
Abstract
With the rapid advancement of educational technology, the complexity of attention allocation among university students in information-rich learning environments has significantly increased. Effective attention allocation is crucial for learning outcomes; however, traditional research methods face limitations in capturing and analyzing dynamically changing cognitive processes. This study aims to utilize neural network technology, particularly the model based on Time-series generative adversarial network (TimeGAN), to identify and analyze the patterns of attention allocation in university students’ cognitive processes. The TimeGAN model, selected for its proficiency in handling time-series data, is employed to reveal the dynamic shifts of attention across various tasks and states. The second part introduces a novel framework that combines a Customized Gate Control (CGC) model with a progressive hierarchical extraction model, aiming to more accurately simulate the management of attention switching in a multitasking environment. These approaches enhance the model’s adaptability to individual differences, offering support for the formulation of personalized learning strategies. Not only does this research expand the application of computational models in the field of educational psychology, but it also provides new theoretical foundations and practical tools for optimizing teaching designs and promoting cognitive development among students.
Keywords
Introduction
In the learning environments of higher education, the cognitive processes and attention allocation patterns of university students exert a decisive impact on learning outcomes.1,2 With the proliferation of digital teaching tools and online resources, students are confronted with an unprecedented flow of information and distractions during their learning activities. These new variables render the strategies and patterns of attention allocation increasingly complex. For educators and learners alike, understanding and optimizing attention allocation is key to enhancing learning efficiency, facilitating knowledge absorption, and fostering cognitive development.3–5 Thus, the employment of neural network technology for the identification and analysis of attention allocation patterns in university students’ cognitive processes not only reveals the intrinsic mechanisms of the learning process but also aids in the design of more rational teaching strategies and learning tools.6–8
To date, numerous achievements have been made in the study of cognitive processes and attention allocation; however, most research still relies on traditional psychological experiments and questionnaire surveys. These methods may fail to capture the rapidly changing cognitive dynamics in certain contexts and are challenging to implement on a large scale.9–11 Moreover, the efficiency and accuracy of traditional methods when dealing with a large amount of complex data are limited. Therefore, exploring new research methods, especially employing advanced computational models to analyze attention allocation, holds significant theoretical and practical implications for the fields of educational psychology and cognitive science.12,13
However, existing computational models exhibit some flaws and limitations in identifying and analyzing attention allocation patterns among university students. Most models have not fully considered the complexity of time-series data, and the modeling of students’ attention switch management and multitasking capabilities is often oversimplified, failing to accurately simulate real cognitive processes.14–16 Additionally, current models lack flexibility in personalized modeling, making it difficult to adapt to different students’ cognitive characteristics and learning habits.17–19
In response to the research gaps identified, this study proposes a novel methodological approach. Initially, based on the TimeGAN model, this study models and analyzes the attention allocation strategies of university students across different cognitive tasks. It captures complex features in time-series data and simulates the dynamic changes of attention across various tasks and states. Furthermore, this study introduces a CGC model and a progressive hierarchical extraction model. This innovative framework aims to more accurately simulate the management of attention switching in multitasking scenarios. The application of these methods not only enhances the precision in identifying attention allocation patterns but also provides a theoretical basis and practical guidance for personalized teaching and cognitive interventions. Overall, the value of this study lies in its application and improvement of modern neural network technologies, offering a new perspective and tools for understanding and optimizing attention allocation patterns in cognitive processes. The primary objective of this study is to enhance and thoroughly analyze university students’ attention allocation strategies in multitasking environments by utilizing the TimeGAN model, the CGC model and the progressive hierarchical extraction model. Particular focus is placed on the dynamic changes of attention between various cognitive tasks and states.
Attention allocation strategies in university students based on TimeGAN
In this study, a data collection unit has been designed as a specialized cognitive monitoring unit for the research on attention allocation in the cognitive processes of university students. This unit integrates advanced sensor technology, behavior tracking algorithms, and neural network processing modules to capture, analyze, and process the temporal data of students’ attention states. The cognitive monitoring unit employed comprises sensors for student behavior and physiological responses, a data adapter card responsible for converting raw monitoring data into a format suitable for neural network processing, a behavioral data cross-link for integrating and synchronizing data from different sensors, a time-series data restoration module based on attention states for reconstructing the structure of attention fluctuation time series, and a data augmentation module for enhancing data features. These components work in concert not only to monitor and record the attention allocation status of university students in complex learning scenarios in real-time but also to train and optimize the attention allocation model using time-series data generated by TimeGAN. Thus, high-quality and high-precision data support is provided for researching the dynamics of attention in cognitive tasks among university students.
Evaluation metrics have been set to reflect the performance of students in maintaining and changing attention during cognitive tasks. These metrics include the duration of inattention, seconds in a highly distracted state, seconds in a mildly distracted state, continuity of attention, and the rate of attention recovery after task completion. These metrics quantify the stability and concentration of attention within specific periods. A standard has been set whereby the cumulative duration of inattention, seconds in highly distracted and mildly distracted states below a certain threshold during cognitive tasks indicates a high efficiency of attention allocation. Through the monitoring and analysis of these cognitive evaluation metrics, the effectiveness of the TimeGAN model in optimizing attention allocation strategies for university students can be assessed, enabling adjustments to teaching methods or cognitive intervention strategies.
In the practical learning and cognitive environment, the monitoring data on university students’ attention allocation may also face an imbalance issue, where most data reflect students in a normal state of attention, and the data on distraction or inattention are relatively scarce. This is attributed to the natural inclination of students to maintain a focused state of attention, whereas distracted states are often more challenging to capture and tend to be brief in duration. However, these instances of distraction hold greater research value for understanding and improving students’ attention allocation strategies. To enable the model to more accurately learn and predict the attention allocation patterns of university students, this paper employs technology based on TimeGAN to generate time-series data resembling actual distracted states, thereby achieving a balanced distribution of attention allocation.
Regarding the attention allocation of university students during the learning process, there are dynamic characteristics of time series, such as fluctuations in attention possibly being related to the difficulty level of the learning content, the fatigue state of the students, and distractions from the surrounding environment. The traditional generative adversarial network (GAN) may not fully capture the temporal associations of such time-series data, thereby affecting the quality of data augmentation. An example of a time-series data augmentation scheme is provided in Figure 1. To address these issues, this study innovatively opts for the TimeGAN model, which captures the dynamic features of time series through embedding functions and reconstructs the original data from the generated time series, thus ensuring the temporal consistency of time-series data. Concurrently, the adversarial training of the sequence generator and sequence discriminator further optimizes the model, enabling the generated data to more effectively simulate the patterns of attention change in university students at different time points. Example of the time-series data augmentation scheme.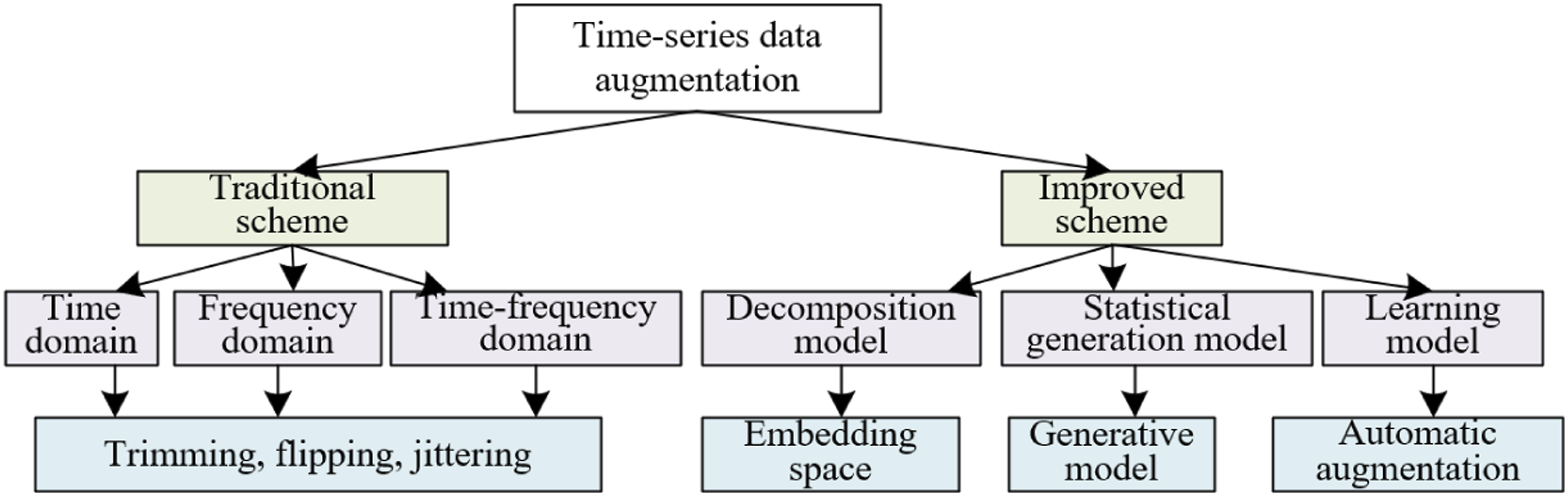
The TimeGAN aimed at university students’ attention allocation consists of four network components: the embedding function, recovery function, sequence generator, and sequence discriminator. The role of the embedding function is to map static features of student attention, such as individual baseline cognitive abilities or personality traits, along with time-varying features such as the difficulty level of learning content, different time periods within a day, or changes in the learning environment, to hidden space vector representations. This step is crucial as it allows the model to capture the complex dynamics behind attention allocation, such as how students allocate their attention during different phases of learning and under what conditions attention fluctuation might occur. Through this mapping, the model can learn deep patterns and dependencies within the attention sequence data.
Let the hidden space corresponding to the static feature space T and the time-varying feature space A be represented by G
T
and G
Z
, respectively. The embedding function is represented by r:T×П
s
A→G
T
×П
s
G
A
, where an embedding network for mapping static features is represented by r
T
:T→G
T
, and a recurrent embedding network for mapping time-series features is represented by r
A
:G
T
×G
A
×A→G
A
. In the opposite direction, the recovery function is represented by e:G
T
×П
s
G
A
→T×П
s
A. Mapping static and time-varying features to their hidden space vectors g
t
and g
s
, the following equation is presented:

The task of the recovery function is to restore the attention data encoded in the hidden space back to its original feature space. This step validates the effectiveness of the embedding function, ensuring that accurate static and time-varying features can be reconstructed from the hidden space vectors. In the context of university students’ attention allocation research, this means that the levels of attention under different learning environments and conditions can be reconstructed from hidden space representations, ensuring the coherence and logic of these reconstructed data in the time series. Assuming the recovery networks for restoring static and time-varying features are represented by e
T
:G
T
→T and e
A
:G
A
→A, respectively, g
t
and g
s
are restored to their original feature representations, as follows:

During the generation process, TimeGAN utilizes a vector space of a known distribution, from which random vectors are extracted as inputs to generate new, synthetic attention allocation data. The emphasis of this step lies in the generation network’s ability to utilize these random vectors, in conjunction with the learned temporal correlations, to produce new hidden space representations of static and time-varying features. For scenarios involving the attention allocation of university students, this means the model is capable of creating various potential attention change scenarios, even those not observed in the real world, thereby providing rich and diverse data support for research. The known distribution vector space is represented by C
T
and C
A
, and the generation function, represented by h:C
T
×П
s
C
A
→G
T
×П
s
G
A
, involves a generation network for static feature mapping represented by h
t
:C
T
→G
T
and a recurrent generation network for time-series feature mapping represented by h
a
:A
T
×G
A
×C
A
→G
A
. The generation function maps static and time-varying random vectors to g
t
and g
s
, as expressed:

The discriminator function in TimeGAN plays the role of a discriminator, receiving static and time-varying hidden space encodings as inputs and determining whether these encodings originate from the real dataset or are produced by the generator. When applied to the research on university students’ attention allocation, the discriminator needs to accurately distinguish between real student attention data and data created by the generator, ensuring the quality of the generated data. This step is crucial for the training process, as an accurate discriminator can prompt the generator to produce more realistic data, making the generated attention allocation data more credible and useful.
Figure 2 illustrates the training mechanism of the TimeGAN constructed. In the joint training process, the objective function for reconstructing original data, also known as reconstruction loss, is deemed essential. By minimizing the reconstruction loss, it is ensured that the model can accurately reconstruct students’ attention data from hidden space vectors. For the cognitive process of students, this implies that the model is capable of reflecting students’ attention allocation to different learning materials in real learning scenarios, including attention variations at different time points, under varying levels of fatigue, and environmental conditions. Assuming the hidden space vectors from the original data t and a are represented by g
t
and g
s
, the reconstruction loss M
E
for reconstructing original data is given as follows: Training mechanism of the TimeGAN.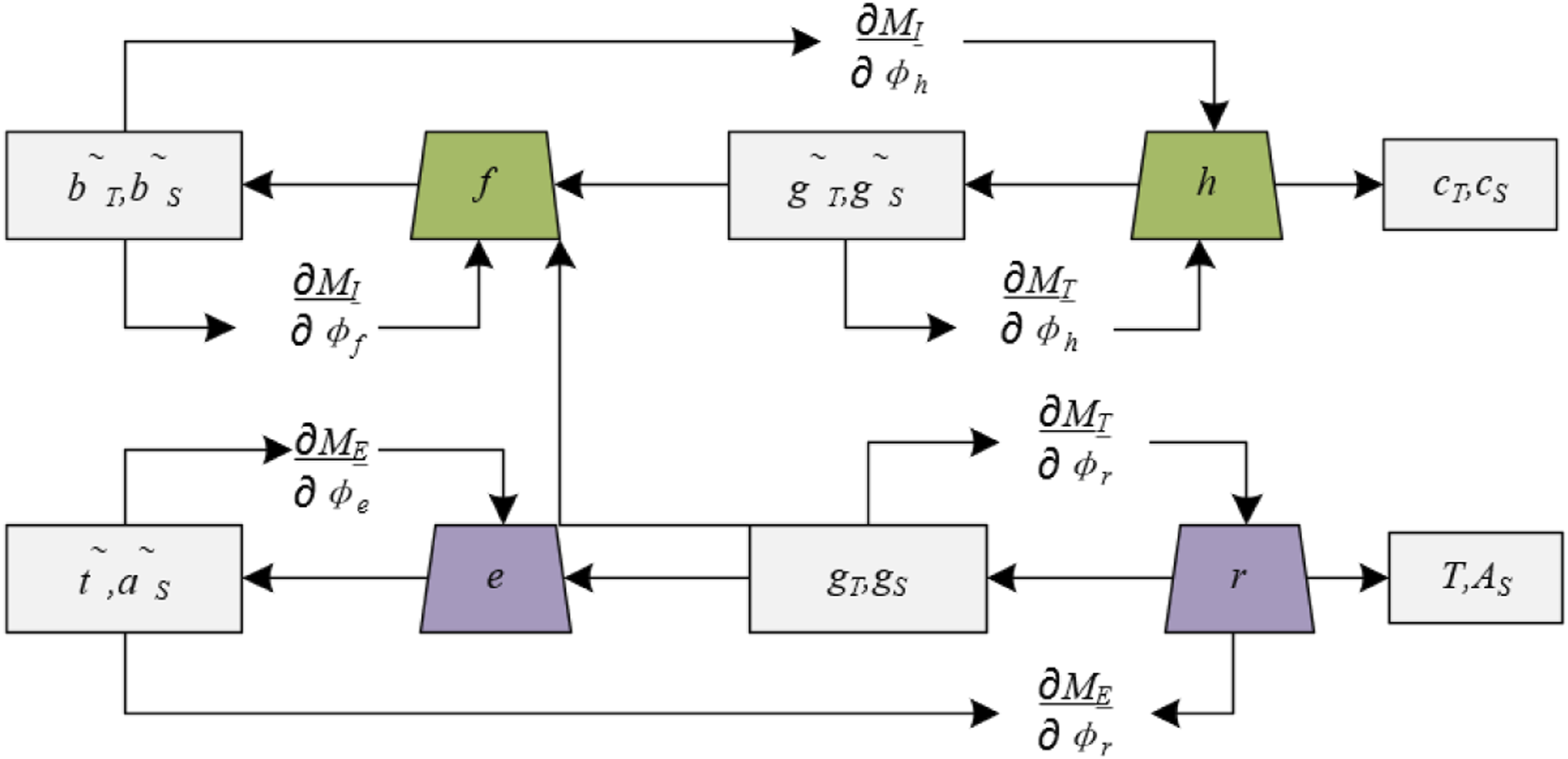

During the training process, the generator receives autoregressive inputs, ensuring the temporal continuity of the generated time-series data. The unsupervised loss allows the model to predict the state of the next moment based on the currently generated data, simulating the natural changes in students’ attention over time during a learning task. Assuming the autoregressive inputs are represented by g^
t
and g^s-1, and the next time-varying encoding by g^
s
, the loss function expression is:
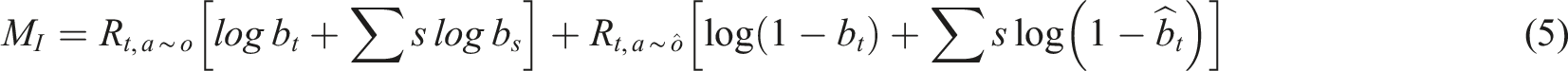
The generator also receives actual data computed by the embedding network to generate the next moment’s hidden space vectors. Through supervised loss, the model learns to reduce the difference between the distribution of real data and generated data. This step is crucial for the accuracy of simulating changes in students’ attention under specific learning conditions. Assuming the actual data computed by the embedding network is gs-1, the supervised loss M
T
for the difference between distributions is calculated by o(G
s
|UG
T
,Gs-1) and o^(G
s
|G
T
,Gs-1), with the expression being:
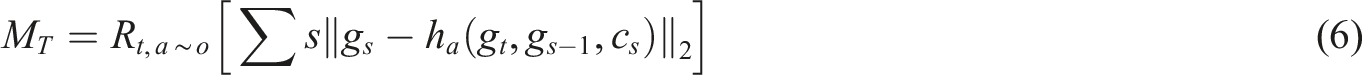
The training of the embedding and recovery networks is an iterative process through which the model learns how to effectively encode both time-varying and static features into the hidden space and how to recover these features from the hidden space. For the research on attention allocation, this ensures that the model can capture the complex factors influencing students’ attention and can reproduce the relationship between these factors and attention. The parameters of the embedding, recovery, generator, and discriminator networks are represented by ϕ
r
, ϕ
e
, ϕ
h
, and ϕ
f
, respectively, and a hyperparameter for the two losses is represented by η, as expressed:

During the adversarial training phase, the generator and discriminator networks compete against each other: the generator attempts to produce increasingly realistic data, while the discriminator strives to distinguish between real and generated data. This dynamic training process helps to improve the quality of the generated data, making it more consistent with the real patterns of attention allocation during university students’ learning processes. Another hyperparameter for the two losses is represented by λ, with the adversarial training expression being:

The training of the generator involves a minimax game on the unsupervised classification accuracy provided by the discriminator, while also minimizing the supervised loss. This allows the model to be trained simultaneously in encoding (features), generating (latent representations), and iteration (across time). For university students’ attention allocation, this training method enables the model to generate dynamic, temporally continuous attention data, providing researchers with a powerful tool to understand and predict students’ cognitive behavior.
Multitask model implementation in the attention switch management among university students
In the study of attention switch management among university students, current methods often independently handle the monitoring, identification, and prediction of student attention without delving into the intrinsic connections between these subtasks. However, the results of attention monitoring can assist in identifying the causes of attention drift, which, in turn, can provide valuable information for predicting future attention trends. To this end, this research proposes the adoption of a multitask learning framework, with traditional implementation methods illustrated in Figure 3. Based on this framework, a progressive hierarchical extraction model is developed, capable of comprehensively handling the tasks of monitoring, identifying, and predicting attention. Through this approach, the model can more thoroughly understand and manage the dynamics of attention in students’ cognitive processes, not only instantly monitoring fluctuations in attention but also identifying the underlying factors causing these fluctuations and predicting future patterns of attention allocation. Implementation methods of the traditional multitask learning model structure.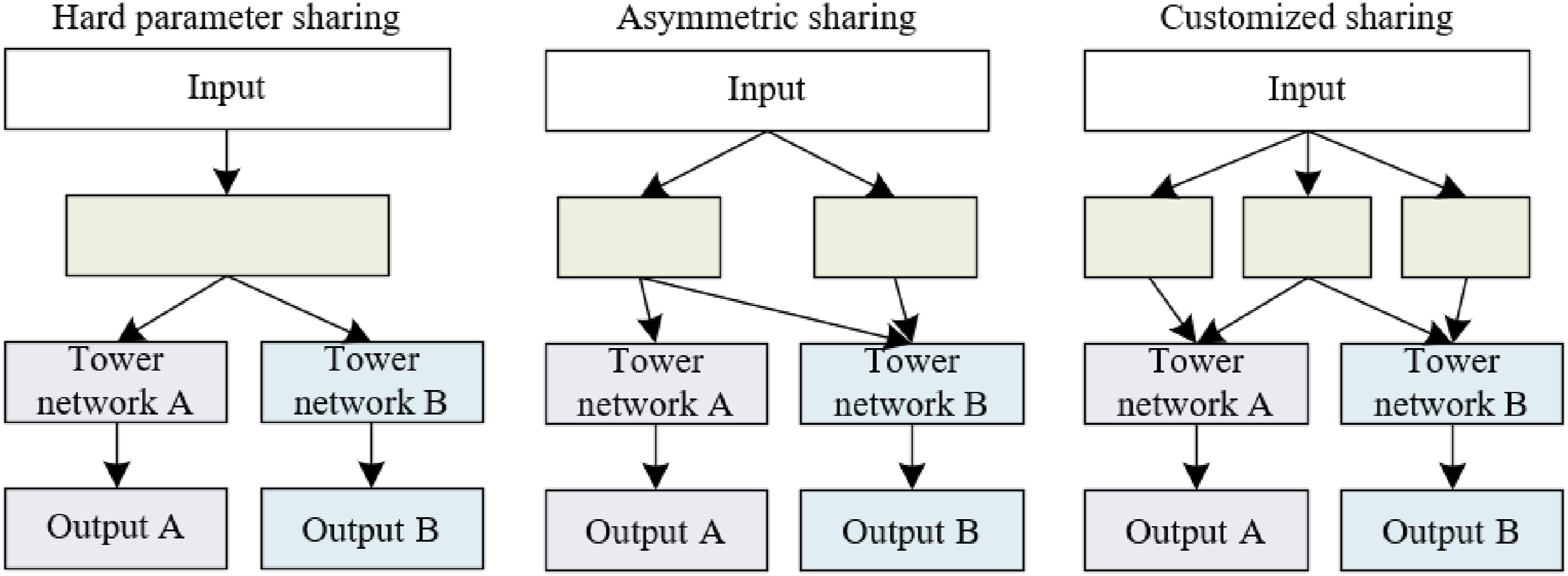
This study initially introduces a CGC model for the management of attention switching in university students. This model can be viewed as a multitask learning architecture designed to process and optimize the allocation of cognitive resources during learning activities. Within this model, input data representing students’ cognitive states and environmental factors are processed through multiple expert modules, each comprising several sub-networks acting as specialists in different cognitive tasks (such as memory, focus, executive functions, etc.). The number of experts within each module is set based on the model’s performance and complexity requirements. At the model’s upper layer, a tower network structure integrates information from all expert modules, where shared expert modules are responsible for mining common features across all cognitive tasks, while task-specific experts focus on extracting features unique to student attention switching. Through the gate control network, knowledge from these experts is selectively integrated to accommodate the individualized needs of different students.
Specifically, the output of the gate control network of task kj is represented as:

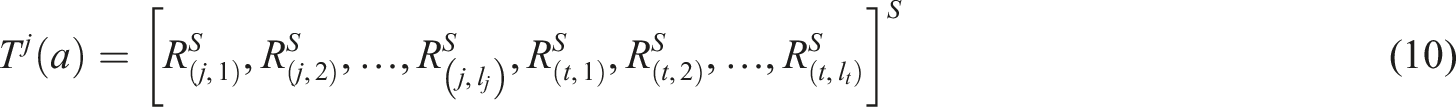
Assuming the tower network for task j is represented by s
j
, the prediction result for task j within the CGC can be represented as:

The gate control network, by balancing the output of different experts, ensures that each part of the model contributes appropriately to the final attention management strategy. In this way, the CGC model can flexibly adapt to each student’s unique learning path, optimizing their attention switching process, thereby enhancing learning efficiency and outcomes.
A Progressive Layered Extraction (PLE) model for the management of attention switching in university students is further introduced. This model effectively captures and refines complex cognitive states and behavioral patterns through a multi-level network structure. These levels, when processing student attention data, consider not only individual cognitive tasks such as learning, memory, and focus in isolation but also progress from basic processing mechanisms to complex higher-order cognitive functions through a layer-by-layer refinement approach. In the PLE model, lower-level networks may extract basic attentional features common across various tasks, while higher-level networks focus more on distinguishing specialized attention patterns required by different learning tasks. As the levels progress, the design of shared gates and task-specific gates allows the model to dynamically adjust the flow of information based on the relevance of semantic representations at different layers.
Specifically, assuming the input is represented by a, the weighted function for task j, with hj,k−1(a) as input, is denoted by q
j,k
(a), and the matrix corresponding to the kth extraction network for task j is represented by T
j,k
(a). Figure 4 presents the schematic diagram of the extraction model. Specifically, the result of the gate control network for task j in the kth extraction network of PLE can be characterized by the following expression: Schematic diagram of the extraction model.

The predicted result for task j within PLE can be obtained through the following calculation:

Figure 5 presents the process of obtaining predicted results in the PLE model. Thus, PLE not only provides a universal learning foundation at lower levels but also offers customized attention management strategies for each specific learning scenario at higher levels. The design of this structure allows the PLE model to identify and predict students’ attention switching more accurately, thereby offering educators more targeted intervention methods to optimize students’ learning processes and outcomes. Process of obtaining predicted results in the PLE model.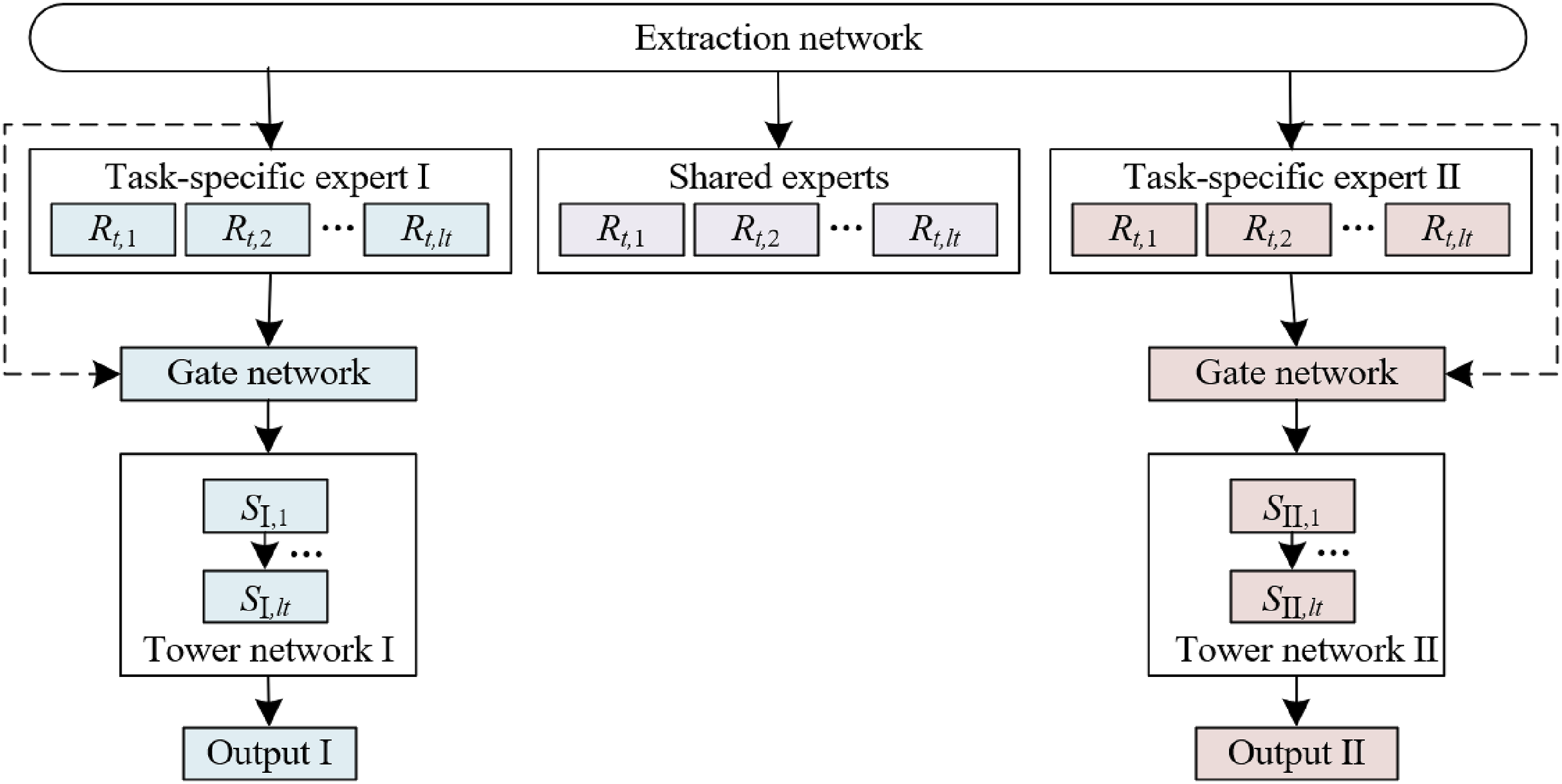
In constructing the PLE model aimed at the management of attention switching in university students, the model is based on a two-layer extraction network architecture, intended to finely capture the dynamic changes and multitasking capabilities of student attention. Each layer of the extraction network is comprised of three expert networks, each consisting of a single-layer deep neural network with 256 neurons, where each task, such as learning and memory tasks, corresponds to a dedicated expert network and a shared expert network. The design of expert networks is aimed at identifying specific attention patterns related to their respective tasks, while the shared network aims at identifying common attention features across tasks. In the first layer of the extraction network, outputs from various expert networks are directly pooled in the gate control network without further neural network processing, and these pooled features are sent to the corresponding expert networks in the second layer of the extraction network. Subsequently, outputs from the second layer of the extraction network are fed into a tower network consisting of a single-layer deep neural network with 64 neurons, which is responsible for integrating all refined features and outputting the model’s final predictions and diagnostic results for each task. This configuration allows the model to learn and extract complex patterns in students’ cognitive and attention processes at different levels, thereby providing strong data support for offering personalized attention management strategies.
In the context of university students’ attention switch management needs, the multitask learning model based on PLE can be used to predict students’ performance on different cognitive tasks over a future period. This multitask model is required to handle multiple continuous outputs, namely, regression tasks. It can be assumed that the dataset includes multiple features related to student attention, such as study time, rest time, cognitive load, and environmental distractions. The model uses these feature data from the first 6 days to predict the attention level of students on specific cognitive tasks on the seventh day, such as learning efficiency, memory retention, and duration of attention. For this purpose, a double-layer PLE network comprising six expert networks is constructed, with each cognitive task corresponding to its own dedicated expert network, and sharing one expert network to capture common features across tasks. The loss function for all tasks is set to mean squared error to assess the accuracy between the model’s predicted values and the actual attention performance. Such a model structure not only provides a deep understanding of individual tasks but also reveals the interplay between different cognitive tasks, thereby assisting in the formulation of personalized attention management strategies to enhance learning outcomes.
Experimental results and analysis
In this study, the inputs for the experiment included time-series data of university students engaged in various cognitive tasks. These data recorded their attention allocation during task performance, encompassing features such as task type, task duration, and attention focus levels. The outputs were the simulated results of these time-series data generated by the TimeGAN model, including dynamic changes in attention allocation strategies and management patterns of attention shifts between different tasks. These outputs not only presented the model’s predictive results on attention states but also included the learning curves of the embedding network and recovery network losses, as well as the discriminator network and generator network losses. Additionally, the t-SNE visualization results were provided, illustrating the model’s capability to distinguish between different attention states.
The dataset for this study was sourced from students across multiple universities. Participants were required to meet selection criteria, including being aged between 18 and 25, having no severe attention deficits or cognitive disorders, and being willing to fully cooperate throughout the experiment. Data collection was conducted in dedicated laboratories on campuses over a 3-month period. The equipment used included high-precision eye trackers and electroencephalograms (EEG), along with standardized questionnaires for supplementary data. The data preprocessing steps began with cleaning all collected raw data to remove obvious noise and outliers. Subsequently, the data were standardized to ensure comparability and consistency across different data types. The specific parameter settings for model training were as follows: a learning rate of 0.0001, a batch size of 64, 200 training epochs, and 128 hidden units. The experimental environment was a high-performance computing cluster equipped with NVIDIA Tesla V100 GPUs.
In this study, the TimeGAN model was utilized to simulate and analyze the attention allocation strategies of university students across various cognitive tasks. By leveraging the capabilities of TimeGAN, the model was effectively able to capture the complex characteristics of student attention over time and simulate dynamic transitions between various tasks and states. The parameter settings for the TimeGAN model were as follows: a learning rate of 0.0001, a batch size of 64, 200 training epochs, 128 hidden units, and a regularization parameter of 0.01. These parameters were selected based on preliminary experimental results and recommendations from relevant literature. The learning rate of 0.0001 was chosen to ensure stable convergence of the model. A batch size of 64 was determined to balance computational efficiency and memory usage. The 200 training epochs allowed the model to adequately learn the data features. The 128 hidden units provided sufficient model capacity to capture complex patterns within the data, while the regularization parameter of 0.01 was used to prevent overfitting. As shown in Figure 6, with a Gated Recurrent Unit (GRU) network as the underlying architecture, the embedding network, during the early stages of joint optimization learning, responded sensitively to the outputs of the discriminator and generator networks, making corresponding feature mapping adjustments. A key indicator of this process is the loss value of the embedding network, which was relatively high in the early stages of training, indicating initial difficulties in extracting features from time-series data. As pretraining progressed, particularly after 1000 pretraining iterations, the recovery network rapidly adapted to adjustments made by the embedding network, learning new feature mapping rules. This progress highlighted the significant role of pretraining in enhancing model performance. Experimental results in Figure 7 show distinct adversarial characteristics in the loss curves of the discriminator and generator networks during the joint optimization process. In the early stages of training, the generator network’s loss was lower, while the discriminator network’s loss was higher, indicating that the quality of data generated by the generator network was high in the initial phase, and the discriminator network was not yet able to effectively distinguish between real and generated data. However, as training progressed, the losses of both networks began to balance, especially after approximately 5000 iterations, where the loss curves intersected, indicating that the performance of the discriminator and generator networks had reached a similar level, meaning the quality of data produced by the generator was good enough that the discriminator found it challenging to differentiate between real and fake, and vice versa. Learning curves for the embedding and recovery networks of TimeGAN. Learning curves for the discriminator and generator networks of TimeGAN.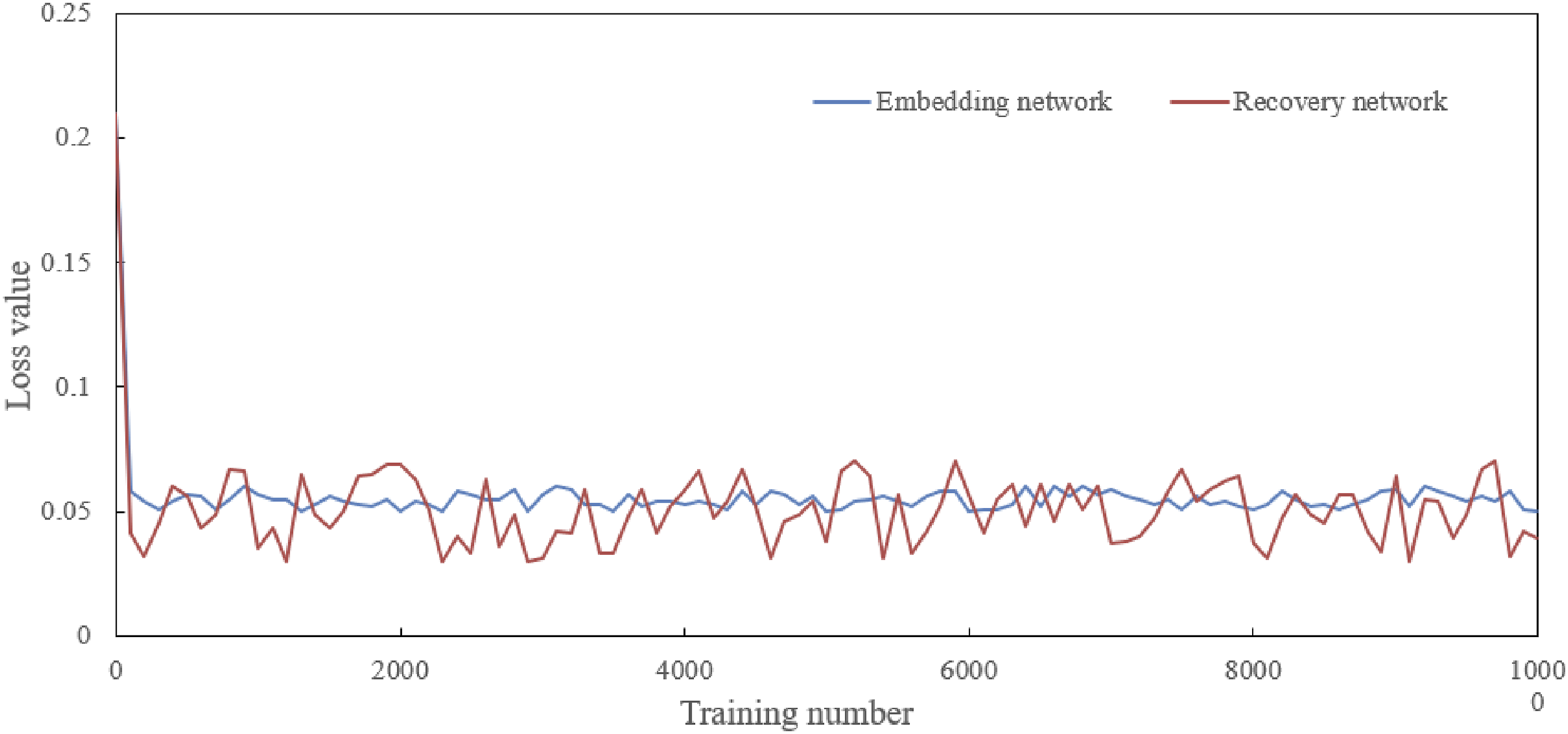
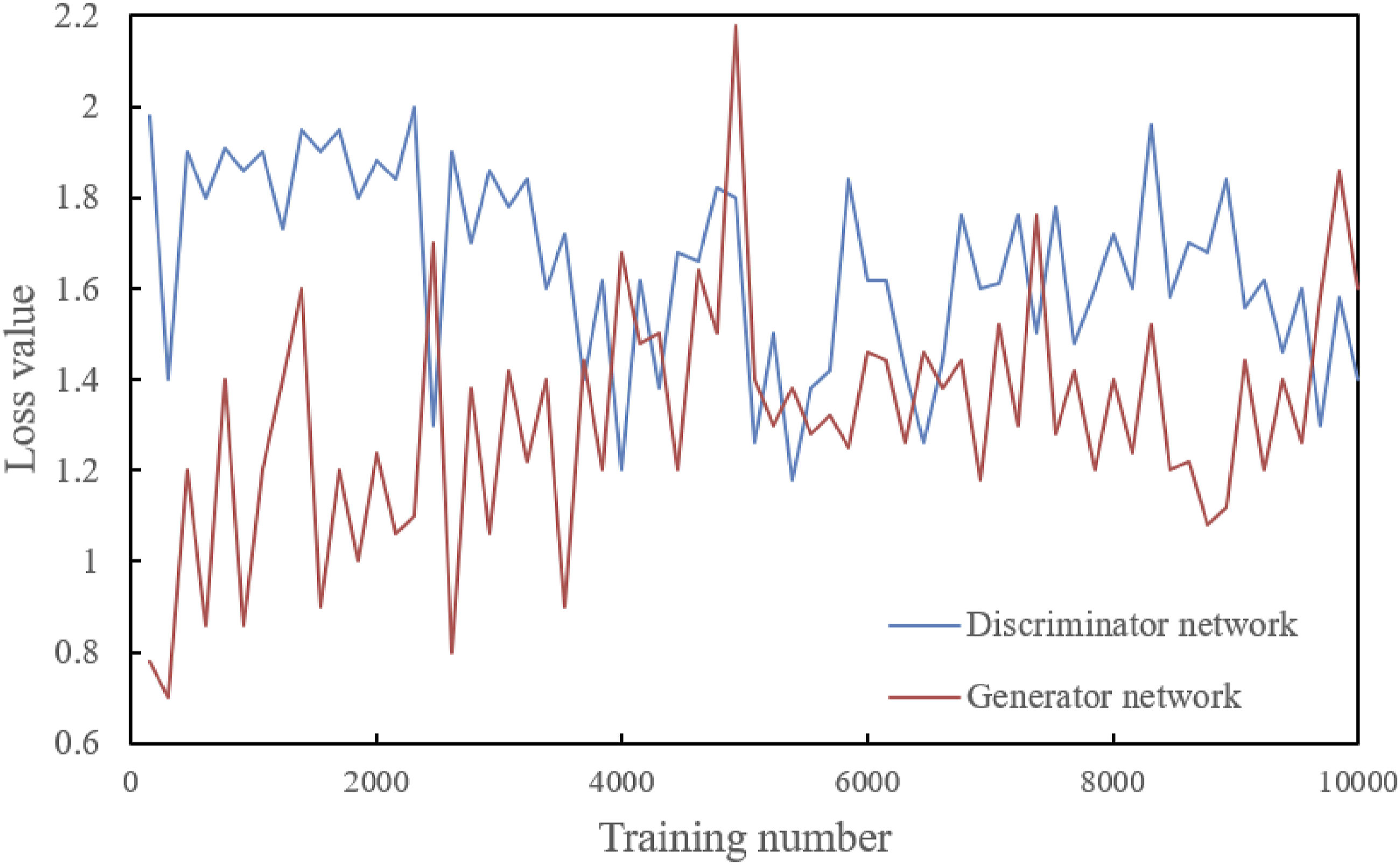
The analysis of the experimental results indicated that, despite slight fluctuations in the loss value of the recovery network throughout the learning process, suggesting the recovery network was still adapting to feature mapping adjustments by the embedding network, overall, the loss values of both networks showed a downward trend, indicating increasingly precise learning of the attention allocation strategies of university students. This reflects the effectiveness of the TimeGAN model in understanding how students adjust their attention according to different tasks and states. The experimental results also demonstrated that the training process based on the TimeGAN model effectively improved the performance of both the generator and discriminator networks. In the later stages of training, although the networks remained in an adversarial state, this adversarial relationship promoted an enhancement in network capabilities, meaning the model became more precise in simulating the attention allocation strategies of university students. This improvement was reflected in the generator network’s ability to produce data with statistical characteristics similar to real attention allocation strategies, while the discriminator network became better at identifying subtle differences between real and generated data.
Through deep learning of time-series data, the model was able to reveal and replicate the changing patterns of attention across different tasks. Figure 8 presents the t-SNE visualization results of TimeGAN. In the initial training phase, the t-SNE visualization technique revealed a clear distinction between the generated data and the real data, with almost no overlap in their distribution as shown in Figure 8, indicating that at this stage, the data produced by the TimeGAN model exhibited significant statistical differences from the real data. However, as the training process advanced, especially after 10,000 training iterations, the t-SNE visualization results showed that the distribution of the generated data began to highly overlap with the distribution of the real data. This indicates that the model has successfully simulated the real attention allocation patterns statistically, and the quality of the generated data was significantly improved. The visualization results strongly suggest that after extensive training, the TimeGAN model was able to effectively capture and replicate the attention allocation strategies of university students across various cognitive tasks. This high level of consistency demonstrates the model’s ability to capture complex features in time-series data and its capability to model the dynamics of university students’ attention allocation. From this, it can be inferred that the more thoroughly the TimeGAN model is trained, the higher the similarity between its generated data and the real data, thereby validating the effectiveness of this model in analyzing and understanding the attention allocation strategies of university students. Research route of this paper.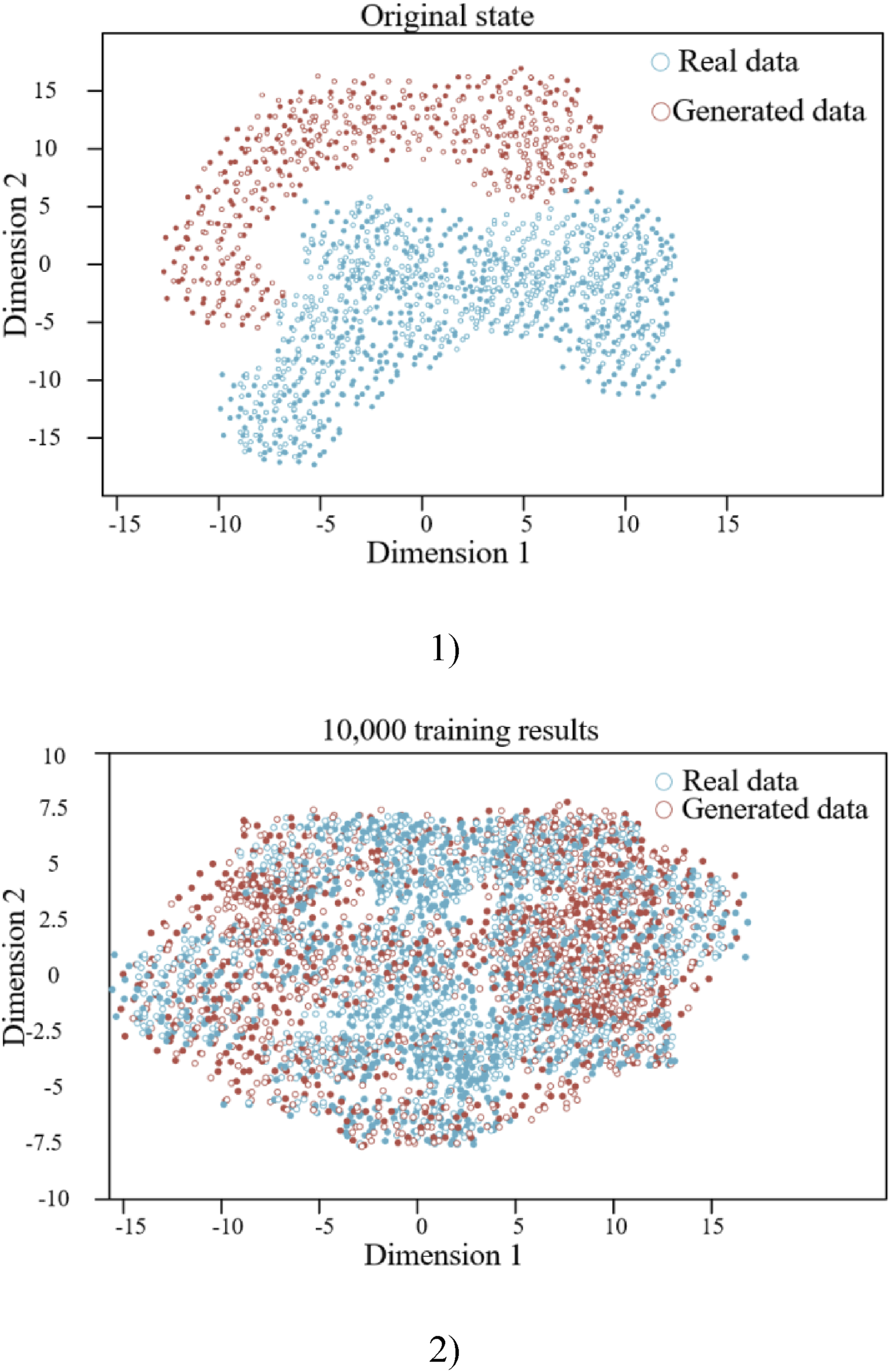
The TimeGAN model demonstrated good convergence across different tasks and attention states, with stable learning curves observed for the losses of the embedding network, recovery network, discriminator network, and generator network. Through t-SNE visualization, the model effectively distinguished various attention states, indicating high accuracy and discrimination capability in capturing attention allocation and switching. The underlying reason for these results lies in the TimeGAN model and its innovative modules, which effectively simulate the complex features and dynamic changes within the time-series data.
Based on the learning curve data provided in Figure 9, it is observed that with an increase in the number of training iterations, there is a clear downward trend in total loss, identification loss, and prediction loss. Starting from an initial value of 0.5, the total loss gradually decreases with the increase in training iterations, particularly dropping below 0.0015 after 5000 training iterations and maintaining a low level throughout the subsequent training, indicating significant optimization effects of the model. Similarly, the identification loss sharply decreases from an initial value of 0.5 to about 0.000015 after 5000 training iterations, demonstrating a substantial increase in the model’s accuracy in distinguishing different attention states. The prediction loss also gradually declines from 0.25 to 0.0015, indicating a steady enhancement in the model’s ability to predict future attention allocation as training progresses. These data represent the model’s learning progress in capturing and simulating the management of attention switching among university students. Multitask model learning curves of university students’ attention switch management.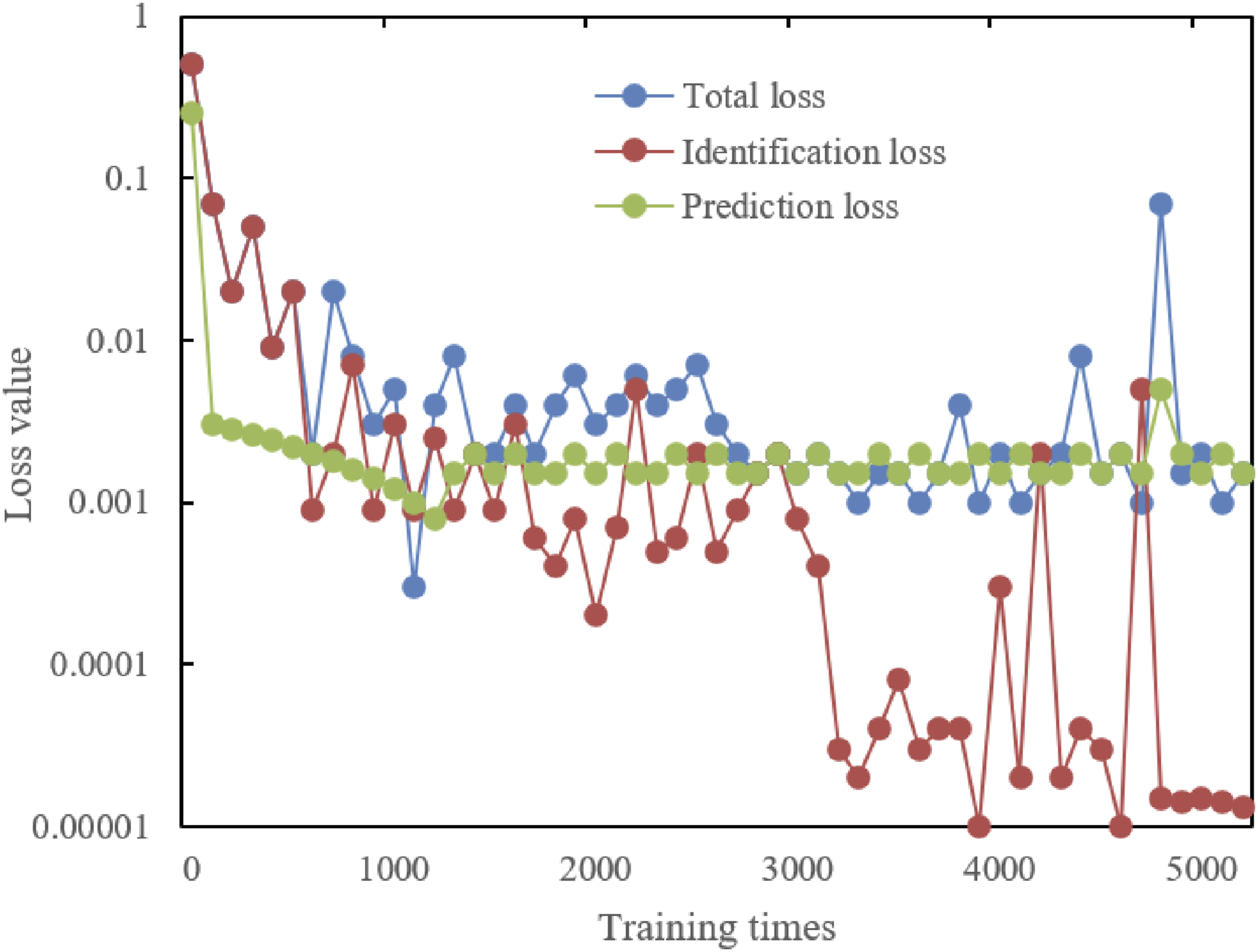
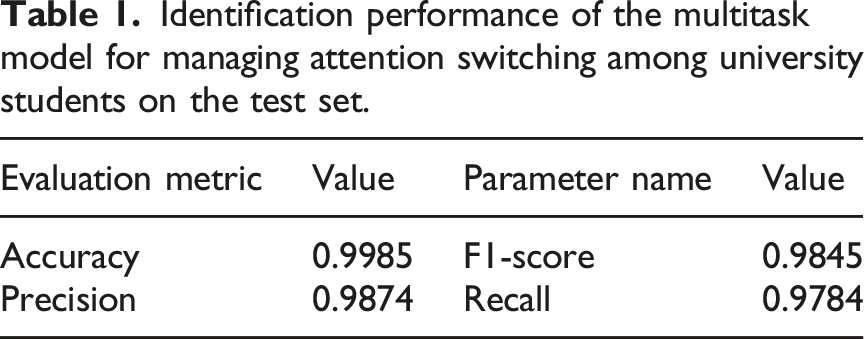
Identification performance of the multitask model for managing attention switching among university students on the test set.
From the data shown in Figure 10, it is observed that in the multitask predictive model for managing attention switching among university students, there is a significant downward trend in the total loss values of each task as the number of training iterations increases. Particularly after the initial 1000 training iterations, the total loss rapidly decreased from 0.25 to 0.003, demonstrating the model’s rapid learning and adaptation ability in the early stages. Subsequently, although some fluctuations in loss values were observed, they remained generally low, indicating that the model efficiently learned and retained information regarding the management of attention switching among university students. Furthermore, the predictive task losses for sustained attention duration, task switching efficiency, and self-monitoring ability also gradually decreased with the increase in training iterations, showing a progressive improvement in the model’s performance on these specific tasks. These experimental results indicate that the multitask model proposed for managing attention switching among university students exhibited efficient learning capabilities and stable performance in handling complex cognitive tasks. The model’s loss values stabilized at a low level after a sufficient number of training iterations, demonstrating that the model can effectively predict and manage the dynamics of attention during multitasking among university students. Learning curves of the multitask predictive model for managing attention switching among university students.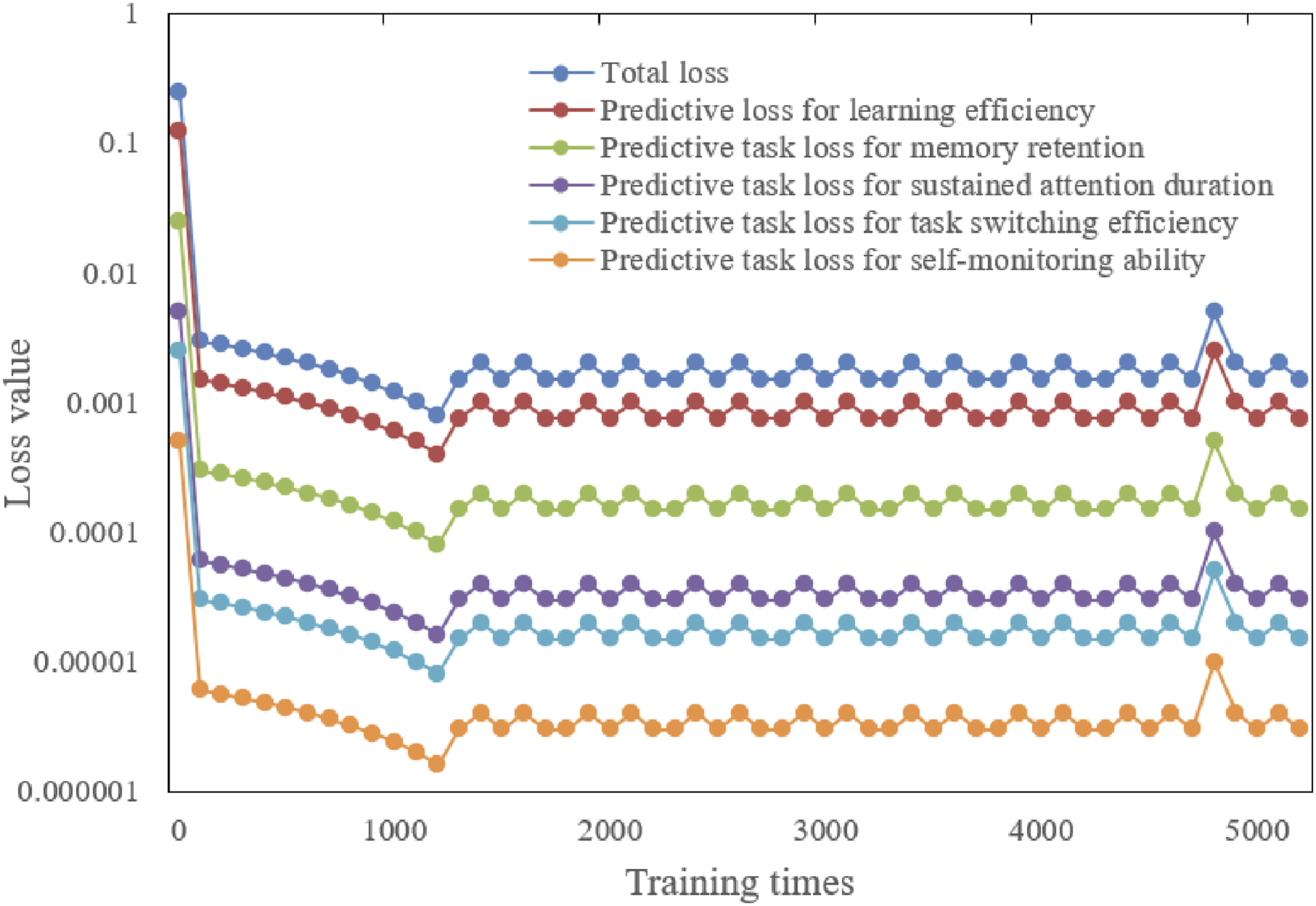
Predictive performance of the multitask predictive model for managing attention switching among university students on the test set.
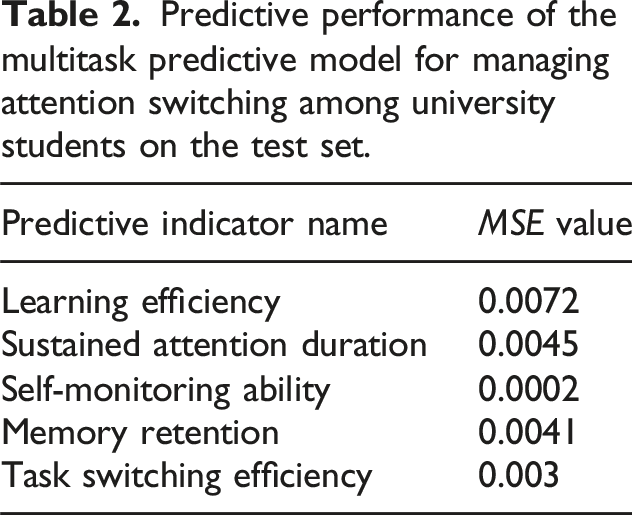
The model proposed in this study significantly improves the ability to manage and predict attention switching among university students in complex cognitive tasks through the design of CGC and PLE models. The low MSE values across various predictive indicators demonstrate the model’s high accuracy and reliability in practical applications. Particularly, the extremely low predictive error for self-monitoring ability highlights the model’s outstanding performance in capturing detailed changes in individual cognitive states, which is of significant importance for designing personalized learning plans and enhancing teaching effectiveness. In summary, these experimental results prove that the multitask model for managing attention switching among university students proposed in this paper not only provides precise real-time monitoring but also serves as a powerful tool for understanding and improving learning and attention management.
To evaluate the performance of the TimeGAN model, several commonly used time-series generation and analysis models were selected as baselines, including Long Short-Term Memory (LSTM), GRU, AutoRegressive Integrated Moving Average (ARIMA), and Prophet (Facebook’s time-series forecasting tool). Comparative experiments were conducted on the same dataset, and the results indicated that the TimeGAN model exhibited superior convergence in the learning curves of the embedding network, recovery network, discriminator network, and generator network losses. Additionally, t-SNE visualization showed that the TimeGAN model was more effective in distinguishing different attention states, demonstrating its advantage in capturing the complex features and dynamic changes in time-series data.
Comparative experiments with existing methods indicated that the TimeGAN model, combined with the CGC model and the progressive hierarchical extraction model, outperformed in managing attention switching in university students’ multitasking processes. This was particularly evident in the significant improvements across multiple evaluation metrics, such as accuracy, precision, recall, and F1-score. Cross-validation experiments further verified the model’s stability and robustness, showcasing consistent performance across different datasets. Compared to traditional time-series models, the TimeGAN model not only achieved faster training convergence but also demonstrated superior recognition performance and multi-metric prediction effectiveness on the test set, highlighting its substantial potential for real-world applications.
Conclusion
This study employed the TimeGAN model as a foundation to conduct in-depth modeling and analysis of university students’ attention allocation strategies across various cognitive tasks. The key advantage of the TimeGAN model lies in its ability to understand and simulate the complex features within time-series data, especially the dynamic changes in attention across multiple tasks and states. To further enhance the model’s performance, this research introduced the CGC and PLE models, innovative methodological approaches aimed at improving the accuracy of simulating attention switch management in multitasking among university students. Experimental results demonstrated that the learning curves for the embedding and recovery networks, as well as the discriminator and generator networks of the TimeGAN model, exhibited good convergence; t-SNE visualization results showed the model’s effectiveness in distinguishing different attention states. Moreover, the multitask model for managing attention switching among university students not only displayed excellent performance in learning curves but also its identification performance and multi-indicator predictive effects on the test set further proved the model’s potential for real-world applications.
In conclusion, this study successfully developed a multitask model capable of precisely predicting and managing attention switching among university students. By integrating the TimeGAN model with the CGC and PLE frameworks, this study holds significant research value in understanding students’ cognitive processes, optimizing learning plans, and enhancing teaching quality. However, the limitations of the study might include the model’s generalization performance across different individuals and complex environments, and its applicability across a broader range of cognitive task types. In future work, methods for testing the model in different educational environments and with a broader sample will first be proposed. This includes conducting intercultural comparative studies and applying the model in various academic disciplines to evaluate its universality and adaptability. Additionally, the integration of the model with educational feedback systems will be explored, such as real-time monitoring of students’ attention allocation to provide personalized learning recommendations, thereby optimizing learning outcomes. Lastly, a feasible roadmap will be proposed, outlining the steps for future research and anticipated challenges. This roadmap will include expanding the data collection scope, developing real-time monitoring systems, conducting large-scale validation experiments, and optimizing the model to improve computational efficiency and accuracy. Anticipated challenges may involve issues related to intercultural data consistency, technical difficulties in the implementation of real-time monitoring systems, and data management and privacy protection in large-scale experiments. Although the TimeGAN model performed excellently in the experiments, its applicability is limited in specific contexts. For instance, the model is highly sensitive to data quality, with noise and outliers potentially significantly affecting the results. Furthermore, the model requires substantial computational resources for training, limiting its application in resource-constrained environments. Future research should further explore the model’s applicability in different educational environments and data conditions, and optimize the model to reduce its computational resource requirements.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.