
Abstract
With the rapid development of e-commerce and the increasing diversity of user demands, personalized recommendations on online shopping platforms have become an important direction of research in the field of e-commerce, which is extremely important for promoting the intelligent transformation of the e-commerce industry. Personalized recommendations on online shopping platforms directly promote the growth of e-commerce sales by improving user experience and satisfaction; at the same time, through the application of intelligent recommendation technology, it accelerates the technological innovation of the e-commerce industry and the changes in the competitive landscape. However, current personalized recommendation algorithms still have problems such as poor algorithm performance, long iteration time, and low recommendation precision. To better achieve personalized recommendations for online shopping, this article applies deep Q-network (DQN) to explore personalized recommendation algorithms in depth. In the article, data is first collected and preprocessed through data augmentation, and based on the deep Q-network, a user–product interaction matrix is constructed. Afterward, based on user behavior characteristic data, user behavior modeling is implemented. Then a DQN-based learning architecture is constructed by combining long-term interests, short-term interests, and prediction modules, and a small batch gradient descent method is used to train the function. Finally, this article evaluates the performance of the algorithm. The research results show that when the length of the recommendation list is 1, the accuracy, recall, and mean average precision of the DQN algorithm are 0.924, 0.875, and 0.901, respectively. The recommendation algorithm based on DQN achieves good results in indicators of recommendation accuracy, recall, and mean average precision. In this article, DQN is applied, and the online shopping recommendation system is optimized by combining deep learning and reinforcement learning, significantly improving the quality and efficiency of recommendations and promoting the intelligent development of the e-commerce industry.
Keywords
Introduction
In today’s digital age, personalized recommendation systems are crucial for online shopping platforms, greatly enhancing user experience and commercial value.1,2 However, traditional recommendation algorithms face many challenges. Issues such as data sparsity, cold start, and user preference dynamics limit the recommendation effect and system response speed. To address these challenges, this article uses an innovative solution: a personalized recommendation algorithm based on deep Q-network (DQN). The DQN algorithm can make reasonable recommendations in sparse data and cold start situations by simulating the environment and reward mechanism.3,4 It utilizes its self-learning and exploratory abilities to provide precise recommendations for new users and products even with little or no historical interaction data.5,6 In addition, the DQN algorithm responds to changes in user behavior in real-time through continuous interaction and feedback loops, improving the timeliness of recommendations and personalized matching. With the powerful expressive power of deep learning, DQN can deeply explore the deep patterns of user behavior, construct complex user preference models, and provide users with a more personalized shopping experience. Meanwhile, the DQN algorithm utilizes an efficient parallel computing framework to significantly enhance big data processing capabilities, ensuring fast response and low latency of recommendation systems. This article hopes that through in-depth research on personalized recommendation algorithms, it can provide direction for the future development of personalized recommendation technology and promote the intelligent transformation of the e-commerce industry.
This article optimizes the personalized recommendation algorithm for online shopping by applying DQN. This algorithm utilizes deep learning techniques to mine user behavior patterns, construct complex preference models, and combines parallel computing to improve data processing efficiency and ensure fast response of recommendation systems. The contribution of this article lies in the successful application of DQN to e-commerce recommendation systems, overcoming multiple limitations of traditional algorithms, especially in dynamic environment learning and large-scale data processing. Compared with traditional algorithms, DQN still iterates efficiently in scenarios where the length of the recommendation list changes, surpassing other recommendation algorithms. The empirical analysis verifies the superiority of DQN on the JD dataset, reducing training difficulty and overfitting risk, and significantly improving recommendation performance.
The research contributions of this article are: - The Deepin Q-network application is successfully applied to the e-commerce recommendation system, which solves the problems of long iteration time and low recommendation accuracy of traditional recommendation algorithms, and significantly improves the quality and efficiency of recommendations. - Using DQN’s strong self-learning and exploration capabilities, it can still provide accurate recommendations even in the case of sparse data and cold start, effectively meeting the recommendation challenges of new users and new products when they join. - By combining deep learning and reinforcement learning, a recommendation model that can capture users’ long-term and short-term interests at the same time is constructed, and the personalization level and real-time responsiveness of recommendations are improved. - It realizes an efficient parallel computing framework, optimizes the big data processing process, and ensures the fast response and low latency of the recommendation system, providing strong technical support for the intelligent transformation of the e-commerce industry.
Related work
Personalized recommendation systems can analyze user behavior and preferences, provide customized recommendations, enhance user experience and satisfaction, and improve enterprise efficiency and profitability, which are key technologies for achieving precise marketing.7,8 In recent years, both academia and industry have made significant progress in the research of personalized recommendation systems. Personalized recommendation systems are one of the important methods to solve the problem of big data overload, but traditional recommendation services face severe challenges. Cao Bin constructed a multi-objective recommendation model and proposed a distributed parallel evolutionary algorithm using non-dominated sorting and crowding distance to optimize the model. Compared with advanced algorithms, this algorithm performed well and was very efficient. 9 Recommendation systems should provide users with accurate and rapid time changes. Cui Zhihua proposed a new recommendation model based on temporal correlation coefficient. Through experiments on two real datasets, MovieLens and Douban, it was found that the proposed model improved precision and was effective for application in Internet of Things (IoT) scenarios. 10 Traditional personalized recommendation systems based on collaborative filtering are prone to time complexity issues. Zhang Jiang proposed a simple and efficient recommendation algorithm that could significantly reduce time complexity while achieving good recommendation performance. The feasibility and accuracy of the system were evaluated through real data. 11 Unlike most personalized recommendation systems, the model proposed by Nitu Paromita considered users’ latest interests by incorporating time-sensitive recency weights into the model. The performance of the proposed model is superior to existing personalized interest location recommendation models, with overall high accuracy. 12 The methods discussed by scholars have improved recommendation effectiveness to some extent, but still face challenges such as insufficient dynamic response capability and limited personalization.
Deep Q-networks have gradually gained attention by simulating user system interaction, dynamically adjusting recommendation strategies, and improving the real-time response capability of recommendation systems.13,14 The goal of a recommendation system is to accurately and actively provide users with potentially interesting items. Lei Yu developed a social attention deep Q-network based on individual user and social neighbor preferences, and used the social attention layer to model the influence between the two to optimize the recommendation system. The proposed social attention deep Q-network significantly outperformed the advanced deep reinforcement learning agents at reasonable computational costs. 15 Personalized recommendation systems have been widely applied in the field of e-learning to adapt to each learner’s own learning speed. Tan Chunxi proposed a new adaptive recommendation strategy under reinforcement learning framework, which was implemented by deep Q-learning algorithm. It could handle lost data properly and handle more individual specific functions to obtain better suggestions. 16 The research methods of the above-mentioned scholars still have shortcomings in dealing with large-scale data and complex user behavior patterns.
Personalized recommendation systems have achieved significant results in improving recommendation accuracy and efficiency, but deep learning still has limitations in capturing dynamic user preferences and mining user behavior patterns, and large-scale data processing capabilities need to be strengthened. Although the research on deep Q-networks and recommendation systems has improved the personalization and adaptability of recommendations, it still faces challenges in terms of data processing efficiency and model interpretability. This article aims to integrate existing advantages and utilize a personalized online shopping recommendation algorithm based on deep Q-networks, emphasizing rapid learning of user preference changes, and combining distributed computing to optimize large-scale data processing capabilities, so as to achieve more efficient and personalized recommendations. The model interpretability is also explored to optimize precision marketing and services in the e-commerce field.
Implementation of personalized recommendation algorithm with deep Q-network
Data preprocessing
Data collection
Online shopping is the most widely used field for personalized recommendation systems.17,18 In e-commerce, due to the large variety and quantity of products, consumers often have to browse through a lot of useless information before finding the products they want, which can easily affect their purchasing enthusiasm. At the same time, when the purpose of online shopping for netizens is unclear, recommendation systems can capture different types of user needs and take corresponding actions to motivate users to make corresponding choices, thereby achieving the goal of selling products.19,20 This means that the recommendation system can accurately match user interests and product information, effectively reduce users’ troubles with a large amount of irrelevant information, and improve the shopping experience; at the same time, it also stimulates users’ desire to buy through personalized recommendations and promotes commodity sales.
Basic information of collected data.
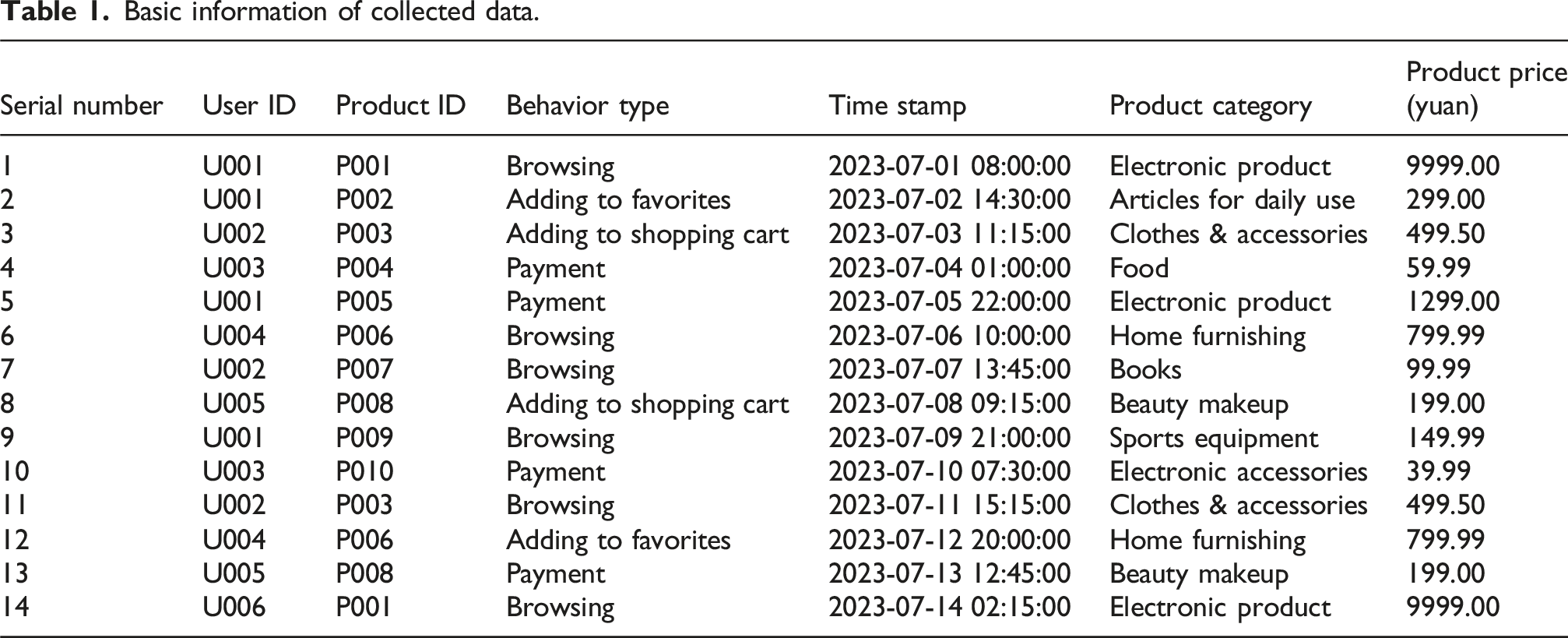
After the collection of raw log data is completed, operations such as data cleaning, filling, sorting, and format conversion need to be carried out. Unreasonable timestamps, missing project ID, and invalid behavior types are excluded. On this basis, by calling the product attribute database, the product information in the log is supplemented, and a matrix diagram of user–product interaction relationship is established. The data set is sorted in chronological order to ensure the consistency of the time interval, so as to realize the model training and evaluation. The processed data is saved in the form of a database and backed up for use during modeling. After collection and processing, this article obtains an interaction record with over 10,000 users, nearly 30,000, covering 365 days. These seemingly simple behavioral records reflect deep-seated behavioral trends such as users’ consumption interests, preferences, and social intentions. The research results of this article provide reliable data support and digital processing methods for in-depth mining of user behavior characteristics and establishing behavior prediction models.
Data augmentation processing
In practical recommendations, when the sample size is small, it often causes network overfitting, which in turn affects the precision of the recommendation results. Therefore, this article studies data augmentation strategies from two aspects: information “exploration” and “utilization,” and based on this, explores spatiotemporal attribute enhancement methods based on bidirectional DTW (Dynamic Time Warping) algorithm, which can meet the needs of users lacking historical data and prevent overfitting caused by data factors. The two-way DTW algorithm is an improved time series similarity calculation method. It not only finds the shortest matching path between the two sequences but also calculates the maximum distance of each path, so as to standardize the cumulative distance, effectively enhance the spatiotemporal properties of the data and reduce the phenomenon of overfitting.
Although conventional DTW algorithms can achieve similarity between two different time series in two dimensions, the accumulated distance obtained is usually greatly affected due to the large amplitude.23,24 Therefore, this article uses a bidirectional DTW algorithm to calculate the similarity between different users. Compared with traditional DTW algorithm, bidirectional DTW algorithm not only calculates the shortest path, but also calculates the maximum distance of each distorted path, achieving cumulative distance standardization. The shortest warping distance can be calculated according to Formula (1)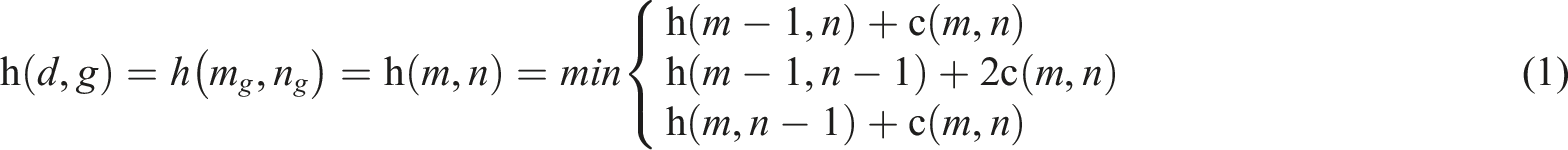
Formula (2) can be obtained from Formula (1)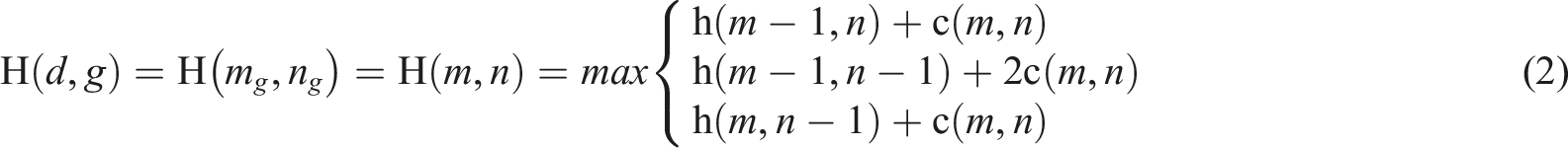
Using the above two methods, the cumulative distance between a set of template sequences and a set of test sequences is calculated, and the formulas are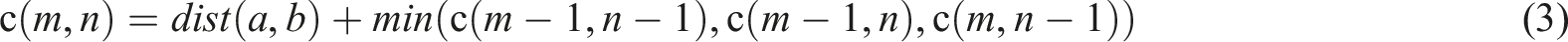
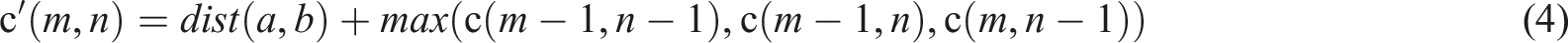
The formula for calculating the similarity between the template sequence and the test sequence can be expressed as
The bidirectional DTW algorithm can reflect the similarity between two users as a whole, but if only relying on the bidirectional DTW algorithm to supplement data, it inevitably leads to excessive noise and reduce recommendation accuracy in the case of sparse user data. Therefore, from the perspective of information utilization, combined with the idea of the longest common point sequence algorithm, users with sparse features are supplemented. However, when using the longest common point sequence to calculate the similarity between users, it often consumes a lot of time and resources in the case of a large data scale. Therefore, this article incorporates the spatiotemporal characteristics of users and preserves the temporal characteristics of the raw data as much as possible. Finally, this article compares the effectiveness of three data augmentation methods: information “exploration,” information “utilization,” and bidirectional DTW algorithm. The specific results are shown in Figure 1: Comparison of the effectiveness of three data augmentation methods.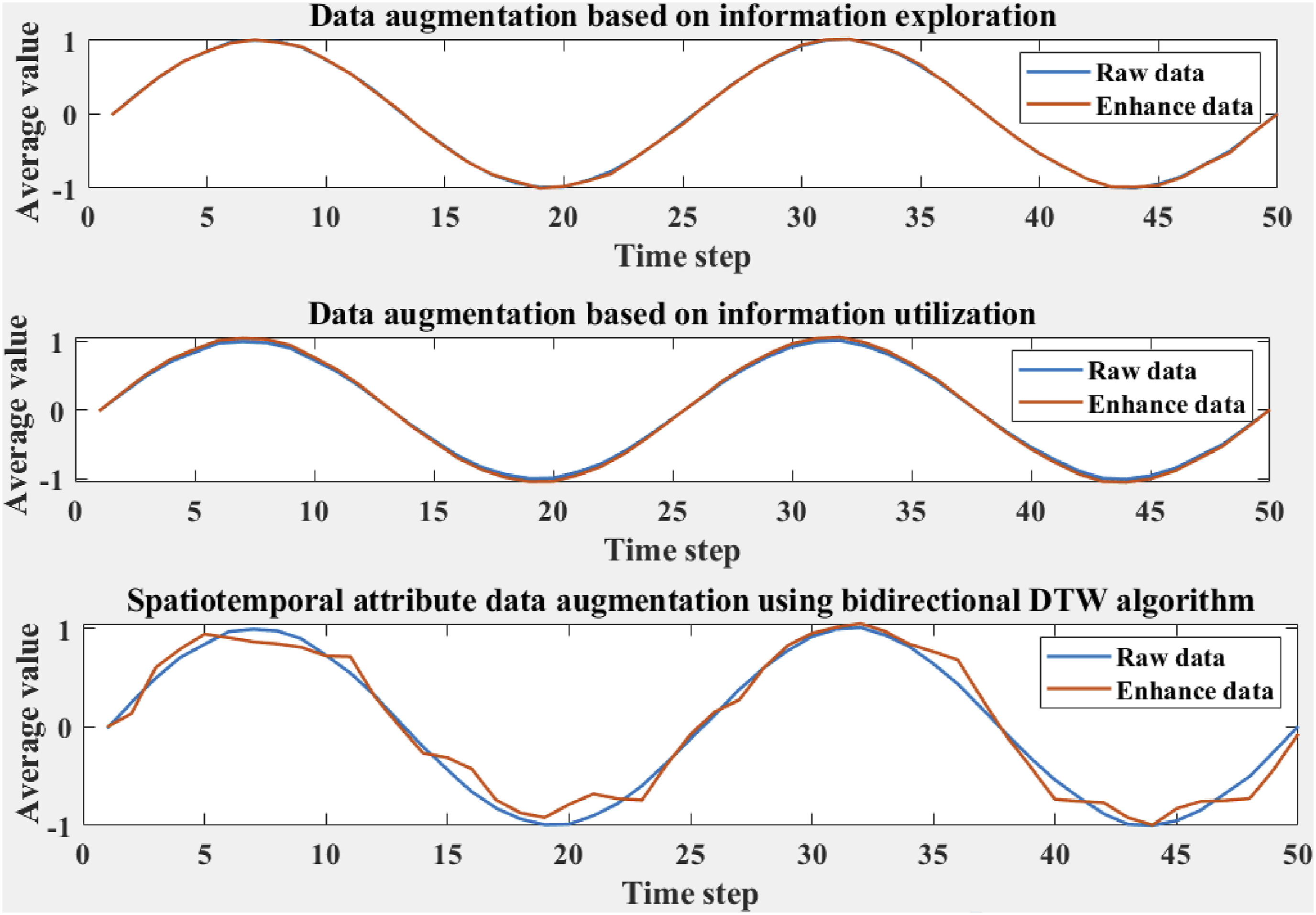
Figure 1 presents the relationship between time steps and data averages, comparing the effectiveness of different data augmentation strategies in processing raw data. In the information “exploration” strategy, the random noise is added to the augmented data, and the overall waveform remains sinusoidal, with peak and valley values of approximately 1 and -1, respectively. This method improves the generalization ability of the model by increasing data diversity. In the information “utilization” strategy, the augmented data is adjusted for amplitude by multiplying it with a random factor, while the overall waveform remains unchanged. This preserves the basic pattern of the data while introducing new information, which makes the data more representative. The augmentation effect of the bidirectional DTW algorithm shows that the raw data fluctuates greatly, but the augmented data matched by DTW aligns better in spatiotemporal attributes, reduces fluctuations, and is smoother. This indicates that the DTW algorithm can better preserve the spatiotemporal correlation of data, improve temporal consistency and stability, reflect the continuity and correlation of user behavior, and enhance recommendation accuracy and user satisfaction. In general, these data enhancement strategies significantly improve the effectiveness of personalized recommendation algorithms by optimizing training data.
Construction of a user-product interaction matrix
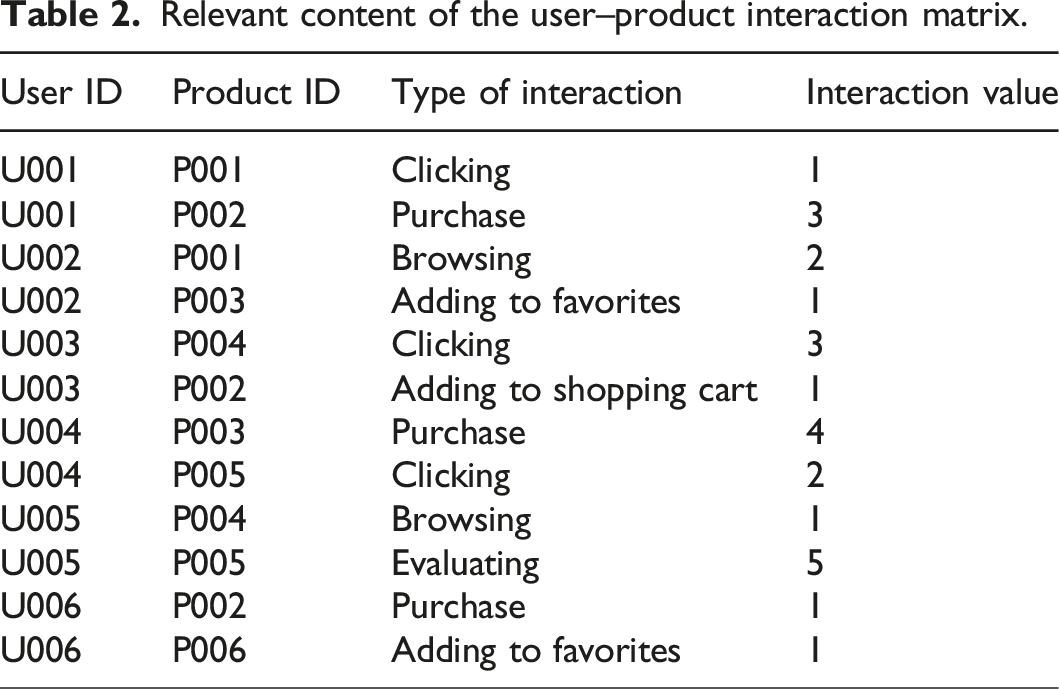
This article is based on a deep Q-network and establishes an interaction matrix consisting of a set 
Relevant content of the user–product interaction matrix.
User behavior modeling
User behavior characteristics mainly include five types of data: clicking (type_c), adding to shopping cart (type-b), purchasing (type_p), adding to favorites (type_s), and browsing (type_g). Among them, the purchase behavior basically indicates the user’s love for the product, so the weight in the preference is the largest, which is 1; the weight of increasing purchases and favorites is slightly lower than purchases, but higher than other behaviors, so the weights of these two behaviors are increased in the expression; the weights of clicking and browsing are the smallest, and the smaller weights are selected in the operation. User v’s preference level 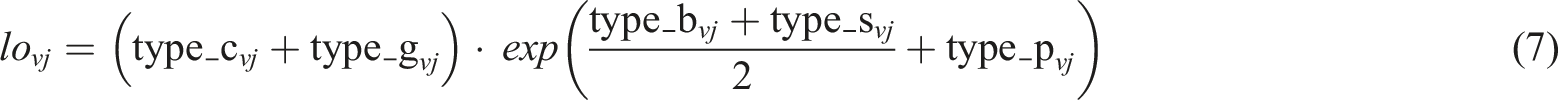

Formula (9) is used to transform the user preference to 0 to 5
The formula for the user rating matrix is
Among them, the non-negative matrix factorization (NMF) algorithm25,26 decomposes the matrix T into a user feature matrix Q and a product feature matrix O, and multiplies the two, that is, T = QO. Q and O are calculated by subtracting the rating matrix T from QO. Compared with other collaborative filtering methods, the results obtained by the NMF method are all non-negative.
The objective of non-negative matrix factorization can be expressed as
When the user feature matrix and product feature matrix are initialized as non-negative, using Formula (11) cannot guarantee that they are always non-negative during iteration, so a learning rate needs to be defined. The formulas are
The learning rate from Formula (12) is substituted into Formula (11) to obtain the iterative expressions for non-negative matrix factorization, which are expressed as
By iteratively using Formula (13), it is ensured that after decomposition, both the user feature matrix and the product feature matrix are non-negative. Based on non-negative matrix factorization, the matrix is biased and regularized to obtain an objective function for non-negative matrix factorization. The formula is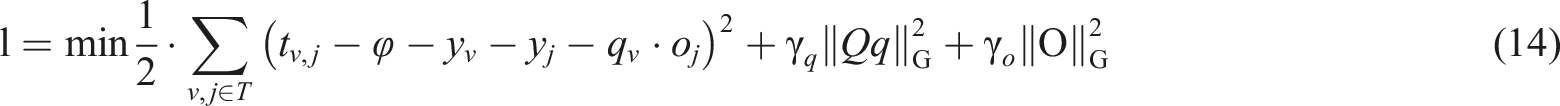
The rating matrix of recommendation systems often has sparsity. Although the NMF algorithm can handle this problem, its indicator matrix is both storage intensive and time-consuming, as it needs to be multiplied with other matrices every iteration. To reduce this additional overhead and improve algorithm precision, DQN is applied in this article.
First, the gradient method is used to solve for user preference information and product preference information, and the partial derivatives of the objective function are obtained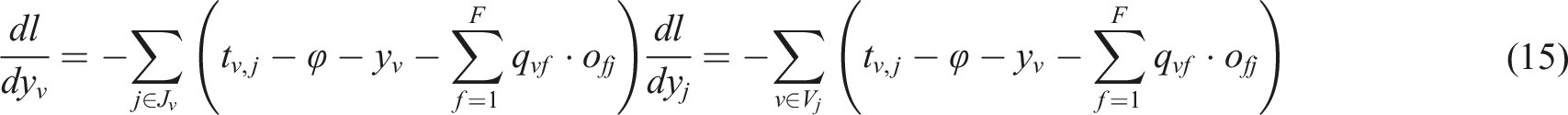
The gradient descent method is used to solve, and iterative formulas for user and product bias are obtained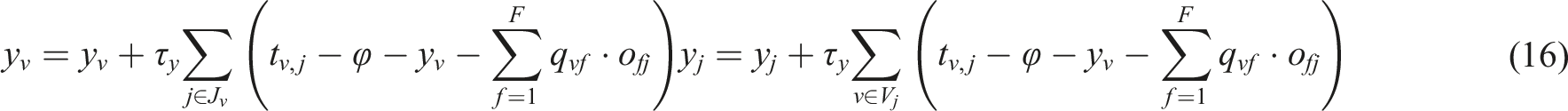
Formula (16) is the final iterative formula. After the above iterative processing, the missing items in the user rating matrix T can be efficiently restored. By ranking the ratings of each user in T, their levels of liking for each product can be obtained based on their behavioral information, and their favorite products can be actively recommended to them.
Construction and training optimization of DQN
This article models online shopping recommendation behavior as an interaction sequence of users selecting products and evaluating them, with the goal of maximizing long-term cumulative rewards in recommendation behavior. This model includes a five tuple of state space, action space, reward space, state transition, and decay factor.
State space Z: state
Reward space S: state
The personalized recommendation algorithm in this article is based on DQN. DQN is a deep reinforcement learning method based on value optimization.27,28 The learning state-action value function can estimate the long-term cumulative reward of the recommendation system for recommending item x in state z. The value function corresponding to the optimal strategy is the optimal value function, which should follow the Bellman equation, with the formula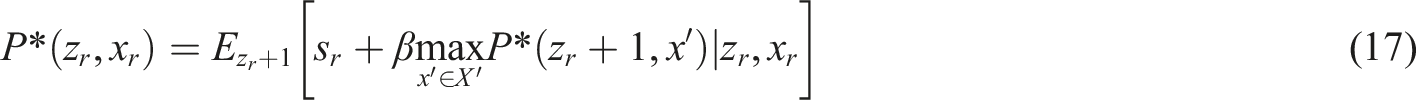
Among them,
Due to the high computational cost of traversing all states and behaviors, it is necessary to use numerical functions of deep Q-networks for approximation. The DQN training process is shown in Figure 2: Training process of DQN.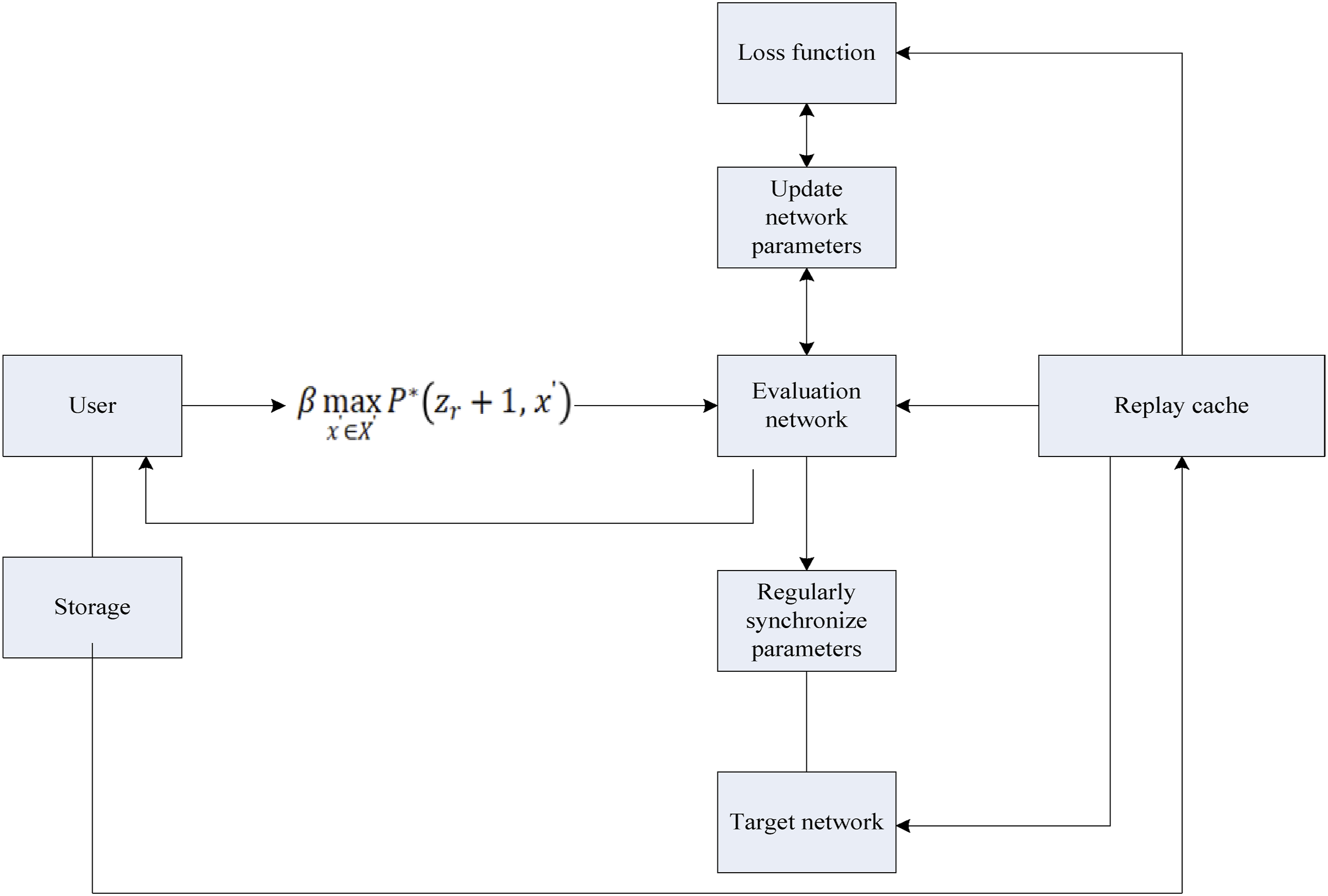
The learning architecture of the personalized recommendation algorithm based on DQN in this article consists of three parts: long-term interest module, short-term interest module, and prediction module. The long-term interests of users are learned using collaborative filtering methods, and the vector representation of users utilizes all interaction history information during the learning process, which can represent the long-term interest preference characteristics of users. User v and product j obtain user vectors and product vectors through the embedding layer and product embedding layer. Different from traditional collaborative filtering algorithms, the personalized recommendation algorithm based on DQN uses two vectors connected to each other, and adds multiple hidden layers on this basis to better understand the interaction between user vectors and item vectors. In the short-term interest module, the positive and negative feedback interaction history sequences are similar. The user’s most recent M positive feedback interaction records
The DQN architecture in this article uses the last hidden layer vector of GRU (Gated Recurrent Unit) as the vector expression for the positive feedback interaction sequence. The DQN architecture reconstructs the structure of the Q-network to achieve synchronous learning of users’ short-term and long-term interests. DQN uses deep neural networks as the main body of the Q-network, extracting deep features of user behavior data through a multi-layer network structure to more accurately represent user interests.
However, in reality, the state and behavior space of a system are often vast, making it difficult to directly obtain their expected values. In practical applications, the commonly used method is small-batch gradient descent. By randomly selecting a small batch of state transition sets, their expected values are calculated, and their parameters are optimized using the Adam (Adaptive Moment Estimation) optimizer.29,30 DQN uses deep neural networks to fit numerical functions, which can easily lead to model instability. To simplify model training, the user and item embedding layers are initialized and fixed with pre-trained vectors and do not update with training. This article uses probability matrix factorization method and Binary Cross Entropy loss function to train embedding layer weights. Meanwhile, the DQN framework introduces L2 regularization term in the loss function to limit the model’s expressive power, stabilize training, and prevent overfitting. During training, a recall process is also included to generate a high-quality candidate set of items.
Evaluation of the effectiveness of personalized recommendation algorithms
Experimental design
To verify the effectiveness of the personalized recommendation algorithm based on deep Q-network in this article, the JD dataset with 130 million purchase records is used as the experimental dataset. First, data preprocessing is required. Preprocessing mainly involves filtering the dataset based on the data preprocessing in section 3. The specific process is as follows: first, users are grouped based on their purchase records to obtain their purchase history grouping. Then, users with purchase records less than 300 times and products with purchase records less than 200 times are deleted. Afterward, a user-product matrix is constructed, and if the user purchases a certain product, the corresponding element of the matrix is set to 1. Next, users and products that purchase less than 150 times are iteratively deleted until they can no longer be deleted. The final filtered dataset has a user-product matrix sparsity rate of 0.541%.
Summary statistics of JD dataset.

In the experiment, in addition to testing the DQN algorithm proposed in this article, it is also compared with several baseline methods, including BPR algorithm (Bayesian Personalized Ranking), ML (machine learning) algorithm, and Deep Walk algorithm. This article first compares the recommendation performance of four algorithms from three perspectives: accuracy, recall, and mean average precision. Then, using root mean squared error as the testing standard, its parameter sensitivity is evaluated, and cross-validation is conducted. Finally, the algorithm iteration time is tested under different iteration times.
Due to the wide variety of products, considering all of them is very time-consuming. Therefore, in the testing set, for each user’s purchased product, this article randomly selects 50 products that the user does not purchased as negative examples, and combines them with the purchased products to form a new product set for testing. This method reduces computational complexity and provides a more comprehensive evaluation of the performance of recommendation systems.
Experimental results
Recommendation effect
Comparison of the accuracy, recall, and mean average precision of the algorithms.
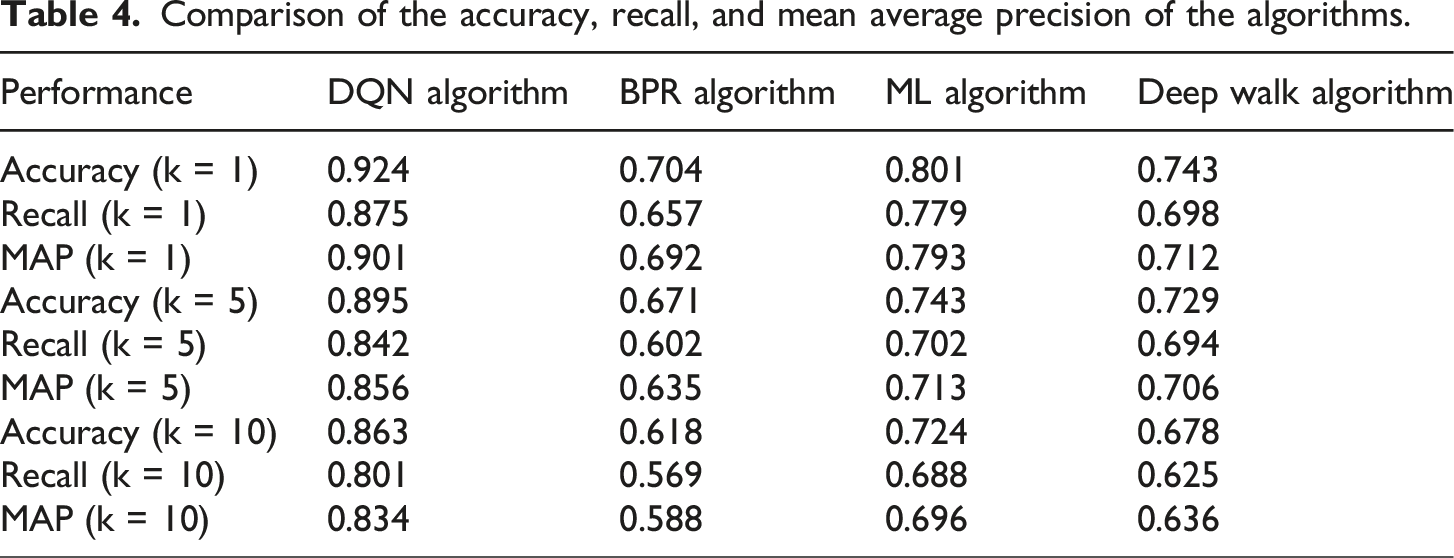
According to Table 4, the DQN algorithm proposed in this article demonstrates its performance advantages in comparison tests with other algorithms such as BPR, ML, and Deep Walk. When the recommendation list length is set to 1, the DQN algorithm exhibits an accuracy of up to 0.924, while at this time the accuracy of BPR, ML, and Deep Walk algorithms are 0.704, 0.801, and 0.743, respectively, with the DQN algorithm far exceeding other algorithms. This means that its recommendation accuracy is extremely high and can effectively improve user instant satisfaction. Its recall rate of 0.875 and mean average precision of 0.901 are significantly ahead, indicating that not only is the single recommendation precise, but it can also cover the actual interests of users well. As the length of the recommendation list increases to 5 and 10, although the various indicators of the DQN algorithm slightly decrease, such as accuracy dropping to 0.863 and recall and MAP dropping to 0.801 and 0.834 when the list length is 10, respectively, it still maintains its leading position. This reflects the stability and effectiveness of the algorithm under different recommendation scales. In contrast, although other algorithms have shown some performance in certain indicators, they have overall failed to surpass the comprehensive recommendation quality of DQN algorithm, verifying the potential and application value of deep Q-network in the field of personalized recommendation.
Root mean squared error
Root mean squared error (RMSE) quantifies the difference between recommendation results and user feedback, reflecting the magnitude of prediction error. By monitoring RMSE, the prediction precision can be evaluated to ensure that recommendations meet user needs. Root mean square error can also optimize objectives, help adjust models to reduce bias, and improve recommendation accuracy and satisfaction. This article tests the RMSE changes under different regularization parameter γ to evaluate its parameter sensitivity. The results are shown in Figure 3: Root mean squared error changes of four algorithms with different regularization parameter γ.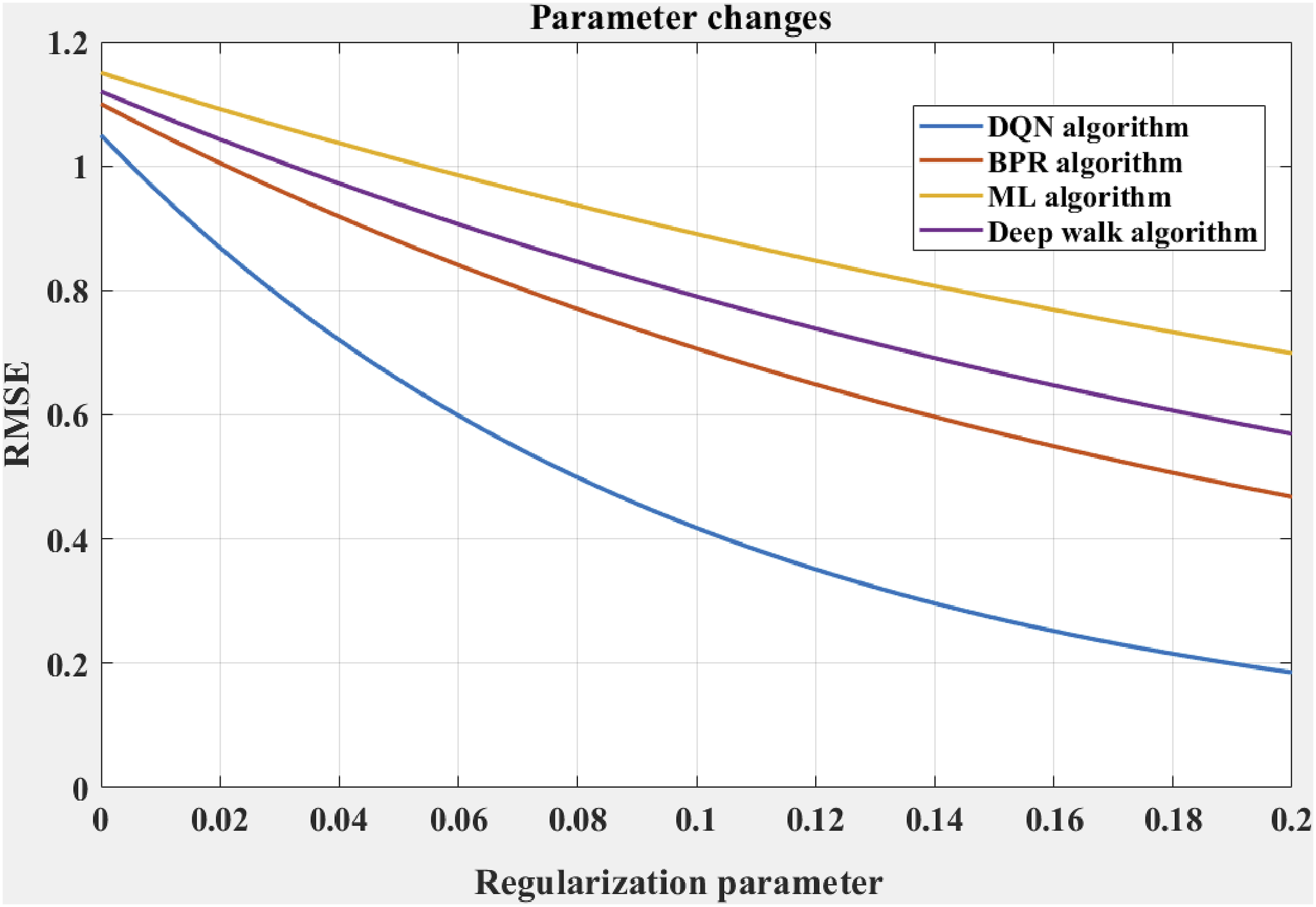
Figure 3 shows the RMSE trends of four algorithms, DQN, BPR, ML, and Deep Walk, as the regularization parameter γ varies from 0 to 0.2. DQN exhibits the most stable performance, with RMSE consistently the lowest, gradually decreasing from 1.05 at γ = 0 to below 0.2. At the beginning, the RMSE of BPR is about 1.1. Although it decreases with increasing γ, it is still higher than DQN, indicating poor effectiveness. The starting RMSE of ML algorithm is about 1.15, with small changes and poor performance, and it is not sensitive to parameter adjustment. The RMSE of Deep Walk is about 1.1 at γ = 0 and shows a decreasing trend with increasing γ. At γ = 0.2, its RMSE is about 0.58. Overall, DQN is more sensitive to the regularization parameter, with higher accuracy and user satisfaction, ensuring stable and efficient operation of recommendation systems. By optimizing parameters, the accuracy, recall, and user satisfaction of the model can be maximized, achieving the best recommendation results.
In addition to comparing the root mean squared error with different regularization parameter, this article also tests the root mean squared error with different cross-validation times for recommendation list lengths (k) of 1, 5, and 10. Figure 4 shows the results: Comparison of root mean squared error at different cross-validation times. (a): Root mean squared error results for a recommendation list length of 1; (b): Root mean squared error results for a recommendation list length of 5; (c): Root mean squared error results for a recommendation list length of 10.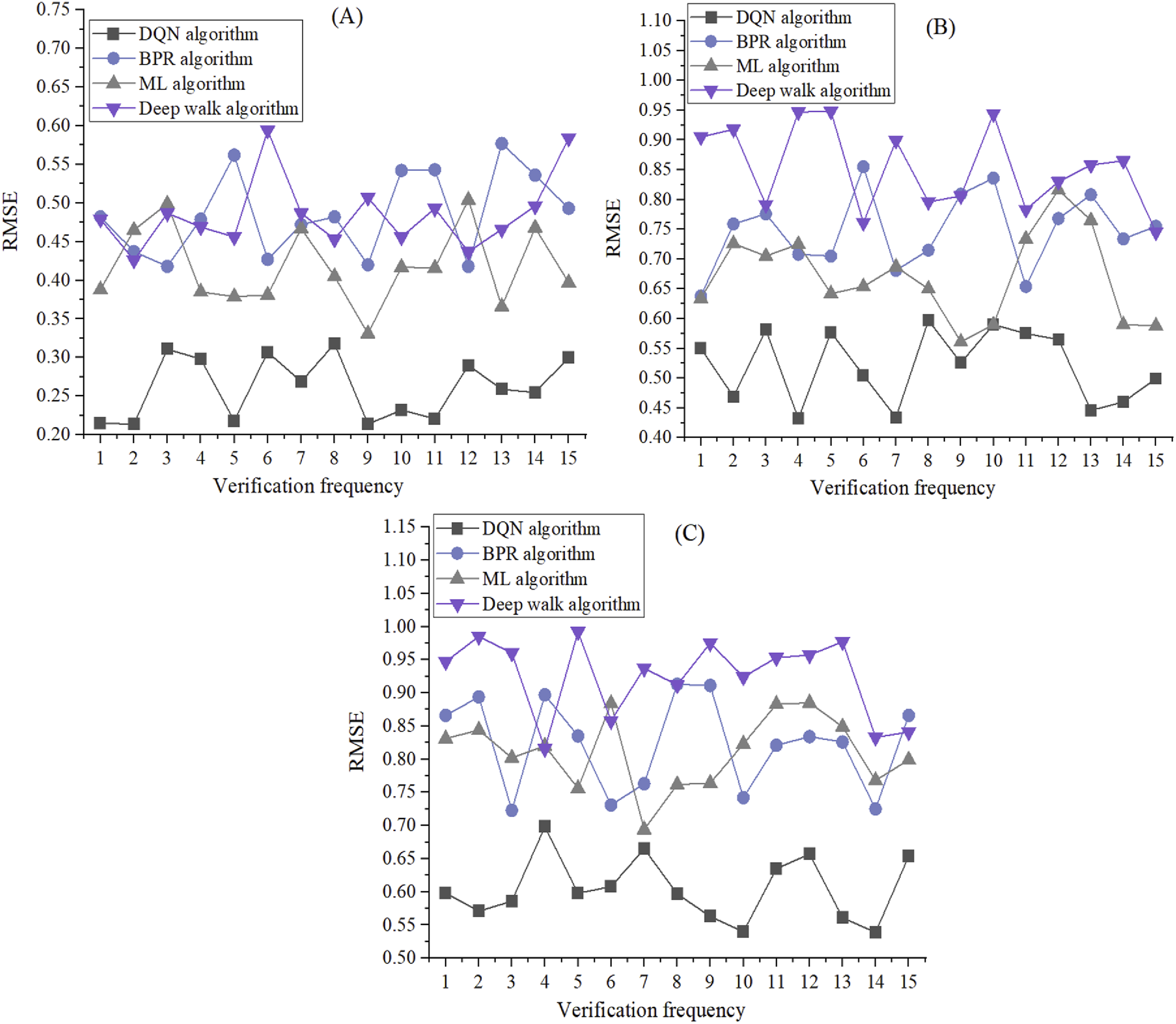
It can be found in Figures 4(a)–(c) that as the number of cross-validations increases from 1 to 15, the RMSE of the DQN algorithm fluctuates under various recommendation list lengths, reflecting the sensitivity and stability of the algorithm to cross-validation. When the length of the recommendation list is 1, the maximum RMSE of the DQN algorithm is 0.318 and the minimum is 0.214. The maximum RMSE of BPR algorithm is 0.577 and the minimum is 0.418. The maximum RMSE of ML algorithm is 0.504 and the minimum is 0.331. The maximum RMSE of the Deep Walk algorithm is 0.594 and the minimum is 0.426. This indicates that the prediction precision of DQN algorithm varies at different validation times, but its root mean squared error remains relatively low overall, outperforming other algorithms such as BPR, ML, and Deep Walk. As the length of the recommendation list increases to 5, the highest RMSE values for DQN, BPR, ML, and Deep Walk algorithms are 0.597, 0.855, 0.816, and 0.948, respectively. The minimum values are 0.432, 0.638, 0.561, and 0.745, respectively. When the length of the recommendation list increases to 10, the highest RMSE values of DQN, BPR, ML, and Deep Walk algorithms are 0.698, 0.913, 0.885, and 0.992, respectively, and the lowest values are 0.539, 0.723, 0.694, and 0.816, respectively. Compared to the other three algorithms, DQN still demonstrates good robustness and prediction precision. These data emphasize the importance of detailed parameter tuning under different settings, as well as the superior performance and robustness of DQN algorithm in handling personalized recommendation tasks, providing empirical basis for improving user personalized experience. This is because the DQN algorithm can better adapt to different recommendation list lengths and cross-verification times, showing high stability and prediction accuracy. At the same time, the algorithm uses deep learning technology and reinforcement learning principles to optimize recommendation strategies, so that it can make more accurate predictions in the face of different recommendation scenarios.
Iteration time
Iteration time is crucial for algorithm efficiency and real-time performance. Short iteration time means fast convergence, which can adapt to user changes and provide new recommendations. Reducing iteration can also improve response speed and enhance experience, which is important for big data processing and high-performance online services. At the end of this article, the time required for each iteration is tested for recommendation list lengths (k) of 1, 5, and 10. The results are shown in Figure 5: Comparison of time required for each iteration. (a): Time required for a single iteration when the recommendation list length is 1; (b): Time required for a single iteration when the recommendation list length is 5; (c): Time required for a single iteration when the recommendation list length is 10.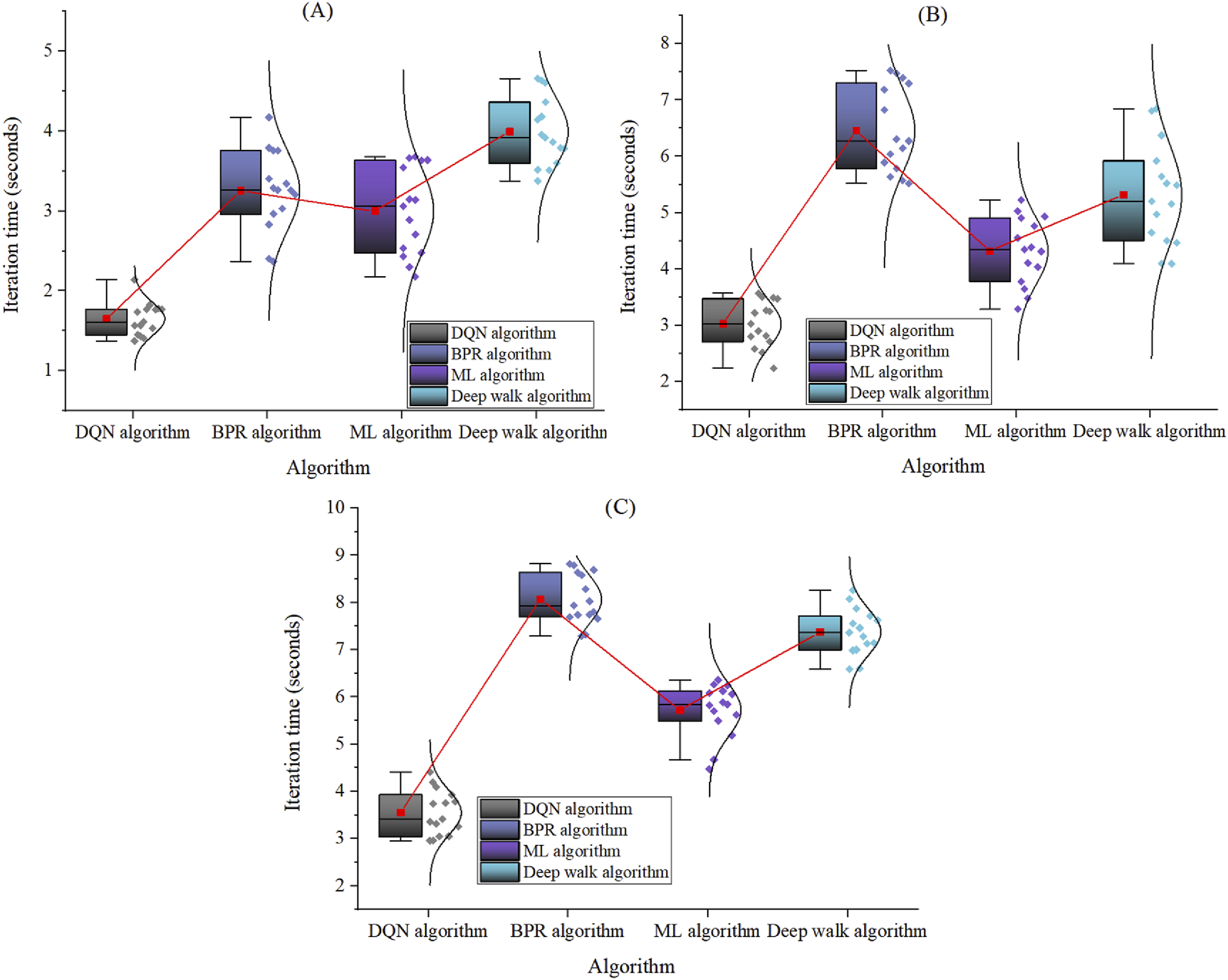
As shown in Figures 5(a)–(c), the DQN algorithm exhibits relatively efficient iterative performance under different recommendation list lengths. Especially when the length of the recommendation list is 1, the iteration time remains between 1.370 seconds and 2.141 seconds, with an average iteration time of 1.647 seconds. The BPR algorithm maintains an iteration time between 2.364 seconds and 4.170 seconds, with an average iteration time of 3.253 seconds. The iteration time of the ML algorithm is maintained between 2.175 seconds and 3.678 seconds, with an average iteration time of 2.999 seconds. The iteration time of the Deep Walk algorithm is maintained between 3.377 seconds and 4.659 seconds, with an average iteration time of 3.993 seconds. The time of DQN algorithm is significantly lower than that of BPR, ML, and Deep Walk algorithms. As the length of the recommendation list increases, the iteration time of all algorithms generally increases, but DQN still maintains a relatively low iteration time. When the recommendation list length is 5 and 10, its average iteration time is 3.024 seconds and 3.548 seconds, respectively. At this point, the average iteration time of the BPR algorithm is 6.461 seconds and 8.073 seconds, respectively. The average iteration time of ML algorithm is 4.321 seconds and 5.720 seconds, respectively. The average iteration time of the Deep Walk algorithm is 5.319 seconds and 7.375 seconds, respectively. This once again validates the efficiency of DQN algorithm in handling more complex recommendation scenarios. These data highlight the advantages of DQN algorithm in iteration efficiency, which not only shortens the model training cycle but also provides technical support for the rapid deployment and response of real-time recommendation systems, ensuring that users can obtain personalized updated shopping suggestions in a timely manner. Therefore, optimizing the iteration time is not only a reflection of algorithm efficiency but also a key factor in enhancing the practical value and market competitiveness of recommendation systems.
Conclusion
In the digital age, personalized recommendations are crucial for e-commerce, but traditional recommendation algorithms have many limitations. This article combines deep learning and reinforcement learning to apply deep Q-networks into recommendation algorithms, in order to overcome traditional problems and bring new breakthroughs to e-commerce platform recommendation systems. This article preprocesses massive data, simulates user-system interaction using DQN, learns recommendations through a reward mechanism, and solves the cold start problem. Meanwhile, it can adapt to changes in user preferences, ensuring timely and personalized recommendations. The deep learning technology constructs complex user preference models to achieve personalized experiences, and the parallel computing improves the processing capability of big data. Experiments have shown that the DQN algorithm outperformed other algorithms such as BPR, ML, and Deep Walk, and is more efficient in handling complex scenes. In the JD dataset testing, the algorithm performs excellently, reducing training difficulty and overfitting risk. Despite significant achievements, there is still room for improvement. Future research directions should focus on how to more effectively integrate users’ long-term and short-term interests, improve the efficiency of models in high-dimensional data processing, and explore more advanced model interpretation techniques to make the recommendation decision-making process more transparent. In addition, with the increasing importance of social networks and multimodal data in e-commerce recommendations, how to integrate this information in the DQN framework to further improve the accuracy and coverage of personalized recommendations is an important topic for future research. Through this technology, this article aims to bring greater convenience and value to users and businesses, achieving a comprehensive upgrade of e-commerce recommendation systems.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.