
Abstract
The rapid advancement in educational technology has ushered in an era where multimodal learning environments are increasingly recognized as crucial for fostering students’ cognitive and emotional development. This research explores the dual impact of these environments, integrating diverse sensory information, including visual and auditory inputs, thus offering enriched learning experiences with potential influences on students’ cognitive and emotional states. A notable gap in current research is the lack of a comprehensive understanding of how multimodal learning environments distinctly affect these aspects of student development. Traditional methodologies in this field often fail to account for the dynamic nature and individual variances inherent in the learning process, thereby limiting the depth of insights into the influence mechanisms of these environments. To bridge these gaps, this study employs a dual-methodological approach. Firstly, a sophisticated correlation matrix is developed to diagnose cognitive development within multimodal learning environments, effectively identifying key factors in cognitive processes. Secondly, an innovative emotion recognition model is utilized, incorporating sensor feature embedding and temporal feature embedding techniques, to adeptly capture students’ emotional fluctuations within these settings. The findings from this study provide substantial implications for educational practice. They enable educators to enhance the design and optimization of learning environments, promoting not only cognitive growth but also emotional well-being among students. This approach underscores the importance of addressing both cognitive and emotional domains in educational settings to foster holistic development. This study innovatively establishes a matrix correlating students, learning items, and knowledge points, facilitating a joint analysis to diagnose the cognitive development mechanism within multimodal learning environments. Additionally, an emotion recognition model, combining both sensor and temporal feature embedding networks, has been constructed. This model accurately identifies and analyzes students’ emotional states. The primary contribution lies in providing a comprehensive method for evaluating both cognitive and emotional states of students, which aids in optimizing personalized learning strategies and enhancing educational outcomes.
Keywords
Introduction
In the contemporary educational paradigm, multimodal learning environments have risen to prominence, characterized by the utilization of an array of information channels, including visual, auditory, and tactile inputs, to augment learning outcomes. Such environments not only diversify the spectrum of learning resources but also significantly transform cognitive structures and modalities of student learning.1–4 Coinciding with advancements in digital technology, the prevalence of multimodal learning environments has escalated, imparting a dual influence on the cognitive and emotional domains of students. It is recognized that cognition and emotion are intertwined within the learning process, collaboratively shaping the caliber of educational outcomes.5,6
The theoretical foundation of multimodal learning environments originates from constructivist learning theory and multi-sensory learning theory, which emphasize the promotion of deep learning through various sensory and interactive forms. The operational mechanism involves providing rich learning resources through multiple media, combined with students’ performance data across different tasks. This is achieved by establishing a matrix correlating students, learning items, and knowledge points, facilitating joint analysis to diagnose students’ cognitive states, and aiding in identifying weaknesses in their learning processes and cognitive development patterns. Investigations into the impact of multimodal learning environments on student cognition and emotion have become critically relevant. Research indicates that these environments may bolster students’ information processing capabilities and learning motivation, thus facilitating cognitive development. 7 Furthermore, the provision of emotional support and positive feedback within these environments has been linked to favorable shifts in students’ emotional states, which in turn can impact learning achievements.8,9 Despite these insights, existing research has primarily concentrated on single-modal learning environments, with a notable deficiency in exploring the interplay between cognition and emotion in multimodal contexts. This gap limits the comprehension of the holistic learning experience.10,11
In multimodal learning environments, potential negative impacts and challenges include reliance on technological devices, issues related to data privacy and security, increased cognitive load on students, and higher requirements for technical literacy among both teachers and students. Additionally, excessive dependence on multimodal data analysis may lead to the neglect of the effectiveness of traditional teaching methods, as well as potential data biases and misjudgments. Efforts to evaluate the impact of multimodal learning environments, while significant, often exhibit methodological limitations. Predominantly, studies have adopted static, cross-sectional analysis approaches, thereby neglecting the dynamic nature of the learning process and the ongoing evolution of students’ cognitive and emotional states.12–14 Moreover, there is a notable deficiency in addressing individual student differences, with many studies falling short in effectively correlating student characteristics with their learning behaviors and outcomes.15–18 Recent relevant studies indicate that significant progress has been made in the application of multimodal learning environments and emotion recognition technology in education. Existing research has demonstrated how multimodal data can effectively enhance learning outcomes and assist teachers in timely adjustments of teaching strategies through emotion recognition. Furthermore, experimental studies have validated the advantages of multimodal environments in personalized learning, particularly in improving student engagement and motivation. These combined research findings further support and validate the perspectives and discoveries presented in this study.
In response to these deficiencies, the current study endeavors to bridge these gaps. It employs a methodology entailing the construction and joint analysis of a correlation matrix, encompassing students, learning items, and knowledge points. This approach facilitates the diagnosis of cognitive development within multimodal learning environments, elucidating the underlying mechanisms of cognitive progression. Furthermore, the development of an emotion recognition model, integrating a sensor feature embedding network, a temporal feature embedding network, and a classification layer, enables the identification and analysis of students’ emotional states in these environments. The research contributes to both the theoretical understanding and practical application of multimodal learning environments. It provides a scientific foundation for educators to enhance these environments, aiming to foster the holistic development of students in both cognitive and emotional aspects.
Student cognition diagnosis in multimodal learning environments
Relationship between students, learning items, and knowledge points
In the sphere of multimodal learning environments, an intricate matrix delineating the correlation between learning items and knowledge points was developed to elucidate the influence of various knowledge points on learning items and the mastery of these points by students. This matrix, embodying multidimensionality and dynamism, serves as a tool to disclose the understanding and application abilities of students for each knowledge point across multiple modalities. Within this matrix, each learning item is segmented into several knowledge points, which constitute the columns, while rows represent individual students, with their respective scores indicating their proficiency levels in each knowledge point. The association matrix between learning items and knowledge points not only reflects the importance of knowledge points to the learning items and the students’ mastery levels but also considers the dependencies and difficulty levels among the knowledge points. The columns of the matrix represent different knowledge points, while the rows indicate the scores of individual students, reflecting their mastery of these knowledge points. The matrix structure is multidimensional and dynamic, capable of illustrating student performance across various learning modalities. In this manner, the matrix can map the relationships between knowledge points in detail and their impact on the overall learning outcomes of students, providing a comprehensive assessment tool. The construction of this matrix takes into account the dependencies and complexities among knowledge points within learning items, thereby facilitating a precise representation of the complex relationships between these points and their overarching impact on students’ learning outcomes. The correlation matrix is represented as E = {ea*b)M*N, where a*b signifies the correlation of the y-th knowledge point with the a-th learning item. The notation ea*b = 1 indicates the inclusion of knowledge point b in the a-th learning item, while ea*b = 0 denotes its exclusion.
Student-learning item score matrix
The assessment of students on learning items leads to the formation of a student-learning item score matrix in a multimodal learning environment. This methodology is centered around the collection and analysis of data derived from students’ interactions in various modalities. This encompasses capturing students’ actions in virtual laboratories, their verbal contributions in online discussions, and their decision-making processes in interactive simulations, providing a comprehensive view of their grasp over the learning content. The score matrix is formulated by integrating item response theory and cognitive diagnostic models, which enhances the accuracy in portraying students’ competency levels and their performance on diverse learning items.
The score matrix, pivotal in this study, exhibits multidimensional and adaptable properties. It is structured such that rows signify individual students, columns denote various learning items, and each cell’s value reflects a specific student’s score or competency estimate for a designated learning item. These scores encapsulate not merely the traditional accuracy but also delve into deeper aspects of the learning process, encompassing problem-solving strategies, the caliber of thought processes, and the efficiency in resolving problems. In a formal representation, a cohort of g students is denoted as T=(t m , t2, …, t g ), with each student t u completing a collection of A learning items, represented as t u s a = {t u s1, t u s2, … , t u s a }. The resultant score matrix for these g students across learning items is articulated as H = {ht u s n }u*n, where ht u s n symbolizes the scoring situation of student t u on learning item n, with a value of 1 indicating a score attained by student s u on item n, and a value of zero signifying no score.
Student-knowledge point failure rate matrix
To evaluate the areas where students exhibit weaknesses in various knowledge points, a Student-Knowledge Point failure rate Matrix has been devised in the multimodal learning environment. This matrix is meticulously designed to offer a specific failure rate metric for each student on individual knowledge points. Rows in the matrix represent diverse students, while columns correspond to distinct knowledge points. The value in each matrix cell denotes the average failure rate of a student for a specific knowledge point. The genesis of this matrix involves analyzing students’ learning outcomes, capturing data such as homework scores, quiz responses, and performances in interactive learning modules. These data are subsequently utilized to compute the error rate or failure rate for each student on individual knowledge points, employing advanced statistical techniques to yield more robust failure rate estimations.
The failure rate for each knowledge point is calculated by the ratio of the number of errors made by students in tasks related to that knowledge point to the total number of attempts. To enhance the accuracy and robustness of the failure rate, a weighted average method has been employed, considering the importance and difficulty coefficient of different tasks. Additionally, time-series analysis has been utilized to smooth out deviations caused by short-term fluctuations, resulting in more reliable failure rate estimates. These detailed calculations of failure rates can help identify students’ weaknesses in different knowledge points and provide a basis for personalized teaching strategies. The failure rate of student t
g
for knowledge point m
b
, labeled as KS, is derived by transforming the score of student t
g
on learning item s
a
into a score pertinent to knowledge point m
b
. The total score for learning item s
u
is indicated as h
su
, and the score of student t
g
on learning item s
a
is expressed as h
SHu
. The association between knowledge point m
b
and learning item s
a
is symbolized as e
ab
. The formula to ascertain the failure rate for a learning item-knowledge point is presented as follows:

The time complexity of the student-learning item-knowledge point association matrix and its joint analysis, constructed in this study, primarily depends on the scale of the matrix, which is determined by the number of students, learning items, and knowledge points. The emotion recognition model includes sensor and temporal feature embedding networks, with computational complexity mainly related to the dimensionality of the sensor data and the length of the temporal features. The overall computational efficiency of the model also depends on the complexity of the classification layer. However, in general, the time complexity of this model can be considered polynomial. This failure rate matrix facilitates the analysis of patterns in which students lose points, uncovering potential misunderstandings or cognitive biases related to knowledge points. Elevated failure rates imply a student’s less robust grasp of a knowledge point, highlighting areas necessitating enhanced learning focus.
Cognition diagnosis of students’ knowledge levels
In the context of multimodal learning environments, the term “unmastered knowledge points” is used to describe content that students are unable to correctly respond to during evaluations, typically signifying an inadequate comprehension or retention of information pertaining to those points. For instance, a student’s inability to accurately answer questions in a virtual reality simulation about a specific historical event, in a learning platform incorporating visual, auditory, and tactile inputs, is indicative of a deficiency in grasping essential facts or concepts related to that event. Knowledge points where mastery is deficient are those which students have encountered but not thoroughly understood or firmly grasped. These are the knowledge points where students might intermittently respond correctly, but exhibit poor performance in varying contexts or when in-depth understanding and application are necessitated, highlighting gaps in their comprehension. Figure 1 depicts a structure of knowledge points, considering both support relationships and areas of deficiency. It is recommended that students focus on reinforcing knowledge points along pathways of greater significance, such as the pathway including m3, m5, and m6. Structure of knowledge points considering support relationships and deficiency points.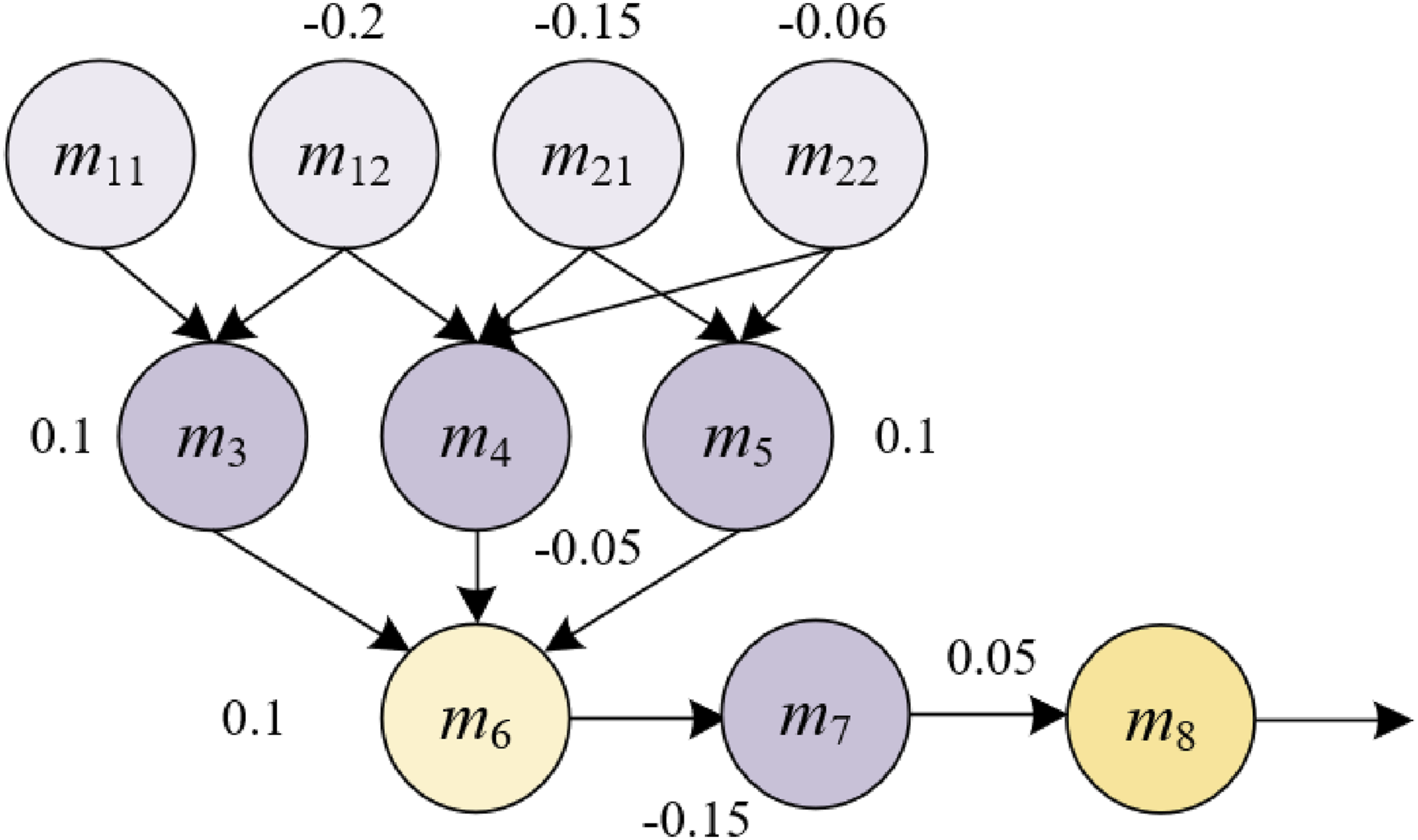
To determine students’ knowledge levels, an integrated analysis of the student-learning item score matrix and the student-learning item-knowledge point correlation matrix is conducted. This analysis begins with the evaluation of students’ responses to unanswered learning items. In this phase, the potential performance of students on yet-to-be-answered learning items is monitored by educators or systems. The mastery status of knowledge points for student t is represented by the vector α
t
= {αt1,αt2, … ,α
tu
}, where α
tu
signifies the mastery level of student t for knowledge point u. Mastery of knowledge point u by student t is indicated by α
tu
= 1, and non-mastery by α
tu
= 0. The formula below represents the approach for assessing students’ responses to unanswered learning items:

A score of O(m) = 0 is assigned if a student does not score on a learning item, while a score of O(m) = 1 indicates scoring on the item.
In consideration of potential errors and misguessing by students during the learning process, a methodology has been developed to calculate the scoring probability for specific items without scores. This calculation is based on an analysis of students’ historical data and the performance of peers encountering similar questions, as delineated by the following formula:

Moreover, the probability of failure on particular items without scores is computed by examining students’ historical responses, the error rates on analogous questions, and their overall learning progression:

The collection of students’ responses to diverse learning items facilitates the determination of their mastery over each knowledge point. An equation is formulated to evaluate students’ responses to learning items:
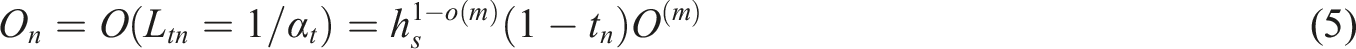
Additionally, the expectation maximization (EM) algorithm is employed to refine the probability of mastery over individual knowledge points. This algorithm operates iteratively, recalculating and updating the error rate and assumption rate parameters for each knowledge point, thereby aiding in the identification of areas where students may exhibit comprehension deficiencies. The relevant formula is presented as follows:

Subsequently, an analysis of students’ performance and advancements in practice sessions is conducted to ascertain the verification probability of their mastery of specific knowledge points. This process involves assessing improvements in performance following reviews and repeated practice of these knowledge points, thus updating the model of students’ cognitive levels.
Student emotion recognition in multimodal learning environments
Problem definition
In multimodal learning environments, the recognition of student emotions is predominantly dependent on the utilization of various sensors. These include cameras for capturing facial expressions, voice analysis tools for detecting tonal changes, and physiological sensors for monitoring fluctuations in heart rates. A significant challenge in this context is the issue of sparse data, which arises when students are not optimally positioned within the sensor range or when they evade monitoring, whether intentionally or not. Additionally, the frequency of data collection may vary across different sensors, and there are instances where certain sensors fail to gather data due to technical malfunctions, incorrect usage, or external environmental factors. This inconsistency and lack of completeness in data collection pose obstacles in accurately discerning students’ emotional states, thus affecting the precision of emotion analysis and the timeliness of educational interventions.
Addressing the sparse data issue in multimodal learning environments involves a structured approach to data representation and problem definition. Let V represent the number of sensors in use. The data from a sensor, denoted as SE
u
, is represented by T
u
∈ℜ
su
*ℜ
DIu
, where DI
u
indicates the dimension of the data, and s
u
= Sduϕ
u
signifies the number of sampling points for SE
u
. The sample collection window length is represented by S, the sampling frequency of SE
u
by d
u
, and the sensor’s missing sampling rate by ϕ
u
∈(0,1). The multimodal sensor sample data is thus expressed as follows:

In addressing the challenge of data incompleteness within multimodal learning environments, and to enhance the accuracy of emotion recognition, a series of measures have been implemented to ensure the quality and completeness of multimodal sensor sample data. Initially, sensor fusion technology is utilized to amalgamate data from disparate sensors, thereby compensating for the limitations inherent in data obtained from individual sensors. Subsequently, during the data preprocessing phase, interpolation methods are applied to supplement missing data points. This process entails careful consideration of time-series continuity and contextual relevance to guarantee the validity of the interpolations. The act of completing and concatenating data is aimed at equalizing the number of sampling points across all sensors, as denoted by the equation s1 = s
u
= … = s
V
. For alignment purposes, the sensor SE
j
∈ℜ
sj
*ℜ
DIj
, which possesses the maximum number of sampling points, is employed as the standard. The formula to calculate the total amount of data required for insertion in the sample is as follows:

Assuming the average of the set {ϕ1, …, ϕ
v
} is represented by ϕ_, the formulas for calculating the sampling rates (d) and data dimensions (DI) for each sensor are:
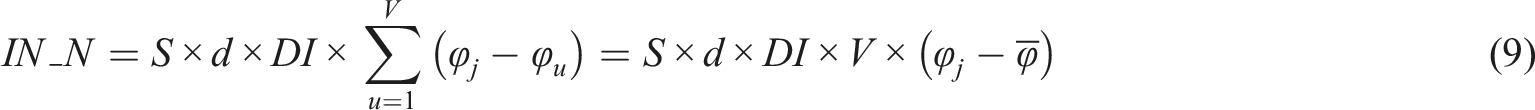
However, it is acknowledged that data interpolation can introduce noise and bias, particularly at higher missing rates, which can substantially diminish the accuracy of the interpolation. Consequently, the study has opted to directly learn a mapping function from sparse data, rather than relying on data interpolation. This approach allows the model to adapt to the actual data distribution, enhancing its capacity to discern latent patterns and relationships within the sparse data. The aim is to address the challenge of student emotion recognition by developing a mapping function capable of extracting pertinent information directly from sparse data, as delineated in the following formula:
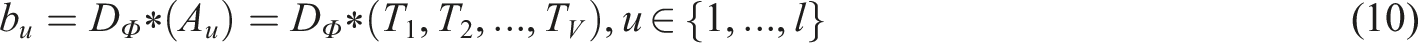
Model construction
The structure of the emotion recognition model comprises three main components: a sensor feature embedding network, a temporal feature embedding network, and a classification layer. The sensor feature embedding network processes multimodal emotional data such as facial expressions, voice, and physiological signals through several convolutional layers (e.g., three convolutional layers, each with 64 filters and a kernel size of 3 × 3) for feature extraction and embedding. The temporal feature embedding network employs Long Short-Term Memory (LSTM) networks or Bidirectional LSTM (Bi-LSTM), typically consisting of 2–3 LSTM layers, each with 128 hidden units, to capture the temporal dynamics of the emotional data. Finally, the classification layer, composed of fully connected layers and a Softmax layer, maps the extracted features to specific emotion categories, such as positive, neutral, and negative emotions. In the domain of multimodal learning environments, a comprehensive student emotion recognition model has been developed, encompassing three integral components, as depicted in Figure 2. The model’s first segment, a sensor feature embedding network, employs one-dimensional convolution to extract high-dimensional features from the data of each sensor. An attention mechanism is incorporated within this network, enhancing the emphasis on significant sensor features, thereby enabling the model to detect nuanced emotion-related signals from the collected sensor data. The second component of the model involves a temporal feature embedding network, which utilizes Bi-LSTM to grasp the dynamic changes and dependencies over extended time sequences. This aspect is crucial for interpreting the progression of students’ emotional states over time. An attention mechanism is further integrated into this network, refining the temporal features that are most pertinent to emotion recognition. This integration ensures the model’s proficiency in comprehending and employing intricate temporal patterns. The final segment, the classification layer, forms the output module of the model. It consists of a fully connected network designed to classify the amalgamated features, facilitating the precise identification of students’ emotional states. Structure of the student emotion recognition model in a multimodal learning environment.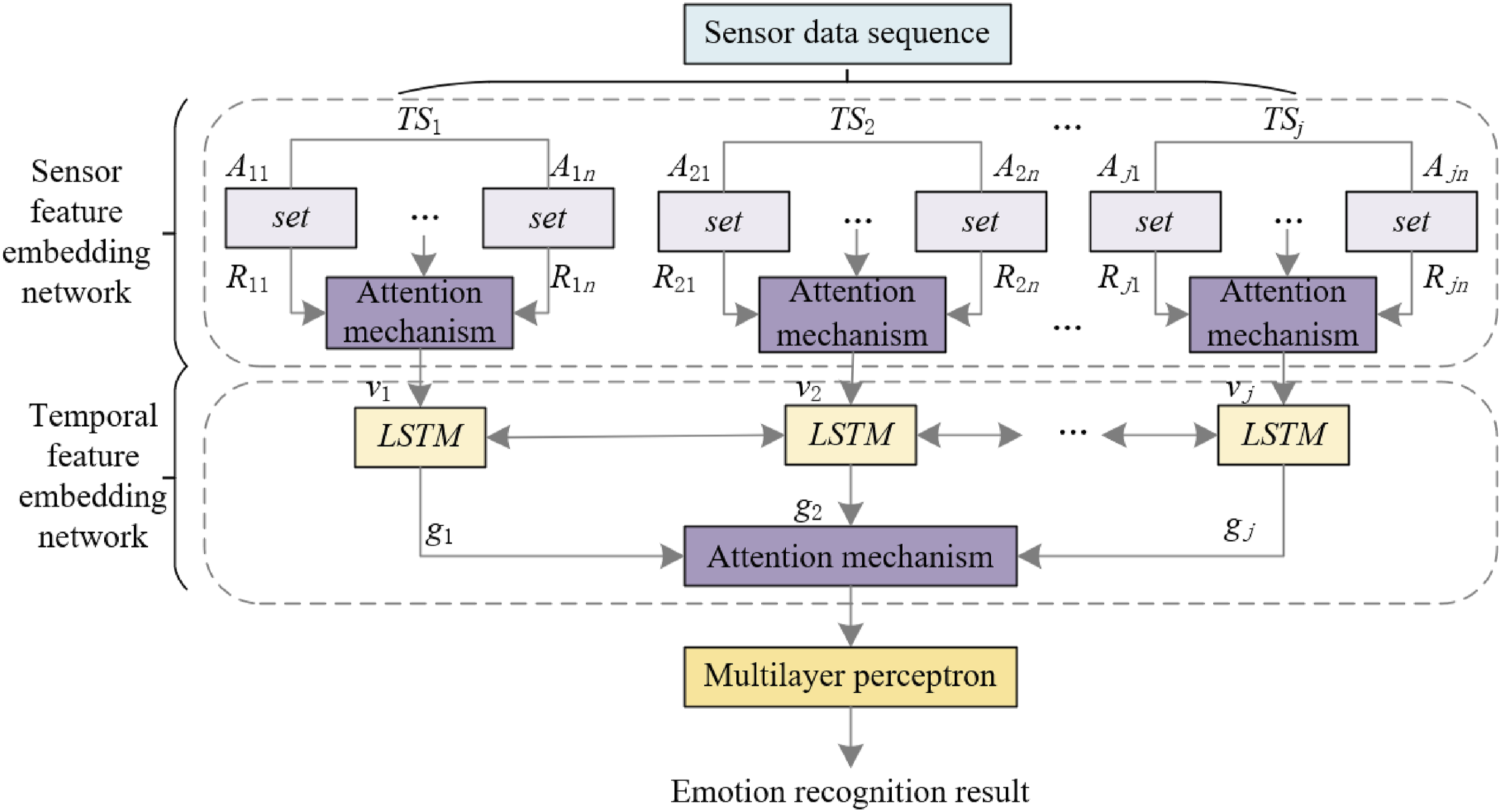
Within the sensor feature embedding network of the model designed for emotion recognition in multimodal learning environments, one-dimensional convolutional layers have been strategically configured to process the temporal data acquired from each sensor. This configuration facilitates the mapping of sampling point data at individual time steps into a high-dimensional feature space, thereby capturing the local features and patterns intrinsic to each sensor over the time series. This method is particularly effective in representing subtle shifts in emotional states. Following the processes of feature embedding and adaptive pooling, a horizontal concatenation of all modal data is performed, leading to the formation of a composite feature array, denoted as N = [n1, n2, …, n
u
, …, N
V
], where each n
u
∈ℜ128. At this juncture, the mixed features do not yet encompass inter-modal weight information. The integration of an attention mechanism into the network augments its capability to differentiate the significance of diverse sensor features. This is achieved through the computation of modal weights and their subsequent weighted summation, culminating in the acquisition of fused features for time step TS1. These operations enable the model to concentrate on sensor data that hold greater relevance for emotion recognition, thus enhancing the specificity and efficiency of feature extraction. Parameters pertinent to the attention component are denoted by q and y, with the attention mechanism represented by the following formula: ∈

The temporal feature embedding network’s core comprises a Bi-LSTM network and a temporal attention mechanism, as illustrated in Figure 3. The Bi-LSTM is adept at capturing both forward and backward dependencies between time steps, effectively unveiling the dynamic evolution of students’ emotional states over time. Owing to its bidirectional architecture, the Bi-LSTM concurrently assimilates information from past and future contexts, a feature paramount in deciphering the continuity and changing patterns of emotions. The temporal attention mechanism equips the model with the proficiency to pinpoint which time step features are most pivotal for emotion recognition, thereby allocating greater weight to these critical moments in the formation of the final feature vector. This design markedly bolsters the model’s sensitivity to emotional fluctuations and its aptitude in identifying and utilizing vital information within extensive temporal data. The concluding component, the classification layer, functions as the decision-making segment of the model, typically embodied by a fully connected neural network. This layer’s primary role is to amalgamate the intricate features extracted and merged by the preceding network segments, culminating in the execution of emotional state classification. It transforms the multidimensional feature vector into a probability distribution across various emotional categories, establishing the correlation between features and emotional states through weight adjustments during training. This process involves not only the nonlinear amalgamation of features but also the delineation of boundaries between distinct emotional states, constituting the crux of automatic emotion recognition. The classification layer’s design ensures that the model can render precise and dependable predictions of emotional states, drawing on multimodal data. Architecture of the temporal feature embedding network.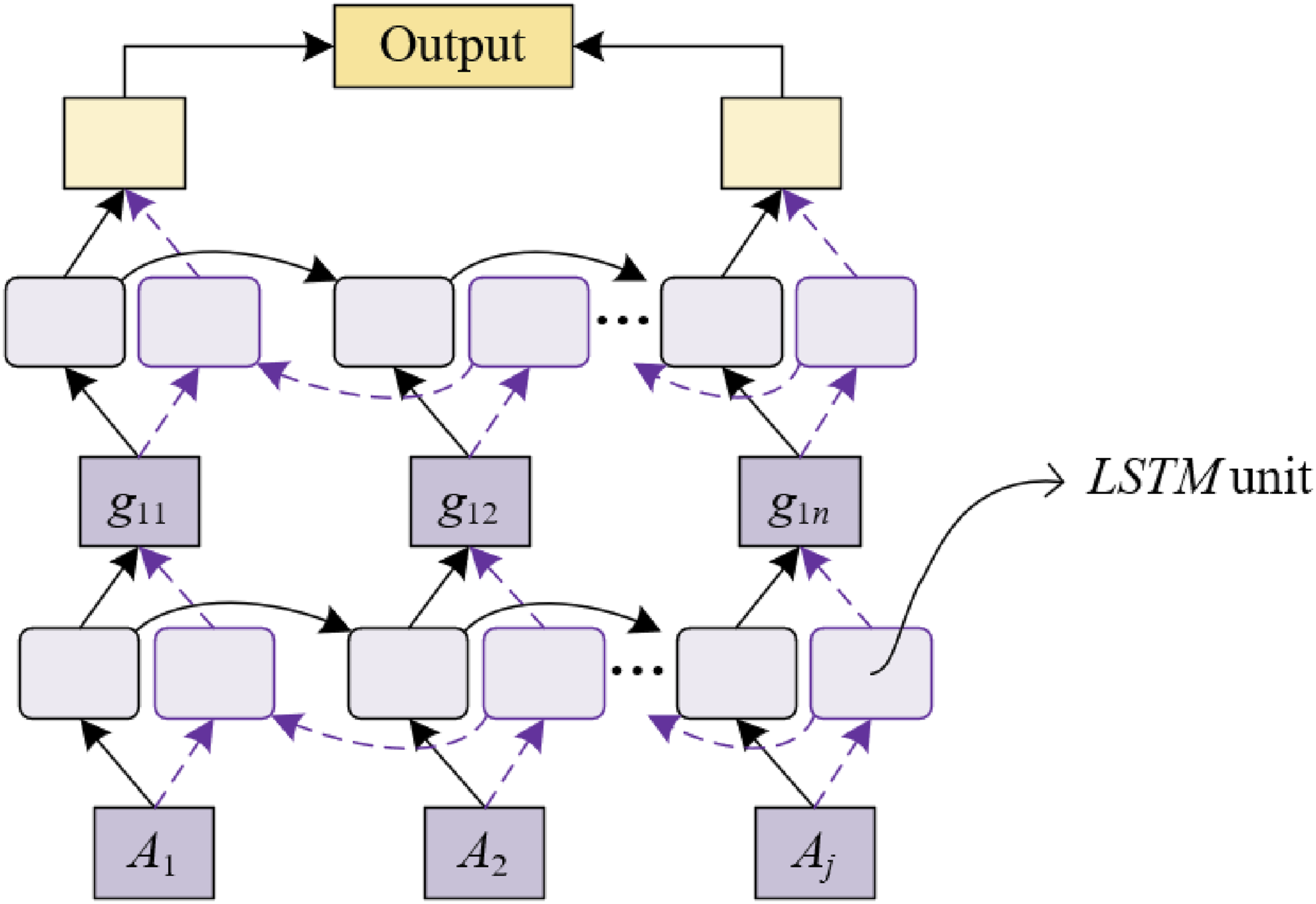
This study provides a detailed analysis of the learning and emotional states of a group of senior students in a multimodal learning environment. Specifically, a particular subject, such as mathematics, was selected, and data were collected on students’ performance in assignments, quizzes, and interactive learning modules across various knowledge points. This data was used to construct a student-learning item-knowledge point association matrix to diagnose students’ cognitive states. Additionally, a case study was conducted using various sensors, such as facial expression recognition, voice analysis, and heart rate monitoring, to collect emotional data from students during the learning process. The emotion recognition model was then applied to analyze students’ emotional states, revealing the relationship between emotional states and learning performance, and providing personalized learning recommendations.
The implementation of the emotion recognition model begins with selecting a representative sample group, typically including students from different grades and learning backgrounds to ensure data diversity and broad applicability. During data collection, various sensor devices are used to record students’ emotional expressions in real-time during the learning process. Data analysis involves extracting multimodal emotional features through the sensor feature embedding network, capturing the temporal dynamics of emotional data using the temporal feature embedding network, and finally identifying and analyzing students’ emotional states through the classification layer.
Experimental results and analysis
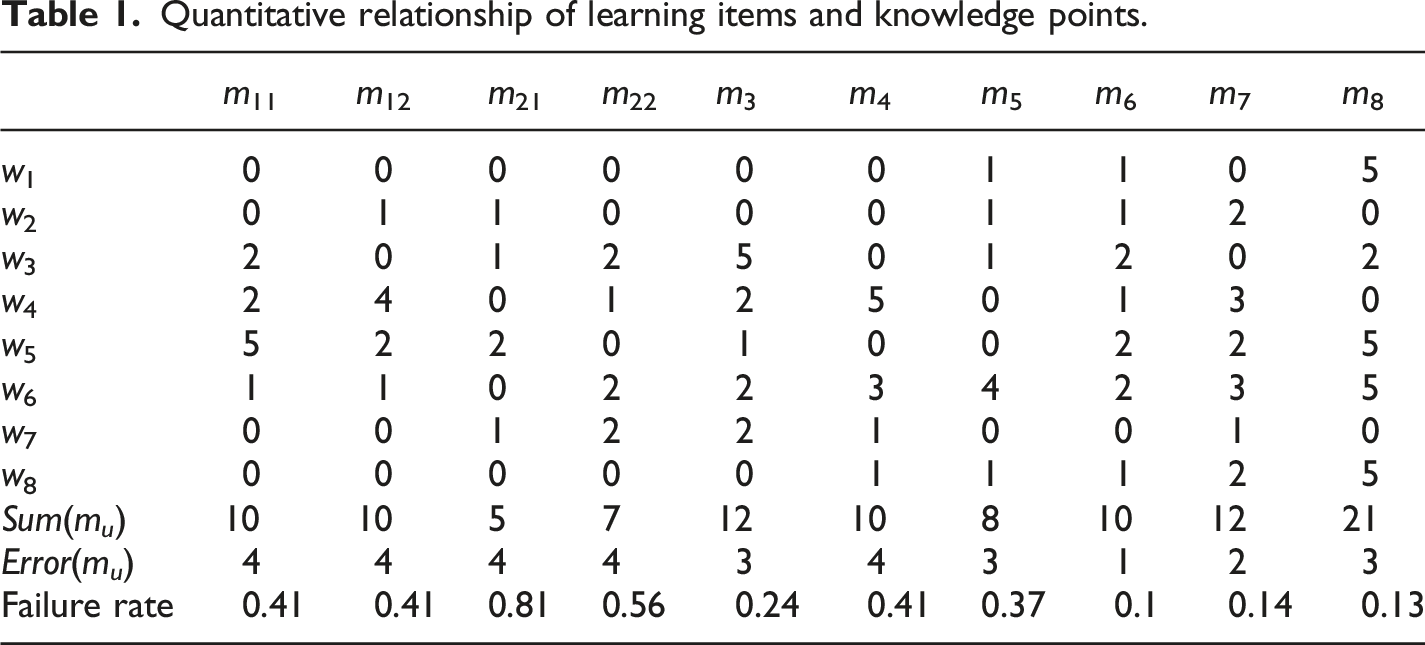
Quantitative relationship of learning items and knowledge points.
The analysis of radar chart data in Figure 4, depicting the proficiency of different students in various knowledge domains, has yielded significant insights. This chart illustrates the mastery levels of Student 1 and Student 2 across diverse knowledge types within a multimodal learning environment. Scores for each student on each knowledge type range from 0 to 1, where higher scores, approaching 1, denote greater mastery. The chart reveals distinct disparities in mastery levels of different knowledge types between the two students, highlighting their individual cognitive and learning requirements. This diagnostic approach enables educators to discern areas of strength and those necessitating further support and resources for each student. For Student 1, an emphasis on augmenting basic academic and skills and application knowledge is advised. Conversely, Student 2 requires more concentrated efforts in practical and operational knowledge, as well as in moral education and social skills. This tailored analysis validates the efficacy of the cognitive diagnostic method proposed in the study, particularly in a multimodal learning context. It offers an exhaustive view of student-learning conditions and assists both educators and students in formulating more effective learning strategies and interventions. The methodology fosters a more personalized learning experience, thereby more aptly catering to the unique needs of each student. Radar charts of different students’ mastery of various types of knowledge points.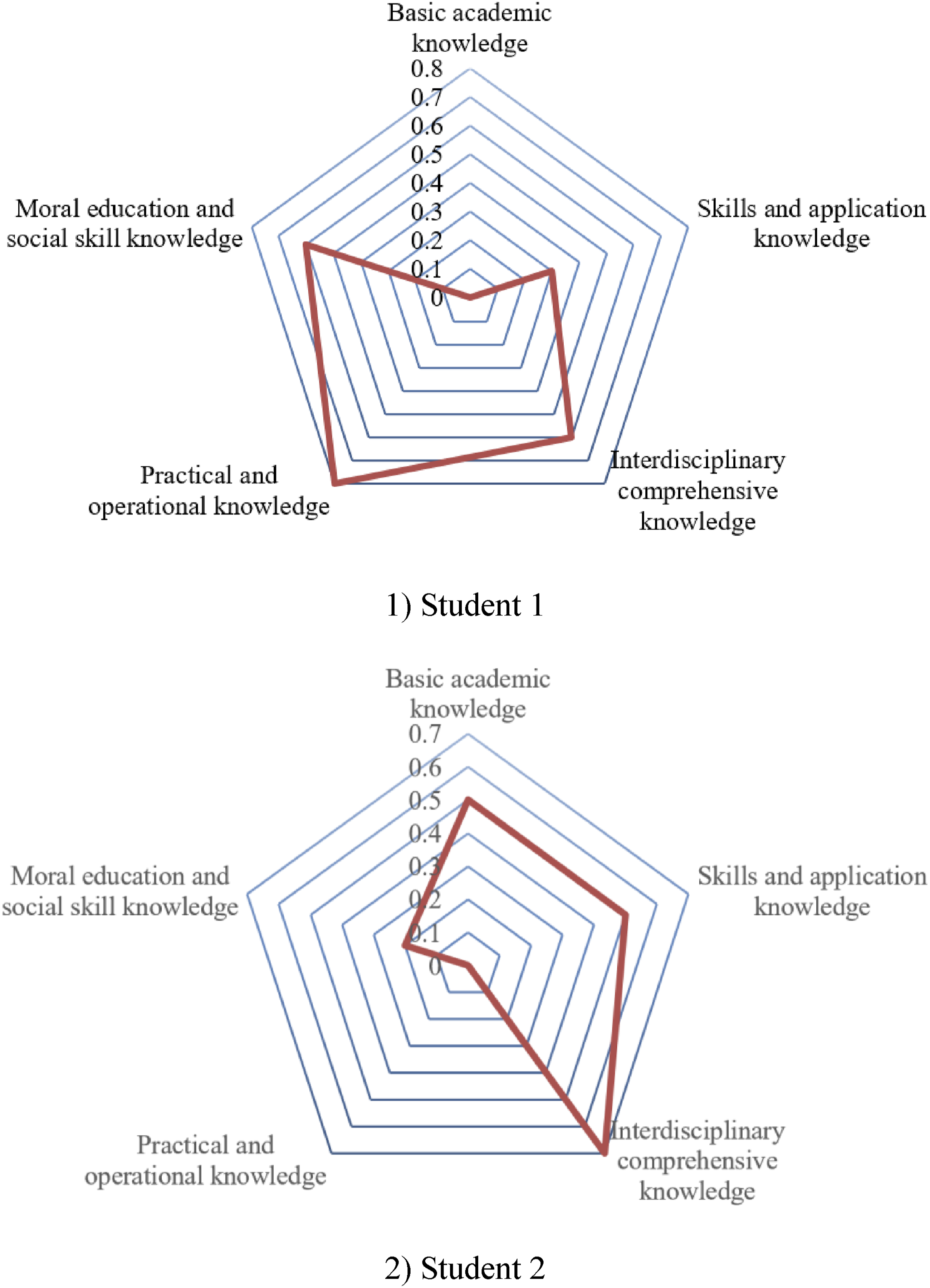
In the comprehensive analysis of the student emotion recognition model, comprising a sensor feature embedding network, a temporal feature embedding network, and a classification layer, the model’s proficiency in identifying and analyzing the emotional states of students in a multimodal learning environment was assessed. As depicted in Figure 5-1, a notable variation in both training and testing accuracy was observed in correlation with the increment in iteration numbers. The model demonstrated an ascending trend in accuracy across the training and testing datasets with each iteration, indicative of its efficacy in learning and recognizing emotional states. Notably, the enhancement in model performance on the testing dataset underscored its robust generalization capability, a critical attribute for real-world applications. The peak testing accuracy recorded was 0.928, a markedly high accuracy level, underscoring the model’s effectiveness in this specific multimodal learning context and its potential for high-quality emotional state recognition in practical scenarios. Accuracy and loss curve graphs for the student emotion recognition model.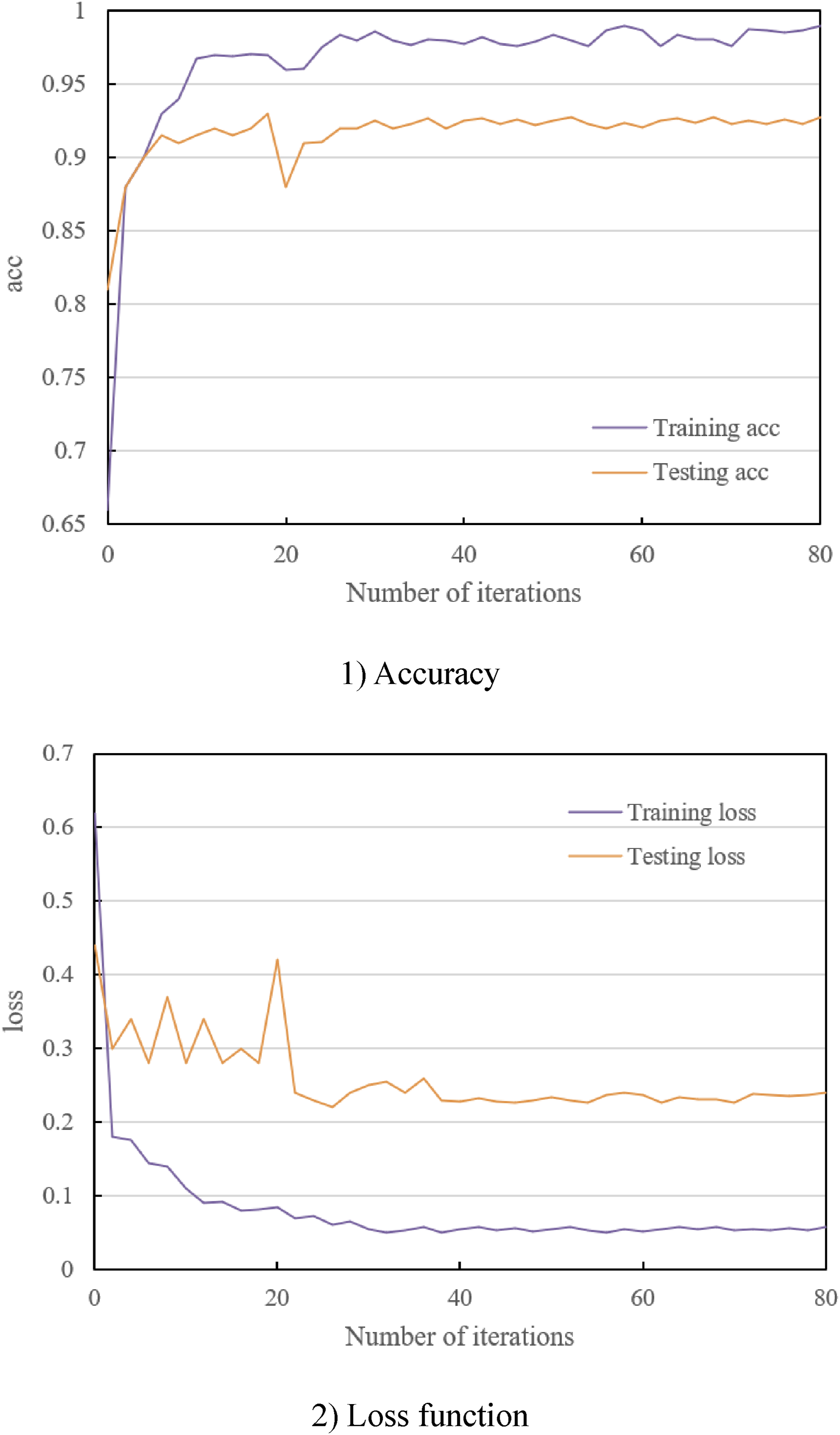
Figure 5-2 provides insights into the model’s loss function values during its training and testing phases. A discernible decrease in training loss was observed, declining from 0.62 to 0.053. This trend signals the model’s ongoing advancement in performance on training data. Despite minor fluctuations, the overarching trend remained downward, suggesting continual learning and optimization by the model. The test loss exhibited variability, initially reducing from 0.44 to 0.22 and subsequently fluctuating between 0.22 and 0.24. These variations can be attributed to the model’s adaptation to novel data or the inherent diversity within the test data. Despite these fluctuations, test loss appeared to stabilize eventually, implying that the model was approaching an optimized state with a solid generalization capacity.
A comparative analysis of F1-score, as delineated in Figure 6, was conducted for different models across various datasets to evaluate their efficacy in the domain of multimodal student emotion recognition. The Recurrent Neural Network (RNN) manifested a degree of effectiveness in all three datasets, notably attaining its highest F1-score (0.34) on the dataset integrating voice, facial expression, and physiological signals. This outcome can be attributed to the RNN’s adeptness at processing sequential data. The Graph Convolutional Network (GCN), while exhibiting comparable performance across the datasets, recorded F1-score marginally below those of the RNN. This finding implies that the GCN’s approach to modeling graph-structured data might be less suitable than sequential data modeling for this particular task. The Variational Autoencoder (VAE) showcased commendable performance across all datasets, achieving an F1-score of 0.32 on the combined dataset of voice, facial expression, and physiological signals. This demonstrates the VAE’s proficiency in learning efficacious feature representations. In contrast, the Sequence-to-Sequence (Seq2Seq) model indicated lower F1-score across all datasets, particularly on the datasets focused on a single modality, suggesting its limited applicability in this emotion recognition context. Both the Generative Adversarial Network (GAN) and the Transformer architecture displayed relatively lower F1-score across all datasets. The Transformer, in particular, might require additional optimization to leverage its inherent capabilities fully in this application. The model presented in this study achieved the highest F1-score across all datasets, especially on the multimodal dataset amalgamating voice, facial expression, and physiological signals, where it reached an F1-score of 0.75. This suggests that the model proposed in this paper surpasses others in processing multimodal data for emotion recognition. The analysis concludes that the multimodal student emotion recognition model introduced in this study exhibits superior performance, especially on datasets incorporating multiple modalities, with F1-score significantly outperforming other models. This outcome evidences the model’s advantage in synthesizing various emotional signals for more precise recognition of students’ emotional states. These results accentuate the potential of multimodal emotion recognition to heighten emotion recognition accuracy and affirm the design and implementation effectiveness of the model proposed in this study. F1-score of different student emotion recognition models on various datasets.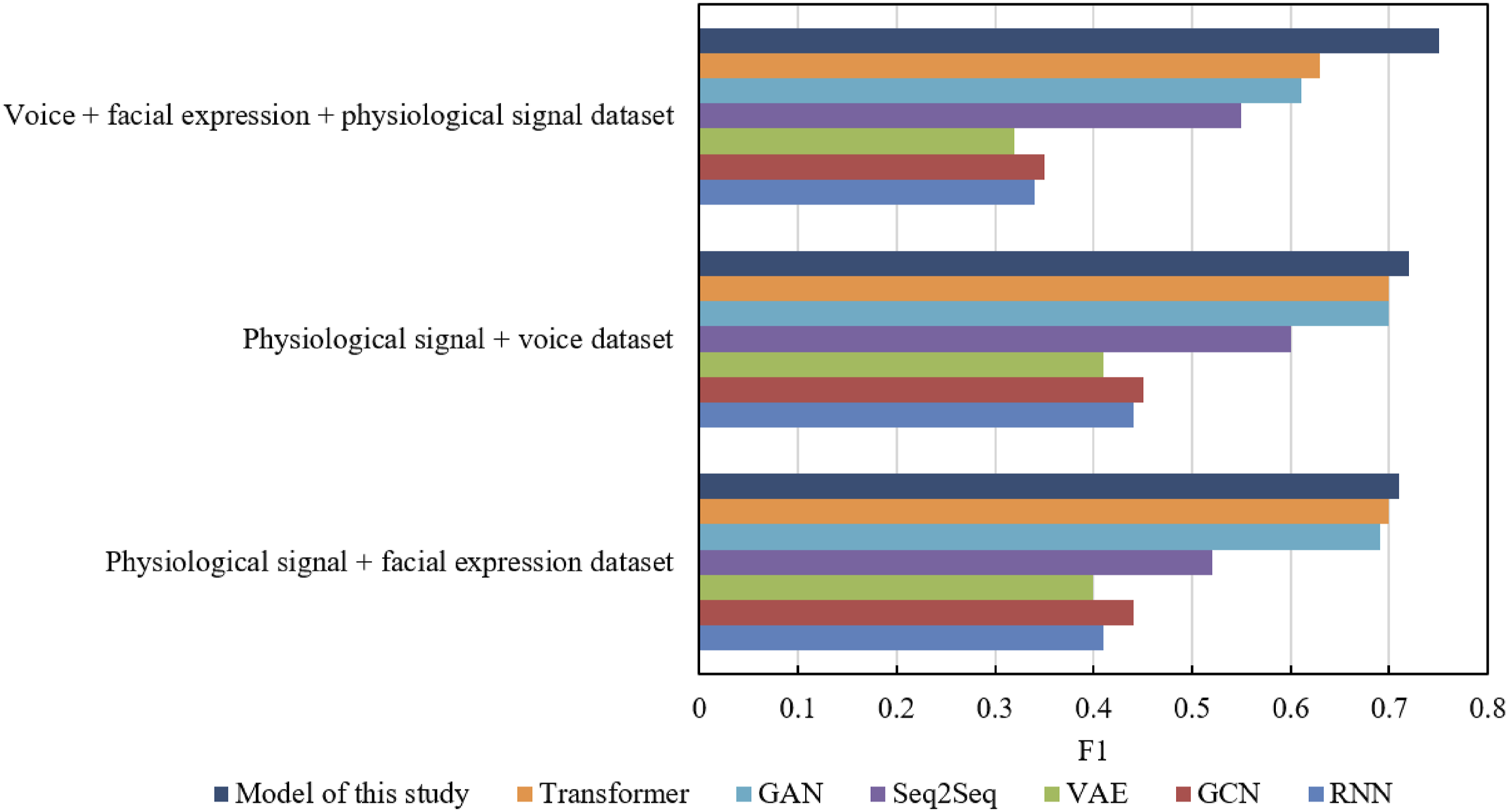
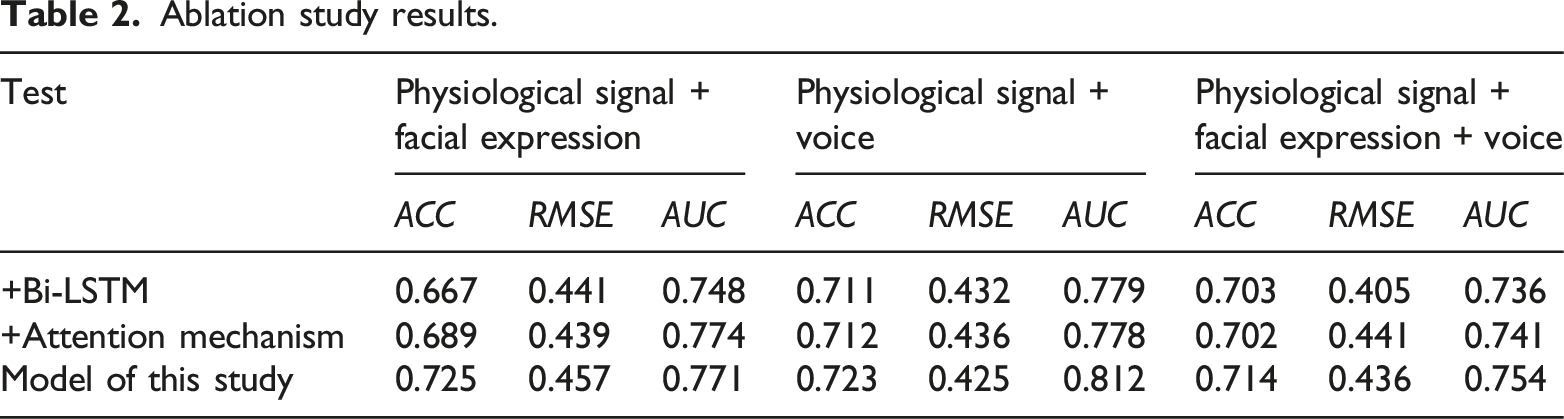
Ablation study results.
Conclusion
In this study, a structured methodology has been developed for analyzing students’ cognitive levels in multimodal learning environments. This approach involved the construction of a correlation matrix, encompassing students, learning items, and knowledge points. Through experimental validation, the method effectively uncovered cognitive weaknesses among students within these environments. The elucidation of quantitative relationships between learning items and knowledge points was achieved, providing a clearer understanding of student-learning dynamics. The analysis of radar charts, depicting various students’ mastery of different knowledge types, validated the personalized nature of learning facilitated by this approach, tailoring educational experiences to individual student needs. Moreover, the study introduced an emotion recognition model integrating sensor feature embedding, temporal feature embedding, and a classification layer. This model is proficient in processing multimodal data, encompassing physiological signals, facial expressions, and voice. Results from ablation studies underscored the significant enhancements in model performance attributable to the incorporation of Bi-LSTM and attention mechanisms, evidenced by improved accuracy, RMSE, and AUC metrics. When all proposed features and mechanisms were integrated, the model demonstrated marked superiority in recognizing multimodal emotional states.
In the realm of a multimodal learning environment, this research has made significant strides in two key areas. Firstly, in the domain of student cognitive diagnosis, the methodology employed has shown proficiency in synthesizing diverse types of educational data. This offers educators a novel perspective for evaluating and fostering students’ cognitive development. Secondly, in the sphere of recognizing students’ emotional states, the model developed herein has substantially enhanced the accuracy of identifying emotional states. This enhancement is attributed to the integration of data from multiple modalities, including physiological signals, facial expressions, and voice, culminating in a reduction of prediction errors and a heightened ability to distinguish between varying emotional states.
The findings and developments in these two areas are mutually reinforcing, providing a robust scientific foundation for comprehending and addressing the cognitive and emotional needs of students within a multimodal learning context. This not only paves the way for the advancement of personalized teaching approaches but also lays the groundwork for designing more efficacious learning interventions.
The findings indicate that cognitive and emotional diagnostics in a multimodal learning environment can significantly enhance the effectiveness of personalized teaching, assist teachers in promptly identifying and addressing students’ learning difficulties, and improve overall teaching quality. Specific recommendations include promoting the use of multimodal learning tools, enhancing teachers’ technological application skills, establishing robust data privacy protection mechanisms, and considering students’ cognitive load and emotional states in instructional design. Future research directions may focus on optimizing multimodal data analysis models, exploring the effectiveness of applications across different subjects and grade levels, and investigating the impact of multimodal learning environments on long-term learning outcomes.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.