
Abstract
As the digital age progresses, gamified learning emerges as a transformative force in education, especially in the realm of environmental studies. This research delves into enhancing environmental education by integrating gaming principles with educational objectives, aiming to create immersive learning experiences. However, traditional gamification approaches in environmental education often overlook the intricate group dynamics and individual learning trajectories of students. Addressing these gaps, this study focuses on optimizing task recommendations and game progression in gamified learning environments through the implementation of advanced attention mechanisms and bidirectional long-short term memory (Bi-LSTM) neural networks. These technologies enable precise predictions of students’ evolving preferences and facilitate the customization of learning tasks, thereby enriching the educational experience. Furthermore, the study explores adaptive strategies for modifying game progression based on real-time learning outcomes, ensuring that educational content remains challenging yet attainable. The insights gained from this research provide a robust theoretical framework and practical tools for effectively employing gamification strategies in environmental education, thereby fostering deeper student engagement and a profound understanding of environmental issues. This study explores the adaptive adjustment of progress plans in gamified learning by focusing on identifying deviation intensity, processing priorities, and determining the appropriate range of deviation values. These findings not only optimize the gamified learning structure but also enhance the personalized instructional effectiveness of educational games.
Keywords
Introduction
The rise of digital technologies has sparked a surge of interest in gamified learning across the educational landscape.1,2 In the realm of environmental education, the challenge of enhancing student engagement, awareness, and commitment to environmental preservation through interactive and immersive methods has been notably acknowledged.3–6 This challenge can be addressed by integrating gaming design principles with educational goals, thereby opening new pathways for gamified learning.
In the context of environmental education gamification, various strategies have been identified that boost students’ enthusiasm for learning and foster the development of a profound connection with and understanding of environmental issues.7–9 Effective gamification techniques are believed to create an engaging and dynamic educational environment, where students can actively participate, reflect, and take action within the game setting. This environment promotes authentic knowledge acquisition and skill development. 2 Hence, examining effective gamification approaches for environmental education is deemed essential for its enhancement and deepening.
However, current gamification strategies in environmental education face challenges. One significant issue is the neglect of differences in student group dynamics over time, leading to a mismatch between the tasks offered by the game and the actual needs and preferences of students.10–13 A generic view of learning behaviors often fails to fully address the diverse learning conditions and requirements of students.14–17 The challenge of dynamically customizing game progression based on real-time student learning outcomes remains a significant hurdle to overcome.
This study focuses on two main areas. The first is the recommendation of tasks within the gamified environmental education framework. By employing an attention mechanism, it was possible to integrate gamified learning behaviors across different time granularities of student groups. The use of Bi-LSTM neural networks enabled the capturing of group dynamics and individual student gamified learning behavior sequences, leading to a comprehensive understanding of diverse behavioral patterns. This method has proven effective in identifying student preferences in gamified learning scenarios with greater precision, thus enabling the delivery of tailored game task recommendations that better align with student needs. The second area of focus is on adapting game progression based on adaptive learning outcomes, aiming to identify the extent of game progression adjustments and develop control rules for adaptive learning outcomes. The insights from this research contribute to both the theoretical understanding and practical application of gamified strategies in environmental education, offering robust tools and methods for designing and implementing gamified learning experiences.
Key findings of this study include the precise prediction of gamified task recommendation within environmental education through the application of attention mechanisms and Bi-LSTM. The effectiveness of gamified learning was enhanced by adjusting game progress adaptively based on learning outcomes. However, this method is restricted to specific gamified learning environments and datasets, which may limit direct generalization to other fields or broader educational contexts. Additionally, challenges remain in accurately predicting and adjusting for complex learning dynamics and student behavioral characteristics, necessitating further research and methodological refinement to improve predictive precision and adaptive adjustment accuracy.
The attention mechanism and Bi-LSTM technology are integrated within the learning environment to analyze and predict student behavior in gamified learning. The attention mechanism focuses on critical factors within student behavior, while Bi-LSTM extracts temporal features from behavioral sequences and incorporates the impact of collective student behavior. Such a model design more accurately captures dynamic student preferences, enabling the recommendation of personalized, multi-label game tasks and adjusting game progress to align with individual learning outcomes. This ensures that the gamified learning process remains challenging yet avoids inducing student frustration.
Enhancing environmental awareness through gamified task recommendations
The theoretical foundation of gamified learning lies in harnessing game design elements and principles to stimulate learners’ intrinsic motivation, thereby enhancing engagement and persistence to improve learning outcomes. When aligned with the objectives of environmental education, gamified learning can be structured to incorporate environmental protection tasks and educational scenarios. Through interactivity and entertainment, students are encouraged to learn environmental protection knowledge while playing, forming positive environmental behavior habits. This approach seeks to achieve dual objectives of education and entertainment.
The quest to instigate environmental awareness within the educational sphere has gained momentum, underscored by the transformative potential of gamified learning.18,19 This innovative approach, noted for its capacity to enrich and potentiate the educational journey, offers a refreshed perspective on environmental education. In our investigation, the fusion of attention mechanisms with Bi-LSTM neural networks served as a pivotal methodology for delving into the nuanced learning behaviors across diverse student groups and temporal scales. This comparative analysis of individual learning patterns enabled the generation of tailored gamified task recommendations for each learner. Such personalized tasks have been shown to not only boost students’ enthusiasm and engagement in environmental topics but also to methodically enhance their knowledge and skills in environmental stewardship. Crucially, these strategies offer immediate or nearly immediate feedback, empowering students with a clearer understanding of their learning progress and needs, which is conjectured to significantly improve their educational outcomes and satisfaction.
The central focus of this research was to unravel the complexities of gamified task recommendation within environmental education. It aimed to conduct an exhaustive analysis of students’ gamified learning behaviors, scrutinizing them from various angles and across different time frames. By documenting interactions within student cohorts and conducting detailed analyses of individual behaviors, the study aimed to extract predictive insights into students’ evolving preferences, guiding the allocation of fitting gamified tasks. A formidable challenge in this exploration was accurately capturing the wide array and dynamic nature of student learning behaviors. Additionally, amalgamating insights at both the collective and individual levels was essential for furnishing students with pertinent and effective gamified tasks tailored to environmental learning.
Definition 1: A sequence of gamified learning behavior, specific to an individual student, is constituted from multi-view learning behavior data, offering a continuous prediction of the student’s behaviors over a predetermined period. This sequence encapsulates the student’s learning patterns across disparate behavioral viewpoints and temporal granularities, amalgamating interactional attributes from the group and individual behavioral traits. Predictions about their imminent learning preferences and requirements are thus deduced. The number of varied tasks engaged by a student u over T terms is denoted by Z iu = {z iu 1,zi u 2,…,z iu t }. The variety of tasks engaged by the same student u across L learning phases is represented by O iu = {o iu 1,oi u 2,…,o iu l }. Lastly, the diversity of tasks student u partakes in during F learning units is denoted by W iu = {w iu 1,wi u 2,…,w iu f }.
Definition 2: The sequence representing the collective gamified learning behavior of the student group encompasses aggregated behavioral data from all students within a predetermined gamified learning timeframe. This includes collaborative or competitive interactions of the group over different time granularities, alongside the individual responses and engagement levels of the group. The variety of tasks that the student group undertakes over T terms is signified by Z H = {z H 1,z H 2,…,z H t }. The quantity of diverse task types the group partakes in during L learning phases is captured by O H = {o H 1,o H 2,…,o H l }. The myriad tasks engaged by the student group within F learning units are represented by W H = {w H 1,w H 2,…,w H f }.
Definition 3: The predictive sequence of an individual’s dynamic gamified learning behavior catalogs continuous data for a student within a designated gamified learning span. This sequence charts interactions, selections, preferences, and student reactions during the gamified process, presenting foundational data for an enhanced grasp of their learning motivations and styles. It is inferred that the known behavioral sequence predicts the student’s future interactions, represented by an M-dimensional vector C∼ = {c1,c2,…,c m }. Each constituent in C∼ denotes the likelihood of the student favoring a specific task type in subsequent engagements.
This section introduces a comprehensive multi-view predictive network model tailored for analyzing dynamic gamified learning behaviors among students. Designed as a holistic approach for suggesting game-based tasks, this model focuses on forecasting the multifaceted dynamics of student engagement in gamified learning scenarios. It integrates three critical elements: the extraction of interactive features within student cohorts, the collaborative synthesis of diverse gamified learning behaviors, and the execution of multi-label predictions. Detailed discussions on the operational mechanics, structural configurations, and underlying concepts of these components are presented.
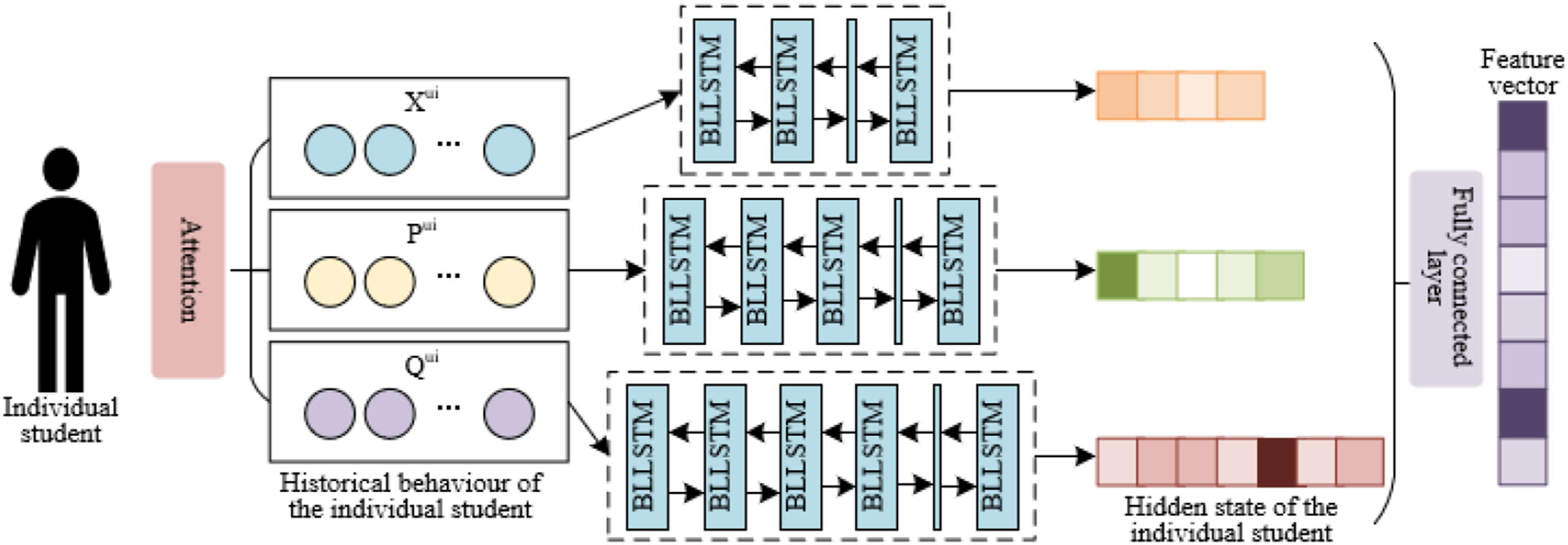
The primary aim of this model is to intricately map out the interactions and learning trajectories of student groups, capturing their essence across various temporal dimensions. This enables a comprehensive portrayal of the prevailing learning tendencies and distinct characteristics within the student body. To achieve this, an attention mechanism plays a pivotal role, meticulously weighting the behaviors of student groups over successive periods. This technique empowers the model to highlight specific behaviors that significantly impact the learning process at critical moments. The architecture and functionality of these mechanisms are depicted in Figures 1 and 2. Architecture of the student group behavior feature extraction module. Architecture of the individual student behavior feature extraction module.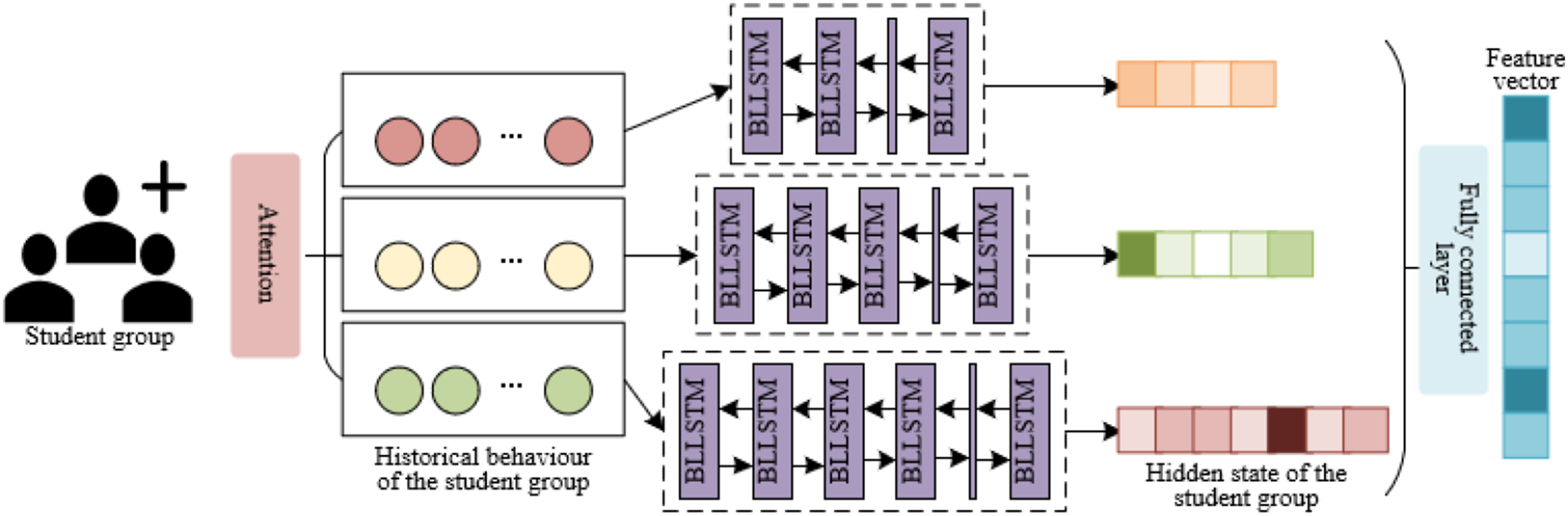
The impact of one student, referred to as student k, on another, student u, is quantified through the function s(i
u
,i
k
). Within this network, the parameters j, q1, and q2 signify the network’s structural constants, whereas c encapsulates the historical behavioral data pertinent to a given student. The formula designed to ascertain the level of similarity or attention between a student and their peers in the group is articulated as follows:

Through the utilization of the attention mechanism, inputs are allocated distinct weights, reflecting their varying levels of importance. This process involves scrutinizing the behaviors of student groups across separate temporal intervals and leveraging the mechanism to ascertain a weighted feature of group interactions. Consequently, for student u, a new vector representation is formulated by amalgamating the attention values obtained from the aforementioned equation with the historical behavioral data of their peer, neighbor k:

To facilitate a straightforward comparison of relational coefficients among students, the weights associated between student u and their B neighbors within the group H are normalized employing the softmax function:

The degree of integration for the gamified learning behavior of student u within group H, denoted as HC(e), is calculated by considering the influence weight of neighbor i
b
on student i
u
, symbolized by s(iu,ib), and incorporating the historical behavior data of neighbor i
b
, represented as C(e)
ib
. This formulation captures the collective gamified learning dynamics within the group.

It’s important to clarify that for e = 1, the historical behavior data C(1)
ib
corresponds to Z
ib
; for e = 2, it translates to O
ib
; and for e = 3, it becomes W
ib
. The collaborative encoding module for multi-gamified learning behaviors endeavors to merge the learning sequences of individual students with those of the wider student group, aiming for a comprehensive understanding of behaviors. This merger is crucial for uncovering insights that might be overlooked when analyzing student behaviors solely on an individual or collective basis. The module incorporates Bi-LSTM, esteemed for its capability to capture both long-term dependencies and the bidirectional context within sequential data (referenced in Figure 3). This process involves encoding the gamified learning behavior sequences of individual students. By integrating these with the group’s interactive features, a deeper comprehension of learning behaviors is achieved. Notably, Bi-LSTM consists of two components: a forward and a backward LSTM. The output of the hidden layer state from the forward LSTM at time y is indicated as gy,d, and from the backward LSTM as gy,n, resulting in the combined hidden layer state output from Bi-LSTM at time y being represented as g
y
= [gy,d, gy,n]. Architecture of the Bi-LSTM network model.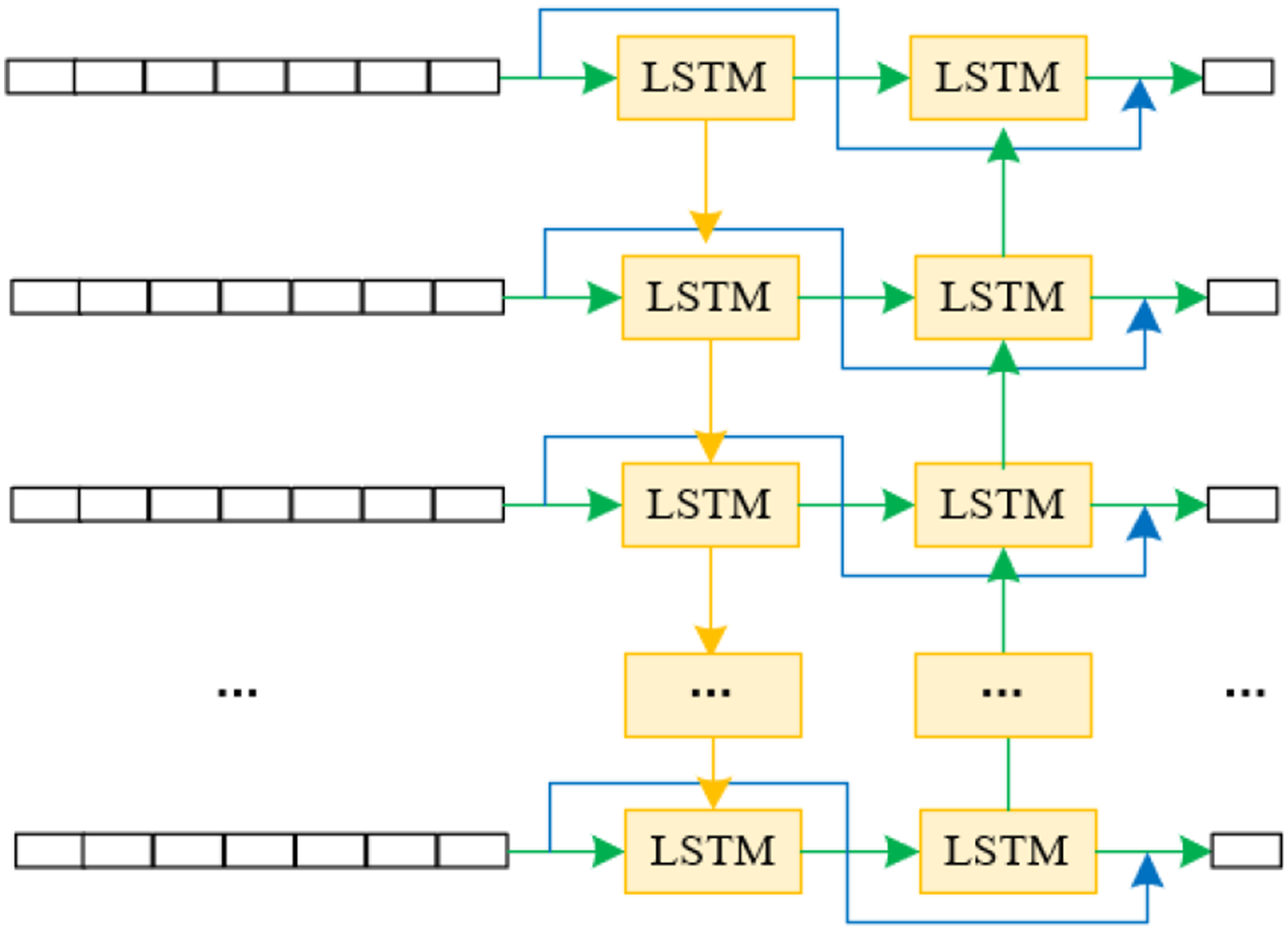


This analysis involves examining the specific historical behaviors of an individual student across various dimensions: z learning units, t learning phases, and x semesters, represented as Z iu , O iu , and W iu , respectively. These dimensions, alongside the collective historical behaviors of the group, denoted as Z H , O H , and W H , facilitate the derivation of encoded representations for both individual and group learning dynamics, labeled as A Z , A O , A W for individuals, and G Z , G O , G W for groups. This comprehensive framework allows for an in-depth evaluation of gamified learning behaviors and their interplay within educational settings.
The objective of this module is to forecast the evolving preferences of students based on their encoded gamified learning patterns. Diverging from conventional single-label approaches, a multi-label classifier is employed to anticipate a variety of potential game tasks for each student. This predictive capability enables the module to pinpoint and decode the learning tendencies of students, leading to the recommendation of an array of game tasks that resonate with their identified preferences. The fusion of the collaborative encoding module for multi-gamified learning behaviors with the multi-label prediction mechanism is depicted in Figure 4. Architecture for the multi-gamified learning behavior collaborative encoding and the multi-label prediction modules.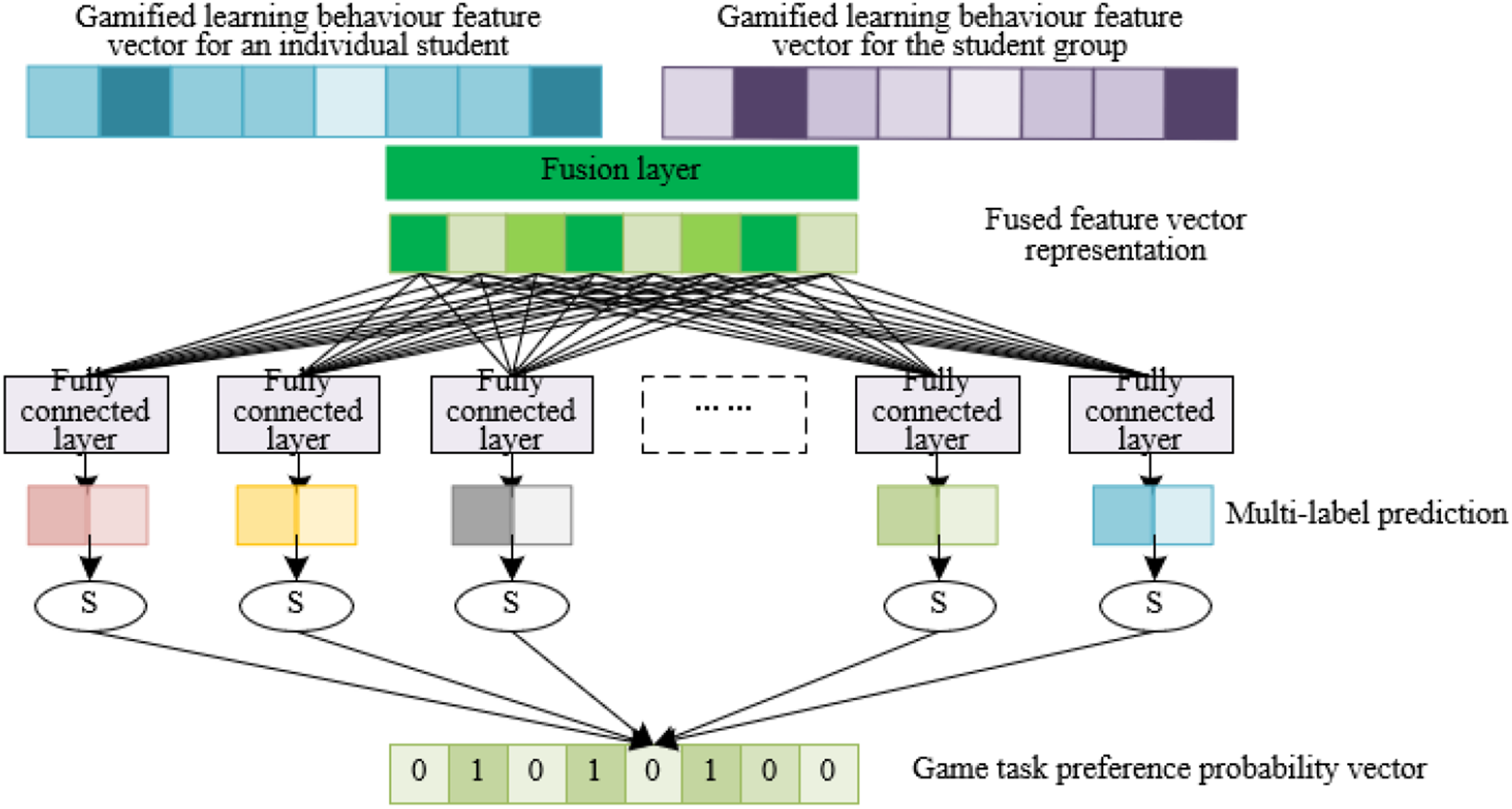
To transform model outputs into a detailed probability distribution, the softmax activation function is utilized in the output layer. This choice is predicated on its efficacy in producing probabilistic outcomes, implying that the forecasted values tied to each game task label can be interpreted as the likelihood of the task being apt for the student. This approach proves to be particularly valuable for multi-label assignments, as it delineates a hierarchy or priority among the various labels. Given that the output from the k-th fully connected layer for a specific student u is symbolized by D
iu
k
, with Q
k
and n
k
representing the trained parameters for this layer, the ensuing calculation is presented:

The cross-entropy function was selected as the loss function due to its proven efficacy in measuring the divergence between predicted probability distributions and the actual label distribution. In the context of multi-label classification, it is understood that this choice effectively motivates the model to align its probability predictions as closely as feasible with the genuine label distribution. By optimizing the cross-entropy loss, training and adaptive refinement of the model weights are enabled, thus enhancing the model’s prediction precision and resulting in more bespoke game task recommendations for students. Given that the aggregate number of training samples is denoted by B, the entirety of discerned task categories by M, the inclination of the u-th student toward the k-th gamified learning task category by T
iu
k
, and the preference probability of the u-th student for the k-th task category represented by δ(D
iu
k
), the computation is formulated as:
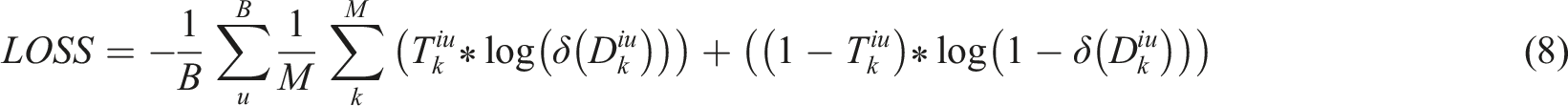
The gamified learning progress adjustment model takes into account dynamic variations across different student groups, including knowledge mastery, learning pace, and areas of interest. The model’s performance and applicability in varying contexts depend on the characteristics of the student group and the specific requirements of the gamified learning environment. For instance, in a diverse student group, the model may need to flexibly adjust the task recommendation algorithm to accommodate differing learner needs. In more homogeneous groups, the model may demonstrate greater stability and accuracy. For groups where interests vary significantly or learning abilities are inconsistent, the model can enhance educational outcomes by personalizing the learning path through adaptive learning effectiveness control rules.
Adaptive learning outcomes shaping game progression
This research delves into how adaptive learning outcomes shape the course of game-based learning, aiming for a personalized educational journey. The central goal is to create an environment that precisely caters to each learner’s strengths and needs. Through careful tracking of students’ feedback and their progress in game tasks, adjustments can be implemented instantly to the complexity, content, and pace of these tasks. This approach ensures a stimulating and engaging learning environment that matches the pace of each learner. Additionally, it is acknowledged for its ability to boost student engagement and immersion, reduce potential frustrations, and streamline the learning experience. The foundational concept behind this adaptive strategy is detailed in Figure 5. Principle of the game progression adjustment strategy based on adaptive learning outcomes.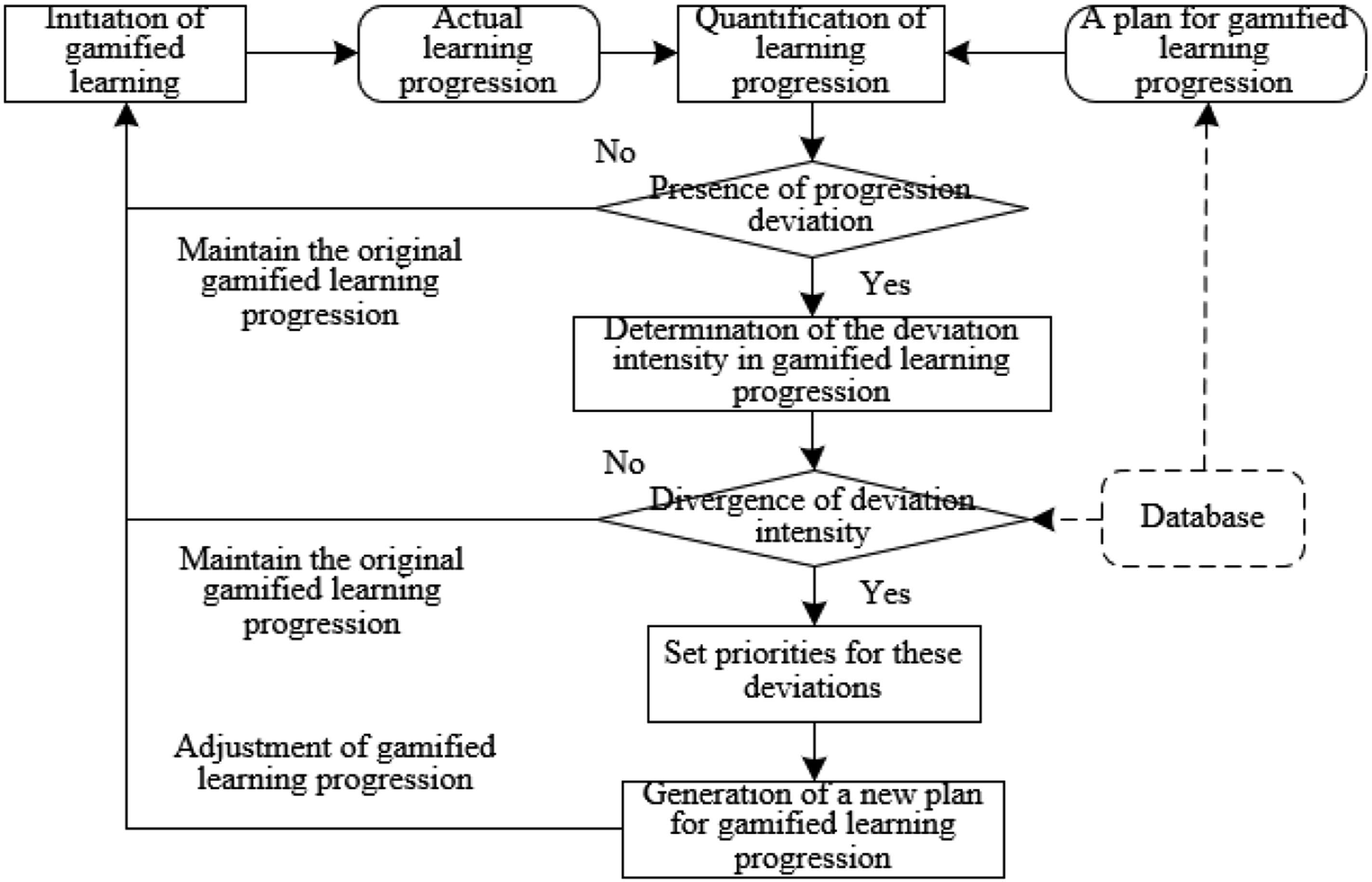
In the realm of gamified environmental education, there’s a critical need for fine-tuning the learning progression. These adjustments are designed to refine the learning experience by aligning it with the individual abilities and requirements of each student. Initially, this involves assessing the variance in the learning progression, with the main aim being to measure the gap between a student’s actual and expected progression, laying the groundwork for subsequent modifications.
Based on this analysis, rules for guiding adaptive learning outcomes are established. Merging real-life learning contexts with student feedback, personalized learning paths and task suggestions are crafted for each student. This method not only maintains high levels of student motivation and engagement but also creates a supportive educational environment through the integration of immediate feedback and adjustments. This environment challenges learners within their capacity, thereby improving both the effectiveness of learning outcomes and student satisfaction.
The intensity of deviation within game progression is crucial for identifying the gap between students’ actual learning experiences and predefined progress markers. These discrepancies can stem from various factors, such as differences in learning speeds, adaptability to the complexity of tasks, or interests in specific game activities. Evaluating the intensity of deviation goes beyond merely counting the tasks completed by students; it also considers the quality of their performance, thereby ensuring that learning goals are genuinely met. If we represent the intensity of monitoring the adaptive learning effect by β
u
, the intensity for monitoring the learning period at control point JC*
u
by β
u
, and denote the actual and desired learning periods for JC*
u
as YJC
u
and YJC*
u
, respectively, while designating the fluctuation coefficient for learning period control as c, we propose the following formula:

Variations in progress may call for tailored interventions. Certain deviations could result from temporary obstacles or lack of interest, while others may be rooted in deep-seated misunderstandings or require more focused instruction on specific subjects. By prioritizing these deviations, educators can methodically tackle the most critical issues first, thereby enhancing learning efficiency. Assuming that the highest and lowest intensities for monitoring the learning period at the control point JC*
u
are defined as β
uMAX
and β
uMIN
, respectively, and the longest and shortest durations for learning tasks within the ideal game progression framework H are indicated by YJC
uMAX
and YJC
uMIN
, respectively, the proposed calculations proceed as follows:


To effectively manage and standardize adjustments in game progression, specific thresholds for deviation intensity have been established. These thresholds ensure that changes are made only when deviations exceed or fall below predefined limits, maintaining that minor discrepancies, likely irrelevant to overall learning success, do not trigger unnecessary adjustments. This method ensures prompt action is taken when truly essential, enhancing the learning process’s efficacy.
In fine-tuning the progression of gamified learning to match adaptive learning outcomes, the overarching goal is to maintain a consistent alignment between a student’s learning journey and their unique needs and abilities. Simply recognizing deviations in student progress is deemed inadequate; there is a pronounced emphasis on identifying precise modifications needed in learning tasks at specific junctures. The concept of the “actual adaptive learning outcome completion adjustment amount” has been introduced to summarize the necessary strategies for realigning students with their intended learning path. For instance, deviations identified at certain checkpoints might signal difficulties with particular subjects, suggesting that students may benefit from additional practice or more detailed explanations. This study proposes that such adaptive actions can significantly improve the uniformity and effectiveness of gamified learning, underscoring the value of tailored educational experiences. This entails crafting and adjusting learning routes to cater to each student’s distinct needs, thereby optimizing potential learning achievements. In the event of deviations at checkpoint JC*
u
, the formula for calculating the actual adaptive learning outcome completion adjustment amount, Δy, is proposed as follows:
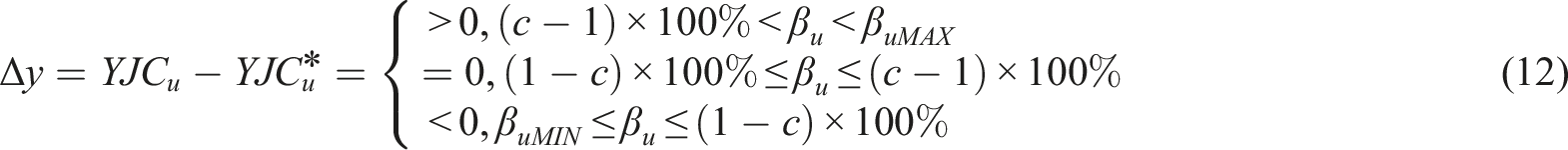
Regarding JC* u , the rules for adjusting the completion of adaptive learning outcomes are distinguished into various categories:
Steady Learning Cycle Rule: This rule is applied when a student’s progress in gamified learning aligns with expectations or minor deviations fall within acceptable ranges. It suggests that such slight differences are unlikely to significantly affect the overall learning framework. Therefore, it is proposed that students continue on their set learning path without the need for extra actions. This rule is commonly relevant for most students, promoting ongoing learning while providing them with a level of self-direction and adaptability. In particular, when Δy equals 0, indicating no adjustment is needed, the signal strength for monitoring the actual learning cycle YJC u at JC* u , labeled as β u , is observed to be within the range of (1-c)×100% to (c-1)×100%. In these scenarios, making changes to the learning plan is considered unnecessary, keeping the intended learning cycle unchanged.
Extended Learning Cycle Rule: This rule comes into play when students encounter difficulties with specific game tasks or complex subject matters, causing their learning progress to be slower than expected. Under these conditions, it is recommended that educators or systems provide extra time and resources to help students overcome these barriers. Possible measures include additional practice, increased educational support, or customized learning aids. Extending the learning period ensures that students do not move on to more advanced levels without mastering essential knowledge or skills.
If the intended learning period for JC*
k
before and after adjustments is represented by YJC*
k
and YJN*
k
, respectively, and considering that the delay in the learning cycle for JC*
u
is denoted by Δy, with the compression time and the maximum compression limit for critical gamified learning tasks between JC*
u
and JC*
k
indicated by Δ(M,O) and Δ
MAX
(M,O), respectively, then adjustments are necessary when Δy exceeds 0 and βu is within the range of (c-1)×100% to β
uMAX
. This alignment ensures the learning cycle meets the specified targets.
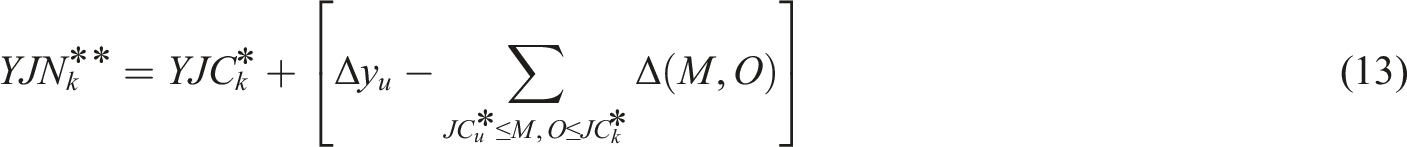

Considering the established range of gamified learning activities marked by y(u,k), where y
MIN
(u,k) illustrates the minimum timeframe, and the maximum extension limit for these tasks is denoted by Δ*
MAX
(u,k), the approach to calculate Δ
MAX
(M,O) is described as follows:


For students who surpass expectations in their gamified learning journey, the advanced learning cycle rule is introduced. This suggests that high achievers may proceed to the next phase of learning earlier than anticipated, maintaining their engagement and curiosity in the educational process. Implementing this rule not only boosts learning efficiency but also enhances student motivation, as they recognize their progress and are encouraged to tackle more challenging tasks.
When Δy is less than 0, indicating accelerated learning, the existing learning cycle’s monitoring signal strength at JC*
u
, represented by YJC
u
, ranges from β
uMIN
to (c-1)×100%. To keep the learning experience challenging and engaging, adjustments in the game progression are required. This adjustment increases the duration of key game-based learning activities between JC*
u
and JC*
k
, while keeping the intended learning cycle for JC*
k
consistent. If the extension and the maximum extension limits for essential game-based learning tasks between JC*
u
and JC*
k
are indicated by Δ(M,O)* and Δ
MAX
(M,O)*, respectively, the total extension should align with:


The adaptive learning progress adjustment method employed aims to tailor progress adjustments based on students’ learning performance. However, its limitations are primarily associated with threshold settings and adjustment frequency. If thresholds are not appropriately configured, excessive adjustments may occur, such as increasing or decreasing task difficulty too frequently. This can disrupt learners' study rhythm and result in frustration or insufficient challenge. Furthermore, implementing adaptive mechanisms requires significant and accurate learning data. Inadequate data or improper data handling could negatively impact the effectiveness and precision of adjustment strategies. Hence, the design of suitable threshold settings and adjustment frequencies, coupled with data quality and accurate processing, is crucial when implementing such strategies.
A specific application example is provided to illustrate the concept. In games designed to teach concepts of sustainable development and environmental protection, beginners might receive recommendations for more foundational tasks and concepts to secure their learning foundation. Students with a pre-existing knowledge base would receive more complex tasks and challenges to further test their problem-solving abilities. Additionally, if students show signs of struggle at any point, the model could adjust game progress to provide supplementary materials or simplify tasks, aiding students in overcoming difficulties. By continuously monitoring students’ progress and feedback, adaptive learning models can refine and optimize individual learning paths to deliver a genuinely personalized learning experience.
The research methodology employed in this study primarily utilizes semi-structured interviews and focus group discussions as the main research tools. The semi-structured interviews allow for an in-depth exploration of participants’ perspectives and experiences within a predetermined framework of questions, while the focus group discussions facilitate interaction among participants, thereby generating richer data. In designing the interview guide and the focus group discussion questions, the design standards of relevant educational and psychological research tools were referenced, and two rounds of expert reviews were conducted to ensure the content validity of the tools.
To enhance the reliability of the research, semi-structured interviews were conducted, and adjustments to the interview guide were made based on the feedback received. Triangulation was employed to increase the credibility of the data, wherein cross-validation of findings from different data sources was conducted to ensure the robustness of the conclusions. Furthermore, the data-coding process was carried out by two independent researchers to minimize subjective bias. The entire research process, including participant recruitment, data collection and analysis, and result validation, was meticulously documented to ensure transparency and replicability.
Experimental results and analysis
To enrich the experimental section and provide a more comprehensive analysis, a qualitative study of students’ learning experiences was conducted. A survey was designed and implemented to assess the impact of the gamified learning environment on student motivation and engagement. The survey results revealed students' perceptions of the gamified learning task recommendation system, their engagement levels, and the specific benefits and challenges it posed. These insights offer a deeper understanding of how to refine gamified learning strategies. The survey results complement the quantitative data and provide educators and researchers with greater insight into how the gamified learning environment can influence or foster student motivation and performance.
In this study, the Bi-LSTM model was configured with parameters such as input sequence length, hidden layer dimensions, and the number of recurrent layers. The training process used specific hyperparameters, including learning rate and batch size, to ensure optimal model performance. Additionally, regularization techniques were applied to improve the model’s generalization ability. Specific optimizers and early stopping strategies were used during training to prevent overfitting. The training process was divided into multiple stages, with varying training strategies or data augmentation techniques at each stage.
The approach to recommending gamified tasks for environmental education was explored. In this exploration, the deployment of an attention mechanism successfully compiled the gamified learning behaviors of student groups over different periods. Moreover, Bi-LSTM neural networks were applied to merge group behaviors into sequences of individual student gamified learning activities, allowing for the integration of various behavioral insights.
Analysis of Figure 6(a) (MAP@5) and Figure 6(b) (Recall@5) demonstrated that as the number of neurons was incrementally raised from 32 to 256, there was a significant enhancement in both MAP@5 and Recall@5 across numerous behavioral timestamps. Yet, increasing the neuron count further from 256 to 384 led to a slowdown in the improvement of these metrics, with slight decreases observed in some cases. This indicates that a neuron count of 256 might be the model’s sweet spot, with higher counts potentially leading to overfitting. Additionally, both figures showed that with the increase in behavioral timestamps, there was an improvement in both MAP@5 and Recall@5. Nonetheless, a downturn was noticed after the third behavioral timestamp. This suggests that the model efficiently captures student learning behaviors and preferences up to the first three timestamps, but beyond that, it may start incorporating irrelevant information, reducing predictive precision. The model achieved its best performance, with MAP@5 and Recall@5 reaching 0.81 and 0.845, respectively, at 256 neurons using data up to the third behavioral timestamp, underscoring the model’s effectiveness and comprehensiveness. Experimental results of the gamified learning task recommendation model (a) MAP@5, (b) Recall@5.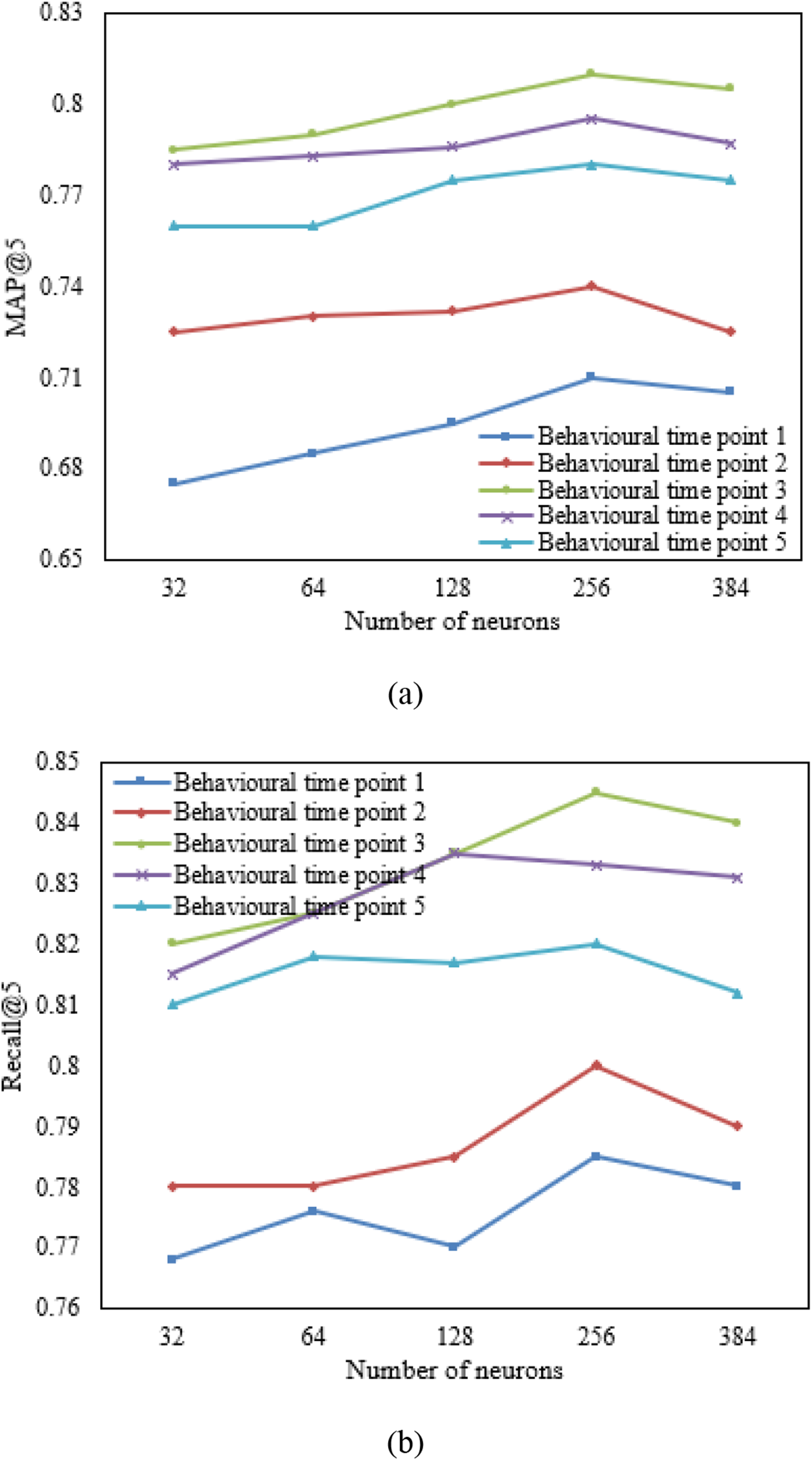
Performance comparison of the proposed model with other gamified learning task recommendation models.
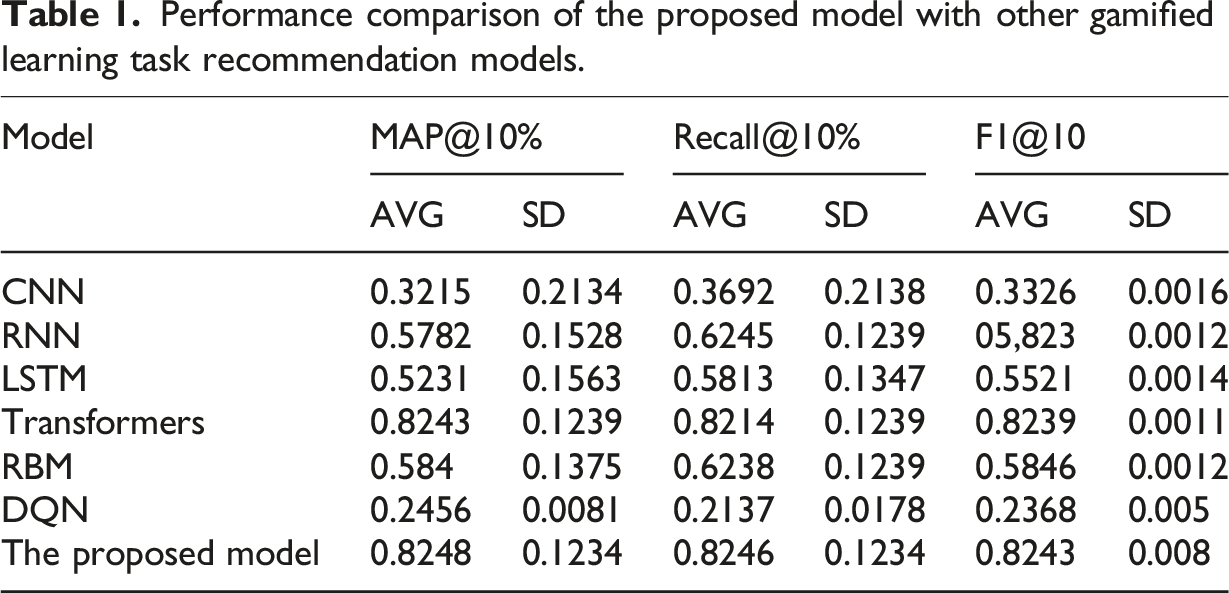
Figure 7 explores how the model’s execution time correlates with the assortment of gamified task types. Analysis across both experimental and control groups revealed that for 15, 30, and 45 task types, the execution times were 37, 44, and 49 seconds, respectively, outperforming three alternate models. These observations indicate that the model requires additional computational efforts and time with an increase in task type complexity. Yet, discussions highlight that the model maintains unparalleled predictive accuracy and performance metrics, despite longer execution times. This suggests a balance: achieving higher accuracy necessitates more computational time. In various practical settings, however, the value of predictive accuracy is often paramount. Therefore, despite the potential for extended computation times, the model’s capability to furnish accurate gamified task recommendations for environmental education remains undisputed. Comparison of model runtime and the number of game task types. (a) Experimental group and (b) control group.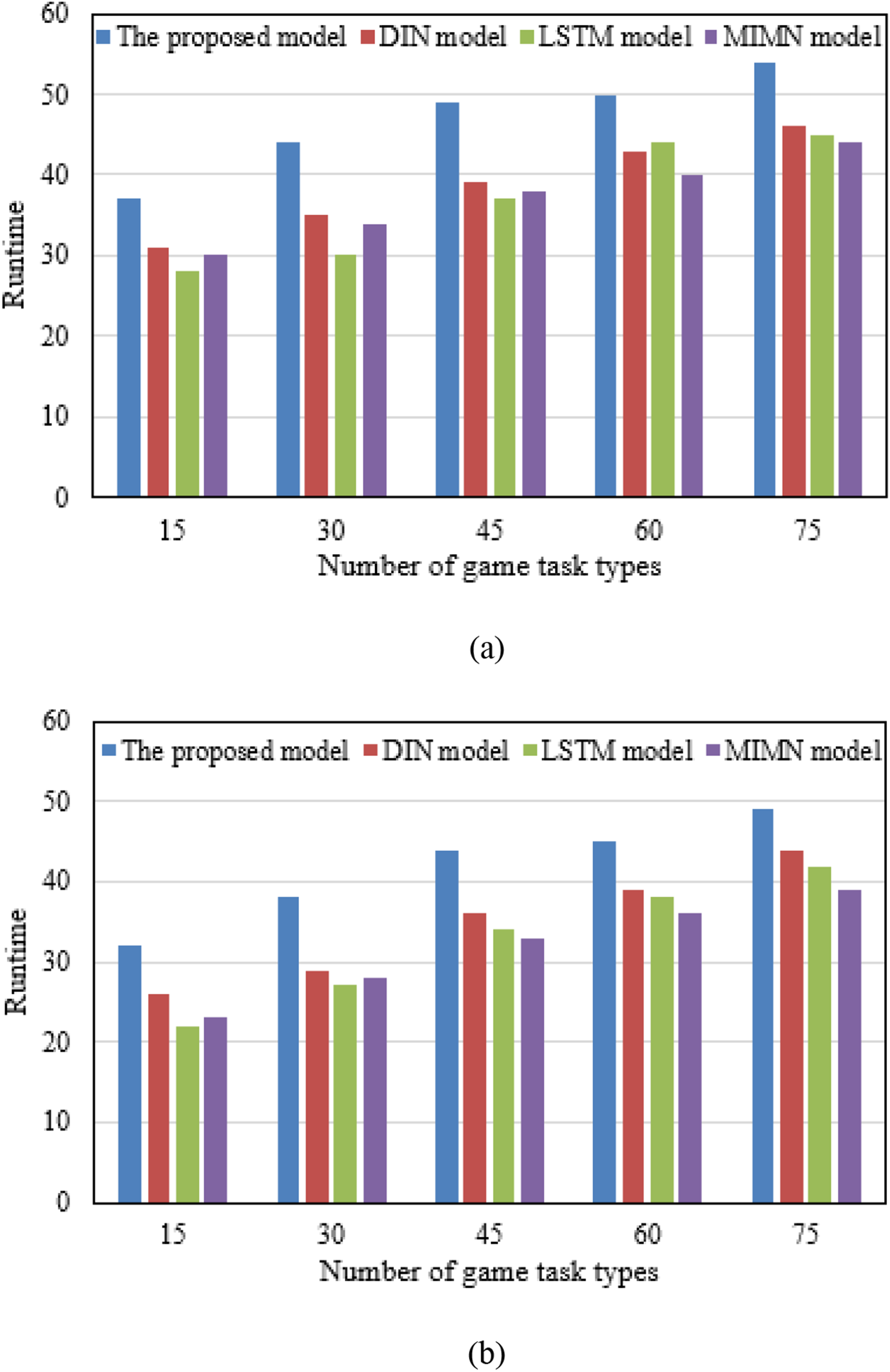
This research introduced a method based on adaptive learning outcomes to adjust game progression, incorporating the assessment of progression deviation and the development of adaptive outcome control rules. This approach not only advances theoretical understanding but also offers practical tools and methods for implementing gamified learning in environmental education effectively.
Comparative analysis of gamified learning task allocation pre- and post-game progression adjustments.
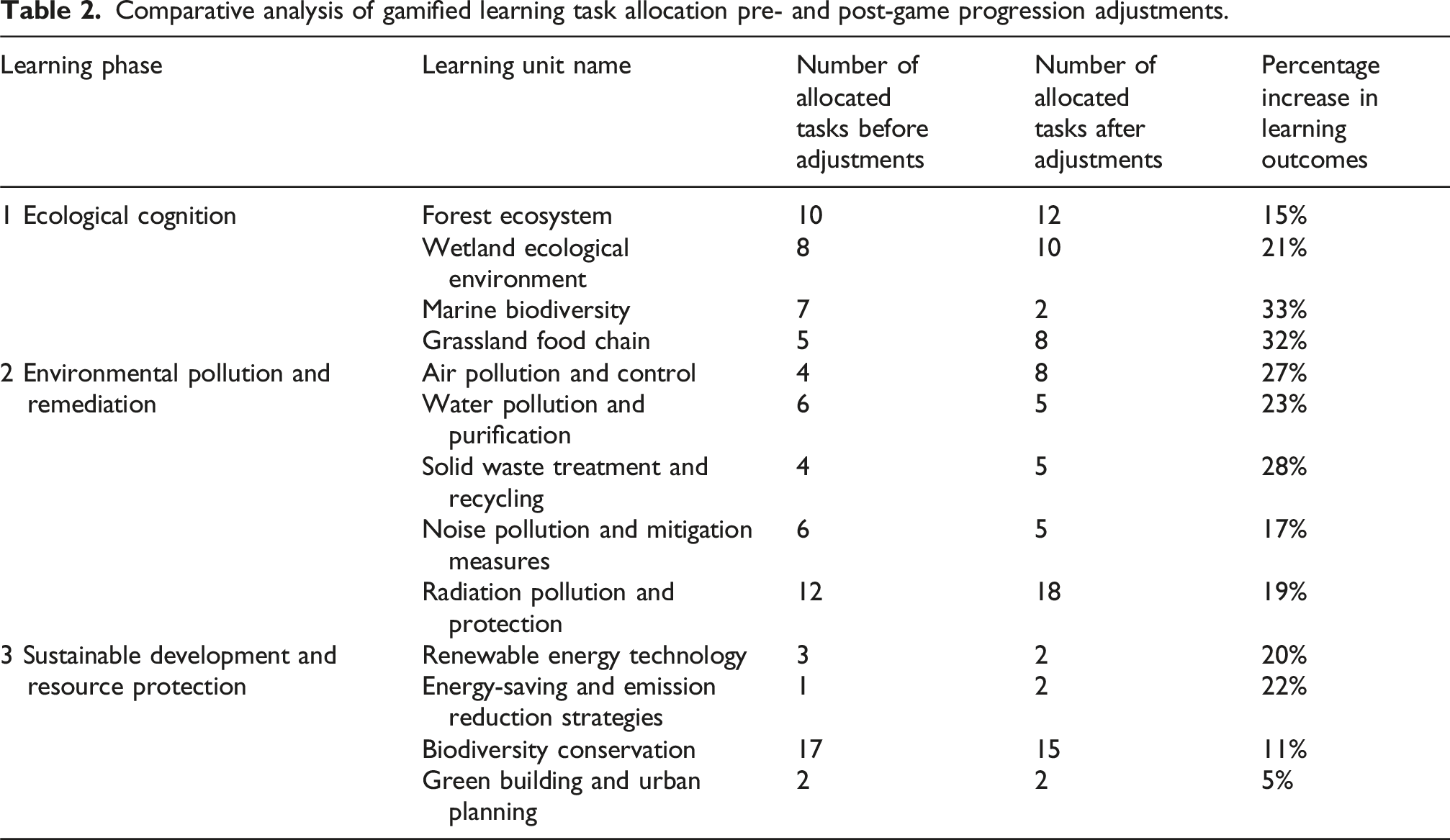
The data clearly indicates that the adaptive learning outcomes-based game progression adjustment strategy has significantly improved learning outcomes, particularly in the areas of “ecological cognition” and “environmental pollution and remediation.” This highlights the strategy’s effectiveness not only in dynamically adjusting tasks based on actual student learning outcomes but also in substantially enhancing these outcomes. By comparing pre- and post-adjustment data alongside the game progression deviation intensity and control rules for adaptive learning outcomes, the efficacy of the strategy is evident. This innovative approach not only advances learning theories but also provides powerful tools and methodologies for implementing gamified environmental education, leading to increased student engagement and improved learning outcomes.
Discrepancies in gamified learning task requirements pre- and post-adjustment.

Despite comparing multiple models for their efficacy in gamified learning task recommendations and demonstrating the positive impact of adaptive learning progress adjustment strategies, certain limitations in the experimental evaluation were identified. First, the relatively small sample size could constrain the generalizability of the findings, thus limiting their applicability across broader educational settings. Second, a potential gap exists between the simulated educational environment used in the experiment and actual educational environments. This discrepancy may lead to deviations in the expected performance of the experimental results when applied in practice. Consequently, further in-depth validation and investigation of the experimental outcomes are required before applying the research findings to real-world educational scenarios to ensure their effectiveness and reliability.
Conclusion
This study primarily focused on exploring strategies for adjusting gamified learning progression. Key components, such as calculating game progression deviation intensity, prioritizing tasks, and defining value ranges for these intensities, were thoroughly examined. At the core of the study, an adaptive learning outcome-driven strategy was developed, which involved determining game progression deviation intensity and establishing control rules for adaptive learning outcomes. Special emphasis was placed on recommending game tasks for environmental education, utilizing Bi-LSTM neural networks with an attention mechanism to enhance the accuracy of these recommendations.
Various models for gamified learning task recommendations, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), LSTM, and Transformers, were compared. While the performance of the model used in this study was sometimes surpassed by alternative models under specific experimental conditions, it demonstrated significant advantages under different scenarios. Following adjustments to game progression, an assessment of learning task allocations before and after revealed the strategy’s ability to better align with student learning needs, thereby improving learning outcomes. The potential of this strategy to provide educators with more precise insights into students’ learning needs was highlighted.
In the game progress adjustment method based on adaptive learning outcomes, further optimization may be achieved by designing a smoothing adjustment strategy to avoid abrupt changes in task difficulty, thereby providing a more coherent and gradually progressive learning experience. The integration of a strategy based on moving averages or exponential decay to regulate game progress deviation intensity could ensure more refined and gradual task difficulty adjustments, reducing the likelihood of drastic changes that learners may find disruptive. Additionally, incorporating an adaptive feedback mechanism, dynamically adjusting content and difficulty based on learners’ real-time performance and feedback, could more precisely align with their current capabilities and learning needs.
Although the potential of the adaptive learning-based game progress adjustment strategy in enhancing students’ learning outcomes has been demonstrated, certain limitations persist. First, the models compared in the experiments are limited and do not encompass all possible gamified learning recommendation models, potentially overlooking more suitable alternatives. Second, the experimental environment and conditions may differ from real-world educational scenarios, limiting the generalizability of the results. Furthermore, while the adjustment strategy shows promise in meeting students' learning needs, its efficacy may be affected by individual differences among students and subject characteristics, necessitating further research to explore more sophisticated adjustment methods. Future research could focus on broader model comparisons and delve deeper into the varying needs and adjustment strategies across different subject areas and student groups to improve the applicability and reliability of the research findings.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.