
Abstract
In education, it is crucial to comprehensively evaluate the physical fitness of students. The limitations of information processing and analysis efficiency make it difficult for traditional evaluation methods to reveal deep physical correlation patterns. Given this, this study will focus on innovative evaluation methods that combine frequent pattern growth algorithms. An Apriori association rule model based on transaction compression and hash optimization is proposed to address association classification between physical fitness indicators. Moreover, this study optimizes operational efficiency through preprocessing techniques and hash acceleration strategies. It introduces enhancement parameters to accurately identify and establish strong association rules to achieve efficient and accurate evaluation of student physical fitness. The results showed that by comparing the running time of K-means + FP-growth and improved FP-growth under different support levels, the improved FP-growth tended to stabilize after a support level of 0.2%. The optimized model improved the execution efficiency by 82.87%–88.4% compared to Apriori and FP-growth in physical measurement data processing. The effectiveness and reliability of the improved algorithm were verified by measuring strong association rules with the introduction of enhancement degree. This study is expected to better understand the physical fitness status of students, and provide new ideas for educational decision-making and practice, which has profound practical significance for promoting innovation in physical fitness assessment methods.
Introduction
In the current field of education, student physical fitness assessment (SPFA) has become a core link in measuring and promoting the physical and mental health (P-MH) development of adolescents. The comprehensive implementation of the “Healthy China 2030” strategy and the deepening of quality education in China have put forward higher requirements for the physical and healthy development of students.1,2 Students are the future of the country, and evaluating their physical health can better understand the physical condition of contemporary students, laying a solid talent foundation for the development of the country. This is also the motivation for research. In the context of the big data era, traditional physical fitness assessment (PFA) methods are limited by their singularity and shallowness, and cannot deeply explore and accurately identify the complex factors and internal correlation patterns that affect students’ physical health. Especially when faced with student physical fitness (SPF) data that includes multiple dimensions such as strength, endurance, and flexibility, effectively extracting key information and conducting in-depth analysis has become an urgent issue to be addressed. Currently, the cross-integration of education and information technology has brought new opportunities to solve this problem. Data mining technology (DMT), as an important tool in modern data analysis, especially frequent itemset (FIS) mining techniques represented by frequent pattern growth (FP-growth) algorithms, has attracted attention due to its efficient ability to process large-scale data.3,4 However, in the specific application of SPFA, the algorithm has not been fully developed and optimized. It has certain limitations in processing high-dimensional and nonlinear data, such as redundant rule mining and excessive memory usage. 5 Based on the industry background and development status, this paper aims to explore the innovative integration of FP-growth algorithm into the SPFA system. By improving algorithms and optimizing data processing procedures, an evaluation model has been constructed that can reveal potential patterns in students’ physical health and meet the needs of refined management. This study combines the latest developments in various fields to address the shortcomings of traditional evaluation methods and provide new theoretical basis and technical support for improving the scientificity, accuracy, and practicality of SPFA. The innovation of this study lies in the introduction of improvement progress to measure strong association rules (SAR), emphasizing the effectiveness of the improved algorithm in association rule mining (ARM).
This article is divided into five sections. The “Introduction” section introduces the research background, problems, and solutions of SPFA. The “Related works” section reviewed the research results of SPFA and summarized the difficulties and shortcomings of the methods. The “Building an SPFA model integrating FP-growth algorithm” section introduces the optimization design method of the SPFA model with integrated FP growth algorithm. The “Performance verification of SPFA model integrating FP-growth algorithm” section designed performance verification experiments to validate the effectiveness of the proposed FP growth model in SPFA analysis. The “Conclusion” section summarizes the research methods, analyzes the experimental results, and points out the shortcomings and prospects of the methods.
Related works
The theory and practice of SPFA have always been a focus of attention in education, sports science, and health. Many studies have emphasized that physical fitness is an essential indicator for measuring the P-MH status of adolescents. Traditional evaluation methods are often limited to the analysis of a single dimension or static data, making it difficult to fully reveal the complex factors and dynamic changes that affect students’ physical health. Gao et al. investigated the impact of leadership development on leadership effectiveness from four dimensions: physical, socio-emotional, spiritual, and psychological, to explore the potential benefits of leadership development in higher education organizations. This cultural change had brought positive effects, including an increase in enrollment, student retention rate, student placement rate, as well as an improvement in teacher research and academic project rankings. 6 Rahawi et al. launched the EIM Campus Program, aimed at improving healthy behavior on university campuses by promoting and guiding sports activities. The stress level significantly decreased after intervention, and there was also a statistically significant improvement in sleep quality. Although the overall physical activity time has improved, it has not reached a statistically significant level. 7 Amer et al. conducted a cross-sectional survey of 617 Indian university students aged between 18 and 30, aiming to investigate the association and interaction between physical activity and sleep quality on the mental health of university students. The level of physical activity was significantly negatively correlated with anxiety and depression scores, while poor sleep quality is significantly positively correlated. 8 Hirotaka et al. evaluated 138 healthy elementary school students using physical fitness tests and academic achievement tests, aiming to explore the relationship between physical fitness and academic performance of students in grades three to six of elementary school. There was a significant correlation between physical assessment scores and grades. The correlation was low, suggesting that this relationship may be influenced by time changes. 9
The FP-growth algorithm, as an effective tool for data mining, is specifically designed to find FISs in large-scale datasets. The frequent pattern tree (FP-tree) facilitates the mining of FISs, circumvents the intricacies of multiple scans of the dataset, and thus enhances efficiency. Yong et al. used the FP-growth to mine strong correlation factors that affect electricity demand, and applied the Generalized Regression Neural Network (GRNN) algorithm to achieve electricity demand prediction, aiming to lift the performance of electricity knowledge text mining. By setting the mini-support and smoothing factor of GRNN reasonably, good performance in power text mining could be achieved. 10 Wang et al. designed a split-based parallel FP-growth aimed at addressing the challenges faced by student course data analysis in universities in terms of storage capacity and computing power. The association rules between course grades obtained from this provided useful suggestions for the learning methods of students and the teaching methods of teachers. 11 Zhang et al. proposed a parallel mining algorithm aimed at solving the problem of FP-tree being stored in independent memory. In this way, the algorithm did not need to generate FP-tree for the transaction database, thus solving the problem of independent memory storage. 12 Li et al. proposed an improved FP-growth algorithm that adds a new tail attribute to the existing frequent item header table, thereby accelerating the construction process of FP-tree. The target was to investigate the collection, integration, and analysis process of tire quality data by analyzing abnormal quality issues during tire manufacturing. This improved FP-growth could effectively improve the efficiency of correlation analysis for tire quality anomaly data. 13
Scholars have proposed various improvement methods for Natural Language Processing (NLP) tasks such as automatic text summarization and deep learning analysis to enhance processing efficiency and result quality. Kirmani et al. proposed an automatic mixed text summarization technique to address the challenge of quickly extracting core content from massive amounts of text information. This method combined the advantages of extraction and abstract summarization, retaining key sentences in the text while generating simplified expressions through natural language. The results showed that this method outperformed single type summarization in multiple evaluation metrics and could more efficiently convey the main points of the original text. 14 The current automatic text summarization lacked abstraction ability. Mohd et al. proposed a hybrid summary generation method that combines NLP features, sorting algorithms, and WordNet. This method first sorted and selected key content from text sentences based on multiple features. Subsequently, a word replacement strategy was introduced to convert some vocabulary into simplified expressions, thereby enhancing the abstraction of the abstract. The results showed that this method outperformed traditional pure extraction summarization methods in information coverage and language conciseness. 15 Asudani et al. systematically reviewed various mainstream methods and their applications regarding the selection of word embeddings and deep learning models in text analysis. By comparing the performance of different models in tasks such as text classification and sentiment analysis, a strategy for selecting embedding methods and deep structures based on domain requirements was proposed. The results showed that using domain specific word vectors combined with LSTM models could significantly improve the accuracy and efficiency of text analysis tasks. 16
In summary, comprehensive quality education is increasingly receiving attention, and SPFA has become a research focus. However, traditional physical fitness tests suffer from incomplete data reflection and low processing efficiency. The FP-growth algorithm can improve data processing efficiency by constructing FP-tree. Therefore, integrating the FP-growth algorithm into SPFA is expected to comprehensively analyze data, explore underlying patterns, provide scientific support for personalized education, and promote students’ comprehensive growth.
Building an SPFA model integrating FP-growth algorithm
Construction and analysis of improved Apriori-based optimization algorithm
In recent years, socio-economic progress and changes in lifestyle have brought about prominent physical health issues among adolescents, such as obesity, myopia, and declining exercise ability. The Chinese government has raised the attention to the P-MH of young people to an unprecedented level in the “Healthy China 2030” national strategy. Therefore, scientifically and strictly implementing student PFA is a specific response to national policy requirements and a key measure to solve and improve the current physical health problems of young people.17–19 In this context, the application of DMT is particularly important. This technology utilizes diverse algorithmic tools to explore, discover, and extract potential patterns, associations, and novel insights from massive data on SPF, aiming to provide information with decision support value. The ability to predict future trends and accurately identify the complex interactions and inherent laws between SPF is of significant benefit. Through such data analysis, it is possible to more effectively understand and optimize the physical development status of adolescents. Figure 1 shows the process of data mining. Flow chart of data mining for student physical fitness assessment.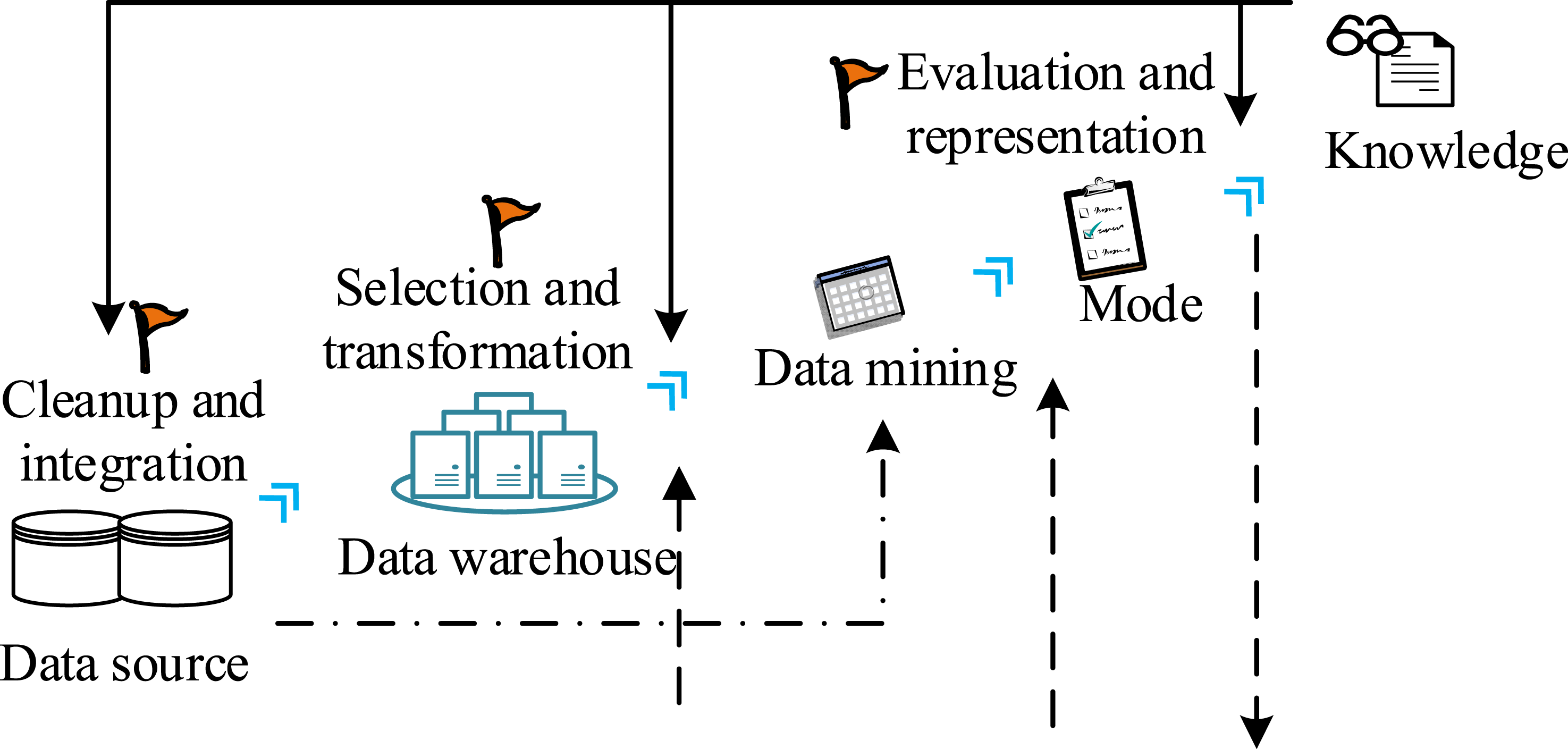
In Figure 1, data mining is a systematic process that includes stages such as data collection and preprocessing, feature selection and transformation, model establishment and evaluation.
20
First, the multidimensional physical fitness test data are collected from students and the data quality and consistency during the preprocessing stage are ensured. Next, DMT (such as association analysis, cluster analysis, and regression analysis) is used to reveal the relationships between physical fitness indicators and the physical characteristics of different groups from massive data. Based on these insights, a scientific SPFA model is constructed. This model can accurately evaluate the current physical health status of individual students and predict their development trends. This provides personalized teaching plans and health management recommendations for educational decision-makers, effectively improving the overall physical health level of adolescents. Figure 2 shows the process of data preprocessing after collecting multidimensional physical fitness test data from students. The data preprocessing process after collecting multi-dimensional physical fitness test data from students.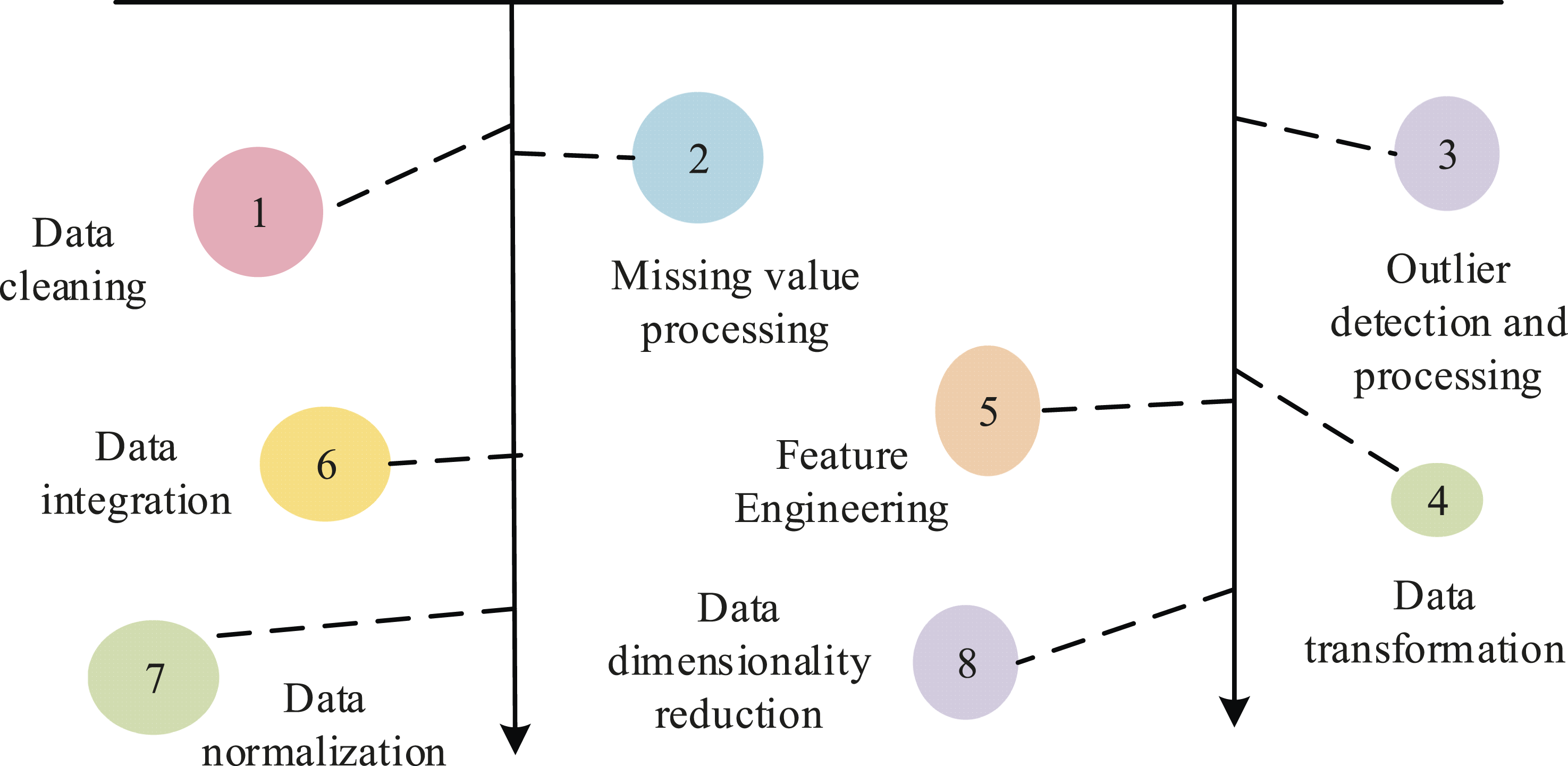
In Figure 2, data preprocessing covers key operations such as data cleaning, missing value handling, outlier detection and processing, data transformation, feature engineering, data integration, data normalization, and data dimensionality reduction.
21
ARM occupies a vital position in the construction of the SPFA model. By calculating the support between different physical fitness indicators, potential associations and patterns between various dimensions of physical fitness can be discovered. Among them, support is an important indicator in ARM, which is the possibility of the quantity of transactions containing both

In equation (1),
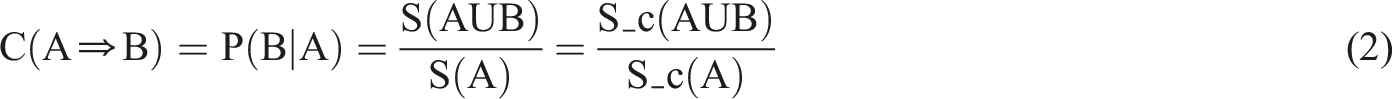
In equation (2),

In equation (3), Apriori algorithm mining frequent item set flow.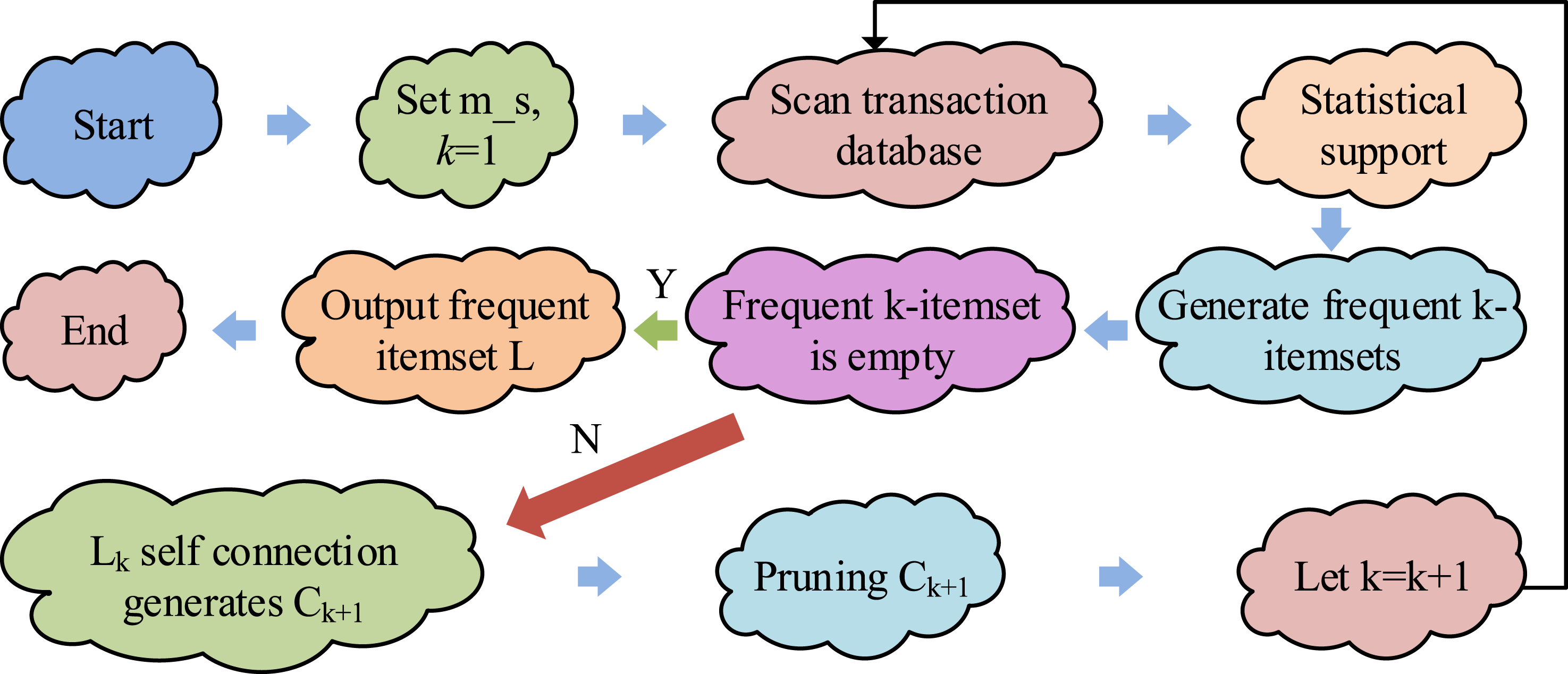
The Apriori algorithm mining process in Figure 3 typically has two main phases: first, by scanning the transaction database, the frequency of individual items is identified to generate FIS. Then, by combining FISs, iteratively to generate FISs containing more items until they cannot be regenerated into new FIS. Figure 4 shows the efficiency method flow of association rules based on improved Apriori. Optimization model construction process based on improved Apriori association rule efficiency.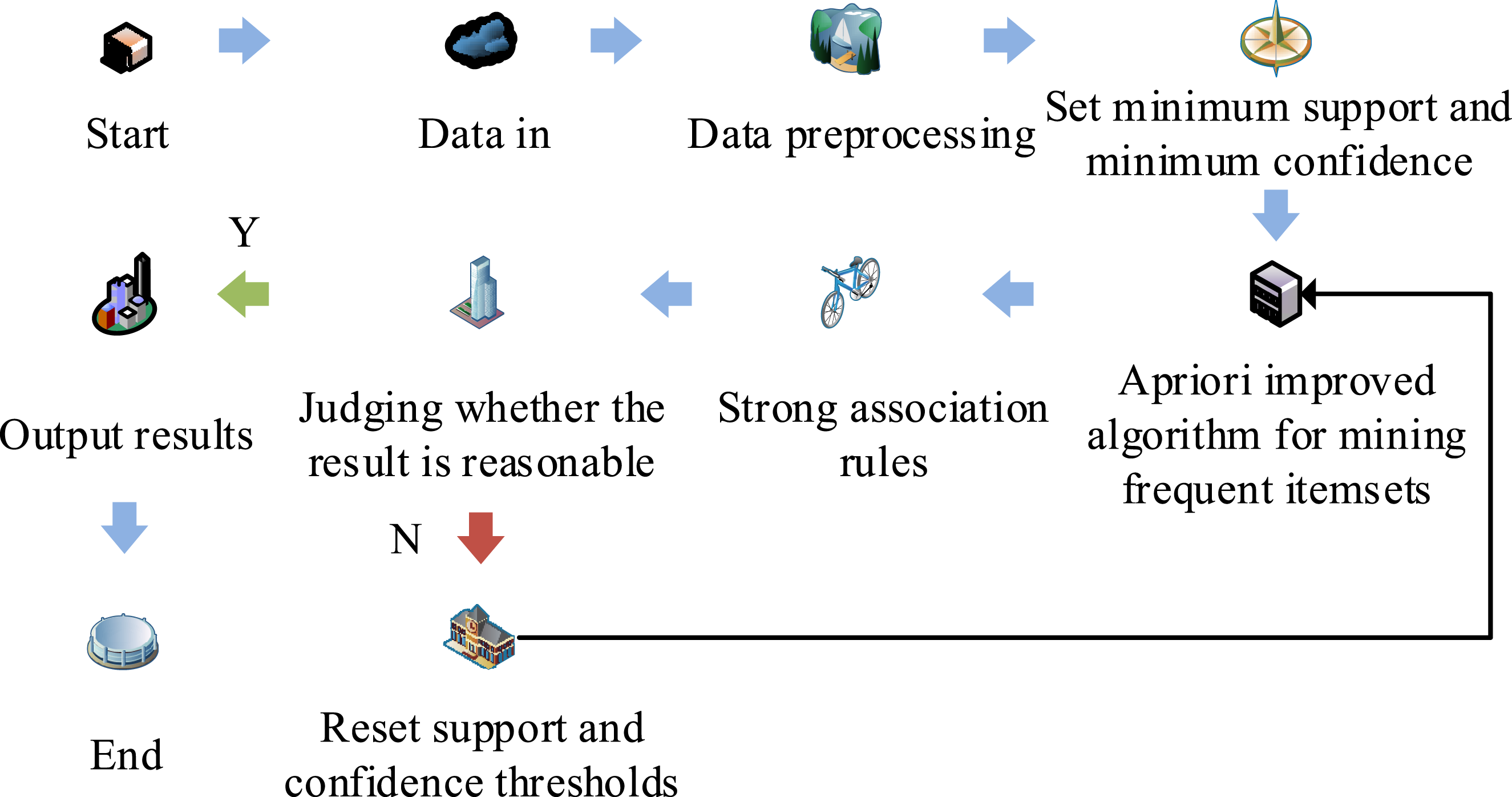
In Figure 4, the first step is to extract data from a physical testing center of a certain school, preprocess it, and present it in a form suitable for association rule algorithm processing. Next, the improved Apriori is used to mine the correlation of sports data. This process generates a large number of association rules that describe the relationship between physical fitness indicators. Under the support confidence framework, these rules are filtered to identify association rules with practical significance.
Construction of an evaluation efficiency optimization model based on improved FP-growth
When using the Apriori under the support confidence framework to explore the association rules between SPF and other possible influencing factors, this method may have the problem of redundant mining results. In view of this, this study further utilizes quantitative analysis methods and adopts the optimized FP-growth to deepen the potential relationship between student physical health and multiple background variables. The FP-growth establishes an FP-tree structure to quickly and effectively identify frequent patterns in large-scale datasets, thereby assisting research in gaining a deeper understanding of the complex social factors and their interaction mechanisms that affect student physical health. Figure 5 shows the process of FP-growth mining FIS. The FP-growth mining frequent itemset process.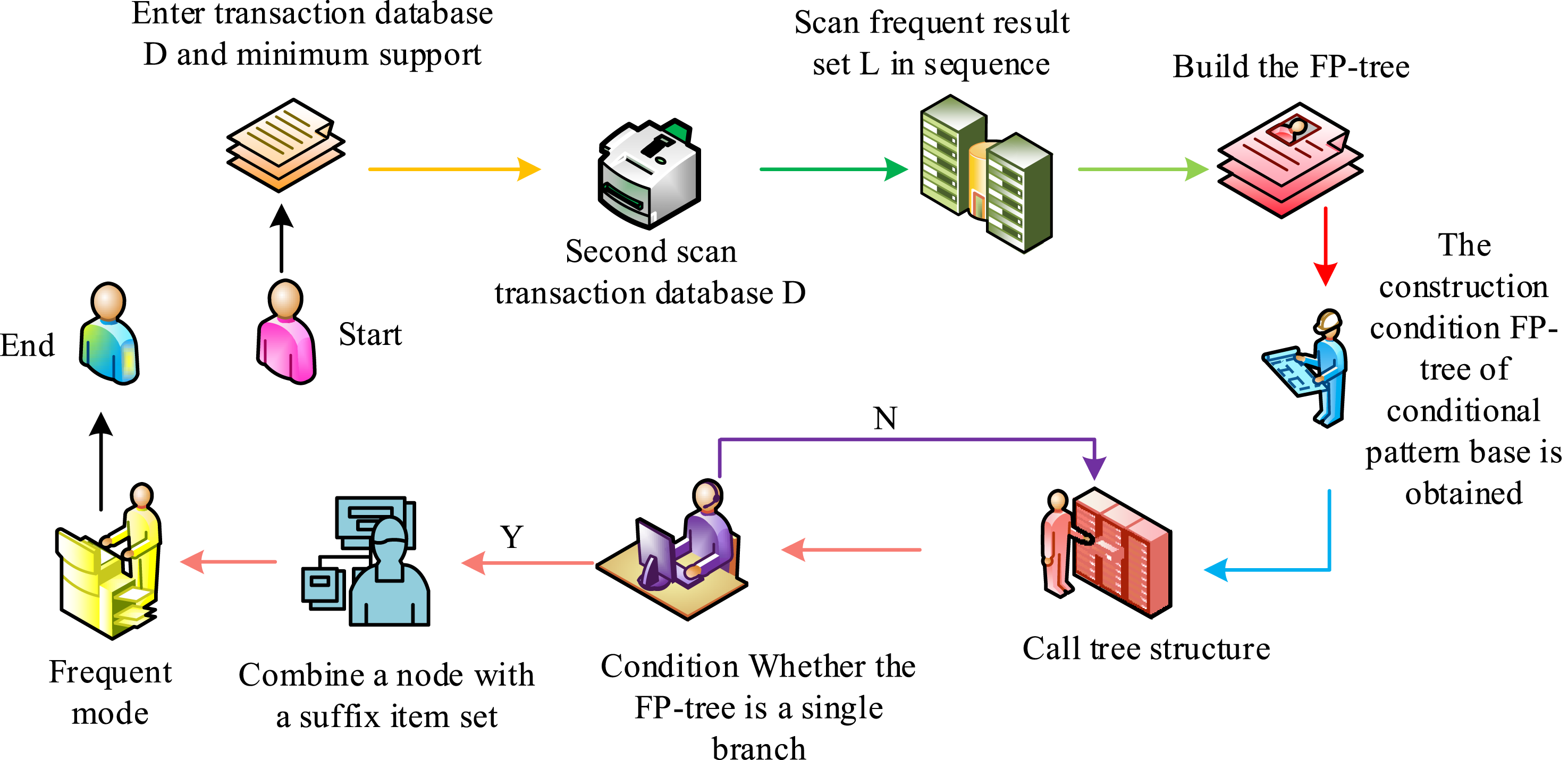
In Figure 5, the FP-growth algorithm first constructs an FP-tree by scanning the transaction dataset through a single pass. Nodes represent different project items, while edges reflect the inclusion relationships of different items in transaction records.25–27 During this process, the algorithm maintains a double linked list header structure in parallel to efficiently locate frequently occurring items. After completing the FP-tree construction, the algorithm will generate a corresponding conditional pattern library for each frequent item registered in the head table, and recursively establish a conditional FP-tree, gradually revealing all FISs. The pseudo-code for the FP-tree construction process is shown in Figure 6. Pseudo-code for FP-tree construction process.
Figure 6 shows the pseudo-code of the FP-tree construction process in the FP-growth algorithm. However, when dealing with extremely large datasets, the original FP-growth algorithm may significantly increase memory consumption due to the need to fully construct the FP-tree structure. Meanwhile, in highly repetitive FIS scenarios, the process of repeatedly constructing conditional FP-trees for each frequent item may become a computational bottleneck, thereby affecting overall efficiency. Therefore, this study further improves the FP-growth and proposes an FIS mining algorithm built on hash for FP-growth. Figure 7 shows the flowchart for constructing an improved FP-growth algorithm model. Improved FP-growth algorithm model construction process.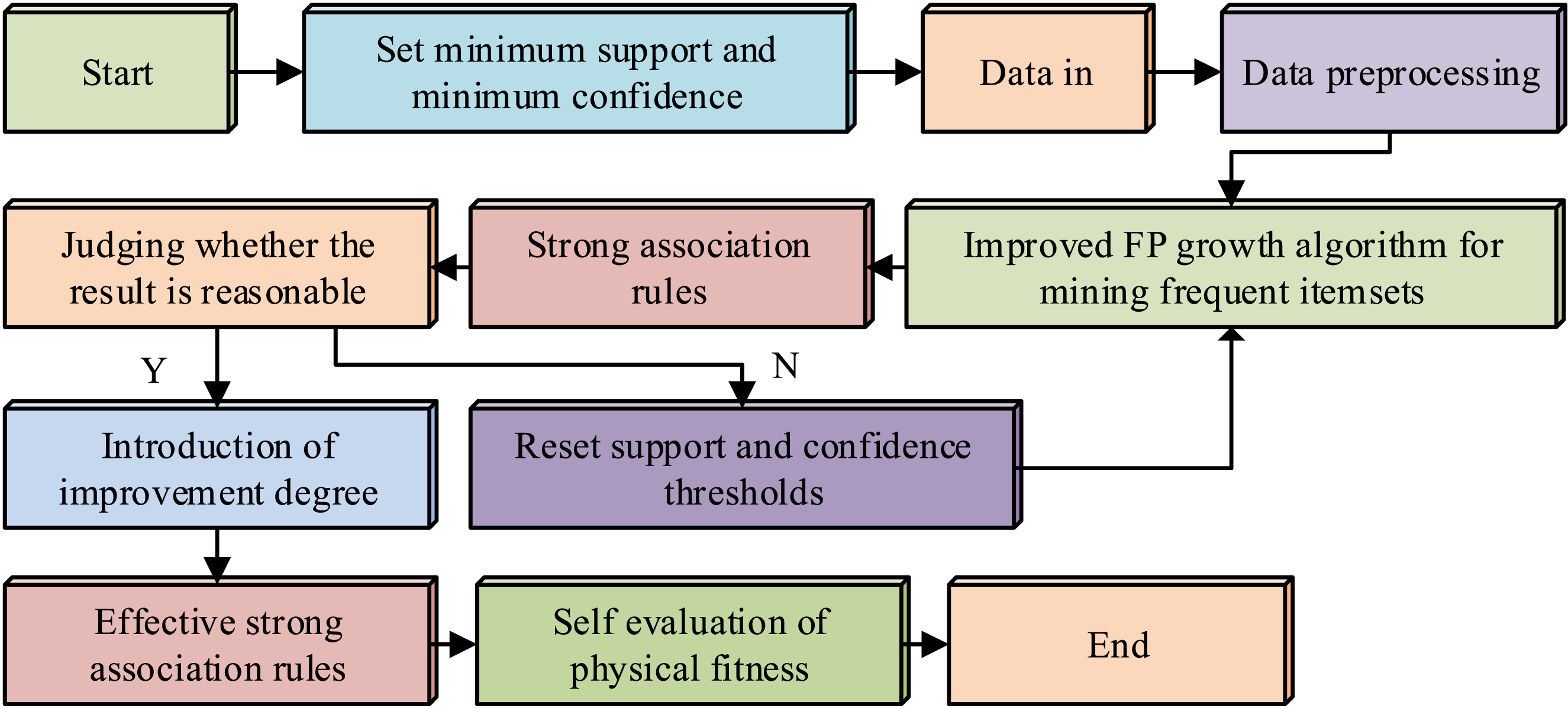
In Figure 7, the minimum support and confidence are first determined to ensure the discovery of meaningful association rules. The data are converted into a format that is available to the FP-growth, and then the algorithm is used to efficiently mine frequent patterns.28,29 On this basis, rules that do not meet the minimum confidence level are eliminated, resulting in SAR.
30
The results are analyzed and the parameters are adjusted. If the rules are too few or redundant, they need to be re-mined. Finally, the association rules are evaluated to ensure the provision of information with practical application significance. After optimizing the core association rule algorithm, to further improve the feature extraction efficiency of physical fitness data, attention mechanism and object detection related technologies are introduced from the model architecture level to construct a more complete evaluation system. This study makes improvements on SENet and further utilizes the ECANet module. The difference between ECANet and SENet modules is that they remove the fully connected layer and use 1D convolution to improve feature fusion efficiency. The size of the convolution kernel is determined by an adaptive function to ensure multi-channel interaction.31–33 The convolutional kernel size adaptive function is shown in equation (4)

In equation (4), Structure of ECA’s mechanism.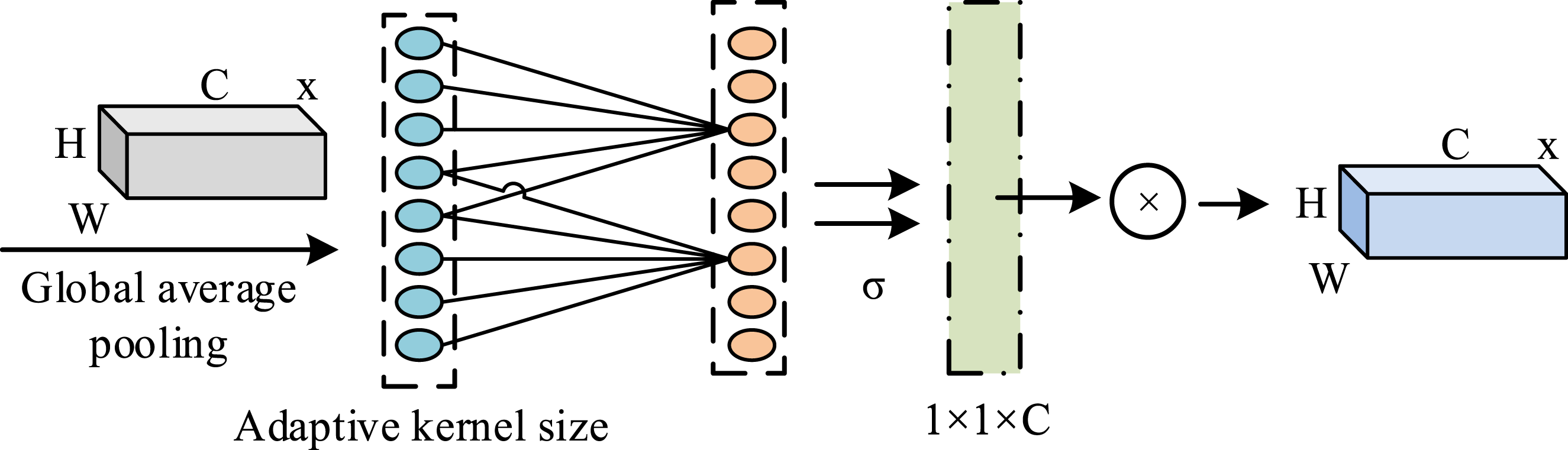
In Figure 8, the structure diagram of the ECA mechanism mainly includes three parts. First, the input feature map is pooled through global average pooling to obtain the global feature vector. Next, 1D convolution is used to perform feature interaction on the global feature vectors, and finally normalized attention weights are obtained through activation functions. These weights are used to weight feature maps, enhance useful information, and suppress unimportant information. The target classification network receives the feature map regions output by the region of interest pooling network and classifies and locates the targets within them. The process expression of its convolution operation is shown in equation (5)

In equation (5),

The four variables

In equation (7),

In equation (8),

In equation (9),
Performance verification of SPFA model integrating FP-growth algorithm
This section tested and analyzed the improved FP-growth’s performance, mainly analyzing the performance of different methods under different support levels. This study conducted performance validation experiments on the research method in terms of execution efficiency, data preprocessing results, SAR results, and other aspects.
Performance verification of ARO model based on improved Apriori
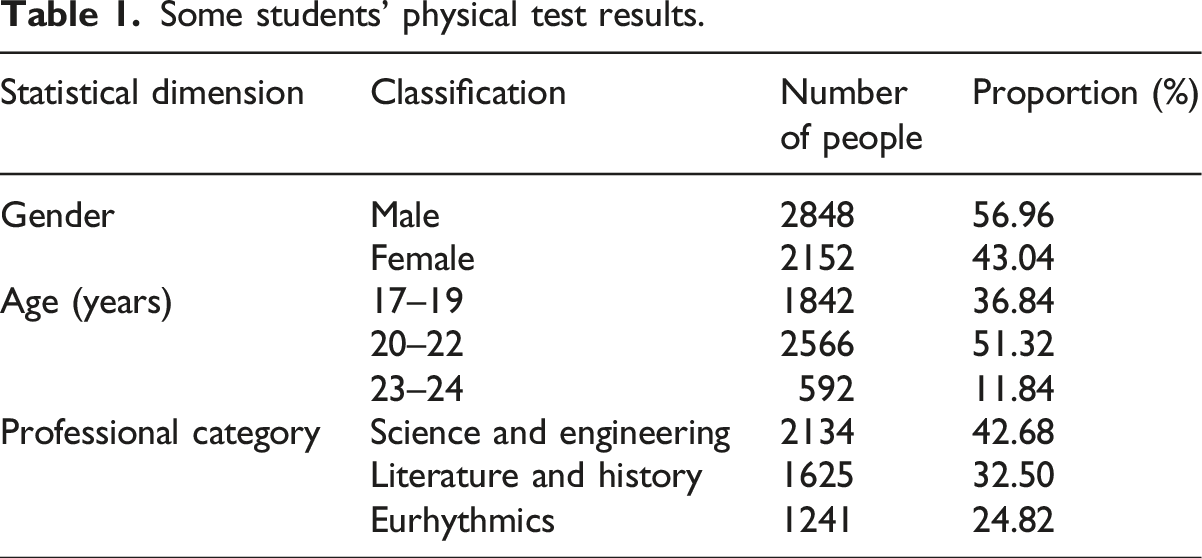
Some students’ physical test results.
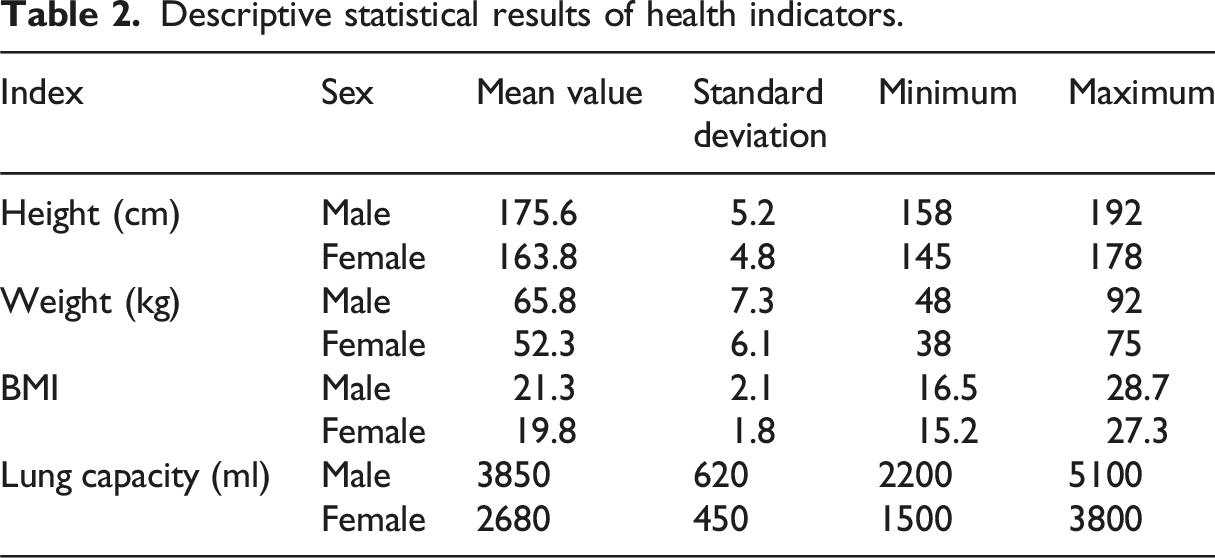
Descriptive statistical results of health indicators.
Some students’ physical test results.
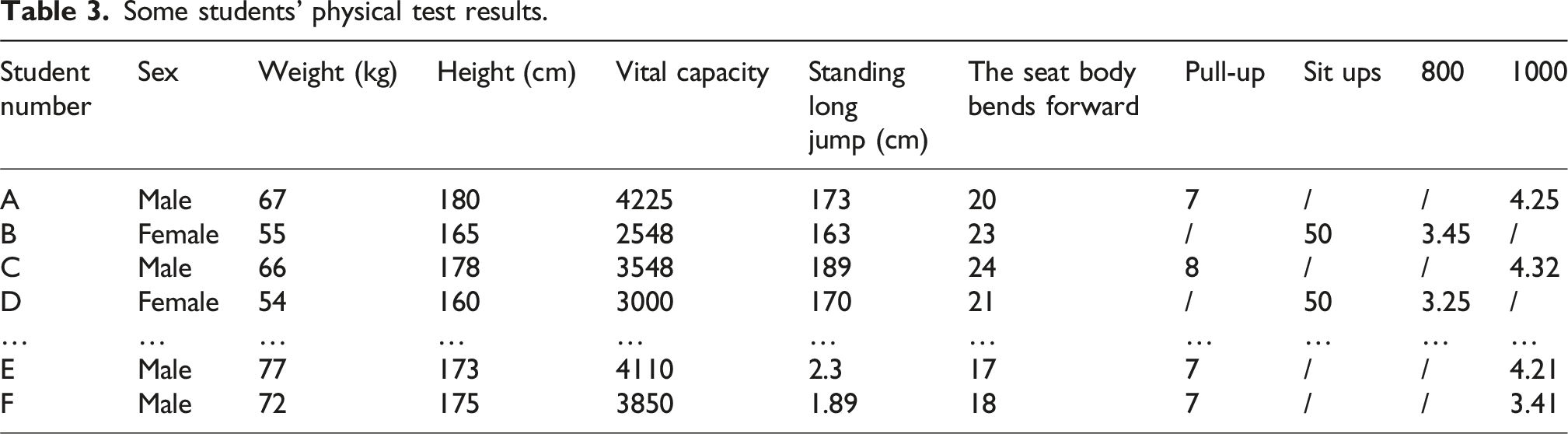
In Table 3, the student registration number served as the primary key, including gender, height, weight, lung capacity, 50 m, standing long jump, sitting forward bending, 800 m (female), 1000 m (male), pull-up (male), and sit ups (female) attributes. Due to gender differences, the corresponding testing items also varied. Therefore, the physical measurement data about gender were extracted separately. This study analyzed the Apriori algorithm, transaction compression-based Apriori algorithm (TC-A), hash-based Apriori algorithm (H-A), and Apriori combining transaction compression and hash (TC + H-A) under five support thresholds (STs) of 0.01, 0.1, 0.2, 0.3, and 0.4. The efficiency comparison chart under different support levels is shown in Figure 9. Efficiency comparison diagram under different support degrees.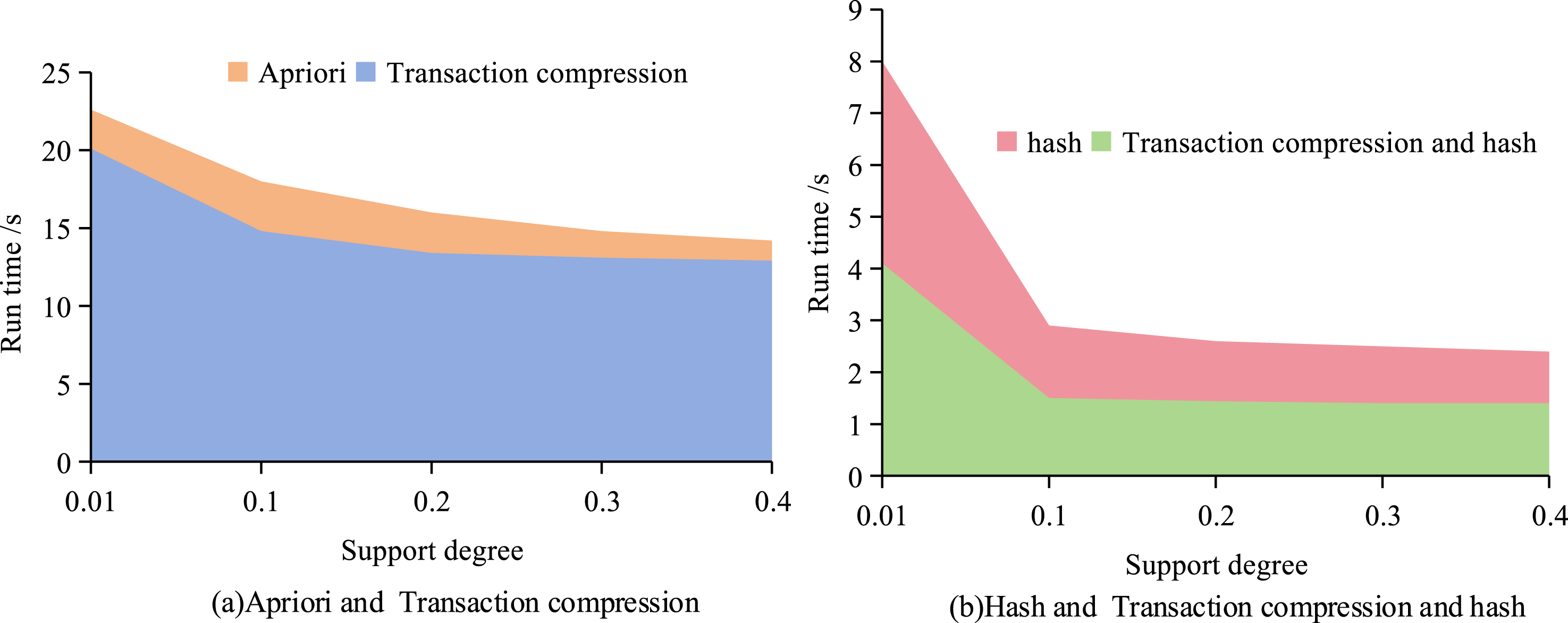
According to Figure 9(a), as the ST increased, the Apriori algorithm and TC-A gradually approached each other in terms of running time. Although the gap between the two gradually decreased, TC-A slightly led in efficiency. In Figure 9(b), the improved TC + H-A algorithm performed better, especially in association rule analysis. When the threshold was 0.01, 0.1, and 0.2, excessive association rules might lead to redundancy. When the threshold was 0.4, there were fewer rules, but important information might be missed. Considering the number of rules and the effectiveness of information, 0.3 was chosen as the optimal ST. With a ST of 0.3, ten different confidence thresholds (CTs) (0.1–0.95) were used to validate the Apriori algorithm, TC-A, H-A, and an improved algorithm of TC + H-A, respectively. The result of running time is shown in Figure 10. Efficiency comparison diagram under different confidence levels.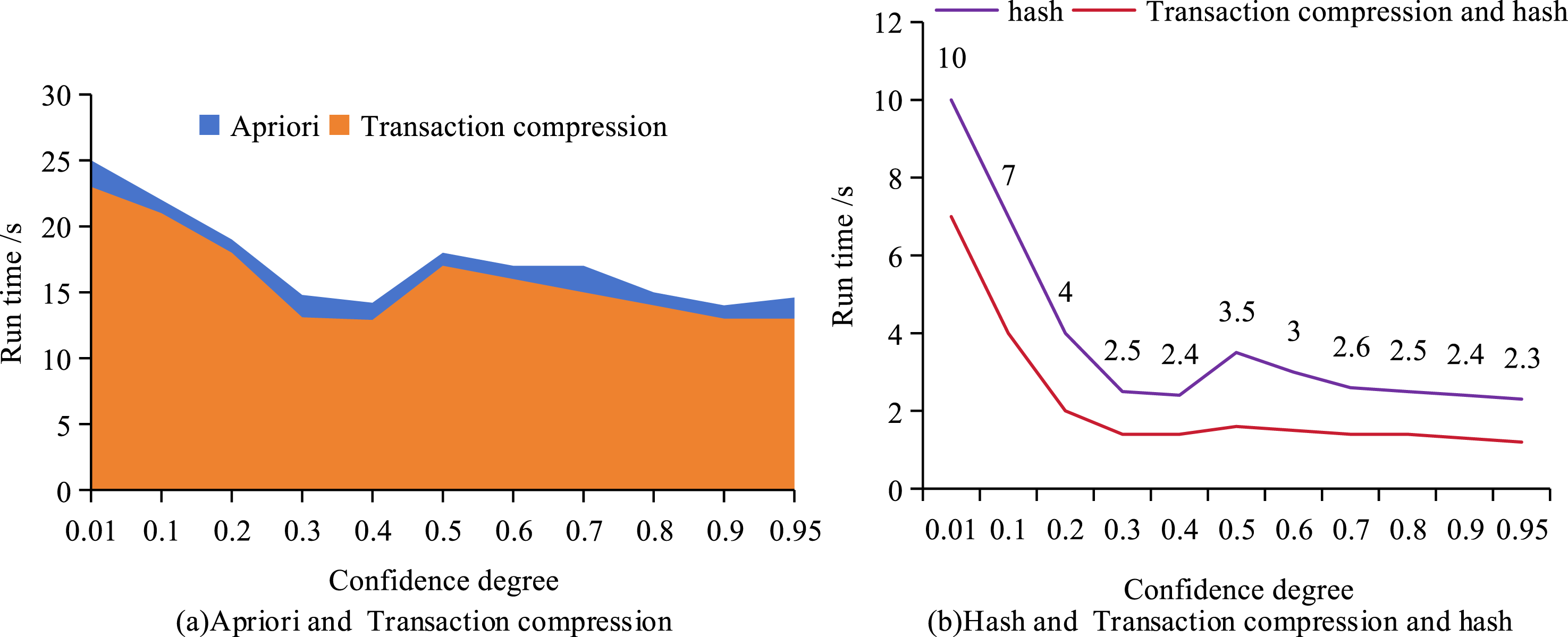
In Figure 10(a), as the CT increased, the running times of Apriori and TC-A gradually converged, with TC-A being slightly more efficient. In Figure 10(b), H-A performed better than Apriori and TC-A. TC + H-A achieved better results, significantly faster than the other three algorithms. Too many redundant rules might be generated when the CT was 0.1–0.8, while there were fewer rules when the CT was 0.95. When the confidence level was 0.9, the generated rules covered the correlation of various indicators and had a significant impact on the key indicators of physical fitness. Therefore, this study chose 0.9 as the optimal CT. This study further utilized these four algorithms for ARM. The specific results of comparing execution efficiency time are shown in Figure 11. Comparison of execution efficiency of four algorithms (unit: second).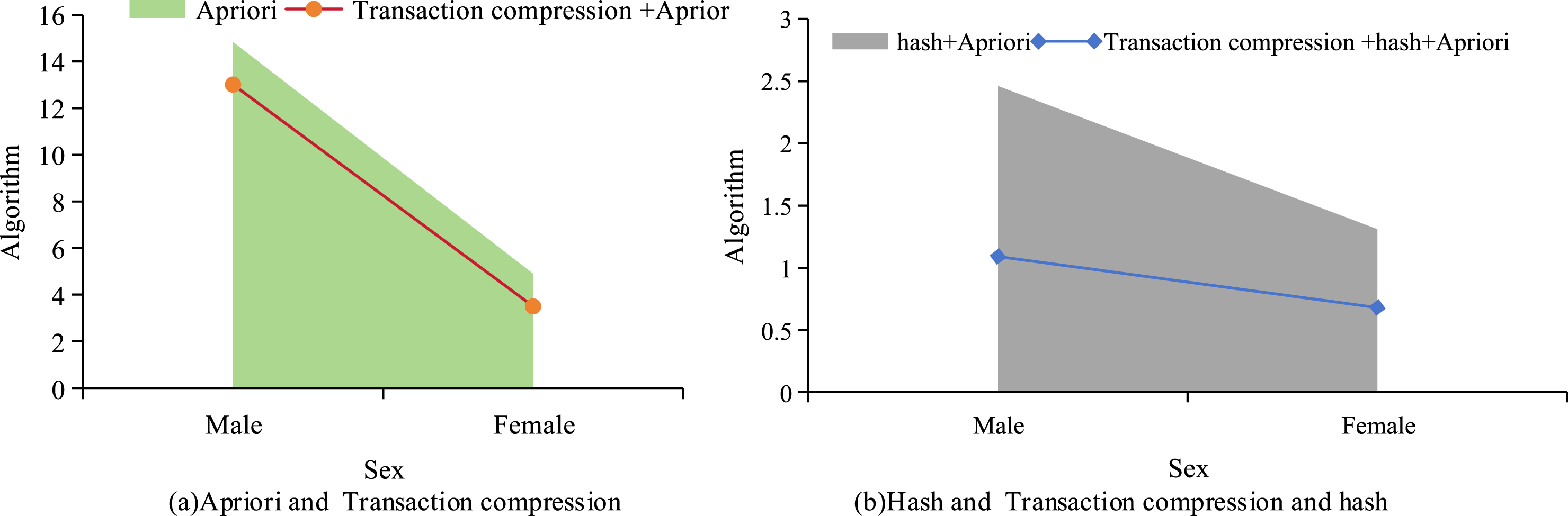
The comparison between Figures 11(a) and (b) showed that the proposed TC + H-A algorithm had better execution efficiency. Compared to the classic Apriori, the execution efficiency of physical measurement data for girls had increased by 86%, and for boys it had increased by 93%. Compared to TC-A, the execution efficiency of physical testing data for girls increased by 80.57%, while for boys it increased by 89.32%. Compared to H-A, the execution efficiency of physical testing data for girls increased by 48.1%, while for boys it increased by 55.69%. This indicated that when applying these four to male-body measurement data, the execution efficiency was higher compared to female data, especially when the dataset size increased, the improvement effect was more significant.
Performance verification of SPFA model based on improved FP-growth algorithm
To further verify the performance of the evaluation efficiency optimization model based on the improved FP-growth, this study further took the physical fitness test data of undergraduate students from a certain university as the experimental object. Thirteen types of attribute data correlated to physical test scores and physical fitness were extracted from the database, including student ID, gender, height, weight, lung capacity, etc. To ensure the reliability of the results, the experiment also carried out preprocessing operations such as data cleaning, data reduction, and data conversion on the original data. The minimum confidence used was 0.3. Under different minimum support levels (0.1%, 1%, 2%, 3%, and 4%), the mining time of Apriori, FP-growth, FP-growth based on k-means improvement, and the proposed improved model were compared. The results are shown in Figure 12. Performance comparison of different support levels.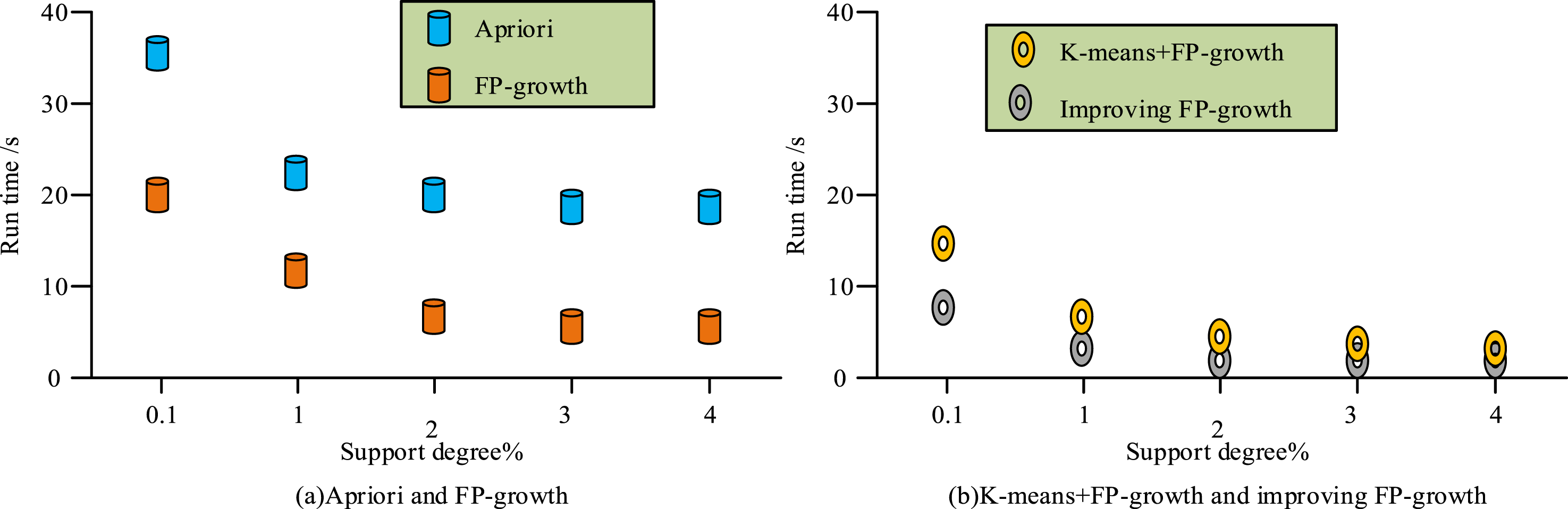
In Figure 12(a), between support levels of 0.1% and 1%, the Apriori and FP-growth methods showed a faster decrease in runtime. The Apriori method had a runtime of around 36 when the support was 0.1%. In Figure 12(b), k-means + FP-growth and improved FP-growth showed a decreasing trend in runtime with support levels between 0.1% and 2%. After a support level of 0.2%, the improved FP-growth method showed a running time of 2.4. Overall, the improved FP-growth method had relatively less runtime and exhibited superior performance. The results of comparing the running time of four models with 10 different CTs ranging from 0.1 to 0.9 with a 3% support are shown in Figure 13. Performance comparison of different confidence levels.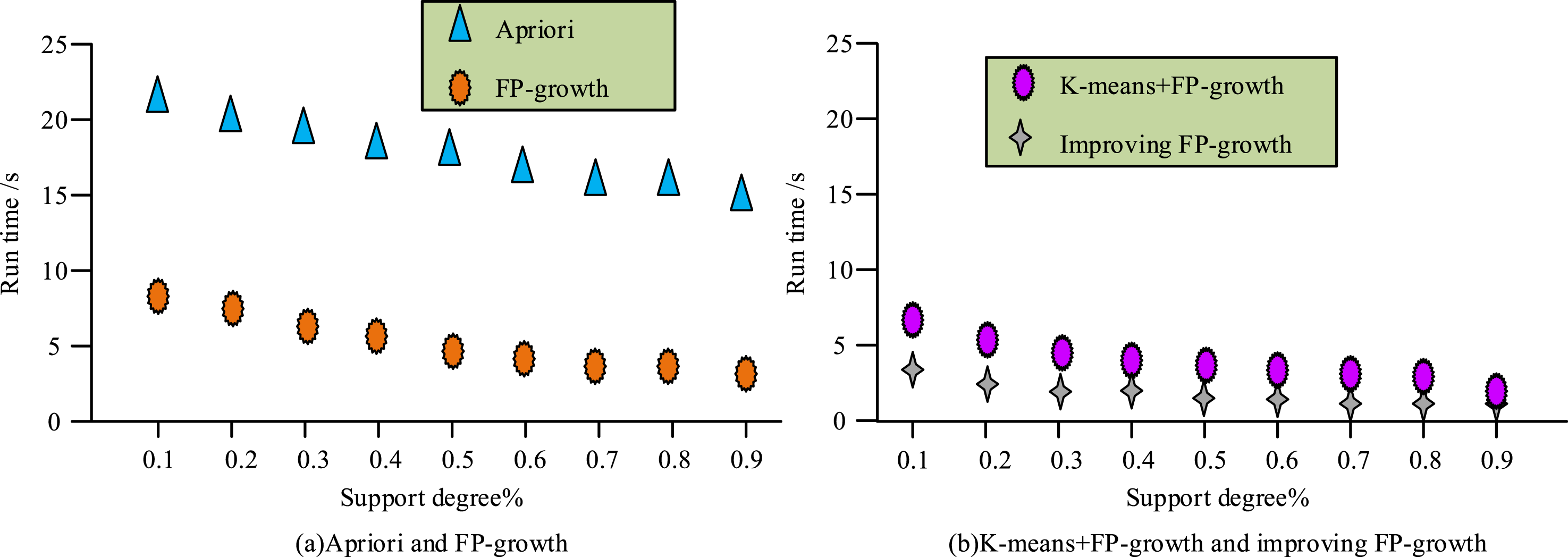
In Figure 13(a), when the support was 0.1%, the running times of Apriori and FP-growth methods were around 21 and 8.5, respectively. The overall running time of both methods showed a decreasing trend, and the Apriori method had a relatively longer running time. When the support was 0.1%, the running times of the k-means + FP-growth and improved FP-growth methods in Figure 13(b) were around 7 and 3.5, respectively. The overall running time of both showed a decreasing trend, and the improved FP-growth method had relatively less running time. Overall, the improved FP-growth method had relatively less runtime and exhibited superior performance. Due to differences in physical fitness testing between men and women, ARM was used to compare the running time of the two types of data, as displayed in Figure 14. The running time of different ARM models in male and female physical fitness data testing.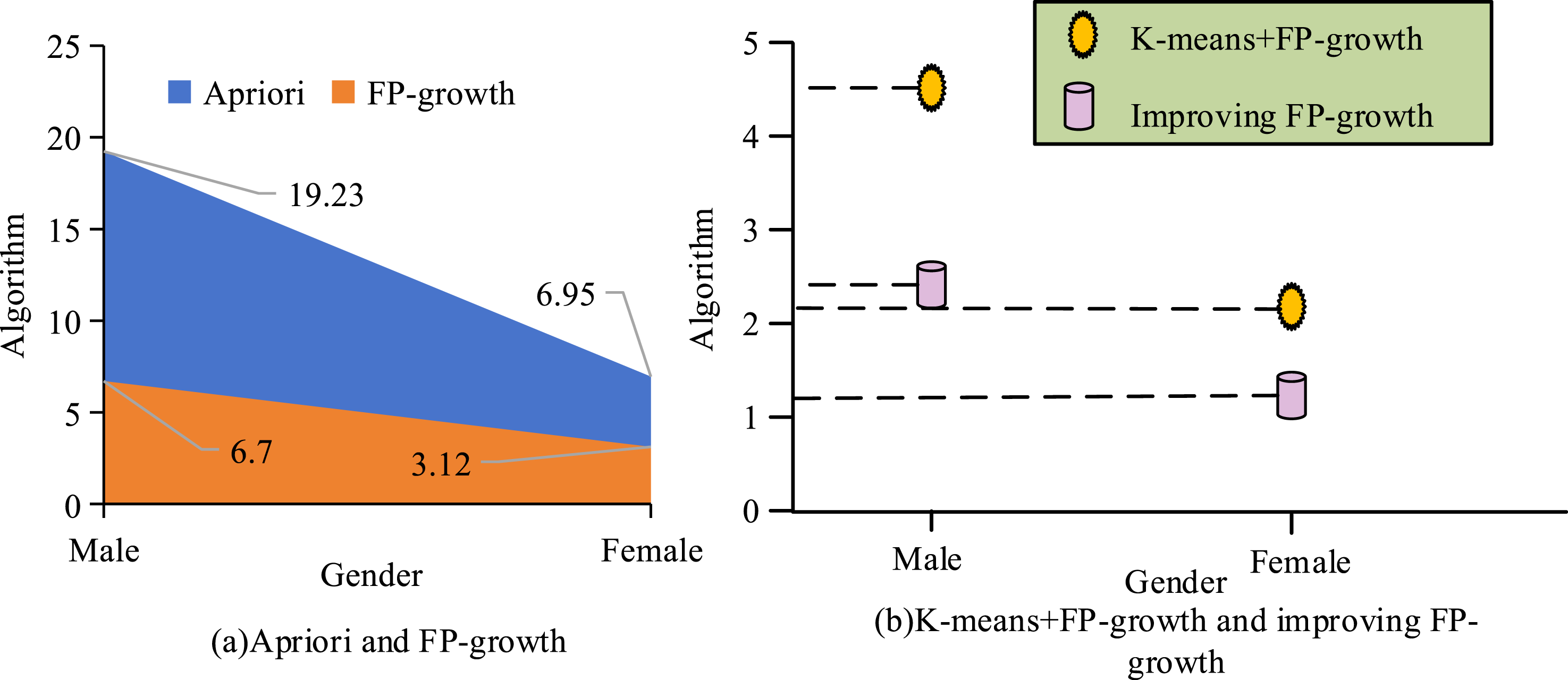
Strong association rules (girls).

Comparison of accuracy and MSE of different algorithms.
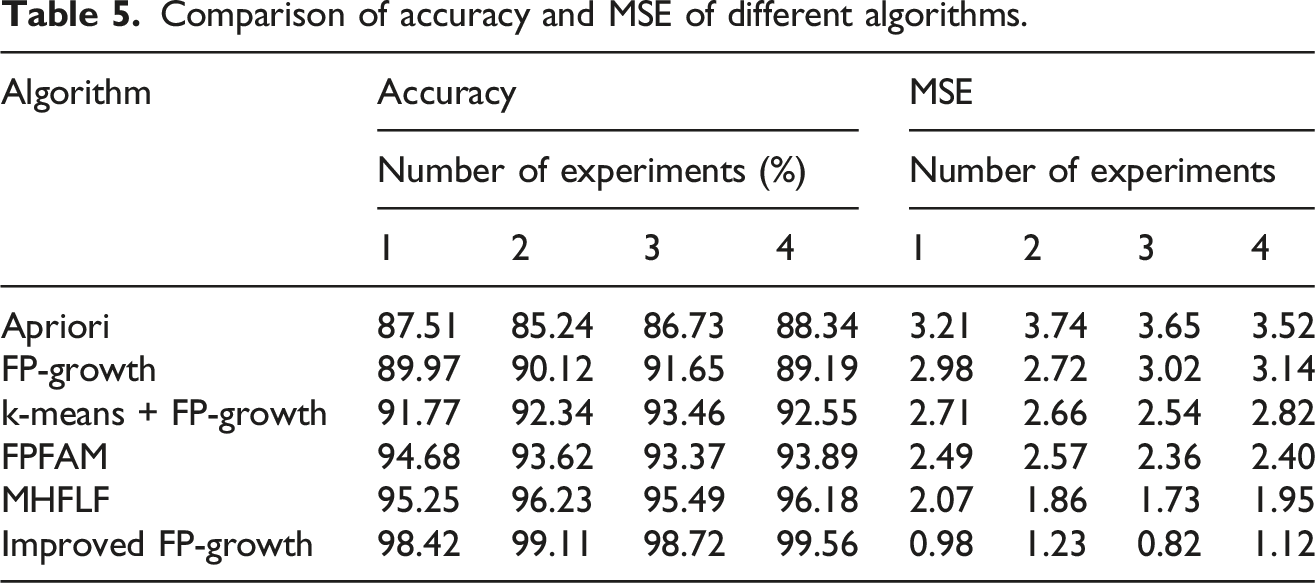
From Table 5, the maximum accuracy value was 99.56%, which appeared on the improved FP-growth algorithm, followed by MHFLF and FPFAM. The minimum accuracy of Apriori algorithm was 85.24%. The maximum and minimum values of MSE were 3.74 and 0.82, respectively, appearing in the Apriori algorithm and the improved FP-growth algorithm. This indicated that the improved FP-growth algorithm had higher accuracy, smaller errors, and better performance.
Conclusion
The widespread development of student sports activities and the increasing importance of PFA are becoming more prominent. To further explore how to integrate the FP-growth algorithm for SPFA, this study combined the FP-growth algorithm and proposed an optimized prior algorithm association rule model, which was improved using transaction compression and hashing techniques. At the same time, an evaluation efficiency optimization model based on the improved FP-growth algorithm was designed, which accelerated the algorithm’s operation and developed more accurate SAR. The results indicated that the TC + H-A algorithm performed the best when the CT was 0.9. Compared to the classic Apriori, the execution efficiency of physical testing data for females had increased by 86%, while for males it had increased by 93%. The optimized model improved the execution efficiency by 82.87%–88.4% compared to Apriori and FP-growth in body measurement data processing. The introduction of ID to measure SAR validated the effectiveness and reliability of the improved algorithm. This study contributes to the improvement of school physical education teaching plans and health management strategies, and is also beneficial for the scientific formulation and implementation of policies for the physical health development of adolescents. It reflects the positive role of the cross-integration of social science and data science and technology in promoting social progress.
However, there are potential biases and scalability challenges in the research. At the data level, the sample mainly consists of undergraduate students from universities. These samples have problems such as a single age group, uneven regional and population distribution, and only covering traditional physical measurement indicators without incorporating behavioral data, which affect the generalization of the model. At the algorithmic level, processing real-time data in the Internet of Things faces issues such as low efficiency in incremental transaction processing and significant differences in cross-age group characteristics. Future work can build an age stratified association mining framework, train models separately on datasets divided by age, and use transfer learning to achieve feature sharing and rule fusion, achieving cross-age group improvement. Meanwhile, an incremental FP-growth algorithm can be developed for real-time fitness applications, maintaining a dynamic FP-tree structure and introducing a thermal decay factor to adapt to the timeliness of data.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.