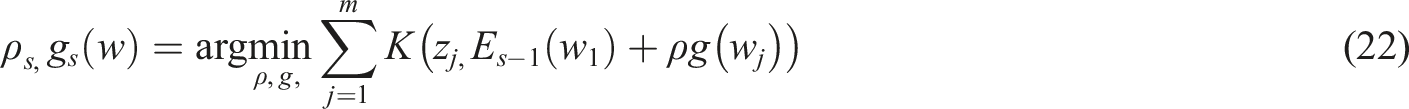
The continuous process captures the remaining phonemic classification errors and changing cognitive response patterns and allows the model to learn difficult phonemic distinctions and context-sensitive neurocognitive loads. The weight 
Light gradient-boosting machine (LGBM)
To provide an accurate classification of phonemic performance and prediction of neurocognitive load in immersive VR-based language learning spaces, this research utilized LGBM as the primary classifier due to its scalability, performance, and capacity to model complex interactions in high-dimensional data.
LGBM is a novel gradient-boosting framework built on decision trees. It employs a leaf-wise growth method with depth limitations and speeds up training by using histogram-based algorithms. Continuous feature values were discretized into k bins using the histogram approach, which lowers memory usage and increases model accuracy. To avoid overfitting, the decision tree’s weak analysis model provides coarser segmentation points. Leaf-wise growth is more efficient, minimizing errors and increasing precision while consistently identifying leaves with the maximum branching gain. However, LGBM adds a maximum pth limit to avoid overfitting, which can be caused by leaf orientation. For the given training dataset 
LGBM will estimate the final model, which is described as follows, by integrating several 
The definition of the regression trees is as follows: 
Newton’s method provides a quick approximation of the objective function. Eliminating the constant term simplifies equation (26):
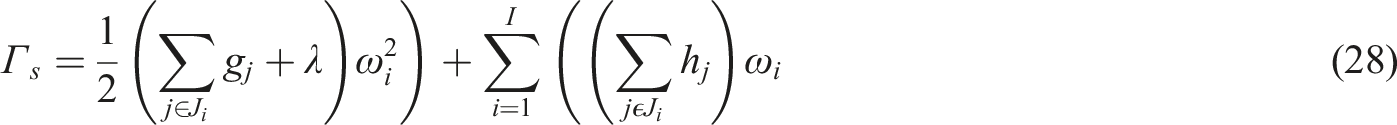
Equations (29) and (30) determine the extreme values of 

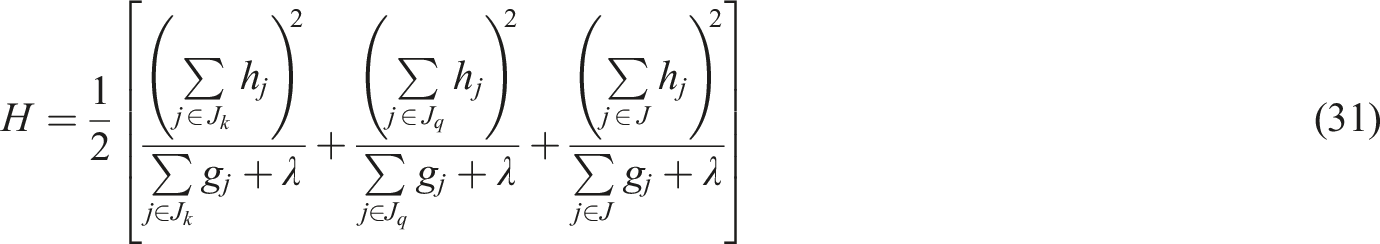
Manta ray foraging optimized (MRFO)
This section summarizes the core steps of the Manta Ray Foraging Optimization (MRFO) algorithm. MRFO simulates three foraging behaviors—chain foraging, cyclone foraging, and somersault foraging—that guide the population of candidate solutions within the search space. These behaviors enable the algorithm to balance exploration and exploitation effectively. In our application, MRFO is employed to optimize hyperparameters of the LGBM classifier, enhancing its ability to accurately classify phonemic performance and predict neurocognitive load during immersive VR language learning.
Chain foraging
In chain foraging, phonemic classification iteratively refines the correctness of the classification by using the most confident phonemic representations for the VR audio and visual information. Manta rays form a line by connecting head to tail in a line to create a foraging chain. According to MRFO, a greater quantity of plankton, the manta rays’ preferred food, is the ideal response. The initial individual primarily moves in the direction of food, but the subsequent individuals in the foraging chain also move in the direction of those in front of them. The following equation (32) is a description of the chain foraging mathematical model.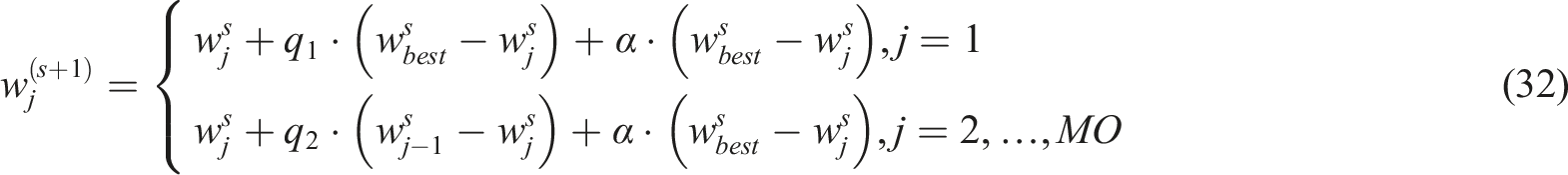
Where
Cyclone foraging
Cyclone foraging used to simulate the spiral cognitive processing involved when learners encounter new or unfamiliar phonemic inputs in immersive VR environments. By spiraling toward the best solution and also accounting for variation among neighboring agents, the algorithm explores subtle cognitive patterns tied to different phoneme complexities.
Manta rays form long hunting chains while finding phytoplankton in deep water, then spiral toward the food. Although it spirals near food and follows the people in front of it, its behavior is comparable to WOA. The following equation (33) provides the mathematical representation of cyclone foraging.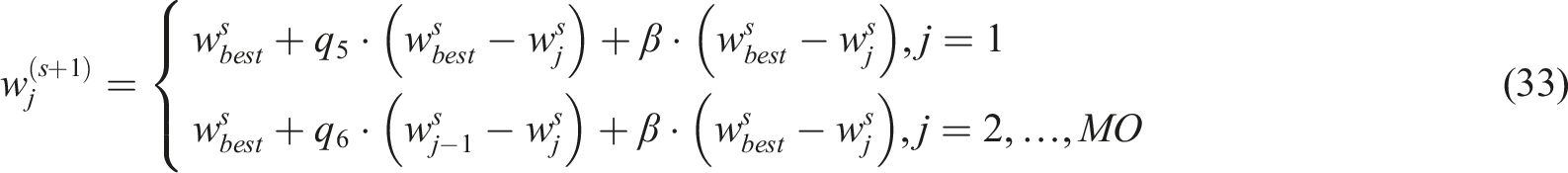
Where 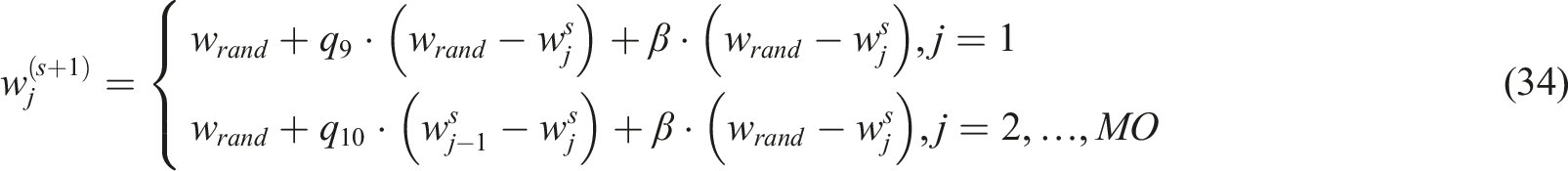
Where
Somersault foraging
Somersault foraging simulates rapid re-evaluation around the best phoneme-cognitive interaction points, essentially acting as a refinement mechanism. The prey location is regarded as a pivot point during this period. Every person rotates the pivot, searching for a new spot in the process. This phase’s mathematical model is shown as follows equation (35).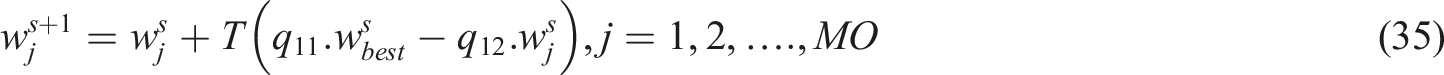
This research utilized the MFRO’s adaptable exploration and exploitation features to demonstrate the ability to concurrently merge linguistic precision and cognitive processing efficiency. Each foraging strategy will play an important role in the exploration of a range of phoneme-cognitive patterns versus the convergence on an optimum decision boundary. Overall, the MFRO-based system will yield not only better approximate English phonemic classification accuracy but also real-time, learner-specific neurocognitive load predictions. Collectively, the MRFO represents a valuable tool for developing responsive and cognitively aware VR-based systems for language acquisition.
Results and discussion
Experimental setup
The experimental design utilized Python 3.10.1 to simulate the proposed MRFO-LGBM-based immersive language learning framework. Python was chosen due to its excellent compatibility with leading scientific computing libraries. The experiments were run with preprocessed multimodal datasets to evaluate the system’s ability to predict learner performance in immersive VR settings.
Performance evaluation of the proposed method
Figure 2 illustrates relationships among various neurocognitive and physiological features related to immersive VR-based English phonemic learning. Notably, MFCC mean exhibits a moderate negative correlation (−0.13) with correct pronunciation. This suggests that audio signal characteristics substantially influence how well audio is parsed and pronounced. This analysis confirmed the validity of incorporating these features into a model for predicting learner performance in VR-enhanced language acquisition systems. Correlation matrix for the relationships among various neurocognitive and physiological features.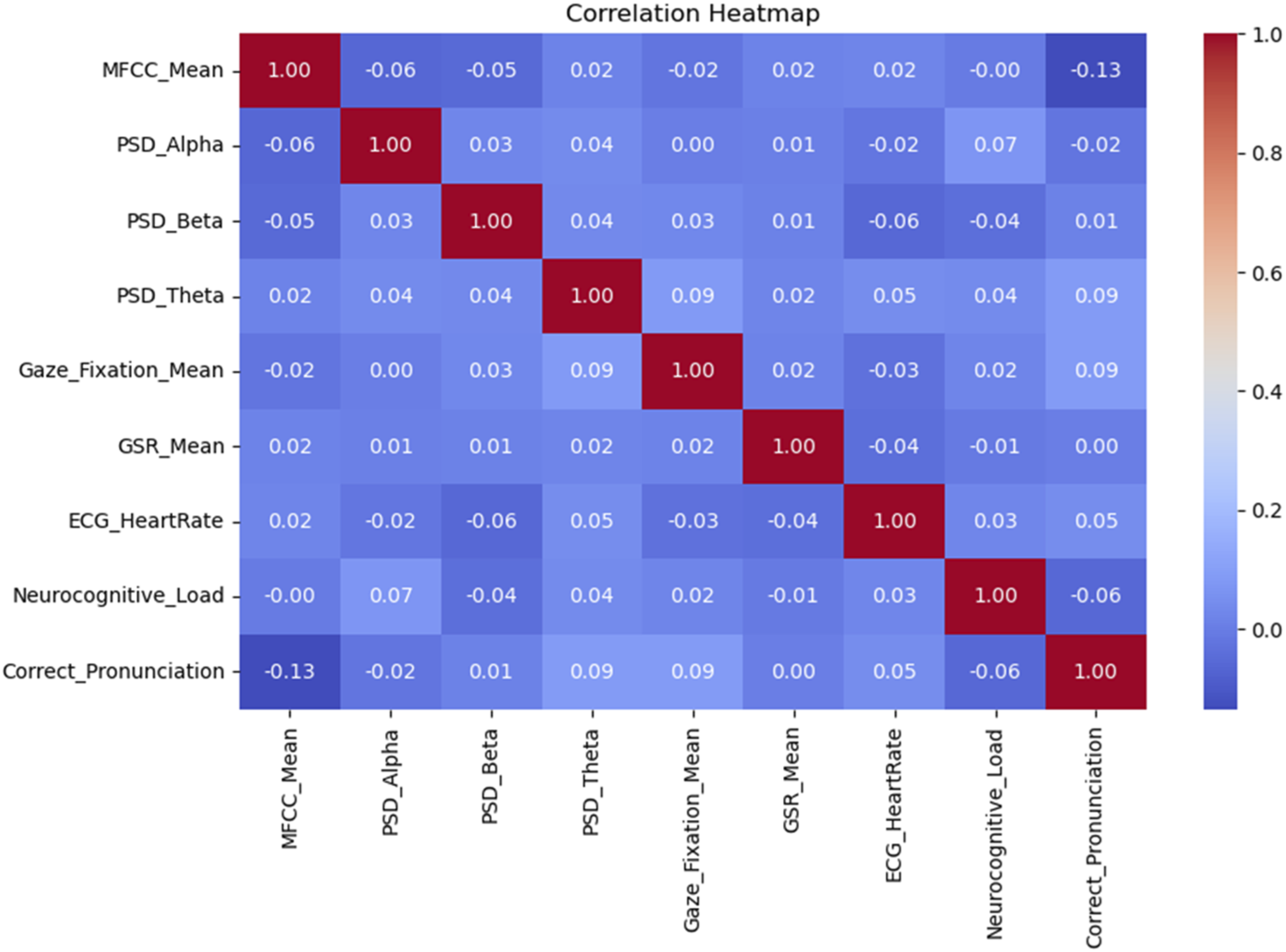
Figure 3 summarizes the occurrence percentages of target phonemes presented during the immersive VR-based phonemic training. Among the target phonemes, /dʒ/ and /θ/ had higher occurrences, suggesting a greater emphasis on voiced affricates and voiceless interdental fricatives. Frequent occurrences of the phonemes /l/, /r/, and /æ/ reflect their significance for learners of English whose pronunciation challenges are articulated by those phonemes. The notably low occurrence of /ʃ/ suggests that the sample of voiceless postalveolar fricatives was relatively small. Overall, this distribution demonstrates a balanced examination of the articulatory complexity of prominent English phonemes in the neurocognitive evaluation process. Phonemes used in the immersive VR-based phonemic training.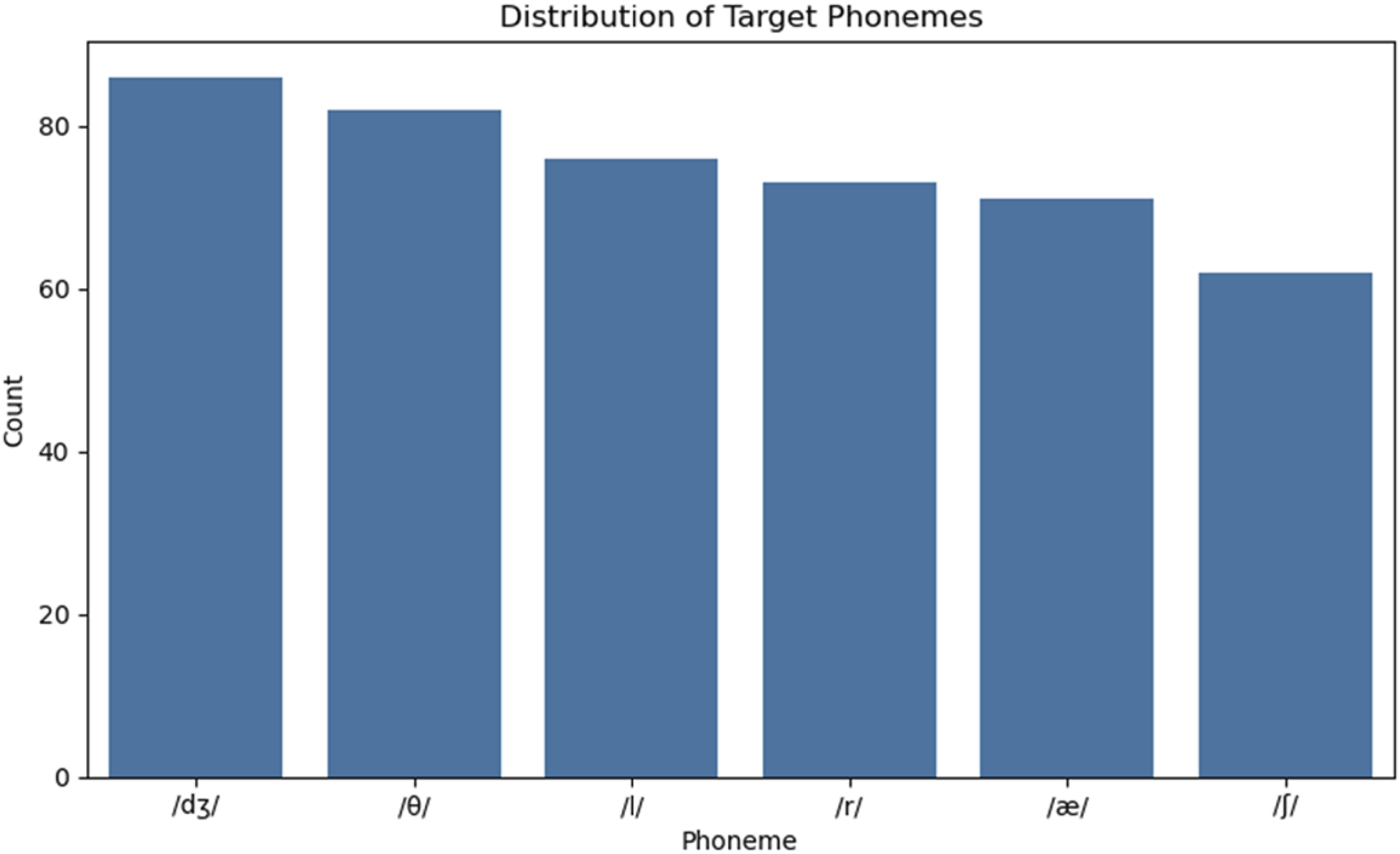
Figure 4 shows that auditory signal quality and theta-band EEG activity are the most influential factors in predicting correct English phoneme pronunciation in an immersive VR setting. Neurocognitive load and PSD beta follow closely, while eye-tracking and physiological signals such as GSR and ECG demonstrate moderate importance. These results validate the model’s reliance on neurocognitive and affective signals to accurately quantify pronunciation accuracy. Feature importance for predicting correct English phoneme pronunciation in an immersive VR setting.
Performance comparison for phonemic classification.
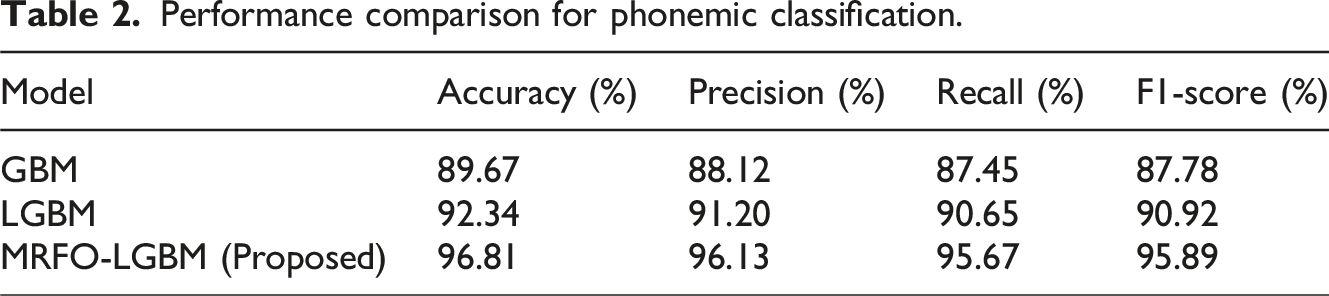
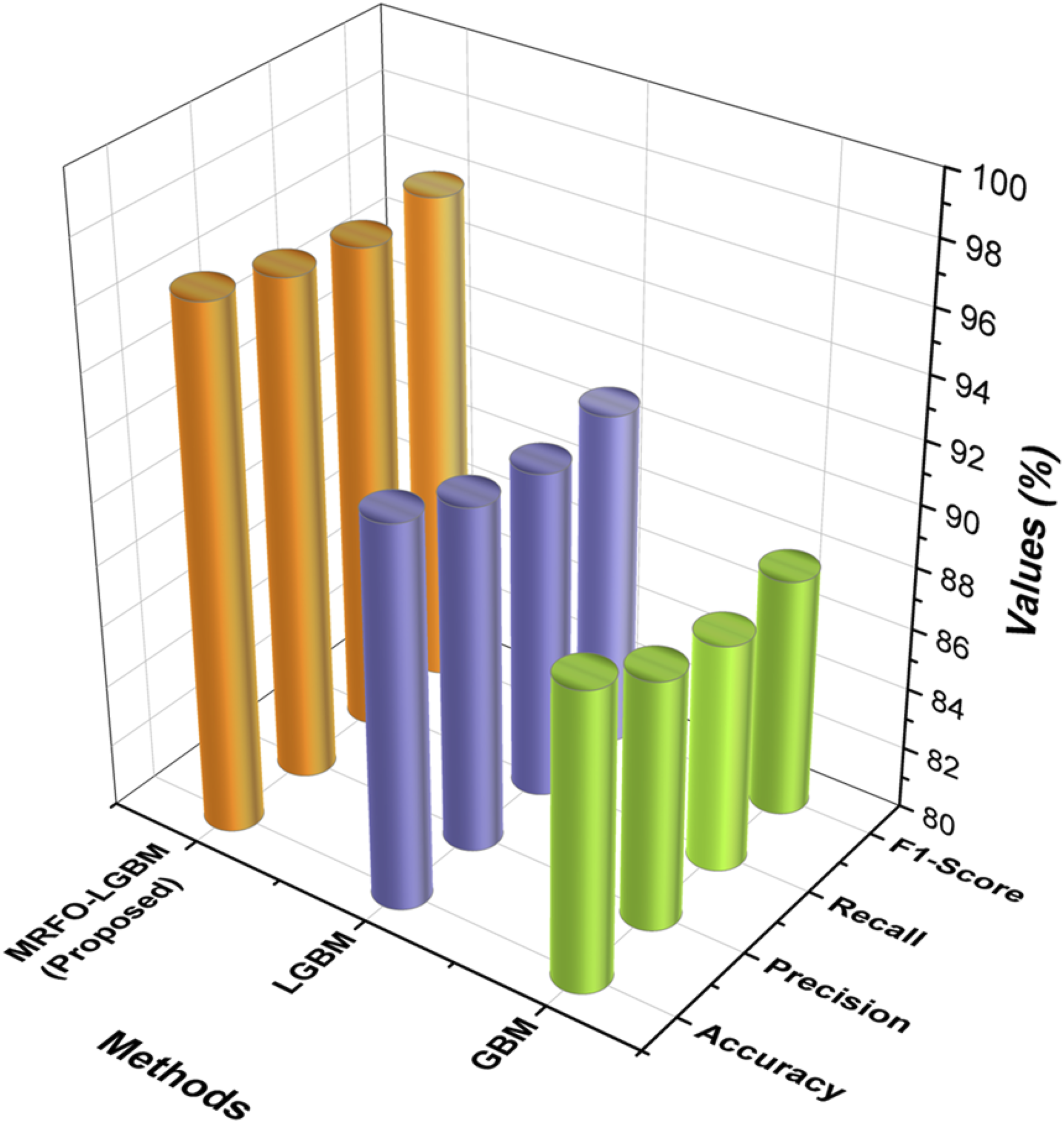
Outcome of the model performance comparison for phonemic classification using MRFO-LGBM.
Phonemic words Classification Performance Comparison.
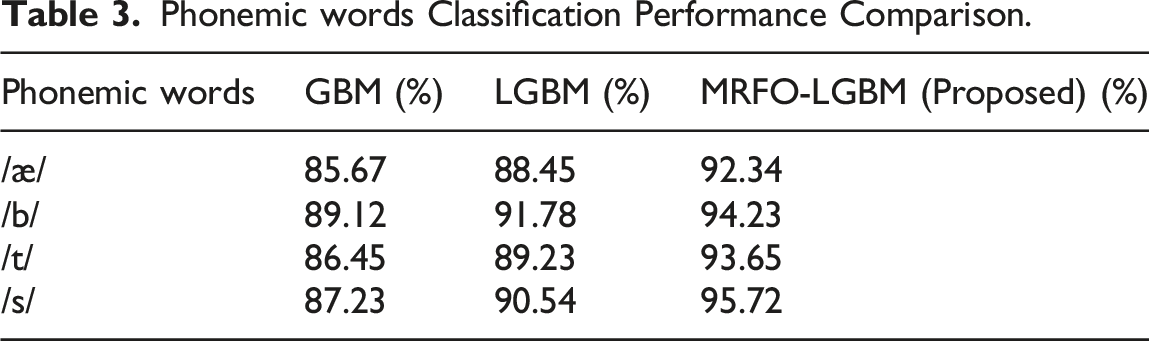
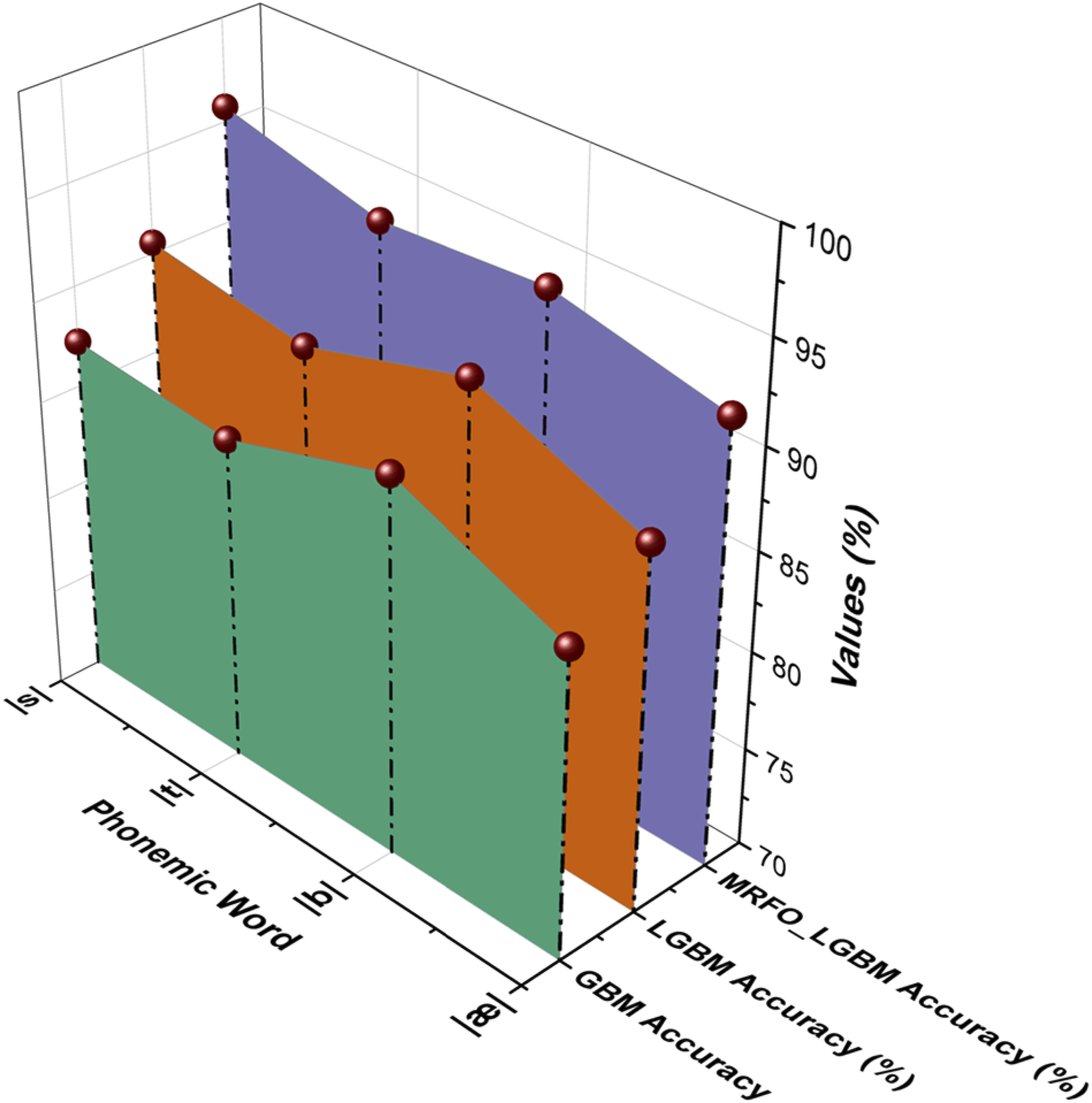
Accuracy results for some phonemic word classifications using MRFO-LGBM.
Discussion
Immersive Language Acquisition demonstrates that virtual reality (VR) technology can improve language learning by activating multiple senses and increasing neurocognitive functioning. The µECoG-based brain decoding system in work 16 exhibited exceptional signal accuracy, but its applicability is limited by the invasive nature and high setup cost, making it unsuitable for widespread educational implementation. The interactive AR system with AI speech recognition presented in research 18 significantly improved phoneme mastery but required long-term evaluation to corroborate learning outcomes. Similarly, the VR-based project approach described in paper 19 increased critical thinking and communication; however, it was limited in linguistic scope and short-term exposure, restricting its generalizability. The use of GBM and LGBM in this research demonstrates specific limitations primarily hindering their ability to capture the inherent complexity within the phonemic word classification tasks, as reflected in their precision of 88.12% and 91.20%. GBM is not ineffective; however, it struggles with overfitting while dealing with high-dimensional datasets. Consequently, when applied to phonemic features with subtleties. LGBM is faster and more efficient, but it also struggles with high dimensionality and the variance of components and variable patterns associated with phonemic recognition. The models failed to accurately predict neurocognitive load and phonemic performance; therefore, more optimal methodology is necessary to yield adequate results.
The MRFO-LGBM was created to solve these problems. The MRFO algorithm is designed to optimize LGBM, thus yielding a more adaptable capacity for the classification of phonemic word patterns. When the MRFO algorithm is utilized to balance exploration and exploitation during calibration, it will improve the accuracy and generalization capacity of LGBM to account for the latent phonemic features and neurocognitive load predictions. The optimization of LGBM capabilities provided by the MRFO algorithm results in a more accurate and reliable model for the recognition of phonemes. Our model shows how MRFO-LGBM outperforms GBM and LGBM to achieve greater phonemic learning and cognitive analysis in the learning of immersive language acquisition.
While demonstrating significant efficacy, this study has several limitations affecting real-world applicability. Firstly, the controlled VR environment, though immersive, may not fully replicate the unpredictable social dynamics and background noise of authentic communication settings, potentially limiting the transferability of acquired phonemic skills. Secondly, the reliance on specific hardware (EEG headsets and eye-trackers) introduces practical constraints for widespread deployment in diverse educational contexts due to cost and setup complexity. Thirdly, individual differences in VR adaptation (e.g., susceptibility to cybersickness and varying levels of technological familiarity) were not explicitly controlled for, which could influence neurocognitive engagement and learning outcomes. Finally, the study focused on a specific demographic (450 learners within the dataset context); broader generalizability across age groups, linguistic backgrounds, and proficiency levels requires further investigation. These factors necessitate cautious interpretation of the results and highlight areas for future development.
Future research should address the current limitations and explore promising extensions. Primarily, developing real-time adaptive VR systems is crucial. These systems would dynamically adjust phoneme difficulty (e.g., noise levels, speaker accent variations, and contextual complexity) and provide personalized feedback based on continuous analysis of learners’ multimodal bio-signals (EEG cognitive load, eye-tracking focus, and pronunciation accuracy via MFCCs). Second, exploring Augmented Reality (AR) integration could create hybrid immersive environments, overlaying phonemic visualizations (e.g., articulatory gestures) onto real-world objects or scenarios, potentially enhancing ecological validity and accessibility. Third, rigorous longitudinal studies are needed to assess the long-term retention of VR-induced phonemic improvements and neurocognitive adaptations beyond the experimental session. Furthermore, expanding the framework to incorporate a broader spectrum of learners (different ages, L1 backgrounds, and learning disabilities) and extend it to multiple languages with diverse phonetic inventories (e.g., tonal languages and languages with click consonants) is essential for establishing generalizability. Such multilingual VR phonemic training platforms hold significant potential for corporate language programs and cross-cultural communication training within the global workforce.
Conclusion
The potential benefits of VR used to improve phonemic competence in second language acquisition were demonstrated in this research. In total, 450 English learners participated in immersive VR contexts to target difficult phonemes. It employed multimodal bio-signal analysis, capturing EEG, eye-tracking, and audio signal data to determine neurocognitive gains. All data were preprocessed using Z-score normalization for EEG and eye-tracking data and a Savitzky–Golay filter denoising process for audio data to maintain phonemic features. Significant features were extracted using techniques like ICA for eye-tracking data and MFCC for audio, to capture phonemic information. The feature-level fusion technique was used to combine normalized features and audio-based MFCC into a unified, high-dimensional feature space for a comprehensive multimodal analysis. The Manta Ray Foraging Optimized Light Gradient-Boosting Machine (MRFO-LGBM) was designed to optimize the LGBM model, improving phonemic performance classification and predicting neurocognitive load. The MRFO-LGBM model had an accuracy of 96.81%, an F1-score of 95.89%, a precision of 96.13%, and a recall of 95.67%.
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the University foreign language teaching and scientific research project of Foreign Language Teaching and Research Press Ltd. (Nos 2023060101, 2022060801, and 2020050601).
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The authors declare that the data supporting the findings of this study are available within the article. The raw/derived data supporting the findings of this study are available from the corresponding author at request.
Appendix