
Abstract
Speech emotion recognition is of great significance in the industry such as social robots, health care, and intelligent education. Due to the obscurity of emotional expression in speech, most works on speech emotion recognition (SER) ignore the consistency of speech emotion recognition, leading to fuzzy expression and low accuracy in emotional recognition. In this paper, we propose a semantic aware speech emotion recognition model to alleviate this issue. Specifically, a speech feature extraction module based on CNN and Transformer is designed to extract local and global information from the speech. Moreover, a semantic embedding support module is proposed to use text semantic information as auxiliary information to assist the model in extracting emotional features of speech, and can effectively overcome the problem of low recognition rate caused by emotional ambiguity. In addition, the model uses a key-value pair attention mechanism to fuse the features, which makes the fusion of speech and text features preferable. In experiments on two benchmark corpora IEMOCAP and EMO-DB, the recognition rates of 74.3% and 72.5% were obtained under respectively, which show that the proposed model can significantly improve the accuracy of emotion recognition.
Introduction
In recent years, automatic emotion recognition has undoubtedly become one of the most popular research topics in the field of sentiment analysis [1]. Automatic emotion recognition automatically recognizes and understands human emotions from different biological features such as speech, text, video, physiological signals, and body posture [2]. Compared with other methods, speech can convey emotions more clearly and quickly. The emotions contained in text data are ambiguous, speakers may express different emotions when they use different tones to say the same text content. Video data such as facial expressions and body posture contain personal privacy and require high data storage and processing requirements. Physiological signal data acquisition equipment is more complex. Speech collection costs are lower and less susceptible to environmental influences, it not only can reflect semantic content but also convey the speaker’s inner emotional state. Therefore, it is necessary to choose speech data as the research object of emotion recognition.
Speech emotion recognition (SER) refers to the analysis of human speech signals through computer technology to determine the speaker’s emotional state. SER mainly includes feature extraction and emotion classification. Feature extraction obtains basic features from acoustic signals, which are called low-level descriptors (LLDs), such as Mel frequency cepstral coefficients (MFCC), spectral features, fundamental frequency, and energy. High-level statistical functions (HSFs) are obtained by summing and averaging LLDs. And then recognize and classify the extracted emotional features. Traditional classification methods are mainly based on machine learning methods. Although they have made some progress in emotion recognition [3–6], due to limited fitting and representation capabilities, these methods cannot effectively process large-scale data. With the rapid development of deep learning technology, many models have been applied in emotion recognition and made breakthroughs [7–9], it makes deep learning play an important role in SER. Due to people’s own experiences and current feelings, the emotions could be different even in the same speech. So, fuzzy emotions cannot be solely dependent on feature extraction from speech, a single modality cannot effectively identify the emotions well. It needs to be combined with the text information of the speaker fully understand the emotions that the speaker wants to express from different perspectives to alleviate the consistency of speech emotion recognition which caused by obscurity of emotional expression in speech. Therefore, how to extract implicit emotional information in speech is an urgent problem to be solved.
Inspired by the ability of human cognition to fully utilize information from multiple perceptual modalities, researchers have attempted to extend traditional single-modal sentiment analysis to multi-modal collaborations and leverage multi-modality to extract implicit emotions. Compared with a single modality, multimodal emotion recognition has the advantage of multi-source information [10]. Both audio and text in multimodal data can provide important emotional clues, which can better identify the speaker’s hidden emotional state. Therefore, the multimodal approach has a greater advantage of extracting implicit emotions. However, the data sources of each modality in multimodal data are different, there is low emotional correlation between different modal data, which leads to the easy misidentification or low recognition rate of implicit emotions. In order to solve this problem, we propose a semantic-aware speech emotion recognition method, which captures the spatial information and temporal information in the speech. Specifically, we extract the semantic information of the text to assist capture the implicit emotion in the speech, which the text is generated through speech to text conversion. Different from multi-modal emotion recognition, the semantic-aware speech emotion recognition method uses text data from the conversion of speech data, and has a strong emotional correlation between the two modalities, which can improve the recognition accuracy of the model for implicit emotions.
Our main contributions are summarized asfollows: Emotions are always implicit in expression and only recognizing emotional features from speech cannot obtain the speaker’s emotional state comprehensively. Therefore, we propose a semantic aware speech emotion recognition model that uses text semantic perception information to help the model extract speech emotional features. CNN can extract local features while ignoring global features. Therefore, we add the Transformer model to enhance the extraction of global features. Using the self-attention module in the Transformer structure can capture the long-distance feature dependence of speech. Simple feature fusion causes feature loss, resulting in overfitting. In this respect, we propose a multimodal fusion method based on an attention mechanism; using a key-value pair attention mechanism to fuse the two emotional features of speech and text into a new feature representation.
The rest of this paper is organized as follows. Section 2 reviews some related works of SER, and Section 3 mainly describes the proposed SASER method. Next, the comprehensive experiments are conducted in Section 4. Finally, Section 5 makes a conclusion of this work.
Related works
Traditional machine learning-based methods
Traditional machine learning-based methods for SER rely on manually designed features and annotations, then use models to recognize and classify these features into different emotions. It mainly consists of two parts, namely emotion feature extraction and emotion classification algorithm. The accuracy of emotion feature extraction determines the performance of the model. The acoustic features in speech features are directly related to emotion [11, 12], and the classification algorithm uses linear or nonlinear classifiers for feature classification. Linear classifiers included Bayesian networks and support vector machines (SVM). Yang N et al. [13] used Back Propagation Neural Network (BPNN), Extreme Learning Machine (ELM), Probabilistic Neural Network (PNN) and SVM as classifiers to extract the MFCC features for SER, and concluded that the MFCC features and the SVM classification models are highly effective in the automatic prediction of emotion. Moreover, Zhang et al. [14] proposed a hierarchical classification to classify the implicit emotions into 19 classes of four levels using an SVM, but the model is time-consuming. Nonlinear classifiers included Gaussian mixture models (GMM) and hidden Markov models (HMM). Shahin et al. [15] showed a hybrid Gaussian mixture model and deep neural network performance in the presence of noise signals. Fahad [16] proposed a novel epoch-based emotion feature and fused it with other acoustic features to improve performance. These models rely on manual feature annotations, and the quality of feature annotations determines the performance of the model. At the same time, they ignore time information, which reduces the accuracy of traditional machine learning emotion classification.
Deep learning-based methods
With the rapid development of deep learning technology, deep learning has gradually replaced machine learning as the main analysis method of SER. It uses deep learning models to automatically learn features in speech data. Compared with traditional machine learning technology for emotion recognition, it can automatically detect and extract complex structures and features in data without manual feature extraction and adjustment; extract features from raw data without feature extraction preprocessing; handle unmarked data. Among them, DNN are based on feedforward structures, which consist of one or more hidden layers between input and output. It has been successfully applied to SER’s emotion classification. Alswaidan N et al. [17] surveyed the state-of-the-art research for explicit and implicit emotion recognition in text, and concluded that deep learning models can capture explicit and implicit information in automatic feature extraction. Sun et al. [18] proposed a speech emotion recognition method based on DNN hybrid model. The model can not only accurately classify speech signals into emotions but also focus on identifying certain unique emotions to alleviate the emotional ambiguity. Recurrent Neural Networks (RNN) are very effective in SER and natural language processing. Mirsamadi et al. [19] used RNN to learn short-term acoustic features related to emotions and used local attention mechanisms to make the model focus on extracting specific areas with more prominent emotions to improve the model’s recognition rate. Although RNN can extract emotional features of short-time speech, however, when processing long sequences, RNN will be problems of gradient disappearance and gradient explosion [20]. Therefore, Long Short-Term Memory (LSTM) is introduced, which can effectively solve the problems that RNN cannot handle. Xie et al. [21] proposed a LSTM model based on the attention mechanism, which combines frame-level speech features with LSTM for SER. Convolutional Neural Networks (CNN) have been introduced into SER because they can extract abundant spatial information. Satt et al. [22] divided the speech input into smaller segments and used CNN to extract spatial information of speech through spectral information of speech, then used LSTM to obtain temporal information of speech, which can greatly improve the accuracy of emotion recognition. Hazarika et al. [23] proposed the interactive conversation memory network (ICON), which combine bidirectional LSTM with a novel pooling strategy using an attention mechanism which enables the network to focus on emotionally salient parts of a sentence. Experimental results on the benchmark dataset IEMOCAP demonstrate that the proposed model outperforms state-of-the-art net-works. Li et al. [24] proposed an attention pooling based representation learning method for SER. The model utilized two sets of convolutional filters with distinct shapes to capture temporal and frequency domain contextual information for speech data, results demonstrate a recognition performance of 71.8% weighted accuracy and 68% unweighted accuracy over four emotions. The single-modal emotion recognition has achieved good results, but the recognition results are not robust. Therefore, Yoon et al. [25] proposed a novel Deep Bidirectional Recurrent Encoder model that leverages both textual data and audio signals to better understand speech data. Specifically, the model employs dual RNNs to encode information from the audio and text sequences, and then combines this information from both sources to predict emotion categories. Transformer has better performance in natural language processing tasks and can extract long-term dependent time information. As a result, researchers began to apply it to SER [26]. Tang et al. [27] proposed a bimodal network based on Audio-Text-Interactional-Attention with ArcFace losss for speech emotion recognition, adopted GRU for textual modality, BLSTM for audio and global attention for obtaining the interactive information of two modalities. Experimental results on the benchmark dataset IEMOCAP demonstrate that the method achieved the improvement of 2.4% and 1.8% in terms of weighted accuracy and unweighted accuracy, respectively. Braunschweiler et al. [28] conducted research on the impact of speech and text on emotion recognition. The experiments have shown that combining speech and text only improves performance when there are significant variations in textual expressions across different emotions on individual corpora, performance declines when the same text expresses different emotions in fixed corpora, and models based solely on speech perform better in such cases.
Methodology
Overview of the modal
To fully recognize the emotions contained in speech and improve the recognition effect of implicit emotions, we propose a semantic aware speech emotion recognition model (SASER). As shown in Fig. 1, SASER includes four modules: feature extraction module, speech embedding support module, feature fusion module, and classification module. The feature extraction module includes a speech feature extraction module and a semantic aware extraction module. In the speech feature extraction module, CNN is used to extract local features of speech, and Transformer model is used to extract global features of speech, which solves the problem that CNN ignores global features when extracting local features of speech. Then, the speech content is converted into text using speech recognition conversion technology, and the text semantic aware module uses GRU model to extract semantic features of the text. The semantic embedding support module uses fine-grained alignment between speech frames and text words to guide finely alignment of the emotional words and speech sequences to effectively solve the embedding difference problem, especially the semantic aware as an auxiliary feature to help the speech feature extraction module extract implicit emotions contained in the speech. The feature fusion module uses two key-value attention mechanisms to fuse two different modal emotion features into new features and then completes emotion recognition through the classification module.
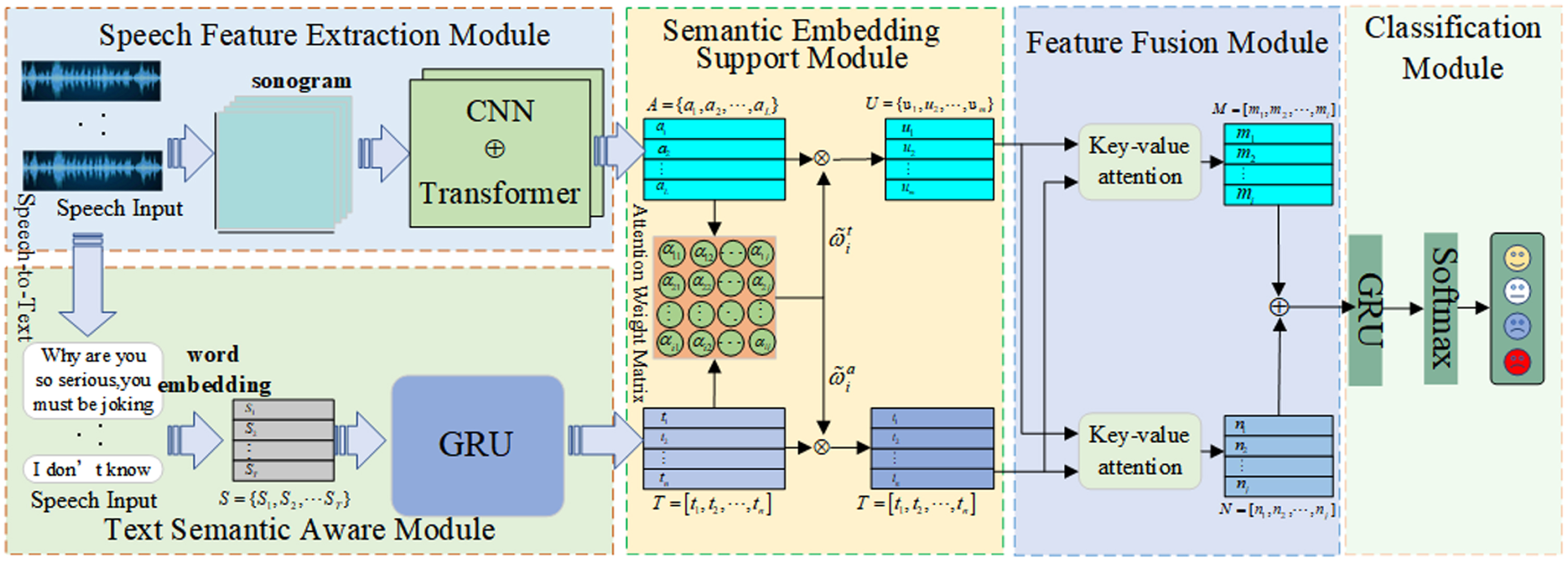
SASER model framework.
The feature extraction module includes a speech feature extraction module and a semantic aware extraction module. The speech feature extraction module includes CNN and Transformer models. Due to the asymmetry between the input features of CNN and Transformer, we connect CNN and Transformer in parallel. CNN has good feature extraction and selection functions, so the CNN structure is used to extract emotional features at a lower dimension of the model. Applying CNN to the model of SERF can overcome the diversity of speech signals by using the translational invariance of convolution. The formula for CNN is expressed as follows:
The text semantic aware module preprocesses the text data, constructs and extracts the text representation, quantifies the text features, and then inputs them into the GRU network to complete the training of the model. GRU is a variant of LSTM with fewer parameters and lower costs. It can effectively solve the problems of gradient explosion and gradient disappearance in the long sequence training process, and reduce the training time of the model, which makes GRU perform better in the long sequence. Assuming the current input sequence is x
t
, the previous hidden state is ht-1, and the current hidden state h
t
can be represented as:
The candidate activation unit
Reset gate r
t
can be represented as:
The semantic embedding support module can solve the embedding differences between two modalities of speech and text, and use semantic information as auxiliary features to help the speech feature extraction module extract implicit emotions contained in the speech. We use semantic embedding to learn the alignment between speech frames and text words, so that emotional words are finely aligned with sequences in speech rather than being forced to align, thereby mapping speech frames to the latent space of text features. Specifically, given an encoded speech embedding A and text embedding T, align the i-th speech frame with the j-th sentiment word, and normalize it to obtain the attention weight
The main multimodal fusion strategies for speech and text are feature-level fusion, model-level fusion, and decision-level fusion. Feature-level fusion directly concatenates, and weights, then sums the features of the two modalities to obtain a completely new feature. It has the advantages of being simple and efficient, and fully retaining the original information, but it may cause dimension explosion because of a large feature dimension; model-level fusion models the intra-modal and inter-modal relationships of multiple modalities to better explore the complementarity between multiple modalities and obtain better multimodal feature representations. Different modalities are encoded separately, and the high-level feature representations output by different modality encoders are fused, and finally emotion prediction is based on the fused features. Decision-level fusion refers to the fact that two different modalities do not affect each other, and the emotion recognition results of each modality are weighted and fused. Although decision-level fusion does not have the problem of dimension explosion, it also ignores the correlation between different modalities. Unlike the above method, the key-value attention mechanism of the feature fusion module uses text semantic features as external information to calculate the correlation between speech as internal information, using one modality to judge the importance of another modality in order to achieve fusion between two modalities. The key-value attention mechanism as shown in Fig. 2.
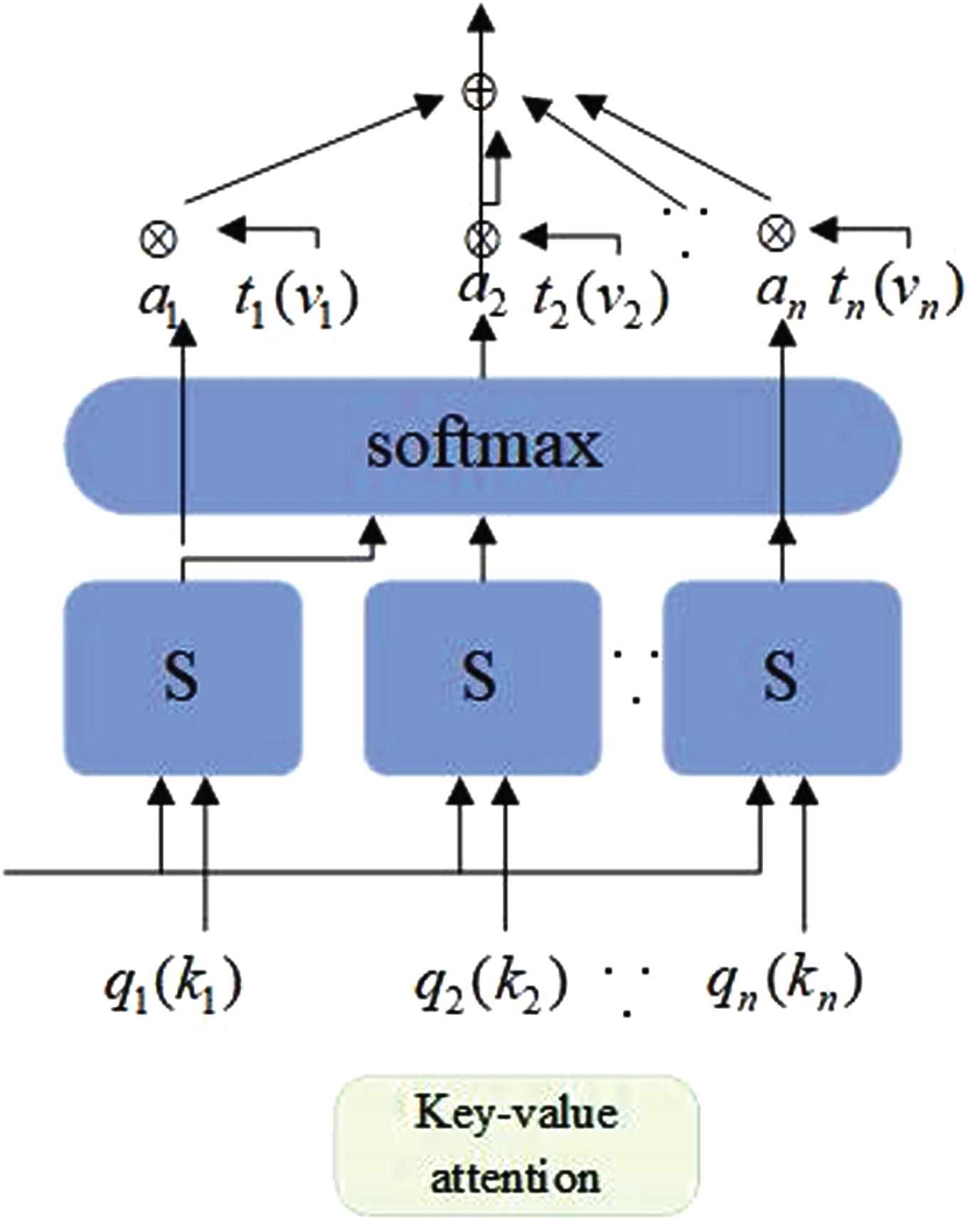
The key-value attention mechanism.
Specifically, calculate the attention score e
ti
of each key k
i
with the query feature q
t
, and use speech features to assist in scoring text features. W represents a learnable parameter matrix. Secondly, use the softmax function to normalize the attention score, obtain the weight α
i
of each key, and weight the corresponding value α
i
as the attention output. Finally, use the attention weight distribution to obtain important information in the text feature, thereby obtaining a new text feature representation M = [m1, m2, ⋯ , m
i
].
Use the text features to extract the important information of the speech features, and obtain a new text feature representation N = [n1, n2, ⋯ , n
j
], the calculation formula can be expressed as:
The newly learned features are input into the fully connected layer (FC) to predict the confidence score of the final emotional state. During the training phase, the target loss function is achieved by using a softmax layer with a cross-entropy function for classification, whose calculation formula is as follows:
Dataset
IEMOCAP [29]: The IEMOCAP dataset is an English database recorded by the University of Southern California. the dataset consisted of five groups of dialogues conducted by 10 professional speakers (5 male and 5 female). Record 12 hours of audio and video content, including improvisation and scripts, and divide emotions into anger, excitement, happiness, neutrality and sadness.
EMO-DB [30]: It contains 535 German speech samples and was recorded by ten actors (five male and five female). The dataset contains seven different emotions: anger, fear, disgust, boredom, neutral, happy, and sad. It is also a publicly available dataset in the field of SER research.
Experimental settings
We implement the proposed on SASER method with the deep learning toolbox PyTroch. The dataset was divided with 60% allocated for training, 20% for validation, and 20% for testing. During the training phase, we optimize the network using the Adma optimizer with weight decay 0.001. The GRU has a hid-den node dimension of 128. The CNN has a convolutional kernel size of 3x3, a stride of 2x2, and uses max-pooling. The Transformer has a dimension of 512, with 6 encoder layers and 8 attention heads. In addition, our model is trained for 60 epochs and a batch size is 64, the initial learning rate is 0.0001, and a dropout is 0.3, the regularization parameter is 0.01.
Evaluation metrics
In the multi-classification task, weighted average accuracy (WA) and unweighted average accuracy (UA) were used as evaluation indicators. Accuracy represents the proportion of correct classification:
In our experiments, we compared the SASER model with other models. Specifically, FSVM [12], RNN [19], ICON [23], CNN [22], CNN+LSTM [22], CNN TF Bilinear [24], MDRE [25], ATIA4 [27], SA-SER-SA, which removes the semantic aware extraction module, and SASER-Att, which removes the attention fusion mechanism. These models were tested on the IEMOCAP dataset and the EMO-DB dataset respectively. The results are shown in Table 1 and Table 2.
Experimental results of WA and UA on IEMOCAP
Experimental results of WA and UA on IEMOCAP
Experimental results of WA and UA on EMO-DB
In the comparative models, [23], [25], [27] are multimodal emotion recognition models for textual and audio. From Table 1 and Table 2, we can find that SASER can achieve the higher scores on WA and UA metrics, which confirms that our method can improve the overall recognition rate of the model. In the IEMOCAP dataset, it can be seen that FSVM achieves a higher WA than CNN, this is because FSVM considers the intercorrelated features between emotions. In the EMO-DB dataset, the FSVM model obtained the lowest WA score, it could be attributed to the dataset was formed through actor performances. By comparing with ICON and RNN, it can be found that there is a contextual relationship in speech emotion. CNN+LSTM has a WA score that is 2.7% higher than CNN, 5% higher than ICON, and 5.3% higher than RNN, indicated that LSTM can effectively extract contextual features in speech emotion. CNN TF Bilinear outperforms CNN+LSTM and ICON in terms of UA, indicated that attention mechanisms can effectively identify distinctive information between modalities in multimodal speech emotion recognition. Comparing MDRE and ATIA3, it is evident that the interactive and fusion features between text and audio have a greater impact than the global information in multimodal settings. Com-paring SASER with CNN and its related models, it can be found that the performance of SASER is bet-ter than CNN, which proves that the SASER model can effectively make up for the shortcomings of CNN for missing global information, and can extracted the global features well. Comparing SASER with CNN TF Bilinear on the IEMOCAP dataset, the CNN TF Bilinear model has a higher UA than SA-SER, it may be that the CNN TF Bilinear model simultaneously considers contextual information in both the temporal and frequency domains for different emotions. By comparing with the Transformer model, the SASER model can better extract the emotional features in speech. In the ablation experiment, it can be seen that the semantic aware module helps SASER improve the WA metrics by 6.5%, which proves that using semantic aware information as auxiliary information to assist the model can improve the extraction of speech emotional features, and improve the recognition rate of the model for implicit emotions. By comparing the ablation experiments of SASER-Att and SASER, it is proved that the attention mechanism is effective in the feature fusion process.
From Fig. 3 we can discover that the convergence speed of the SASER model in the IEMOCAP dataset is higher than that in the EMO-DB dataset, regardless of the training set or the test set. Because the EMO-DB dataset has 7 emotion classifications, while the IEMOCAP dataset has only 4 emotion classifications; The accuracy of the SASER model in the IEMOCAP dataset is 74.3%, and the accuracy in the EMO-DB dataset is 72.5%. It is higher than that in the EMO-DB dataset.
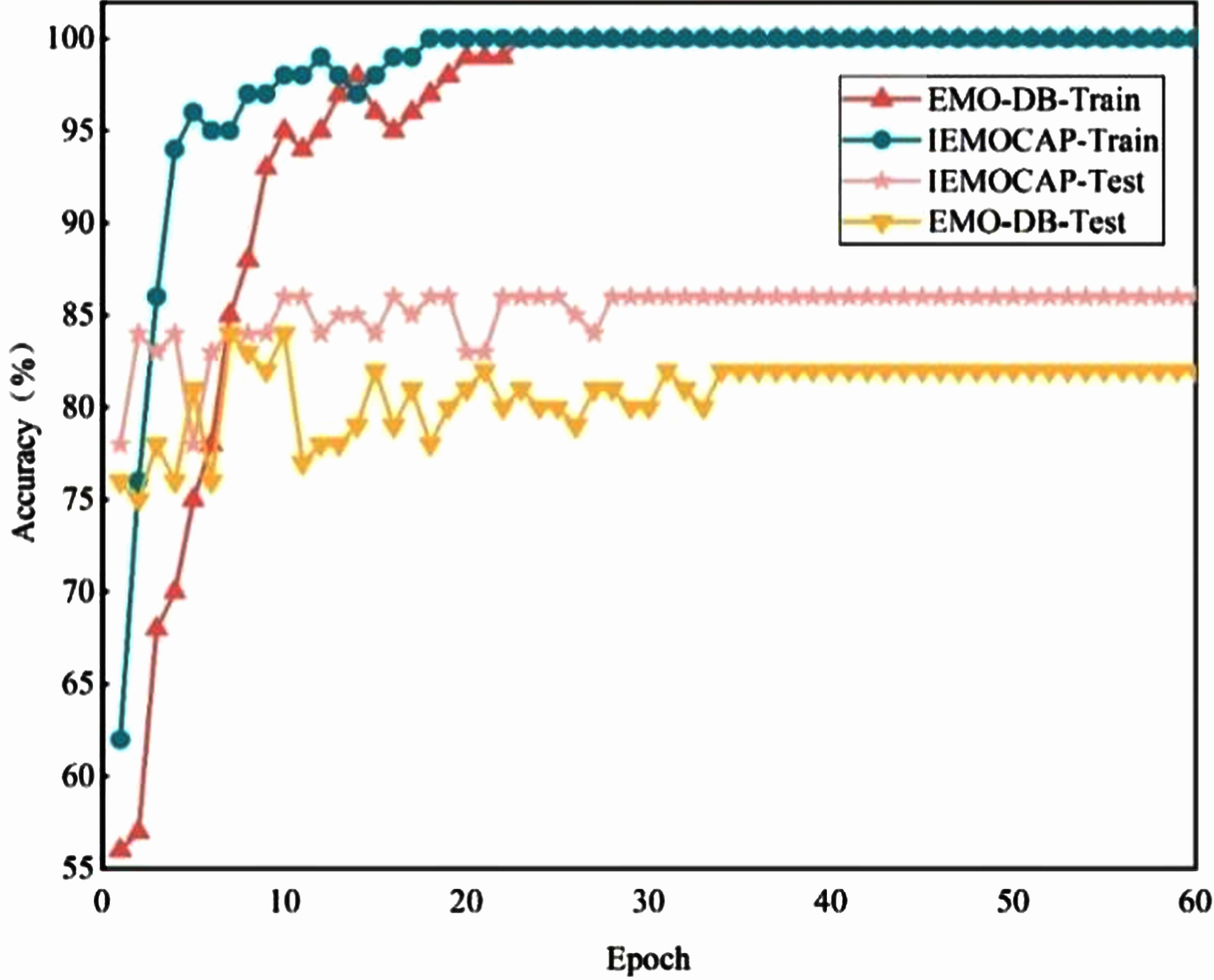
Accuracy of the training process for different data sets.
Figures 4 and 5 show the recognition accuracy of each emotion category, we can observe that. 1) SASER has the highest recognition rate of neutral emotion in IEMOCAP and EMO-DB data sets, reaching 80.5% and 75.1% respectively, which indicates that the SASER model can improve the recognition rate of neutral emotion, since it can extract hidden emotion information from emotional features and avoid mistakenly recognizing hidden emotion as neutral emotion. Compared with IEMOCAP dataset, the recognition rate of EMO-DB is lower than that of the former. It may be that IEMOCAP has more data and fewer categories than EMO-DB, which will help model train a better network.
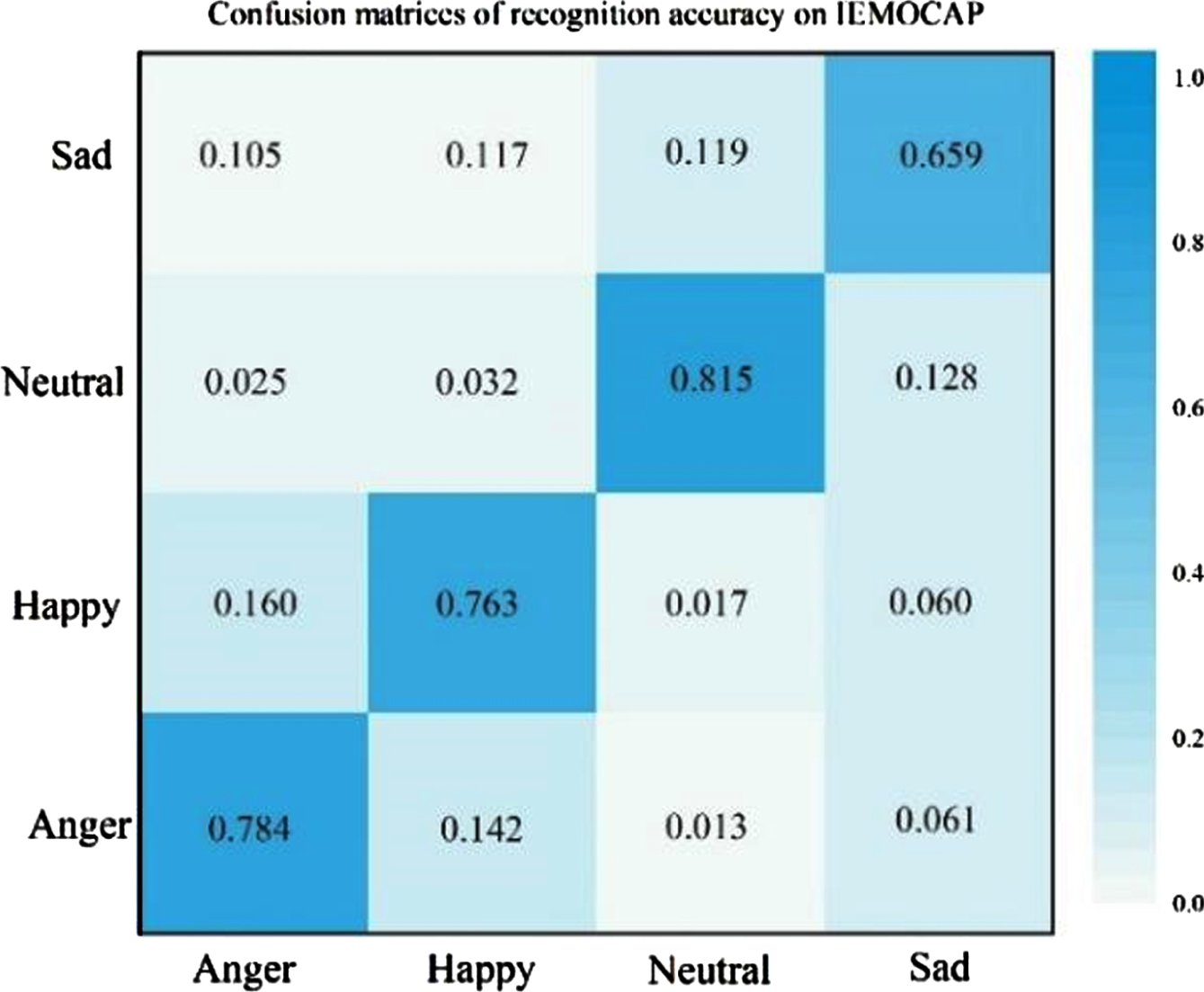
Confusion matrices of accuracy on IEMOCAP.
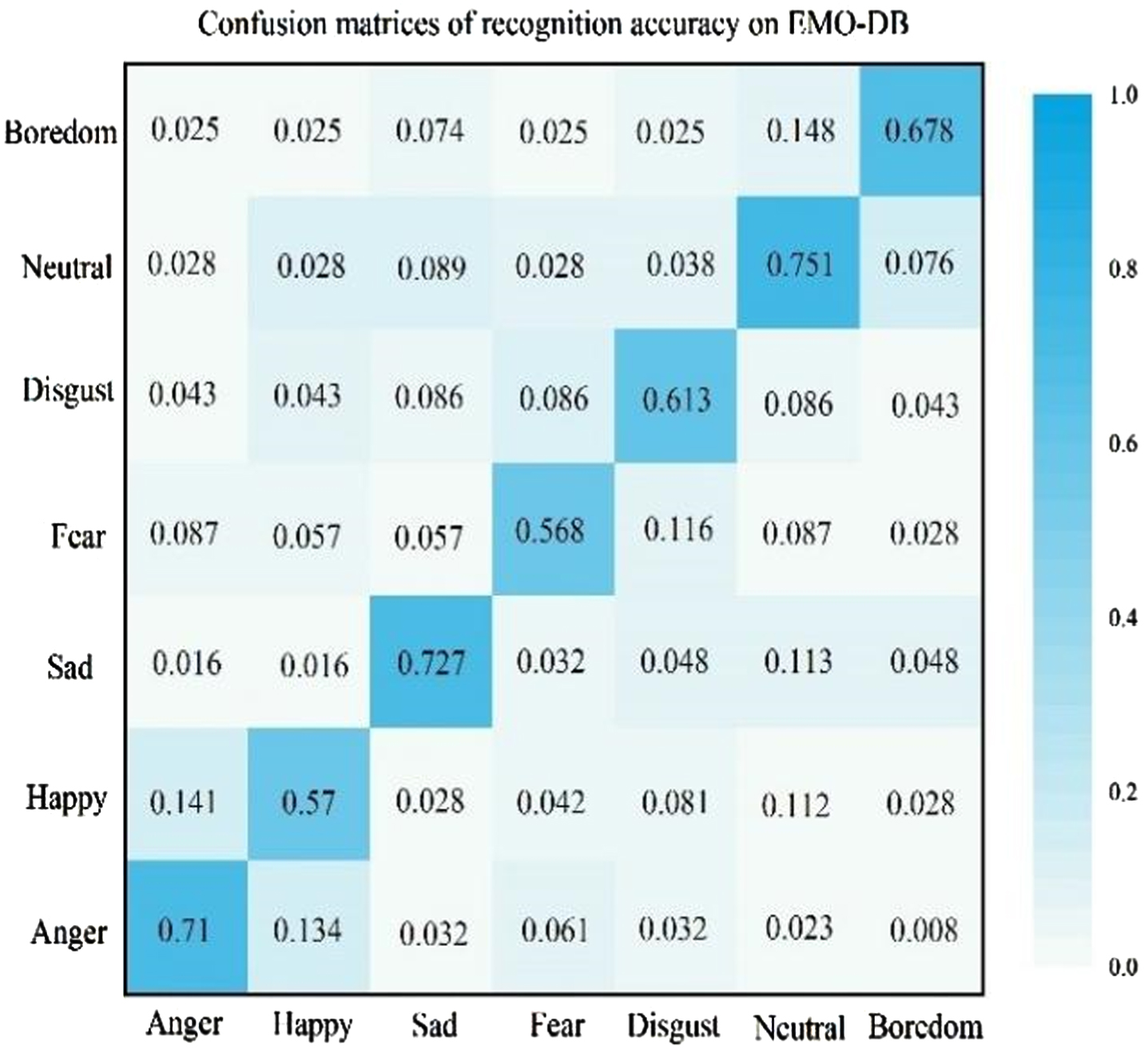
Confusion matrices of accuracy on EMO-DB.
To select the number of CNN modules with the best generalization ability, we comparing different number of CNN modules in the dataset, which is shown in Fig. 6. The number of CNN modules is increased in turn. The indicators increase first and then start to decrease. Among them, the IEMOCAP dataset reaches the maximum value when the number is 3, and the EMO-DB dataset reaches the maximum value when the number is 2. This indicates that the increase of the number of CNN modules will increase the complexity of the model, the training time becomes longer, so continuously increase the number of CNN cannot improve the accuracy of SER. Therefore, we selected the most appropriate number of CNN in the subsequent experiments.
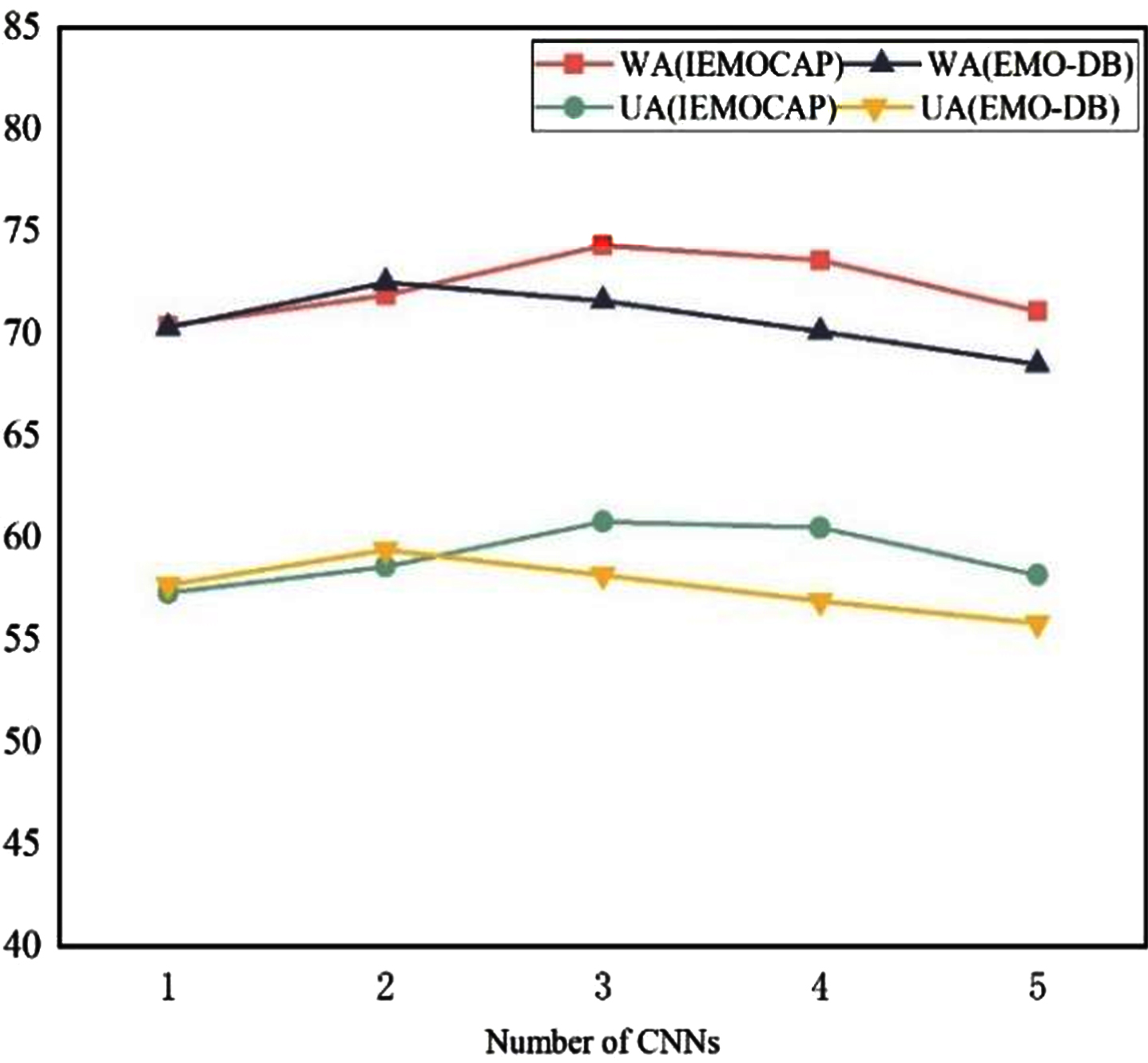
Performances of CNN with different numbers ondataset.
In order to intuitively demonstrate the effectiveness of the proposed semantic aware module for emotion classification, we compared the SASER model with the SASER-SA model without the semantic perception module and the SASER-Att model without the feature fusion module. The confusion matrices of the emotions recognized by the models in IEMOCAP dataset are shown in Figs. 7, Fig. 8 and Fig. 9.
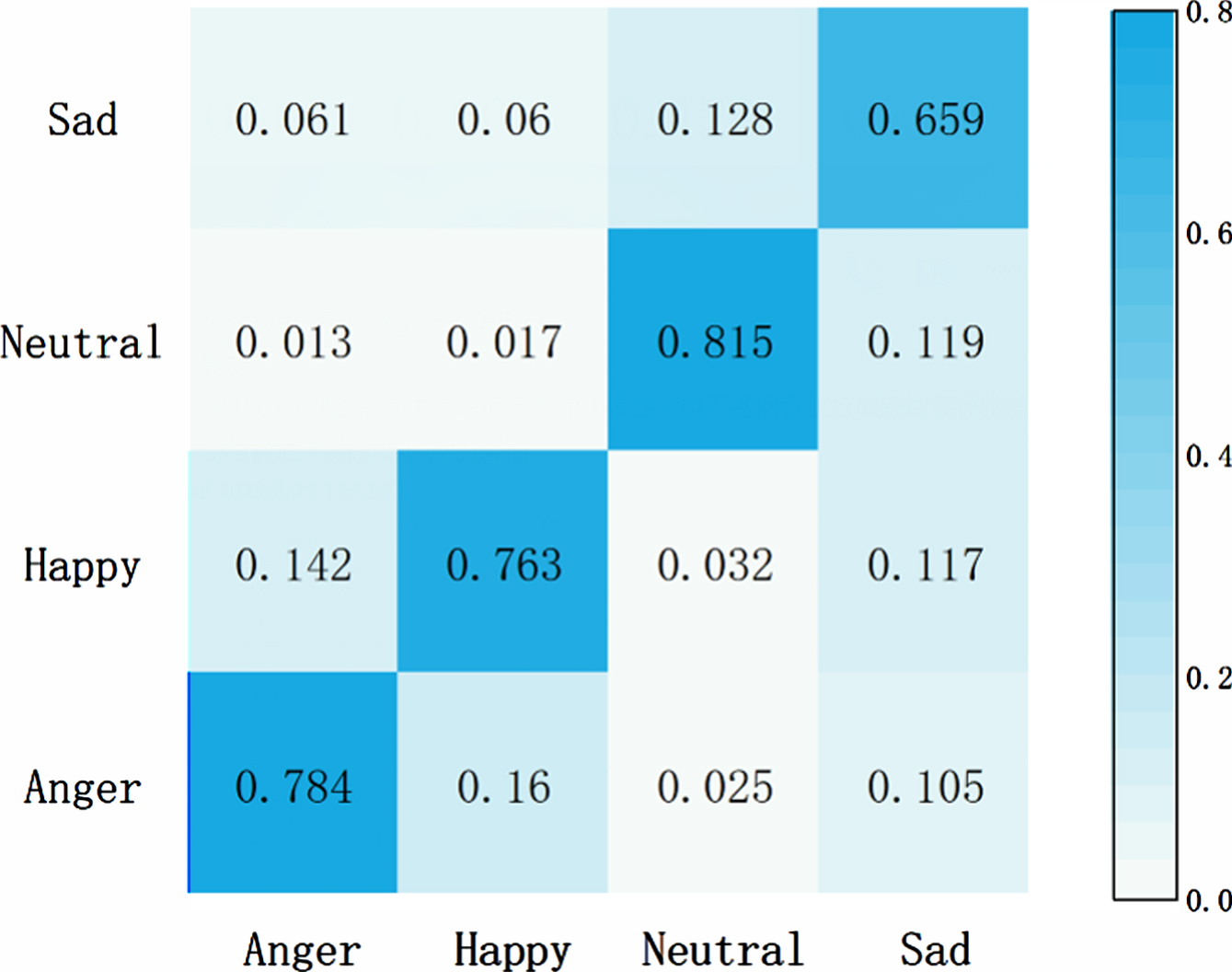
The confusion matrix of SASER on IEMOCAP.
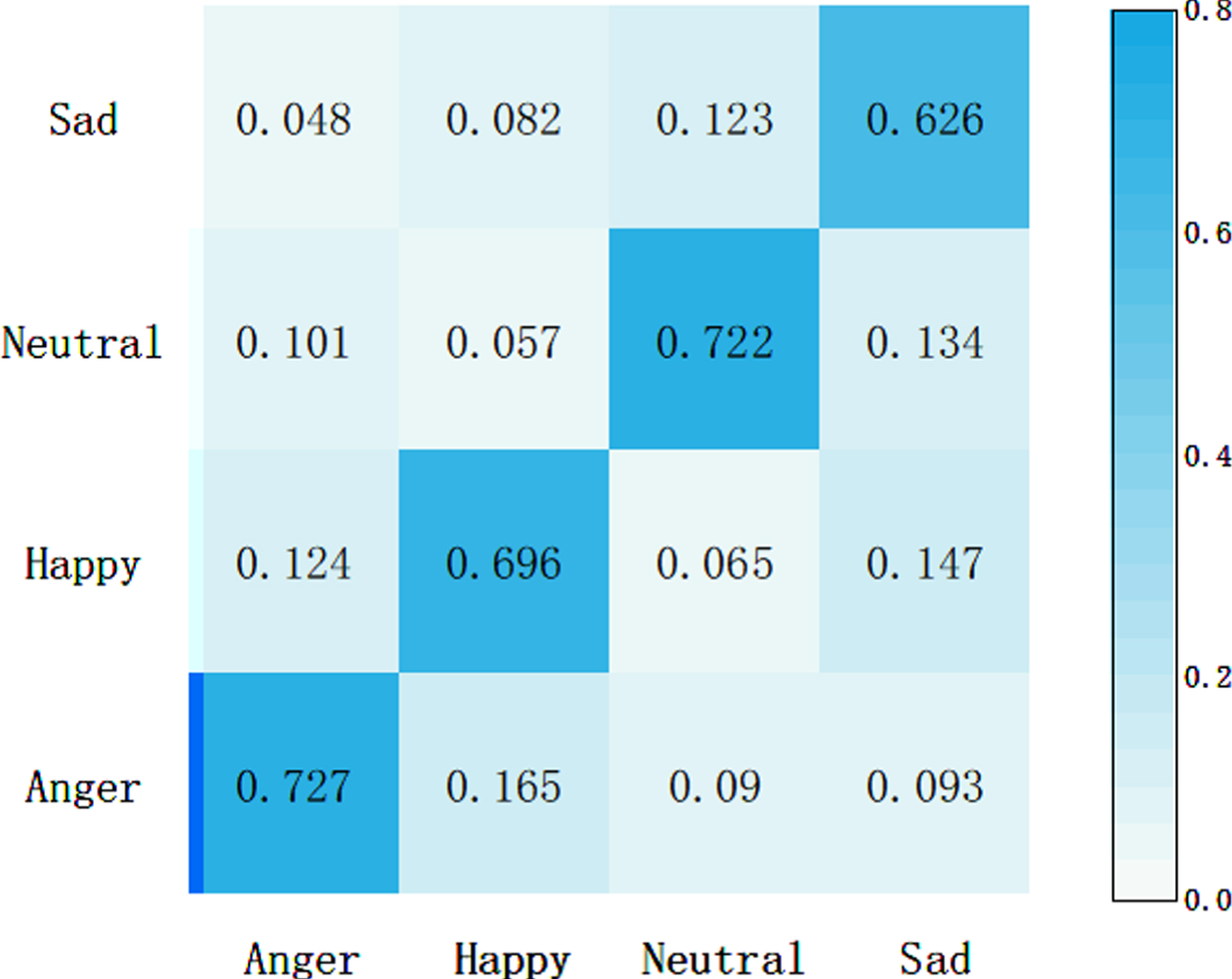
The confusion matrix of SASER-SA on IEMOCAP.
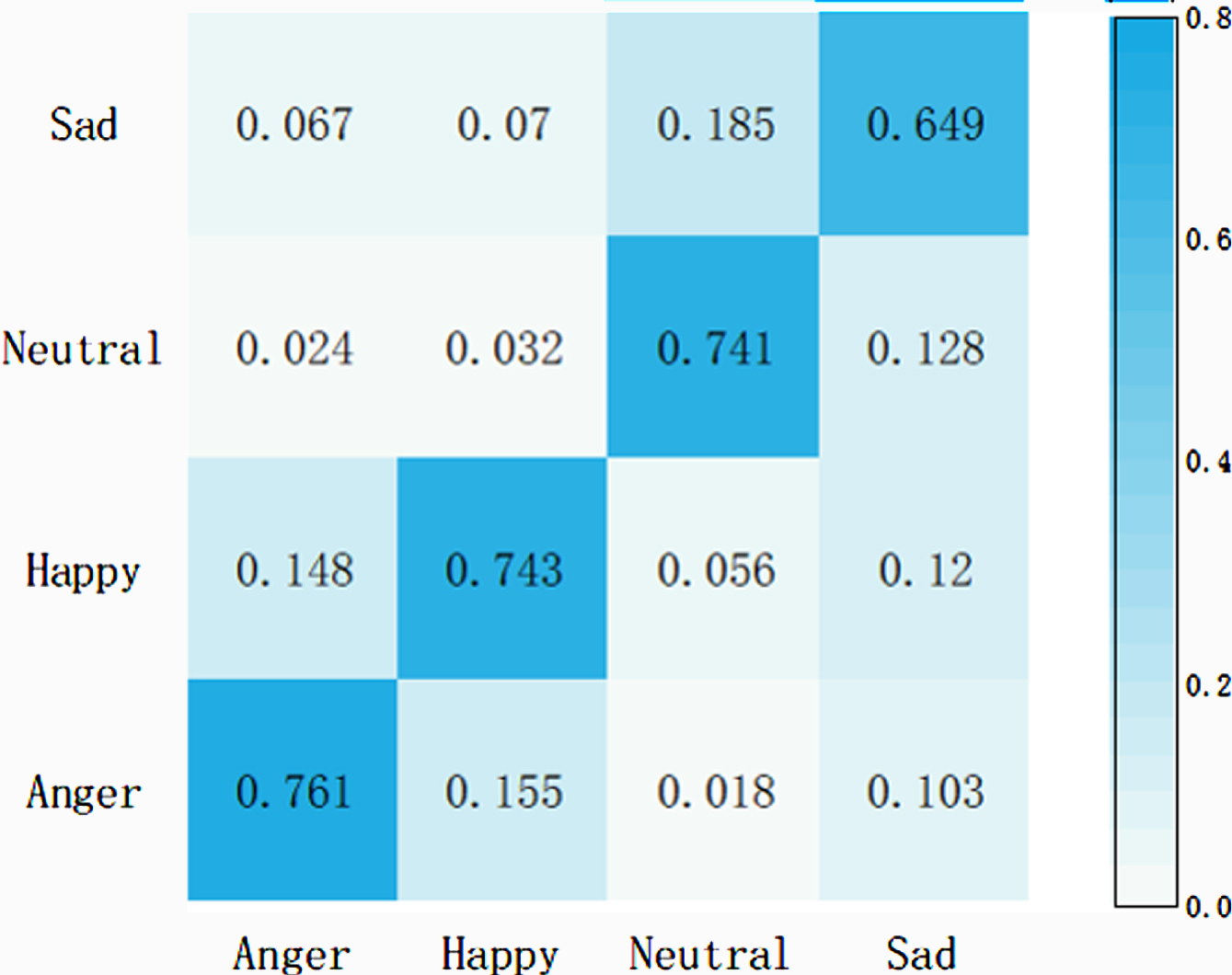
The confusion matrix of SASER-Att on IEMOCAP.
Comparing Fig. 7 and Fig. 8, we can discover that the overall recognition rate of the SASER model for the four emotions is higher than that of the SASER-SA model, especially the recognition effect of neutral emotion is improved best, which is increased by 9.3%. It indicates that the semantic aware extraction module plays an important role in the recognition of neutral emotion and verifies the effectiveness of the proposed semantic aware extraction module. Comparing Fig. 7 and Fig. 9, it can be seen that the overall performance of the SASER model is higher than that of the SASER-Att model, and the error recognition rate of other emotions in the SASER model for neutral emotion is also reduced, which indicates that semantic information assistance has solved the problem of implicit emotion in speech to a certain extent. In addition, the semantic aware extraction module has a great effect on the recognition effect of neutral and sad emotions, while although the accuracy of anger and surprise recognition has been improved, the degree of improvement is small. This may owe to anger and surprise are high-emotion-changing emotional features that are easier to extract and recognize than neutral and sad emotions, and these two emotions can be well recognized even without semantic aware extraction module.
In addition, we further compare our SASER framework with two different types of unimodal settings, i.e., the “Speech” and “Text” models. Specifically, the “Speech” model is only built on the proposed speech feature extraction module, while the “Text” model is initialized with the proposed semantic aware extraction module. Table 3 shows the comparison results with different unimodal branches. As is shown above, the worst-performing model is “Speech,” where it achieves the WA scores of 68.4% and 65.4% on IEMOCAP and EMO-DB, respectively. By contrast, the “Text” model outperforms the “Speech” model, possibly because many people prefer to euphemistically express their emotions or rely on logic inferring. The accuracy of our proposed model is better than the types of unimodal settings.
Comparisons of WA and UA with two different types of unimodal settings
In this paper, we propose a semantic aware speech emotion recognition model, which is mainly used to solve the problem of the obscurity of emotion in speech. The main core of the proposed SASER model is the text semantic information extracted by the semantic perception sub module to assist in extracting hidden emotion in speech. The CNN and Transformer models are used to extract the local and global features of speech. The semantic perception is used to fine-grained alignment between speech frames and text words to assist extract the implicit emotional features in the speech. Finally, the speech and text emotional features are fused into a new feature representation using the key value pair attention mechanism to achieve complementarity and fusion between the text semantic features and speech semantic features. Extensive experiments and results analysis are conducted in the benchmark data sets, proving the superiority of the design model SASER. Despite significant achievements, the full extraction and utilization of emotional information is still challenging. In our future work, we will try to combine more modals, such as images and physiological data, to further improve the performance of emotional recognition.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China (No. 62277008) “Human–like emotional interaction and intelligent adaptation for virtual learning environment”, National General Project of National Education Science Planning “Research on Policy System for Deep Integration of Artificial Intelligence and Education” (No. BGA210055), and 2021 Chongqing Special Key Project for Technology Innovation and Application Development “R&D and Application of Key Technologies for Intelligent Education Evaluation” (No. CSTC2021jscx–gksbX0059).