
Abstract
Manually verifying the authenticity of the physical documents (personal identity card, certificates, passports, legal documents) increases the administrative overhead and takes a lot of time. Later image processing techniques were used. But most of the image processing based forgery document detection methods are less accurate. To improve the accuracy, this paper proposes an automatic document verification model using Convolutional Neural Networks (CNN). Furthermore, we use Optical Character Recognition (OCR) and Linear Binary Pattern (LBP) to extract the textual information and regional edges from the documents. Later, Oriented fast and Rotated Brief (ORB) is used to extract the images from the scanned documents. To train the CNN, MIDV-500 dataset of 256 Azerbaijani passport images, each with the size of 1040*744 pixels is taken. The proposed CNN model uses sliding window operations layers to evaluate the authenticity. The proposed model analyzes both the textual authenticity and image (seal, stamp and hologram) authenticity of the scanned document. The experimental analysis is carried out on the TensorFlow using python programming language. The results derived from the proposed CNN based forgery detection model is compared with existing models and the results are promising to implement on the real time applications
Keywords
Introduction
After the evolution of computers and internet technologies, multi-national organizations, banking, government and private sectors has adopted various computer based techniques to manage their day-to-day needs. One of such important adoption is digital documents. Usage of digital documents has increased exponentially. As per the report published by International Data Corporation (IDC), the practice of using digital documents in the internet has increased by 36% in 2018 [1]. Digital documents allows the companies to instantly search, manipulate the documents. Now-a-days, all banking sectors are collecting digital KYC documents from the customers.
On the other hand, the usage of forged document in the internet is also increasing rapidly. About 500,000 people in the United States are victims of forged documents every year, with a negative financial crisis of approximately $750 million. Detecting the forged scanned document is a really challenging task [2]. Because, a document issued by the government or private sectors will have several information like customer image, seals, hologram, texts, stamps, etc. Validating all the security features in a scanned document is important because sometime a small part of the document might have been forged and all thother part might show genuineness. For example, in any document, (a) holograms and seal are genuine, but the image (customer photo) present in the document are forged (b) image is genuine, but the seal and holograms are forged (c) image, seal, hologram are genuine, but textual contents are forged (d) image, seal, hologram, textual contents are genuine, but signature is forged.
Many multi-national companies, private and government organizations are outsourcing the document verification process to a third party Business Process Outsourcing providers (BPO). The recent report from Thomson Reuters mentions that the estimated cost of outsourced BPOs on KYC verification in 2017 is 32 billion US Dollars. By automating the document verification process, huge amount of money and manpower wastage can be reduced. Adopting cognitive automation technologies in document verification process ensure faster and better business solution. Instead of focusing on the document verification process, the organizations can directly focus on its core competencies. To collect the KYC documents from the customers, Robotic Process Automation (RPA) is used. It helps the organization to easily access, manage and use the digital documents of their customers. RPA behaves like a human interaction machine to satisfy the business needs [3].
Once, after the information and documents are collected from the customers, the automatic system has to verify the authenticity of the KYC documents. Because the documents issued by the user might be a manipulated or counterfeited one. So far, the authenticity of the user document are verified manually, which is a time consuming and a cost intensifying process. The recent study on KYC processing by Thomson Reuters reveals that the average number of employees working on Know Your Customer (KYC) document has increased by the factor of about 3 to 4.5 between 2016 and 2017.
Depending upon the importance of the document, the major factors that an automatic document verification system has to consider for verification are, (a) authenticity of the seal, holograms and images (b) authenticity of the signature. To verify the genuineness of the seals engraved in the scanned documents, Partha et al. [4], proposed a method using Generalized Hough Transformation (GHT). Here, Rotational invariant feature extraction method is used to extract the seal from the scanned document. Later it measures the Euclidian distance between each pixel of the seal object to find out the authenticity of the seal. In this method, the result highly depends upon the Euclidian distance between the pixels in the seal. Moreover, this method verifies only the seal object in the document and doesn’t verifies other security parameters. Later, Pawel et al. [5], proposed a method to detect and classify (genuine /forged) the rubber stamp instances in the scanned documents. It uses a variety of methods from image processing, pattern recognition techniques. To retrieve the stamps from the scanned documents, shape based algorithms are used (i.e.) it takes circular shape, straight time shape, triangular shape to retrieve stamps. Later, the entire scanned document is converted into binary images and the Gray Level Co-occurrence Matrix (GLCM) is created to find out the genuineness of the stamps.
On the other hand, several image processing techniques were proposed to verify the authenticity of the signature present in the scanned document. Muhammad et al. [6], proposed a method to automatically verify the signature stability analysis using local features. It uses speed up robust features to extract the nearby local feature in the signature. This method achieves a better equation error rate as 15% in analyzing the signature. Later, Hamadene et al. [7], proposed a one-class writer independent system to classify the signature using Feature Dissimilarity Measures (FDM). It also uses Contourlet Transform (CT) based Directional Code Co-Occurrence Matrix (DCCM) for feature generation. Though, the main objective of the one-class writer independent method is classification, it doesn’t use any specific machine learning classifiers like SVM or Neural network to train the dissimilates between the handwritten signature. The results of signature resemblance highly depends on Feature Dissimilarity Measure (FDM) algorithm only. Later, Yanzhi et al. [8], proposed a signature verification system using a critical segment method to secure mobile (document) transactions. It identifies the invariant segments in the user’s signature to capture the intrinsic signing behavior. It extracts the geometric layout of the signature as well as the behavioral and physiological characteristics in the user signing process. Likewise, Luiz et al. [9], used Convolution Neural Network along with proper organization of adversarial examples to classify the signature. Later, Nabil et al. [10], proposed a method to verify the personal identity document. It uses pattern matching and recognition methods to perform the verification. It uses both supervised and unsupervised machine learning technique such as distance measure (sum of squared difference; sum of absolute difference) and SVM classifier. Depends upon the quantifying level of image, the accuracy falls between 62.6% and 85.09%. Traditional forgery document detection methods mainly focus on the appearances of the features (i.e. shape of seal, signature and logo), whereas it doesn’t verifies whether the particular region is manipulated or not. Though, the need of forgery detection in a scanned document remains high, there is no proper machine learning based automatic document verification system to detect all the possibilities (text, signature, image, seal and hologram) of the forgery in a document.
In this research work, we have created a Convolution Neural Network based automatic document verification system to verify all the security features of the document. The proposed system allows the users/customers/employees to upload the digital document directly to the verification system. Later, the CNN algorithm is programmed to check for discrepancies and forgeries in the document. The verification system takes each and every document of the user automatically and extracts the important information and verifies the authenticity of the document.
The proposed system uses Optimal Character Recognition (OCR) and Linear Binary Pattern (LBP) to retrieve the important textual information from the scanned documents. It retrieves information like name, identification number, Date of Birth, scored marks along with its regional edges. To convert the physical document into machine readable format, the OCR system turns the physical document into a gray scale image. Later the OCR system discriminates the dark and light areas of the gray scale image [11]. The dark area is identified as characters/letters and light area is identified as background of the document.
Information like seals, holograms, and signature are retrieved using ORB algorithm. It is an efficient and alternative method to SIFT) and SURF feature detection methods. ORB techniques comprise both FAST key point detector and Brief descriptor method to achieve good performance and low implementation cost. The results of the text extraction (OCR) and image extraction (ORB) are fed as an input to the Convolution Neural Network (CNN) to identify the authenticity of the certificate. CNN is a deep learning technique which uses multiple layers of neurons for processing complex datasets. It also supports both forward propagation as well as backward propagation to efficiently learn.
Our contribution to the proposed automatic forgery detection system are, Developing a faster and accurate forgery document detecting system to detect all the forgery possibilities in a scanned document based on sliding window Convolutional Neural Network (CNN). Deriving a high quality of text feature extraction using Optical Character Recognition (OCR) method and Local Binary Pattern (LBP) method to analyze the neighborhood of each pixel to identify the forged text. Deriving a high quality image extraction (seal, hologram, signature and stamp) using Oriented Fast and Rotated Brief (i.e.) Feature from Accelerated Segmented Test (FAST) and Binary Robust Independent Elementary Feature (BRIEF) algorithm.
The rest of the paper is organized as follows: Sect. 2 summarizes the related works that are carried on forged document detection methods. Sect. 3 explains the proposed Convolution Neural Network based forged document detection method. The performance evaluation of the proposed model is explained with implemented results in Sect. 4 and Sect. 5 concludes the paper.
Related works
Addressing the challenges in the digital document verification and finding out the counterfeited document is a highly valued research area. To mitigate the challenges in forgery document verification, several techniques were proposed earlier. The important security methods used to protect the physical documents are watermarks, seals and holograms. But, when the physical document is scanned using scanners, mobile phones, the quality of the watermarks, holograms and seals are reduced. So that, verifying the authenticity becomes a challenging task. In later years, two dimensional barcodes and QR code were introduced. Barcode can store information in a visual, machine readable format. These information stored in the barcodes is later used to verify the authenticity of the document. Moreover, it uses cryptographic encryptions to secure the information about the physical documents. But the problem with barcodes is, it can be easily edited or replaced.
Depending upon the nature of the forgery detection methods, it can be categorized into (a) textual forgery detection and (b) image forgery detection (seal, stamp and hologram). (c) Machine learning based forgery detection. The related works that have been carried out on the text, image and machine learning based forgery detection methods are explained below.
Textual forgery detection in scanned documents
Khan et al. [12], proposed a method to identify the genuineness of the handwritten notes in a physical document by the hyper spectral imaging method. To prove the genuineness of a document, the hyper spectral imaging method detects the ink color mismatching. If the letters are written with the same ink, then its claims that the entire document is non-forged document. If any of the ‘letter’ or ‘number’ mismatches the ink used, then the particular region (letter/number) is identified as forged text. But the accuracy of Khan et al. [12] is found to be very less. Later Shang et al. [13], proposed a method to identify the type of printer in which the document is printed using the text feature extracted from the document. Later, by analyzing the characteristics associated with the laser/inkjet printer and text features, the genuineness of the document is verified. The result of the Shang et al. [13] reaches a maximum accuracy, only if the printer (inkjet/laser) is from different manufacturers. If the original and forged texts are printed in the same printers, then the proposed method fails to detect the forgery. Abramova et al. [14], proposed a block based detection of near duplicates in a scanned document. To find out the textual forgeries in a document, Copy Move Forgery Detection (CMFD) algorithm is used.
Khan et al. [15], proposed a method to improve the accuracy of ink mismatching detection in Khan et al. [12], using fuzzy clustering and hyper spectral imaging method. Here, Fuzzy C-Mean clustering method is used to divide the spectral responses of ink pixels in handwritten notes into multiple clusters of same ink used in the document. It also uses Sauvola’s local thresholding method to segment texts from the document. After the evolution of machine learning techniques and artificial Intelligence, Maryam et al. [16], proposed a text forgery detection using Convolution Neural Network (CNN) method. It uses a text independent approach for effective characterization of source printer using deep visual features of the letters in the document. Likewise, Tsai et al. [17], proposed a method to detect forged text in a printed document using Support Vector Machine (SVM) and Convolution Neural Network (CNN) method. In here, SVM is used to perform feature based classification and CNN is used to perform deep learning based classification.
Image forgery detection in scanned documents
Image forgery detection is one of the hot topics in digital forensic studies. Because, now-a-days most of the private and governmental sectors rely on the digital documents. Ensuring the originality of the documents is important. The traditional image forgery technique can be categorized into Copy Move Forgery Detection (CMFD) and Image splitting detection. In copy-move forgery, a particular region of an image is selected and pasted into some other part of the same image. So there will be a high correlation between the two regions. Kumar et al. [18], proposed a DCT-PCA (Discrete Cosine Transform – Principle Component Analysis) and block matching based method to detect a copy-move forgeries in digital images. But the time taken to execute block matching method is too high to implement on the real-time. Later, Mahmood et al. [19], proposed a new method to detect copy-move forgery attack by diving the images into overlapping square blocks and DCT (Discrete Cosine Transform) and then the Gaussian RBF kernel and PCA is applied to find out the forged region in the image.
Another traditional method of image forgery detection is, image splicing method. In here, a particular region of an image is taken out and added to some other image. The image splicing detection analyzes the clues that are left after the tampering process on an image. The tampered region is believed to have an abnormal artifact in the edges. The most common abnormal activities of tampered region are discontinuity of edge, mismatch of letters due to brightness, geometric place. Manu et al. [20], proposed an image splicing detection method based on visual artifacts of uncomposed images. It uses blockiness, blur and combination of artifact methods to identify the region of the forged image. Later, Ambili et al. [21], proposed an image splicing detection method based on comparing the blur in the original image and the forged region of the image. Later Linear Discriminative Analysis (LDA) is used to differentiate the original and forged region based on the blur.
Deep learning based forgery detection
Zhang et al. [22], suggested two step mechanism for detection forged images using deep learning techniques. The first step is to divide the image into patches and second is to stack auto encoder to learn the features from the each patch using contextual information. Hou et al. [23], proposed a method to detect the image forgery by analyzing the contextual violations in an image using deep neural network. It uses Context Learning – Convolutional Neural Network (CL-CNN) and Region – Convolution Neural network (R-CNN) to identify the exact region of the forged image. However, the accuracy of the Hou et al. [23] is low as the region based object detector fails to identify the background of the image. Later, Salloum et al. [24], proposed the solution to address image splicing forgery using Multi-Task Fully Convolution Network (MFCN). It utilizes two output branches for learning. One is used to learn the surface label and another is used to learn the edges of the spliced region. Later Su et al. [25], proposed a Hough transformation method to detect imprint borders and edge difference between the original image and forged image. Later, SVM (Support Vector Machine) is used to differentiate the original and forged region.
Other methods to detect forgery
The important security feature of a physical document is, hologram. It is a flat surface which illuminates to contain a three dimensional structure in an image. It prevents the counterfeits of documents such as credit cards, driver license, tickets, degree certificates, passports. To verify the genuineness of the scanned documents using holograms, Mayor et al. [26], has proposed a novel technique to identify the document forgery using Lateral Chromatic Aberration (LCA). It mainly focuses on detecting the forged by localizing LCA consistencies. To find the particular region, they have created a statistical model to capture the inconsistency between global and local estimates of LCA. Later they hypothesis testing to derive a statistical detection. It also proposed a new method of LCA estimation algorithm to detect the regions. But the detection method of this LCA method is 73% as it doesn’t uses machine learning techniques. Soukup et al. [27], developed a hologram verification technique based on the mobile application and deep learning technique for physical documents. This work needs a physical copy of the document. The multi-view and photometric image acquisition of the hologram engraved in the physical document is taken. Later the images are analysis used convolution neural network to find the authenticity of the hologram.
In all the above mentioned research work, the authors have only focused either on textual forgery detection or on image forgery detection. But as far as scanned documents issued by the government or the private sector is concerned, the forgery can be in any form (textual as well as an image). So, to overcome the issues with the existing methods, a fast and accurate forgery document detecting system is introduced to detect all the possibilities of forgery in a scanned document based on sliding window and Convolutional Neural Network (CNN) algorithms.
Proposed model
The main objective of the proposed forgery detection system is to analyze all the possibilities of forgeries in a document with less time and provide a better accuracy than existing methods. The first step after the document enters the Forgery document detection system is preprocessing. User uploaded documents may contain certain amount of noise or defects depending upon the resolution of the scanned document (i.e.) the characters in the user uploaded documents may be smeared or broken. Some of the noise in the documents may cause poor recognition rates. To reduce the noise in the document, preprocessing is performed. Preprocessing uses filling and thinning technique to improve the quality of the character. Filling eliminates the small gaps, breaks and holes in the characters and thinning improves the border line of the characters. If the document has low resolution and poor quality, the user interface system will reject the user document and request new high quality document.
Once, after the scanned document is preprocessed, the step is to extract the textual and image information present in the document. Scanned documents will be in an image format. (i.e.) jpeg, jpg, etc. The information composes in the image (scanned document) is neither editable nor searchable. So, to extract the information from the document, Optical Character Recognition (OCR) is used. Optical Character Recognition technique transforms the two dimensional documents containing handwritten characters and machine printed character into a machine readable format. It extracts the textual contents from the scanned document and converts into a structured data that is editable and searchable. OCR extracts the textual content from the document effectively. But OCR doesn’t have the capability to find out counterfeited ‘letters’ or ‘numbers’ from a scanned document. By analyzing the local or nearer edges of the letters, the changes in the region can be identified. To find out the edges of the counterfeited letters, Local Binary Pattern (LBP) algorithm is used along with the OCR. Algorithms used in the feature extraction phase is shown in Fig. 1.
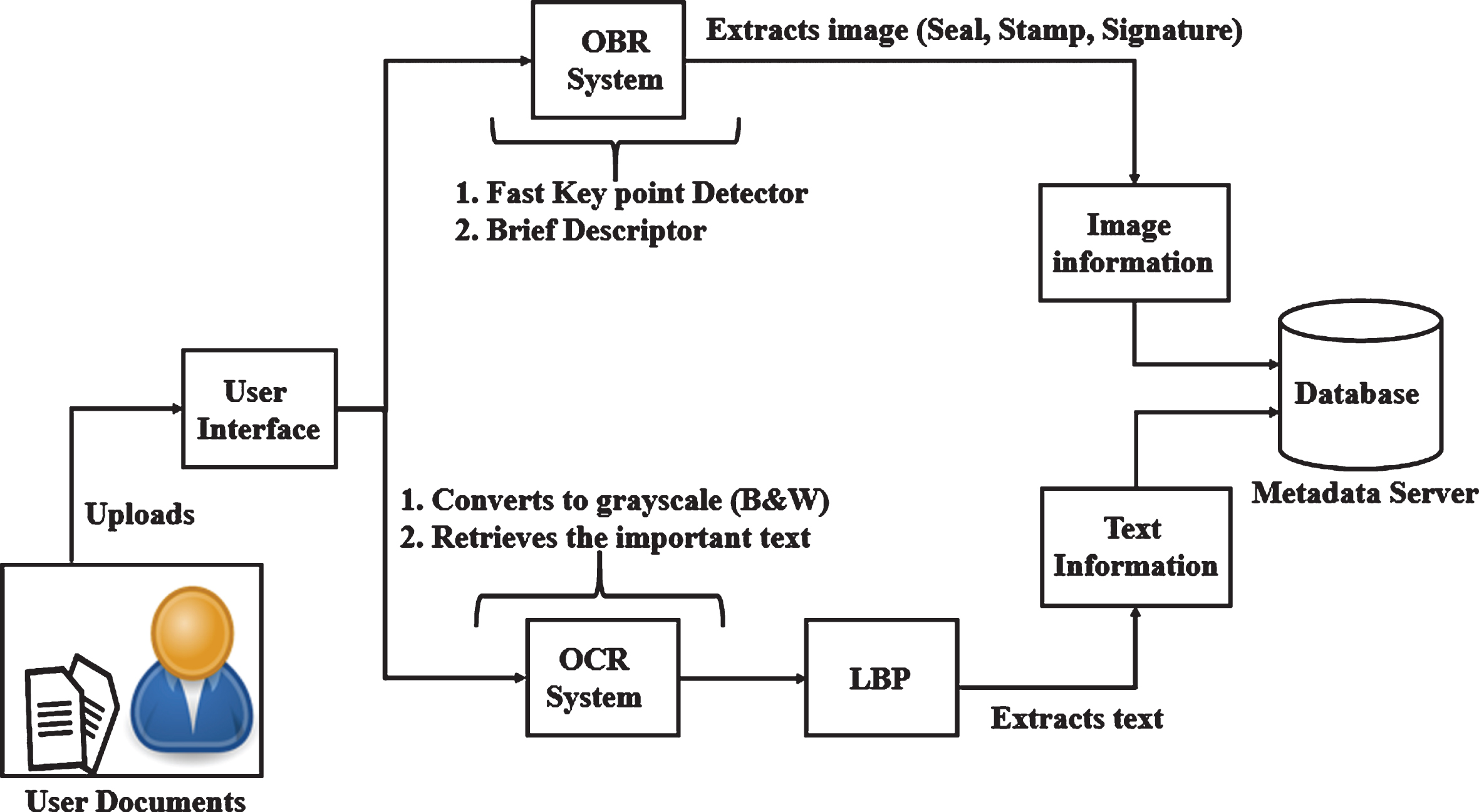
Flow chart of feature extraction and detection.
Segmentation is a process which determines the constituents of an image. It identifies the important segments and regions where data are written or printed. Segmentation techniques splits the text character from the figures, seals, holograms and the graphical images. In the proposed work, name, surname, passport register number, date of birth, nationality, birthplace, sex, expiry date are segmented as a character and given as an input to the OCR unit. The proposed OCR algorithm segments the words into isolated characters which are recognized individually. OCR performs a structural analysis of the characters (texts, number) to recognize the patterns. It extracts the geometric and topological structure of each and every character. By using these structural and geometric values, the system attempts to create the physical makeup of the character. The structural analysis method gives high tolerance to noisy documents. Figure 2 shows the text segmentation code of OCR in python programming language.

Python code of character extraction method.
Local Binary Pattern (LBP) is an efficient local structural operator which labels the pixels of a character, numbers by setting a threshold on the circular neighborhoods and finds out the binary result. The circular neighborhood pixels are defined as S (r,b) , where ‘S’ represents the sampling point, ‘r’ is the radius of the neighborhood and ‘b’ represents the number of samples taken. In the proposed method, for each character, 3 sampling points are taken and the binary values of their circular neighborhood are calculated. Because performing LBP for all the pixels in a scanned document is a time consuming process. Depending upon the importance of the characters, the sampling points can be adjusted. The binary operator is derived from,
After deriving the binary points of the circular neighborhood using thresholds, the genuineness of the textual characters (i.e.) letters and numbers will be verified. Likewise, CNN model will be trained with the information gathered from the Optical Character Recognition (OCR) and Linear Binary Pattern (LBP) to detect the tampered region of the texts.
Oriented fast and Rotated Brief (ORB) is a feature detecting method used to identify the important images (seal, holograms, and graphs) from the user provided scanned documents. It is a fast and robust feature detection algorithm. In the proposed work, feature detection is carried out by two major algorithms such as, FAST (Feature from Accelerated Segmented Test) key-point detector and visual descriptor BREIF (Binary Robust Independent Elementary Feature).
Feature from accelerated segment test algorithm
Features from Accelerated Segment Test (FAST) is an efficient edge detection algorithm used to extract feature points and map to the computer vision tasks. It has a high computational efficiency compared to other image feature detection algorithms. In this proposed method, the corners of the image such as seals, hologram, stamps and signature are detected by drawing Bresenhan circle of radius 3 for each and every pixel. It also uses 12point segment detection on the Bresenhan circle to detect the exact corners of the image. The algorithm of FAST corner detection algorithm is explained in Algorithm 1 and Fig. 3 shows the FAST corner detection of the hologram image in the passport.

Corner detection of the images in the scanned document using FAST algorithm.
Traditional image feature detection algorithms such as SIFT and SURF takes too much of memory (512bytes and 256 bytes respectively) and makes feature detection unfeasible. Allocating such a large amount of memory of each image makes the system very slow. But BRIEF feature detection algorithm provides an easy way to find the binary string in the image without finding the actual descriptor. It uses pixel intensifying comparisons to find the actual descriptor. (i.e.) the BREIF system takes intensifying factor of two pixels and compares the values to find the descriptor points. BRIEF algorithm does not follow a particular sampling pattern as like SURF or SIFT. The pairs can be chosen at any point on the S*S patch. Likewise, to construct a BRIEF descriptor of length ‘n’, ‘X’ and ‘Y’ vector points are randomly sampled for each pair using Gaussian distribution method (i.e.) nearer points to the center of the patches are chosen randomly. The memory needed for executing the BRIEF algorithm is just 64 bytes.
One after the OCR-LDP and OBR algorithms extracts the information from the scanned image, the result are stored in the metadata server and are used to train the Convolution Neural Network (CNN).
Convolution Neural Network for forgery document detection
Convolution Neural Network is a non-linear interconnecting neurons developed based on the idea of the functionality of the human neurons. In the proposed forgery detection method, the MIDV-500 dataset of 256 Azerbaijani’s passport images are preprocessed and are split into 80 : 20 ratio (i.e.) 80% of the dataset is used for training the CNN and 20% of images are used for testing the CNN model. The resolution of each input image in the MIDV-500 dataset is 1040*744 pixel and are of 944KB size.
The textual and image feature extraction and detection methods will find out the appropriate regions of the scanned documents (i.e.) regions with higher priority like characters (text and number), seals, stamps, holograms will be identified and stored in a metadata server. Later, OCR-LBP and OBR extracted information will be given as input to the Convolution Neural Network. The training images passes through the various stages of the CNN like, Convolution layers, pooling and connected layers. Figure 4 explains the workflow of the proposed CNN method.
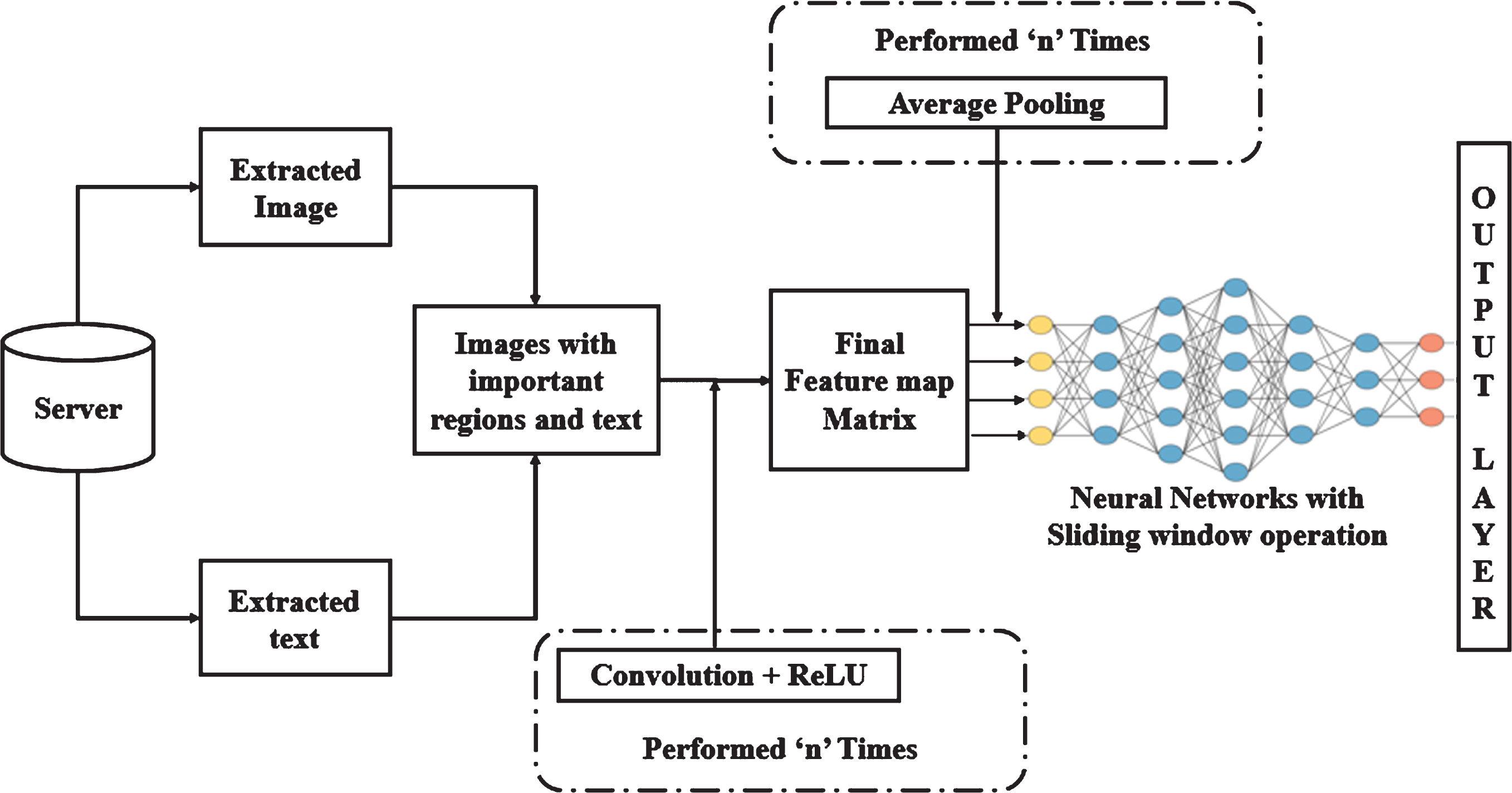
Workflow of sliding window based CNN technique.
Convolution layer is a mathematical operation, which takes two inputs such as image matrix and a filter matrix values to learn about the image feature using the small squares of input data between the pixels. To identify the outer regions of the images (stamp, seal, Hologram), we have used edge detection filter. Moreover, ReLU (Rectified Linear Unit) is also used in the convolution layer to identify the non-linear operations. As a result, convolution layer produces the feature maps of the chosen image. Later, the derived feature maps will be given as an input to the next layer called, pooling layer. In here, we have used average pooling method to reduce the number of unwanted parameters of the feature map derived from the convolution layer. (i.e.) it reduces the dimension of each feature map and retains important information. In the proposed method, we have used seven convolution layers and seven pooling methods for getting accurate feature map matrix of the high priority regions.
Once, after the feature map derived from the convolution layer is fine-tuned using pooling methods, the feature maps are flattened into vectors and fed to the connected layer. The connected layer uses sliding window mechanism to create a well-trained forgery document detection model. The output layer of the convolution neural network classifies the text or images with probabilistic values between 0 and 1. If the resultant probabilistic value is 1, then the particular region of the scanned document is understood to be forged one. If the probabilistic value of all the elements is a document (text, seal, stamp and holograms) is 0, then the document is classified into genuine document. In the next section, the accuracy of all the possibilities of forgery (text, seal, stamp and holograms) are derived and tabulated.
The experiments of the proposed forgery document detection using Convolution Neural Network (CNN) are carried on TensorFlow and python programming language. The proposed system is evaluated under various criteria to find out the performance and the legitimacy. The factors we considered are evaluating the performance are, (i) Accuracy of OCR (ii) Computation time taken to perform feature detection using the ORB algorithm. (iii) Accuracy of the text forgery detection. (iv) Accuracy of image (seal and hologram) forgery detection. The dataset used in the proposed work is MIDV-500 dataset which consists of 256 Azerbaijani’s passport images, each with the resolution of 1040*744 pixel and of 945Kb size. The Azerbaijan’s passport had both Azerbaijani’s language and English in its main page. In Fig. 5(a) and Fig. 5(b), an image from input dataset is given to OCR and the results of textual extraction is shown.

(a) Example Azerbaijani’s passport from MIDV-500 dataset. (b) Result of OCR extracted Azerbaijani’s passport using TensorFlow.
The programmed OCR algorithm is designed to extract only the English characters. But the problem we faced while extracting the English characters from the Azerbaijani’s passport is, character resemblance of Azerbaijani language and English. For example, the word used for the “surname” is Azerbaijani language is “soyadi”. When OCR reads the characters of “soyadi” as ‘s’, ‘o’, ‘y’, ‘a’, ‘d’, ‘i’. These characters resemble English letters of ‘s’, ‘o’, ‘y’, ‘a’, ‘d’, ‘i’. Because of this issue, accuracy of the programmed OCR algorithm is not as much as expected. But, while using an English typed scanned documents, the accuracy reaches up to 96% even in low-brightness.
To measure the performance of the OCR algorithm, characters (Azerbaijan and English) present in the passport is manually counted and compared with Optical Character Recognition derived results. The accuracy of the OCR system is 93%. The major factors that are considered to measure the performance of accuracy are, correctly recognized English character (CRE), wrongly recognized English character (WRE), correctly recognized Azerbaijan character (CRA), wrongly recognized Azerbaijan character (WRA). Table. 1 represents the accuracy level of the OCR algorithm.
Accuracy of OCR Algorithm
Accuracy of OCR Algorithm
Since the CNN model is not programmed to understand the Azerbaijan language, the count of wrongly recognized Azerbaijan character is high. This can be further improved by training the CNN machine learning model with Azerbaijani language.
In this work, the ORB algorithm is used to increase the speed of the feature detection in the passport. So the time taken to perform feature detection for image, seals, and holograms are compared with the existing well known techniques called SIFT and SURF. Table 2 represents the time taken to perform feature detection using various algorithms.
Time taken to perform feature detection
Time taken to perform feature detection
The performance of the CNN algorithm in finding out the forgery document is measured by calculating accuracy, sensitivity and specificity of (i) accuracy of test forgery detection (ii) accuracy of seal, sstamp (ii) accuracy of Hologram.
To measure the accuracy of the proposed CNN methods, four major factors are considered such as true positive (TP), true negative (TN), false negative (FN) and false positive (FP). The true positive is the value where the detection of forgery is true as the counterfeit is made to the document, the true negative is the case where there will be no counterfeiting but the predicted result is forged document. The false positive is the case where the document is counterfeited, but the prediction system finds it and the false negative is the case where the document is counterfeit and it is not detected. The efficiency of the system can be found by estimating the accuracy (A), sensitivity (S) and the specificity (F) as,
The performance measure of the text forgery detection in a scanned document using Convolution Neural Network is shown is derived and compared with existing model (Maryam et al. [16] and Tsai et al. [17]) in Fig. 6.
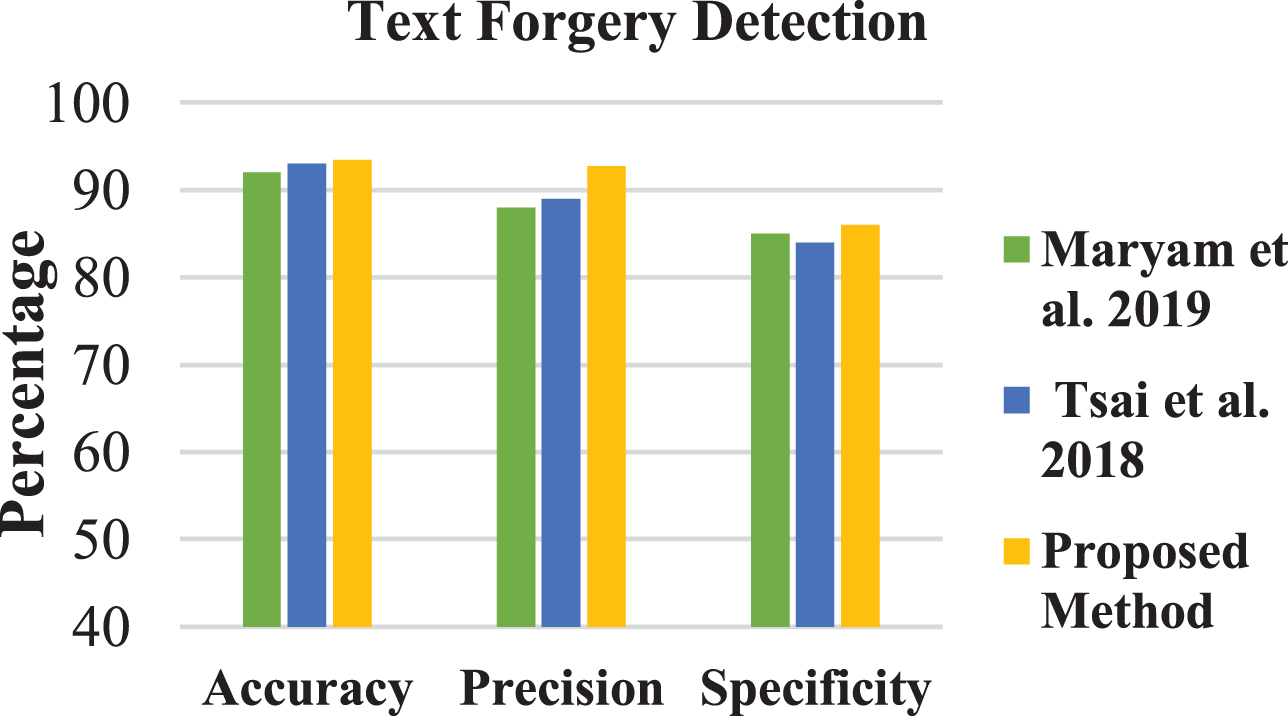
Performance of the proposed text forgery detection.
Likewise, the performance metric of seal and stamp and hologram is shown in Fig. 7(a) and Fig. 7(b) respectively. In Fig. 7(a) the performance of the stamp/seal forgery detection is compared with Salloum et al. [24] and Su et al. [25] and in Fig. 7(b) the performance of the hologram forgery detection method is compared with Mayor et al. [26] and Souk et al. [27]. The efficiency of the proposed model is derived and compared with two other existing models.

(a) Performance of the proposed image forgery detection. (b) Performance of the proposed CNN based Hologram forgery detection.
From the Fig. 6, Fig. 7(a) and 7(b), the proposed CNN model performs well against textual and image (seal and stamp) forgeries compared to the existing model. The accuracy, precision and specificity of proposed CCN based forgery document detection model on detecting textual forgeries are 93.5 %, 92.8% and 86% respectively. Likewise, for image forgery (stamp and seal) detection, the accuracy, precision and specificity are 97%, 92.8% and 90.5%. But, while considering the hologram forgery detection in the scanned document, the performance of the proposed CNN method is comparatively very less.
Because, in physical document holograms will give a visual effect of 3-dimensional image where as in a scanned document, the quality of the hologram will get reduced. So attaining maximum accuracy on hologram forgeries is still an emerging research work. In our proposed method, accuracy of the hologram forgery detection lies between 70 to 76 percentages for various hologram dataset.
In this research work, a forgery document detection method is developed using Convolution Neural Network (CNN). The main objective of the proposed forgery detection system is to analyze all the possibilities of forgeries in a scanned document. The proposed method uses an Optimal Character Recognition (OCR) technique and Local Binary Pattern (LBP) algorithm to extract the textual information from the scanned documents and uses ORB (Oriented fast and Rotated Brief) technique to extract the non-textual images (Hologram, seal, and stamps) from the document. To train the CNN model, MIDV-500 dataset of 256 Azerbaijani passport images, each with the size of 1040*744 pixels is chosen. The experimental analysis is shows that the results derived from the CNN based forgery document detection methods are promising. The accuracy of textual forgery detection, image forgery detection and hologram forgery detection are 93.5%, 97%, 76% respectively. Moreover, the time taken for detecting the important features (image) in the document using OBR technique is reduced by 20% because of using BRIEF feature detection algorithm.
Footnotes
Acknowledgments
This research work is financially supported by Science and Engineering Research Board (DST-SERB), Department of Science and Technology, Government of India under the grant number ECR/2016/000546.