
Abstract
In the digital age, integrated circuit learning path planning and personalized recommendation are crucial to improving learning outcomes. Traditional education models are difficult to meet the personalized needs of learners. This study constructs an integrated circuit learning path planning and personalized recommendation system based on genetic algorithm optimization. Learning path planning is abstracted as a combinatorial optimization problem, and an objective function with constraints such as time and mastery is constructed, and a dynamic weight adjustment strategy is introduced. The genetic algorithm is improved in many aspects such as population initialization, crossover strategy, and mutation mechanism to achieve collaborative work among various modules of the system. The experiment is based on real data from 5000 users of an online learning platform. The results show that the average path score of the improved genetic algorithm group is about eight points higher than that of the traditional genetic algorithm group, and the mastery improvement is 0.08 higher than that of the traditional group, and the user feedback satisfaction is higher. The system significantly improves the efficiency and personalization of learning path planning, providing a new solution for the field of integrated circuit education and personalized recommendation.
Introduction
Learning path planning and personalized recommendation for integrated circuits is an important direction of the intersection of modern educational technology and artificial intelligence. With the advent of the digital age, the demand for personalized learning has exploded. 1 In the traditional education model, students’ learning paths are often determined by the established course structure, lacking precise adjustments based on personal interests and abilities. 2 Although this approach is universal, it often ignores the significant differences in knowledge background, cognitive style, and learning goals among different students, resulting in uneven learning effects. 3 In the highly specialized and complex knowledge system of integrated circuits, the challenges faced by learners are particularly obvious: they must master a deep theoretical foundation while keeping up with the forefront of technological development.
Similar gaps appear in neighboring domains where learning sequences are prerequisite-constrained and time-bounded. In cybersecurity certification, health-profession training and large-scale programming MOOCs, static sequencing, and pure collaborative filtering struggle with cold starts, cross-course dependencies, and the trade-off between time and demonstrable mastery. Vocational and engineering curricula likewise require dynamic re-routing when prior skills are uneven or when standards evolve. These settings share the same structure we target—graph-linked knowledge, heterogeneous learner states, and competing objectives—suggesting that our GA-based, feedback-aware equation can generalize to build adaptive paths that remain feasible, interpretable, and efficient across disciplines.
The pace of change in IC toolchains, process nodes, and design methodologies shortens the half-life of skills and widens the gap between curricular sequences and workplace requirements. Learners must reconfigure prerequisite paths as standards, EDA workflows, and verification practices evolve across semesters. Static syllabi and one-shot recommenders miss these shifts, producing detours that inflate time-to-mastery and delay competency milestones in capstone projects and internships. A path planner that is both constraint-feasible and feedback-adaptive is therefore not merely desirable but urgent for sustaining workforce readiness in a volatile skills landscape.
Particle swarm optimization (PSO) and ant colony optimization (ACO) are strong global search baselines, yet their native operators are less aligned with discrete, graph-constrained curricula. PSO’s velocity updates favor continuous spaces and require nontrivial rounding and repair to preserve prerequisites; feasibility often degrades under multi-objective trade-offs. ACO encodes path construction well, but its pheromone dynamics can bias early popular segments and complicate integrating per-learner weights without careful evaporation tuning. Our GA uses permutation-aware crossover, constraint-aware repair, and fitness-rank selection to maintain feasibility over directed acyclic graphs while supporting dynamic weighting from user feedback. Empirically, this yields faster convergence to high-quality feasible paths with controllable exploration compared to PSO/ACO under identical time and mastery constraints.
The rapid development of educational technology has made it possible to solve this problem. For example, using data-driven analysis methods to build personalized learning paths can effectively improve learning efficiency and learning experience. 4 However, it is difficult to dynamically adapt to learners’ actual needs by relying solely on static knowledge graphs or simple recommendation algorithms. In reality, how to develop the optimal learning path based on learners’ knowledge reserves, learning habits, and learning preferences is still a difficult problem that has not been completely solved. 5
Intelligent optimization methods represented by genetic algorithms provide a new perspective for solving the above problems. Genetic algorithms are inspired by the laws of biological evolution and have the characteristics of strong search capabilities and wide adaptability. In problems such as path planning and resource allocation, genetic algorithms have shown excellent efficiency and flexibility. This makes them a powerful tool for solving complex problems. 6 Introducing genetic algorithms into integrated circuit learning path planning can better cope with the diversity and dynamics of personalized needs and inject new vitality into the development of educational technology.
In recent years, personalized recommendation systems have been widely used in many fields, especially in e-commerce, film and television content recommendation, and online education. These systems provide users with personalized services that meet their interests and needs through data mining and machine learning techniques. In the study of learning path planning, different models and algorithms have been proposed, including rule-based systems, collaborative filtering methods, and deep learning models.7,8 However, these methods often have certain limitations when facing dynamically changing learning scenarios. For example, collaborative filtering methods are prone to cold start problems when user data is insufficient, while the high complexity of deep learning models places higher demands on computing resources. 9
At the same time, the introduction of optimization algorithms provides a new solution for learning path planning. Metaheuristic methods such as genetic algorithms, particle swarm optimization algorithms, and ant colony algorithms have gradually become research hotspots due to their advantages in global search and complex problem solving. Existing studies have shown that genetic algorithms have broad application potential in areas such as path planning and timetable optimization. 10 However, in specific educational scenarios, there are still many technical challenges in how to combine genetic algorithms with learning path planning to achieve real-time and dynamic recommendations. In addition, most of the research on personalized recommendations focuses on improving algorithm performance, while paying relatively little attention to user experience and learning effects.
In the field of integrated circuit education, research focuses mainly on the modular design of knowledge points and the integration of teaching resources, while exploration of learning path optimization is still relatively scarce. Existing research is mostly based on static models and fails to fully consider the dynamic feedback and learning behavior of students. Therefore, it is particularly urgent to develop a dynamic, intelligent, and adaptable learning path planning system. 11
This study aims to design and implement an integrated circuit learning path planning and personalized recommendation system based on genetic algorithms to fill the gaps in current research. Specifically, the research will focus on the following three core goals. First, a path planning model that dynamically responds to learners’ needs is constructed, and the learning path is optimized using genetic algorithms to achieve personalized recommendations. Second, the applicability of genetic algorithms in educational scenarios is explored, especially in multi-objective optimization problems, and its effectiveness in processing learners’ dynamic feedback is evaluated. Then a prototype system is developed to verify its actual effect in improving learning efficiency and learning experience through experiments.
The theoretical significance of this study is that it combines genetic algorithms with learning path planning to provide new solutions to optimization problems in educational technology. This not only expands the application field of genetic algorithms but also provides a new perspective for theoretical research on learning path optimization. In practice, the system is expected to significantly improve learners’ learning outcomes in integrated circuit education and reduce the time cost and resource waste in the learning process. At the same time, this study also provides experience for the design and implementation of personalized recommendation systems.
We tackle six tightly coupled subproblems in IC learning path optimization: (i) Prerequisite encoding—formalizing course knowledge as a directed acyclic graph with typed dependencies; (ii) Multi-objective equation—jointly optimizing mastery gains, time cost, and interest relevance under feasibility constraints; (iii) Feasibility-preserving search—designing crossover, mutation, and repair operators that keep paths valid on the graph; (iv) Cold-start personalization—initializing preferences with proxy signals and priors when traces are sparse; (v) Online adaptation—updating objective weights from behavioral feedback to handle non-stationary learner states; and (vi) Scalability and interoperability—supporting LMS integration and low-latency planning for large curricula. This decomposition guides our algorithmic choices and evaluation.
Framework at a glance.
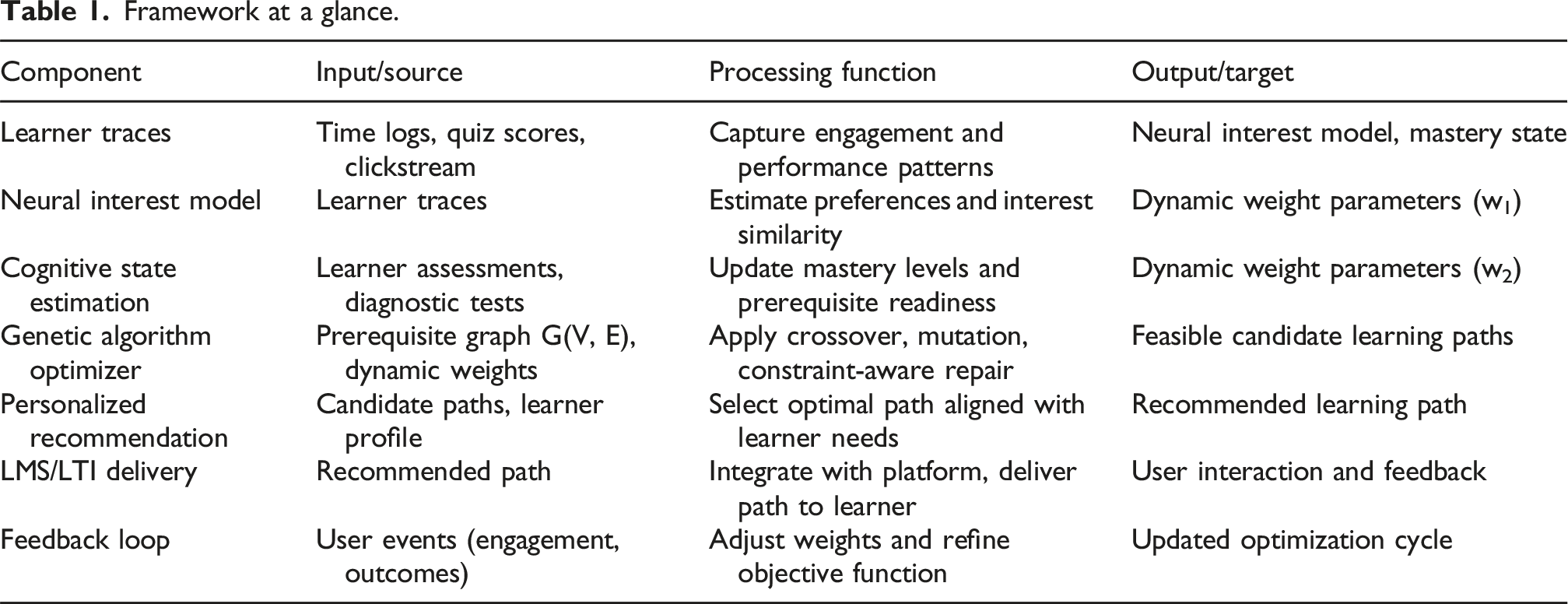
Literature review
Prior research on learning path formation clusters into five strands: (a) Rule-based sequencing and static knowledge maps, which ensure interpretability but lack adaptivity; (b) Collaborative filtering and sequence mining, effective with dense histories yet fragile under cold starts and cross-course dependencies; (c) Deep models over graphs—knowledge graphs, GNNs, and RL—capturing complex structure but often ignoring hard feasibility constraints; (d) Metaheuristic optimizers (GA/PSO/ACO), strong for global search yet rarely coupled with real-time feedback; and (e) Hybrid closed-loop systems that integrate tracing/diagnosis with recommendation, still limited by partial objectives and weak constraint handling. Our framework sits at the hybrid frontier, combining graph-feasible metaheuristics with feedback-driven personalization.
Research progress on integrated circuit learning path optimization
The research on learning path optimization has gradually shifted from static knowledge models to more dynamic and intelligent design directions. In recent years, dynamic learning path generation based on knowledge graphs has received widespread attention. This method can effectively capture the intrinsic structure of learning content by constructing semantic associations between knowledge points. Some studies have attempted to introduce a reinforcement learning framework to model learners’ behavior as a dynamic decision-making process, thereby achieving personalized path planning. This method not only improves the flexibility of path planning but also significantly enhances the system’s adaptability to learners’ behavioral feedback. In addition, path optimization models combined with deep learning technology have shown high accuracy in predicting learners’ needs by extracting complex data patterns.12,13
However, these studies still face challenges when dealing with multi-objective optimization problems. For example, existing models usually prioritize the coherence of knowledge points while ignoring the changes in learners’ psychological states during the learning process. Some scholars have proposed that the actual experience of learners can be better reflected by embedding sentiment analysis algorithms into path planning models. Although this approach is theoretically attractive, its computational complexity may limit the real-time performance of the system. 14
Application and extension of genetic algorithm in path planning
Genetic algorithms have been widely used in path planning and resource optimization due to their advantages in global search capabilities and flexibility. In educational technology, the application of genetic algorithms is mostly concentrated in aspects such as course scheduling and teaching resource allocation. However, the latest research has begun to explore the introduction of genetic algorithms into personalized learning path recommendations to cope with complex needs in dynamic environments.15,16 Studies have shown that genetic algorithms can effectively explore large-scale search spaces and find approximate optimal solutions by simulating the process of natural selection and genetic mutation. To further improve the efficiency of the algorithm, some studies have combined adaptive crossover and mutation strategies to dynamically adjust algorithm parameters to improve the convergence speed.17,18
In addition, the application of multi-objective optimization genetic algorithms is increasing. Such algorithms can optimize multiple objectives simultaneously, such as minimizing learning time and maximizing knowledge mastery. In the field of integrated circuit education, some models attempt to introduce multi-objective genetic algorithms and adjust the priority of learning objectives as weight parameters. 19 The advantage of this method is that it can balance the conflicts between different learning needs, but its implementation process depends on the accurate modeling of learners’ needs, which needs to be further verified in practice. 20
Innovative practices of personalized recommendation systems
Personalized recommendation systems have been widely used in educational scenarios in recent years, and their research focus has gradually shifted from traditional collaborative filtering methods to those based on deep learning and optimization algorithms. Although traditional methods are intuitive and easy to implement, they perform poorly in data sparseness and dynamic environments. 21 To address this problem, recommendation algorithms based on deep neural networks effectively alleviate the cold start and data sparsity problems by extracting multi-level features.
At the same time, combining metaheuristic optimization algorithms with recommendation systems has become a new research trend. By introducing genetic algorithms into the recommendation process, the optimal recommendation strategy can be efficiently found in a vast search space. For example, some studies have proposed a recommendation system framework based on co-evolution, in which genetic algorithms are used to optimize the weight distribution of user interest models. This framework can capture user preferences more accurately and significantly improve the personalization effect of the recommendation system.22,23
However, the design of personalized recommendation does not just stay at the algorithm level. Some studies have begun to focus on the overall improvement of user experience, such as enhancing the user’s sense of interaction through a visual interface, or achieving real-time optimization of recommendations through a user feedback mechanism. This research direction starting from the user’s perspective not only highlights the humanized design of the system but also provides important inspiration for the development of future personalized recommendation systems.24,25
In summary, the literature review starts from three aspects: integrated circuit learning path optimization, genetic algorithm application, and innovative practice of personalized recommendation system, analyzes the latest research progress and existing challenges, and provides a solid theoretical foundation for the research of this paper.
The review indicates that deep recommenders improve preference modeling yet lack constraint feasibility, while metaheuristics navigate large search spaces but rarely couple with real-time feedback. These insights motivate a design that unifies a graph-constrained, multi-objective optimizer with a learner-interest model and a mechanism for adaptive weighting. Accordingly, the next section details a GA-centered framework that encodes prerequisite graphs, enforces time and mastery constraints, and updates objective weights from user feedback to close the loop between recommendation and optimization.
Prior efforts increasingly close the loop between recommendation and learning signals by leveraging online updates—for example, knowledge tracing or cognitive diagnosis to refresh mastery states, contextual bandits to balance exploration and exploitation, and A/B or interleaved testing to select policies under uncertainty. Such systems show that real-time event streams (clicks, dwell, quiz outcomes) materially improve next-step decisions when folded back into the recommender. Building on these insights, our framework integrates a neural interest model with GA optimization and updates the objective weights via a gradient-style rule (equation (10)), thereby aligning path generation with observed engagement and attainment rather than static priors.
Mainstream recommenders optimize click-level accuracy but under-represent feasibility (violated prerequisites), non-stationarity (drifting interests and mastery), and multi-objective trade-offs (time vs attainment). Data sparsity and cold-start hinder personalization for new learners; deep models raise compute and latency barriers for classroom deployment; explanations are thin, limiting instructor trust and intervention. These gaps motivate a design that enforces graph validity, updates objectives from feedback, and exposes controllable trade-offs.
Method
Model theoretical framework and design basis
In today’s learning system in the field of integrated circuits, how to accurately optimize the learning path and achieve personalized recommendations has become the key to improving learning effectiveness and efficiency. In order to achieve this goal, this paper ingeniously constructs an intelligent optimization model based on genetic algorithms. In terms of construction ideas, we cleverly abstract the complex learning path planning into a combinatorial optimization problem. This innovative way of thinking has laid a solid foundation for subsequent model design.
In the process of constructing the objective function, the model fully demonstrates its comprehensiveness and scientificity. On the one hand, it deeply considers the pros and cons of the path itself, and evaluates whether the path is efficient and reasonable from multiple dimensions; on the other hand, it closely fits the personalized needs of users, fully respects the uniqueness of each learner, and is committed to providing them with the most suitable learning path. At the same time, combined with a series of constraints, such as actual learning time limits and knowledge mastery requirements, it fully ensures the feasibility of the planned path in practical applications and avoids the disconnection between theory and practice. The birth of this model is not accidental. It is the result of the deep integration of path planning theory, personalized recommendation theory and genetic algorithm optimization theory. These three theories have injected strong vitality into the model from different angles, enabling it to play a precise role in complex learning scenarios.
In the specific representation of the system model, we carefully represent the knowledge points in integrated circuit learning as a set of nodes
In this model, the learning path is strictly defined as
The first is the time constraint, which is based on the fact that learners have limited time in reality. The total learning time of the path cannot exceed the maximum time limit preset in equation (1).
The detailed information
The second is the mastery constraint, which is the key to ensuring learning quality. As shown in equation (2), the mastery of each knowledge point in the path cannot be lower than the preset threshold 
This constraint ensures that learners can achieve a certain level of mastery of each knowledge point during the learning process, avoids superficial and half-understanding learning, and effectively guarantees learning results.
The design of the objective function is a highlight of the model. Equation (3) cleverly combines the path score and personalized recommendation effect.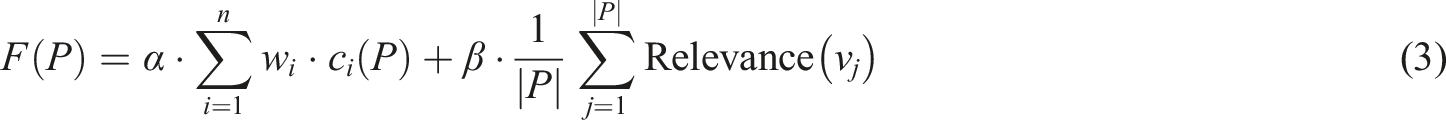
Among them,
In order to further improve the model’s ability to respond to personalized needs, this paper pioneered the introduction of a dynamic weight adjustment strategy. The weight 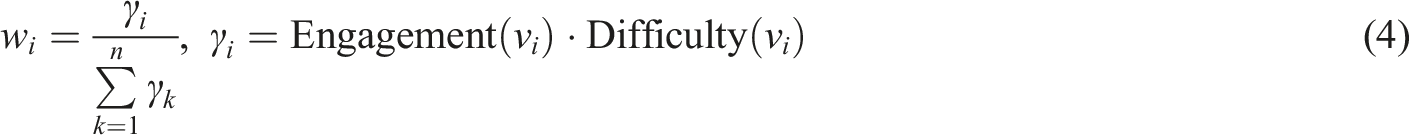
Here, it is the user
Implementation and improvement of genetic algorithm
In solving the complex problem of learning path planning, genetic algorithms are carefully designed as the main solution tool due to their unique advantages. As a heuristic algorithm that simulates the biological evolution process, the core idea of genetic algorithms is derived from the evolutionary mechanism of organisms in nature, and gradually approaches the global optimal solution through population evolution. It is like a virtual biological evolution journey, in which various candidate paths are like different biological individuals. In the process of continuous evolution, they gradually adapt to the environment and become better.
However, the learning path planning problem has its own complexity and uniqueness, and traditional genetic algorithms are difficult to directly meet its needs. Therefore, this paper makes all-round and multi-dimensional improvements to traditional genetic algorithms, covering multiple key aspects such as population initialization, crossover strategy, mutation mechanism, and fitness function design.
Population initialization
In the population initialization phase, in order to build a rich, diverse, and potential initial population, we use a random generation method to generate a set of candidate paths that meet the constraints. These candidate paths are like the starting point of the evolutionary journey of the genetic algorithm. Their quality and diversity directly affect the effect of subsequent evolution. Each path is cleverly represented as a gene sequence
In order to further improve the diversity of the population and give the genetic algorithm more possibilities and choices during the evolution process, we have adopted a variety of random generation strategies in the initialization process. For example, random path generation based on node priority, this strategy generates paths in a targeted manner according to the importance of knowledge points or other pre-set priorities, so that the generated paths can, to a certain extent, give priority to important knowledge points; there is also path generation based on heuristic rules, which uses some existing experience and knowledge, such as the common learning order and difficulty matching between knowledge points, to generate paths that are more in line with actual learning rules. Through these diverse strategies, we can generate a richer and more comprehensive initial population, laying a solid foundation for the subsequent genetic algorithm optimization process.
Crossover operation
Crossover operation is an important part of genetic algorithm to realize gene information exchange and recombination. It is like gene fusion in biological reproduction process, which generates offspring individuals with new characteristics by recombining the gene information of parent individuals. In this paper, we innovatively adopt the strategy of combining single-point crossover with multi-point crossover to give full play to the advantages of both crossover methods and improve the diversity and evolution efficiency of population.
Equation (5) is a mathematical description of single-point crossover.
Among them,
Multi-point crossover combines parental gene information in segments by randomly selecting multiple crossover points. For example, we randomly select three crossover points
Mutation mechanism
In the evolution process of the genetic algorithm, in order to prevent the population from falling into the local optimum, just as the biological evolution process needs to constantly introduce new mutations to adapt to environmental changes, we carefully designed a probabilistic mutation mechanism. As shown in equation (6), during the mutation process, 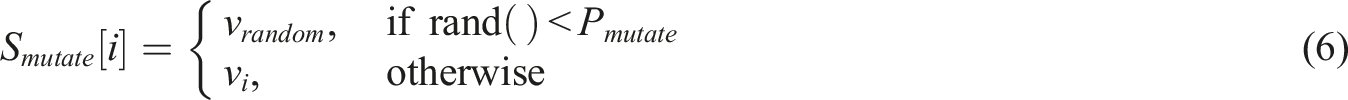
Here rand() is a function that generates random numbers, which
It should be noted that the mutated path needs to re-verify the constraints, which is a key step to ensure that the mutated path still meets the requirements of the actual learning path. If the mutated path violates any constraint such as time constraint and mastery constraint, we need to correct it or mutate it again to ensure the feasibility and effectiveness of the path.
Fitness function and selection strategy
The fitness function plays a vital role in the genetic algorithm. It is like an evaluation standard to measure the quality of each path. In this paper, the design of the fitness function is based on the objective function 
In the selection operation, in order to ensure that excellent individuals are more likely to be selected while maintaining the diversity of the population, we adopt the fitness proportional selection mechanism based on sorting in equation (8).
Early stopping strategy
In order to improve computational efficiency and prevent the genetic algorithm from wasting too much time and resources on unnecessary calculations, we set an early stopping condition for it. When the population fitness function does not improve significantly in multiple generations of iterations, it means that the algorithm may have approached the optimal solution or fallen into a local optimal solution, and continuing to iterate may not bring significant improvements. At this point, the algorithm terminates, thereby effectively reducing unnecessary calculations and improving the operating efficiency of the entire model. We can set a threshold. When
System integration and module interaction
The successful implementation of the model is inseparable from the close collaboration between various modules. The path optimization module, personalized recommendation module and user feedback adjustment module work together under a unified system architecture to complete the core task of learning path optimization.
Path optimization module
As one of the core engines of the entire system, the path optimization module uses genetic algorithms as a powerful driving force to generate candidate paths and continuously update the population. In this module, the genetic algorithm follows the steps we designed earlier, starting from population initialization, and continuously optimizes and screens the paths through crossover operations, mutation mechanisms, and the synergy of fitness functions and selection strategies. The optimized paths are like carefully polished works of art with higher quality and practicality. These optimized paths are transmitted to the personalized recommendation module through the efficient communication method of message queues, providing a solid foundation for subsequent personalized recommendations. The use of message queues is like an information highway, ensuring that path information can be quickly and accurately transmitted between different modules, avoiding congestion and loss during data transmission.
Personalized recommendation module
The personalized recommendation module is like a caring learning consultant. It builds an interest model based on the user’s historical behavior and deeply explores the user’s preferences and habits in the learning process. Using the powerful tool of deep learning technology, this module can accurately calculate the correlation between user interests and knowledge points. Equation (9) is the node scoring equation of the recommendation algorithm.
Among them,
User feedback adjustment module
The user feedback adjustment module is the dynamic optimizer of the entire system. By deeply analyzing user feedback data, it can keenly capture the user’s feelings and changes in needs during use. Based on this feedback information, the module dynamically adjusts the objective function weight and recommendation strategy according to equation (10) to achieve continuous optimization of the model.
Among them,
Experimental design
Experimental objectives
The experiment aims to verify the effectiveness of the genetic algorithm-based learning path optimization model in practical applications. Specific goals include: (1) testing the model’s ability to generate personalized learning paths; (2) verifying the improvement of the genetic algorithm’s improved strategy on the efficiency of path optimization; and (3) evaluating the adaptability and robustness of the system under different learning scenarios and user needs. The design of this experiment runs through theoretical verification and application exploration, and strives to comprehensively measure the performance of the model in multi-dimensional indicators.
Dataset and experimental environment
The experimental data set is based on real data from an online learning platform, and contains the learning behavior records of 5000 users. The data covers 1000 knowledge points in the field of integrated circuits. Each knowledge point is modeled through a directed graph, and the edge weights between nodes reflect the strength of the dependency relationship between the knowledge points. In addition, user data includes learning time, preferences, and historical scores, providing rich feature support for personalized recommendations.
The experiment was run in a Linux environment, and the code was mainly written in Python. The genetic algorithm module was optimized using NumPy, and the personalized recommendation module was implemented using PyTorch. The hardware environment included Intel Xeon CPU and NVIDIA A100 GPU to ensure efficient processing of large amounts of computing tasks.
Experimental variables and control group design
Experimental variables are divided into independent variables and dependent variables. Independent variables include genetic algorithm parameters (population size, crossover probability, mutation probability), personalized recommendation weight parameters (
The control group design includes three experimental conditions: (1) the improved genetic algorithm group (experimental group), which adopts the adaptive crossover and mutation strategy; (2) the traditional genetic algorithm group (control group 1), which does not use the improved strategy; (3) the non-personalized recommendation group (control group 2), which is optimized only based on the global path optimization goal. By comparing the experimental results of each group, the actual role of genetic algorithm improvement and personalized recommendation is analyzed.
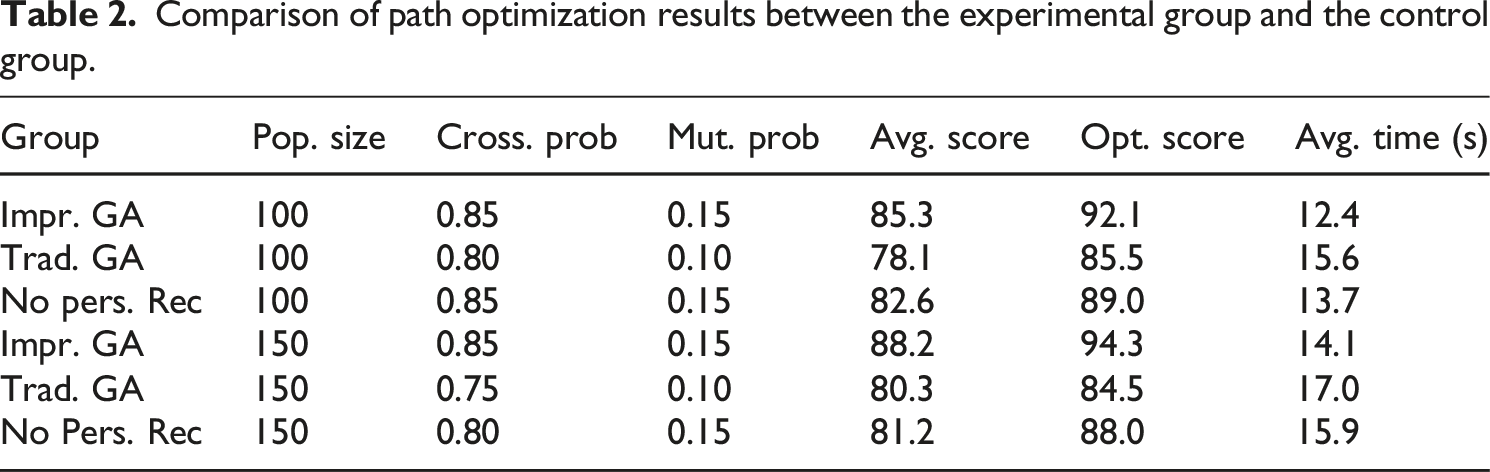
Comparison of path optimization results between the experimental group and the control group.
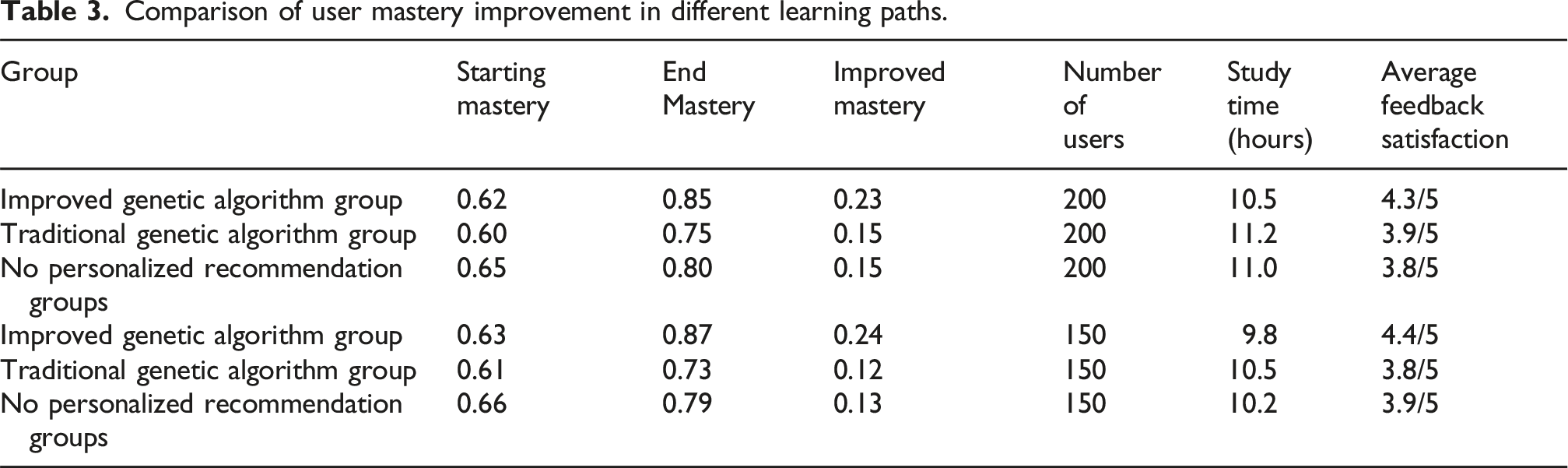
Comparison of user mastery improvement in different learning paths.
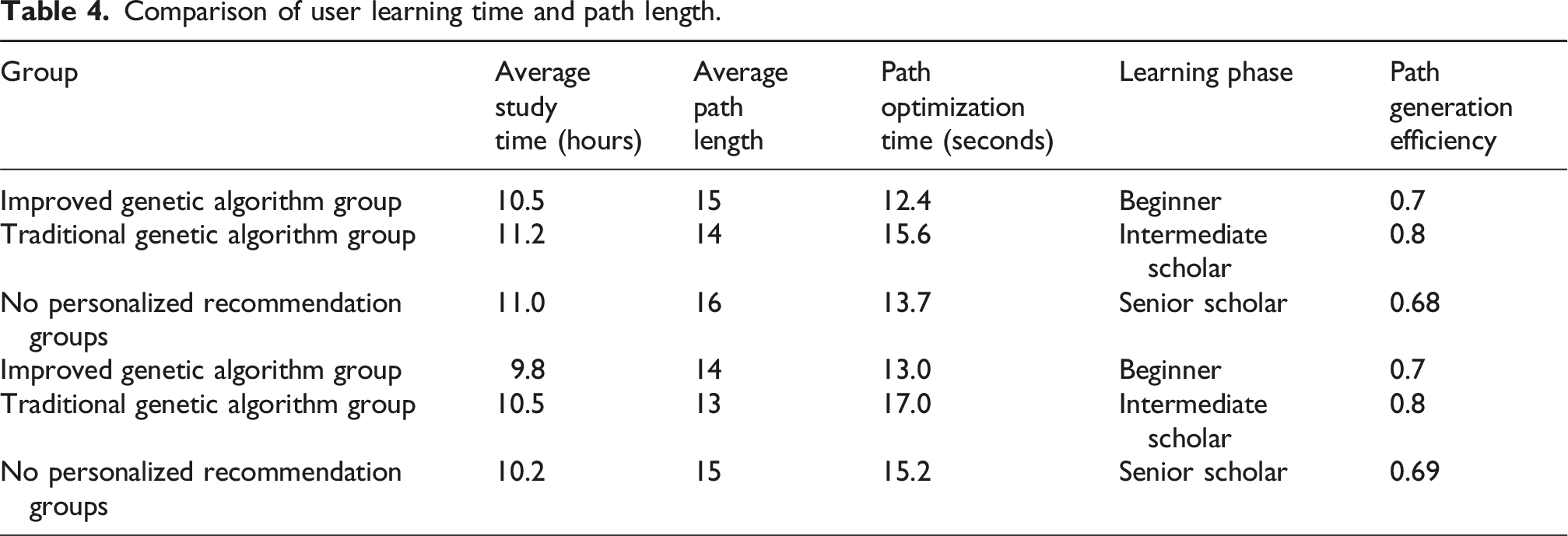
Comparison of user learning time and path length.
As shown in Figure 1, the optimization effect of the genetic algorithm varies significantly with the change of the crossover probability. When the crossover probability is 0.85, the average path score reaches 85.3, the optimal path score is 92.1, the path recommendation accuracy reaches 88.2%, and the user feedback satisfaction is also high, at 4.3/5. This is because the appropriate crossover probability can promote the gene exchange of individuals in the population, increase the diversity of the population, and thus make it more likely to search for a better solution. However, with a lower crossover probability such as 0.60, the average path score is only 79.2, the generation time is long, and the path recommendation accuracy is low, indicating that a crossover probability that is too low is not conducive to the algorithm’s search for the optimal path. The 0.85 crossover probability set in the improved genetic algorithm performs well in balancing search efficiency and path quality, and is suitable for application scenarios that require high-precision path optimization. Optimization effect of genetic algorithm under different crossover probabilities.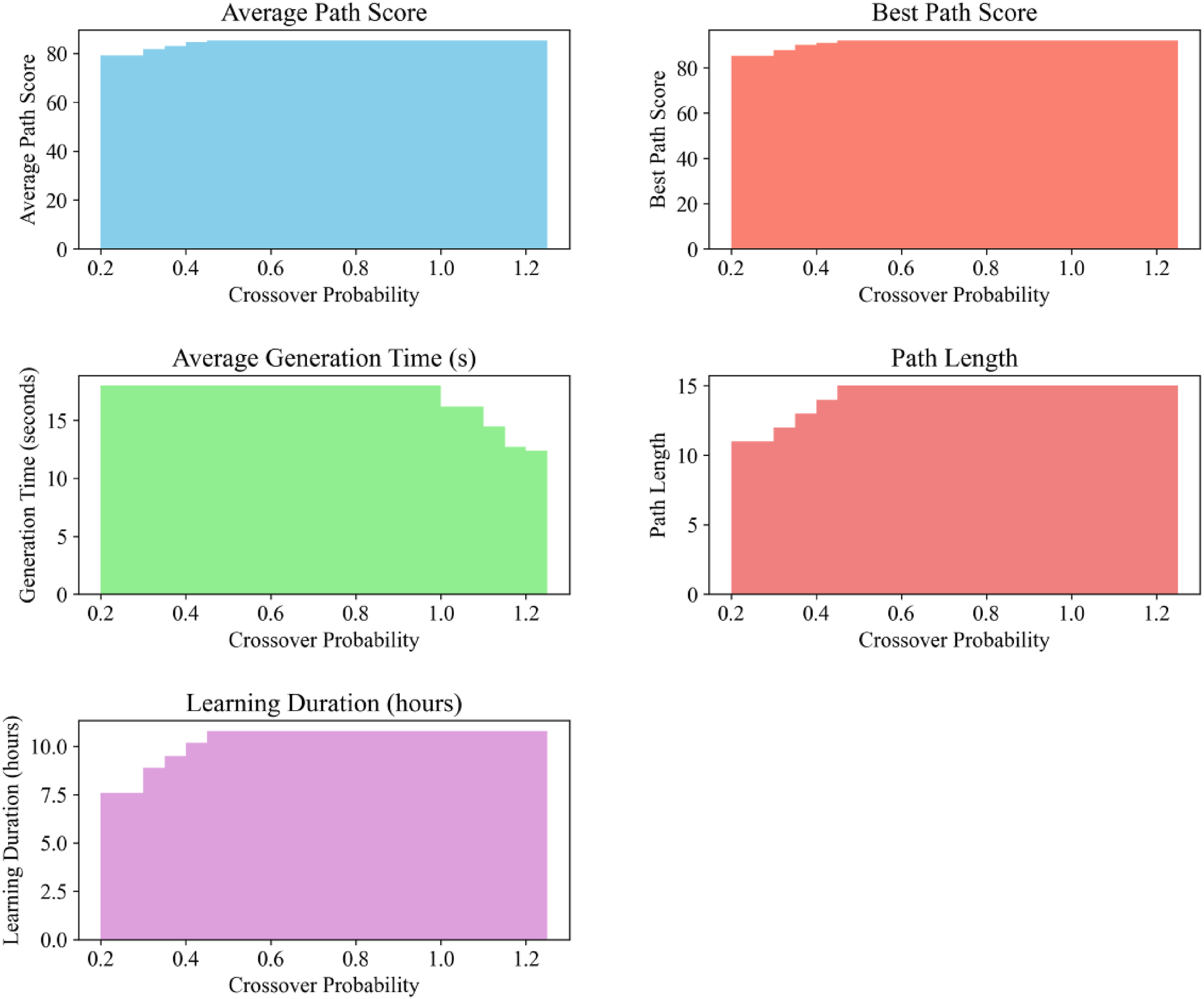
Path optimization effect under different personalized recommendation weights.
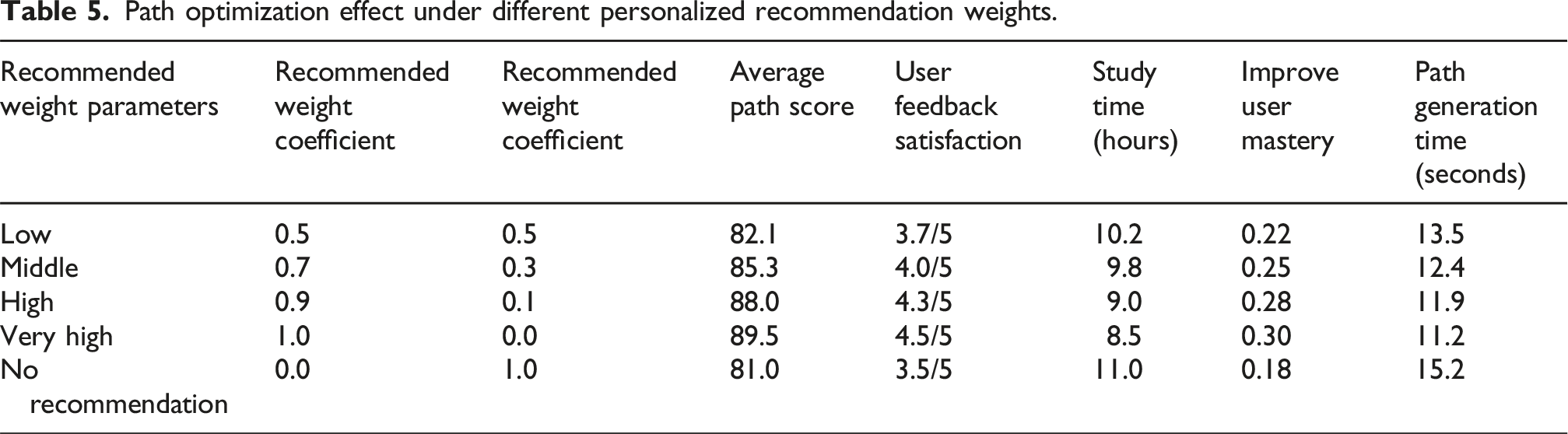
As shown in Figure 2, the change in population size has a positive correlation with the optimization effect of the genetic algorithm. As the population size increases from 50 to 250, the average path score increases from 81.2 to 89.3, the optimal path score increases from 89.0 to 95.2, the user mastery increases from 0.20 to 0.30, and the user feedback satisfaction also gradually increases. This is because a larger population size contains more solution space information, which can provide the algorithm with richer gene combinations and increase the probability of finding the global optimal solution. But at the same time, an increase in population size will also lead to a longer average generation time. For example, when the population size is 250, the average generation time is 16.2 s. The improved genetic algorithm can maintain good optimization effects at different population sizes, and is suitable for scenarios with different requirements for solution space exploration. The appropriate population size can be selected according to actual needs. Genetic algorithm optimization effect under different population sizes.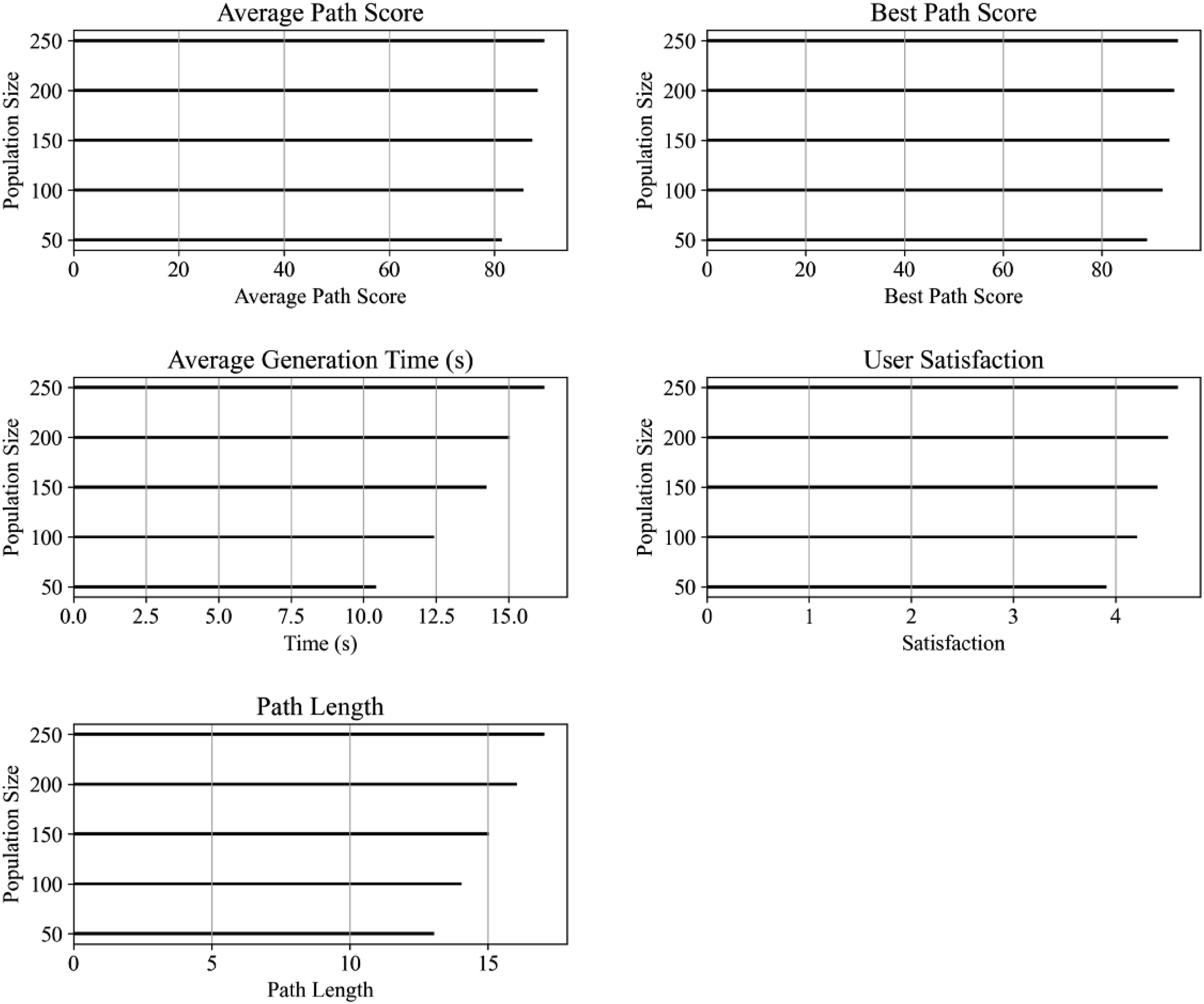
As shown in Figure 3, path length is closely related to user satisfaction. As the path length increases from 10 to 18, the average path score increases from 82.5 to 87.0, the optimal path score increases from 89.2 to 94.0, the user satisfaction also increases from 3.8/5 to 4.5/5, and the path recommendation relevance increases from 75% to 90%. Longer paths may contain more comprehensive information and better meet user needs, thereby improving user satisfaction. At the same time, the average path generation time also increases slightly with the increase of path length, but it is still within an acceptable range. This shows that in path planning, appropriately increasing the path length can improve the path quality and user experience within a reasonable generation time. The path generated by the improved genetic algorithm performs well in balancing path length and user satisfaction, and is suitable for path planning scenarios that pursue high user satisfaction. Relationship between different path lengths and user satisfaction.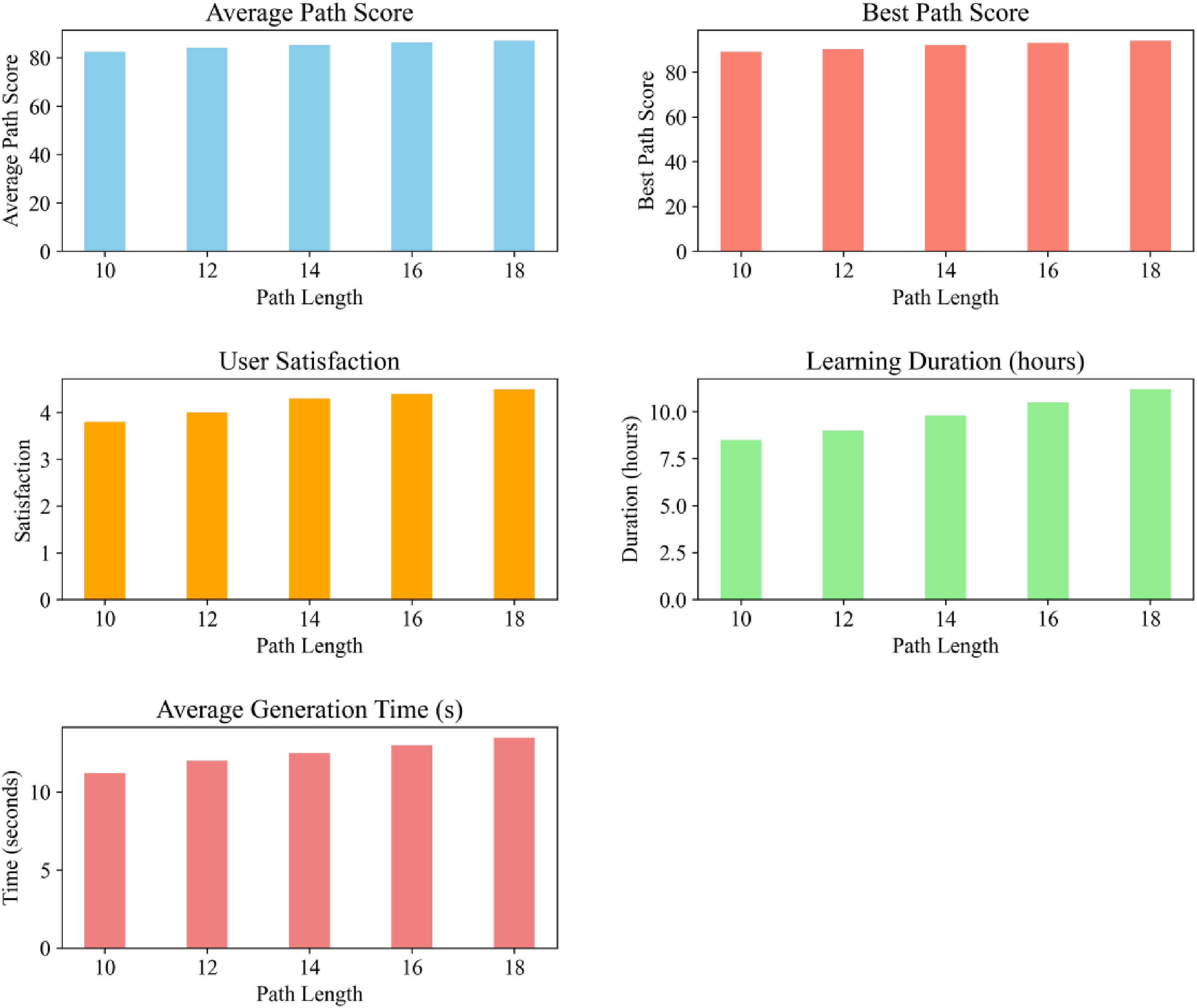
As shown in Figure 4, mutation probability is a key control parameter in the genetic algorithm, which has a significant impact on the path optimization results. From the table data, it can be seen that as the mutation probability gradually increases from 0.05 to 0.25, the average path score steadily increases from 82.3 to 86.2, the optimal path score also increases from 89.0 to 93.2, the user mastery increases from 0.22 to 0.30, and the user satisfaction also increases from 3.9/5 to 4.5/5 accordingly. This is because appropriately increasing the mutation probability can increase the diversity of population genes, avoid the algorithm from converging to the local optimal solution too early, and enable the algorithm to explore a better path. At the same time, the path generation time gradually shortens with the increase of the mutation probability, which shows that a higher mutation probability improves the search efficiency of the algorithm to a certain extent. The improved genetic algorithm shows good adaptability in the setting of the mutation probability, which can effectively improve the quality and efficiency of path optimization and is suitable for complex and changeable path optimization environments. Path optimization results under different mutation probabilities of genetic algorithm.
As shown in Figure 5, the initial population distribution plays an important role in the optimization effect of the genetic algorithm. The clustered distribution and highly clustered population distribution methods performed relatively well. Under the clustered distribution, the average path score reached 85.3, the optimal path score was 92.1, the user mastery was improved by 0.25, and the user feedback satisfaction was 4.3/5; when highly clustered, the average path score was 86.0, the optimal path score was 93.0, the user mastery was improved by 0.28, and the user feedback satisfaction was 4.4/5. This is because such a distribution makes the population have a certain structure and trend in the initial stage, and the algorithm can search for a better solution more efficiently based on these characteristics. Although random distribution and uniform distribution can also obtain good results, they are relatively lacking in certain directionality. All indicators are poor under abnormal distribution, because abnormal distribution may cause the population to contain too many unreasonable individuals, interfering with the normal search of the algorithm. The improved genetic algorithm can maintain a certain optimization ability under different initial population distributions, especially when facing an initial population with a certain structure, it can give full play to its advantages and quickly find high-quality paths, which is suitable for path optimization tasks under different initial conditions. Relationship between genetic algorithm optimization effect and initial population distribution.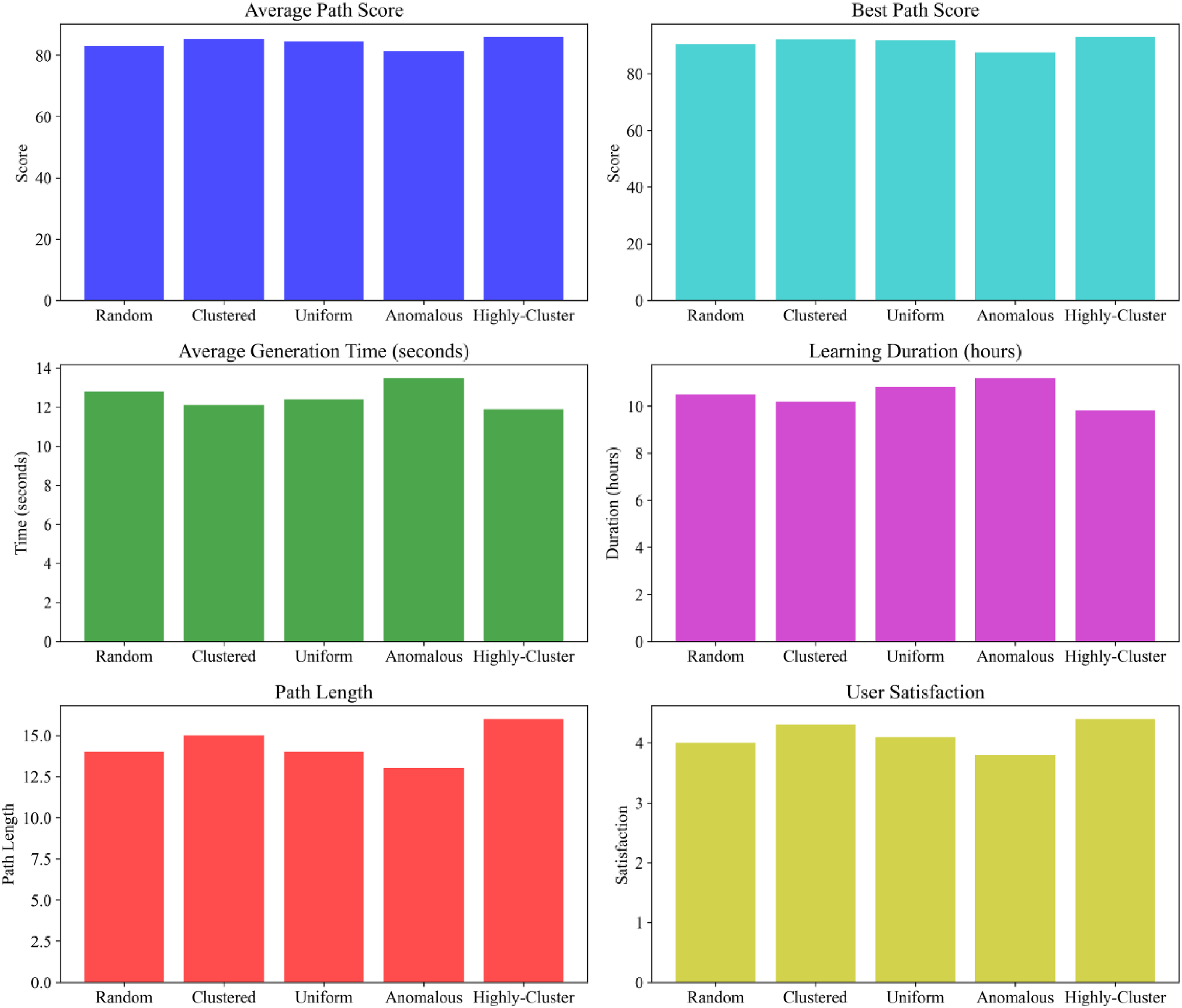
As shown in Figure 6, users at different learning stages have different needs for path optimization, and the improved genetic algorithm can adapt to this difference well. As the learning stage gradually improves from beginners to senior experts, the average path score continues to rise from 82.5 to 87.2, the optimal path score increases from 89.0 to 94.0, the user mastery increases from 0.20 to 0.30, and the user satisfaction also increases from 3.9/5 to 4.5/5. In the beginner stage, the shorter learning time of 8.5 h and the relatively simple path length of 14, combined with the lower average generation time of 12.8 s, meet the needs of beginners to get started quickly; as the learning stage deepens, users need more complex and comprehensive learning paths. The path length generated by the improved genetic algorithm gradually increases, and the score continues to improve. It can provide users at different stages with the optimal path that meets their learning ability and knowledge reserves, effectively improve the learning effect, and is suitable for learning path planning scenarios at all stages. Path optimization effects at different learning stages.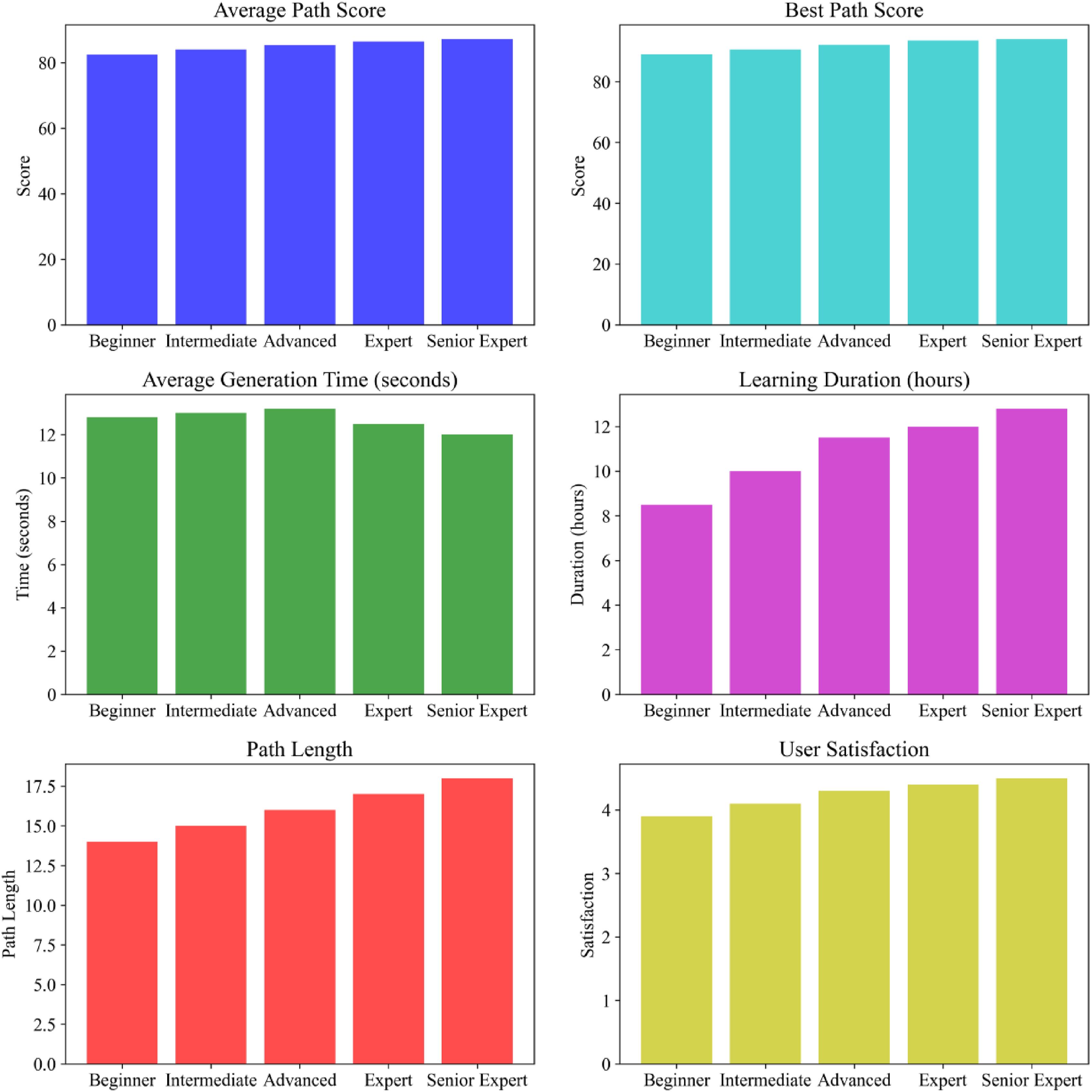
Discussion
According to the research results, it is found that the learning path planning model based on genetic algorithm optimization performs well in generating personalized learning paths, improving path optimization efficiency, and adapting to different learning scenarios and user needs. The improved genetic algorithm group outperforms the traditional genetic algorithm group and the non-personalized recommendation group in key indicators such as average path score, optimal path score, mastery improvement, and user feedback satisfaction. This shows that the improved genetic algorithm and personalized recommendation strategy effectively improve the quality of learning path planning and user experience. The results are consistent with the existing literature on the research on genetic algorithms in path planning and personalized recommendation, further verifying the application potential of genetic algorithms in this field. The limitations of this study are that the data set only comes from a certain online learning platform, which may affect the universality of the results; and the model only considers some constraints such as learning time and mastery, and does not cover all factors affecting the learning path. These limitations may limit the adaptability of the model in complex real-life scenarios. Future research can expand the scope of the data set, include more learning influencing factors, optimize the model to improve its performance in complex and changeable real-life scenarios, and provide more accurate and efficient learning path planning services for a wider range of learners. This study provides new insights into learning path optimization and personalized recommendation system design in the field of integrated circuit education, which has important practical significance, especially in improving learning efficiency and personalized services.
Conclusion
Extending the approach beyond IC faces several hurdles. First, prerequisite graphs differ in density and semantics across disciplines (e.g., lab competencies in health training vs abstract theory in mathematics), complicating ontology alignment and transfer of weights. Second, assessment heterogeneity and rubric drift can distort mastery signals, requiring normalization and domain-specific reliability checks. Third, fairness and accessibility constraints may conflict with pure optimality—certain cohorts need time buffers or alternative sequences—which must be encoded as explicit constraints. Finally, cross-program deployments magnify compute and data-governance demands; privacy-preserving aggregation and robust drift detection become necessary to sustain closed-loop updates at scale.
This study aims to design and implement an integrated circuit learning path planning and personalized recommendation system based on genetic algorithms. It innovatively abstracts complex learning path planning into a combinatorial optimization problem, and solves the problem of personalized learning path planning by constructing a scientific objective function, improving the key links of the genetic algorithm, and realizing the collaboration of system modules. The study found that the improved genetic algorithm is significantly better than the traditional algorithm and the non-personalized recommendation in various indicators, and effectively improves the learning path score, user mastery and satisfaction. However, the study has limitations such as a single data set source and incomplete consideration of constraints. Future research can expand the data source, improve the constraints, and further optimize the model, which is expected to promote the development of integrated circuit education and personalized recommendation systems and improve learning effects and efficiency.
As foundation models and contextual bandits mature, our framework can infer prerequisite relations from unstructured artifacts, augment sparse graphs, and personalize exploration–exploitation at session level. Surrogate modeling and neuroevolution can guide mutation and crossover with learned reward landscapes, while federated optimization preserves privacy across institutions. These upgrades keep the optimizer data-efficient, explainable and robust as curricula expand and learner behavior shifts. The system can integrate with modern adaptive platforms via LTI-compliant services and xAPI or Caliper event streams to ingest fine-grained learning traces. Real-time mastery estimates from Bayesian knowledge tracing or cognitive diagnosis can update our dynamic weights, while A/B or bandit-driven policy selection can govern when to re-plan paths. Such interoperability with LMSs like Moodle or Canvas strengthens deployment readiness and enhances forward-looking adaptability in multi-course, multi-institution settings.
The study formalizes learning path design as a constrained multi-objective optimization with dynamic weighting driven by behavioral feedback, linking operational research with learning sciences. We introduce feasibility-aware genetic operators on prerequisite graphs and a closed-loop coupling between optimization and recommendation. This yields a general pattern for theory: represent curricula as constraint graphs, define measurable objectives across mastery–time–relevance, and adapt weights from observed signals. Empirical results indicate Pareto improvements, offering a testable blueprint for future theoretical and algorithmic work in education optimization.
Deployments should ensure fairness, privacy, and learner autonomy. We recommend (i) auditing disparate impact across demographics and adding fairness constraints to the objective; (ii) privacy-preserving data flows (federated updates or differential privacy) for trace collection; (iii) transparent model cards and path rationales to support instructor oversight; (iv) opt-out and controllable exploration to avoid over-prescription; and (v) accessibility checks so paths respect accommodations. Embedding these safeguards in the optimization loop strengthens trust and aligns personalization with educational values.
Footnotes
Author contributions
Lihua Dai: Conceptualization, Xuemin Cheng: Methodology, Lei Cheng: Investigation, Ben Wang: Investigation, Junyi Xu: Methodology, Hao Wang: Writing—review and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: this work was supported by the Key Project of Jiangsu Higher Education Teaching Reform Research—“Research on Digitalization of Virtual Simulation and Practical Training Teaching,” “Qinglan Project” of Higher Education Institutions of Jiangsu Province, Young academic leaders sub-project, also supported by the research start-up fund of Suzhou Vocational Institute of Industrial Technology (No. 2017kyqd002).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data supporting the findings of this study are available within the article.