
Abstract
With the increasing importance of safety management in chemical and bioengineering laboratories, how to quickly and accurately detect and warn dangerous behaviors is becoming a popular topic. In this study, a dangerous behavior detection method based on improved You Only Look Once v5s model and human posture estimation is proposed. It is applied to the safety management of chemical and bioengineering laboratories. First, by improving the You Only Look Once v5s model, the detection accuracy and speed are improved. Then, the detected dangerous behaviors are further analyzed and judged by combining the human posture estimation technique. Finally, an indoor personnel safety video surveillance system is developed by adopting a distributed architecture and modularized design strategy. The results validated that the precision of the improved model was 97.68%, the recall rate was 96.79%, the detection time consumed was 0.022 s, and the GPU performance was 10.1. The method can quickly and accurately detect and warn dangerous behaviors. The optimized model designed by the study has important practical application value.
Keywords
Introduction
As important places for scientific research, the safety management of chemical and biological engineering laboratories is of vital importance. However, the current laboratory safety management is facing many challenges. On the one hand, laboratories involve a large number of hazardous chemicals, biological agents and complex experimental equipment. 1 A slight mistake may cause safety accidents, such as chemical leakage, fire and explosion, posing a serious threat to personnel safety and laboratory property. On the other hand, the traditional safety management approach mainly relies on manual monitoring and regular inspections. 2 This method is not only inefficient but also prone to causing potential safety hazards to be overlooked due to human negligence. For instance, during the experiment, researchers may violate the operation rules due to fatigue or negligence, such as not wearing protective equipment correctly or having improper postures when handling hazardous chemicals. All these behaviors may cause danger. In addition, there is frequent personnel turnover in the laboratory, and different personnel have varying degrees of understanding and implementation of safety regulations, which also increases the difficulty of safety management. 3 With the rapid development of computer vision technology, object detection and human pose estimation techniques based on deep learning have gradually matured and have been widely applied in multiple fields. The Yolov5s model, as an efficient and lightweight object detection algorithm, has the advantages of fast detection speed and high accuracy, and is capable of real-time identification and location of personnel and objects in the laboratory. Human pose estimation technology can detect the key points of the human body, analyze and judge the movements and postures of personnel, thereby providing an important basis for the identification of dangerous behaviors. Introducing these two technologies into the safety management of chemical and biological engineering laboratories can not only make up for the deficiencies of traditional manual monitoring, but also achieve real-time and automated monitoring of the laboratory environment, promptly detect and warn of potential dangerous behaviors, effectively reduce the probability of accidents, and enhance the overall safety of the laboratory.4,5 Therefore, it is of great practical significance and urgency to study the detection method of dangerous behaviors based on the improved Yolov5s model and human pose estimation, and apply it to the safety management of chemical and biological engineering laboratories.
The contribution of hazardous behavior detection based on improved Yolov5s model and HPE in the applied research of chemical and biological engineering laboratory safety management is mainly reflected in the following aspects. The first is to improve the detection accuracy. The Yolov5s model has been improved to enhance the capability of feature extraction and target recognition, thus improving the accuracy of DBD. This improvement enhances the accuracy of identifying and warning of potentially dangerous behaviors, reducing the occurrence of false and missed alarms. Additionally, the second is to enhance safety by detecting and warning of dangerous behaviors in a timely manner, providing a more reliable guarantee for laboratory safety management. This helps to reduce the probability of accidents, reduce the risk of casualties and property damage, and improve the overall safety of the laboratory. The third is to assist HPE. The introduction of HPE technology as an auxiliary judgment can more accurately judge whether a behavior is a dangerous behavior. By identifying multiple types of human gestures, the classification and early warning of behaviors can be further refined to provide more detailed and accurate information. The fourth is to promote intelligent management, and the DBD method based on deep learning provides technical support for the intelligent management of CBL. Automated and intelligent detection methods can reduce the burden of manual monitoring, improve management efficiency, and decrease the risk of human error and omission. Fifth, this approach provides a research basis for detecting risky behavior and offers new methods and ideas for subsequent research.
The innovation of the research is mainly reflected in the following aspects. Firstly, in response to the actual needs of safety management in chemical and biological engineering laboratories, targeted improvements were made to the Yolov5s model. By introducing depth-separable convolution and grouped convolution, the computational complexity and the number of parameters of the model were optimized. Meanwhile, the CBAM attention mechanism was introduced to further enhance the model’s ability to focus on the target features, thereby improving the accuracy and real-time performance of dangerous behavior detection. Secondly, the research combined the human pose estimation technology with the improved Yolov5s model to form a complete dangerous behavior detection system. This combination not only makes full use of the advantages of human pose estimation in action analysis, but also achieves accurate recognition and classification of human poses in complex environments through multi-scale feature fusion and spatio-temporal graph convolutional neural network (ST-GCN), further improving the accuracy and reliability of dangerous behavior detection. In addition, the research has developed an indoor personnel safety video monitoring system based on a distributed architecture and modular design. This system can monitor the personnel activities in the laboratory in real time and provide rapid early warnings for the detected dangerous behaviors, providing intelligent technical support for laboratory safety management.
The paper is segmented into four parts. The first part reviews the literature, which discusses and analyzes the current research status of human area detection algorithms and HPE algorithms in video dangerous behavior judgment at home and abroad. The second part proposes an improved Yolov5s object detection model and designs the overall process of HPE. The third part verifies the effectiveness and performance of this method through experiments. The fourth part summarizes the research results.
Related works
There are a lot of studies about the Yolov5 algorithm. Yolov5s is an efficient and lightweight ODA suitable for many real-time detection (RTD) scenarios. To address the issue of low accuracy in detecting underwater targets, Wen et al. proposed an enhanced YOLOv5s network. This was achieved by increasing the number of bottlenecks, embedding a coordinate attention module, and an extrusion excitation module to improve target attention. According to the experimental results, the improved network’s average accuracy increased by 2.4%. 6 Dai et al. proposed the GCD-Yolov5 for armored target recognition in complex battlefield conditions to achieve real-time performance while reducing missed and false alarms. The GCD-Yolov5 was accurate, significantly improving the recognition ability of armored targets. 7 To address the issue of low accuracy in small target detection, Tan et al. adopted an improved method connected with the Yolov5s. The improved algorithm significantly increased the detection accuracy of small aircraft and ship targets in complex environments, and greatly reduced the missed detection rate, especially for small targets. 8 Xu et al. proposed an improved YOLOv5 deep convolutional neural network (CNN) for real-time hand detection and recognition in intelligent service robots. The network’s feature extraction capability for small targets was enhanced by adding an SE attention module to the neck detection layer, resulting in improved detection performance. The experimental results indicated that this method had an accuracy of 99.02%, which is 6.54% higher than the original YOLOv5. 9 Shen et al. adopted an improved ASFF-Yolov5s-based RTD algorithm for small targets in unmanned aerial vehicles (UAVs) to address issues such as high flight altitude, large changes in target scale, and dense occlusion of targets. The proposed way completed an accuracy value of 32.55% and an F1 score of 39.62%, meeting the task needs of RTD of UAVs aerial images. 10 Zhang et al. adopted a vehicle detection method and Yolov5 to address the poor generalization ability and robustness of traditional artificial feature-based ODA. This algorithm could accurately segment and recognize vehicles based on their edge contours. 11
Currently, there are many research methods for HPE. The methods built on deep learning have made significant progress in HPE. Carpenter et al. used computer vision analysis to address the issues of high cost, time-consuming behavior observation, and the need for a large amount of professional knowledge to complete. By calculating and encoding facial movements and expressions based on tablet evaluation, differences in emotional expression could be detected. 12 Pereira et al. adopted a machine learning system for tracking the posture of multiple animals in response to research issues related to their social behavior or natural environment. This method achieved higher accuracy, with a speed exceeding 800 frames per second. 13 To address the issue of existing methods only focusing on scene images or the driver’s gaze or head posture, Hu et al. adopted a dual view scene approach based on uncalibrated gaze direction. This was feasible and superior to the most advanced methods. 14 Chen et al. adopted a fully convolutional propagation architecture with long jump connections to address the issue of three-dimensional HPE in videos. The model performed better than the original best results on the Human3.6M and MPI-INF-3DHP, and the effectiveness of the model was verified. 15 To address the issue of finding cross perspective correspondence in noisy and incomplete 2D pose prediction, Dong et al. used a multi-directional matching algorithm to cluster the detected 2D poses in all views. The proposed method achieved state-of-the-art on the Campus and Shelf datasets. 16 In response to the problem of HPE, Zheng et al. conducted a comprehensive review of 2D and 3D pose estimation solutions based on deep learning. They investigated and analyzed the performance comparison of different methods, aiming to address the problems of insufficient training data, depth blur, and occlusion. The results indicated that although deep learning methods have achieved high performance in HPE, they still face challenges. 17
In summary, great progress has been made in Yolov5s model and HPE in recent years. Different from the above studies, this study focuses on improving the integration and optimization of Yolov5s model and HPE technology, so as to form an efficient and reliable risk behavior detection system. Through the integration and optimization of the system, the advantages of the two technologies can be fully utilized to achieve more accurate and efficient DBD. The computer vision and HPE techniques are applied to the safety management of CBL. This cross-field application not only broadens the practical application range of related technologies, but also provides new ideas and methods for laboratory safety management.
Laboratory risk behavior detection based on improved Yolov5s
This study utilizes Yolov5 to enhance the model and implements separable convolution and grouped convolution methods to decrease network parameters. Additionally, SPP is retained and the prediction box loss function is optimized. The study also integrates human posture detection for efficient safety management in CBL.
Improving the construction of Yolov5s ODA
Yolov5s is a deep learning-based ODA, and the improved Yolov5s model is a significant improvement in technology compared to previous versions. By adopting more advanced BFENs and introducing attention mechanisms, the model performs more accurately and reliably in target detection tasks. This improvement helps to improve the accuracy of hazardous behavior detection and provides a more effective tool for the safety management of CBL. Although the Yolov5s model performs well in the field of object detection, there are still some problems. The Yolov5s model has been improved through the introduction of an attention mechanism, the enhancement of BFEN, and multi-scale feature fusion. These modifications can enhance the model’s detection accuracy and real-time performance, making it more effective in target detection tasks.
18
Figure 1 shows the structure of the Yolov5. Framework structure of the Yolov5 model.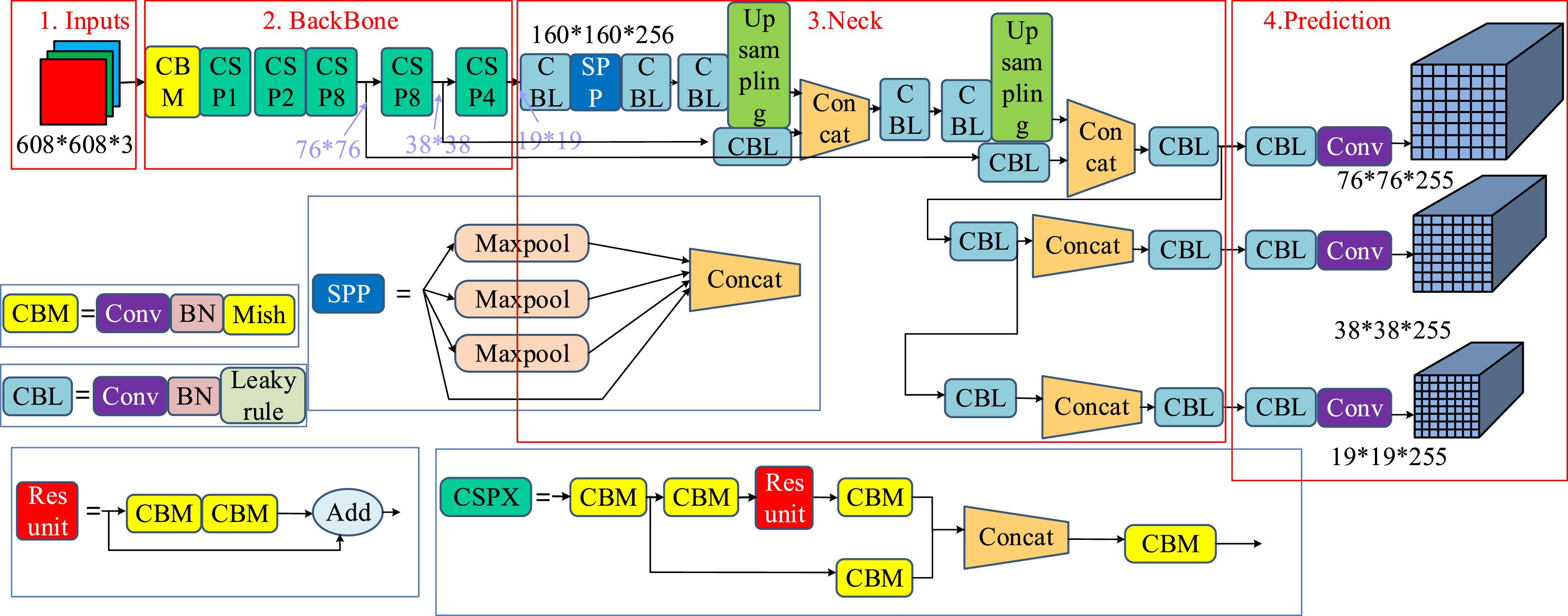
In Figure 1, Yolov5s uses an improved CSP Darknet53 as the backbone network, which is a version based on Darknet53. The backbone network is segmented into two branches by the CSP. One branch is responsible for extracting low-level features, while the other is responsible for extracting high-level features. These features are then integrated through cross-stage connections. This structure improves feature expression ability and model efficiency. In terms of detection heads, Yolov5s adopts the Path Aggregation Network (PAN) structure. It enhances the model’s ability to measure objects at distinct scales by fusing feature maps at different levels through a multi-scale feature fusion method. Compared to ordinary direct convolution operations, the calculation formula is shown in equation (1).

In equation (1),

In equation (2),
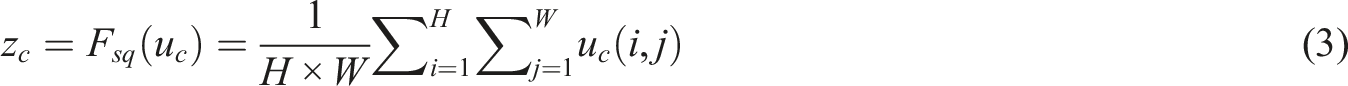
In equation (3),
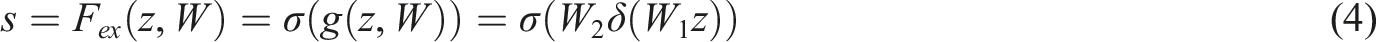
In equation (4), CBAM attention structure map.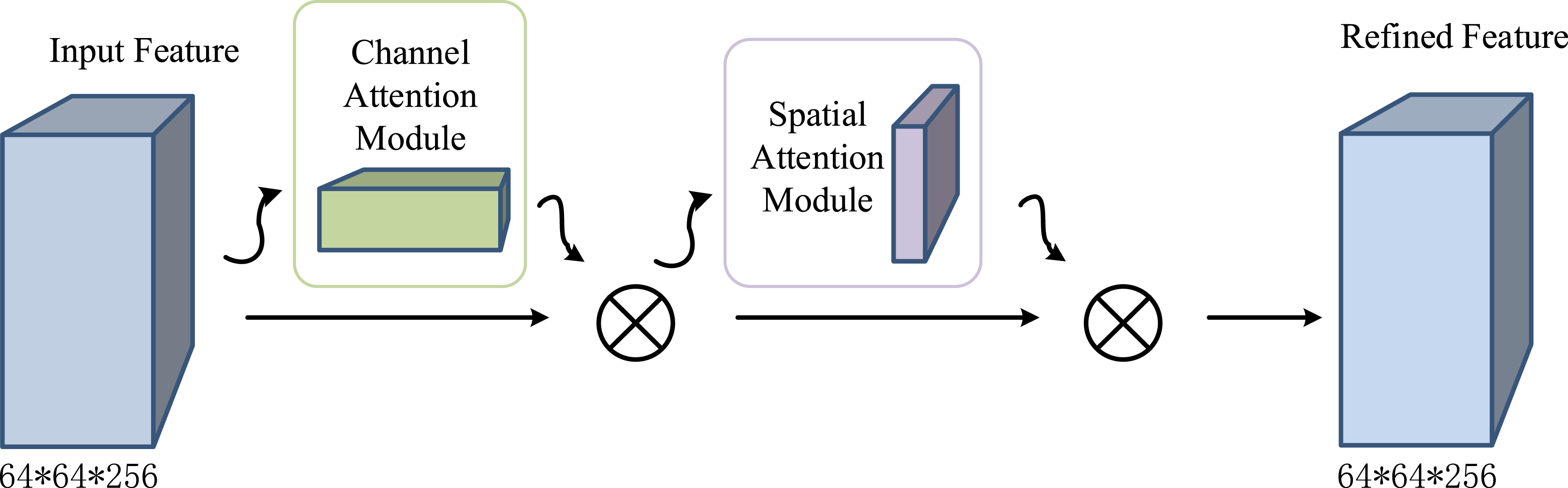
The improved CSPNet adopts the Bottleneck * N structure, in which the N value is optimized according to the specific configuration of the model. In the improved version of Yolov5s, the N value is set to 3 to balance the computational efficiency and detection accuracy of the model. The CBAM module is integrated in the middle layer of the backbone network, that is, after passing through several Bottleneck modules, to enhance the discrimination ability of the characteristics of the middle layer. The processed feature layer will be fused multiple times with other feature layers, making better use of the weighted feature layer information, as shown in equation (5).
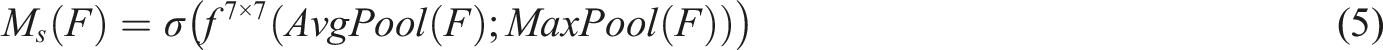
The influence of sigmoid and ReLU activation functions on attention weights.
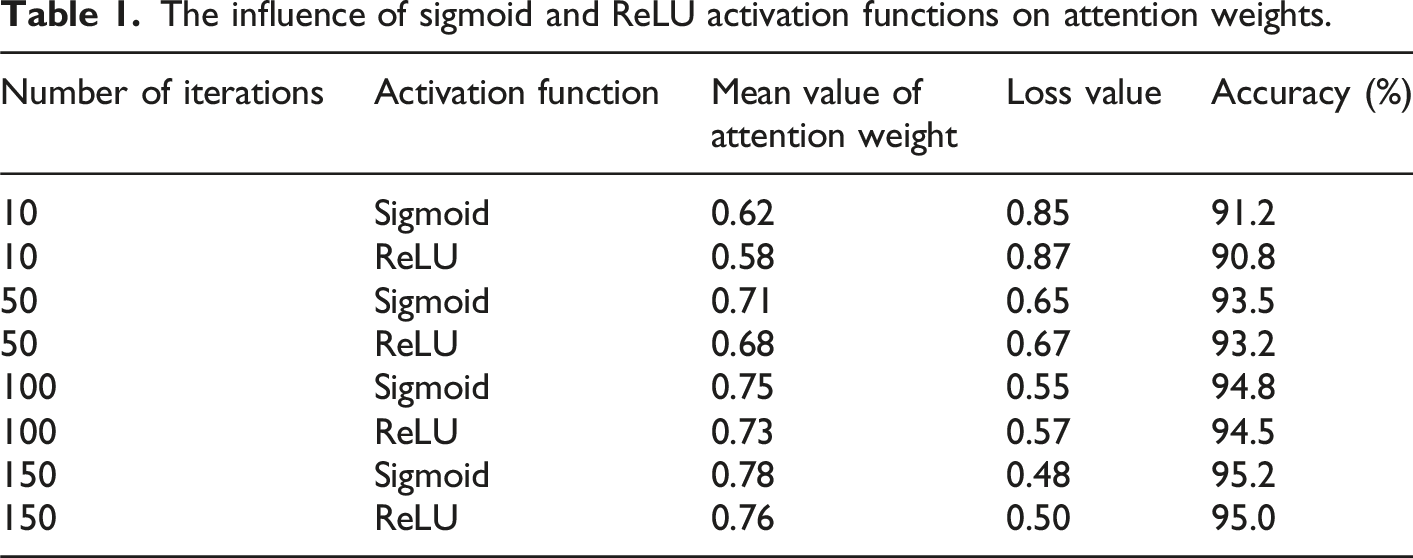
It can be seen from Table 1 that with the increase of the number of iterations, the mean value of the attention weights using the Sigmoid activation function gradually exceeds that of ReLU, indicating that Sigmoid performs better in the normalization of attention weights and helps the model focus on key features more accurately. Meanwhile, the Sigmoid activation function can achieve lower loss values and higher accuracy under a higher number of iterations. However, the ReLU activation function shows a faster convergence rate in the early iterations, which may be related to its advantages in accelerating the training process. The BFEN of Yolov5 is replaced with a network structure of deep separable convolution and grouped convolution parts.
21
The specific structural diagram is Figure 3. Improved Yolov5s partial model.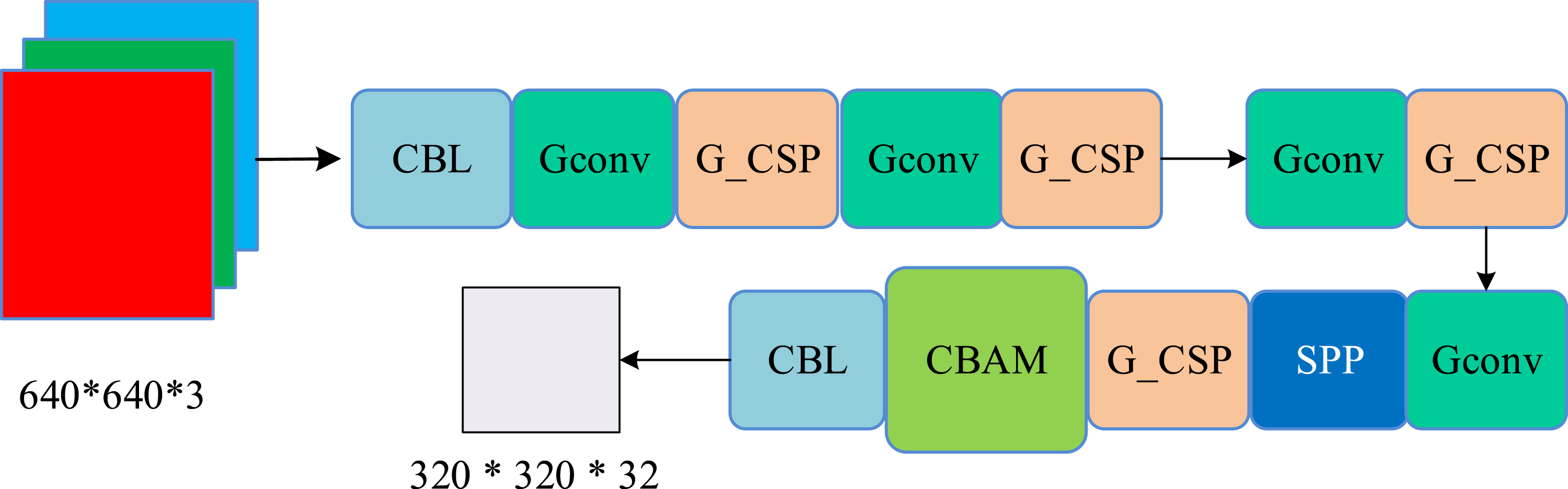
In Figure 3, CBL is a standard convolution module, consisting of a common convolution layer (Conv), a batch normalization layer (BN) and a LeakyReLU activation function layer. Grouped CSPNet (G_CSP) is a method that divides the original input into two branches. Each branch performs convolution operations to halve the number of channels. Then, one branch undergoes Bottleneck * N operations. Finally, the two branches are concatenated to produce Bottleneck CSP input and output of the same size. SPP refers to spatial pyramid pool, and CNAM is a channel attention module. The study aims to reduce computational complexity and improves the original Focus layer. By replacing it with a basic convolutional layer, the original image size was reduced from 640 * 640 * 3 to a feature layer of 320 * 320 * 32. In addition, the experiment used CBL standard convolution for image down sampling. While retaining the SPP module, local features at different scales were obtained through pooling operations at different scales, effectively expanding the receptive field of the BFEN. By using deep separability and group convolution, the number of parameters in the overall network is decreased through the decomposition steps of addition and multiplication. In addition, the CBAM has been introduced to reduce computational parameters and improve target detection accuracy.
In conclusion, the improved model replaces the original backbone feature extraction network CSPDarknet53 with a network structure consisting of depth-separable convolution and grouped convolution parts to reduce the computational complexity and network parameters. The CBAM attention mechanism module was introduced and embedded in the last layer of the backbone feature layer network. Through the combination of channel attention and spatial attention, the model’s ability to focus on the target features was enhanced. In terms of feature fusion, the improved Yolov5s retains SPP and fuses feature maps at different levels through a multi-scale feature fusion method, thereby enhancing the model’s detection ability for targets at different scales. Figure 4 shows the Pseudocode for the Improved Yolov5s + HPE Pipeline. Pseudocode for the improved Yolov5s + HPE pipeline.
In Figure 4, the provided pseudocode encapsulates the entire workflow of the proposed Yolov5s + HPE pipeline, starting with object detection using the improved Yolov5s model to identify persons within the input frame, followed by human pose estimation on the detected person regions using AlphaPose, and then classifying the detected poses into behaviors with ST-GCN, where dangerous behaviors trigger alerts and logging for further action.
Construction of laboratory monitoring system based on AlphaPose
After making a series of improvements to the Yolov5s model to enhance its detection performance, the research further applied the improved model to the monitoring system of chemical and biological engineering laboratories, and combined with human pose estimation technology to construct a complete dangerous behavior detection system. Figure 5 shows the specific detection process. Yolov5s target detection model flowchart.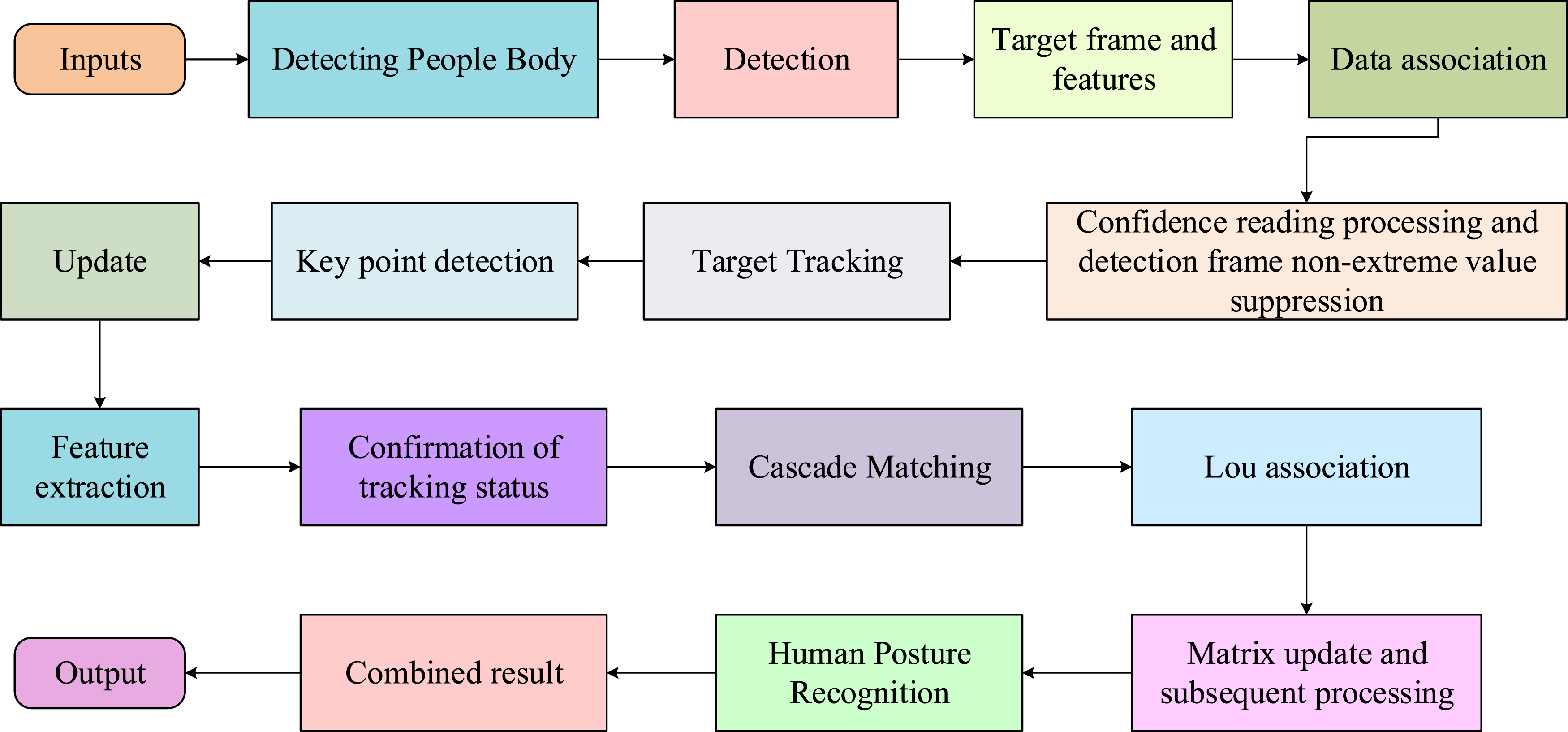
In Figure 5, deep sort utilizes the Kalman filtering algorithm to predict personnel targets detected by the previous frames of ODA to obtain more stable tracking targets. Then, the tracked indoor personnel area is cropped and input into the key point detection algorithm module, and the previously detected key point information is fed into the graph convolutional network. To classify the current action based on the key point information from the first 30 frames. Next, the camera transmits the results to the mobile end. If there are non-standard behaviors or dangerous behaviors such as accidents in the experiment, a red label will be used and a warning will be issued. If relevant rescue is needed, relevant personnel will be contacted for rescue. Deep sort comprehensively considers motion features and target appearance features in the allocation problem, and uses the square formula of Markov distance to merge motion information, as displayed in equation (6).
In equation (6), 
In equation (7), 
In equation (8), 
In equation (9), the threshold of 
In the matching stage, deep sort introduces a cascading matching method, mainly used to ensure that the most recent targets are given priority matching weights. The AlphaPose key point detection algorithm was used in the research on human key point detection. To address the issue of inaccurate human body position detected by detectors, AlphaPose has designed a new network structure called regional multi-person pose estimation (RMPE). It can simultaneously detect multiple human bodies, thereby improving detection efficiency.
23
The specific RMPE network structure is Figure 6. AlphaPose network structure diagram.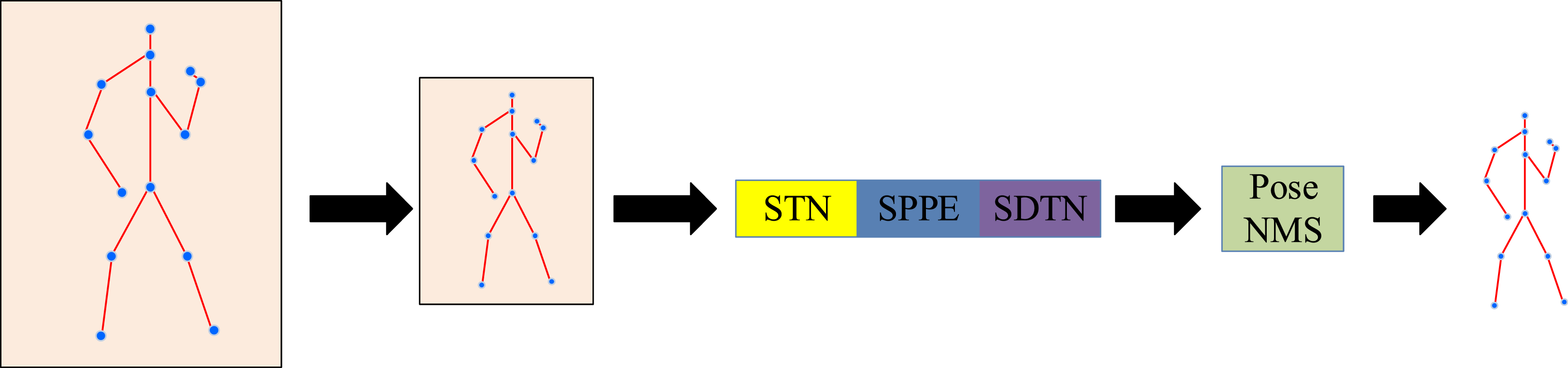
In Figure 6, the process of AlphaPose is roughly as follows: first to input the human body clipping region, then to perform feature processing through the RMPE network, and finally to output the human body key point information. AlphaPose has been improved in the single person attitude estimation phase by introducing a set of symmetric networks, namely, the Spatial Transformer Network (STN) and Spatial DE transformer Network (SDTN). In terms of mathematical principles, the affine transformation in the two-dimensional graph represented by STN is equation (11).
In equation (11), 
The non-maximum suppression of posture solves the problem of redundant human posture detection, and the relevant elimination criteria are shown in equation (13).
In equation (13), it is assumed that a measure of the similarity distance between two postures is 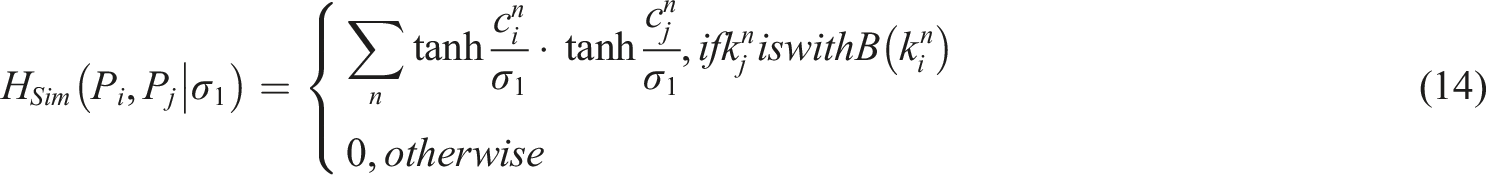
In equation (14), 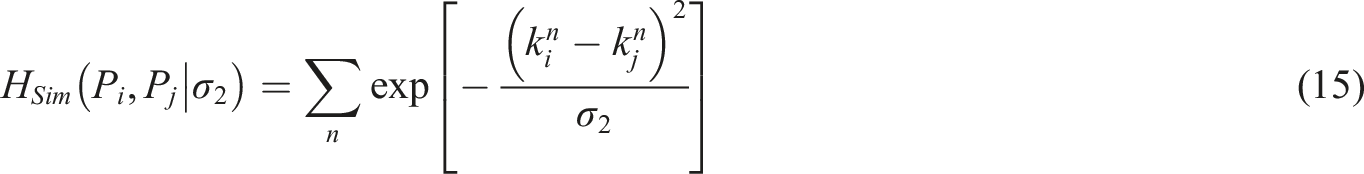
In equation (15),
The spatio-temporal graph convolutional neural network (ST-GCN) was introduced in the human pose recognition and classification stage of the study. ST-GCN focuses more on the relationship between bone connections in space and the changes in key points of the human body in time series, as shown in Figure 7. ST-GCN training general flow chart.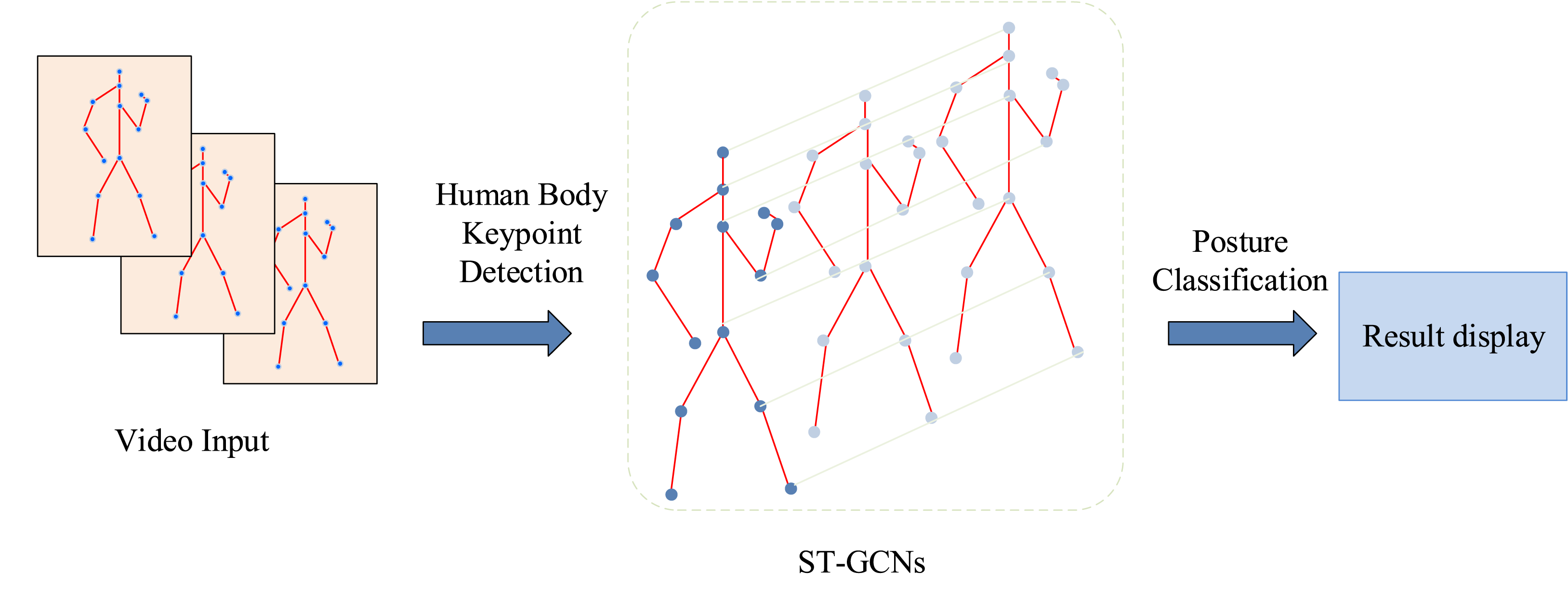
Mathematical symbols and their meanings.

Experimental result
The first step is to train the improved Yolov5s model. The improved Yolov5s is compared with the pre improvement and other relevant models, including speed, accuracy, and recall. Then, to analyze the process of HPE designed in the previous chapter and compare its training results and errors.
Training results of improved Yolov5 network model
The simulation configuration parameters.
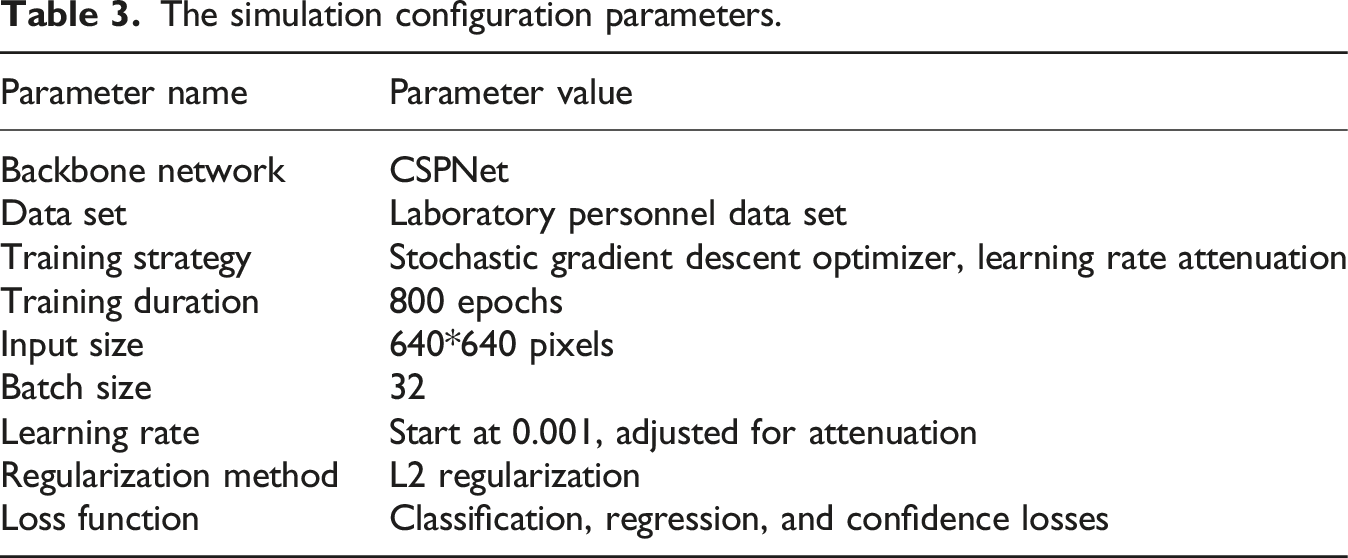
In Table 3, the study selects a CBL risk behavior dataset for training and validation. To train the model, a stochastic gradient descent optimizer is used and a suitable learning rate attenuation strategy is set. The training duration is approximately 800 epochs to ensure that the model is fully trained. The input size is set to 640 × 640 pixels to accommodate different monitoring scenarios. The batch size is set to 32 to balance training speed and memory usage. To prevent over-fitting, L2 regularization method is adopted. The loss function selects a mixed loss function, including classification loss, regression loss, and confidence loss, to comprehensively consider all aspects of target detection. The models for the comparative experiment include the improved Yolov5s and the original Yolov5s. The iterative diagrams of the loss functions for the two models are shown in Figure 8. Loss function and iterative plot of best fitness.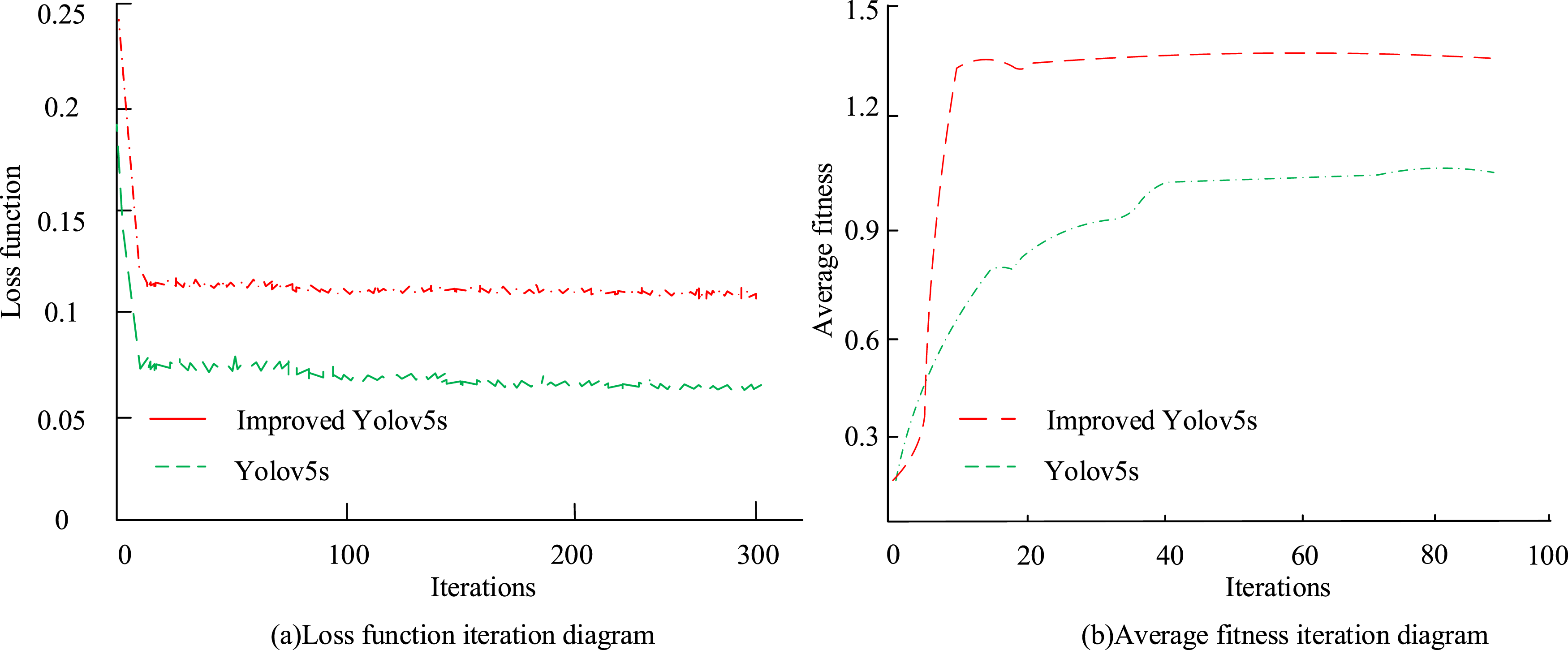
In Figure 8, the training loss function curves of the Yolov5s and improved Yolov5s models are roughly similar. In the first 15 iterations, both show superior performance in fast convergence. And after 300 iterations, the loss function can converge to around 0.1 level. In contrast, due to its more convolutional structure, Yolov5m performs better overall during the training phase, with faster convergence speed and lower loss function values. The improved Yolov5s model also has more advantages in terms of average fitness. The precision (P) and recall (R)of the improved Yolov5s and Yolov5s are exhibited in Figure 9. Precision and recall of the IYolov5s and the Yolov5s.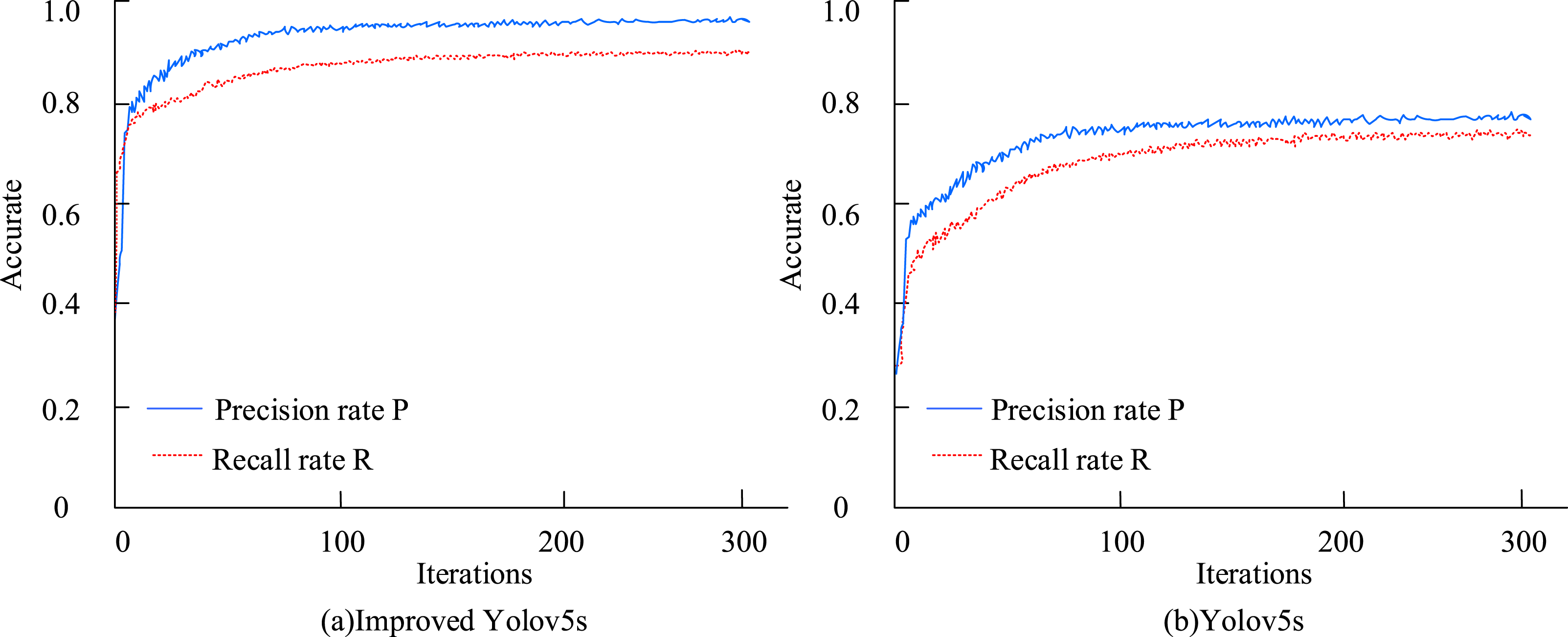
Yolov5s series metrics comparison.
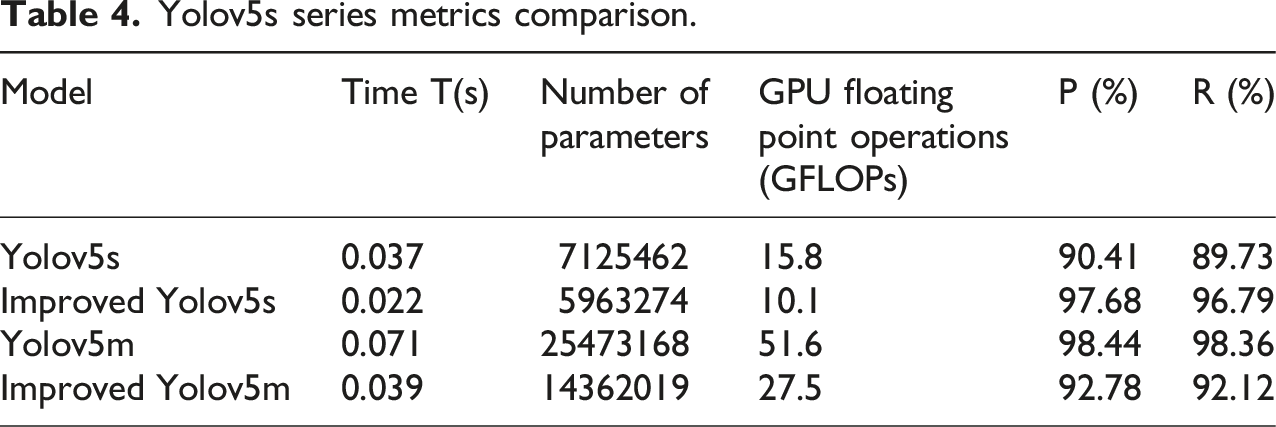
From Table 4, the improved Yolov5s model far outperforms the original Yolov5s in overall performance. Compared to the Yolov5s, the improved Yolov5s successfully reduces the number of parameters by 30% and reduces processing time by 0.015 seconds. In terms of P indicators, the performance of the improved Yolov5s is 7.27% higher than that of the Yolov5s. In terms of R index, the improved Yolov5s also achieves a performance improvement of 7.06%. The improved Yolov5s can achieve higher detection accuracy of the original model, and its performance is close to that of the larger Yolov5m model. The detection accuracy of the improved Yolov5s algorithm (Method 1) is compared with the current popular and advanced target detection methods. The methods of comparison include target detection framework based on Detectron2 (Method 2), target detection method based on CenterNet (Method 3), target detection algorithm based on EfficientDet (Method 4), and single-stage target detection algorithm based on RetinaNet, as shown in Figure 10. Comparison of detection accuracy of five methods.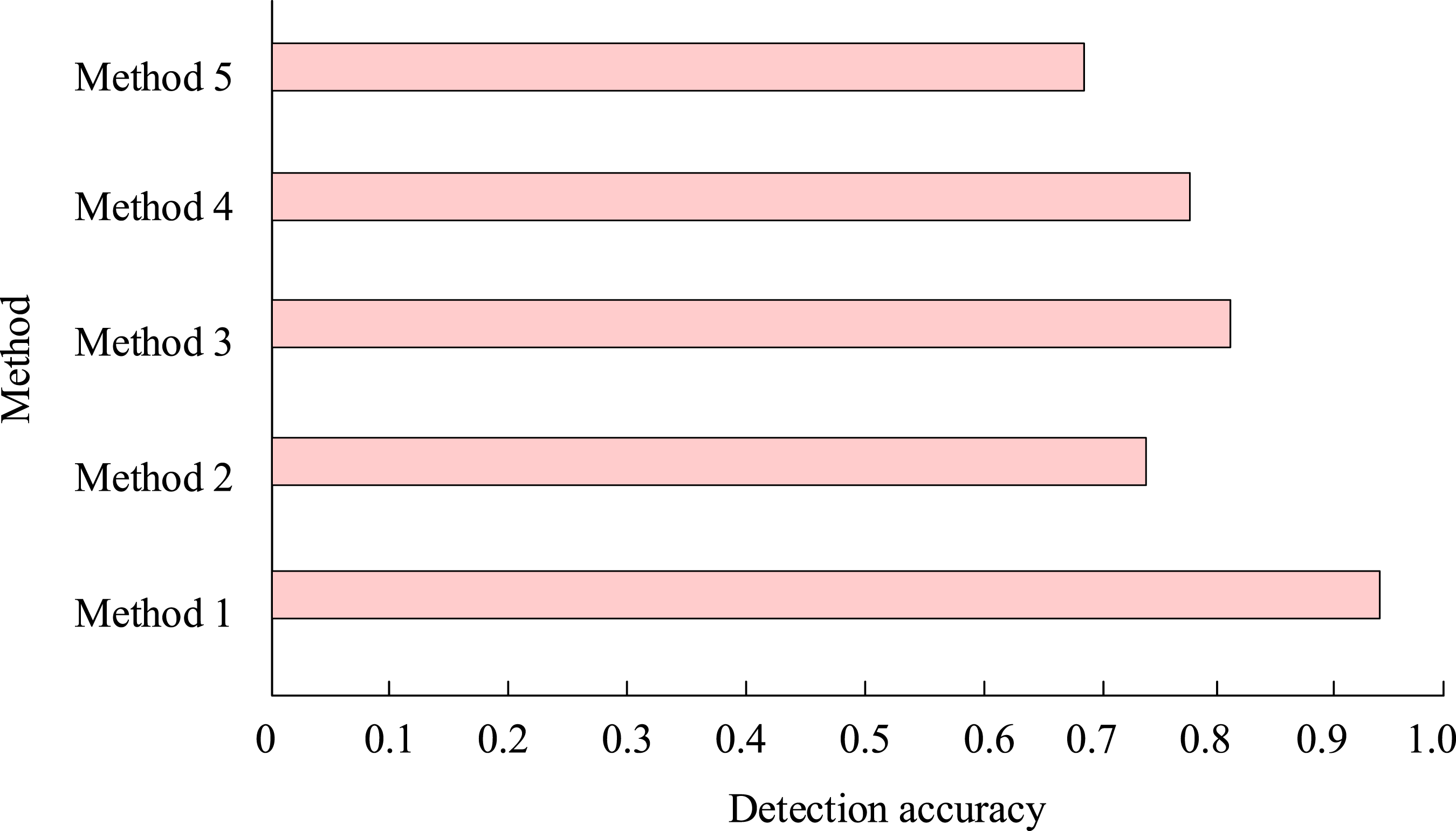
Performance comparison of different models.
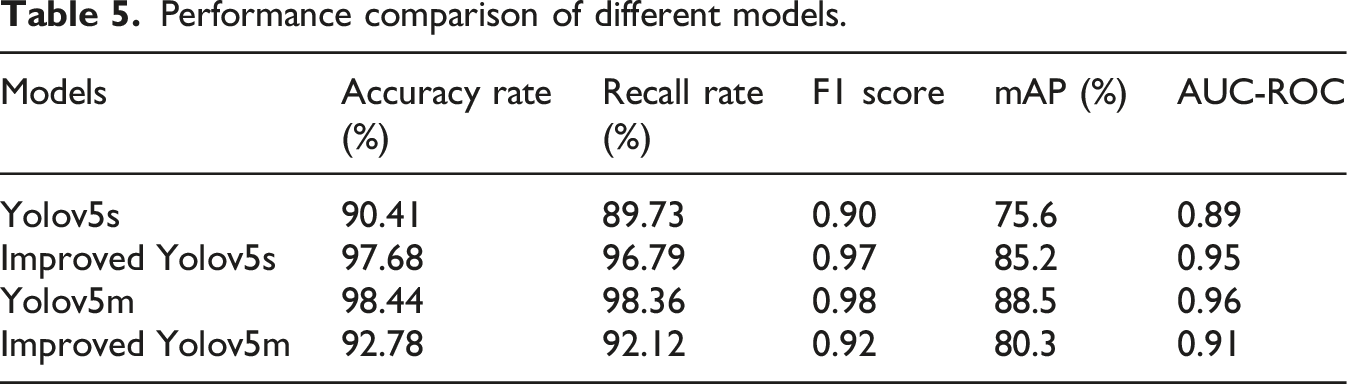
It can be seen from Table 5 that the improved Yolov5s model outperforms the original Yolov5s model in all key indicators, especially with significant improvements in F1 Score and mAP, reaching 0.97 and 85.2%, respectively. This indicates that the improved model has achieved a better balance between precision and recall, and has significantly improved the average accuracy of target detection. Furthermore, the improved Yolov5s model also performed outstandingly on AUC-ROC, reaching 0.95, demonstrating its superior performance in classification tasks. Compared with the Yolov5m model, although there is a slight gap in precision and recall rate, the performance on F1 Score and mAP is similar. This indicates that the improved Yolov5s model has fewer parameters and a faster processing speed while maintaining higher performance. These results further prove the validity and practicability of the improved model.
HPE experimental analysis
In the training phase of HPE, the training set video contains many actions, and their information changes rapidly within 1 second. The video frame rate for this experiment is 25 frames, which means there will be 25 images per second. Therefore, the time series parameters are set to 25 frames and are used to infer the action for the next frame. The specific training process is Figure 11. Training phase loss function and accuracy.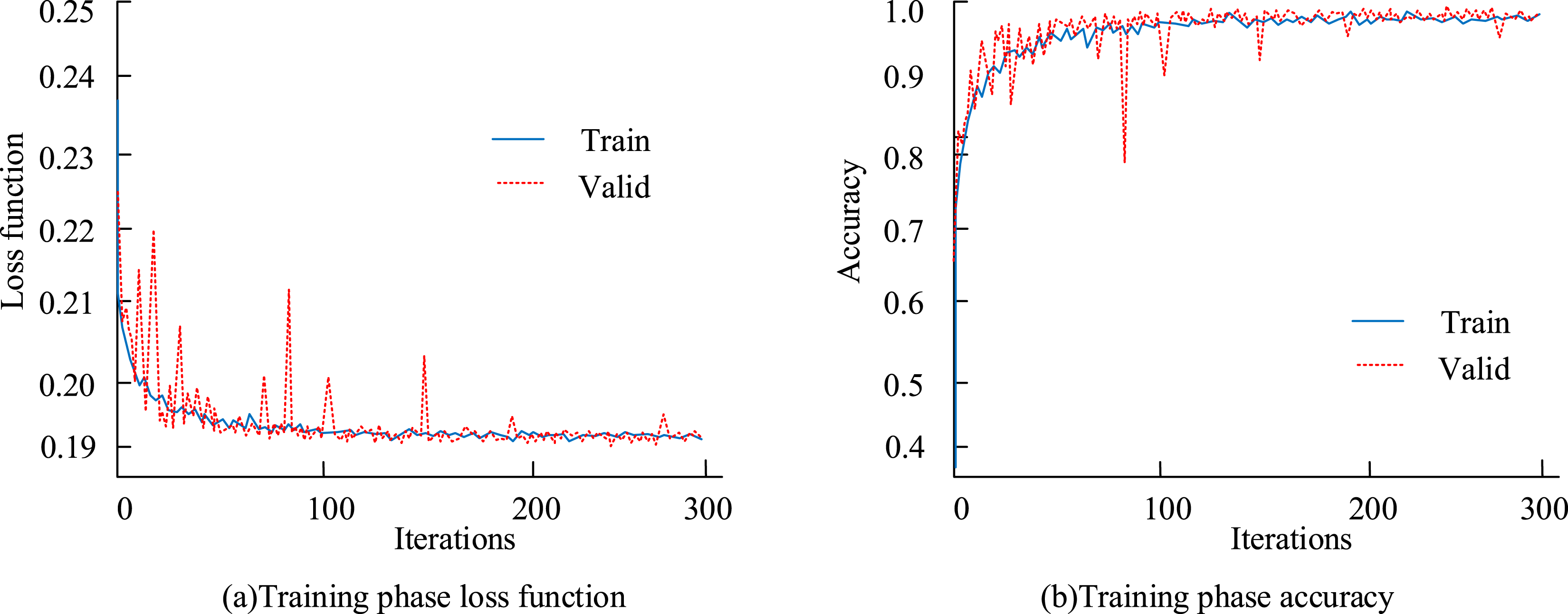
In Figure 11, the loss function value of the training set tends to smooth after the 25th iteration and ultimately stabilizes at around 0.19. The loss function value of the validation set tends to stabilize after the 75th iteration, with small fluctuations, and ultimately stabilizes at around 0.99. Overall, during the training phase, the model exhibits the advantages of fast convergence and stable convergence. Next, the pre improved and post improved models were used to predict and evaluate the final 20 sets of sample data, and the prediction results are shown in Figure 12. Human posture estimation.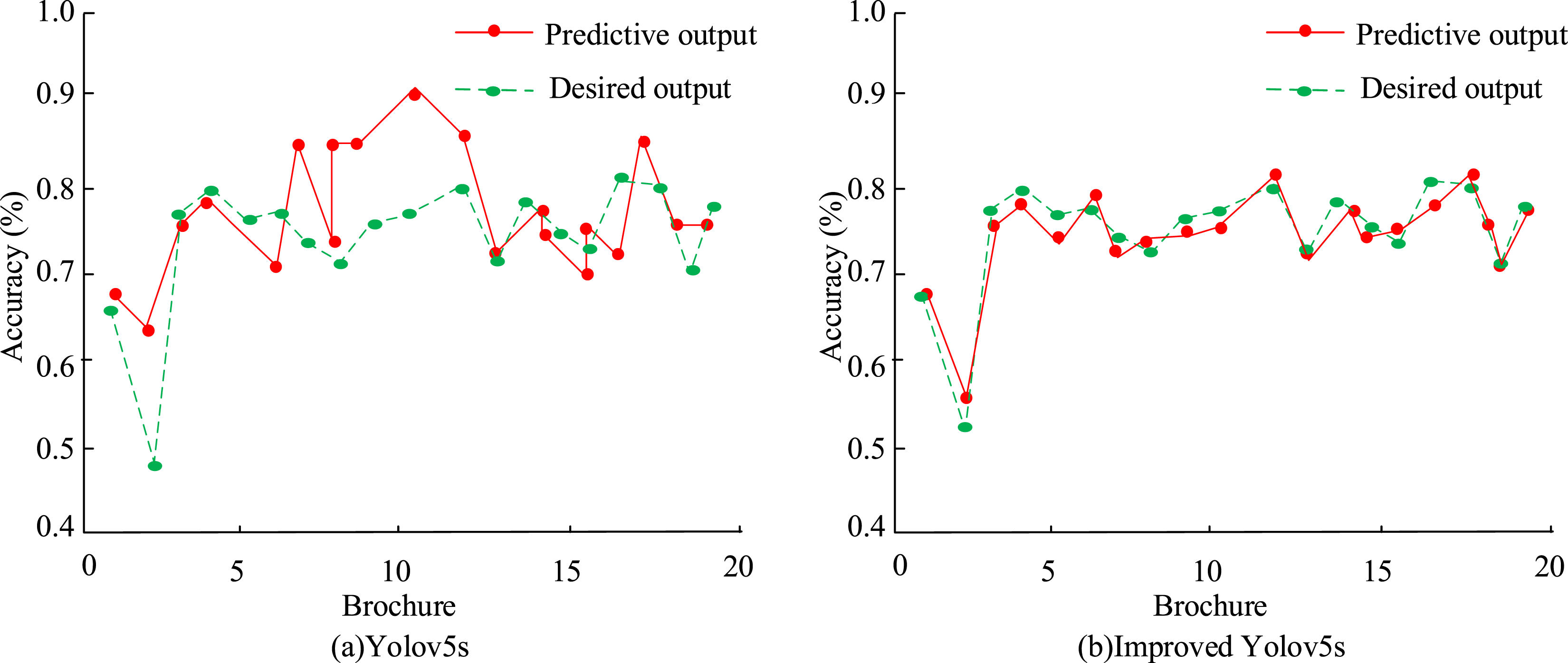
In Figure 12, the prediction error of the improved model is relatively large, while the predicted results of it are basically consistent with the actual results. The improved model has better application value and can accurately evaluate human posture. The accuracy of HPE (M1) in this experiment is compared with the current popular HPE model. The comparative models include HPE based on lightweight high-resolution network (M2), HPE based on improved hourglass network (M3), 3D HPE based on self adjusting graph convolution Unset (M4), and 3D HPE based on adaptive perceptron combination network (M5). The comparison between accuracy and recall is Figure 13. Comparison of precision and recall rates of five models.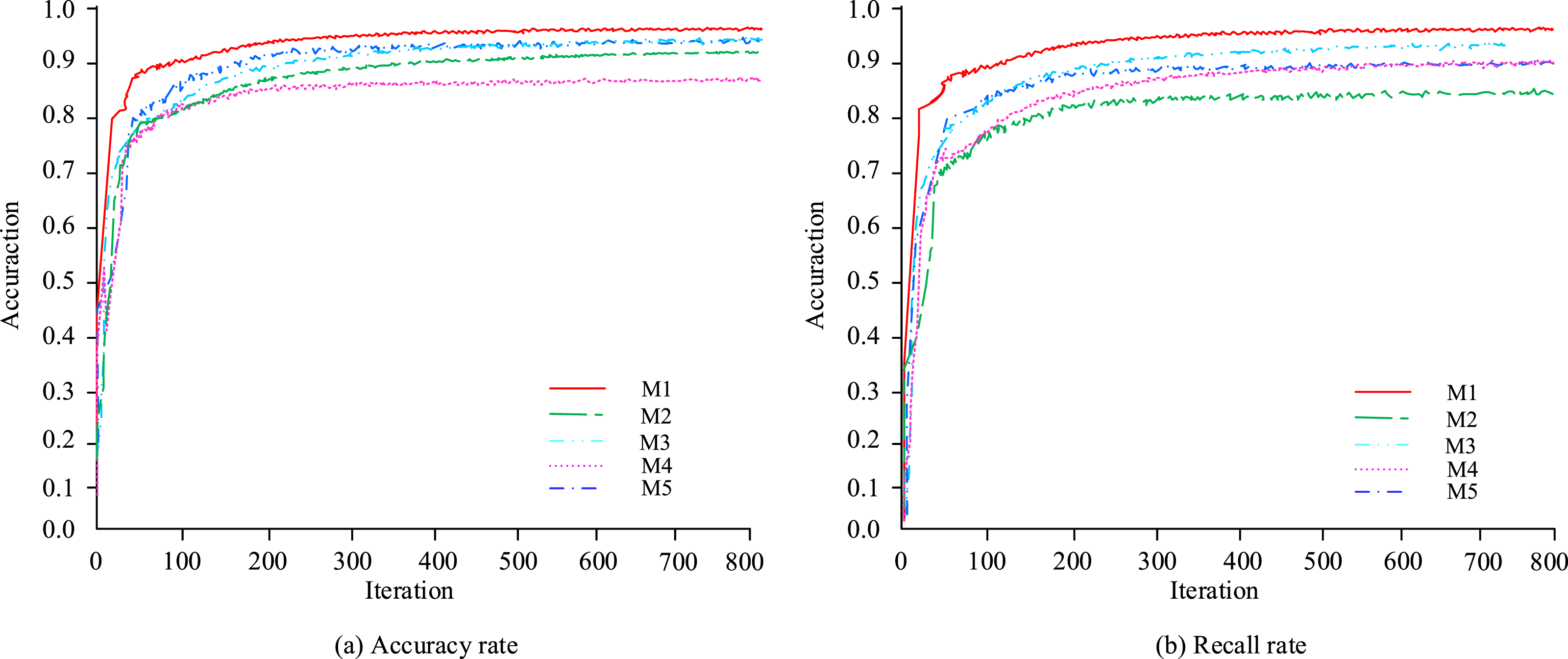
In Figure 13, Model 1 has the highest accuracy and recall rates, stable at 97.68% and 96.79%, respectively. The iteration speed of Model 1 is also the fastest. The accuracy and recall of models 2, 3, 4, and 5 are ultimately stable at over 80%. Therefore, the DBD built on the improved Yolov5s and HPE in this experiment has excellent performance of easy training and high accuracy, and will have good applications in CBL security management.
Model limitation
Model performance and ablation experiment results.
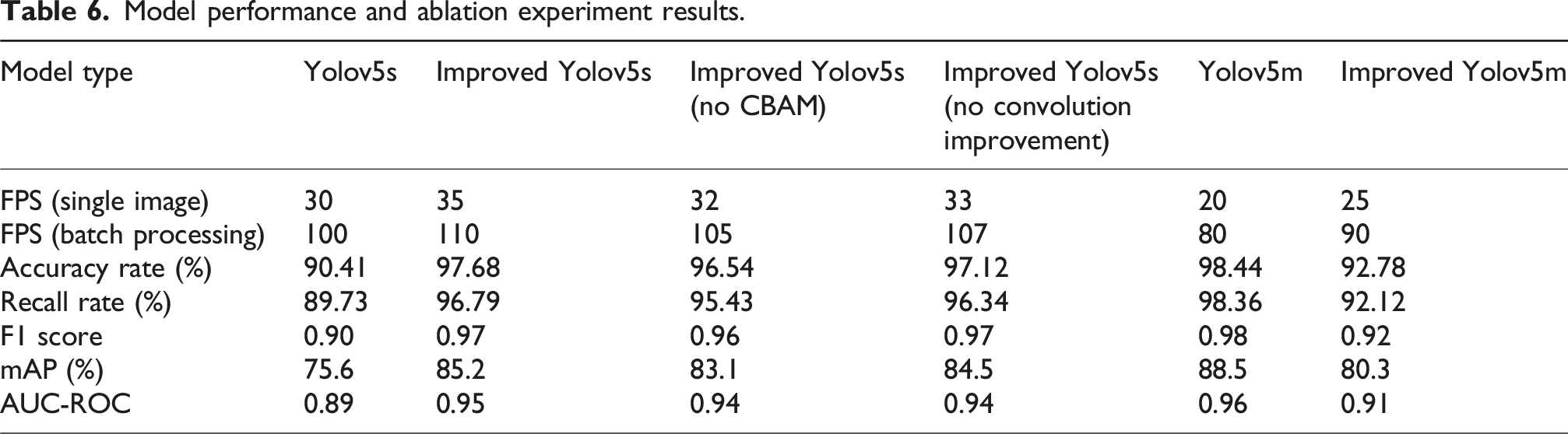
In Table 6, the improved Yolov5s model outperforms the original Yolov5s model in both single-image and batch processing inference speeds, reaching 35 FPS and 110 FPS, respectively. This indicates that the improved model not only maintains high detection accuracy but also enhances computational efficiency. The complete improved Yolov5s model performed exceptionally well in all key performance indicators, especially in terms of precision, recall and F1 score, reaching 97.68%, 96.79%, and 0.97, respectively. The ablation experiment results show that removing the CBAM attention mechanism or improving convolution will lead to a slight decline in performance, but it is still better than the original Yolov5s model, indicating that these components have a significant positive impact on the model performance. Especially the CBAM module, its removal led to a decrease of 1.14% in the precision rate and 1.36% in the recall rate, respectively, a decrease of 0.01 in the F1 score, and a decrease of 2.1% in the mAP, demonstrating the important role of CBAM in improving the model performance.
Conclusion
In response to the various hidden dangers in CBL security, this study proposed a DBD method combined with the improved Yolov5s and HPE, and applied it to CBL security management. The experiment proved that the improved Yolov5s index accuracy reached 0.9 after about 10 iterations, and converged to around 0.9 at an extremely fast iteration speed. The recall rate of the indicator also had an extremely fast convergence speed, and the recall rate gradually increased, maintaining an overall level of around 0.88 when the number of iterations was around 150. In this experiment, HPE achieved a high accuracy of 99%. When conducting DBD, improved Yolov5s HPE could significantly perfect the accuracy and effectiveness of detection. Therefore, this method can quickly and accurately detect and warn dangerous behaviors, and has important practical application value for the safety management of CBL. Through the improved target detection model and HPE technology, dangerous behaviors can be detected and warned more accurately, thus improving the safety of the laboratory. This improvement helps to reduce the probability of accidents and reduce the risk of casualties and property damage. While this study has improved the Yolov5s model, its generalization ability still requires further enhancement when dealing with diverse scenarios and data distributions. The model may experience performance degradation in new environments and situations, which necessitates further research and improvement. Future research could combine other modal information, such as audio and text, with visual information to enhance the accuracy and reliability of risky behavior detection through multi-modal fusion.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.