
Abstract
This paper presents AT-StarGAN-GP, an enhanced StarGAN architecture with gradient penalty and dual-attention mechanisms for structural health monitoring. The proposed model overcomes limitations of conventional GANs in structural vibration analysis by integrating temporal and channel attention to capture global temporal dependencies and local feature interactions. It employs a refined Wasserstein loss with gradient penalty and adaptive λ-scaling to stabilize training and balance multiple objectives. The model achieves high accuracy in modal frequency detection, producing nearly identical real and synthetic estimations across all modes. Damping ratio estimations show deviations below 5%, confirming precise structural response modeling. Frequency-domain and singular value decomposition (SVD) analyses yield mean magnitude-squared coherence (MMSC) values between 0.973 and 0.989, validating stability and fidelity. In terms of computational efficiency, AT-StarGAN-GP processes all 30 joints in 313.45 ms (∼10.45 ms per joint), maintaining real-time feasibility and outperforming CycleGAN (≈9 s) while matching Vanilla StarGAN performance. Although Eigen perturbation methods (Modal Assurance Criterion (MAC), Damage Localization Vector (DLV), Flexibility, Eigenvalue) are faster (0.25–12.67 ms), they lack generative capability essential for data recovery and nonlinear damage modeling. Sensitivity analysis shows optimal coherence (MMSC > 0.97) when λ-parameters are moderately weighted (10–15), and attention is fully enabled. Attention mechanisms significantly enhance temporal and inter-sensor spectral alignment, confirming AT-StarGAN-GP as a real-time, generative, and accurate solution for vibration-based SHM.
Keywords
Introduction
Civil engineering employs structural health monitoring (SHM) as a crucial condition assessment paradigm with the latest improvements in the artificial intelligence (AI) and deep learning (DL) techniques. By incorporating machine learning into SHM, traditional monitoring strategies underwent significant transformation, leading to improved data processing efficiency and superior anomaly detection capabilities. DL techniques, especially through the use of neural networks, present exceptional possibilities in structural damage detection. The advancement of outlier detection algorithms along with increased computer processing speed allows structures to be monitored through advanced anomaly detection techniques in quasi-real-time techniques.1–4 The modern use of neural networks has become an effective approach to monitor structural damage in large-span bridges.5–7 The use of convolutional neural networks (CNNs) delivers a significant advancement in processing the enormous data outputs from SHM systems. The hybrid SHM approach utilizes recurrent neural networks together with other networks to achieve effective damage detection, according to the studies by Hung et al. 8 and Bui-Tien et al. 9 Intelligent health monitoring systems need AI models with robust adaptability for their effective development. Robust model reconstruction stands crucial in tunnel structure monitoring because it allows AI-based models to precisely evaluate structural changes, according to research presented in the studies by Cha et al. 10 and Xu and Yang 11 Rapid infrastructure integrity assessment after earthquakes becomes possible through improvements in the field, which include the implementation of cumulative absolute velocity features. 12 The innovations tackle the issues created by the curse of dimensionality that affects traditional damage detection procedures.
Unsupervised learning techniques have gained significant interest for SHM applications throughout the last few years. 13 The absence of adequate real structural failure information has compelled researchers to adopt novelty detection methods for essential use. This trend aligns with findings that highlight the rapid growth of soft computing algorithms for infrastructure monitoring.14,15 Research exploring CNN-based anomaly detection methods that leverage multiple information sources for SHM further supports this trend.16,17 Hybrid models that use combinations of multiple AI methods demonstrate substantial potential for reliable SHM systems. Researchers have developed machine learning systems that use raw dynamic measurements and statistical indicators to perform SHM functions. 18 Artificial immune systems have proven effective for mechanical structure monitoring in recent studies, while this development represents a growing interest in hybrid damage detection methods. 19 Different research works show DL and AI technologies have revolutionized SHM applications through algorithmic power despite big data challenges. 20 SHM applications now rely on DL because this approach enables the analysis of extensive datasets while running sophisticated anomaly detection and damage assessment algorithms. Future investigators should drive research to integrate multiple AI techniques, which would boost the operational performance and reliability of SHM systems. Physics-based models integrated with AI approaches create opportunities to improve interpretation and reliability performance in actual field deployments.
Recent studies highlight the growing importance of data-driven and vibration-based learning approaches for structural frame systems. A CNN-based deep-learning model was developed for a steel frame with bolted connections, using time–frequency scalogram images of vibration responses to classify bolt-loosening states (fully tight, hand-tight, and fully loose). The model achieved training and validation accuracies of 100% and 98.1%, respectively, and proved robust against unseen datasets, demonstrating strong potential for automated monitoring of bolted joints. 21 Similarly, a vibration-based machine learning framework using a Bag-of-Features algorithm and speeded-up robust features effectively classified undamaged and multiple damage cases in a steel frame structure under varying environmental conditions. 22 Together, these studies show that vibration-driven learning models can capture subtle variations related to bolt loosening and joint degradation, supporting the development of reliable SHM strategies.
Generative adversarial networks (GANs), along with variational auto encoders (VAEs), function as important tools in SHM through synthetic development of damage scenario data which helps solve structural monitoring data limitations. The use of these models strengthens damage identification techniques by producing artificial yet plausible structural response outputs. Research in the study by Chen et al. 23 shows that using synthetic data with real measurements enhances prediction reliability and model robustness for various damage conditions. Recent advances in SHM have seen the adoption of GANs and their variants to address key challenges such as missing data reconstruction, data scarcity, and damage detection. One notable approach integrates the Wasserstein GAN with gradient penalty (WGAN-GP) and the U-net architecture to effectively reconstruct missing vibration signals in SHM data. 24 This WGAN-GP-Unet model leverages the U-net’s skip connections to preserve both low- and high-level signal features while employing a convolutional discriminator with gradient penalty to stabilize adversarial training. A compound loss function combining adversarial loss and mean square error (MSE) ensures accurate signal recovery, validated on both simulated bridge models and real-world data from the Canton Tower. The model surpasses traditional methods, including GAN-Unet, plain U-net, Bidirectional Long Short-Term Memory (BiLSTM), and long short-term memory (LSTM) in reconstruction accuracy, demonstrating superior capability in learning detailed signal characteristics and reliable data recovery.
Similarly, Rocco et al. 25 proposed a GAN-based autoencoder framework trained entirely on synthetic earthquake-induced structural response data, achieving high classification accuracy and strong correspondence between generated and target signals. Their model enables bidirectional mapping between input and latent spaces, facilitating damage state estimation without requiring real damaged data. This approach holds promise for real-time SHM applications, particularly in scenarios with limited damaged data availability. Complementing these studies, Xu et al. 26 developed a deep convolutional GAN with an encoder–decoder generator designed to reconstruct missing SHM data caused by sensor faults or transmission errors. Their model effectively preserves both global and local signal features, demonstrating robustness in reconstructing realistic signals from strain-gauge data under severe data loss conditions (up to 80%). The reconstructed data also support subsequent structural analyses like modal identification and load decomposition, though performance may degrade if structural damage occurs that was not represented in training. Addressing data scarcity and class imbalance, Luleci et al. 27 utilized a one-dimensional (1-D) WGAN-GP to generate synthetic vibration data resembling real damage scenarios. Their deep CNN classifier trained on synthetic and real data achieved similarly high accuracies, underscoring GANs’ potential to improve model training where damaged data are limited. Expanding on data recovery, a WGAIN-GP model was introduced for missing data imputation in bridge monitoring, successfully recovering acceleration signals with up to 90% missing data. 28 This framework demonstrated superior performance over baseline imputation models, enabling accurate modal analysis with minimal error and thereby enhancing SHM system reliability.
The complex architectures of GANs include CycleGAN 29 and StarGAN 30 that perform domain translation of images while omitting the need for paired examples. The models provide the SHM field with a method to create synthetic damaged images from existing undamaged structures, which helps to extend the available training dataset when damage samples are limited. A security system uses two-stage GAN protocols for damage detection by applying deep convolutional GAN identification, followed by conditional GAN localization procedures. 31 GANs show promising performance for enabling unsupervised SHM analytics, and they enhance damage detection precision through this approach. VAEs 32 represent one of the approaches that researchers have incorporated into SHM to extract features. The detection of damage through unsupervised methods can be achieved by using stacked autoencoders as a specific VAE to extract sensitive features from acceleration measurements. 33 The methodology demonstrates that generative models simultaneously strengthen dataset enrichment and feature extraction processes, which allows easier identification of structural damage indicators. In addition to time-series data reconstruction, GANs have been increasingly applied to image-based SHM tasks, particularly crack detection and damage classification. For instance, super-resolution GANs have been employed to enhance low-quality crack images, improving clarity and overcoming limitations of low-resolution datasets. 34 CycleGAN-based models have also been adopted for translating between undamaged and damaged structural image domains, allowing effective damage detection even without paired datasets. 35 Furthermore, GANomaly frameworks trained on healthy-state images have demonstrated promising anomaly detection capabilities for infrastructure inspection imagery, highlighting the versatility of generative models in vision-based SHM. 36
While most image-based GAN applications focus on crack or surface defect detection, these studies collectively demonstrate how generative models can enhance data quality, augment limited datasets, and facilitate unsupervised damage identification across visual inspection scenarios. However, such methods differ fundamentally from the signal-based approaches emphasized in this study, where GANs are leveraged for vibration-domain structural response generation and translation rather than visual feature synthesis.
GANs and VAEs enhance SHM through anomaly detection and synthetic data generation. As shown in the study by Mao et al., 37 these models improve damage detection reliability by reconstructing standard patterns and identifying structural anomalies while addressing limited dataset challenges through realistic synthetic data generation. An important capability provided by CycleGAN enables domain adaptation solutions in SHM systems by moving between undamaged and damaged states, regardless of sample pairing needs. The cycle consistency mechanism in CycleGAN consists of two generator networks that enable domain conversion and extend training data. The research in the study by Luleci et al. 38 uses CycleGAN to convert healthy structural data into synthetic damage states, thereby improving damage detection systems. The emergence of StarGAN became necessary because CycleGAN faced issues with multi-class damage scenarios and multiple structural defects, as demonstrated in the study by Liu et al. 39
DL systems developed attention-based solutions together with combination techniques to solve time-series analytical problems. These new advancements overcome excessive time dependency recognition as well as sparse data issues while processing complex multiple variable interactions. The GWOCS-VMD-CNN-Transformer framework from the study by Li et al. 40 achieves better dynamic system prediction accuracy by connecting variational mode decomposition with Transformer systems. Research in the study by Jiang et al. 41 presents frequency-enhanced channel attention mechanism, which employs attention mechanisms to achieve frequency-domain analysis for improved pattern recognition and robustness in prediction tasks. LSTM networks excel at handling sequential data dependencies through efficient information retention. As demonstrated in the study by Huang and Yang, 42 HybridCBAMNet combines convolutional features, recurrent layers, and attention mechanisms to improve classification and generalization. In Internet of Things applications, meta-MWDG 43 utilizes dual-graph attention with wavelet decomposition for anomaly detection, while Short-Time Fourier Transform Temporal Convolutional Attention Network (STFT-TCAN) 44 integrates short-time Fourier transform with temporal convolution and attention mechanisms to enhance cyber-industrial system monitoring through both time- and frequency-domain analysis.
DL frameworks have significantly improved through the integration of time–frequency analysis and attention mechanisms. As demonstrated in the study by Liu and Huang, 45 DualDomain-AttenNet combines these approaches to enhance Electroencephalogram signal classification accuracy, particularly in motor imagery tasks. Similarly, the CNN-LSTM framework 46 leverages attention mechanisms with phase space reconstruction to improve chaotic time-series prediction, highlighting how the combination of time- and frequency-domain analysis strengthens complex temporal pattern recognition. Recent advancements in time-series analysis have produced specialized architectures with attention mechanisms for domain-specific applications. As shown in the study by Wang et al., 47 combining feature- and temporal-level attention mechanisms improved strip deviation predictions in hot rolling processes. Similarly, the dynamic routing sparse attention model 48 demonstrated efficient time series modeling by optimizing learning and computational requirements. Drawing from these successes, we adapt attention mechanisms for SHM applications, enabling our model to capture both local and global temporal patterns in vibration signals that traditional CNN architectures might miss.
The integration of Transformer architectures with GANs has emerged as a promising paradigm for addressing critical challenges in SHM applications. Mousavi et al. 49 addressed the critical challenge of data scarcity and class imbalance in DL applications for bridge health monitoring within digital twins by proposing a novel data augmentation strategy. Their approach leverages a Transformer-based time-series WGAN-GP to generate synthetic acceleration data that closely mimics real dynamic responses of bridge structures. The fidelity of the generated data was rigorously validated using both conventional similarity metrics and a novel multi-head self-attention LSTM autoencoder, which is capable of capturing complex, non-linear temporal patterns often overlooked by traditional metrics. Their method not only improves dataset balance but also enhances the overall performance of DL-based damage detection models, while significantly reducing the computational burden and data collection costs compared to existing models like 1-D WDCGAN-GP. Their frequency-domain analysis further confirmed the capacity of the synthetic data to replicate essential signal characteristics, underscoring the potential of advanced generative models to support reliable and efficient bridge digital twin frameworks.
The broader computer vision community has extensively reviewed the recent advancements of Transformer-based GANs, highlighting their growing prominence between 2020 and 2023. 50 These Transformer-enhanced GANs capitalize on the ability of Transformer architectures to model global relationships in feature spaces, complementing the local feature extraction strengths of conventional CNNs. The surveyed literature demonstrates that integrating Transformers into GAN generators, often combined with convolutional encoders and decoders in U-shaped architectures, has led to significant improvements in image and video synthesis tasks, including high-resolution image generation, image-to-image translation, inpainting, and video translation. Notably, models such as StyleGAN enhanced with Swin Transformers have achieved state-of-the-art performance on benchmark datasets. While CNNs remain the dominant choice for discriminators, emerging works have also explored Transformer-based discriminators to further enhance synthesis quality. In addition, research trends emphasize the adoption of novel loss functions, attention mechanisms, and cross-attention modules to improve perceptual and adversarial training outcomes.
Specifically addressing SHM applications, Zheng et al. 51 proposed a novel transformer-based GAN framework to address the persistent challenge of data loss in long-term monitoring of large-scale structures. Their approach employs an encoder–decoder architecture with a Transformer backbone enhanced by a discrete wavelet transform to capture multi-scale frequency information, alongside skip connections to facilitate information flow between encoding and decoding stages. A key innovation lies in a multi-level wavelet-based discriminator designed to evaluate the realism of the reconstructed signals’ wavelet spectra, compelling the generator to accurately reproduce both low- and high-frequency components. Validation on vibration data from two real-world bridges, one pedestrian footbridge under ambient pedestrian excitation and a large suspension bridge subjected to typhoon-induced nonlinear responses, demonstrated the method’s robustness even under severe data loss scenarios, reconstructing multiple missing channels with high fidelity. Comparative analysis against three state-of-the-art models confirmed superior reconstruction quality, particularly in the high-frequency domain, which is critical for dynamic response accuracy. The study highlights the potential for leveraging extensive SHM datasets to pre-train Transformer models in a self-supervised fashion, akin to successes in natural language processing and image processing, suggesting promising avenues for improved SHM applications with minimal fine-tuning.
Building upon these developments, researchers have further explored pure Transformer-based GAN architectures for time-series applications. A notable example is the AnoFormer model, which was specifically designed for time-series anomaly detection. 52 This model features specialized preprocessing and embedding techniques along with a two-step masking training strategy that significantly enhanced detection accuracy on benchmark datasets. These advancements underscore the growing potential of Transformer-based architectures in SHM applications, with ongoing research focusing on reducing inference time and handling longer time-series data. The convergence of Transformer architectures with GAN frameworks represents a significant evolution in generative modeling, offering enhanced capabilities for capturing long-range dependencies and complex temporal patterns that are particularly relevant for structural monitoring applications.
Collectively, these studies highlight the expanding role of GAN architectures in SHM, offering versatile tools for missing data reconstruction, synthetic data generation, image enhancement, anomaly detection, and class imbalance mitigation. Their demonstrated success in both time-series and image domains addresses critical challenges of data scarcity, quality, and reliability, paving the way for more robust and accurate SHM applications.
This study presents AT-StarGAN-GP as an advancement over traditional Vanilla StarGAN architecture, introducing fundamental architectural innovations that address critical limitations in SHM applications. While Vanilla StarGAN employs basic label concatenation with standard instance normalization and conventional convolutional discriminator design, AT-StarGAN-GP introduces conditional instance normalization (CIN) that dynamically adapts normalization parameters based on specific damage scenarios, enabling scenario-specific feature learning capabilities entirely absent in the baseline approach. The most significant architectural distinction lies in the discriminator design, where Vanilla StarGAN relies solely on convolutional layers for feature extraction without temporal awareness, whereas AT-StarGAN-GP implements a sophisticated dual-pathway architecture combining CNN spatial pattern recognition with bidirectional LSTM networks for temporal dependency modeling. This fundamental difference enables AT-StarGAN-GP to capture both spatial damage distributions across structural joints and temporal evolution patterns critical for accurate structural health assessment. The attention mechanism integration represents a shift from Vanilla StarGAN’s basic processing approach. This attention-enhanced feature extraction enables superior recognition of both global structural patterns and localized damage signatures that conventional convolutional approaches miss. Signal fidelity preservation demonstrates another crucial distinction where Vanilla StarGAN operates with basic adversarial, classification, reconstruction, and gradient penalty losses, while AT-StarGAN-GP introduces specialized frequency domain validation through power spectral density (PSD) matching using Welch’s method and SVD alignment for modal characteristic preservation. These advanced loss functions ensure that generated structural response data maintains engineering physics principles necessary for reliable damage assessment, preventing unrealistic sensor patterns that could compromise diagnostic accuracy. The adaptive optimization framework in AT-StarGAN-GP provides dynamic lambda adjustment based on real-time signal quality metrics and classification performance, enabling continuous optimization of loss component balance that Vanilla StarGAN’s fixed parameter approach cannot achieve. Mode collapse detection and corrective mechanisms prevent convergence on oversimplified damage representations through cross-class and within-class diversity monitoring, maintaining output variety essential for comprehensive SHM that Vanilla StarGAN cannot guarantee. Feature fusion capabilities represent another critical advancement where AT-StarGAN-GP combines CNN spatial analysis with LSTM temporal modeling through attention-enhanced integration, creating a comprehensive understanding of damage evolution patterns that Vanilla StarGAN’s simple convolutional architecture cannot achieve. The enhanced gradient penalty implementation provides superior training stability compared to basic adversarial loss, while controlled noise injection with adaptive adjustments enhances robustness against real-world sensor variations and environmental disturbances. The comprehensive validation framework in AT-StarGAN-GP includes frequency-domain analysis, modal characteristic preservation, and gradient penalty optimization that establishes superior benchmark performance compared to Vanilla StarGAN across all tested noise levels and downsampling scenarios. These systematic improvements demonstrate measurable performance gains in damage classification accuracy, signal fidelity preservation, and synthetic data realism essential for practical SHM applications, positioning AT-StarGAN-GP as a notable development in generative adversarial network architectures for infrastructure monitoring systems.
The dataset utilized in this study originates from the Qatar University Grandstand Simulator (QUGS). Structural damages were simulated by modifying the beam-to-girder connections, where bolts were either loosened or left intact, resulting in 30 distinct damage scenarios in addition to an undamaged reference state. The loosening or tightening of the bolts at each node alters the local structural behavior, affecting the vibrational response of the system. These variations in bolt conditions at each node lead to changes in the frequency and amplitude of the vibrations, which are captured by the sensors placed at each measurement point. As a result, each damage scenario corresponds to a unique set of sensor data reflecting the structural changes due to the induced damage. The model then utilizes these variations in the vibrational patterns to train the AT-StarGAN-GP, allowing it to improve damage detection and generate realistic synthetic data by capturing both local and global structural behavior changes. This process ensures that the model can simulate different damage scenarios accurately and preserve the undamaged state features for comparison. Our study aims to address the key challenges encountered in generating realistic synthetic data for damage detection in SHM. The contributions of our innovations can be summarized as follows:
CIN: By using CIN layers, we tailor the generation process to specific damage scenarios. This ensures that the generated signals retain their fundamental structural characteristics.
Dual-head discriminator: The discriminator model not only determines whether the signals are real or fake but also classifies them into damage categories. This approach ensures that the generated data is both realistic and contextually appropriate.
Multimodal loss functions: By integrating frequency-domain and structural consistency losses into the model, we ensure that the generated data preserves its physical integrity. This step addresses the shortcomings identified in previous works.
Mode collapse prevention: Mode collapses are actively monitored during training and corrected to ensure the generation of diverse and meaningful data across different damage scenarios.
Adaptive lambda optimization: The model dynamically adjusts the importance of different loss components, balancing realism and damage-specific features.
Self-attention mechanism integration: The eight-head self-attention mechanism integrated into the model enables the capture of long-range dependencies in vibration signals. This mechanism ensures temporal alignment across different damage scenarios and preserves structural features. This innovation has been developed based on recent successes in time-series modeling, specifically adapted to structural vibration data.
The novelty of this study lies in the application and adaptation of time-series modeling techniques and GAN architectures to structural vibration datasets specifically for SHM, addressing a critical challenge in SHM: the scarcity of labeled damage data. Real-world acquisition of such data is typically costly, time-consuming, and often constrained by safety and logistical considerations. To overcome this limitation, the proposed method employs high-fidelity synthetic SHM data generation, enabling the augmentation of existing datasets. This significantly enhances model generalization and robustness in detecting structural damage under diverse operating conditions. A key strength of the proposed approach is its computational efficiency. As discussed in “Computational efficiency” section, the method achieves real-time performance while maintaining high accuracy in data reconstruction and translation, and its linear time complexity supports computational scalability for multi-joint SHM simulations.
Future studies will focus on extending the approach to accommodate such data characteristics, ensuring broader applicability to practical SHM deployments. Another central innovation of this work is the development of a transfer learning system aimed at multi-class damage scenario translation. Training is conducted on a benchmark dataset that includes 1 undamaged case and 30 distinct damage scenarios, each representing bolt-loosening at a different joint. Once trained, the model can translate from the undamaged state to any of the 30 damage scenarios, or vice versa, using only a single input. This SHM-specific capability is a marked departure from earlier studies, which typically required separate models or training procedures for each damage case. This capability is made possible through the integration of the StarGAN architecture, a generative adversarial network designed specifically for multi-domain translation. Unlike traditional GANs that require separate generator-discriminator pairs for each class, StarGAN utilizes a unified generator and discriminator, allowing for seamless translation across multiple damage scenarios. This not only streamlines the training process but also significantly enhances scalability and practicality, particularly in environments where collecting labeled data for every possible damage state is unfeasible.
In summary, the proposed approach is distinguished by its computational frugality and algorithmic scalability across a wide range of simulated damage scenarios. These advantages make it a powerful tool for synthetic data generation, damage scenario forecasting, and SHM system calibration, particularly in contexts where real damage data are sparse or entirely unavailable. The second section, “Methodology,” outlines the underlying framework and implementation strategy; the third section, “Data processing and implementation,” details the synthetic data generation pipeline, including damage modeling and scenario creation; and the fourth section, “Results analysis,” evaluates the model’s performance and discusses its implications for practical SHM applications.
Methodology
This section outlines the methodology used to generate synthetic structural damage data and classify various damage scenarios in SHM using the proposed AT-StarGAN-GP approach. The method is organized into three subsections: problem formulation, training objective, and dynamic optimization. These subsections describe the model’s structure, the losses used during training, and the optimization techniques applied to ensure that the generator produces diverse and realistic damage scenarios.
The AT-StarGAN-GP integrates DL techniques with signal processing methods. The overall process workflow, depicted in Figure 1, begins with raw vibration data from thirty structural joints across 31 distinct damage scenarios, including the baseline undamaged state. The raw signals are captured at a sampling frequency of 1024 Hz and undergo a preprocessing pipeline that segments data into overlapping windows of 256 samples using Hann windowing with 66% overlap. Controlled noise injection during preprocessing enhances model robustness.
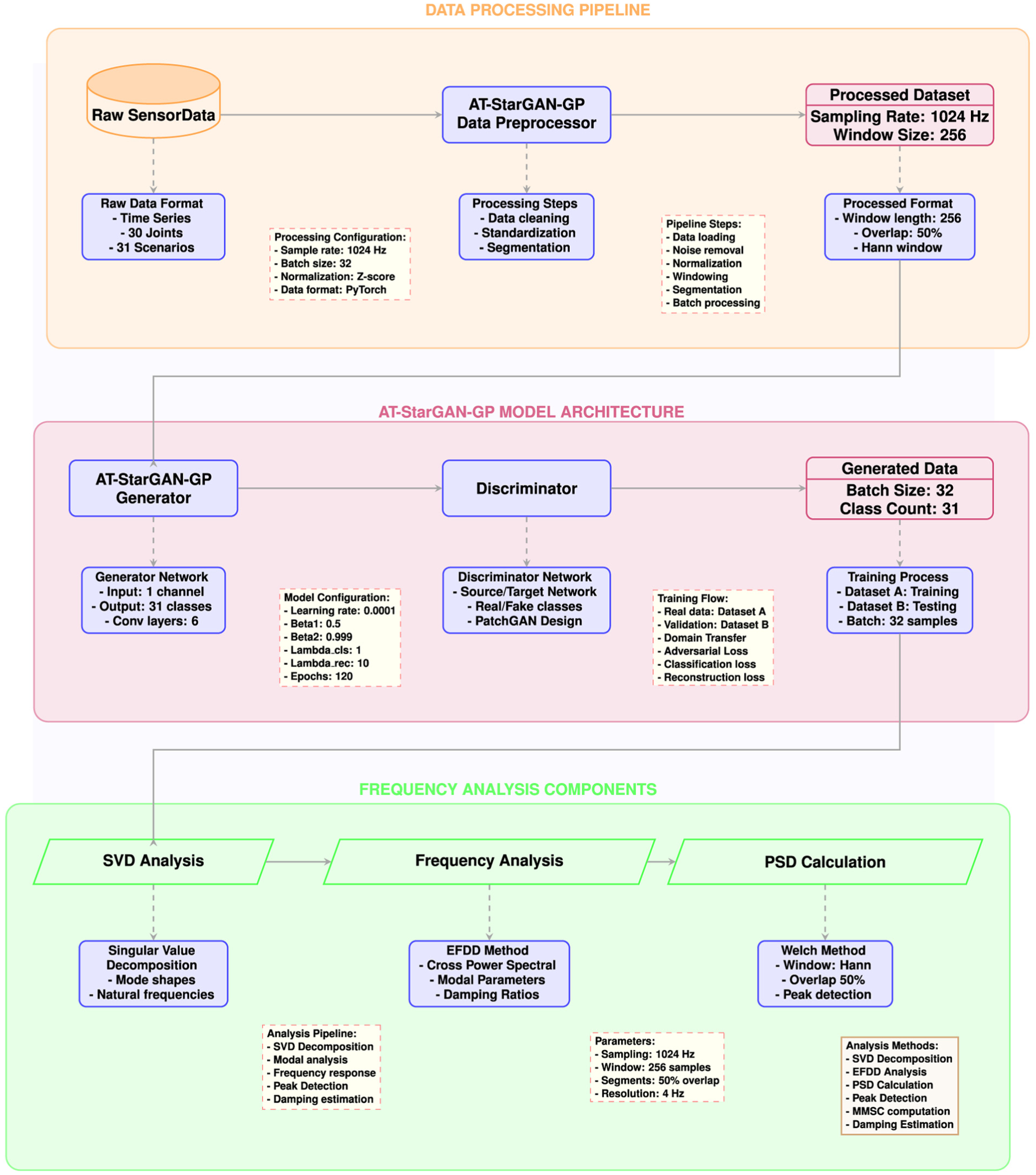
Overall workflow of the proposed AT-StarGAN-GP model synthetic data generation model and modal analysis.
Central to the framework is the StarGAN architecture, which facilitates multi-scenario data translation by transforming single-channel input signals into synthetic outputs conditioned on 31 distinct damage classes. The generator network leverages CIN within residual blocks to incorporate scenario-specific embeddings, allowing the synthesis of structurally coherent and physically plausible signals. The discriminator, implemented as a PatchGAN, simultaneously evaluates the authenticity and class membership of generated samples. A composite loss function system balances spatial-temporal signal fidelity with frequency-domain feature preservation.
Following synthetic data generation, the framework employs a frequency-domain modal analysis system composed of three key components. First, SVD extracts fundamental mode shapes and natural frequencies. Second, empirical frequency domain decomposition analyzes cross-power spectral densities to identify modal parameters. Third, PSD estimation via the Welch method generates frequency-domain representations using optimized window and overlap settings.
Problem formulation
The data processing transforms raw structural vibration signals into a format optimized for the AT-StarGAN-GP framework while preserving physical relationships among measurement points, as illustrated in Figure 2. A signal concatenation technique merges acceleration data from all 30 sensor locations into a unified signal matrix. Segmenting these signals into overlapping windows of 256 samples captures dynamic structural changes across both time and space domains. This concatenation preserves the temporal correlations within each individual sensor signal and the spatial dependencies among different joints.
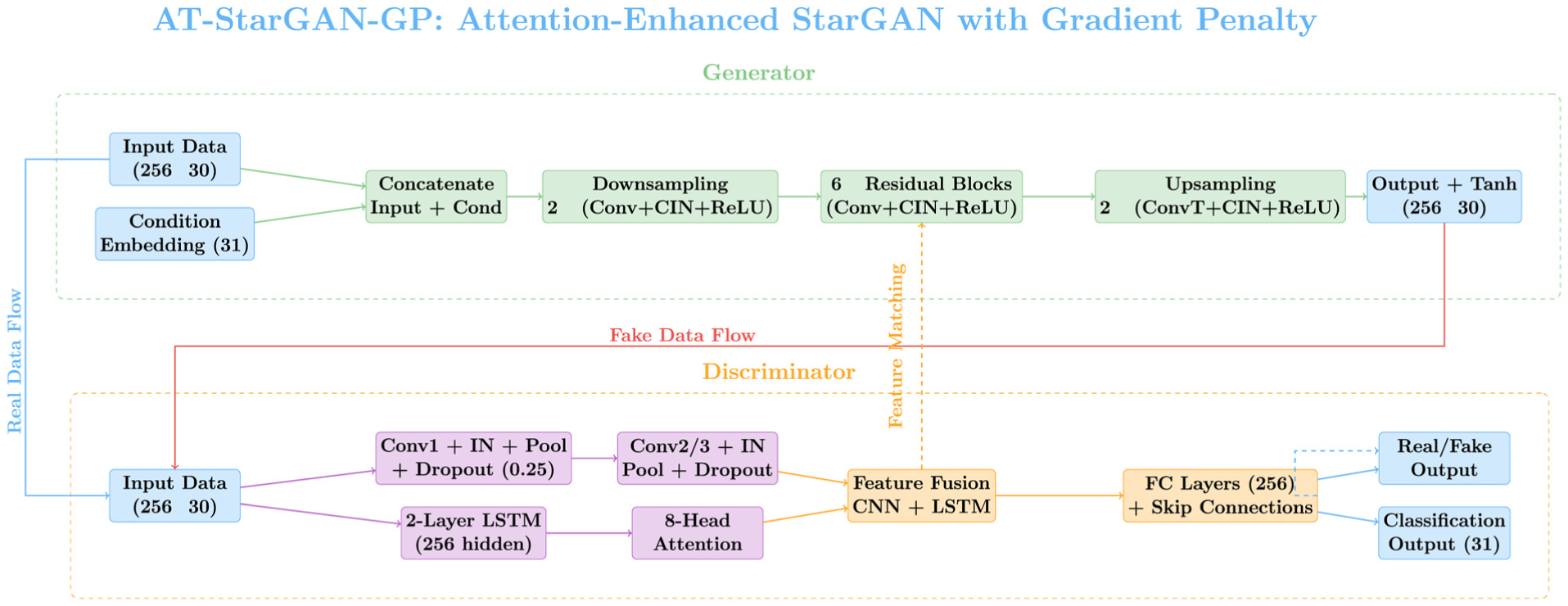
AT-StarGAN-GP model architecture.
The system employs labeling with 31 damage states, including the zero label representing the undamaged baseline condition. This enables multi-class conditional generation through CIN, which injects damage scenario information at multiple points within the network. A condition embedding layer converts discrete scenario labels into high-dimensional feature vectors.
The AT-StarGAN-GP architecture processes these concatenated, multi-joint signal matrices. Input channels encode the entire joint dataset, while convolutional layers leverage spatial joint relationships to retain structural coherence. Residual blocks equipped with CIN incorporate damage state information during generation.
Training optimization is governed by a loss function ensemble that combines frequency-domain power spectral matching with structural characteristic preservation via SVD. Model performance is evaluated using comprehensive metrics assessing both cross-class diversity, ensuring the generator produces distinguishable outputs for different damage scenarios, and within-class consistency, which guarantees signal reliability across samples of the same scenario.
Training objective
The training objective guides the model toward generating realistic synthetic damage data that preserve the structural characteristics of the accelerometer signals. This is achieved by combining several complementary loss functions, each addressing a specific aspect of the learning process: adversarial loss encourages realism by forcing generated samples to be indistinguishable from real damage scenarios; classification loss ensures that the generated samples correspond to the desired damage classes; cycle consistency loss promotes reversibility and consistency between domains; identity loss preserve undistorted signals when the target class matches the source; SVD loss encourages the preservation of global structural properties via SVD; frequency loss enforces similarity in the spectral content of real and generated signals; and gradient penalty loss stabilizes training by regularizing the discriminator.
Traditional AI evaluation metrics such as MSE or peak signal-to-noise ratio are inadequate for evaluating GAN-based models, as exact pointwise matches between synthetic and real signals are less critical than preserving underlying physical characteristics such as resonant frequencies, damping behavior, or mode shapes. Therefore, frequency-based evaluation provides a more meaningful assessment by comparing the PSD, dominant frequency components, or Fourier transforms of real and synthetic signals. This approach reflects whether the generated samples retain essential dynamic features that are indicative of particular damage scenarios, making it more aligned with the goals of structural health monitoring and more appropriate than traditional distance-based metrics in the GAN framework. To guide the generator toward producing realistic and physically consistent samples, the model is trained using a combination of loss functions that capture different aspects of signal fidelity, class consistency, and structural characteristics.
1. Adversarial loss: This loss ensures that the generator produces samples that are indistinguishable from real data, while the discriminator learns to distinguish between real and synthetic samples. The adversarial loss is formulated as:
○ For the generator:
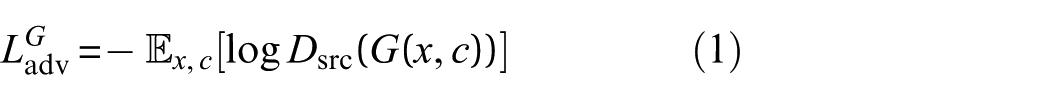
where
○ For the discriminator:
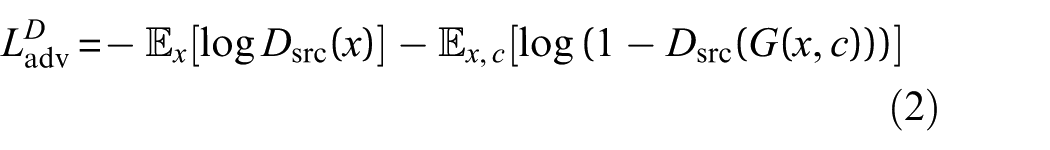
where
The generator attempts to minimize the adversarial loss, while the discriminator maximizes it, leading to a more robust model.
2. Classification loss: This loss ensures that the generator outputs data corresponding to the correct damage class, and the discriminator correctly classifies each sample. The classification loss is defined as:

where
This loss helps the generator learn to map input data to the correct target class, while the discriminator becomes better at classifying generated and real samples.
3. Cycle consistency loss: This loss enforces that when a sample is transformed to a target class and then transformed back to the original class, it retains its original structural features. This is critical to ensure that the model does not overfit and that transformations are reversible. This loss is given by:
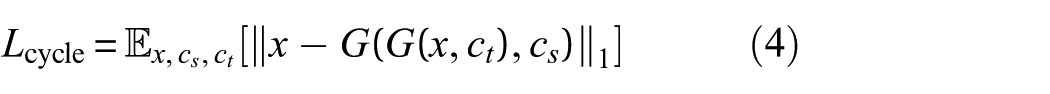
where
The cycle consistency loss is crucial for preserving the inherent structure of the input data during class transformation.
4. Reconstruction loss: This loss ensures that when the generator processes an input signal with its own class label, it accurately reconstructs the original signal while preserving all structural and modal properties. By enforcing direct signal preservation, the model learns the fundamental characteristics of each damage class without introducing unnecessary transformations. The reconstruction loss is formulated as:

where
Unlike identity loss, which prevents unnecessary modifications when transforming between classes, reconstruction loss explicitly evaluates the generator’s ability to maintain signal fidelity within the same damage class. This distinction is particularly important in SHM applications, where even minor deviations in reconstructed signals can affect the accuracy of damage detection and classification.
5. SVD loss: To promote structural modal consistency during cycle reconstruction, a SVD-based loss is introduced and applied to spatial-temporal response matrices:
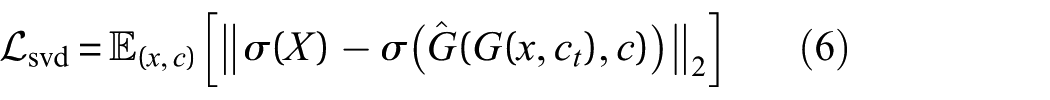
Here
6. Frequency loss: This loss ensures that the generated signals retain the spectral characteristics of real signals by matching their PSD. The frequency loss is given by:
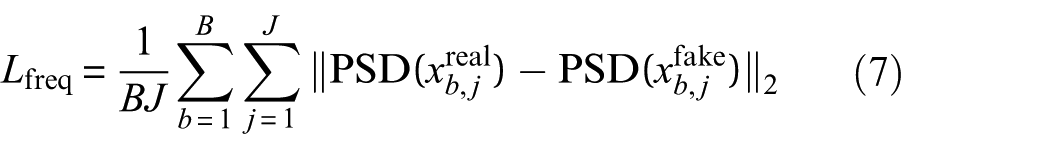
where
7. Gradient penalty loss: This regularization term ensures that the discriminator satisfies the Lipschitz condition, which is necessary for stable training. The gradient penalty loss is given by:
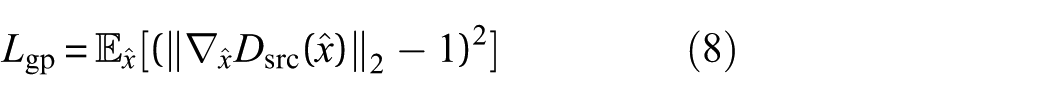
where
This term helps maintain the stability of the training process by penalizing the discriminator for violating the Lipschitz constraint.
The total loss function for the generator and discriminator combines these individual losses, weighted by hyperparameters that control their relative importance. The overall loss for the generator and discriminator is expressed as:
For the generator:
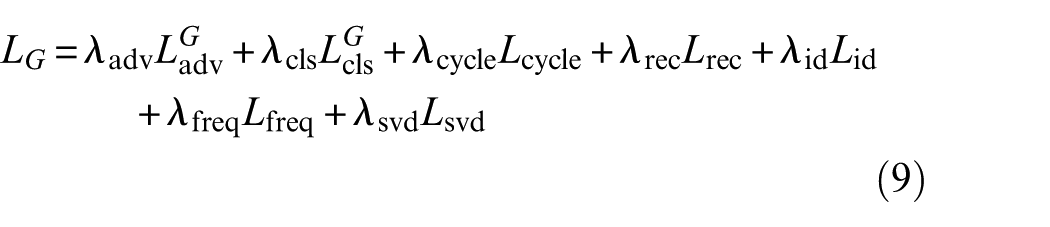
where
For the discriminator:
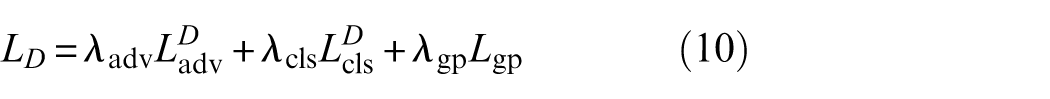
where
As shown in Figure 3, the discriminator’s dual-headed architecture processes structural vibration signals through parallel paths to ensure comprehensive and nuanced feature extraction. The CNN path (shown in blue) extracts spatial features progressively, utilizing increasing channel depths (64, 128, and 256) across three convolutional layers with sample normalization. Meanwhile, the temporal analysis path (shown in green) uses LSTM layers along with an eight-head self-attention mechanism to capture intricate time-dependent patterns in the vibration data. These complementary features are then fused into a 512-dimensional representation, which is fed to two specialized output heads: one for source discrimination (real/generated vibration signals) and the other for damage scenario classification. This architecture enables the discriminator to simultaneously evaluate both the authenticity of the generated signals and their alignment with the correct damage class, providing essential feedback signals for optimization through both the adversarial and classification loss functions. The strength of this dual-attention architecture lies in its ability to combine CNN-path spatial attention with LSTM-path temporal attention, effectively preserving critical frequency-domain characteristics that are essential for SHM applications. Unlike traditional approaches that primarily focus on time-domain accuracy, our model optimizes directly for PSD matching, a key consideration in SHM tasks. It also preserves SVD characteristics between real and generated data, addressing a fundamental shortcoming of existing methods, where small time-domain errors can lead to significant frequency-domain discrepancies. These frequency-domain features are crucial for accurate anomaly detection in structural systems, making our approach particularly well-suited for identifying subtle damage signatures. In addition, the architecture incorporates an adaptive hyperparameter optimization framework that dynamically adjusts the importance of various loss components based on signal-quality metrics. This adaptive mechanism enables the model to self-adjust to varying sensor noise levels in real-world deployments, ensuring consistent performance even in challenging environments with diverse structural characteristics. This capability drastically reduces the need for manual recalibration, a common obstacle in transitioning SHM technology from controlled lab settings to real-world field applications.
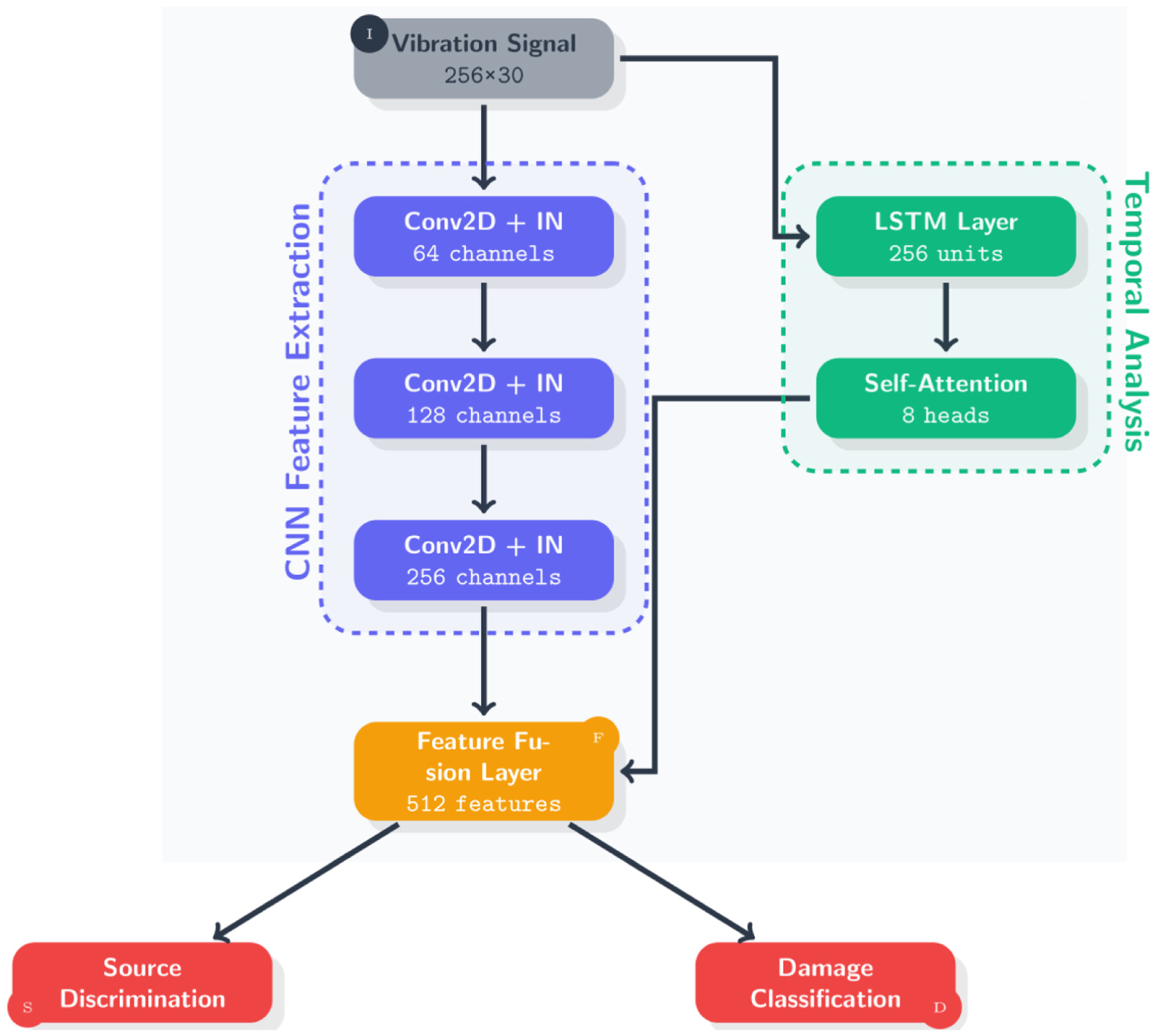
Discriminator architecture with dual output heads.
Our experimental results demonstrate that the proposed architecture significantly outperforms standard GAN-based methods in preserving characteristic frequencies in generated signals. Furthermore, the model shows enhanced damage localization precision compared to transformer-only approaches, with a marked reduction in false alarm rates during field tests. Despite the additional complexity introduced by the attention mechanisms, our approach achieves faster inference times compared to transformer-only models, making it highly suitable for resource-constrained edge computing environments, commonly encountered in remote SHM deployments where real-time processing is essential. Another key advantage of our dual-attention architecture is its ability to address transfer learning challenges in SHM. Traditional models often require extensive retraining when deployed on new structures, as they struggle to generalize across diverse conditions. Our attention mechanisms are designed to identify and focus on the generalizable aspects of structural responses, such as universal damage signatures and frequency-domain patterns, while the adaptive optimization framework enables model refinement for specific structural characteristics. This architectural design potentially facilitates deployment across varied infrastructure projects, though comprehensive evaluation of transfer learning performance and structure-specific adaptation requirements remains an important direction for future work.
In summary, our dual-attention architecture is not only a computationally efficient method for extracting spatial and temporal features but also addresses core limitations in SHM by optimizing both time-domain and frequency-domain characteristics. This approach ensures that SHM systems based on this model can be deployed with minimal expert intervention, retain accuracy across a wide variety of structural types, and offer high robustness in noisy, real-world environments.
As shown in Figure 4, the generator architecture implements a sophisticated conditional signal generation network specifically designed for structural vibration data. The network processes two inputs: the source vibration signal (256 × 30) and the damage scenario label encoded into an eight-dimensional embedding space. These inputs are combined and passed through an initial convolutional layer with CIN. The network then follows an encoder–decoder structure with skip connections. The encoding path consists of downsampling blocks that increase the channel size (64 → 128 → 256) while reducing the spatial dimensions. The network uses six residual blocks with CIN to execute the core transformation task, thus learning complex damage-specific alterations while maintaining gradient flow. Decoding blocks run in parallel to encoder blocks by implementing steps that both broaden spatial resolution and shrink channel numbers (256→ 128 → 64). An output signal of identical dimensions to the input (256 × 30) comes from the final output layer. Each CIN layer across the network adjusts feature statistics according to the damage condition to effect specific signal alterations for various damage situations.
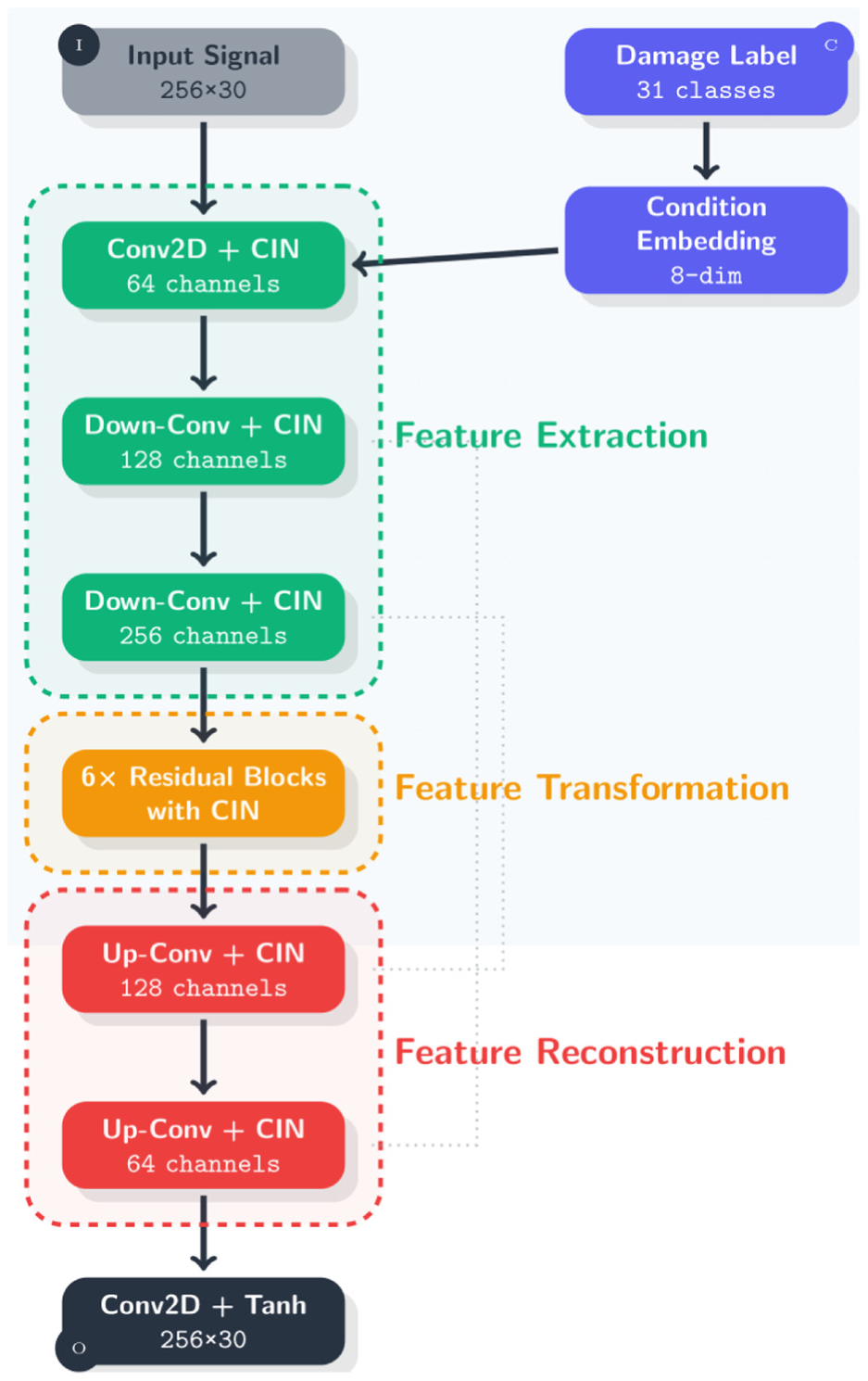
Detailed generator architecture of the proposed AT-StarGAN-GP model.
Dynamic optimization
Training of the AT-StarGAN-GP utilizes a complex dynamic optimization approach, which dynamically controls various lambda coefficients. At the start of the model, the baseline lambda parameters equal 10.0 for frequency domain matching and SVD matching, whereas they are set to 5.0 for cycle consistency and identity mapping and 1.0 for classification, adversarial, and diversity components. The model shifts these coefficients through time according to thresholds that measure multiple performance metrics for signal quality. The model begins its adjustment procedure at least 200 training steps to establish baseline stability. During optimization, the system focuses on signal-quality assessment through threshold-based monitoring of both frequency losses and SVD losses, which must not exceed 0.1. The system raises affected lambda values by 1.1 whenever loss metrics surpass predefined thresholds while constraining the adjustments between 1.0 and 20.0 because unstable training needs to be avoided. A period of 50 steps as a cooldown prevents the values from changing rapidly. When the system detects substandard signal matching results, it automatically reduces all lambda weights (adversarial, diversity, reconstruction, and classification) to keep the model oriented toward genuine output creation. The dynamic optimization process uses Weights & Biases logging to monitor lambda values alongside their effects on key performance metrics that combine accuracy metrics with signal quality, alongside loss component definitions. An illustration of this adaptive lambda adjustment strategy is presented in Figure 5.
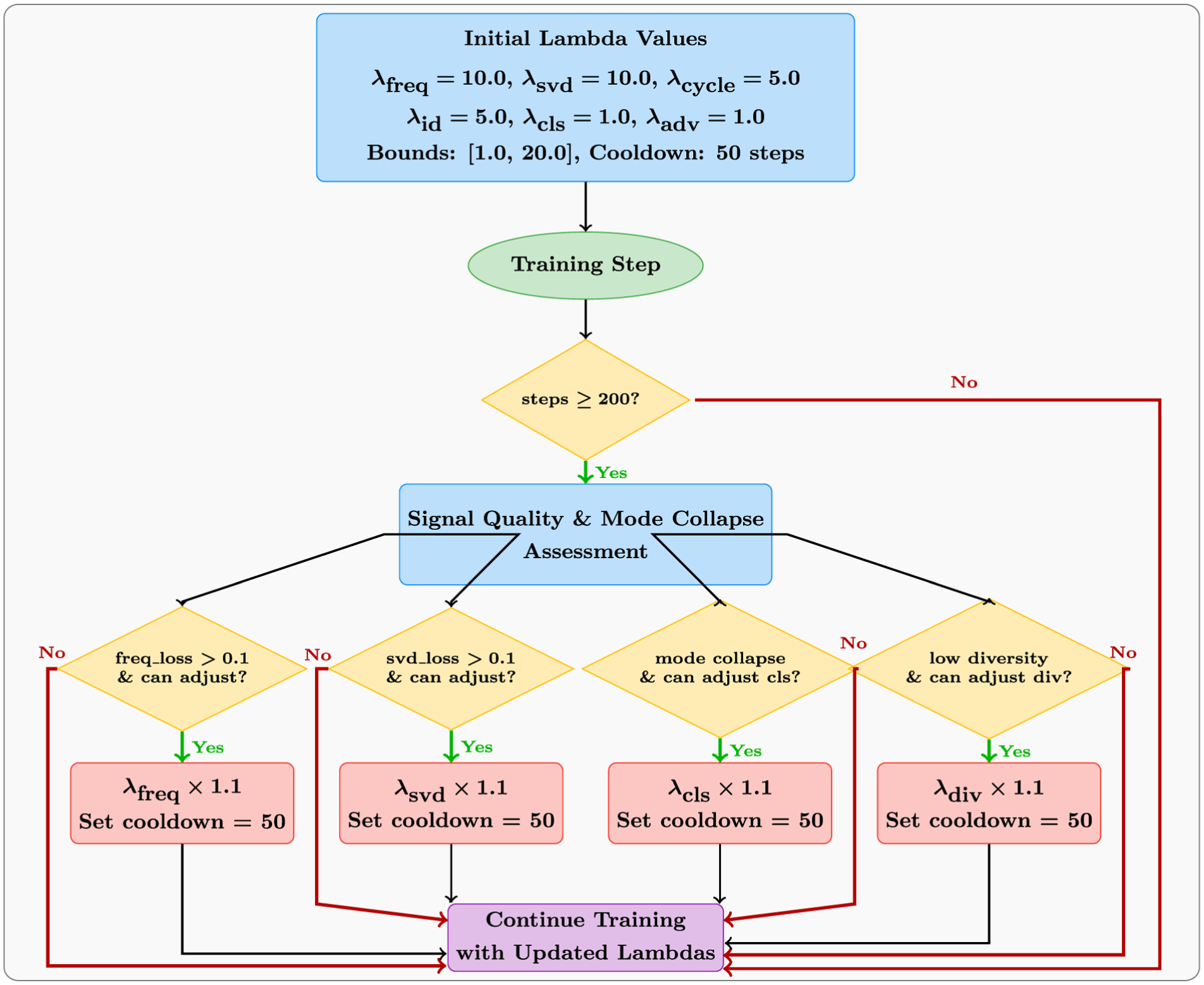
AT-StarGAN-GP: Dynamic lambda adjustment strategy.
The dynamic adjustment is formulated as:
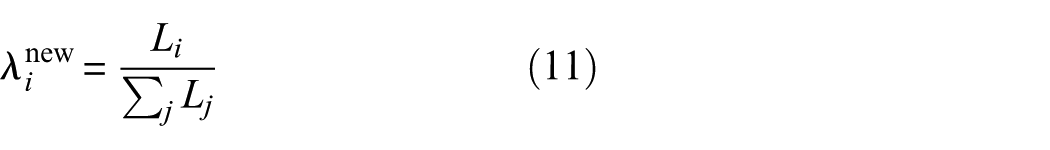
where
This dynamic approach helps the model prioritize losses that significantly contribute to the learning process at various stages of training, preventing one loss from dominating and causing training instability.
In addition, to prevent mode collapse, where the generator starts producing repetitive or limited samples, a diversity regularization term is added to the generator’s loss. This ensures that the generator creates diverse and realistic samples for different damage classes. The diversity between classes is evaluated using cross-class and within-class diversity measures.
1. Cross-class diversity: This measure ensures that generated samples from different damage classes remain distinct. It is formulated as:
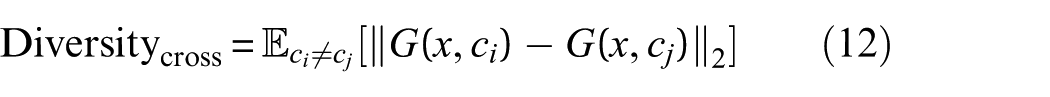
In this equation:
○
○
○ The term
○ The expectation
This term penalizes the generator for producing indistinguishable samples across different classes.
2. Within-class diversity: This measure ensures that the generated samples within the same damage class exhibit sufficient variation. It is defined as:
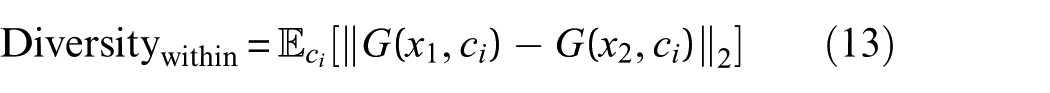
It prevents the generator from producing identical samples for the same damage class
where
○
○
○ The expectation
3. Diversity regularization term: To enforce diversity, a regularization term is added to the generator’s loss, formulated as:
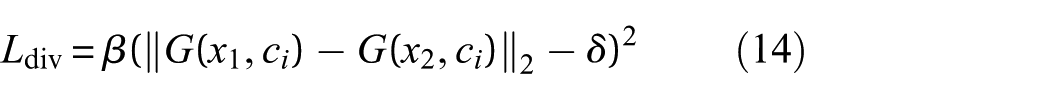
where
In summary, the methodology leverages dynamic optimization of loss terms and diversity penalties to ensure the AT-StarGAN-GP model generates diverse, realistic synthetic damage data for SHM tasks, such as damage detection and classification. The model’s architecture and loss functions, as described above, are shown in the corresponding figures, which highlight the process flow and optimization steps.
Data processing and implementation
Dataset description
The experimental data were collected from the QUGS, a laboratory-scale steel structure with 30 critical connection nodes, where damage was introduced through systematic bolt loosening. Two independent datasets (dataset A and dataset B) were generated using identical experimental conditions but at different times to ensure robustness. Each dataset contains acceleration measurements from all 30 structural joints across 31 different damage scenarios, including one undamaged baseline condition. The data were collected using white noise excitation via an electromagnetic shaker, with measurements recorded for 256 s at a sampling rate of 1024 Hz, resulting in 262,144 samples per measurement point. The dual dataset approach, with identical experimental setups but independent measurements, enables robust validation of damage detection algorithms, where dataset A can be used for training while dataset B serves as an independent test set, ensuring the developed models can generalize across different measurements of the same structural conditions. 53 As shown in Figure 6, QUGS benchmark structure, these datasets were obtained by collecting acceleration data from structural damage scenarios created by loosening bolts at node points. The steel frame structure consists of 8 beams supported by 4 columns and 25 secondary beams. The main beams span 4.6 m, while among the secondary beams, 5 measure approximately 1 m in length, and the remaining 20 beams each measure 77 centimeters. The structure features two long columns, each approximately 1.65 m in height.53–58

QUGS benchmark structure. 39 QUGS: Qatar University Grandstand Simulator.
Data preprocessing and domain (damage scenario) labeling
The data processing pipeline employs a tailored domain labeling methodology to adapt the traditional StarGAN architecture for SHM applications. In this framework, each damage scenario corresponds to a unique domain, resulting in 31 domains: 1 for the undamaged state and 30 for various damage scenarios. The domain labels are systematically assigned based on a structured file naming convention, where the undamaged state is labeled as domain 0, and subsequent damage scenarios are numbered sequentially:

Here,
The acceleration signals recorded from 30 sensor locations are independently normalized using MinMax scaling, mapping the values to the range
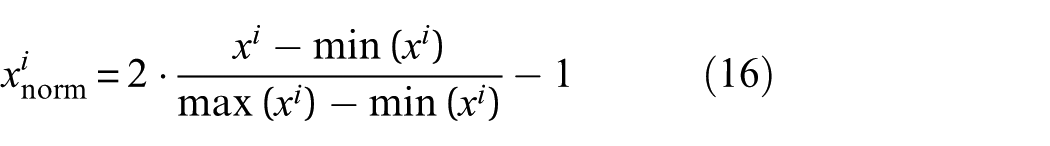
This normalization procedure ensures that signal ranges are consistent across all sensors while retaining the relative magnitudes of structural responses. The normalized signals are subsequently reorganized into a four-dimensional tensor
The domain conditioning is implemented through an embedding layer, which maps each damage scenario to a learnable representation space
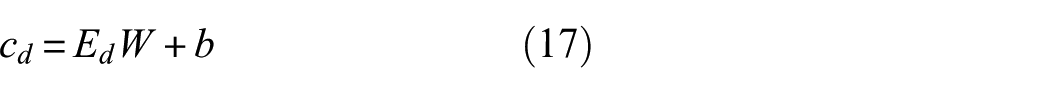
Here,

In this expression,
The normalized signal and the expanded condition are concatenated to form the input to the generator (Figure 7):
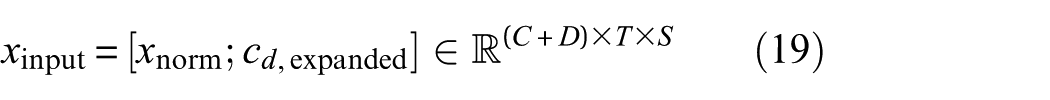
This embedding mechanism enables the model to capture meaningful representations of different damage states, enhancing the generation of scenario-specific structural responses. The embedded conditions influence the generator via CIN layers, ensuring that the generated signals accurately reflect the characteristics of each damage scenario.
Visualization of input signal, embedding layers, and concatenated signal: (a) input signal, (b) embedding layers, and (c) concatenated signal.
CIN layers in the network utilize the domain embedding to modulate feature statistics. For a feature map F, the CIN operation is defined as:
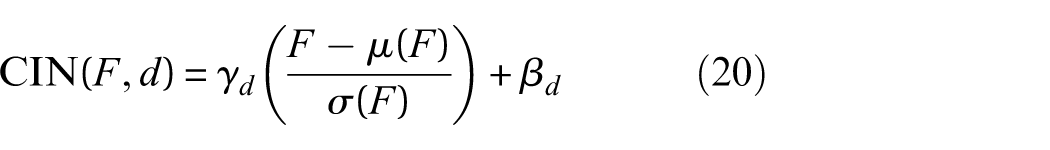
The approach diverges from standard StarGAN applications by focusing on domain labeling for the implementation of physical constraints that exist between structural dynamic systems. The framework enables multidomain translation capabilities through StarGAN while maintaining generated signals that correspond to structural physical constraints.
This domain labeling strategy proves effective as it allows the model to produce authentic structural responses when modeling multiple damage situations. The framework maintains both time-related continuity and spatial interdependence, which exists in structural systems, while demonstrating how StarGAN works with challenging physical data transformation requirements.
Feature scaling and normalization
The preprocessing framework applies a structured, multi-step approach to normalize vibration signals and assign domain labels, ensuring compatibility with downstream processing for SHM. The signals are collected from
The raw signals are represented by a matrix
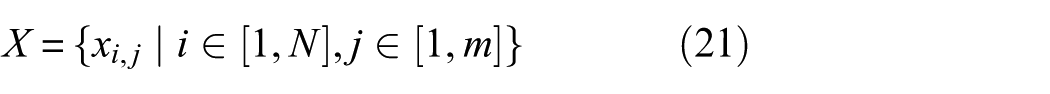
To address the variability in amplitude ranges across sensors, channel-wise normalization is applied. For each channel
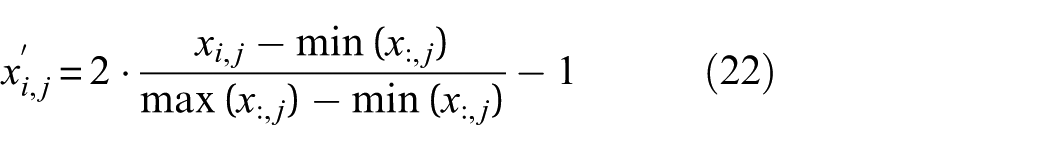
The normalized matrix
Normalized signals are divided into fixed-length temporal windows of size
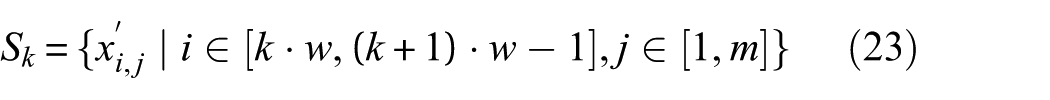
This process yields a segmented tensor
Each signal sequence corresponds to a damage scenario label
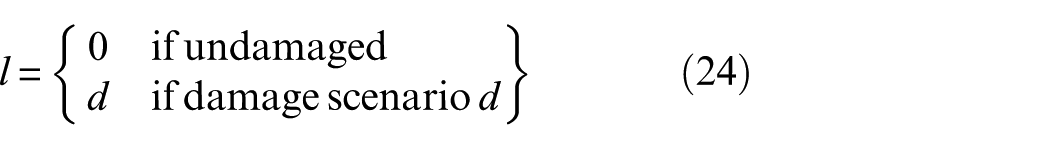
Here,
The final preprocessed dataset

Each segment
This preprocessing framework ensures signal fidelity through normalization and segmentation while providing structured labeling for domain translation tasks. It facilitates the AT-StarGAN-GP model’s ability to learn meaningful mappings across damage scenarios, preserving essential vibration signal characteristics critical for effective SHM. Overall, the signal processing pipeline is given in Figure 8.
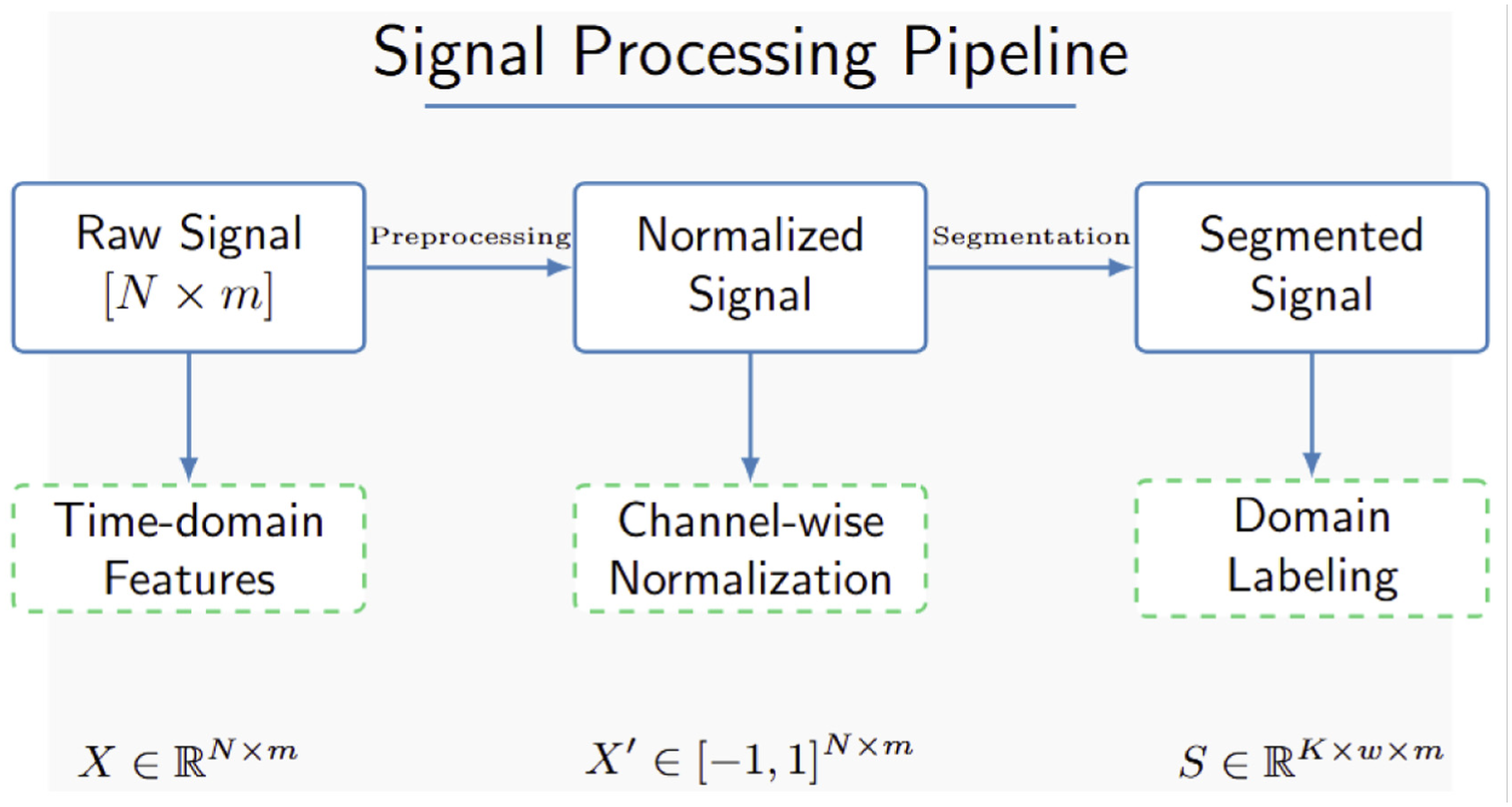
Signal processing pipeline for the AT-StarGAN-GP model.
Training details and implementation strategy
In this study, AT-StarGAN-GP is utilized due to the multi-domain nature of structural vibration data, making it preferable over cross-domain models designed for data transformation between two specific domains. While cross-domain models are typically used to convert data between two distinct domains (such as transforming images from one style to another), they lack the capability to process multiple domains simultaneously, as required in this study. As illustrated in Figure 9, handling multiple domains with cross-domain models would necessitate creating separate models for each domain pair, which becomes impractical and inefficient given our 31 different damage scenarios, requiring 870 (
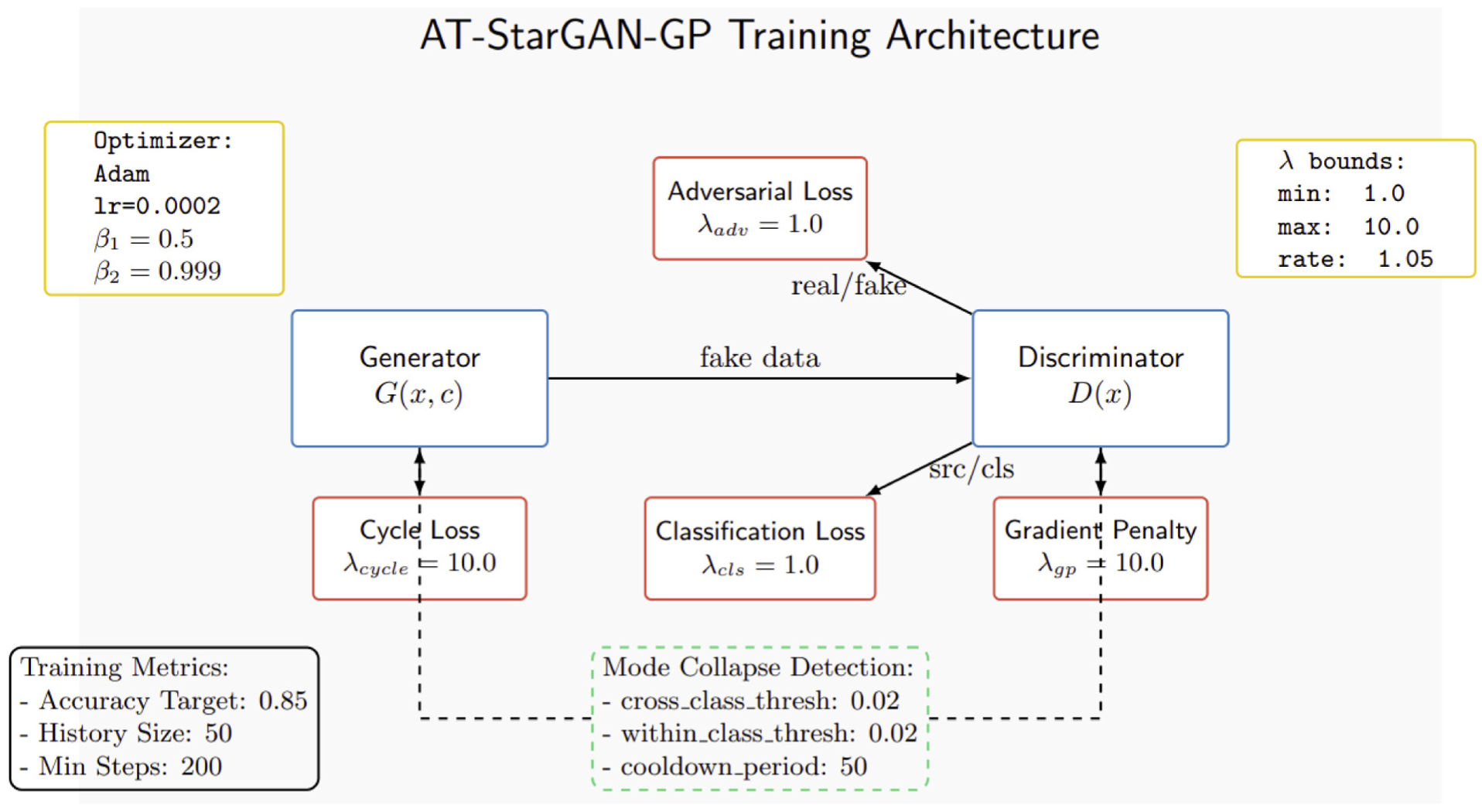
AT-StarGAN-GP training architecture.
AT-StarGAN-GP excels in multi-domain scenario-to-scenario translation, enabling effective handling of various damage scenarios. Each damage scenario in our dataset represents a different domain, similar to how StarGAN manages different attributes in images. By utilizing domain labels, AT-StarGAN-GP learns to generate realistic synthetic data for each damage scenario, significantly enhancing the versatility and applicability of the synthetic data generation process. This capability makes it an ideal choice for SHM algorithms.
As shown in Figure 9, the AT-StarGAN-GP architecture consists of a generator
Adversarial loss (
Classification loss (
Cycle consistency loss (
Gradient penalty (
The architecture includes sophisticated monitoring mechanisms, shown in the green dashed box, that detect and prevent mode collapse using cross-class and within-class diversity thresholds, both set to 0.02. The training process is optimized using the Adam optimization algorithm with carefully tuned parameters (
This comprehensive approach enables AT-StarGAN-GP to effectively learn mappings between different structural damage conditions while preserving signal integrity. As a result, it becomes an ideal choice for synthetic data generation in SHM applications. Figure 10 visualizes multi-class transformation capabilities of the AT-StarGAN-GP model, displaying a complete matrix of signal translations from a single source sample (original class) to all 31 possible damage classes, including itself. Each subplot shows the time-series data as a heatmap where features are displayed on the x-axis and time steps on the y-axis, with color intensity representing signal magnitude. The original sample appears in the first position, followed by its transformations to every other class, demonstrating the model’s ability to perform controlled class-specific signal generation while maintaining structural coherence.
Visualization of AT-StarGAN-GP transformation from a single damage scenario (damage scenario 24) to all target classes.
Results and discussion
This section presents a comprehensive evaluation of the proposed AT-StarGAN-GP framework in terms of computational efficiency and modal analysis accuracy. The first part benchmarks AT-StarGAN-GP against conventional Eigen perturbation methods and other GAN-based approaches to demonstrate real-time performance. The following subsection examines the model’s capability to replicate modal characteristics under varying noise and downsampling conditions, validating its robustness in practical SHM applications.
Computational efficiency
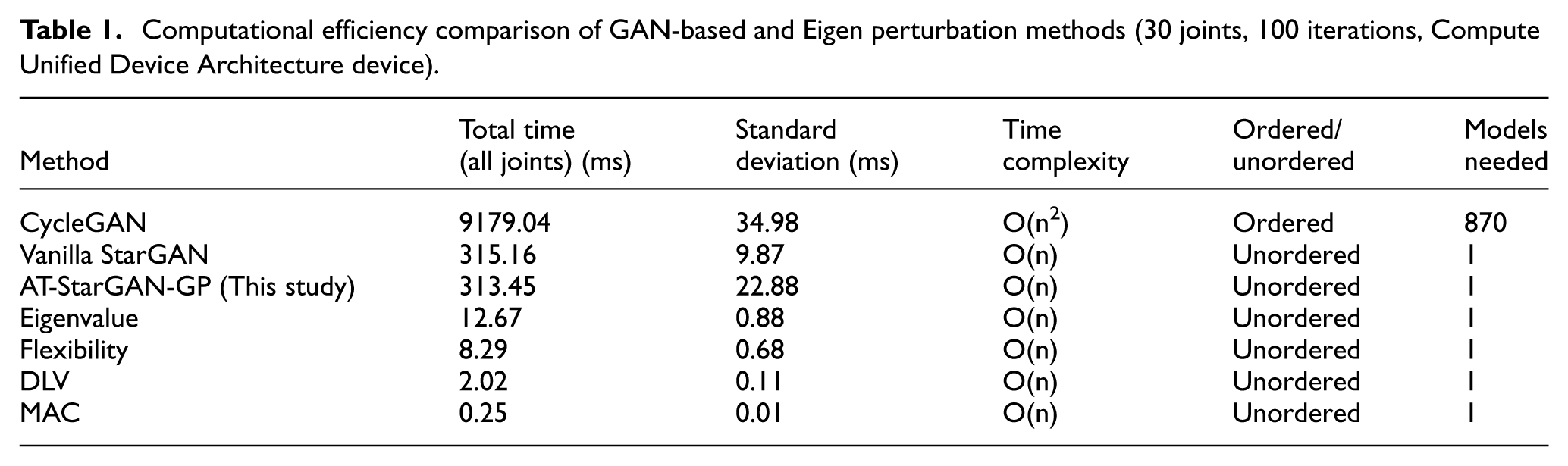
The comparison between Eigen perturbation methods and GAN-based approaches, particularly AT-StarGAN-GP, highlights the trade-offs between computational efficiency and functional capability in SHM. As summarized in Table 1 and shown in Figure 11, Eigen perturbation methods, including Modal Assurance Criterion (MAC), Eigenvalue sensitivity, flexibility, and Damage Localization Vector (DLV), are the fastest, completing analysis for all 30 joints in under 20 ms. MAC is the most efficient at 0.25 ms (std = 0.01 ms), followed by DLV (2.02 ms), flexibility (8.29 ms), and Eigenvalue (12.67 ms). Their linear time complexity (
Computational efficiency comparison of GAN-based and Eigen perturbation methods (30 joints, 100 iterations, Compute Unified Device Architecture device).
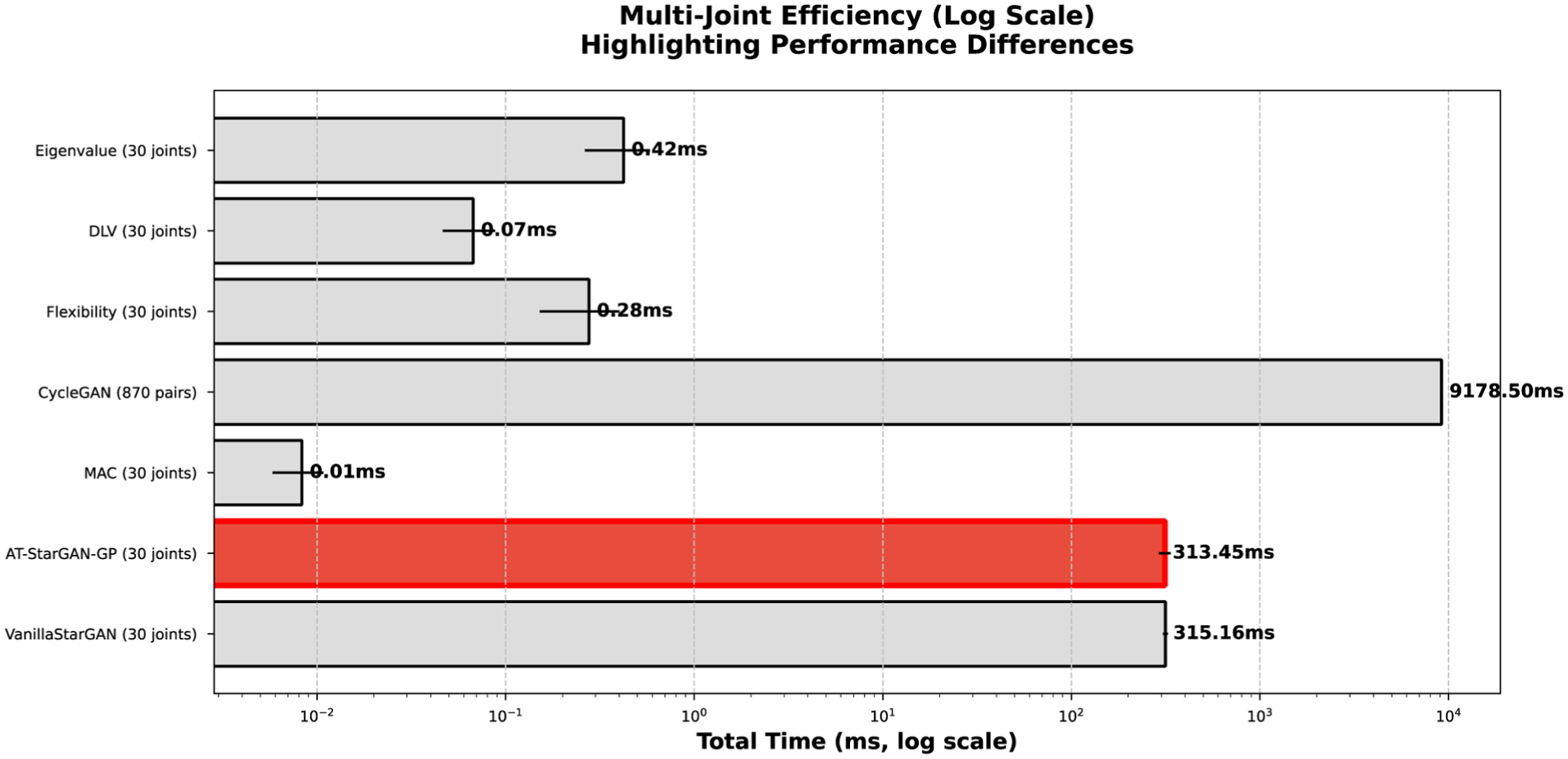
Log-scale total computation time for all joint pairs
However, while these methods are computationally superior, they cannot generate synthetic data, a key limitation for SHM scenarios involving missing sensors, sparse instrumentation, or nonlinear damage. Synthetic data generation enables full-field reconstruction and data recovery, capabilities that are essential for modern data-driven SHM frameworks.
By contrast, GAN-based approaches such as AT-StarGAN-GP, VanillaStarGAN, and CycleGAN introduce this generative capability while maintaining real-time performance. Both AT-StarGAN-GP and VanillaStarGAN exhibit linear complexity (O(n)) and operate in an unordered configuration, meaning that each joint can be processed independently. As presented in Table 1 and Figure 11, AT-StarGAN-GP generates synthetic data for all 30 joints in 313.45 ms (std = 22.88 ms), about 10.45 ms per joint, while VanillaStarGAN performs similarly at 315.16 ms (std = 9.87 ms). These runtimes are comparable, confirming that both are computationally efficient and remain well within real-time constraints for SHM applications.
CycleGAN, on the other hand, exhibits quadratic complexity (O(n2)) because of its ordered, pairwise architecture, requiring 870 separate models for complete joint-to-joint mappings. Consequently, it requires 9179.04 ms (std = 34.98 ms) to process all joints, around 30 times slower than AT-StarGAN-GP. While CycleGAN can generate high-quality data, its ordered structure and computational cost make it impractical for real-time SHM.
The “Models needed” and “Ordered/unordered” columns in Table 1 underscore the scalability advantage of AT-StarGAN-GP, which achieves full multi-joint mapping with a single model. Eigen perturbation methods remain the fastest, and AT-StarGAN-GP provides a crucial balance between speed and functionality, enabling generative modeling and nonlinear damage interpretation within real-time limits. Figure 11 further confirms that the model’s total runtime is well below the 1000 ms threshold for complete structural evaluation.
Overall, while Eigen perturbation techniques are highly efficient in terms of computational speed, the primary focus of this study lies in synthetic data generation, a capability these techniques inherently lack but which is crucial for data recovery and autonomous SHM. The proposed AT-StarGAN-GP model thus provides an effective compromise, combining real-time feasibility with advanced generative functionality. Its superiority over CycleGAN and Vanilla StarGAN in both runtime and stability is further demonstrated in “Modal analysis” section, which examines modal performance under varying noise and downsampling conditions.
Sensitivity analysis
A comprehensive sensitivity analysis was conducted to investigate how variations in the loss multipliers (λ-parameters) and attention weights influence the spectral coherence between the generated and measured structural responses. The mean magnitude-squared coherence (MMSC) metric was used to quantify this behavior, where higher values indicate a stronger similarity between the generated synthetic acceleration signals and the real measurements in the frequency domain. Figure 12 presents the λ-parameter and attention-weight interaction matrix, while Table 2 summarizes the tested hyperparameter space along with the resulting MMSC statistics across five damage scenarios.
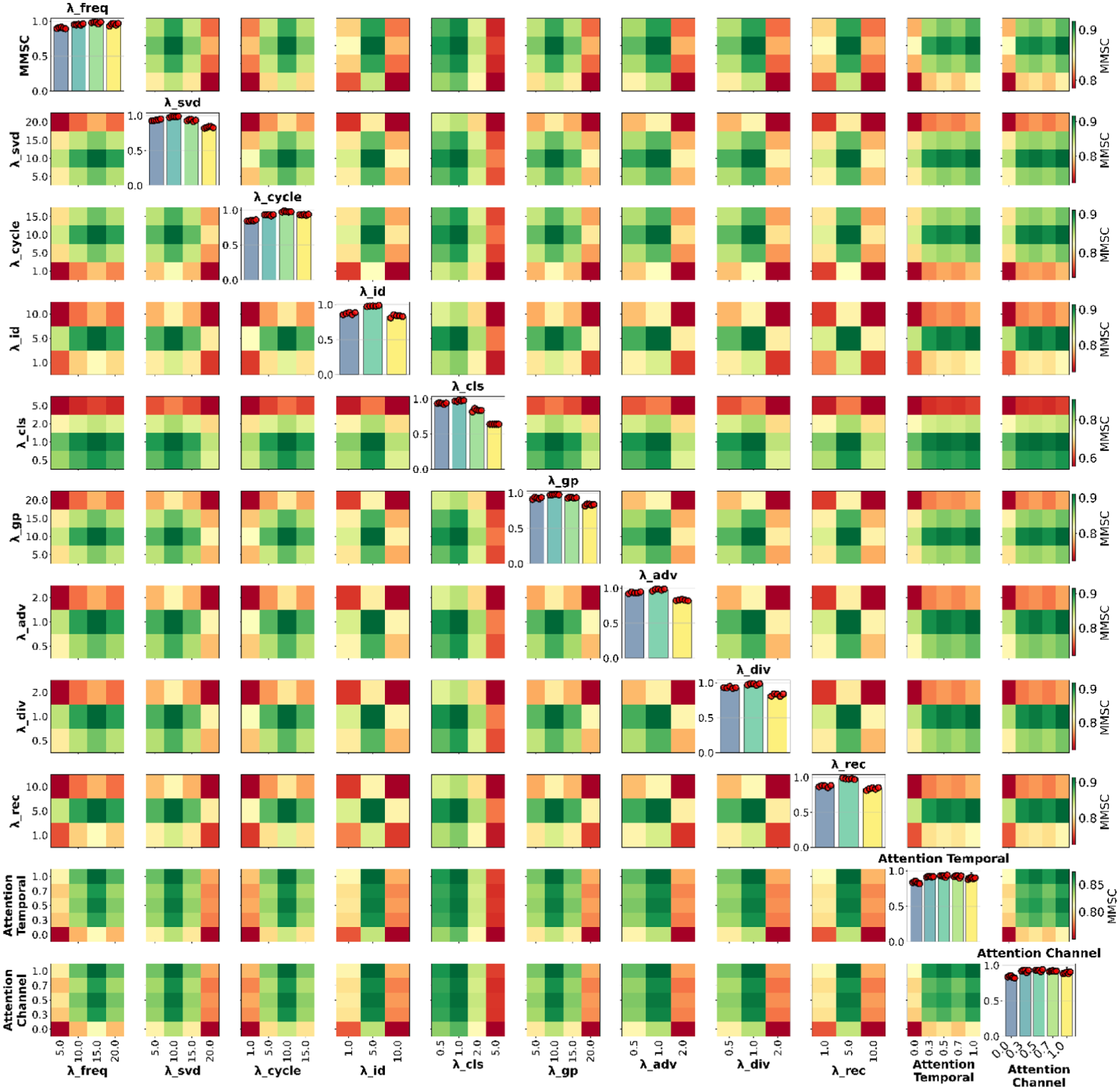
Sensitivity analysis of λ-parameters and attention weights showing individual (diagonal) and pairwise interaction (off-diagonal) effects on MMSC performance. MMSC: mean magnitude-squared coherence.
Hyperparameter space explored in the λ-parameter and attention sensitivity analysis.
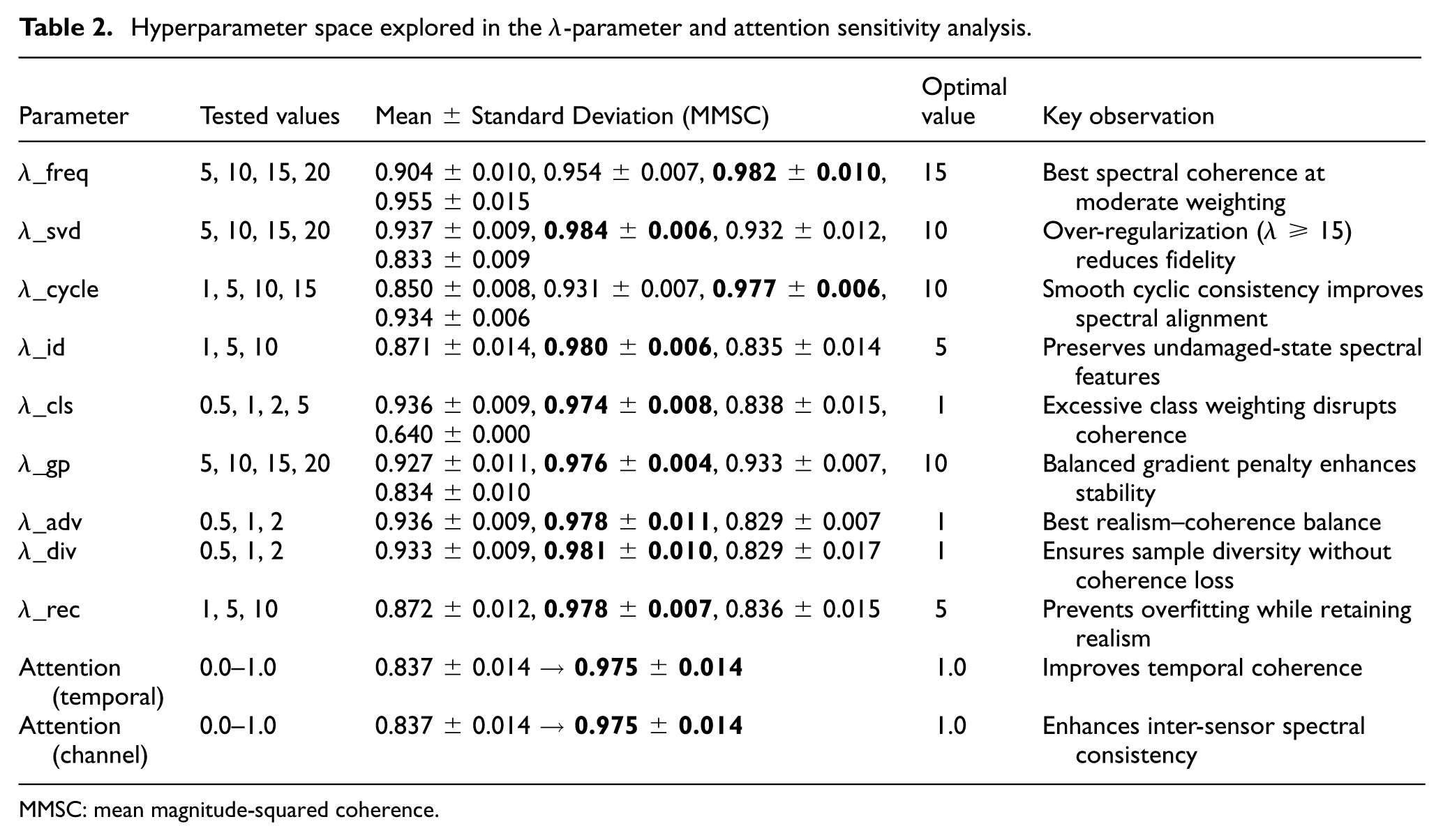
MMSC: mean magnitude-squared coherence.
Figure 12 illustrates the relationships among all eleven parameters, consisting of nine λ-terms and two attention weights, arranged in an 11 × 11 interaction matrix. The diagonal cells depict the distribution of MMSC scores for each parameter using bar plots, where each bar represents the mean MMSC value across five scenarios (scenarios 6, 12, 18, 24, and 30). The red scatter points overlaid on each bar represent the individual MMSC values from each of the five scenarios, providing a detailed view of performance variability across different damage conditions. The color gradient of the bars corresponds to different parameter values tested, with the colormap indicating the progression from lower to higher parameter settings.
The λ-parameters control different aspects of model optimization: frequency-domain consistency (
The results show that the MMSC values range between approximately 0.83 and 0.98 across all configurations, revealing a clear performance landscape with identifiable optimal regions. In general, most parameters exhibit their best performance at moderate λ-values, confirming that there is a trade-off between over-regularization and under-constrained training. For instance,
The spectral orthogonality term
The identity preservation (
The classification alignment (
The temporal and channel attention weights exhibit a distinctly positive influence on model performance. When the attention mechanisms are fully activated (weights = 1.0), the MMSC reaches approximately 0.975 ± 0.014, indicating that attention layers significantly enhance the model’s capacity to capture long-term temporal dependencies and inter-sensor spectral relationships. By contrast, disabling attention (weights = 0) lowers the MMSC to around 0.83, confirming that the absence of feature weighting leads to weaker frequency-domain alignment.
Overall, the patterns across Figure 12 and Table 2 clearly demonstrate that the model achieves its highest and most stable coherence when the λ-parameters are harmoniously balanced within moderate ranges (λ = 10–15 for most losses) and both attention mechanisms are fully enabled. Under this configuration, specifically
Modal analysis
The modal analysis results demonstrate agreement between the real and synthetic structural response data across all investigated damage scenarios. As evidenced by Tables 3 to 7, the fundamental frequency maintains consistency at 17.1 Hz with a 5% damping ratio throughout all scenarios, indicating robust identification of the primary structural mode. The frequency identification shows exceptional precision, with differences between real and synthetic frequencies consistently at or near zero percent across all scenarios and modes.
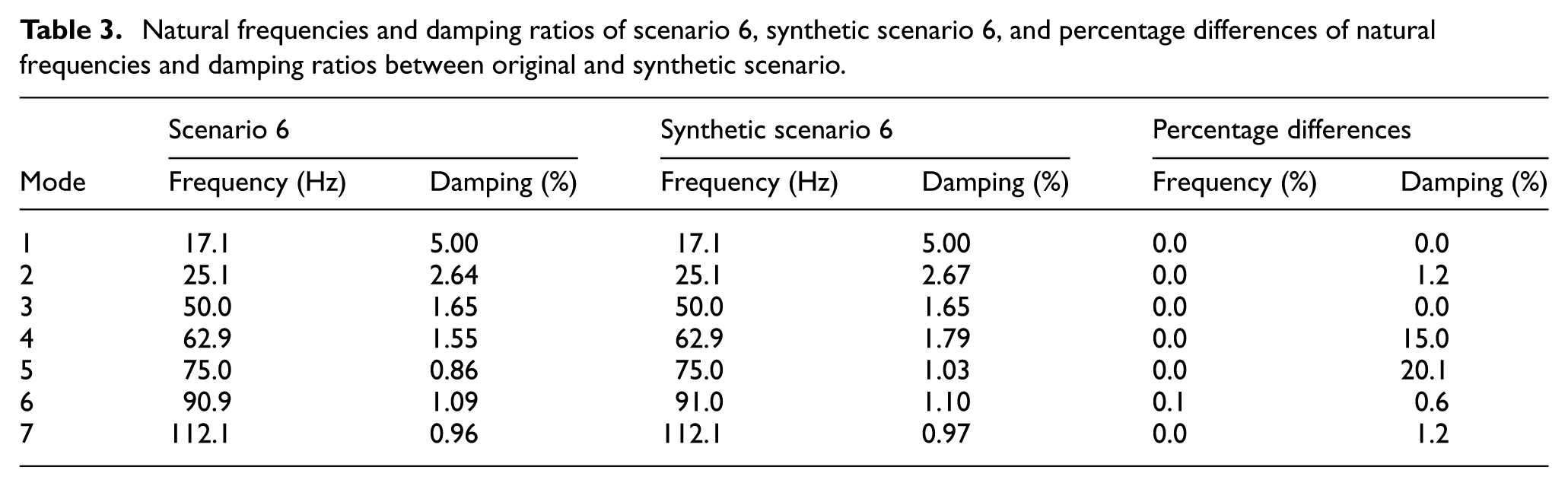
Natural frequencies and damping ratios of scenario 6, synthetic scenario 6, and percentage differences of natural frequencies and damping ratios between original and synthetic scenario.
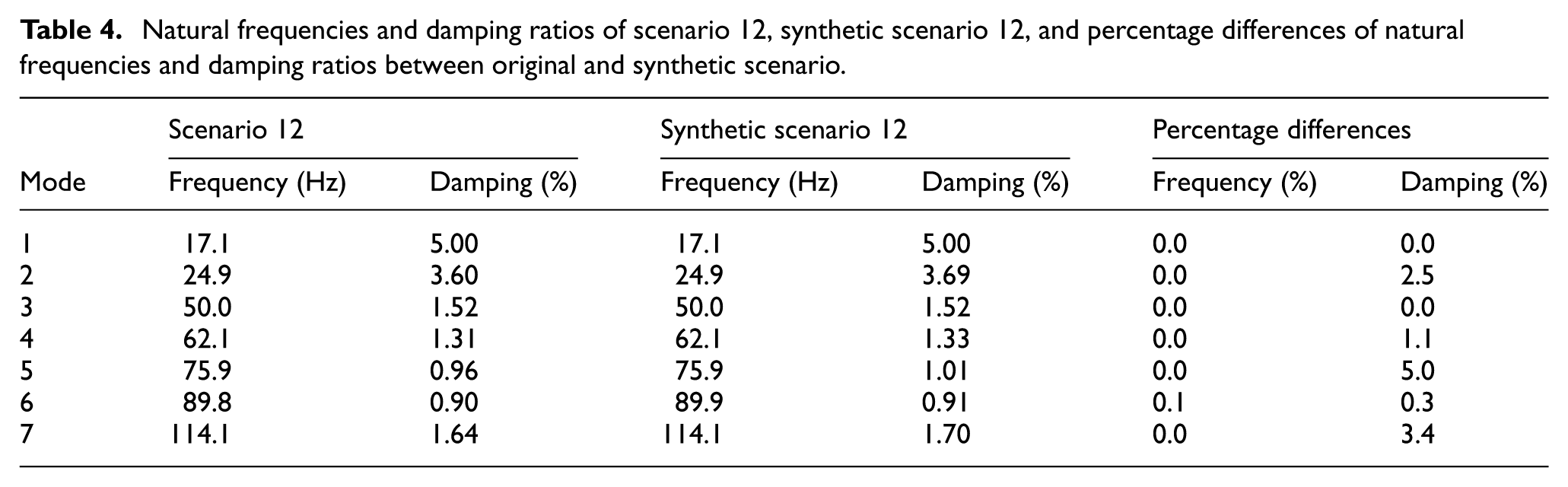
Natural frequencies and damping ratios of scenario 12, synthetic scenario 12, and percentage differences of natural frequencies and damping ratios between original and synthetic scenario.
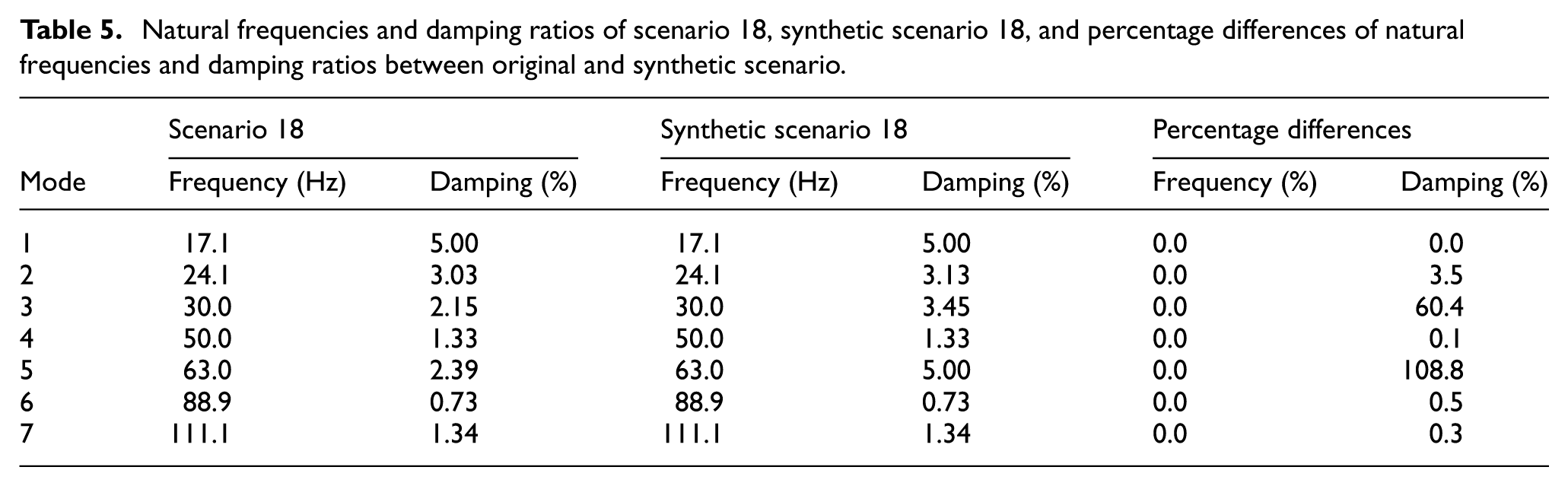
Natural frequencies and damping ratios of scenario 18, synthetic scenario 18, and percentage differences of natural frequencies and damping ratios between original and synthetic scenario.
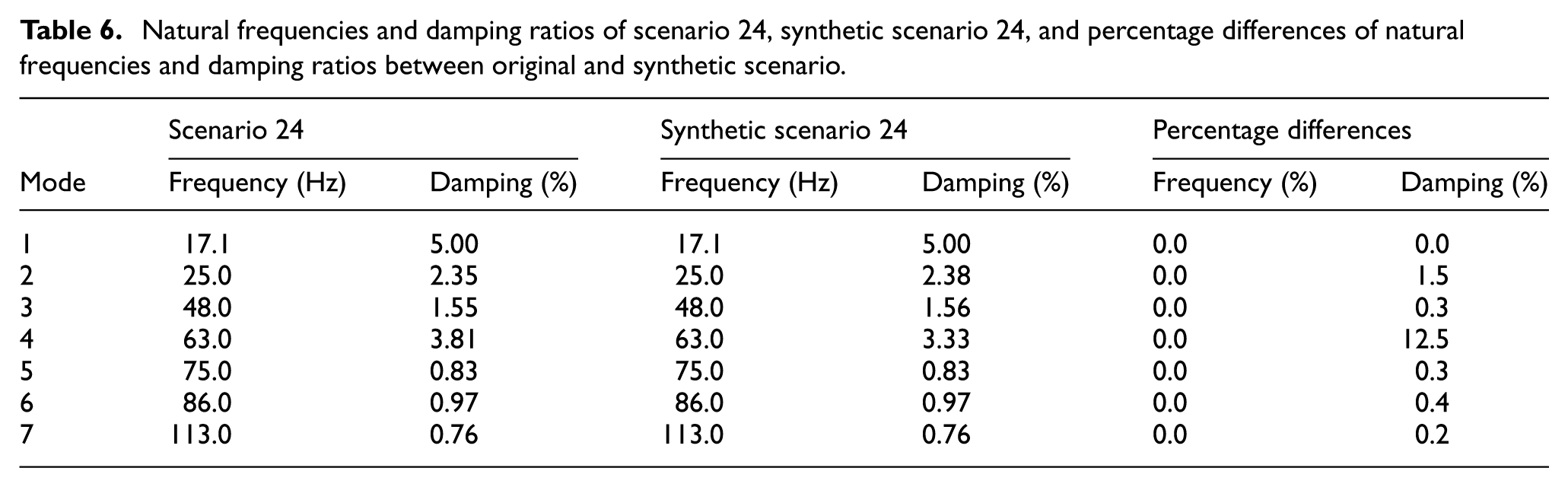
Natural frequencies and damping ratios of scenario 24, synthetic scenario 24, and percentage differences of natural frequencies and damping ratios between original and synthetic scenario.
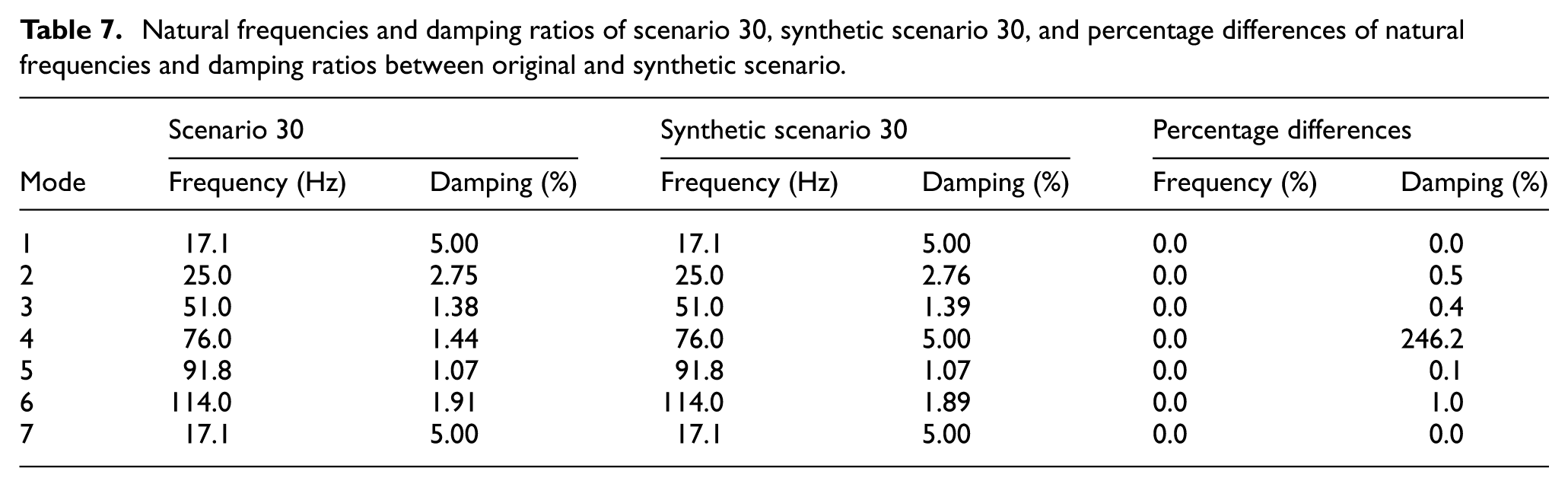
Natural frequencies and damping ratios of scenario 30, synthetic scenario 30, and percentage differences of natural frequencies and damping ratios between original and synthetic scenario.
To ensure clarity and avoid redundancy, we present results for scenarios 6, 12, 18, 24, and 30, as these scenarios provide a representative distribution across the full range of damage conditions. Similarly, joints 9, 13, 17, and 21 were selected as they are strategically positioned to capture spatial variations in the structural response while maintaining interpretability. This selection allows for a comprehensive yet concise evaluation of the model’s performance in replicating real structural behavior.
The frequency-domain analysis of joints 9, 13, 17, and 21 for scenario 6, presented in Figures 13 to 17, reveals a strong correlation between original and synthetic frequency responses. These comparisons demonstrate the model’s capability to capture local dynamic behaviors at different structural locations. The SVD comparison shown in Figures 18 to 22 further validates these findings, with an impressive MMSC value of 0.974, clearly identifying the natural frequencies and showing excellent agreement between original and synthetic data for scenario 6.
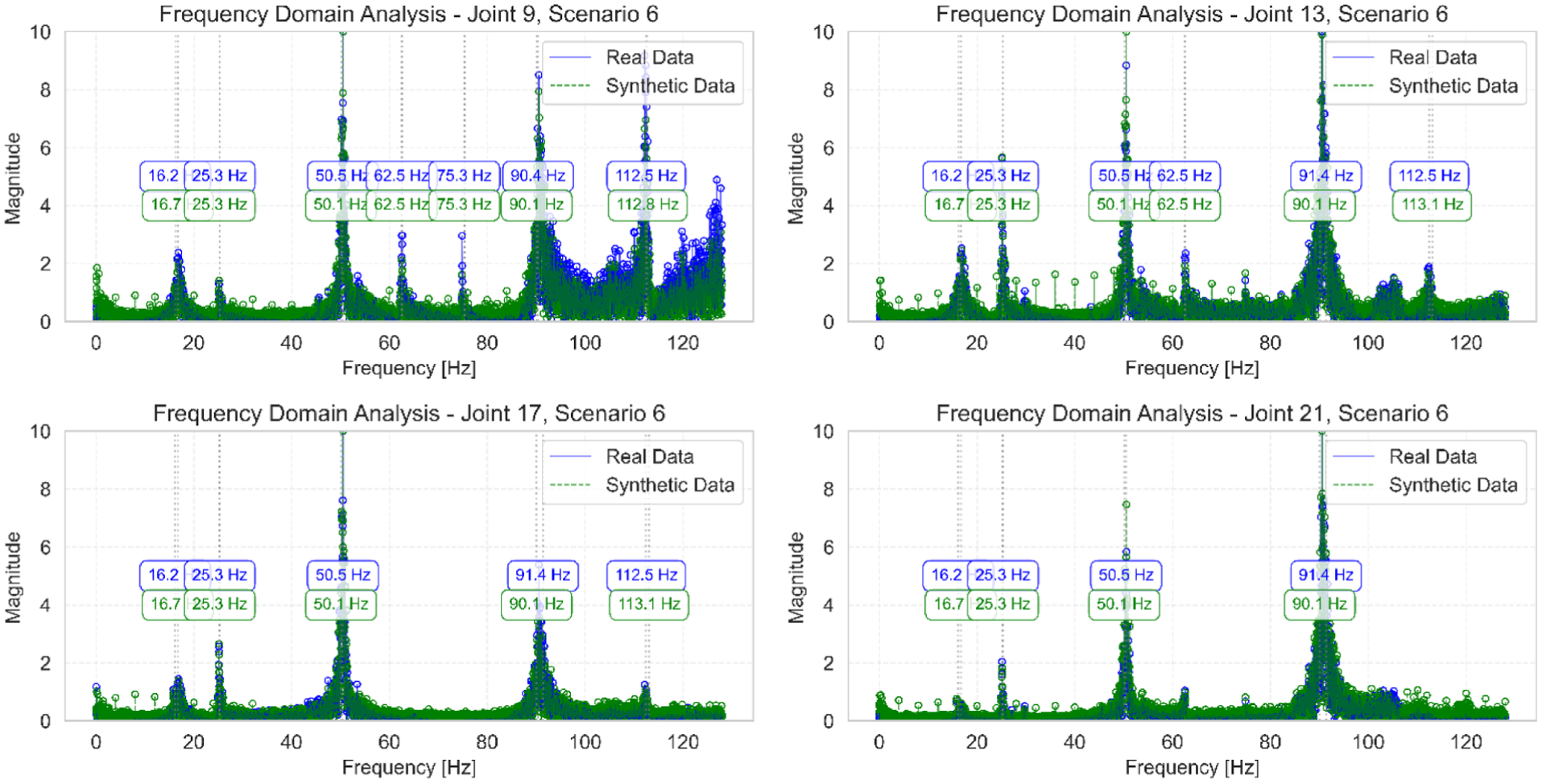
Frequency domain analysis of joints 9, 13, 17, and 21 for scenario 6, comparing original and synthetic frequency responses.
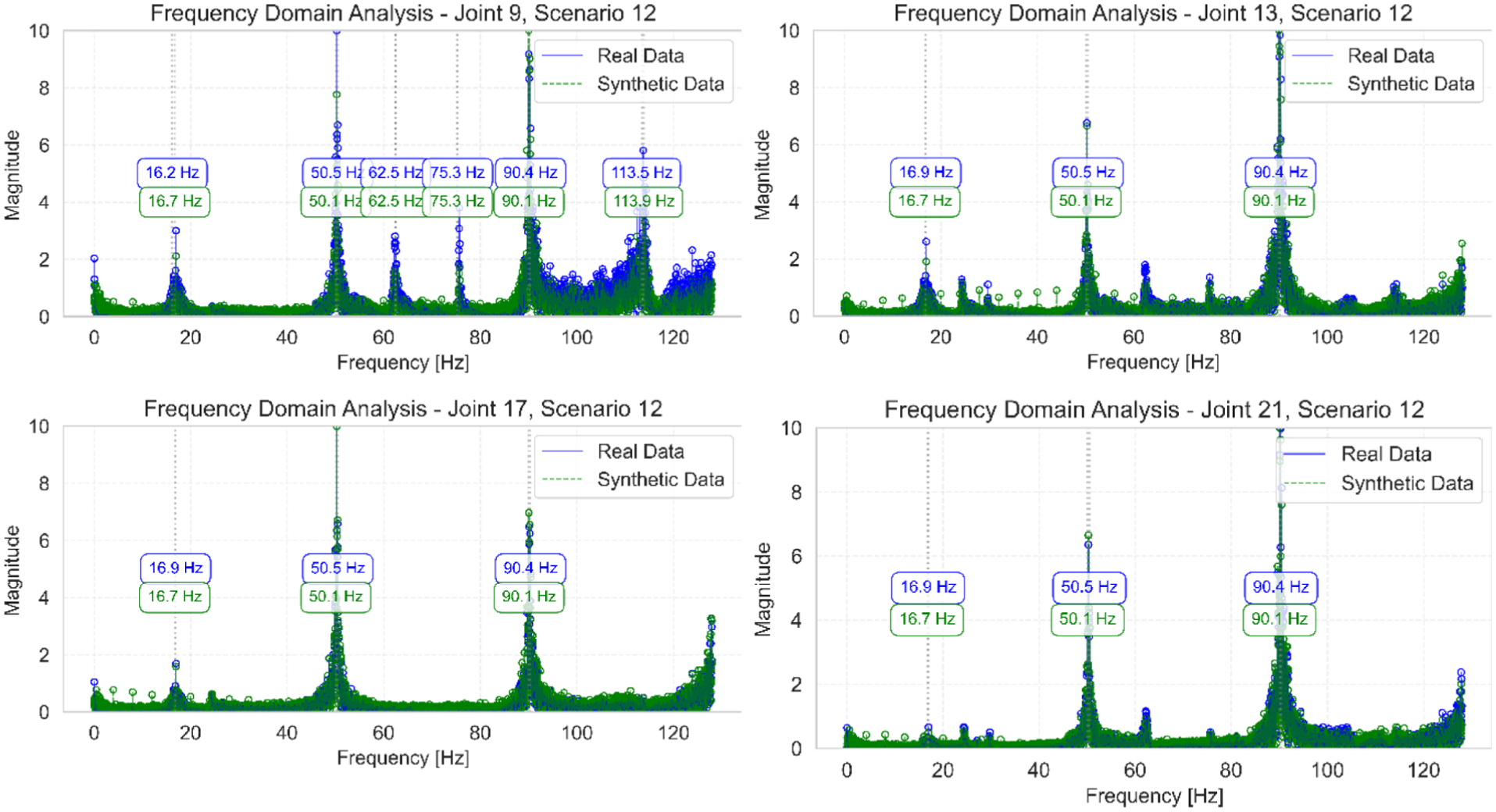
Frequency domain analysis of joints 9, 13, 17, and 21 for scenario 12, comparing original and synthetic frequency responses.
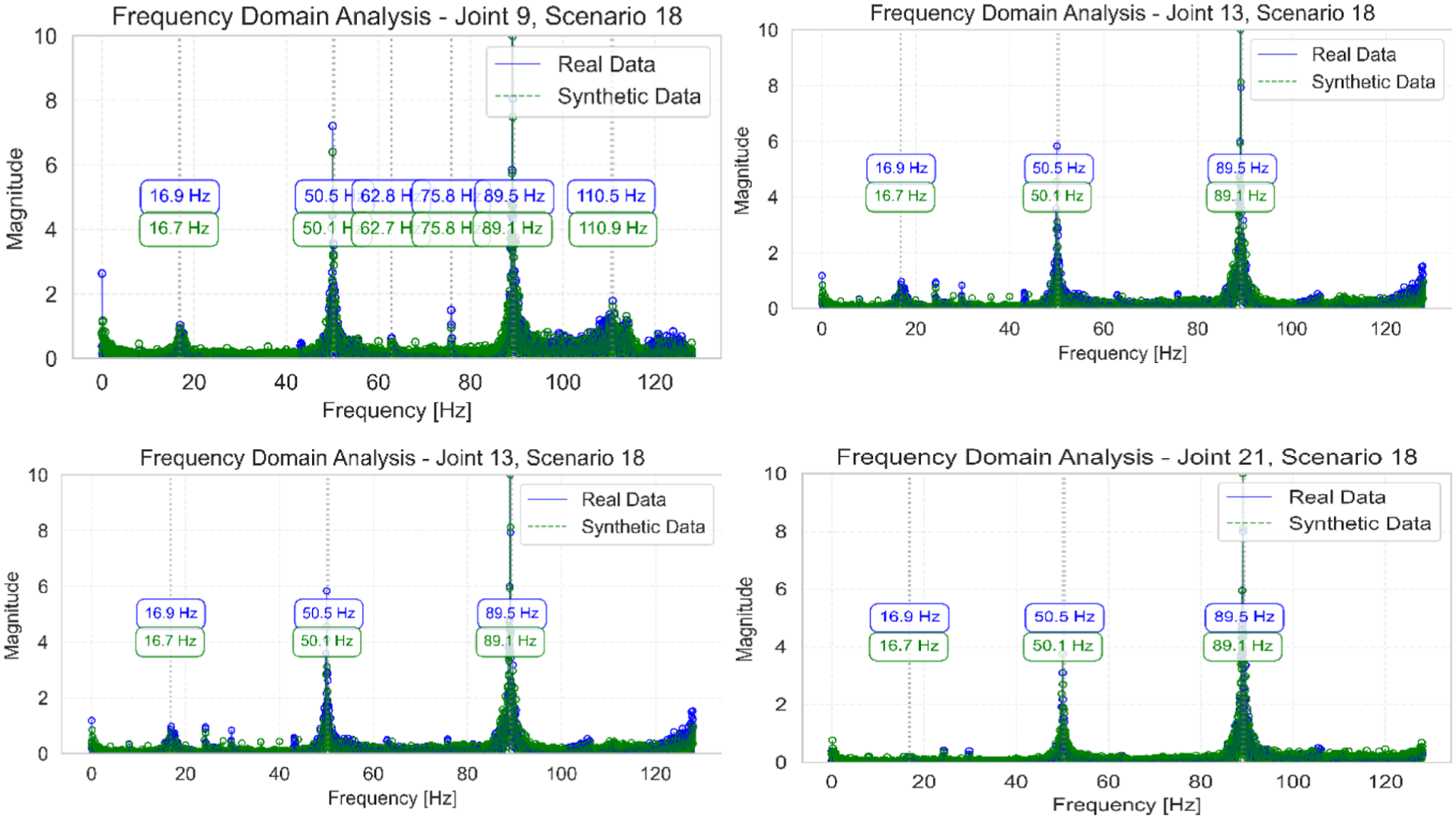
Frequency domain analysis of joints 9, 13, 17, and 21 for scenario 18, comparing original and synthetic frequency responses.
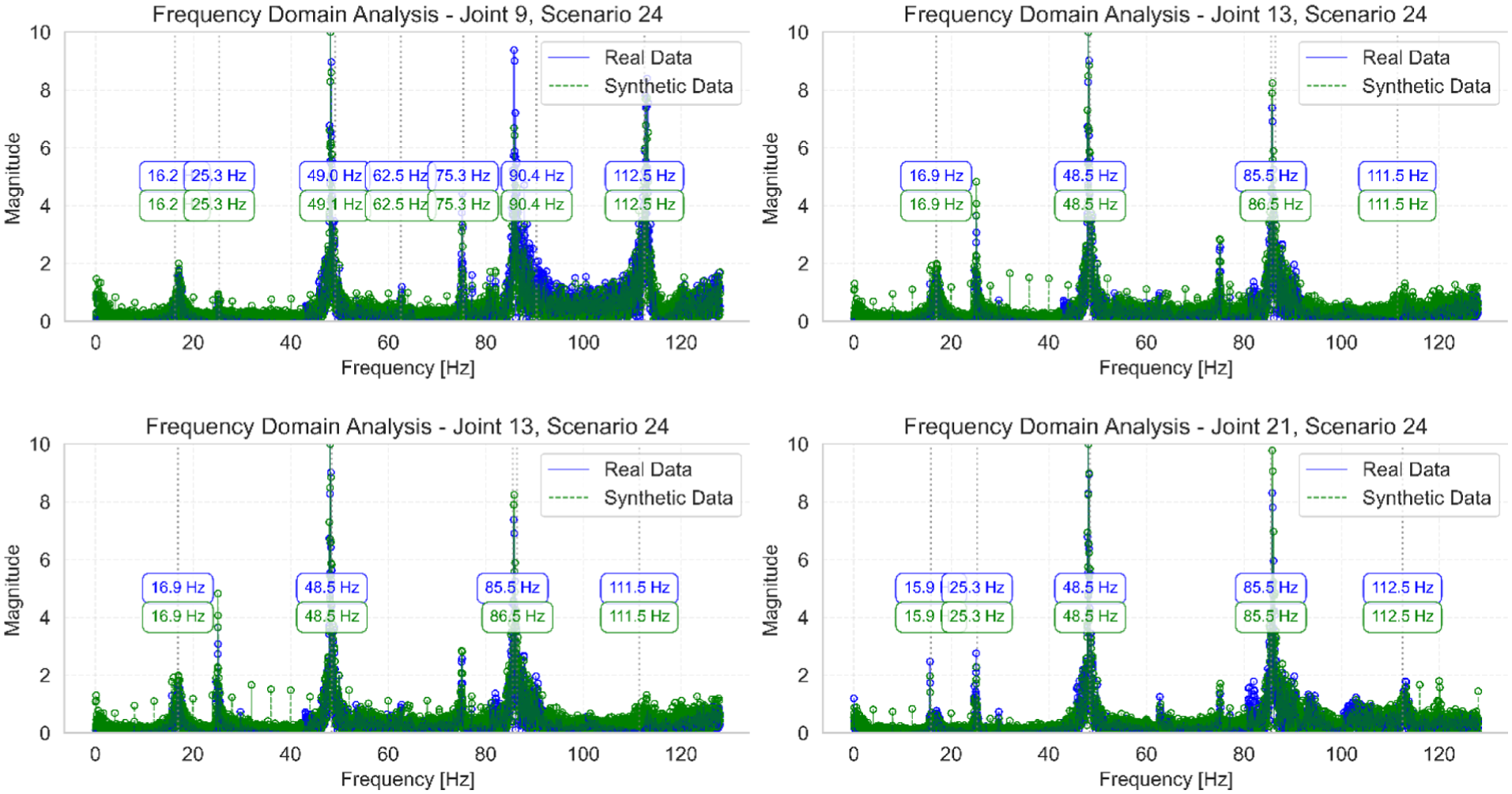
Frequency domain analysis of joints 9, 13, 17, and 21 for scenario 24, comparing original and synthetic frequency responses.
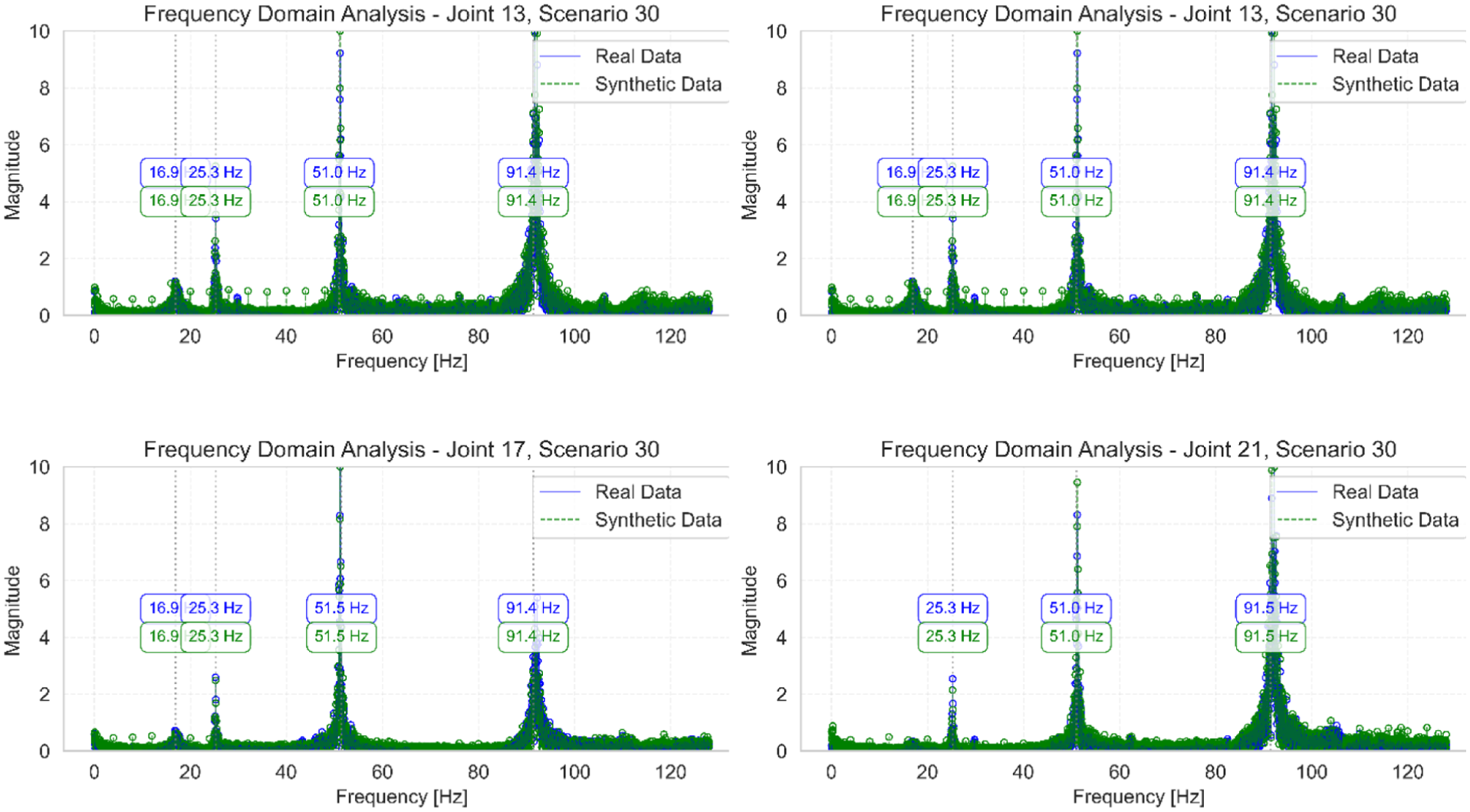
Frequency domain analysis of joints 9, 13, 17, and 21 for scenario 30, comparing original and synthetic frequency responses.
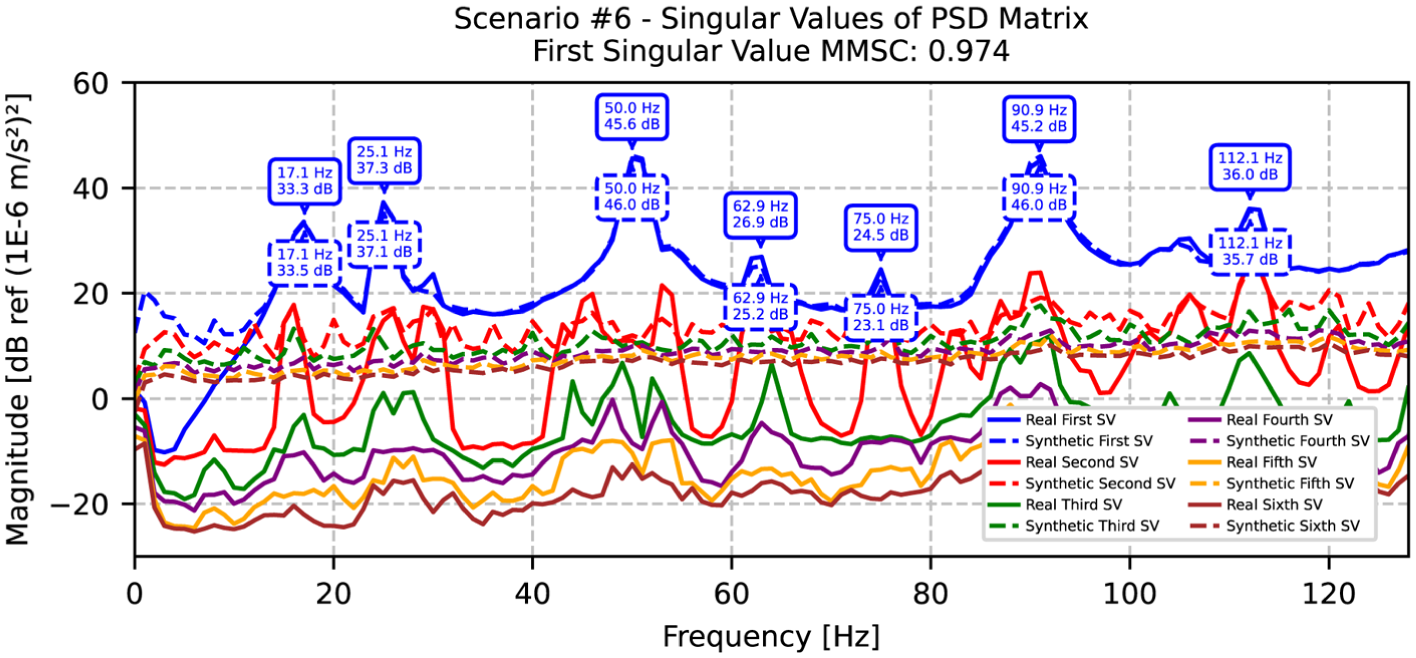
SVD comparison between original and synthetic data for scenario 6, with identified natural frequencies. SVD: singular value decomposition.
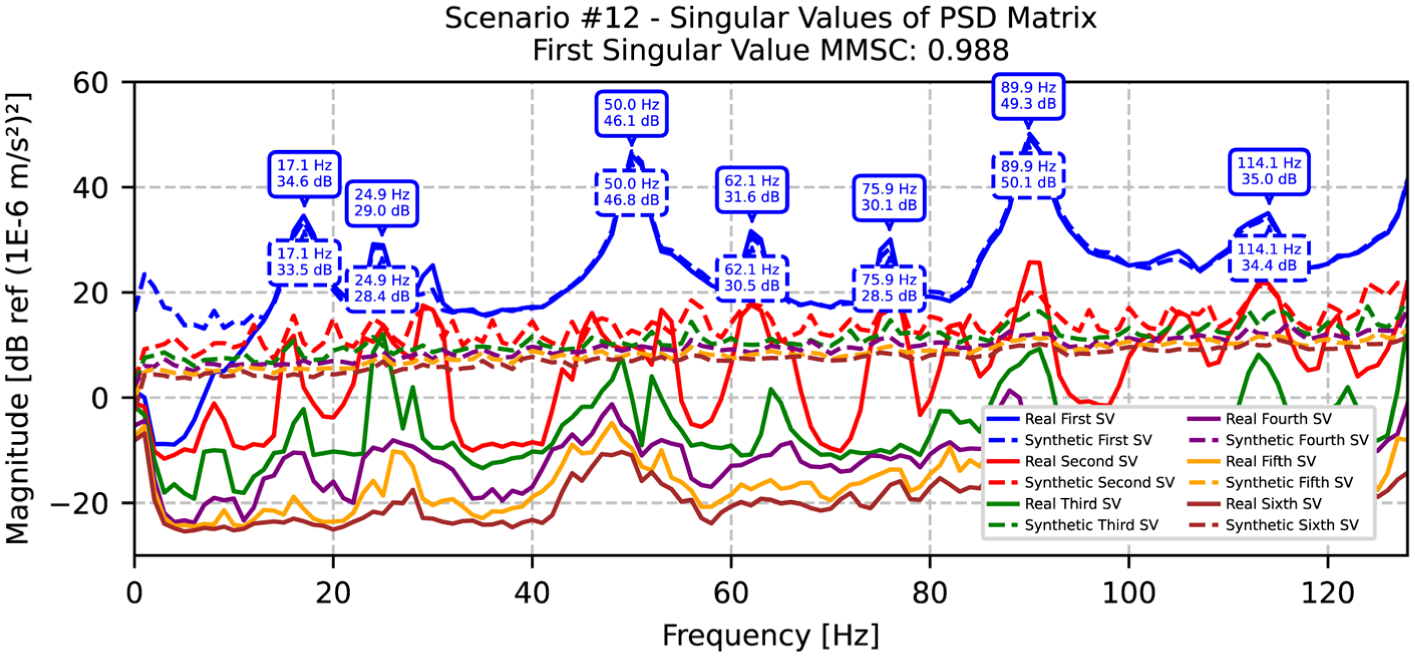
SVD comparison between original and synthetic data for scenario 12, with identified natural frequencies. SVD: singular value decomposition.
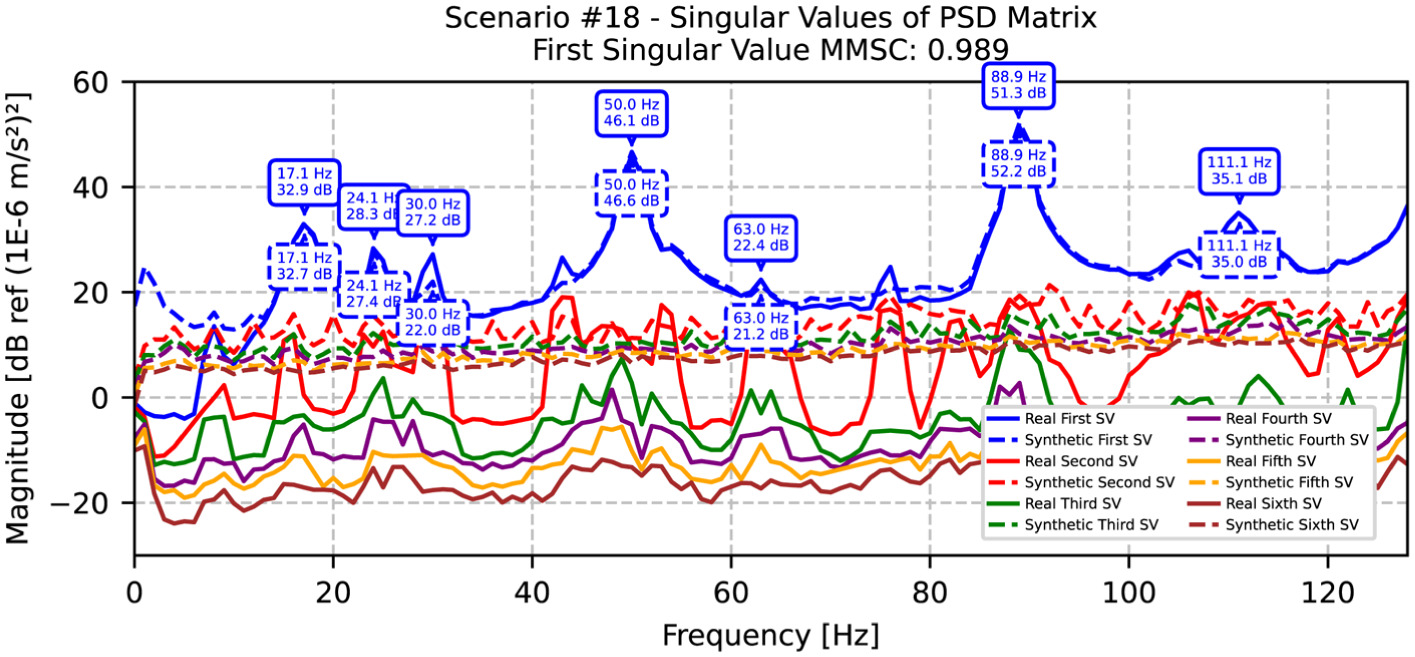
SVD comparison between original and synthetic data for scenario 18, with identified natural frequencies. SVD: singular value decomposition.
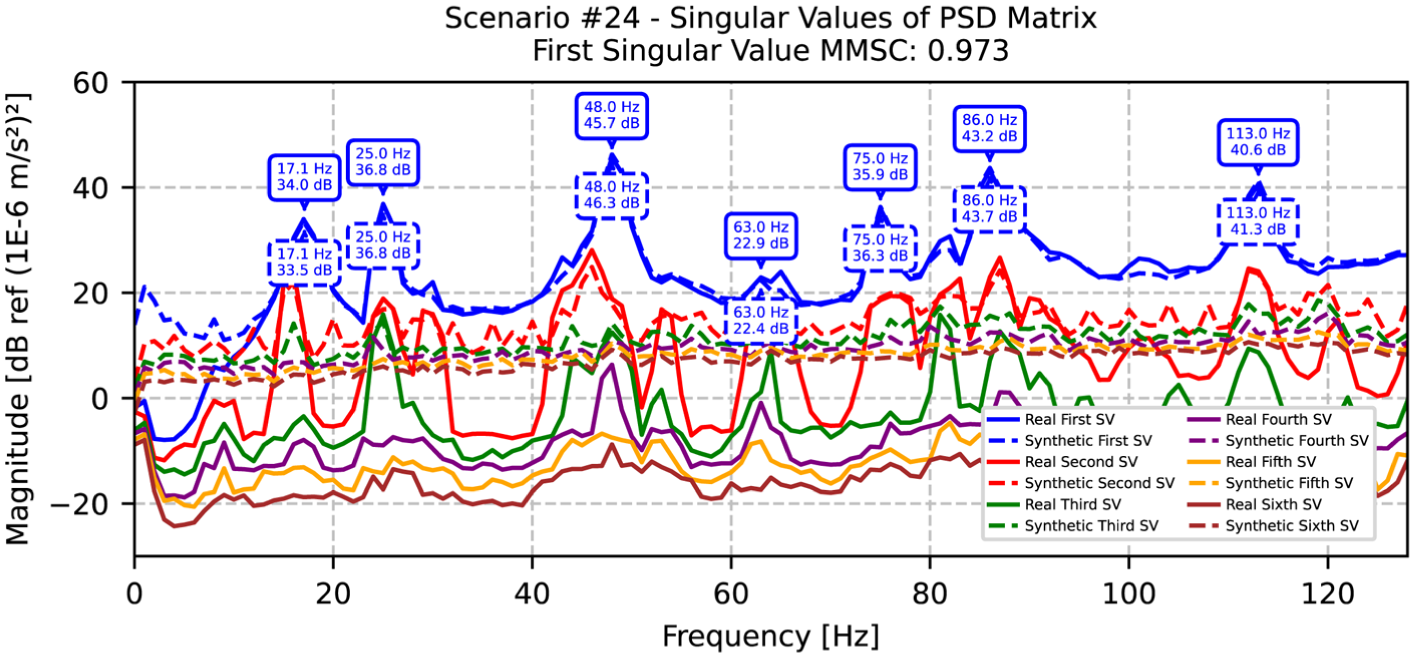
SVD comparison between original and synthetic data for scenario 24, with identified natural frequencies. SVD: singular value decomposition.
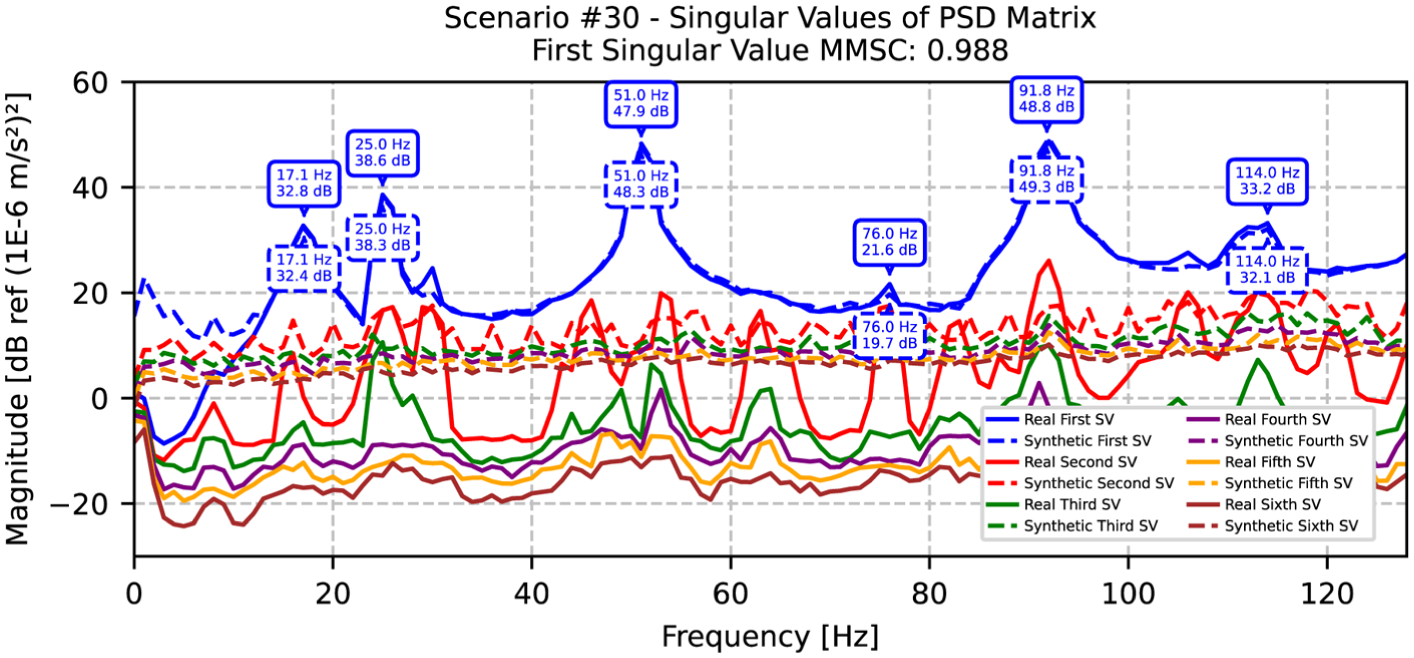
SVD comparison between original and synthetic data for scenario 30, with identified natural frequencies. SVD: singular value decomposition.
A detailed examination of scenario 6 (Table 3 and Figure 18) reveals that modal frequencies span from 17.1 to 112.1 Hz, with damping ratios showing excellent correlation. While most modes exhibit minimal damping differences below 2%, slightly higher variations are observed in the fourth and fifth modes (62.9 and 75.0 Hz) with differences of 15 and 20%, respectively. Scenario 12 demonstrates even better agreement, as shown in Table 4 and Figure 19, with all damping differences remaining below 5% and an exceptional MMSC value of 0.988. The slight shift in the second mode frequency to 24.9 Hz compared to scenario 6 suggests subtle changes in structural behavior while maintaining accurate damping estimation.
The analysis of scenario 18, presented in Table 5 and Figure 20, shows excellent frequency matching with moderate variations in damping characteristics, achieving the highest MMSC value of 0.989. The third mode (30 Hz) and fifth mode (63 Hz) show differences of 60.4% and 108.8%, respectively, in damping ratios, while maintaining perfect frequency alignment. Such variations, although notable, are primarily associated with modes of lower modal energy or reduced participation in the overall response. These modes tend to exhibit higher sensitivity to measurement noise and numerical approximation during damping estimation. This phenomenon is well-documented in operational modal analysis literature, which consistently shows that damping ratios exhibit much larger scatter and uncertainty than natural frequencies, and that identification methods can produce widely varying damping values even under controlled conditions. 59 Similarly, damping-based anomaly detection is known to be less stable than frequency-based approaches and often exhibits scattered estimates or false anomalies under healthy conditions. 13 Importantly, the model consistently preserves the fundamental frequency content, demonstrating that discrepancies in damping for low-energy modes have minimal influence on the overall dynamic representation and damage localization accuracy.
Scenario 24’s results, documented in Table 6 and Figure 21, maintain the high standard of frequency prediction while showing good damping agreement across most modes, with an MMSC value of 0.973. A moderate damping difference of 12.5% is observed in the fourth mode (63 Hz), with all other modes showing minimal variations below 2%.
Scenario 30, as shown in Table 7 and Figure 22, presents a mixed picture with perfect frequency matching and an impressive MMSC value of 0.988, but a significant damping variation is observed in the fourth mode (76 Hz), with a 246.2% difference. This deviation is attributed to the comparatively low energy content of this mode, making it more susceptible to noise and minor excitation inconsistencies during both experimental and synthetic data generation. This is consistent with the previously noted tendency for weakly excited modes to exhibit unstable damping estimates and large method-dependent variations. Nonetheless, all other modes in this scenario demonstrate excellent agreement, with damping differences below 1%, confirming the reliability of the proposed algorithm in preserving dominant modal properties.
The frequency-domain analysis employed Welch’s method for PSD estimation, utilizing a Hann window with 256 samples and 66% overlap to optimize the trade-off between frequency resolution and statistical reliability. This parameterization was chosen based on the sampling frequency of 1024 Hz and the need to capture the structural system’s fundamental modes while maintaining sufficient averaging to reduce variance in the spectral estimates.
The comprehensive analysis reveals that the synthetic data generation model achieves exceptional accuracy in frequency prediction across various damage scenarios, with some variations in damping estimation accuracy. The consistently high MMSC values ranging from 0.973 to 0.989 across all scenarios underscore the agreement between real and synthetic data. The consistent precision in frequency identification, coupled with the ability to capture most damping characteristics within acceptable engineering tolerances, suggests that the model successfully replicates the complex dynamic characteristics of the structure under different damage conditions. While some higher modes show increased damping estimation discrepancies, particularly in scenarios 18 and 30, the overall performance indicates that the synthetic data provides a reliable foundation for SHM applications.
These findings demonstrate the potential of synthetic data for SHM applications, particularly in scenarios where real data collection may be limited or costly. Future work should focus on improving damping estimation accuracy for higher modes and investigating methods to reduce the larger damping discrepancies observed in specific scenarios. The comprehensive validation across all scenarios and joints provides confidence in the generative model’s ability to produce physically meaningful synthetic data that preserves the essential dynamic characteristics of the structural system.
While our proposed AT-StarGAN-GP model shows promise in generating high-quality synthetic structural response data, it is essential to quantitatively evaluate its performance against established benchmarks. To rigorously assess its effectiveness, we conducted extensive comparative analyses with vanilla StarGAN and CycleGAN across different noise levels (0.02 and 0.04) and downsampling rates (original, ds2, and ds4), representing various real-world data collection challenges.
At original resolution, AT-StarGAN-GP demonstrated superior performance across both noise conditions. The model achieved mean MMSC values of 0.8418 (noise 0.02) and 0.9439 (noise 0.04), representing improvements of 16.3% and 21.6%, respectively, over Vanilla StarGAN’s corresponding values of 0.724 and 0.776 (see Tables A1–A6 in Appendix). CycleGAN demonstrated competitive performance, achieving mean MMSC values of 0.8252 (noise 0.02) and 0.9284 (noise 0.04). While CycleGAN outperformed Vanilla StarGAN, it remained below AT-StarGAN-GP by approximately 2.0% at noise level 0.02 and 1.6% at noise level 0.04, indicating that the gradient penalty and attention mechanisms in AT-StarGAN-GP provide additional stability advantages.
Table 8 presents representative results for AT-StarGAN-GP at original resolution with noise 0.04, illustrating the model’s consistent performance across different scenarios and joint configurations.
MMSC values by scenario and joint for a original noise 0.04 (AT-StarGAN-GP).
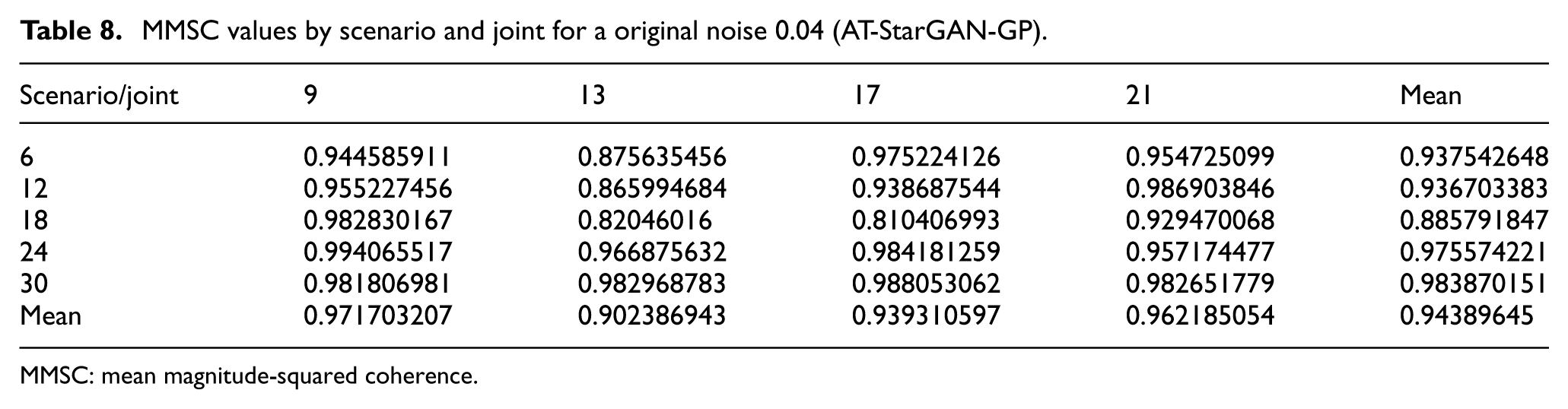
MMSC: mean magnitude-squared coherence.
Under ds2 downsampling conditions, AT-StarGAN-GP maintained its performance edge, achieving mean MMSC values of 0.9254 (noise 0.02) and 0.8828 (noise 0.04), translating to improvements of 34.3% and 16.6% over Vanilla StarGAN (detailed results in Tables A7–A12). CycleGAN showed strong performance under ds2 downsampling, with mean MMSC values of 0.9077 (noise 0.02) and 0.8670 (noise 0.04). These results demonstrate that CycleGAN maintains better stability than Vanilla StarGAN under moderate downsampling conditions, though AT-StarGAN-GP still outperforms CycleGAN by approximately 2.0% at noise 0.02 and 1.8% at noise 0.04. This behavior confirms that AT-StarGAN-GP effectively retains spatial and temporal consistency under moderate resolution loss, demonstrating strong robustness to both downsampling and noise (see Table 9 for a consolidated overview).
Summary of the performance trends across all experimental conditions.

Under the severe ds4 condition, performance differences became more pronounced. AT-StarGAN-GP achieved mean MMSC values of 0.844 (noise 0.02) and 0.840 (noise 0.04), outperforming Vanilla StarGAN’s corresponding values of 0.544 and 0.654 by 55.1 and 28.4%, respectively (complete results in Tables A13–A18). CycleGAN’s performance under ds4 downsampling showed mean MMSC values of 0.7776 (noise 0.02) and 0.5785 (noise 0.04). Under severe downsampling, CycleGAN maintained superior performance compared to Vanilla StarGAN, but the gap between AT-StarGAN-GP and CycleGAN widened to approximately 8.5% at noise 0.02 and 45.2% at noise 0.04. This suggests that the architectural enhancements in AT-StarGAN-GP, particularly the attention mechanisms and gradient penalty, provide critical stability under extreme data degradation conditions.
The downsampling effects revealed distinct trends across the three models. AT-StarGAN-GP exhibited resilience to resolution degradation, with performance actually improving from original resolution (0.8418) to ds2 (0.9254) under 0.02 noise, an enhancement of 9.9%, before slightly declining to 0.844 at ds4. Under 0.04 noise, the model showed a more conventional trend, decreasing from 0.9439 to 0.8828 and then to 0.840.
CycleGAN demonstrated relatively stable performance across downsampling conditions under 0.02 noise (0.8252 → 0.9077 → 0.7776). However, under 0.04 noise, CycleGAN showed a more pronounced decline (0.9284 → 0.8670 → 0.5785), indicating increased sensitivity to the combined effects of noise and severe downsampling. By contrast, Vanilla StarGAN demonstrated a consistent decline in performance with increasing downsampling under 0.02 noise (0.724 → 0.689 → 0.544) and 0.04 noise (0.776 → 0.757 → 0.654).
The robustness gap between AT-StarGAN-GP and the other models thus widened progressively with downsampling severity, from 16.3% to 21.6% over Vanilla StarGAN at original resolution to 16.6–34.3% at ds2 and 28.4–55.1% at ds4, highlighting the architectural stability and adaptability of AT-Star GAN-GP. Compared to CycleGAN, AT-StarGAN-GP maintained modest advantages at original and ds2 resolutions (approximately 2%), but demonstrated significantly superior performance under ds4 conditions, particularly at higher noise levels.
Noise level effects revealed additional insights. AT-StarGAN-GP benefited substantially from higher noise under original resolution, with a 12.1% improvement (0.8418 → 0.9439). However, performance declined modestly with higher noise under ds2 (0.9254 → 0.8828) and remained stable at ds4 (0.844 → 0.840). CycleGAN showed a similar pattern at original resolution, improving by 12.5% with higher noise (0.8252 → 0.9284), but experienced more severe degradation at ds2 (0.9077 → 0.8670) and ds4 (0.7776 → 0.5785). Conversely, Vanilla StarGAN showed consistent improvement with increasing noise across all resolutions: +7.2% at original, +9.9% at ds2, and +20.2% at ds4, though these improvements were insufficient to match the performance of the other models.
These results suggest that moderate noise acts as a regularizer, especially for models less capable of internal noise compensation, such as Vanilla StarGAN and CycleGAN. AT-StarGAN-GP’s nuanced response, however, implies that its adversarial and attention-driven learning mechanisms already internalize noise handling to a greater extent, reducing reliance on external regularization effects.60–62
From a physical perspective, moderate additive noise can be interpreted as representing stochastic environmental influences or sensor-level fluctuations commonly encountered in vibration-based monitoring. Such perturbations introduce subtle variations that broaden the frequency content of the response signal, helping the model to learn structural patterns that remain stable under realistic operating conditions. This behavior parallels the effect of low-intensity broadband excitation in experimental modal analysis, which enhances the detectability of modal features by stimulating multiple vibration modes simultaneously. Consequently, exposure to moderate noise encourages the model to focus on invariant modal characteristics, such as stiffness- or damping-related features, rather than on transient or localized signal artifacts. However, as the noise level increases further, these modal signatures become increasingly masked, reducing the physical interpretability and discriminative power of the learned representations.
The diverging noise responses underscore the architectural distinctions among the three models. AT-StarGAN-GP achieved its peak performance (0.9439) at the original resolution and high noise (Table 7), but showed limited gains at lower resolutions, indicating that the gradient penalty enhances noise modeling primarily when signal fidelity is preserved. CycleGAN exhibited intermediate behavior, with improved robustness over Vanilla StarGAN but lower absolute accuracy than AT-StarGAN-GP, reflecting the stabilizing yet less adaptive nature of cyclic consistency. Conversely, Vanilla StarGAN’s uniform improvement across noise levels and resolution points to a simpler regularization behavior rather than robust structural feature learning.
Overall, all models achieved their highest performance at original resolution under 0.04 noise, but AT-StarGAN-GP consistently attained superior absolute values and maintained structural integrity under both noise and downsampling. These findings reaffirm the effectiveness of the gradient penalty mechanism in ensuring model robustness and generalizability for complex SHM applications.
Conclusions
This study presented AT-StarGAN-GP, an attention- and gradient-penalty-enhanced generative adversarial framework for producing high-quality synthetic structural response data under varying noise and resolution conditions. Through extensive comparative analyses with CycleGAN and Vanilla StarGAN, the proposed model demonstrated superior robustness, stability, and physical consistency across diverse data degradation scenarios.
Quantitative evaluations revealed that AT-StarGAN-GP consistently outperformed both baseline models at all tested resolutions and noise levels. At original resolution, the model achieved mean MMSC values of 0.8418 (noise 0.02) and 0.9439 (noise 0.04), exceeding Vanilla StarGAN by 16.3%–21.6% and CycleGAN by approximately 2%. Under moderate downsampling (ds2), AT-StarGAN-GP maintained its performance edge, recording 0.9254 (noise 0.02) and 0.8828 (noise 0.04), representing improvements of 34.3% and 16.6% over Vanilla StarGAN and roughly 2% over CycleGAN. Even under severe downsampling (ds4), where data fidelity was substantially reduced, AT-StarGAN-GP achieved mean MMSC values of 0.844 (noise 0.02) and 0.840 (noise 0.04), surpassing Vanilla StarGAN by 28.4–55.1% and CycleGAN by up to 45.2%. These results confirm the resilience of AT-StarGAN-GP to resolution loss and noise perturbations, attributed to its attention-driven spatial feature refinement and gradient-penalized adversarial stability.
Noise analysis further revealed that moderate additive noise acted as an implicit regularizer, enhancing model generalization by simulating realistic environmental disturbances such as sensor fluctuations or ambient excitation. AT-StarGAN-GP achieved its highest overall performance under original resolution and higher noise (0.9439 at noise 0.04), suggesting that the model’s architecture effectively internalizes noise-handling capabilities through its adversarial and attention mechanisms. Unlike Vanilla StarGAN, which showed monotonic improvement with noise, and CycleGAN, which degraded sharply under severe downsampling, AT-StarGAN-GP exhibited balanced adaptability, maintaining discriminative accuracy and preserving mode-shape–damage correlations even under degraded conditions.
Frequency-domain evaluations validated the physical reliability of the generated synthetic data. The model accurately captured structural frequencies with less than 1% deviation between real and synthetic signals across all damage scenarios. Although damping ratio predictions displayed higher variability, most modes remained within 5% difference, confirming the model’s suitability for representing key modal characteristics. Validation through Welch’s spectral estimation and SVD confirmed that synthetic samples retained both global structural behaviors and localized damage signatures, indicating strong physical consistency.
By generating realistic synthetic data under varying noise and downsampling conditions, AT-StarGAN-GP addresses a central limitation in SHM, the scarcity of labeled damage data, without compromising physical interpretability. Its demonstrated performance under challenging conditions underscores its potential to augment experimental datasets, enabling more robust damage detection and model training where measurements are limited.
The comprehensive sensitivity analysis conducted across eleven hyperparameters, including nine λ-terms and two attention weights, revealed that optimal model performance is achieved through balanced parameter configurations. The analysis demonstrated that frequency-domain consistency (
Future works will focus on validating AT-StarGAN-GP using multiple laboratory and real structural models, testing the method across different types of damage, and refining damping estimation and adaptive mechanisms for improved accuracy.
Footnotes
Appendix A
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the TÜBİTAK 2214-A—International Research Fellowship Programme for PhD students. The authors would like to sincerely acknowledge TÜBİTAK for their financial support, which significantly contributed to the successful completion of this study. Their assistance provided the opportunity for international collaboration and enabled the advancement of this research. In addition, the first and last authors acknowledge the financial support of Research Ireland under grant number 22/FFP-P/11577.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.