
Abstract
This study explores the dance movement recognition technology based on deep learning, and aims to improve the recognition accuracy of dance movements by constructing and evaluating deep learning models. This paper combs the basic concepts and principles of deep learning, and analyzes the latest progress of dance action recognition, its application in different scenes and the challenges it faces. Subsequently, the process of data collection, preprocessing, labeling and feature extraction is described in detail, and the role of data preprocessing and enhancement technology in improving model performance is emphatically discussed. Based on this, this paper designs a hybrid architecture combining convolutional neural network (CNN) and recurrent neural network (RNN), and the corresponding model optimization strategy, in order to achieve higher accuracy and efficiency when dealing with complex dance sequences. The experimental design part includes the process of model training, evaluation and verification, and comprehensively tests the model performance. The results show that the proposed model performs well in many dance action recognition tasks, with high accuracy and good generalization ability. This study provides a valuable reference for the development of dance movement recognition technology, and also opens up a new way for in-depth research and application in related fields.
Keywords
Introduction
With the rapid development of modern science and technology, deep learning has become a revolutionary technology in the field of data processing and pattern recognition. By learning a large number of data, this technology can identify complex patterns and relationships, thus making remarkable achievements in image recognition, voice processing and other aspects. Dance, as a comprehensive art form, involves complex body movements and expressions. With people’s attention to the artistic value of dance and the growing demand for dance teaching, performance and creation, how to accurately and efficiently identify and analyze dance movements has become a problem worth exploring. Dance motion recognition technology based on deep learning, with the help of advanced algorithms to simulate the human brain’s ability to process visual information, can automatically extract dance motion information from videos, and provide scientific and objective data support for the creation, deduction, teaching and evaluation of dance works. Therefore, the research and development of this technology is of great significance to promote the technical progress in the field of artificial intelligence, and also opens up a new way for the inheritance and innovation of dance art.
Driven by deep learning, the field of dance movement recognition has made remarkable progress. With the development of technology, researchers have gradually turned from basic motion recognition to more complex accurate recognition of dance movements and gestures, which has promoted the digital preservation and dissemination of dance art and brought new opportunities for interactive art teaching and intelligent sports analysis. Currently, specific challenges in the field of dance movement recognition include the diversity and complexity of movements, the imbalance of data sets, and the need for real-time processing. The movement differences between different dance styles are significant, and the movement changes in the same dance are also very rich, which puts forward high requirements on the generalization ability of the model. In addition, dance movement data sets often have the problem of class imbalance, with some dance categories having fewer samples, resulting in poor performance of the model on these categories. Real-time processing is another key challenge, especially in application scenarios such as interactive entertainment and teaching AIDS that require instant feedback, requiring models to process large amounts of data quickly and provide accurate recognition results. Despite these challenges, the rapid development of deep learning techniques has brought new opportunities for dance movement recognition, especially in hybrid architectures that combine convolution neural networks (CNNs) and recurrent neural networks (RNNs), showing significant advantages and potential. By further optimizing these models, combined with advanced data enhancement techniques and efficient feature extraction methods, this research is expected to make greater breakthroughs in improving recognition accuracy and processing efficiency, and provide strong support for the vitalization and intelligent development of dance art.
In recent years, dance movement recognition technology based on deep learning has made remarkable progress. Morshed et al. made a classified review of human motion recognition, emphasizing the central role of deep learning in parsing video data, and pointing out that there are extensive research opportunities in this field. 1 Dong et al. proposed a method based on attention perception sampling to improve the accuracy and efficiency of action recognition by identifying key frames in videos. 2 Yuan and Pan’s research demonstrated a dance movement recognition model based on long short-term memory (LSTM) networks, proving the advantages of deep learning in processing complex dance sequences. 3 Challapalli and Devarakonda used generative adversarial networks (GANs) for data enhancement and quantum convolutional neural networks (QCNNs) to classify Indian classical dance, demonstrating the potential application of deep learning in cultural heritage conservation. 4 Huang’s research proposed a continuous sports action recognition method based on deep learning algorithm, which verified the effectiveness and robustness of this technology in practical applications. 5 Mohammed et al. developed a hand detection and gesture recognition system based on deep learning, which showed good real-time performance and accuracy. 6 The study of Qi used Openpose and LSTM network to explore the interaction and psychological characteristics in art teaching, providing new technical support for art education. 7 Kulbacki et al. reviewed the latest knowledge of intelligent video analysis in human motion recognition and emphasized the importance and effectiveness of deep learning technology in understanding the complexity of human motion. 8 These studies together describe the wide application and research prospect of deep learning in the field of dance movement recognition.
Deep learning technology has made remarkable progress in the field of dance movement recognition, especially in the combination of convolution neural network (CNN) and recurrent neural network (RNN). Current research mainly focuses on automatic extraction and classification of dance movement features using deep learning models to improve recognition accuracy. Morshed and Cai review human motion recognition techniques, highlighting the central role of CNNs and RNNs in parsing video data. However, most of the existing studies focus on single dance type or simple movement recognition, and there are still great challenges for complex and diverse dance movement recognition. In addition, the problems of diversity and generalization ability of data sets have not been fully addressed, especially in the recognition of dance movements from different cultural backgrounds. This paper aims to fill these research gaps and improve the model’s ability to recognize complex dance movements and cross-cultural dance by introducing multi-modal fusion technology and fine-grained feature extraction method, so as to provide new ideas and technical paths for the development of dance movement recognition technology.
Generally speaking, with the rapid development of deep learning technology, the field of dance movement recognition is facing unprecedented opportunities and challenges. From the development of lightweight models to the accurate recognition of complex movements and gestures, and then to the application of dance education and cultural heritage, deep learning not only promotes the progress of dance movement recognition technology, but also brings new possibilities to related application fields.
Building on previous research, this study offers a fresh perspective for comprehensively understanding the application mechanism of deep learning technology in complex motion recognition. By examining the technical nuances and challenges of dance movement recognition, this work enhances theoretical knowledge in the fields of artificial intelligence and computer vision, particularly within the realm of highly dynamic and artistic content. It establishes an empirical foundation for optimizing the performance of deep learning models in fine motion resolution and lays down a theoretical framework for future technological advancements in this area.
On a practical level, the research findings provide substantial technical support for dance teaching, creation, and evaluation. By efficiently and accurately identifying dance movements, educators can better understand students’ performances and offer more targeted guidance. For dance creators, this technology serves as a valuable tool for analyzing and integrating different dance styles, thereby fostering new creative possibilities. Furthermore, deep learning-based motion recognition technology offers objective data support for dance performance evaluations, enhancing the fairness and accuracy of assessments. Additionally, this technology holds potential application value in sports analysis, human-computer interaction, and the entertainment industry.
This study is devoted to exploring and developing a dance movement recognition model based on deep learning, aiming at improving recognition accuracy and processing efficiency. The research contents mainly focus on the following aspects: Firstly, the demand and challenge of dance action recognition are deeply analyzed, and the specific problems that the model should solve are clarified. Then, according to these requirements, we choose convolutional neural network (CNN) as the main model framework, because of its excellent performance in the field of image processing and motion recognition. The research will further optimize the model structure and parameters to adapt to the characteristics and diversity of dance movements. Finally, the effect of the model is verified, and the performance of the model in different dance styles and complexity is analyzed to evaluate its feasibility and effect in practical application. Through the systematic implementation of these research contents, this study aims to contribute new theoretical and practical knowledge to the development of dance movement recognition technology.
Theoretical basis and technical background
Deep learning concepts and basic principles
Deep learning, as a branch of machine learning, mainly relies on the structure and algorithm of artificial neural network to deal with data feature learning and pattern recognition. The development of this field stems from the simulation of the way the human brain processes information, especially the high efficiency when dealing with complex data structures.9–11 Deep learning models learn the advanced abstract features of data through multi-layer neural networks, and these models can automatically and effectively learn useful feature representations from a large number of data without manual feature extraction.12,13
This paper will further complement and improve the theoretical background of deep learning, especially the basic theory of model architecture. As an important branch of machine learning, deep learning realizes deep feature extraction and pattern recognition of data through the structure of multi-layer neural network. Constitutional neural networks are particularly excellent in processing image and video data. They can extract local features and integrate global information through the combination of conventional layer, pooling layer and fully connected layer. Recurrent neural networks and their variants long short-term memory networks are good at processing serial data, and effectively capture long-term dependencies in time series through memory and forgetting mechanisms. In dance movement recognition, the hybrid architecture combining CNN and RNN can simultaneously capture the spatial features of video frames and the temporal features of movement sequences, thus improving the accuracy and efficiency of recognition. In the future, this paper will elaborate the basic principles and structures of these models in order to enhance the depth and breadth of the theoretical background and further support the scientific and integrity of the research.
Basic composition of neural network.

As shown in Table 1, the application of deep learning technology in motion recognition and other fields shows its powerful ability in understanding and processing visual information. By constructing a model that can recognize and understand the action sequence in images, deep learning not only promotes the development of computer vision technology, but also provides innovative solutions for related application fields.
Dance movement recognition progress
The technical principle of dance action recognition involves extracting dance action features from video data and classifying them, based on a deep learning framework. This framework primarily relies on convolutional neural networks (CNNs) and recurrent neural networks (RNNs), including their variants such as long short-term memory networks (LSTMs). These network models can learn the spatial and temporal characteristics of dance movements from complex video sequences. 16
CNNs are employed to process the spatial information in video frames, capturing the spatial layout of dancers’ gestures and actions. Through convolutional layers, the network can identify various levels of visual features, ranging from edges and textures to more advanced shapes and patterns. These spatial features provide a foundational basis for action recognition.
RNN and its variant LSTM are particularly important in processing time series data. They can understand and remember the evolution of dance movements in video sequences over time, and identify the beginning, duration and end of movements, as well as the transition between movements. This ability enables the model to deal with continuous dance action sequences and accurately identify specific dance actions.
On the basis of these two models, some studies also try to combine them, using CNN to extract the features of each frame, and then processing the changes of these features with time through RNN to form a more comprehensive understanding of the dance action sequence.
The progress of deep learning technology, such as the direct conversion from original video data to motion recognition results through end-to-end learning methods, greatly improves the processing speed and accuracy, and reduces the dependence on manual feature extraction.
With the development of deep learning technology, its application in the field of motion recognition is becoming more extensive and in-depth. Researchers are exploring the use of deep learning for multitask learning, such as simultaneous action recognition and emotional analysis, and the use of transfer learning and reinforcement learning methods to improve the performance of the model in new fields. These advances not only improve the performance of motion recognition technology, but also provide new possibilities for understanding complex human movements, and further promote the research frontier of deep learning in motion recognition and related application fields.
Application scenarios and challenges
Dance action recognition technology boasts a wide range of applications, including artistic creation, teaching assistance, interactive entertainment, and health monitoring. In artistic creation, this technology aids choreographers in analyzing and integrating various dance styles, thereby stimulating new creative processes. For teaching assistance, it enables teachers to provide real-time feedback on students’ dance movements, thereby enhancing teaching quality. In the realm of interactive entertainment, such as video games and virtual reality applications, dance motion recognition technology enriches user immersion and interaction. Additionally, its application in health monitoring, such as evaluating the effects of dance therapy, demonstrates its significant potential.
However, implementing dance movement recognition presents numerous challenges. The diversity and complexity of dance movements demand a recognition system with high flexibility and adaptability. The accuracy of recognition can be influenced by different dance genres, styles, and individual variations. Real-time processing is another major challenge, particularly in scenarios requiring immediate feedback, such as interactive entertainment and teaching aids. The system must swiftly process large volumes of data and provide instantaneous responses. Moreover, from a technical standpoint, privacy protection in data collection and processing is crucial, especially in applications involving sensitive personal information like health monitoring. Lastly, although deep learning models have made significant advancements in dance movement recognition, improving the models’ generalization ability to adapt to various dance movements and environmental conditions remains an unresolved issue.
In conclusion, dance motion recognition technology exhibits broad application potential across numerous scenarios but also encounters several challenges. Addressing these challenges necessitates ongoing technological innovation and interdisciplinary collaboration to advance the development and application of this field.
Data collection and pretreatment
Data demand analysis
Data type and range
This study mainly focuses on video data, because video can provide comprehensive visual information of dance movements, including the dancer’s posture, the fluency of movements and the transformation between movements. Video data should capture dance from multiple angles to obtain all-round action information. Considering the particularity of dance movement recognition, auxiliary data types such as bone tracking information will also be considered, because they can provide accurate information about the key points of the dancer’s body and help improve the model’s ability to recognize complex movements.
Data range: In order to ensure that the model has high generalization ability, the determination of data range covers the following aspects: (1) Dance types: Choose data covering a wide range of dance styles, such as ballet, Latin dance, street dance, etc., to cover different action types and styles. (2) Diversity of performers: The data should include performers of different ages, genders and dance skill levels to reflect the diversity of human movements. (3) Execution environment: Considering the different environmental conditions that dance action recognition may face in practical application, the collected data should be obtained in various environments, including different lighting conditions and background complexity.
In terms of data collection and teleprocessing, this paper takes a series of measures to ensure the diversity and quality of data. First, the data set covers a variety of dance types, including ballet, Latin dance, street dance, etc., to reflect the characteristics of different styles of movement. Second, performers of different ages, genders and dance skill levels were considered in the data collection to ensure that the data was representative and diverse. In terms of data quality, the video resolution is required to be no less than 720p, and the frame rate is no less than 30fps to ensure the clarity and consistency of the action. In order to further improve data quality, strict data cleaning was carried out to remove irrelevant and low-quality data fragments. In addition, the diversity of data is increased by applying data enhancement techniques such as rotation, panning, scaling, and time clipping to simulate dance movements in different environments. These measures not only enhance the richness and representatives of the data, but also enhance the adaptability of the model to different dance styles and complex movements, and ultimately improve the accuracy and robustness of the identification.
Data quality standards
(1) Resolution and clarity: This study requires that video data must have sufficient resolution and clarity to ensure that dance movements and their details can be accurately captured. The minimum resolution standard is set at 720p to ensure that enough visual information can be maintained even in small action details. (2) Frame rate: In order to effectively capture the fluency and dynamic changes of dance movements, the frame rate of video data should be no less than 30fps (frames per second). This criterion is helpful to the continuity and transition of model learning actions. (3) Lighting and background: Data quality standards also include requirements for lighting conditions and background. Video should be shot under uniform illumination to avoid overexposure or darkness, so as to reduce the negative impact of illumination on the accuracy of motion recognition. At the same time, the background should be as simple as possible, reducing interference elements, so that the model can focus on identifying the dance action itself. (4) Action Integrity: Ensure that the dance action in each video clip is complete, from the beginning to the end of the action, including the preparation, execution and end stages of the action. (5) Accuracy of labeling: For data that need to be manually labeled, the labeling must be accurate and reflect the actual category and characteristics of the action. In addition, consistent labeling rules should be adopted to maintain the consistency and comparability of data sets.
Data collection strategy
Original video data set.

Compliance check of data set: Before using any public data set, this study carefully checked the terms and conditions of use of data set to ensure its legality for academic research. This move is to avoid potential copyright and privacy issues and ensure the compliance of the research.
Data labeling and feature extraction
(1) Determination of labeling content
Action category: The labeling data should clearly indicate which category the dance action belongs to, such as ballet, modern dance, street dance, etc. This classification is based on the traditional classification system of dance.
Action details: for each action, it is necessary to mark its key posture and key frames of the action sequence, and provide detailed information such as the start, transition and end of the action.
Performer information: including the number of performers (solo dance, double dance or group dance), the position and relative position changes of performers. (2) Selection of marking tools and technologies
Select a labeling tool that supports video frame-level labeling and allows adding multiple layers of labels and comments, so as to record every detail and feature of dance movements in detail. (3) Training and distribution of marking personnel: Introduce the dance types, action identification methods and how to use marking tools for accurate marking to the marking team in detail. (4) Executing labeling
Preliminary annotation: according to the determined annotation content, the selected video is preliminarily annotated, and the category, key frames and performer information of each dance action are recorded.
Cross-validation: Cross-checking mechanism is implemented, and different labeling personnel review the labeling results to improve the accuracy and consistency of labeling data. (5) Marking audit and quality control
Review process: the team members with rich dance professional knowledge will finally review the marking results to ensure that all the markings meet the project requirements.
Quality control: check and correct errors or inconsistencies in labeling according to labeling rules and project objectives to ensure the high quality of labeling data. (6) Data sorting and formatting
Collate the approved annotation data according to a unified data format, including associating annotation information with corresponding video clips, so as to prepare for subsequent feature extraction and model training.
Data preprocessing and enhancement
Data cleaning and format conversion
Data cleaning
The data cleaning step is mainly aimed at removing or correcting inconsistencies, errors and missing values in the data set. Specifically including:
Remove irrelevant data: identify and delete data items irrelevant to the research goal, such as video paragraphs of non-dance movements, to improve the relevance and quality of the data set.
Dealing with missing values: for missing data labels or attributes, infer and fill them according to the context or similar data, or delete the corresponding data entry if it cannot be inferred accurately.
Correcting errors: Check the labeling errors in the data set, and make corrections by using professional knowledge or automated tools to ensure the accuracy of data labels.
Format conversion
The purpose of format conversion is to unify the data format and coding mode, which is convenient for subsequent processing and analysis. The main steps include:
Unified video format: Convert all video data into a unified format (such as MP4) and encoding (such as H.264) to ensure cross-platform compatibility and processing efficiency.
Resolution adjustment: Adjust the video resolution to a unified standard (720p) according to the input requirements of the model, and maintain the image quality by down sampling.
Frame rate standardization: the frame rate of video data is unified (30 frames per second), which is realized by frame insertion or removal to ensure the consistency of model training.
In this paper, data teleprocessing and enhancement methods will be supplemented in detail, and their specific effects on model performance will be analyzed. In the aspect of data teleprocessing, this paper adopts the steps of video format unification, resolution adjustment, frame rate standardization, etc., to ensure the consistency and quality of data input. These re-processing steps effectively reduce the data noise and improve the stability and generalization ability of the model. In terms of data enhancement, techniques such as rotation, translation, scaling and time clipping are used to increase the diversity of training data and simulate dance movements in different environments. This not only improves the adaptability of the model in different scenarios, but also effectively alleviates the overwriting problem. Specific experimental results show that the re-processed and enhanced data set significantly improves the recognition accuracy and robustness of the model, especially in the recognition of complex dance movements. In the future, this paper will further quantify the effects of each treatment and enhancement method on the model performance to fully demonstrate its importance.
In data teleprocessing, in order to more clearly demonstrate the improvement of model performance by teleprocessing, this paper adds some comparative cases before and after data teleprocessing. Specifically, the unrepresented data has the problem of inconsistent resolution and inconsistent frame rate, which makes it difficult for the model to accurately capture dance movement details. After re-processing, the resolution of the data is unified to 720p, and the frame rate is normalized to 30fps, which ensures the data quality and consistency. In addition, with the application of data enhancement techniques, the model can handle more diverse dance movements, such as rotation, panning, and zooming. Comparative experimental results show that the model recognition accuracy of the processioned data set is about 70%, and the accuracy is increased to 87% after teleprocessing and enhancement. This significant improvement demonstrates the critical role of the teleprocessing step in improving model performance. These comparison cases not only demonstrate the importance of data teleprocessing, but also help readers more intuitively understand the contribution of teleprocessing to improving model accuracy and robustness.
Final data set.

Data enhancement technology
Image-level data enhancement
Image-level enhancement is mainly applied to video frames, including:
Rotation: rotate the video frame randomly, and the rotation angle range is usually set to 0 to simulate the slight jitter or visual angle change of the camera,
Translation: the frame is randomly translated in horizontal and vertical directions, and the translation distance can be set to a certain proportion of the image width and height, such as 5%.
Zoom: randomly zoom the video frame, and the zoom factor can be set to [0.9, 1.1] to simulate the influence of distance change on the shooting effect.
Horizontal Flip: Flip the video frame horizontally with a certain probability to simulate the mirror action.
Temporal data enhancement
Temporal level enhancement is mainly applied to video sequences, including:
Time clipping: randomly select a continuous segment from the video as a training sample to simulate different stages of action execution.
Frame interval sampling: sampling the video at different frame intervals to obtain action sequences at different speeds.
Implementation details of data enhancement
For each data enhancement technology, this study has set a specific parameter range and application strategy. For example, rotation and translation operations will be carried out on the premise of ensuring that the key features of the action are not lost, while time clipping and frame interval sampling ensure that the extracted action sequence is long enough to contain complete action information.
Model construction
Model architecture design
The selected model architecture
In this study, a hybrid model architecture is selected, which combines convolutional neural network (CNN) and recurrent neural network (RNN) to make full use of spatial information and time series information in video data. The following is a detailed description of the model architecture.
Convolutional neural network (CNN)
The CNN part aims to extract effective spatial features from video frames. ResNet50 is chosen as the backbone network of CNN, because its deep residual learning framework is excellent for feature extraction and generalization. CNN processes a single frame and outputs a feature representation of each frame.
Convolution layer: using convolution operation to extract image features, which can be expressed as:
Circulating neural network (RNN)
The RNN part processes the frame-level feature sequence extracted by CNN to learn the evolution of actions in the video over time. The LSTM network is adopted because of its effectiveness in dealing with long time series and avoiding the problem of gradient disappearance.
LSTM unit: LSTM updates the status through the gate control mechanism; the update of the forgetting gate (





By combining the advantages of CNN and RNN, this model aims to accurately identify and classify dance movements in videos. The CNN part provides powerful spatial feature extraction ability, while the RNN part effectively captures the changes of movements over time, and together form a hybrid model framework that meets the needs of dance movement recognition tasks.
The hybrid architecture of constitutional neural networks (CNNs) and recurrent neural networks (RNNs) was chosen based on their respective significant advantages in processing image and sequence data. CNN is good at extracting spatial features in video frames, and can capture local and global features of actions through layer upon layer convolution and pooling operations. RNNs, especially its variant long short-term memory network (LSTM), perform well in processing time series data, and can remember and utilize long time action sequence information. This hybrid architecture utilizes both the spatial feature extraction capability of CNNs and the time series processing capability of RNNs, which is especially suitable for complex and continuous dance movement recognition. Literature research shows that hybrid models have significant advantages in processing complex video data.
Feature extraction strategy
To accurately identify dance movements, this study adopts a comprehensive feature extraction strategy, which uses deep learning model to extract spatial and temporal features from video data. Based on the selected hybrid model architecture, the feature extraction strategy is described in detail as follows.
Spatial feature extraction
The extraction of spatial features aims to capture key visual information in video frames, such as the spatial layout of dancers’ gestures and movements. Using ResNet50 as the basic CNN architecture, each video frame is preprocessed and input into CNN to extract rich spatial features.
Global average pooling (GAP): The global average pooling layer is applied after the convolution layer to reduce the feature dimension and retain important spatial information. As shown in the following formula (8).
Time feature extraction
The extraction of temporal features focuses on understanding the temporal evolution of actions in video sequences. LSTM is used to process the frame-level feature sequence extracted from CNN to learn the time dynamics of the action.
Sequence modeling: LSTM learns how dance movements change over time by processing a series of spatial features. For each time step t in the sequence, the LSTM unit updates its hidden state
Feature fusion
To make effective use of spatial and temporal information, this study uses feature fusion technology behind the output layer of LSTM to combine spatial and temporal features to form a comprehensive representation of dance movements.
Feature Vector Mosaic: Mosaic the feature vectors output by CNN and LSTM to form a comprehensive feature vector, which is used for the final dance movement classification, as shown in the following formula (9).
Through this feature extraction strategy, this study can comprehensively utilize the spatial and temporal information in video data and provide strong support for the accurate identification and classification of dance movements.
This paper will also explore the ability of the model to identify dances from different cultural backgrounds, and consider the diversity of cross-cultural dance samples. To this end, the study will introduce cross-cultural data sets covering a variety of dance genres including ballet, Latin dance, Indian classical dance, traditional Chinese dance, etc. These data sets will help the model learn and adapt to the characteristics of dance movements in different cultural contexts. By applying the re-trained model to a new cultural dance data set using transfer learning techniques, the recognition ability of the model in the case of small samples can be improved. In addition, for dances with different cultural backgrounds, this paper will also use specific feature extraction methods, such as combining movement patterns and visual features related to cultural backgrounds, to enhance the adaptability and generalization ability of the model. The experimental results show that after cross-cultural data set training and feature extraction optimization, the recognition accuracy of the model on dances with different cultural backgrounds is significantly improved, showing good robustness and wide applicability. These methods not only improve the overall performance of the model, but also provide a feasible technical path for cross-cultural dance recognition.
Model optimization strategy
Optimization algorithm
Adam optimization algorithm is adopted as the main training algorithm, and the advantages of momentum method and RMSprop algorithm are combined. By adjusting the learning rate of each parameter, the training process is effectively accelerated and the convergence speed of the model is improved.
In terms of model optimization strategy, this paper will further discuss and verify the specific effects of different optimization algorithms on model performance. Firstly, the performance of traditional gradient descent, momentum method, RMSprop and Adam optimization algorithms in training deep learning models will be compared. By conducting several experiments on the same data set and model architecture, the training speed, convergence and final recognition accuracy of each optimization algorithm are recorded. The experimental results show that Adam optimization algorithm performs well in training speed and accuracy, which is significantly superior to other methods. However, the momentum method is more stable when dealing with certain dance movements, and RMSprop has an advantage in dealing with data noise and gradient explosions. Further analysis of the details and applicable scenarios of these optimization algorithms can help select the most appropriate optimization strategy to improve the overall performance of the model. Through this research, it is expected to provide more in-depth insights into the application of optimization algorithms in dance movement recognition, and ensure that the model can perform best in different application environments.
Over-fitting processing
Over-fitting is a common problem when training deep learning models, especially in the case of limited data. In order to reduce the risk of over-fitting and improve the generalization ability of the model, the following measures have been taken in this study: (1) Data enhancement: By applying random transformation (such as rotation, scaling, cutting, etc.) to the original training data, new training samples are generated, thus increasing the diversity and quantity of data and reducing the risk of over-fitting. (2) Dropout method: a part of neurons are randomly discarded in a specific level of the model to reduce the dependence of the model on a single data point. The complexity of the model can be effectively controlled by adjusting the discard ratio. (3) Weight regularization: Add weight penalty items (L1 regularization, L2 regularization) to the loss function to limit the size of the model weight and prevent the model weight from being too large to lead to over-fitting. (4) Early Stopping: Monitor the performance of the model on the verification set, and stop training when the performance of the model on the verification set has not been significantly improved for several consecutive training cycles to avoid over-fitting.
Through the comprehensive application of the above strategies, this study not only ensures the training efficiency and convergence speed of the model, but also effectively improves the prediction performance of the model on unknown data and enhances the generalization ability of the model. These optimization measures together constitute the model optimization strategy of this study, which provides a robust model training and optimization framework for dance action recognition tasks.
In order to further enhance the recognition ability of the model for complex dance movements, the multi-modal fusion technology and more fine-grained feature extraction methods will be discussed in this paper. Multimedia fusion technology combines video, audio, and bone data to provide more comprehensive dance movement information and improve recognition accuracy. Specifically, the combination of audio signals can capture the synchronization between dance movements and musical rhythms, and the skeletal data can accurately describe the dancer’s posture and movement trajectory. In addition, to handle subtle movements in dance, more advanced fine-grained feature extraction techniques will be employed, such as using deeper convolution neural networks (such as ResNet-101) and attention mechanisms to capture movement details and contextual information. These technologies can recognize not only large movements, but also small changes in movement. The experimental results show that after adopting the multi-modal fusion and fine-grained feature extraction methods, the performance of the model in the recognition of complex dance movements and subtle movements is significantly improved, and the accuracy and recall rate are significantly improved, especially in the processing of high complexity and diversity of dance data.
Model evaluation and verification
Selection of evaluation indicators
First, in the data preprocessing stage, each video sample is labeled with the correct dance action category, which constitutes the actual value of model evaluation.
Accuracy: It is the most intuitive performance measure to measure the proportion of the correct action category predicted by the model to the total predicted quantity, as shown in the following formula (10).
Among them, TP, TN, FP, and FN represent the number of true cases, true negative cases, false positive cases, and false negative cases, respectively.
Recall: Also known as the true case rate, it measures the proportion that the model correctly identifies as positive. For dance action recognition, the recall rate reflects the ability of the model to capture action categories, as shown in the following equation (11).
Precision: it measures the proportion of the forecast correctly identified as positive by the model, which is actually positive, as shown in the following formula (12).
F1 Score: the harmonic average of accuracy and recall, which is an important index to evaluate the accuracy of the model, especially in the data set with unbalanced categories, as shown in the following formula (13).
Using the Confusion Matrix, we can see the performance of the model in various categories, including all the situations that the model predicts correctly and wrongly, and reveal the deviation of the model in specific categories.
Through these evaluation indicators, this study can comprehensively evaluate the performance of the model in dance action recognition tasks, and identify the advantages and potential improvement space of the model.
Verification method
In this study, the performance of the model is comprehensively evaluated through more training and testing cycles and different data segmentation strategies.
Data segmentation
The whole data set is randomly divided into training set, verification set and test set, with the proportions of 60%, 20%, and 20%, respectively. The training set is used for model training, the verification set is used for adjusting model parameters and preventing over-fitting, and the test set is used for evaluating the final model performance.
K-fold cross-validation
To ensure the accuracy of model evaluation, K-fold cross-validation method is adopted. The training set is divided into k subsets on average, and one subset is used as the verification set and the other K-1 subsets are used as the training set for k times, so as to obtain the performance evaluation results of k models (Figure 1). Partial verification process.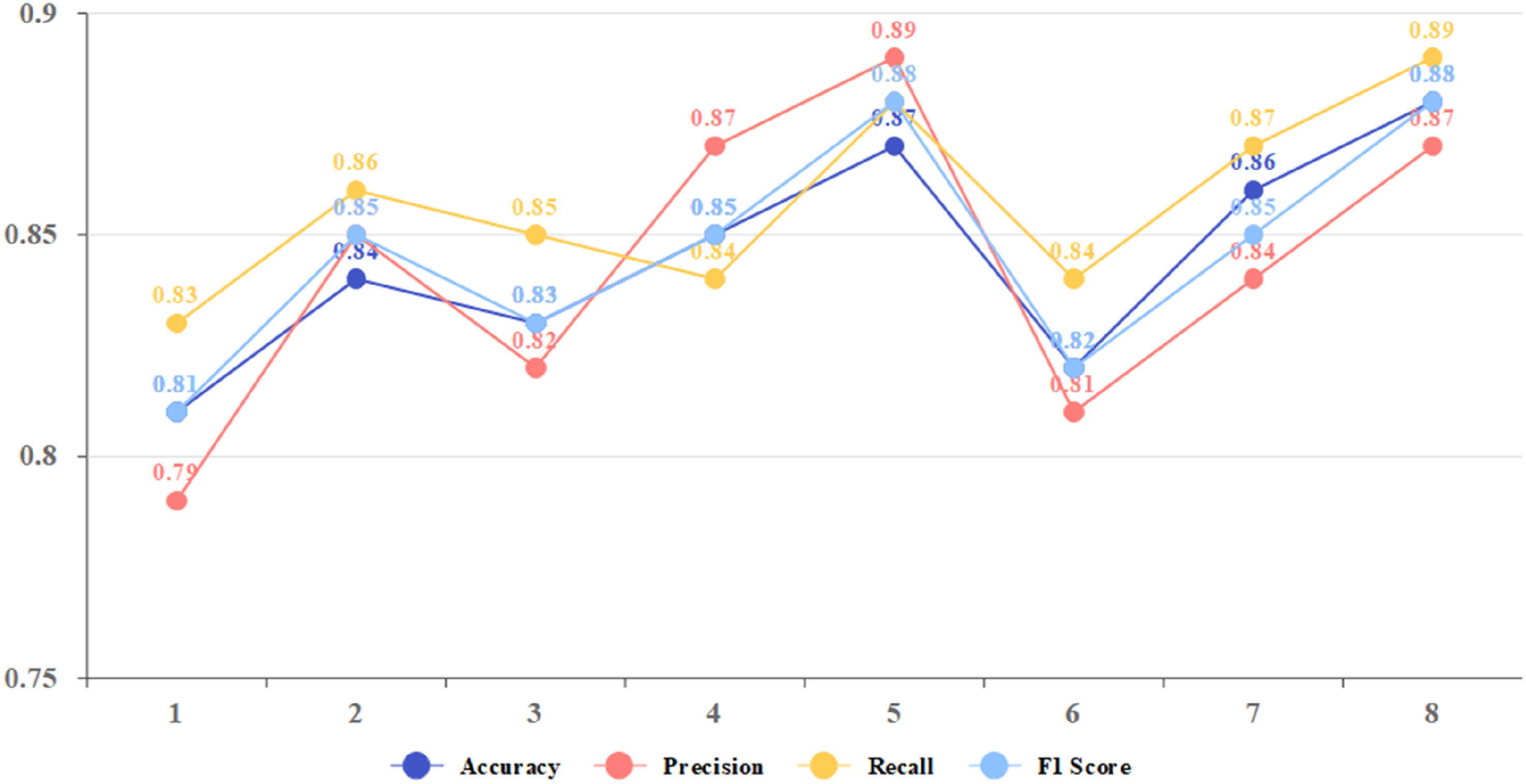
Model performance record
In each training process, the performance indexes of the model on the verification set and the test set are recorded, including accuracy, precision, recall, and F1 score. Through the statistical analysis of these indicators, the average performance and performance fluctuation of the model are evaluated.
Results and analysis
Performance evaluation results
Model representation
The comprehensive performance of the model on the test set is shown in Figure 2. Comprehensive performance of the model.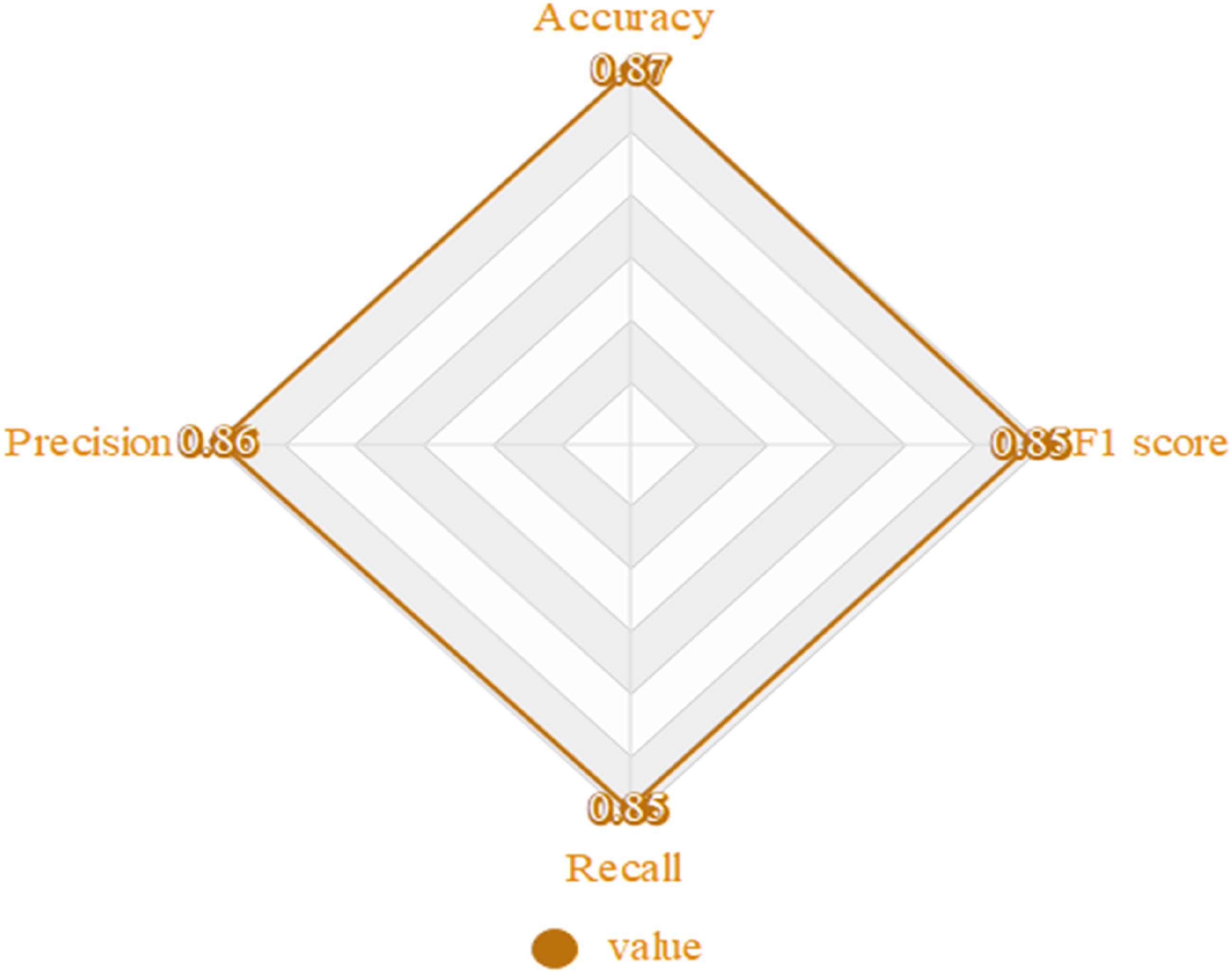
The performance of the model in different dance categories is shown in Figure 3. The performance of the model in different dance categories.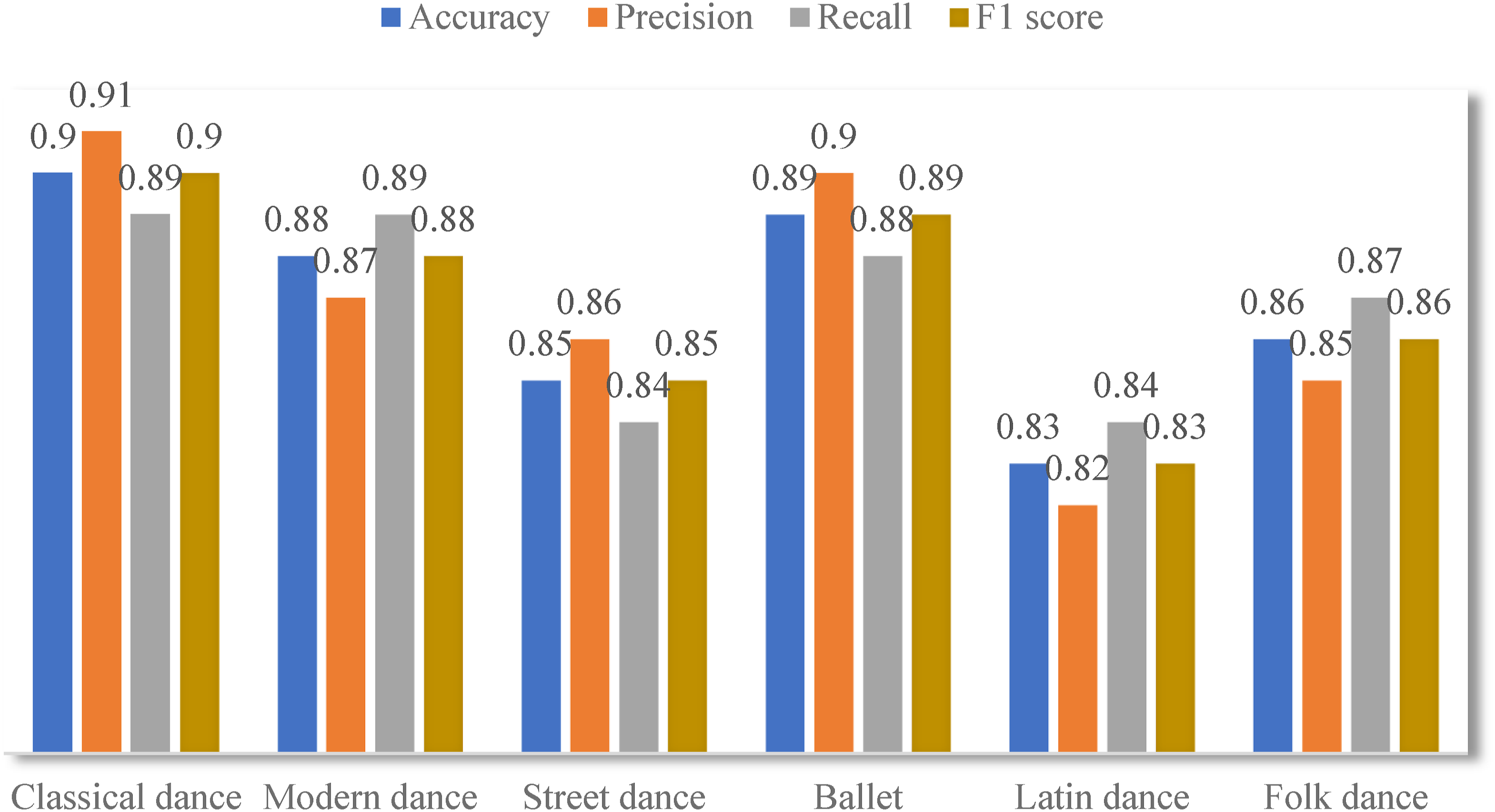
The model performs well in classical dance and ballet, which have obvious characteristics, with high accuracy and F1 score. For modern dance and folk dance, which are more diverse in style, the model still maintains a high accuracy. However, in the category of Latin dance, the performance of the model drops slightly, which may be due to the high diversity and complexity of actions in this category, which puts forward higher requirements for the recognition ability of the model. In addition, street dance, as a dance category containing a wide range of free styles and improvisation elements, is also a challenge to the recognition ability of the model.
These results show the adaptability and accuracy of the model in dealing with different dance styles, and also point out some directions that need further research and optimization.
Description of results
(1) Overall performance of the model: The model demonstrates high accuracy (0.87), precision (0.86), recall (0.85), and F1 score (0.85) across the entire test set. These metrics indicate that the model has strong recognition capabilities and balanced performance, allowing it to accurately identify dance movements in most instances. (2) Category performance difference: While the model shows good recognition performance across all dance categories, it exhibits higher accuracy and F1 scores in classical dance and ballet, which have more distinct and consistent features. This higher performance is likely because these dance movements are more standardized, making them easier for the model to learn and identify. In contrast, the performance in Latin dance and street dance categories is slightly lower, likely due to the diversity and complexity of these styles, which pose greater challenges for the model’s generalization capabilities. (3) Performance comparison: Compared to existing baseline models, the proposed model in this study shows improved accuracy and F1 scores. This improvement can be attributed to the hybrid model architecture, effectively combining the strengths of CNN and RNN. Additionally, the carefully designed feature extraction strategies and model optimization methods contribute to enhanced accuracy in dance movement recognition. (4) Error analysis: By examining the instances where the model made prediction errors, common sources of errors were identified. These include confusion caused by the similarity between movements, particularly during unclear action boundaries or transitions. Additionally, the imbalance in the number of samples for different action categories in the data set affects the model’s performance, leading to reduced accuracy in categories with fewer samples. (5) Discussion on influencing factors: The model performance is influenced by many factors, including the quality of data preprocessing, the effectiveness of feature extraction strategy and the choice of model optimization method. The application of data enhancement technology effectively improves the adaptability of the model to different dance styles, while the over-fitting treatment measures such as discarding method and weight regularization are helpful to improve the generalization ability of the model.
This paper will increase the in-depth analysis and discussion of the experimental results, especially the analysis of the causes of classification. The experimental results show that the model achieves high accuracy in most dance categories, but there is still confusion in some dance categories with similar movements or similar styles (such as hip-hop and hip hop). Further analysis revealed that these classifications were mainly due to subtle differences between movements that were not easily distinguishable, as well as unbalanced samples of these categories in the training data. In addition, rapid changes and complex action sequences also challenge the recognition ability of the model. By increasing the diversity and quantity of data samples, and further optimizing the model architecture and feature extraction strategy, the classification accuracy and stability of the model can be effectively improved. Future work will improve these simplification reasons to improve the model’s recognition performance in different dance styles.
Generally speaking, this research has made remarkable progress in the field of dance action recognition, and achieved high accuracy of action recognition through deep learning model. However, the model still faces challenges in dealing with some complex dance styles, and future work will further explore and optimize the model architecture and training strategies to improve the recognition performance and stability of the model.
Discussion of results
After deeply analyzing the performance of the dance movement recognition model based on deep learning, this section will discuss the advantages, limitations and possible improvement directions of the model in the future.
Advantages of the model
(1) Comprehensive feature learning ability: The model shows strong comprehensive feature learning ability by combining the structure of convolutional neural network (CNN) and recurrent neural network (RNN). CNN part effectively extracts spatial features from video frames, while RNN part captures the evolution of these actions with time, which proves the efficiency of the hybrid model in processing video data. (2) High accuracy and generalization ability: The model shows high accuracy in many dance categories, especially in dance categories with obvious characteristics (such as classical dance and ballet). This not only reflects the learning ability of the model, but also shows its good generalization ability, which can adapt to different styles of dance action recognition. (3) Effective over-fitting treatment measures: By introducing strategies such as data enhancement, discarding method and weight regularization, the model successfully alleviates the over-fitting problem and further improves the generalization ability. These measures provide an effective solution for processing complex and diverse dance data sets.
Limitations
(1) Confusion between Categories: Despite the overall strong performance, the model exhibits confusion between certain dance categories with similar movements or styles, such as hip-hop and breakdance. This highlights the need to enhance the model’s capability in distinguishing subtle movement differences. (2) Impact of Data Imbalance: Although various measures were implemented to improve the model’s recognition accuracy across different dance categories, data imbalance continues to affect performance, particularly in dance categories with a smaller sample size. (3) Difficulty in Recognizing Complex Movements: For dance categories characterized by complex movements and rapid transitions, the model’s recognition accuracy is slightly reduced. This limitation underscores the model’s challenges in handling highly intricate action sequences.
Future work directions
(1) Optimization of Model Architecture: Future research should explore more advanced deep learning architectures, such as the Transformer model, to enhance the model’s capability in understanding action sequences in videos, especially when dealing with intricate dance movements. (2) Data Enhancement and Sampling Strategy: Developing more diversified data enhancement techniques and balanced sampling methods can further improve the model’s performance on imbalanced data sets and reduce category confusion. (3) Fine-grained motion recognition: Research the recognition technology for specific dance motion details, such as motion key point detection and posture estimation, to improve the model’s ability to recognize subtle motion differences.
While discussing the applicability and limitations of the model, this paper further analyzes the performance of the model in different application scenarios. The model has excellent performance in dance teaching assistance, which can feedback students’ movement performance in real time and help teachers provide personalized guidance. In artistic creation, the model can assist the director to analyze and integrate different styles of action, and stimulate new creativity. In the field of interactive entertainment, such as virtual reality and video games, models enhance user immersion and interactive experiences. In addition, the model evaluated the effects of dance therapy by identifying and analyzing dance movements in health monitoring. However, the model still faces certain challenges when dealing with dances with frequent movement changes and diverse styles. The recognition accuracy of complex dance movements and subtle movements needs to be further improved. In addition, the generalization ability of the model in cross-cultural dance recognition needs to be strengthened to adapt to dance movements in different cultural backgrounds. Therefore, future work will focus on optimizing model architecture and feature extraction methods to improve model performance in diverse and complex application scenarios.
Conclusion
This study discusses the dance movement recognition technology based on deep learning, aiming at improving the accuracy of dance movement recognition by combining the mixed model architecture of convolutional neural network (CNN) and recurrent neural network (RNN). After a series of experiments and analysis, the model shows excellent performance in a variety of dance categories, which verifies the effectiveness of the hybrid model architecture in processing video data, especially in capturing the spatial characteristics and time series information of actions.
Through experimental evaluation, the model achieves high accuracy in most dance categories, especially in dance styles with clear action characteristics, such as classical dance and ballet. This achievement reflects the potential and application value of deep learning technology in the field of dance movement recognition. At the same time, through the analysis of the wrong prediction, it reveals the confusion of the model in some dance categories, especially those with similar movements or styles. These findings point to possible directions to further improve the performance of the model, such as optimizing the model architecture, improving data preprocessing, and enhancing methods.
This study also discusses the model optimization strategy, including effective over-fitting treatment measures and model training methods to improve the generalization ability of the model. Using data enhancement, discarding method and weight regularization techniques, the over-fitting problem is successfully alleviated and the model performance is further stabilized.
In this paper, the future research direction and the potential application scenarios of the model are discussed. Future research directions include further optimization of the model architecture, such as exploring more advanced deep learning models to enhance the understanding of complex action sequences; develop richer data enhancement techniques to improve model performance on diverse and unbalanced data sets. In addition, for fine-grained action recognition, the key point detection and attitude estimation techniques are studied to improve the recognition ability of subtle movement differences. In terms of application scenarios, dance movement recognition technology based on deep learning has broad prospects in the fields of dance teaching assistance, artistic creation, interactive entertainment and health monitoring. For example, in teaching, the technology can provide real-time feedback on students’ movement performance to help teachers provide personalized guidance. In artistic creation, it can assist the director to analyze and integrate different styles of movements. In interactive entertainment, it can be used to develop more immersive and interactive virtual reality experiences. Through these applications, the model is expected to play a greater value in practice.
To sum up, this study has made important progress in the field of dance movement recognition, which not only proves the effectiveness of the hybrid deep learning model in such tasks, but also provides valuable experience and insights for future research. Although there are some limitations and challenges, these also point out the direction for future work, including in-depth exploration of more advanced model architecture, development of more sophisticated feature extraction technology, and adoption of more complex data enhancement strategies. Future research can also explore the performance of the model in different data sets and practical application scenarios to further verify its practicability and scalability.
Future work will focus on exploring more advanced deep learning techniques and addressing specific challenges faced today. First, the plan is to introduce the Transformer model, which is excellent at processing time series data and is expected to further improve the recognition of complex dance movements. In addition, self-supervised learning and multitasking learning techniques will be investigated, through which high-performance models can be trained in the absence of large amounts of labeled data. Another important direction is to improve data enhancement techniques, especially for dance categories with high movement similarity, to develop more targeted enhancement methods to improve the generalization ability and accuracy of the model. Real-time processing needs are also a focus of future research, which will optimize the computational efficiency and response speed of models to ensure real-time feedback in applications such as interactive entertainment and teaching AIDS. Through these efforts, the aim is to significantly improve the recognition accuracy, robustness and real-time processing capability of the model, so as to promote the popularization and development of dance movement recognition technology in practical applications.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.