
Abstract
In martial arts action recognition, complex poses, occlusions, and dynamic changes can lead to insufficient estimation accuracy, and traditional methods suffer from inaccurate joint localization and poor recognition of continuous pose jumps. In response to this, the research proposes the Dilated Convolution-Attention-Stacked Hourglass Network Pose Estimation (MS-DConv-Att-SHN) to achieve martial arts action recognition. Firstly, multiple dilated convolutions and mixed attention are proposed to improve the computational complexity and loss of joint information in stacked hourglass networks, enhancing the ability to capture subtle joint displacements. This is crucial for accurate estimation of complex poses such as movement, flicker, and virtual real transformations in martial arts. Secondly, in response to the strong coherence of martial arts movements, local feature refinement and channel fusion techniques are used to enhance the correlation analysis between consecutive action frames, solving the problem of traditional methods’ fragmented recognition of action chains such as “exertion contraction.” A martial arts action recognition system based on the improved MS-DConv-Att-SHN method has been developed to better identify individual movements and capture the intrinsic relationships between movements in routines. This provides key technical support for the digital inheritance, intelligent evaluation, and standardized promotion of martial arts, making it more closely aligned with the movement characteristics of martial arts that combine form and spirit. The results indicate that structural improvements to the stacked hourglass network can effectively increase its percentage of correct keypoints (PCK) and mean average precision (mAP) for both datasets, with PCK and mAP values exceeding 92% and 85%, respectively. The average recognition accuracy of attitude keypoints in the MS-DConv-Att-SHN model is superior to other comparison models, with a difference of over 1.2% compared to other models. The improved MS-DConv-Att-SHN model achieves recognition accuracy of over 90% for different martial arts movements, showing smaller parameter counts and PCK values compared to other comparative models. The research method can effectively provide technical support for the automation analysis of martial arts movements, sports training assistance systems, and intelligent martial arts teaching.
Keywords
Introduction
The breakthroughs in computer vision and deep learning technology have made human pose estimation technology an important support for intelligent applications in multiple fields, and it has gradually expanded to multidimensional pose estimation, lightweight deployment, and target tracking due to development needs, attracting the attention of most scholars. 1 Martial arts, as an important part of traditional Chinese culture, have unique morphological characteristics and temporal and spatial complexity in their movements. Each move and gesture embodies the wisdom of the Chinese nation and has positive significance such as strengthening the body and exercising willpower. 2 However, traditional martial arts movements involve hand shapes, footwork, moves, and other aspects, with many standards and classifications, and mainly rely on manual observation for evaluation. The evaluation results are subjective, and the overall application efficiency is relatively low. These martial arts movements are often taught through mentorship, and there are differences between different schools, which increase the difficulty for ordinary people to learn and makes it difficult to achieve standardization and large-scale application and promotion. 3 Martial arts movements are complex and diverse, involving many non-standard postures such as soaring and rotating, and some movements have quick transitions, emphasizing the combination of spirit and form. 4 Existing research has attempted various methods to improve the recognition effect of martial arts movements, such as Zhao et al. optimizing the background subtraction algorithm to enhance the recognition effect of martial arts movements, which extracts background disparity using symmetric disparity methods and proposes using disparity consistency constraints to eliminate artifacts generated by target movements. The results show that this method can significantly enhance the foreground segmentation effect and eliminate shadows. 5 Li et al. extracted martial arts incorrect actions based on keyframes and identified them using optical flow method and K-means clustering algorithm. The results show that the recognition accuracy of this method exceeds 95%, and the recognition time is less than 12 s. 6 Husheng et al. used wavelet transform and sliding window technology to segment data, and constructed a hidden Markov model and Viterbi algorithm to achieve martial arts action state recognition. The results show that the recognition accuracy of this method far exceeds 95% and has good recognition performance. 7 However, most of these methods rely on traditional computer vision technology and lack modeling of the spatiotemporal correlations of complex martial arts movements, making it difficult to adapt to challenges such as rapid changes in moves and occlusion. At present, the collection of martial arts action data mostly relies on single camera shooting, involving few professional datasets, and has problems such as high annotation costs and obvious data occlusion. 8
The Stacked Hourglass Network (SHN) is widely used in human pose estimation and keypoint prediction due to its unique recursive refinement mechanism, which can provide a high-precision spatial feature extraction basis for martial arts action recognition. However, there are still significant limitations in processing martial arts movements: (1) high computational complexity, making it difficult to meet real-time requirements. (2) The loss of key point information leads to significant estimation errors in rapid movements (such as “whirlwind feet”) or occlusion situations (such as “cloud hand” sleeve occlusion). (3) It is difficult to distinguish similar postures, and subtle differences in movements such as “lunges” and “horse steps” can easily be misjudged. 9 To improve the two major technical bottlenecks faced by traditional martial arts, namely, low accuracy in recognizing complex martial arts movements and reliance on professional annotated data, and insufficient model adaptability in handling subtle differences in martial arts movements, this study proposes a method for martial arts movement recognition through an improved human pose estimation method, by introducing multiple dilated convolution and attention mechanisms, as well as refining local features, to promote the intelligent transformation of martial arts teaching, competitive scoring, and other applications. The research aims to improve the stacked hourglass network SHN and design a lightweight pose estimation model to address key issues such as high-precision spatiotemporal modeling, real-time optimization, and standardization support in martial arts action recognition. The innovation of the research lies in two aspects. Firstly, using Multi-scale Dilated Convolution (MS-DConv) and mixed attention to achieve lightweight design of stacked hourglass, providing expression and correlation of different features. Secondly, considering the difficulty of skeleton data recognition, it is proposed to use local feature refinement and channel fusion methods to further improve martial arts action posture recognition and feature capture, and reduce the interference caused by occlusion. The research aims to provide a new technological path for the modernization and inheritance of traditional martial arts by designing a method for recognizing martial arts movements and postures.
Literature review
Human pose estimation can achieve martial arts action recognition by detecting the position and motion trajectory of key points in the human body, and its spatiotemporal features can effectively improve the accuracy of action recognition. Xu proposed a method that integrates resolution-aware networks, self-supervised loss, and learning schemes to improve the accuracy of 3D human pose recognition. The results showed that this method could achieve good processing of low-resolution image videos and enhance the consistency of deep features. 10 Papic et al. used neural networks to analyze sports videos and found that this method could effectively identify and detect body marker positions, reducing motion analysis time. 11 Chen proposed a pose recognition algorithm based on random forest and bone feature extraction for the analysis of leg movement recognition in martial arts. The results indicated that this method could effectively classify different leg movements and had good posture recognition performance. 12 The coordination ability of sports is closely related to posture balance. Cherepov et al. used experimental design to analyze the coordination ability of different martial arts athletes and found that coordination ability affected posture balance and sports performance. 13 Yamei et al. designed a dynamic light acquisition system and proposed combining virtual reality devices for interactive martial arts teaching. The results indicated that this method could significantly improve the effectiveness and quality of martial arts teaching. 14 Echeverria et al. applied pose estimation algorithms to extract predefined action features, and then analyzed the psychomotor performance in martial arts movements. The results indicated that this method had good effectiveness and could provide reference for the analysis of martial arts movements. 15 Pang et al. proposed to improve the accuracy and objectivity of martial arts action scoring and feedback by using feature alignment techniques and adaptive weighted multi models to extract key features. The results showed that the error values of this method on multiple datasets were smaller than other comparison algorithms, and it could effectively achieve automatic scoring of martial arts. 16 Jia et al. used optical sensors to capture martial arts movements and converted them into visual image trajectories. The results indicated that the system performed well in capturing and simulating image trajectories. 17
Considering that existing video analysis methods are difficult to accurately model the subtle differences in martial arts and robustly expand, Chen developed a deep learning framework and utilized integrated convolutional neural networks and gated recurrent units to achieve visual feature extraction and pose sequence processing. The results showed that the accuracy of martial arts action recognition on the dataset exceeded 90%, and the mean square error of pose estimation was less than 3, indicating good martial arts skill evaluation performance. 18 Hui Scholar has developed an AI based visualization system for martial arts training movements to address the issue of low popularity of martial arts education. Using bone feature extraction and long short-term memory network action classification model, combined with object-oriented graphics rendering engine to achieve action rendering. The results indicate that this method can effectively recognize martial arts movements and achieve dynamic visualization, providing a feasible solution for remote martial arts teaching. 19 Lei et al. proposed a kinematic analysis method for Sanda athletes based on feature extraction. Optimize action feature selection through adaptive enhancement algorithm and analyze the time characteristics of different action stages. The results indicate that this method can accurately extract technical action features and provide data support for athlete tactical evaluation. 20 Liu et al. utilized accelerometers and machine learning to recognize kicking movements in taekwondo, and analyzed waist and ankle sensor data using support vector machines and decision trees. It was found that combining only waist data with support vector machine model can achieve a classification accuracy of 96%, which reduces the equipment dependence of taekwondo movement monitoring. 21 Cheng et al. constructed a motion training management system based on convolutional neural networks, achieving an accuracy rate of over 90% in action recognition and taking only half the time of traditional methods. 22 Shang et al. utilized neural networks to enhance martial arts action recognition and assist in training, tracking joint angles. The results showed that the action recognition accuracy of this method approached 95% and had good auxiliary training effects. 23
The existing research on martial arts action recognition mainly focuses on multi-modal fusion, neural networks, feature optimization, sensors, and other aspects to achieve human pose estimation. The key feature is to improve feature extraction or temporal modeling to enhance recognition performance. Although the above methods can improve the accuracy of pose estimation and action segmentation classification to a certain extent, they still have the following shortcomings: Firstly, their sensitivity to subtle pose differences in martial arts (such as joint rotation angles) is insufficient. Secondly, it is difficult to balance real-time performance and robustness, and it is more susceptible to background interference or rapid actions, leading to error accumulation. Based on this, the study proposes the implementation of martial arts action recognition using the MS-DConv-Att-SHN method. Specifically, human pose estimation achieves martial arts action recognition by detecting key point positions and motion trajectories, and its spatiotemporal features can effectively improve recognition accuracy. Xu proposed a method that integrates resolution-aware networks with self-supervised loss, significantly improving the accuracy of 3D pose estimation in low-resolution videos. However, this method has not been optimized for the common fast movements and occlusion problems in martial arts, and the robustness of the model in occlusion situations is slightly insufficient. Regarding the analysis of martial arts movements, the method proposed by Chen et al. relies heavily on static skeletal data and is difficult to handle rapid variations in moves. Similarly, the integrated framework proposed by Chen et al. exhibits high computational complexity. In contrast, the research method utilizes the design ideas of multiple dilated convolutions and mixed attention to achieve better spatiotemporal feature fusion with lower computational load, enhancing the ability to capture subtle postures in martial arts. Moreover, existing research has paid insufficient attention to the issue of occlusion in martial arts. For example, although Hui’s AI visualization system can render 3D actions, it has not solved the problem of missing key points under partial occlusion. In addition, although Liu’s accelerometer scheme is effective for classifying Taekwondo kicks in free environments, it relies on hardware deployment. Pang’s feature alignment technique did not consider the impact of action coherence on scoring. The real-time performance of Yamei’s VR teaching system is insufficient. The research method proposes to refine the local features of skeleton data to avoid difficulties in distinguishing similar poses, and the idea of channel fusion can also effectively correlate the correlation between different pose action features, balancing real-time performance and accuracy.
Martial arts action recognition based on improved SHN human pose estimation method
Design of improved method for SHN human pose estimation
The cascaded network structure of SHN can extract feature maps of different scales through repeated downsampling (encoding) and upsampling (decoding), and its top-down and layered design structure can achieve multi-scale information fusion, obtaining feature maps that are the same size as the input image.
24
In SHN, the feature map of the input image after preliminary feature extraction and convolution processing will be used as the input for the next hourglass network. It achieves feature learning through loss comparison and gradient descent, and its multi-stage intermediate supervision can effectively achieve feature prediction, thereby improving prediction accuracy.25,26 To reduce the computational complexity of network parameters, research is being conducted on using skip connections to improve the training speed of encoders and decoders. This can be achieved by reconstructing higher-level features in a stacked form, which can improve network performance while ensuring that the network size remains essentially unchanged. Figure 1 shows the lightweight hourglass module structure improved by multiple convolutions. Lightweight hourglass module structure improved by multiple convolutions.
In Figure 1, the hourglass module is composed of multiple convolution improved residual blocks, which include encoder and decoder architectures. The residual blocks in the purple dashed box are saved and fused with multi-layer encoder features, and the stacked feature map can preserve the hierarchical information of the image without changing the size of the input image. Convolution processing can generate heat maps with different feature probabilities along the edges, thereby improving recognition accuracy. The residual module constructed by dilated convolution can replace the middle layer of the pre activated residual block with depthwise separable convolution, and use convolution processing to reduce the size of the residual network and expand the receptive field. Considering that SHN is inevitably affected by noise and occlusion when collecting features of different resolutions, a Local Attention (LA) module containing position and channel is added to filter irrelevant information. The position attention in the LA module can weight the attention of channel features to better correlate spatial contextual information, while channel attention focuses on distinguishing different feature channels.
27
Meanwhile, to integrate the global information of the image, the research also introduces the attention features generated by the attention module into the next layer, achieving the construction of the global attention (GA) framework. Figure 2 shows the framework of LA and GA modules. Framework of LA and GA modules.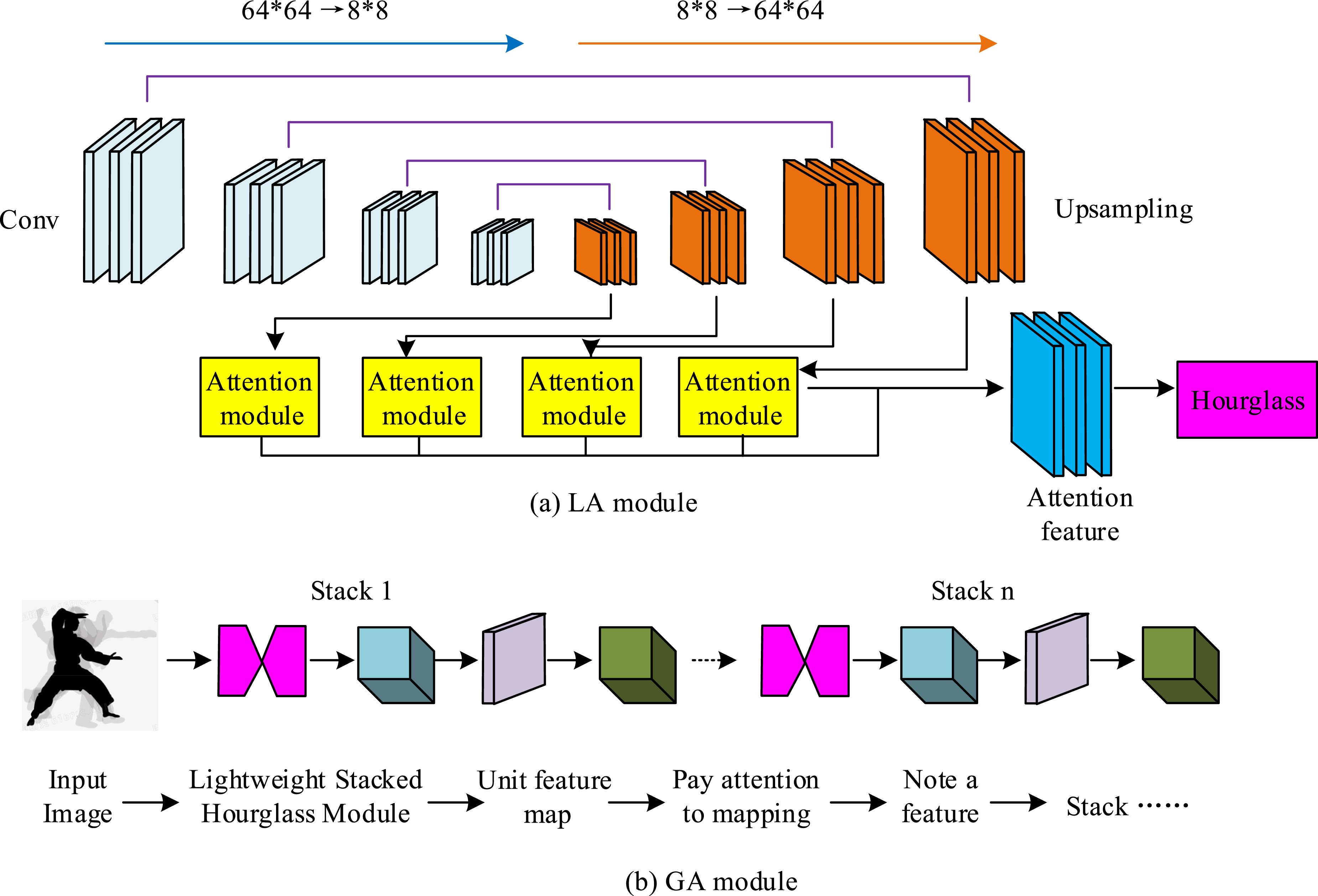
The LA module in Figure 2 can use positional attention and channel attention to re integrate the features of the hourglass network, and fuse the obtained attention features with the original features to generate features of different scales. GA applies lightweight processing to the input image, and then maps and combines the feature maps input by each unit. The fused result can be used as the input for the next hourglass unit, and the feature maps under the stack structure can obtain image information at different levels. Equation (1) is the mathematical expression of attention mapping.
28
MS-DConv-Att-SHN.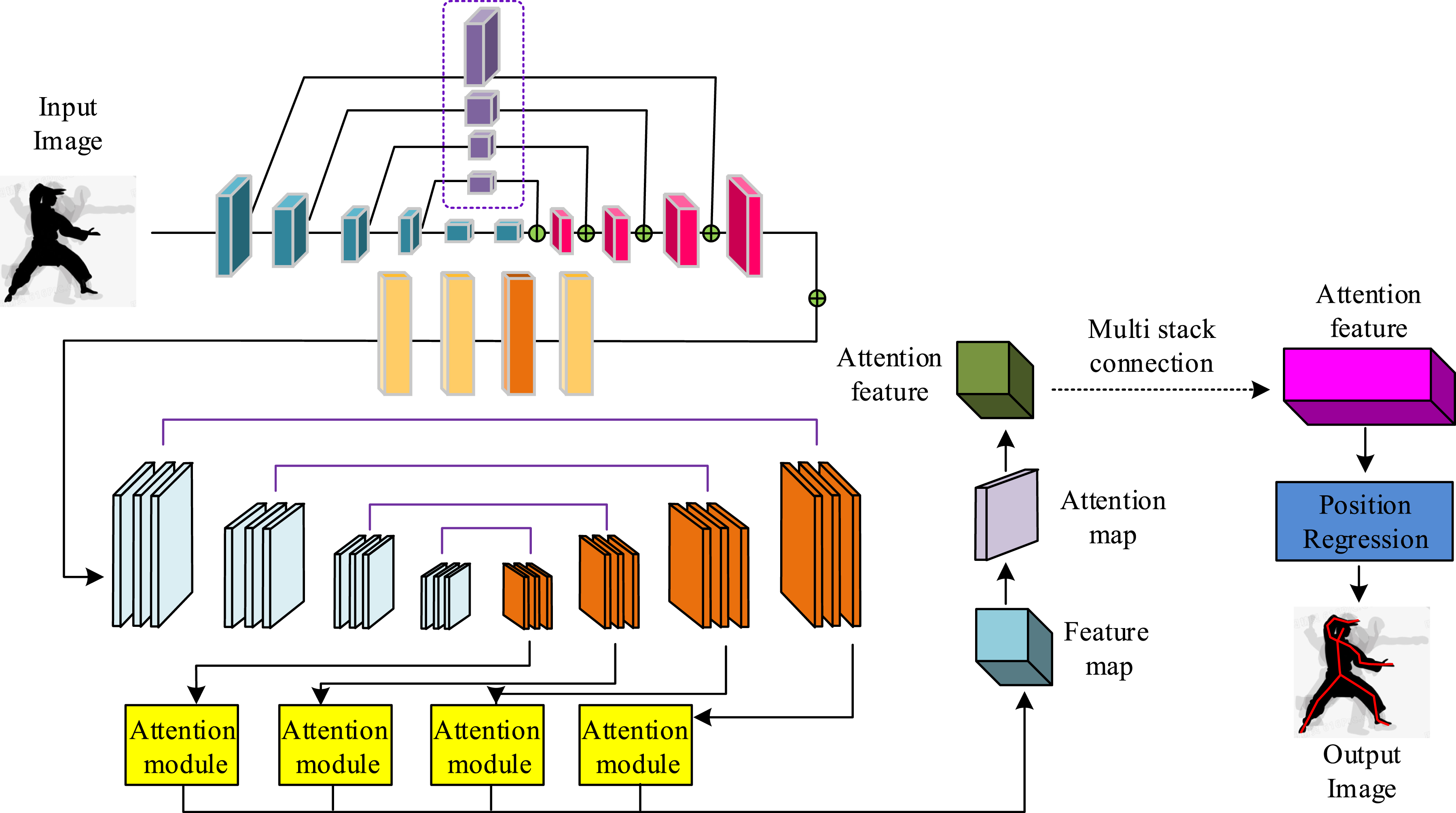


In Figure 3, the MS-DConv-Att-SHN mainly includes lightweight modules for multi-convolution processing, LA modules, and GA modules. After multiple convolution processing of the input image, feature maps at different resolutions can be obtained. The feature maps are processed by the attention module to obtain attention features. After applying regression loss processing to the multi-layer attention features obtained from stack processing, the final action posture recognition result can be output.
Martial arts action recognition based on improved method of human body posture estimation
To better identify similar martial arts movements, it is not only necessary to consider their global posture, but also to pay attention to local postures, in order to better distinguish the characteristics of different types of movements. Therefore, based on the above research, a design idea of refining and fusing local features is proposed to improve the performance of MS-DConv-Att-SHN network. Human action recognition mainly includes four aspects: image acquisition, skeleton data acquisition, feature extraction, and recognition. How to effectively recognize actions with skeleton data is an important content.
29
On the basis of considering the correlation between local human body parts, a local spatiotemporal feature extraction module is added to the MS-DConv-Att-SHN network to further subdivide and analyze the fused information feature module. Figure 4 is a schematic diagram of the improved MS-DConv-Att-SHN structure. Improved MS-DConv-Att-SHN.
In Figure 4, the local spatiotemporal feature extraction module achieves local feature refinement through a dual branch architecture (spatial branch + motion branch). It inputs adjacent frames of the video clip into an improved human pose estimation model, generating a human pose estimation map (including keypoint coordinates and confidence). Afterward, spatial features are extracted from the pose map using a 7 × 7 convolutional layer, preserving the topological relationships between joint points to achieve motion feature extraction. The differential calculation of motion branches can capture small displacements, while the channel weighting mechanism can suppress ineffective motion noise in occluded areas. Feature refinement can solve the core problems of local information loss and occlusion interference in martial arts movements. The adjacent video frames that are input will be extracted through the aforementioned human pose estimation model to generate a pose estimation map. The pose estimation map obtains spatial features through convolutional layers, and then calculates the pixel differences of video frames and stacks them according to the channel dimension to obtain motion differential feature Feature information fusion module.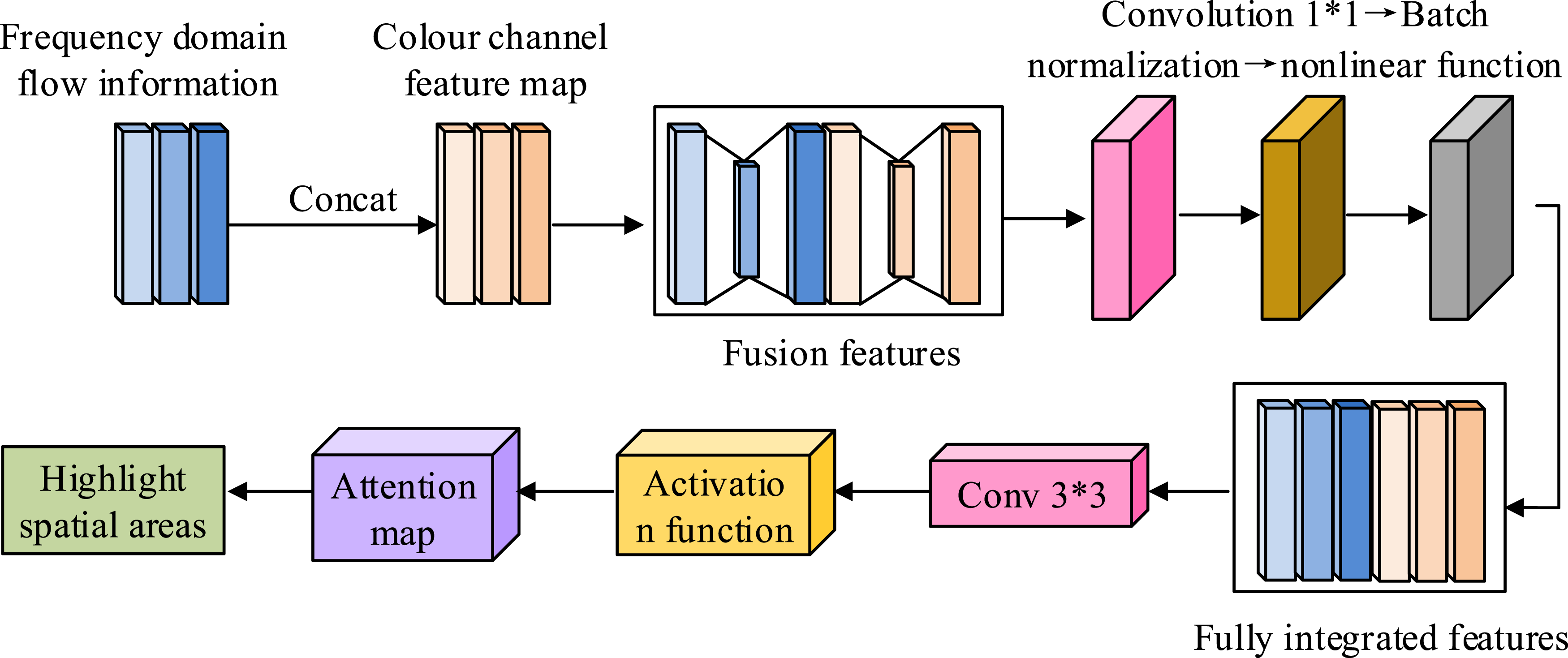
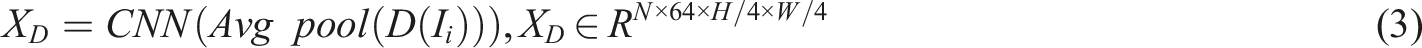
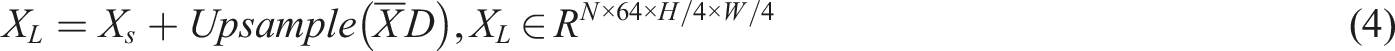


In Figure 5, the frequency domain information and color channel information features are connected together and subjected to batch normalization and nonlinear convolution processing to obtain fused information. The mathematical expression of fused feature

Design of martial arts action recognition system
The estimation and recognition of human posture in martial arts movements consists of two parts: posture estimation and action recognition. The research designs a system from the aspects of data collection, posture estimation, action recognition, and data management. In the data collection section, the study utilized high frame rate RGB cameras (≥60 fps) and depth sensors (Kinect) for real-time video data collection. The collection environment was a standardized martial arts training ground, and lighting conditions were controlled. The constructed martial arts action set included different action categories. After inputting human skeleton data, the improved MS-DConv-Att-SHN network method was used to achieve human action classification and recognition. The system can display and manage the skeleton action judgment results, so as to view and analyze the human pose estimation and action recognition results at any time. Figure 6 is a schematic diagram of the overall system architecture design. Schematic diagram of overall system architecture design.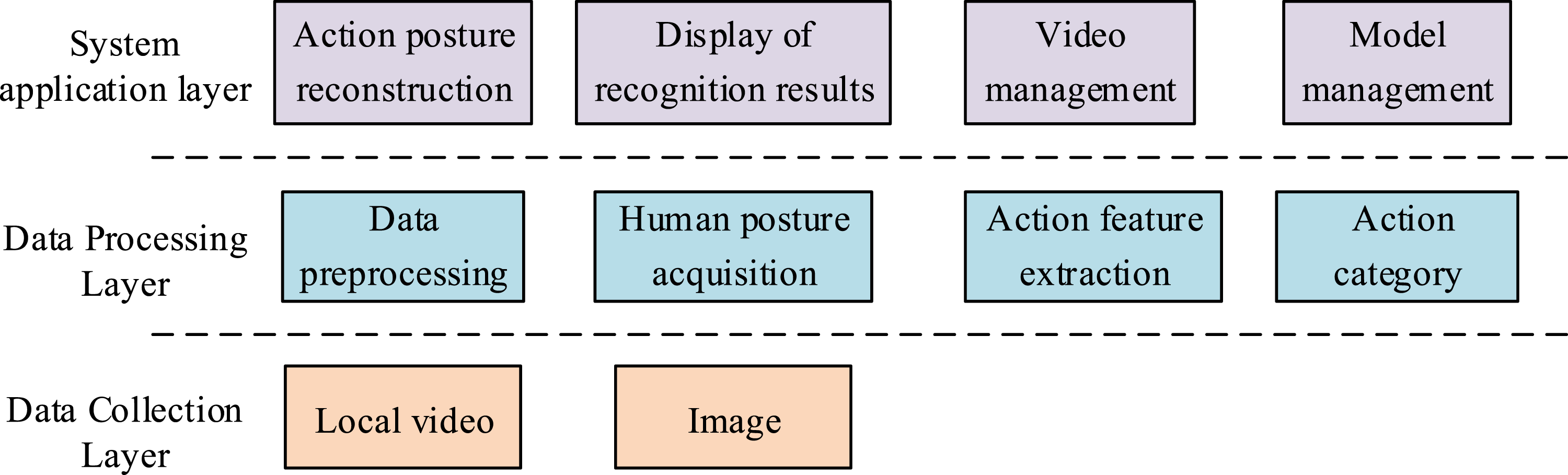
In Figure 6, the system includes an acquisition layer, a processing layer, and an application layer. The data acquisition layer mainly collects videos and stores them for backup, while the data processing layer implements preprocessing of video frames and extraction of pose and action features and types. The data application layer provides interactive functions such as result display and data management. Figure 7 shows the system implementation content. Implementation content of martial arts action recognition system.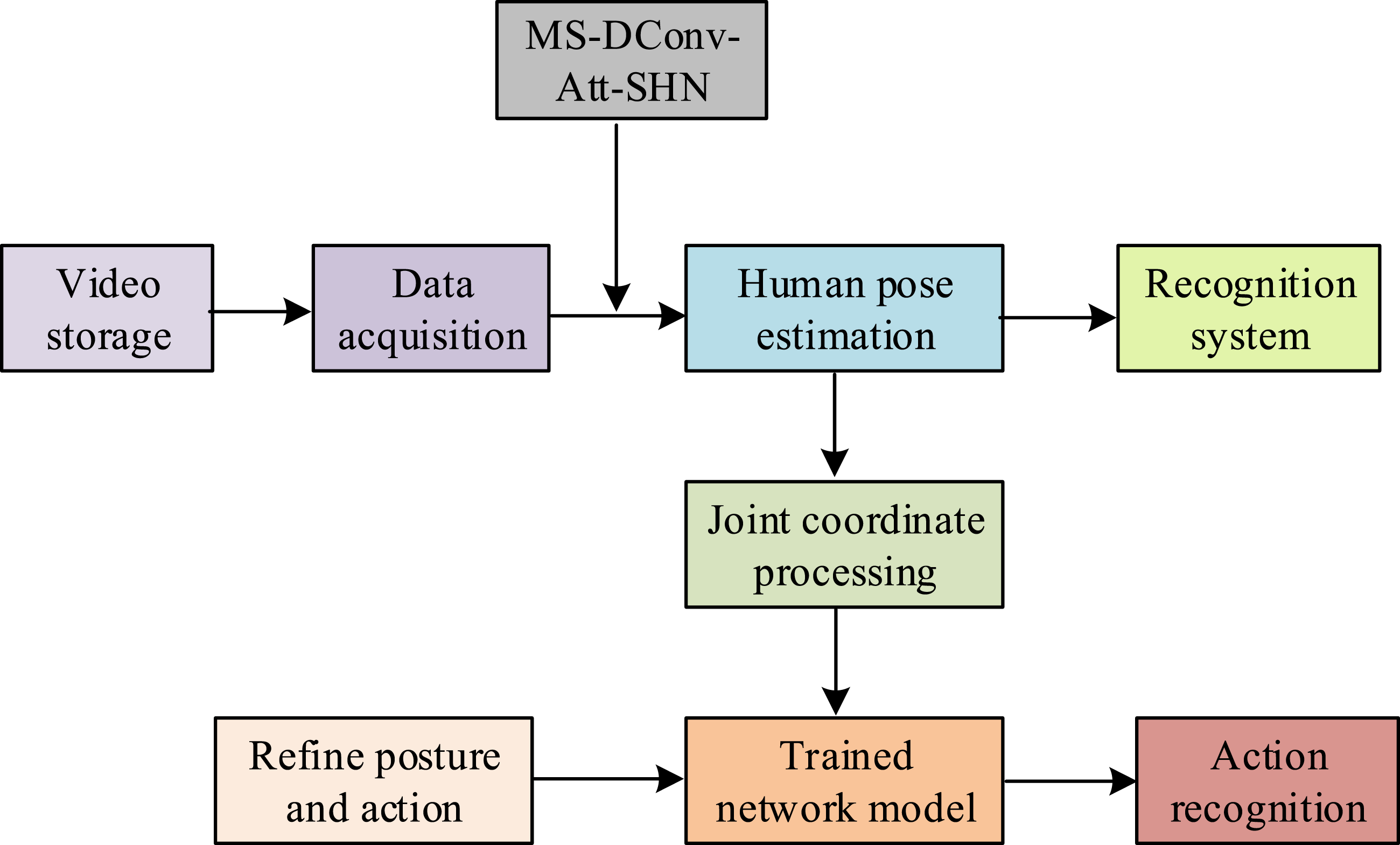
In Figure 7, the improved MS-DConv-Att-SHN network can achieve human pose estimation, where each hourglass module includes downsampling and upsampling paths, skip connections preserve spatial information, and attention mechanisms achieve multi-scale feature fusion. The refinement and improvement of local features can recognize actions and finally display the recognized action categories. The spatiotemporal feature database stores daily training data and automatically generates training reports based on attention weighted keyframe extraction technology. The system platform can quantify progress indicators by comparing historical data, optimize the lightweighting degree of models for different scenarios, and establish a martial arts action standard parameter library as a benchmark for evaluation.
This research created a self-made dataset of martial arts movements and selected the movements from “Chinese Fist” for recognition, including horse step frame fighting, withdrawal step fork palm, parallel step punching, bow step punching, and other movements. By using binocular cameras to record video data and annotating different martial arts movements separately, the resulting martial arts video movements can be segmented into frames. In data collection, the video stream receiving program programming interface and action recognition interface include two parts: single action and continuous action.
33
In system action evaluation, the research selects indicators such as the percentage of correct keypoints (PCK) for pose evaluation, and evaluates action recognition using indicators such as classification accuracy, confusion matrix, and mean average precision (mAP) for temporal action detection.34,35 Equation (8) is the mathematical expression for PCK and PCP.
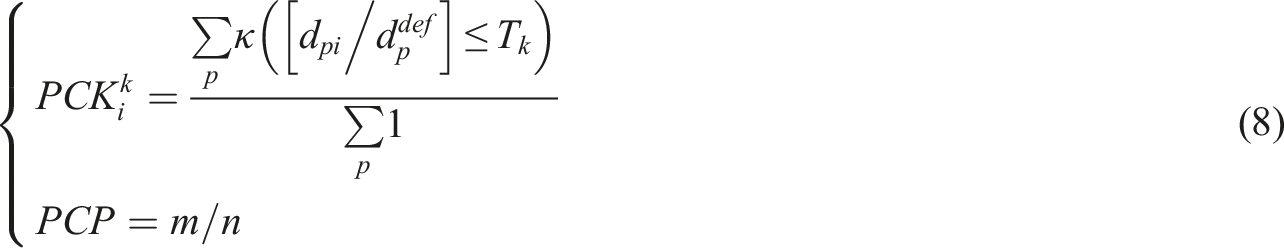
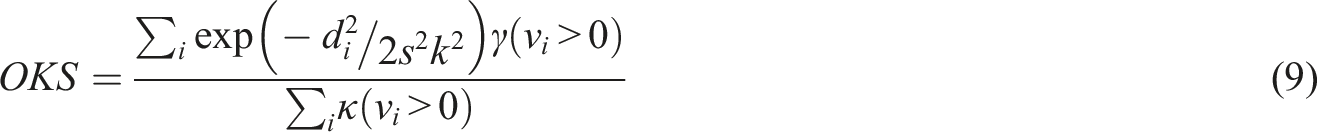
Analysis of martial arts action recognition results under the improved estimation method
Experimental environment setting and dataset source
To better recognize martial arts movements, an experimental environment was set up with an operating system of Windows 10 64bit, DDR4 2400 MHz 32 GB of memory, 12th Gen Intel (R) Core (TM) i5-12400F CPU model, PyTorch 3.8 deep learning framework deployed for system development, Python 3.10 programming language, FastAPI backend service, and Vue. Js frontend interface. The software platform was OpenCV, with a video file resolution of 480 p and a frame rate of 30 fps. The parameter optimizer was Adam, with an initial learning rate of 0.001, 200 iterations, and a batch size of 16. The study selected publicly available datasets of MPII and NTU RGB + D 60, as well as a self-made martial arts action dataset for training and testing. The MPII dataset contains over 20000 human pose estimation images and over 40000 body joint annotation information, providing rich human pose annotation information. The NTU RGB + D 60 dataset includes 56880 action samples and 60 types of martial arts movements. The RGB video is 1920 × 1080 (30 FPS), and skeletal keypoints were captured using Kinect v2, including martial-arts-related actions such as kicking and punching. The research randomly divided the public dataset into a test set and a training set in a 6:4 ratio, and set a threshold of 0.9 based on the similarity calculated from posture. A self-built martial arts action dataset was collected using a depth camera to capture martial arts videos. A total of 300 videos were recorded, and martial arts videos were randomly selected as the training and validation sets in a 5:1 ratio. The main action points (such as fist hugging, cross palm, split palm, bright palm, counter fist, grid fist, punch, frame punch, and piercing palm) were annotated. The research set the time series output length and key point count of the dataset to 100 and 46, respectively. Indicators such as PCK, PCP, accuracy, and confusion matrix were employed.
Effectiveness of SHN for human pose estimation method
The study conducted multiple convolution residual improvement on SHN to better evaluate the impact of residual structure improvement on human pose estimation. SHNs with different residual structures were evaluated, and the compared residuals included bottleneck residual block improvement (Bottleneck Res), depthwise separable convolution improvement (DS Conv), MS-DConv, and standard error residual (SE residual), with the help of parameter quantity and a threshold of 50% PCK value(PCK@0.5)The comparison results are shown in Figure 8. Performance testing of improved structure of SHN.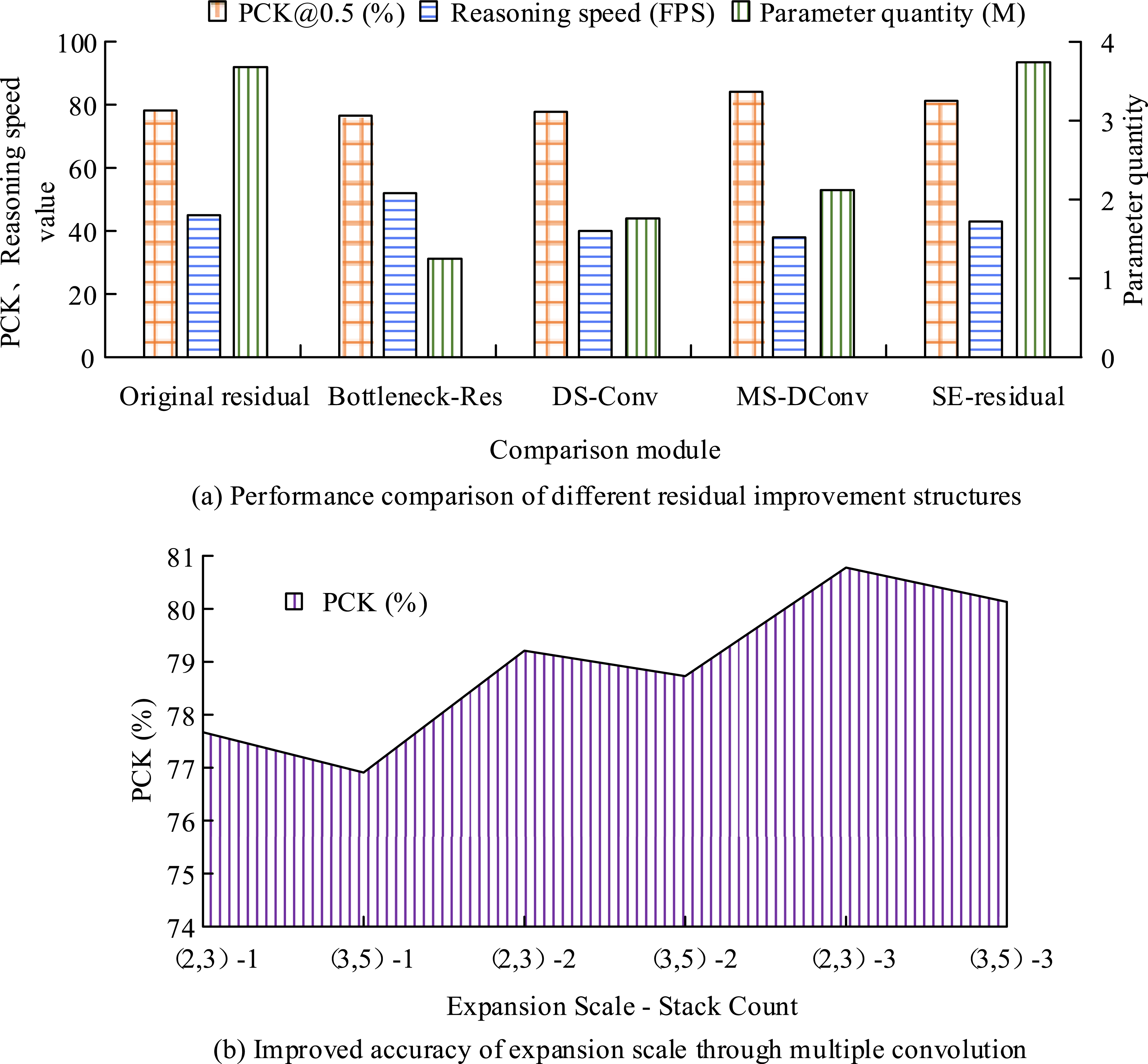
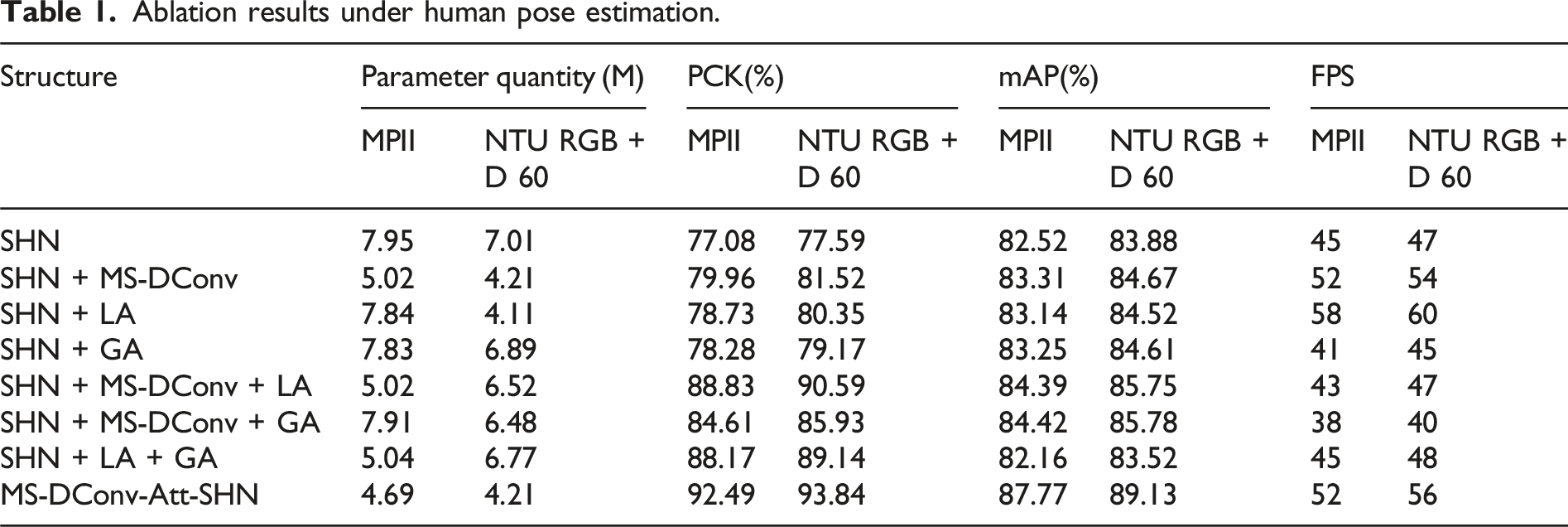
Ablation results under human pose estimation.
Ablation results under human posture recognition.
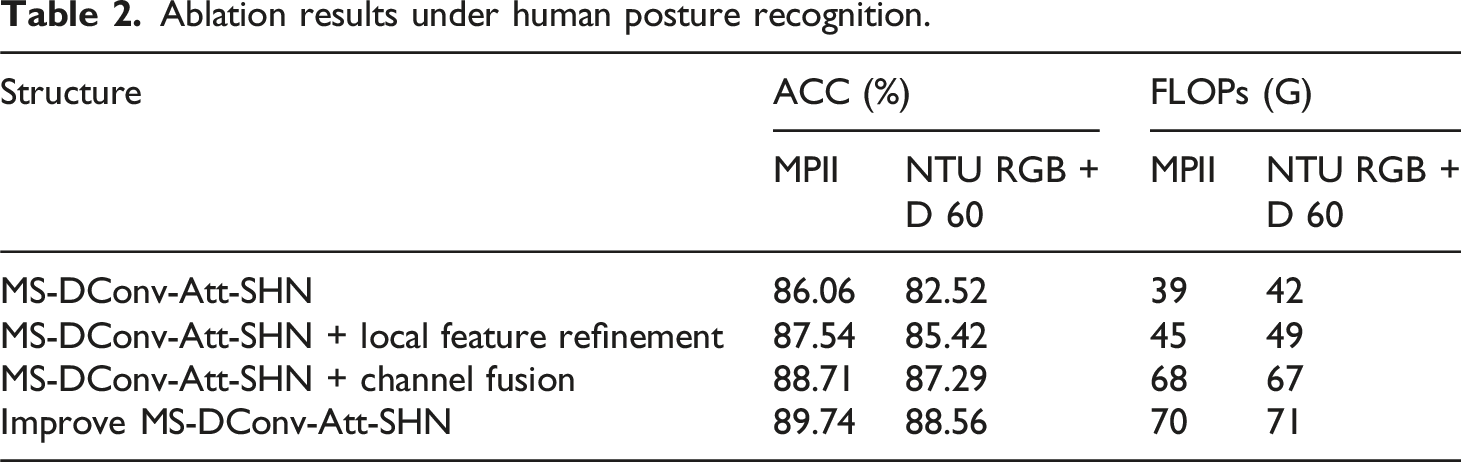
In Table 2, the MS-DConv-Att-SHN model demonstrated an improvement in recognition accuracy and computational complexity after incorporating local features and channel fusion. Its recognition accuracy on two datasets was 89.74% and 88.56%, respectively, and the complexity values were 70G and 71G. This indicated that the model had good classification performance and computational effectiveness. Afterward, the improved MS-DConv-Att-SHN algorithm proposed in the study was compared with resolution-aware network fusion methods (RNF), Random Forest Pose Recognition Algorithm (RF-PR), Spatial Temporal Graph Convolutional Network (ST-GCN), and PoseC3D for keypoint recognition performance. The results are shown in Figure 9. Key point recognition effect.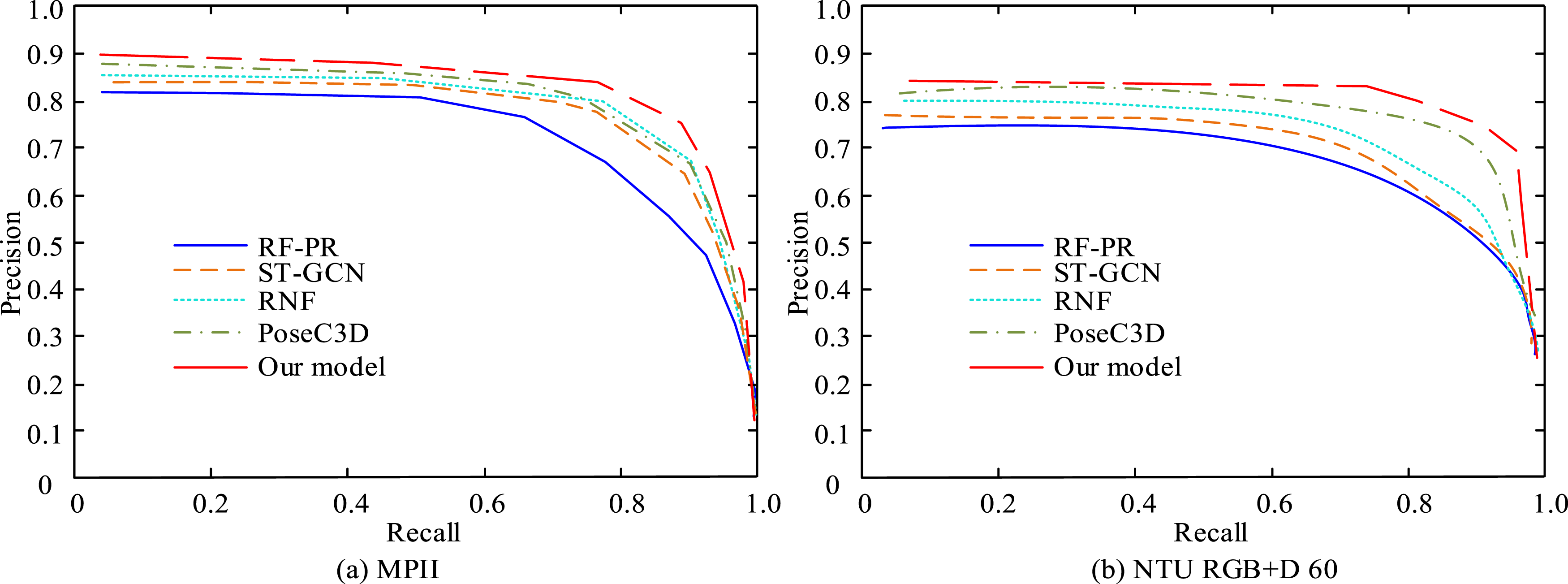
In Figure 9(a), the human pose keypoint recognition of the RF-PR model was poor, with an average value of no more than 85%. Meanwhile, the average recognition accuracy of the ST-GCN, RNF, and PoseC3D models differed from that of the research model by 3.24%, 2.16%, and 1.37%, respectively. The keypoint recognition performance of the fusion model proposed in the study was significantly better than that of other models. In Figure 9(b), the recognition performance of the comparative model decreased, and it was more significantly affected by optical interference from the information contained in the dataset. The research model still showed good keypoint recognition performance, with an average value exceeding 84%.
Martial arts action posture estimation and action recognition results
The proposed martial arts action recognition method was tested on a self-made martial arts dataset, and Figure 10 was obtained. Recognition results of different continuous martial arts movements.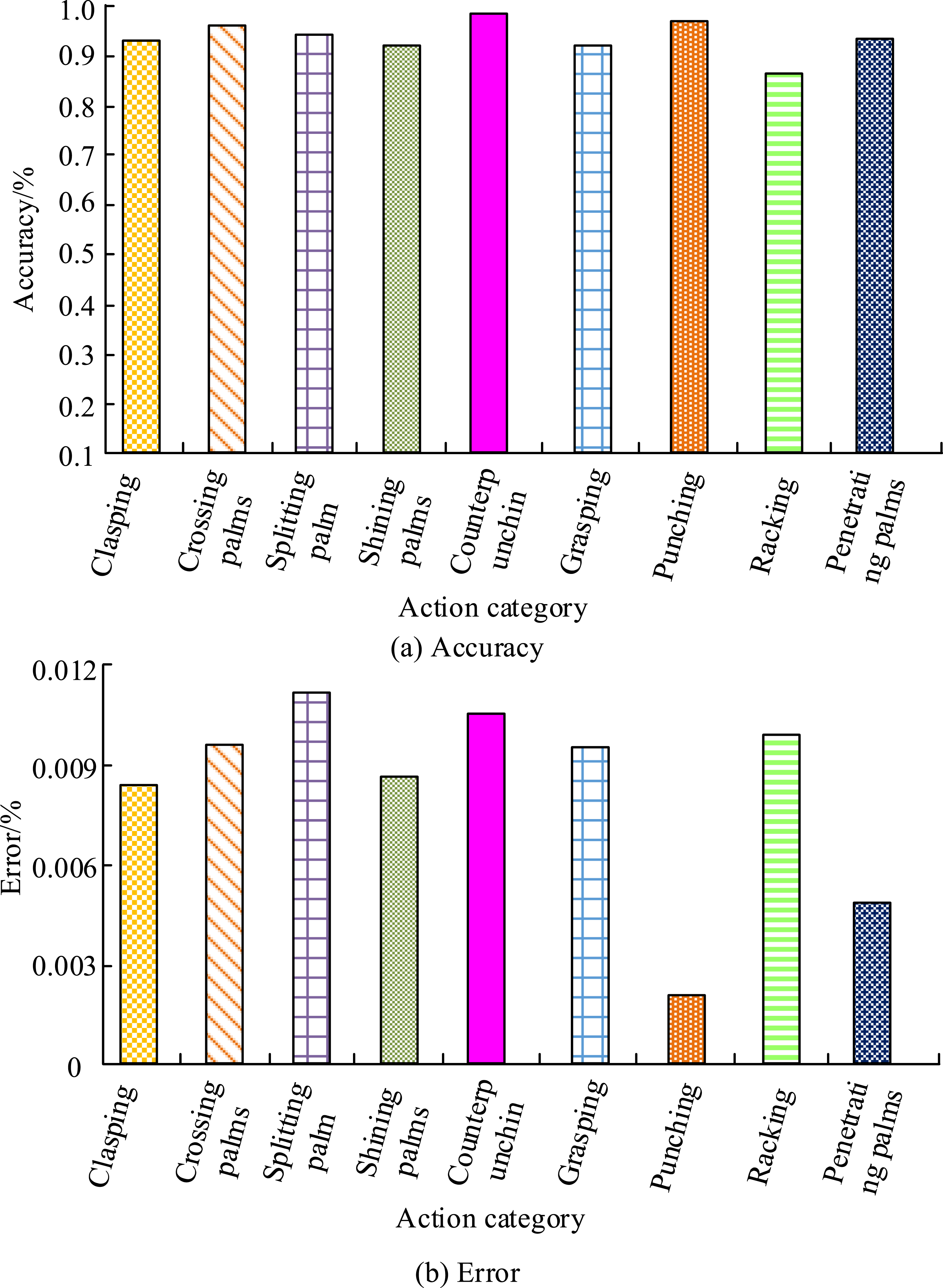
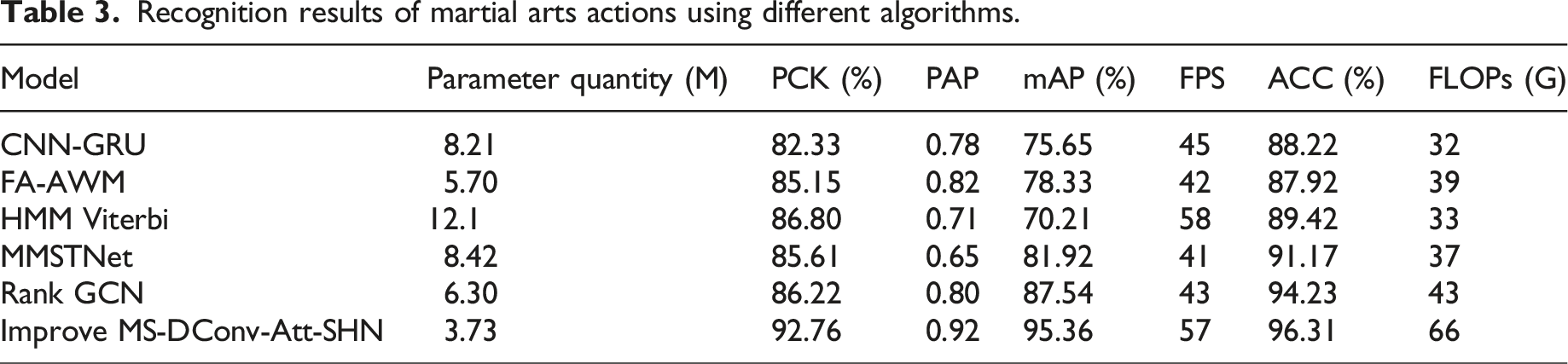
Recognition results of martial arts actions using different algorithms.
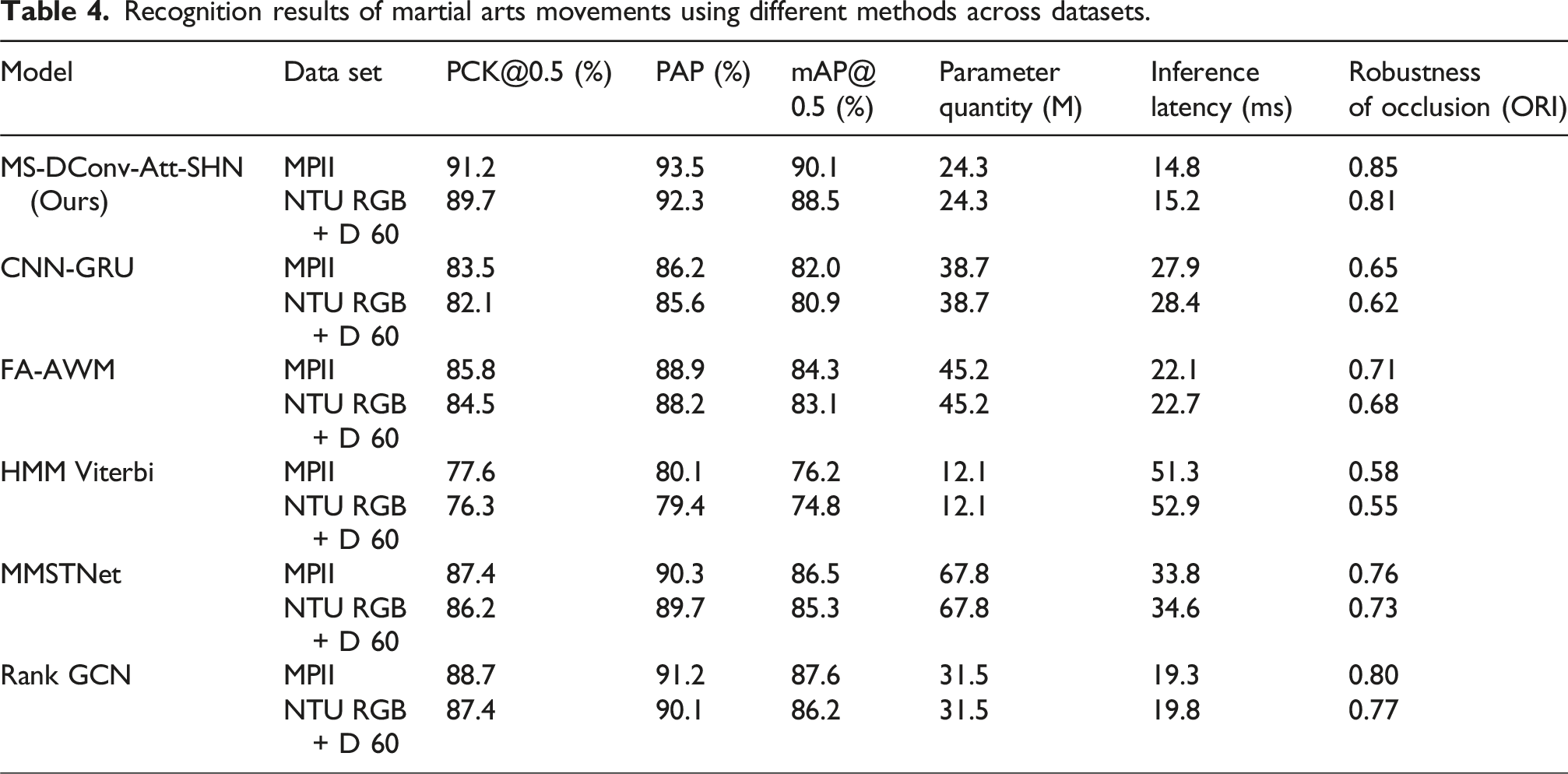
Recognition results of martial arts movements using different methods across datasets.
Martial arts action recognition results (PCK) of different algorithms.
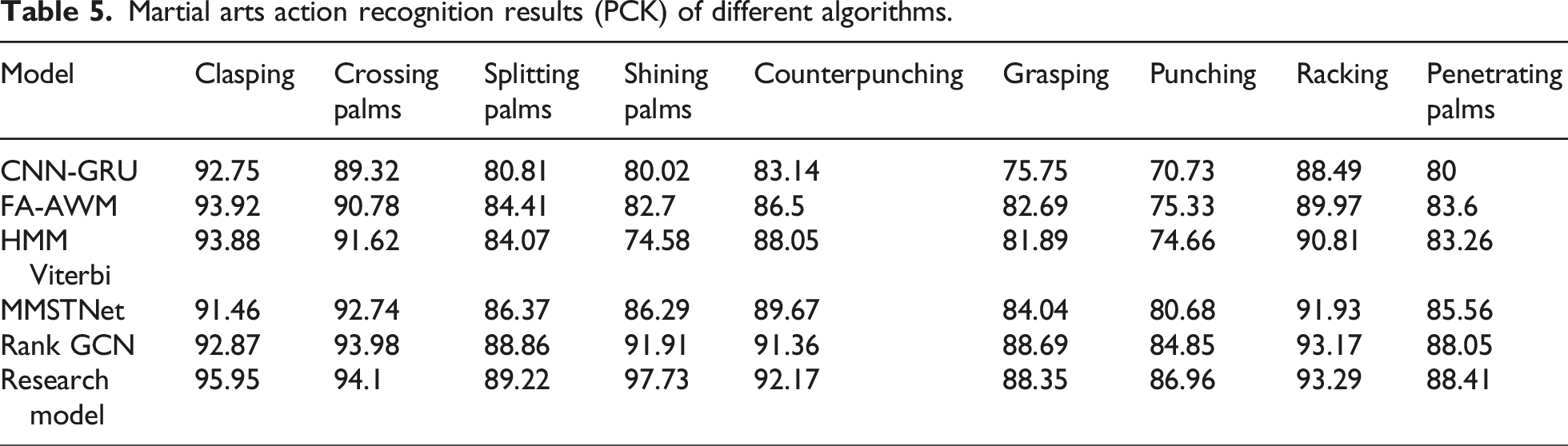
In Table 5, the PCK values of the research model for fist hugging, cross palm, split palm, bright palm, opposing palm, grid fist, punching, fighting, and piercing palm movements all exceeded 85%, and the maximum value approached 97.73%. The bright palm movement has a typical three-dimensional spatial feature of “palm abduction forearm rotation elbow slight flexion,” and the spatial distribution of its key nodes presents high discrimination. And the peak angular velocity of its bright palm movement (120°/s) is lower than that of punching (300°/s), the degree of motion blur is lower, and the rigid motion characteristics of the palm root wrist joint simplify trajectory prediction. Therefore, the expansion convolution of the research model can better capture the radial features of palm expansion, and its channel attention mechanism can improve the feature weights of palm regions, resulting in better control of key point detection errors for geometric features. The MMSTNet model and Rank GCN model, which performed well, had a maximum PCK recognition value of no more than 95% for different actions, and their values for punching actions were only 80.68% and 84.85%, respectively. The CNN-GRU model and FA-AWM model only performed well in recognizing fist hugging, cross palm, split palm, and bright palm movements, but their overall recognition performance was far inferior to other comparative methods. MMSTNet and Rank GCN perform poorly in some actions (such as “punching”) (PCK<85%), revealing their shortcomings in adapting to fast linear attack actions. However, the research model still maintains high accuracy in such actions (PCK>92%), proving that it is more suitable for practical action analysis. CNN-GRU and FA-AWM only perform well in static postures (such as “fist hugging”), indicating that traditional temporal models lack adaptability to dynamic martial arts. This comparison highlights the technological superiority of the research model in complex martial arts scenarios (rapid change of moves, transition between offense and defense), providing a better solution for competitive martial arts training and tactical analysis. Afterward, the real-time performance of different models was compared on a self-made dataset, and the results are shown in Figure 11. Real-time performance results of different models on a self-made dataset.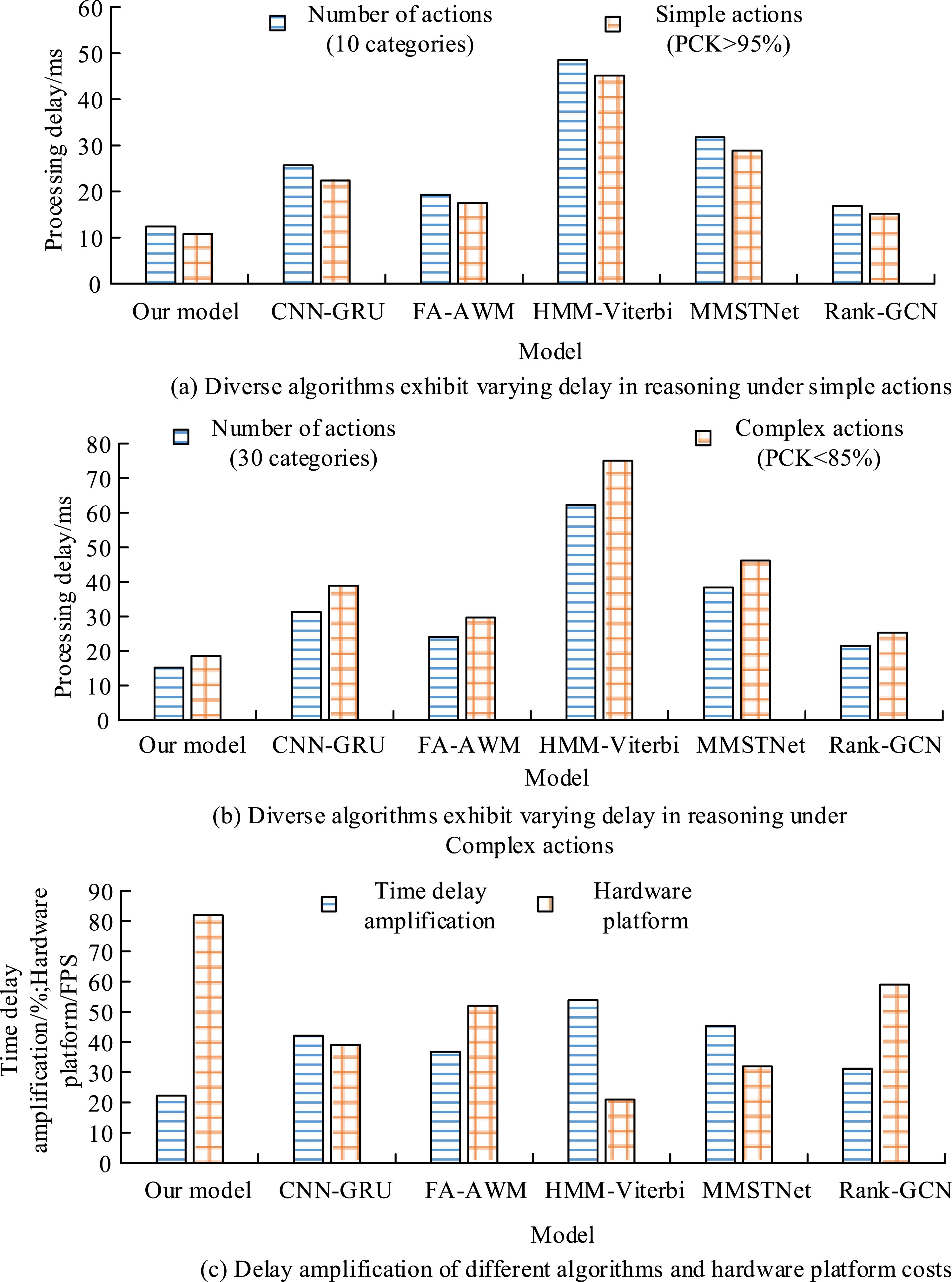
In Figure 11, simple actions refer to static or low-speed actions (such as “boxing” and “clapping”), while complex actions refer to high-speed or full body coordinated actions (such as “whirlwind feet” and “flying feet”). Delay amplification refers to the percentage increase in delay between occluded scenes and normal scenes. In the results of Figure 11(a), the research model only increased latency by 22.6% (12.4 → 15.2 ms) when the action category increased from 10 to 30, significantly better than the MMSTNet model (+20.8%) and CNN-GRU model (+21.4%). Moreover, the delay amplification of the research model under occlusion (22.3%) is smaller than other comparison models, and the FPS value (82) is 1.4 times that of the Rank GCN model. The CNN-GRU model has a significant increase in latency due to full sequence recalculation, and the Rank GCN model may have asynchronous action feedback. Afterward, the confusion matrix was used to analyze the martial arts action recognition results before and after the improvement of the research method, and the results are shown in Figure 12. Confusion matrix of martial arts action recognition before and after the improvement of SHN.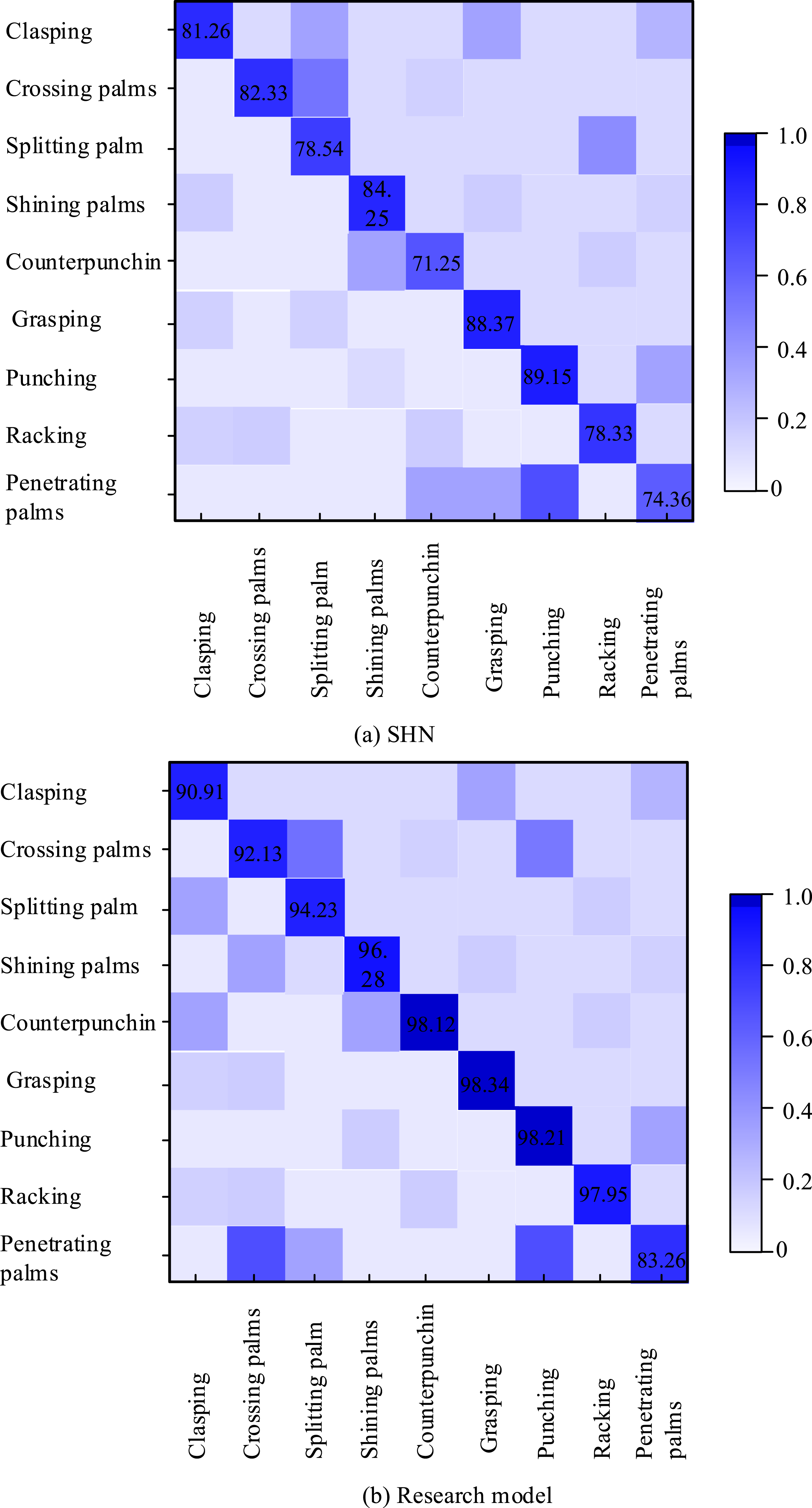
Comparison results of martial arts action recognition system and manual evaluation.
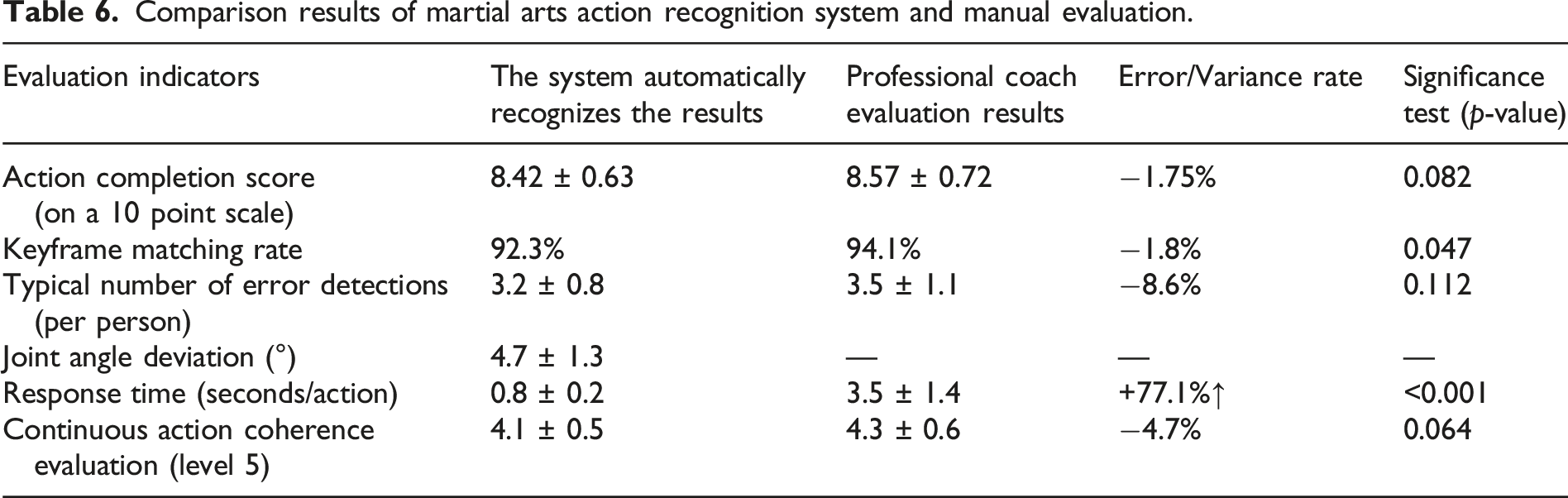
In the results of Table 6, the difference rate between the system score and manual evaluation is less than 5%, and there is no statistically significant difference in action completion (p = 0.082) and coherence (p = 0.064). The system response speed (0.8 s) is faster than manual speed (3.5 s), making it suitable for high-frequency action correction. And the system can automatically generate error reports, including posture deviation, rhythm errors, and other situations.
Discussion
To improve the limitations of traditional martial arts human pose recognition estimation, the research proposed to improve the SHN network and designed a martial arts action recognition system that includes data collection, pose estimation, and other content. The results indicated that in the ablation experiment, multiple dilated convolutions could improve the detection accuracy and inference speed of SHN, and the difference in PCK index values between the two datasets exceeded 2.5%. The detection accuracy exhibited by the expansion scale of (2,3) under the same number of stacks was greater than that of (3,5). The reason was that an excessively large expansion scale could cause zero padding in the convolution, resulting in missing feature learning and limited detection accuracy. The PCK values of the MS-DConv-Att-SHN model in the two datasets were 92.49% and 93.84%, respectively, with mAP values exceeding 85%. This reduced the number of parameters and computational complexity. Compared with the resolution-aware network proposed by Xu, 10 the research method not only improved low-resolution adaptability but also enhanced multi-scale feature extraction ability through dilated convolution. It enabled joint detection to maintain high accuracy even under occlusion and motion blur. In addition, although Chen’s CNN-GRU framework 18 could achieve a recognition rate of 90%, its mean square error (<3) was still higher than the PCK value of the research method (>92%). This indicated that improving SHN had more advantages in spatiotemporal feature modeling. In the recognition results of key points in human posture, the improved MS-DConv-Att-SHN algorithm had better recognition performance than other comparative models. The average recognition accuracy of the RF-PR model did not exceed 85%, and the average recognition accuracy of ST-GCN and RNF differed from that of the research model by 3.24% and 2.16%, respectively. The reason for this result was that MS-DConv-Att-SHN constructed a more efficient multi-scale feature extraction network through multiple dilated convolutions. Compared with the fixed receptive field of ST-GCN and the resolution adaptive mechanism of RNF, this design could simultaneously capture local details and global contextual information, which was suitable for the common fast movements and large posture changes in martial arts movements. Moreover, the introduced attention module effectively solved the performance degradation problem of traditional methods in occlusion situations. Compared with manual feature-based algorithms such as RF-PR and PoseC3D’s 3D convolution features, it could highlight the feature representation of key joints.
MS-DConv-Att-SHN maintained high accuracy (PCK > 92%) while having lower computational complexity than temporal models such as ST-GCN and PoseC3D, effectively avoiding the complex graph structure calculations of ST-GCN. Compared to PoseC3D’s 3D convolution, adopting its improved structure could maintain high precision without increasing too many parameters. The recognition accuracy of the research model on continuous martial arts movements exceeded 90%, which was superior to other comparative models and could achieve a good balance between recognition accuracy and real-time performance. The PCK values of the Rank GCN model and the HMM Viterbi model did not exceed 87%. The recognition accuracy of the HMM Viterbi model did not exceed 90%. The research model effectively avoided the dependence of traditional methods (HMM Viterbi model7 7 ) on complex temporal modeling while maintaining a continuous action recognition rate of over 90%. The research method was consistent with the goal of C. Papic’s neural network motion analysis, 11 but the study further balanced accuracy and speed through lightweight design, filling the gap in real-time performance of Chen’s random forest method. 12
In the specific recognition of martial arts movements, the PCK values of the research model for fist hugging, cross palm, split palm, bright palm, counter fist, grid fist, punching, fighting, and piercing palm movements all exceeded 85%. However, the MMSTNet model and Rank GCN model only achieved values of 80.68% and 84.85% in punching actions, while the CNN-GRU model and FA-AWM model had poor overall recognition performance. The reason for the above results was that martial arts movements focused more on coherence and contained more subtle movements, which made it difficult for algorithms that ignore temporal features (such as CNN-GRU and HMM Viterbi) to perform well in recognition. Martial arts movements had unique motion patterns (such as specific force application methods and movement trajectories), and the MS-DConv-Att-SHN model had better adaptability. The dilated convolution was suitable for capturing long-distance spatial dependencies in martial arts movements, and the mixed attention mechanism could enhance the feature expression of specific key points (such as wrists and elbows) in typical martial arts movements, breaking through the performance bottleneck of manual feature methods in RF-PR models. J. Echeverria’s pose sequence analysis 15 and Pang’s feature alignment technique 16 emphasized temporal correlation. The research results showed that the use of multi-convolution-attention mechanism could partially replace complex temporal models, providing new ideas for pose estimation.
Conclusion
The improved MS-DConv-Att-SHN model proposed in the study had good martial arts action recognition performance and application performance. Its improvement on the SHN network could effectively balance accuracy performance and computational efficiency, providing a feasible solution for real-time interactive systems. The improved model proposed in the study can effectively calculate the standard degree of movements and can be deployed in provincial martial arts championships to achieve automatic scoring and slow motion replay analysis, thereby improving the efficiency of manual scoring. And the local feature refinement module in the research model can effectively detect the posture and joint angles of learners, which helps to achieve intelligent teaching correction effects. However, there is still room for improvement in research methods, such as the diversity of martial arts movements and tracking of joint angles. Specifically, the self-made dataset selected for the research model does not cover some unconventional movements of characteristic schools (such as the “lying down fist” rolling movement), and lacks modeling of joint instrument interaction features of instrument martial arts, resulting in a small sample size in the training dataset. Moreover, studying joint data based on posture analysis results can easily overlook the temporal joint drift caused by motion blur during fast rotating martial arts movements. In the future, efforts will be made to introduce interactive virtual technology, model simplification technology, and other techniques to improve the real-time and applicability of research model applications. Specifically, dedicated model compression techniques (channel pruning + hybrid quantization) will be developed or step wise spatiotemporal convolution modules will be designed to optimize model lightweighting and real-time performance, reducing the accumulation of errors in long action sequences. Develop a biomechanical analysis module, integrate millimeter wave radar and electromyographic signals, and construct a multi person interactive recognition system to enhance the dynamic environmental adaptability of the model. At the same time, research can also consider more types of martial arts movements and video image shooting angles, attempting to construct a knowledge graph of martial arts movements to improve joint prediction performance and action recognition accuracy, and enhance model training efficiency.
ORCID iD
Zhigang Chen https://orcid.org/0009-0004-0458-5912
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by Xinjiang Hetian College, “Value Reconstruction of Ethnic Traditional Sports Events in Promoting Rural Revitalization” in Southern Xinjiang (Project No. 2025SK006).
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.