
Abstract
Traditional apprenticeship models struggle to scale as the construction industry faces a growing shortage of skilled workers and an aging workforce. This study evaluates the potential and strategies of Large Language Models (LLMs) to support apprentices in learning hands-on construction tasks through real-time, conversational instruction. Drawing on prior research in conversational AI and intelligent tutoring systems, we conduct a comparative analysis of LLM-based guidance versus traditional video demonstrations in controlled masonry tasks. Through a mixed-methods approach, we assess task performance, interaction patterns, and participants’ self-reported confidence and understanding. Findings from our exploratory comparative study suggest that LLMs can deliver relevant, adaptive, and context-aware procedural guidance. However, limitations emerged in conveying tacit knowledge and adapting tool use to the specific task context. The results underscore the importance of interface design and instructional modality in sustaining engagement. This work offers early insights into the design of scalable, AI-assisted learning systems for skilled trades.
Keywords
Introduction
The construction industry faces a critical shortage of skilled labor. 1 In the United States, recent projections from the U.S. Bureau of Labor Statistics indicate that demand for skilled workers continues to grow, while the existing workforce is aging and fewer young people are entering the trades. 2 Between 2003 and 2020, the share of construction workers aged 55 and older nearly doubled, from 11.5% to 22.7%, with the current median age of 42 years now exceeding that of the general labor force. At the same time, more than 663,500 construction-related job openings emerge annually. However, traditional apprenticeship-based training models, typically structured around one-to-one mentorship, struggle to scale to this level of demand. This limitation is further compounded by low completion rates in apprenticeship programs worldwide. 3
In response, educational research has increasingly explored technology-enhanced training, including virtual reality (VR) and mixed reality (MR) platforms.4,5 Prior studies show that immersive technologies can support experiential and situated learning, enabling students to grasp complex construction tasks in safe, controlled environments.6,7 By situating learners within interactive, task-based simulations, these systems connect conceptual understanding with embodied action, supporting the transfer of design knowledge into applied construction skills.
However, most existing solutions typically rely on predefined scenarios that are difficult to adapt to individual learners or varying task requirements. 8 As a result, they offer limited flexibility in accommodating diverse skill levels, constraining their scalability and pedagogical responsiveness.
More recently, Large Language Models (LLMs) have emerged as promising tools for supporting personalized learning in domains such as computer science, language acquisition, and physics.9–11 In the Architecture, Engineering, and Construction (AEC) sector, researchers are exploring LLMs for instructing collaborative robots,12,13 while Saka et al. 14 argue that they can provide personalized educational resources for self-directed learning. They specifically point to the potential for AI to capture tacit knowledge that is difficult to manage in the construction industry.
However, most current applications of LLMs in the AEC domain focus on design, planning, or regulatory tasks,15,16 with limited empirical research investigating LLMs as interactive tutors in physically grounded construction contexts. To our knowledge, this study represents one of the first controlled investigations of conversational AI in an embodied, on-site craft training context.
We conducted an exploratory comparative study using a between-subjects design in which novice participants completed two masonry tasks, a straight wall and a corner segment, under either conversational LLM guidance (Figure 1) or a video demonstration by a certified mason. To systematically examine performance, confidence, and instructional experience, we employed a mixed-methods approach combining quantitative performance assessments, qualitative observations, and detailed interaction logs. Participants in the AI condition interacted with ChatGPT-4o-latest, a widely accessible, general-purpose model used without domain-specific fine-tuning. By intentionally evaluating an off-the-shelf system, the study establishes an empirical reference point for how conversational AI performs in real-time, hands-on instruction for embodied tasks. P7 adjusts brick alignment using a mason’s line, guided by ChatGPT-4o-latest.
Beyond comparing performance outcomes, this study investigates whether conversational LLM guidance can improve novice task performance, how such guidance shapes learners’ perceived confidence and understanding, and how these outcomes compare with established video-based instructional methods. We also examine interaction design considerations including conversational structure, prompting strategies, and learner engagement patterns. Our findings provide a reference point for future research on specialized, multi-modal, and domain-adapted AI tutors for skilled trades, particularly as such systems become integrated with VR, MR, and other software-supported learning environments for on-site training and embodied task instruction.
State of the art
This research situates itself at the convergence of three interconnected domains: theories of embodied and situated learning that position construction as a tacit, materially engaged practice, the integration of conversational AI within AEC workflows and the emergence of LLMs as adaptive tutors in educational contexts.
Embodied and situated learning
Craftsmanship is a fundamental form of situated learning where knowledge is inseparable from the material context and physical activity. 17 This practice aligns with the 4E cognition paradigm (Embodied, Embedded, Enacted, Extended), 18 which rejects cartesian mind-body separation by viewing the body as the primary vehicle for “being-in-the-world”.19,20 In construction trades, cognition is enacted through a continuous “material dialogue”, a process of “thinking through hands” where a practitioner’s understanding of material affordances and resistance is refined through a loop of perception and action. 17 In this framework, materials act as “co-agents” rather than passive recipients of design. 21
Conversational AI transforms embodied cognition in design education by shifting instructional modalities from visual “showing how” to linguistic “telling how”. 22 Within a cognitive apprenticeship framework, LLM-based tutors mimic the “active and passive flows” of human experts by providing adaptive, context-aware scaffolding during critical incident of a task.21,23 While digital systems currently struggle to directly mediate the subtle sensorimotor feedback, or “feeling how” of manual work, they facilitate computational craft by externalizing and deconstructing procedural expertise into manageable, interactive instructions. This creates an augmentative layer that can help novices internalize tacit expert judgment, effectively bridging the gap between digital modeling and embodied physical making.24–26
Understanding how LLMs engage with embodied craft tasks is therefore essential to determining whether conversational AI can extend cognitive apprenticeship into domains traditionally defined by tacit, sensorimotor expertise.
Conversational AI in AEC
Conversational AI, especially leveraging LLMs, has become increasingly integrated into AEC workflows, primarily to support information management, reporting, and training. For instance, Pulkkinen 27 explored using LLMs to identify conflicts in construction documents, noting their ability to streamline manual analysis but highlighting the need for further refinement due to limited reliability in complex scenarios. Similarly, automated systems combining ChatGPT with computer vision have successfully generated daily construction reports from video footage, significantly improving project monitoring and decision-making efficiency. 28
Beyond documentation and reporting, conversational AI has shown promise in educational and training contexts. Eiris-Pereira and Gheisari 8 and Dong et al. 29 introduced a virtual agent within BIM environments to assist students in practicing procedural communication. While effective for dialogue-based tasks, its pre-scripted nature limited adaptability for real-time, hands-on activities. Uddin et al. 30 demonstrated ChatGPT’s effectiveness in enhancing construction safety education by generating personalized hazard recognition content, significantly improving worker preparedness. Additionally, AI-integrated AR systems employing text-to-action functionalities have facilitated real-time, actionable instructions directly within workers’ visual fields, notably improving precision and reducing cognitive load during operations and maintenance tasks. 31
Despite these advancements, current studies primarily focus on theoretical instruction, procedural training, or pre-scripted interactions. They have not extensively examined how conversational AI can effectively support the nuanced, real-time demands of physically performed construction tasks.32,33 This research gap is crucial given the significant disconnect identified between theoretical instruction and practical application, highlighting a persistent need for hybrid learning models that integrate AI-driven theoretical instruction with practical, field-based experience.34,35
LLMs as tutors in other domains
LLMs have demonstrated promise in education beyond AEC. Tutor CoPilot 36 illustrates how LLMs support mathematics tutors in real-time, enhancing tutor effectiveness and student mastery through adaptive guidance, especially beneficial for less-experienced tutors. Baillifard et al. 37 integrated GPT-3 to deliver personalized microlearning through spaced repetition and retrieval practices in university settings, significantly improving student grades. Despite these successes, their predefined question approach limits application in physically nuanced tasks, highlighting the need for more flexible, open-ended interactions, as explored in our study.
Similarly, NewtBot utilized GPT-3.5 for physics education, enhancing student engagement and satisfaction. However, they encountered limitations in chatbot-generated responses due to their generalized nature, indicating that task-specific configurations outperform general-purpose ones. 10 Ye et al. 9 demonstrated that LLMs effectively support language learning by providing personalized, interactive tutoring experiences across various language skills. Nonetheless, their effectiveness diminishes without pedagogically aligned feedback and appropriate adaptive capabilities.
Collectively, these examples illustrate the strengths and limitations of LLM-based tutoring, emphasizing the necessity for domain-specific context integration and real-time, adaptable instructional methods to fully leverage AI’s educational potential.
Study design
We conducted an exploratory comparative study to investigate whether LLMs can effectively support novices in learning hands-on construction tasks. The study followed a between-subjects design in which participants were assigned to one of two instructional conditions (Video or LLM) and one of two task types (Straight or Corner).
Instructional methods
To evaluate the instructional effectiveness of LLMs, we compared them against a widely adopted digital learning method: video tutorials. More than half of adult YouTube users consider the platform an essential resource for learning how to do things they haven’t done before. 38 Unlike live expert demonstrations, which offer adaptive, real-time feedback but are difficult to scale and standardize, pre-recorded videos provide a consistent baseline for comparison. We implemented and compared the following two instructional methods:
Method A - video instruction
Participants received guidance through a concise, pre-recorded demonstration video (Figure 2-left). Although many bricklaying tutorials are publicly available, we produced a custom video featuring a certified and experienced mason to ensure clarity, brevity, and coverage of all essential subtasks. The video was filmed at the same location and with the same tools used in the study, enabling a direct correspondence between the visual instructions and the physical workspace. Method A: Video-based instruction (Left). Method B: LLM-based instruction (Right).
Method B – LLM instruction
Participants received instructional support from an LLM through a text-based interface (Figure 2-right). They could interact with the system via typed input, speech-to-text, or image-based prompts, enabling flexible, on-demand guidance tailored to individual queries and learning pace.
Tasks
Participants completed a masonry bricklaying task as a representative example of embodied construction work. Bricklaying requires spatial reasoning, sequential execution, and physical dexterity, core components of many hands-on construction tasks. It involves minimal use of complex machinery, making it suitable for novice users in a controlled study setting. Because most individuals lack prior masonry training, the task also ensured a relatively consistent baseline of inexperience across participants.
In addition, masonry work is supported by a well-established and descriptive technical vocabulary, making it particularly suitable for language-based instruction. The task is also scalable and adaptable across different countries, contexts, and trades, enhancing the broader relevance of the study’s findings.
We defined two task scenarios:
Task A
Lay one course of bricks on a straight wall segment (Figure 3-left). This is the most common starting scenario in bricklaying practice. Task A: Participant performing straight wall task (Left). Task B: Participant performing corner wall task (Right).
Task B
Lay one course of bricks on a 90-degree corner wall segment (Figure 3-right). This setup introduces greater spatial complexity.
Both tasks followed a traditional running bond pattern with a fixed wall depth of 8 inches (20 cm). Each task involved a sequence of four steps: (1) line setup, (2) mortar mixing and application (3) brick placement and leveling, (4) joint finishing (Figure 4). Sequence of steps for tasks completion.
Study setup
The experiment was conducted in a controlled university workshop environment. The setup for both instructional conditions is illustrated in Figure 5. To standardize the task, the first three courses of bricks for the straight wall and the first four for the corner were pre-assembled by the certified mason. Materials were organized in a designated materials area. Tools were arranged in a separate tool area, while standard personal protective equipment (PPE) was provided. Spatial layout of the experimental workspace, divided into Tool (blue), PPE (red), Material (orange), and Task Areas (yellow).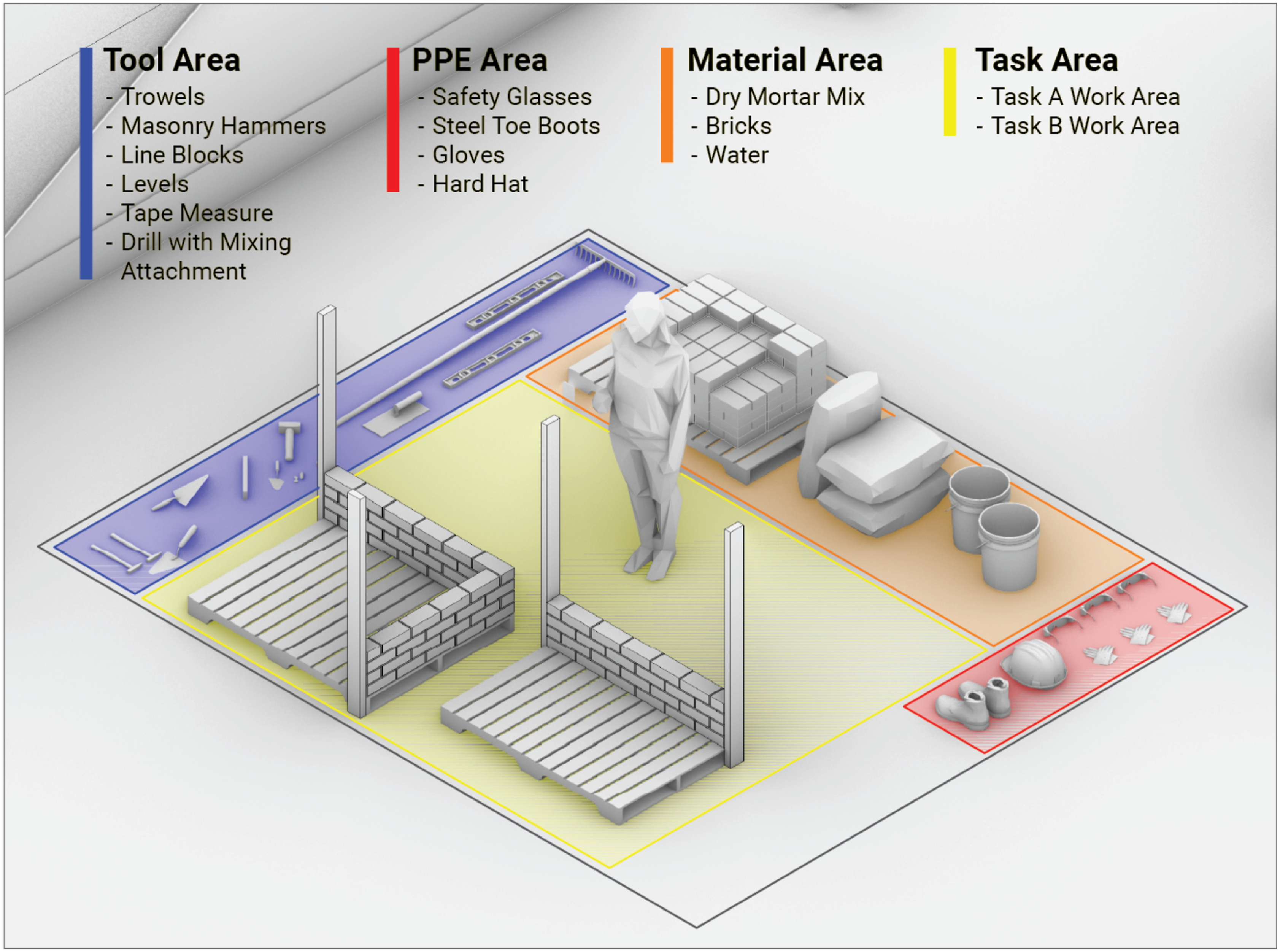
For the LLM instruction, participants used the same Google Pixel 8 smartphone to interact with ChatGPT-4o-latest, 39 a general-purpose, closed-source LLM, accessed via a PLUS account created specifically for this study. For the Video instruction, participants watched the tutorial on a laptop connected to an external monitor to facilitate ease of viewing during task execution.
Participants
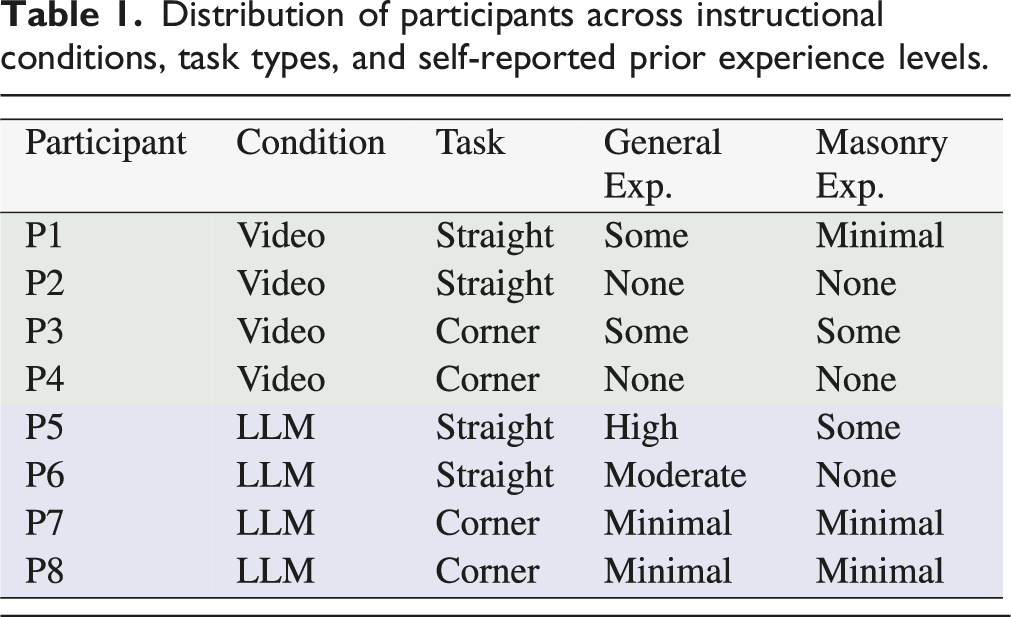
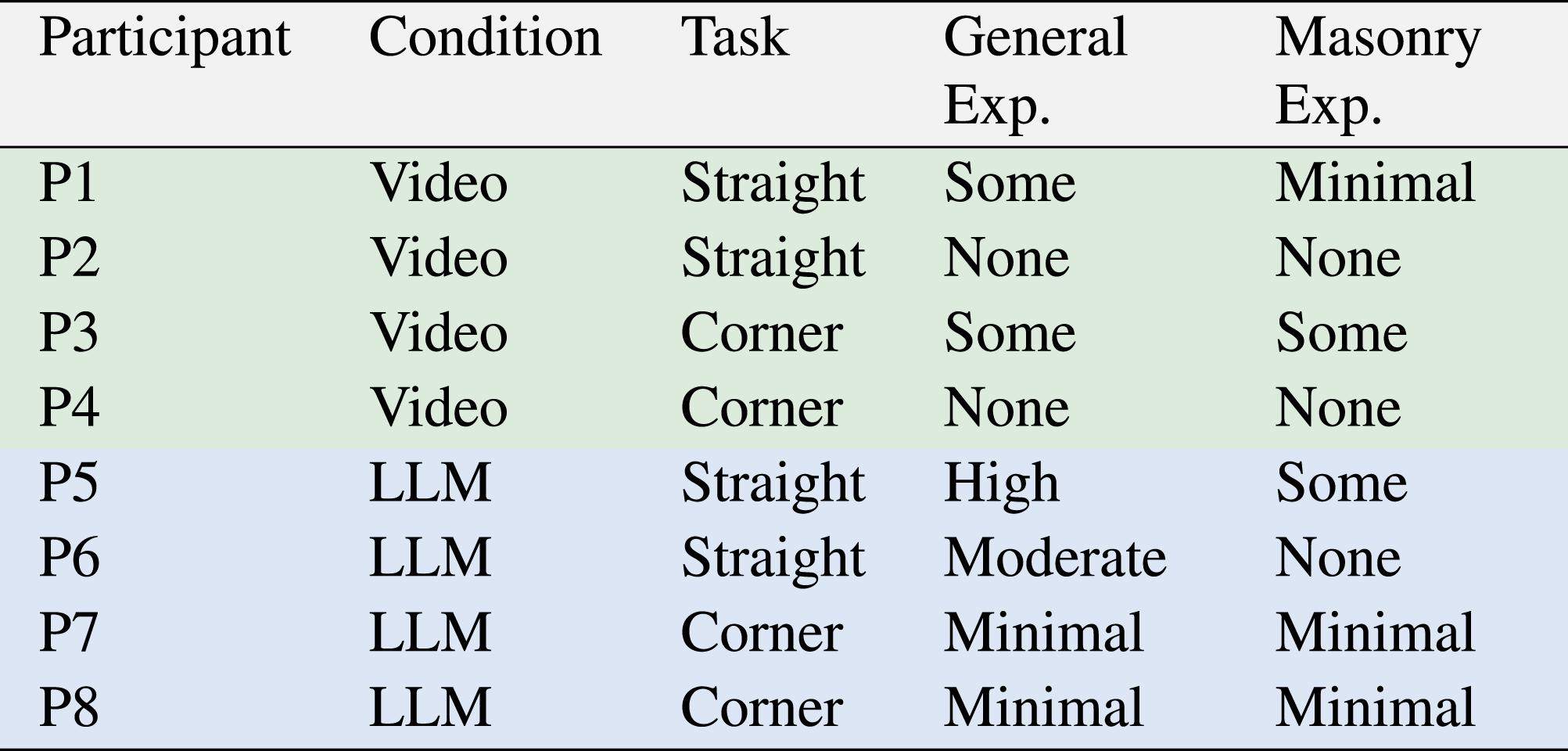
We recruited 8 participants (3 female, 5 male) between the ages of 23 and 36 (
Six of the eight participants had backgrounds in architecture or engineering, reflecting the intended audience for craft-based assembly tasks. The remaining two participants had backgrounds in economics and geo-sciences.
Prior to beginning the study, we administered a pre-study questionnaire to assess participants’ prior experience with both hands-on construction work and masonry-related tasks. Participants selected their experience level from a five-point multiple-choice scale ranging from “no prior experience” to “high experience.” In addition, we collected self-reported confidence in completing the assigned task using a 7-point Likert scale (1 = very confident, 7 = not confident).
Responses indicated varied levels of general construction exposure: 25% reported no prior experience (2/8), 25% minimal experience (2/8), 25% some experience (2/8), 12.5% moderate experience (1/8), and 12.5% high experience (1/8). In contrast, masonry-specific experience was limited. Three participants (37.5%) reported no prior masonry experience, three (37.5%) reported minimal exposure, and two (25%) reported occasional experience. No participant reported moderate or high masonry expertise.
Procedure
Distribution of participants across instructional conditions, task types, and self-reported prior experience levels.
At the beginning of each session, participants received a brief safety orientation and task overview. Each participant was allocated up to 60 min to complete their assigned task, but they were permitted to finish earlier or take additional time as needed to reduce stress and accommodate individual working pace. A think-aloud protocol was encouraged throughout the task, and participants were informed that they could pause or discontinue the study at any time (Figure 6). Study procedure.
Participants in the video instruction were given unlimited access to the pre-recorded tutorial and could review or replay any segment at their discretion throughout task execution.
Standardized introductory prompt template used to initialize LLM instruction.

After each session, chat transcripts were downloaded and deleted to ensure that ChatGPT did not retain memory of prior interactions. All eight participants successfully completed their assigned tasks. Following task completion, each participant filled out a post-study questionnaire, which took approximately 8–10 min to complete.
Evaluation approach
To address our overarching research objective, assessing the effectiveness of LLMs in supporting novice learners during hands-on construction tasks, we consolidated our initial research questions into three primary areas of inquiry:
To systematically evaluate these questions, we employed a mixed-methods approach combining quantitative assessments, qualitative participant feedback, and detailed interaction logs.
Quantitative assessment
Task performance metrics
Each completed course was evaluated by a certified mason, blinded to the construction method, using a standardized 7-point anchored rating scale (1 = Very Poor, 7 = Excellent). The rubric assessed brick orientation, levelness, plumbness, mortar consistency, bond consistency, tooling, and overall craftsmanship. In addition, objective performance was assessed through task completion time, pattern fidelity, and the frequency of execution errors.
Interaction metrics
For the LLM condition, we quantified the total number of queries posed by participants, the frequency of interactions, and categorized the types of inquiries into: Quantification (questions about measurements or quantities), Instructional (task-specific procedural prompts), Validation (confirmations of correctness), Clarification (requests for additional explanation). For the video condition, we used a custom HTML-based viewer to track each participant’s interaction with the video, logging events such as play, pause, and rewind actions. These interaction traces allowed us to capture how and when participants relied on the tutorial during task execution.
Qualitative measures
Self-reported confidence and competence
Using adapted questionnaires from the Intrinsic Motivation Inventory, 40 Self-efficacy Scale, 41 and Post-Task Questionnaires, 42 we collected pre- and post-task data to capture shifts in participants’ self-perceived competence and confidence in task execution.
Open-ended feedback
Participants provided qualitative insights on instructional clarity, instructional media preference, and specific instructional deficiencies through open-ended responses, highlighting contextual factors influencing their perceived mastery and satisfaction.
Observational analysis
Video recordings and observations
Each session was video-recorded and reviewed by the authors to identify and code key behavioral indicators of task difficulty or instructional clarity, including moments of hesitation, confusion, frustration, or visible ease. These behavioral markers were triangulated with performance outcomes and self-reports to enrich our understanding of instructional efficacy.
Results
LLM guidance can enable novices to achieve high craftsmanship in masonry tasks (Addressing RQ1)
Participants in the LLM condition demonstrated strong performance in completing a hands-on masonry task, as reflected in the blinded expert mason ratings (Figure 7 and Table 3), despite reporting little to no prior experience with bricklaying. All participants in the LLM group received scores of 5 (“good”) or higher in overall craftsmanship, with a mean craftsmanship rating of 5.5, compared to 3.75 in the Video condition. The highest individual participant average score across all evaluation criteria was achieved by P5 (5.14), who reported significant prior construction experience, suggesting that domain familiarity may further enhance LLM-guided outcomes. Final wall assemblies showing individual participant contributions by row. Expert ratings of task performance using a 7-point anchored scale (1 = Very Poor, 7 = Excellent). Scores are shown for Video instruction (green) and LLM instruction (blue) across evaluation criteria, including participant-level means and condition averages.
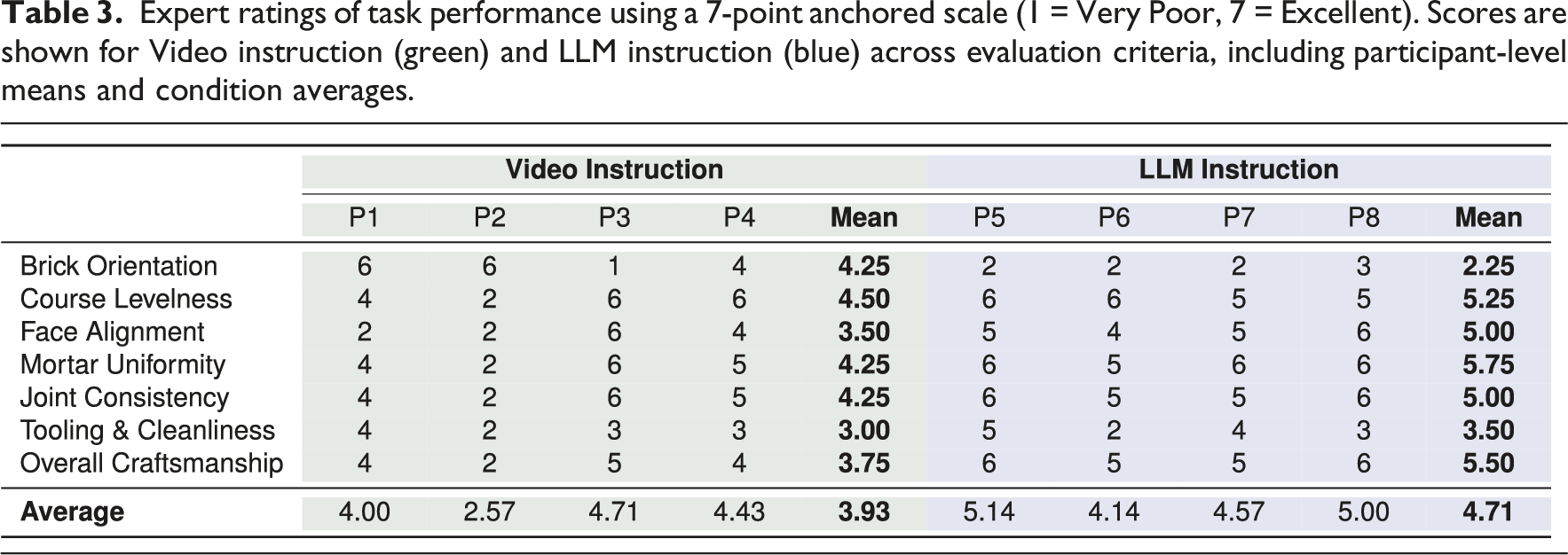
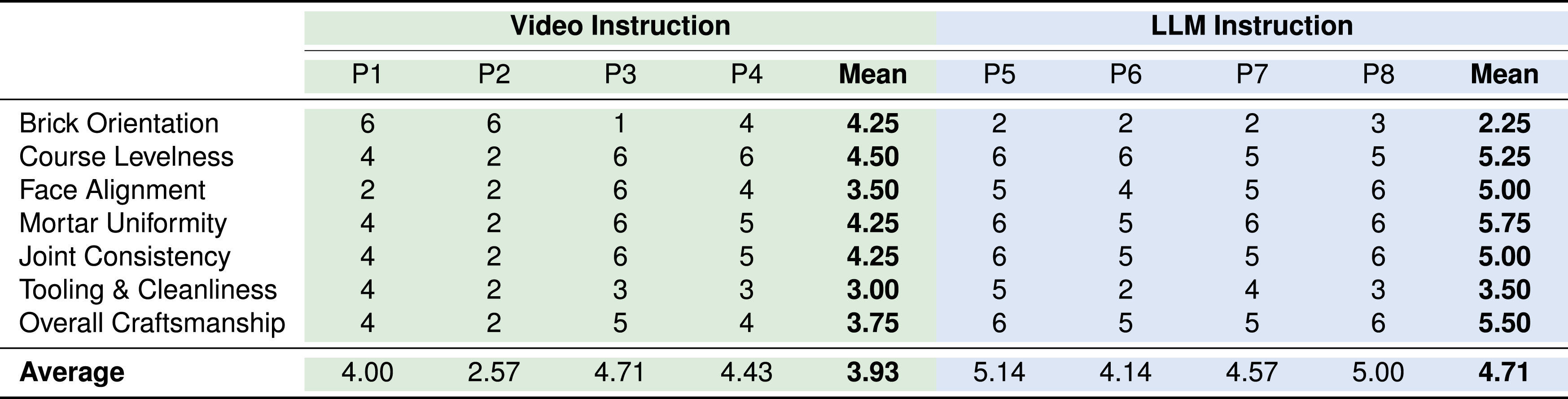
Across evaluation criteria, the LLM condition outperformed the Video condition in most categories (Table 3), including course levelness, face alignment, mortar uniformity, and joint consistency. When averaging participant scores across all rubric categories, the LLM group achieved a higher overall mean (4.71) compared to the Video group (3.93). These results suggest that LLM guidance effectively communicated procedural knowledge, enabling novices to perform with greater consistency and structural accuracy.
Performance in the LLM instruction group was lower in two categories. Brick orientation likely suffered due to the model omitting the detail that the selected bricks have a designated face for visual alignment, an implicit craft convention not explicitly queried or explained. Tooling and cleanliness, the final step in the task, received modest scores in both conditions. As a cognitively demanding phase occurring after an intense workflow, tooling was deprioritized due to mental fatigue. All the participants appeared to lack the attentional capacity to execute finishing details thoroughly.
LLM guidance reduced participant confidence in handling unfamiliar future scenarios (Addressing RQ2)
Although LLM-guided participants performed well based on expert assessment, their self-reported confidence revealed notable declines. Of the three metrics captured before and after the task (Figure 8-blue), only “perceived understanding of task requirements” showed consistent improvement. In contrast, “confidence in successfully completing the task” slightly declined, and “confidence in handling unexpected situations” dropped significantly for three out of four participants. Pre and post task confidence ratings for participants P1-P8 across three measures (left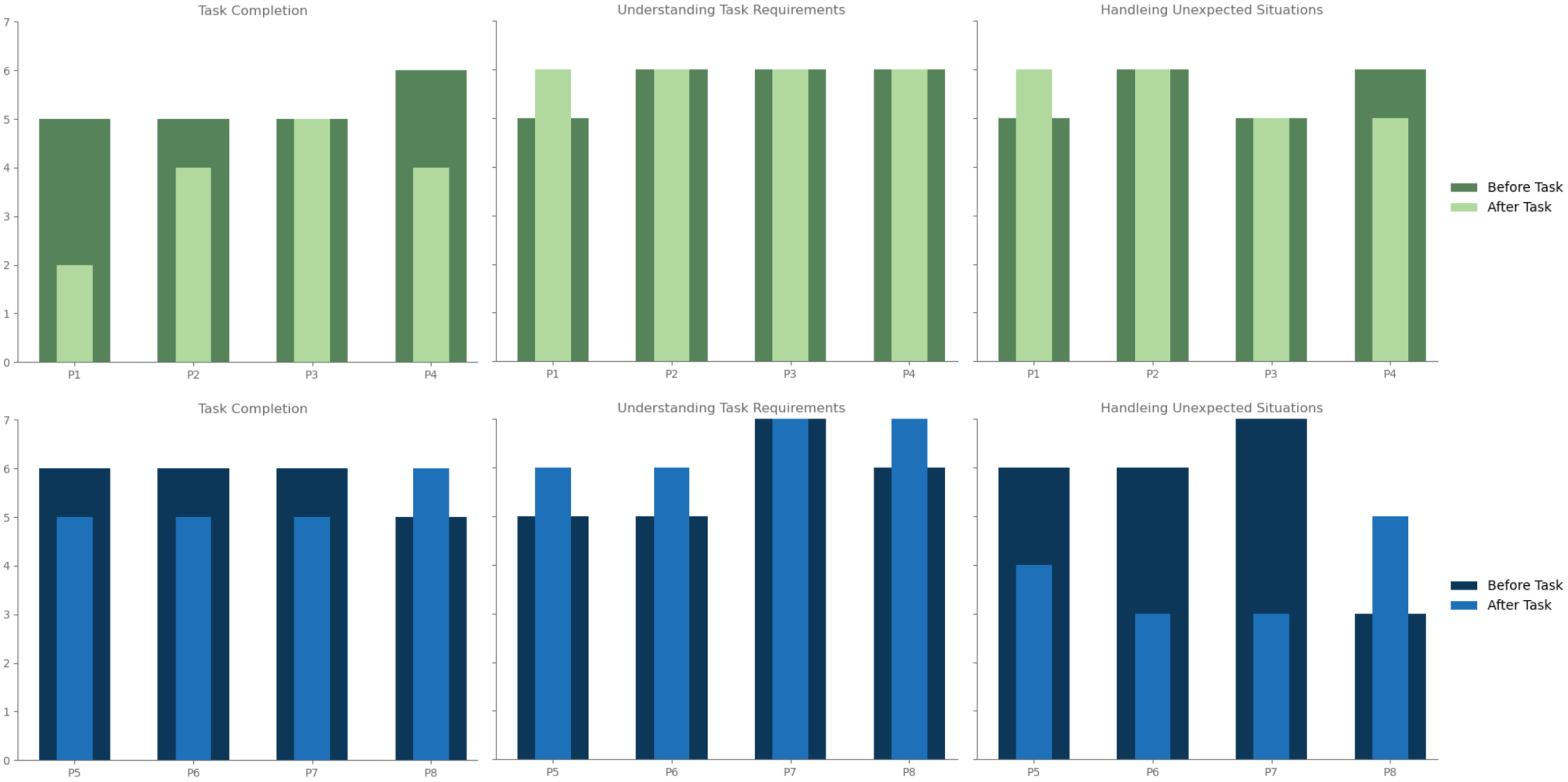
While the LLM-based group declined across two of the three self-reported performance metrics, the video-based instructional group showed a steady decline only in “confidence in successfully completing the task” (Figure 8-green). In the video condition, self-reported scores more closely aligned with the ratings of the expert mason: P3 reported no loss in task confidence and received the highest score within the video group (third highest overall), whereas P1 reported the largest decline in confidence across all participants in both conditions (3 points) and received the second lowest score both within the video group and overall (4.00/7.00). However, the most pronounced difference between the LLM and video groups emerged in “confidence in handling unexpected situations”, where nearly all participants in the video condition reported equivalent or higher post-task scores compared to their pre-task ratings.
LLM-guided participants attributed their uncertainty to misleading or vague information provided by the LLM, particularly regarding tool use. P5 remarked that “ChatGPT gave me an image with the wrong way of orienting the tool”, and later noted that following the experiment, they “had to look up a YouTube video” to clarify the proper use. P8 reported that instructions on setting mason lines were “useless”, and instead chose to “improvise based on a video”. Similarly, P7 commented that instructions were“not always clear” and defaulted to a method that “worked, but might not be correct”.
Further, All LLM-guided participants requested visual references during task execution. P6 and P7 received exclusively web-retrieved images (three instances each), typically when clarifying unfamiliar tools or construction tasks (e.g., “Give me a picture of a paddle mixer?”; “Can you show me a picture of the string line attached to the corner brick?”) (Figure 9.C). In contrast, P5 and P8 received only AI-generated images (two instances each), using prompts oriented toward spatial or procedural clarification (e.g., “Show me how the line block is positioned”; Do you have a schema?”) (Figure 9.B). Although the prompting variations were subtle, we observed a consistent interaction pattern: when participants explicitly requested a picture, ChatGPT tended to continue providing web-retrieved images. When requests were more general, the system instead generated diagrammatic visuals. Overall, web-retrieved images more effectively supported tool recognition through material realism and contextual detail, whereas AI-generated visuals sometimes lacked sufficient spatial specificity for embodied task execution (Figure 9) (Figure 9.D-G). Comparison of visual references used during task execution. (A) Ground truth string line setup from the experiment. (B) AI-generated schematic . (C) Web-retrieved reference images. (D–E) Tool depictions and (F–G) procedure depictions, comparing AI-generated images with web-retrieved images.
Additionally in analysis of the LLM transcripts revealed recurring patterns of ambiguity that help explain participant uncertainty. In several cases, procedural instructions lacked measurable or quantitative reference. For example, mortar preparation guidance estimated that participants would use “1/4–1/5 of a bag (10–12 pounds)” without clarifying bag-size variability, yield assumptions, or mixture compression behavior. Material descriptions also relied heavily on metaphor (e.g., “like peanut butter” or “cookie dough”), offering intuitive comparison but no measurable or quantitative references for novices. Implicit craft conventions, such as designated finished brick faces, were not explicitly articulated, contributing to lower performance in orientation scoring.
As a result, participants increasingly relied on personal judgment, observation, and trial-and-error. P6 stated they “learned more from mistakes than from ChatGPT”, while P5 expressed satisfaction that they “used common sense to finish the task”, even after receiving incorrect guidance. This apparent contradiction suggests that improved performance in the LLM condition may not have relied on flawless instruction, but on the interactive structure it enabled. The conversational format encouraged iterative questioning and reflection, allowing participants to detect and compensate for ambiguities during task execution.
Prior work has noted that AI assistance can lead learners to overestimate their knowledge 43 ; however, our findings point in the opposite direction. Participants’ lowered confidence post-task may reflect a corrective calibration, a shift from participants’ initial overconfidence to a more realistic self-assessment after engaging with the task’s complexity.
LLMs supported flexible, question-driven learning, while videos offered structured but passive guidance (Addressing RQ3)
Participants in the LLM instruction largely followed a predictable interaction pattern: after reading the initial step-by-step guide generated by ChatGPT, they posed short follow-up questions aligned with the specific stage of the task they were working on. The number and type of questions varied across participants, as did the order in which they were asked (Figure 10). While some followed a linear pattern aligned with the task sequence, others jumped between clarification and procedural queries based on confusion or uncertainty in specific moments. Notably, two participants focused more heavily on terminology, asking clarification questions such as “What is a torpedo level?” or “How much mortar should I use?” early in the process (Figure 11-right). This emphasis reflected gaps in domain-specific vocabulary and underscored the need for systems that can dynamically support conceptual as well as procedural understanding. Sequence of participant questions during LLM-guided instruction, color coded by catagory, Instructional, Clarification, Validation, Quntification, and Initial Prompt. LLM-generated responses to participant photo prompts. Feedback on wall quality and mortar cleanup. (Left) Identification of the brick jointer tool from a user-submitted image (Right).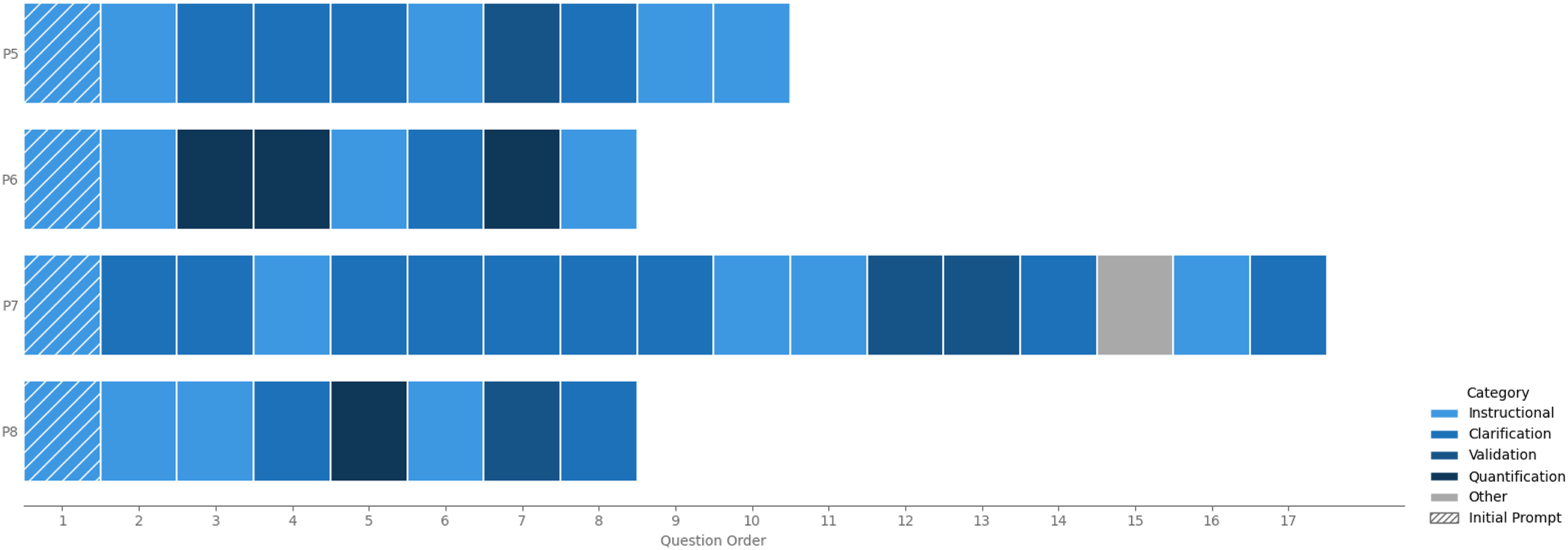

In addition to terminology clarification, participants used the LLM to resolve highly specific, situational uncertainties during task execution. Queries ranged from procedural refinement (e.g., “Do I need to put 2 corner bricks first?”), to material timing (“How long do I have until the mortar hardens?”), to tool adaptation based on available resources (“Are there any tools from my list that can help me with breaking the brick?”). Others requested contextual adjustments such as unit conversion (“Can you update all instructions in metric system”), or detailed clarification of tool setup (“How to adjust the hole of the drill to insert the paddle mixer?”). These exchanges demonstrate that participants engaged the LLM not as a static tutorial, but as an on-demand support system for resolving small, task-specific ambiguities in real time.
However, once participants began the physical assembly, use of the LLM declined significantly. Most stopped interacting with the model altogether during the bricklaying phase, relying instead on improvisation or self-assessment. Only one participant used a photo to validate task completion by asking whether the wall had been assembled correctly (Figure 11). The LLM responded with general verification and additional quality control tips, which were partially followed by the participant.
In contrast, all video-guided participants actively navigated the content (Figure 12). Some watched the full demonstration up front, but all paused or rewatched segments during moments of uncertainty. The video instruction appeared to support continuous reference throughout the task, although it lacked the interactive feedback available in the LLM setting. User actions during video-based instruction, showing learning behavior across tasks and participants through actions such as Play (circle), Pause (square), and Seek (triangle).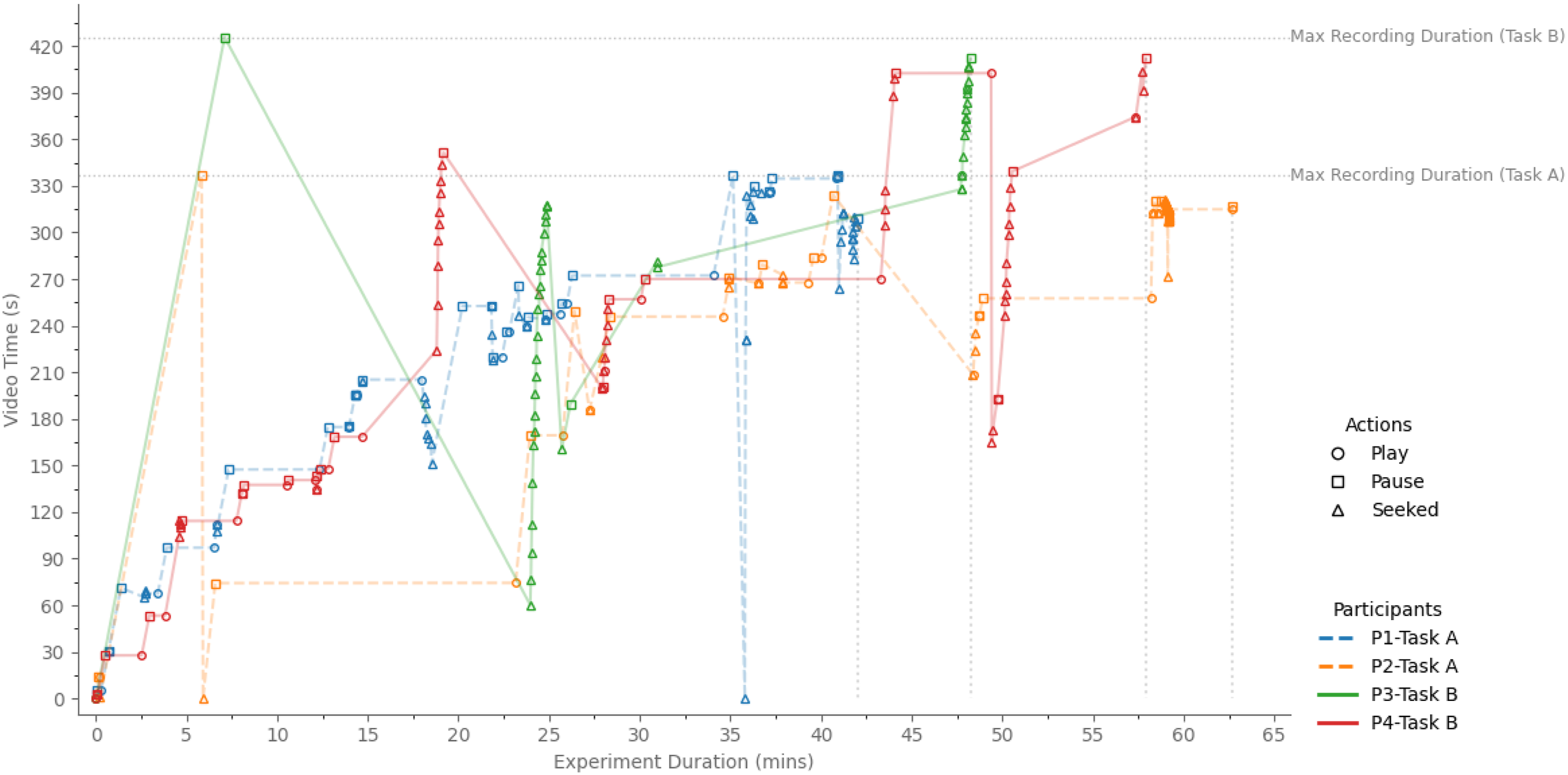
Across both conditions, the instructional styles revealed contrasting strengths. LLMs supported flexible, user-driven inquiry and real-time clarification, but their effectiveness diminished when participants encountered spatial challenges or required visual interpretation. Without direct prompting for visuals or specific follow-up, LLM responses were often too abstract or incomplete. As P6 noted, “Terminology was confusing—one image is a thousand words”, while P5 reflected, “Maybe next time I should ask for external references or links to get more clarity”. Similarly, P8 remarked, “Chat told me mortar should be like peanut butter, but I would have preferred a video showing how runny a good mortar is”, highlighting the limitations of purely textual explanations for conveying material properties. In contrast, the video provided consistent visual guidance but lacked adaptability. For example, P1’s misplaced brick affected P2’s task and led to cascading uncertainty. Since the video did not cover how to correct such deviations, participants had no opportunity for clarification. As P3 explained, “What I missed in the process is having someone I can ask questions or for reasoning behind certain steps, which can be missing from the video tutorial or written instruction”. In comparison, the LLM modality allows for context-specific follow-up, though the quality of support depends heavily on the user’s prompting style.
Discussion
To better understand the implications of these findings, we examine both quantitative performance measures and qualitative participant reflections across instructional conditions.
Quantitative results
From a quantitative perspective, the expert rankings presented in Sec. LLM Guidance Can Enable Novices to Achieve High Craftsmanship in Masonry Tasks (Addressing RQ1) show that the LLM group outperformed the video-based instructional condition. These results demonstrate that conversational AI can provide effective structured guidance, including ordered procedural steps, clarification of terminology, and tool-use instructions. Together, this suggests that conversational AI may serve as a useful support tool for novices learning hands on construction tasks.
However, when considering participants’ self-reported confidence measures (Sec. LLM Guidance Reduced Participant Confidence in Handling Unfamiliar Future Scenarios (Addressing RQ2)), a contrasting pattern emerges. Although the LLM group achieved higher expert-rated scores, the majority of participants (P5, P6, P7) reported diminished confidence in completing the task and in handling unexpected conditions, despite increased or sustained awareness of the task’s complexity. This suggests that, rather than reinforcing certainty, interaction with the LLM made participants aware of the limits of text-based procedural guidance once translated into physical action, exposing a gap between verbal instruction and embodied execution.
In contrast, participants in the video condition exhibited more stable confidence trajectories that more closely aligned with expert assessment. While declines were largely confined to task completion, with little to no reduction in perceived ability to manage unexpected situations. This suggests that clear visual instruction may have grounded participants’ judgments in observable action, enabling them to more confidently interpret their own performance and anticipate potential challenges.
Taken together, these findings indicate that while conversational AI can effectively support procedural learning, it does not mediate sensory feedback, material resistance, or situational judgment during execution. Conversational instruction alone therefore cannot replace demonstration, real-time correction, or physically grounded feedback in hands-on skill acquisition.
Qualitative results
From a qualitative perspective the participants of the LLM instruction group acknowledged that the LLM provided clear step-by-step guidance and flexibility to ask questions. However, many emphasized the limitations of relying solely on AI. When asked what additional support they would want, several mentioned the need for videos from experienced masons or real-time feedback from experts, underscoring the irreplaceable role of human expertise.
In contrast, participants in the video condition expressed fewer concerns about instructional credibility, but emphasized the lack of interactivity when facing uncertainty. Although the demonstration provided clear visual grounding, it did not offer explicit measurements or opportunities for clarification (P1, P2, P4). As P4 noted, “I would like to be able to do follow-up questions on specific unclear parts.” Unlike the conversational format, the video could not adapt to situational deviations during execution, limiting its responsiveness within an apprenticeship model.
LLM participants also expressed a desire to fact-check or supplement the LLM’s responses with external resources. As P7 noted, “If I had watched videos or done more research, I would be able to use ChatGPT more effectively”. P8 added, “It was not bad for superficial information… but if I had any experience in masonry, I don’t think ChatGPT would have helped much at all”. These insights align with a broader understanding that craftsmanship involves both procedural expertise and expert judgment, which artisans develop over the years through repeated exposure and adaptation to varied, real-world conditions. This suggests that LLMs may function most effectively as scaffolding tools during early phases of skill acquisition.
While some participants appreciated ChatGPT’s adaptability and capacity for answering specific queries, they remained skeptical about its tutoring usefulness. As P5 concluded, “Maybe, but not by itself”, and P8 suggested that “ChatGPT plus a skilled mason could have created a good step-by-step instruction”.
As P8 put it, “The difficulty lies in doing the last 20%”. Mastery of hands-on construction tasks often depends on details that require physical feedback, situational awareness, and accumulated tacit knowledge. 44 This observation reinforces the distinction between sequential procedural explanation and embodied learning processes.
These findings suggest that conversational AI may function most effectively as an augmentative layer within apprenticeship structures rather than as a replacement for expert supervision. In industrial and workforce training contexts, responsible integration will require careful alignment with existing instructional hierarchies, safety protocols, and human oversight to ensure reliability and accountability.
Limitations
The study was deliberately designed as a controlled, exploratory investigation to examine the integration of conversational AI within an embodied craft context. Rather than aiming for statistical generalization, the emphasis was placed on close observation and interaction dynamics in situ. While this methodological choice enabled tight control over key variables and careful qualitative analysis, it does not reflect the full variability of construction practice, including diverse task types, environmental conditions, and differences in prior skill levels. Additionally, the sample size was relatively small (n = 8), and the focus on only two masonry tasks constrains the generalizability of the findings. While this is consistent with other domains like interaction design, a larger and more diverse participant groups and expanded task contexts will be necessary to support stronger empirical validation.45,46
Furthermore, the instructional system relied on a general-purpose, commercially available LLM (ChatGPT-4o) without domain-specific fine-tuning or architectural adaptation. This allowed isolation of the instructional affordances of an off-the-shelf conversational model but limited control over domain alignment and contextual specificity. Prior research indicates that domain-adapted or knowledge-augmented models can improve task-specific reliability in specialized instructional settings.16,47
The study focused on text-based conversational exchange via a mobile interface and did not incorporate sensor-integrated or spatially grounded capabilities such as real-time computer vision, spatial tracking, or augmented reality overlays. This limited visual grounding during embodied task execution and allowed us to isolate the instructional dynamics of language-mediated guidance. Additionally, throughout the study, several participants disengaged from the LLM due to the inconvenience of typing on mobile devices, underscoring the constraints of text-based interaction in physically intensive task environments and suggesting the value of more ergonomic, hands-free modalities such as voice input.
Finally, although LLMs are capable of adapting tone, length, and content based on user interaction history, this adaptive potential was not fully leveraged within the constraints of the study design.
Future work
To move from exploratory feasibility toward robust deployment, future work must refine system architecture, strengthen domain-specific knowledge integration, and expand empirical evaluation across tasks and expertise levels.
System architecture and interaction design
Building on the observed interaction patterns and breakdowns in our results, future system design should support multimodal interaction modalities, including speech input, image-based prompting, and context-aware responsiveness. Participants frequently formulated questions that were highly situational and materially and tool specific, indicating the need for systems that can interpret visual context and evolving task states in addition to verbal input.
To address moments where textual explanations alone proved insufficient, particularly in spatial alignment and tool handling, hybrid multimodal feedback mechanisms may provide more precise, context-sensitive guidance during execution.
Furthermore, as participants remained physically engaged with materials and tools throughout the task, user comfort and flexibility should be prioritized through hands-free wearable interfaces, such as head mounted displays (HMDs) or lightweight wearable devices, that enable seamless interaction and potential MR integration without interrupting embodied performance.
Finally, instructional support must remain readily accessible through unobtrusive interface designs that preserve visibility of the workspace and avoid disrupting workflow, a need directly reflected in participants’ preference for minimal cognitive and visual interference during construction.
Data curation and instructional reliability
Improving reliability in tool-specific and spatially complex tasks will require curated, expert-validated instructional data. Instead of relying solely on general web-trained models, critical craft knowledge should be structured and linked to specific tools, materials, spatial conditions, and measurable parameters. Grounding guidance in this way can reduce ambiguity, improve accuracy, and strengthen trust in AI-generated instruction. Further, In safety-critical construction contexts, curated and certified knowledge bases may be necessary to ensure instructional accountability and prevent the propagation of incorrect or misleading information. Additionally, structured frameworks that support adaptive scaffolding—tailored to individual skill levels, task stages, and environmental conditions—may further enhance instructional effectiveness and learner confidence.
Prompting quality also emerged as a critical factor influencing interaction outcomes. While open-ended prompting enabled personalized support, future systems may benefit from structured prompting templates that guide users in asking more effective, context-relevant questions, for example, suggesting task-specific phrasing like “How should I hold the trowel when spreading mortar?” rather than a vague query like “How do I use the trowel?”. A redesigned interface could incorporate voice input, visual feedback, or object tracking to dynamically tailor support during task execution.
Beyond technical refinement, future research must address the broader implications of deploying AI tutors within workforce training environments. Rather than replacing skilled supervision, such systems should be understood as augmentative, supporting apprenticeship models through blended learning structures that combine AI guidance with experienced craftspeople oversight. Careful examination of how these tools integrate into existing training pipelines, certification standards, and on-site supervision practices will be essential for responsible and scalable implementation.
Task generalization and craftsperson evaluation
Future work should expand to varied tasks, such as timber framing or drywall taping, that involve different spatial configurations, tool use, and sequencing demands, to evaluate how LLMs generalize across skill-sets. Broader empirical validation across construction systems and instructional contexts will be necessary to understand domain transferability and limitations.
Conclusion
This study explored the instructional potential of LLMs in supporting novices during a hands-on masonry task, comparing their performance and experience to those guided by traditional video demonstrations. While LLM-guided participants relied on short, goal-oriented interactions, they successfully completed core aspects of the task and demonstrated craftsmanship on par with or exceeding that of the video-guided group. The ability to pose clarification questions in real time proved especially valuable. However, participants also encountered limitations, particularly when visual detail, tool specificity, or nuanced technique was required. These findings suggest that while LLMs offer promising support for procedural learning, their effectiveness depends on the user’s ability to prompt appropriately and the system’s access to context-rich, domain-specific knowledge. Moving forward, hybrid models that blend conversational AI with expert-authored content and multimodal feedback may better meet the demands of embodied, craft-based learning.
Footnotes
Acknowledgements
We would like to thank the Mason Shop in the Facilities Department at Princeton University for their generous support of this study, including providing the masonry materials and sharing their expertise. We are especially grateful to Alby Cianflone for demonstrating the masonry tasks for the instructional videos, evaluating the completed work, and generously contributing his guidance and time throughout the project. We also thank Alby’s assistant, for supporting the study setup and execution. We would also like to thank Carmine Fiocca, supervisor of the Mason Shop, Marie Baretsky, Manager of the Fabrication Lab at the School of Architecture, and the lab technicians for their coordination and logistical support. Finally, we are grateful to the participants in our study and to the students of COS 598B: Advanced Topics in Computer Science – Machine Behavior, Spring 2025, Princeton University, for their valuable comments during the study design phase.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.