
Abstract
With the development of artificial intelligence technology and deep learning, the application of related network algorithm models in human motion posture recognition is becoming increasingly widespread. To address low accuracy and complex networks in traditional algorithms for human motion posture recognition, this study proposes a method based on particle swarm optimization to improve the backpropagation neural network for recognizing and analyzing human motion posture. The model first extracts key nodes from image data through improved OpenPose, performs viewpoint transformation, and uses an optimized backpropagation neural network to recognize relevant human postures. The experiments showed that the improved OpenPose algorithm had high accuracy in extracting key nodes. When the viewing angle was 108°, the error value generated by viewing angle conversion was the smallest and the accuracy was the highest. The Schaffer function of the backpropagation neural network model optimized by particle swarm optimization and small batch gradient descent converged after 60 and 99 iterations, respectively. The Griebank function converged after 78 and 98 iterations. The particle swarm optimization-based backpropagation neural network achieved an average improvement of 20%, 22%, 16%, and 12% in recognition rates for four different human motion postures compared to other algorithms. The results show that the particle swarm algorithm-improved backpropagation neural network has higher computational efficiency and better accuracy in human motion posture recognition.
Introduction
The development of artificial intelligence has led to the emergence of more and more intelligent products. Human Motion Posture (HMP) recognition is a major research hotspot today, which focuses on accurately classifying human joints and limbs based on their position information in complex and changing scenes.1,2 By accurately classifying HMP, human motion analysis, and related exercise training can be achieved.3,4 In recent years, the recognition research of HMP mainly uses corresponding pose templates as inputs, but in the actual process, the pedestrian pose is easily affected by factors such as camera angle, motion speed, resolution, and clothing. This greatly increases the difficulty of extracting HMP features. 5 At present, research on human posture is mainly based on GEI, but the cumulative effect of related sequences leads to the loss of corresponding information.6,7 Currently, some scholars have researched Human Pose Recognition (HPR). Yu et al. combined the Particle Swarm Optimization (PSO) algorithm with Support Vector Machine (SVM) to classify human gait. The PSO-SVM algorithm outperformed other algorithms in the gait phase and recognition hierarchy, achieving a recognition rate of 95%. 8 Upadhyay et al. proposed the TFlite-Movenet model to recognize yoga poses. This model assisted users in completing specified yoga movements with an accuracy rate of 99.88%, and its performance was superior to the Pose-Net Convolutional Neural Network (CNN) model.9,10 Ciccarelli et al. proposed a sensor-independent parallel deep convolutional learning network, Spectre, to classify human postures in working states. The established indicators such as accuracy, recall, and F1 score reflected Spectre’s good performance, which could accurately distinguish postures and infer the weight ratio of each motion posture input. 11 Malik et al. extracted 2D skeleton data based on OpenPose and used it as input for CNN-LSTM for action recognition. The accuracy of OpenPose CNN-LSTM for corresponding action recognition reached 94.4%, and the number of input features was reduced to 50, significantly reducing the computational complexity.12,13 Santos C F G et al. proposed a deep learning based model to replace the traditional ISP process for image signal processing. The results showed that deep learning methods performed well in tasks such as image denoising, mosaic removal, and enhancement. The model could significantly improve image quality and outperform traditional methods in some cases.14,15 Ganesan P et al. proposed an image classification method that combines fine-grained feature descriptor submodules with graph neural networks to address the current scarcity of data in image classification tasks. The results showed that this method significantly improved the classification accuracy and outperformed the traditional few-shot image classification methods, especially excelling in processing spatial information, scale invariance, and high-resolution images. 16 Reddy B S H et al. proposed a deep learning based detection method to address the current difficulty in early diagnosis of hair and scalp diseases. The results showed that this method achieved a training accuracy rate of 97% and a verification accuracy rate of 92%, significantly improving the diagnostic efficiency.17,18 Chugh H et al. proposed an image retrieval framework based on saliency structure and color difference histogram to address the current application status of plant leaf image retrieval in the agricultural field. The results showed that the model performed best at the 80% Euclidean distance threshold, with an accuracy rate of 1.00, a recall rate of 0.96, and an F1 score of 0.97. 19 Dave M et al. proposed a video surveillance system based on distributed edge fog nodes to address the issues of privacy infringement and resource waste that traditional centralized security monitoring systems may cause in smart home environments. The results showed that while providing better privacy protection functions, this system consumed fewer resources.20,21
Although the above method can accurately extract human body posture, it also has the problems of complex networks and low computational efficiency. At present, some scholars have applied the PSO—Backpropagation Neural Network (PSO-BP) to identify rocks, numbers, etc., indicating that the PSO-BP model can effectively identify and classify target objects.22,23 The current standard ViT implementation usually divides the image into patches of fixed size and encodes these patches directly. This method may overlook the spatial relationship between human joints and limbs when processing HPR tasks, resulting in limited accuracy in pose recognition. Based on this, this study proposes a PSO-BP model for identifying and analyzing HMP. The innovation lies in using an improved OpenPose algorithm for effective extraction of video image data, and introducing PSO and Small Batch Gradient Stochastic Descent (SBGSD) to optimize BP. At the same time, the recognition performance of two types of BP for HMP is compared, and the neural network with high accuracy is selected. Compared with the traditional PSO-BP algorithm, the PSO-BP model in this paper adopts a more advanced network structure and optimization strategy in the task of HPR, improving the recognition accuracy and computational efficiency. Meanwhile, the proposed improved OpenPose algorithm optimizes the accuracy and efficiency of key point extraction by introducing the Squeezenet network structure and adjusting the convolution kernel configuration. This improvement can capture the key point information more accurately when dealing with complex backgrounds and human postures from different perspectives. In addition, this research method utilizes the VTM algorithm to convert human postures from different perspectives into a 90° perspective, which can effectively reduce the impact of perspective changes on posture recognition.
Methods and materials
HMP extraction based on improved OpenPose algorithm
At present, there are mainly two forms of HMP extraction algorithms, namely refinement and relying on distance changes. Traditional methods have certain limitations, and the shallow refinement of the problem results in low accuracy in the final recognition.24,25 The recognition of motion posture through the human skeleton has been proven to have good robustness, and using only the lower body feature values for posture recognition is better than recognizing the joints of the entire body. Therefore, improving the OpenPose algorithm only preserves the key features of the hip joint and below. OpenPose is an open-source project model based on CNN, which is not only compatible with multiple systems but also a model that can synchronously recognize HMP.
26
The network structure of OpenPose is shown in Figure 1. Framework of the OpenPose algorithm.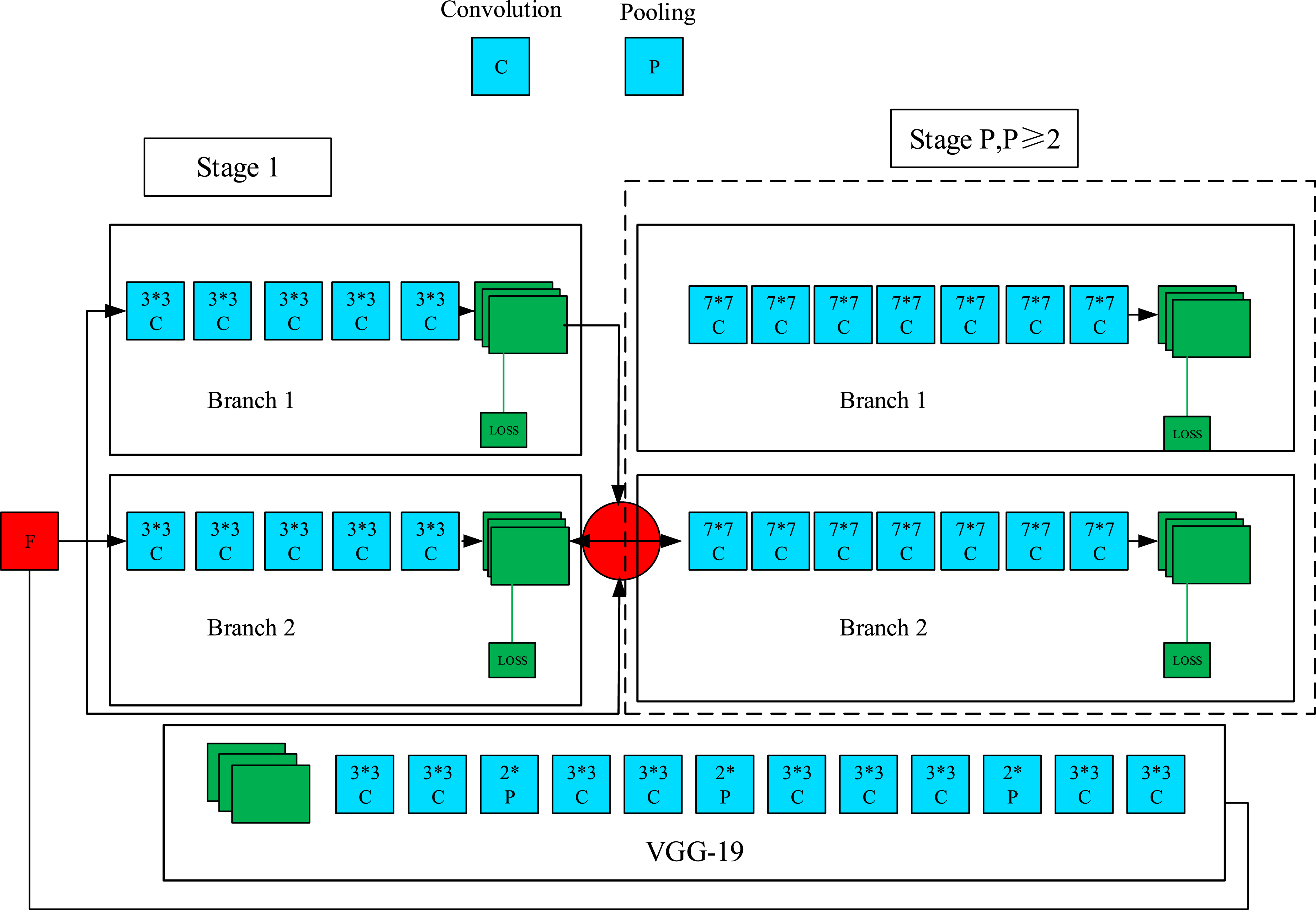
In Figure 1, this framework has been optimized based on the VGG-19 network structure. The first stage is responsible for extracting the basic features of the image, and the second stage further refines the features. Each stage contains two branches, and each branch is composed of a series of convolutional layers and pooling layers, which are used for extracting and downsampling feature maps. After the first stage, the feature maps of the two branches are merged through the fusion layer. Meanwhile, the input layer and the loss layer are used to receive the original image data and calculate the differences between the predicted results and the real labels. In real life, due to issues such as incomplete recognition of certain human joints, it is necessary to weigh the loss function of the space in which they are located. The loss function at time

In formula (1),

To ensure the accuracy and feasibility of the method, this study conducts experimental verification using 18 human joint points based on the gait database of the Chinese Academy of Sciences. Firstly, based on OpenCV, files in the database are cropped into a static image frame. Subsequently, the cut gait sequence is imported into the OpenPose network to extract the human skeleton and corresponding nodes. Figure 2 shows the corresponding skeleton extraction diagram. Key points of human body obtained by OpenPose algorithm.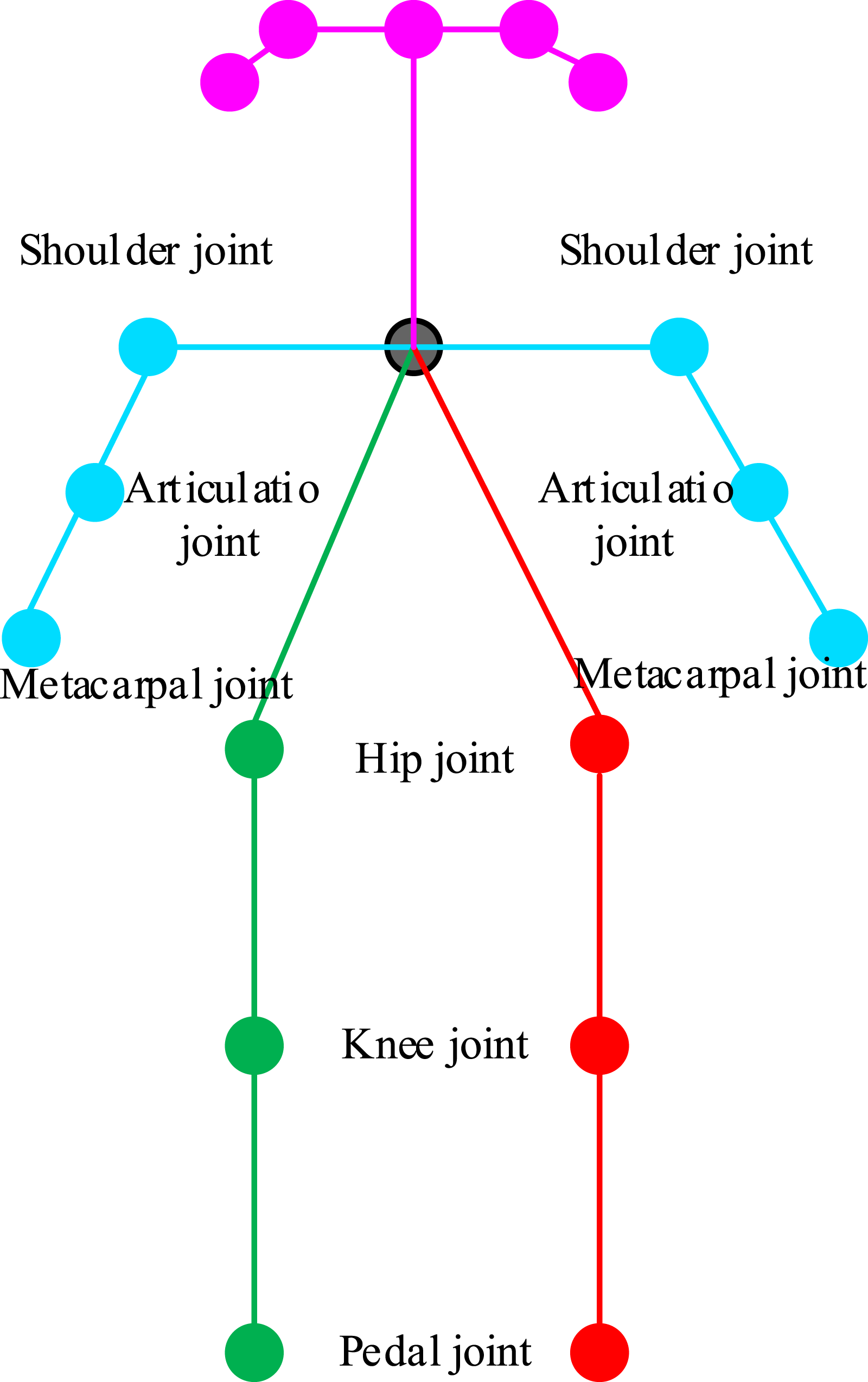
In Figure 2, the OpenPose algorithm extracts joint node positions with high accuracy, and there is no overlap or intersection between joint points and corresponding lines, which effectively compensates for the problem of inaccurate positioning in the skeleton in previous studies. However, when the input image perspective is large, there may be errors in identifying key nodes, which can lead to image errors. Therefore, this study proposes an improved OpenPose algorithm to extract corresponding features. First, based on the original network structure, three 3 × 3 convolution kernels are used to replace the 7 × 7 convolution kernels to compress the size of the grid. Second, the Squeezenet network is introduced, with its core being the Fire module. One of them is the Squeeze section, which mainly uses 1 × 1 convolution kernels to reduce the dimensionality of the input data. The other part is the Expand layer, which mainly uses a mixture of 1 × 1 and 3 × 3 convolution kernels. Figure 3 shows the steps of the Fire module. Specific operation of the Fire module.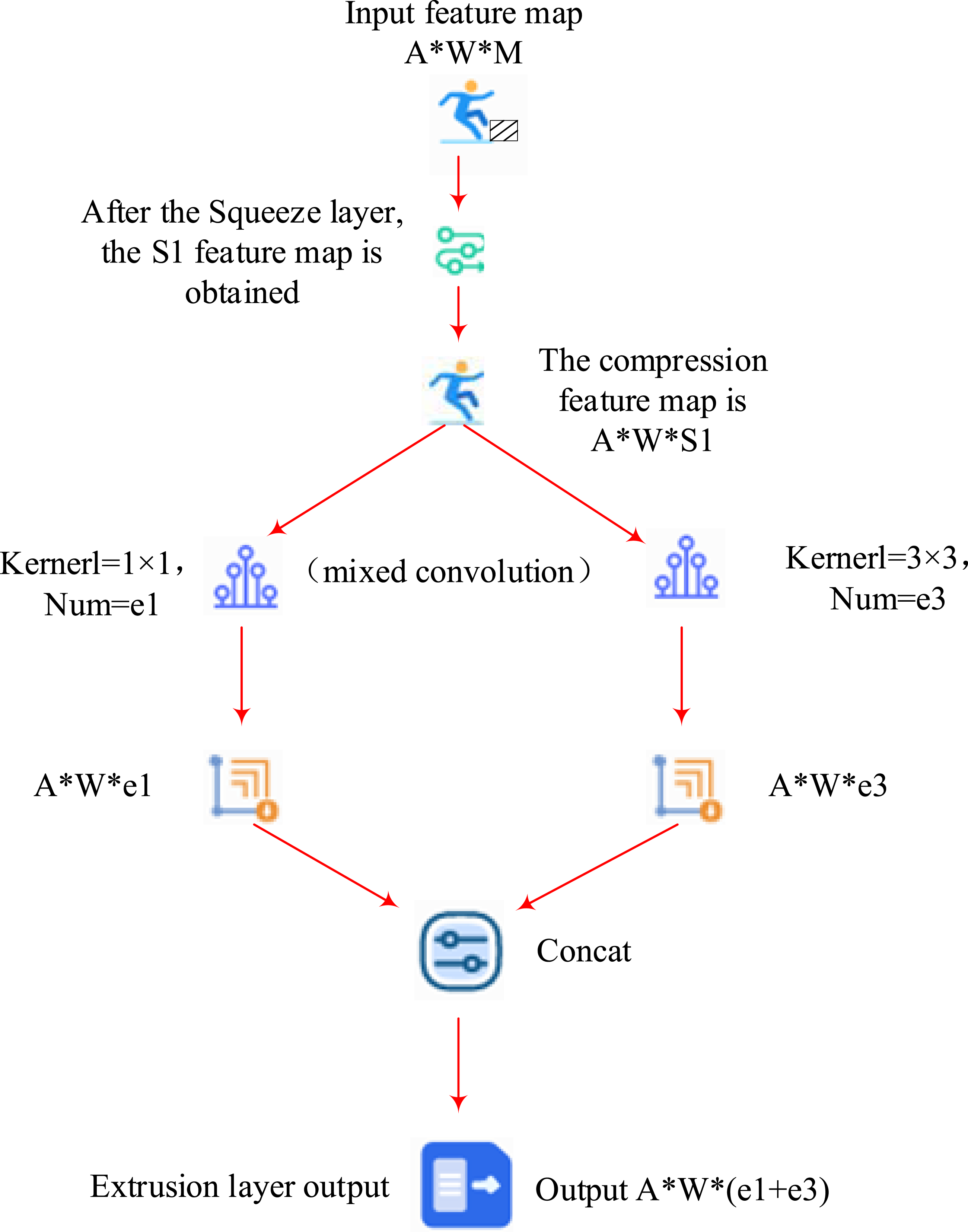
Fire module related parameters.

Due to the perspective issue, it is usually necessary to convert the gait sequences from other perspectives to a 90° perspective. Therefore, this study uses the VTM algorithm for viewpoint conversion. It compares the perspective coordinates with the vertical coordinates of the human neck joint at 90°, selects the same features as the boundary points, and calculates the Euclidean Distance (ED) of the coordinates before and after transformation to evaluate the performance of the method. VTM is a model used to convert an image from one perspective to another, and its main steps are shown in Figure 4. The main steps and processes of VTM.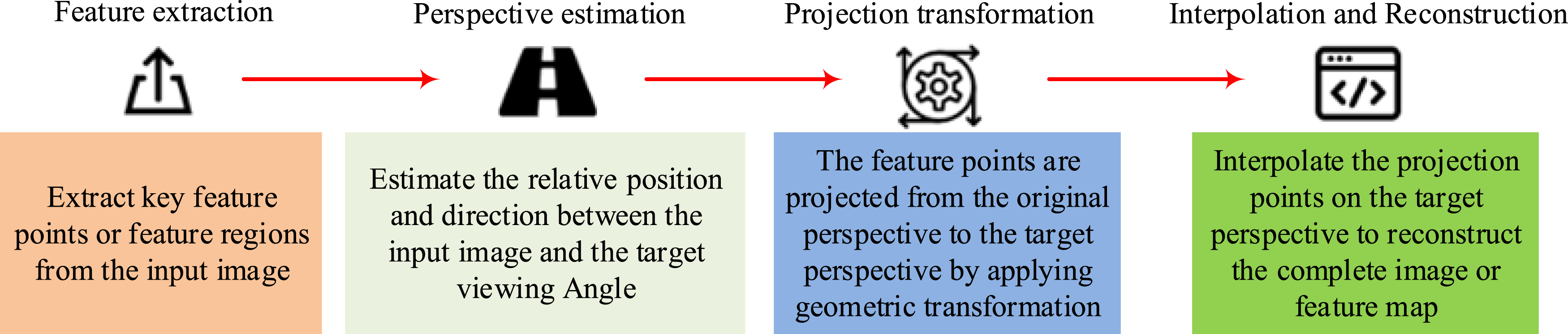
In Figure 4, the main difference between VTM and affine transformation is that VTM can handle more complex perspective changes, including non planar surfaces and depth information. Affine transformations are usually only applicable to rotation, scaling, and translation within a plane. This study uses ED to perform similarity detection on gait features. The calculation of ED is shown in formula (3)
In formula (3),
Identification of HMP based on PSO-BP
PSO is a simple algorithm for global optimization that relies on the competition and collaboration between particles. If a group has 
A single particle is required to constantly adjust its position in order to find new solutions. At this point, the update speed and update position of a single particle are shown in formula (5)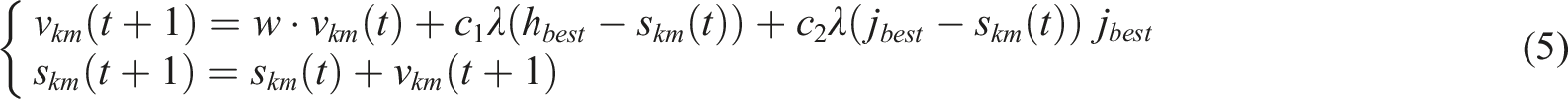
In formula (5), 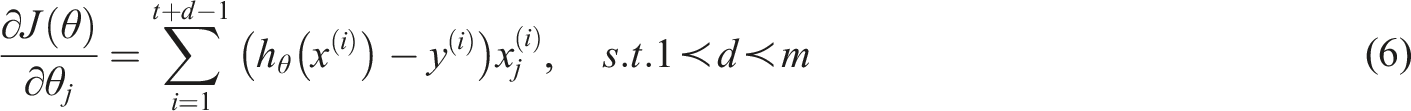
In formula (6), 
In formula (7), 
Combining and connecting neurons can fill the gap where a single neuron cannot solve complex problems. The structure of BP is shown in Figure 5. Structure of a BP network.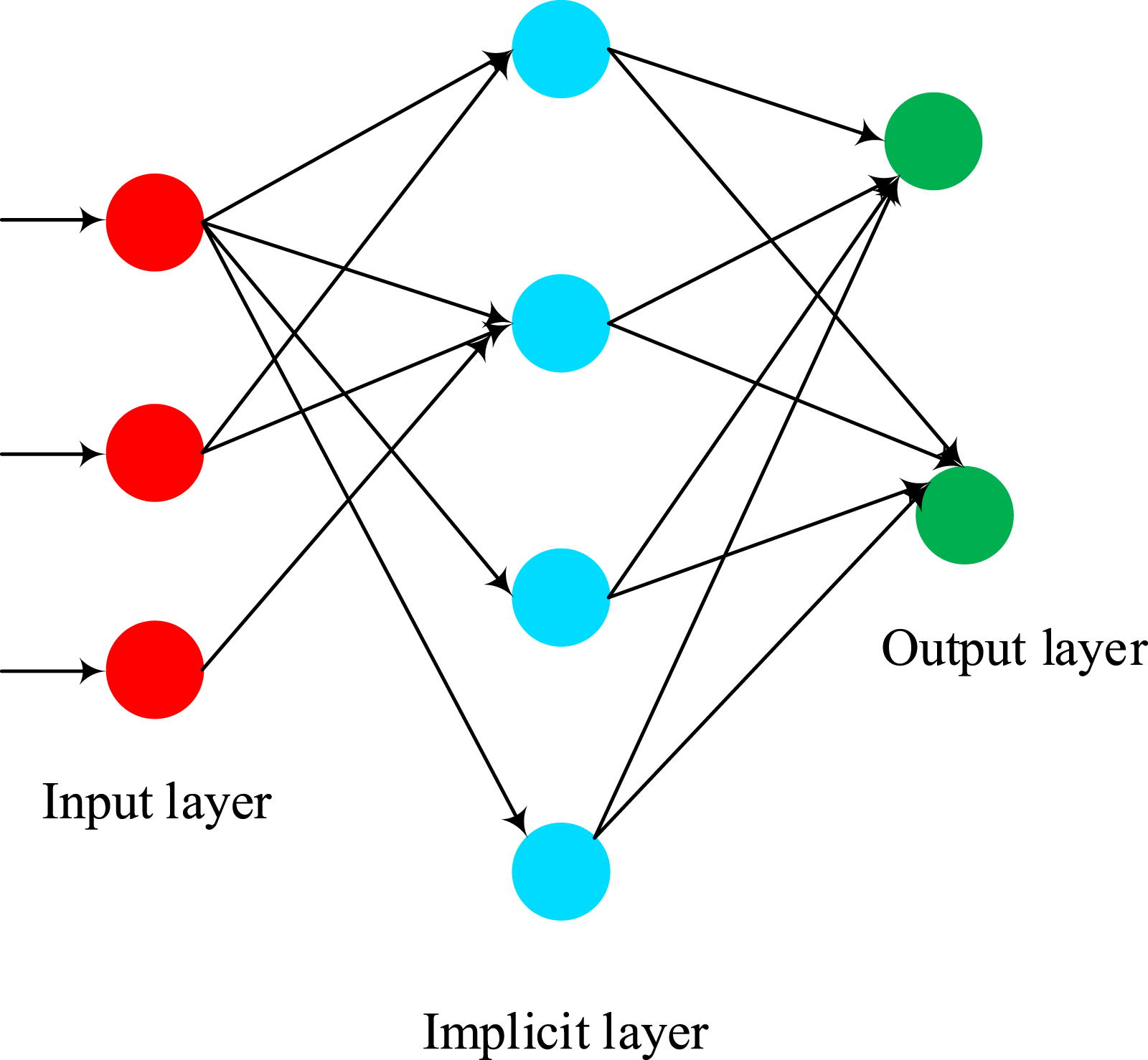
In the process of forward propagation, based on PSO, the optimal hidden layer is identified, and a corresponding forward propagation algorithm model is constructed. During the process of reverse conduction, the connection weights between the second and third layers are corrected, and relevant models are constructed. For the initial value range, after obtaining the initial position and initial velocity, they are substituted into the fitness function, and the fitness values for the remaining particles are calculated, as shown in formula (9)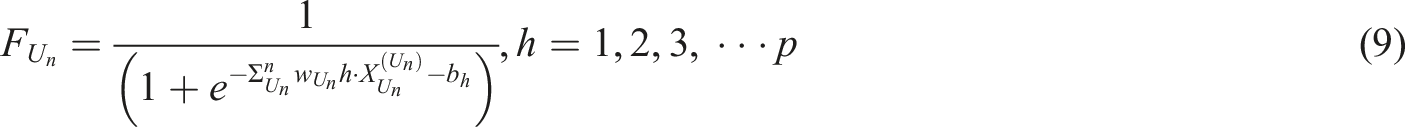
In formula (9), 
In formula (10), 
In formula (11), 
In formula (12), 
In formula (13), 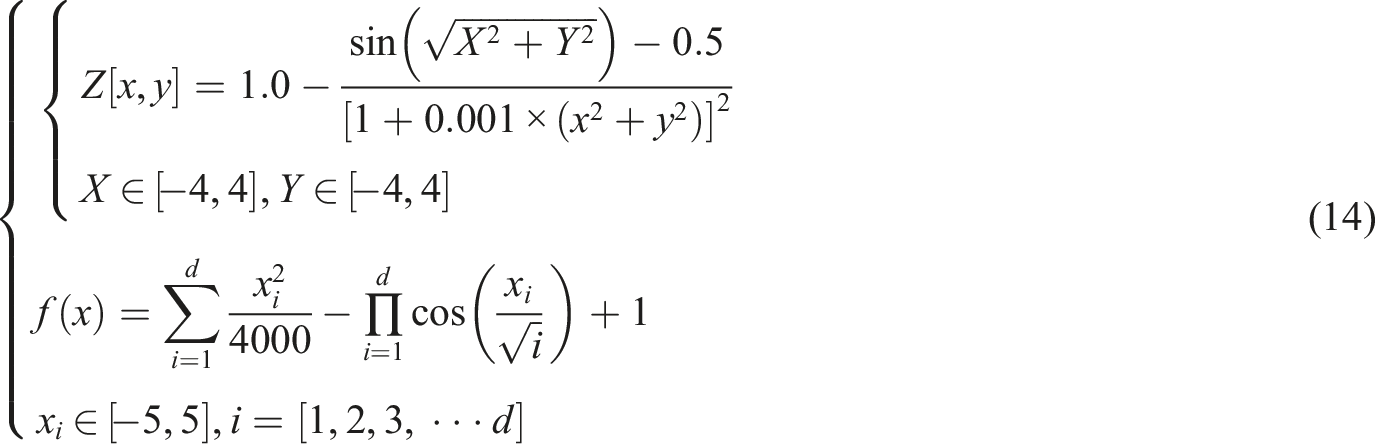
When dealing with multiple local optima, the Schaffer function can be used to test the performance of the model. When dealing with problems with complex search spaces, the Griebank function can be used to evaluate the model’s ability. The Schaffer function and Griebank function are related to human motion modeling, as they simulate the complexity and diversity of human motion.
Results
Comparative analysis of joint coordinate extraction and transformation based on video images
In this experimental environment, the operating system is Windows 10 Professional Edition, the CPU is Intel Core i7-9700K, the GPU is NVIDIA GeForce RTX 2070, the total memory is 32 GB, the total hard drive is 1 TB, and the motherboard is MSI Z390-A PRO. In the PSO-BP, the batch size is set to 32, the total number of rounds of model training is set to 1000 rounds, the initial learning rate is 0.001, and the optimizer is Adam. The population size of the PSO algorithm is 40, the maximum number of iterations is 200, the inertia factor is dynamically adjusted within the range of [0.4, 0.9], and the learning factor is all set to 2. The datasets selected are the CASIA Gait Dataset of the Chinese Academy of Sciences and the Leeds Sports Pose (LSP) dataset. Among them, the video resolution of the CASIA gait database is 640×480 pixels and the frame rate is 25 fps. The images in the LSP dataset are scaled to 640×480 pixels to ensure the consistency of the input data. The CASIA gait database covers various scenarios such as normal walking, walking with items, and walking in different clothing. The LSP dataset contains various human postures and labels 14 key points of the human body. To improve the generalization ability and robustness of the model, the study conducts data augmentation by means of random clipping and scaling, horizontal flipping, and rotation and distortion. By comparing the OpenPose network before and after improvement to extract joint coordinates, the results are shown in Figure 6. Coordinate comparison chart. (a) Coordinate extraction analysis of typical Position 1. (b) Coordinate extraction analysis of typical Position 2.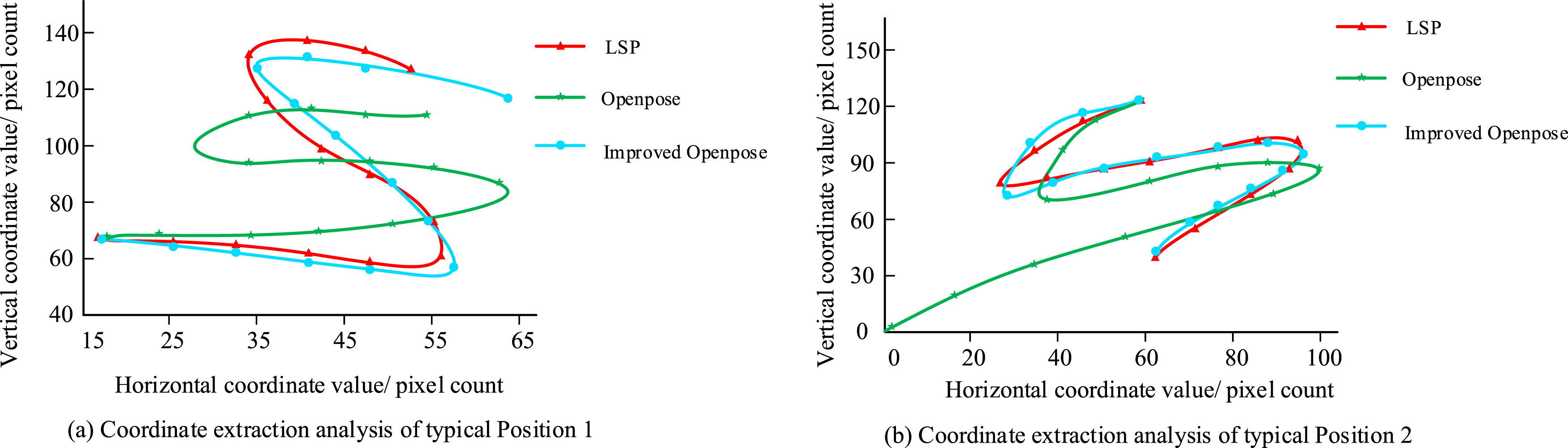
Critical point selection.

After the above critical points are determined, the VTM model converts the horizontal and vertical coordinates of human joint points from all angles except for 90°. Based on similarity data, the results of viewpoint transformation are evaluated by comparing the average similarity of all joint coordinate data before and after transformation with the vertical viewpoint, as shown in Figure 7. Similarity comparison based on coordinate transformation. (a) Comparison of similarity before and after 0–36 degree coordinate transform. (b) Comparison of similarity before and after 54–108 degree coordinate transformation. (c) Comparison of similarity before and after 126–162 degree coordinate transformation.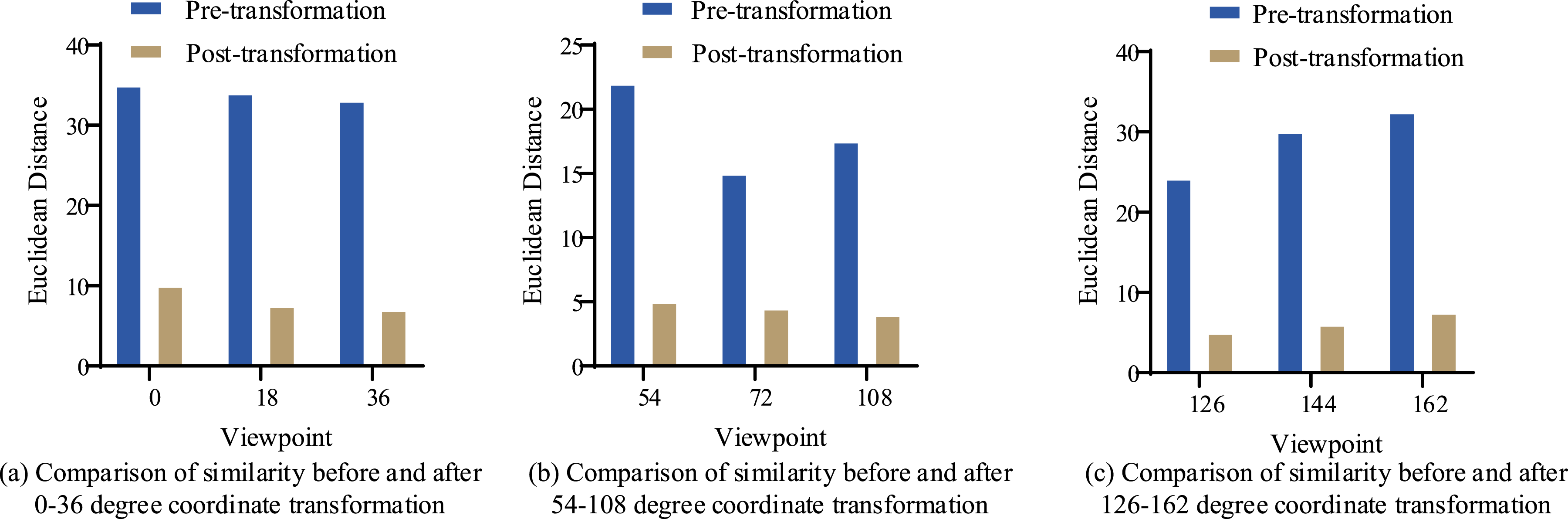
Figure 7(a)–(c) show the similarity comparison before and after coordinate transformation for 0–36°, 54–108°, and 126–162°. The distance between all perspectives and the vertical coordinate changes after transformation has decreased, indicating that the similarity has increased after algorithm transformation. Among them, the closer the viewing angle is to 90°, the smaller the error generated during conversion. When the viewing angle is 108°, the error value generated is the smallest and the accuracy is the highest.
Performance analysis of algorithm based on PSO-BP
Comparison of model performance indicators.
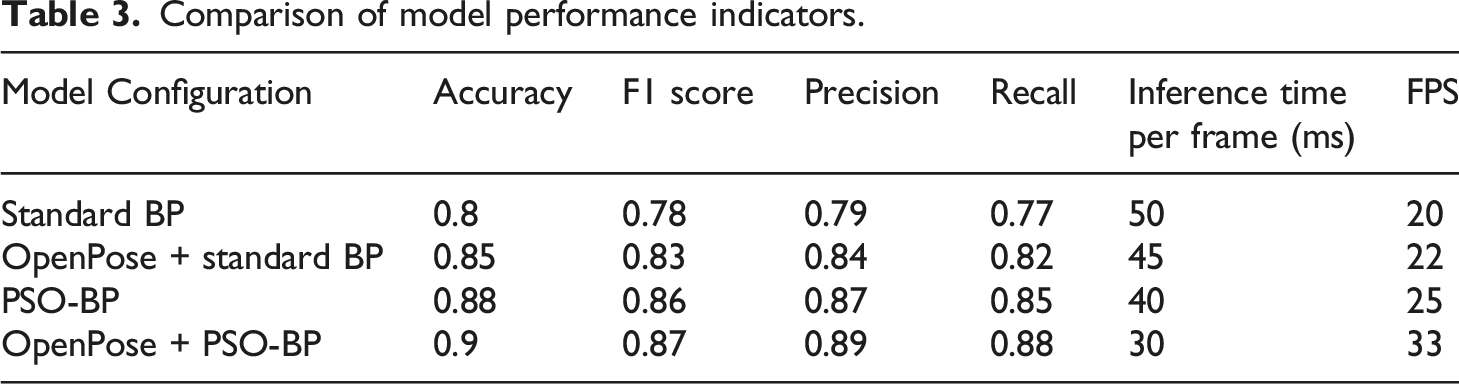
The OpenPose + PSO-BP model has the highest accuracy rate, which is 0.90. The F1 score of the OpenPose + PSO-BP model is the highest, which is 0.87. The OpenPose + PSO-BP model has the highest precision of 0.89, indicating that the combination of OpenPose and PSO-BP can further improve the precision of the model. The reasoning time of the OpenPose + PSO-BP model is the shortest, which is 30 ms. Meanwhile, its FPS is the highest, at 33, significantly higher than that of other models, indicating that it has a higher processing rate. The convergence of the function based on SBGSD method and PSO-BP is shown in Figure 8. Schaffer function iteration process. (a) Convergence of variable X with increasing iteration. (b) Convergence of variable Y with increasing iteration process.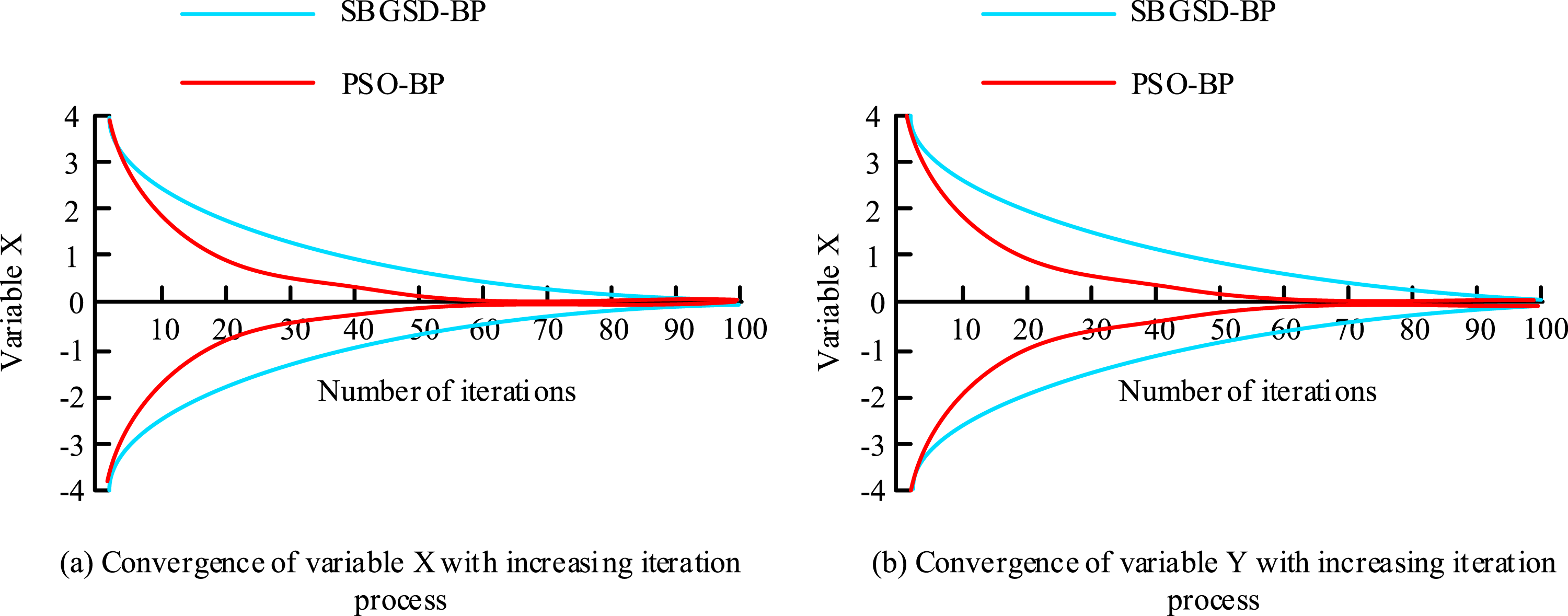
Figure 8(a) shows the convergence of the variable X. Figure 8(b) shows the convergence of the variable Y. The PSO-BP algorithm converges to the origin on both variables X and Y when the number of iterations is 60, while the SBGSD method converges to the origin when the number of iterations is 99. Further, the Griewank function is used for the correlation performance analysis. The presence of multiple extremum points within its domain further leads to inconsistent search results each time. Therefore, the study only presents one search result, as shown in Figure 9. Iterative computational procedure for the Griewank function. (a) Iteration 1. (b) Iteration 1. (c) Iteration 49. (d) Iteration 39. (e) Iteration 98. (f) Iteration 78.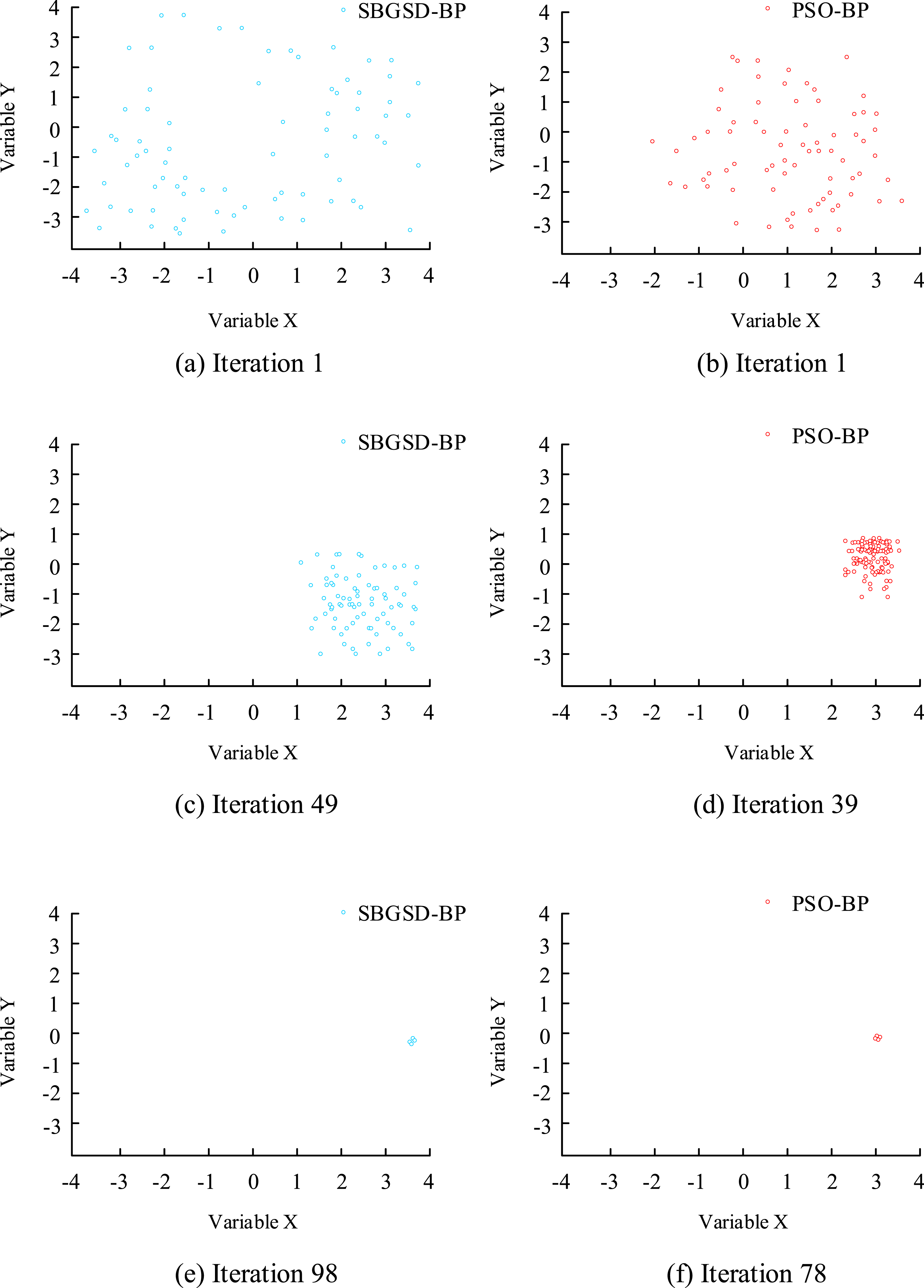
Figure 9 (a)–(e) show the convergence of the SBGSD-BP. Figure 9(b), (d), and (f) show the convergence of the function through PSO-BP. The SBGSD-BP algorithm is relatively concentrated during the first convergence. As the number of iterations increases, both algorithms gradually converge. At 78 iterations, the PSO-BP model has already converged, while the SBGSD-BP model only begins to converge at 98 iterations. This indicates that PSO-BP has faster computational efficiency than SBGSD-BP.
Identification and analysis of HMP based on PSO-BP
The experimental environment is set as follows: the computer system is Win10, the CPU is Intel i7-9700k, two RTX2070 GPUs are configured, the graphics card driver is 410, and the GPU acceleration is CUDA9.0. The virtual environment required for Python 3.7 and Tensorflow-gpu. 8.0 is configured for the Anaconda. To compare the recognition rate of BP, this study uses the recognition rate from different perspectives as a reference indicator, as shown in Figure 10. Comparative analysis of recognition rate of two kinds of optimized BP.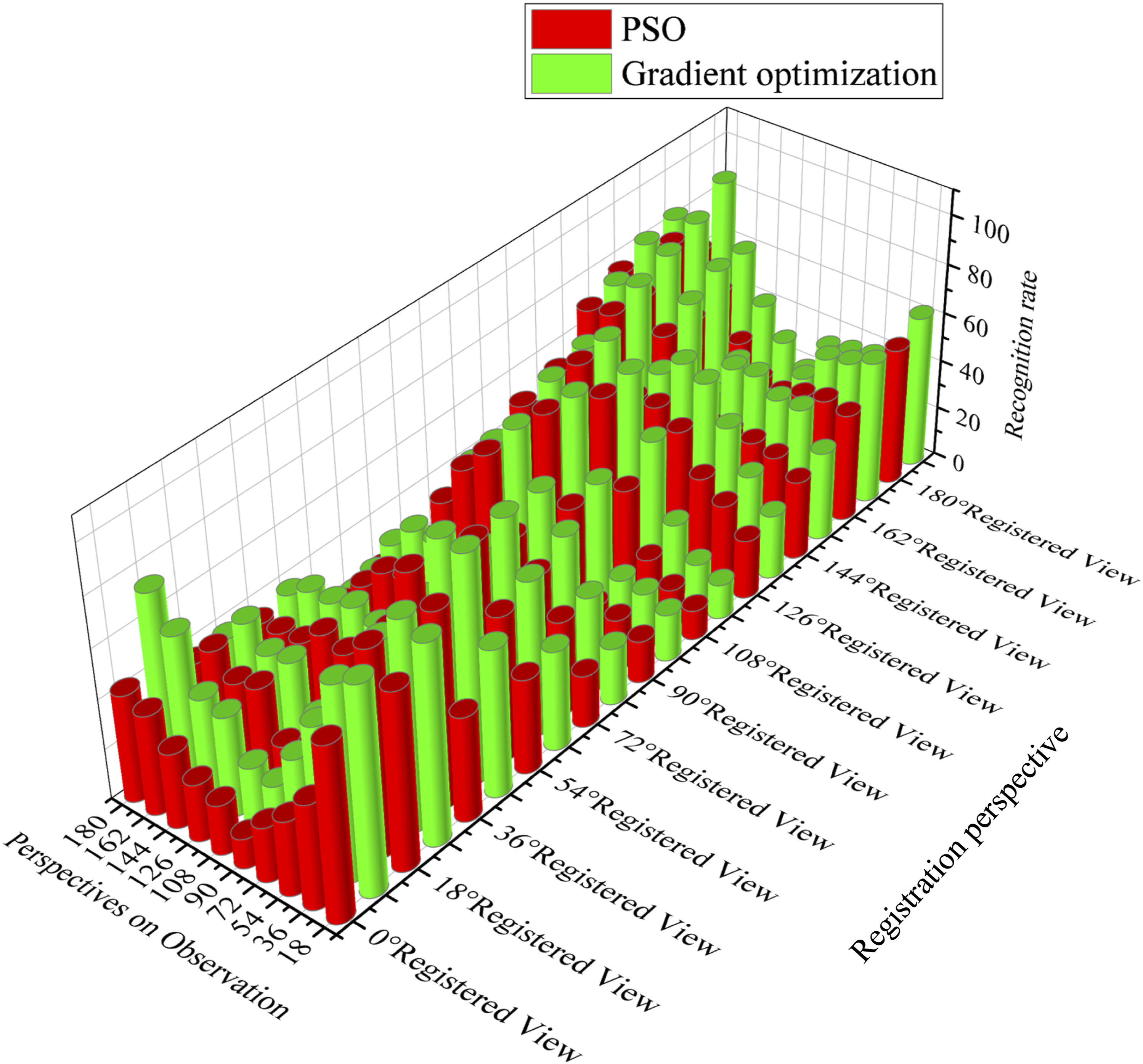
In Figure 10, the recognition rate of the PSO-BP at each registration perspective is superior to that of the SBGSD-BP method. When the registration angle is 126° and the observation angle is 108°, the recognition rate of the PSO-BP is the highest, at 96.5%.
40 collectors who performed typical actions are selected, and the data are used as training data to train two types of BP and the BP-optimized methods in reference 27. The collector performs four exercise postures: stationary, going upstairs, going downstairs, and walking, with a ratio of 1:1:1:1. The test set consists of feature maps for four types of actions, with a total number defined as 200. The number ratio of the four postures is also set to 1:1:1:1, and the recognition results are shown in Figure 11. Comparison of the number of human postures recognized by two optimized BP.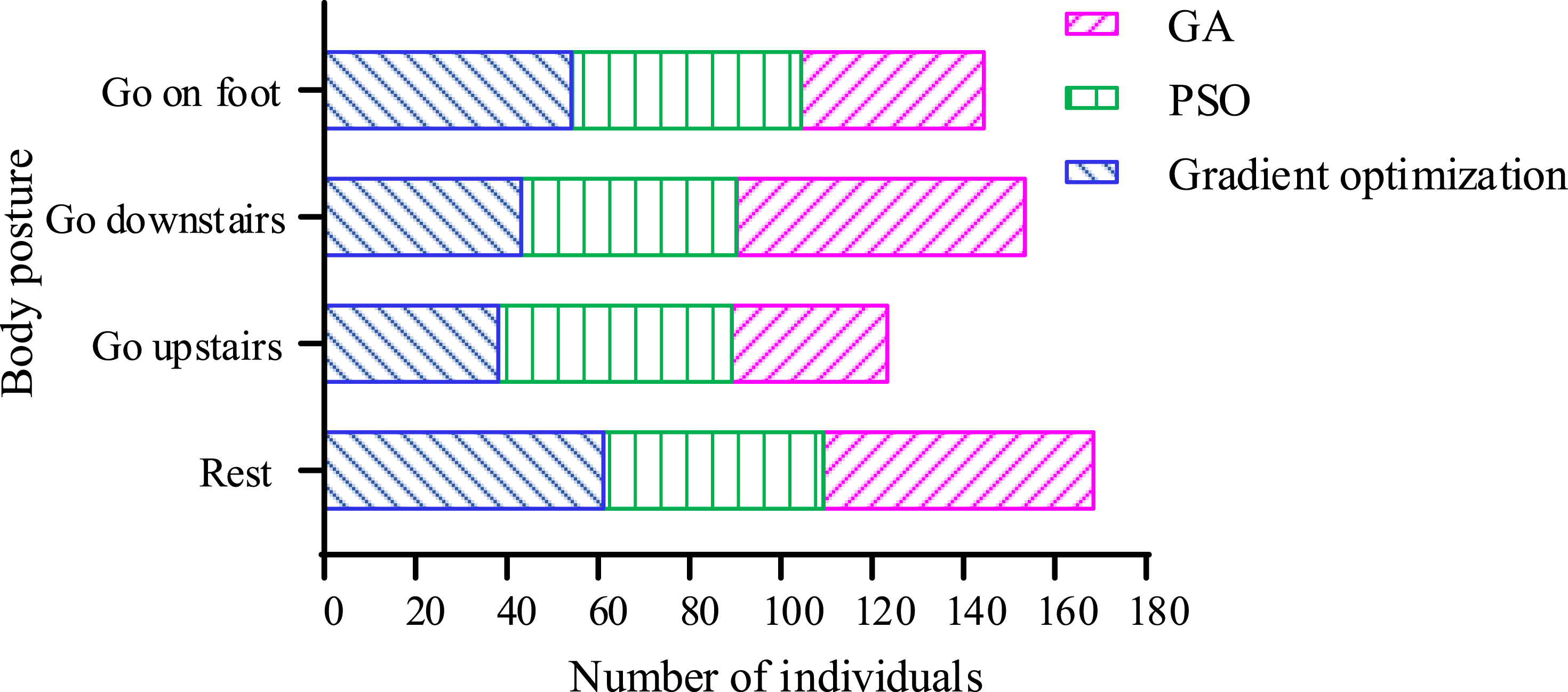
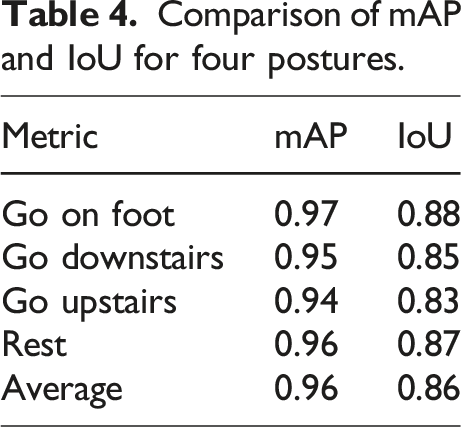
Comparison of mAP and IoU for four postures.
Comparison of the four models in mAP and loU.
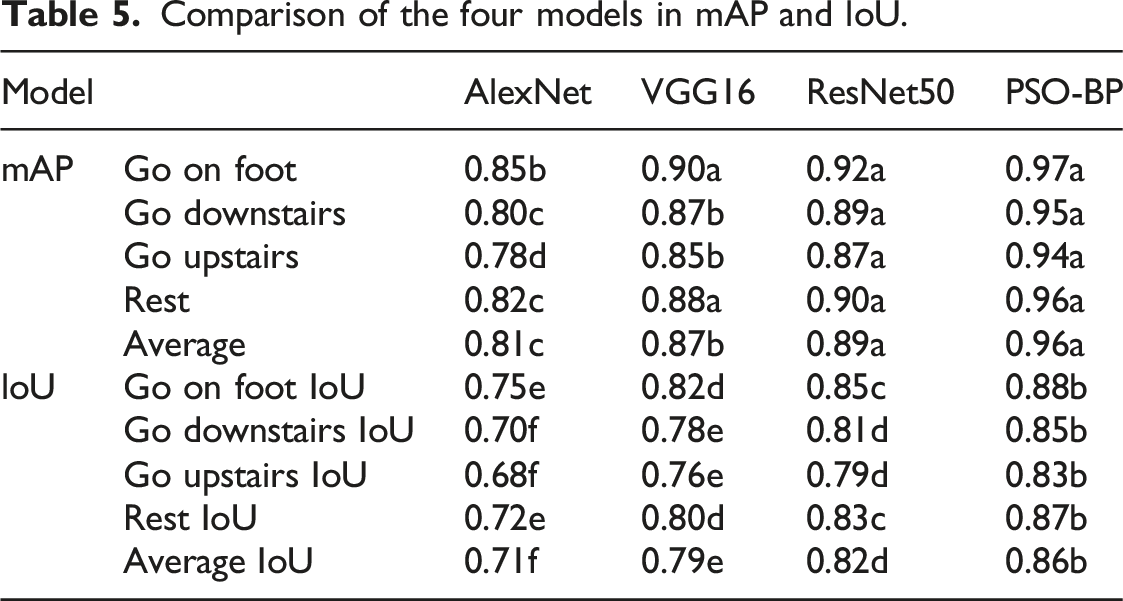
In Table 5, the PSO-BP model shows the highest performance on both the mAP and IoU indicators, and is marked as “a” in all columns. This indicates that the PSO-BP model performs significantly better than other models in the task of HMP recognition. Similarly, in the “Go downstairs” column, both the PSO-BP and ResNet50 models are marked as “b,” while VGG16 and AlexNet are marked as “e” and “f,” respectively. This result further confirms that PSO-BP and ResNet50 have significantly better positioning accuracy for this action than other models. The study compares the performance indicators of the PSO-BP model with several Transformer variants, and the results are shown in Figure 12. Performance metrics of the PSO-BP model and several Transformer variants.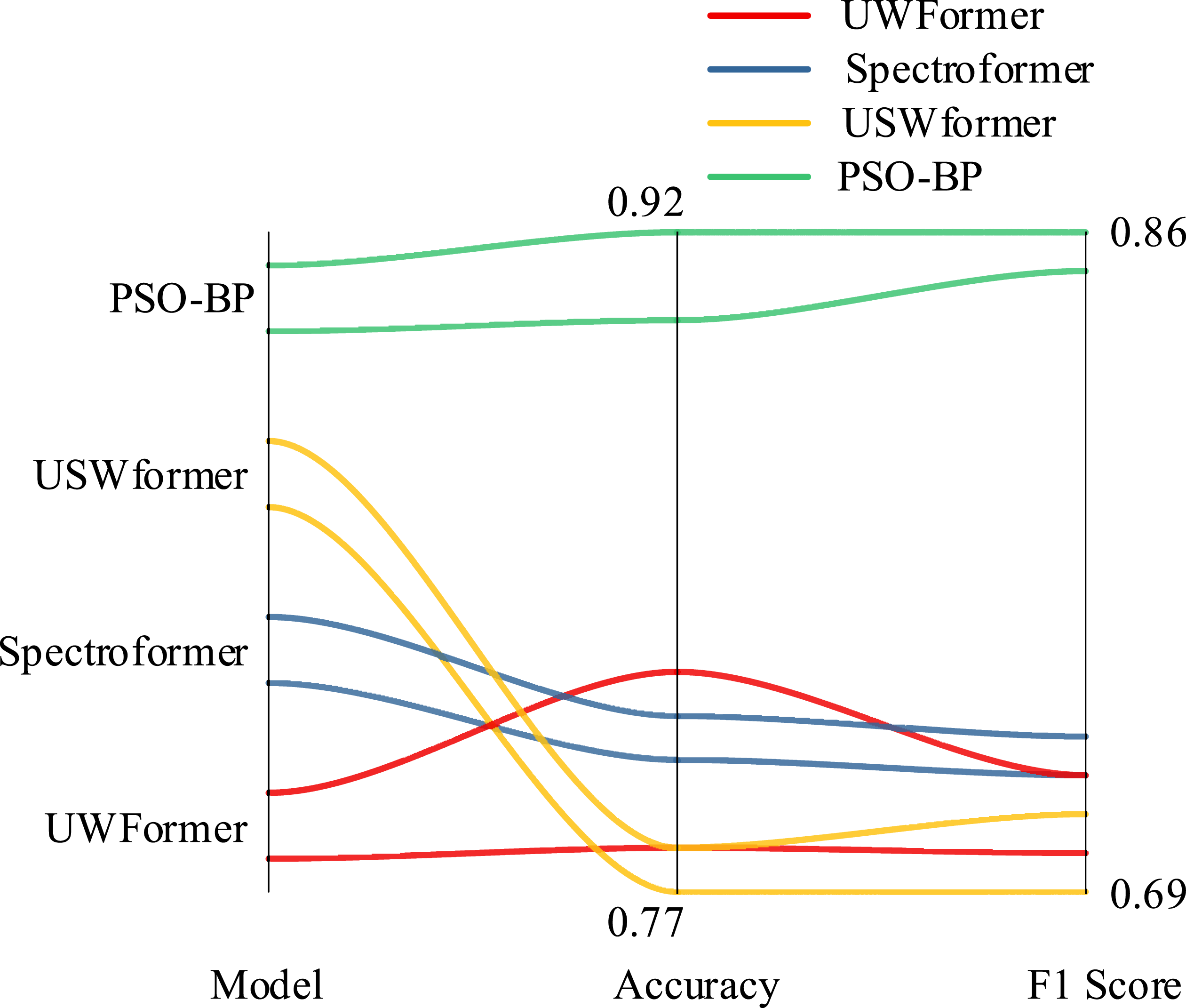
In Figure 12, the average accuracy rate of the PSO-BP model is 0.91, significantly higher than other models. The average accuracy rate of USWformer is the lowest, which is 0.78. The average F1 score of the PSO-BP model is 0.86. To sum up, through the data analysis of the two parallel experiments, the validity and practicability of the PSO-BP model have been further verified. The study further compares the confidence score heat maps of the four models, and the results are shown in Figure 13. Comparison of heat maps of confidence scores.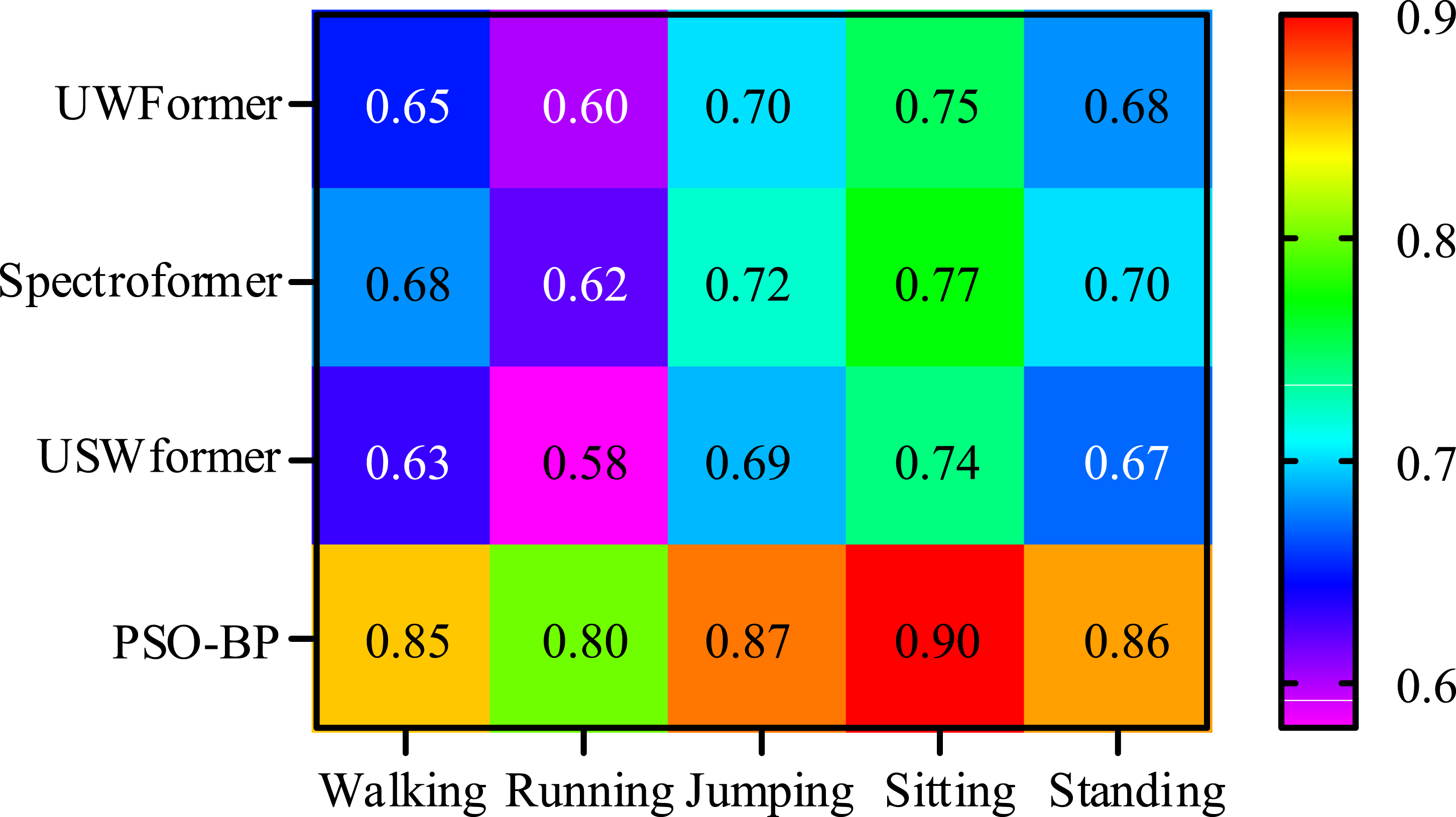
Comparison of model performance indicators.
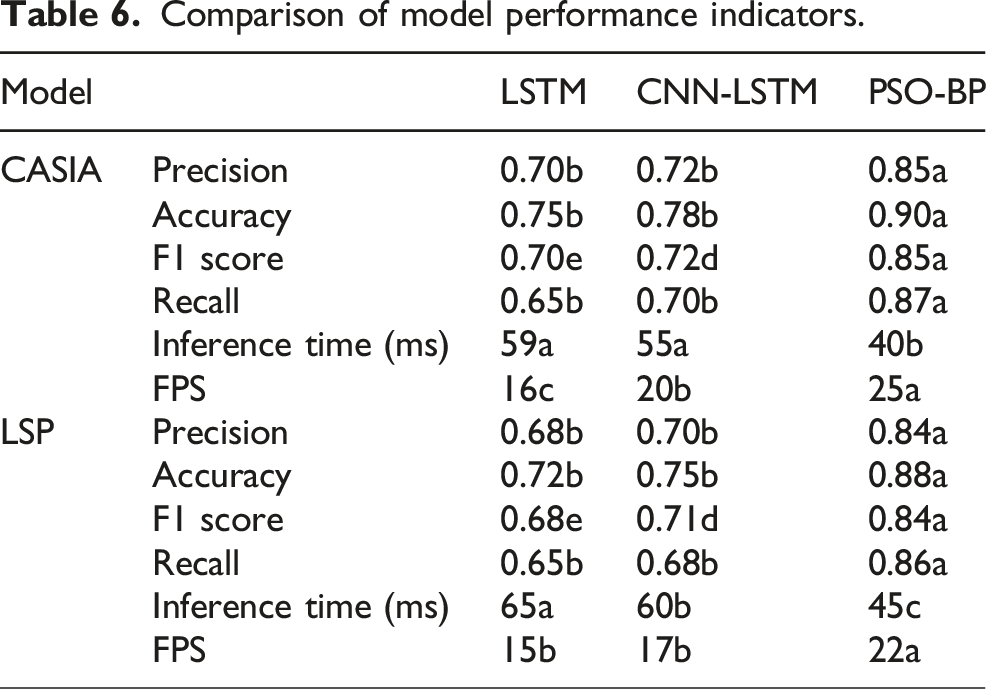
In Table 6, on the CASIA gait database, the PSO-BP model has the highest precision (0.85), accuracy of 0.90, F1 score of 0.85, and recall of 0.87, significantly higher than the LSTM and CNN-LSTM models. On the LSP dataset, all performance indicators of the PSO-BP model are superior to those of the control models. This indicates that the PSO-BP model is more suitable for high-precision and high reliability HMP recognition tasks.
Discussion
In the research results, the improved OpenPose extracted 14 joint points from typical pose 1, but only one joint point had poor coordinate extraction. In the original OpenPose extraction process, there were 6 joint point coordinates that deviated. In typical pose 2, the improved OpenPose perfectly extracted the coordinates corresponding to 14 joint points, while there were 8 joint point coordinates that deviated from the original OpenPose extracted coordinates. The Schaffer function of the BP model optimized by PSO and SBGSD converged at 60 and 99 iterations. The Griebank function converged after 78 and 98 iterations. When the registration angle was 126° and the observation angle was 108°, the recognition rate of PSO-BP was the highest at 96.5%. PSO-BP showed an average improvement of 20%, 22%, 16%, and 12% in recognition rates compared to other optimized BP algorithms in four different HMPs. The results indicated that the improved OpenPose achieved high accuracy in extracting key nodes while reducing network parameters. When the viewing angle based on the VTM algorithm was 108°, the error value generated at this time was the smallest and the accuracy was the highest. PSO-BP had faster computational efficiency than SBGSD-BP, and was less prone to getting stuck in local optima, whereas SBGSD-BP had such drawbacks. This in turn made PSO-BO perform better than SBGSD-BP in any different registration perspectives. Finally, PSO-BP had a high level of accuracy in recognizing four typical HMPs.28,29 Marusic et al. proposed an improved OpenPose algorithm for human rehabilitation motion analysis. This improved algorithm had higher accuracy in obtaining key nodes compared to RGB-d camera and BlazePose algorithm, and could be used to assist in human physical rehabilitation exercise. This confirmed that the improved OpenPose algorithm had high extraction accuracy. 30 Yu et al. combined PSO and SVM to classify human gait and found that the PSO-SVM algorithm outperformed other levels in the gait phase and recognition hierarchy, achieving a recognition rate of 95%. The research results confirmed the feasibility of using PSO to optimize relevant network models and have a high level of accuracy. 11 In summary, PSO-BP exhibits significant superiority in HPR, ensuring high accuracy while also having fast computational efficiency.
In the real world, models can be used to monitor patients’ gait and movement patterns and evaluate the rehabilitation process. Meanwhile, in sports training, the model can help coaches analyze the movements of athletes and provide suggestions for improvement. When challenges such as occlusion or illumination changes exist, multi-view data fusion and time series analysis can be adopted to reduce the impact of occlusion on the model performance. Meanwhile, adaptive image enhancement and illumination normalization techniques are used to improve the robustness of the model under different illumination conditions. Finally, to improve the generalization ability across datasets, the transfer learning approach can be adopted, that is, a general feature extractor is trained using large-scale datasets and then fine-tuned for specific tasks.
Conclusion
In exploring the problem of image data and BP on HPR, this study first introduced the OpenPose algorithm to extract joint coordinates in human pose and compressed the mesh size by replacing some convolution kernels. Second, the Squeezenet network was introduced to improve the OpenPose algorithm. The VTM algorithm was used to convert human features from other perspectives to a 90° perspective, and then Schaffer and Griebank functions were introduced to evaluate the computational efficiency of the BP network optimized by PSO and SBGSD. The results demonstrated that PSO-BP had faster computational efficiency. Finally, the recognition rates of PSO-BP and other models under different registration perspectives, as well as the recognition rates of typical human postures, were compared, confirming the feasibility of PSO-optimized BP network classification. The recognition accuracy of PSO-BP was relatively high. Although the proposed PSO-BP based on image data had a high level of recognition rate for human posture, there were also some issues. Since algorithms typically have high recognition rates for specific databases, their recognition performance may not be satisfactory on other databases. Therefore, a set of relevant algorithms for HPR can be designed, and a real-time attitude recognition system using the OpenPose algorithm can be developed to assist in completing HPR.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data generated or analyzed during this study are included in this article.